
Предлагаю вашему вниманию любопытный проект по мониторингу одиночного хоста с Docker - domolo. Сразу скажу, что это продукт уровня курсовой работы с каких-нибудь курсов по DevOps на тему мониторинга. Он представляет из себя преднастроенный набор контейнеров на современном стеке.
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
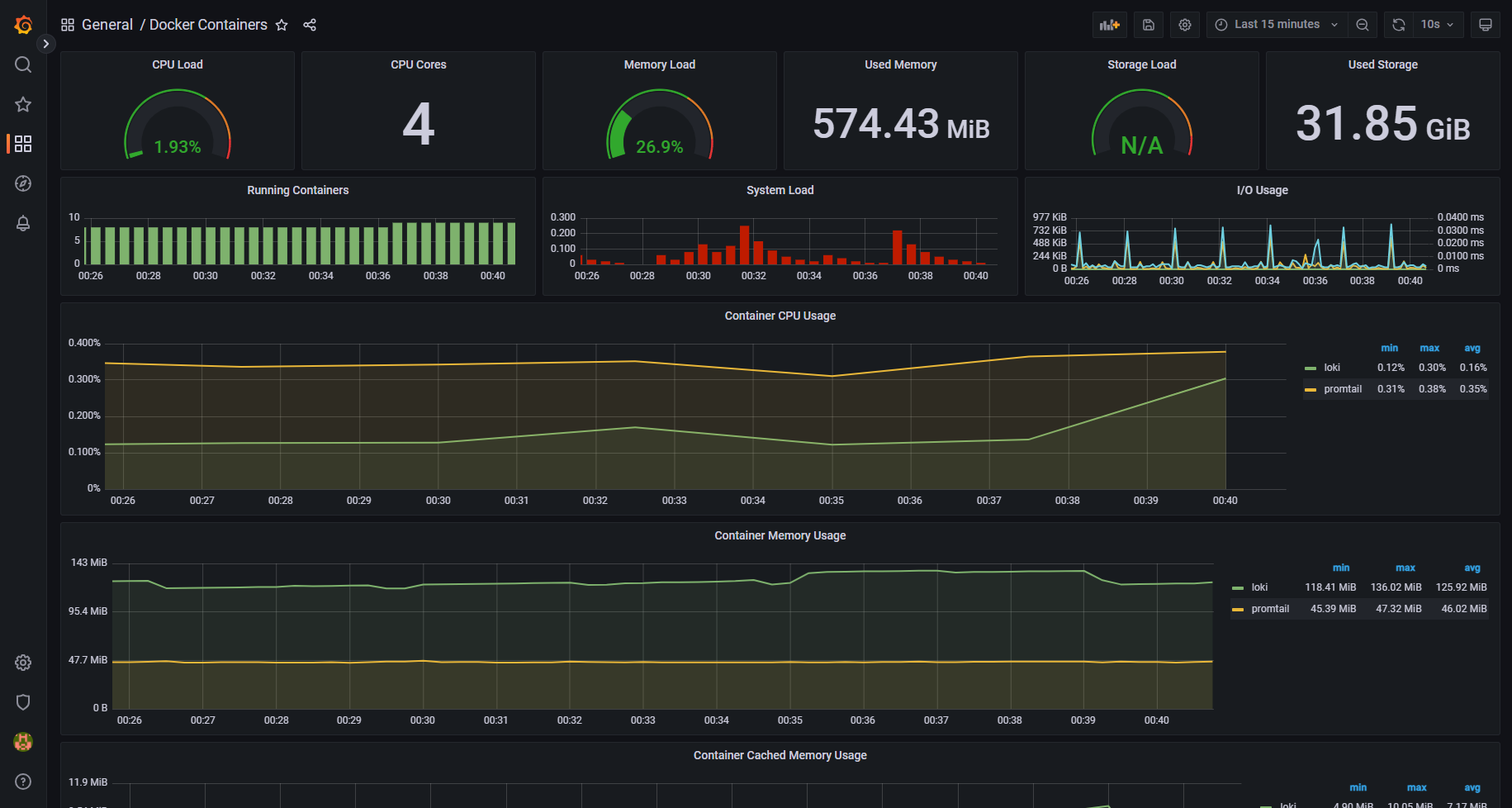
Идём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
# git clone https://github.com/ductnn/domolo.git# cd domolo# docker-compose up -dИдём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
{kind=link}
Выбирая между софтовым или железным рейдом, я чаще всего выберу софтовый, если не будет остро стоять вопрос быстродействия дисковой подсистемы. А в бюджетном сегменте обычно и выбирать не приходится. Хотя и дорогой сервер могу взять без встроенного рейд контроллера, особенно если там быстрые ssd или nvme диски.
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
и выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
Получаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
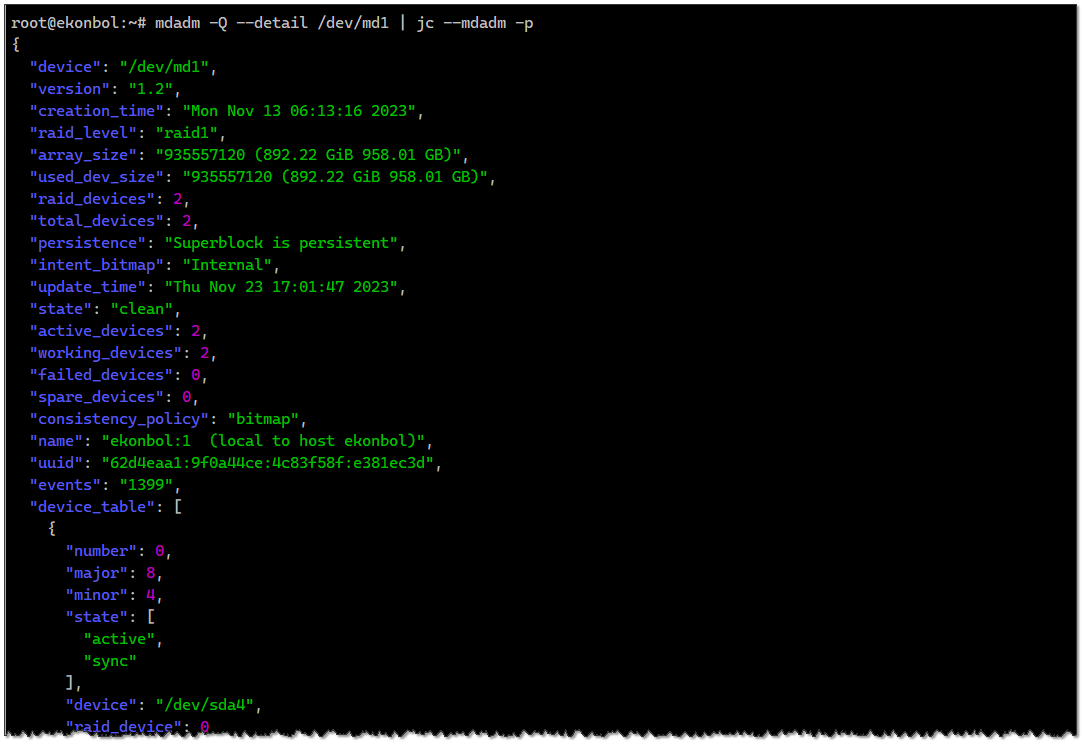
То же самое с mdadm. Смотрим состояние:
Добавляем утилиту jc:
Выгружаем полную информацию о массиве в формате json:
И отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
# apt install smartmontoolsи выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
# smartctl -i /dev/sdd -j# smartctl -A /dev/sdd -jПолучаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
То же самое с mdadm. Смотрим состояние:
# mdadm -Q --detail /dev/md1Добавляем утилиту jc:
# apt install jcВыгружаем полную информацию о массиве в формате json:
# mdadm -Q --detail /dev/md1 | jc --mdadm -pИ отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
{kind=link}
Существует довольно старая система мониторинга под названием Sensu. Ей лет 10 точно есть. Изначально она была написана на Ruby. На этом же языке писались и самостоятельные проверки, дополнения и т.д. Судя по всему в какой-то момент разработчики поняли, что это не самая удачная реализация и переписали всё на Go, а язык для проверок реализовали на JavaScript.
По сути сейчас это новая система мониторинга, полностью заточенная на реализацию подхода IaC в виде его уточнения - Monitoring-as-Code. Я изучил сайт, посмотрел возможности, обзорное видео, инструкцию по разворачиванию. Выглядит современно и удобно. Сами они себя позиционируют как инструмент для DevOps и SRE команд. При этом я вообще нигде и никогда не видел упоминание про этот мониторинг ни в современных статьях, ни где-то в выступлениях на тему мониторинга.
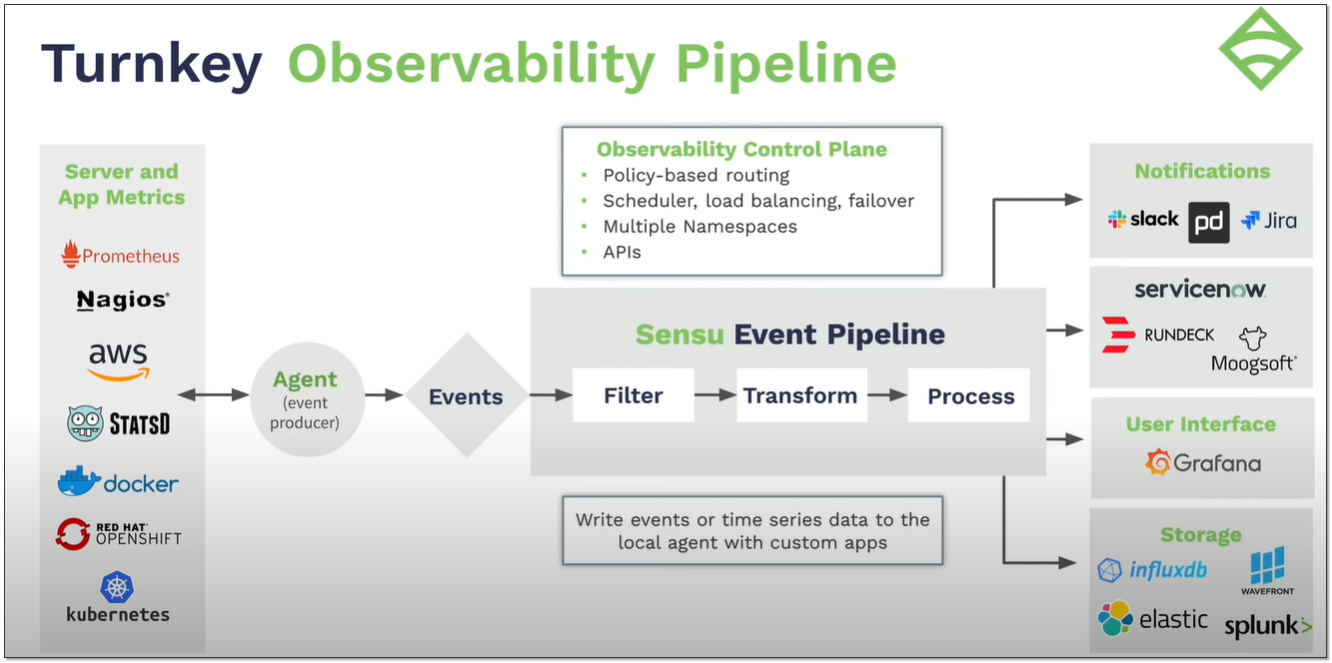
Базовый продукт open source. То есть можно спокойно развернуть у себя. Sensu состоит из следующих компонентов:
◽Sensu Backend - основной компонент, который собирает, обрабатывает и хранит данные.
