
Stolon и Patroni — два наиболее известных решения для построения кластера PostgreSQL типа Leader-Followers. Про Patroni я уже как-то рассказывал. Для него есть готовый плейбук ansible — postgresql_cluster, с помощью которого можно легко и быстро развернуть нужную конфигурацию кластера.
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
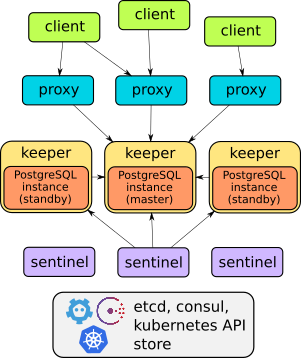
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
{kind=link}
Попереживал тут на днях из-за своей неаккуратности. Настроил сервер 1С примерно так же, как описано у меня в статье:
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
3️⃣ Проверяю, создалась ли база:
4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
# sudo -u postgres /usr/bin/createdb -U postgres -T template0 base1C-restored3️⃣ Проверяю, создалась ли база:
# sudo -u postgres /usr/bin/psql -U postgres -l4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
# sudo -u postgres /usr/bin/psql -U postgres base1C-restored < /tmp/backup.sql5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
Я уже делал серию заметок про CIS (Center for Internet Security). Это некоммерческая организация, которая разрабатывает собственные рекомендации по обеспечению безопасности различных систем. Я проработал рекомендации для:
- Nginx
- MySQL 5.7
- Apache 2.4
- Debian 11
- Docker
- Ubuntu 22.04 LTS
Основная проблема этих рекомендаций - они составлены в огромные pdf книги, иногда до 800 страниц и покрывают очень широкий вектор атак. Выбрать из них то, что вам нужно, довольно хлопотно. Я выделяю основные рекомендации, которые стоит учесть при базовом использовании стреднестатиcтической системы. В этот раз разобрал рекомендации для PostgreSQL 16.
🔹Убедитесь, что настроено логирование ошибок. Задаётся параметром
🔹Для повышения возможностей аудита имеет смысл включить логирование подключений и отключений клиентов. Параметры
🔹Если вам необходимо отслеживать активность в базе данных, то имеет смысл настроить параметр
🔹Для расширенного аудита используйте отдельный модуль pgAudit. Обычно ставится в виде отдельного пакета. Для расширенного контроля за действиями superuser используйте расширение set_user.
🔹Если есть необходимость работать с postgresql в консоли, установите и настройте утилиту sudo, чтобы можно было контролировать и отслеживать действия различных пользователей.
🔹Рекомендованным методом аутентификации соединения является scram-sha-256, а не популярный md5, у которого есть уязвимость (it is vulnerable to packet replay attacks). Настраивается в pg_hba.conf.
🔹Настройте работу СУБД на том сетевом интерфейсе, на котором она будет принимать соединения. Параметр
🔹Если есть необходимость шифровать TCP трафик от и к серверу, то не забудьте настроить TLS. За это отвечает параметр
🔹Для репликации создавайте отдельных пользователей. Не используйте существующих или superuser.
🔹Не забудьте проверить и настроить создание бэкапов. Используйте pg_basebackup для создания полных бэкапов и копии WAL журналов для бэкапа транзакций.
Остальные рекомендации были в основном связаны с ролями, правами доступа и т.д. Это уже особенности конкретной эксплуатации. Не стал о них писать.
Сам файл с рекомендациями живёт тут. Для доступа нужна регистрация.
#cis #postgresql
- Nginx
- MySQL 5.7
- Apache 2.4
- Debian 11
- Docker
- Ubuntu 22.04 LTS
Основная проблема этих рекомендаций - они составлены в огромные pdf книги, иногда до 800 страниц и покрывают очень широкий вектор атак. Выбрать из них то, что вам нужно, довольно хлопотно. Я выделяю основные рекомендации, которые стоит учесть при базовом использовании стреднестатиcтической системы. В этот раз разобрал рекомендации для PostgreSQL 16.
🔹Убедитесь, что настроено логирование ошибок. Задаётся параметром
log_destination. По умолчанию пишет в системный поток stderr. Считается, что это ненадёжный способ, поэтому рекомендуется отдельно настроить logging_collector и отправлять логи через него. По умолчанию он отключен. Если настроено сохранение логов в файлы, то не забыть закрыть доступ к ним и настроить ротацию средствами postgresql (log_truncate_on_rotation, log_rotation_age и т.д.)🔹Для повышения возможностей аудита имеет смысл включить логирование подключений и отключений клиентов. Параметры
log_connections и log_disconnections. По умолчанию отключено. 🔹Если вам необходимо отслеживать активность в базе данных, то имеет смысл настроить параметр
log_statement. Значение ddl позволит собирать информацию о действиях CREATE, ALTER, DROP. 🔹Для расширенного аудита используйте отдельный модуль pgAudit. Обычно ставится в виде отдельного пакета. Для расширенного контроля за действиями superuser используйте расширение set_user.
🔹Если есть необходимость работать с postgresql в консоли, установите и настройте утилиту sudo, чтобы можно было контролировать и отслеживать действия различных пользователей.
🔹Рекомендованным методом аутентификации соединения является scram-sha-256, а не популярный md5, у которого есть уязвимость (it is vulnerable to packet replay attacks). Настраивается в pg_hba.conf.
🔹Настройте работу СУБД на том сетевом интерфейсе, на котором она будет принимать соединения. Параметр
listen_addresses, по умолчанию указан только localhost. Если используется внешний сетевой интерфейс, не забудьте ограничить к нему доступ средствами firewall.🔹Если есть необходимость шифровать TCP трафик от и к серверу, то не забудьте настроить TLS. За это отвечает параметр
hostssl в pg_hba.conf и параметры ssl, ssl_cert_file, ssl_key_file в postgresql.conf. Поддерживается работа с self-signed сертификатами.🔹Для репликации создавайте отдельных пользователей. Не используйте существующих или superuser.
