
Существует программа для тестирования производительности сервера - sysbench. Она умеет всякими разными способами нагружать систему, но мне обычно это не надо. Да и в целом софта для теста процессора, памяти, дисков существует много. Гораздо полезнее другая ее возможность - тестирование производительности Mysql или Postgresql сервера.
Программа бесплатная, живет на github. Можно самому собирать, можно поставить из репозитория. Есть под все популярные системы. Быстро добавить репу можно через скрипт. Содержимое небольшое, можно проверить перед установкой:
# curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
# yum install sysbench
Список доступных тестов можно посмотреть в директории /usr/share/sysbench/. Перед началом тестов, надо создать тестовую базу:
Я буду подключаться локально, авторизация через root уже настроена. Наполняем тестовую базу данными. Будут 16 таблиц по 10000 строк в каждой.
Смотрим, что получилось:
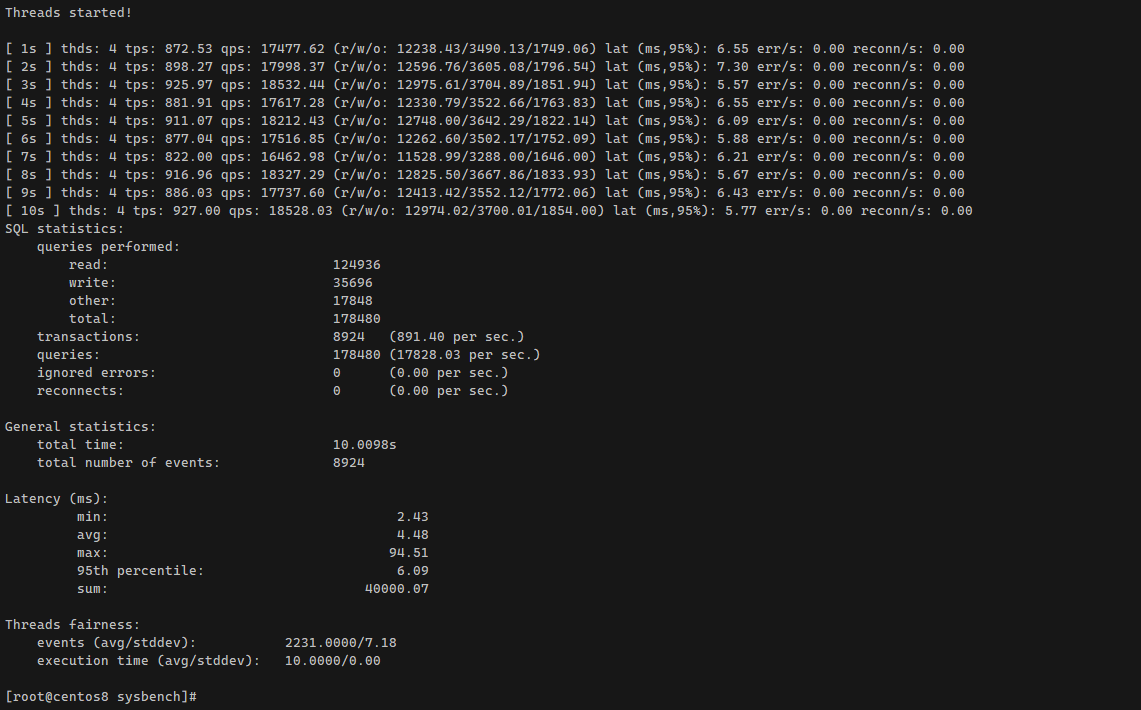
После этого запускаем сам тест oltp_read_write на 10 секунд:
На выходе получите количество транзакций в секунду и некоторые другие данные. Настроек и возможностей у sysbench много, в рамках заметки это всё не рассказать. Надеюсь, показал главное - этой утилитой достаточно легко пользоваться. Не надо долго разбираться. Можно быстро оценить производительность, сравнить разные виртуальные машины или конфигурации mysql / postgresql.
#terminal #утилита
Программа бесплатная, живет на github. Можно самому собирать, можно поставить из репозитория. Есть под все популярные системы. Быстро добавить репу можно через скрипт. Содержимое небольшое, можно проверить перед установкой:
# curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
# yum install sysbench
Список доступных тестов можно посмотреть в директории /usr/share/sysbench/. Перед началом тестов, надо создать тестовую базу:
> create database sbtest;Я буду подключаться локально, авторизация через root уже настроена. Наполняем тестовую базу данными. Будут 16 таблиц по 10000 строк в каждой.
# sysbench \--db-driver=mysql \--mysql-user=root \--mysql-db=sbtest \--mysql-host=127.0.0.1 \--mysql-port=3306 \--tables=16 \--table-size=10000 \/usr/share/sysbench/oltp_read_write.lua prepareСмотрим, что получилось:
# du -sh /var/lib/mysql/sbtest/161M /var/lib/mysql/sbtest/После этого запускаем сам тест oltp_read_write на 10 секунд:
# sysbench \--db-driver=mysql \--mysql-user=root \--mysql-db=sbtest \--mysql-host=127.0.0.1 \--mysql-port=3306 \--tables=16 \--table-size=10000 \--threads=4 \--time=10 \--events=0 \--report-interval=1 \/usr/share/sysbench/oltp_read_write.lua runНа выходе получите количество транзакций в секунду и некоторые другие данные. Настроек и возможностей у sysbench много, в рамках заметки это всё не рассказать. Надеюсь, показал главное - этой утилитой достаточно легко пользоваться. Не надо долго разбираться. Можно быстро оценить производительность, сравнить разные виртуальные машины или конфигурации mysql / postgresql.