◽Sensu API - интерфейс для взаимодействия с бэкендом.
◽Sensuctl - CLI интерфейс для взаимодействия с бэкендом через API.
◽Sensu Agent - агенты, которые устанавливаются на конечные хосты для сбора и отправки данных.
Из архитектуры понятно, что это агентский мониторинг. Реализован он немного необычно, с акцентом на простоту и скорость разворачивания агентов. Все правила по сбору метрик вы настраиваете на сервере. Каждое правило - отдельный yaml файл. Когда вы разворачиваете агент, указываете только url апишки и набор подписок на сервере. Всё, на агенте больше ничего настраивать не надо.
На самом сервере абсолютно все настройки расположены в yaml файлах: интеграции, проверки, хранилища, оповещения и т.д. Под каждую настройку создаётся отдельный yaml файл. Примерно так это выглядит:
Создали конфигурацию хранилища, добавили оповещения и метрику для сбора информации о нагрузке на cpu. Теперь настройки этой метрики можно опубликовать, а агенты на неё подпишутся и будут отправлять данные. После каждой выполненной команды будет создан соответствующий yaml файл, где можно будет настроить параметры. Sensu поддерживает namespaces для разделения доступа на большой системе. Примерно так, как это реализовано в Kubernetes. Sensu вообще в плане организации работы сильно похожа на кубер.
Подобная схема идеально подходит под современный подход к разработке и эксплуатации со встраиванием мониторинга в пайплайны. При этом Sensu объединяет в себе метрики, логи и трейсы. То есть закрывает все задачи разом.
Сам сервер Sensu под Linux. Есть как deb и rpm пакеты, так и Docker контейнер. Агенты тоже есть под все Linux, а также под Windows. У Sensu много готовых интеграций и плагинов. К примеру, он умеет забирать метрики с экспортеров Prometheus или плагинов Nagios. Может складывать данные в Elasticsearch, InfluxDB, TimescaleDB. Имеет интеграцию с Grafana.
В комплекте c бэкендом есть свой веб интерфейс, где можно наблюдать состояние всей системы. Всё, что вы создали через CLI и Yaml файлы, а также все агенты будут там видны.
По описанию и возможностям система выглядит очень привлекательно. Разработчики заявляют, что она покрывает всё, от baremetal до кластеров Kubernetes. Мне не совсем понятна её малая распространённость и известность. Может это особенность русскоязычной среды. Я вообще ничего не знаю и не слышал про этот мониторинг. Если кто-то использовал его, поделитесь информацией на этот счёт.
⇨ Сайт / Исходники / Видеообзор
#мониторинг
По сути сейчас это новая система мониторинга, полностью заточенная на реализацию подхода IaC в виде его уточнения - Monitoring-as-Code. Я изучил сайт, посмотрел возможности, обзорное видео, инструкцию по разворачиванию. Выглядит современно и удобно. Сами они себя позиционируют как инструмент для DevOps и SRE команд. При этом я вообще нигде и никогда не видел упоминание про этот мониторинг ни в современных статьях, ни где-то в выступлениях на тему мониторинга.
Базовый продукт open source. То есть можно спокойно развернуть у себя. Sensu состоит из следующих компонентов:
◽Sensu Backend - основной компонент, который собирает, обрабатывает и хранит данные.
◽Sensu API - интерфейс для взаимодействия с бэкендом.
◽Sensuctl - CLI интерфейс для взаимодействия с бэкендом через API.
◽Sensu Agent - агенты, которые устанавливаются на конечные хосты для сбора и отправки данных.
Из архитектуры понятно, что это агентский мониторинг. Реализован он немного необычно, с акцентом на простоту и скорость разворачивания агентов. Все правила по сбору метрик вы настраиваете на сервере. Каждое правило - отдельный yaml файл. Когда вы разворачиваете агент, указываете только url апишки и набор подписок на сервере. Всё, на агенте больше ничего настраивать не надо.
На самом сервере абсолютно все настройки расположены в yaml файлах: интеграции, проверки, хранилища, оповещения и т.д. Под каждую настройку создаётся отдельный yaml файл. Примерно так это выглядит:
# sensuctl create -f metric-storage/influxdb.yaml# sensuctl create -f alert/slack.yaml# sensuctl create -r -f system/linux/cpuСоздали конфигурацию хранилища, добавили оповещения и метрику для сбора информации о нагрузке на cpu. Теперь настройки этой метрики можно опубликовать, а агенты на неё подпишутся и будут отправлять данные. После каждой выполненной команды будет создан соответствующий yaml файл, где можно будет настроить параметры. Sensu поддерживает namespaces для разделения доступа на большой системе. Примерно так, как это реализовано в Kubernetes. Sensu вообще в плане организации работы сильно похожа на кубер.
Подобная схема идеально подходит под современный подход к разработке и эксплуатации со встраиванием мониторинга в пайплайны. При этом Sensu объединяет в себе метрики, логи и трейсы. То есть закрывает все задачи разом.
Сам сервер Sensu под Linux. Есть как deb и rpm пакеты, так и Docker контейнер. Агенты тоже есть под все Linux, а также под Windows. У Sensu много готовых интеграций и плагинов. К примеру, он умеет забирать метрики с экспортеров Prometheus или плагинов Nagios. Может складывать данные в Elasticsearch, InfluxDB, TimescaleDB. Имеет интеграцию с Grafana.
В комплекте c бэкендом есть свой веб интерфейс, где можно наблюдать состояние всей системы. Всё, что вы создали через CLI и Yaml файлы, а также все агенты будут там видны.
По описанию и возможностям система выглядит очень привлекательно. Разработчики заявляют, что она покрывает всё, от baremetal до кластеров Kubernetes. Мне не совсем понятна её малая распространённость и известность. Может это особенность русскоязычной среды. Я вообще ничего не знаю и не слышал про этот мониторинг. Если кто-то использовал его, поделитесь информацией на этот счёт.
⇨ Сайт / Исходники / Видеообзор
#мониторинг
{kind=link}
Я активно использую технологию wake on lan в личных целях. Запускаю разное железо дома, когда это нужно. Сам для этого использую Mikrotik и его функциональность в виде tool wol и встроенной системы скриптов. Скрипт выглядит вот так:
Что-то вручную запускаю, что-то по таймеру. Если у вас нету Микротика, либо хочется что-то более красивое, удобное, то можно воспользоваться готовой панелькой для этого - UpSnap. Это простенькая веб панель с приятным внешним видом. Запустить можно в Docker:
Всё, можно идти смотреть на http://172.20.4.92:8090/_/. Это админский url, где нужно будет зарегистрироваться. Сам дашборд будет доступен под той же учёткой, только по адресу без подчёркивания: http://172.20.4.92:8090/
Основные возможности UpSnap:
▪ Общий Dashboard со всеми добавленными устройствами, с которыми можно выполнять настроенные действия: будить, завершать работу, наблюдать за открытыми портами и т.д.
▪ Использовать планировщик для запланированных действий
▪ Сканировать сеть с помощью nmap
▪ Разделение прав с помощью пользователей
Выглядит симпатично. Подойдёт и в качестве простого мониторинга. Не знаю, насколько эти применимо где-то в работе, а для дома нормально. У меня всё то же самое реализовано на базе, как уже сказал, Mikrotik и Zabbix. Я и включаю, и выключаю, и слежу за запущенными устройствами с его помощью. Обычно перед сном смотрю, что в доме включенным осталось. Если дети или жена забыли свои компы выключить, могу это сделать удалённо. То же самое с дачей, котлом, компом и камерами там. Понятно, что для личного пользования Zabbix для этих целей перебор, но так как это один из основных моих рабочих инструментов, использую его везде.
UpSnap может заменить простенький мониторинг с проверкой хостов пингом и наличием настроенных открытых tcp портов. Разбираться не придётся, настроек минимум. Можно развернуть и сходу всё настроить.
⇨ Исходники
#мониторинг
tool wol interface=ether1 mac=00:25:21:BC:39:42Что-то вручную запускаю, что-то по таймеру. Если у вас нету Микротика, либо хочется что-то более красивое, удобное, то можно воспользоваться готовой панелькой для этого - UpSnap. Это простенькая веб панель с приятным внешним видом. Запустить можно в Docker:
# git clone https://github.com/seriousm4x/UpSnap# cd UpSnap# docker compose upВсё, можно идти смотреть на http://172.20.4.92:8090/_/. Это админский url, где нужно будет зарегистрироваться. Сам дашборд будет доступен под той же учёткой, только по адресу без подчёркивания: http://172.20.4.92:8090/
Основные возможности UpSnap:
▪ Общий Dashboard со всеми добавленными устройствами, с которыми можно выполнять настроенные действия: будить, завершать работу, наблюдать за открытыми портами и т.д.
▪ Использовать планировщик для запланированных действий
▪ Сканировать сеть с помощью nmap
▪ Разделение прав с помощью пользователей
Выглядит симпатично. Подойдёт и в качестве простого мониторинга. Не знаю, насколько эти применимо где-то в работе, а для дома нормально. У меня всё то же самое реализовано на базе, как уже сказал, Mikrotik и Zabbix. Я и включаю, и выключаю, и слежу за запущенными устройствами с его помощью. Обычно перед сном смотрю, что в доме включенным осталось. Если дети или жена забыли свои компы выключить, могу это сделать удалённо. То же самое с дачей, котлом, компом и камерами там. Понятно, что для личного пользования Zabbix для этих целей перебор, но так как это один из основных моих рабочих инструментов, использую его везде.
