
На канале Zabbix вышло очередное видео с описанием реализации конкретной возможности сервера мониторинга - Авторегистрация хостов. В ролике очень кратко (4 минуты), но полностью показано, как автоматически регистрировать хосты на сервере. Поясню, о чём идёт речь.
Если у вас много хостов, которые вы хотите добавить в мониторинг, нет необходимости каждый их них вручную добавлять на сервер. Достаточно на сервере создать действие по авторегистрации, снабдив его определёнными условиями, по которым хосты будут попадать под действие этого правила. А само правило будет добавлять хостам указанные шаблоны и помещать их в заданные группы.
После этого на хостах мониторинга достаточно в настройка zabbix-agent указать параметры сервера, имя хоста и некие метаданные, совпадающие с ними же в правиле авторегистрации. После запуска агента, хост автоматически будет зарегистрирован на сервере. Таким образом можно автоматически развернуть мониторинг на большой инфраструктуре с минимумом ручных действий. Вам нужно только продумать доставку zabbix-agent с нужным конфигом на целевые машины.
Automating Zabbix host deployment with autoregistration
#zabbix
Если у вас много хостов, которые вы хотите добавить в мониторинг, нет необходимости каждый их них вручную добавлять на сервер. Достаточно на сервере создать действие по авторегистрации, снабдив его определёнными условиями, по которым хосты будут попадать под действие этого правила. А само правило будет добавлять хостам указанные шаблоны и помещать их в заданные группы.
После этого на хостах мониторинга достаточно в настройка zabbix-agent указать параметры сервера, имя хоста и некие метаданные, совпадающие с ними же в правиле авторегистрации. После запуска агента, хост автоматически будет зарегистрирован на сервере. Таким образом можно автоматически развернуть мониторинг на большой инфраструктуре с минимумом ручных действий. Вам нужно только продумать доставку zabbix-agent с нужным конфигом на целевые машины.
Automating Zabbix host deployment with autoregistration
#zabbix
YouTube
Zabbix Handy Tips: Automating Zabbix host deployment with autoregistration
Zabbix Handy Tips - is byte-sized news for busy techies, focused on one particular topic. In this video, we will learn how to automatically deploy Zabbix agent hosts by using the agent autoregistration functionality.
Subscribe here: https://www.zabbix.com/subscribe…
Subscribe here: https://www.zabbix.com/subscribe…
Удивительно, как я умудрился не заметить одно из нововведений Zabbix. Он оказывается умеет делать безагентные проверки по ssh, подключаясь напрямую к хосту. Не знаю, когда это появилось, но по факту сейчас это есть.
Вы можете создать айтем, указать тип проверки - SSH Agent и выбрать команду, которая будет исполнена на хосте. Её вывод будет передан на Zabbix Server. Авторизацию можно выполнить по логину и паролю, указав их тут же в айтеме, либо по сертификату.
С помощью подобных айтемов можно упростить некоторые проверки, которые делались с помощью скриптов на хосте. Вместо этого можно напрямую забирать нужную информацию. Например, список работающих процессов, количество сетевых соединений с нужной выборкой, статус массива mdadm и т.д. То есть все однострочники, которые выполнялись в скриптах, можно перенести на запуск через SSH Agent.
Видео с примером того, как это настраивается: https://www.youtube.com/watch?v=w4mSE4lzpb0
#zabbix
Вы можете создать айтем, указать тип проверки - SSH Agent и выбрать команду, которая будет исполнена на хосте. Её вывод будет передан на Zabbix Server. Авторизацию можно выполнить по логину и паролю, указав их тут же в айтеме, либо по сертификату.
С помощью подобных айтемов можно упростить некоторые проверки, которые делались с помощью скриптов на хосте. Вместо этого можно напрямую забирать нужную информацию. Например, список работающих процессов, количество сетевых соединений с нужной выборкой, статус массива mdadm и т.д. То есть все однострочники, которые выполнялись в скриптах, можно перенести на запуск через SSH Agent.
