
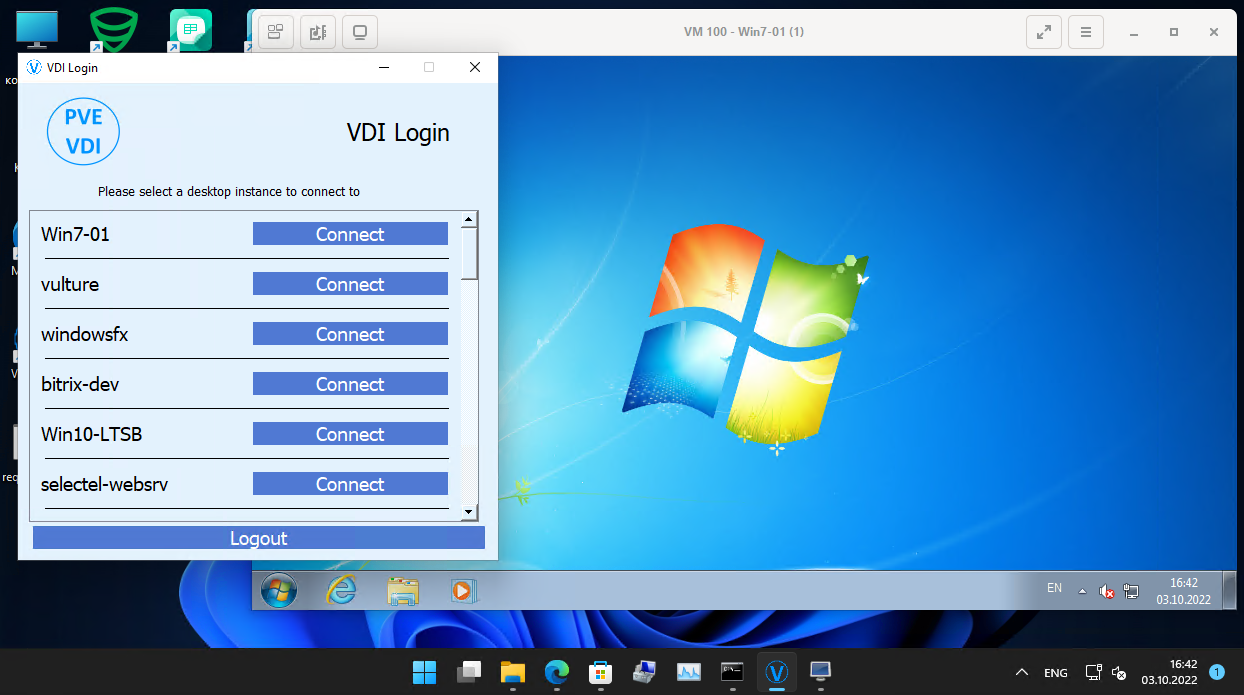
В комментариях в заметке про VDI со мной поделились классным софтом - PVE-VDIClient. Это простой клиент на Python, с помощью которого можно напрямую подключаться к виртуальным машинам PVE по протоколу SPICE. Не нужен никакой дополнительный софт, типа RDP или VNC. Вы напрямую подключаетесь к консоли виртуальной машины.
Для чего это может понадобиться? Например, у вас есть Raspberry Pi и вы хотите сделать тонкий клиент для работы в ОС Windows с пробросом микрофона, камеры и звука. Вот подробное видео реализации:
⇨ https://www.youtube.com/watch?v=TuDrmq4RQzU
Я вчера потратил несколько часов, пока не разобрался полностью как это работает. В итоге запустил PVE-VDIClient на Windows 10 и 11. Рассказываю по шагам, что нужно сделать.
1️⃣ Добавляем в PVE новых пользователей и отдельную группу для них. Назначаем этой группе права доступа: VM.PowerMgmt, VM.Console, VM.Audit. Можно на конкретные виртуальные машины или на все сразу.
2️⃣ Виртуальным машинам, к которым будем подключаться по SPICE, в настройках указываем Display: SPICE и добавляем ещё один USB Device: Spice Port.
3️⃣ На ОС Windows, с которой будем подключаться, устанавливаем Python 3.10. Я установил через Microsoft Store. Далее идём в репозиторий, скачиваем файл requirements.bat и запускаем его. Либо просто вручную установите pip пакеты, которые там указаны.
4️⃣ Далее скачиваем virt-viewer под Windows и устанавливаем. После этого идём в releases и скачиваем последнюю версию PVE VDI client, устанавливаем.
5️⃣ В директорию C:\Program Files\VDIClient кладём файл vdiclient.ini, образец которого есть в репозитории под именем vdiclient.ini.example (example удаляем). Тут важно сделать несколько настроек, без которых у меня ничего не работало.
В разделе [Hosts] пишем адрес своего гипервизора и его порт 8006:
В разделе [SpiceProxyRedirect] редактируем параметр:
prox.zeroxzed.ru - имя хоста, которое можно посмотреть в веб интерфейсе, в разделе System ⇨ Hosts. В инструкции нигде не указано, что нужно это сделать, а дефолтная запись выглядит вот так:
Попробуй тут догадайся, что надо написать.
В разделе [Authentication] есть параметр auth_backend. По умолчанию он имеет значение:
Если поменять его на
Сможете подключаться дефолтной учёткой root, под которой заходите в веб интерфейс. Если это ваш тестовый гипервзиор, то логичнее поступить именно так и не создавать отдельных пользователей.
6️⃣ Теперь можно запускать VDI клиент, подключаться к гипервизору под созданной учётной записью и запускать виртуальную машину. Для увеличения быстродействия и лучшей работы с видео, в гостевые ОС рекомендуется установить SPICE guest tools. Но и без них всё будет работать.
Получилась готовая инструкция, которой в сети нет. Так что если вам интересна эта тема, сохраните к себе. Мне лично очень понравилось. Работать с виртуальными машинами так гораздо удобнее, чем по SSH или RDP. Можно спокойно добавить к машине несколько мониторов и переключаться между ними. В видео, которое я показал выше, автор демонстрирует такую возможность.
Полезные ссылки, которые пригодились в процессе настройки:
Исходники - https://github.com/joshpatten/PVE-VDIClient
Virt-manager - https://virt-manager.org/download/
Spice-guest-tools - https://www.spice-space.org/download.html
PVE SPICE - https://pve.proxmox.com/wiki/SPICE
Raspberry Pi THIN CLIENT for Proxmox VMs -
https://www.youtube.com/watch?v=TuDrmq4RQzU
#vdi #proxmox #виртуализация
Для чего это может понадобиться? Например, у вас есть Raspberry Pi и вы хотите сделать тонкий клиент для работы в ОС Windows с пробросом микрофона, камеры и звука. Вот подробное видео реализации:
⇨ https://www.youtube.com/watch?v=TuDrmq4RQzU
Я вчера потратил несколько часов, пока не разобрался полностью как это работает. В итоге запустил PVE-VDIClient на Windows 10 и 11. Рассказываю по шагам, что нужно сделать.
1️⃣ Добавляем в PVE новых пользователей и отдельную группу для них. Назначаем этой группе права доступа: VM.PowerMgmt, VM.Console, VM.Audit. Можно на конкретные виртуальные машины или на все сразу.
2️⃣ Виртуальным машинам, к которым будем подключаться по SPICE, в настройках указываем Display: SPICE и добавляем ещё один USB Device: Spice Port.
3️⃣ На ОС Windows, с которой будем подключаться, устанавливаем Python 3.10. Я установил через Microsoft Store. Далее идём в репозиторий, скачиваем файл requirements.bat и запускаем его. Либо просто вручную установите pip пакеты, которые там указаны.
4️⃣ Далее скачиваем virt-viewer под Windows и устанавливаем. После этого идём в releases и скачиваем последнюю версию PVE VDI client, устанавливаем.
5️⃣ В директорию C:\Program Files\VDIClient кладём файл vdiclient.ini, образец которого есть в репозитории под именем vdiclient.ini.example (example удаляем). Тут важно сделать несколько настроек, без которых у меня ничего не работало.
В разделе [Hosts] пишем адрес своего гипервизора и его порт 8006:
10.20.1.2 = 8006В разделе [SpiceProxyRedirect] редактируем параметр:
prox.zeroxzed.ru:3128 = 10.20.1.2:3128prox.zeroxzed.ru - имя хоста, которое можно посмотреть в веб интерфейсе, в разделе System ⇨ Hosts. В инструкции нигде не указано, что нужно это сделать, а дефолтная запись выглядит вот так:
pve1.example.com:3128 = 123.123.123.123:6000Попробуй тут догадайся, что надо написать.
В разделе [Authentication] есть параметр auth_backend. По умолчанию он имеет значение:
auth_backend = pveЕсли поменять его на
auth_backend = pamСможете подключаться дефолтной учёткой root, под которой заходите в веб интерфейс. Если это ваш тестовый гипервзиор, то логичнее поступить именно так и не создавать отдельных пользователей.
6️⃣ Теперь можно запускать VDI клиент, подключаться к гипервизору под созданной учётной записью и запускать виртуальную машину. Для увеличения быстродействия и лучшей работы с видео, в гостевые ОС рекомендуется установить SPICE guest tools. Но и без них всё будет работать.
Получилась готовая инструкция, которой в сети нет. Так что если вам интересна эта тема, сохраните к себе. Мне лично очень понравилось. Работать с виртуальными машинами так гораздо удобнее, чем по SSH или RDP. Можно спокойно добавить к машине несколько мониторов и переключаться между ними. В видео, которое я показал выше, автор демонстрирует такую возможность.
Полезные ссылки, которые пригодились в процессе настройки:
Исходники - https://github.com/joshpatten/PVE-VDIClient
Virt-manager - https://virt-manager.org/download/
Spice-guest-tools - https://www.spice-space.org/download.html
PVE SPICE - https://pve.proxmox.com/wiki/SPICE
Raspberry Pi THIN CLIENT for Proxmox VMs -
https://www.youtube.com/watch?v=TuDrmq4RQzU
#vdi #proxmox #виртуализация
{kind=link}
Последние заметки про VDI (Virtual Desktop Infrastructure,) породили много вопросов в комментариях на тему того, зачем всё это нужно, если есть протокол RDP для удалённой работы. Во-первых, системы VDI не противопоставляют себя каким-то другим доступам. Более того, они чаще всего включают в себя поддержку и RDP соединений и многих других (VNC, SPICE). Во-вторых, если и сравнивать VDI, то с Remote Desktop Services (RDS) в составе Windows Server.
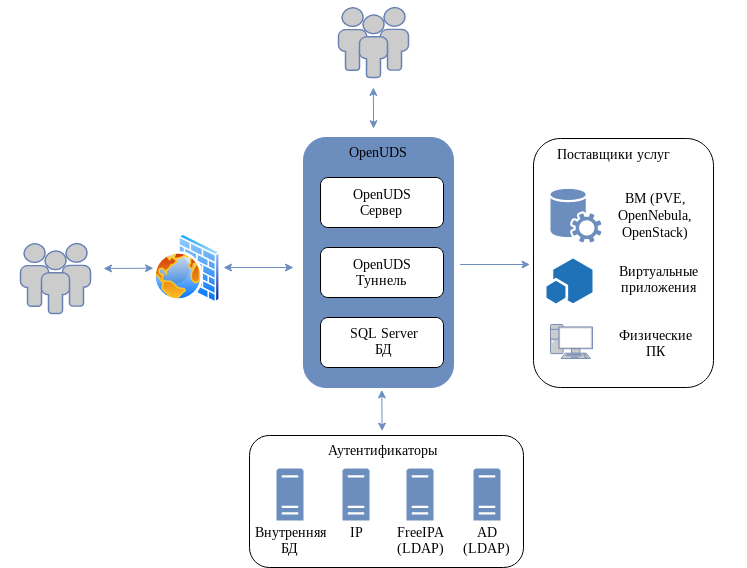
Например, есть бесплатное решение OpenUDS для организации VDI. Вот его основные возможности:
◽ Поддержка open source платформ виртуализации: oVirt, OpenNebula, Open Stack, XCP-ng, Proxmox, а также платных: Citrix Hypervisor, Microsoft Hyper-V, Nutanix Acropolis, VMware.