UpSnap может заменить простенький мониторинг с проверкой хостов пингом и наличием настроенных открытых tcp портов. Разбираться не придётся, настроек минимум. Можно развернуть и сходу всё настроить.
⇨ Исходники
#мониторинг
{kind=link}
В ОС на базе Linux есть разные способы измерить время выполнения той или иной команды. Самый простой с помощью утилиты time:
Сразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
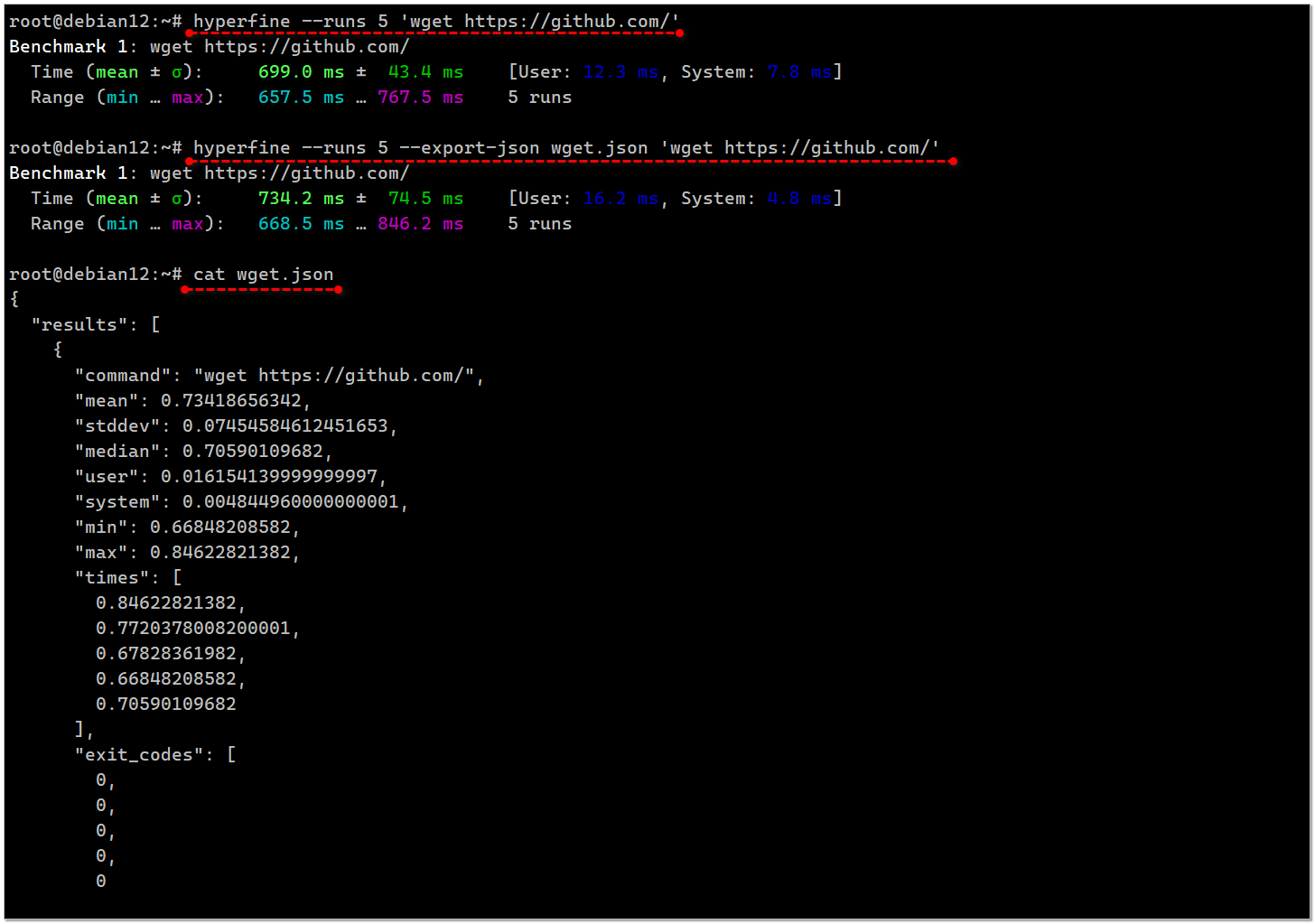
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
С его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
На выходе получаем файл
Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
# time curl http://127.0.0.1/server-statusActive connections: 1 server accepts handled requests 6726 6726 4110 Reading: 0 Writing: 1 Waiting: 0 real 0m0.015suser 0m0.006ssys 0m0.009sСразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
# apt install hyperfineС его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
# hyperfine --runs 1 --export-json mysqldump.json 'mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql'На выходе получаем файл
mysqldump.json с информацией:{ "results": [ { "command": "mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql", "mean": 2.7331184105, "stddev": null, "median": 2.7331184105, "user": 2.1372425799999997, "system": 0.35953332, "min": 2.7331184105, "max": 2.7331184105, "times": [ 2.7331184105 ], "exit_codes": [ 0 ] } ]}Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
# hyperfine --runs 3 'curl -s https://github.com/'Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
{kind=link}
Я когда-то давно уже рассказывал про сервис мониторинга UptimeRobot. Хочу лишний раз про него напомнить, так как сам с тех пор им так и пользуюсь для личных нужд.
По своей сути это простая пинговалка, проверка открытых TCP портов и доступности сайтов. У неё есть бесплатный тарифный план на 50 проверок с периодичностью не чаще одного раза в 5 минут. Для личных нужд этого за глаза.
В целом, ничего особенного, если бы не приятный внешний вид и самое главное - 🔥мобильное приложение. Я вообще не знаю бесплатных мониторингов с мобильным приложением. А тут оно не просто бесплатное, оно ещё и красивое, удобное. В бесплатном тарифном плане есть отправка пушей.
Я туда загнал всякие свои личные проверки типа интернета в квартире и на даче, личные VPS и т.д. Для работы как-то особо не надо. Там и так везде разные мониторинги. А для себя просто по кайфу этим приложением пользоваться.
Если кто-то знает ещё хорошие приложения мониторинга для смартфона, поделитесь информацией. Не понимаю, почему Zabbix не запилит какое-нибудь родное приложение. Для него вообще ничего на смартфоне нет. Какие-то отдельные приложения есть от одиночных авторов, но они никакущие. Я все их пробовал.
#мониторинг #бесплатно
По своей сути это простая пинговалка, проверка открытых TCP портов и доступности сайтов. У неё есть бесплатный тарифный план на 50 проверок с периодичностью не чаще одного раза в 5 минут. Для личных нужд этого за глаза.
В целом, ничего особенного, если бы не приятный внешний вид и самое главное - 🔥мобильное приложение. Я вообще не знаю бесплатных мониторингов с мобильным приложением. А тут оно не просто бесплатное, оно ещё и красивое, удобное. В бесплатном тарифном плане есть отправка пушей.
Я туда загнал всякие свои личные проверки типа интернета в квартире и на даче, личные VPS и т.д. Для работы как-то особо не надо. Там и так везде разные мониторинги. А для себя просто по кайфу этим приложением пользоваться.
Если кто-то знает ещё хорошие приложения мониторинга для смартфона, поделитесь информацией. Не понимаю, почему Zabbix не запилит какое-нибудь родное приложение. Для него вообще ничего на смартфоне нет. Какие-то отдельные приложения есть от одиночных авторов, но они никакущие. Я все их пробовал.
#мониторинг #бесплатно
{kind=link}
На днях разработчики Angie анонсировали свой готовый Dashboard для мониторинга веб сервера через Prometheus и Grafana. Решил сразу его попробовать. Забегая вперёд скажу, что всё это существенно упрощает настройку мониторинга, который и так уже был на хорошем уровне в Angie. Стало просто отлично.
Напомню, что у Angie есть встроенный prometheus exporter. Включаем его так. Добавляем куда-нибудь location. Я обычно на ip адрес его вешаю в default сервер и ограничиваю доступ:
И добавляем в секцию http:
Далее добавляем в prometheus:
Только убедитесь, что ваш веб сервер отдаёт метрики по http://1.2.3.4/p8s. Либо какой-то другой url используйте, который настроили.