Видео с примером того, как это настраивается: https://www.youtube.com/watch?v=w4mSE4lzpb0
#zabbix
YouTube
Zabbix Handy Tips: Agentless metric collection with SSH checks
Zabbix Handy Tips - is byte-sized news for busy techies, focused on one particular topic. In this video, we will learn how to collect metrics without using an agent by executing SSH commands or scripts.
Subscribe here: https://www.zabbix.com/subscribe
to…
Subscribe here: https://www.zabbix.com/subscribe
to…
Небольшая, простая, но при этом почти полная инструкция по настройке Zabbix HA Cluster из двух нод. Последовательность действий там такая:
1️⃣ Прописываем параметр HANodeName с уникальным именем на всех нодах кластера, а так же NodeAddress с ip адресом и портом, на котором работает Zabbix Server данной ноды. Эти адреса от каждой ноды уедут в базу данных и будут использованы фронтендом (веб интерфейсом) для подключения.
2️⃣ Убираем параметры адреса и порта Zabbix Server из настроек веб интерфейса. В таком случае он будет брать их из базы данных.
3️⃣ Теперь можно перезапустить серверы мониторинга и проверить статус кластера через консольные команды, либо в веб интерфейсе.
Настраивается всё максимально просто. Я только не понял, почему в ролике совсем не сказано ничего про настройку агентов. Это тоже важно. Если я правильно понял, то в настройках агентов надо указывать через точку с запятой все адреса нод кластера, чтобы данные в итоге попали в мониторинг в случае проблем с каким-то сервером.
Простая и приятна реализация, не требующая плавающего адреса или еще каких-то дополнительных сущностей. Легко деплоить и управлять. Но не стоит забывать, что HA для фронтенда и базы данных нужно настраивать отдельно. Без них смысла в кластере самого мониторинга нет.
https://www.youtube.com/watch?v=KbqS4s6DaQE
#zabbix
1️⃣ Прописываем параметр HANodeName с уникальным именем на всех нодах кластера, а так же NodeAddress с ip адресом и портом, на котором работает Zabbix Server данной ноды. Эти адреса от каждой ноды уедут в базу данных и будут использованы фронтендом (веб интерфейсом) для подключения.
2️⃣ Убираем параметры адреса и порта Zabbix Server из настроек веб интерфейса. В таком случае он будет брать их из базы данных.
3️⃣ Теперь можно перезапустить серверы мониторинга и проверить статус кластера через консольные команды, либо в веб интерфейсе.
Настраивается всё максимально просто. Я только не понял, почему в ролике совсем не сказано ничего про настройку агентов. Это тоже важно. Если я правильно понял, то в настройках агентов надо указывать через точку с запятой все адреса нод кластера, чтобы данные в итоге попали в мониторинг в случае проблем с каким-то сервером.
Простая и приятна реализация, не требующая плавающего адреса или еще каких-то дополнительных сущностей. Легко деплоить и управлять. Но не стоит забывать, что HA для фронтенда и базы данных нужно настраивать отдельно. Без них смысла в кластере самого мониторинга нет.
https://www.youtube.com/watch?v=KbqS4s6DaQE
#zabbix
YouTube
Zabbix Handy Tips: Preventing downtimes with the Zabbix HA cluster
Zabbix Handy Tips - is byte-sized news for busy techies, focused on one particular topic. In this video, we will deploy a Zabbix server High availability cluster by using the native Zabbix server HA cluster functionality.
Subscribe here: https://www.zab…
Subscribe here: https://www.zab…
Мне недавно прилетела типовая задача по бэкапу и мониторингу сайта. Решил по шагам расписать, что и как я сделал. Думаю, информация полезна, потому что описан будет мой личный опыт.
Задача. Есть типовой веб проект, который разработчики запустили в докере: фронт, бэк и база данных (postgresql). Нужно:
- настроить бэкап данных в виде файлов и базы данных
- настроить мониторинг сервера, сайта, домена, tls сертификата, бэкапов
- оповещения с мониторинга отправлять в telegram
Заказано:
- VPS 1 CPU, 1 Гб RAM, 20 Гб Disk для сервера Zabbix.