#terminal #утилита
{kind=link}
Вы знали, что в rpm-based дистрибутивах есть утилита, которая определяет, нужна серверу в данный момент перезагрузка или нет? Она живет в базовом репозитории (baseos) и называется needs-restarting. Входит в состав пакета yum-utils.
Проверяем, нужна ли перезагрузка:
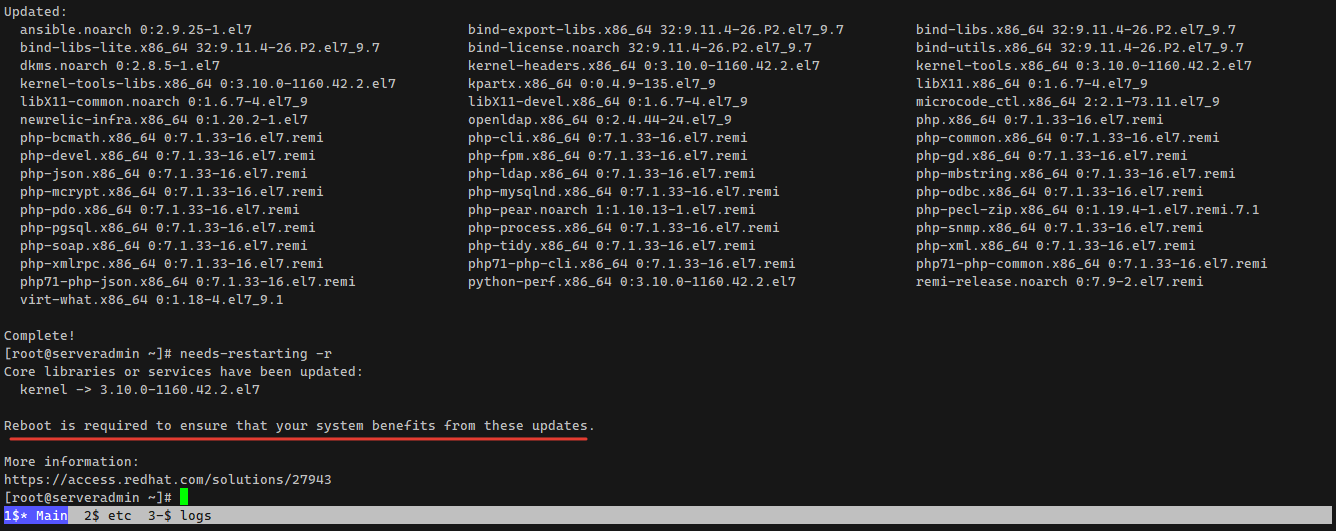
После установки обновлений вывод меняется:
Debian и Ubuntu эту информацию выдают обычно в приветствии после ssh подключения. Не знаю, на основе чего там реализован этот функционал, не разбирался.
#terminal #утилита
# yum install yum-utilsПроверяем, нужна ли перезагрузка:
# needs-restarting -rNo core libraries or services have been updated since boot-up.Reboot should not be necessary.После установки обновлений вывод меняется:
# needs-restarting -rCore libraries or services have been updated: kernel -> 3.10.0-1160.42.2.el7Reboot is required to ensure that your system benefits from these updates.More information:https://access.redhat.com/solutions/27943Debian и Ubuntu эту информацию выдают обычно в приветствии после ssh подключения. Не знаю, на основе чего там реализован этот функционал, не разбирался.
#terminal #утилита
{kind=link}
В репозиториях популярных дистрибутивов живёт небольшая утилита exa, которая делает всё то же самое, что и ls, только красиво окрашивает вывод. В Debian/Ubuntu она в unstable репе. В rpm-based дистрах в федореном репозитории.
https://github.com/ogham/exa
https://the.exa.website/
Утилита состоит из одного бинарника, так что можно просто скачать и запустить. Есть поддержка git, так что можно увидеть статус (modified, Untracked) каждого файла.