◽ Поддержка протоколов доставки рабочего стола: RDP (в том числе через HTML5), X2Go, SPICE (только для QEMU).
◽ Поддержка аутентификации: LDAP (в том числе MS AD), IP/mac-адреса, внутренняя БД, Radius.
◽ Клиенты Linux и Windows для подключений.
Как это выглядит на практике. Вы берёте гипервизоры Proxmox, можно кластер. Настраиваете OpenUDS и подключаете через провайдера гипервизоры к системе. Настраиваете ту или иную аутентификацию пользователей, создаёте их. Готовите шаблоны операционных систем. Настраиваете поведение тех или иных систем. Например, при отключении пользователя система может уничтожаться, а при подключении разворачиваться заново из шаблона. Либо сделать постоянные рабочие места с сохранением состояния.
Далее создаёте транспорт в виде различных протоколов доступа к системам и связываете из с пользователями. Кто-то будет подключаться по RDP, кто-то по X2Go, кто-то по SPICE. Пользователю на компьютер устанавливается openuds-client, с помощью которого он подключается к системам, к которым имеет доступ. Это объяснение на пальцах, как принципе всё работает.
❓Зачем может пригодиться подключение по SPICE, если есть RDP? Во первых, SPICE работает на уровне гипервизора. У вас всегда будет доступ к VM. В теории SPICE умеет работать с видеокартами на хосте, он умеет адекватно обрабатывать видео, прокидывать видеокамеру, микрофон. С его помощью можно организовать полноценное удалённое рабочее место того же дизайнера или проектировщика. Это в теории, на практике там наверняка много нюансов и надо разбираться. Скорее всего не всё и не везде поддерживается. Разработчики Termidesk рассказывали, что они дорабатывали SPICE самостоятельно, чтобы он нормально работал c видеокартами и жал видеопоток от камеры. По умолчанию он этого не делает, поэтому нужен широкий канал для нормальной картинки.
Очень подробное описание и настройка OpenUDS:
⇨ https://www.altlinux.org/VDI/OpenUDS
Я изучил инструкцию. На вид всё довольно просто и логично настраивается. В основном через веб интерфейс. Есть возможность поднять HA кластер:
⇨ https://www.altlinux.org/OpenUDS_HA
Хочу отметить, что у команды altlinux очень хорошие подробные руководства, по которым зачастую копипастом можно настроить.
Для бесплатного продукта очень приличный функционал. Первое, что приходит в голову, где это точно пригодится, даже если нет больших масштабов - учебные классы. Понятно, что обычных офисных сотрудников проще на RDS посадить, но не забываем, что это стоит приличных денег, если мы работаем в белую.
#vdi #виртуализация
Например, есть бесплатное решение OpenUDS для организации VDI. Вот его основные возможности:
◽ Поддержка open source платформ виртуализации: oVirt, OpenNebula, Open Stack, XCP-ng, Proxmox, а также платных: Citrix Hypervisor, Microsoft Hyper-V, Nutanix Acropolis, VMware.
◽ Поддержка протоколов доставки рабочего стола: RDP (в том числе через HTML5), X2Go, SPICE (только для QEMU).
◽ Поддержка аутентификации: LDAP (в том числе MS AD), IP/mac-адреса, внутренняя БД, Radius.
◽ Клиенты Linux и Windows для подключений.
Как это выглядит на практике. Вы берёте гипервизоры Proxmox, можно кластер. Настраиваете OpenUDS и подключаете через провайдера гипервизоры к системе. Настраиваете ту или иную аутентификацию пользователей, создаёте их. Готовите шаблоны операционных систем. Настраиваете поведение тех или иных систем. Например, при отключении пользователя система может уничтожаться, а при подключении разворачиваться заново из шаблона. Либо сделать постоянные рабочие места с сохранением состояния.
Далее создаёте транспорт в виде различных протоколов доступа к системам и связываете из с пользователями. Кто-то будет подключаться по RDP, кто-то по X2Go, кто-то по SPICE. Пользователю на компьютер устанавливается openuds-client, с помощью которого он подключается к системам, к которым имеет доступ. Это объяснение на пальцах, как принципе всё работает.
❓Зачем может пригодиться подключение по SPICE, если есть RDP? Во первых, SPICE работает на уровне гипервизора. У вас всегда будет доступ к VM. В теории SPICE умеет работать с видеокартами на хосте, он умеет адекватно обрабатывать видео, прокидывать видеокамеру, микрофон. С его помощью можно организовать полноценное удалённое рабочее место того же дизайнера или проектировщика. Это в теории, на практике там наверняка много нюансов и надо разбираться. Скорее всего не всё и не везде поддерживается. Разработчики Termidesk рассказывали, что они дорабатывали SPICE самостоятельно, чтобы он нормально работал c видеокартами и жал видеопоток от камеры. По умолчанию он этого не делает, поэтому нужен широкий канал для нормальной картинки.
Очень подробное описание и настройка OpenUDS:
⇨ https://www.altlinux.org/VDI/OpenUDS
Я изучил инструкцию. На вид всё довольно просто и логично настраивается. В основном через веб интерфейс. Есть возможность поднять HA кластер:
⇨ https://www.altlinux.org/OpenUDS_HA
Хочу отметить, что у команды altlinux очень хорошие подробные руководства, по которым зачастую копипастом можно настроить.
Для бесплатного продукта очень приличный функционал. Первое, что приходит в голову, где это точно пригодится, даже если нет больших масштабов - учебные классы. Понятно, что обычных офисных сотрудников проще на RDS посадить, но не забываем, что это стоит приличных денег, если мы работаем в белую.
#vdi #виртуализация
{kind=link}
Не раз получал просьбу кратко описать современные гипервизоры. Просьба логична и понятна. Если плотно с этим не работаешь, то не очевидно, как выбрать подходящую виртуализацию. А выбирать есть из чего. Расскажу своими словами на основе опыта, что есть у меня. Это будет полностью субъективный текст в масштабах малого и среднего бизнеса, не претендующий на истину.
📌 VMware. Начну с явного и очевидного лидера, с которым у меня опыта не так много. Гипервизор от этой компании наиболее функционален и распространён в крупном бизнесе. Я видел и в среднем крякнутые версии. Есть бесплатная версия гипервизора, у которой в разное время были разные ограничения, но в любом случае она всегда была только для одиночного хоста.
➖ Главный минус VMware для меня - нельзя установить на программный рейд. И для железных рейдов надо проверять поддержку, как и для некоторого вида железа. Под капотом там модифицированный Linux, так что есть некоторые неудобства по сравнению с гипервизорами, где используется стандартный Linux дистрибутив в основе.
➕ Плюс - можно бэкапить с помощью Veeam, но только платную версию.
📌 Hyper-V. Лично мне всегда нравился и нравится этот гипервизор. В основе бесплатной версии лежит стандартный Windows Server Core. Работать с ним удобно и понятно, хотя есть некоторые нюансы, связанные с установкой оснасток на системы для управления. Частично этот вопрос закрывает Windows Admin Center, который позволяет управлять гипервизором через браузер.
➖ Cущественных минусов я даже не припомню, кроме невозможности пробросить USB устройство.
➕ Из плюсов, как я у же сказал - стандартная Windows система. Надо передать какой-то iso или файл на гипервизор - расшариваем папку и кладём файл. То же самое, если надо забрать что-то, например виртуальный диск. Поддерживает софтовые рейды, а также встроенные от intel. Хотя надёжность там так себе, я бы не советовал. Можно бэкапить с помощью Veeam.
📌 KVM. Важная ремарка, чтобы предупредить комментарии на эту тему. KVM - это модуль ядра Linux, который обеспечивает аппаратную виртуализацию и сам по себе гипервизором не является, но для простоты его так называют. Чаще всего он является частью готовых систем виртуализации, таких как RHV, oVirt, Proxmox, Qemu и т.д. Я использовал KVM с управлением через консоль с помощью virsh, с помощью графического интерфейса virt-manager. А последние года 3-4 в составе гипервизора Proxmox, когда он полностью созрел и завоевал популярность. На заре моего использования KVM это было не так.
Про плюсы и минусы KVM скажу в контексте Proxmox VE, так как использую его только в таком виде.
➕ Из плюсов это полная бесплатность и возможность собрать кластер даже в бесплатной версии. Есть встроенные средства для бэкапов, причём довольно функциональные, с инкрементными бэкапами. Под капотом почти обычный Linux, так что вы не ограничены в управлении, мониторинге, установке на mdadm и т.д. Поддерживается всё железо, которое поддерживает Linux.
➖ Из минусов лично мне больше всего не нравится, что в Veeam нет поддержки KVM.
📌 XenServer. Использовал этот бесплатный гипервизор очень плотно, пока не набрал популярность Proxmox VE. Он был один из первых с хорошим функционалом и простой настройкой.
➕ Из плюсов то, что под капотом был почти стандартный Centos со всеми вытекающими преимуществами. Также очень удобная консоль управления под Windows. Лично мне она даже сейчас кажется максимально удобной для управления среди всех известных гипервизоров. На момент использования (2010-2015 г) был бесплатный софт для бэкапа Xen с поддержкой дедупликации и инкрементных бэкапов.
➖ Минус в лицензии, которую нужно было получать отдельно. В какой-то момент поддержку старых версий бесплатных гипервизоров отключили просто закрыв этот сервис. Я с тех пор с XenServer и попрощался. Также в одной из версий пропала возможность поставить гипервизор на mdadm, что тоже отбило желание использовать этот гипервизор. Сейчас я знаю, что на базе Xen есть XCP-ng, но мне уже особо не нужно. Пробовал его, но пользоваться не стал. Устраивает Proxmox VE.
#виртуализация
📌 VMware. Начну с явного и очевидного лидера, с которым у меня опыта не так много. Гипервизор от этой компании наиболее функционален и распространён в крупном бизнесе. Я видел и в среднем крякнутые версии. Есть бесплатная версия гипервизора, у которой в разное время были разные ограничения, но в любом случае она всегда была только для одиночного хоста.
➖ Главный минус VMware для меня - нельзя установить на программный рейд. И для железных рейдов надо проверять поддержку, как и для некоторого вида железа. Под капотом там модифицированный Linux, так что есть некоторые неудобства по сравнению с гипервизорами, где используется стандартный Linux дистрибутив в основе.
➕ Плюс - можно бэкапить с помощью Veeam, но только платную версию.
📌 Hyper-V. Лично мне всегда нравился и нравится этот гипервизор. В основе бесплатной версии лежит стандартный Windows Server Core. Работать с ним удобно и понятно, хотя есть некоторые нюансы, связанные с установкой оснасток на системы для управления. Частично этот вопрос закрывает Windows Admin Center, который позволяет управлять гипервизором через браузер.
