
Почти во всех популярных дистрибутивах Linux в составе присутствует утилита vmstat. С её помощью можно узнать подробную информацию по использованию оперативной памяти, cpu и дисках. Лично я её не люблю, потому что вывод неинформативен. Утилита больше для какой-то глубокой диагностики или мониторинга, нежели простого использования в консоли.
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
Как можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
# vmstat 1 -w -S MКак можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
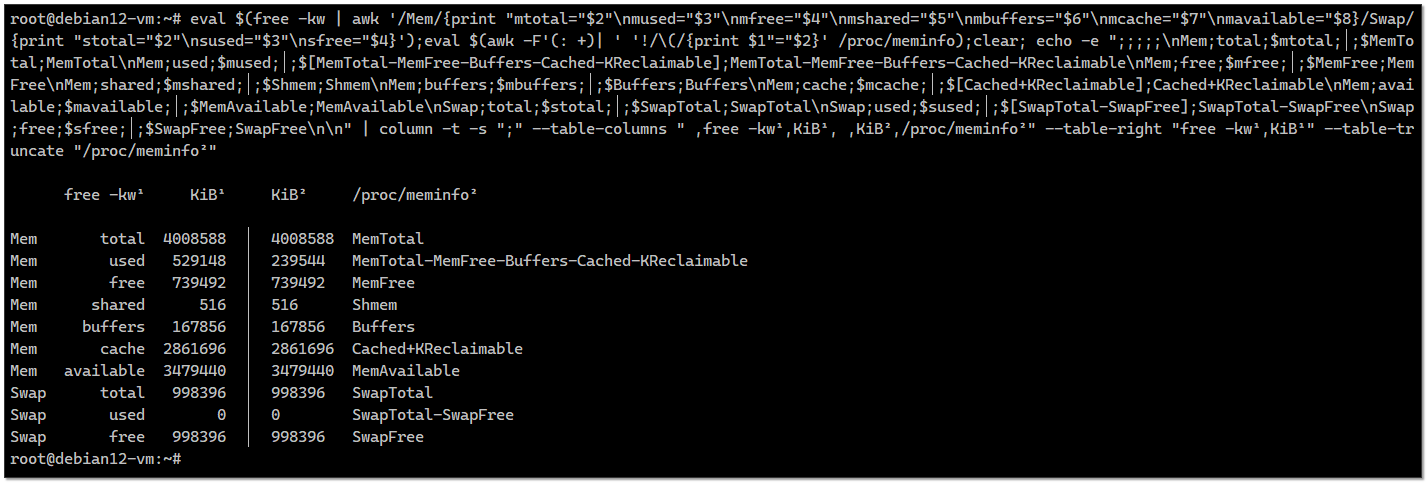
man vmstat они подробно описаны, так что с интерпретацией проблем не должно возникать.А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
free и cat /proc/meminfo: # eval $(free -kw | awk '/Mem/{print "mtotal="$2"\nmused="$3"\nmfree="$4"\nmshared="$5"\nmbuffers="$6"\nmcache="$7"\nmavailable="$8}/Swap/{print "stotal="$2"\nsused="$3"\nsfree="$4}');eval $(awk -F'(: +)| ' '!/\(/{print $1"="$2}' /proc/meminfo);clear; echo -e ";;;;;\nMem;total;$mtotal;│;$MemTotal;MemTotal\nMem;used;$mused;│;$[MemTotal-MemFree-Buffers-Cached-KReclaimable];MemTotal-MemFree-Buffers-Cached-KReclaimable\nMem;free;$mfree;│;$MemFree;MemFree\nMem;shared;$mshared;│;$Shmem;Shmem\nMem;buffers;$mbuffers;│;$Buffers;Buffers\nMem;cache;$mcache;│;$[Cached+KReclaimable];Cached+KReclaimable\nMem;available;$mavailable;│;$MemAvailable;MemAvailable\nSwap;total;$stotal;│;$SwapTotal;SwapTotal\nSwap;used;$sused;│;$[SwapTotal-SwapFree];SwapTotal-SwapFree\nSwap;free;$sfree;│;$SwapFree;SwapFree\n\n" | column -t -s ";" --table-columns " ,free -kw¹,KiB¹, ,KiB²,/proc/meminfo²" --table-right "free -kw¹,KiB¹" --table-truncate "/proc/meminfo²"Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
{kind=link}
Если вам необходимо кому-то передать свой bash скрипт, но при этом вы не хотите, чтобы этот кто-то видел его содержимое, то есть простое решение. С помощью утилиты shc его можно транслировать в язык C и скомпилировать. На выходе будет обычный бинарник, который будет успешно работать практически на любой ОС Linux.
Это может быть актуально, если вы делаете кому-то что-то на заказ и надо продемонстрировать работоспособность решения. Если сразу отдать скрипт, то недобросовестные заказчики могут не заплатить, так как всё решение это и есть текст скрипта. Возможно, вы просто захотите от кого-то скрыть чувствительные данные или идею реализации той или иной функциональности.
Shc живёт в базовых репозиториях Debian или Ubuntu, возможно и в других дистрибутивах. Для сборки также понадобится пакет gcc.
Пользоваться ей очень просто. Покажу на примере небольшого скрипта с вводом переменной в консоли.