Вот и всё. Теперь идём в свою Grafana и добавляем готовый дашборд. Вот он:
⇨ https://grafana.com/grafana/dashboards/20719-angie-dashboard
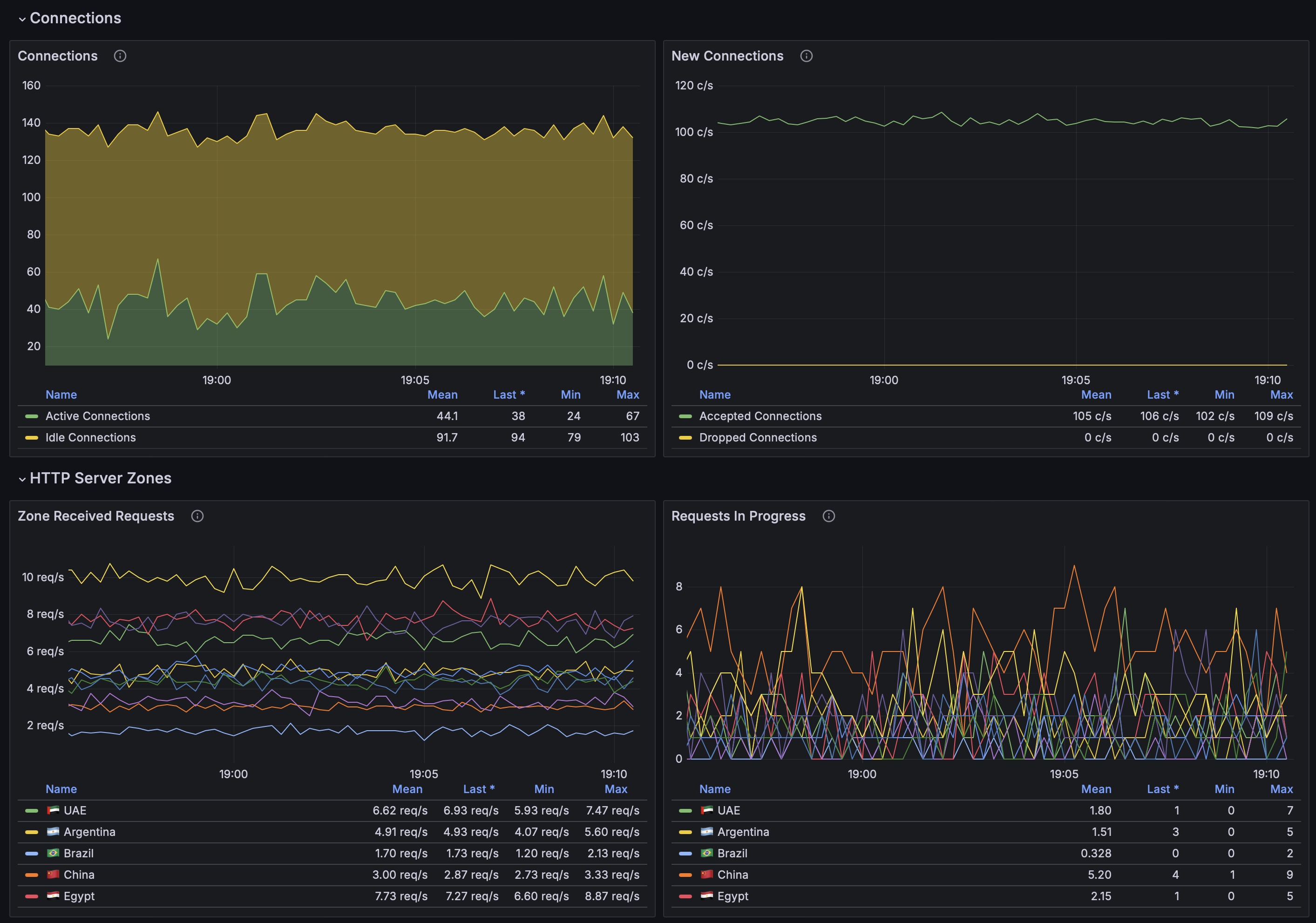
Дашборд полностью автоматизирован. Сам подхватывает все настройки из Angie. Покажу, как это работает. Допустим, вы хотите получать метрики по какому-то конкретному виртуальному хосту. Идём в него и добавляем в секцию server:
Перезапускаем Angie и переходим в Dashboard. В разделе HTTP Server Zones появится отдельная статистика по этому виртуальному хосту. То же самое можно сделать с отдельными location. Добавим отдельную зону в основной location и с php бэкендом:
или
Идём в раздел HTTP Location Zones и смотрим там статистику по указанным location.
Статистика по бэкендам, зонам с лимитами тоже подхватывается автоматически, если они у вас настроены, и сразу видна в дашборде.
Сделано всё очень удобно. Мониторинг веб сервера настраивается максимально быстро и при этом очень функционально.
Отдельно напомню, что у Angie вся эта же статистика видна в веб интерфейсе Console Light. И так же доступна через модуль API. Я через него сделал шаблон для Zabbix с основными метриками. Шаблон по ссылке стоит рассматривать только как пример создания. Он был сделан на скорую руку. Я его у себя немного доделал, но новую версию не выкладывал. Уже не помню, какие там отличия. С выходом этого дашборда для графаны мне шаблоном для Zabbix заниматься не хочется. Довольно хлопотно всё это реализовывать в нём и не особо имеет смысл, раз уже всё сделано за нас. Графаной я и так постоянно пользуюсь в связке с Zabbix, и Prometheus тоже использую.
📌 Ссылки по теме:
⇨ Настройка панели Prometheus
⇨ Модуль API
⇨ Директива status_zone
⇨ Web Console Demo
Как по мне, возможностей бесплатного веб сервера Angie на текущий момент существенно больше, чем у бесплатного Nginx. И речь не только о мониторинге. Там есть много других удобств. Разница в функциональности тянет уже на отдельную заметку.
#angie #мониторинг #grafana
Напомню, что у Angie есть встроенный prometheus exporter. Включаем его так. Добавляем куда-нибудь location. Я обычно на ip адрес его вешаю в default сервер и ограничиваю доступ:
location =/p8s { prometheus all; allow 127.0.0.1; allow 1.2.3.4; allow 4.3.2.1; deny all; }И добавляем в секцию http:
include prometheus_all.conf;Далее добавляем в prometheus:
scrape_configs: - job_name: "angie" scrape_interval: 15s metrics_path: "/p8s" static_configs: - targets: ["1.2.3.4:80"]Только убедитесь, что ваш веб сервер отдаёт метрики по http://1.2.3.4/p8s. Либо какой-то другой url используйте, который настроили.
Вот и всё. Теперь идём в свою Grafana и добавляем готовый дашборд. Вот он:
⇨ https://grafana.com/grafana/dashboards/20719-angie-dashboard
Дашборд полностью автоматизирован. Сам подхватывает все настройки из Angie. Покажу, как это работает. Допустим, вы хотите получать метрики по какому-то конкретному виртуальному хосту. Идём в него и добавляем в секцию server:
server { server_name serveradmin.ru; status_zone serveradmin.ru; ................}Перезапускаем Angie и переходим в Dashboard. В разделе HTTP Server Zones появится отдельная статистика по этому виртуальному хосту. То же самое можно сделать с отдельными location. Добавим отдельную зону в основной location и с php бэкендом:
location / { status_zone main; ...............}или
location ~ \.php$ { status_zone php; ...................}Идём в раздел HTTP Location Zones и смотрим там статистику по указанным location.
Статистика по бэкендам, зонам с лимитами тоже подхватывается автоматически, если они у вас настроены, и сразу видна в дашборде.
Сделано всё очень удобно. Мониторинг веб сервера настраивается максимально быстро и при этом очень функционально.
Отдельно напомню, что у Angie вся эта же статистика видна в веб интерфейсе Console Light. И так же доступна через модуль API. Я через него сделал шаблон для Zabbix с основными метриками. Шаблон по ссылке стоит рассматривать только как пример создания. Он был сделан на скорую руку. Я его у себя немного доделал, но новую версию не выкладывал. Уже не помню, какие там отличия. С выходом этого дашборда для графаны мне шаблоном для Zabbix заниматься не хочется. Довольно хлопотно всё это реализовывать в нём и не особо имеет смысл, раз уже всё сделано за нас. Графаной я и так постоянно пользуюсь в связке с Zabbix, и Prometheus тоже использую.
📌 Ссылки по теме:
⇨ Настройка панели Prometheus
⇨ Модуль API
⇨ Директива status_zone
⇨ Web Console Demo
Как по мне, возможностей бесплатного веб сервера Angie на текущий момент существенно больше, чем у бесплатного Nginx. И речь не только о мониторинге. Там есть много других удобств. Разница в функциональности тянет уже на отдельную заметку.
#angie #мониторинг #grafana
{kind=link}
Расскажу про очень простую и функциональную систему отправки уведомлений во все современные каналы - Apprise. Она представляет из себя консольное приложение, в которое через параметры командной строки можно передавать настройки для отправки уведомлений.
Apprise поддерживает Telegram, Discord, Mattermost, NextcloudTalk, Revolt, Rocket.Chat, Slack, WhatsApp и т.д. Помимо мессенджеров сообщения можно доставлять в Syslog, Pushover, ntfy, Mailgun, обычную почту и кучу других сервисов, в том числе пуши на комп можно отправлять. Они все перечислены в репозитории. Список очень большой.
Работает это примерно так. Ставим Apprise из pip:
Открываем репозиторий и смотрим синтаксис необходимого вам направления. Пример для Telegram:
От правили вывод утилиты uptime в Telegram. Формат конфигурации такой:
или для нескольких чатов
Понятно, что только для Telegram это не имеет смысла. Туда можно и напрямую слать. Идея в том, что у тебя один инструмент объединяет все каналы. Можно сделать конфиг, в котором будут указаны разные каналы. Отправив информацию в apprise, он сам разошлёт по всем указанным направлениям. Ну и как плюс, более простая настройка, так как формат настроек разных направлений примерно одинаковый. Это просто удобно.
С помощью Apprise легко настроить отправку пушей через сервис pushover.net. У него бесплатный тарифный план позволяет отправлять 10,000 в месяц. Для многих задач этого будет заглаза.
Настройки можно выполнять через веб интерфейс. Для этого собрали готовый Docker образ. Там можно подготовить конфигурации отправлений, протэгировать их и использовать в консольных командах, отправляя запросы к Apprise API.
Система простая в настройке. Не надо изучать и разбираться с API сторонних сервисов. В Apprise они уже все собраны, а работа с ними унифицирована с помощью встроенного API или конфигураций. У продукта есть подробная wiki.
⇨ Исходники / Docker
#мониторинг
Apprise поддерживает Telegram, Discord, Mattermost, NextcloudTalk, Revolt, Rocket.Chat, Slack, WhatsApp и т.д. Помимо мессенджеров сообщения можно доставлять в Syslog, Pushover, ntfy, Mailgun, обычную почту и кучу других сервисов, в том числе пуши на комп можно отправлять. Они все перечислены в репозитории. Список очень большой.
Работает это примерно так. Ставим Apprise из pip:
# apt install python3-pip# pip install apprise --break-system-packagesОткрываем репозиторий и смотрим синтаксис необходимого вам направления. Пример для Telegram:
# uptime | apprise -vv \ 'tgram://1393668911:AAHtETAKqxUH8ZpyC28R-wxKfvH8WR6-vdNw/211805263'От правили вывод утилиты uptime в Telegram. Формат конфигурации такой:
tgram://bottoken/ChatID или для нескольких чатов
tgram://bottoken/ChatID1/ChatID2/ChatIDNПонятно, что только для Telegram это не имеет смысла. Туда можно и напрямую слать. Идея в том, что у тебя один инструмент объединяет все каналы. Можно сделать конфиг, в котором будут указаны разные каналы. Отправив информацию в apprise, он сам разошлёт по всем указанным направлениям. Ну и как плюс, более простая настройка, так как формат настроек разных направлений примерно одинаковый. Это просто удобно.
С помощью Apprise легко настроить отправку пушей через сервис pushover.net. У него бесплатный тарифный план позволяет отправлять 10,000 в месяц. Для многих задач этого будет заглаза.
Настройки можно выполнять через веб интерфейс. Для этого собрали готовый Docker образ. Там можно подготовить конфигурации отправлений, протэгировать их и использовать в консольных командах, отправляя запросы к Apprise API.
Система простая в настройке. Не надо изучать и разбираться с API сторонних сервисов. В Apprise они уже все собраны, а работа с ними унифицирована с помощью встроенного API или конфигураций. У продукта есть подробная wiki.