🔹Не забудьте проверить и настроить создание бэкапов. Используйте pg_basebackup для создания полных бэкапов и копии WAL журналов для бэкапа транзакций.
Остальные рекомендации были в основном связаны с ролями, правами доступа и т.д. Это уже особенности конкретной эксплуатации. Не стал о них писать.
Сам файл с рекомендациями живёт тут. Для доступа нужна регистрация.
#cis #postgresql
{kind=link}
Для мониторинга СУБД PostgreSQL существует много вариантов настройки. Собственно, как и для всего остального. Тема мониторинга очень хорошо развита в IT. Есть из чего выбирать, чему отдать предпочтение.
Одним из наиболее простых и быстрых для внедрения инструментов именно для psql является Pgwatch2. Это известная штука, для которой много инструкций и руководств. Есть обзоры на youtube. Отдельно отмечу, что если вы используете систему мониторинга Zabbix, то искать что-то ещё, большого смысла нет. У неё есть хороший встроенный шаблон, который собирает много различных метрик. В общем случае этого мониторинга будет за глаза.
Если вы не знаете Zabbix, у вас его нет и ставить не планируете, то закрыть вопрос с мониторингом PostgreSQL можно с помощью Pgwatch2. Этот продукт состоит из следующих компонентов:
▪ Хранилище метрик. В его качестве может выступать сама PostgreSQL, в том числе с расширением TimescaleDB. Также метрики можно хранить в InfluxDB. Либо их можно отправить в Prometheus, а он положит куда-то у себя.
▪ Сборщик метрик, написанный на GO.
▪ Веб интерфейс для управления, написанный на Python
▪ Grafana для просмотра дашбордов с метриками.
Всё это есть в готовом виде, упакованное в Docker. Если использовать для хранения метрик PostgreSQL, достаточно создать базу для хранения и пользователя для доступа к метрикам. Далее указать эти данные и запустить контейнеры. Процесс подробно описан в документации.
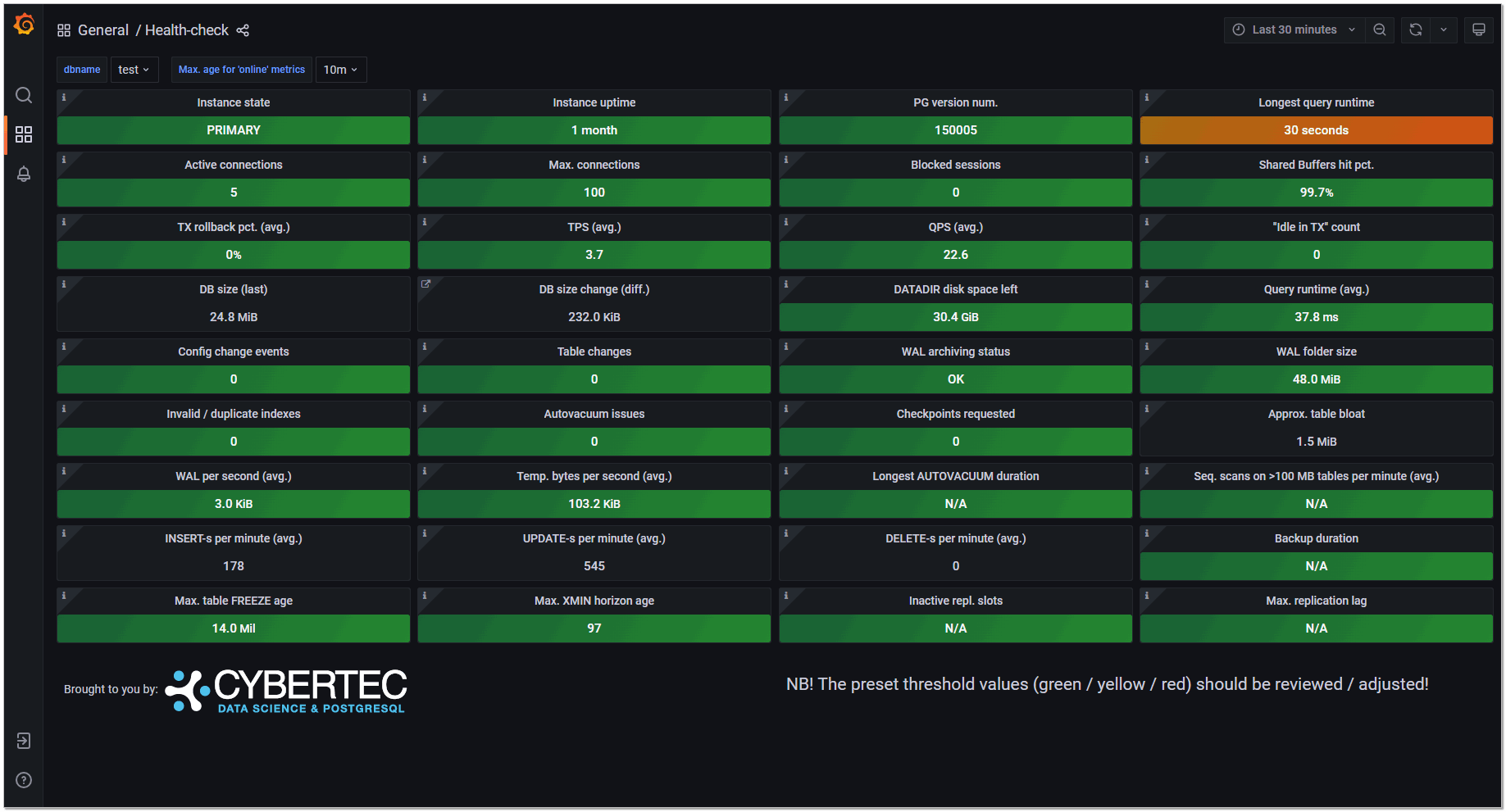
Посмотреть, как выглядит итоговый мониторинг, можно в публичном DEMO. Там из коробки настроено много дашбордов, не забудьте их посмотреть. Информацию по конкретной базе удобно смотреть в дашборде DB overview.