- Файловое хранилище с доступом по ssh, rsync для бэкапов.
Настроено.
Бэкап. Сделал небольшой скрипт на веб сервере, который делает дамп базы, проверяет его начало и конец на наличие строк об успешном окончании создания дампа. Результат пишет в лог файл. Потом этот файл будет анализировать мониторинг. Другой скрипт создаёт пустые файлы и кладёт их в некоторые директории. Позже мониторинг по наличию и дате этих файлов будет судить о свежести бэкапов.
Файловое хранилище с доступом по SSH и CRON. Настроил скрипт, который ходит на веб сервер и сам с помощью RSYNC забирает оттуда все необходимые данные - сырые файлы сайта, БД и дамп БД. Все изменения файлов между синхронизациями сохраняются. Всегда имеется свежая полная копия файлов и изменения после каждой синхронизации.
Мониторинг. Тут всё более ли менее стандартно. Настраивается Zabbix Server, на веб сервер ставится агент. Настраиваются типовые проверки по стандартному шаблону Linux Server. Отдельно настраивается мониторинг делегирования домена, tls сертификата. На канале было много заметок по этому поводу.
Далее мониторинг web сайта тоже делается встроенными проверками. Отслеживается его доступность, время отклика, коды ответа, содержимое ключевых страниц. Если отклик растёт выше обычного, предупреждаем.
Для мониторинга бэкапов подключаю по sshfs в режиме чтения директорию с сервера бэкапов. Настраиваю проверки размера дампа, содержимое лога с проверкой дампа БД. С помощью анализа даты создания пустых файлов, о которых упоминал выше, понимаю, когда была последняя синхронизация бэкапов с веб сервера. Если разница больше суток, считаем, что проблема.
Оповещения в telegram настроены дефолтным способом через встроенный webhook в Zabbix Server. На всякий случай добавил ещё и по email их.
Вот и всё. В принципе, ничего особенного или сложного, когда делаешь это постоянно. Но на каждом этапе есть какие-то свои нюансы, которые надо решать. Так что на деле получить мониторинг всего того, что я описал, не так просто. Нет какого-то готового даже платного решения, чтобы купил и у тебя всё хорошо. Нужно ещё учесть, что тут ежемесячных расходов очень мало. По сути только на минимальную VPS и хранилище для бэкапов.
Следующим этапом нужно купить ещё одну VPS, заскриптовать восстановление из бэкапа и сделать мониторинг восстановленного сайта. Нужно понимать, что всё восстановилось и сайт реально работает.
Если кому-то интересно, сколько подобная настройка стоит, то лично я беру за первый этап 10 т.р., если всё стандартно, как описано тут. За второй этап столько же, если там нет каких-то особых проблем. На каждый этап уходит примерно день, если делать всё аккуратно, проверять, записывать.
#website #monitoring #backup
Задача. Есть типовой веб проект, который разработчики запустили в докере: фронт, бэк и база данных (postgresql). Нужно:
- настроить бэкап данных в виде файлов и базы данных
- настроить мониторинг сервера, сайта, домена, tls сертификата, бэкапов
- оповещения с мониторинга отправлять в telegram
Заказано:
- VPS 1 CPU, 1 Гб RAM, 20 Гб Disk для сервера Zabbix.
- Файловое хранилище с доступом по ssh, rsync для бэкапов.
Настроено.
Бэкап. Сделал небольшой скрипт на веб сервере, который делает дамп базы, проверяет его начало и конец на наличие строк об успешном окончании создания дампа. Результат пишет в лог файл. Потом этот файл будет анализировать мониторинг. Другой скрипт создаёт пустые файлы и кладёт их в некоторые директории. Позже мониторинг по наличию и дате этих файлов будет судить о свежести бэкапов.
Файловое хранилище с доступом по SSH и CRON. Настроил скрипт, который ходит на веб сервер и сам с помощью RSYNC забирает оттуда все необходимые данные - сырые файлы сайта, БД и дамп БД. Все изменения файлов между синхронизациями сохраняются. Всегда имеется свежая полная копия файлов и изменения после каждой синхронизации.