Запускаем:
Теперь компилируем его в бинарник:
На выходе получаем два файла:
- script.sh.x - бинарник
- script.sh.x.c - исходный код
Запускаем бинарь:
Отработал точно так же, как и bash скрипт. С помощью shc можно указать дату, после которой скрипт запускаться не будет. Выглядит это примерно так:
Я подозреваю, что прятать какие-то важные пароли таким образом опасно. Наверняка есть способ, чтобы его вытащить оттуда. Мне даже кажется, что это и не слишком сложно. В памяти то всё равно содержимое будет в каком-то виде отображаться. Можно сдампить память в момент запуска и посмотреть.
Быстро поискал и нашёл готовое решение по расшифровке таких файлов:
⇨ https://github.com/yanncam/UnSHc
Так что имейте ввиду, что это в основном защита от дурака.
#bash #script
Это может быть актуально, если вы делаете кому-то что-то на заказ и надо продемонстрировать работоспособность решения. Если сразу отдать скрипт, то недобросовестные заказчики могут не заплатить, так как всё решение это и есть текст скрипта. Возможно, вы просто захотите от кого-то скрыть чувствительные данные или идею реализации той или иной функциональности.
Shc живёт в базовых репозиториях Debian или Ubuntu, возможно и в других дистрибутивах. Для сборки также понадобится пакет gcc.
# apt install shc gccПользоваться ей очень просто. Покажу на примере небольшого скрипта с вводом переменной в консоли.
#!/bin/bashv=$1echo "Simple BASH script. Entered VARIABLE: $v"Запускаем:
# ./script.sh 111Simple BASH script. Entered VARIABLE: 111Теперь компилируем его в бинарник:
# shc -f -r script.shНа выходе получаем два файла:
- script.sh.x - бинарник
- script.sh.x.c - исходный код
Запускаем бинарь:
# ./script.sh.x 123Simple BASH script. Entered VARIABLE: 123Отработал точно так же, как и bash скрипт. С помощью shc можно указать дату, после которой скрипт запускаться не будет. Выглядит это примерно так:
# shc -e 31/12/2023 -m "Извини, но ты опоздал!" -f -r script.sh# ./script.sh.x./script.sh.x: has expired!Извини, но ты опоздал!Я подозреваю, что прятать какие-то важные пароли таким образом опасно. Наверняка есть способ, чтобы его вытащить оттуда. Мне даже кажется, что это и не слишком сложно. В памяти то всё равно содержимое будет в каком-то виде отображаться. Можно сдампить память в момент запуска и посмотреть.
Быстро поискал и нашёл готовое решение по расшифровке таких файлов:
⇨ https://github.com/yanncam/UnSHc
Так что имейте ввиду, что это в основном защита от дурака.
#bash #script
{kind=link}
Если вам нужно хорошенько нагрузить интернет канал и желательно с возможностью некоторого управления суммарным объёмом трафика, то предлагаю вам свой простенький скрипт, который набросал на днях. Он использует публичные Looking Glass российских хостеров, у которых сервер проверки стоит в Москве. Мне так надо было. Подобрать нужных хостеров можно тут.
Запускаем скрипт, указывая нужное количество проходок скачивания указанных файлов:
И скрипт 5 раз пройдёт по этому списку, скачав 500 мегабайт за проход. Чаще всего у хостеров есть там же файлы по 1000MB. Так что зачастую просто добавив нолик в урле, можно увеличить размер файла. Мне не надо было, поэтому качал по 100. Сам список тоже можно сделать очень длинным.
Скрипт удобно использовать для отладки триггеров в мониторинге на загрузку сетевого интерфейса.
#script
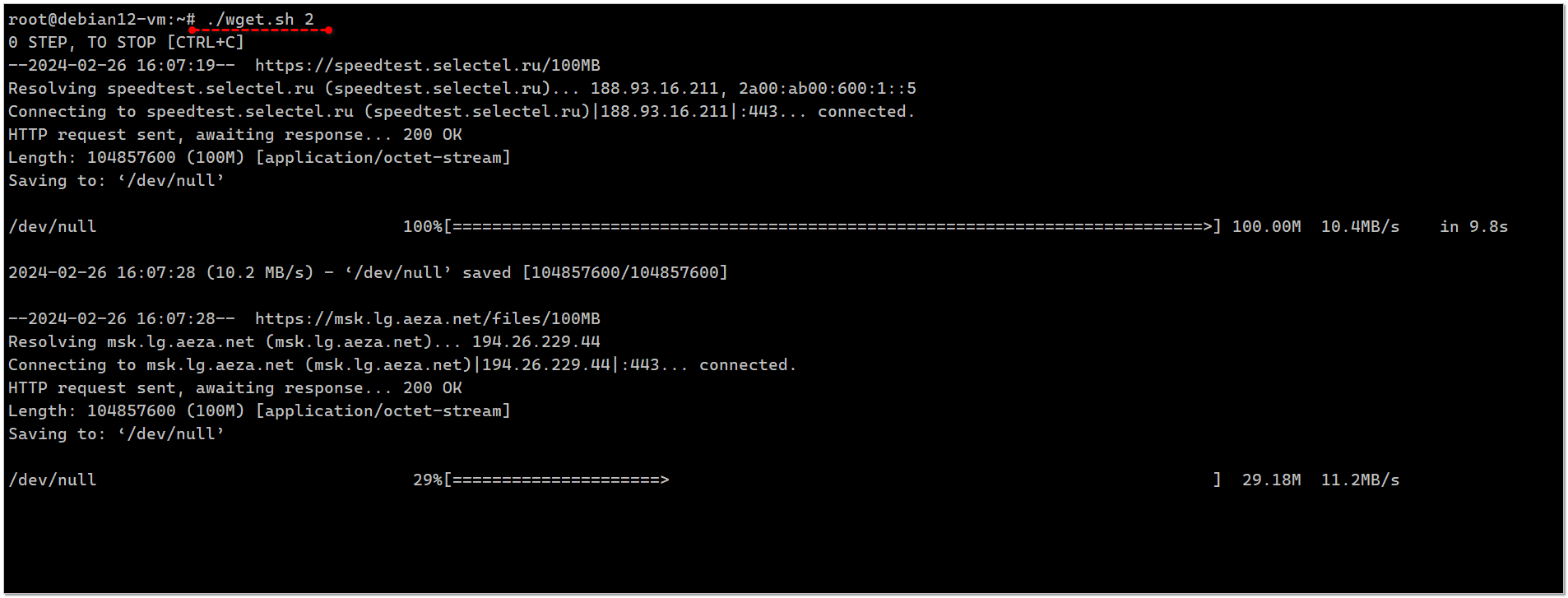
#!/bin/bashsteps=$1for ((i=0;i<$steps;i++))do echo "$i STEP, TO STOP [CTRL+C]" wget -O /dev/null https://speedtest.selectel.ru/100MB wget -O /dev/null https://msk.lg.aeza.net/files/100MB wget -O /dev/null https://45-67-230-12.lg.looking.house/100.mb wget -O /dev/null https://185-43-4-155.lg.looking.house/100.mb wget -O /dev/null https://185-231-154-182.lg.looking.house/100.mbdoneЗапускаем скрипт, указывая нужное количество проходок скачивания указанных файлов:
# ./wget.sh 5И скрипт 5 раз пройдёт по этому списку, скачав 500 мегабайт за проход. Чаще всего у хостеров есть там же файлы по 1000MB. Так что зачастую просто добавив нолик в урле, можно увеличить размер файла. Мне не надо было, поэтому качал по 100. Сам список тоже можно сделать очень длинным.
Скрипт удобно использовать для отладки триггеров в мониторинге на загрузку сетевого интерфейса.
#script
{kind=link}
Возникла небольшая прикладная задача. Нужно было периодически с одного mysql сервера перекидывать дамп одной таблицы из базы на другой сервер в такую же базу. Решений этой задачи может быть много. Я взял и решил в лоб набором простых команд на bash. Делюсь с вами итоговым скриптом. Даже если он вам не нужен в рамках этой задачи, то можете взять какие-то моменты для использования в другой.
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
#!/bin/bash
# Дамп базы с заменой общего комплексного параметра --opt, где используется ключ --lock-tables на набор отдельных ключей, где вместо lock-tables используется --single-transaction
/usr/bin/mysqldump --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob --databases database01 -u'userdb' -p'password' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
# Из общего дампа вырезаю дамп только данных таблицы table01. Общий дамп тоже оставляю, потому что он нужен для других задач
/usr/bin/cat /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql | /usr/bin/awk '/LOCK TABLES `table01`/,/UNLOCK TABLES/' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Сжимаю оба дампа
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Копирую дамп таблицы на второй сервер, аутентификация по ключам
/usr/bin/scp /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql.gz sshuser@10.20.30.45:/tmp
# Выполняю на втором сервере ряд заданий в рамках ssh сессии: распаковываю дамп таблицы, очищаю таблицу на этом сервере, заливаю туда данные из дампа
/usr/bin/ssh sshuser@10.20.30.45 '/usr/bin/gunzip /tmp/"$(date +%Y-%m-%d)"-table01.sql.gz && /usr/bin/mysql -e "delete from database01.table01; use database01; source /tmp/"$(date +%Y-%m-%d)"-table01.sql;"'
# Удаляю дамп
/usr/bin/ssh sshuser@10.20.30.45 'rm /tmp/"$(date +%Y-%m-%d)"-table01.sql'
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
Пробую в ежедневной рутине использовать в качестве помощника ИИ. В данном случае я имею ввиду Openchat-3.5-0106, которым пользуюсь. Как я уже отмечал ранее, там, где нужно выдать какую-то справочную информацию или скомбинировать известную информацию, он способен помочь. А где надо немного подумать и что-то написать новое, то уже не очень.
У меня возникла простая задача. В запросах к API на выборку данных нужно указывать год, номер месяца, дни месяца. Это нетрудно сделать с помощью bash. Решил сразу задать вопрос боту и посмотреть результат. Сформулировал запрос так:
Напиши bash скрипт, который будет показывать текущую дату, номер текущего месяца, текущий год, первый и последний день текущего месяца, прошлого месяца и будущего месяца.
Получил на выходе частично работающий скрипт. Текущий год, месяц и дату показывает, первые дни нет. Вот скрипт, который предложил ИИ.
Гугл первой же ссылкой дал правильный ответ на stackexchange. Идею я понял, немного переделал скрипт под свои потребности. То есть сделал сразу себе мини-шпаргалку, заготовку. Получилось вот так:
Можете себе забрать, если есть нужда работать с датами. Иногда это нужно для работы с бэкапами, которые по маске с датой создаются. Директории удобно по месяцам и годам делать. Потом оттуда удобно забирать данные или чистить старое. То же самое с API. К ним часто нужно указывать интервал запроса. Года, месяцы, даты чаще всего отдельными переменными идут.