⇨ Исходники / Документация / Demo / Видеобозор (на русском)
#postgresql #monitoring
Одним из наиболее простых и быстрых для внедрения инструментов именно для psql является Pgwatch2. Это известная штука, для которой много инструкций и руководств. Есть обзоры на youtube. Отдельно отмечу, что если вы используете систему мониторинга Zabbix, то искать что-то ещё, большого смысла нет. У неё есть хороший встроенный шаблон, который собирает много различных метрик. В общем случае этого мониторинга будет за глаза.
Если вы не знаете Zabbix, у вас его нет и ставить не планируете, то закрыть вопрос с мониторингом PostgreSQL можно с помощью Pgwatch2. Этот продукт состоит из следующих компонентов:
▪ Хранилище метрик. В его качестве может выступать сама PostgreSQL, в том числе с расширением TimescaleDB. Также метрики можно хранить в InfluxDB. Либо их можно отправить в Prometheus, а он положит куда-то у себя.
▪ Сборщик метрик, написанный на GO.
▪ Веб интерфейс для управления, написанный на Python
▪ Grafana для просмотра дашбордов с метриками.
Всё это есть в готовом виде, упакованное в Docker. Если использовать для хранения метрик PostgreSQL, достаточно создать базу для хранения и пользователя для доступа к метрикам. Далее указать эти данные и запустить контейнеры. Процесс подробно описан в документации.
Посмотреть, как выглядит итоговый мониторинг, можно в публичном DEMO. Там из коробки настроено много дашбордов, не забудьте их посмотреть. Информацию по конкретной базе удобно смотреть в дашборде DB overview.
⇨ Исходники / Документация / Demo / Видеобозор (на русском)
#postgresql #monitoring
{kind=link}
🎓 У компании Postgres Professional есть очень качественные бесплатные курсы по СУБД PostgreSQL. Не припоминаю, чтобы у каких-то других коммерческих компаний были бы курсы в таком же формате. Вы можете пройти обучение в авторизованных учебных центрах с помощью преподавателей, либо изучать материалы курса самостоятельно. Они полностью бесплатны:
⇨ https://postgrespro.ru/education/courses
Доступны следующие курсы для администраторов PostgreSQL:
▪ DBA1. Администрирование PostgreSQL. Базовый курс
▪ DBA2. Администрирование PostgreSQL. Настройка и мониторинг
▪ DBA3. Администрирование PostgreSQL. Резервное копирование и репликация
▪ QPT. Оптимизация запросов
▪ PGPRO. Возможности Postgres Pro Enterprise
Каждый курс - это набор подробных текстовых презентаций и видеоуроков к каждой теме. Причём не обязательно курсы проходить последовательно. Можно обращаться к конкретной теме, которая вас интересует в данный момент.
Например, вам надо обновить сервер или кластер серверов на новую ветку. Идём на курс Администрирование PostgreSQL 13. Настройка и мониторинг, смотрим тему 17. Обновление сервера. Для экономии времени достаточно посмотреть презентацию. Там будет и теория по теме, и точные команды в консоли для выполнения тех или иных действий. Если хочется более подробную информацию с комментариями преподавателя, то можно посмотреть видео.
То же самое про бэкап. Хотите разобраться - открываете курс Администрирование PostgreSQL 13. Резервное копирование и репликация, тема 2. Базовая резервная копия. Там вся теория и примеры по холодным, горячим копиям, плюсы и минусы разных подходов, инструменты для бэкапа, как их проверять. Не пересказы каких-то блогеров или спикеров конференций, а первичка от разработчиков.
Сейчас почти все сервера 1С, да и многое другое, использует PostgreSQL, так что тема актуальна. Я и Zabbix Server все уже года два поднимаю с PostgreSQL, а не MySQL, как раньше.
#обучение #postgresql
⇨ https://postgrespro.ru/education/courses
Доступны следующие курсы для администраторов PostgreSQL:
▪ DBA1. Администрирование PostgreSQL. Базовый курс
▪ DBA2. Администрирование PostgreSQL. Настройка и мониторинг
▪ DBA3. Администрирование PostgreSQL. Резервное копирование и репликация
▪ QPT. Оптимизация запросов
▪ PGPRO. Возможности Postgres Pro Enterprise
Каждый курс - это набор подробных текстовых презентаций и видеоуроков к каждой теме. Причём не обязательно курсы проходить последовательно. Можно обращаться к конкретной теме, которая вас интересует в данный момент.
Например, вам надо обновить сервер или кластер серверов на новую ветку. Идём на курс Администрирование PostgreSQL 13. Настройка и мониторинг, смотрим тему 17. Обновление сервера. Для экономии времени достаточно посмотреть презентацию. Там будет и теория по теме, и точные команды в консоли для выполнения тех или иных действий. Если хочется более подробную информацию с комментариями преподавателя, то можно посмотреть видео.
То же самое про бэкап. Хотите разобраться - открываете курс Администрирование PostgreSQL 13. Резервное копирование и репликация, тема 2. Базовая резервная копия. Там вся теория и примеры по холодным, горячим копиям, плюсы и минусы разных подходов, инструменты для бэкапа, как их проверять. Не пересказы каких-то блогеров или спикеров конференций, а первичка от разработчиков.
