
Современные операционные системы сегодня живут своей жизнью. Иногда бывает забавно посмотреть на сетевой трафик и ужаснуться от того, сколько там различных сетевых соединений, которые инициировали не вы. Проще всего их отследить по DNS запросам, настроив свой DNS сервер с логированием всех запросов.
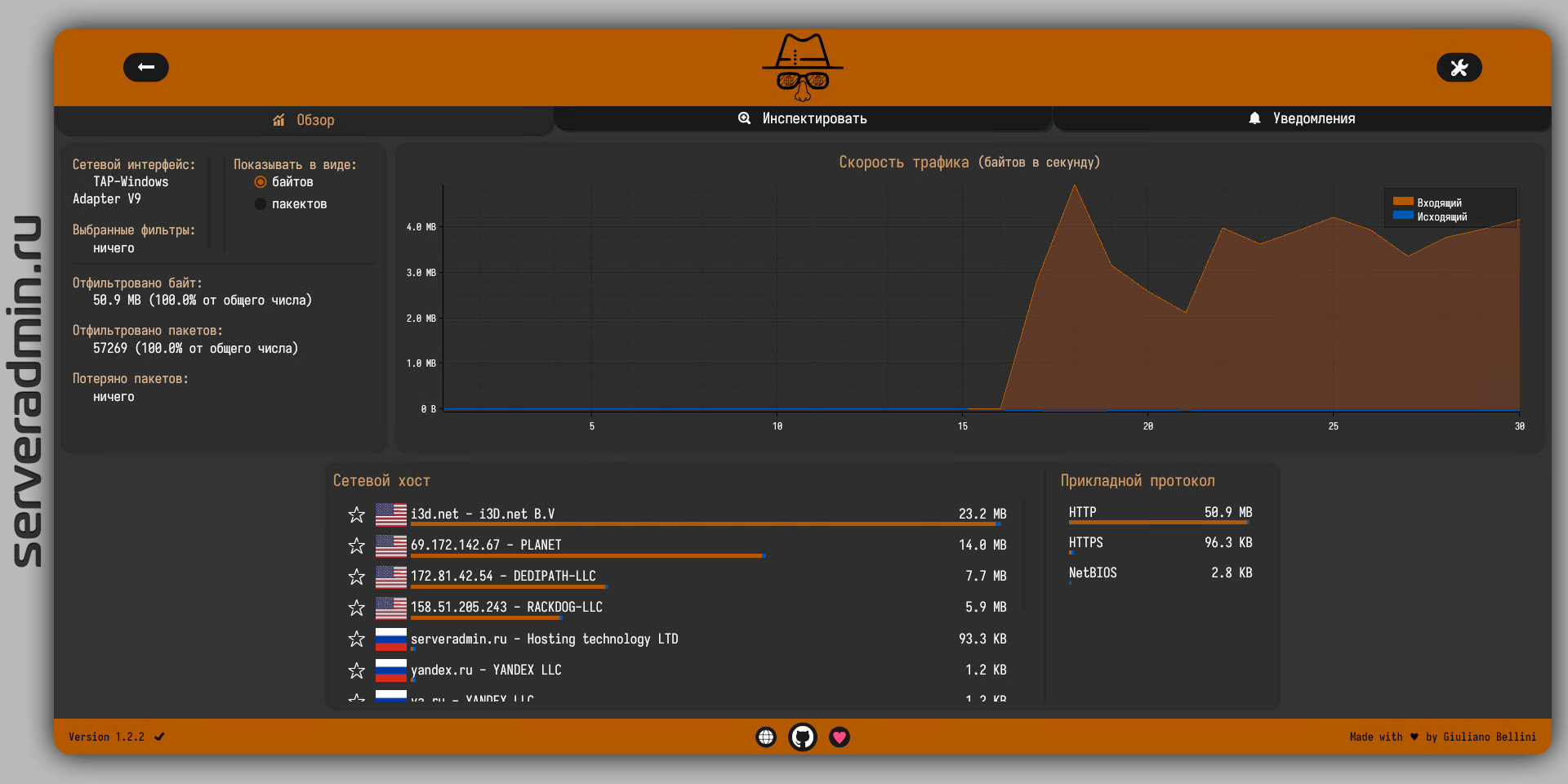
Но есть способы проще. Например, взять open source приложение Sniffnet и посмотреть в удобном виде всю сетевую активность. Причём приложение кроссплатформенное. Я сначала не понял, как такая простая и маленькая программа на Rust может одинаково работать на всех платформах. Оказалось, она использует библиотеку pcap: libpcap в unix и npcap в windows. Для тех, кто не в курсе, поясню, что это та же библиотека, что используется в Nmap и Wireshark.
Sniffnet позволяет подключиться к конкретному сетевому интерфейсу и посмотреть его активность. Работает в том числе с VPN интерфейсами. Например, если вы заворачиваете весь трафик в VPN, то на основном интерфейсе увидите только трафик в сторону VPN сервера. А если заглянете в VPN интерфейс, там уже будет детальна информация. Можно быстро проверить, точно ли весь нужный трафик идёт в VPN.
В Sniffnet можно настроить 3 типа уведомлений:
1️⃣ Превышение порога по частоте передачи пакетов.
2️⃣ Превышение порога полосы пропускания.
3️⃣ Соединение с указанными IP адресами.
Уведомления фиксируются и отображаются в отдельной вкладке интерфейса.
Поддерживаются оба протокола: ipv4 и ipv6. В программе, в принципе, ничего особенного нет. Но сделана добротно и удобно, приятный интерфейс, есть русский язык. Можно взять на заметку, если понадобится подобный функционал. Я, к примеру, так сходу и не вспомню, чем так же трафик посмотреть на Windows. Первыми на ум приходят различные application firewalls, но это немного не то. Более навороченные и функциональные программы.
В Windows предварительно надо будет установить Npcap (installer), в Linux libpcap и звуки со шрифтами:
А потом уже сам Sniffnet.
⇨ Сайт / Исходники
#network
Но есть способы проще. Например, взять open source приложение Sniffnet и посмотреть в удобном виде всю сетевую активность. Причём приложение кроссплатформенное. Я сначала не понял, как такая простая и маленькая программа на Rust может одинаково работать на всех платформах. Оказалось, она использует библиотеку pcap: libpcap в unix и npcap в windows. Для тех, кто не в курсе, поясню, что это та же библиотека, что используется в Nmap и Wireshark.
Sniffnet позволяет подключиться к конкретному сетевому интерфейсу и посмотреть его активность. Работает в том числе с VPN интерфейсами. Например, если вы заворачиваете весь трафик в VPN, то на основном интерфейсе увидите только трафик в сторону VPN сервера. А если заглянете в VPN интерфейс, там уже будет детальна информация. Можно быстро проверить, точно ли весь нужный трафик идёт в VPN.
В Sniffnet можно настроить 3 типа уведомлений:
1️⃣ Превышение порога по частоте передачи пакетов.
2️⃣ Превышение порога полосы пропускания.
3️⃣ Соединение с указанными IP адресами.
Уведомления фиксируются и отображаются в отдельной вкладке интерфейса.
Поддерживаются оба протокола: ipv4 и ipv6. В программе, в принципе, ничего особенного нет. Но сделана добротно и удобно, приятный интерфейс, есть русский язык. Можно взять на заметку, если понадобится подобный функционал. Я, к примеру, так сходу и не вспомню, чем так же трафик посмотреть на Windows. Первыми на ум приходят различные application firewalls, но это немного не то. Более навороченные и функциональные программы.
В Windows предварительно надо будет установить Npcap (installer), в Linux libpcap и звуки со шрифтами:
# apt install libpcap-dev libasound2-dev libfontconfig1-devА потом уже сам Sniffnet.
⇨ Сайт / Исходники
#network
{kind=link}
Запомнился один момент с недавней конференции, где я присутствовал. Выступающий рассказывал, если не ошибаюсь, про технологию VDI и оптимизацию полосы пропускания, что позволяет комфортно общаться по видеосвязи. В подтверждение своих слов с цифрами показал картинку, где справа окно терминала.
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Когда вы настраиваете VPN, встаёт вопрос выбора размера MTU (maximum transmission unit) внутри туннеля. Это размер полезного блока с данными в одном пакете. Как известно, в сетевом пакете часть информации уходит для служебной информации в заголовках. Различные технологии VPN используют разный объём служебных заголовков. А если VPN пущен поверх другого VPN канала, то этот вопрос встаёт особенно остро.
Если ошибиться с размером MTU, то пакеты начнут разбиваться на несколько, чтобы передать полезный блок с данными. Это очень сильно снижает скорость передачи данных. Минимум в 2 раза, но на деле гораздо больше.
Правильно выбрать размер MTU можно с помощью готового калькулятора - Visual packet size calculator. Его автор, кстати, Даниил Батурин, который иногда ведёт бесплатные вебинары Rebrain, которые я периодически рекламирую. Рекомендую послушать, интересно.
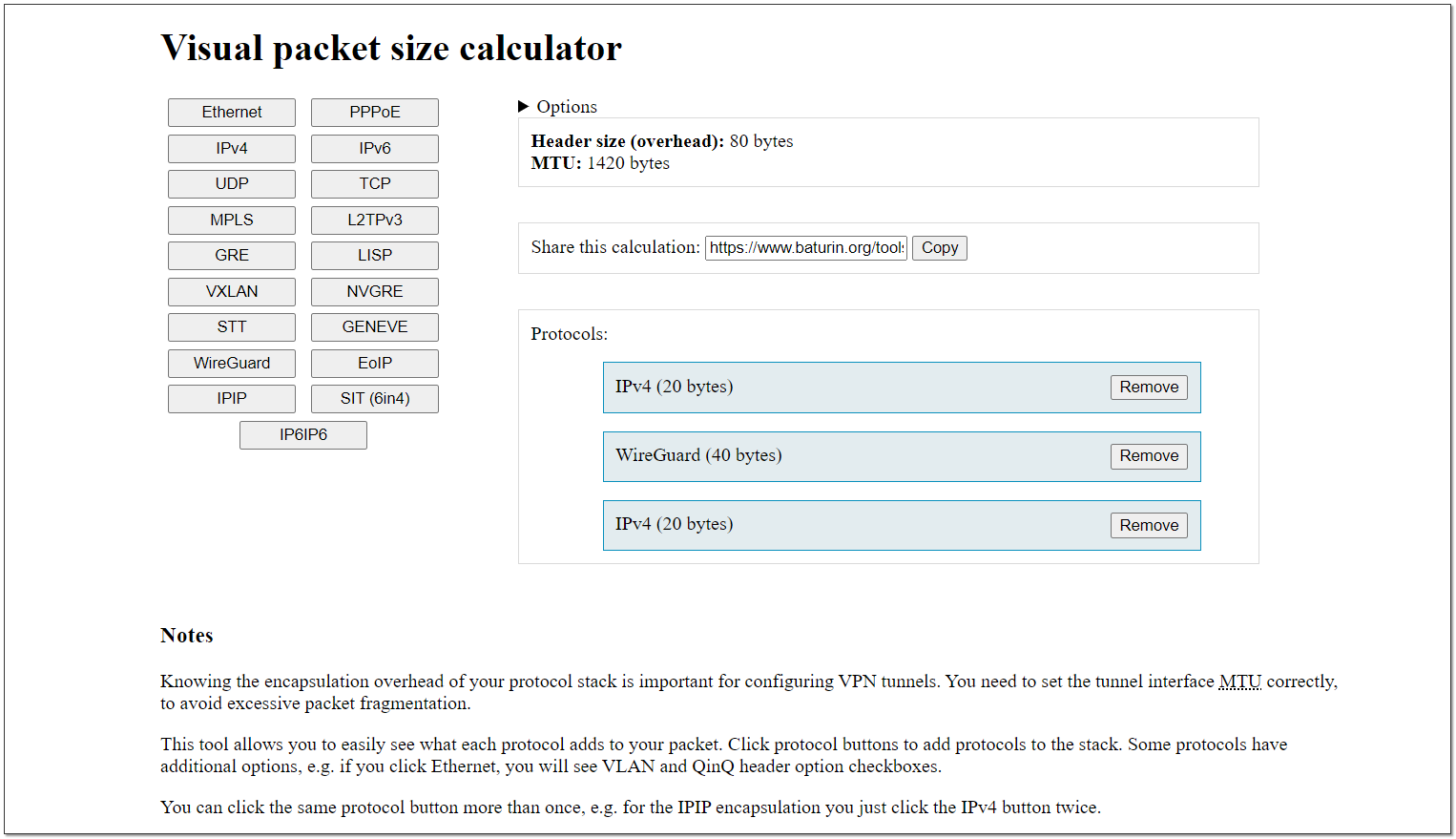
К сожалению, в калькуляторе нет OpenVPN. И я как-то сходу не смог найти информацию, сколько места занимают служебные заголовки этого протокола. Покажу пример для WireGuard, если я всё правильно понимаю. Если ошибаюсь, прошу поправить.
Мы устанавливаем туннель WireGuard, чтобы гонять по нему ipv4 трафик. Идём в калькулятор и выстраиваем там цепочку:
IPv4 (20 bytes) ⇨ WireGuard (40 bytes) ⇨ IPv4 (20 bytes)
Имея на родительском интерфейсе MTU 1500, внутри туннеля нам необходимо установить его 1420. Если не ошибаюсь, это как раз значение по умолчанию для WireGuard.
Тема MTU довольно сложная. Если вы не сетевой инженер и специально ей не интересовались, то вникнуть непросто. На практике я сталкивался с подобными проблемами. Решал их в меру своих сил и способностей - просто уменьшал MTU до некоторых значений, когда проблем пропадала. Если вы не разбираетесь детально в этой теме, рекомендую поступать так же. И важно знать, что если у вас PPPoE соединение от провайдера, то оно дополнительно 8 байт занимает на заголовки. Часто дефолтные значения различного софта не учитывают этого нюанса и нужно будет поправить вручную.