Проверять подобные скрипты удобно с помощью faketime:
Я в своей деятельности пока не вижу какой-то значимой пользы от использования ИИ. Не было так, что вот задал ему вопрос и получил готовый ответ.
#bash #script
У меня возникла простая задача. В запросах к API на выборку данных нужно указывать год, номер месяца, дни месяца. Это нетрудно сделать с помощью bash. Решил сразу задать вопрос боту и посмотреть результат. Сформулировал запрос так:
Напиши bash скрипт, который будет показывать текущую дату, номер текущего месяца, текущий год, первый и последний день текущего месяца, прошлого месяца и будущего месяца.
Получил на выходе частично работающий скрипт. Текущий год, месяц и дату показывает, первые дни нет. Вот скрипт, который предложил ИИ.
Гугл первой же ссылкой дал правильный ответ на stackexchange. Идею я понял, немного переделал скрипт под свои потребности. То есть сделал сразу себе мини-шпаргалку, заготовку. Получилось вот так:
#!/bin/bash
CUR_DATE=$(date "+%F")
CUR_YEAR=$(date "+%Y")
CUR_MONTH=$(date "+%m")
DAY_CUR_START_FULL=$(date +%Y-%m-01)
DAY_CUR_START=$(date "+%d" -d $(date +'%Y-%m-01'))
DAY_CUR_END_FULL=$(date -d "`date +%Y%m01` +1 month -1 day" +%Y-%m-%d)
DAY_CUR_END=$(date "+%d" -d "$DAY_CUR_START_FULL +1 month -1 day")
LAST_MONTH_DATE=$(date "+%F" -d "$(date +'%Y-%m-01') -1 month")
LAST_MONTH_YEAR=$(date "+%Y" -d "$(date +'%Y-%m-01') -1 month")
LAST_MONTH=$(date "+%m" -d "$(date +'%Y-%m-01') -1 month")
DAY_LAST_START=$(date "+%d" -d "$(date +'%Y-%m-01') -1 month")
DAY_LAST_START_FULL=$(date "+%Y-%m-01" -d "$(date +'%Y-%m-01') -1 month")
DAY_LAST_END=$(date "+%d" -d "$LAST_MONTH_DATE +1 month -1 day")
DAY_LAST_END_FULL=$(date -d "$LAST_MONTH_DATE +1 month -1 day" +%Y-%m-%d)
echo -e "\n"
echo "Полная текущая дата: $CUR_DATE"
echo "Текущий год: $CUR_YEAR"
echo "Номер текущего месяца: $CUR_MONTH"
echo "Первый день этого месяца: $DAY_CUR_START_FULL, $DAY_CUR_START"
echo "Последний день этого месяца: $DAY_CUR_END_FULL, $DAY_CUR_END"
echo -e "\n"
echo "Начало прошлого месяца: $LAST_MONTH_DATE"
echo "Год прошлого месяца: $LAST_MONTH_YEAR"
echo "Номер прошлого месяца: $LAST_MONTH"
echo "Первый день прошлого месяца: $DAY_LAST_START_FULL, $DAY_LAST_START"
echo "Последний день прошлого месяца: $DAY_LAST_END_FULL, $DAY_LAST_END"
echo -e "\n"
Можете себе забрать, если есть нужда работать с датами. Иногда это нужно для работы с бэкапами, которые по маске с датой создаются. Директории удобно по месяцам и годам делать. Потом оттуда удобно забирать данные или чистить старое. То же самое с API. К ним часто нужно указывать интервал запроса. Года, месяцы, даты чаще всего отдельными переменными идут.
Проверять подобные скрипты удобно с помощью faketime:
# apt install faketime# faketime '2024-01-05' bash date.shЯ в своей деятельности пока не вижу какой-то значимой пользы от использования ИИ. Не было так, что вот задал ему вопрос и получил готовый ответ.
#bash #script
В комментариях один подписчик поделился open source проектом в виде сервера для управления и использования скриптов - script-server. Штука вроде интересная. Я развернул и начал тестировать. Но всё как-то неинтуитивно и неудобно. В процессе я понял, что уже видел на эту тему готовые продукты, но более функциональные и проработанные. В итоге бросил script-server, вспомнил аналог, которым я когда-то давно пользовался - Rundeck. Решил написать про него.
Кратко скажу, что такое Rundeck. Это веб интерфейс для управления своими костылями в виде различных скриптов. Их можно запускать как вручную, так и по расписанию, заменяя локальные cron на отдельных узлах. Вы добавляете в систему свои сервера, пишите скрипты и связываете эти скрипты с серверами. Это альтернатива крупным CI/CD системам для тех, кому они не нужны, но хочется как-то упорядочить управление своими костылями в небольшой инфраструктуре.
📌 Основные возможности Rundeck:
🔹Запуск составных заданий, которые могут состоять из локальных команд и скриптов, скриптов из централизованного хранилища, HTTP запросов, Ansible плейбуков, задач на копирование файлов.
🔹Задания могут запускаться вручную через веб интерфейс или по расписанию.
🔹Выполнение заданий логируется, после выполнения могут отправляться уведомления.
🔹Функциональность системы расширяется плагинами и интеграциями. Например, можно запускать задачи Rundeck после билдов в Jenkins, или добавлять результат работы команды в комментарии в задачам в Jira. Список плагинов большой.
🔹Различные планы исполнения массовых заданий: последовательные, параллельные сразу на всех хостах, остановка или продолжение исполнения в случае неудач и т.д.