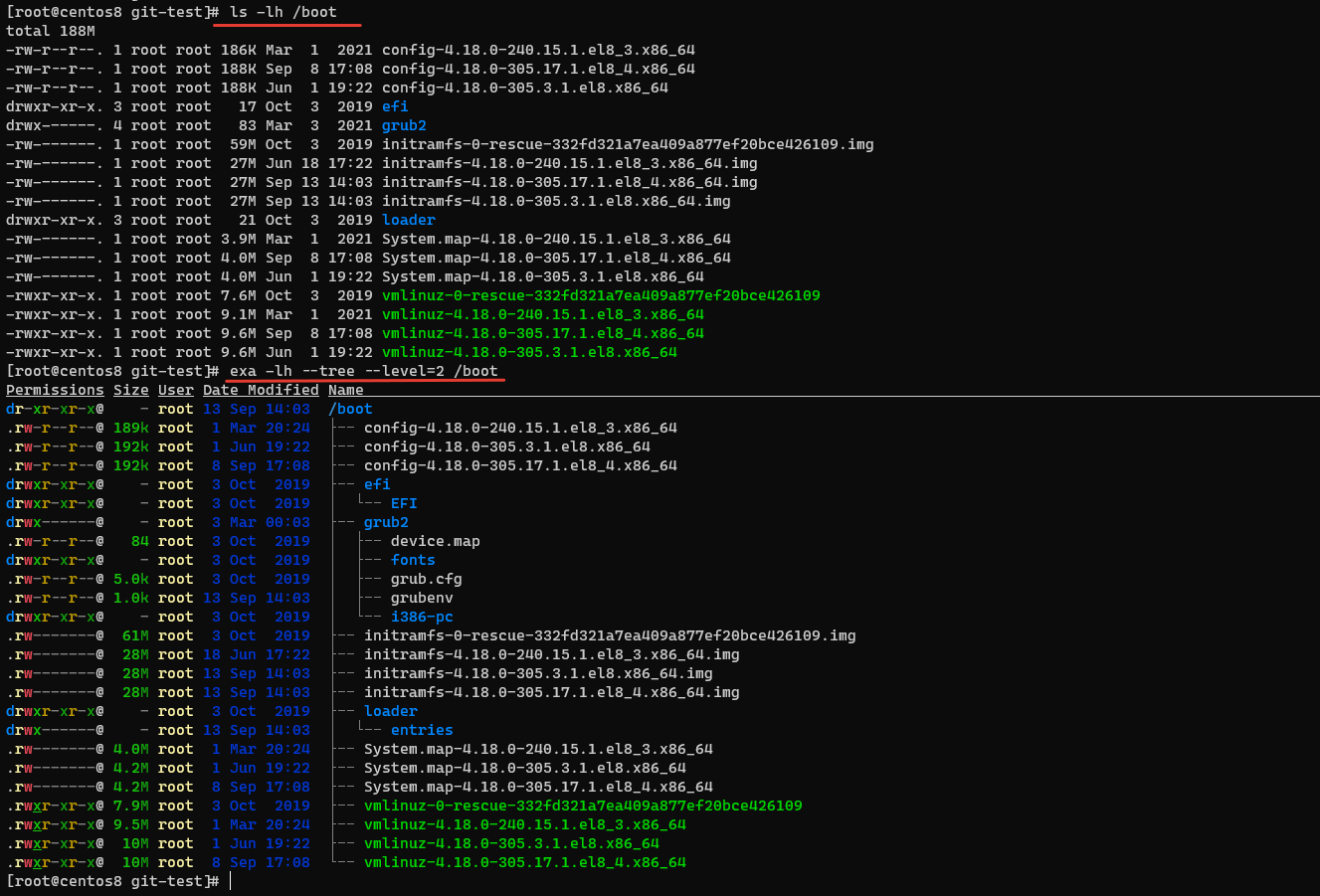
Exa умеет делать древовидное отображение каталогов и файлов с возможностью ограничивать глубину. Например:
# exa --tree --level=2 /boot
Удобная и функциональная утилита. Можно просто заменить ls символьной ссылкой и пользоваться только exa. Работает так же быстро.
#terminal #утилита
https://github.com/ogham/exa
https://the.exa.website/
Утилита состоит из одного бинарника, так что можно просто скачать и запустить. Есть поддержка git, так что можно увидеть статус (modified, Untracked) каждого файла.
Exa умеет делать древовидное отображение каталогов и файлов с возможностью ограничивать глубину. Например:
# exa --tree --level=2 /boot
Удобная и функциональная утилита. Можно просто заменить ls символьной ссылкой и пользоваться только exa. Работает так же быстро.
#terminal #утилита
{kind=link}
Одна из программ командной строки Linux, которую часто приходится использовать - find. При этом у неё не очень простой синтаксис. Я лично постоянно его забываю, поэтому всегда использую шпаргалку с наиболее часто используемыми конструкциями.
Существует утилита fd (https://github.com/sharkdp/fd), которая упрощает использование поиска через консоль. Она есть под все популярные системы, даже windows. В репе перечислены все способы установки, а также ссылки на готовые пакеты. Бинарник после установки будет называться fdfind, так как в некоторых системах имя fd уже занято. Чтобы использовать короткое обозначение придётся либо алиас, либо символьную ссылку сделать.
Основные особенности утилиты:
◽ интуитивный синтаксис и дефолтные значения
◽ быстрый параллельный поиск
◽ возможность выполнить внешнюю команду не с каждым результатом поиска, а отправить весь результат, как аргумент (это может существенно ускорить удаление огромного кол-ва файлов, но это не точно 😁)
◽ расцветка вывода
Примеры использования.