#vpn #network
Если ошибиться с размером MTU, то пакеты начнут разбиваться на несколько, чтобы передать полезный блок с данными. Это очень сильно снижает скорость передачи данных. Минимум в 2 раза, но на деле гораздо больше.
Правильно выбрать размер MTU можно с помощью готового калькулятора - Visual packet size calculator. Его автор, кстати, Даниил Батурин, который иногда ведёт бесплатные вебинары Rebrain, которые я периодически рекламирую. Рекомендую послушать, интересно.
К сожалению, в калькуляторе нет OpenVPN. И я как-то сходу не смог найти информацию, сколько места занимают служебные заголовки этого протокола. Покажу пример для WireGuard, если я всё правильно понимаю. Если ошибаюсь, прошу поправить.
Мы устанавливаем туннель WireGuard, чтобы гонять по нему ipv4 трафик. Идём в калькулятор и выстраиваем там цепочку:
IPv4 (20 bytes) ⇨ WireGuard (40 bytes) ⇨ IPv4 (20 bytes)
Имея на родительском интерфейсе MTU 1500, внутри туннеля нам необходимо установить его 1420. Если не ошибаюсь, это как раз значение по умолчанию для WireGuard.
Тема MTU довольно сложная. Если вы не сетевой инженер и специально ей не интересовались, то вникнуть непросто. На практике я сталкивался с подобными проблемами. Решал их в меру своих сил и способностей - просто уменьшал MTU до некоторых значений, когда проблем пропадала. Если вы не разбираетесь детально в этой теме, рекомендую поступать так же. И важно знать, что если у вас PPPoE соединение от провайдера, то оно дополнительно 8 байт занимает на заголовки. Часто дефолтные значения различного софта не учитывают этого нюанса и нужно будет поправить вручную.
#vpn #network
{kind=link}
Часто слышал выражение, что трафик отправляют в blackhole. Обычно это делает провайдер, когда вас ддосят. Вас просто отключают, отбрасывая весь адресованный вам трафик. А что за сущность такая blackhole, я не знал. Решил узнать, заодно и вам рассказать.
Я изначально думал, что это какое-то образное выражение, которое переводится как чёрная дыра. А на деле предполагал, что соединения просто дропают где-то на файрволе, да и всё. Оказывается, blackhole это реальная запись в таблице маршрутизации. Вы на своём Linux сервере тоже можете отправить весь трафик в blackhole, просто создав соответствующий маршрут:
Проверяем:
Все пакеты с маршрутом до 1.2.3.4 будут удалены с причиной No route to host. На практике на своём сервере кого-то отправлять в blackhole большого смысла нет. Если я правильно понимаю, это провайдеры отправляют в blackhole весь трафик, адресованный какому-то хосту, которого ддосят. Таким образом они разгружают своё оборудование. И это более эффективно и просто, чем что-то делать на файрволе.
Если я правильно понимаю, подобные маршруты где-то у себя имеет смысл использовать, чтобы гарантированно отсечь какой-то исходящий трафик в случае динамических маршрутов. Например, у вас есть какой-то трафик по vpn, который должен уходить строго по определённому маршруту. Если этого маршрута не будет, то трафик не должен никуда идти. В таком случае делаете blackhole маршрут с максимальной дистанцией, а легитимные маршруты с дистанцией меньше. В итоге если легитимного маршрута не будет, весь трафик пойдёт в blackhole. Таким образом можно подстраховывать себя от ошибок в файрволе.
#network
Я изначально думал, что это какое-то образное выражение, которое переводится как чёрная дыра. А на деле предполагал, что соединения просто дропают где-то на файрволе, да и всё. Оказывается, blackhole это реальная запись в таблице маршрутизации. Вы на своём Linux сервере тоже можете отправить весь трафик в blackhole, просто создав соответствующий маршрут:
# ip route add blackhole 1.2.3.4Проверяем:
# ip r | grep blackholeblackhole 1.2.3.4Все пакеты с маршрутом до 1.2.3.4 будут удалены с причиной No route to host. На практике на своём сервере кого-то отправлять в blackhole большого смысла нет. Если я правильно понимаю, это провайдеры отправляют в blackhole весь трафик, адресованный какому-то хосту, которого ддосят. Таким образом они разгружают своё оборудование. И это более эффективно и просто, чем что-то делать на файрволе.
Если я правильно понимаю, подобные маршруты где-то у себя имеет смысл использовать, чтобы гарантированно отсечь какой-то исходящий трафик в случае динамических маршрутов. Например, у вас есть какой-то трафик по vpn, который должен уходить строго по определённому маршруту. Если этого маршрута не будет, то трафик не должен никуда идти. В таком случае делаете blackhole маршрут с максимальной дистанцией, а легитимные маршруты с дистанцией меньше. В итоге если легитимного маршрута не будет, весь трафик пойдёт в blackhole. Таким образом можно подстраховывать себя от ошибок в файрволе.
#network
{kind=link}
В Linux существует относительно простой способ шейпирования (ограничения) трафика с помощью утилиты tc (traffic control) из пакета iproute2. Простой в том плане, что какие-то базовые вещи делаются просто и быстро. Но в то же время это очень мощный инструмент с иерархической структурой, который позволяет очень гибко управлять трафиком.
Сразу сделаю важную ремарку, суть которой некоторые не понимают. Шейпировать можно только исходящий трафик. Управлять входящим трафиком без его потери невозможно. На входе вы можете только отбрасывать пакеты, но не выстраивать в определённые очереди.
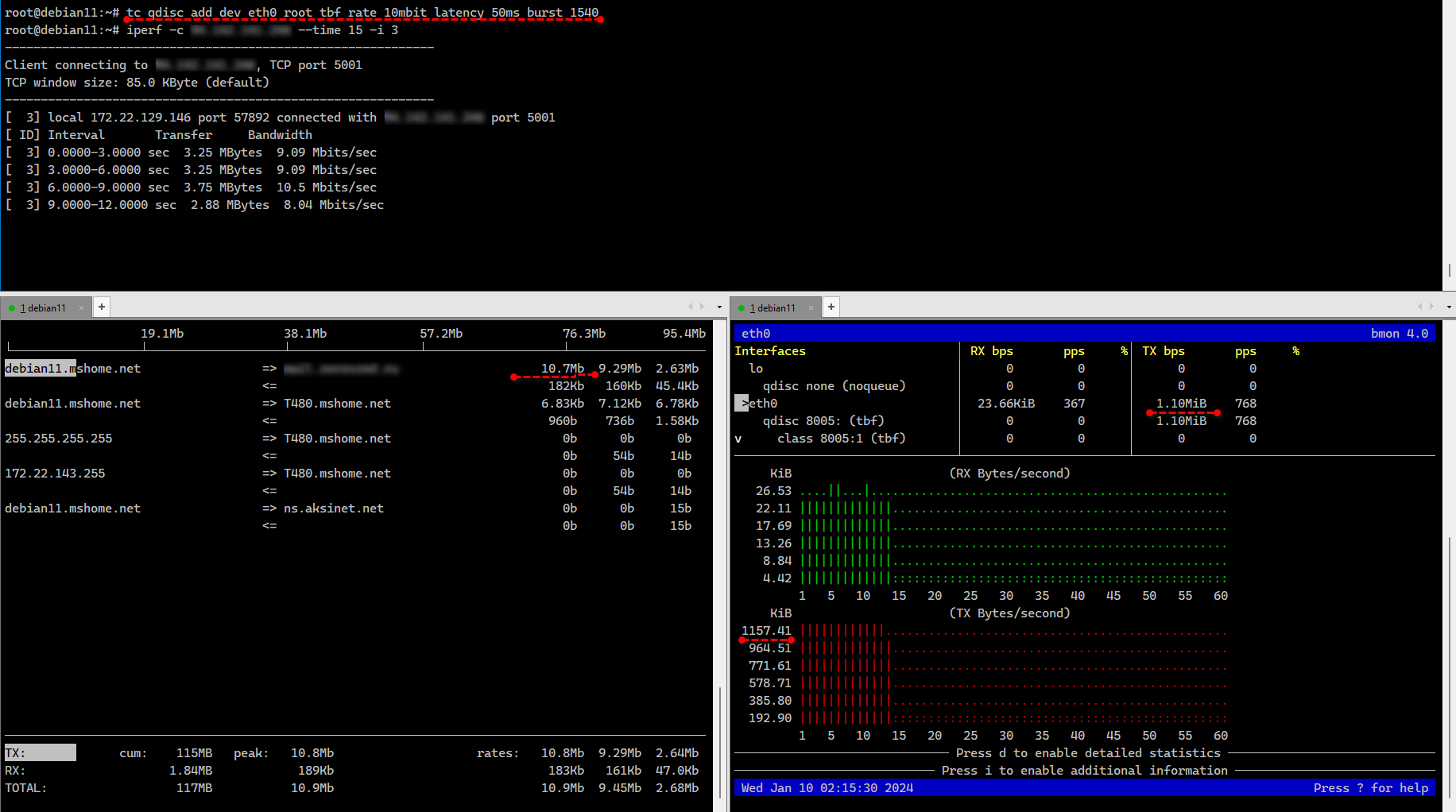
Я не буду подробно рассказывать, как tc работает, потому что это долго и в целом не имеет смысла в рамках заметки. В интернете очень много материала по этой теме. Покажу для начала простой пример ограничения исходящего трафика на конкретном интерфейсе с помощью алгоритма TBF. В минимальной установке Debian tc уже присутствует, так что отдельно ставить не надо.
Ограничили исходящую скорость на интерфейсе eth0 10Mbit/s или примерно 1,25MB/s. В данном случае параметры latency - максимальное время пакета в очереди и burst - размер буфера, обязательны. Посмотреть применённые настройки можно так:
Тестировать ограничение скорость проще всего с помощью iperf или speedtest-cli. Удалить правило можно так же, как и добавляли, только вместо add указать del:
В примере выше мы использовали бесклассовую дисциплину с алгоритмом TBF. Его можно применять только к интерфейсу без возможности фильтрации пакетов. Если нужно настроить ограничение по порту или ip адресу, то воспользуемся другим алгоритмом. Укажем ограничение скорости для конкретного TCP порта с помощью классовой дисциплины HTB. Например, ограничим порт 5001, который использует по умолчанию iperf:
Так как это классовая дисциплина, мы вначале создали общий класс по умолчанию для всего трафика без ограничений. Потом создали класс с идентификатором 1:1 с ограничением скорости. Затем в этот класс с ограничением добавили порт 5001. По аналогии можно создавать другие классы и добавлять туда фильтры на основе разных признаков: порты, ip адреса, протоколы. Примерно так же назначаются и приоритеты трафика.
Подробно настройка tc описана в этом how-to. Разделы 9, 10, 11, 12.
Для tc есть небольшая python обёртка, которая упрощает настройку - traffictoll. Там конфигурацию можно в yaml файлах писать. Причём эта штука поддерживает в том числе фильтрацию по процессам. Честно говоря, я не понял, как там это реализовано. Насколько я знаю, tc по процессам фильтровать не умеет. Поковырялся в исходниках traffictoll, но реализацию так и не нашёл. Вижу, что используется библиотека psutil для получения информации о процессе, подгружается модуль ядра ifb numifbs=1, но где правила для процессов задаются, не понял.
#network
Сразу сделаю важную ремарку, суть которой некоторые не понимают. Шейпировать можно только исходящий трафик. Управлять входящим трафиком без его потери невозможно. На входе вы можете только отбрасывать пакеты, но не выстраивать в определённые очереди.
Я не буду подробно рассказывать, как tc работает, потому что это долго и в целом не имеет смысла в рамках заметки. В интернете очень много материала по этой теме. Покажу для начала простой пример ограничения исходящего трафика на конкретном интерфейсе с помощью алгоритма TBF. В минимальной установке Debian tc уже присутствует, так что отдельно ставить не надо.
# tc qdisc add dev eth0 root tbf rate 10mbit latency 50ms burst 10kОграничили исходящую скорость на интерфейсе eth0 10Mbit/s или примерно 1,25MB/s. В данном случае параметры latency - максимальное время пакета в очереди и burst - размер буфера, обязательны. Посмотреть применённые настройки можно так:
# tc qdisc show dev eth0Тестировать ограничение скорость проще всего с помощью iperf или speedtest-cli. Удалить правило можно так же, как и добавляли, только вместо add указать del:
# tc qdisc del dev eth0 root tbf rate 10mbit latency 50ms burst 10kВ примере выше мы использовали бесклассовую дисциплину с алгоритмом TBF. Его можно применять только к интерфейсу без возможности фильтрации пакетов. Если нужно настроить ограничение по порту или ip адресу, то воспользуемся другим алгоритмом. Укажем ограничение скорости для конкретного TCP порта с помощью классовой дисциплины HTB. Например, ограничим порт 5001, который использует по умолчанию iperf:
# tc qdisc add dev eth0 root handle 1: htb default 20# tc class add dev eth0 parent 1: classid 1:1 htb rate 10mbit ceil 10mbit# tc filter add dev eth0 protocol ip parent 1: prio 1 u32 match ip dport 5001 0xffff flowid 1:1Так как это классовая дисциплина, мы вначале создали общий класс по умолчанию для всего трафика без ограничений. Потом создали класс с идентификатором 1:1 с ограничением скорости. Затем в этот класс с ограничением добавили порт 5001. По аналогии можно создавать другие классы и добавлять туда фильтры на основе разных признаков: порты, ip адреса, протоколы. Примерно так же назначаются и приоритеты трафика.
Подробно настройка tc описана в этом how-to. Разделы 9, 10, 11, 12.
Для tc есть небольшая python обёртка, которая упрощает настройку - traffictoll. Там конфигурацию можно в yaml файлах писать. Причём эта штука поддерживает в том числе фильтрацию по процессам. Честно говоря, я не понял, как там это реализовано. Насколько я знаю, tc по процессам фильтровать не умеет. Поковырялся в исходниках traffictoll, но реализацию так и не нашёл. Вижу, что используется библиотека psutil для получения информации о процессе, подгружается модуль ядра ifb numifbs=1, но где правила для процессов задаются, не понял.