🔹Управление правами доступа в проектах на основе групп и ролей.
🔹На Linux сервера ходит по SSH, на виндовые через WinRM.
Продукт уже зрелый и развитый. Настолько развитый, что загрузку Community версии спрятали за форму регистрации. Я знаю, что есть Docker версия, поэтому просто сходил в hub, посмотрел номер свежего релиза и запустил его:
Можно идти по IP адресу на порт 4440, учётка по умолчанию - admin / admin. Интерфейс и логика работы интуитивно понятны. Создаём job с различными параметрами, добавляем хосты (делается в настройках проекта), настраиваем запуск заданий на хостах. Есть несколько механизмов по автоматическому добавлению хостов. Rundesk их может брать из:
◽️Ansible inventory
◽️Директории, где лежат подготовленные файлы с описанием хостов
◽️Единого конфига, где описаны все хосты
Соответственно, хосты он подгружает из заранее подготовленного места. Пример файла с описанием нод есть в документации. Там всё просто. Надо заполнить основные поля - имя, адрес, архитектура, система, тэги и т.д. То ли я затупил, то ли такую возможность убрали из бесплатной версии. Не понял, как одну ноду вручную добавить в веб интерфейс. Каждый раз редактировать файл неудобно.
В качестве примеров можете посмотреть готовые задания из репозитория. Они в формате yml. Можете скачать и импортировать к себе.
Я пару часов поразбирался с этой системой, в целом, всё получилось, но есть нюансы. Последовательность действий такая:
1️⃣ Добавляем проект.
2️⃣ В свойствах проекта в разделе Default Node Executor указываем SSH Authentication privateKey.
3️⃣ Идём в Key Storage, добавляем ключ. Сохраняем его Storage path.
4️⃣ Готовим файл с нодами
5️⃣ Копируем этот файл в контейнер:
6️⃣ В разделе Edit Nodes добавляем Node Source в виде File. Путь указываем
Всё, теперь можно создавать задания и выполнять их на нодах.
⇨ 🌐 Сайт / Исходники
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#script #devops
Кратко скажу, что такое Rundeck. Это веб интерфейс для управления своими костылями в виде различных скриптов. Их можно запускать как вручную, так и по расписанию, заменяя локальные cron на отдельных узлах. Вы добавляете в систему свои сервера, пишите скрипты и связываете эти скрипты с серверами. Это альтернатива крупным CI/CD системам для тех, кому они не нужны, но хочется как-то упорядочить управление своими костылями в небольшой инфраструктуре.
📌 Основные возможности Rundeck:
🔹Запуск составных заданий, которые могут состоять из локальных команд и скриптов, скриптов из централизованного хранилища, HTTP запросов, Ansible плейбуков, задач на копирование файлов.
🔹Задания могут запускаться вручную через веб интерфейс или по расписанию.
🔹Выполнение заданий логируется, после выполнения могут отправляться уведомления.
🔹Функциональность системы расширяется плагинами и интеграциями. Например, можно запускать задачи Rundeck после билдов в Jenkins, или добавлять результат работы команды в комментарии в задачам в Jira. Список плагинов большой.
🔹Различные планы исполнения массовых заданий: последовательные, параллельные сразу на всех хостах, остановка или продолжение исполнения в случае неудач и т.д.
🔹Управление правами доступа в проектах на основе групп и ролей.
🔹На Linux сервера ходит по SSH, на виндовые через WinRM.
Продукт уже зрелый и развитый. Настолько развитый, что загрузку Community версии спрятали за форму регистрации. Я знаю, что есть Docker версия, поэтому просто сходил в hub, посмотрел номер свежего релиза и запустил его:
# docker run --name rundeck -e RUNDECK_GRAILS_URL=http://10.20.1.36:4440 -p 4440:4440 -v data:/home/rundeck/server/data rundeck/rundeck:5.7.0Можно идти по IP адресу на порт 4440, учётка по умолчанию - admin / admin. Интерфейс и логика работы интуитивно понятны. Создаём job с различными параметрами, добавляем хосты (делается в настройках проекта), настраиваем запуск заданий на хостах. Есть несколько механизмов по автоматическому добавлению хостов. Rundesk их может брать из:
◽️Ansible inventory
◽️Директории, где лежат подготовленные файлы с описанием хостов
◽️Единого конфига, где описаны все хосты
Соответственно, хосты он подгружает из заранее подготовленного места. Пример файла с описанием нод есть в документации. Там всё просто. Надо заполнить основные поля - имя, адрес, архитектура, система, тэги и т.д. То ли я затупил, то ли такую возможность убрали из бесплатной версии. Не понял, как одну ноду вручную добавить в веб интерфейс. Каждый раз редактировать файл неудобно.
В качестве примеров можете посмотреть готовые задания из репозитория. Они в формате yml. Можете скачать и импортировать к себе.
Я пару часов поразбирался с этой системой, в целом, всё получилось, но есть нюансы. Последовательность действий такая:
resources.yml. Описываем там ноды, в параметре ssh-key-storage-path указываем Storage path из предыдущего пункта.# docker cp ~/resources.yml rundeck:/home/rundeck/resources.yml/home/rundeck/resources.yml. Сохраняем настройку. Всё, теперь можно создавать задания и выполнять их на нодах.
