
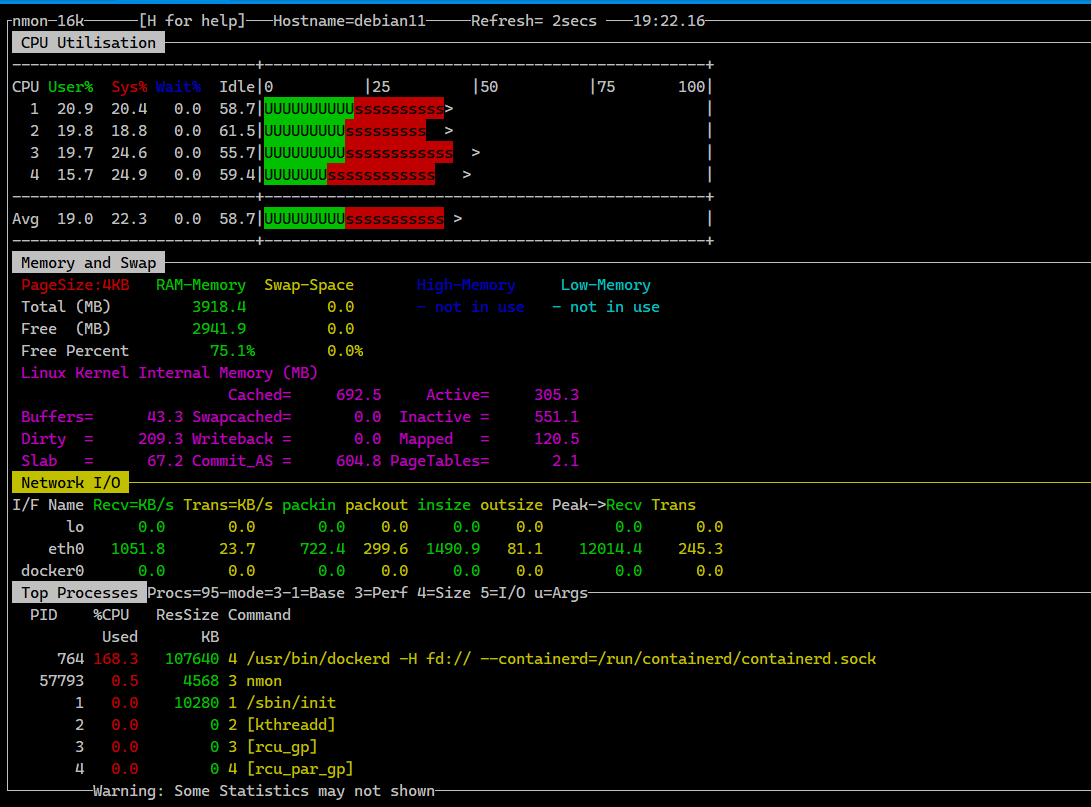
Представляю вашему вниманию очень старую, прямо таки олдскульную программу для анализа нагрузки Linux сервера — nmon. Она периодически всплывает в обсуждениях, рекомендациях. Я почему-то был уверен, что писал о ней. Но поиск по каналу неумолим — ни одного упоминания в заметках. Хотя программа известная, удобная и актуальная по сей день. Не заброшена, развивается, есть в репозиториях популярных дистрибутивов.
По своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
# apt install nmonПо своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
{kind=link}
Утилиту lsof в дистрибутивах Linux чаще всего используют для просмотра открытых файлов. Я и сам так делаю, и много материалов на эту тему видел. Да и название у неё говорящее. Оно как раз образовано от фразы list open files.
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
или так:
▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
▪ Смотрим открытые файлы конкретного пользователя:
Часто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
А теперь то же самое, только наоборот исключим открытые файлы пользователя:
Рассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
▪ Список TCP соединений к конкретному IP адресу:
▪ Список TCP соединений конкретного пользователя:
▪ Помимо TCP, можно и UDP соединения смотреть:
Публикацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
# lsof | grep '(deleted)'или так:
# lsof +L1▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
# lsof +D /var/log▪ Смотрим открытые файлы конкретного пользователя:
# lsof -u userЧасто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
# lsof -u user | wc -lА теперь то же самое, только наоборот исключим открытые файлы пользователя:
# lsof -u^user | wc -lРассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
# kill -9 `lsof -t -u user`▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
# lsof -p 94169▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
# lsof -ni▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
# lsof -ni TCP:80 ▪ Список TCP соединений к конкретному IP адресу:
# lsof -ni TCP@172.29.139.228▪ Список TCP соединений конкретного пользователя:
# lsof -ai -u nginx▪ Помимо TCP, можно и UDP соединения смотреть:
# lsof -iUDPПубликацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Вчера слушал вебинар Rebrain на тему диагностики производительности в Linux. Его вёл Лавлинский Николай. Выступление получилось интересное, хотя чего-то принципиально нового я не услышал. Все эти темы так или иначе разбирал в своих заметках в разное время, но всё это сейчас разрознено. Постараюсь оформить на днях в какую-то удобную единую заметку со ссылками. Заодно дополню той информацией, что узнал из вебинара.
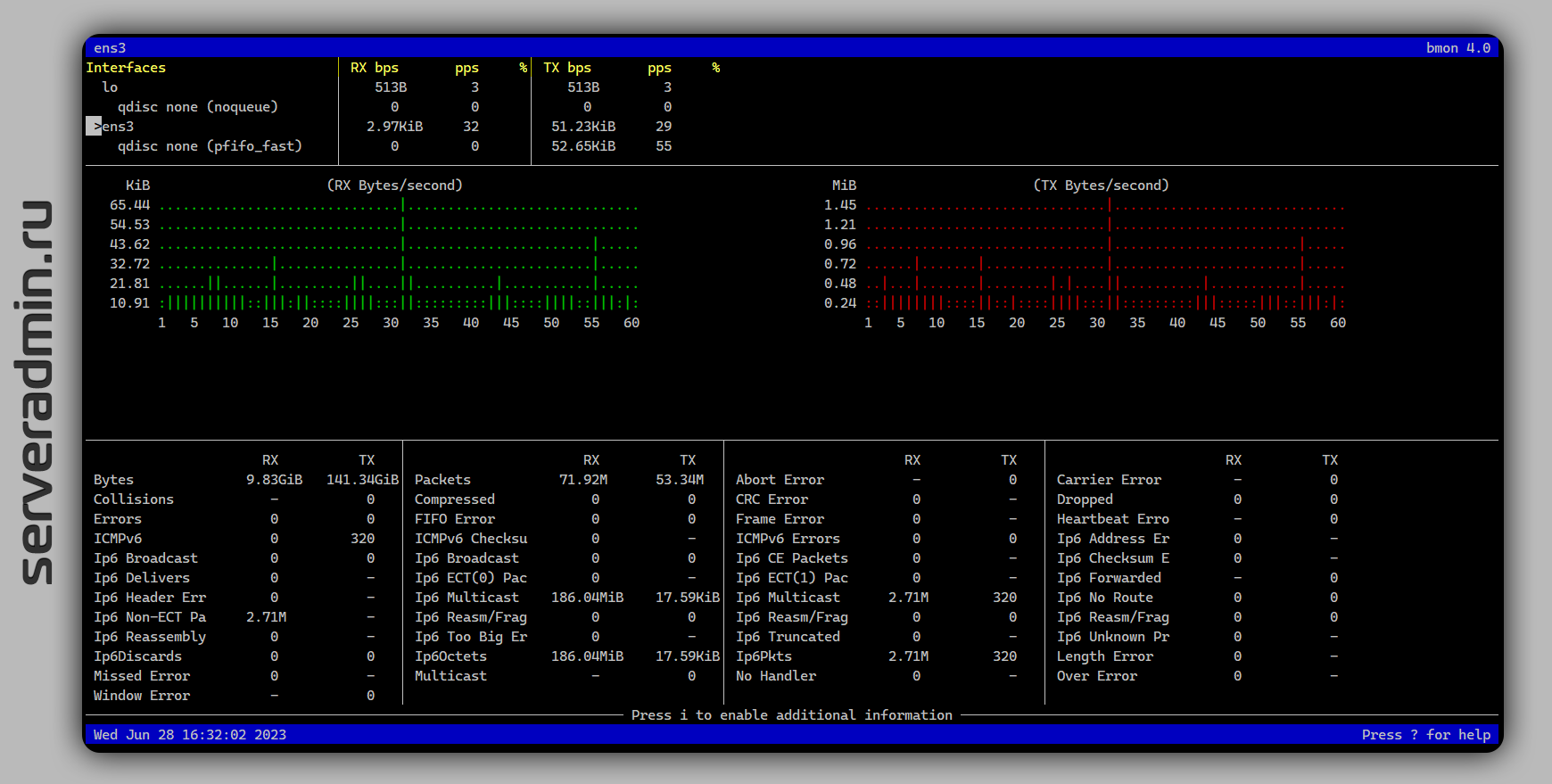
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
Рекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
# apt install bmonРекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
{kind=link}
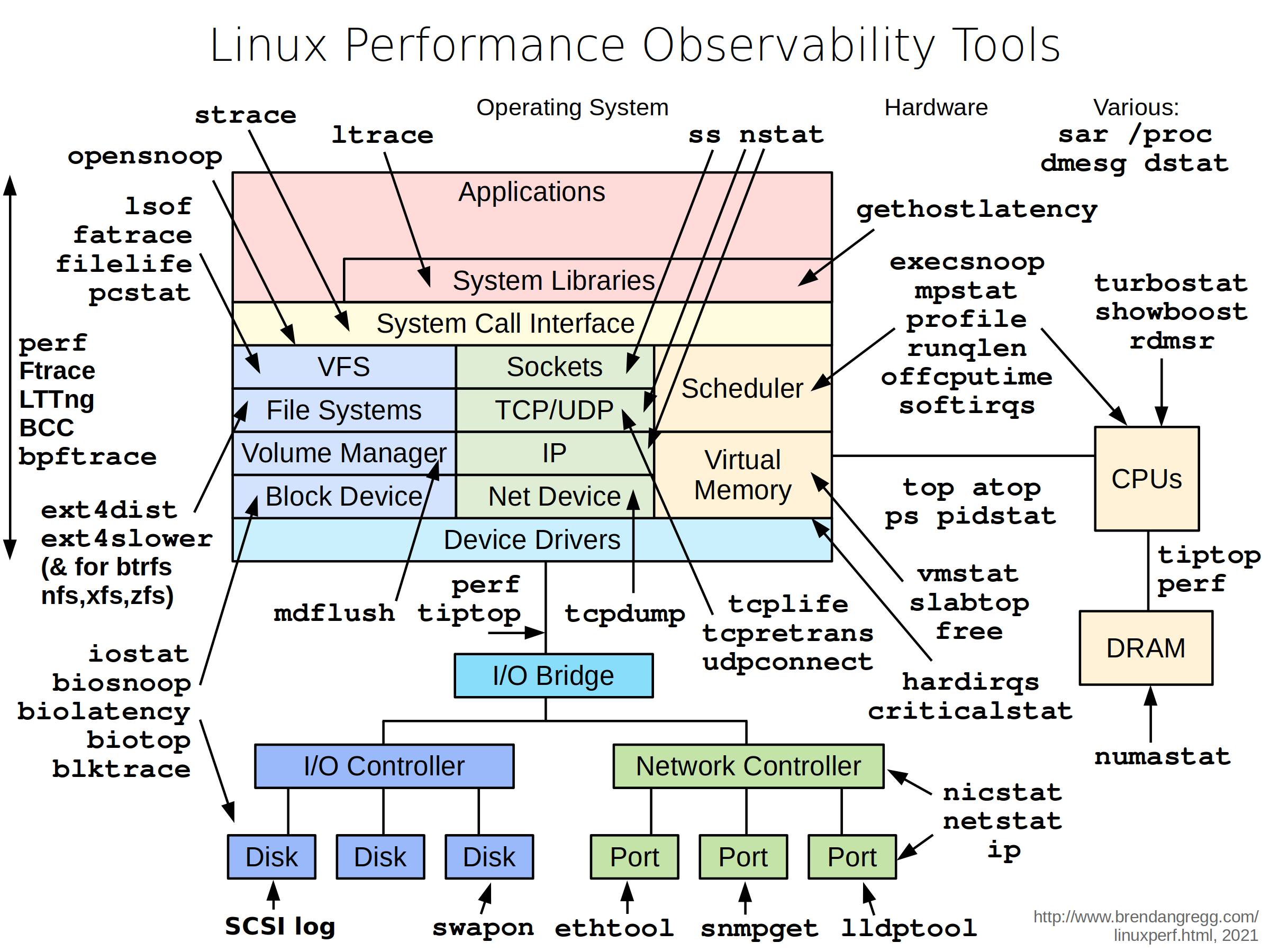
Как и обещал, подготовил заметку по профилированию нагрузки в Linux. Первое, что нужно понимать — для диагностики нужна методика. Хаотичное использование различных инструментов только в самом простом случае даст положительный результат.
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
top ,atop или любом другом менеджере процессов. Это универсальная метрика, с которой обязательно надо разобраться и понять, что конкретно она показывает. У меня есть заметка по ней. ✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
free -m. С памятью в Linux тоже не всё так просто. Недавно делал заметку на эту тему в рамках рассказа о pmon. Там же подробности того, как оценивать используемую и доступную память. Наряду с памятью стоит заглянуть в swap и посмотреть, кто и как его использует.✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
{kind=link}
Небольшой совет по быстродействию сайтов и веб приложений, который очень простой, но если вы его не знаете, то можете потратить уйму времени на поиски причин медленного ответа веб сервера.
Всегда проверяйте внешние ссылки на ресурсы и, по возможности, копируйте их к себе на веб сервер. Особенно много проблем может доставить какой-нибудь curl к внешнему ресурсу в самом коде. Это вообще бомба замедленного действия, которую потом очень трудно и неочевидно отлаживать. Если внешний ресурс начнёт отвечать с задержкой в 5-10 секунд, то при определённых обстоятельствах, у вас вся страница будет ждать это же время, прежде чем уедет к клиенту.
В коде за такие штуки можно только бить по рукам программистов. А вот если это статика для сайта в виде шрифтов, js кода, стилей, то это можно исправить и самостоятельно. К примеру, я давно и успешно практикую загрузку javascript кода от Яндекс.Метрики локально со своего сервера. Для этого сделал простенький скрипт:
Он работает по расписанию раз в день. В коде счётчика на сайте указан не внешний адрес mc.yandex.ru/metrika/watch.js к скрипту, а локальный serveradmin.ru/watch.js. Подобная конструкция у меня работает уже не один год и никаких проблем с работой статистики нет. При этом минус лишний запрос к внешнему источнику. Причём очень медленный запрос.
То же самое делаю с внешними шрифтами и другими скриптами. Всё, что можно, копирую локально. А то, что не нужно, отключаю. К примеру, я видел сайт, где был подключен код от reCaptcha, но она не использовалась. В какой-то момент отключили, а код оставили. Он очень сильно замедляет загрузку страницы, так как там куча внешних запросов к сторонним серверам.
Внешние запросы статики легко отследить с помощью типовых сервисов по проверке скорости загрузки сайта, типа webpagetest, gtmetrix, или обычной панели разработчика в браузере. Если это в коде используется, то всё намного сложнее. Надо либо код смотреть, либо как-то профилировать работу скриптов и смотреть, где там задержки.
Я когда-то давно писал статью по поводу ускорения работы сайта. Там описана в том числе и эта проблема. Пробежал глазами по статье. Она не устарела. Всё, что там перечислено, актуально и по сей день. Если поддерживаете сайты, почитайте, будет полезно. Там такие вещи, на которые некоторые в принципе не обращают внимания, так как на работу в целом это никак не влияет. Только на скорость отдачи страниц.
#webserver #perfomance
Всегда проверяйте внешние ссылки на ресурсы и, по возможности, копируйте их к себе на веб сервер. Особенно много проблем может доставить какой-нибудь curl к внешнему ресурсу в самом коде. Это вообще бомба замедленного действия, которую потом очень трудно и неочевидно отлаживать. Если внешний ресурс начнёт отвечать с задержкой в 5-10 секунд, то при определённых обстоятельствах, у вас вся страница будет ждать это же время, прежде чем уедет к клиенту.
В коде за такие штуки можно только бить по рукам программистов. А вот если это статика для сайта в виде шрифтов, js кода, стилей, то это можно исправить и самостоятельно. К примеру, я давно и успешно практикую загрузку javascript кода от Яндекс.Метрики локально со своего сервера. Для этого сделал простенький скрипт:
#!/bin/bashcurl -o /web/sites/serveradmin.ru/www/watch.js https://mc.yandex.ru/metrika/watch.jschown serveradmin.ru:nginx /web/sites/serveradmin.ru/www/watch.jsОн работает по расписанию раз в день. В коде счётчика на сайте указан не внешний адрес mc.yandex.ru/metrika/watch.js к скрипту, а локальный serveradmin.ru/watch.js. Подобная конструкция у меня работает уже не один год и никаких проблем с работой статистики нет. При этом минус лишний запрос к внешнему источнику. Причём очень медленный запрос.
То же самое делаю с внешними шрифтами и другими скриптами. Всё, что можно, копирую локально. А то, что не нужно, отключаю. К примеру, я видел сайт, где был подключен код от reCaptcha, но она не использовалась. В какой-то момент отключили, а код оставили. Он очень сильно замедляет загрузку страницы, так как там куча внешних запросов к сторонним серверам.
Внешние запросы статики легко отследить с помощью типовых сервисов по проверке скорости загрузки сайта, типа webpagetest, gtmetrix, или обычной панели разработчика в браузере. Если это в коде используется, то всё намного сложнее. Надо либо код смотреть, либо как-то профилировать работу скриптов и смотреть, где там задержки.
Я когда-то давно писал статью по поводу ускорения работы сайта. Там описана в том числе и эта проблема. Пробежал глазами по статье. Она не устарела. Всё, что там перечислено, актуально и по сей день. Если поддерживаете сайты, почитайте, будет полезно. Там такие вещи, на которые некоторые в принципе не обращают внимания, так как на работу в целом это никак не влияет. Только на скорость отдачи страниц.
#webserver #perfomance
Server Admin
Оптимизация скорости сайта, аудит сайта | serveradmin.ru
На конкретном примере тестирую работу сайта, показываю инструменты для этого и выполняю оптимизацию скорости загрузки сайта.
Я посмотрел два больших информативных вебинара про оптимизацию запросов в MySQL. Понятно, что в формате заметки невозможно раскрыть тему, поэтому я сделаю выжимку основных этапов и инструментов, которые используются. Кому нужна будет эта тема, сможет раскрутить её на основе этих вводных.
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
log_error = /var/log/mysql/error.logslow_query_logslow_query_log_file = /var/log/mysql/slow.loglong_query_time = 2.0Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
{kind=link}
Запомнился один момент с недавней конференции, где я присутствовал. Выступающий рассказывал, если не ошибаюсь, про технологию VDI и оптимизацию полосы пропускания, что позволяет комфортно общаться по видеосвязи. В подтверждение своих слов с цифрами показал картинку, где справа окно терминала.
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Почти во всех популярных дистрибутивах Linux в составе присутствует утилита vmstat. С её помощью можно узнать подробную информацию по использованию оперативной памяти, cpu и дисках. Лично я её не люблю, потому что вывод неинформативен. Утилита больше для какой-то глубокой диагностики или мониторинга, нежели простого использования в консоли.