#network
{kind=link}
Расскажу своими словами о такой характеристики сетевого пакета как TTL (Time to live). Думаю, многие если что-то и знают или слышали об этом, то не вдавались в подробности, так как базово системному администратору не так часто приходится подробно разбираться с временем жизни пакета.
Вообще, я впервые познакомился с этим термином, когда купил свой первый модем Yota и захотел не просто пользоваться интернетом на одном устройстве, но и раздать его другим. В то время у Yota был безлимит только для конкретного устройства, в который воткнут модем или сим карта. А одним из способов определить, что интернет раздаётся, был анализ его TTL. Но не только. Из забавного расскажу, что также был контроль ресурсов, к которым обращается пользователь. Я тогда ещё иногда админил Freebsd, а на ноуте была тестовая виртуалка с ней. Как только я пытался обновить список портов (это аналог обновления репозитория в Linux), мне провайдер отключал интернет за нарушение условий использования. Видимо какой-то местный админ, настраивавший ограничения, решил, что пользователь Yota с usb модемом не может обновлять пакеты для Freebsd. Обходил это VPN соединением. Сразу весь траф в него заворачивал, чтобы не палить.
Возвращаюсь к TTL. Это число, которое присутствует в отдельном поле IP заголовка сетевого пакета. После прохождения каждого маршрутизатора этот параметр уменьшается на единицу. Как только это число станет равно 0, пакет уничтожается. Сделано это для того, чтобы ограничить способность пакета бесконечно перемещаться по сети. Рано или поздно он будет уничтожен, если не достигнет адресата.
Как это работает на практике, наглядно можно показать на примере ограничений Yota того периода. У разных устройств и систем по умолчанию устанавливается разное TTL. Для Linux, Android обычно это 64, для Windows 128. Если вы используете интернет напрямую на смартфоне, то TTL выходящего из вашего устройства пакета будет 64. Если же вы раздаёте интернет другому смартфону, то на вашем устройстве TTL будет 64, на втором устройстве, которому раздали интернет, будет 63. И провайдер на своём оборудовании увидит TTL 63, а не 64. Это позволяет ему определить раздачу. Способ простой, но эффективный для большей части абонентов.
Изменить TTL довольно просто, если у вас есть навыки и инструменты системы. Можно поменять настройки по умолчанию TTL на системе, раздающей интернет. Просто увеличить значение на 1. Пример для Linux:
Но будет неудобно, если вы выходите с этого устройства в интернет напрямую. Можно на ходу с помощью iptables править время жизни пакетов. Настройка будет зависеть от того, раздающее это устройство или использующее интернет. Пример для раздающего:
Для android устройств (рутованных) и многих usb модемов (перепрошитых) выпускали патчи, где как раз с помощью параметра системы или iptables решали этот вопрос. Под Windows он решался таким же способом, только другими инструментами.
Сейчас, по идее, всё это неактуально стало, так как законодательно запретили провайдерам ограничивать раздачу интернета. Но для понимания TTL этот пример актуален, так как не знаю, где ещё можно с этим столкнуться. В обычных сетевых задачах с TTL мне не приходилось сталкиваться.
#network
Вообще, я впервые познакомился с этим термином, когда купил свой первый модем Yota и захотел не просто пользоваться интернетом на одном устройстве, но и раздать его другим. В то время у Yota был безлимит только для конкретного устройства, в который воткнут модем или сим карта. А одним из способов определить, что интернет раздаётся, был анализ его TTL. Но не только. Из забавного расскажу, что также был контроль ресурсов, к которым обращается пользователь. Я тогда ещё иногда админил Freebsd, а на ноуте была тестовая виртуалка с ней. Как только я пытался обновить список портов (это аналог обновления репозитория в Linux), мне провайдер отключал интернет за нарушение условий использования. Видимо какой-то местный админ, настраивавший ограничения, решил, что пользователь Yota с usb модемом не может обновлять пакеты для Freebsd. Обходил это VPN соединением. Сразу весь траф в него заворачивал, чтобы не палить.
Возвращаюсь к TTL. Это число, которое присутствует в отдельном поле IP заголовка сетевого пакета. После прохождения каждого маршрутизатора этот параметр уменьшается на единицу. Как только это число станет равно 0, пакет уничтожается. Сделано это для того, чтобы ограничить способность пакета бесконечно перемещаться по сети. Рано или поздно он будет уничтожен, если не достигнет адресата.
Как это работает на практике, наглядно можно показать на примере ограничений Yota того периода. У разных устройств и систем по умолчанию устанавливается разное TTL. Для Linux, Android обычно это 64, для Windows 128. Если вы используете интернет напрямую на смартфоне, то TTL выходящего из вашего устройства пакета будет 64. Если же вы раздаёте интернет другому смартфону, то на вашем устройстве TTL будет 64, на втором устройстве, которому раздали интернет, будет 63. И провайдер на своём оборудовании увидит TTL 63, а не 64. Это позволяет ему определить раздачу. Способ простой, но эффективный для большей части абонентов.
Изменить TTL довольно просто, если у вас есть навыки и инструменты системы. Можно поменять настройки по умолчанию TTL на системе, раздающей интернет. Просто увеличить значение на 1. Пример для Linux:
# sysctl -w net.ipv4.ip_default_ttl=65Но будет неудобно, если вы выходите с этого устройства в интернет напрямую. Можно на ходу с помощью iptables править время жизни пакетов. Настройка будет зависеть от того, раздающее это устройство или использующее интернет. Пример для раздающего:
# iptables -t mangle -A POSTROUTING -j TTL --ttl-set 65Для android устройств (рутованных) и многих usb модемов (перепрошитых) выпускали патчи, где как раз с помощью параметра системы или iptables решали этот вопрос. Под Windows он решался таким же способом, только другими инструментами.
Сейчас, по идее, всё это неактуально стало, так как законодательно запретили провайдерам ограничивать раздачу интернета. Но для понимания TTL этот пример актуален, так как не знаю, где ещё можно с этим столкнуться. В обычных сетевых задачах с TTL мне не приходилось сталкиваться.
#network
❓Как бы вы решили следующую задачу.
Как проверить, есть ли обращение клиента на порт TCP 22 сервера с определённого IP адреса и порта?
Это, кстати, вопрос из того же списка, что я публиковал ранее, но я решил его вынести в отдельную публикацию, потому что он объёмный, а там уже лимит сообщения был превышен.
В таком виде этот вопрос выглядит довольно просто, так как тут речь скорее всего про службу sshd, которая по умолчанию логируется практически везде. Можно просто зайти в её лог и посмотреть, какие там были подключения.
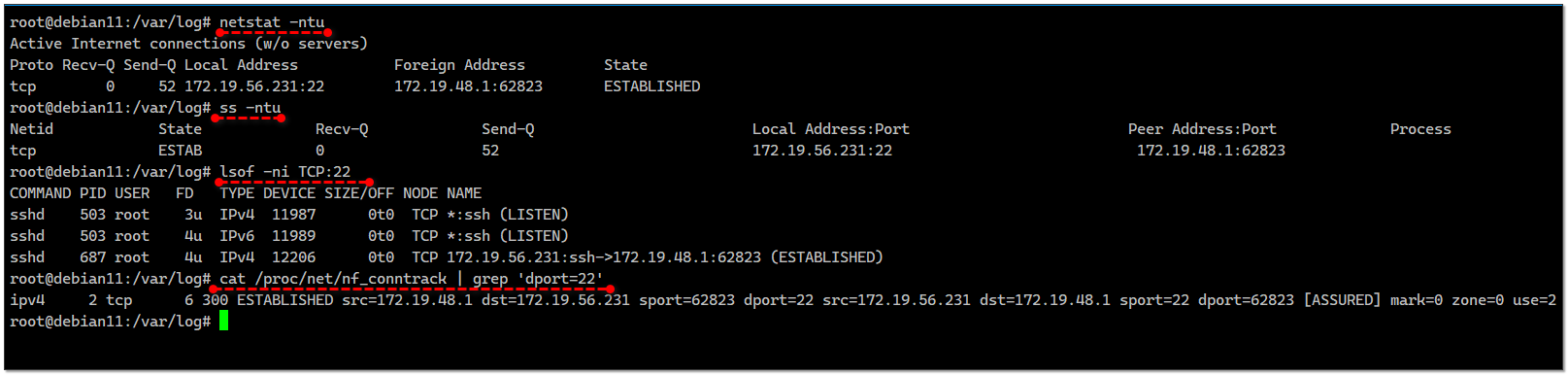
Если же речь идёт о любом другом соединении, то если оно активно, посмотреть его можно с помощью
Нужный адрес и порт можно грепнуть:
Менее очевидный вариант с помощью
Если же речь вести про прошлые, а не активные соединения, то первое, что мне приходит на ум из подручных системных средств - логирование с помощью firewall. В iptables я это делаю примерно так:
Сделал отдельную цепочку для логирования и отправил туда запись всех пакетов с портом назначения 22. Логи будут по умолчанию собираться в системном логе syslog. При желании можно в отдельный файл вынести через правило в rsyslog. Отдельную цепочку для каждой службы я обычно не делаю. Вместо этого создаю три цепочки - input, output, forward, куда добавляю правила для тех адресов и портов, которые я хочу логировать.
Это всё, что мне пришло в голову по данному вопросу. Если знаете ещё какие-то способы, то напишите. Будет интересно посмотреть.
Пока заканчивал материал, вспомнил про ещё один:
В принципе, это тот же самый ss или netstat. Они скорее всего отсюда и берут информацию.
#network #terminal
Как проверить, есть ли обращение клиента на порт TCP 22 сервера с определённого IP адреса и порта?
Это, кстати, вопрос из того же списка, что я публиковал ранее, но я решил его вынести в отдельную публикацию, потому что он объёмный, а там уже лимит сообщения был превышен.
В таком виде этот вопрос выглядит довольно просто, так как тут речь скорее всего про службу sshd, которая по умолчанию логируется практически везде. Можно просто зайти в её лог и посмотреть, какие там были подключения.
Если же речь идёт о любом другом соединении, то если оно активно, посмотреть его можно с помощью
netstat или более современного ss:# netstat -ntu# ss -ntuНужный адрес и порт можно грепнуть:
# netstat -ntu | grep ':22'Менее очевидный вариант с помощью
lsof:# lsof -ni TCP:22Если же речь вести про прошлые, а не активные соединения, то первое, что мне приходит на ум из подручных системных средств - логирование с помощью firewall. В iptables я это делаю примерно так:
# iptables -N ssh_in# iptables -A INPUT -j ssh_in# iptables -A ssh_in -j LOG --log-level info --log-prefix "--IN--SSH--"# iptables -A INPUT -p tcp --dport 22 -j ACCEPTСделал отдельную цепочку для логирования и отправил туда запись всех пакетов с портом назначения 22. Логи будут по умолчанию собираться в системном логе syslog. При желании можно в отдельный файл вынести через правило в rsyslog. Отдельную цепочку для каждой службы я обычно не делаю. Вместо этого создаю три цепочки - input, output, forward, куда добавляю правила для тех адресов и портов, которые я хочу логировать.
Это всё, что мне пришло в голову по данному вопросу. Если знаете ещё какие-то способы, то напишите. Будет интересно посмотреть.
Пока заканчивал материал, вспомнил про ещё один:
# cat /proc/net/nf_conntrack | grep 'dport=22'В принципе, это тот же самый ss или netstat. Они скорее всего отсюда и берут информацию.
#network #terminal
{kind=link}
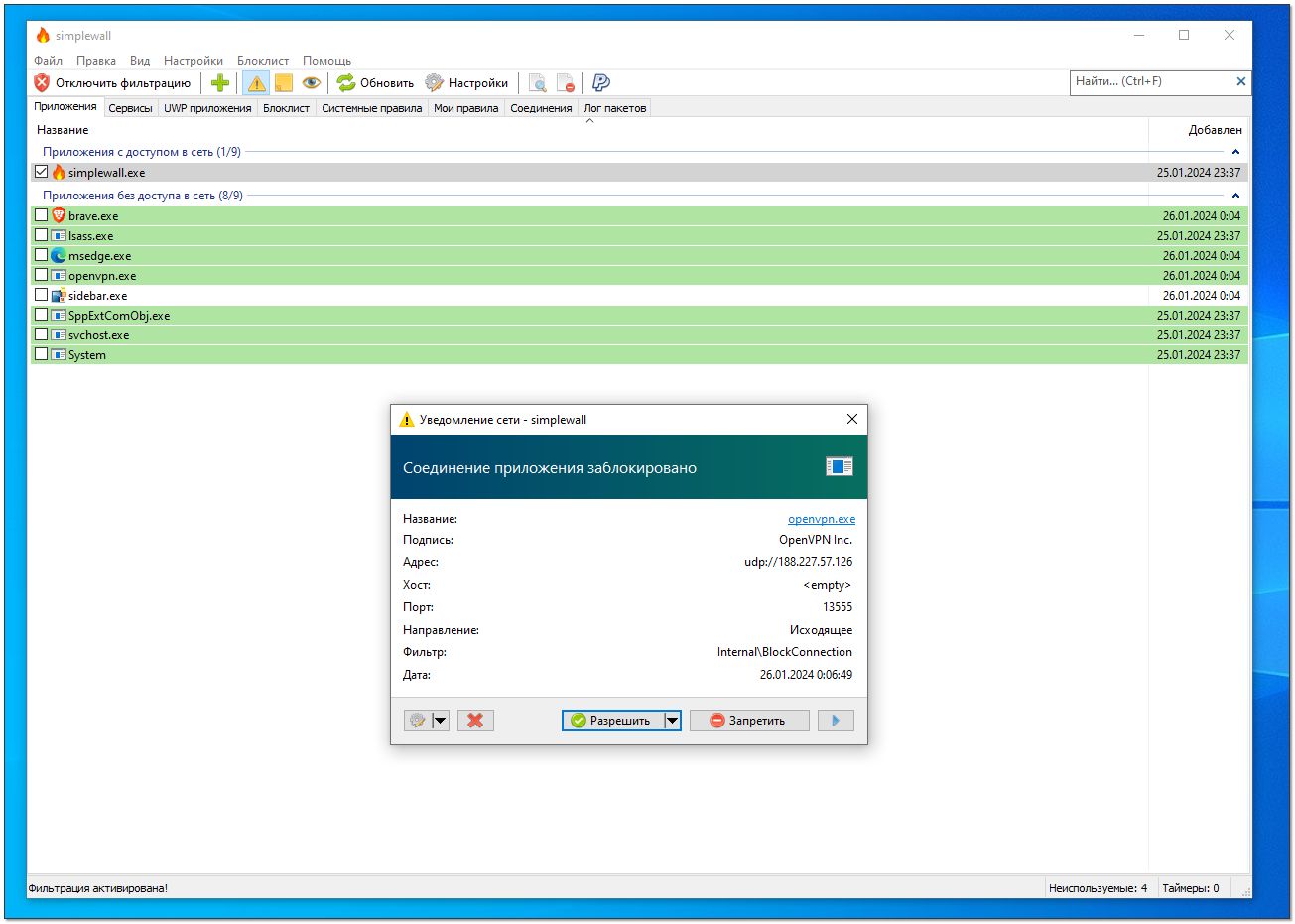
Тема с Portmaster получила очень живой отклик в виде сохранений заметки. Решил её немного развить и предложить альтернативу этому хоть и удобному, но очень объёмному и тяжёлому приложению. Тяжёл прежде всего интерфейс на Electron, само ядро там на Go. В противовес можно поставить simplewall. Это обёртка над Windows Filtering Platform (WFP) весом буквально в мегабайт. В репозитории все скрины на русском языке, так что автор, судя по всему, русскоязычный.