➖ Cущественных минусов я даже не припомню, кроме невозможности пробросить USB устройство.
➕ Из плюсов, как я у же сказал - стандартная Windows система. Надо передать какой-то iso или файл на гипервизор - расшариваем папку и кладём файл. То же самое, если надо забрать что-то, например виртуальный диск. Поддерживает софтовые рейды, а также встроенные от intel. Хотя надёжность там так себе, я бы не советовал. Можно бэкапить с помощью Veeam.
📌 KVM. Важная ремарка, чтобы предупредить комментарии на эту тему. KVM - это модуль ядра Linux, который обеспечивает аппаратную виртуализацию и сам по себе гипервизором не является, но для простоты его так называют. Чаще всего он является частью готовых систем виртуализации, таких как RHV, oVirt, Proxmox, Qemu и т.д. Я использовал KVM с управлением через консоль с помощью virsh, с помощью графического интерфейса virt-manager. А последние года 3-4 в составе гипервизора Proxmox, когда он полностью созрел и завоевал популярность. На заре моего использования KVM это было не так.
Про плюсы и минусы KVM скажу в контексте Proxmox VE, так как использую его только в таком виде.
➕ Из плюсов это полная бесплатность и возможность собрать кластер даже в бесплатной версии. Есть встроенные средства для бэкапов, причём довольно функциональные, с инкрементными бэкапами. Под капотом почти обычный Linux, так что вы не ограничены в управлении, мониторинге, установке на mdadm и т.д. Поддерживается всё железо, которое поддерживает Linux.
➖ Из минусов лично мне больше всего не нравится, что в Veeam нет поддержки KVM.
📌 XenServer. Использовал этот бесплатный гипервизор очень плотно, пока не набрал популярность Proxmox VE. Он был один из первых с хорошим функционалом и простой настройкой.
➕ Из плюсов то, что под капотом был почти стандартный Centos со всеми вытекающими преимуществами. Также очень удобная консоль управления под Windows. Лично мне она даже сейчас кажется максимально удобной для управления среди всех известных гипервизоров. На момент использования (2010-2015 г) был бесплатный софт для бэкапа Xen с поддержкой дедупликации и инкрементных бэкапов.
➖ Минус в лицензии, которую нужно было получать отдельно. В какой-то момент поддержку старых версий бесплатных гипервизоров отключили просто закрыв этот сервис. Я с тех пор с XenServer и попрощался. Также в одной из версий пропала возможность поставить гипервизор на mdadm, что тоже отбило желание использовать этот гипервизор. Сейчас я знаю, что на базе Xen есть XCP-ng, но мне уже особо не нужно. Пробовал его, но пользоваться не стал. Устраивает Proxmox VE.
#виртуализация
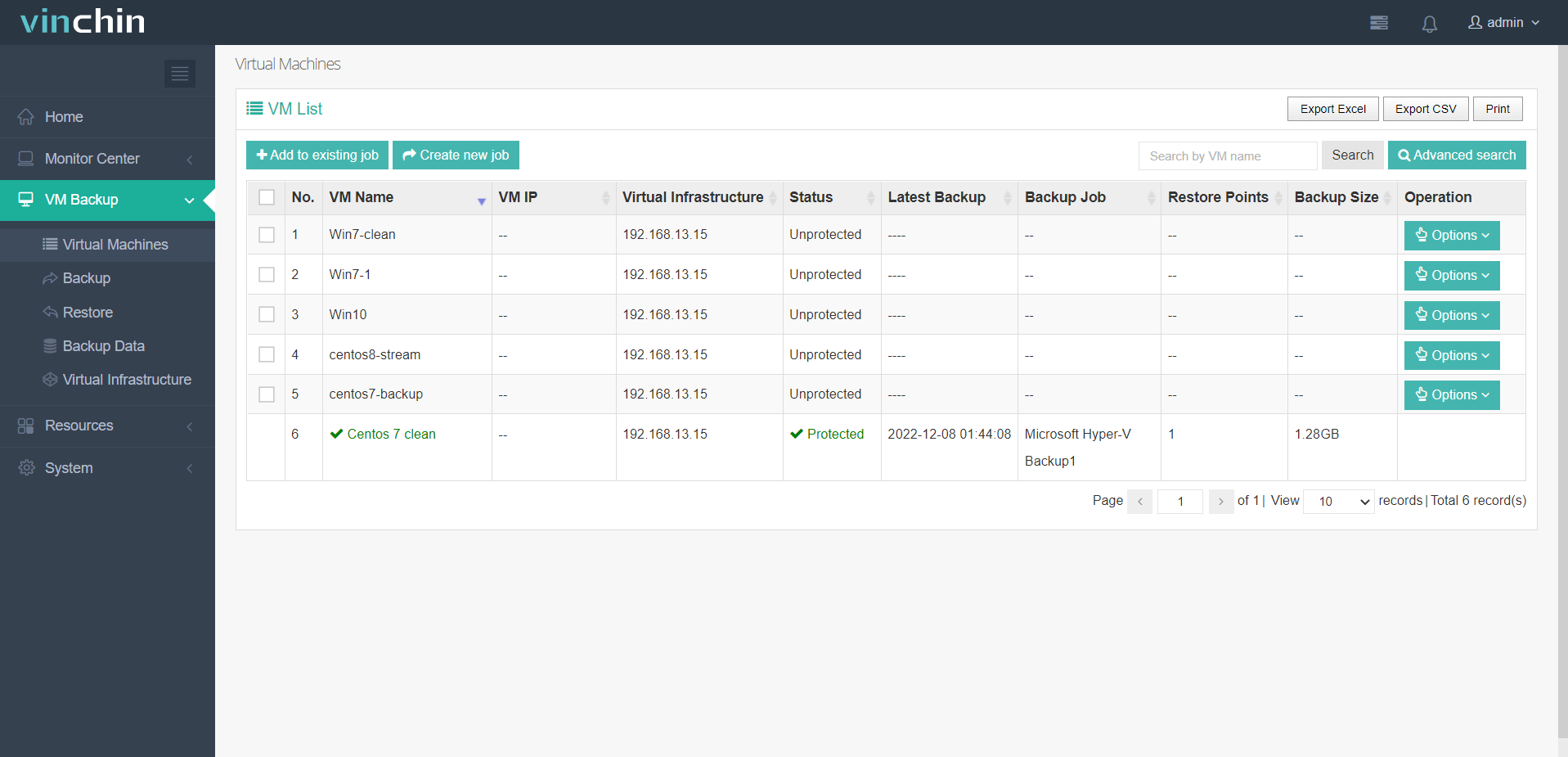
Ко мне недавно поступило необычное предложение. Китайские представители компании Vinchin захотели опубликовать на сайте обзор их продукта Vinchin Backup & Recovery. Ранее я ничего о нём не слышал и не знал. Стало любопытно, что это вообще такое. Оказывается, это решение для бэкапа мультивендорной виртуализации.
Обычно я пишу статьи сам, но тут впервые пришлось общаться с китайцами, для которых русский явно не родной, а общение было судя по всему через переводчик. Поэтому решил не рисковать и попросил готовый текст, чтобы понять, что они вообще хотят получить в статье. Статья получилось вот такая:
⇨ https://serveradmin.ru/vinchin-backup-recovery-rezervnoe-kopirovanie-ovirt-i-xenserver-v-multi-hypervisor-srede/
Я выполнил только редактуру и адаптацию на русский язык, исправив явные несоответствия с русской лексикой. Но если прочитать статью, становится понятно, что её писал не русскоязычный человек.
А теперь непосредственно о Vinchin Backup & Recovery. Как можно догадаться из названия, продукт метит в ту же категорию, где находится Veeam Backup & Replication. И он действительно на него похож в общих чертах. Это тоже единый сервер для бэкапа виртуальных сред. Вот только список поддерживаемых гипервизоров у него значительно шире:
◽ VMware
◽ Hyper-V
◽ Citrix Hypervisor, XenServer и XCP-ng
◽ Red Hat Virtualization и oVirt
◽ OpenStack
◽ Sangfor HCI, Huawei FusionCompute (KVM), H3C CAS
К сожалению, чистого KVM или Proxmox в списке поддерживаемых платформ нет.
Vinchin Backup & Recovery поставляется в виде ISO образа на базе Centos 7. Установщик 1 в 1 от Centos, и ставится всё так же, как стандартная система. После установки всё управление и настройка выполняется через веб интерфейс.
Есть бесплатная версия, к сожалению, только для бэкапа 3 VM. Так что для практической эксплуатации вряд ли подойдёт, только для теста. Я решил посмотреть своими глазами, как всё это работает, хоть меня и не просили об этом. Установка никаких вопросов не вызвала. Развернул систему из образа и зашел через браузер.
Дальше тоже всё просто. Добавляем хранилище для бэкапов. Поддерживаются следующие типы: раздел диска, весь диск, локальная директория, lvm том, fibre channel, iscsi, nfs и cifs share. Я добавил локальную директорию. Далее добавляем хост виртуализации. У меня под рукой был Hyper-V, поэтому тестировал на нём. На гипервизор надо установить плагин, а потом добавить его в панель управления. Для этого достаточно указать адрес и админскую учётку.
А дальше получаем список VM и настраиваем задания бэкапа. Понравилась при создании задания карта загруженности хранилища по времени, чтобы было удобно расписание выбрать. В целом, всё просто и понятно. Даже в документацию лазить не пришлось, только дефолтную учётку посмотрел. Хотя уже потом заметил, что она была указана ещё в письме, которое прилетело со ссылкой для загрузки ISO.
Я сначала когда статью прочитал, подумал, что какой-то неполный кусок инструкции подготовили и решили опубликовать. А когда сам поставил и настроил, понял, что там реально почти ничего делать не надо. Всё сделано максимально просто и понятно. Даже удивился. Не ожидал от китайского продукта такой простоты.
Vinchin Backup & Recovery реально интересный продукт. Аналогов с поддержкой такого количества гипервизоров я не знаю. Они все популярные охватили. Причём можно сделать бэкап VM с одного гипервизора, а восстановить на другом. Насколько всё это надёжно работает, судить не могу. По ценам тоже не понятно. Их нет на сайте. Указано только, что есть бессрочные лицензии, а есть по подписке.
Есть русскоязычная версия сайта. Видел информацию в их группе VK, что они хотят работать на рынке РФ и СНГ, поэтому пишут поддержку российских систем виртуализации. Уже заявлена поддержка zVirt.
Чтобы попробовать, можно скачать либо 60-ти дневный триал, либо Free Edition. Если у кого-то есть опыт использования этого продукта, дайте обратную связь.
#backup #виртуализация
Обычно я пишу статьи сам, но тут впервые пришлось общаться с китайцами, для которых русский явно не родной, а общение было судя по всему через переводчик. Поэтому решил не рисковать и попросил готовый текст, чтобы понять, что они вообще хотят получить в статье. Статья получилось вот такая:
⇨ https://serveradmin.ru/vinchin-backup-recovery-rezervnoe-kopirovanie-ovirt-i-xenserver-v-multi-hypervisor-srede/
Я выполнил только редактуру и адаптацию на русский язык, исправив явные несоответствия с русской лексикой. Но если прочитать статью, становится понятно, что её писал не русскоязычный человек.