Поиск файла в текущей директории:
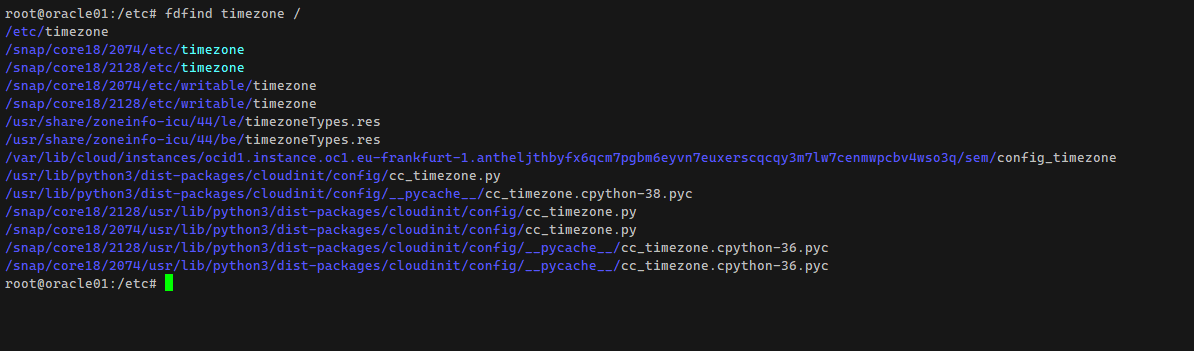
Поиск файла в конкретной директории. По умолчанию он будет рекурсивный. Для поиска по всему серверу можно использовать корень.
Поиск файлов с определённым расширением:
Найти все архивы и распаковать их:
Найти файлы и удалить одной командой:
Еще больше примеров разобраны в описании репозитория. Для простого поиска этой утилитой реально удобнее пользоваться, чем стандартным find. Более сложные конструкции я не тестировал. Они обычно в скриптах используются, а там уже не критично, где один раз собрать команду.
#terminal #утилита
Существует утилита fd (https://github.com/sharkdp/fd), которая упрощает использование поиска через консоль. Она есть под все популярные системы, даже windows. В репе перечислены все способы установки, а также ссылки на готовые пакеты. Бинарник после установки будет называться fdfind, так как в некоторых системах имя fd уже занято. Чтобы использовать короткое обозначение придётся либо алиас, либо символьную ссылку сделать.
Основные особенности утилиты:
◽ интуитивный синтаксис и дефолтные значения
◽ быстрый параллельный поиск
◽ возможность выполнить внешнюю команду не с каждым результатом поиска, а отправить весь результат, как аргумент (это может существенно ускорить удаление огромного кол-ва файлов, но это не точно 😁)
◽ расцветка вывода
Примеры использования.
Поиск файла в текущей директории:
fdfind fileПоиск файла в конкретной директории. По умолчанию он будет рекурсивный. Для поиска по всему серверу можно использовать корень.
fdfind file /varfdfind file /Поиск файлов с определённым расширением:
fdfind -e phpНайти все архивы и распаковать их:
fdfind -e zip -x unzipНайти файлы и удалить одной командой:
fdfind -e log -X rmЕще больше примеров разобраны в описании репозитория. Для простого поиска этой утилитой реально удобнее пользоваться, чем стандартным find. Более сложные конструкции я не тестировал. Они обычно в скриптах используются, а там уже не критично, где один раз собрать команду.
#terminal #утилита
{kind=link}
Существует крутой консольный просмотрщик логов Lnav. Он умеет объединять логи из разных источников, подсвечивать их, распаковывать из архивов, фильтровать по регуляркам и многое другое. При этом пользоваться им достаточно просто. Не надо изучать и вникать в работу. Всё интуитивно и максимально просто.
Lnav это просто одиночный бинарник, который можно загрузить из github - https://github.com/tstack/lnav/releases.
# wget https://github.com/tstack/lnav/releases/download/v0.10.0/lnav-0.10.0-musl-64bit.zip
# unzip lnav-0.10.0-musl-64bit.zip
# mv lnav-0.10.0/lnav /usr/local/bin
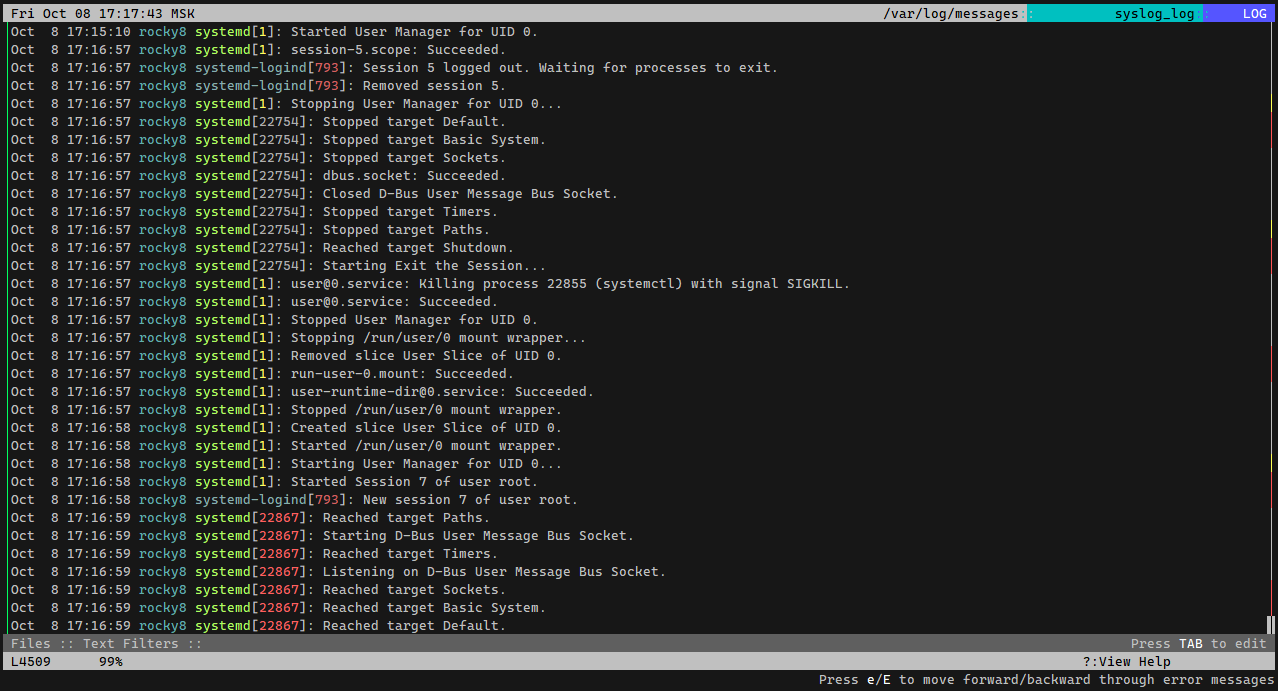
Теперь, к примеру, можно разом посмотреть все логи /var/log/messages, в том числе и сжатые, ротированные файлы:
Можно неудобочитаемый вывод journalctl направить в lnav:
При просмотре логов автоматически работает всторенная навигация на перемещение к ошибкам по горячей клавише e (error) или предупреждениям по клавише w (warning). Новые строки логов автоматически отображаются, то есть lnav можно использовать вместо tail -f.