Компания Microsoft действует очень разумно и логично в своей массовой системе Windows. Закрывает наиболее актуальные потребности людей, замыкая их в своей экосистеме. Отрезает всех остальных от бигдаты пользователей. Её встроенных средств безопасности и защиты достаточно среднестатистическому пользователю. Нет необходимости ставить сторонние антивирусы или прочие приложения.
WFP - это набор системных служб для фильтрации трафика, охватывающий все основные сетевые уровни, от транспортного (TCP/UDP) до канального (Ethernet). Simplewall взаимодействует с WFP через встроенный API. То есть это не обёртка над Windows Firewall, как может показаться вначале.
Основная функция Simplewall - контроль сетевой активности. Вы можете заблокировать весь сетевой доступ, а при попытке какого-то приложения получить этот доступ, увидите сообщение от программы, где можно либо разрешить активность, либо запретить. Можно создавать готовые правила для тех или иных приложений.
Simplewall поддерживает работу с системными службами, приложениями из магазина, WSL, с обычными приложениями. Можно логировать сетевую активность приложений или служб. Несмотря на то, что используется встроенный системный инструмент, он позволяет заблокировать в том числе и обновления системы с телеметрией.
Особенность Simplewall в том, что все настроенные правила будут действовать даже если приложение не запущено. Реальная фильтрация выполняется с помощью WFP по преднастроенным правилам. По умолчанию, после запуска фильтрации, программа заблокирует всю сетевую активность. На каждое приложение, которое попросится в сеть, будет выскакивать окно с запросом разрешения или запрета сетевой активности. То есть это очень простой способ заблокировать все запросы с машины во вне.
#windows #security #network
Компания Microsoft действует очень разумно и логично в своей массовой системе Windows. Закрывает наиболее актуальные потребности людей, замыкая их в своей экосистеме. Отрезает всех остальных от бигдаты пользователей. Её встроенных средств безопасности и защиты достаточно среднестатистическому пользователю. Нет необходимости ставить сторонние антивирусы или прочие приложения.
WFP - это набор системных служб для фильтрации трафика, охватывающий все основные сетевые уровни, от транспортного (TCP/UDP) до канального (Ethernet). Simplewall взаимодействует с WFP через встроенный API. То есть это не обёртка над Windows Firewall, как может показаться вначале.
Основная функция Simplewall - контроль сетевой активности. Вы можете заблокировать весь сетевой доступ, а при попытке какого-то приложения получить этот доступ, увидите сообщение от программы, где можно либо разрешить активность, либо запретить. Можно создавать готовые правила для тех или иных приложений.
Simplewall поддерживает работу с системными службами, приложениями из магазина, WSL, с обычными приложениями. Можно логировать сетевую активность приложений или служб. Несмотря на то, что используется встроенный системный инструмент, он позволяет заблокировать в том числе и обновления системы с телеметрией.
Особенность Simplewall в том, что все настроенные правила будут действовать даже если приложение не запущено. Реальная фильтрация выполняется с помощью WFP по преднастроенным правилам. По умолчанию, после запуска фильтрации, программа заблокирует всю сетевую активность. На каждое приложение, которое попросится в сеть, будет выскакивать окно с запросом разрешения или запрета сетевой активности. То есть это очень простой способ заблокировать все запросы с машины во вне.
#windows #security #network
{kind=link}
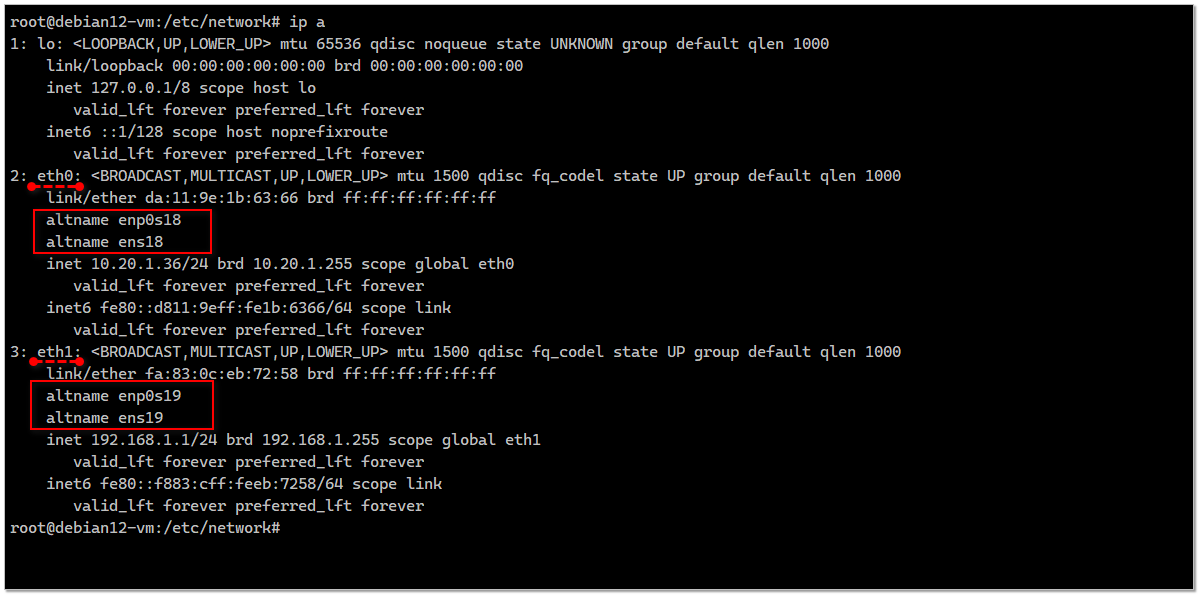
Если вам по какой-то причине не нравится современное именование сетевых интерфейсов в Linux вида ens18, enp0s18 и т.д. то вы можете довольно просто вернуться к привычным названиям eth0, eth1 и т.д. Только сразу предупрежу, что не стоит это делать на уже работающем сервере. Если уж вам так хочется переименовать сетевые интерфейсы, то делайте это сразу после установки системы.
Итак, если вам хочется вернуть старое именование интерфейсов, то в файле конфигурации grub
У вас уже могут быть указаны какие-то другие значения. Новые добавьте через пробел. Изначально их вообще может не быть, а параметр указан вот так:
Или могут быть какие-то другие значения:
После этого нужно обновить загрузчик. В зависимости от дистрибутива, это может выглядеть по-разному. В deb дистрибутивах то выглядит так:
В rpm уже точно не помню, специально не проверял, но вроде бы раньше это выглядело так:
Как в современных версиях уже не знаю, так как не использую их.
После этого нужно везде в сетевых настройках изменить имена интерфейсов со старых на новые. Для Debian достаточно отредактировать
Теперь можно перезагружать сервер. Загрузится он со старыми названиями сетевых интерфейсов.
Попутно задам вопрос, на который у меня нет ответа. Я не понимаю, почему в некоторых виртуалках по умолчанию используется старое именование сетевых интерфейсов, а в некоторых новое. Причём, это не зависит от версии ОС. У меня прямо сейчас есть две одинаковые Debian 11, где на одной eth0, а на другой ens18. Первая на HyperV, вторая на Proxmox. Подозреваю, что это зависит от типа эмулируемой сетевухи и драйвера, который используется в системе.
#linux #network
Итак, если вам хочется вернуть старое именование интерфейсов, то в файле конфигурации grub
/etc/default/grub добавьте в параметр GRUB_CMDLINE_LINUX дополнительные значения net.ifnames и biosdevname:GRUB_CMDLINE_LINUX="net.ifnames=0 biosdevname=0"У вас уже могут быть указаны какие-то другие значения. Новые добавьте через пробел. Изначально их вообще может не быть, а параметр указан вот так:
GRUB_CMDLINE_LINUX=""Или могут быть какие-то другие значения:
GRUB_CMDLINE_LINUX="crashkernel=auto rhgb quiet"После этого нужно обновить загрузчик. В зависимости от дистрибутива, это может выглядеть по-разному. В deb дистрибутивах то выглядит так:
# dpkg-reconfigure grub-pc В rpm уже точно не помню, специально не проверял, но вроде бы раньше это выглядело так:
# grub2-mkconfig -o /boot/grub2/grub.cfgКак в современных версиях уже не знаю, так как не использую их.
После этого нужно везде в сетевых настройках изменить имена интерфейсов со старых на новые. Для Debian достаточно отредактировать
/etc/network/interfaces. Не забудьте про firewall, если у вас правила привязаны к именам интерфейсов. Теперь можно перезагружать сервер. Загрузится он со старыми названиями сетевых интерфейсов.
Попутно задам вопрос, на который у меня нет ответа. Я не понимаю, почему в некоторых виртуалках по умолчанию используется старое именование сетевых интерфейсов, а в некоторых новое. Причём, это не зависит от версии ОС. У меня прямо сейчас есть две одинаковые Debian 11, где на одной eth0, а на другой ens18. Первая на HyperV, вторая на Proxmox. Подозреваю, что это зависит от типа эмулируемой сетевухи и драйвера, который используется в системе.
#linux #network
{kind=link}
Протокол ipv6 получил уже довольно широкое распространение по миру. Но конкретно в нашей стране, а тем более в локальной инфраструктуре он присутствует примерно нигде. По крайней мере я ни сам не видел его, ни упоминания о том, что кто-то использует его в своих локальных сетях. В этом просто нет смысла. Это в интернете заканчиваются IP адреса, а не в наших локалках.
С такими вводными оставлять включенным протокол ipv6 не имеет большого смысла. Его надо отдельно настраивать, следить за безопасностью, совместимостью и т.д. Как минимум, надо не забывать настраивать файрвол для него. Если ipv6 вам не нужен, то логично его просто отключить. В Linux это можно сделать разными способами:
1. Через настройки sysctl.
2. Через параметры GRUB.
3. Через сетевые настройки конкретного интерфейса.
Я не знаю, какой из них оптимальный.
В разное время и в разных ситуациях я действую по обстоятельствам. Если система уже настроена и введена в эксплуатацию, то системные настройки трогать уже не буду. Просто отключу на всех сервисах, что слушают ipv6 интерфейс, его работу.
Если же система только настраивается, то можно в GRUB отключить использование ipv6. Это глобальный метод, который гарантированно отключает во всей системе ipv6. Для этого в его конфиг (
После этого нужно обновить загрузчик. В зависимости от системы выглядеть это может по-разному:
Первые три варианта с большей вероятностью подойдут для deb дистрибутивов (для Debian 12 точно подойдут), последняя для rpm. Лучше отдельно уточнить этот момент для вашей системы.