Сейчас почти все сервера 1С, да и многое другое, использует PostgreSQL, так что тема актуальна. Я и Zabbix Server все уже года два поднимаю с PostgreSQL, а не MySQL, как раньше.
#обучение #postgresql
postgrespro.ru
Учебные курсы
Postgres Professional - российская компания, разработчик систем управления базами данных
Запуская СУБД PostgreSQL в работу, необходимо в обязательном порядке выполнить хотя бы базовую начальную настройку, которая будет соответствовать количеству ядер и оперативной памяти сервера, а также профилю нагрузки. Это нетривиальная задача, так как там очень много нюансов, а тюнингом баз данных обычно занимаются отдельные специалисты - DBA (Database administrator).
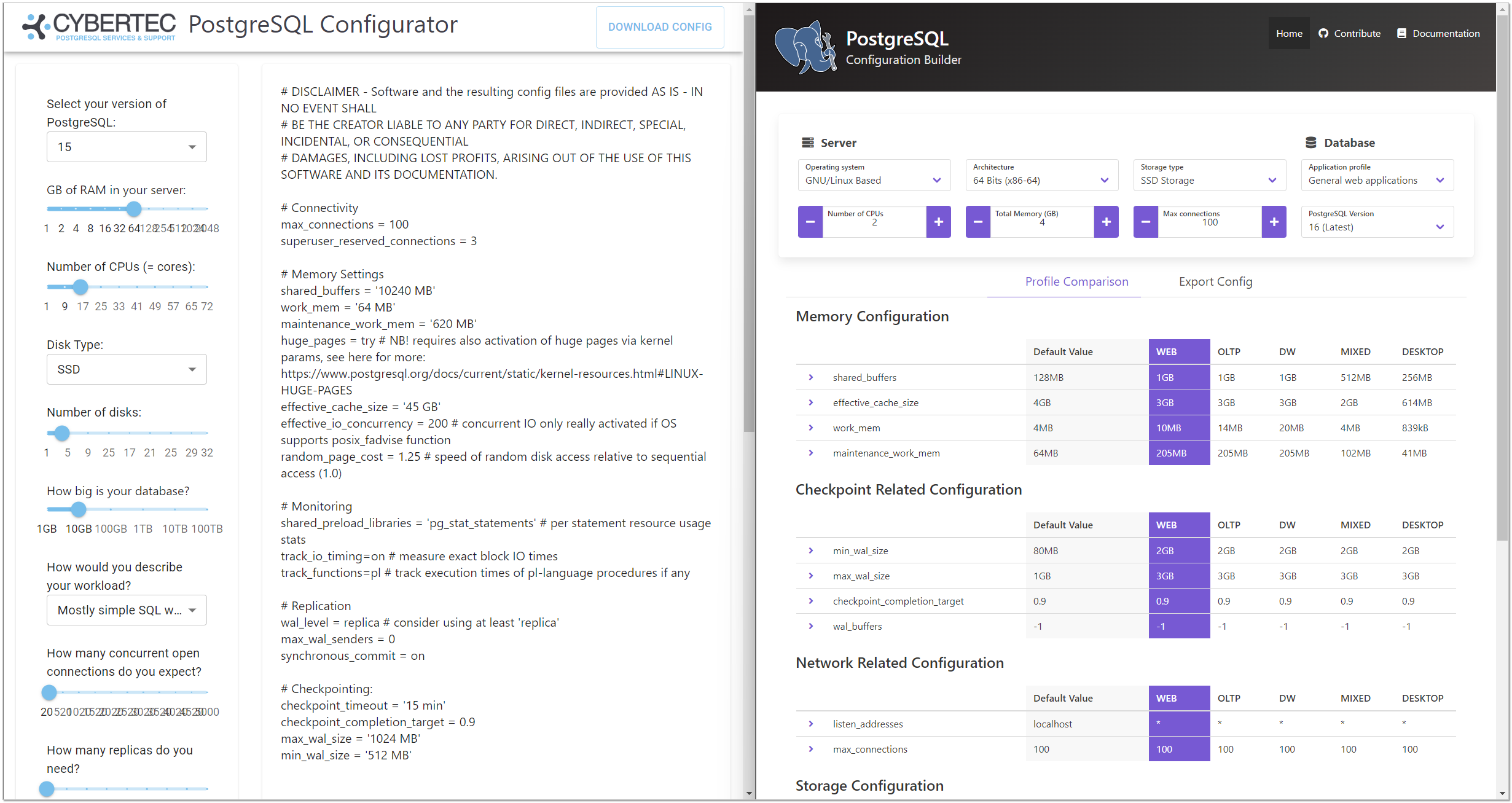
Если у вас такого специалиста нет, а сами вы не особо разбираетесь в этой теме, то можно воспользоваться готовым конфигуратором, который в целом выдаст адекватную настройку для типового использования. Я знаю два таких конфигуратора:
⇨ https://pgconfigurator.cybertec.at
⇨ https://www.pgconfig.org
Первый предлагает немного больше настроек, но во втором есть подробное описание каждой. В целом, у них плюс-минус похожие конфигурации получаются. Можно использовать оба сайта. Если не разбираетесь в настройках, лучше воспользоваться ими.
Отдельно отмечу, что если вы устанавливаете сборку СУБД PostgreSQL для 1C от компании PostgresPro, то там базовые оптимизации уже выполнены. Вы можете увидеть их в самом конце файла
Например, для 1С в сборках PostgresPro неизменно установлен параметр:
Я это проверил и на старом сервере 13-й версии и на более свежем 15-й. В общем случае в 0 его ставить не рекомендуется. Он и дефолтный не 0, и все оптимизаторы его не ставят в 0. Но для 1С рекомендуется именно 0. Я не знаю, в чём тут нюанс, а параметр это важный. Так что для 1С надо быть аккуратным при настройке PostgreSQL. Я из-за этого всегда использую сборки от PostgresPro. Там умные люди уже подумали над оптимизацией.