⇨ 🌐 Сайт / Исходники
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#script #devops
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Нашёл на github простой скрипт, который делает одну вещь - следит за конкретным лог файлом или набором файлов на предмет появления там заданных строк. Как только их видит, отправляет уведомление в Telegram.
https://github.com/dobanov/mon_log_and_send_keywords_to_telegram
Я проверил версию на python. Работает очень просто. Копируем репу:
Устанавливаем необходимые пакеты:
Запускаем скрипт без параметров:
Он ругнётся, что не переданы параметры и нет файла конфигурации. Создаст пустой
В этом примере я указал две строки из файла auth.log, куда записывается вся информация об SSH сессиях. В данном случае в Telegram прилетят две строки:
То есть полная информация о подключении - IP адрес и пользователь.
Запускаем скрипт:
Открываем новую SSH сессию и наблюдаем уведомление в телеге. В данном случае обе строки не нужны, сделал так для примера.
Всё очень просто и быстро. Код скрипта можете сами посмотреть, он небольшой. В репе лежит простенький шаблон для создания systemd службы, чтобы запускать скрипт в фоне.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#script #logs
https://github.com/dobanov/mon_log_and_send_keywords_to_telegram
Я проверил версию на python. Работает очень просто. Копируем репу:
# git clone https://github.com/dobanov/mon_log_and_send_keywords_to_telegram# cd mon_log_and_send_keywords_to_telegramУстанавливаем необходимые пакеты:
# apt install python3-pip python3-watchdogЗапускаем скрипт без параметров:
# python3 tg_mon.pyОн ругнётся, что не переданы параметры и нет файла конфигурации. Создаст пустой
~/.config/tg_log.ini. Заполняем его:filename=/var/log/auth.logkeyword=Accepted password,session openedn=100bot_id=5731668668:AAFxcwvp8XjvepZzDMIAN87l1D_MuiI1Ve9chat_id=210856265debug=trueВ этом примере я указал две строки из файла auth.log, куда записывается вся информация об SSH сессиях. В данном случае в Telegram прилетят две строки:
2024-12-04T18:35:23.679324+03:00 debian12-vm sshd[4282]: Accepted password for root from 10.8.2.2 port 9669 ssh22024-12-04T18:35:23.680422+03:00 debian12-vm sshd[4282]: pam_unix(sshd:session): session opened for user root(uid=0) by (uid=0)То есть полная информация о подключении - IP адрес и пользователь.
Запускаем скрипт:
# python3 tg_mon.pyОткрываем новую SSH сессию и наблюдаем уведомление в телеге. В данном случае обе строки не нужны, сделал так для примера.
Всё очень просто и быстро. Код скрипта можете сами посмотреть, он небольшой. В репе лежит простенький шаблон для создания systemd службы, чтобы запускать скрипт в фоне.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#script #logs
Подписчик поделился полезным скриптом для аудита VPS серверов - VPS Security Audit Script. Я кстати, всегда с благодарностью отношусь ко всем рекомендациям. Всё читаю, смотрю, о чём-то пишу потом.
Возвращаясь к скрипту. Сначала прохладно отнёсся. Думаю, мало смысла на сервер нести какой-то посторонний софт. Но потом посмотрел исходники и поменял своё мнение. Там очень простой bash код, который легко читается. В скрипте никакой экзотики. Просто анализ типовых настроек с использованием стандартных утилит командной строки Linux.
📌 Скрипт проверяет:
▪️Настройки SSH: номер порта, аутентификацию по паролю и под root
▪️Статус Firewall
▪️Настройку автоматических установок обновлений безопасности
▪️Работу Fail2Ban или CrowdSec
▪️Количество неудачных попыток логина
▪️Количество доступных, но не установленных обновлений
▪️Количество работающих служб
▪️Количество открытых на внешнем интерфейсе портов
▪️Логирование команд через sudo
▪️Некоторые системные метрики: uptime, cpu, disk, memory
▪️Необходимость перезагрузки сервера после обновления ядра
▪️Наличие файлов с SUID (Set User ID) - флаг прав доступа, позволяющий запустить исполняемый файл с правами владельца.
Кстати, понравился способ посмотреть количество доступных к обновлению пакетов:
Результат работы скрипта сохраняется в текстовый файл. Эти файлы можно хранить в системе для хранения логов, либо парсить и передавать данные в систему мониторинга. Например, можно добавить в Zabbix и сделать триггер на фразу FAIL в логе.
Скрипт интересный. Ничего особенного, но всё аккуратно собрано в одном месте. Можно его рассмотреть и взять себе что-то для встраивания в свой мониторинг или скрипты. Я сохранил.
⇨ 🌐 Исходники
Сам использую немного другую шутку, но решаю похожие задачи:
⇨ Мониторинг безопасности сервера с помощью Lynis и Zabbix
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#мониторинг #script
Возвращаясь к скрипту. Сначала прохладно отнёсся. Думаю, мало смысла на сервер нести какой-то посторонний софт. Но потом посмотрел исходники и поменял своё мнение. Там очень простой bash код, который легко читается. В скрипте никакой экзотики. Просто анализ типовых настроек с использованием стандартных утилит командной строки Linux.
📌 Скрипт проверяет:
▪️Настройки SSH: номер порта, аутентификацию по паролю и под root
▪️Статус Firewall
▪️Настройку автоматических установок обновлений безопасности
▪️Работу Fail2Ban или CrowdSec
▪️Количество неудачных попыток логина
▪️Количество доступных, но не установленных обновлений
▪️Количество работающих служб
▪️Количество открытых на внешнем интерфейсе портов
▪️Логирование команд через sudo
▪️Некоторые системные метрики: uptime, cpu, disk, memory
▪️Необходимость перезагрузки сервера после обновления ядра
▪️Наличие файлов с SUID (Set User ID) - флаг прав доступа, позволяющий запустить исполняемый файл с правами владельца.