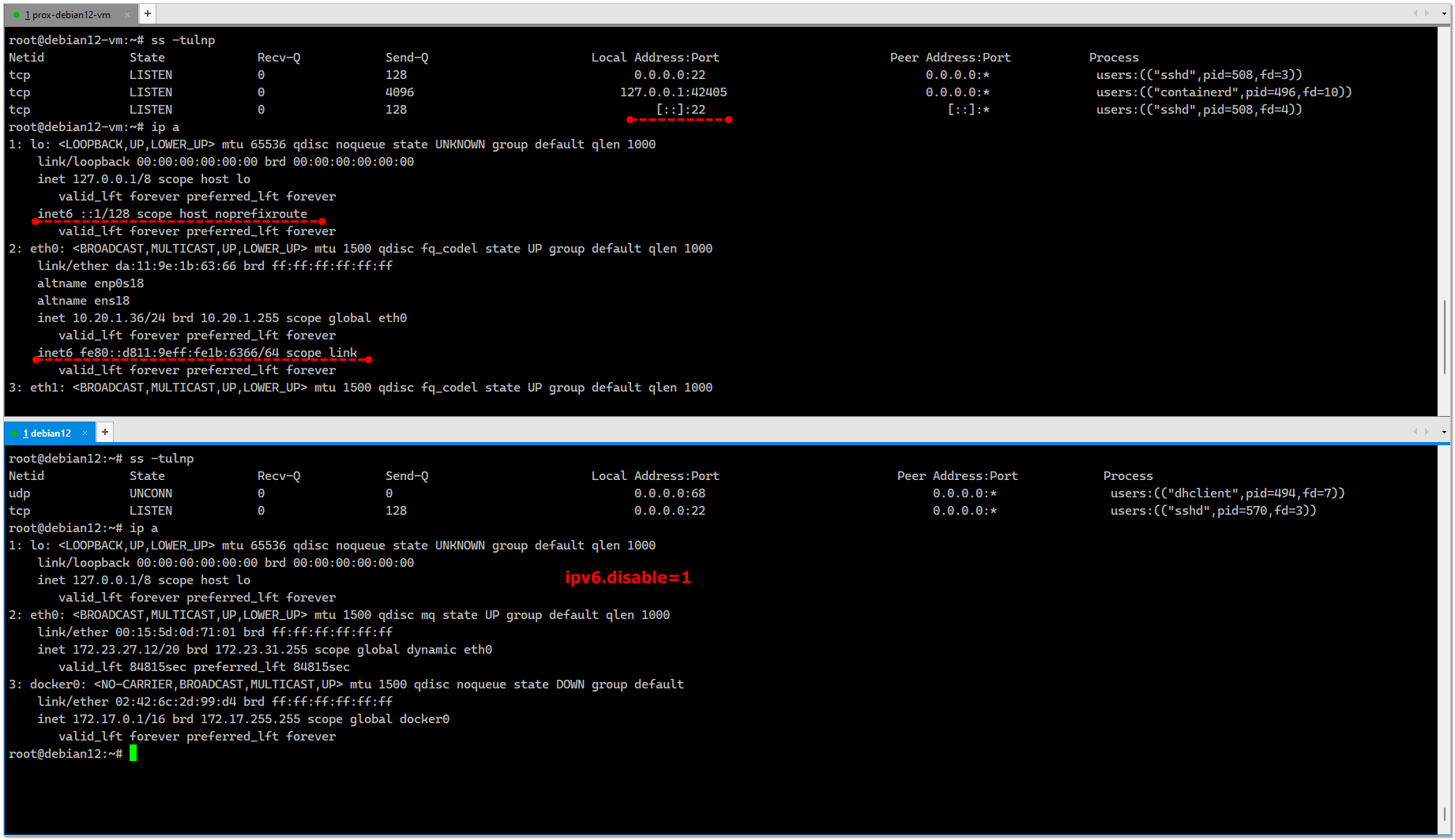
После этого нужно перезагрузить систему и проверить результат. В настройках сетевых интерфейсов не должно быть ipv6 адресов, как и в открытых портах:
Для Windows такую рекомендацию не могу дать, так как слышал информацию, что отключение ipv6 там может привести к проблемам с системой. Так что лучше этот протокол не трогать. Деталей не знаю, подробно не изучал тему, но что-то там ломается без ipv6.
Отключаете у себя ipv6?
#linux #network #ipv6
С такими вводными оставлять включенным протокол ipv6 не имеет большого смысла. Его надо отдельно настраивать, следить за безопасностью, совместимостью и т.д. Как минимум, надо не забывать настраивать файрвол для него. Если ipv6 вам не нужен, то логично его просто отключить. В Linux это можно сделать разными способами:
1. Через настройки sysctl.
2. Через параметры GRUB.
3. Через сетевые настройки конкретного интерфейса.
Я не знаю, какой из них оптимальный.
В разное время и в разных ситуациях я действую по обстоятельствам. Если система уже настроена и введена в эксплуатацию, то системные настройки трогать уже не буду. Просто отключу на всех сервисах, что слушают ipv6 интерфейс, его работу.
Если же система только настраивается, то можно в GRUB отключить использование ipv6. Это глобальный метод, который гарантированно отключает во всей системе ipv6. Для этого в его конфиг (
/etc/default/grub), конкретно в параметр GRUB_CMDLINE_LINUX, нужно добавить значение ipv6.disable=1. Если там уже указаны другие значения, то перечислены они должны быть через пробел. Примерно так:GRUB_CMDLINE_LINUX="crashkernel=auto rhgb quiet ipv6.disable=1"После этого нужно обновить загрузчик. В зависимости от системы выглядеть это может по-разному:
# dpkg-reconfigure grub-pc# update-grub# grub-mkconfig -o /boot/grub/grub.cfg# grub2-mkconfig -o /boot/grub2/grub.cfgПервые три варианта с большей вероятностью подойдут для deb дистрибутивов (для Debian 12 точно подойдут), последняя для rpm. Лучше отдельно уточнить этот момент для вашей системы.
После этого нужно перезагрузить систему и проверить результат. В настройках сетевых интерфейсов не должно быть ipv6 адресов, как и в открытых портах:
# ip a# ss -tulnpДля Windows такую рекомендацию не могу дать, так как слышал информацию, что отключение ipv6 там может привести к проблемам с системой. Так что лучше этот протокол не трогать. Деталей не знаю, подробно не изучал тему, но что-то там ломается без ipv6.
Отключаете у себя ipv6?
#linux #network #ipv6
{kind=link}
На прошлой неделе подписчик поделился со мной полезной информацией, которая может пригодиться более широкой аудитории, нежели только я. Искренне выражаю благодарность всем, кто мне пишет какую-то полезную информацию, так как желание бескорыстно (а зачастую и анонимно) помогать другим благотворно влияет и на тех, кто помогает, и на тех, кто получает. Не всё из этого я публикую, потому что что-то не формат канала, что-то не кажется мне полезным аудитории, что-то я не успеваю проверить и забываю.
Сегодня речь пойдёт об утилите dhcptest и скрипте на powershell для автоматического поиска в сети постороннего DHCP сервера с уведомлением в Telegram об IP этого сервера и его MAC адресе. Думаю, многие администраторы сталкивались с ситуацией, когда в сети появляется посторонний DHCP сервер. В зависимости от настроек сетевого оборудования, он может наделать много бед. Обычно эти беды приходят, когда сталкиваешься с этим в первый раз. А потом уже начинаешь искать информацию и думать, как от этого защититься. Я сталкивался с подобным много раз.
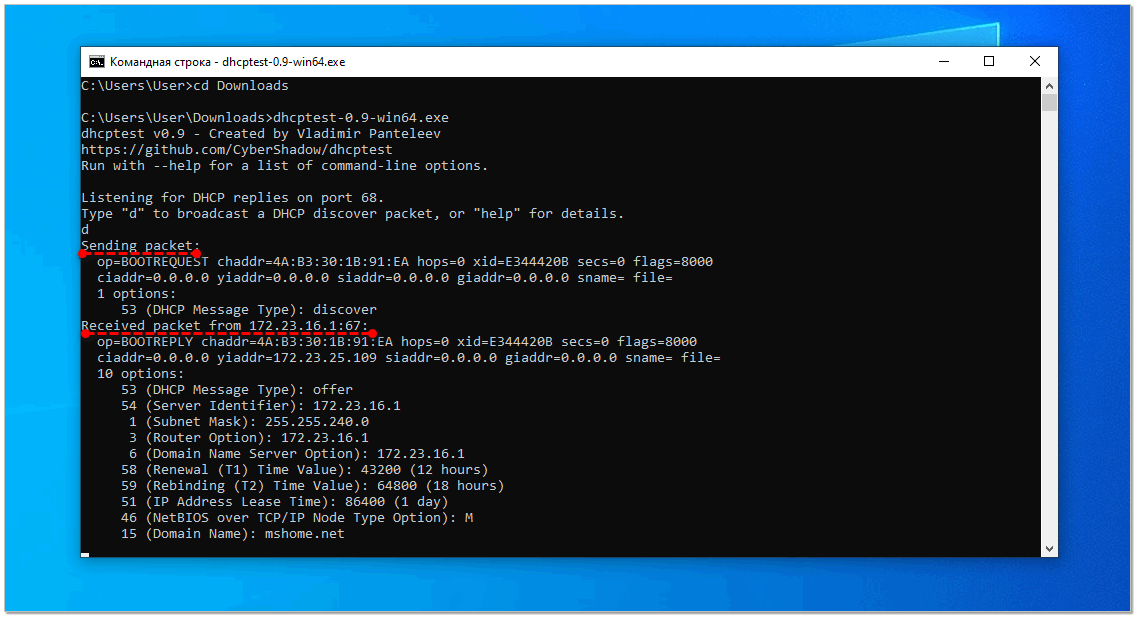
Dhcptest делает очень простую работу – отправляет запрос на получение сетевых настроек и собирает информацию об ответивших. Она может работать как в интерактивном режиме, так и автоматически с заданием настроек через ключи запуска. В скрипте как раз будет такой пример. В репозитории лежат только исходники, но там же есть ссылка на сайт автора, где есть собранный бинарник под Windows.
Скрипт на powershell делает следующее:
1️⃣ Скачивает утилиту, переименовывает и кладёт её рядом с собой.
2️⃣ Запускает раз в минуту dhcp тест с запросом настроек и получает IP адрес ответившего сервера.
3️⃣ Если этого сервера нет в вашем списке DHCP серверов, то пингует этот сервер, проверяя его доступность, смотрит ARP таблицу и пытается получить его MAC.
4️⃣ Отправляет IP и MAC постороннего сервера в Telegram.
Понятно, что задачу по защите локальной сети от посторонних DHCP серверов можно и нужно решать другими способами, а не такими костылями. Обычно управляемые свитчи позволяют ограничивать активность неавторизованных DHCP серверов с помощью технологии DHCP Snooping. Но если ничего другого нет, то можно воспользоваться предложенным способом. К тому же вопрос с уведомлениями всё равно каким-то образом нужно будет решать отдельно.
Сам скрипт опубликован ниже в следующем сообщении.
⬇️⬇️⬇️⬇️⬇️
#network #dhcp
Сегодня речь пойдёт об утилите dhcptest и скрипте на powershell для автоматического поиска в сети постороннего DHCP сервера с уведомлением в Telegram об IP этого сервера и его MAC адресе. Думаю, многие администраторы сталкивались с ситуацией, когда в сети появляется посторонний DHCP сервер. В зависимости от настроек сетевого оборудования, он может наделать много бед. Обычно эти беды приходят, когда сталкиваешься с этим в первый раз. А потом уже начинаешь искать информацию и думать, как от этого защититься. Я сталкивался с подобным много раз.
Dhcptest делает очень простую работу – отправляет запрос на получение сетевых настроек и собирает информацию об ответивших. Она может работать как в интерактивном режиме, так и автоматически с заданием настроек через ключи запуска. В скрипте как раз будет такой пример. В репозитории лежат только исходники, но там же есть ссылка на сайт автора, где есть собранный бинарник под Windows.
Скрипт на powershell делает следующее:
1️⃣ Скачивает утилиту, переименовывает и кладёт её рядом с собой.
2️⃣ Запускает раз в минуту dhcp тест с запросом настроек и получает IP адрес ответившего сервера.
3️⃣ Если этого сервера нет в вашем списке DHCP серверов, то пингует этот сервер, проверяя его доступность, смотрит ARP таблицу и пытается получить его MAC.
4️⃣ Отправляет IP и MAC постороннего сервера в Telegram.
Понятно, что задачу по защите локальной сети от посторонних DHCP серверов можно и нужно решать другими способами, а не такими костылями. Обычно управляемые свитчи позволяют ограничивать активность неавторизованных DHCP серверов с помощью технологии DHCP Snooping. Но если ничего другого нет, то можно воспользоваться предложенным способом. К тому же вопрос с уведомлениями всё равно каким-то образом нужно будет решать отдельно.
Сам скрипт опубликован ниже в следующем сообщении.
⬇️⬇️⬇️⬇️⬇️
#network #dhcp
{kind=link}
$AllowedDHCPServer = "ЗДЕСЬ_АЙПИШНИК_ТВОЕГО_DHCP"
#Замените URL-адрес загрузки на тот, куда вы сами загрузили файл DHCPTest. Мы загрузим этот файл только один раз.
$DownloadURL = "https://files.cy.md/dhcptest/dhcptest-0.9-win64.exe"
$DownloadLocation = "$(pwd)\DHCPTest"
$BotToken = "СЮДА_СУЙ_ТОКЕН_БОТА"
# Объявление массива с идентификаторами чатов
$ChatIDs = @("USERID1", "USERID2")
$NMinutes = 1 # Интервал времени для повторения проверки в минутах
# Функция для отправки сообщений в Telegram
function Send-TelegramMessage {
param (
[Parameter(Mandatory=$true)]
[string]$MessageText,
[Parameter(Mandatory=$true)]
[string[]]$ChatIDs
)
$TelegramAPI = "https://api.telegram.org/bot$BotToken/sendMessage"
foreach ($ChatID in $ChatIDs) {
$params = @{
chat_id = $ChatID
text = $MessageText
parse_mode = "Markdown"
}
$response = Invoke-WebRequest -Uri $TelegramAPI -Method Post -Body $params -ContentType "application/x-www-form-urlencoded"
}
}
# Бесконечный цикл для периодической проверки
while ($true) {
try {
$TestDownloadLocation = Test-Path $DownloadLocation
if (!$TestDownloadLocation) { New-Item $DownloadLocation -ItemType Directory -Force }
$TestDownloadLocationZip = Test-Path "$DownloadLocation\DHCPTest.exe"
if (!$TestDownloadLocationZip) { Invoke-WebRequest -UseBasicParsing -Uri $DownloadURL -OutFile "$($DownloadLocation)\DHCPTest.exe" }
}
catch {
$ErrorMessage = "Загрузка и извлечение DHCPTest не удались. Ошибка: $($_.Exception.Message)"
Send-TelegramMessage -MessageText $ErrorMessage -ChatIDs $ChatIDs
break # Выход из цикла в случае ошибки
}
$Tests = 0
$ListedDHCPServers = do {
& "$DownloadLocation\DHCPTest.exe" --quiet --query --print-only 54 --wait --timeout 3
$Tests++
} while ($Tests -lt 2)
$DHCPHealthMessages = @()
foreach ($ListedServer in $ListedDHCPServers) {
if ($ListedServer -ne $AllowedDHCPServer) {
# Выполнение команды ping для гарантии наличия IP в ARP-таблице
ping $ListedServer -n 1 | Out-Null
# Получение MAC-адреса из ARP-таблицы
$arpResult = [String]::Join(' ', (arp -a $ListedServer ))
$MACAddress = if ($arpResult -match "(\w{2}-\w{2}-\w{2}-\w{2}-\w{2}-\w{2})") {$matches[0]} else {"MAC адрес не найден"}
$DHCPHealthMessages += "Обнаружен неавторизованный DHCP-сервер. IP-адрес неавторизованного сервера: $ListedServer, MAC адрес: $MACAddress"
}
}
if ($DHCPHealthMessages.Count -gt 0) {
$DHCPHealthMessage = $DHCPHealthMessages -join "`n"
Send-TelegramMessage -MessageText $DHCPHealthMessage -ChatIDs $ChatIDs
}
Start-Sleep -Seconds ($NMinutes * 60) # Пауза перед следующей итерацией цикла
}
#network #dhcp
Опишу своими словами сетевую настройку в ситуации, когда у вас условно от провайдера есть один провод с интернетом и на нём несколько IP адресов. Многие люди не понимают, как в таком случае настраивать сеть, чтобы иметь возможность использовать разные IP адреса. Я много раз получал такие вопросы и даже голосом некоторым рассказывал, как с этим работать.