А теперь непосредственно о Vinchin Backup & Recovery. Как можно догадаться из названия, продукт метит в ту же категорию, где находится Veeam Backup & Replication. И он действительно на него похож в общих чертах. Это тоже единый сервер для бэкапа виртуальных сред. Вот только список поддерживаемых гипервизоров у него значительно шире:
◽ VMware
◽ Hyper-V
◽ Citrix Hypervisor, XenServer и XCP-ng
◽ Red Hat Virtualization и oVirt
◽ OpenStack
◽ Sangfor HCI, Huawei FusionCompute (KVM), H3C CAS
К сожалению, чистого KVM или Proxmox в списке поддерживаемых платформ нет.
Vinchin Backup & Recovery поставляется в виде ISO образа на базе Centos 7. Установщик 1 в 1 от Centos, и ставится всё так же, как стандартная система. После установки всё управление и настройка выполняется через веб интерфейс.
Есть бесплатная версия, к сожалению, только для бэкапа 3 VM. Так что для практической эксплуатации вряд ли подойдёт, только для теста. Я решил посмотреть своими глазами, как всё это работает, хоть меня и не просили об этом. Установка никаких вопросов не вызвала. Развернул систему из образа и зашел через браузер.
Дальше тоже всё просто. Добавляем хранилище для бэкапов. Поддерживаются следующие типы: раздел диска, весь диск, локальная директория, lvm том, fibre channel, iscsi, nfs и cifs share. Я добавил локальную директорию. Далее добавляем хост виртуализации. У меня под рукой был Hyper-V, поэтому тестировал на нём. На гипервизор надо установить плагин, а потом добавить его в панель управления. Для этого достаточно указать адрес и админскую учётку.
А дальше получаем список VM и настраиваем задания бэкапа. Понравилась при создании задания карта загруженности хранилища по времени, чтобы было удобно расписание выбрать. В целом, всё просто и понятно. Даже в документацию лазить не пришлось, только дефолтную учётку посмотрел. Хотя уже потом заметил, что она была указана ещё в письме, которое прилетело со ссылкой для загрузки ISO.
Я сначала когда статью прочитал, подумал, что какой-то неполный кусок инструкции подготовили и решили опубликовать. А когда сам поставил и настроил, понял, что там реально почти ничего делать не надо. Всё сделано максимально просто и понятно. Даже удивился. Не ожидал от китайского продукта такой простоты.
Vinchin Backup & Recovery реально интересный продукт. Аналогов с поддержкой такого количества гипервизоров я не знаю. Они все популярные охватили. Причём можно сделать бэкап VM с одного гипервизора, а восстановить на другом. Насколько всё это надёжно работает, судить не могу. По ценам тоже не понятно. Их нет на сайте. Указано только, что есть бессрочные лицензии, а есть по подписке.
Есть русскоязычная версия сайта. Видел информацию в их группе VK, что они хотят работать на рынке РФ и СНГ, поэтому пишут поддержку российских систем виртуализации. Уже заявлена поддержка zVirt.
Чтобы попробовать, можно скачать либо 60-ти дневный триал, либо Free Edition. Если у кого-то есть опыт использования этого продукта, дайте обратную связь.
#backup #виртуализация
{kind=link}
Я давно слышал информацию об Альт Сервер Виртуализации, но до конца не понимал, что это такое. Решил разобраться. Из описания не совсем понятно, что на практике из себя представляет этот продукт. В описании видно, что он почти полностью состоит из open source компонентов и это не скрывается. Но при этом продаётся за деньги, хоть и относительно небольшие.
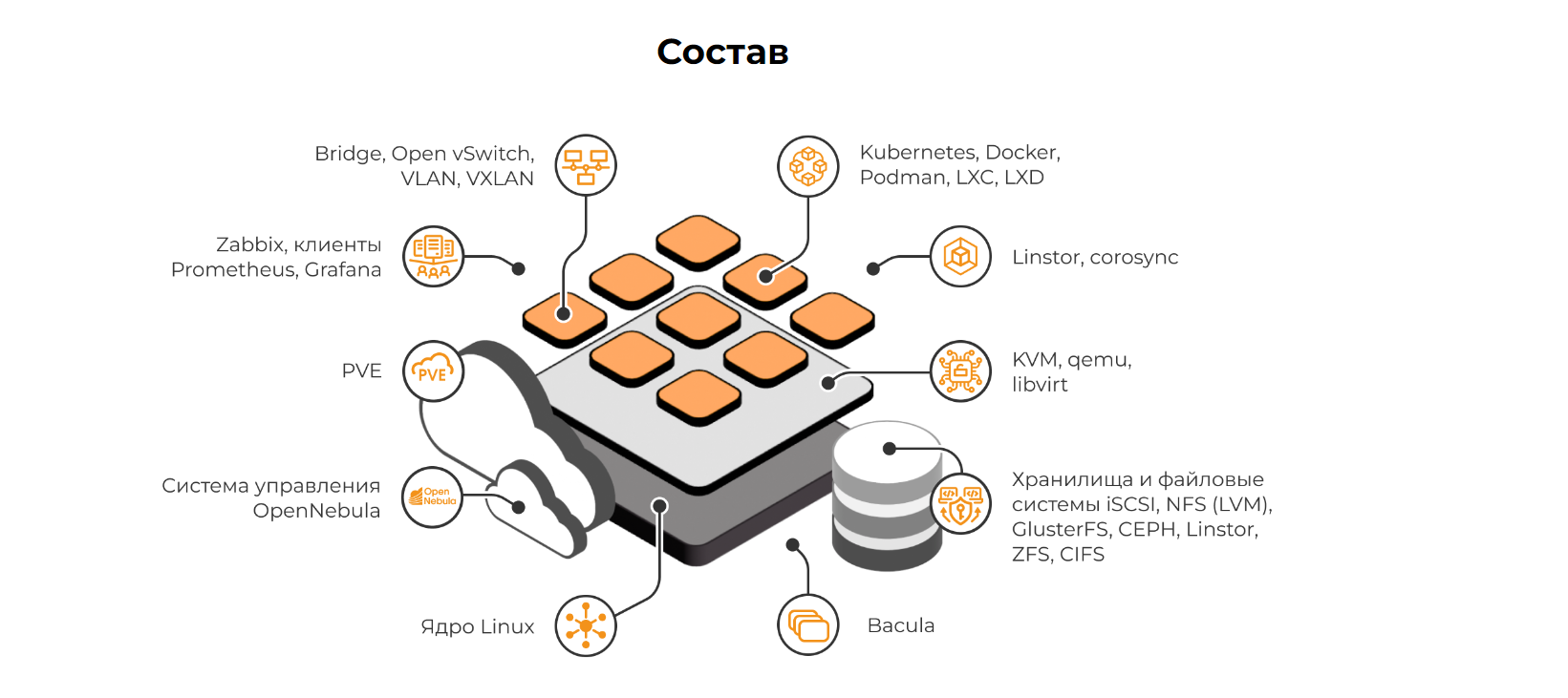
Я решил развернуть его у себя в редакции кластер виртуализации PVE. Помимо него есть ещё три:
◽базовый гипервизор KVM;
◽облачная виртуализация OpenNebula;
◽контейнерная виртуализация (LXC/LXD, Docker/Podman).
Установщик полностью на русском языке. Используется один ISO образ для всех редакций, которые можно выбирать в процессе установки. Помимо основных пакетов, можно выбрать дополнительные. Например, сразу установить агент мониторинга различных систем, или, к примеру, nginx сервер для проксирования, rsyslog, HAProxy для отказоустойчивого веб интерфейса и некоторый другой популярный софт.
У установщика есть широкие возможности по разбивке диска, что встречается не так часто. Можно установить систему на одиночный диск, на mdadm массив, на LVM, на BTRF. ZFS почему-то в списке не было. На разделы, соответственно, тоже можно вручную разбить.
После установки я увидел обычный Proxmox. В последней версии alt-server-v-10.1 версия PVE 7.2. Из примечательного, в alt используется пакетный менеджер apt-get, а пакеты rpm. Подключены только репозитории alt. То есть привязки к инфраструктуре компании Proxmox нет. Я так понял, что все пакеты в репозитории alt собираются разработчиками дистрибутива.
Отдельно отмечу хорошую документацию по продукту на русском языке. Если вы хотите посмотреть документацию на русском языке по Proxmox или OpenNebula, можно воспользоваться этой.
Собственно, становится понятно, за что нужно будет заплатить в коммерческом использовании (для физических лиц всё бесплатно). Если вам нужен Proxmox или OpenNebula с возможностью использования там, где можно брать только отечественное ПО, то Альт Сервер Виртуализации — это ваш случай. Он есть в реестре отечественного ПО, он привязан к репозиториям alt и по идее устойчив ко всяким санкциям, ограничениям и т.д. Также можно купить техподдержку.
⇨ Сайт / Загрузка / Обзор (кластер)
#виртуализация #отечественное #proxmox
Я решил развернуть его у себя в редакции кластер виртуализации PVE. Помимо него есть ещё три:
◽базовый гипервизор KVM;
◽облачная виртуализация OpenNebula;
◽контейнерная виртуализация (LXC/LXD, Docker/Podman).
Установщик полностью на русском языке. Используется один ISO образ для всех редакций, которые можно выбирать в процессе установки. Помимо основных пакетов, можно выбрать дополнительные. Например, сразу установить агент мониторинга различных систем, или, к примеру, nginx сервер для проксирования, rsyslog, HAProxy для отказоустойчивого веб интерфейса и некоторый другой популярный софт.
У установщика есть широкие возможности по разбивке диска, что встречается не так часто. Можно установить систему на одиночный диск, на mdadm массив, на LVM, на BTRF. ZFS почему-то в списке не было. На разделы, соответственно, тоже можно вручную разбить.
После установки я увидел обычный Proxmox. В последней версии alt-server-v-10.1 версия PVE 7.2. Из примечательного, в alt используется пакетный менеджер apt-get, а пакеты rpm. Подключены только репозитории alt. То есть привязки к инфраструктуре компании Proxmox нет. Я так понял, что все пакеты в репозитории alt собираются разработчиками дистрибутива.
Отдельно отмечу хорошую документацию по продукту на русском языке. Если вы хотите посмотреть документацию на русском языке по Proxmox или OpenNebula, можно воспользоваться этой.
Собственно, становится понятно, за что нужно будет заплатить в коммерческом использовании (для физических лиц всё бесплатно). Если вам нужен Proxmox или OpenNebula с возможностью использования там, где можно брать только отечественное ПО, то Альт Сервер Виртуализации — это ваш случай. Он есть в реестре отечественного ПО, он привязан к репозиториям alt и по идее устойчив ко всяким санкциям, ограничениям и т.д. Также можно купить техподдержку.
⇨ Сайт / Загрузка / Обзор (кластер)
#виртуализация #отечественное #proxmox
{kind=link}
Перенос VM с Hyper-V на Proxmox
На днях стояла задача перенести виртуальные машины Linux (Debian 11) с Hyper-V на KVM (Proxmox). Помучался изрядно, но в итоге всё получилось. Если VM первого поколения без EFI раздела, то проблем вообще никаких. Просто переносим диск виртуальной машины, конвертируем и подключаем к VM. Вообще ничего перенастраивать не надо, все имена дисков и сетевых адаптеров будут те же, что и на Hyper-V. А вот если машины второго поколения с загрузкой по EFI, то начинаются танцы с бубном. Причём у каждого свои, судя по информации из интернета.
Рассказываю, как в итоге сделал я, чтобы всё заработало. Перенос делал следующим образом:
1️⃣ Завершаю работу VM на Hyper-V.
2️⃣ Копирую файл диска vhdx на хост Proxmox.
3️⃣ Создаю в Proxmox новую виртуальную машину и обязательно указываю Bios: OVMF (UEFI), SCSI Controller: VirtIO SCSI. Остальное не принципиально. Диски можно никакие не добавлять. Но при этом у вас будет автоматически подключен EFI Disk, с какими-то своими параметрами, из которых я выбрал только формат - qcow2.
4️⃣ В консоли Proxmox конвертируем vhdx диск в диск виртуальной машины:
Формат команды следующий:
5️⃣ После импорта диск цепляется к VM в отключенном виде. Подключаем его как SCSI и настраиваем с него загрузку.
6️⃣ Загружаем VM с этого диска. Тут по многим руководствам из инета виртуалка уже запускается и нормально работает. Но не у меня. Я проваливался в uefi interactive shell v2.2 proxmox.
7️⃣ Заходим в bios этой виртуалки и отключаем там Secure Boot. Делается это в разделе Device Manager ⇨ Secure Boot Configuration. После этого у некоторых VM начинает загружаться, но опять не у меня.
8️⃣ Опять иду в bios, в раздел Boot Maintenance Manager ⇨ Boot Options ⇨ Add Boot Option. Выбираю импортированный диск VM. Там кроме него будет только CD-ROM, так что легко понять, что надо выбрать. Открывается обзор файловой системы EFI раздела от нашей системы. Перемещаемся там по директориям
А я сначала пробовал разные настройки VM, загружался с LiveCD и проверял разделы диска, загрузчик. Там всё ОК, данные нормально переезжают. Проблема именно в настройке загрузки через EFI раздел. Почему-то автоматом он не подхватывался. Может это была особенность Debian 11. Я переносил именно их.
❗️Сразу добавлю полезную информацию по поводу Centos 7. Может это будет актуально и для каких-то других система. Когда я переносил виртуалки с этой системой между гипервизорами, они не загружались, пока не пересоберёшь initramfs под конкретным гипервизором. Если просто перенести, то загрузка не ехала дальше из-за проблем с определением дисков на этапе загрузки. Пересборка initramfs решала эту проблему.
❗️И ещё один нюанс с переездами между гипервизорами, с которым сталкивался. Иногда система не грузится, потому что в fstab были прописаны имена дисков, которые на новом гипервизоре получили другие названия. Тогда грузимся с LiveCD и меняем диски в fstab и возможно в grub.
Тема переезда между разными типами гипервизоров непростая. Иногда проще воспользоваться какой-то системой, типа Veeam Agent For Linux или Rescuezilla. Так как я более ли менее теорию понимаю по этой теме, то переношу обычно вручную.
#linux #hyperv #виртуализация
На днях стояла задача перенести виртуальные машины Linux (Debian 11) с Hyper-V на KVM (Proxmox). Помучался изрядно, но в итоге всё получилось. Если VM первого поколения без EFI раздела, то проблем вообще никаких. Просто переносим диск виртуальной машины, конвертируем и подключаем к VM. Вообще ничего перенастраивать не надо, все имена дисков и сетевых адаптеров будут те же, что и на Hyper-V. А вот если машины второго поколения с загрузкой по EFI, то начинаются танцы с бубном. Причём у каждого свои, судя по информации из интернета.
Рассказываю, как в итоге сделал я, чтобы всё заработало. Перенос делал следующим образом:
1️⃣ Завершаю работу VM на Hyper-V.
2️⃣ Копирую файл диска vhdx на хост Proxmox.
3️⃣ Создаю в Proxmox новую виртуальную машину и обязательно указываю Bios: OVMF (UEFI), SCSI Controller: VirtIO SCSI. Остальное не принципиально. Диски можно никакие не добавлять. Но при этом у вас будет автоматически подключен EFI Disk, с какими-то своими параметрами, из которых я выбрал только формат - qcow2.
4️⃣ В консоли Proxmox конвертируем vhdx диск в диск виртуальной машины:
# qm importdisk 102 /mnt/500G/Debian11.vhdx local-500GФормат команды следующий:
# qm importdisk <vmid> <source> <storage>5️⃣ После импорта диск цепляется к VM в отключенном виде. Подключаем его как SCSI и настраиваем с него загрузку.
6️⃣ Загружаем VM с этого диска. Тут по многим руководствам из инета виртуалка уже запускается и нормально работает. Но не у меня. Я проваливался в uefi interactive shell v2.2 proxmox.
7️⃣ Заходим в bios этой виртуалки и отключаем там Secure Boot. Делается это в разделе Device Manager ⇨ Secure Boot Configuration. После этого у некоторых VM начинает загружаться, но опять не у меня.
8️⃣ Опять иду в bios, в раздел Boot Maintenance Manager ⇨ Boot Options ⇨ Add Boot Option. Выбираю импортированный диск VM. Там кроме него будет только CD-ROM, так что легко понять, что надо выбрать. Открывается обзор файловой системы EFI раздела от нашей системы. Перемещаемся там по директориям
/EFI/debian, выбираем файл grubx64.efi. То есть мы создаём новый вариант загрузки системы, выбрав этот файл. Там же пишем какое-то название для этой загрузки, чтобы отличить от остальных вариантов. Далее идём в раздел Boot Maintenance Manager ⇨ Boot Options ⇨ Change Boot Order и назначаем первым номером только что созданный вариант для загрузки. Сохраняем изменения и загружаемся. Теперь всё ОК, система загрузилась. А я сначала пробовал разные настройки VM, загружался с LiveCD и проверял разделы диска, загрузчик. Там всё ОК, данные нормально переезжают. Проблема именно в настройке загрузки через EFI раздел. Почему-то автоматом он не подхватывался. Может это была особенность Debian 11. Я переносил именно их.
❗️Сразу добавлю полезную информацию по поводу Centos 7. Может это будет актуально и для каких-то других система. Когда я переносил виртуалки с этой системой между гипервизорами, они не загружались, пока не пересоберёшь initramfs под конкретным гипервизором. Если просто перенести, то загрузка не ехала дальше из-за проблем с определением дисков на этапе загрузки. Пересборка initramfs решала эту проблему.
❗️И ещё один нюанс с переездами между гипервизорами, с которым сталкивался. Иногда система не грузится, потому что в fstab были прописаны имена дисков, которые на новом гипервизоре получили другие названия. Тогда грузимся с LiveCD и меняем диски в fstab и возможно в grub.
Тема переезда между разными типами гипервизоров непростая. Иногда проще воспользоваться какой-то системой, типа Veeam Agent For Linux или Rescuezilla. Так как я более ли менее теорию понимаю по этой теме, то переношу обычно вручную.
#linux #hyperv #виртуализация
{kind=link}
Обратил внимание, что большинство прокомментировавших вчерашнюю заметку про перенос VM не уловили суть проблем, с которыми можно столкнуться при любом переносе системы на другое "железо". А смена типа гипервизора это по сути смена железа.
Причём система Windows, на удивление, гораздо лучше переживает переезд, чем Linux. Многие вещи она умеет делать автоматически при проблемах с загрузкой. Вообще не припоминаю с ней проблем, кроме установки драйверов virtio при переезде на KVM. А вот с Linux проблемы как раз бывают.
Всем спасибо за содержательные комментарии. В них упоминали несколько инструментов по конвертации дисков:
◽Starwind V2V
◽qemu-img convert
◽virt-p2v
Они все делают примерно одинаковые вещи - конвертируют формат дисков между форматами разных гипервизоров, либо из физической машины делают образ диска для виртуальной. Это только часть задачи по переносу VM и зачастую самая простая.
Проблема возникает именно в том, что на новом железе исходная система не работает, скопированная 1 в 1 в неизменном виде. То есть вам нужно либо перед конвертацией её подготовить к перемещению, либо потом по месту выполнять какие-то манипуляции, чтобы запустить.
Приведу самый простой пример подготовки. Я в своё время переносил много систем с гипервизора Xen, и там диски имели имена /dev/vdX, а при переезде на KVM - /dev/sdX. Если просто скопировать систему, то на новом гипервизоре она не запускалась. Надо было поправить grub и fstab. Можно было это делать предварительно, перед снятием образа системы, либо потом с помощью LiveCD на перенесённой системе.
Другой пример - Initramfs. Это файловая система, содержащая файлы, необходимые для загрузки системы Linux. Она запускается перед загрузкой основной системы. С её помощью, к примеру, монтируются разделы диска с основной системой. Соответственно, если Initramfs создавалась под одно железо, а потом переехала на другое, она может не определить, к примеру, диски, и основная система не загрузится. Это наиболее частая проблема при переезде.
Есть бесплатный Veeam Agent For Linux Free. Вот он как раз не просто делает образ диска для переноса, но и готовит загрузочный диск со списком оборудования вашей системы, чтобы в процессе восстановления на основании этого списка попытаться гарантированно запустить вашу систему. И чаще всего у него это получается.
То же самое делает Rear, я о ней писал и тестировал.
Сходу не могу припомнить ещё какие-то программы такого же класса, как Veeam Agent For Linux или Rear, которые не просто переносят данные, но и подготавливают системы. Если вы такие знаете, то поделитесь информацией.
Отдельным пунктом идут проблемы, связанные с EFI. Там тоже много своих нюансов. В итоге переезд виртуальных машин может выглядеть очень непростой задачей, но всегда решаемой. По крайней мере я ни разу не сталкивался с тем, что нельзя было перенести какую-то виртуалку. Если понимаешь теорию, то починить загрузку почти всегда получается. Надо идти последовательно по пути:
✅ EFI (в том числе настройки VM в гипервизоре) ⇨ GRUB ⇨ INITRAMFS ⇨ Настройки системы.
Ещё момент. Лично я до конца не понимаю, зачем виртулакам EFI. Он усложняет эксплуатацию, а какую проблему решает - не знаю, если только вы не используете для загрузки диск более 2ТБ, что для виртуалок нетипично. Если у вас повышенные требования к безопасности и используется Secure Boot, тогда понятно. Хотя опять же, при работе в виртуальной машине не факт, что эта защита эффективна. Во всех остальных случаях не вижу смысла его (EFI) использовать. Возможно, я ошибаюсь.
#виртуализация
Причём система Windows, на удивление, гораздо лучше переживает переезд, чем Linux. Многие вещи она умеет делать автоматически при проблемах с загрузкой. Вообще не припоминаю с ней проблем, кроме установки драйверов virtio при переезде на KVM. А вот с Linux проблемы как раз бывают.
Всем спасибо за содержательные комментарии. В них упоминали несколько инструментов по конвертации дисков:
◽Starwind V2V
◽qemu-img convert
◽virt-p2v
Они все делают примерно одинаковые вещи - конвертируют формат дисков между форматами разных гипервизоров, либо из физической машины делают образ диска для виртуальной. Это только часть задачи по переносу VM и зачастую самая простая.
Проблема возникает именно в том, что на новом железе исходная система не работает, скопированная 1 в 1 в неизменном виде. То есть вам нужно либо перед конвертацией её подготовить к перемещению, либо потом по месту выполнять какие-то манипуляции, чтобы запустить.
Приведу самый простой пример подготовки. Я в своё время переносил много систем с гипервизора Xen, и там диски имели имена /dev/vdX, а при переезде на KVM - /dev/sdX. Если просто скопировать систему, то на новом гипервизоре она не запускалась. Надо было поправить grub и fstab. Можно было это делать предварительно, перед снятием образа системы, либо потом с помощью LiveCD на перенесённой системе.
Другой пример - Initramfs. Это файловая система, содержащая файлы, необходимые для загрузки системы Linux. Она запускается перед загрузкой основной системы. С её помощью, к примеру, монтируются разделы диска с основной системой. Соответственно, если Initramfs создавалась под одно железо, а потом переехала на другое, она может не определить, к примеру, диски, и основная система не загрузится. Это наиболее частая проблема при переезде.
Есть бесплатный Veeam Agent For Linux Free. Вот он как раз не просто делает образ диска для переноса, но и готовит загрузочный диск со списком оборудования вашей системы, чтобы в процессе восстановления на основании этого списка попытаться гарантированно запустить вашу систему. И чаще всего у него это получается.
То же самое делает Rear, я о ней писал и тестировал.
Сходу не могу припомнить ещё какие-то программы такого же класса, как Veeam Agent For Linux или Rear, которые не просто переносят данные, но и подготавливают системы. Если вы такие знаете, то поделитесь информацией.
Отдельным пунктом идут проблемы, связанные с EFI. Там тоже много своих нюансов. В итоге переезд виртуальных машин может выглядеть очень непростой задачей, но всегда решаемой. По крайней мере я ни разу не сталкивался с тем, что нельзя было перенести какую-то виртуалку. Если понимаешь теорию, то починить загрузку почти всегда получается. Надо идти последовательно по пути:
✅ EFI (в том числе настройки VM в гипервизоре) ⇨ GRUB ⇨ INITRAMFS ⇨ Настройки системы.
Ещё момент. Лично я до конца не понимаю, зачем виртулакам EFI. Он усложняет эксплуатацию, а какую проблему решает - не знаю, если только вы не используете для загрузки диск более 2ТБ, что для виртуалок нетипично. Если у вас повышенные требования к безопасности и используется Secure Boot, тогда понятно. Хотя опять же, при работе в виртуальной машине не факт, что эта защита эффективна. Во всех остальных случаях не вижу смысла его (EFI) использовать. Возможно, я ошибаюсь.
#виртуализация
Telegram
ServerAdmin.ru
У меня на канале и на сайте много материалов по теме бэкапов и инструментов для их выполнения, так что найти что-то новое и полезное довольно трудно. Напомню, что материалы по бэкапам удобнее всего посмотреть по тэгу #backup, к нему можно добавить тэг #подборка…
Пока ещё не закончились праздники, а отдыхать уже надоело, есть возможность изучить что-то новое. Например, OpenStack 🤖 Для тех, кто не в курсе, поясню, что это модульная open source платформа, реализующая типовую функциональность современных облачных провайдеров. Установить её можно самостоятельно на своих мощностях. А для изучения есть упрощённые проекты для быстрого разворачивания.
Одним из таких проектов является snap пакет MicroStack от компании Canonical. С его помощью можно развернуть учебный OpenStack на одном хосте. Поставляется он в виде готового snap пакета под Ubuntu, так что ставится в пару действий. Внутри живёт Kubernetes, а MicroStack разворачивается поверх него. Установить можно даже в виртуальную машину на своём рабочем ноуте.
Cистемные требования MicroStack, заявленные на его сайте:
◽4 CPUs
◽16G Memory
◽50G Disk
Сама установка выполняется в пару команд:
Минут 10 будет длиться инициализация. Когда закончится, можно идти в веб интерфейс по ip адресу сервера. Логин - admin, а пароль смотрим так:
Если у вас в браузере указан русский язык, то вы получите 502 ошибку nginx после аутентификации. Так было у меня. Чтобы исправить, нужно залогиниться в систему, получить 502-ю ошибку, зайти по урлу https://10.20.1.29/identity/, он должен нормально открыться. В правом верхнем углу будут настройки пользователя. Нужно зайти туда и выбрать язык интерфейса English. После этого нормально заработает.
В консоли можно работать с кластером через клиента microstack.openstack. К примеру, смотрим список стандартных шаблонов:
Можно использовать стандартный openstackclient. Для этого там же в настройках пользователя в веб интерфейсе в выпадающем списке качаем OpenStack RC File. Ставим стандартный openstack client:
Читаем скачанный файл с переменными окружения:
Теперь можно использовать консольный клиент openstack, добавляя опцию
Если не хочется каждый раз вводить пароль администратора, можно добавить его явно в
На этом собирался закончить заметку, но всё же кратко покажу, как с этой штукой работать. Чтобы запустить виртуалку нам нужно:
1️⃣ Создать проект и добавить туда пользователя.
2️⃣ Создать сеть и подсеть в ней.
3️⃣ Создать роутер и связать его с бриджем во внешнюю сеть.
4️⃣ Создать виртуальную машину с бриджем в этой подсети.
5️⃣ Создать группу безопасности и правило в ней для разрешения подключений по ssh.
6️⃣ Связать эту группу безопасности и виртуалку.
Команды приведу кратко, без описаний, опустив в начале
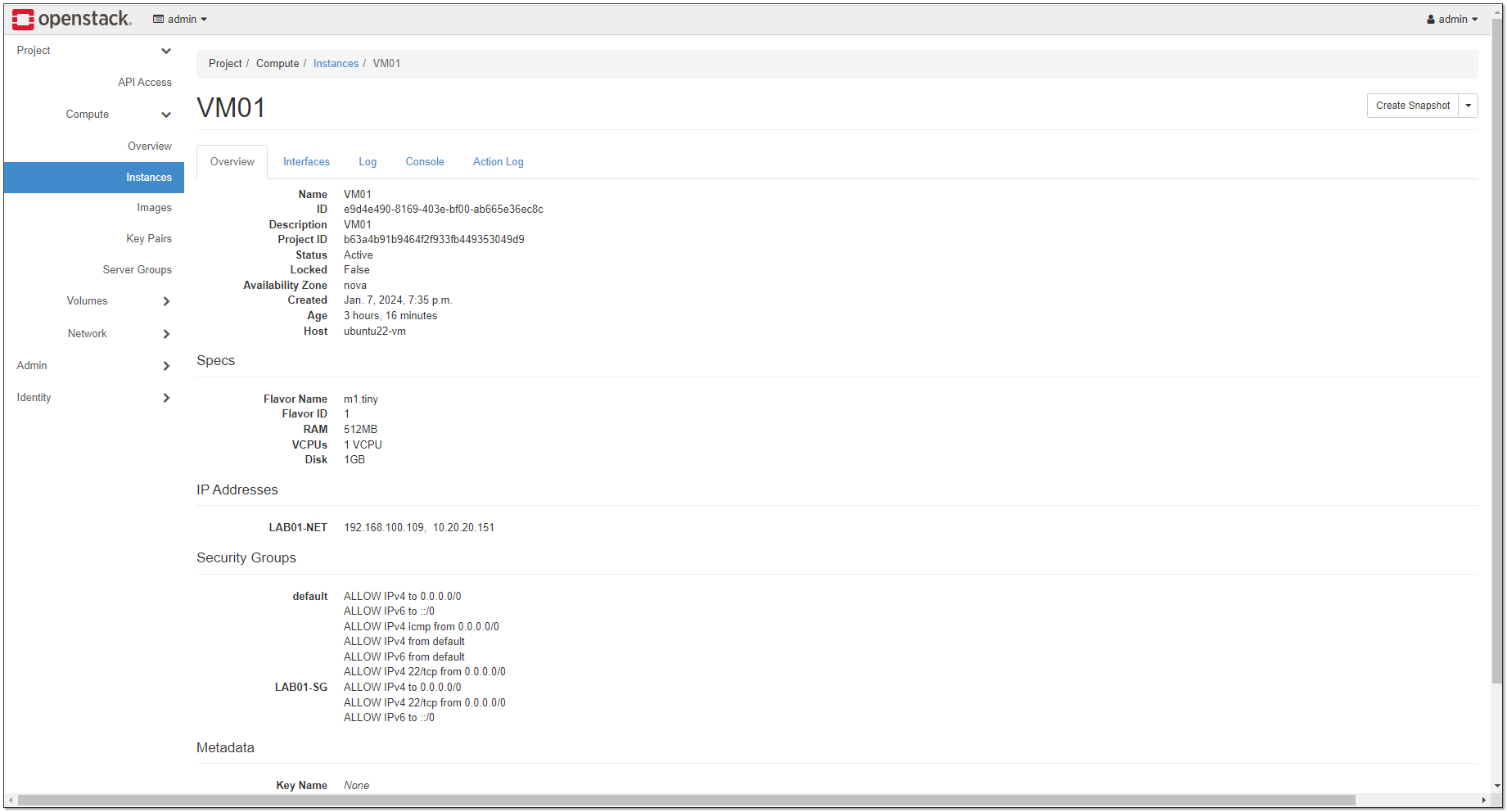
То же самое можно сделать руками через веб интерфейс. Можно подключиться к новой виртуалке через её floating ip из диапазона 10.20.20.0/24, который будет сопоставлен настроенному IP из 192.168.100.0/24. В веб интерфейсе все настройки будут отражены. Там же и консоль VM.
Поздравляю, теперь вы админ OpenStack. Можете развернуть для собственных нужд и тренироваться.
#виртуализация
Одним из таких проектов является snap пакет MicroStack от компании Canonical. С его помощью можно развернуть учебный OpenStack на одном хосте. Поставляется он в виде готового snap пакета под Ubuntu, так что ставится в пару действий. Внутри живёт Kubernetes, а MicroStack разворачивается поверх него. Установить можно даже в виртуальную машину на своём рабочем ноуте.
Cистемные требования MicroStack, заявленные на его сайте:
◽4 CPUs
◽16G Memory
◽50G Disk
Сама установка выполняется в пару команд:
# snap install microstack --beta# microstack init --auto --controlМинут 10 будет длиться инициализация. Когда закончится, можно идти в веб интерфейс по ip адресу сервера. Логин - admin, а пароль смотрим так:
# snap get microstack config.credentials.keystone-passwordЕсли у вас в браузере указан русский язык, то вы получите 502 ошибку nginx после аутентификации. Так было у меня. Чтобы исправить, нужно залогиниться в систему, получить 502-ю ошибку, зайти по урлу https://10.20.1.29/identity/, он должен нормально открыться. В правом верхнем углу будут настройки пользователя. Нужно зайти туда и выбрать язык интерфейса English. После этого нормально заработает.
В консоли можно работать с кластером через клиента microstack.openstack. К примеру, смотрим список стандартных шаблонов:
# microstack.openstack flavor listМожно использовать стандартный openstackclient. Для этого там же в настройках пользователя в веб интерфейсе в выпадающем списке качаем OpenStack RC File. Ставим стандартный openstack client:
# apt install python3-openstackclientЧитаем скачанный файл с переменными окружения:
# source ./admin-openrc.shТеперь можно использовать консольный клиент openstack, добавляя опцию
--insecure, так как сертификат самоподписанный:# openstack --insecure project listЕсли не хочется каждый раз вводить пароль администратора, можно добавить его явно в
admin-openrc.sh в переменную OS_PASSWORD. На этом собирался закончить заметку, но всё же кратко покажу, как с этой штукой работать. Чтобы запустить виртуалку нам нужно:
1️⃣ Создать проект и добавить туда пользователя.
2️⃣ Создать сеть и подсеть в ней.