#postgresql
Если у вас такого специалиста нет, а сами вы не особо разбираетесь в этой теме, то можно воспользоваться готовым конфигуратором, который в целом выдаст адекватную настройку для типового использования. Я знаю два таких конфигуратора:
⇨ https://pgconfigurator.cybertec.at
⇨ https://www.pgconfig.org
Первый предлагает немного больше настроек, но во втором есть подробное описание каждой. В целом, у них плюс-минус похожие конфигурации получаются. Можно использовать оба сайта. Если не разбираетесь в настройках, лучше воспользоваться ими.
Отдельно отмечу, что если вы устанавливаете сборку СУБД PostgreSQL для 1C от компании PostgresPro, то там базовые оптимизации уже выполнены. Вы можете увидеть их в самом конце файла
postgresql.conf. Там более 30-ти изменённых параметров. В этом случае использовать какие-то сторонние конфигураторы не стоит, так как настройки могут отличаться принципиально. Например, для 1С в сборках PostgresPro неизменно установлен параметр:
max_parallel_workers_per_gather = 0Я это проверил и на старом сервере 13-й версии и на более свежем 15-й. В общем случае в 0 его ставить не рекомендуется. Он и дефолтный не 0, и все оптимизаторы его не ставят в 0. Но для 1С рекомендуется именно 0. Я не знаю, в чём тут нюанс, а параметр это важный. Так что для 1С надо быть аккуратным при настройке PostgreSQL. Я из-за этого всегда использую сборки от PostgresPro. Там умные люди уже подумали над оптимизацией.
#postgresql
{kind=link}
Для тестирования производительности PostgreSQL есть относительно простая утилита pgbench, которая входит в состав установки PostgreSQL. Ставить отдельно не придётся. Даже если вы несильно разбираетесь в тюнинге СУБД и не собираетесь им заниматься, pgbench хотя бы базово позволит сравнить разные конфигурации VM, разных хостеров, разное железо. Например, сравнить, на какой файловой системе или на каком дисковом хранилище будут лучше показатели быстродействия. Просто создайте две разные виртуалки и сравните.
Тест выполняет на существующей базе данных. В ней создаются служебные таблицы и наполняются данными. Покажу, как это выглядит на практике. Ставим postgresql:
Проверяем, что работает:
Создаём базу данных:
Наполняем тестовую базу данными, увеличив стандартный набор в 10 раз:
Запускаем тест в 5 клиентов, в 2 рабочих потока, на 60 секунд с отсечкой результата каждые 5 секунд, чтобы в консоли интересно наблюдать было. Если будете в файл выводить результаты, то это делать не надо.
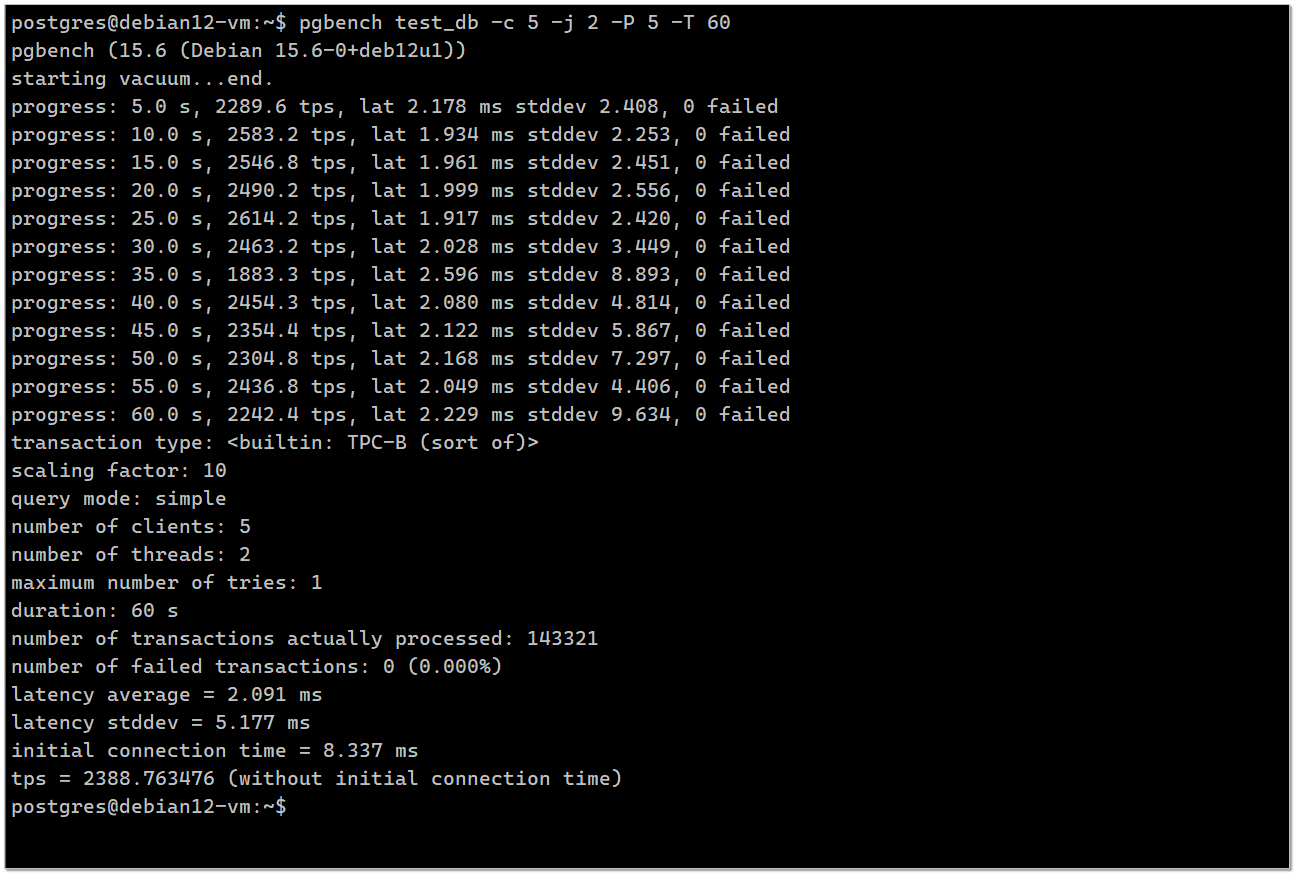
СУБД обработала 219950 транзакций со средней скоростью 3665.930847 транзакций в секунду. Эти данные и стоит сравнивать.