Мониторинг. Тут всё более ли менее стандартно. Настраивается Zabbix Server, на веб сервер ставится агент. Настраиваются типовые проверки по стандартному шаблону Linux Server. Отдельно настраивается мониторинг делегирования домена, tls сертификата. На канале было много заметок по этому поводу.
Далее мониторинг web сайта тоже делается встроенными проверками. Отслеживается его доступность, время отклика, коды ответа, содержимое ключевых страниц. Если отклик растёт выше обычного, предупреждаем.
Для мониторинга бэкапов подключаю по sshfs в режиме чтения директорию с сервера бэкапов. Настраиваю проверки размера дампа, содержимое лога с проверкой дампа БД. С помощью анализа даты создания пустых файлов, о которых упоминал выше, понимаю, когда была последняя синхронизация бэкапов с веб сервера. Если разница больше суток, считаем, что проблема.
Оповещения в telegram настроены дефолтным способом через встроенный webhook в Zabbix Server. На всякий случай добавил ещё и по email их.
Вот и всё. В принципе, ничего особенного или сложного, когда делаешь это постоянно. Но на каждом этапе есть какие-то свои нюансы, которые надо решать. Так что на деле получить мониторинг всего того, что я описал, не так просто. Нет какого-то готового даже платного решения, чтобы купил и у тебя всё хорошо. Нужно ещё учесть, что тут ежемесячных расходов очень мало. По сути только на минимальную VPS и хранилище для бэкапов.
Следующим этапом нужно купить ещё одну VPS, заскриптовать восстановление из бэкапа и сделать мониторинг восстановленного сайта. Нужно понимать, что всё восстановилось и сайт реально работает.