3️⃣ Создать роутер и связать его с бриджем во внешнюю сеть.
4️⃣ Создать виртуальную машину с бриджем в этой подсети.
5️⃣ Создать группу безопасности и правило в ней для разрешения подключений по ssh.
6️⃣ Связать эту группу безопасности и виртуалку.
Команды приведу кратко, без описаний, опустив в начале
openstack --insecure, так как лимит на длину публикации:# project create LAB01# role add --user admin --project LAB01 admin# network create LAB01-NET# subnet create --network LAB01-NET --subnet-range 192.168.100.0/24 --allocation-pool start=192.168.100.10,end=192.168.100.200 --dns-nameserver 77.88.8.1 LAB01-SUBNET# router create LAB01-R# router set LAB01-R --external-gateway external# router add subnet LAB01-R LAB01-SUBNET# floating ip create external# server create --flavor m1.tiny --image cirros --network LAB01-NET --wait VM01# server add floating ip VM01 596909d8-5c8a-403f-a902-f31f5bd89eae# security group create LAB01-SG# security group rule create --remote-ip 0.0.0.0/0 --dst-port 22:22 --protocol tcp --ingress LAB01-SG# server add security group VM01 LAB01-SGТо же самое можно сделать руками через веб интерфейс. Можно подключиться к новой виртуалке через её floating ip из диапазона 10.20.20.0/24, который будет сопоставлен настроенному IP из 192.168.100.0/24. В веб интерфейсе все настройки будут отражены. Там же и консоль VM.
Поздравляю, теперь вы админ OpenStack. Можете развернуть для собственных нужд и тренироваться.
#виртуализация
{kind=link}
Продолжу тему OpenStack, так как вчера всё не уместилось в одну публикацию. Я немного поразбирался с ним, посмотрел, как работает. Стала понятна логика работы некоторых облачных провайдеров, так как в основе у них, судя по всему, OpenStack и есть. Все эти проекты, назначение прав, настройка портов на firewall для доступа, сопоставление внешнего IP внутренним и т.д.
🔹Для того, чтобы развернуть OpenStack, есть множество разных проектов помимо MicroStack. Для изучения и разработки наиболее известный - DevStac. Это набор скриптов для поднятия OpenStack как на одиночной машине, так и в составе кластера. Разрабатывается тем же сообществом, что и OpenStack.
🔹Для прода есть Ansible Playbooks - openstack-ansible. Вся функциональность там почему-то упакована в LXC контейнеры, что выглядит немного непривычно. Не знаю, почему выбрали именно их. Это тоже проект команды разработки OpenStack. Есть проект Kolla, который упаковывает стэк в Docker контейнеры. И от них же есть готовые плейбуки на основе docker - kolla-ansible.
🔹Для деплоя в Kubernetes есть helm-chart - OpenStack-Helm. Также развернуть OpenStack в кубере можно с помощью Sunbeam. В настоящий момент в официальном руководстве для MicroStack используется как раз он. Я, когда разбирался с ним, не сразу понял, почему в куче руководств в интернете используется один тип управления, а на самом сайте проекта уже используется Sunbeam. Судя по всему недавно на него перешли.
🔹На голое железо установить OpenStack можно с помощью kayobe. Для деплоя используются упомянутые ранее контейнеры Kolla и плейбуки с ними. Также для железа есть проект от OpenStack Foundation - Airship. Он разворачивает на железо кластер Kubernetes, а поверх уже можно накатить OpenStack.
Обратил внимание при изучении упомянутых выше проектов, что большая часть из них сделана на основе организации OpenInfra Foundation. Они все свои исходники размещают в репозитории opendev.org, который работает на базе gitea.
Кто-нибудь разворачивал кластер OpenStack хотя бы из трёх нод? Какой из описанных способов наиболее простой и дружелюбный для новичков? Когда изучал ceph и kuber, разворачивал из ansible playbooks с помощью kubespray и ceph-ansible соответственно. Не могу сказать, что это было просто.
#виртуализация
🔹Для того, чтобы развернуть OpenStack, есть множество разных проектов помимо MicroStack. Для изучения и разработки наиболее известный - DevStac. Это набор скриптов для поднятия OpenStack как на одиночной машине, так и в составе кластера. Разрабатывается тем же сообществом, что и OpenStack.
🔹Для прода есть Ansible Playbooks - openstack-ansible. Вся функциональность там почему-то упакована в LXC контейнеры, что выглядит немного непривычно. Не знаю, почему выбрали именно их. Это тоже проект команды разработки OpenStack. Есть проект Kolla, который упаковывает стэк в Docker контейнеры. И от них же есть готовые плейбуки на основе docker - kolla-ansible.
🔹Для деплоя в Kubernetes есть helm-chart - OpenStack-Helm. Также развернуть OpenStack в кубере можно с помощью Sunbeam. В настоящий момент в официальном руководстве для MicroStack используется как раз он. Я, когда разбирался с ним, не сразу понял, почему в куче руководств в интернете используется один тип управления, а на самом сайте проекта уже используется Sunbeam. Судя по всему недавно на него перешли.
🔹На голое железо установить OpenStack можно с помощью kayobe. Для деплоя используются упомянутые ранее контейнеры Kolla и плейбуки с ними. Также для железа есть проект от OpenStack Foundation - Airship. Он разворачивает на железо кластер Kubernetes, а поверх уже можно накатить OpenStack.
Обратил внимание при изучении упомянутых выше проектов, что большая часть из них сделана на основе организации OpenInfra Foundation. Они все свои исходники размещают в репозитории opendev.org, который работает на базе gitea.
Кто-нибудь разворачивал кластер OpenStack хотя бы из трёх нод? Какой из описанных способов наиболее простой и дружелюбный для новичков? Когда изучал ceph и kuber, разворачивал из ansible playbooks с помощью kubespray и ceph-ansible соответственно. Не могу сказать, что это было просто.
#виртуализация
{kind=link}
На днях на моём форуме человек задал вопрос на тему того, как лучше организовать сетевые настройки и виртуальные машины на двух выделенных серверах. Я написал подробный ответ, который хорошо подойдёт под формат заметки сюда. Плюс, тема общая, может быть полезна кому-то ещё. Вот его вопрос:
Очень нужен совет. Имеется два выделенных сервера, арендованных в Selectel. Сервера с приватной сетью. На серверах планируется поставить RDP сервер на Windows и сервер под базу данных. Сервера должны уметь общаться между собой. Плюс еще нужен безопасный доступ к RDP серверу. Как лучше на ваш взгляд все это организовать? Поставить на оба сервер Proxmox и на него виртуалки? Возможно ли при таком раскладе чтобы виртуалки с разных хостов Proxmox видели друг друга? Как обезопасить доступ RDP? Поднимать какой-то шлюз или как? Или вообще без Proxmox обойтись?
Я бы делал следующим образом:
1️⃣ В обязательном порядке на сервера поставил Proxmox и всю функциональность реализовывал бы только в виртуальных машинах. Так как есть приватная сеть, никаких дополнительных сложностей со взаимодействием виртуальных машин не будет. Делаем бридж на интерфейсах приватной сети и добавляем сетевые интерфейсы с этим бриджем виртуальным машинам. Они будут обращаться друг к другу напрямую.
2️⃣ На машине с терминальным сервером сделал бы отдельную виртуалку под шлюз. Все остальные виртуальные машины ходили бы в интернет через неё. В эту виртуалку прокинул бы сетевой интерфейс с внешним IP. Сами гипервизоры настроил бы только в приватной сети, чтобы они ходили в интернет тоже только через этот шлюз. Обязательно настроить автоматический запуск этой виртуальной машины.
3️⃣ На шлюзе настроил бы firewall и управлял доступом к виртуалкам и их доступом в интернет через него. На него же поставил бы Nginx для проксирования запросов к внутренним веб ресурсам.
4️⃣ Доступ к терминальному серверу реализовал бы либо с помощью Openvpn, если нужен прямой доступ через терминальный клиент, либо с помощью Guacamole, если будет достаточен такой режим работы на сервере через браузер. Настраивал бы это на шлюзе. Можно сразу и то, и другое.
5️⃣ В отдельной виртуальной машине поднял бы Zabbix для мониторинга всего этого хозяйства и какую-то систему для сбора логов (ELK или Loki). И добавил бы внешний мониторинг, типа uptimerobot или uptime-kuma.
6️⃣ Если есть возможность по месту на дисках, на одном из серверов организовал бы вируталку под локальные бэкапы как самих виртуальных машин, так и сырых данных. С этой виртуалки забирал бы данные куда-то во вне. Если есть возможность поднять Proxmox Backup Server, поднял бы его для внешнего бэкапа виртуалок целиком.
Итого, получается следующая минимальная конфигурация по виртуалкам:
▪ СУБД
▪ Терминальник
▪ Шлюз
▪ Мониторинг и логи
▪ Бэкап.
Раскидываются между серверами в зависимости от ресурсов и нагрузки. Скорее всего СУБД и Мониторинг с логами это один сервер, Терминальник, Шлюз и Бэкап это второй сервер. При желании можно раздробить всё это на большее количество виртуальных машин. Мониторинг, Guacamole, Логи разнести по разным машинам. Это будет удобнее и безопаснее, но больше расходов по ресурсам и поддержке.
По ссылке в начале можно посмотреть небольшое обсуждение этого вопроса и итоговое решение, которое принял автор. Если у вас есть замечания, возражения, рекомендации, делитесь. Это чисто мои мысли, которые сходу родились в голове на основе моего опыта построения похожих систем.
#виртуализация #совет
Очень нужен совет. Имеется два выделенных сервера, арендованных в Selectel. Сервера с приватной сетью. На серверах планируется поставить RDP сервер на Windows и сервер под базу данных. Сервера должны уметь общаться между собой. Плюс еще нужен безопасный доступ к RDP серверу. Как лучше на ваш взгляд все это организовать? Поставить на оба сервер Proxmox и на него виртуалки? Возможно ли при таком раскладе чтобы виртуалки с разных хостов Proxmox видели друг друга? Как обезопасить доступ RDP? Поднимать какой-то шлюз или как? Или вообще без Proxmox обойтись?
Я бы делал следующим образом:
1️⃣ В обязательном порядке на сервера поставил Proxmox и всю функциональность реализовывал бы только в виртуальных машинах. Так как есть приватная сеть, никаких дополнительных сложностей со взаимодействием виртуальных машин не будет. Делаем бридж на интерфейсах приватной сети и добавляем сетевые интерфейсы с этим бриджем виртуальным машинам. Они будут обращаться друг к другу напрямую.
2️⃣ На машине с терминальным сервером сделал бы отдельную виртуалку под шлюз. Все остальные виртуальные машины ходили бы в интернет через неё. В эту виртуалку прокинул бы сетевой интерфейс с внешним IP. Сами гипервизоры настроил бы только в приватной сети, чтобы они ходили в интернет тоже только через этот шлюз. Обязательно настроить автоматический запуск этой виртуальной машины.
3️⃣ На шлюзе настроил бы firewall и управлял доступом к виртуалкам и их доступом в интернет через него. На него же поставил бы Nginx для проксирования запросов к внутренним веб ресурсам.
4️⃣ Доступ к терминальному серверу реализовал бы либо с помощью Openvpn, если нужен прямой доступ через терминальный клиент, либо с помощью Guacamole, если будет достаточен такой режим работы на сервере через браузер. Настраивал бы это на шлюзе. Можно сразу и то, и другое.