Возьму популярный пример, когда вы арендуете выделенный сервер и с ним /29 подсеть. Либо у вас в офис от провайдера приходит провод с /29 подсетью, а это всё воткнуто в какой-то шлюз. Например, в Mikrotik. Тогда заметка будет актуальна для обоих ситуаций, так как в Mikrotik линуксовый файрвол iptables. Принцип настройки которого один и тот же.
Итак, у вас сервер и несколько IP адресов. Если это гипервизор, то у вас могут быть 2 принципиально разных варианта настроек:
1️⃣ Вы делаете сетевой бридж с интерфейсом, на который приходят IP адреса. На самом гипервизоре и на виртуальных машинах настраиваете этот бридж. Файрвол на гипервизоре можно вообще не настраивать, он тут не нужен для управления трафиком. Каждая VM получает свой внешний IP адрес. Это самый простой вариант настройки. Но тут виртуалок с разными IP адресами может быть не больше, чем у вас есть IP адресов. Если нужно 3 виртуалки выпускать в интернет через один IP адрес, а 2 других через другой, то такой вариант уже не подходит.
2️⃣ У вас может быть несколько серверов и куча виртуальных машин за шлюзом, к которому подключен шнурок от провайдера. И вы хотите какие-то подсети выпускать в интернет через один IP адрес, а какие-то через другой. Здесь уже нужен будет файрвол на шлюзе. Если это гипервизор Proxmox, то можно настраивать iptables прям на нём. Но лучше вынести такую задачу на отдельную виртуальную машину.
Принцип настройки тут будет следующий. Вы на шлюзе настраиваете все внешние IP адреса, какие будете использовать. Далее с помощью iptables маркируете (mangle) трафик из разных подсетей разными метками. Признак маркировки - источник в виде адреса подсети или отдельных IP адресов, если вам не подсетями делить нужно, а отдельными адресами. После этого вы создаёте маршруты через нужные внешние IP адреса на основе меток. Трафик с разными метками будет выходить через разные IP адреса. И в завершении нужно будет добавить правила NAT (snat) для разных внешних IP адресов (--to-source). Тоже на основе меток.
Первый раз такая настройка кажется запутанной и непонятной. Но на самом деле настроить это не сложно. Главное, понять суть. Чисто технически тут не придётся делать много сложных настроек. Если всё сложится, то вскоре у меня появится возможность показать подобный пример в виде статьи.
3️⃣ Есть ещё промежуточный вариант, более простой, чем второй. Вы настраиваете, как в первом случае, каждой машине свой внешний IP адрес через бридж. И эти машины делаете шлюзами для разных подсетей. Тогда вам не придётся заниматься маркировкой и маршрутизацией как во втором случае. Ситуация менее гибкая, но зато простая в настройке.
#network
Возьму популярный пример, когда вы арендуете выделенный сервер и с ним /29 подсеть. Либо у вас в офис от провайдера приходит провод с /29 подсетью, а это всё воткнуто в какой-то шлюз. Например, в Mikrotik. Тогда заметка будет актуальна для обоих ситуаций, так как в Mikrotik линуксовый файрвол iptables. Принцип настройки которого один и тот же.
Итак, у вас сервер и несколько IP адресов. Если это гипервизор, то у вас могут быть 2 принципиально разных варианта настроек:
1️⃣ Вы делаете сетевой бридж с интерфейсом, на который приходят IP адреса. На самом гипервизоре и на виртуальных машинах настраиваете этот бридж. Файрвол на гипервизоре можно вообще не настраивать, он тут не нужен для управления трафиком. Каждая VM получает свой внешний IP адрес. Это самый простой вариант настройки. Но тут виртуалок с разными IP адресами может быть не больше, чем у вас есть IP адресов. Если нужно 3 виртуалки выпускать в интернет через один IP адрес, а 2 других через другой, то такой вариант уже не подходит.
2️⃣ У вас может быть несколько серверов и куча виртуальных машин за шлюзом, к которому подключен шнурок от провайдера. И вы хотите какие-то подсети выпускать в интернет через один IP адрес, а какие-то через другой. Здесь уже нужен будет файрвол на шлюзе. Если это гипервизор Proxmox, то можно настраивать iptables прям на нём. Но лучше вынести такую задачу на отдельную виртуальную машину.
Принцип настройки тут будет следующий. Вы на шлюзе настраиваете все внешние IP адреса, какие будете использовать. Далее с помощью iptables маркируете (mangle) трафик из разных подсетей разными метками. Признак маркировки - источник в виде адреса подсети или отдельных IP адресов, если вам не подсетями делить нужно, а отдельными адресами. После этого вы создаёте маршруты через нужные внешние IP адреса на основе меток. Трафик с разными метками будет выходить через разные IP адреса. И в завершении нужно будет добавить правила NAT (snat) для разных внешних IP адресов (--to-source). Тоже на основе меток.
Первый раз такая настройка кажется запутанной и непонятной. Но на самом деле настроить это не сложно. Главное, понять суть. Чисто технически тут не придётся делать много сложных настроек. Если всё сложится, то вскоре у меня появится возможность показать подобный пример в виде статьи.
3️⃣ Есть ещё промежуточный вариант, более простой, чем второй. Вы настраиваете, как в первом случае, каждой машине свой внешний IP адрес через бридж. И эти машины делаете шлюзами для разных подсетей. Тогда вам не придётся заниматься маркировкой и маршрутизацией как во втором случае. Ситуация менее гибкая, но зато простая в настройке.
#network
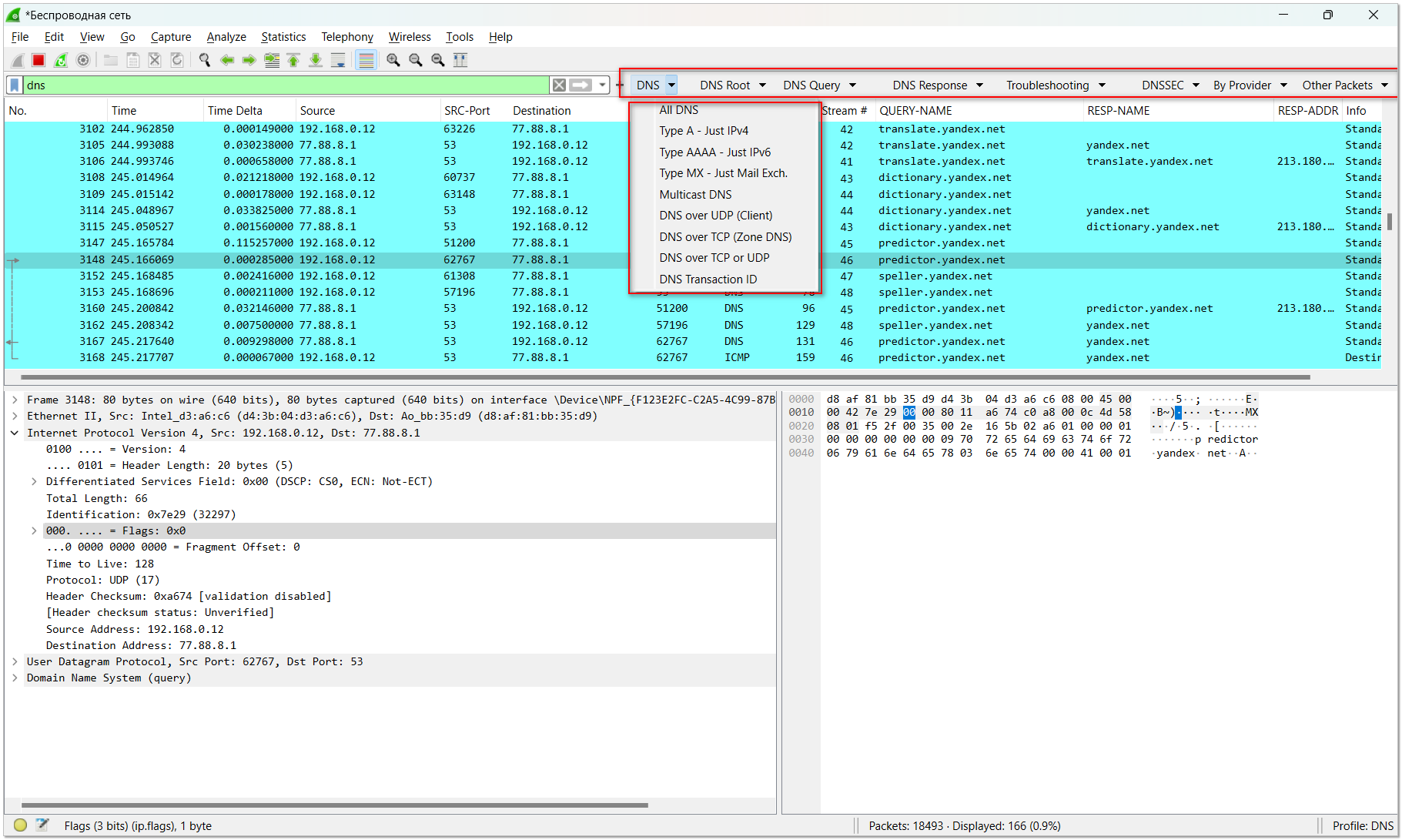
Если вам иногда приходится работать в Wireshark, а любому админу рано или поздно приходится это делать, то у меня для вас есть полезный репозиторий. Даже если он вам сейчас не нужен, сохраните его. Пригодится, когда расчехлите Wireshark.
⇨ https://github.com/amwalding/wireshark_profiles
Здесь собрано множество готовых профилей для анализа того или иного трафика. Рассказываю на пальцах, как им пользоваться.
1️⃣ Скачиваете из репозитория zip файл нужного вам профиля. Например, DNS.
2️⃣ В Wireshark идёте в раздел Edit ⇨ Configuration Profiles. Жмёте Import from zip files и импортируете скачанный профайл в zip файле. Выбираете его.
3️⃣ Выбираете сетевой интерфейс, с которого хотите собирать пакеты. Откроется основной интерфейс программы с готовыми настройками фильтров.
4️⃣ Потом загруженные фильтры можно быстро переключать в правом нижнем углу программы.
Ничего особенного тут нет, можно и самому набросать себе нужные фильтры. Но тут всё сделали за нас, упростив задачу. Как минимум, не помешают базовые фильтры на DNS, DHCP, HTTP, ARP, SMB, VLAN и т.д.
#network #wireshark
⇨ https://github.com/amwalding/wireshark_profiles
Здесь собрано множество готовых профилей для анализа того или иного трафика. Рассказываю на пальцах, как им пользоваться.
1️⃣ Скачиваете из репозитория zip файл нужного вам профиля. Например, DNS.
2️⃣ В Wireshark идёте в раздел Edit ⇨ Configuration Profiles. Жмёте Import from zip files и импортируете скачанный профайл в zip файле. Выбираете его.
3️⃣ Выбираете сетевой интерфейс, с которого хотите собирать пакеты. Откроется основной интерфейс программы с готовыми настройками фильтров.
4️⃣ Потом загруженные фильтры можно быстро переключать в правом нижнем углу программы.
Ничего особенного тут нет, можно и самому набросать себе нужные фильтры. Но тут всё сделали за нас, упростив задачу. Как минимум, не помешают базовые фильтры на DNS, DHCP, HTTP, ARP, SMB, VLAN и т.д.
#network #wireshark
{kind=link}
С удивлением недавно узнал, что известный и популярный ISC DHCP Server с 2022 года не развивается и не поддерживается. Вот соответствующая новость на сайте разработчиков:
⇨ ISC DHCP Server has reached EOL
Я начинал работу с DHCP серверами в Linux как раз с этим сервером. Его базовая настройка была простая и быстрая. Один конфиг с несколькими опциями и дальше настройка подсетей и резервирований. Лог файл и выданные leases в отдельных текстовых файлах. Было удобно поддерживать и дебажить.
Со временем переехал на Dnsmasq, так как он объединяет службы dns и dhcp, что для небольших сетей удобно, поэтому за isc-dhcp следить перестал. Разработчики перестали его развивать, потому что с их слов его код труден для тестирования и внедрения нововведений. Поэтому они прекратили его поддержку, а всё развитие продолжили в новом проекте Kea DHCP, внедрив туда:
◽модульную структуру, где DHCPv4, DHCPv6, DDNS службы работают независимо друг от друга;
◽изменение конфигурации на лету через запросы к REST API;
◽конфигурация в json формате;
◽графический дашборд через web интерфейс;
◽поддержку разных бэкендов для хранения конфигурации: MySQL, PostgreSQL, Cassandra или CSV файл;
◽возмжоность настроить отказоустойчивую конфигурацию;
Сразу отмечу, что для Kea есть пакет netbox-kea-dhcp для интеграции с известным сервисом netbox.
Все компоненты kea есть в стандартном репозитории Debian. Как уже было упомянуто, структура продукта модульная, так что для каждой службы есть отдельный пакет:
▪️ kea - как я понял общий пакет, который в зависимостях тянет все остальные
▪️ kea-admin - утилиты управления
▪️ kea-common - общие библиотеки сервера
▪️ kea-ctrl-agent - служба REST API
▪️ kea-dhcp-ddns-server - служба DDNS
▪️ kea-dhcp4-server - IPv4 DHCP сервер
▪️ kea-dhcp6-server - IPv6 DHCP сервер
Есть инструмент для автоматической миграции с isc-dhcp в одно действие. Примерно так:
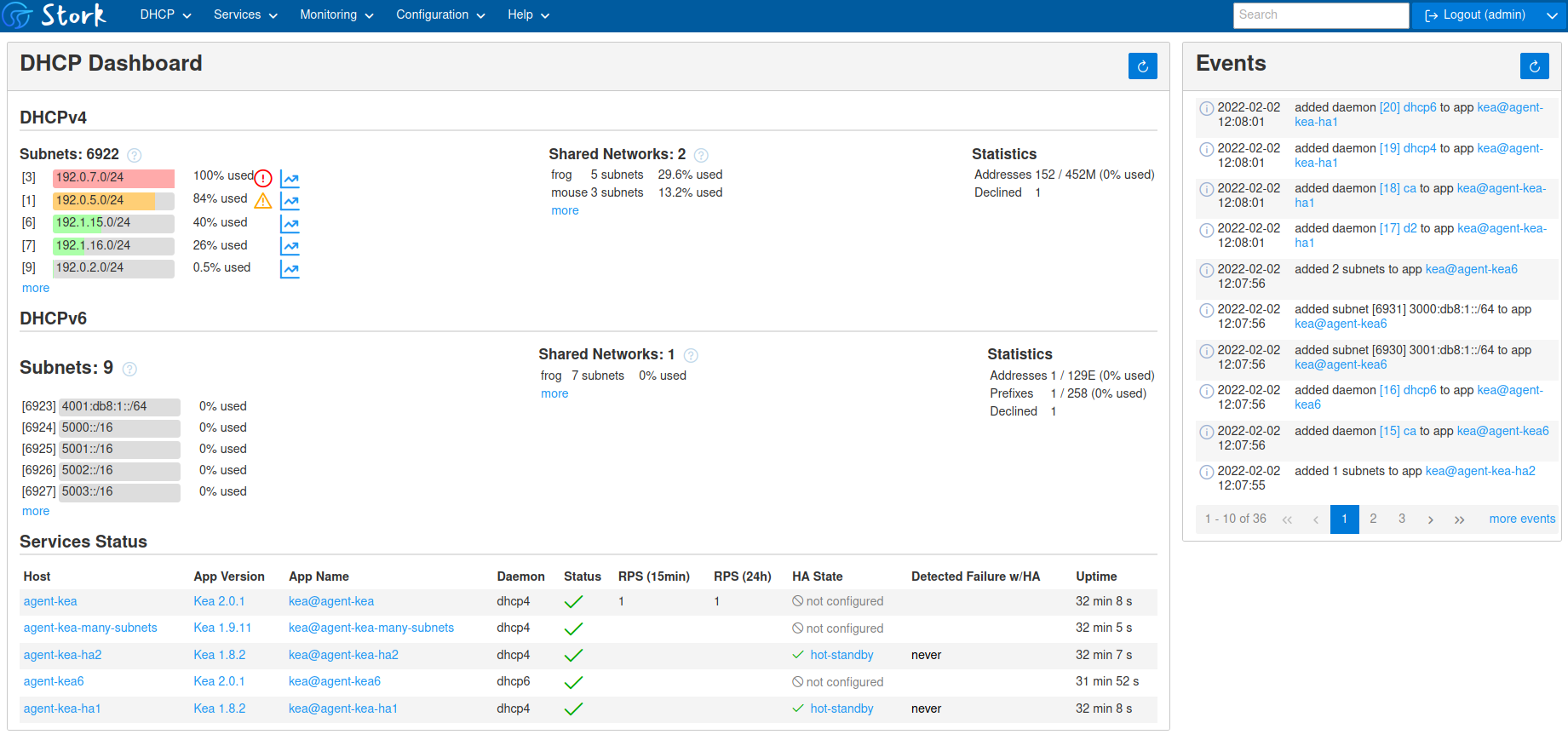
Dashboard для Kea реализован на базе отдельного продукта от тех же авторов - Stork. Помимо непосредственно веб интерфейса с информацией о работе сервисов, stork предоставляет экспорт метрик в prometheus и готовые дашборды для Grafana.
Все описанные возмжоности представлены в open source версии. Я посмотрел примеры настроек. Там всё относительно просто. Не сложнее, чем было в isc-dhcp. Вместе с веб интерфейсом, метриками и дашбордами это выглядит наиболее привлекательным dhcp сервером на текущий момент. При случае попробую его натсроить вместо dnsmasq.
#network #dhcp
⇨ ISC DHCP Server has reached EOL
Я начинал работу с DHCP серверами в Linux как раз с этим сервером. Его базовая настройка была простая и быстрая. Один конфиг с несколькими опциями и дальше настройка подсетей и резервирований. Лог файл и выданные leases в отдельных текстовых файлах. Было удобно поддерживать и дебажить.
Со временем переехал на Dnsmasq, так как он объединяет службы dns и dhcp, что для небольших сетей удобно, поэтому за isc-dhcp следить перестал. Разработчики перестали его развивать, потому что с их слов его код труден для тестирования и внедрения нововведений. Поэтому они прекратили его поддержку, а всё развитие продолжили в новом проекте Kea DHCP, внедрив туда:
◽модульную структуру, где DHCPv4, DHCPv6, DDNS службы работают независимо друг от друга;
◽изменение конфигурации на лету через запросы к REST API;
◽конфигурация в json формате;
◽графический дашборд через web интерфейс;
◽поддержку разных бэкендов для хранения конфигурации: MySQL, PostgreSQL, Cassandra или CSV файл;
◽возмжоность настроить отказоустойчивую конфигурацию;
Сразу отмечу, что для Kea есть пакет netbox-kea-dhcp для интеграции с известным сервисом netbox.
Все компоненты kea есть в стандартном репозитории Debian. Как уже было упомянуто, структура продукта модульная, так что для каждой службы есть отдельный пакет:
▪️ kea - как я понял общий пакет, который в зависимостях тянет все остальные
▪️ kea-admin - утилиты управления
▪️ kea-common - общие библиотеки сервера
▪️ kea-ctrl-agent - служба REST API
▪️ kea-dhcp-ddns-server - служба DDNS
▪️ kea-dhcp4-server - IPv4 DHCP сервер
▪️ kea-dhcp6-server - IPv6 DHCP сервер
Есть инструмент для автоматической миграции с isc-dhcp в одно действие. Примерно так:
# keama -4 -i /etc/dhcp/dhcp4.conf -o /etc/kea/kea-dhcp4.confDashboard для Kea реализован на базе отдельного продукта от тех же авторов - Stork. Помимо непосредственно веб интерфейса с информацией о работе сервисов, stork предоставляет экспорт метрик в prometheus и готовые дашборды для Grafana.
Все описанные возмжоности представлены в open source версии. Я посмотрел примеры настроек. Там всё относительно просто. Не сложнее, чем было в isc-dhcp. Вместе с веб интерфейсом, метриками и дашбордами это выглядит наиболее привлекательным dhcp сервером на текущий момент. При случае попробую его натсроить вместо dnsmasq.
#network #dhcp
{kind=link}
Услышал неожиданную и новую для себя информацию. Нельзя последовательно соединить две и более rj45 розетки для того, чтобы пользоваться только одной из них одновременно. Работать будет только последняя розетка. Спорить не стал, но слегка удивился, так как для меня это неочевидная информация. К тому же я сам у себя в доме электрические розетки собирал и некоторые из них соединялись последовательно. То же самое для температурных датчиков делал, которые соединял последовательно на шине от контроллера. То есть для меня такая схема подключения выглядит вполне привычной. Я бы даже не подумал, что тут есть какой-то нюанс.
Полез в интернет за подробностями и действительно нашёл подтверждение этому. Последовательно соединять ethernet розетки нельзя, даже если будет использоваться только одна. Если подключиться к розетке посередине, то тот конец, что идёт до дальней розетки, будет отражать сигнал. Это будет приводить к помехам в сети, соединение будет либо постоянно обрываться, либо вообще не установится.
Надо либо отдельный кабель кидать к каждой розетке, либо ставить какое-то устройство, которое будет физически отсекать конец кабеля до других розеток, чтобы подключенная была последней в цепи.
❗️Век живи, век учись. Знали об этом? Либо может быть сталкивались с таким соединением?
#железо #network
Полез в интернет за подробностями и действительно нашёл подтверждение этому. Последовательно соединять ethernet розетки нельзя, даже если будет использоваться только одна. Если подключиться к розетке посередине, то тот конец, что идёт до дальней розетки, будет отражать сигнал. Это будет приводить к помехам в сети, соединение будет либо постоянно обрываться, либо вообще не установится.
Надо либо отдельный кабель кидать к каждой розетке, либо ставить какое-то устройство, которое будет физически отсекать конец кабеля до других розеток, чтобы подключенная была последней в цепи.
❗️Век живи, век учись. Знали об этом? Либо может быть сталкивались с таким соединением?
#железо #network
Я недавно рассказывал про namespaces в Linux. На основе этой изоляции работает множество софта. Далее будет пример одного из них, который использует network namespaces для записи дампа трафика конкретного приложения.
Речь пойдёт про nsntrace. Это относительно простое приложение, которое, как я уже сказал, может собрать дамп трафика отдельного приложения. Для этого оно делает следующие вещи:
1️⃣ Создаёт отдельный network namespace для исследуемого приложения.
2️⃣ Для того, чтобы там был доступ в интернет, создаются виртуальные сетевые интерфейсы. Один в новом namespace, другой в основном. В новом используется шлюз из основного namespace. Из-за этой схемы у запускаемого приложения будет IP адрес виртуальной сети.
3️⃣ Средствами iptables трафик натится из виртуальной сети в реальную.
4️⃣ Запускает приложение в новом namespace и собирает его трафик с помощью libpcap. Результат сохраняет в обычный pcap файл.
Nsntrace есть в базовых репах Debian:
Самый банальный пример, чтобы проверить работу:
На выходе получаем nsntrace.pcap, который можно посмотреть тут же, если у вас есть tshark:
Можно и в режиме реального времени наблюдать:
Помимо обычных приложений, снимать трафик можно и со скриптов:
Проверим на простом python скрипте:
Запускаем анализ сетевой активности:
Смотрим:
Можно передать .pcap на другую машину и посмотреть в Wireshark.
Удобный инструмент. Нужен не часто, но конкретно для скриптов мне реализация понравилась. Обычно это нетривиальная задача, посмотреть, куда он стучится и что делает. Нужно вычленять именно его запросы из общего трафика, а это не всегда просто. Либо трассировку работы делать, что тоже сложнее, чем просто воспользоваться nsntrace.
#network #perfomance
Речь пойдёт про nsntrace. Это относительно простое приложение, которое, как я уже сказал, может собрать дамп трафика отдельного приложения. Для этого оно делает следующие вещи:
1️⃣ Создаёт отдельный network namespace для исследуемого приложения.
2️⃣ Для того, чтобы там был доступ в интернет, создаются виртуальные сетевые интерфейсы. Один в новом namespace, другой в основном. В новом используется шлюз из основного namespace. Из-за этой схемы у запускаемого приложения будет IP адрес виртуальной сети.
3️⃣ Средствами iptables трафик натится из виртуальной сети в реальную.
4️⃣ Запускает приложение в новом namespace и собирает его трафик с помощью libpcap. Результат сохраняет в обычный pcap файл.