По умолчанию pgbench запускает смешанный TPC-B (Transaction Processing Performance Council) тест, который состоит из пяти команд
Из любопытства перекинул тестовую виртуалку с обычного одиночного SSD на RAID10 из 4-х HDD. Настройки в Proxmox те же, кэширование гипервизора отключено (Default (No cache)). Прогнал этот же тест.
Получилось на ~40% медленнее при идентичных настройках.
#postgresql
Тест выполняет на существующей базе данных. В ней создаются служебные таблицы и наполняются данными. Покажу, как это выглядит на практике. Ставим postgresql:
# apt install postgresqlПроверяем, что работает:
# systemctl status postgresqlСоздаём базу данных:
# su - postgres$ psql$ create database test_db;$ \qНаполняем тестовую базу данными, увеличив стандартный набор в 10 раз:
$ pgbench -i test_db -s 10Запускаем тест в 5 клиентов, в 2 рабочих потока, на 60 секунд с отсечкой результата каждые 5 секунд, чтобы в консоли интересно наблюдать было. Если будете в файл выводить результаты, то это делать не надо.
$ pgbench test_db -c 5 -j 2 -P 5 -T 60transaction type: <builtin: TPC-B (sort of)>scaling factor: 10query mode: simplenumber of clients: 5number of threads: 2maximum number of tries: 1 duration: 60 snumber of transactions actually processed: 219950number of failed transactions: 0 (0.000%)latency average = 1.362 mslatency stddev = 0.661 msinitial connection time = 8.368 mstps = 3665.930847 (without initial connection time)СУБД обработала 219950 транзакций со средней скоростью 3665.930847 транзакций в секунду. Эти данные и стоит сравнивать.
По умолчанию pgbench запускает смешанный TPC-B (Transaction Processing Performance Council) тест, который состоит из пяти команд
SELECT, UPDATE и INSERT в одной транзакции. Сценарий можно менять, создавая собственные скрипты для тестирования. Все возможности pgbench подробно описаны на русском языке в документации от postgrespro.Из любопытства перекинул тестовую виртуалку с обычного одиночного SSD на RAID10 из 4-х HDD. Настройки в Proxmox те же, кэширование гипервизора отключено (Default (No cache)). Прогнал этот же тест.
tps = 2262.544160Получилось на ~40% медленнее при идентичных настройках.
#postgresql
{kind=link}
🎓 У хостера Selectel есть небольшая "академия", где в открытом доступе есть набор курсов. Они неплохого качества. Где-то по верхам в основном теория, а где-то полезные практические вещи. Я бы обратил внимание на два курса, которые показались наиболее полезными:
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
{kind=link}
При обновлении кода сайта или веб сервиса легко сделать проверку изменений или выполнить откат в случае каких-то проблем. Задача сильно усложняется, когда обновление затрагивает изменение в структуре базы данных. Если вы накатили изменение, которое затрагивает базу данных, не получится просто откатить всё назад на уровне кода. Нужно откатывать и состояние базы. Для таких ситуация придумали миграции базы данных.
Сразу покажу на примере, как это работает. Существует популярная open source утилита для этих целей - migrate. Она поддерживает все наиболее распространённые СУБД. Миграции можно выполнять с помощью готовой библиотеки на Go, либо в консоли через CLI. Я буду использовать CLI, СУБД PostgreSQL и ОС Debian 12.
Для Migrate собран deb пакет, хотя по своей сути это одиночный бинарник. Можно скачать только его. Для порядка ставим из пакета, который берём в репозитории:
Для удобства добавим строку на подключение к локальной базе данных в переменную:
Я подключаюсь без ssl к базе данных test_migrations под учёткой postgres с паролем pass123. С рабочей базой так делать не надо, чтобы пароль не улетел в history.
Принцип работы migrate в том, что создаются 2 файла с sql командами. Первый файл выполняется, когда мы применяем обновление, а второй - когда мы откатываем. В своём примере я добавлю таблицу test01 с простой структурой, а потом удалю её в случае отката.
В директории были созданы 2 файла. В первый файл с up в имени добавим sql код создания таблицы test01:
А во второй с down - удаление:
Проверим, как это работает:
Смотрим, появилась ли таблица:
Вы должны увидеть структуру таблицы test01. Теперь откатим наше изменение:
Проверяем:
Таблицы нет. Принцип тут простой - пишем SQL код, который исполняем. На деле, конечно, изменения бывают сложные, особенно когда не добавляются или удаляются таблицы, а меняется структура существующих таблиц с данными. Инструменты типа migrate позволяют описать все изменения и проработать процесс обновления/отката в тестовых средах. В простых случаях можно обойтись и своими bash скриптами, но migrate упрощает эту задачу, так как, во-первых поддерживает множество СУБД. Во-вторых, автоматически нумерует миграции и исполняет последовательно. В-третьих, может, к примеру, забирать миграции напрямую из git репозитория.