Кстати, понравился способ посмотреть количество доступных к обновлению пакетов:
# apt-get -s upgrade 2>/dev/null | grep -P '^\d+ upgraded' | cut -d" " -f149Результат работы скрипта сохраняется в текстовый файл. Эти файлы можно хранить в системе для хранения логов, либо парсить и передавать данные в систему мониторинга. Например, можно добавить в Zabbix и сделать триггер на фразу FAIL в логе.
Скрипт интересный. Ничего особенного, но всё аккуратно собрано в одном месте. Можно его рассмотреть и взять себе что-то для встраивания в свой мониторинг или скрипты. Я сохранил.
⇨ 🌐 Исходники
Сам использую немного другую шутку, но решаю похожие задачи:
⇨ Мониторинг безопасности сервера с помощью Lynis и Zabbix
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#мониторинг #script
На канале было опубликовано много всевозможных прикладных bash скриптов, которые я сам постоянно использую. У меня они все в отдельном репозитории лежат. Решил их собрать для вашего удобства в отдельную публикацию.
▪️lynis.sh - проверка системы с помощью lynis и выгрузка результатов в Zabbix
▪️vps-audit.sh - аудит безопасности сервера
▪️dir_size.sh - определяет размер директорий и записывает результат вместе с датой замеров в файл
▪️postgres.sh - отдельные консольные команды postgresql сервера для использования в своих скриптах (pg_dump, createdb, reindexdb, vacuumdb и т.д.)
▪️copy-last.day.sh - передача с помощью rsync с одного сервера на другой бэкапы прошлого дня, более старые не трогает, забирает файлы со стороны стороннего сервера, а не исходного, где лежат файлы
▪️tg_mon.py - следит за заданными строками в лог файле и шлёт уведомления в telegram, когда их видит
▪️dates.sh - заготовка под работу с датами в скриптах
▪️copy-mysql-table.sh - копирование отдельной таблицы базы данных с одного сервера на другой
▪️wget-speedtest.sh - загружает интернет канал загрузкой данных с публичных Looking Glass
▪️findmnt.sh - проверка существования точки монтирования
▪️ps_mem.py - использование оперативной памяти программами (не процессами)
▪️check_nginx_running.sh - анализ работы веб сервера Nginx для экспорта в логи или мониторинг
▪️contry-block.sh - блокировка стран с помощью ipset и iptables
▪️mysql-stat.sh - оптимизация конфигурации MySQL сервера под имеющуюся оперативную память
🔥topdiskconsumer.sh - очень удобная статистика по занимаемому месту
▪️swap.sh - использование swap процессами
▪️trash.sh - самостоятельная реализация корзины при удалении файлов
📌 Софт для работы со скриптами:
◽️Rundeck - веб интерфейс для централизованного управления работой скриптов на серверах.
◽️Cronicle - система планирования и управления задачами серверов. Условно его можно назвать продвинутым Cron с веб интерфейсом.
◽️Task - утилита, написанная на Gо, которая умеет запускать задачи на основе конфигурации в формате yaml. Более простая и функциональная замена утилите make.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#script #подборка
▪️lynis.sh - проверка системы с помощью lynis и выгрузка результатов в Zabbix
▪️vps-audit.sh - аудит безопасности сервера
▪️dir_size.sh - определяет размер директорий и записывает результат вместе с датой замеров в файл
▪️postgres.sh - отдельные консольные команды postgresql сервера для использования в своих скриптах (pg_dump, createdb, reindexdb, vacuumdb и т.д.)
▪️copy-last.day.sh - передача с помощью rsync с одного сервера на другой бэкапы прошлого дня, более старые не трогает, забирает файлы со стороны стороннего сервера, а не исходного, где лежат файлы
▪️tg_mon.py - следит за заданными строками в лог файле и шлёт уведомления в telegram, когда их видит
▪️dates.sh - заготовка под работу с датами в скриптах
▪️copy-mysql-table.sh - копирование отдельной таблицы базы данных с одного сервера на другой
▪️wget-speedtest.sh - загружает интернет канал загрузкой данных с публичных Looking Glass
▪️findmnt.sh - проверка существования точки монтирования
▪️ps_mem.py - использование оперативной памяти программами (не процессами)
▪️check_nginx_running.sh - анализ работы веб сервера Nginx для экспорта в логи или мониторинг
▪️contry-block.sh - блокировка стран с помощью ipset и iptables
▪️mysql-stat.sh - оптимизация конфигурации MySQL сервера под имеющуюся оперативную память
🔥topdiskconsumer.sh - очень удобная статистика по занимаемому месту
▪️swap.sh - использование swap процессами
▪️trash.sh - самостоятельная реализация корзины при удалении файлов
📌 Софт для работы со скриптами:
◽️Rundeck - веб интерфейс для централизованного управления работой скриптов на серверах.
◽️Cronicle - система планирования и управления задачами серверов. Условно его можно назвать продвинутым Cron с веб интерфейсом.