⇨ Исходники / Docker
#мониторинг
{kind=link}
После установки обновлений иногда необходимо выполнить перезагрузку системы. Точно надо это сделать, если обновилось ядро. Необходимо загрузиться с новым ядром. В коммерческих системах Linux от разных разработчиков есть механизмы обновления ядра без перезагрузки. В бесплатных системах такого не видел.
Для того, чтобы отслеживать этот момент, можно воспользоваться программой needrestart. Она есть в базовых репах:
В rpm дистрибутивах название будет needs-restarting. Если просто запустить программу, то она в интерактивном режиме покажет, какие службы необходимо перезапустить, чтобы подгрузить обновлённые библиотеки, либо скажет, что надо перезапустить систему, чтобы применить обновление ядра.
Для того, чтобы использовать её в автоматизации, есть ключ
Здесь перечислены службы, которые нужно перезапустить после обновления системы. И показана информация об ядре. Значение NEEDRESTART-KSTA может принимать следующие состояния необходимости обновления ядра:
0: неизвестно, либо не удалось определить
1: нет необходимости в обновлении
2: ожидается какое-то ABI совместимое обновление (не понял, что это такое)
3: ожидается обновление версии
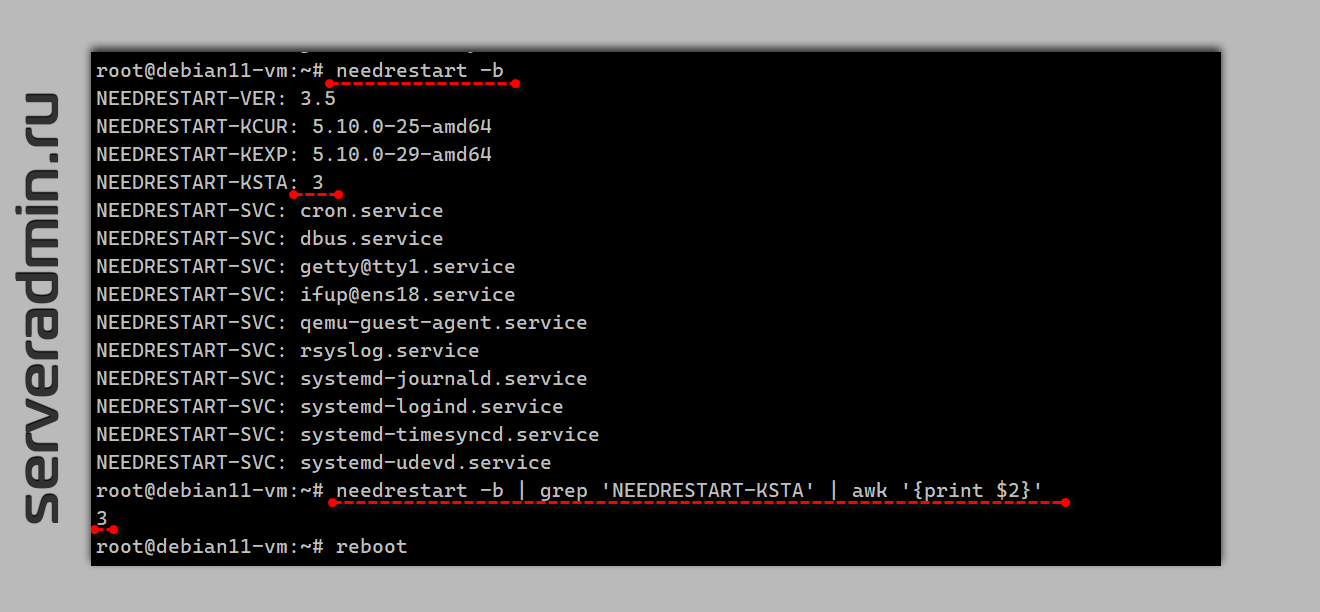
Если у вас значение 3, как у меня в примере, значит систему нужно перезагрузить, чтобы обновлённое ядро 5.10.0-29-amd64 заменило текущее загруженное 5.10.0-25-amd64.
Значение NEEDRESTART-KSTA можно передать в мониторинг и отслеживать необходимость перезагрузки. Например, В Zabbix можно передать вывод следующей команды:
Если на выходе будет 3, активируем триггер. Передать значение можно любым доступным способом, которому вы отдаёте предпочтение в своей инфраструктуре:
◽с помощью локального скрипта и параметра UserParameter в агенте
◽с помощью EnableRemoteCommands в агенте и ключа system.run на сервере
◽с помощью zabbix_sender
◽с помощью скрипта и передачи значения ключа напрямую в сервер через его API
Zabbix в этом плане очень гибкая система, предлагает разные способы решения одной и той же задачи.
После перезагрузки значение NEEDRESTART-KSTA станет равно единице:
В выводе не будет ни одной службы, которую следует перезапустить. Если нет системы мониторинга, но есть система сбора логов, то можно вывод отправить туда и там уже следить за службами и состоянием ядра.
Покажу, как строку сразу преобразовать в нормальный json, чтобы потом можно было легко анализировать:
Обработал в лоб. Взял утилиту jo, заменил
Придумал это без помощи ChatGPT. Даже не знаю уже, хорошо это или плохо. По привычке трачу время и пишу такие штуки сам.
#linux #мониторинг
Для того, чтобы отслеживать этот момент, можно воспользоваться программой needrestart. Она есть в базовых репах:
# apt install needrestartВ rpm дистрибутивах название будет needs-restarting. Если просто запустить программу, то она в интерактивном режиме покажет, какие службы необходимо перезапустить, чтобы подгрузить обновлённые библиотеки, либо скажет, что надо перезапустить систему, чтобы применить обновление ядра.
Для того, чтобы использовать её в автоматизации, есть ключ
-b, batch mode:# needrestart -bNEEDRESTART-VER: 3.5NEEDRESTART-KCUR: 5.10.0-25-amd64NEEDRESTART-KEXP: 5.10.0-29-amd64NEEDRESTART-KSTA: 3NEEDRESTART-SVC: cron.serviceNEEDRESTART-SVC: dbus.serviceNEEDRESTART-SVC: getty@tty1.serviceNEEDRESTART-SVC: ifup@ens18.serviceNEEDRESTART-SVC: qemu-guest-agent.serviceNEEDRESTART-SVC: rsyslog.serviceNEEDRESTART-SVC: systemd-journald.serviceNEEDRESTART-SVC: systemd-logind.serviceNEEDRESTART-SVC: systemd-timesyncd.serviceNEEDRESTART-SVC: systemd-udevd.serviceЗдесь перечислены службы, которые нужно перезапустить после обновления системы. И показана информация об ядре. Значение NEEDRESTART-KSTA может принимать следующие состояния необходимости обновления ядра:
0: неизвестно, либо не удалось определить
1: нет необходимости в обновлении
2: ожидается какое-то ABI совместимое обновление (не понял, что это такое)
3: ожидается обновление версии
Если у вас значение 3, как у меня в примере, значит систему нужно перезагрузить, чтобы обновлённое ядро 5.10.0-29-amd64 заменило текущее загруженное 5.10.0-25-amd64.
Значение NEEDRESTART-KSTA можно передать в мониторинг и отслеживать необходимость перезагрузки. Например, В Zabbix можно передать вывод следующей команды:
# needrestart -b | grep 'NEEDRESTART-KSTA' | awk '{print $2}'Если на выходе будет 3, активируем триггер. Передать значение можно любым доступным способом, которому вы отдаёте предпочтение в своей инфраструктуре:
◽с помощью локального скрипта и параметра UserParameter в агенте
◽с помощью EnableRemoteCommands в агенте и ключа system.run на сервере
◽с помощью zabbix_sender
◽с помощью скрипта и передачи значения ключа напрямую в сервер через его API
Zabbix в этом плане очень гибкая система, предлагает разные способы решения одной и той же задачи.
После перезагрузки значение NEEDRESTART-KSTA станет равно единице:
# needrestart -bNEEDRESTART-VER: 3.5NEEDRESTART-KCUR: 5.10.0-29-amd64NEEDRESTART-KEXP: 5.10.0-29-amd64NEEDRESTART-KSTA: 1В выводе не будет ни одной службы, которую следует перезапустить. Если нет системы мониторинга, но есть система сбора логов, то можно вывод отправить туда и там уже следить за службами и состоянием ядра.
Покажу, как строку сразу преобразовать в нормальный json, чтобы потом можно было легко анализировать:
# needrestart -b | tr ':' '=' | tr -d ' ' | jo -p{ "NEEDRESTART-VER": 3.5, "NEEDRESTART-KCUR": "5.10.0-29-amd64", "NEEDRESTART-KEXP": "5.10.0-29-amd64", "NEEDRESTART-KSTA": 1}Обработал в лоб. Взял утилиту jo, заменил
: на = c помощью tr, потому что jo понимает только =, потом убрал лишние пробелы опять же с помощью tr. Получили чистый json, из которого с помощью jsonpath можно забрать необходимое для анализа значение.# needrestart -b | tr ':' '=' | tr -d ' ' | jo -p | jq .'"NEEDRESTART-KSTA"'1Придумал это без помощи ChatGPT. Даже не знаю уже, хорошо это или плохо. По привычке трачу время и пишу такие штуки сам.
#linux #мониторинг
{kind=link}
Наиболее популярным и простым в настройке мониторингом сейчас является Prometheus. Простым не в плане возможностей, а в плане начальной настройки. Так как для него очень много всего автоматизировано, начать сбор метрик можно в несколько простых действий. Мониторинг сразу заработает и дальше с ним можно разбираться и настраивать.
Напишу краткую шпаргалку по запуску связки Prometheus + Grafana, чтобы её можно было сохранить и использовать по мере надобности. Я установлю их в Docker, сразу буду мониторить сам Prometheus и локальных хост Linux. Подключу для примера ещё один внешний Linux сервер.
Ставим Docker:
Готовим файл
Содержимое файла:
И рядом кладём конфиг
Запускаем весь стек:
Если будут ошибки, прогоните весь yaml через какой-нибудь валидатор. При копировании он часто ломается.
Ждём, когда всё поднимется, и идём по IP адресу сервера на порт 3000. Логинимся в Grafana под учёткой admin / admin. Заходим в Connections ⇨ Data sources и добавляем источник prometheus. В качестве параметра Prometheus server URL указываем http://prometheus:9090. Сохраняем.
Идём в Dashboards, нажимаем New ⇨ Import. Вводим ID дашборда для Node Exporter - 1860. Сохраняем и идём смотреть дашборд. Увидите все доступные графики и метрики хоста Linux, на котором всё запущено.