Если кому-то интересно, сколько подобная настройка стоит, то лично я беру за первый этап 10 т.р., если всё стандартно, как описано тут. За второй этап столько же, если там нет каких-то особых проблем. На каждый этап уходит примерно день, если делать всё аккуратно, проверять, записывать.
#website #monitoring #backup
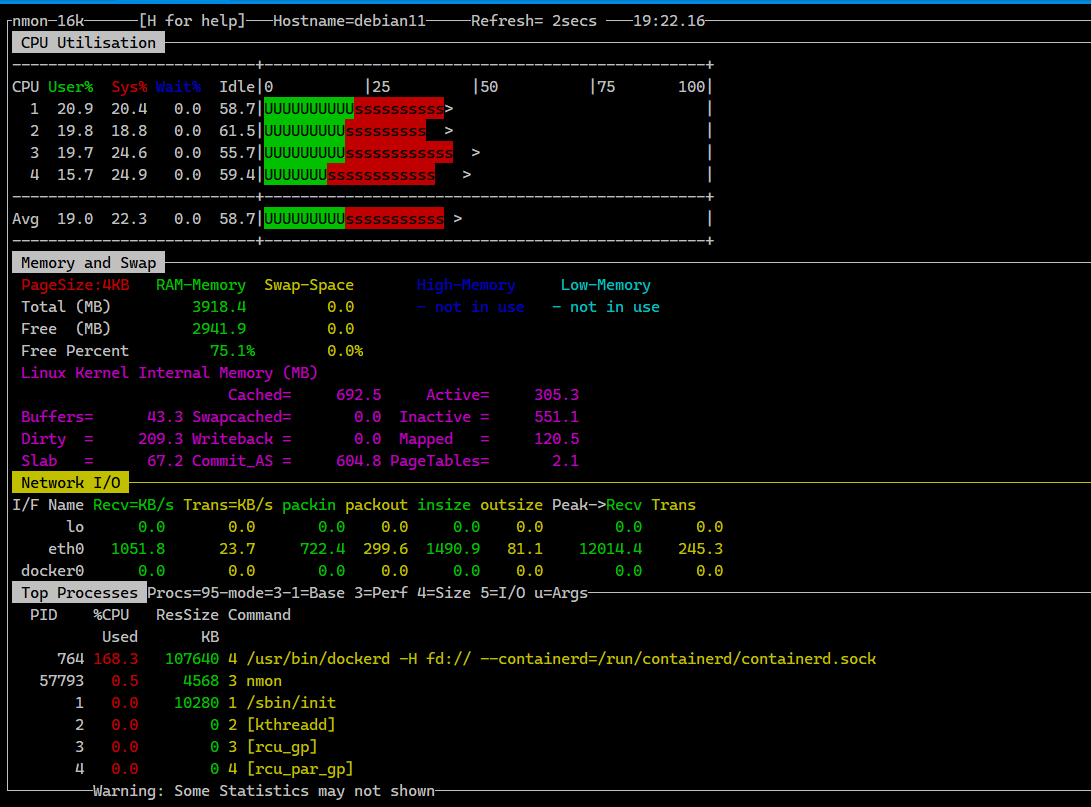
Представляю вашему вниманию очень старую, прямо таки олдскульную программу для анализа нагрузки Linux сервера — nmon. Она периодически всплывает в обсуждениях, рекомендациях. Я почему-то был уверен, что писал о ней. Но поиск по каналу неумолим — ни одного упоминания в заметках. Хотя программа известная, удобная и актуальная по сей день. Не заброшена, развивается, есть в репозиториях популярных дистрибутивов.
По своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
# apt install nmonПо своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
{kind=link}
Для мониторинга СУБД PostgreSQL существует много вариантов настройки. Собственно, как и для всего остального. Тема мониторинга очень хорошо развита в IT. Есть из чего выбирать, чему отдать предпочтение.
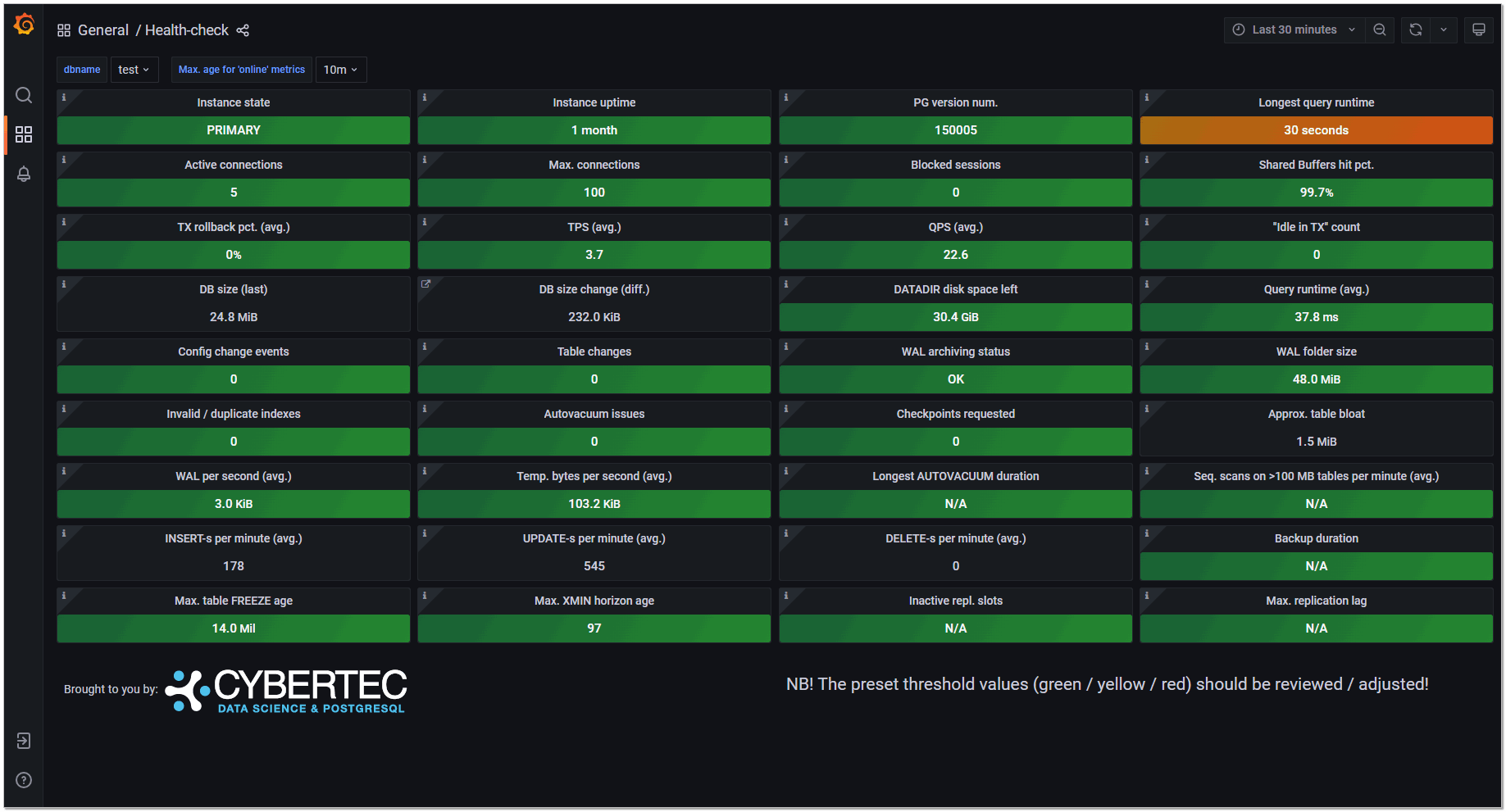
Одним из наиболее простых и быстрых для внедрения инструментов именно для psql является Pgwatch2. Это известная штука, для которой много инструкций и руководств. Есть обзоры на youtube. Отдельно отмечу, что если вы используете систему мониторинга Zabbix, то искать что-то ещё, большого смысла нет. У неё есть хороший встроенный шаблон, который собирает много различных метрик. В общем случае этого мониторинга будет за глаза.
Если вы не знаете Zabbix, у вас его нет и ставить не планируете, то закрыть вопрос с мониторингом PostgreSQL можно с помощью Pgwatch2. Этот продукт состоит из следующих компонентов:
▪ Хранилище метрик. В его качестве может выступать сама PostgreSQL, в том числе с расширением TimescaleDB. Также метрики можно хранить в InfluxDB. Либо их можно отправить в Prometheus, а он положит куда-то у себя.
▪ Сборщик метрик, написанный на GO.
▪ Веб интерфейс для управления, написанный на Python
▪ Grafana для просмотра дашбордов с метриками.
Всё это есть в готовом виде, упакованное в Docker. Если использовать для хранения метрик PostgreSQL, достаточно создать базу для хранения и пользователя для доступа к метрикам. Далее указать эти данные и запустить контейнеры. Процесс подробно описан в документации.
Посмотреть, как выглядит итоговый мониторинг, можно в публичном DEMO. Там из коробки настроено много дашбордов, не забудьте их посмотреть. Информацию по конкретной базе удобно смотреть в дашборде DB overview.
⇨ Исходники / Документация / Demo / Видеобозор (на русском)
#postgresql #monitoring
Одним из наиболее простых и быстрых для внедрения инструментов именно для psql является Pgwatch2. Это известная штука, для которой много инструкций и руководств. Есть обзоры на youtube. Отдельно отмечу, что если вы используете систему мониторинга Zabbix, то искать что-то ещё, большого смысла нет. У неё есть хороший встроенный шаблон, который собирает много различных метрик. В общем случае этого мониторинга будет за глаза.
Если вы не знаете Zabbix, у вас его нет и ставить не планируете, то закрыть вопрос с мониторингом PostgreSQL можно с помощью Pgwatch2. Этот продукт состоит из следующих компонентов:
▪ Хранилище метрик. В его качестве может выступать сама PostgreSQL, в том числе с расширением TimescaleDB. Также метрики можно хранить в InfluxDB. Либо их можно отправить в Prometheus, а он положит куда-то у себя.
▪ Сборщик метрик, написанный на GO.
▪ Веб интерфейс для управления, написанный на Python
▪ Grafana для просмотра дашбордов с метриками.
Всё это есть в готовом виде, упакованное в Docker. Если использовать для хранения метрик PostgreSQL, достаточно создать базу для хранения и пользователя для доступа к метрикам. Далее указать эти данные и запустить контейнеры. Процесс подробно описан в документации.
Посмотреть, как выглядит итоговый мониторинг, можно в публичном DEMO. Там из коробки настроено много дашбордов, не забудьте их посмотреть. Информацию по конкретной базе удобно смотреть в дашборде DB overview.
⇨ Исходники / Документация / Demo / Видеобозор (на русском)
#postgresql #monitoring
{kind=link}
Всем привет. Закончился продолжительный отпуск в 3 недели. Никогда такого не было. С самого начала моей трудовой деятельности везде отпуска были по 2 недели 2 раза в год. В этот раз получилось организовать 3 полных недели. Вообще выпал из рабочих будней. В походе замёрз ночью пипец (+8-9 несколько ночей было, спал в куртке, штанах, шапке). Убедился, что походы и жизнь в палатке это не моё. Больше не пойду. Сын тоже не проникся, хотя мы всего неделю в палатках прожили. Ещё неделю на даче родителей с семьёй прожил, и неделю у себя на даче поработал.
Самое главное, что всё прошло очень гладко. Нигде ничего не упало. Мне никто не звонил ни по каким важным делам. Были только пару звонков и то по незначительным вещам от людей, которые были не в курсе, что я в отпуске. Немного общался в Telegram, но без напряга. Просто чтобы в первый день не было вала непрочитанных сообщений. Разгребать то всё равно их мне. А так всё подбито, задачи раскиданы и сегодня обычный трудовой день.
Перед отпуском подготовил удалённое рабочее место с доступом по RDP со смартфона. Закрыл его через VPN и для подстраховки, если VPN по какой-то причине не будет работать через мобильный интернет, сделал прямой доступ через port knocking. Проверил и убедился, что всё работает. Использовал следующий софт:
▪️ OpenVPN Connect
▪️ PingTools Network Utilities
▪️ Remote Desktop
SSH клиент на смартфон не ставлю, не вижу смысла. Со смартфона очень неудобно в терминале работать. По RDP с обычного компа удобнее. Там все соединения уже настроены. Не надо всё это в смартфон переносить.
Перед отпуском в ручном режиме проверил все бэкапы. Настоятельно рекомендую это делать регулярно. Нашёл свой очень серьёзный косяк, от которого аж холодок по спине пробежал, когда заметил. На одном серваке с 1С на скорую руку настроил бэкапы через дампы базы данных и забыл переделать.
В скрипте останавливал сервер 1С перед бэкапом. Чисто для профилактики, чтобы он не вис и не просили перезапускать вручную. Там это можно было делать ночью. Юнит systemd, который останавливает сервер, в своём названии содержит версию сервера. В какой-то момент сервер обновили, а скрипт я не поправил. В итоге бэкапы просто не делались месяц. Хорошо, что ничего не упало в это время.
Косяк мой было в том, что я не настроил проверку бэкапов (так или так), хотя обычно это делаю. А тут поторопился, отложил на потом и в итоге забыл. Всё откладывал на тот момент, когда настрою запасной сервер, куда эти дампы буду восстанавливать. Это и была бы сразу проверка создания и их работоспособность.
Я неоднократно находил ошибки в бэкапах при ручной проверке. Как бы ты не автоматизировал создание и проверки, всегда есть шанс, что что-то пойдёт не так, как ты планировал. Так что если масштабы позволяют, то лучше хотя бы раз в месяц, а лучше раз в неделю, проверять всё вручную. У меня это выглядит так:
1️⃣ Захожу на бэкап сервера с сырыми данными и вручную проверяю директории с данными. У меня везде создаются файлы-метки перед копированием данных, так что по ним я всегда вижу, какая дата в этой метке, чтобы понимать, была ли вообще синхронизация в последнее время.