◽️Task - утилита, написанная на Gо, которая умеет запускать задачи на основе конфигурации в формате yaml. Более простая и функциональная замена утилите make.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#script #подборка
Существует удобный и функциональный инструмент для добавления интерактива в shell скрипты под названием Gum. Я посмотрел несколько примеров, в том числе на ютубе, как люди решают те или иные задачи с его помощью. Синтаксис очень простой, особо разбираться не надо. Можно сходу брать и писать скрипт.
Я для примера решил сделать поиск по директории с выводом топ 10 самых больших файлов, из которых можно какие-то выбрать и удалить. Сделал просто в лоб на bash – сформировал список, отправил его в gum и добавил действие для выбранных файлов:
Понял, что всё получилось и решил как-то это усложнить и сделать более удобным. Дай, думаю, попрошу Chatgpt что-то написать. На самом деле не рассчитывал на успех, так как это не особо популярный инструмент. Откуда ему взять навык написания скриптов для gum? Вряд ли их много в интернете можно найти.
Отправил ему адрес репозитория и попросил сделать 2 списка: один с самыми большими файлами, второй – с самыми старыми. Причём вывести их вместе на один экран, в списках отобразить размер файлов и их даты.
Задача не сильно сложная, но немного муторная, так как списки надо правильно сформировать, объединить, пункты выбора насытить дополнительной информацией в виде размера файлов и даты. Потом всё это надо очистить, чтобы передать на удаление только имя файла. Чтобы самому это сделать, надо потратить какое-то время.
Chatgpt меня удивил, когда практически сразу же выдал рабочее решение. Там были ошибки по части bash. Нужно было что-то экранировать, а что-то получше очистить. А вот в части непосредственно Gum он на удивление сразу же всё корректно оформил в соответствии с его возможностями. Я думал, что-то выдумает от себя нерабочее, но нет.
В итоге минут за 15-20 со всеми тестами я получил рабочий вариант скрипта. Реально, был очень удивлён. Не так давно его мучал конфигурациями Nginx, по которым море примеров в сети, но так и не добился того, что хотел. А тут какой-то Gum и сразу всё заработало.
☝️ Какое в итоге резюме. Gum – прикольная штука, которую можно приспособить под какие-то свои задачи. Например, выбор подключений по SSH, работа с ветками GIT, работа со списками файлов и т.д. Тут уж каждому своё. А второй момент – используйте ИИ для своих задач. Где-то он мимо советует, а где-то сразу рабочий вариант даёт. Причём в таких небольших прикладных задачах он нормально работает. На bash пишет уверенно. Есть проблемы, но поправить после него намного проще, чем написать самому, вспомнив все возможности и ключи консольных утилит.
⇨ Итоговый скрипт
Использовать:
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#bash #AI #script
Я для примера решил сделать поиск по директории с выводом топ 10 самых больших файлов, из которых можно какие-то выбрать и удалить. Сделал просто в лоб на bash – сформировал список, отправил его в gum и добавил действие для выбранных файлов:
#!/bin/bash
DIR="/tmp/backup"
files=$(find "$DIR" -type f -exec du -b {} + 2>/dev/null | sort -nr | head -n 10 | awk '{print $2}')
selected=$(echo "$files" | gum choose --no-limit)
delete=$(echo -e "$selected")
if [[ -z "$delete" ]]; then
echo "Ничего не выбрано."
exit 0
fi
gum confirm "Удалить выбранные файлы?" &&
echo "$delete" | xargs -d '\n' rm -f && echo "Выбранное удалено."
Понял, что всё получилось и решил как-то это усложнить и сделать более удобным. Дай, думаю, попрошу Chatgpt что-то написать. На самом деле не рассчитывал на успех, так как это не особо популярный инструмент. Откуда ему взять навык написания скриптов для gum? Вряд ли их много в интернете можно найти.
Отправил ему адрес репозитория и попросил сделать 2 списка: один с самыми большими файлами, второй – с самыми старыми. Причём вывести их вместе на один экран, в списках отобразить размер файлов и их даты.
Задача не сильно сложная, но немного муторная, так как списки надо правильно сформировать, объединить, пункты выбора насытить дополнительной информацией в виде размера файлов и даты. Потом всё это надо очистить, чтобы передать на удаление только имя файла. Чтобы самому это сделать, надо потратить какое-то время.
Chatgpt меня удивил, когда практически сразу же выдал рабочее решение. Там были ошибки по части bash. Нужно было что-то экранировать, а что-то получше очистить. А вот в части непосредственно Gum он на удивление сразу же всё корректно оформил в соответствии с его возможностями. Я думал, что-то выдумает от себя нерабочее, но нет.
В итоге минут за 15-20 со всеми тестами я получил рабочий вариант скрипта. Реально, был очень удивлён. Не так давно его мучал конфигурациями Nginx, по которым море примеров в сети, но так и не добился того, что хотел. А тут какой-то Gum и сразу всё заработало.
☝️ Какое в итоге резюме. Gum – прикольная штука, которую можно приспособить под какие-то свои задачи. Например, выбор подключений по SSH, работа с ветками GIT, работа со списками файлов и т.д. Тут уж каждому своё. А второй момент – используйте ИИ для своих задач. Где-то он мимо советует, а где-то сразу рабочий вариант даёт. Причём в таких небольших прикладных задачах он нормально работает. На bash пишет уверенно. Есть проблемы, но поправить после него намного проще, чем написать самому, вспомнив все возможности и ключи консольных утилит.
⇨ Итоговый скрипт
Использовать:
# ./cleanup-with-gum.sh /mnt/backup❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#bash #AI #script