Идём на удалённый Linux хост и запускаем там любым подходящим способом node-exporter. Например, через Docker напрямую:
Проверяем, что сервис запущен на порту 9100:
Возвращаемся на сервер с prometheus и добавляем в его конфиг еще одну job с этим сервером:
Перезапускаем стек:
Идём в Dashboard в Grafana и выбираем сверху в выпадающем списке job от этого нового сервера - node-remote.
На всю настройку уйдёт минут 10. Потом ещё 10 на настройку базовых уведомлений. У меня уже места не хватило их добавить сюда. Наглядно видна простота и скорость настройки, о которых я сказал в начале.
❗️В проде не забывайте ограничивать доступ ко всем открытым портам хостов с помощью файрвола.
#мониторинг #prometheus #devops
Напишу краткую шпаргалку по запуску связки Prometheus + Grafana, чтобы её можно было сохранить и использовать по мере надобности. Я установлю их в Docker, сразу буду мониторить сам Prometheus и локальных хост Linux. Подключу для примера ещё один внешний Linux сервер.
Ставим Docker:
# curl https://get.docker.com | bash -Готовим файл
docker-compose.yml:# mkdir ~/prometheus && cd ~/prometheus# touch docker-compose.ymlСодержимое файла:
version: '3.9'networks: monitoring: driver: bridgevolumes: prometheus_data: {}services: prometheus: image: prom/prometheus:latest volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml - prometheus_data:/prometheus container_name: prometheus hostname: prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' expose: - 9090 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoring node-exporter: image: prom/node-exporter volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro container_name: exporter hostname: exporter command: - '--path.procfs=/host/proc' - '--path.rootfs=/rootfs' - '--path.sysfs=/host/sys' - '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)' expose: - 9100 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoring grafana: image: grafana/grafana user: root depends_on: - prometheus ports: - 3000:3000 volumes: - ./grafana:/var/lib/grafana - ./grafana/provisioning/:/etc/grafana/provisioning/ container_name: grafana hostname: grafana restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoringИ рядом кладём конфиг
prometheus.yml:scrape_configs: - job_name: 'prometheus' scrape_interval: 5s scrape_timeout: 5s static_configs: - targets: ['localhost:9090'] - job_name: 'node-local' scrape_interval: 5s static_configs: - targets: ['node-exporter:9100']Запускаем весь стек:
# docker-compose up -dЕсли будут ошибки, прогоните весь yaml через какой-нибудь валидатор. При копировании он часто ломается.
Ждём, когда всё поднимется, и идём по IP адресу сервера на порт 3000. Логинимся в Grafana под учёткой admin / admin. Заходим в Connections ⇨ Data sources и добавляем источник prometheus. В качестве параметра Prometheus server URL указываем http://prometheus:9090. Сохраняем.
Идём в Dashboards, нажимаем New ⇨ Import. Вводим ID дашборда для Node Exporter - 1860. Сохраняем и идём смотреть дашборд. Увидите все доступные графики и метрики хоста Linux, на котором всё запущено.
Идём на удалённый Linux хост и запускаем там любым подходящим способом node-exporter. Например, через Docker напрямую:
# docker run -d --net="host" --pid="host" -v "/:/host:ro,rslave" prom/node-exporter:latest --path.rootfs=/hostПроверяем, что сервис запущен на порту 9100:
# ss -tulnp | grep 9100Возвращаемся на сервер с prometheus и добавляем в его конфиг еще одну job с этим сервером:
- job_name: 'node-remote' scrape_interval: 5s static_configs: - targets: ['10.20.1.56:9100']Перезапускаем стек:
# docker compose restartИдём в Dashboard в Grafana и выбираем сверху в выпадающем списке job от этого нового сервера - node-remote.
На всю настройку уйдёт минут 10. Потом ещё 10 на настройку базовых уведомлений. У меня уже места не хватило их добавить сюда. Наглядно видна простота и скорость настройки, о которых я сказал в начале.
❗️В проде не забывайте ограничивать доступ ко всем открытым портам хостов с помощью файрвола.
#мониторинг #prometheus #devops
{kind=link}
Вчера была заметка про быструю установку связки Prometheus + Grafana. Из-за лимита Telegram на длину сообщений разом всё описать не представляется возможным. А для полноты картины не хватает настройки уведомлений, так как мониторинг без них это не мониторинг, а красивые картинки.
Для примера я настрою два типа уведомлений:
◽SMTP для только для метки critical
◽Telegram для меток critical и warning
Уведомления будут отправляться на основе двух событий:
▪️ С хоста нету метрик, то есть он недоступен мониторингу, метка critical
▪️ На хосте процессор занят в течении минуты более чем на 70%, метка warning
Я взял именно эти ситуации, так как на их основе будет понятен сам принцип настройки и формирования конфигов, чтобы каждый потом смог доработать под свои потребности.
Постить сюда все конфигурации в формате yaml неудобно, поэтому решил их собрать в архив и прикрепить в следующем сообщении. Там будут 4 файла:
-
-
-
-
Для запуска всего стека с уведомлениями достаточно положить эти 4 файла в отдельную директорию и там запустить compose:
На момент отладки рекомендую запускать прямо в консоли, чтобы отлавливать ошибки. Если где-то ошибётесь в конфигурациях правил или alertmanager, сразу увидите ошибки и конкретные строки конфигурации, с которыми что-то не так. В таком случае останавливайте стэк:
Исправляйте конфиги и заново запускайте. Зайдя по IP адресу сервера на порт 9090, вы попадёте в веб интерфейс Prometheus. Там будет отдельный раздел Alerts, где можно следить за работой уведомлений.
В данном примере со всем стэком наглядно показан принцип построения современного мониторинга с подходом инфраструктура как код (IaC). Имея несколько файлов конфигурации, мы поднимаем необходимую систему во всей полноте. Её легко переносить, изменять конфигурацию и отслеживать эти изменения через git.
#мониторинг #prometheus #devops
Для примера я настрою два типа уведомлений:
◽SMTP для только для метки critical
◽Telegram для меток critical и warning
Уведомления будут отправляться на основе двух событий:
▪️ С хоста нету метрик, то есть он недоступен мониторингу, метка critical
▪️ На хосте процессор занят в течении минуты более чем на 70%, метка warning
Я взял именно эти ситуации, так как на их основе будет понятен сам принцип настройки и формирования конфигов, чтобы каждый потом смог доработать под свои потребности.
Постить сюда все конфигурации в формате yaml неудобно, поэтому решил их собрать в архив и прикрепить в следующем сообщении. Там будут 4 файла:
-
docker-compose.yml - основной файл с конфигурацией всех сервисов. Его описание можно посмотреть в предыдущем посте. Там добавился новый контейнер с alertmanager и файл с правилами для prometheus - alert.rules-
prometheus.yml - настройки Прометеуса.-
alert.rules - файл с двумя правилами уведомлений о недоступности хоста и превышении нагрузки CPU.-
alertmanager.yml - настройки alertmanager с двумя источниками для уведомлений: email и telegram. Не забудьте там поменять токен бота, id своего аккаунта, куда бот будет отправлять уведомления и настройки smtp.Для запуска всего стека с уведомлениями достаточно положить эти 4 файла в отдельную директорию и там запустить compose:
# docker compose upНа момент отладки рекомендую запускать прямо в консоли, чтобы отлавливать ошибки. Если где-то ошибётесь в конфигурациях правил или alertmanager, сразу увидите ошибки и конкретные строки конфигурации, с которыми что-то не так. В таком случае останавливайте стэк:
# docker compose stopИсправляйте конфиги и заново запускайте. Зайдя по IP адресу сервера на порт 9090, вы попадёте в веб интерфейс Prometheus. Там будет отдельный раздел Alerts, где можно следить за работой уведомлений.
В данном примере со всем стэком наглядно показан принцип построения современного мониторинга с подходом инфраструктура как код (IaC). Имея несколько файлов конфигурации, мы поднимаем необходимую систему во всей полноте. Её легко переносить, изменять конфигурацию и отслеживать эти изменения через git.
#мониторинг #prometheus #devops
{kind=link}
Когда речь заходит о современном мониторинге, в первую очередь на ум приходит Prometheus и прочие совместимые с ним системы. Более возрастные специалисты возможно назовут Zabbix и в целом не ошибутся. Сколько его ни хоронят, но на самом деле он остаётся вполне современным и востребованным.
А вот дальше уже идёт список из менее популярных систем, которые тем не менее живут, развиваются и находят своё применение. Про один из таких современных мониторингов с вполне солидной историей я кратко расскажу. Речь пойдёт про TICK Stack (Telegraf, InfluxDB, Chronograf, Kapacitor). Я могу ошибаться, но вроде бы мониторинг на базе InfluxDB и Telegraf появился чуть раньше, чем подобный стэк на базе Prometheus. По крайней мере я про них давно знаю. Он был немного экзотичен, но в целом использовался. Сам не пробовал, но читал много обзорных статей по его использованию.
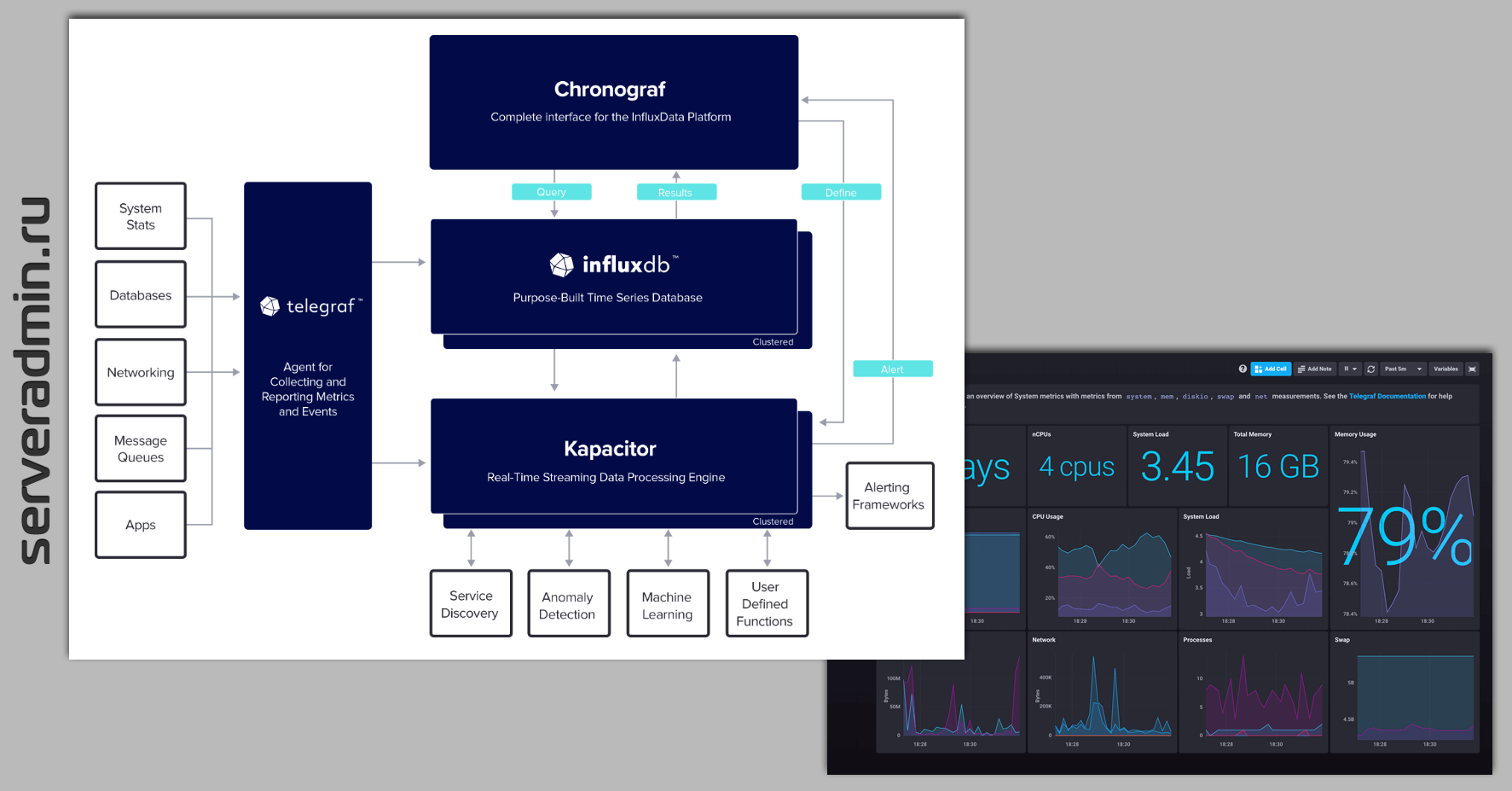
TICK Stack состоит из следующих компонентов:
◽Telegraf — агент, который собирает метрики, логи и передаёт в базу influxdb, но умеет также передавать в elasticsearch, prometheus или graphite.
◽InfluxDB — СУБД для хранения временных рядов (TSDB - time series database).
◽Chronograf — веб интерфейс для визуализации метрик.
◽Kapacitor — система поиска аномалий и отправки уведомлений.
Из этого стэка при желании можно убрать Chronograf и Kapacitor, а вместо них взять Grafana. Она поддерживает просмотр метрик из Influxdb. TICK Stack архитектурно похож на мониторинг на базе Prometheus. Тот же набор компонентов - агент для метрик, база данных, веб интерфейс и уведомления.
📌 Основные отличия Prometheus от TICK Stack:
🔹Ключевое отличие скорее всего в языке запросов - InfluxQL против PromQL. Первый сильно похож на SQL, в то время как PromQL вообще ни на что не похож. Его придётся учить с нуля.
🔹InfluxDB полностью поддерживает хранение строк. То есть туда можно складывать и логи. Она нормально с ними работает.
🔹Подход сбора метрик у низ разный. Пром сам собирает метрики по модели pull, а TICK Stack получает их от агентов по модели push, которые сами отправляют данные.
🔹У InfluxDB есть коммерческая версия с готовым масштабируемым кластером.
🔹В среднем TICK Stack потребляет больше ресурсов, чем аналог стека на базе Prometheus.
Попробовать всё это хозяйство очень просто. Есть готовое тестовое окружение в docker-compose. Там сразу представлены и документация, и примеры конфигов, и управляющий скрипт.
Будет поднято окружение по предоставленному docker-compose.yaml. У меня не запустился контейнер с Chronograf. Посмотрел его лог, ругается на то, что не хватает прав. Разбираться не стал, просто дал директориям chronograf/data права 777 и ещё раз запустил. Стэк поднялся полностью.
Chronograf запускается на порту 8888. Можно идти в веб интерфейс и смотреть, как там всё устроено. Примеры конфигов в соответствующих директориях в репозитории. По умолчанию Telegraf передаёт только метрики CPU и самой InfluxDB. Полная информация по деплою есть в документации.
Мониторинг TICK Stack ориентирован как на мониторинг контейнеров, в том числе кластеров Kubernetes и конечных приложений, так и непосредственно операционных систем. У Telegraf есть готовые плагины на все случаи жизни. Полный список можно посмотреть в документации. Чего там только нет. Поддерживаются все популярные системы, в том числе Windows. Можно, к примеру, собирать её логи. То есть система универсальна. Тут и мониторинг, и логи. Два в одном.
Из необычного, нашёл плагин для мониторинга за ютуб каналами - подписчики, просмотры, видео. Есть плагин мониторинга таймеров systemd, sql запросов в субд, атрибутов смарт через smartctl, гипервизора proxmox, плагин для сбора метрик с экспортеров прометеуса и много всего интересного. На вид система неплохо выглядит. Как на практике, не знаю. Я не использовал.
⇨ Сайт / Список плагинов
#мониторинг
А вот дальше уже идёт список из менее популярных систем, которые тем не менее живут, развиваются и находят своё применение. Про один из таких современных мониторингов с вполне солидной историей я кратко расскажу. Речь пойдёт про TICK Stack (Telegraf, InfluxDB, Chronograf, Kapacitor). Я могу ошибаться, но вроде бы мониторинг на базе InfluxDB и Telegraf появился чуть раньше, чем подобный стэк на базе Prometheus. По крайней мере я про них давно знаю. Он был немного экзотичен, но в целом использовался. Сам не пробовал, но читал много обзорных статей по его использованию.
TICK Stack состоит из следующих компонентов:
◽Telegraf — агент, который собирает метрики, логи и передаёт в базу influxdb, но умеет также передавать в elasticsearch, prometheus или graphite.
◽InfluxDB — СУБД для хранения временных рядов (TSDB - time series database).
◽Chronograf — веб интерфейс для визуализации метрик.
◽Kapacitor — система поиска аномалий и отправки уведомлений.
Из этого стэка при желании можно убрать Chronograf и Kapacitor, а вместо них взять Grafana. Она поддерживает просмотр метрик из Influxdb. TICK Stack архитектурно похож на мониторинг на базе Prometheus. Тот же набор компонентов - агент для метрик, база данных, веб интерфейс и уведомления.
📌 Основные отличия Prometheus от TICK Stack:
🔹Ключевое отличие скорее всего в языке запросов - InfluxQL против PromQL. Первый сильно похож на SQL, в то время как PromQL вообще ни на что не похож. Его придётся учить с нуля.
🔹InfluxDB полностью поддерживает хранение строк. То есть туда можно складывать и логи. Она нормально с ними работает.
🔹Подход сбора метрик у низ разный. Пром сам собирает метрики по модели pull, а TICK Stack получает их от агентов по модели push, которые сами отправляют данные.
🔹У InfluxDB есть коммерческая версия с готовым масштабируемым кластером.
🔹В среднем TICK Stack потребляет больше ресурсов, чем аналог стека на базе Prometheus.
Попробовать всё это хозяйство очень просто. Есть готовое тестовое окружение в docker-compose. Там сразу представлены и документация, и примеры конфигов, и управляющий скрипт.
# git clone https://github.com/influxdata/sandbox.git# cd sandbox# ./sandbox upБудет поднято окружение по предоставленному docker-compose.yaml. У меня не запустился контейнер с Chronograf. Посмотрел его лог, ругается на то, что не хватает прав. Разбираться не стал, просто дал директориям chronograf/data права 777 и ещё раз запустил. Стэк поднялся полностью.
Chronograf запускается на порту 8888. Можно идти в веб интерфейс и смотреть, как там всё устроено. Примеры конфигов в соответствующих директориях в репозитории. По умолчанию Telegraf передаёт только метрики CPU и самой InfluxDB. Полная информация по деплою есть в документации.
Мониторинг TICK Stack ориентирован как на мониторинг контейнеров, в том числе кластеров Kubernetes и конечных приложений, так и непосредственно операционных систем. У Telegraf есть готовые плагины на все случаи жизни. Полный список можно посмотреть в документации. Чего там только нет. Поддерживаются все популярные системы, в том числе Windows. Можно, к примеру, собирать её логи. То есть система универсальна. Тут и мониторинг, и логи. Два в одном.
Из необычного, нашёл плагин для мониторинга за ютуб каналами - подписчики, просмотры, видео. Есть плагин мониторинга таймеров systemd, sql запросов в субд, атрибутов смарт через smartctl, гипервизора proxmox, плагин для сбора метрик с экспортеров прометеуса и много всего интересного. На вид система неплохо выглядит. Как на практике, не знаю. Я не использовал.
⇨ Сайт / Список плагинов
#мониторинг
{kind=link}
У меня было очень много заметок про различные мониторинги. Кажется, что я уже про всё более-менее полезное что-то да писал. Оказалось, что нет. Расскажу про очередной небольшой и удобный мониторинг, который позволяет очень просто и быстро создать дашборд с зелёными и красными кнопками. Если зелёные, то всё ОК, если красные, то НЕ ОК.
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
Запускаем Docker контейнер и цепляем к нему этот файл:
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
Речь пойдёт про Gatus. С его помощью очень удобно создавать Status Page. Сразу покажу, как это будет выглядеть:
⇨ https://status.twin.sh
И сразу же простой пример, как это настраивается. Там всё максимально просто и быстро. Мы будем проверять следующие условия:
◽️Подключение к сайту zabbix.com проходит успешно, а его IP равен 188.114.99.224. Так как этот домен резолвится в разные IP, можно будет увидеть, как срабатывает проверка.
◽️Сайт github.com отдаёт код 200 при подключении и содержит заголовок страницы GitHub: Let’s build from here · GitHub.
◽️Сайт ya.ru отдаёт код 200 и имеет отклик менее 10 мс. На практике он будет больше, посмотрим, как срабатывает триггер. По этой проверке будет уведомление в Telegram.
◽️Домен vk.com имеет сертификат со сроком истечения не менее 48 часов и делегирование домена не менее 720 часов.
