
Буквально на днях узнал, что в bash квадратная скобка [ и утилита test это одно и то же. Точнее, я вообще не знал, что существует эта встроенная утилита. Всегда и везде в скриптах видел и сам использовал именно скобку.
Синтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
Сделаем проверку, что он существует, как я обычно это делаю:
А теперь то же самое, только через test:
Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
# type testtest is a shell builtin# type [[ is a shell builtinСинтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
# touch file.txtСделаем проверку, что он существует, как я обычно это делаю:
#!/bin/bashif [ -e file.txt]then echo "File exist"else echo "There is no testfile"А теперь то же самое, только через test:
#!/bin/bashif test -e file.txtthen echo "File exist"else echo "There is no testfile"Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
Хочу дать пару простых советов, которые не все знают и используют, но они могут сильно упростить жизнь при работе со стандартными утилитами Unix в консоли.
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
Тут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
Получится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
В этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
А если c $, получим то, что надо:
Можно совместить:
А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
#bash #script
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
# grep -E -v '^#' nginx.confТут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
# grep -E -v '^ #' nginx.confПолучится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
# ls | grep ^errorerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngВ этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
# ls | grep .pngerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngА если c $, получим то, что надо:
# ls | grep .png$error-windows-10-share-110x75.pngerror-windows-10-share-150x150.pngМожно совместить:
# ls | grep ^error | grep png$А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
# grep -E -v '^#|^$' nginx.conf#bash #script
{kind=link}
Провёл небольшое исследование на тему того, чем в консоли bash быстрее всего удалить большое количество директорий и файлов. Думаю, не все знают, что очень много файлов могут стать большой проблемой. Пока с этим не столкнёшься, не думаешь об этом. Если у тебя сервер бэкапов на обычных дисках и надо удалить миллионы файлов, это может оказаться непростой задачей.
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
И последняя команда, ради которой всё затевалось:
Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
Создаю 500 000 файлов в цикле по 50 000 с помощью
и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
Для второго теста сделал такой скрипт:
Создаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
# rm -r test/# rm -r test/*# find test/ -type f -delete# cd test/ ; ls . | xargs -n 100 rm #только для файлов работаетИ последняя команда, ради которой всё затевалось:
# rsync -a --delete empty/ test/Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
#!/bin/bashmkdir testcount=1while test $count -le 10do touch test/file$count-{000..50000}count=$(( $count + 1 ))donels test | wc -lСоздаю 500 000 файлов в цикле по 50 000 с помощью
touch. Больше за раз не получается создать, touch ругается на слишком большой список аргументов. После этого запускаю приведённые выше команды с подсчётом времени их выполнения с помощью time:# time rm -r test/и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
rm -r test/* в какой-то момент перестанет работать и будет ругаться на большое количество аргументов.Для второго теста сделал такой скрипт:
#!/bin/bashcount=1while test $count -le 10do mkdir -p test/dir$count-{000..500}touch test/dir$count-{000..500}/file-{000..100}count=$(( $count + 1 ))donefind test/ | wc -lСоздаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync
Linux всегда меня восхищал и радовал простыми решениями по возможностям работы с текстовыми файлами через командную строку. Слово простые можно было бы взять в кавычки, так как в реальности не просто изучить синтаксис подходящих консольных утилит. Но никто не мешает найти готовое выражение и использовать его. В Windows чаще всего можно решить эти же задачи с помощью своих программ, но обычно это занимает больше времени.
Самый простой пример того, о чём я говорю — автоматическая замена определённого текста в заданных файлах. Мне лично чаще всего это нужно, когда что-то делаешь с исходниками сайтов. Помню, как свои первые сайты делал более 20-ти лет назад на чистом html в Dreamweaver. При этом страниц там было сотни. Обновлял вручную копипастом. Это было тяжело, но в то время большинство сайтов были статичными, так как бесплатных хостингов на php не существовало. Но это я отвлёкся, заметка планируется про другое.
Допустим, у вас есть какой-то большой сайт на php и вам надо во всех файлах заменить устаревшую функцию на новую. В общем случае замену текста можно сделать с помощью sed, примерно так:
Или посложнее пример с вырезанием вредоносного куска кода из всех файлов, которые заразил какой-то вирус. Допустим, это некий код следующего содержания:
Текста между тэгами script может быть много, поэтому искать проще всего по этому тэгу и началу строки с function aeaab19d(a).