2️⃣ Проверяю админки Proxmox Backup Server, смотрю логи, свободное место и т.д.
3️⃣ Проверяю админки Veeam, задания на бэкапы, репликацию, логи и т.д.
Как я уже сказал, неоднократно находил таким образом проблемы. То письма не отправляются по какой-то причине и ты не в курсе, что у тебя уже давно бэкапы VM не делаются, то просто ошибся где-то с мониторингом, а у тебя давно что-то отвалилось и ты не в курсе.
Кто как отдохнул этим летом? Получилось полностью отключиться от работы, или дёргают регулярно?
#разное
Самое главное, что всё прошло очень гладко. Нигде ничего не упало. Мне никто не звонил ни по каким важным делам. Были только пару звонков и то по незначительным вещам от людей, которые были не в курсе, что я в отпуске. Немного общался в Telegram, но без напряга. Просто чтобы в первый день не было вала непрочитанных сообщений. Разгребать то всё равно их мне. А так всё подбито, задачи раскиданы и сегодня обычный трудовой день.
Перед отпуском подготовил удалённое рабочее место с доступом по RDP со смартфона. Закрыл его через VPN и для подстраховки, если VPN по какой-то причине не будет работать через мобильный интернет, сделал прямой доступ через port knocking. Проверил и убедился, что всё работает. Использовал следующий софт:
▪️ OpenVPN Connect
▪️ PingTools Network Utilities
▪️ Remote Desktop
SSH клиент на смартфон не ставлю, не вижу смысла. Со смартфона очень неудобно в терминале работать. По RDP с обычного компа удобнее. Там все соединения уже настроены. Не надо всё это в смартфон переносить.
Перед отпуском в ручном режиме проверил все бэкапы. Настоятельно рекомендую это делать регулярно. Нашёл свой очень серьёзный косяк, от которого аж холодок по спине пробежал, когда заметил. На одном серваке с 1С на скорую руку настроил бэкапы через дампы базы данных и забыл переделать.
В скрипте останавливал сервер 1С перед бэкапом. Чисто для профилактики, чтобы он не вис и не просили перезапускать вручную. Там это можно было делать ночью. Юнит systemd, который останавливает сервер, в своём названии содержит версию сервера. В какой-то момент сервер обновили, а скрипт я не поправил. В итоге бэкапы просто не делались месяц. Хорошо, что ничего не упало в это время.
Косяк мой было в том, что я не настроил проверку бэкапов (так или так), хотя обычно это делаю. А тут поторопился, отложил на потом и в итоге забыл. Всё откладывал на тот момент, когда настрою запасной сервер, куда эти дампы буду восстанавливать. Это и была бы сразу проверка создания и их работоспособность.
Я неоднократно находил ошибки в бэкапах при ручной проверке. Как бы ты не автоматизировал создание и проверки, всегда есть шанс, что что-то пойдёт не так, как ты планировал. Так что если масштабы позволяют, то лучше хотя бы раз в месяц, а лучше раз в неделю, проверять всё вручную. У меня это выглядит так:
1️⃣ Захожу на бэкап сервера с сырыми данными и вручную проверяю директории с данными. У меня везде создаются файлы-метки перед копированием данных, так что по ним я всегда вижу, какая дата в этой метке, чтобы понимать, была ли вообще синхронизация в последнее время.
2️⃣ Проверяю админки Proxmox Backup Server, смотрю логи, свободное место и т.д.
3️⃣ Проверяю админки Veeam, задания на бэкапы, репликацию, логи и т.д.
Как я уже сказал, неоднократно находил таким образом проблемы. То письма не отправляются по какой-то причине и ты не в курсе, что у тебя уже давно бэкапы VM не делаются, то просто ошибся где-то с мониторингом, а у тебя давно что-то отвалилось и ты не в курсе.
Кто как отдохнул этим летом? Получилось полностью отключиться от работы, или дёргают регулярно?
#разное
{kind=link}