Для каждой СУБД в репозитории Migrate есть примеры настройки миграций.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
⇨ Исходники
#postgresql #mysql
Сразу покажу на примере, как это работает. Существует популярная open source утилита для этих целей - migrate. Она поддерживает все наиболее распространённые СУБД. Миграции можно выполнять с помощью готовой библиотеки на Go, либо в консоли через CLI. Я буду использовать CLI, СУБД PostgreSQL и ОС Debian 12.
Для Migrate собран deb пакет, хотя по своей сути это одиночный бинарник. Можно скачать только его. Для порядка ставим из пакета, который берём в репозитории:
# wget https://github.com/golang-migrate/migrate/releases/download/v4.18.1/migrate.linux-amd64.deb# dpkg -i migrate.linux-amd64.debДля удобства добавим строку на подключение к локальной базе данных в переменную:
# export POSTGRESQL_URL='postgres://postgres:pass123@localhost:5432/test_migrations?sslmode=disable'Я подключаюсь без ssl к базе данных test_migrations под учёткой postgres с паролем pass123. С рабочей базой так делать не надо, чтобы пароль не улетел в history.
Принцип работы migrate в том, что создаются 2 файла с sql командами. Первый файл выполняется, когда мы применяем обновление, а второй - когда мы откатываем. В своём примере я добавлю таблицу test01 с простой структурой, а потом удалю её в случае отката.
# cd ~ && mkdir migrations# migrate create -ext sql -dir migrations -seq create_test01_table~/migrations/000001_create_test01_table.up.sql~/migrations/000001_create_test01_table.down.sqlВ директории были созданы 2 файла. В первый файл с up в имени добавим sql код создания таблицы test01:
CREATE TABLE IF NOT EXISTS test01(
user_id serial PRIMARY KEY,
username VARCHAR (50) UNIQUE NOT NULL,
password VARCHAR (50) NOT NULL,
email VARCHAR (300) UNIQUE NOT NULL
);
А во второй с down - удаление:
DROP TABLE IF EXISTS test01;
Проверим, как это работает:
# migrate -database ${POSTGRESQL_URL} -path migrations up1/u create_test01_table (24.160815ms)Смотрим, появилась ли таблица:
# psql ${POSTGRESQL_URL} -c "\d test01"Вы должны увидеть структуру таблицы test01. Теперь откатим наше изменение:
# migrate -database ${POSTGRESQL_URL} -path migrations downAre you sure you want to apply all down migrations? [y/N]yApplying all down migrations1/d create_test01_table (15.851045ms)Проверяем:
# psql ${POSTGRESQL_URL} -c "\d test01"Did not find any relation named "test01".Таблицы нет. Принцип тут простой - пишем SQL код, который исполняем. На деле, конечно, изменения бывают сложные, особенно когда не добавляются или удаляются таблицы, а меняется структура существующих таблиц с данными. Инструменты типа migrate позволяют описать все изменения и проработать процесс обновления/отката в тестовых средах. В простых случаях можно обойтись и своими bash скриптами, но migrate упрощает эту задачу, так как, во-первых поддерживает множество СУБД. Во-вторых, автоматически нумерует миграции и исполняет последовательно. В-третьих, может, к примеру, забирать миграции напрямую из git репозитория.
Для каждой СУБД в репозитории Migrate есть примеры настройки миграций.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
⇨ Исходники
#postgresql #mysql
Для тех, кто много работает с базами данных, есть простой и удобный инструмент для их проектирования – dbdiagram.io. Мы не разработчики, тем не менее, покажу, как этот сервис может быть полезен. У него удобная визуализация структуры базы данных. Намного удобнее, чем, к примеру, в привычном phpmyadmin.
Можно выгрузить обычный дам из СУБД без данных и загрузить его в dbdiagram. Получите наглядную схему базы. При желании, её можно отредактировать, или просто экспортнуть в виде картинки. Покажу на примере MySQL. Выгружаем дамп базы postfix без данных, только структуру:
Передаём к себе на комп полученный дамп. В dbdiagram.io открываем Import ⇨ From MySQL ⇨ Upload .sql ⇨ Submit. Наблюдаем схему базы данных со всеми связями. Причём она сразу отформатирована по таблицам так, что все их наглядно видно.
При желании можно что-то изменить в структуре и выгрузить новый sql файл уже с изменениями. Если выбрать Export ⇨ To PNG, то сразу же получите аккуратную картинку со схемой, без лишних вопросов. Очень быстро и удобно, если нужно куда-то приложить схему базы данных.
⇨ 🌐 Сайт
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mysql #postgresql
Можно выгрузить обычный дам из СУБД без данных и загрузить его в dbdiagram. Получите наглядную схему базы. При желании, её можно отредактировать, или просто экспортнуть в виде картинки. Покажу на примере MySQL. Выгружаем дамп базы postfix без данных, только структуру:
# mysqldump --no-data -u dbuser -p postfix > ~/schema.sqlПередаём к себе на комп полученный дамп. В dbdiagram.io открываем Import ⇨ From MySQL ⇨ Upload .sql ⇨ Submit. Наблюдаем схему базы данных со всеми связями. Причём она сразу отформатирована по таблицам так, что все их наглядно видно.
При желании можно что-то изменить в структуре и выгрузить новый sql файл уже с изменениями. Если выбрать Export ⇨ To PNG, то сразу же получите аккуратную картинку со схемой, без лишних вопросов. Очень быстро и удобно, если нужно куда-то приложить схему базы данных.
⇨ 🌐 Сайт
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mysql #postgresql
Расскажу про парочку инструментов, которые упростят обслуживание сервера PostgreSQL. Начну с наиболее простого - pgBadger. Это анализатор лога, который на его основе генерирует отчёты в формате html. На выходе получаются одиночные html файлы, которые можно просто открыть в браузере. Сделано всё аккуратно и добротно, легко настраивается, отчёты наглядные и информационные.