Тут я использую ключ -r для поддержки регулярных выражений, конкретно
Можно ещё усложнить и выполнить замену кода между каких-то строк. Для усложнения возьмём какой-нибудь XML:
Заменим user01 на user02
Тут важны круглые скобки и \1 и \2. Мы в первой части выражения запомнили текст в круглых скобках, а во второй части его использовали — сначала первую скобку, потом вторую.
Это были примеры для одиночных файлов, а теперь добавляем сюда find и используем sed на любом наборе файлов, который найдёт find.
Добавляем к sed ключ -i для того, чтобы он сразу изменял файл. Кстати, для find наиболее популярные примеры можете посмотреть через тэг #find.
Очень аккуратно выполняйте массовые действия. Сначала всё отладьте на тестовых файлах. Потом сделайте бэкап исходных файлов. И только потом выполняйте массовые изменения. И будьте готовы быстро всё откатить обратно.
Примеры рекомендую записать. Если надо быстро что-то сделать, то сходу правильно регулярку вы так просто не наберёте. К тому же в таком использовании есть свои нюансы. К примеру, я так и не смог победить команду sed, которая удаляет весь код <script>, если внутри есть переход на новую строку. Вроде бы легко найти, как заставить
Не забывайте про сервисы, которые помогают отлаживать регулярки. Собрал их в отдельной заметке.
#linux #bash #script
Самый простой пример того, о чём я говорю — автоматическая замена определённого текста в заданных файлах. Мне лично чаще всего это нужно, когда что-то делаешь с исходниками сайтов. Помню, как свои первые сайты делал более 20-ти лет назад на чистом html в Dreamweaver. При этом страниц там было сотни. Обновлял вручную копипастом. Это было тяжело, но в то время большинство сайтов были статичными, так как бесплатных хостингов на php не существовало. Но это я отвлёкся, заметка планируется про другое.
Допустим, у вас есть какой-то большой сайт на php и вам надо во всех файлах заменить устаревшую функцию на новую. В общем случае замену текста можно сделать с помощью sed, примерно так:
# sed 's/old_function/new_function/g' oldfilename > newfilenameИли посложнее пример с вырезанием вредоносного куска кода из всех файлов, которые заразил какой-то вирус. Допустим, это некий код следующего содержания:
<script>function aeaab19d(a)...................</script>Текста между тэгами script может быть много, поэтому искать проще всего по этому тэгу и началу строки с function aeaab19d(a).
# sed -r 's/<script>function aeaab19d\(a\).*?<\/script>//' test.phpТут я использую ключ -r для поддержки регулярных выражений, конкретно
.*?. Можно ещё усложнить и выполнить замену кода между каких-то строк. Для усложнения возьмём какой-нибудь XML:
<username><![CDATA[user01]]></username><password><![CDATA[password01]]></password><dbname><![CDATA[database]]></dbname>Заменим user01 на user02
# sed -r 's/(<username>.+)user01(.+<\/username>)/\1user02\2/' test.xmlТут важны круглые скобки и \1 и \2. Мы в первой части выражения запомнили текст в круглых скобках, а во второй части его использовали — сначала первую скобку, потом вторую.
Это были примеры для одиночных файлов, а теперь добавляем сюда find и используем sed на любом наборе файлов, который найдёт find.
# find /var/www/ -type f -name \*.php -exec \sed -i -r 's/<script>function aeaab19d\(a\).*?<\/script>//' {} \;Добавляем к sed ключ -i для того, чтобы он сразу изменял файл. Кстати, для find наиболее популярные примеры можете посмотреть через тэг #find.
Очень аккуратно выполняйте массовые действия. Сначала всё отладьте на тестовых файлах. Потом сделайте бэкап исходных файлов. И только потом выполняйте массовые изменения. И будьте готовы быстро всё откатить обратно.
Примеры рекомендую записать. Если надо быстро что-то сделать, то сходу правильно регулярку вы так просто не наберёте. К тому же в таком использовании есть свои нюансы. К примеру, я так и не смог победить команду sed, которая удаляет весь код <script>, если внутри есть переход на новую строку. Вроде бы легко найти, как заставить
. в регулярках учитывать и переход на новую строку, но на практике у меня это не получилось сделать. Я не понял, как правильно составить выражение для sed. Не забывайте про сервисы, которые помогают отлаживать регулярки. Собрал их в отдельной заметке.