Nsntrace есть в базовых репах Debian:
# apt install nsntraceСамый банальный пример, чтобы проверить работу:
# nsntrace wget google.comНа выходе получаем nsntrace.pcap, который можно посмотреть тут же, если у вас есть tshark:
# tshark -r nsntrace.pcapМожно и в режиме реального времени наблюдать:
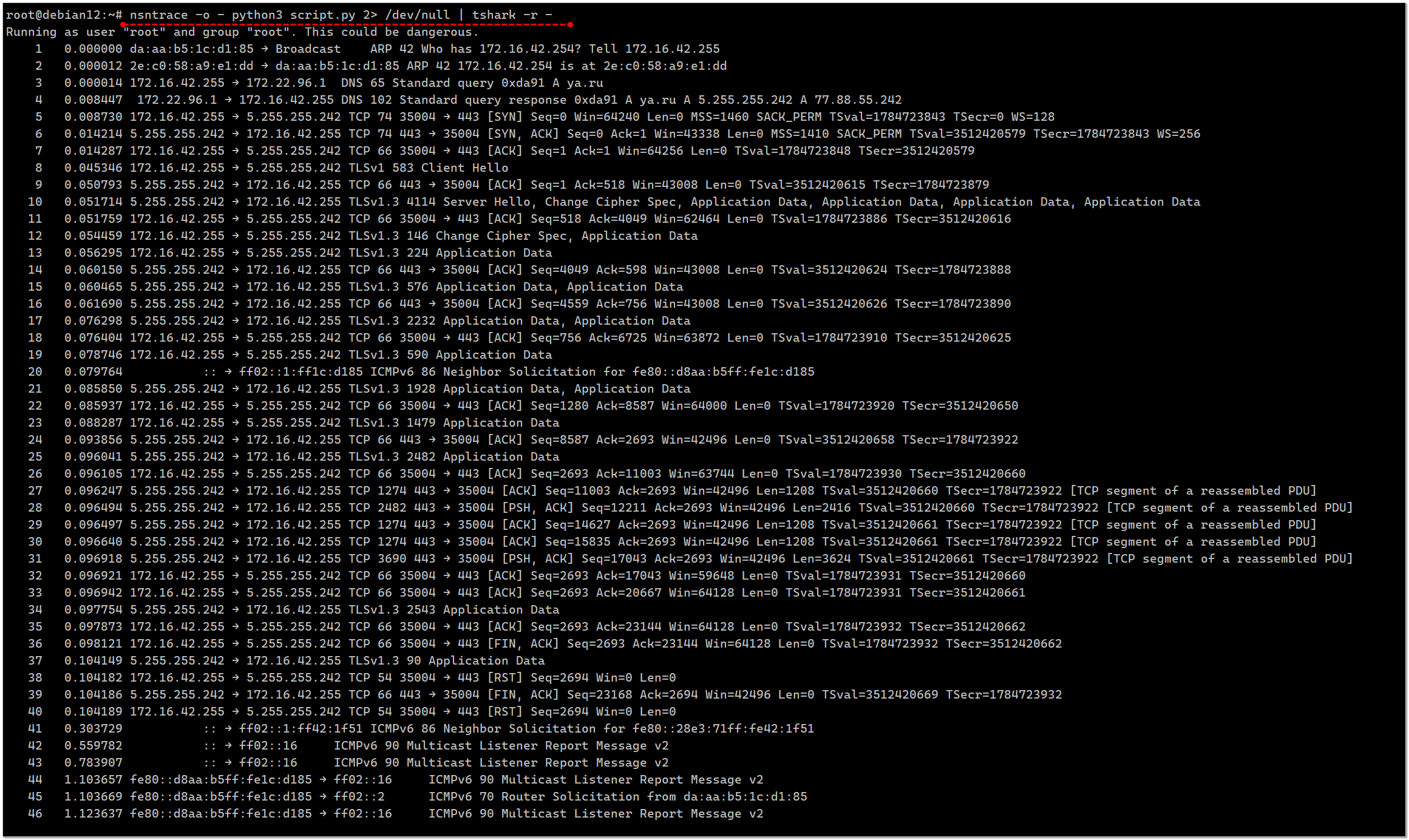
# nsntrace -o - wget google.com 2> /dev/null | tshark -r -Помимо обычных приложений, снимать трафик можно и со скриптов:
# nsntrace php script.php# nsntrace python script.pyПроверим на простом python скрипте:
import requestsres = requests.get('https://ya.ru')Запускаем анализ сетевой активности:
# nsntrace python3 script.pyStarting network trace of 'python3' on interface eth0.Your IP address in this trace is 172.16.42.255.Use ctrl-c to end at any time.Finished capturing 57 packets.Смотрим:
# tshark -r nsntrace.pcapМожно передать .pcap на другую машину и посмотреть в Wireshark.
Удобный инструмент. Нужен не часто, но конкретно для скриптов мне реализация понравилась. Обычно это нетривиальная задача, посмотреть, куда он стучится и что делает. Нужно вычленять именно его запросы из общего трафика, а это не всегда просто. Либо трассировку работы делать, что тоже сложнее, чем просто воспользоваться nsntrace.
#network #perfomance
{kind=link}
Расскажу про непривычное представление IP адреса, которое вряд ли где-то на практике пригодится. Информация чисто для расширения кругозора. Можно использовать для собеседований или приколов над коллегами:
Вот такая тема работает. Можно пинговать хосты, представляя их IP адреса в десятичной системе исчисления. Показываю, как это сделать.
Берём IP адрес 77.88.8.1 и преобразуем его в двоичное представление. Можно по отдельности каждый окет, либо на каком-то калькуляторе. Например, тут:
⇨ https://infocisco.ru/ip_to_bin.php
77.88.8.1 ⇨ 01001101010110000000100000000001
А теперь это двоичное представление переводим в десятичный вид. Например, тут:
⇨ https://calcus.ru/perevod-sistem-schisleniya/iz-dvoichnoy-v-desyatichnuyu
01001101010110000000100000000001 ⇨ 1297614849
И теперь этот адрес в виде десятичного числа можно использовать вместо IP адреса. К сожалению, я не нашёл, где ещё его можно использовать в таком виде. Попытался в hosts добавлять, но ни в Windows, ни в Linux представление в таком виде не работает. Команда
Если кто-то знает, где ещё можно в десятичном виде использовать IP адреса, поделитесь информацией.
#network
🦖 Selectel — дешёвые и не очень дедики с аукционом!
$ ping 1297614849PING 1297614849 (77.88.8.1) 56(84) bytes of data.64 bytes from 77.88.8.1: icmp_seq=1 ttl=56 time=8.03 ms64 bytes from 77.88.8.1: icmp_seq=2 ttl=56 time=8.39 ms64 bytes from 77.88.8.1: icmp_seq=3 ttl=56 time=8.08 ms64 bytes from 77.88.8.1: icmp_seq=4 ttl=56 time=7.94 msВот такая тема работает. Можно пинговать хосты, представляя их IP адреса в десятичной системе исчисления. Показываю, как это сделать.
Берём IP адрес 77.88.8.1 и преобразуем его в двоичное представление. Можно по отдельности каждый окет, либо на каком-то калькуляторе. Например, тут:
⇨ https://infocisco.ru/ip_to_bin.php
77.88.8.1 ⇨ 01001101010110000000100000000001
А теперь это двоичное представление переводим в десятичный вид. Например, тут:
⇨ https://calcus.ru/perevod-sistem-schisleniya/iz-dvoichnoy-v-desyatichnuyu
01001101010110000000100000000001 ⇨ 1297614849
И теперь этот адрес в виде десятичного числа можно использовать вместо IP адреса. К сожалению, я не нашёл, где ещё его можно использовать в таком виде. Попытался в hosts добавлять, но ни в Windows, ни в Linux представление в таком виде не работает. Команда
host тоже не принимает в таком виде, в статические записи DNS в микротике тоже не проходит. Работает в ping, tracert, traceroute.Если кто-то знает, где ещё можно в десятичном виде использовать IP адреса, поделитесь информацией.
#network
Please open Telegram to view this post
VIEW IN TELEGRAM
Очень простой и быстрый способ измерить ширину канала с помощью Linux без установки дополнительных пакетов. Понадобится только netcat, который чаще всего есть в составе базовых утилит. По крайней мере в Debian это так.
Берём условный сервер 10.20.1.50 и запускаем там netcat на порту 5201:
Идём на другую машину и запускаем netcat в режиме клиента, передавая туда 10 блоков размером 10 мегабайт:
Когда измерял так скорость, немного усомнился в достоверности результатов. Решил провести одинаковые тесты с помощью netcat и iperf3. На скоростях до 1 Gbits/sec замеры показывают одинаковые числа, плюс-минус в районе погрешности измерений. Можно смело использовать netcat. Это реально работает для быстрой проверки канала до какой-то VPS.
А вот в сетях в рамках гипервизора, где скорости значительно больше, идут большие расхождения. Iperf3 показывает раза в 4 больше скорость (~15.0 Gbits/sec), чем netcat (~4.0 Gbits/sec). Гипервизор объявляет скорость своего бриджа в 10 Gbits/sec. И тут уже трудно судить, кто ближе к истине. Корректно выполнить замеры на реальных данных затруднительно, так как много факторов, которые влияют на итоговый результат.
Напомню, что у меня есть хорошая заметка про netcat с различными практическими примерами применения этой утилиты.
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux #network
Берём условный сервер 10.20.1.50 и запускаем там netcat на порту 5201:
# nc -lvp 5201 > /dev/nullИдём на другую машину и запускаем netcat в режиме клиента, передавая туда 10 блоков размером 10 мегабайт:
# dd if=/dev/zero bs=10M count=10 | nc 10.20.1.50 5201Когда измерял так скорость, немного усомнился в достоверности результатов. Решил провести одинаковые тесты с помощью netcat и iperf3. На скоростях до 1 Gbits/sec замеры показывают одинаковые числа, плюс-минус в районе погрешности измерений. Можно смело использовать netcat. Это реально работает для быстрой проверки канала до какой-то VPS.
А вот в сетях в рамках гипервизора, где скорости значительно больше, идут большие расхождения. Iperf3 показывает раза в 4 больше скорость (~15.0 Gbits/sec), чем netcat (~4.0 Gbits/sec). Гипервизор объявляет скорость своего бриджа в 10 Gbits/sec. И тут уже трудно судить, кто ближе к истине. Корректно выполнить замеры на реальных данных затруднительно, так как много факторов, которые влияют на итоговый результат.
Напомню, что у меня есть хорошая заметка про netcat с различными практическими примерами применения этой утилиты.
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux #network
Я уже давно использую заметки с канала как свои шпаргалки. Всё полезное из личных заметок перенёс сюда, плюс оформил всё это аккуратно и дополнил. Когда ищу какую-то информацию, в первую очередь иду сюда, ищу по тегам или содержимому.
Обнаружил, что тут нет заметки про tcpdump, хотя личная шпаргалка по этой программе у меня есть. Переношу сюда. По tcpdump можно много всего написать, материала море. Я напишу кратко, только те команды, что использую сам. Их немного. Tcpdump использую редко, если есть острая необходимость.
Я ко всем командам добавляю ключ
📌 Список сетевых интерфейсов, с которых tcpdump может смотреть пакеты:
Если запустить программу без ключей, то трафик будет захвачен с первого активного интерфейса из списка выше.
📌 Слушаем все интерфейсы:
Или только конкретный:
📌 Исключаем SSH протокол. Если в трафике, на который мы смотрим, будет SSH соединение, то оно забивает весь вывод своей активностью. Глазами уже не разобрать. Исключаю его по номеру порта:
По аналогии исключается любой другой трафик по портам. Если убираем слово not, то слушаем трафик только указанного порта.
📌 Пакеты к определённому адресату или адресатам:
Комбинация порта и адресата:
Подобным образом можно комбинировать любые параметры: src, dst, port и т.д. с помощью операторов and, or, not,
📌 Смотрим конкретный протокол или исключаем его и не только:
На этом всё. Лично мне этих команд в повседневной деятельности достаточно. Не припоминаю, чтобы хоть раз использовал что-то ещё. Если надо проанализировать большой список, то просто направляю вывод в файл:
На основе приведённых выше примеров можно посмотреть, к примеру, на SIP трафик по VPN туннелю от конкретного пользователя к VOIP серверу:
Если не знакомы с tcpdump, рекомендую обязательно познакомиться и научиться пользоваться. Это не трудно, хоть на первый взгляд вывод выглядит жутковато и запутанно. Сильно в нём разбираться чаще всего не нужно, а важно увидеть какие пакеты и куда направляются. Это очень помогает в отладке. Чаще всего достаточно вот этого в выводе:
Протокол IP, адрес источника и порт > адрес получателя и его порт.
#network
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
Обнаружил, что тут нет заметки про tcpdump, хотя личная шпаргалка по этой программе у меня есть. Переношу сюда. По tcpdump можно много всего написать, материала море. Я напишу кратко, только те команды, что использую сам. Их немного. Tcpdump использую редко, если есть острая необходимость.
Я ко всем командам добавляю ключ
-nn, чтобы не резолвить IP адреса в домены и не заменять номера портов именем протокола. Мне это мешает. 📌 Список сетевых интерфейсов, с которых tcpdump может смотреть пакеты:
# tcpdump -DЕсли запустить программу без ключей, то трафик будет захвачен с первого активного интерфейса из списка выше.
📌 Слушаем все интерфейсы:
# tcpdump -nn -i anyИли только конкретный:
# tcpdump -nn -i ens3📌 Исключаем SSH протокол. Если в трафике, на который мы смотрим, будет SSH соединение, то оно забивает весь вывод своей активностью. Глазами уже не разобрать. Исключаю его по номеру порта:
# tcpdump -nn -i any port not 22По аналогии исключается любой другой трафик по портам. Если убираем слово not, то слушаем трафик только указанного порта.
📌 Пакеты к определённому адресату или адресатам:
# tcpdump -nn dst 8.8.8.8# tcpdump -nn dst 8.8.8.8 or dst 8.8.4.4Комбинация порта и адресата:
# tcpdump -nn dst 8.8.8.8 and port 53Подобным образом можно комбинировать любые параметры: src, dst, port и т.д. с помощью операторов and, or, not,
📌 Смотрим конкретный протокол или исключаем его и не только:
# tcpdump arp -nn -i any# tcpdump not arp -nn -i any# tcpdump not arp and not icmp -nn -i anyНа этом всё. Лично мне этих команд в повседневной деятельности достаточно. Не припоминаю, чтобы хоть раз использовал что-то ещё. Если надо проанализировать большой список, то просто направляю вывод в файл:
# tcpdump -nn -i any > ~/tcpdump.txtНа основе приведённых выше примеров можно посмотреть, к примеру, на SIP трафик по VPN туннелю от конкретного пользователя к VOIP серверу:
# tcpdump -nn -i tun4 src 10.1.4.23 and dst 10.1.3.205 and port 5060Если не знакомы с tcpdump, рекомендую обязательно познакомиться и научиться пользоваться. Это не трудно, хоть на первый взгляд вывод выглядит жутковато и запутанно. Сильно в нём разбираться чаще всего не нужно, а важно увидеть какие пакеты и куда направляются. Это очень помогает в отладке. Чаще всего достаточно вот этого в выводе:
IP 10.8.2.2.13083 > 10.8.2.3.8118Протокол IP, адрес источника и порт > адрес получателя и его порт.
#network
Если заметка вам полезна, не забудьте 👍 и забрать в закладки.