Специально подобрал разнообразные примеры, чтобы вы оценили возможности мониторинга. Я просто открыл документацию и сходу по ней всё сделал. Всё очень просто и понятно, особо разбираться не пришлось. Создаём конфигурационный файл для этих проверок:
# mkdir gatus && cd gatus
# touch config.yaml
alerting:
telegram:
token: "1393668911:AAHtEAKqxUH7ZpyX28R-wxKfvH1WR6-vdNw"
id: "210806260"
endpoints:
- name: Zabbix Connection
url: "https://zabbix.com"
interval: 30s
conditions:
- "[CONNECTED] == true"
- "[IP] == 188.114.99.224"
- name: Github Title
url: "https://github.com"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY] == pat(*<title>GitHub: Let’s build from here · GitHub</title>*)"
- name: Yandex response
url: "https://ya.ru"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[RESPONSE_TIME] < 10"
alerts:
- type: telegram
send-on-resolved: true
- name: VK cert & domain
url: "https://vk.com"
interval: 5m
conditions:
- "[CERTIFICATE_EXPIRATION] > 48h"
- "[DOMAIN_EXPIRATION] > 720h"
Запускаем Docker контейнер и цепляем к нему этот файл:
# docker run -p 8080:8080 -d \
--mount type=bind,source="$(pwd)"/config.yaml,target=/config/config.yaml \
--name gatus twinproduction/gatus
Идём по IP адресу сервера на порт 8080 и смотрим на свой мониторинг. Данные могут храниться в оперативной памяти, sqlite или postgresql базе. Если выберите последнее, то вот готовый docker-compose для этого. По умолчанию данные хранятся в оперативной памяти и после перезапуска контейнера пропадают.
Штука простая и удобная. Меня не раз просили посоветовать что-то для простого дашборда с зелёными кнопками, когда всё нормально и красными, когда нет. Вот это идеальный вариант под такую задачу.
Также с помощью этого мониторинга удобно сделать дашборд для мониторинга мониторингов, чтобы понимать, живы они или нет.
#мониторинг
В пятницу в подборке видео я упоминал про обзор проекта changedetection.io. Хочу остановиться на нём отдельно, так как это очень крутой продукт. С его помощью можно отслеживать изменения на сайтах, используя практически полноценный браузер под капотом. Сразу приведу ссылку на видео с подробным обзором, описанием установки и настройки:
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
В принципе, там есть всё, чтобы сразу запустить и настроить сервис на своём сервисе. Для запуска надо склонировать репозиторий и запустить compose:
Можно идти в браузер на порт сервера 5000 и пользоваться. По умолчанию никакой аутентификации нет. Настройка интуитивна и относительно проста. Можно сразу пользоваться, потыкав мышкой.
По умолчанию используется обычный текстовый парсер, который толком ничего не умеет, плюс сайты на русском языке парсятся в виде крякозябр. Сначала расстроился, что нифига не работает. На самом деле это не проблема, так как сервис лучше сразу использовать с полноценным браузером Chrome под капотом. Там проблем с языком нет.
Как всё настроить, можно посмотреть в видео, но мне хватило и комментариев в
Changedetection можно использовать как для банального мониторинга сайтов и веб интерфейсов различных железок, так и для каких-то бытовых задач, типа парсинга цены на какой-нибудь товар в магазине или на авито. При этом можно писать сложные сценарии с переходами по различным ссылкам и меню, чтобы попасть в нужный раздел. Для этого есть визуальный конструктор запросов. Кодить ничего не надо, всё визуально настраивается. Есть много разных способов уведомлений, работающих через библиотеку apprise.
Сохраняется как история текстовых изменений, которые можно сравнивать за разные промежутки времени, так и скриншоты страниц. Для быстрого добавления сайтов на проверку есть плагин для Chrome. А для масштабного парсинга есть поддержка множества прокси и сервисов по распознаванию каптчи.
Сервис простой, удобный и лёгкий в настройке. Мне очень понравился. Иногда хочется замониторить какую-нибудь железку, типа камеры, которая ничего не отдаёт сама для мониторинга. С Changedetection это сделать очень просто. Можно за сайтами следить вместо rss подписок, которые сейчас есть не везде, за API. В общем, применения можно много найти. Плюс, у самого Changedetection есть встроенное API для управления и отслеживания изменений. Функциональная штука.
⇨ Сайт / Исходники / Обзор
#мониторинг
⇨ Meet ChangeDetection - A Self-Hosted Website Change Detector!
В принципе, там есть всё, чтобы сразу запустить и настроить сервис на своём сервисе. Для запуска надо склонировать репозиторий и запустить compose:
# git clone https://github.com/dgtlmoon/changedetection.io# cd changedetection.io# docker compose up -dМожно идти в браузер на порт сервера 5000 и пользоваться. По умолчанию никакой аутентификации нет. Настройка интуитивна и относительно проста. Можно сразу пользоваться, потыкав мышкой.
По умолчанию используется обычный текстовый парсер, который толком ничего не умеет, плюс сайты на русском языке парсятся в виде крякозябр. Сначала расстроился, что нифига не работает. На самом деле это не проблема, так как сервис лучше сразу использовать с полноценным браузером Chrome под капотом. Там проблем с языком нет.
Как всё настроить, можно посмотреть в видео, но мне хватило и комментариев в
docker-compose.yml. Раскомментировал некоторые строки и запустил всё заново. Зашёл в настройки, выбрал в разделе Fetching не Basic fast Plaintext/HTTP Client, а Playwright Chromium/Javascript. Русские сайты начали нормально парситься. Changedetection можно использовать как для банального мониторинга сайтов и веб интерфейсов различных железок, так и для каких-то бытовых задач, типа парсинга цены на какой-нибудь товар в магазине или на авито. При этом можно писать сложные сценарии с переходами по различным ссылкам и меню, чтобы попасть в нужный раздел. Для этого есть визуальный конструктор запросов. Кодить ничего не надо, всё визуально настраивается. Есть много разных способов уведомлений, работающих через библиотеку apprise.
Сохраняется как история текстовых изменений, которые можно сравнивать за разные промежутки времени, так и скриншоты страниц. Для быстрого добавления сайтов на проверку есть плагин для Chrome. А для масштабного парсинга есть поддержка множества прокси и сервисов по распознаванию каптчи.
Сервис простой, удобный и лёгкий в настройке. Мне очень понравился. Иногда хочется замониторить какую-нибудь железку, типа камеры, которая ничего не отдаёт сама для мониторинга. С Changedetection это сделать очень просто. Можно за сайтами следить вместо rss подписок, которые сейчас есть не везде, за API. В общем, применения можно много найти. Плюс, у самого Changedetection есть встроенное API для управления и отслеживания изменений. Функциональная штука.
⇨ Сайт / Исходники / Обзор
#мониторинг
{kind=link}
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
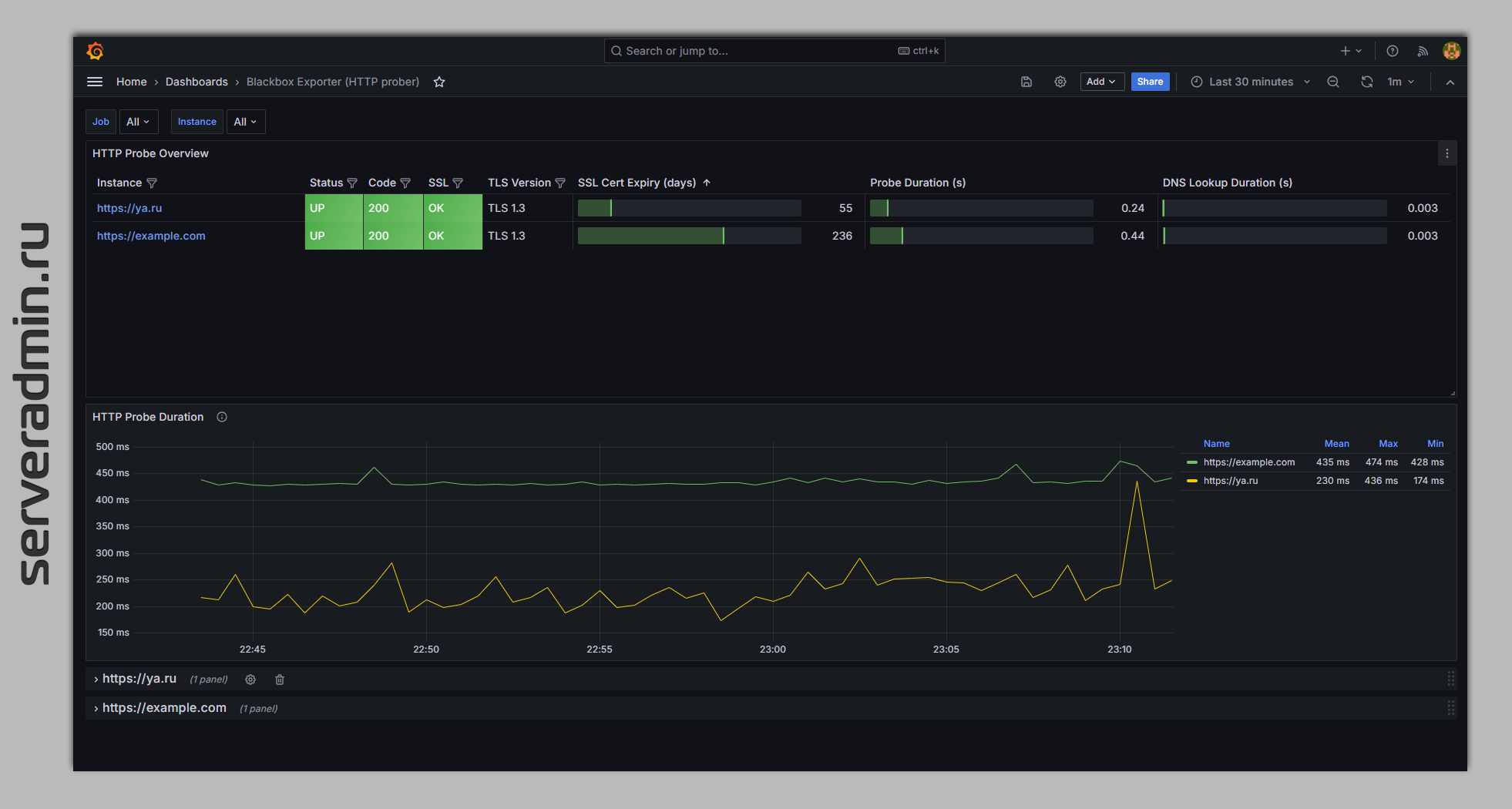
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}