Для корректной работы lnav нужен 256 цветный терминал. Если у вас используется обычный term, то надо добавить в ~/.bashrc и перезайти:
Сайт программы - https://lnav.org На нём описаны все возможности этой утилиты.
#утилита #terminal
Lnav это просто одиночный бинарник, который можно загрузить из github - https://github.com/tstack/lnav/releases.
# wget https://github.com/tstack/lnav/releases/download/v0.10.0/lnav-0.10.0-musl-64bit.zip
# unzip lnav-0.10.0-musl-64bit.zip
# mv lnav-0.10.0/lnav /usr/local/bin
Теперь, к примеру, можно разом посмотреть все логи /var/log/messages, в том числе и сжатые, ротированные файлы:
# lnav /var/log/messages*Можно неудобочитаемый вывод journalctl направить в lnav:
# journalctl | lnavПри просмотре логов автоматически работает всторенная навигация на перемещение к ошибкам по горячей клавише e (error) или предупреждениям по клавише w (warning). Новые строки логов автоматически отображаются, то есть lnav можно использовать вместо tail -f.
Для корректной работы lnav нужен 256 цветный терминал. Если у вас используется обычный term, то надо добавить в ~/.bashrc и перезайти:
export TERM=xterm-256colorСайт программы - https://lnav.org На нём описаны все возможности этой утилиты.
#утилита #terminal
{kind=link}
Существует любопытная консольная утилита для пинга хостов - gping. Казалось бы, что тут можно придумать. Утилита ping есть почти во всех системах и работает примерно одинаково. Что еще можно ожидать от обычного пинга?
Авторы gping сумели наполнить обычный ping новым функционалом. Утилита умеет:
◽ Строить график времени отклика хоста
◽ Одновременно пинговать и строить график для нескольких хостов
Последнее особенно полезно, когда надо понять, это у тебя проблемы с сетью или у какого-то удаленного хоста. Можно для теста пингануть несколько разных серверов и проверить.
Утилиты нет в стандартных репозиториях систем, но можно найти в сторонних.
# dnf copr enable atim/gping
# dnf install gping
# echo "deb http://packages.azlux.fr/debian/ buster main" | sudo tee /etc/apt/sources.list.d/azlux.list
# wget -qO - https://azlux.fr/repo.gpg.key | sudo apt-key add -
# apt update && apt install gping
Gping есть и под Windows. Поставить можно через choco:
# choco install gping
Или просто скачать бинарник.
Github - https://github.com/orf/gping
#terminal #утилита
Авторы gping сумели наполнить обычный ping новым функционалом. Утилита умеет:
◽ Строить график времени отклика хоста
◽ Одновременно пинговать и строить график для нескольких хостов
Последнее особенно полезно, когда надо понять, это у тебя проблемы с сетью или у какого-то удаленного хоста. Можно для теста пингануть несколько разных серверов и проверить.
Утилиты нет в стандартных репозиториях систем, но можно найти в сторонних.
# dnf copr enable atim/gping
# dnf install gping
# echo "deb http://packages.azlux.fr/debian/ buster main" | sudo tee /etc/apt/sources.list.d/azlux.list
# wget -qO - https://azlux.fr/repo.gpg.key | sudo apt-key add -
# apt update && apt install gping
Gping есть и под Windows. Поставить можно через choco:
# choco install gping
Или просто скачать бинарник.
Github - https://github.com/orf/gping
#terminal #утилита
{kind=link}
Простая и современная утилита для шифрования данных - age. Написана в духе Unix-style. Никаких конфигов. Всё управление ключами. Для шифрования используется связка приватного и публичного ключа.
Отлично подходит для автоматизации, юниксовых пайпов и скриптов. В стандартных репах ubuntu / centos я ее не нашел, так что ставить придётся с гитхаба. Утилита представляет из себя два бинарника - непосредственно шифровальщик и keygen для паролей.
Установка:
# wget https://github.com/FiloSottile/age/releases/download/v1.0.0/age-v1.0.0-linux-amd64.tar.gz
# tar xzvf age-v1.0.0-linux-amd64.tar.gz
# mv age/* /usr/local/bin
Использование. Сформируем ключи:
# age-keygen -o key.txt
Шифруем обычный файл с использованием публичного ключа:
# echo "Actually Good Encryption" > file.txt
# age -r age1ql3z7hjy54pw3hyww5ayyfg7zqgvc7w3j2elw8zmrj2kg5sfn9aqmcac8p file.txt > file.txt.age
Убеждаемся, что файл зашифрован и затем расшифровываем его закрытым ключом:
# cat file.txt.age
# age -d -i key.txt file.txt.age > file_decrypted.txt
# cat file_decrypted.txt
Если используете ключи для подключения по ssh, то age может использовать их точно так же, как и свои. Никакой разницы не будет.
github - https://github.com/FiloSottile/age
#terminal #утилита
Отлично подходит для автоматизации, юниксовых пайпов и скриптов. В стандартных репах ubuntu / centos я ее не нашел, так что ставить придётся с гитхаба. Утилита представляет из себя два бинарника - непосредственно шифровальщик и keygen для паролей.
Установка:
# wget https://github.com/FiloSottile/age/releases/download/v1.0.0/age-v1.0.0-linux-amd64.tar.gz
# tar xzvf age-v1.0.0-linux-amd64.tar.gz
# mv age/* /usr/local/bin
Использование. Сформируем ключи:
# age-keygen -o key.txt
Шифруем обычный файл с использованием публичного ключа:
# echo "Actually Good Encryption" > file.txt
# age -r age1ql3z7hjy54pw3hyww5ayyfg7zqgvc7w3j2elw8zmrj2kg5sfn9aqmcac8p file.txt > file.txt.age
Убеждаемся, что файл зашифрован и затем расшифровываем его закрытым ключом:
# cat file.txt.age
# age -d -i key.txt file.txt.age > file_decrypted.txt
# cat file_decrypted.txt
Если используете ключи для подключения по ssh, то age может использовать их точно так же, как и свои. Никакой разницы не будет.
github - https://github.com/FiloSottile/age
#terminal #утилита
{kind=link}
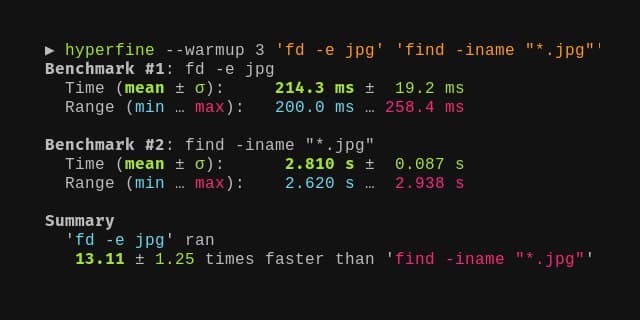
Иногда бывает нужно замерить время выполнения какой-то команды. Есть специальная утилита, в которой это сделать очень удобно - Hyperfine. Это более продвинутый аналог time. Если запустить её без дополнительных параметров, то по умолчанию она не менее 10 раз выполнит заданную команду и выведет среднее время выполнения.
Проще всего проверить работу программы на команде sleep:
Где это может пригодиться кому-то из вас, не знаю. Первое, что приходит на ум, в мониторинге. Например, я иногда делаю item в Zabbix для мониторинга за локальным nginx следующего типа. Через curl дергал http://localhost/nginx-status и замерял время отклика. Ставил триггер на отклонение от среднего значения.
Для этих целей удобно использовать hyperfine, так как он умеет экспортировать результат в json. В том же Zabbix можно сразу же распарсить его в постобработке через jsonpath и записать результат. Если по нескольку раз дергать какой-то url и замерять через hyperfine, то точность мониторинга будет выше, чем есть в стандартном функционале.
На выходе получите сразу же min, max, медианное время выполнения запроса. Если любопытно, можете просто сравнить отклик сайта по http и https.
В общем, утилита интересная, может пригодиться в хозяйстве. Есть deb пакет, всё остальное из репозитория можно взять. Это просто бинарник.
# wget https://github.com/sharkdp/hyperfine/releases/download/v1.12.0/hyperfine_1.12.0_amd64.deb
# dpkg -i hyperfine_1.12.0_amd64.deb
Исходники - https://github.com/sharkdp/hyperfine
#terminal #утилита
Проще всего проверить работу программы на команде sleep:
# hyperfine 'sleep 0.5'Benchmark 1: sleep 0.5 Time (mean ± σ): 501.3 ms ± 0.2 ms [User: 1.2 ms, System: 0.1 ms] Range (min … max): 501.0 ms … 501.8 ms 10 runsГде это может пригодиться кому-то из вас, не знаю. Первое, что приходит на ум, в мониторинге. Например, я иногда делаю item в Zabbix для мониторинга за локальным nginx следующего типа. Через curl дергал http://localhost/nginx-status и замерял время отклика. Ставил триггер на отклонение от среднего значения.