🔹Чтобы было что анализировать, необходимо включить логирование интересующих вас событий. Для разовой отладки это всё можно включать на ходу, либо постоянно через файл конфигурации
Вся включенная статистика стала писаться в общий лог-файл
Анализируем лог файл:
Тут же в директории, где его запускали, увидите файл out.html. Забирайте его к себе и смотрите. Там будет информация с общей статистикой сервера, информация по запросам и их типам, времени исполнения, подключениям, по пользователям, базам и хостам откуда подключались и много всего остального.
PgBadger удобен тем, что по сути это одиночный скрипт на Perl. Можно включить логирование в конфигурации, применить её через
🔹Второй инструмент - PgHero, он показывает примерно то же самое, только в режиме реального времени и работает в виде веб сервиса. Для него уже надо создавать пользователя, настраивать доступ, отдельную базу. Немного другой подход. Надо будет дёргать сервер с СУБД.
Надо перейти в консоль и создать необходимые сущности:
Разрешаем этому пользователю подключаться. Добавляем в
172.17.0.0/24 - подсеть, из которой будет подключаться PgHero. В данном случае это Docker контейнер, запущенный на этом же хосте. PostgreSQL должен принимать запросы с локального IP адреса, к которому будет доступ из Docker сети. Можно добавить в конфиг
Перезапускаем PotgreSQL:
Запускаем PgHero в Docker контейнере:
Идём на порт севера 8080, где запущен контейнер и смотрим информацию о PostgreSQL. Если у вас не настроено расширение pg_stat_statements, которое использует PgHero для сбора статистики, то установите его. Для этого в конфигурацию
Перезапустите Postgresql и выполните в консоли СУБД:
Теперь можно возвращаться в веб интерфейс и смотреть информацию. По умолчанию, пользователь pghero не будет видеть запросы других пользователей, если ему не дать права superuser. Это можно исправить, выдав ему набор прав и ролей из этой инструкции.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql
🔹Чтобы было что анализировать, необходимо включить логирование интересующих вас событий. Для разовой отладки это всё можно включать на ходу, либо постоянно через файл конфигурации
postgresql.conf и перезапуск сервера. Он обычно хорошо прокомментирован. Вас будут интересовать параметры, начинающие с log_*. Они собраны все в отдельном блоке. Для примера я включил почти всё:log_min_duration_statement = 0log_checkpoints = onlog_connections = onlog_disconnections = onlog_duration = onlog_line_prefix = '%m [%p] %q%u@%d 'log_lock_waits = onlog_temp_files = 0log_timezone = 'Europe/Moscow'Вся включенная статистика стала писаться в общий лог-файл
/var/log/postgresql/postgresql-17-main.log. С ним и будем работать. Устанавливаем pgBadger:# wget https://github.com/darold/pgbadger/archive/refs/tags/v13.1.tar.gz# tar xzvf v13.1.tar.gz# cd pgbadger-*# apt install make# make && make installАнализируем лог файл:
# pgbadger /var/log/postgresql/postgresql-17-main.logТут же в директории, где его запускали, увидите файл out.html. Забирайте его к себе и смотрите. Там будет информация с общей статистикой сервера, информация по запросам и их типам, времени исполнения, подключениям, по пользователям, базам и хостам откуда подключались и много всего остального.
PgBadger удобен тем, что по сути это одиночный скрипт на Perl. Можно включить логирование в конфигурации, применить её через
SELECT pg_reload_conf(); без перезапуска сервера СУБД. Пособирать некоторое время данные, забрать лог и анализировать его. Логирование отключить и снова перечитать конфиг. В итоге всё будет сделано без перезапуска сервера.🔹Второй инструмент - PgHero, он показывает примерно то же самое, только в режиме реального времени и работает в виде веб сервиса. Для него уже надо создавать пользователя, настраивать доступ, отдельную базу. Немного другой подход. Надо будет дёргать сервер с СУБД.
Надо перейти в консоль и создать необходимые сущности:
# su postgres# psql> CREATE USER pghero WITH PASSWORD 'pgheropass';> CREATE DATABASE pgherodb OWNER pghero;> \qРазрешаем этому пользователю подключаться. Добавляем в
pg_hba.conf строку:host pgherodb pghero 172.17.0.0/24 md5172.17.0.0/24 - подсеть, из которой будет подключаться PgHero. В данном случае это Docker контейнер, запущенный на этом же хосте. PostgreSQL должен принимать запросы с локального IP адреса, к которому будет доступ из Docker сети. Можно добавить в конфиг
postgresql.conf параметр:listen_addresses = 'localhost,172.17.0.1'Перезапускаем PotgreSQL:
# systemctl restart postgresqlЗапускаем PgHero в Docker контейнере:
# docker run -ti -e DATABASE_URL=postgres://pghero:pgheropass@172.17.0.1:5432/pgherodb -p 8080:8080 ankane/pgheroИдём на порт севера 8080, где запущен контейнер и смотрим информацию о PostgreSQL. Если у вас не настроено расширение pg_stat_statements, которое использует PgHero для сбора статистики, то установите его. Для этого в конфигурацию
postgresql.conf добавьте параметры:shared_preload_libraries = 'pg_stat_statements'pg_stat_statements.track = allpg_stat_statements.max = 10000track_activity_query_size = 2048Перезапустите Postgresql и выполните в консоли СУБД:
> CREATE EXTENSION IF NOT EXISTS pg_stat_statements;> GRANT pg_read_all_stats TO pghero;Теперь можно возвращаться в веб интерфейс и смотреть информацию. По умолчанию, пользователь pghero не будет видеть запросы других пользователей, если ему не дать права superuser. Это можно исправить, выдав ему набор прав и ролей из этой инструкции.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql