
Для автоматической проверки Docker образов на уязвимости (CVE) есть хороший open source инструмент Trivy. Год назад я делал по нему пару заметок с обзором и автоматическим исправлением уязвимостей. Потом всё это в небольшую статью оформил.
Этот продукт хорошо дополняет open source утилита Dockle. Она тоже проверяет контейнеры на уязвимости, но помимо этого проверяет образ на соответствие best-practice Dockerfile и рекомендации CIS Docker Benchmarks (#cis).
Использовать очень просто, так как это по сути одиночный бинарник. В репозитории есть пакеты для установки под все популярные системы. Можно запустить и в Docker без установки:
Пример отчёта можно посмотреть на тестовом образе, для которого есть замечания:
С помощью ключа
⇨ Исходники
#docker #devops #cicd #security
Этот продукт хорошо дополняет open source утилита Dockle. Она тоже проверяет контейнеры на уязвимости, но помимо этого проверяет образ на соответствие best-practice Dockerfile и рекомендации CIS Docker Benchmarks (#cis).
Использовать очень просто, так как это по сути одиночный бинарник. В репозитории есть пакеты для установки под все популярные системы. Можно запустить и в Docker без установки:
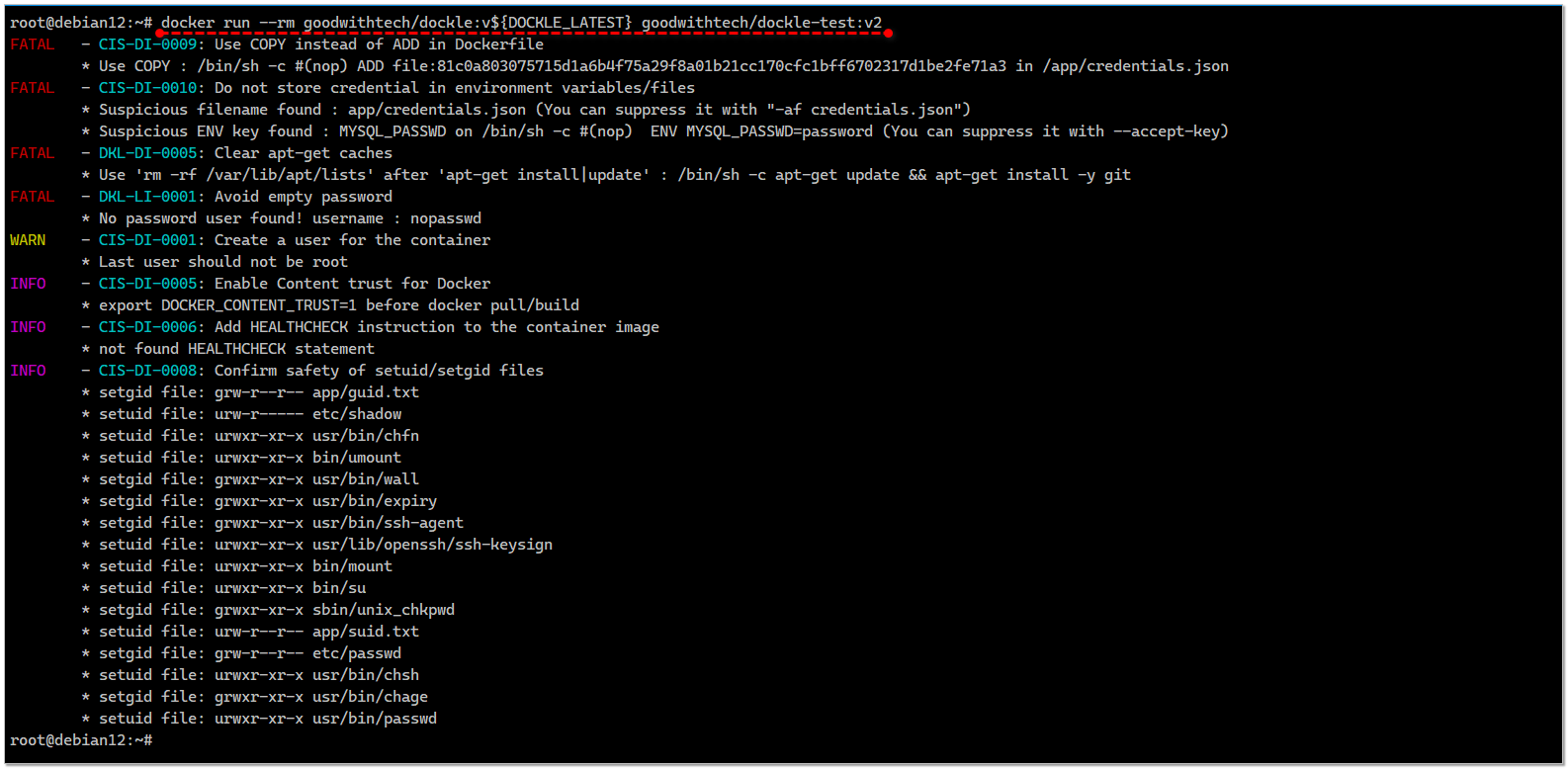
# docker run --rm goodwithtech/dockle:v0.4.14 [YOUR_IMAGE_NAME]Пример отчёта можно посмотреть на тестовом образе, для которого есть замечания:
# docker run --rm goodwithtech/dockle:v0.4.14 goodwithtech/dockle-test:v2С помощью ключа
-f json вывод можно сохранить в json файле. Dockle легко интегрировать в пайплайн. В репозитории есть примеры (gitlab).⇨ Исходники
#docker #devops #cicd #security
{kind=link}
Если вам нужно продебажить какой-то контейнер, в котором нет никаких инструментов для диагностики (а это почти всегда так), то для этого можно воспользоваться специально собранным для этих целей контейнером - Network-Multitool. Его ещё любят в кубернетисе запускать для отладки. Известная штука.
Работает он примерно так. Запускаем контейнер, внутри которого ничего нет, кроме nginx:
Подключаем к нему network-multitool:
Дальше всё остальное можно запускать: ping, dig, tcpdump и т.д.
Я тут выбрал самую жирную сборку alpine-extra, где максимальный набор инструментов, в том числе tshark, ApacheBench, mysql & postgresql client, git и т.д. Если всё это не надо, то используйте alpine-minimal. Описание сборок в репозитории.
Похожую функциональность имеет cdebug. У него принцип работы такой же, только он для удобства собран в бинарник. А подключается он к контейнерам точно так же.
Кстати, с помощью network-multitool можно и хост дебажить, если не хочется его засорять различными утилитами. Запускаем его в сети хоста и пользуемся:
На хост ничего ставить не надо. Полезная штука, берите на вооружение.