Для этих целей удобно использовать hyperfine, так как он умеет экспортировать результат в json. В том же Zabbix можно сразу же распарсить его в постобработке через jsonpath и записать результат. Если по нескольку раз дергать какой-то url и замерять через hyperfine, то точность мониторинга будет выше, чем есть в стандартном функционале.
# hyperfine 'curl http://127.0.0.1:80' --export-json ~/curl.jsonНа выходе получите сразу же min, max, медианное время выполнения запроса. Если любопытно, можете просто сравнить отклик сайта по http и https.
# hyperfine 'curl http://127.0.0.1' 'curl https://127.0.0.1'В общем, утилита интересная, может пригодиться в хозяйстве. Есть deb пакет, всё остальное из репозитория можно взять. Это просто бинарник.
# wget https://github.com/sharkdp/hyperfine/releases/download/v1.12.0/hyperfine_1.12.0_amd64.deb
# dpkg -i hyperfine_1.12.0_amd64.deb
Исходники - https://github.com/sharkdp/hyperfine
#terminal #утилита
{kind=link}
Команда, которую часто приходится использовать в Linux - ps. Но не просто ps, а с ключами:
Она выводит список всех процессов. Чаще всего этот список приходится грепать, чтобы получить подробную информацию о конкретном процессе.
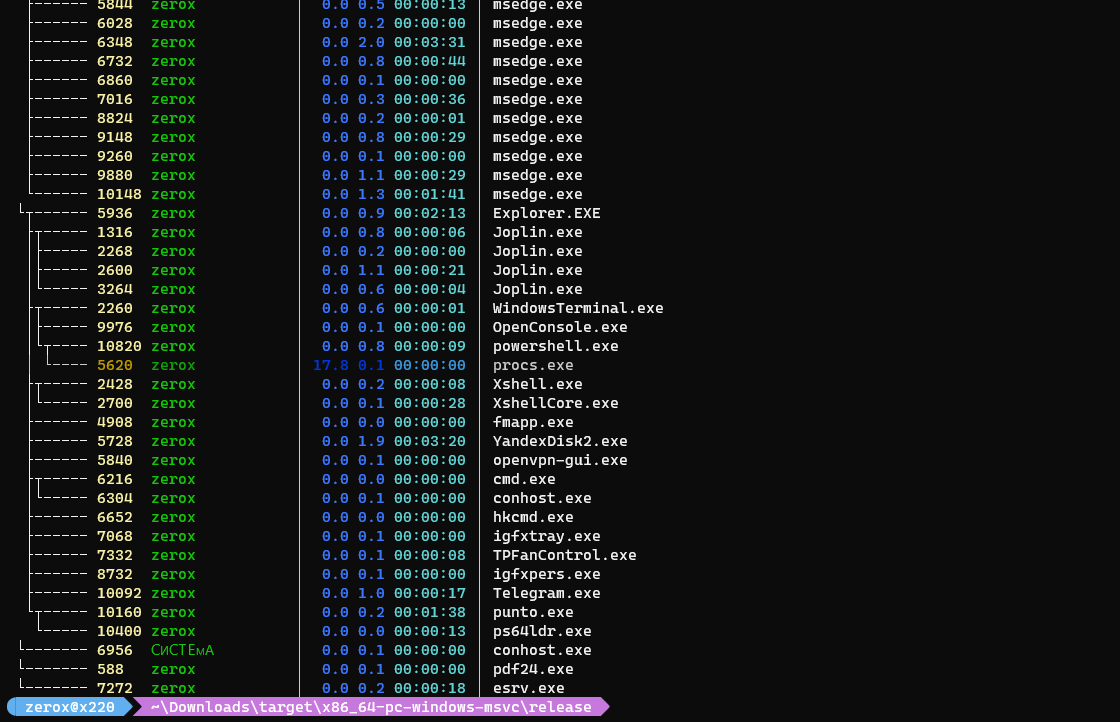
Есть утилита procs, которая расширяет функционал ps. Она имеет более удобный для восприятия вывод и некоторые другие возможности. Например, добавляет информацию о занимаемых TCP/UDP портах. В ней можно использовать поиск, делать древовидный вывод и многое другое.
Procs есть под Linux, Macos и даже Windows. Есть готовый rpm пакет:
# rpm -i https://github.com/dalance/procs/releases/download/v0.11.10/procs-0.11.10-1.x86_64.rpm
В Ubuntu можно из snap поставить:
Под винду экзешник из репозитория надо скачать. Я попробовал, реально работает на Win10. Единственное, что я не понял, так это почему у меня не отображались используемые процессом порты. Ни в centos, ни в windows. Всё описание и все ключи запуска изучил, но так и не понял, как вывести эту информацию. На скринах из репозитория она есть.
У меня как-то появилась идея получать список запущенных процессов в системе после того, как в Zabbix сработает триггер на нагрузку CPU. Так можно сразу понять, кто нагрузил систему. В Linux я без проблем это реализовал с помощью ps. Подробно описал в статье. Если нужно будет сделать то же самое в Windows, то можно взять для этого утилиту procs.
Исходники - https://github.com/dalance/procs
#утилита #terminal
# ps ax или ps auxОна выводит список всех процессов. Чаще всего этот список приходится грепать, чтобы получить подробную информацию о конкретном процессе.
# ps ax | grep mysqlЕсть утилита procs, которая расширяет функционал ps. Она имеет более удобный для восприятия вывод и некоторые другие возможности. Например, добавляет информацию о занимаемых TCP/UDP портах. В ней можно использовать поиск, делать древовидный вывод и многое другое.
Procs есть под Linux, Macos и даже Windows. Есть готовый rpm пакет:
# rpm -i https://github.com/dalance/procs/releases/download/v0.11.10/procs-0.11.10-1.x86_64.rpm
В Ubuntu можно из snap поставить:
# snap install procsПод винду экзешник из репозитория надо скачать. Я попробовал, реально работает на Win10. Единственное, что я не понял, так это почему у меня не отображались используемые процессом порты. Ни в centos, ни в windows. Всё описание и все ключи запуска изучил, но так и не понял, как вывести эту информацию. На скринах из репозитория она есть.
У меня как-то появилась идея получать список запущенных процессов в системе после того, как в Zabbix сработает триггер на нагрузку CPU. Так можно сразу понять, кто нагрузил систему. В Linux я без проблем это реализовал с помощью ps. Подробно описал в статье. Если нужно будет сделать то же самое в Windows, то можно взять для этого утилиту procs.
Исходники - https://github.com/dalance/procs
#утилита #terminal
{kind=link}
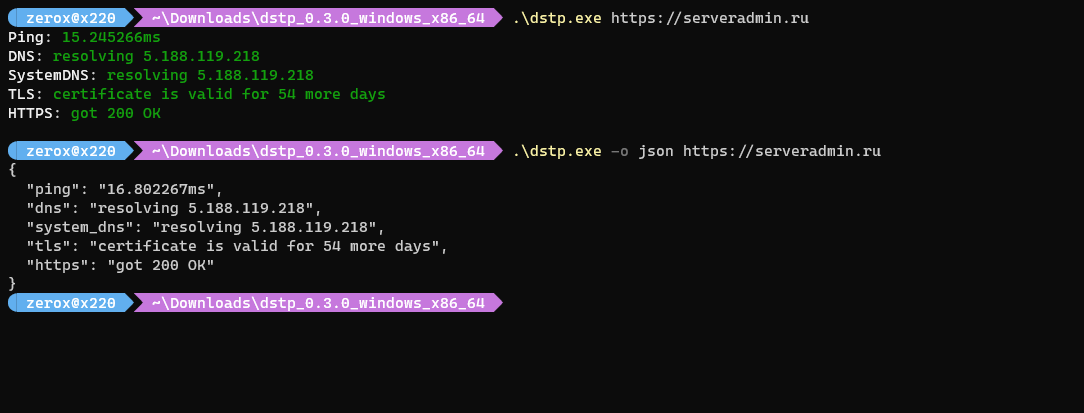
Буквально на днях вышла в свет очень простая утилита на Go - dstp. Вот, что она делает:
◽ Показывает пинг сайта
◽ Resolve ip адреса локальным dns и ns сервером домена
◽ Срок действия TLS сертификата
◽ HTTP код ответа
Утилита собрана под все популярные системы в виде готового бинарника. Вывод может быть в тектсовом виде, либо в json. Авторы в репозитории пишут, что кто-то очень просил подобную утилиту и они сделали.
В целом, штука полезная, но понятное дело, вручную качать бинарник особо смысла и желания нет, если не нужен прям вот именно этот функционал. Если приедет в стандартные репозитории дистрибутивов, то будет неплохо. Для мониторинга много где может пригодиться, особенно если вывод чуть подрихтуют, убрав оттуда строковые значения. Проверка на локальные и глобальные dns записи, думаю, не просто так туда попала. В каких-то случаях нужны такие проверки где-то в тестовых лабах.
Исходники - https://github.com/ycd/dstp
#утилита
◽ Показывает пинг сайта
◽ Resolve ip адреса локальным dns и ns сервером домена
◽ Срок действия TLS сертификата
◽ HTTP код ответа
Утилита собрана под все популярные системы в виде готового бинарника. Вывод может быть в тектсовом виде, либо в json. Авторы в репозитории пишут, что кто-то очень просил подобную утилиту и они сделали.
В целом, штука полезная, но понятное дело, вручную качать бинарник особо смысла и желания нет, если не нужен прям вот именно этот функционал. Если приедет в стандартные репозитории дистрибутивов, то будет неплохо. Для мониторинга много где может пригодиться, особенно если вывод чуть подрихтуют, убрав оттуда строковые значения. Проверка на локальные и глобальные dns записи, думаю, не просто так туда попала. В каких-то случаях нужны такие проверки где-то в тестовых лабах.
Исходники - https://github.com/ycd/dstp
#утилита
{kind=link}