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
Как можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
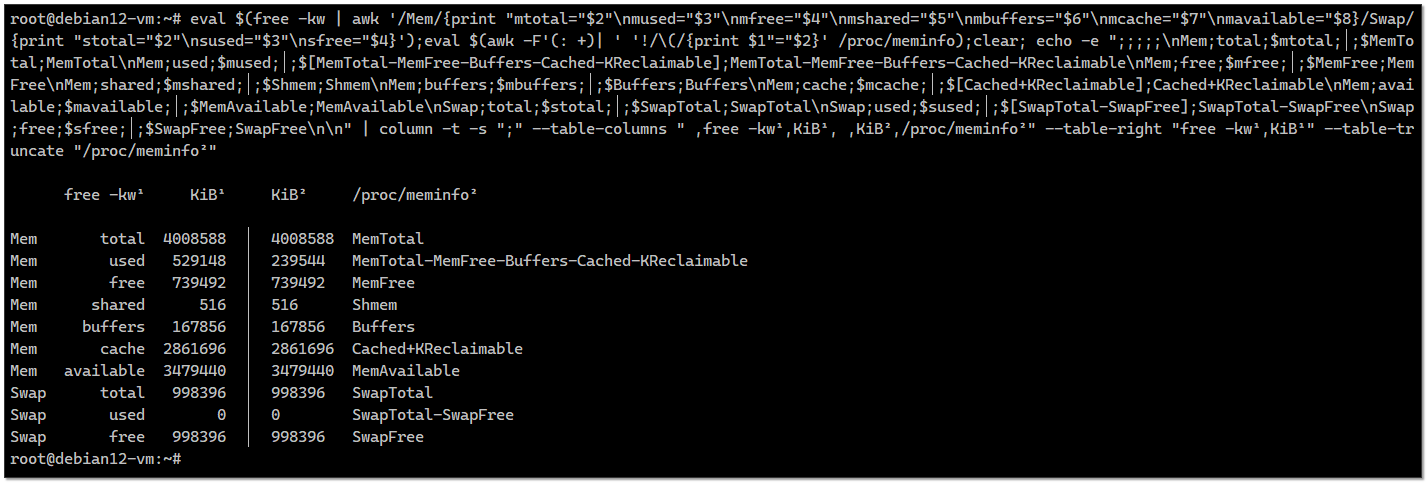
А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
# vmstat 1 -w -S MКак можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
man vmstat они подробно описаны, так что с интерпретацией проблем не должно возникать.А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
free и cat /proc/meminfo: # eval $(free -kw | awk '/Mem/{print "mtotal="$2"\nmused="$3"\nmfree="$4"\nmshared="$5"\nmbuffers="$6"\nmcache="$7"\nmavailable="$8}/Swap/{print "stotal="$2"\nsused="$3"\nsfree="$4}');eval $(awk -F'(: +)| ' '!/\(/{print $1"="$2}' /proc/meminfo);clear; echo -e ";;;;;\nMem;total;$mtotal;│;$MemTotal;MemTotal\nMem;used;$mused;│;$[MemTotal-MemFree-Buffers-Cached-KReclaimable];MemTotal-MemFree-Buffers-Cached-KReclaimable\nMem;free;$mfree;│;$MemFree;MemFree\nMem;shared;$mshared;│;$Shmem;Shmem\nMem;buffers;$mbuffers;│;$Buffers;Buffers\nMem;cache;$mcache;│;$[Cached+KReclaimable];Cached+KReclaimable\nMem;available;$mavailable;│;$MemAvailable;MemAvailable\nSwap;total;$stotal;│;$SwapTotal;SwapTotal\nSwap;used;$sused;│;$[SwapTotal-SwapFree];SwapTotal-SwapFree\nSwap;free;$sfree;│;$SwapFree;SwapFree\n\n" | column -t -s ";" --table-columns " ,free -kw¹,KiB¹, ,KiB²,/proc/meminfo²" --table-right "free -kw¹,KiB¹" --table-truncate "/proc/meminfo²"Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
{kind=link}
Каких только top-ов в Linux нет. Встречайте ещё один, про который большинство скорее всего не слышали - dnstop. Живёт в базовых репах:
Пригодится в основном на локальном dns сервере, но не обязательно только там. С помощью dnstop можно в режиме реального времени смотреть статистику dns запросов, как приходящих на сервер, так и исходящих от него самого.
Для запуска надо указать сетевой интерфейс, который будем слушать:
Если хотите сразу исключить локальные запросы сервера, то исключите его IP адрес с помощью ключа -i:
После запуска вы увидите основной экран с IP адресами источников запросов и количеством запросов. С помощью клавиш вы можете выбрать различные режимы отображения информации:
◽ s - таблица source address, экран по умолчанию после запуска
◽ d - таблица destination address
◽ t - статистика по типам запросов
◽ r - таблица кодов ответов
◽ @ - таблица source + адреса доменов 2-го уровня в запросе
Это не все горячие клавиши. Я перечислил только те, что показались полезными. Остальные возможности можно посмотреть в man.
По своей сути dnstop похож на tcpdump, потому что использует библиотеку libpcap, только она анализирует исключительно dns запросы. Результат работы можно сохранить в pcap файл с помощью ключа
#dns #perfomance
# apt install dnstopПригодится в основном на локальном dns сервере, но не обязательно только там. С помощью dnstop можно в режиме реального времени смотреть статистику dns запросов, как приходящих на сервер, так и исходящих от него самого.
Для запуска надо указать сетевой интерфейс, который будем слушать:
# dnstop eth0Если хотите сразу исключить локальные запросы сервера, то исключите его IP адрес с помощью ключа -i:
# dnstop eth0 -i 10.20.1.2После запуска вы увидите основной экран с IP адресами источников запросов и количеством запросов. С помощью клавиш вы можете выбрать различные режимы отображения информации:
◽ s - таблица source address, экран по умолчанию после запуска
◽ d - таблица destination address
◽ t - статистика по типам запросов
◽ r - таблица кодов ответов
◽ @ - таблица source + адреса доменов 2-го уровня в запросе
Это не все горячие клавиши. Я перечислил только те, что показались полезными. Остальные возможности можно посмотреть в man.
По своей сути dnstop похож на tcpdump, потому что использует библиотеку libpcap, только она анализирует исключительно dns запросы. Результат работы можно сохранить в pcap файл с помощью ключа
savefile.#dns #perfomance
Вчера посмотрел короткое видео на тему тормозов php сайта. В данном примере это был Битрикс, но проблема была не в нём, а в настройках веб сервера. Мне понравился способ решения проблемы с помощью perf, поэтому решил его отдельно разобрать текстом:
▶️ Причина торможения PHP в Битриксе
Обращаю внимание на автора ролика. Он ведёт открытые уроки в Rebrain и Otus. У Отус видел его преподавателем на некоторых курсах.
В видео описана проблема, когда один и тот же сайт на одном сервере тормозит, а на другом работает нормально. Причём разница в производительности конкретного тормозного скрипта отличается во много раз. На первый взгляд не понятно, в чём проблема.
Автор взял инструмент для профилирования нагрузки perf:
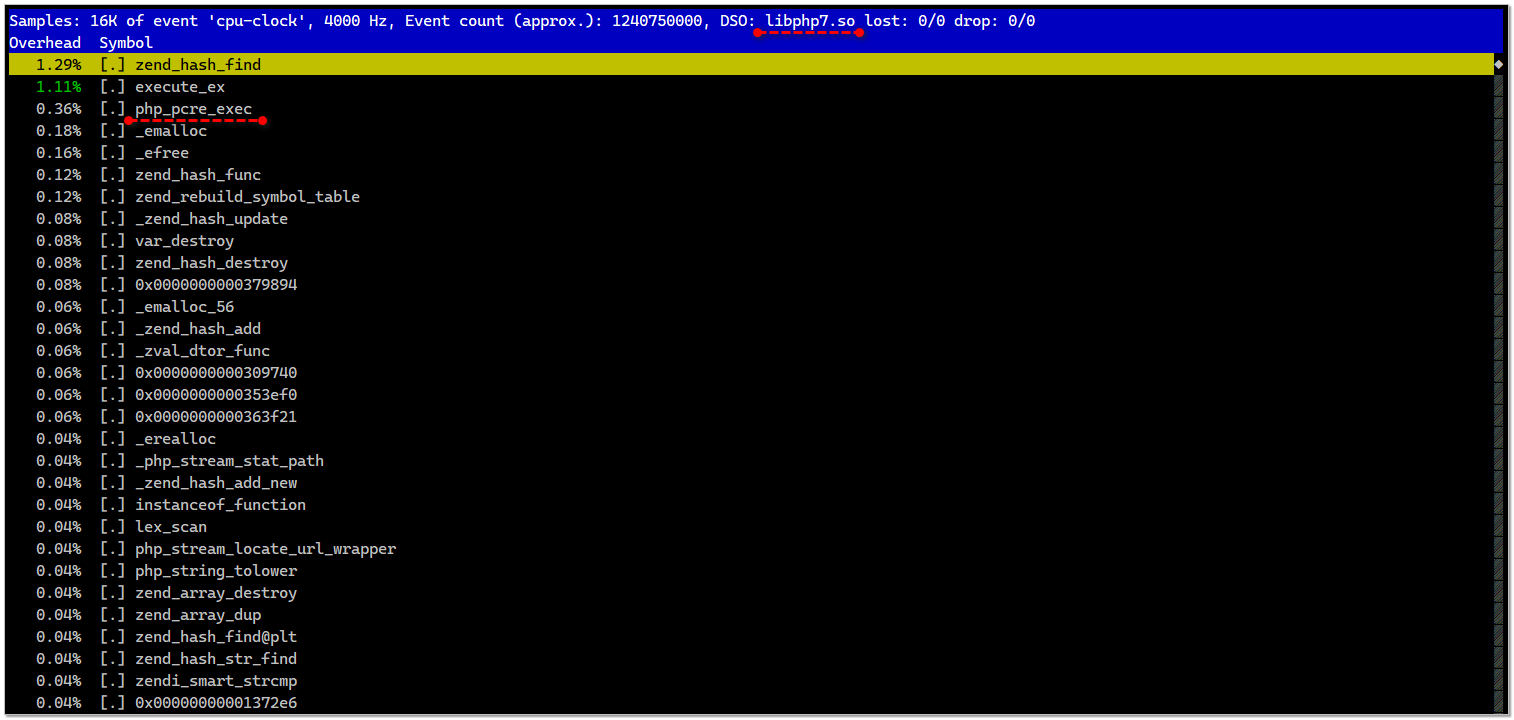
И просто запустил его встроенный топ:
Там увидел профиль библиотеки libphp7.so, которая отвечает за исполнение php кода. Зашёл в её подробности и там увидел, что существенную нагрузку даёт исполнение функции php_pcre_exec. Я пишу подробно, потому что повторил всё то же самое на одном из своих нагруженных сайтов на Битриксе.
Исходя из этой информации автор предположил, что причина катастрофического падения производительности как-то связана с модулем php pcre. На деле так и вышло. Этот модуль был по какой-то причине отключен (хотя по умолчанию он должен быть включен, кто-то побаловался с настройками), что и приводило к жутким тормозам. Когда его включили, сайт заработал нормально.
Я обратил внимание на это видео, потому что понравилось простое и быстрое решение. Не думал, что perf может так быстро помочь. Обычно с его помощью снимают полные стек-трейсы, в которых смогут разобраться не только лишь все. Нужны глубокие знания в системных вызовах Linux, функциях ядра, аппаратных счётчиках и т.д. Я, к примеру, особо в этом не разбираюсь, поэтому и не смотрю. Но в данном примере perf довольно быстро и легко помог решить проблему. Берите на вооружение.
#perfomance
▶️ Причина торможения PHP в Битриксе
Обращаю внимание на автора ролика. Он ведёт открытые уроки в Rebrain и Otus. У Отус видел его преподавателем на некоторых курсах.
В видео описана проблема, когда один и тот же сайт на одном сервере тормозит, а на другом работает нормально. Причём разница в производительности конкретного тормозного скрипта отличается во много раз. На первый взгляд не понятно, в чём проблема.
Автор взял инструмент для профилирования нагрузки perf:
# apt install linux-perf# yum install perfИ просто запустил его встроенный топ:
# perf topТам увидел профиль библиотеки libphp7.so, которая отвечает за исполнение php кода. Зашёл в её подробности и там увидел, что существенную нагрузку даёт исполнение функции php_pcre_exec. Я пишу подробно, потому что повторил всё то же самое на одном из своих нагруженных сайтов на Битриксе.
Исходя из этой информации автор предположил, что причина катастрофического падения производительности как-то связана с модулем php pcre. На деле так и вышло. Этот модуль был по какой-то причине отключен (хотя по умолчанию он должен быть включен, кто-то побаловался с настройками), что и приводило к жутким тормозам. Когда его включили, сайт заработал нормально.
Я обратил внимание на это видео, потому что понравилось простое и быстрое решение. Не думал, что perf может так быстро помочь. Обычно с его помощью снимают полные стек-трейсы, в которых смогут разобраться не только лишь все. Нужны глубокие знания в системных вызовах Linux, функциях ядра, аппаратных счётчиках и т.д. Я, к примеру, особо в этом не разбираюсь, поэтому и не смотрю. Но в данном примере perf довольно быстро и легко помог решить проблему. Берите на вооружение.
#perfomance
{kind=link}
Хочу привлечь ваше внимание к моей старой публикации, к которой я сам постоянно обращаюсь. Это заметка про анализ дисковой активности в Linux. Вчера в очередной раз к ней обращался, поэтому решил и вам напомнить.
В Zabbix прилетели триггеры на тему повышенного сетевого трафика с виртуальной машины разработчиков 1C и нагрузки на общий файловый сервер, который они используют для обмена информацией. Так как разработчики внешние на аутсорсе, внимание к этой виртуалке повышенное, поэтому я сразу решил проверить, в чём дело. В общем случае это некритичные триггеры, в основной инфраструктуре у них пороги либо очень высокие, либо вообще отключены.
Зашёл на виртуалку, сразу увидел через
Там оказались какие-то выгрузки 1С. Сразу позвонил человеку, который отвечает за эти дела. Он подтвердил, что да, всё по плану.
Чуть раньше тоже разбирался с работой веб сервера и конкретно MySQL, смотрел, что и куда пишет служба, чтобы понять, в чём конкретно узкое место и как можно разнести файловую нагрузку. Надо было решить вопрос, почему сервер тормозил и медленно отвечал сайт.
В общем, эти утилиты по анализу дисковой активности прям топ. Сильно упрощают задачу анализа работы сервера. Перечислю их тут списком:
- btrace
- iostat
- iotop
- fatrace
- strace
- lsof
- iosnoop
- biosnoop
Ну а подробности с примерами тут.
#perfomance
В Zabbix прилетели триггеры на тему повышенного сетевого трафика с виртуальной машины разработчиков 1C и нагрузки на общий файловый сервер, который они используют для обмена информацией. Так как разработчики внешние на аутсорсе, внимание к этой виртуалке повышенное, поэтому я сразу решил проверить, в чём дело. В общем случае это некритичные триггеры, в основной инфраструктуре у них пороги либо очень высокие, либо вообще отключены.
Зашёл на виртуалку, сразу увидел через
htop, что нагрузку даёт samba. Через iftop увидел, что активно идёт трафик с указанной виртуалки. Захотелось узнать, что конкретно пишут. Тут я сходу не вспомнил утилиту, поэтому полез в указанную заметку. Что конкретно в данный момент пишется на диск смотрю командой:# fatrace -f Wsmbd(20632): W /data/1c-bases/БП обновление 2024 ТЕСТ/1Cv8.1CDТам оказались какие-то выгрузки 1С. Сразу позвонил человеку, который отвечает за эти дела. Он подтвердил, что да, всё по плану.
Чуть раньше тоже разбирался с работой веб сервера и конкретно MySQL, смотрел, что и куда пишет служба, чтобы понять, в чём конкретно узкое место и как можно разнести файловую нагрузку. Надо было решить вопрос, почему сервер тормозил и медленно отвечал сайт.
В общем, эти утилиты по анализу дисковой активности прям топ. Сильно упрощают задачу анализа работы сервера. Перечислю их тут списком:
- btrace
- iostat
- iotop
- fatrace
- strace
- lsof
- iosnoop
- biosnoop
Ну а подробности с примерами тут.
#perfomance
В ОС на базе Linux есть разные способы измерить время выполнения той или иной команды. Самый простой с помощью утилиты time:
Сразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
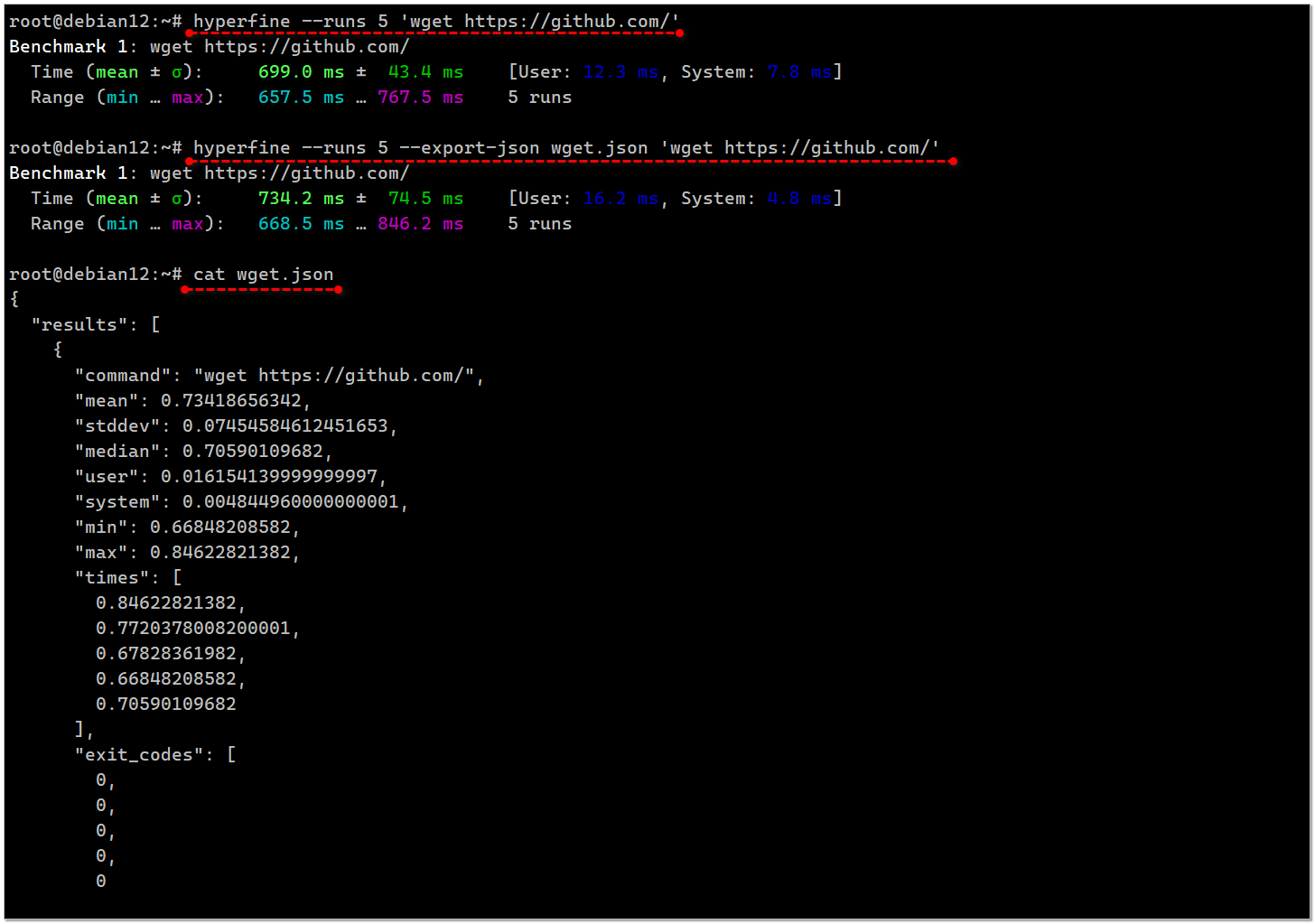
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
С его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
На выходе получаем файл
Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
# time curl http://127.0.0.1/server-statusActive connections: 1 server accepts handled requests 6726 6726 4110 Reading: 0 Writing: 1 Waiting: 0 real 0m0.015suser 0m0.006ssys 0m0.009sСразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
# apt install hyperfineС его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
# hyperfine --runs 1 --export-json mysqldump.json 'mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql'На выходе получаем файл
mysqldump.json с информацией:{ "results": [ { "command": "mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql", "mean": 2.7331184105, "stddev": null, "median": 2.7331184105, "user": 2.1372425799999997, "system": 0.35953332, "min": 2.7331184105, "max": 2.7331184105, "times": [ 2.7331184105 ], "exit_codes": [ 0 ] } ]}Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
# hyperfine --runs 3 'curl -s https://github.com/'Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
{kind=link}
Для того, чтобы получить быстрое представление о производительности системы, а тем более сравнить её с другой, можно воспользоваться простой утилитой sysbench. Во времена Centos её приходилось ставить либо вручную, либо из стороннего репозитория. В Debian 12 она живёт в базовой репе:
Причём, я уже писал о ней раньше в контексте нагрузочных тестирований Mysql или Postgresql сервера. Это наиболее простое и поэтому популярное решение для подобных задач. Если тюните СУБД где-то на тесте, то возьмите на вооружение эту утилиту и делайте на ней прогоны.
А сейчас перейдёт к стандартным нагрузочным тестам системы. Для CPU, судя по man утилиты, есть только один тест -
Смотрим на events per second и total number of events, чем больше, тем лучше.
Тест памяти, соответственно:
Смотреть надо на Total operations или transferred MiB/sec. В абсолютных значениях это мало что скажет. Подойдёт для сравнения двух серверов.
С тестированием диска не всё очевидно и просто. Там уже имеет смысл заморочиться с параметрами, так надо учесть системный кэш, кэш гипервизора, если он есть, кэш рейд контроллера, если он используется и т.д. То есть надо немного разбираться в теме, иначе можно получить неверные представления о результатах теста. Как минимум, надо задать размер тестового файла больше оперативной памяти сервера и выбрать тип операций для теста. Например, запустим тест на последовательную запись суммарного объёма файлов в 10G:
По умолчанию запись идёт в один поток. В результатах смотреть надо на Throughput written, MiB/s, total number of events. Тут ещё на Latency имеет смысл посмотреть. Важный параметр для дисков.
Посмотреть все доступные настройки можно так:
В целом, там более-менее всё понятно по описанию. Можно менять количество потоков, размер блоков, типы операций, использование флагов sync, dsync или direct. Если вам всё это не знакомо, имеет смысл изучить. Это нужная база для понимания работы в Linux с дисками.
После работы тестов на диск, остаются тестовые файлы. Их надо удалить либо вручную, либо автоматически:
Запускаете ту же команду, только на конце не
Такая вот простая и полезная утилита. Я во время написания заметки гонял её на двух разных VPS. По памяти и процу разница была примерно в 1,5-2 раза. А по диску почти идентично. Когда ты арендуешь виртуалку, невозможно оценить, насколько стоимость будет соотноситься с производительностью. Только на тестах можно это увидеть.
Sysbench, кстати, можно гонять и в Windows, в WSL. Я погонял на своём рабочем ноуте в виртуалке HyperV и в WSL. Тесты по CPU и Памяти идентичны в пределах стат погрешностей. Сделал несколько прогонов. Думал, что по диску будет разница, но тоже нет. Тесты последовательной записи проходят идентично. Другие не делал.
⇨ Исходники
#perfomance
# apt install sysbenchПричём, я уже писал о ней раньше в контексте нагрузочных тестирований Mysql или Postgresql сервера. Это наиболее простое и поэтому популярное решение для подобных задач. Если тюните СУБД где-то на тесте, то возьмите на вооружение эту утилиту и делайте на ней прогоны.
А сейчас перейдёт к стандартным нагрузочным тестам системы. Для CPU, судя по man утилиты, есть только один тест -
--cpu-max-prime, генератор простых чисел. Можно указать верхнюю границу чисел, а можно этого не делать. По умолчанию запускается в одном потоке на одном ядре CPU на 10 секунд с лимитом в 10000:# sysbench cpu runСмотрим на events per second и total number of events, чем больше, тем лучше.
Тест памяти, соответственно:
# sysbench memory runСмотреть надо на Total operations или transferred MiB/sec. В абсолютных значениях это мало что скажет. Подойдёт для сравнения двух серверов.
С тестированием диска не всё очевидно и просто. Там уже имеет смысл заморочиться с параметрами, так надо учесть системный кэш, кэш гипервизора, если он есть, кэш рейд контроллера, если он используется и т.д. То есть надо немного разбираться в теме, иначе можно получить неверные представления о результатах теста. Как минимум, надо задать размер тестового файла больше оперативной памяти сервера и выбрать тип операций для теста. Например, запустим тест на последовательную запись суммарного объёма файлов в 10G:
# sysbench fileio --file-total-size=10G --file-test-mode=seqwr runПо умолчанию запись идёт в один поток. В результатах смотреть надо на Throughput written, MiB/s, total number of events. Тут ещё на Latency имеет смысл посмотреть. Важный параметр для дисков.
Посмотреть все доступные настройки можно так:
# sysbench fileio helpВ целом, там более-менее всё понятно по описанию. Можно менять количество потоков, размер блоков, типы операций, использование флагов sync, dsync или direct. Если вам всё это не знакомо, имеет смысл изучить. Это нужная база для понимания работы в Linux с дисками.
После работы тестов на диск, остаются тестовые файлы. Их надо удалить либо вручную, либо автоматически:
# sysbench fileio --file-total-size=10G --file-test-mode=seqwr cleanupЗапускаете ту же команду, только на конце не
run, а cleanup.Такая вот простая и полезная утилита. Я во время написания заметки гонял её на двух разных VPS. По памяти и процу разница была примерно в 1,5-2 раза. А по диску почти идентично. Когда ты арендуешь виртуалку, невозможно оценить, насколько стоимость будет соотноситься с производительностью. Только на тестах можно это увидеть.
Sysbench, кстати, можно гонять и в Windows, в WSL. Я погонял на своём рабочем ноуте в виртуалке HyperV и в WSL. Тесты по CPU и Памяти идентичны в пределах стат погрешностей. Сделал несколько прогонов. Думал, что по диску будет разница, но тоже нет. Тесты последовательной записи проходят идентично. Другие не делал.
⇨ Исходники
#perfomance
GitHub
GitHub - akopytov/sysbench: Scriptable database and system performance benchmark
Scriptable database and system performance benchmark - akopytov/sysbench
Как быстро и малыми усилиями попытаться выяснить, почему что-то тормозит в php коде сайта? Расскажу, с чего уместнее всего начать расследование, если вы используете php-fpm. Если нет каких-то особых требований, то лично я всегда исользую именно его.
У него есть две простые настройки, которые можно применить в нужном пуле, когда проводите расследование:
Таймаут выставляете под свои требования. Если сайт в целом тормозной (bitrix, админка wordpress), то 1 секунда слишком малый интервал, но в идеале хочется, чтобы весь код выполнялся быстрее этого времени.
Далее необходимо перезаустить php-fpm и идти смотреть лог:
В логе запросов будет не только информация о скрипте, который долго выполняется, но и его трассировака. Она будет включать в себя все инклюды и функции. То, что было вызвано сначала, будет внизу трейса, последняя функция - в самом верху. Причём верхней функцией будет та, что выполнялась в момент наступления времени, указанного в request_slowlog_timeout. Часто именно она и причина тормозов.
Разобраться во всём этом не такая простая задача, но в целом выполнимая даже админом. Самое главное, что иногда можно сразу получить подсказку, которая ответит на ворос о том, что именно томозит. Бывает не понятно, какой именно запрос приводит к выполнению того или иного скрипта. Нужно сопоставить по времени запрос в access.log веб сервера и slowlog php-fpm.
Очень часто тормозят какие-то заросы к внешним сервисам. Они могут делаться, к примеру, через curl_exec. И вы это сразу увидите в slowlog в самом верху трейса. Нужно будет только пройтись по функуциям и зависимостям, и найти то место, откуда функция с curl вызывается. Также часто в самом верху трейса можно увидеть функцию mysqli_query или что-то в этом роде. Тогда понятно, что тормозят запросы к базе.
По факту это самый простой инструмент, который имеет смысл использовать в самом начале разборов. Зачастую с его помощью можно сразу найти проблему. Ну а если нет, то можно подключать strace и смотреть более детально, что там внутри происходит. Но это уже сложнее, хотя какие-то простые вещи тоже можно сразу отловить. Тот же внешний тормозящий запрос тоже будет виден сразу.
#php #webserver #perfomance
У него есть две простые настройки, которые можно применить в нужном пуле, когда проводите расследование:
slowlog = /var/log/php-fpm/site01.ru.slow.logrequest_slowlog_timeout = 1sТаймаут выставляете под свои требования. Если сайт в целом тормозной (bitrix, админка wordpress), то 1 секунда слишком малый интервал, но в идеале хочется, чтобы весь код выполнялся быстрее этого времени.
Далее необходимо перезаустить php-fpm и идти смотреть лог:
# systemctl restart php8.0-fpmВ логе запросов будет не только информация о скрипте, который долго выполняется, но и его трассировака. Она будет включать в себя все инклюды и функции. То, что было вызвано сначала, будет внизу трейса, последняя функция - в самом верху. Причём верхней функцией будет та, что выполнялась в момент наступления времени, указанного в request_slowlog_timeout. Часто именно она и причина тормозов.
Разобраться во всём этом не такая простая задача, но в целом выполнимая даже админом. Самое главное, что иногда можно сразу получить подсказку, которая ответит на ворос о том, что именно томозит. Бывает не понятно, какой именно запрос приводит к выполнению того или иного скрипта. Нужно сопоставить по времени запрос в access.log веб сервера и slowlog php-fpm.
Очень часто тормозят какие-то заросы к внешним сервисам. Они могут делаться, к примеру, через curl_exec. И вы это сразу увидите в slowlog в самом верху трейса. Нужно будет только пройтись по функуциям и зависимостям, и найти то место, откуда функция с curl вызывается. Также часто в самом верху трейса можно увидеть функцию mysqli_query или что-то в этом роде. Тогда понятно, что тормозят запросы к базе.
По факту это самый простой инструмент, который имеет смысл использовать в самом начале разборов. Зачастую с его помощью можно сразу найти проблему. Ну а если нет, то можно подключать strace и смотреть более детально, что там внутри происходит. Но это уже сложнее, хотя какие-то простые вещи тоже можно сразу отловить. Тот же внешний тормозящий запрос тоже будет виден сразу.
#php #webserver #perfomance
{kind=link}
Я недавно рассказывал про namespaces в Linux. На основе этой изоляции работает множество софта. Далее будет пример одного из них, который использует network namespaces для записи дампа трафика конкретного приложения.
Речь пойдёт про nsntrace. Это относительно простое приложение, которое, как я уже сказал, может собрать дамп трафика отдельного приложения. Для этого оно делает следующие вещи:
1️⃣ Создаёт отдельный network namespace для исследуемого приложения.
2️⃣ Для того, чтобы там был доступ в интернет, создаются виртуальные сетевые интерфейсы. Один в новом namespace, другой в основном. В новом используется шлюз из основного namespace. Из-за этой схемы у запускаемого приложения будет IP адрес виртуальной сети.
3️⃣ Средствами iptables трафик натится из виртуальной сети в реальную.
4️⃣ Запускает приложение в новом namespace и собирает его трафик с помощью libpcap. Результат сохраняет в обычный pcap файл.
Nsntrace есть в базовых репах Debian:
Самый банальный пример, чтобы проверить работу:
На выходе получаем nsntrace.pcap, который можно посмотреть тут же, если у вас есть tshark:
Можно и в режиме реального времени наблюдать:
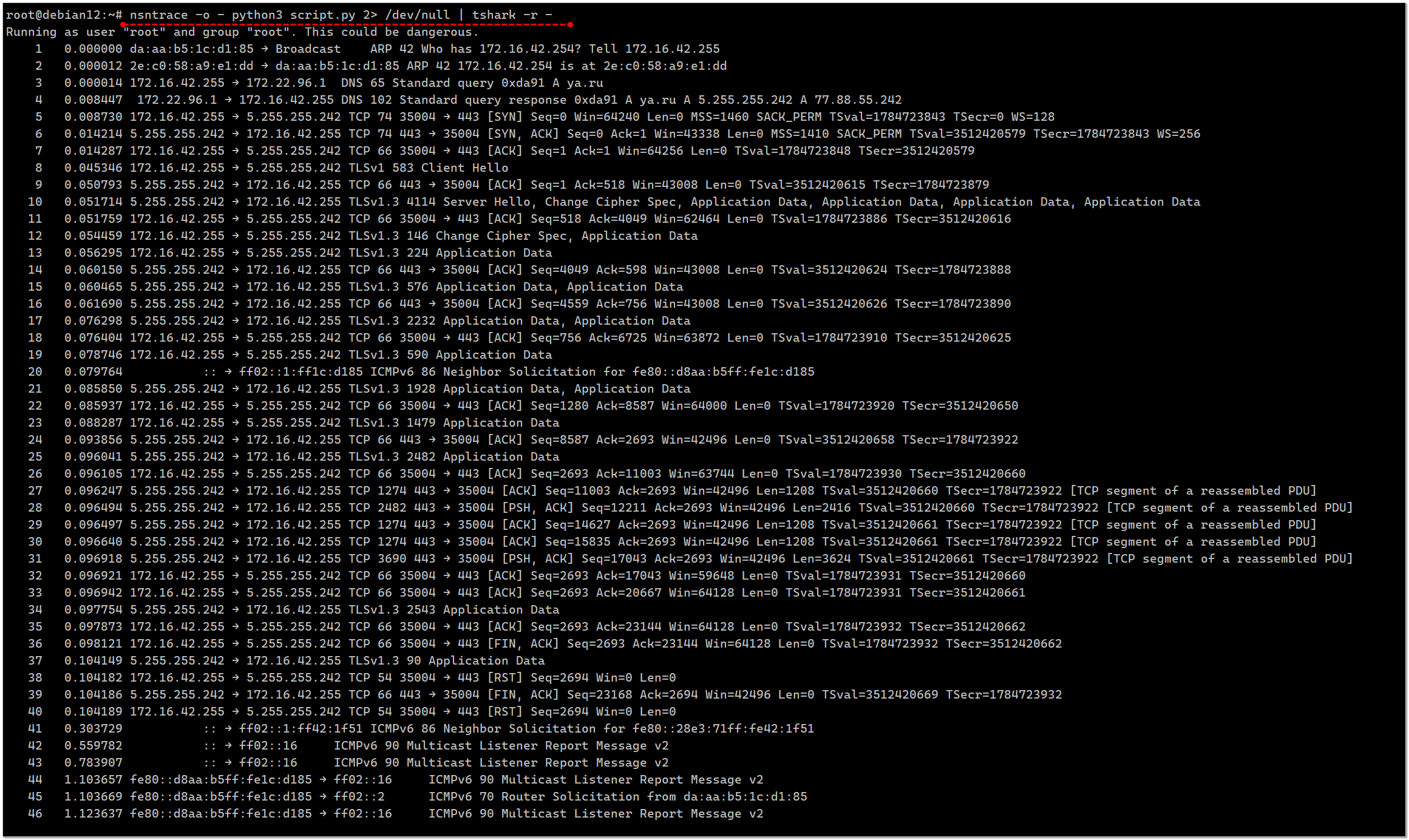
Помимо обычных приложений, снимать трафик можно и со скриптов:
Проверим на простом python скрипте:
Запускаем анализ сетевой активности:
Смотрим:
Можно передать .pcap на другую машину и посмотреть в Wireshark.
Удобный инструмент. Нужен не часто, но конкретно для скриптов мне реализация понравилась. Обычно это нетривиальная задача, посмотреть, куда он стучится и что делает. Нужно вычленять именно его запросы из общего трафика, а это не всегда просто. Либо трассировку работы делать, что тоже сложнее, чем просто воспользоваться nsntrace.
#network #perfomance
Речь пойдёт про nsntrace. Это относительно простое приложение, которое, как я уже сказал, может собрать дамп трафика отдельного приложения. Для этого оно делает следующие вещи:
1️⃣ Создаёт отдельный network namespace для исследуемого приложения.
2️⃣ Для того, чтобы там был доступ в интернет, создаются виртуальные сетевые интерфейсы. Один в новом namespace, другой в основном. В новом используется шлюз из основного namespace. Из-за этой схемы у запускаемого приложения будет IP адрес виртуальной сети.
3️⃣ Средствами iptables трафик натится из виртуальной сети в реальную.
4️⃣ Запускает приложение в новом namespace и собирает его трафик с помощью libpcap. Результат сохраняет в обычный pcap файл.
Nsntrace есть в базовых репах Debian:
# apt install nsntraceСамый банальный пример, чтобы проверить работу:
# nsntrace wget google.comНа выходе получаем nsntrace.pcap, который можно посмотреть тут же, если у вас есть tshark:
# tshark -r nsntrace.pcapМожно и в режиме реального времени наблюдать:
# nsntrace -o - wget google.com 2> /dev/null | tshark -r -Помимо обычных приложений, снимать трафик можно и со скриптов:
# nsntrace php script.php# nsntrace python script.pyПроверим на простом python скрипте:
import requestsres = requests.get('https://ya.ru')Запускаем анализ сетевой активности:
# nsntrace python3 script.pyStarting network trace of 'python3' on interface eth0.Your IP address in this trace is 172.16.42.255.Use ctrl-c to end at any time.Finished capturing 57 packets.Смотрим:
# tshark -r nsntrace.pcapМожно передать .pcap на другую машину и посмотреть в Wireshark.
Удобный инструмент. Нужен не часто, но конкретно для скриптов мне реализация понравилась. Обычно это нетривиальная задача, посмотреть, куда он стучится и что делает. Нужно вычленять именно его запросы из общего трафика, а это не всегда просто. Либо трассировку работы делать, что тоже сложнее, чем просто воспользоваться nsntrace.
#network #perfomance
{kind=link}
В Linux есть простой и удобный инструмент для просмотра дисковой активности в режиме реального времени - iotop. У него формат вывода похож на традиционный top, только вся информация в выводе посвящена дисковой активности процессов.
В последнее время стал замечать, что в основном везде используется iotop-c. Это тот же iotop, только переписанный на C. Новая реализация поддерживается и понемногу развивается, в то время, как оригинальный iotop не развивается очень давно.
В каких-то дистрибутивах остались обе эти утилиты, а в каких-то iotop полностью заметили на iotop-c. Например, в Debian остались обе:
А в Fedora iotop полностью заменили на iotop-c, с сохранением старого названия.
Так что если захотите воспользоваться iotop, чтобы отследить дисковую активность отдельных процессов, то ставьте на всякий случай сразу iotop-c. Программа простая и удобная. Запустили, отсортировали по нужному столбцу (стрелками влево или вправо) и смотрим активность. Обычно в первую очередь запись интересует.
Напомню, что у меня есть небольшая заметка про комплексный анализ дисковой активности в Linux с помощью различных консольных утилит.
#perfomance
В последнее время стал замечать, что в основном везде используется iotop-c. Это тот же iotop, только переписанный на C. Новая реализация поддерживается и понемногу развивается, в то время, как оригинальный iotop не развивается очень давно.
В каких-то дистрибутивах остались обе эти утилиты, а в каких-то iotop полностью заметили на iotop-c. Например, в Debian остались обе:
# apt search iotopiotop/stable 0.6-42-ga14256a-0.1+b2 amd64 simple top-like I/O monitoriotop-c/stable,now 1.23-1+deb12u1 amd64 [installed] simple top-like I/O monitor (implemented in C)А в Fedora iotop полностью заменили на iotop-c, с сохранением старого названия.
Так что если захотите воспользоваться iotop, чтобы отследить дисковую активность отдельных процессов, то ставьте на всякий случай сразу iotop-c. Программа простая и удобная. Запустили, отсортировали по нужному столбцу (стрелками влево или вправо) и смотрим активность. Обычно в первую очередь запись интересует.
Напомню, что у меня есть небольшая заметка про комплексный анализ дисковой активности в Linux с помощью различных консольных утилит.
#perfomance
{kind=link}
Вчера в заметке я немного рассказал про планировщики процессов для блочных устройств в Linux и чуток ошибся. Тема новая и непростая, особо не погружался в неё, поэтому не совсем правильно понял. Немного больше её изучил, поэтому своими словами дам краткую выжимку того, что я по ней понял и узнал.
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
Тут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
Тут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
Загрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
А для применения планировщика создайте правило udev, например в отдельном файле
В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineТут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
# cat /sys/block/vda/queue/scheduler[mq-deadline] kyber bfq noneТут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
# cat /sys/block/sda/queue/scheduler[none] mq-deadline# modprobe kyber-iosched# cat /sys/block/sda/queue/scheduler[none] mq-deadline kyber# echo kyber > /sys/block/sda/queue/scheduler# cat /sys/block/sda/queue/schedulermq-deadline [kyber] noneЗагрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
/etc/modules-load.d/modules.conf название модуля:kyber-ioschedА для применения планировщика создайте правило udev, например в отдельном файле
/etc/udev/rules.d/schedulerset.rules:ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="sd?", ATTR{queue/scheduler}="kyber"В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Вчера очень внимательно читал статью на хабре про расследование паразитного чтения диска, когда не было понятно, кто и почему его постоянно читает и таким образом нагружает:
⇨ Расследуем фантомные чтения с диска в Linux
Я люблю такие материалы, так как обычно конспектирую, если нахожу что-то новое. Записываю себе в свою базу знаний. Частично из неё потом получаются заметки здесь.
Там расследовали чтение с помощью blktrace. Я знаю этот инструмент, но он довольно сложный с большим количеством подробностей, которые не нужны, если ты не разбираешься в нюансах работы ядра. Я воспроизвёл описанную историю. Покажу по шагам:
1️⃣ Через
2️⃣ Запускаем
Вывод примерно такой:
В данном случае
3️⃣ Смотрим, что это за блок:
То есть этот блок имеет номер айноды
4️⃣ Смотрим, что это за файл:
Нашли файл, который активно читает процесс questdb-ilpwrit.
Я всё это воспроизвёл у себя на тесте, записал последовательность. Вариант рабочий, но утомительный, если всё делать вручную. Может быть много временных файлов, которых уже не будет существовать, когда ты будешь искать номер айноды соответствующего блока.
Был уверен, что это можно сделать проще, так как я уже занимался подобными вопросами. Вспомнил про утилиту fatrace. Она заменяет более сложные strace или blktrace в простых случаях.
Просто запускаем её и наблюдаем
В соседней консоли откроем лог:
Смотрим в консоль fatrace:
Результат тот же самый, что и выше с blktrace, только намного проще. В fatrace можно сразу отфильтровать вывод по типам операций. Например, только чтение или запись:
Собираем все события в течении 30 секунд с записью в текстовый лог:
Не хватает только наблюдения за конкретным процессом. Почему-то ключ
Можно исключить, к примеру bash или sshd. Они обычно не нужны для расследований.
Рекомендую заметку сохранить, особенно про fatrace. Я себе отдельно записал ещё вот это:
#linux #perfomance
⇨ Расследуем фантомные чтения с диска в Linux
Я люблю такие материалы, так как обычно конспектирую, если нахожу что-то новое. Записываю себе в свою базу знаний. Частично из неё потом получаются заметки здесь.
Там расследовали чтение с помощью blktrace. Я знаю этот инструмент, но он довольно сложный с большим количеством подробностей, которые не нужны, если ты не разбираешься в нюансах работы ядра. Я воспроизвёл описанную историю. Покажу по шагам:
1️⃣ Через
iostat смотрим нагрузку на диск и убеждаемся, что кто-то его активно читает. Сейчас уже не обязательно iostat ставить, так как htop может показать то же самое. 2️⃣ Запускаем
blktrace в режиме наблюдения за операциями чтения с выводом результата в консоль:# blktrace -d /dev/sda1 -a read -o - | blkparse -i -Вывод примерно такой:
259,0 7 4618 5.943408644 425548 Q RA 536514808 + 8 [questdb-ilpwrit]В данном случае
RA 536514808 это событие чтения с диска начиная с блока 536514808.3️⃣ Смотрим, что это за блок:
# debugfs -R 'icheck 536514808 ' /dev/sda1debugfs 1.46.5 (30-Dec-2021)Block Inode number536514808 8270377То есть этот блок имеет номер айноды
8270377. 4️⃣ Смотрим, что это за файл:
debugfs -R 'ncheck 8270377' /dev/sda1Inode Pathname8270377 /home/ubuntu/.questdb/db/table_name/2022-10-04/symbol_col9.d.1092Нашли файл, который активно читает процесс questdb-ilpwrit.
Я всё это воспроизвёл у себя на тесте, записал последовательность. Вариант рабочий, но утомительный, если всё делать вручную. Может быть много временных файлов, которых уже не будет существовать, когда ты будешь искать номер айноды соответствующего блока.
Был уверен, что это можно сделать проще, так как я уже занимался подобными вопросами. Вспомнил про утилиту fatrace. Она заменяет более сложные strace или blktrace в простых случаях.
# apt install fatraceПросто запускаем её и наблюдаем
# fatraceВ соседней консоли откроем лог:
# tail -n 10 /var/log/syslogСмотрим в консоль fatrace:
bash(2143): RO /usr/bin/tailtail(2143): RO /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2tail(2143): O /etc/ld.so.cachetail(2143): RO /usr/lib/x86_64-linux-gnu/libc.so.6tail(2143): C /etc/ld.so.cachetail(2143): O /usr/lib/locale/locale-archivetail(2143): RCO /etc/locale.aliastail(2143): O /var/log/syslogtail(2143): R /var/log/syslogРезультат тот же самый, что и выше с blktrace, только намного проще. В fatrace можно сразу отфильтровать вывод по типам операций. Например, только чтение или запись:
# fatrace -f R# fatrace -f WСобираем все события в течении 30 секунд с записью в текстовый лог:
# fatrace -s -t 30 -o /tmp/fatrace.logНе хватает только наблюдения за конкретным процессом. Почему-то ключ
-p позволяет не задать конкретный пид процесса для наблюдения, а исключить из результатов операции процесса с этим pid:# fatrace -p 697Можно исключить, к примеру bash или sshd. Они обычно не нужны для расследований.
Рекомендую заметку сохранить, особенно про fatrace. Я себе отдельно записал ещё вот это:
# debugfs -R 'icheck 536514808 ' /dev/sda1# debugfs -R 'ncheck 8270377' /dev/sda1#linux #perfomance
{kind=link}
В выходные прочитал интересную статью:
⇨ Как настроить веб-приложение под высокие нагрузки
Первый раз попал на этот ресурс. Понравилось качество контента. С удовольствием прочитал несколько статей. Эта понравилась больше всего, поэтому решил поделиться и сделать небольшую выжимку для тех, кто не захочет тратить время на весь материал. Там есть интересные для админов моменты.
Автор рассказал, как один проект лавинообразно начал расти и тормозить под нагрузкой во время пандемии, когда его посещаемость выросла в разы. Он поэтапно описал, как они изменяли железо, настройки, архитектуру приложения.
Изначально это был небольшой проект на PHP и его фреймворке Symfony, который писали 3-5 проектировщиков. СУБД была PostgreSQL, под кэш Redis, написана API и очередь для неё на RabbitMQ. Такое типовое классическое веб приложение. Проект располагался на 16 физических серверах, фронтенды и бэкенды — по 24 ядра и 128 ОЗУ каждый, ноды СУБД имели 56 ядер и 512 ГБ ОЗУ.
Огромную помощью в решении возникающих проблем оказывал мониторинг. Он был реализован на базе Zabbix, Symfony Profiler, Cockpit, DBeaver, Nginx Amplify.
🔹Одним из узких мест оказались логи Nginx. Была включена буферизация логов. В момент скидывания буферов на диск, они тормозили. Временно перенесли логи в RAM-диски (tmpfs). Потом перенастроили систему хранения логов.
🔹Другим узким местом была главная страница. Её целиком закешировали и поместили в Redis. Далее весь код перетряхнули и по возможности настроили использование кэша в Redis. После этого Redis вынесли в отдельный кластер. Это привело к тому, что даже в границах одной серверной и максимально быстрой сети, кэш стал работать медленнее, а на саму локалку сильно выросла сетевая нагрузка. Пришлось разбить кэш на 2 уровня. Первый хранить в локальных инстансах Redis, а второй в отдельном кластере с доступом по сети.
🔹Для разгрузки СУБД установили PgBouncer для управления пулом соединений, постановки их в очередь, если всё занято. Один огромный сервер под СУБД распили на кластер из 5-ти серверов. Запросы к кластеру стали распределять с помощью PGPool. INSERT, UPDATE, DELETE отправляли на Master, всё остальное распределяли между остальными серверами.
🔹В какой-то момент все серверные мощности были нагружены на 70-80%. Это стало приводить к проблемам, когда что-то из железа выходило из строя. Пришлось добавить серверов, чтобы нагрузка стала 40-50%.
🔹Далее упёрлись в ёмкость входного канала. Пришлось переходить на использование геораспределённой CDN.
#perfomance
⇨ Как настроить веб-приложение под высокие нагрузки
Первый раз попал на этот ресурс. Понравилось качество контента. С удовольствием прочитал несколько статей. Эта понравилась больше всего, поэтому решил поделиться и сделать небольшую выжимку для тех, кто не захочет тратить время на весь материал. Там есть интересные для админов моменты.
Автор рассказал, как один проект лавинообразно начал расти и тормозить под нагрузкой во время пандемии, когда его посещаемость выросла в разы. Он поэтапно описал, как они изменяли железо, настройки, архитектуру приложения.
Изначально это был небольшой проект на PHP и его фреймворке Symfony, который писали 3-5 проектировщиков. СУБД была PostgreSQL, под кэш Redis, написана API и очередь для неё на RabbitMQ. Такое типовое классическое веб приложение. Проект располагался на 16 физических серверах, фронтенды и бэкенды — по 24 ядра и 128 ОЗУ каждый, ноды СУБД имели 56 ядер и 512 ГБ ОЗУ.
Огромную помощью в решении возникающих проблем оказывал мониторинг. Он был реализован на базе Zabbix, Symfony Profiler, Cockpit, DBeaver, Nginx Amplify.
🔹Одним из узких мест оказались логи Nginx. Была включена буферизация логов. В момент скидывания буферов на диск, они тормозили. Временно перенесли логи в RAM-диски (tmpfs). Потом перенастроили систему хранения логов.
🔹Другим узким местом была главная страница. Её целиком закешировали и поместили в Redis. Далее весь код перетряхнули и по возможности настроили использование кэша в Redis. После этого Redis вынесли в отдельный кластер. Это привело к тому, что даже в границах одной серверной и максимально быстрой сети, кэш стал работать медленнее, а на саму локалку сильно выросла сетевая нагрузка. Пришлось разбить кэш на 2 уровня. Первый хранить в локальных инстансах Redis, а второй в отдельном кластере с доступом по сети.
🔹Для разгрузки СУБД установили PgBouncer для управления пулом соединений, постановки их в очередь, если всё занято. Один огромный сервер под СУБД распили на кластер из 5-ти серверов. Запросы к кластеру стали распределять с помощью PGPool. INSERT, UPDATE, DELETE отправляли на Master, всё остальное распределяли между остальными серверами.
🔹В какой-то момент все серверные мощности были нагружены на 70-80%. Это стало приводить к проблемам, когда что-то из железа выходило из строя. Пришлось добавить серверов, чтобы нагрузка стала 40-50%.
🔹Далее упёрлись в ёмкость входного канала. Пришлось переходить на использование геораспределённой CDN.
#perfomance
Прочитал очень интересную техническую статью на хабре, в которой много просто любопытных и прикладных моментов. Зафиксирую некоторые их них в заметке для тех, кто не захочет читать весь материал. Он объёмный.
⇨ Как небольшой «тюнинг» Talos Linux увеличил производительность NVMe SSD в 2.5 раза
1️⃣ Кто-то заезжает в облака, кто-то выезжает. Автор построил Kubernetes кластер на Bare Metal, снизив затраты по сравнению с Google Cloud в 4 раза, увеличив производительность в 4 раза! Так что не стоит полностью забывать железо и жить в облачных абстракциях. В каких-то случаях стоит спускаться на землю и не терять навык работы на ней.
2️⃣ Очень объёмный и насыщенный материал по тестированию дисковой подсистемы с конкретными примерами для fio. Если не хочется сильно вникать, то можно сразу брать готовые команды для линейного чтения, линейной записи, задержки случайного чтения и т.д. Там для всех популярных метрик есть примеры.
3️⃣ Автор собрал свой Docker контейнер, который выполнят весь набор тестов и выводит результат в формате CSV для удобного экспорта в табличку с графиками.
❗️Тест fio с записью на диск деструктивный. Нельзя запускать этот тест на диске с данными. Они будут уничтожены. Это для чистых блочных устройств. Я попробовал эти тесты. Удобно сделано. Рекомендую забрать к себе. Там всё самое интересное в скрипте
Полученные данные каким-то образом переносятся вот в такую наглядную таблицу. Я не понял, как это сделано, но надеюсь, что получиться разобраться. Очень удобно и наглядно проводить тестирование и сравнивать результаты.
4️⃣ Производительность дисковой подсистемы в Talos Linux по сравнению с обычным Debian была в 1,5-2 раза ниже. Причина была в разных параметрах ядра.
5️⃣ Настроек ядра очень много. Сравнение настроек в разных дистрибутивах вручную очень трудоёмкая задача. Автор сгрузил diff файл параметров ядра указанных систем в ChatGPT и он сразу же выдал ответ, какой параметр приводит к снижению производительности:
В Talos Linux включен параметр CONFIG_IOMMU_DEFAULT_DMA_STRICT=y, в то время как в Debian используется CONFIG_IOMMU_DEFAULT_DMA_LAZY=y. Режим strict в IOMMU заставляет ядро немедленно выполнять сброс кэшей IOMMU при каждом связывании и отвязывании DMA (то есть при каждом вводе-выводе), что приводит к дополнительной нагрузке на систему и может значительно снизить производительность ввода-вывода при интенсивных операциях, таких как тестирование IOPS.
6️⃣ Разница в производительности может быть значительной между разными версиями ядра Linux. Это связано с патчами безопасности, которые снижают производительность. Для каких-то старых ядер, которые уже не поддерживаются, этих патчей может не быть. На них производительность будет выше (а безопасность ниже).
7️⃣ Благодаря множественным манипуляциям над системой Talos Linux автору удалось подтянуть её производительность до оригинального Debian. Но всё равно она была ниже. Из этого можно сделать вывод, что различные альтернативные дистрибутивы Linux стоит использовать осторожно и осмысленно. Изначальная разница в производительности в 2 раза как-бы не мелочь.
Статью рекомендую прочитать полностью. Если работаете с железом и Linux, будет полезно. Я для себя забрал оттуда тесты и табличку. Попробую всё это скрестить, чтобы так же красиво и быстро сравнивать результаты. Пригодится как минимум для тестов разных типов хранилищ в системах виртуализации.
☝️ Отметил для себя полезность ИИ. Надо начинать пользоваться.
#linux #perfomance
⇨ Как небольшой «тюнинг» Talos Linux увеличил производительность NVMe SSD в 2.5 раза
# docker run -it --rm --entrypoint /run.sh --privileged maxpain/fio:latest /dev/nvme0n1❗️Тест fio с записью на диск деструктивный. Нельзя запускать этот тест на диске с данными. Они будут уничтожены. Это для чистых блочных устройств. Я попробовал эти тесты. Удобно сделано. Рекомендую забрать к себе. Там всё самое интересное в скрипте
/run.sh. Можно сохранить к себе на память только его:# docker create --name fio maxpain/fio:latest false# docker cp fio:/run.sh ~/run.shПолученные данные каким-то образом переносятся вот в такую наглядную таблицу. Я не понял, как это сделано, но надеюсь, что получиться разобраться. Очень удобно и наглядно проводить тестирование и сравнивать результаты.
В Talos Linux включен параметр CONFIG_IOMMU_DEFAULT_DMA_STRICT=y, в то время как в Debian используется CONFIG_IOMMU_DEFAULT_DMA_LAZY=y. Режим strict в IOMMU заставляет ядро немедленно выполнять сброс кэшей IOMMU при каждом связывании и отвязывании DMA (то есть при каждом вводе-выводе), что приводит к дополнительной нагрузке на систему и может значительно снизить производительность ввода-вывода при интенсивных операциях, таких как тестирование IOPS.
Статью рекомендую прочитать полностью. Если работаете с железом и Linux, будет полезно. Я для себя забрал оттуда тесты и табличку. Попробую всё это скрестить, чтобы так же красиво и быстро сравнивать результаты. Пригодится как минимум для тестов разных типов хранилищ в системах виртуализации.
☝️ Отметил для себя полезность ИИ. Надо начинать пользоваться.
#linux #perfomance
Please open Telegram to view this post
VIEW IN TELEGRAM
Хабр
Как небольшой «тюнинг» Talos Linux увеличил производительность NVMe SSD в 2.5 раза
Предыстория Недавно я начал готовить очередной Kubernetes кластер на Bare Metal серверах для одного из наших проектов дабы съехать с Google Cloud и снизить расходы на инфраструктуру примерно в 4 раза,...