#docker #devops
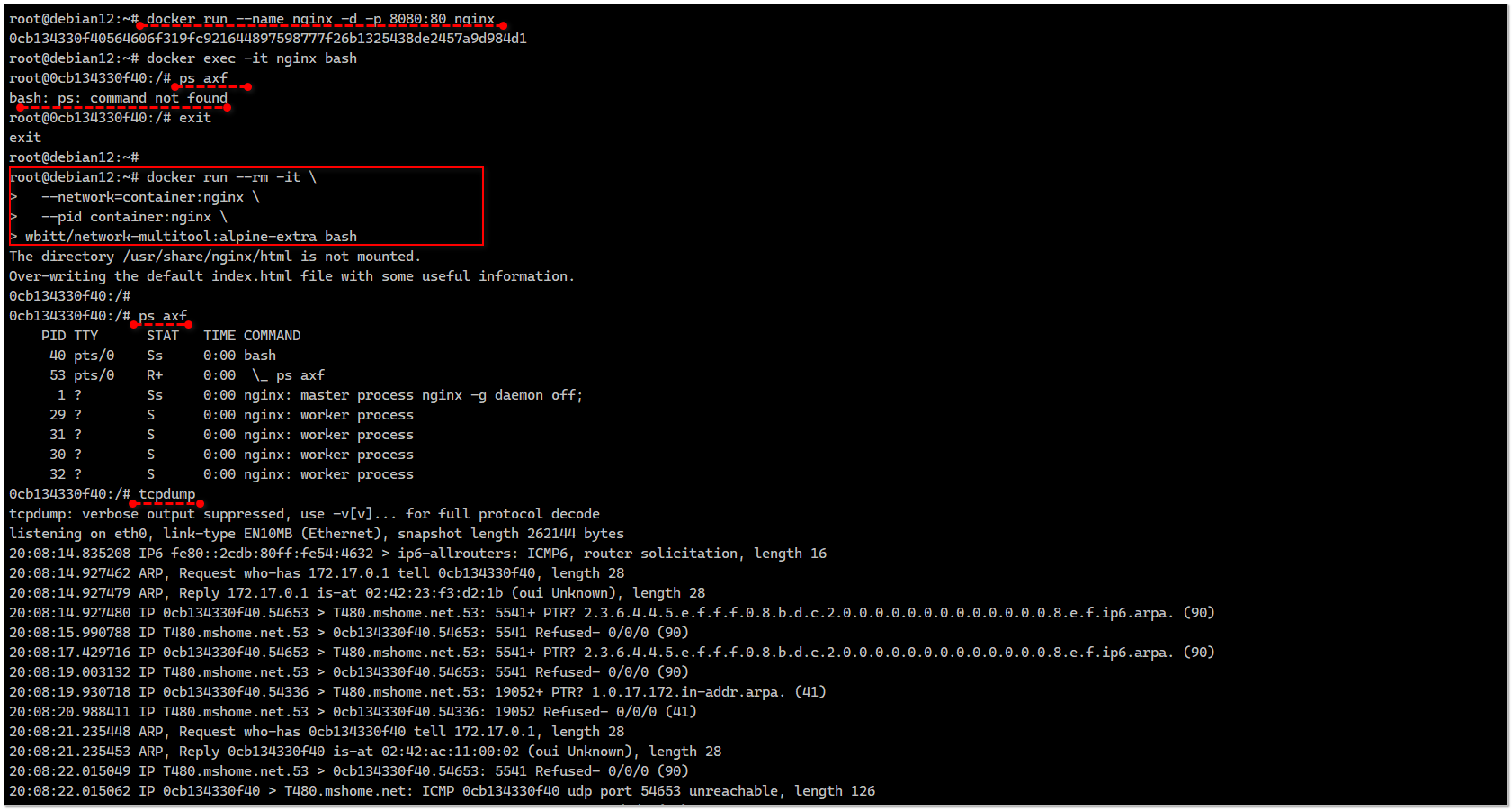
Работает он примерно так. Запускаем контейнер, внутри которого ничего нет, кроме nginx:
# docker run --name nginx -d -p 8080:80 nginx# docker exec -it nginx bash# ps axfbash: ps: command not foundПодключаем к нему network-multitool:
# docker run --rm -it \ --network=container:nginx \ --pid container:nginx \wbitt/network-multitool:alpine-extra bash# ps axf PID TTY STAT TIME COMMAND 47 pts/0 Ss 0:00 bash 60 pts/0 R+ 0:00 \_ ps axf 1 ? Ss 0:00 nginx: master process nginx -g daemon off; 29 ? S 0:00 nginx: worker process 31 ? S 0:00 nginx: worker process 30 ? S 0:00 nginx: worker process 32 ? S 0:00 nginx: worker processДальше всё остальное можно запускать: ping, dig, tcpdump и т.д.
Я тут выбрал самую жирную сборку alpine-extra, где максимальный набор инструментов, в том числе tshark, ApacheBench, mysql & postgresql client, git и т.д. Если всё это не надо, то используйте alpine-minimal. Описание сборок в репозитории.
Похожую функциональность имеет cdebug. У него принцип работы такой же, только он для удобства собран в бинарник. А подключается он к контейнерам точно так же.
Кстати, с помощью network-multitool можно и хост дебажить, если не хочется его засорять различными утилитами. Запускаем его в сети хоста и пользуемся:
# docker run --rm -it --network=host wbitt/network-multitool:alpine-extra bash# tcpdumpНа хост ничего ставить не надо. Полезная штука, берите на вооружение.
#docker #devops
{kind=link}
Недавно посмотрел видео про Diun (Docker Image Update Notifier). Это маленькая консольная утилита, которая делает одно простое действие - проверяет наличие обновлений для образов запущенных контейнеров на хосте. Если обновление есть, уведомляет через email, telegram, gotify, slack и другие каналы. Больше ничего не делает, не качает обновление, не применяет, не перезапускает образ.
Diun состоит из одного бинарника. Запустить можно как на хосте, создав службу systemd, так и в контейнере, прокинув туда docker.sock. Процесс описан в документации:
Конфигурацию можно передать либо через переменные, либо через конфигурационный файл. Примеры обоих способов тоже есть в документации.
Diun умеет следить за актуальностью образов запущенных Docker контейнеров, образов подов в Kubernetes, Swarm, Nomad. Также можно настроить наблюдение за образами, используемыми в определённых Dockerfiles или конфигурационных файлах yaml, где указаны образы.
Простая, маленькая, удобная утилита. Описание установки, настройки, работы:
▶️ Diun - это вам не watchtower
⇨ Сайт / Исходники
#docker #devops
Diun состоит из одного бинарника. Запустить можно как на хосте, создав службу systemd, так и в контейнере, прокинув туда docker.sock. Процесс описан в документации:
# docker run -d --name diun \ -e "TZ=Europe/Moscow" \ -e "DIUN_WATCH_WORKERS=20" \ -e "DIUN_WATCH_SCHEDULE=0 */6 * * *" \ -e "DIUN_WATCH_JITTER=30s" \ -e "DIUN_PROVIDERS_DOCKER=true" \ -e "DIUN_NOTIF_TELEGRAM_TOKEN=1493678911:AAHtETAKqxUH8ZpyC28R-wxKfvH8WR6-vdNw" \ -e "DIUN_NOTIF_TELEGRAM_CHATIDS=211805263" \ -v "$PWD/data:/data" \ -v "/var/run/docker.sock:/var/run/docker.sock" \ -l "diun.enable=true" \ crazymax/diun:latestКонфигурацию можно передать либо через переменные, либо через конфигурационный файл. Примеры обоих способов тоже есть в документации.
Diun умеет следить за актуальностью образов запущенных Docker контейнеров, образов подов в Kubernetes, Swarm, Nomad. Также можно настроить наблюдение за образами, используемыми в определённых Dockerfiles или конфигурационных файлах yaml, где указаны образы.
Простая, маленькая, удобная утилита. Описание установки, настройки, работы:
▶️ Diun - это вам не watchtower
⇨ Сайт / Исходники
#docker #devops
{kind=link}
Наиболее популярным и простым в настройке мониторингом сейчас является Prometheus. Простым не в плане возможностей, а в плане начальной настройки. Так как для него очень много всего автоматизировано, начать сбор метрик можно в несколько простых действий. Мониторинг сразу заработает и дальше с ним можно разбираться и настраивать.
Напишу краткую шпаргалку по запуску связки Prometheus + Grafana, чтобы её можно было сохранить и использовать по мере надобности. Я установлю их в Docker, сразу буду мониторить сам Prometheus и локальных хост Linux. Подключу для примера ещё один внешний Linux сервер.
Ставим Docker:
Готовим файл
Содержимое файла:
И рядом кладём конфиг
Запускаем весь стек:
Если будут ошибки, прогоните весь yaml через какой-нибудь валидатор. При копировании он часто ломается.
Ждём, когда всё поднимется, и идём по IP адресу сервера на порт 3000. Логинимся в Grafana под учёткой admin / admin. Заходим в Connections ⇨ Data sources и добавляем источник prometheus. В качестве параметра Prometheus server URL указываем http://prometheus:9090. Сохраняем.
Идём в Dashboards, нажимаем New ⇨ Import. Вводим ID дашборда для Node Exporter - 1860. Сохраняем и идём смотреть дашборд. Увидите все доступные графики и метрики хоста Linux, на котором всё запущено.
Идём на удалённый Linux хост и запускаем там любым подходящим способом node-exporter. Например, через Docker напрямую:
Проверяем, что сервис запущен на порту 9100:
Возвращаемся на сервер с prometheus и добавляем в его конфиг еще одну job с этим сервером:
Перезапускаем стек:
Идём в Dashboard в Grafana и выбираем сверху в выпадающем списке job от этого нового сервера - node-remote.
На всю настройку уйдёт минут 10. Потом ещё 10 на настройку базовых уведомлений. У меня уже места не хватило их добавить сюда. Наглядно видна простота и скорость настройки, о которых я сказал в начале.
❗️В проде не забывайте ограничивать доступ ко всем открытым портам хостов с помощью файрвола.
#мониторинг #prometheus #devops
Напишу краткую шпаргалку по запуску связки Prometheus + Grafana, чтобы её можно было сохранить и использовать по мере надобности. Я установлю их в Docker, сразу буду мониторить сам Prometheus и локальных хост Linux. Подключу для примера ещё один внешний Linux сервер.
Ставим Docker:
# curl https://get.docker.com | bash -Готовим файл
docker-compose.yml:# mkdir ~/prometheus && cd ~/prometheus# touch docker-compose.ymlСодержимое файла:
version: '3.9'networks: monitoring: driver: bridgevolumes: prometheus_data: {}services: prometheus: image: prom/prometheus:latest volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml - prometheus_data:/prometheus container_name: prometheus hostname: prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' expose: - 9090 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoring node-exporter: image: prom/node-exporter volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro container_name: exporter hostname: exporter command: - '--path.procfs=/host/proc' - '--path.rootfs=/rootfs' - '--path.sysfs=/host/sys' - '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)' expose: - 9100 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoring grafana: image: grafana/grafana user: root depends_on: - prometheus ports: - 3000:3000 volumes: - ./grafana:/var/lib/grafana - ./grafana/provisioning/:/etc/grafana/provisioning/ container_name: grafana hostname: grafana restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoringИ рядом кладём конфиг
prometheus.yml:scrape_configs: - job_name: 'prometheus' scrape_interval: 5s scrape_timeout: 5s static_configs: - targets: ['localhost:9090'] - job_name: 'node-local' scrape_interval: 5s static_configs: - targets: ['node-exporter:9100']Запускаем весь стек:
# docker-compose up -dЕсли будут ошибки, прогоните весь yaml через какой-нибудь валидатор. При копировании он часто ломается.
Ждём, когда всё поднимется, и идём по IP адресу сервера на порт 3000. Логинимся в Grafana под учёткой admin / admin. Заходим в Connections ⇨ Data sources и добавляем источник prometheus. В качестве параметра Prometheus server URL указываем http://prometheus:9090. Сохраняем.
Идём в Dashboards, нажимаем New ⇨ Import. Вводим ID дашборда для Node Exporter - 1860. Сохраняем и идём смотреть дашборд. Увидите все доступные графики и метрики хоста Linux, на котором всё запущено.
Идём на удалённый Linux хост и запускаем там любым подходящим способом node-exporter. Например, через Docker напрямую:
# docker run -d --net="host" --pid="host" -v "/:/host:ro,rslave" prom/node-exporter:latest --path.rootfs=/hostПроверяем, что сервис запущен на порту 9100:
# ss -tulnp | grep 9100Возвращаемся на сервер с prometheus и добавляем в его конфиг еще одну job с этим сервером:
- job_name: 'node-remote' scrape_interval: 5s static_configs: - targets: ['10.20.1.56:9100']Перезапускаем стек:
# docker compose restartИдём в Dashboard в Grafana и выбираем сверху в выпадающем списке job от этого нового сервера - node-remote.
На всю настройку уйдёт минут 10. Потом ещё 10 на настройку базовых уведомлений. У меня уже места не хватило их добавить сюда. Наглядно видна простота и скорость настройки, о которых я сказал в начале.
❗️В проде не забывайте ограничивать доступ ко всем открытым портам хостов с помощью файрвола.
#мониторинг #prometheus #devops
{kind=link}
Вчера была заметка про быструю установку связки Prometheus + Grafana. Из-за лимита Telegram на длину сообщений разом всё описать не представляется возможным. А для полноты картины не хватает настройки уведомлений, так как мониторинг без них это не мониторинг, а красивые картинки.
Для примера я настрою два типа уведомлений:
◽SMTP для только для метки critical
◽Telegram для меток critical и warning
Уведомления будут отправляться на основе двух событий:
▪️ С хоста нету метрик, то есть он недоступен мониторингу, метка critical
▪️ На хосте процессор занят в течении минуты более чем на 70%, метка warning
Я взял именно эти ситуации, так как на их основе будет понятен сам принцип настройки и формирования конфигов, чтобы каждый потом смог доработать под свои потребности.
Постить сюда все конфигурации в формате yaml неудобно, поэтому решил их собрать в архив и прикрепить в следующем сообщении. Там будут 4 файла:
-
-
-
-
Для запуска всего стека с уведомлениями достаточно положить эти 4 файла в отдельную директорию и там запустить compose:
На момент отладки рекомендую запускать прямо в консоли, чтобы отлавливать ошибки. Если где-то ошибётесь в конфигурациях правил или alertmanager, сразу увидите ошибки и конкретные строки конфигурации, с которыми что-то не так. В таком случае останавливайте стэк:
Исправляйте конфиги и заново запускайте. Зайдя по IP адресу сервера на порт 9090, вы попадёте в веб интерфейс Prometheus. Там будет отдельный раздел Alerts, где можно следить за работой уведомлений.
В данном примере со всем стэком наглядно показан принцип построения современного мониторинга с подходом инфраструктура как код (IaC). Имея несколько файлов конфигурации, мы поднимаем необходимую систему во всей полноте. Её легко переносить, изменять конфигурацию и отслеживать эти изменения через git.
#мониторинг #prometheus #devops
Для примера я настрою два типа уведомлений:
◽SMTP для только для метки critical
◽Telegram для меток critical и warning
Уведомления будут отправляться на основе двух событий:
▪️ С хоста нету метрик, то есть он недоступен мониторингу, метка critical
▪️ На хосте процессор занят в течении минуты более чем на 70%, метка warning
Я взял именно эти ситуации, так как на их основе будет понятен сам принцип настройки и формирования конфигов, чтобы каждый потом смог доработать под свои потребности.
Постить сюда все конфигурации в формате yaml неудобно, поэтому решил их собрать в архив и прикрепить в следующем сообщении. Там будут 4 файла:
-
docker-compose.yml - основной файл с конфигурацией всех сервисов. Его описание можно посмотреть в предыдущем посте. Там добавился новый контейнер с alertmanager и файл с правилами для prometheus - alert.rules-
prometheus.yml - настройки Прометеуса.-
alert.rules - файл с двумя правилами уведомлений о недоступности хоста и превышении нагрузки CPU.-
alertmanager.yml - настройки alertmanager с двумя источниками для уведомлений: email и telegram. Не забудьте там поменять токен бота, id своего аккаунта, куда бот будет отправлять уведомления и настройки smtp.Для запуска всего стека с уведомлениями достаточно положить эти 4 файла в отдельную директорию и там запустить compose:
# docker compose upНа момент отладки рекомендую запускать прямо в консоли, чтобы отлавливать ошибки. Если где-то ошибётесь в конфигурациях правил или alertmanager, сразу увидите ошибки и конкретные строки конфигурации, с которыми что-то не так. В таком случае останавливайте стэк:
# docker compose stopИсправляйте конфиги и заново запускайте. Зайдя по IP адресу сервера на порт 9090, вы попадёте в веб интерфейс Prometheus. Там будет отдельный раздел Alerts, где можно следить за работой уведомлений.
В данном примере со всем стэком наглядно показан принцип построения современного мониторинга с подходом инфраструктура как код (IaC). Имея несколько файлов конфигурации, мы поднимаем необходимую систему во всей полноте. Её легко переносить, изменять конфигурацию и отслеживать эти изменения через git.
#мониторинг #prometheus #devops
{kind=link}
Вчера свершилось знаменательное событие - заблокировали доступ к hub.docker.com с IP адресов в России. Теперь без лишних телодвижений не скачать образы из этого репозитория. Не очень понятно, зачем это сделали, почему только сейчас и в чём тут смысл, если обойти эту блокировку, как и многие другие, не представляет каких-то проблем.
Расскажу несколько простых разных способов обхода этой блокировки.
1️⃣ Самый простой - переключиться на какое-то зеркало. Их сейчас много появится и встанет вопрос доверия к ним. Пока можно гугловское зеркало использовать, но его скорее всего тоже рано или поздно для нас заблокируют. Для этого достаточно создать конфиг
Перезапускаем службу и пользуемся, как раньше.
Больше ничего менять не надо.
2️⃣ Использовать локально подключение докера к своему реджистри через прокси. Недавно я об этом рассказывал и там многие написали, типа зачем всё это, доступ не заблокирован. Потому что не будет вашего итальянского сыра ХАХАХАХА. Сегодня этот реджистри, завтра все остальные. Прокси тоже относительно просто решает вопрос для единичного хоста.
3️⃣ Можно глобально на общем шлюзе настроить VPN подключение к серверу за пределами РФ, маркировать весь трафик, что блокируется и отправлять его через VPN соединение. Я так делаю дома для себя и своих тестовых стендов. Рассказывал про эту настройку на примере Mikrotik.
4️⃣ Поднять собственный прокси для докера, который будет иметь доступ к hub.docker.com. Не важно, как это будет сделано у него: через VPN он будет подключаться, или сразу поднят на VPS за пределами РФ. Вы со своей стороны будете подключаться к этому прокси, а он будет по вашим запросам загружать образы.
Проще всего подобный прокси поднять с помощью Nexus repository. Показываю, как это сделать. Я сразу взял VPS за пределами РФ и развернул там:
В файле
Переходим в раздел управления и добавляем новый репозиторий. Тип выбираем docker (proxy). Если вы сами к прокси будете подключаться через VPN или проксировать к нему запросы через ещё какой-то прокси, типа Nginx или HAproxy, то можно в свойствах репозитория выбрать только HTTP и порт 8082. Это упростит настройку. Рекомендую идти именно по этому пути, чтобы ограничить тем или иным способом доступ к этому репозиторию. Вы же не будете его открывать в общий доступ для всех. В таком случае можно будет установить флаг Allow anonymous docker pull. Не нужно будет на всех хостах аутентификацию проходить.
В качестве Remote Storage можно указать https://registry-1.docker.io. Это докеровский репозиторий. Остальные настройки можно оставить по умолчанию, либо изменить в зависимости от ваших предпочтений.
Также зайдите в раздел Security ⇨ Realms и добавьте Docker Bearer Token Realm. Без него аутентификация в реджистри не будет работать.
После создания репозитория, можно его открыть. Там будет показан его url в зависимости от ваших настроек порта, http и адреса самого Nexus. Теперь его можно использовать в настройках
Перезапускайте службу Docker и пробуйте. Можно аутентифицироваться в своём реджистри и что-то загрузить:
Идём в веб интерфейс Nexus, смотрим обзор репозитория и видим там скачанный образ Nginx.
Пока на практике каких-то реальный проблем с ограничением доступа нет. Если кто-то использует другие способы, поделитесь информацией. С помощью Nexus можно прокси для любых репозиториев делать, не только Docker.
#devops #docker
Расскажу несколько простых разных способов обхода этой блокировки.
1️⃣ Самый простой - переключиться на какое-то зеркало. Их сейчас много появится и встанет вопрос доверия к ним. Пока можно гугловское зеркало использовать, но его скорее всего тоже рано или поздно для нас заблокируют. Для этого достаточно создать конфиг
/etc/docker/daemon.json, если у вас его нет, следующего содержания:{ "registry-mirrors": ["https://mirror.gcr.io"] }Перезапускаем службу и пользуемся, как раньше.
# systemctl restart dockerБольше ничего менять не надо.
2️⃣ Использовать локально подключение докера к своему реджистри через прокси. Недавно я об этом рассказывал и там многие написали, типа зачем всё это, доступ не заблокирован. Потому что не будет вашего итальянского сыра ХАХАХАХА. Сегодня этот реджистри, завтра все остальные. Прокси тоже относительно просто решает вопрос для единичного хоста.
3️⃣ Можно глобально на общем шлюзе настроить VPN подключение к серверу за пределами РФ, маркировать весь трафик, что блокируется и отправлять его через VPN соединение. Я так делаю дома для себя и своих тестовых стендов. Рассказывал про эту настройку на примере Mikrotik.
4️⃣ Поднять собственный прокси для докера, который будет иметь доступ к hub.docker.com. Не важно, как это будет сделано у него: через VPN он будет подключаться, или сразу поднят на VPS за пределами РФ. Вы со своей стороны будете подключаться к этому прокси, а он будет по вашим запросам загружать образы.
Проще всего подобный прокси поднять с помощью Nexus repository. Показываю, как это сделать. Я сразу взял VPS за пределами РФ и развернул там:
# docker volume create --name nexus-data# docker run -d -p 8081:8081 -p 8082:8082 --name nexus \-v nexus-data:/nexus-data sonatype/nexus3В файле
/var/lib/docker/volumes/nexus-data/_data/admin.password смотрим пароль от пользователя admin. Идём в веб интерфейс Nexus по IP адресу сервера на порт 8081.Переходим в раздел управления и добавляем новый репозиторий. Тип выбираем docker (proxy). Если вы сами к прокси будете подключаться через VPN или проксировать к нему запросы через ещё какой-то прокси, типа Nginx или HAproxy, то можно в свойствах репозитория выбрать только HTTP и порт 8082. Это упростит настройку. Рекомендую идти именно по этому пути, чтобы ограничить тем или иным способом доступ к этому репозиторию. Вы же не будете его открывать в общий доступ для всех. В таком случае можно будет установить флаг Allow anonymous docker pull. Не нужно будет на всех хостах аутентификацию проходить.
В качестве Remote Storage можно указать https://registry-1.docker.io. Это докеровский репозиторий. Остальные настройки можно оставить по умолчанию, либо изменить в зависимости от ваших предпочтений.
Также зайдите в раздел Security ⇨ Realms и добавьте Docker Bearer Token Realm. Без него аутентификация в реджистри не будет работать.
После создания репозитория, можно его открыть. Там будет показан его url в зависимости от ваших настроек порта, http и адреса самого Nexus. Теперь его можно использовать в настройках
/etc/docker/daemon.json:{ "insecure-registries": ["10.105.10.105:8082"], "registry-mirrors": ["http://10.105.10.105:8082"]}Перезапускайте службу Docker и пробуйте. Можно аутентифицироваться в своём реджистри и что-то загрузить:
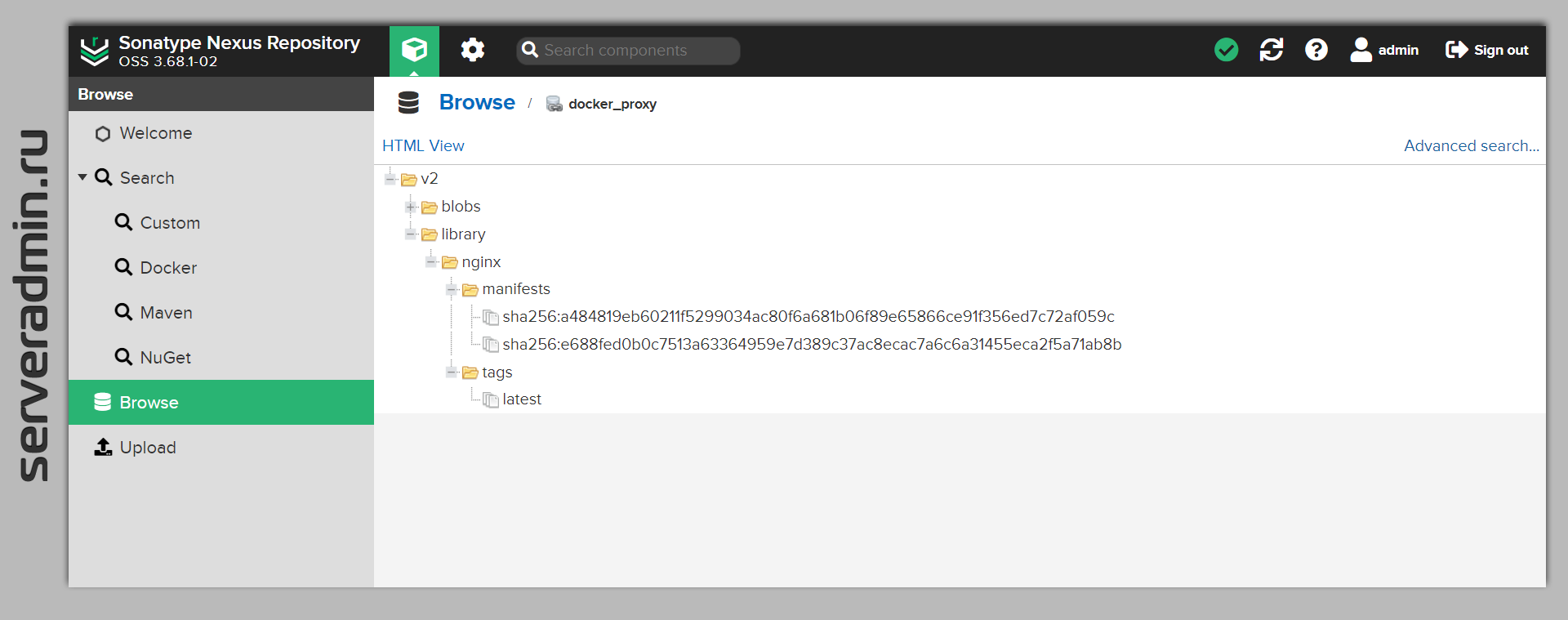
# docker login 10.105.10.105:8082# docker pull nginxИдём в веб интерфейс Nexus, смотрим обзор репозитория и видим там скачанный образ Nginx.
Пока на практике каких-то реальный проблем с ограничением доступа нет. Если кто-то использует другие способы, поделитесь информацией. С помощью Nexus можно прокси для любых репозиториев делать, не только Docker.
#devops #docker
{kind=link}
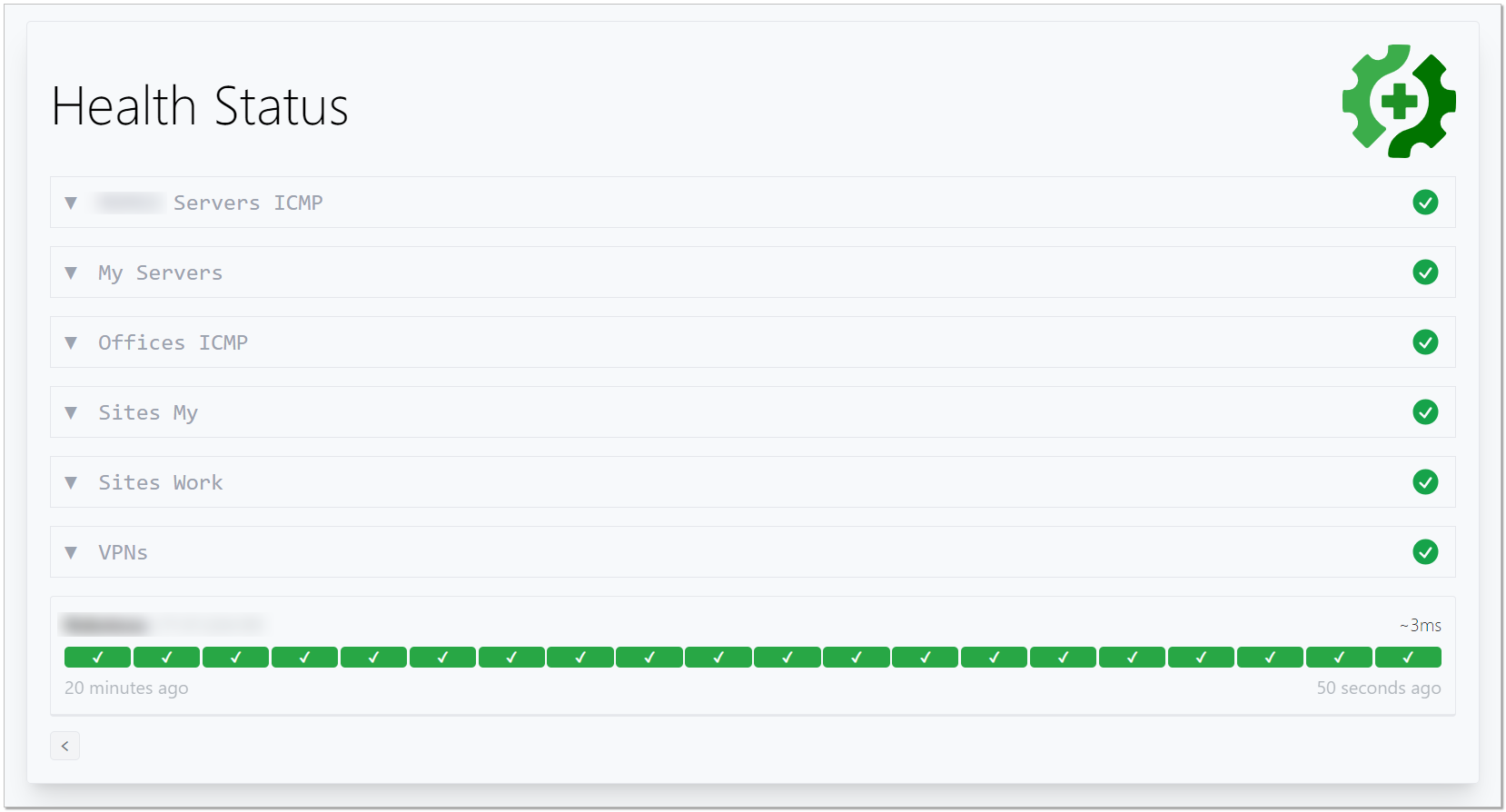
Я в пятницу рассказал про систему мониторинга Gatus. Система мне понравилась, так что решил её сразу внедрить у себя. Понравилась за 3 вещи:
▪️ простая настройка в едином конфигурационном файле;
▪️ информативные уведомления в Telegram;
▪️ наглядный дашборд со статусами как отдельных проверок, так и объединённых в группы.
На примере настройки Gatus я покажу, как собрал простейший конвейер по деплою настроек для этой системы мониторинга.
Настройка Gatus у меня сейчас выглядит следующим образом. Я открываю в VSCode конфигурационный файл config.yaml, который сохранён у меня локально на ноуте. Вношу в него правки, сохраняю и пушу в git репозиторий. Дальше изменения автоматом доходят до VPS, где всё развёрнуто и автоматически применяются. Через 10 секунд после пуша я иду в браузере проверять изменения.
Рассказываю по шагам, что я сделал для этого.
1️⃣ Взял самую простую VPS с 1 CPU и 1 GB оперативной памяти. Установил туда Docker и запустил Gatus.
2️⃣ В бесплатной учётной записи на gitlab.com создал отдельный репозиторий для Gatus.
3️⃣ На VPS установил gitlub-runner с shell executor, запустил и подключил к проекту Gatus.
4️⃣ Для проекта настроил простейший CI/CD средствами Gitlab (по факту только CD) с помощью файла
5️⃣ Скопировал репозиторий к себе на ноут, где установлен VSCode с расширением GitLab Workflow. С его помощью подключаю локальные репозитории к репозиториям gitlab.
Итого у меня в репозитории 2 файла:
◽
◽
Когда мне нужно добавить или отредактировать проверку в Gatus, я открываю у себя на ноуте конфиг и вношу туда изменения. Коммичу их и пушу изменения в репозиторий в Gitlab. Сервис видит наличие файла
На простом примере показал, как работает простейшая доставка кода на целевую машину и его применение. Даже если вы не участвуете в разработке ПО, рекомендую разобраться с этой темой и применять на практике. Это много где может пригодится даже чисто в админских делах.
#devops #cicd
▪️ простая настройка в едином конфигурационном файле;
▪️ информативные уведомления в Telegram;
▪️ наглядный дашборд со статусами как отдельных проверок, так и объединённых в группы.
На примере настройки Gatus я покажу, как собрал простейший конвейер по деплою настроек для этой системы мониторинга.
Настройка Gatus у меня сейчас выглядит следующим образом. Я открываю в VSCode конфигурационный файл config.yaml, который сохранён у меня локально на ноуте. Вношу в него правки, сохраняю и пушу в git репозиторий. Дальше изменения автоматом доходят до VPS, где всё развёрнуто и автоматически применяются. Через 10 секунд после пуша я иду в браузере проверять изменения.
Рассказываю по шагам, что я сделал для этого.
1️⃣ Взял самую простую VPS с 1 CPU и 1 GB оперативной памяти. Установил туда Docker и запустил Gatus.
2️⃣ В бесплатной учётной записи на gitlab.com создал отдельный репозиторий для Gatus.
3️⃣ На VPS установил gitlub-runner с shell executor, запустил и подключил к проекту Gatus.
4️⃣ Для проекта настроил простейший CI/CD средствами Gitlab (по факту только CD) с помощью файла
.gitlab-ci.yml. Добавил туда всего 3 действия:deploy-prod: stage: deploy script: - cd /home/gitlab-runner/gatus - git pull - /usr/bin/docker restart gatus5️⃣ Скопировал репозиторий к себе на ноут, где установлен VSCode с расширением GitLab Workflow. С его помощью подключаю локальные репозитории к репозиториям gitlab.
Итого у меня в репозитории 2 файла:
◽
config.yaml - конфигурация gatus◽
.gitlab-ci.yml - описание команд, которые будет выполнять gitlab-runnerКогда мне нужно добавить или отредактировать проверку в Gatus, я открываю у себя на ноуте конфиг и вношу туда изменения. Коммичу их и пушу изменения в репозиторий в Gitlab. Сервис видит наличие файла
.gitlab-ci.yml и отдаёт команду gitlab-runner, установленному на VPS на выполнение заданных действий: обновление локального репозитория, чтобы поучить обновлённый конфиг и перезапуск контейнера, который необходим для применения изменений. На простом примере показал, как работает простейшая доставка кода на целевую машину и его применение. Даже если вы не участвуете в разработке ПО, рекомендую разобраться с этой темой и применять на практике. Это много где может пригодится даже чисто в админских делах.
#devops #cicd
{kind=link}
Я много раз упоминал в заметках, что надо стараться максимально скрывать сервисы от доступа из интернета. И проверять это, потому что часто они туда попадают случайно из-за того, что что-то забыли или неверно настроили. Решил через shodan глянуть открытые Node Exporter от Prometheus. Они часто болтаются в открытом виде, потому что по умолчанию никаких ограничений доступа в них нет. Заходи, кто хочешь, и смотри, что там есть.
И первым же IP адресом с открытым Node Exporter, на который я зашёл, оказалась чья-то нода Kubernetes. Причём для меня она сразу стала не чей-то, а я конкретно нашёл, кому она принадлежит. Мало того, что сам Node Exporter вываливает просто кучу информации в открытый доступ. Например, по volumes от контейнеров стало понятно, какие сервисы там крутятся. Видны названия lvm томов, точки монтирования, информация о разделах и дисках, биос, материнка, версия ОС, система виртуализации и т.д.
На этом же IP висел Kubernetes API. Доступа к нему не было, он отдавал 401 Unauthorized. Но по сертификату, который доступен, в Alternative Name можно найти кучу доменов и сервисов, которые засветились на этом кластере. Я не знаю, по какому принципу они туда попадают, но я их увидел. Там я нашёл сервисы n8n, vaultwarden, freshrss. Не знаю, должны ли в данном случае их веб интерфейсы быть в открытом доступе или нет, но я в окна аутентификации от этих сервисов попал.
Там же нашёл информацию о блоге судя по всему владельца этого хозяйства. Плодовитый специалист из Бахрейна. Много open source проектов, которые он развивает и поддерживает. Там же резюме его как DevOps, разработчика, SysOps. Нашёл на поддоменах и прошлую версию блога, черновики и кучу каких-то других сервисов. Не стал уже дальше ковыряться.
Ссылки и IP адреса приводить не буду, чтобы не навредить этому человеку. Скорее всего это какие-то его личные проекты, но не факт. В любом случае, вываливать в открытый доступ всю свою подноготную смысла нет. Закрыть файрволом и нет проблем. Конечно, всё это так или иначе можно собрать. История выпущенных сертификатов и dns записей хранится в открытом доступе. Но тем не менее, тут всё вообще в куче лежит прямо на активном сервере.
Для тех, кто не в курсе, поясню, что всю историю выпущенных сертификатов конкретного домена со всеми поддоменами можно посмотреть тут:
⇨ https://crt.sh
Можете себя проверить.
#devops #security
И первым же IP адресом с открытым Node Exporter, на который я зашёл, оказалась чья-то нода Kubernetes. Причём для меня она сразу стала не чей-то, а я конкретно нашёл, кому она принадлежит. Мало того, что сам Node Exporter вываливает просто кучу информации в открытый доступ. Например, по volumes от контейнеров стало понятно, какие сервисы там крутятся. Видны названия lvm томов, точки монтирования, информация о разделах и дисках, биос, материнка, версия ОС, система виртуализации и т.д.
На этом же IP висел Kubernetes API. Доступа к нему не было, он отдавал 401 Unauthorized. Но по сертификату, который доступен, в Alternative Name можно найти кучу доменов и сервисов, которые засветились на этом кластере. Я не знаю, по какому принципу они туда попадают, но я их увидел. Там я нашёл сервисы n8n, vaultwarden, freshrss. Не знаю, должны ли в данном случае их веб интерфейсы быть в открытом доступе или нет, но я в окна аутентификации от этих сервисов попал.
Там же нашёл информацию о блоге судя по всему владельца этого хозяйства. Плодовитый специалист из Бахрейна. Много open source проектов, которые он развивает и поддерживает. Там же резюме его как DevOps, разработчика, SysOps. Нашёл на поддоменах и прошлую версию блога, черновики и кучу каких-то других сервисов. Не стал уже дальше ковыряться.
Ссылки и IP адреса приводить не буду, чтобы не навредить этому человеку. Скорее всего это какие-то его личные проекты, но не факт. В любом случае, вываливать в открытый доступ всю свою подноготную смысла нет. Закрыть файрволом и нет проблем. Конечно, всё это так или иначе можно собрать. История выпущенных сертификатов и dns записей хранится в открытом доступе. Но тем не менее, тут всё вообще в куче лежит прямо на активном сервере.
Для тех, кто не в курсе, поясню, что всю историю выпущенных сертификатов конкретного домена со всеми поддоменами можно посмотреть тут:
⇨ https://crt.sh
Можете себя проверить.
#devops #security
Часто доступ к веб ресурсам осуществляется не напрямую, а через обратные прокси. Причём чаще доступ именно такой, а не прямой. При возможности, я всегда ставлю обратные прокси перед сайтами даже в небольших проектах. Это и удобнее, и безопаснее, но немного более хлопотно в управлении.
Для проксирования запросов в Docker контейнеры очень удобно использовать Traefik. Удобство это в первую очередь проявляется в тестовых задачах, где часто меняется конфигурация контейнеров с приложениями, их домены, а также возникают задачи по запуску нескольких копий типовых проектов. Для прода это не так актуально, потому что он обычно более статичен в этом плане.
Сразу покажу на практике, в чём заключается удобство Traefik и в каких случаях имеет смысл им воспользоваться. Для примера запущу через Traefik 2 проекта test1 и test2, состоящих из nginx и apache и тестовой страницы, где будет указано имя проекта. В этом примере будет наглядно виден принцип работы Traefik.
Запускаем Traefik через
Можно сходить в веб интерфейс по ip адресу сервера на порт 8080. Пока там пусто, так как нет проектов. Создаём первый тестовый проект. Готовим для него файлы:
Запускаем этот проект:
В веб интерфейсе Traefik, в разделе HTTP появится запись:
Теперь можно скопировать проект test1, изменить в нём имя домена и имя внутренней сети на test2 и запустить. Traefik автоматом подцепит этот проект и будет проксировать запросы к test2.server.local в nginx-test2. Работу этой схемы легко проверить, зайдя откуда-то извне браузером на test1.server.local и test2.server.local. Вы получите соответствующую страницу index.html от запрошенного проекта.
К Traefik легко добавить автоматическое получение TLS сертификатов от Let's Encrypt. Примеров в сети и документации много, настроить не составляет проблемы. Не стал показывать этот пример, так как не уместил бы его в формат заметки. Мне важно было показать суть - запустив один раз Traefik, можно его больше не трогать. По меткам в контейнерах он будет автоматом настраивать проксирование. В некоторых ситуациях это очень удобно.
#webserver #traefik #devops
Для проксирования запросов в Docker контейнеры очень удобно использовать Traefik. Удобство это в первую очередь проявляется в тестовых задачах, где часто меняется конфигурация контейнеров с приложениями, их домены, а также возникают задачи по запуску нескольких копий типовых проектов. Для прода это не так актуально, потому что он обычно более статичен в этом плане.
Сразу покажу на практике, в чём заключается удобство Traefik и в каких случаях имеет смысл им воспользоваться. Для примера запущу через Traefik 2 проекта test1 и test2, состоящих из nginx и apache и тестовой страницы, где будет указано имя проекта. В этом примере будет наглядно виден принцип работы Traefik.
Запускаем Traefik через
docker-compose.yaml:# mkdir traefik && cd traefik
# mcedit docker-compose.yaml
services:
reverse-proxy:
image: traefik:v3.0
command: --api.insecure=true --providers.docker
ports:
- "80:80"
- "8080:8080"
networks:
- traefik_default
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
traefik_default:
external: true
# docker compose up
Можно сходить в веб интерфейс по ip адресу сервера на порт 8080. Пока там пусто, так как нет проектов. Создаём первый тестовый проект. Готовим для него файлы:
# mkdir test1 && cd test1
# mcedit docker-compose.yaml
services:
nginx:
image: nginx:latest
volumes:
- ./app/index.html:/app/index.html
- ./default.conf:/etc/nginx/conf.d/default.conf
labels:
- "traefik.enable=true"
- "traefik.http.routers.nginx-test1.rule=Host(`test1.server.local`)"
- "traefik.http.services.nginx-test1.loadbalancer.server.port=8080"
- "traefik.docker.network=traefik_default"
networks:
- traefik_default
- test1
httpd:
image: httpd:latest
volumes:
- ./app/index.html:/usr/local/apache2/htdocs/index.html
networks:
- test1
networks:
traefik_default:
external: true
test1:
internal: true
# mcedit default.conf
server {
listen 8080;
server_name _;
root /app;
index index.php index.html;
location / {
proxy_pass http://httpd:80;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}# mcedit app/index.html
It's Container for project test1
Запускаем этот проект:
# docker compose up
В веб интерфейсе Traefik, в разделе HTTP появится запись:
Host(`test1.server.local`) http nginx-test1@docker nginx-test1Он по меткам в docker-compose проекта test1 автоматом подхватил настройки и включил проксирование всех запросов к домену test1.server.local в контейнер nginx-test1. При этом сам проект test1 внутри себя взаимодействует по своей внутренней сети test1, а с Traefik по сети traefik_default, которая является внешней для приёма запросов извне.
Теперь можно скопировать проект test1, изменить в нём имя домена и имя внутренней сети на test2 и запустить. Traefik автоматом подцепит этот проект и будет проксировать запросы к test2.server.local в nginx-test2. Работу этой схемы легко проверить, зайдя откуда-то извне браузером на test1.server.local и test2.server.local. Вы получите соответствующую страницу index.html от запрошенного проекта.
К Traefik легко добавить автоматическое получение TLS сертификатов от Let's Encrypt. Примеров в сети и документации много, настроить не составляет проблемы. Не стал показывать этот пример, так как не уместил бы его в формат заметки. Мне важно было показать суть - запустив один раз Traefik, можно его больше не трогать. По меткам в контейнерах он будет автоматом настраивать проксирование. В некоторых ситуациях это очень удобно.
#webserver #traefik #devops
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
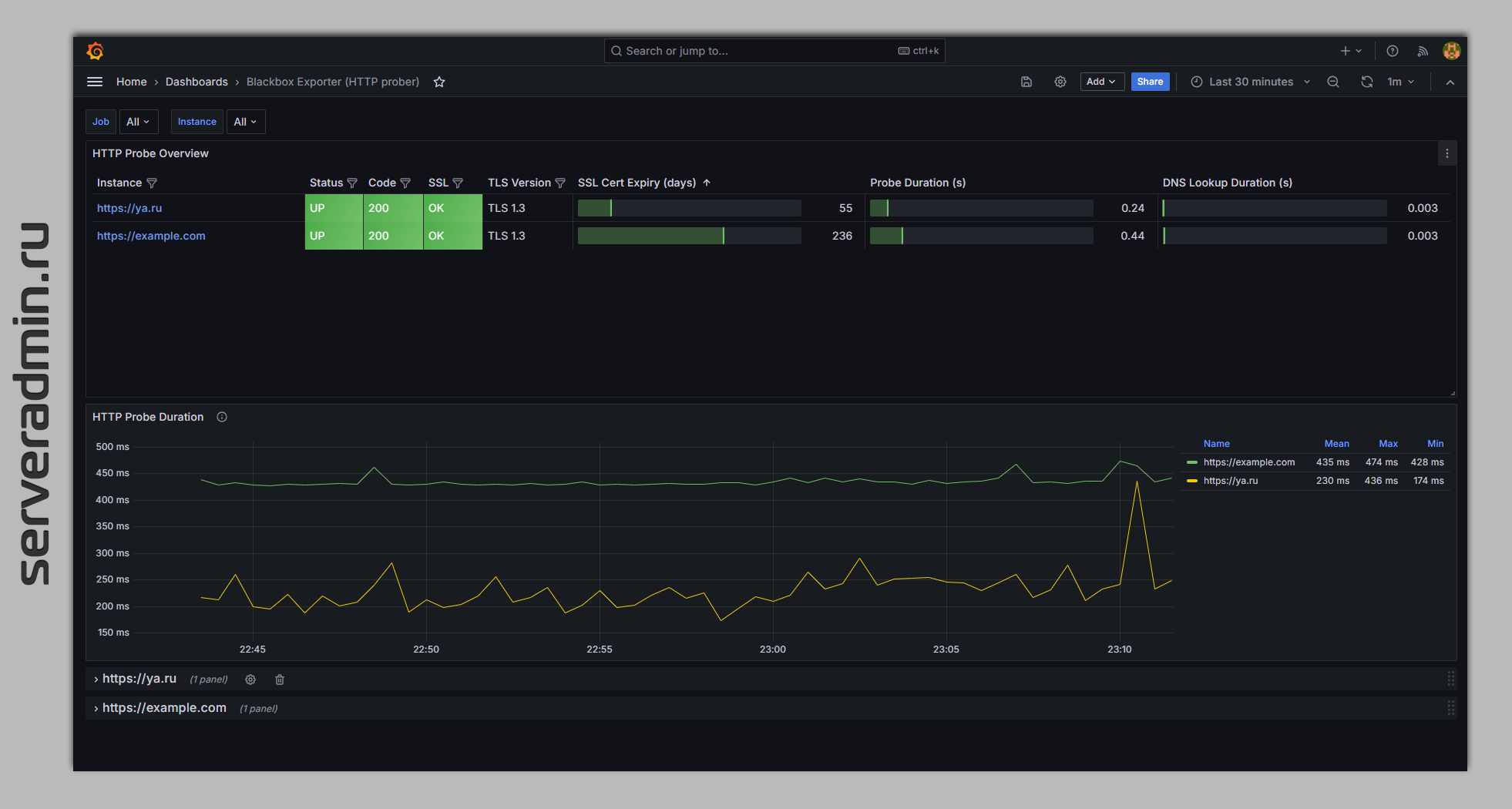
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}