#linux #bash #script
{kind=link}
Рекомендую очень полезный скрипт для Mysql, который помогает настраивать параметры сервера в зависимости от имеющейся памяти. Я уже неоднократно писал в заметках примерный алгоритм действий для этого. Подробности можно посмотреть в статье про настройку сервера под Битрикс в разделе про Mysql. Можно вот эту заметку посмотреть, где я частично эту же тему поднимаю.
Скрипт простой в плане функциональности, так как только парсит внутреннюю статистику Mysql и выводит те параметры, что больше всего нужны для оптимизации потребления памяти. Но сделано аккуратно и удобно. Сразу показывает, сколько памяти потребляет каждое соединение.
Причём автор поддерживает этот скрипт. Я в апреле на одном из серверов заметил, что он даёт ошибку деления на ноль. Не стал разбираться, в чём там проблема. А сейчас зашёл и вижу, что автор внёс исправление как раз по этой части. Похоже, какое-то обновление Mysql сломало работу.
Вот прямая ссылка на код: mysql-stat.sh. Результат работы на картинке ниже. Добавить к нему нечего. Использовать так:
Не забудьте поставить пробел перед командой, чтобы она вместе с паролем не залетела в history. Либо почистите её после работы скрипта, так как пробел не всегда работает. Зависит от настроек. Это при условии, что у вас парольное подключение к MySQL.
#bash #script #mysql
Скрипт простой в плане функциональности, так как только парсит внутреннюю статистику Mysql и выводит те параметры, что больше всего нужны для оптимизации потребления памяти. Но сделано аккуратно и удобно. Сразу показывает, сколько памяти потребляет каждое соединение.
Причём автор поддерживает этот скрипт. Я в апреле на одном из серверов заметил, что он даёт ошибку деления на ноль. Не стал разбираться, в чём там проблема. А сейчас зашёл и вижу, что автор внёс исправление как раз по этой части. Похоже, какое-то обновление Mysql сломало работу.
Вот прямая ссылка на код: mysql-stat.sh. Результат работы на картинке ниже. Добавить к нему нечего. Использовать так:
# ./mysql-stat.sh --user root --password "superpass"Не забудьте поставить пробел перед командой, чтобы она вместе с паролем не залетела в history. Либо почистите её после работы скрипта, так как пробел не всегда работает. Зависит от настроек. Это при условии, что у вас парольное подключение к MySQL.
#bash #script #mysql
{kind=link}
Смотрите, какая интересная коллекция приёмов на bash для выполнения различных обработок строк, массивов, файлов и т.д.:
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
Использовать следующим образом:
Примерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
Используем для примера:
Понятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
lower() { printf '%s\n' "${1,,}"}Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
#!/bin/bashlower() { printf '%s\n' "${1,,}"}lower "$1"Использовать следующим образом:
# ./lower.sh HELLOhelloПримерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
#!/bin/bashbasename() { local tmp tmp=${1%"${1##*[!/]}"} tmp=${tmp##*/} tmp=${tmp%"${2/"$tmp"}"} printf '%s\n' "${tmp:-/}"}Используем для примера:
# ./basename.sh /var/log/syslog.2.gzsyslog.2.gzПонятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
basename и dirname для вычленения имени файла или пути директории, в котором лежит файл. Но это будут внешние зависимости к отдельным бинарникам, а не код на bash.Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
{kind=link}
Если вам нужно заблокировать какую-то страну, чтобы ограничить доступ к вашим сервисам, например, с помощью iptables или nginx, потребуется список IP адресов по странам.
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
Тут я создаю список IP адресов для ipset, а потом использую его в iptables:
Если в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
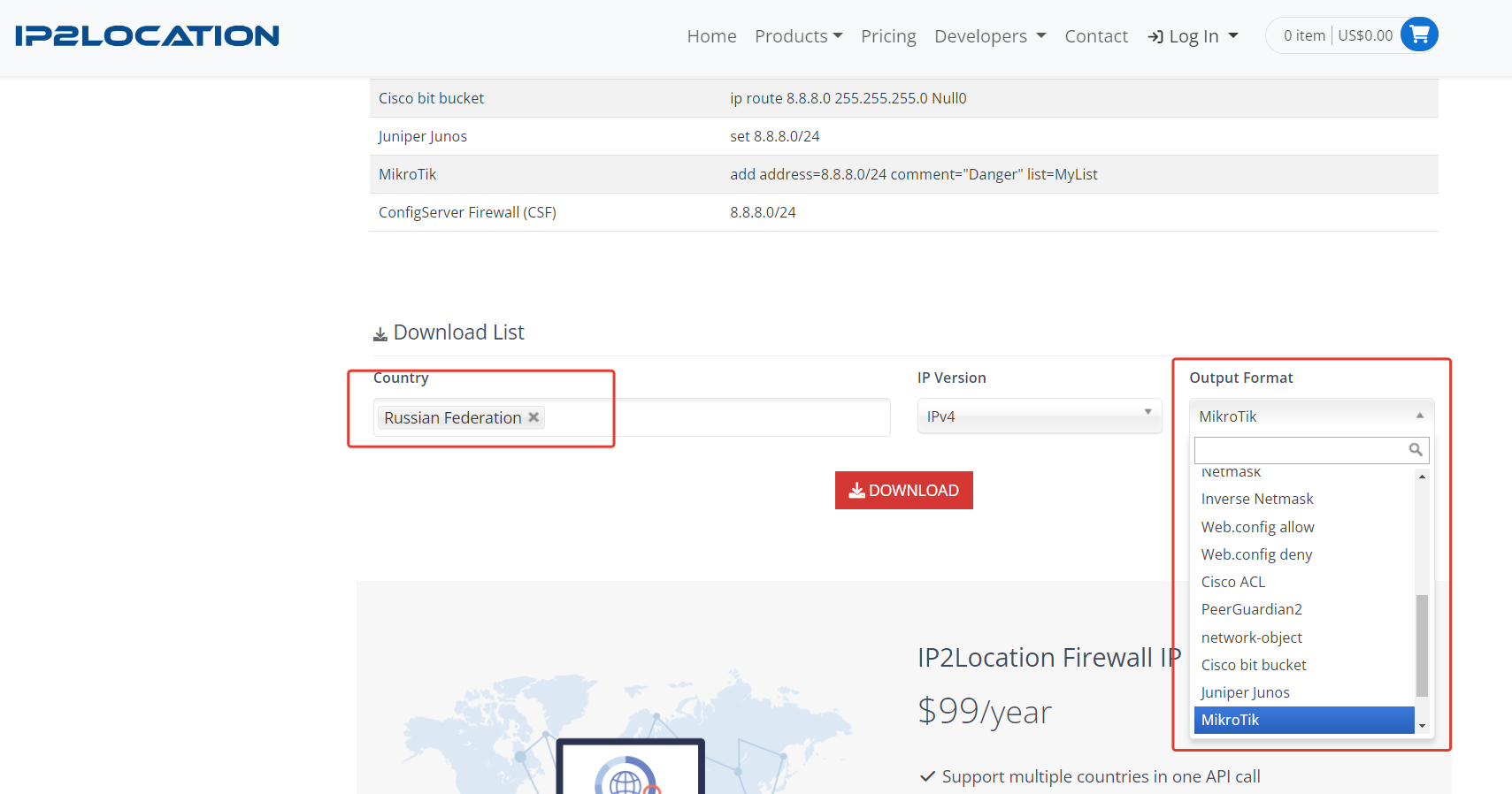
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
#!/bin/bash# Удаляем список, если он уже естьipset -X whitelist# Создаем новый списокipset -N whitelist nethash# Скачиваем файлы тех стран, что нас интересуют и сразу объединяем в единый списокwget -O netwhite http://www.ipdeny.com/ipblocks/data/countries/{ru,ua,kz,by,uz,md,kg,de,am,az,ge,ee,tj,lv}.zoneecho -n "Загружаем белый список в IPSET..."# Читаем список сетей и построчно добавляем в ipsetlist=$(cat netwhite)for ipnet in $list do ipset -A whitelist $ipnet doneecho "Завершено"# Выгружаем созданный список в файл для проверки составаipset -L whitelist > w-exportТут я создаю список IP адресов для ipset, а потом использую его в iptables:
iptables -A INPUT -i $WAN -m set --match-set whitenet src -p tcp --dport 80 -j ACCEPTЕсли в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
{kind=link}
Хочу предложить вашему вниманию bash скрипт по проверке статуса работы Nginx. Обращаю внимание именно на него, потому что он классно написан и его можно взять за основу для любой похожей задачи. Сейчас подробно расскажу, что там происходит.
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
{kind=link}
Делюсь с вами очень классным скриптом для Linux, с помощью которого можно быстро и в удобном виде посмотреть использование оперативной памяти программами (не процессами!). Я изначально нашёл только скрипт на Python и использовал его, а потом понял, что этот же скрипт есть и в стандартных репозиториях некоторых дистрибутивов.
Например в Centos или форках RHEL:
В deb дистрибутивах нет, но можно поставить через pip:
Либо просто скопировать исходный код на Python:
https://github.com/pixelb/ps_mem/blob/master/ps_mem.py
и запустить:
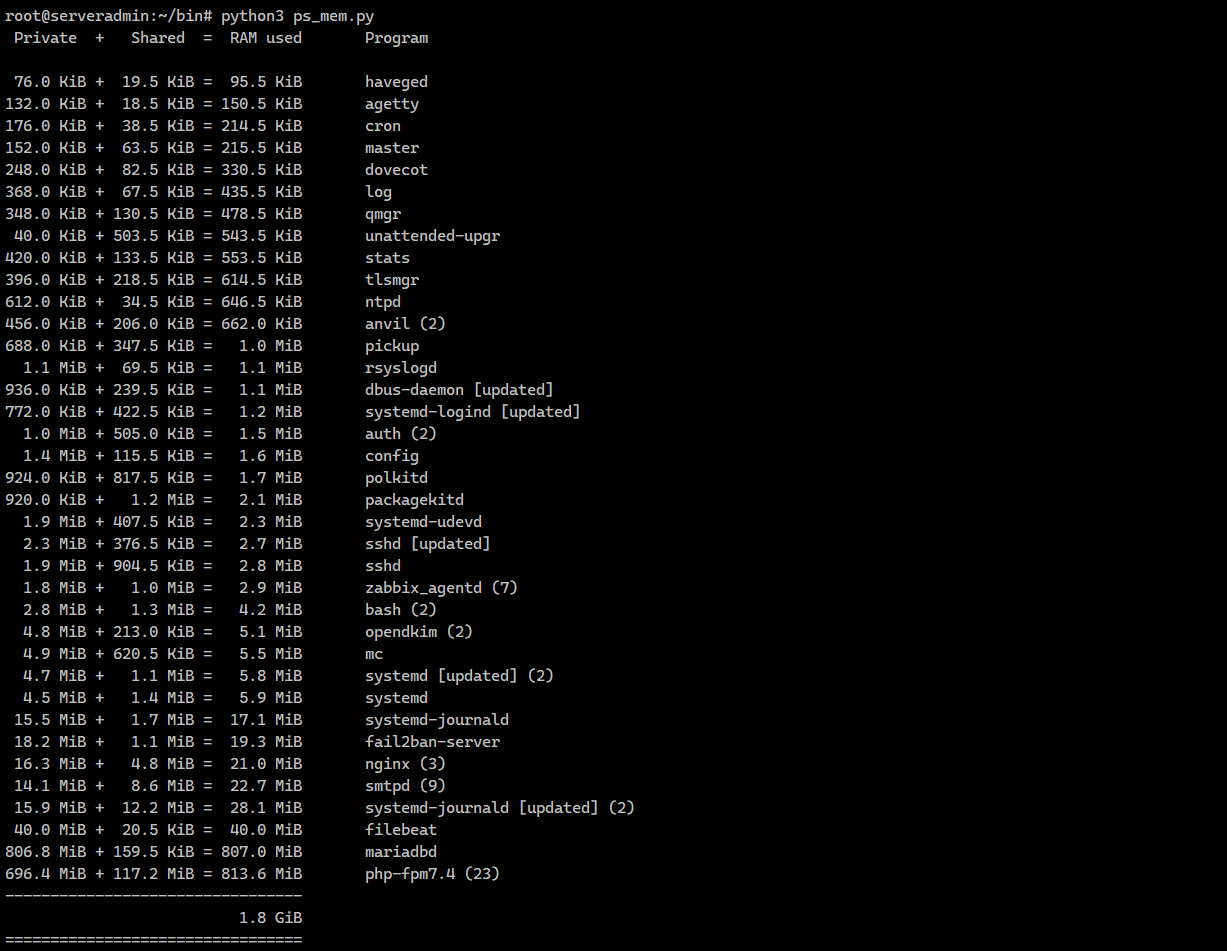
Увидите примерно такой список. Я не разобрался, как конкретно этот скрипт считает потребление памяти. Сам автор пишет:
In detail it reports: sum(private RAM for program processes) + sum(Shared RAM for program processes). The shared RAM is problematic to calculate, and this script automatically selects the most accurate method available for your kernel.
Если взять, к примеру, один из предыдущих вариантов, который я предлагал для подсчёта памяти программы и всех её процессов:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
То разница в результатах для программ, которые порождают множество подпроцессов, будет существенная. В принципе, это логично, потому что реально потребляемая память будет меньше, чем сумма RSS всех процессов программы. Для одиночных процессов данные совпадают.
У меня была заметка про потребление памяти в Linux: https://t.me/srv_admin/2859
Там рассказано, как вручную с помощью pmap разобраться в потреблении памяти программами в Linux. Я вручную проверил все процессы Nginx и сравнил с результатом скрипта ps_mem. Результаты не совпадали полностью, но были близки. Так что этот скрипт выдаёт хорошую информацию.
Я себе сохранил скрипт к себе в коллекцию.
#linux #script
Например в Centos или форках RHEL:
# yum/dnf install ps_memВ deb дистрибутивах нет, но можно поставить через pip:
# pip install ps_memЛибо просто скопировать исходный код на Python:
https://github.com/pixelb/ps_mem/blob/master/ps_mem.py
и запустить:
# python3 ps_mem.py Private + Shared = RAM used Program 18.2 MiB + 1.1 MiB = 19.2 MiB fail2ban-server 16.3 MiB + 4.7 MiB = 21.0 MiB nginx (3) 17.5 MiB + 5.5 MiB = 23.0 MiB smtpd (11) 15.5 MiB + 10.3 MiB = 25.8 MiB systemd-journald [updated] (2) 39.2 MiB + 18.5 KiB = 39.2 MiB filebeat806.8 MiB + 145.5 KiB = 806.9 MiB mariadbd709.4 MiB + 120.2 MiB = 829.5 MiB php-fpm7.4 (23)Увидите примерно такой список. Я не разобрался, как конкретно этот скрипт считает потребление памяти. Сам автор пишет:
In detail it reports: sum(private RAM for program processes) + sum(Shared RAM for program processes). The shared RAM is problematic to calculate, and this script automatically selects the most accurate method available for your kernel.
Если взять, к примеру, один из предыдущих вариантов, который я предлагал для подсчёта памяти программы и всех её процессов:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
То разница в результатах для программ, которые порождают множество подпроцессов, будет существенная. В принципе, это логично, потому что реально потребляемая память будет меньше, чем сумма RSS всех процессов программы. Для одиночных процессов данные совпадают.
У меня была заметка про потребление памяти в Linux: https://t.me/srv_admin/2859
Там рассказано, как вручную с помощью pmap разобраться в потреблении памяти программами в Linux. Я вручную проверил все процессы Nginx и сравнил с результатом скрипта ps_mem. Результаты не совпадали полностью, но были близки. Так что этот скрипт выдаёт хорошую информацию.
Я себе сохранил скрипт к себе в коллекцию.
#linux #script
{kind=link}
Протестировал новый для себя инструмент, с которым раньше не был знаком. Он очень понравился и показался удобнее аналогичных, про которые знал и использовал раньше. Речь пойдёт про систему планирования и управления задачами серверов Cronicle. Условно его можно назвать продвинутым Cron с веб интерфейсом. Очень похож на Rundeck, про который когда-то писал.
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽️работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽️работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽️автоматически находить соседние сервера;
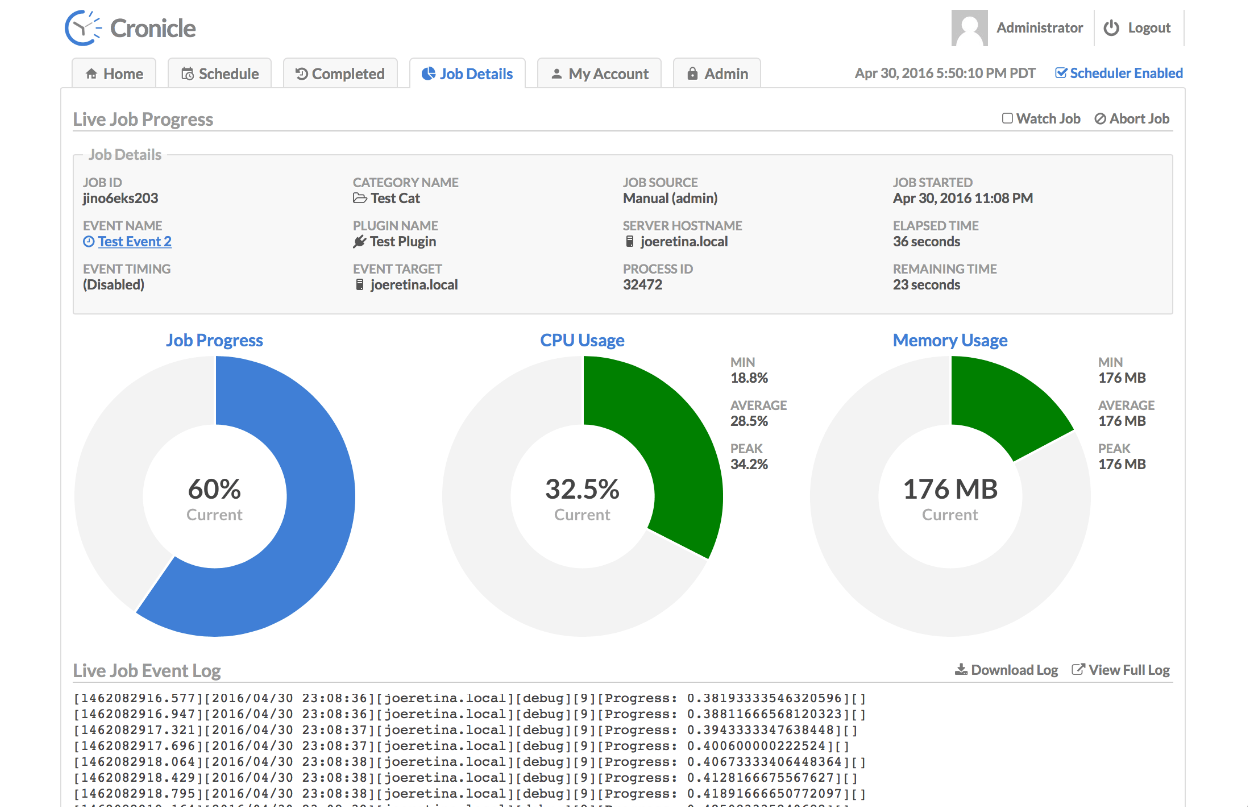
◽️запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽️подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽️отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽️поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
Теперь ставим сам Cronicle. Для этого есть готовый скрипт:
Установка будет выполнена в директорию
А потом запустите:
Теперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#script #devops
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽️работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽️работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽️автоматически находить соседние сервера;
◽️запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽️подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽️отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽️поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
# apt update# apt install ca-certificates curl gnupg# mkdir -p /etc/apt/keyrings# curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key \| gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg# NODE_MAJOR=20# echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_$NODE_MAJOR.x nodistro main" \| tee /etc/apt/sources.list.d/nodesource.list# apt update# apt install nodejsТеперь ставим сам Cronicle. Для этого есть готовый скрипт:
# curl -s https://raw.githubusercontent.com/jhuckaby/Cronicle/master/bin/install.js \| nodeУстановка будет выполнена в директорию
/opt/cronicle. Если ставите master сервер, то после установки выполните setup:# /opt/cronicle/bin/control.sh setupА потом запустите:
# /opt/cronicle/bin/control.sh startТеперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
/opt/cronicle/conf/config.json с master сервера. Там прописаны ключи, которые должны везде быть одинаковые. В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#script #devops
{kind=link}