5️⃣ В отдельной виртуальной машине поднял бы Zabbix для мониторинга всего этого хозяйства и какую-то систему для сбора логов (ELK или Loki). И добавил бы внешний мониторинг, типа uptimerobot или uptime-kuma.
6️⃣ Если есть возможность по месту на дисках, на одном из серверов организовал бы вируталку под локальные бэкапы как самих виртуальных машин, так и сырых данных. С этой виртуалки забирал бы данные куда-то во вне. Если есть возможность поднять Proxmox Backup Server, поднял бы его для внешнего бэкапа виртуалок целиком.
Итого, получается следующая минимальная конфигурация по виртуалкам:
▪ СУБД
▪ Терминальник
▪ Шлюз
▪ Мониторинг и логи
▪ Бэкап.
Раскидываются между серверами в зависимости от ресурсов и нагрузки. Скорее всего СУБД и Мониторинг с логами это один сервер, Терминальник, Шлюз и Бэкап это второй сервер. При желании можно раздробить всё это на большее количество виртуальных машин. Мониторинг, Guacamole, Логи разнести по разным машинам. Это будет удобнее и безопаснее, но больше расходов по ресурсам и поддержке.
По ссылке в начале можно посмотреть небольшое обсуждение этого вопроса и итоговое решение, которое принял автор. Если у вас есть замечания, возражения, рекомендации, делитесь. Это чисто мои мысли, которые сходу родились в голове на основе моего опыта построения похожих систем.
#виртуализация #совет
Server Admin
Объединение выделенных серверов в сеть
Всем привет! Очень нужен совет. Имеется два выделенных сервера, арендованных в Selectel. Сервера с приватной сетью. На серверах планируется поставит...
Небольшая заметка-напоминание по мотивам моих действий на одном из серверов. Пару месяцев назад обновлял почтовый сервер. Не помню точно, что там за нюансы были, но на всякий случай сделал контрольную точку виртуальной машине, чтобы можно было быстро откатиться в случае проблем.
Ну и благополучно забыл про неё, когда всё удачно завершилось. Заметил это в выходные случайно, когда просматривал сервера. Нужно будет заменить один старый сервер на новый и перераспределить виртуалки. Плюс, в виду завершения развития бесплатного Hyper-V, буду постепенно переводить все эти гипервизоры на Proxmox.
Возвращаясь к контрольной точке. Там сервер довольно крупный. За это время расхождение со снимком набежало почти на 150 Гб. Смержить это всё быстро не получится. Немного запереживал, так как сервер там в целом нагружен. Дождался позднего вечера, сделал бэкап и потушил машину. На выключенной виртуалке удалил контрольную точку. Слияние минут 15-20 длилось. Прошло успешно.
Не люблю такие моменты. Затяжное слияние контрольных точек потенциально небезопасная процедура, поэтому не рекомендуется накапливать большие расхождения. Сделал контрольную точку, накатил изменения, убедился, что всё в порядке, удаляй. Нельзя оставлять их надолго. В этот раз обошлось. Я уже не первый раз так забываю. Как то раз целый год у меня провисела контрольная точка. Тоже благополучно объединилась с основой.
Но я видел и проблемы, особенно когда по ошибке выстраивалась цепочка контрольных точек. Не у меня было, но меня просили помочь разобраться. В какой-то момент виртуалка повисла и перестала запускаться. Контрольные точки объединить не получилось. Пришлось восстанавливать виртуалку из бэкапов. А так как эти контрольные точки создавала программа для бэкапов, она в какой-то момент тоже стала глючить. В итоге часть данных потеряли, так как восстановились на бэкап недельной давности.
В общем, с контрольными точками надо быть аккуратным и без особой необходимости их не плодить. И следить, чтобы программы для бэкапа не оставляли контрольные точки. Часто именно они их создают и из-за глюков могут оставлять.
#виртуализация
Ну и благополучно забыл про неё, когда всё удачно завершилось. Заметил это в выходные случайно, когда просматривал сервера. Нужно будет заменить один старый сервер на новый и перераспределить виртуалки. Плюс, в виду завершения развития бесплатного Hyper-V, буду постепенно переводить все эти гипервизоры на Proxmox.
Возвращаясь к контрольной точке. Там сервер довольно крупный. За это время расхождение со снимком набежало почти на 150 Гб. Смержить это всё быстро не получится. Немного запереживал, так как сервер там в целом нагружен. Дождался позднего вечера, сделал бэкап и потушил машину. На выключенной виртуалке удалил контрольную точку. Слияние минут 15-20 длилось. Прошло успешно.
Не люблю такие моменты. Затяжное слияние контрольных точек потенциально небезопасная процедура, поэтому не рекомендуется накапливать большие расхождения. Сделал контрольную точку, накатил изменения, убедился, что всё в порядке, удаляй. Нельзя оставлять их надолго. В этот раз обошлось. Я уже не первый раз так забываю. Как то раз целый год у меня провисела контрольная точка. Тоже благополучно объединилась с основой.
Но я видел и проблемы, особенно когда по ошибке выстраивалась цепочка контрольных точек. Не у меня было, но меня просили помочь разобраться. В какой-то момент виртуалка повисла и перестала запускаться. Контрольные точки объединить не получилось. Пришлось восстанавливать виртуалку из бэкапов. А так как эти контрольные точки создавала программа для бэкапов, она в какой-то момент тоже стала глючить. В итоге часть данных потеряли, так как восстановились на бэкап недельной давности.
В общем, с контрольными точками надо быть аккуратным и без особой необходимости их не плодить. И следить, чтобы программы для бэкапа не оставляли контрольные точки. Часто именно они их создают и из-за глюков могут оставлять.
#виртуализация
Если я где-то упоминаю о том, что настроил гипервизор и поднял на нём одну виртуальную машину, неизменно получаю вопросы, зачем так делать. В данном случае вроде как и смысла нет. Помню, что когда-то уже писал по этому поводу, но не смог найти заметку, поэтому пишу снова.
Итак, зачем поднимать гипервизор ради одной виртуалки? На первый взгляд логичнее всё сделать на железе и получить максимальную утилизацию ресурсов сервера. Дальше сугубо моё личное мнение. Не призываю делать именно так и не утверждаю, что это правильно.
1️⃣ Работа на гипервизоре отвязывает вас от железа. Вы без каких-либо проблем можете переехать на другой сервер с таким же гипервизором и без особых проблем на другой гипервизор. Перенести систему с железа хоть и тоже решаемая задача, но более трудоёмкая и длительная. Это существенный плюс. Просто покупаешь другой сервер и перекидываешь туда виртуалку. Никаких проблем.
2️⃣ Виртуальную машину проще бэкапить целиком с уровня гипервизора без остановки. Быстрее развернуть копию в другом месте. Удобнее автоматически проверять бэкапы. Быстрее делаются инкрементные копии. С этой стороны явные плюсы. Все гипервизоры имеют поддержку создания бэкапов со своего уровня.
3️⃣ Проще управлять ресурсами сервера. Если не занят весь диск, то возможно вам когда-то понадобится добавить виртуальные машины. Возможно нужно будет протестировать работу виртуалки в более зажатом состоянии по ресурсам, чтобы проверить, как она себя поведёт перед переездом в другое место. Может дорастёте до кластера и добавите этот гипервизор в кластер. Тут более широкое пространство для манёвра.
➖ Минус только один - вы немного теряете в производительности из-за лишней прослойки в виде виртуализации. По CPU и RAM разница минимальна, на уровне погрешности измерений. Для дисковых операций разница может быть более существенной, но не кардинально. Цифры могут сильно плавать в зависимости от гипервизоров, файловых систем, типов дисков и т.д. Если взять LXC контейнер, то там накладных расходов ещё меньше, практически нет. Но переносимость у такой системы будет хуже.
Таким образом, я уже очень давно всю полезную нагрузку запускаю только и исключительно в виртуальных машинах. Ничего на железо, кроме гипервизора, не ставлю, даже если одна виртуалка будет утилизировать все ресурсы сервера.
#виртуализация
Итак, зачем поднимать гипервизор ради одной виртуалки? На первый взгляд логичнее всё сделать на железе и получить максимальную утилизацию ресурсов сервера. Дальше сугубо моё личное мнение. Не призываю делать именно так и не утверждаю, что это правильно.
1️⃣ Работа на гипервизоре отвязывает вас от железа. Вы без каких-либо проблем можете переехать на другой сервер с таким же гипервизором и без особых проблем на другой гипервизор. Перенести систему с железа хоть и тоже решаемая задача, но более трудоёмкая и длительная. Это существенный плюс. Просто покупаешь другой сервер и перекидываешь туда виртуалку. Никаких проблем.
2️⃣ Виртуальную машину проще бэкапить целиком с уровня гипервизора без остановки. Быстрее развернуть копию в другом месте. Удобнее автоматически проверять бэкапы. Быстрее делаются инкрементные копии. С этой стороны явные плюсы. Все гипервизоры имеют поддержку создания бэкапов со своего уровня.
3️⃣ Проще управлять ресурсами сервера. Если не занят весь диск, то возможно вам когда-то понадобится добавить виртуальные машины. Возможно нужно будет протестировать работу виртуалки в более зажатом состоянии по ресурсам, чтобы проверить, как она себя поведёт перед переездом в другое место. Может дорастёте до кластера и добавите этот гипервизор в кластер. Тут более широкое пространство для манёвра.
➖ Минус только один - вы немного теряете в производительности из-за лишней прослойки в виде виртуализации. По CPU и RAM разница минимальна, на уровне погрешности измерений. Для дисковых операций разница может быть более существенной, но не кардинально. Цифры могут сильно плавать в зависимости от гипервизоров, файловых систем, типов дисков и т.д. Если взять LXC контейнер, то там накладных расходов ещё меньше, практически нет. Но переносимость у такой системы будет хуже.
Таким образом, я уже очень давно всю полезную нагрузку запускаю только и исключительно в виртуальных машинах. Ничего на железо, кроме гипервизора, не ставлю, даже если одна виртуалка будет утилизировать все ресурсы сервера.
#виртуализация
Если вы используете динамический размер дисков под виртуальные машины, то рано или поздно возникнет ситуация, когда реально внутри VM данных будет условно 50 ГБ, а динамический диск размером в 100 ГБ будет занимать эти же 100 ГБ на гипервизоре.
Я раньше решал эту задачу для HyperV и виртуалок с Linux. Сейчас уже не помню точную реализацию, но смысл был в том, что незанятое пространство внутри VM надо было принудительно заполнить нулями и выполнить что-то со стороны гипервизора. Помню виртуалку в 500 ГБ, где реально использовалось 40 ГБ. Она была очень критичная, там был самописный call центр на базе Elastix. Интересно, кто-нибудь помнит его? Хороший был продукт для VOIP. Так вот, эта виртуалка занимала на диске гипервизора реальные 500 ГБ и не получалось её перенести в доступное для этого окно. Call центр почти круглые сутки работал. Ужать по размеру диска её не получилось, но когда она стала занимать реальные 40 ГБ, переносить её стало значительно проще и быстрее.
С Proxmox сейчас стало всё намного проще. Никаких ручных действий. Если у вас в виртуалках динамические диски, а это иногда оправданно для экономии места, когда есть возможность расселять виртуалки, когда на гипервизоре заканчивается место (так делают почти все хостеры VPS), то достаточно выполнить пару простых действий, чтобы виртуалки занимали тот объём, сколько реальных данных там есть.
Для этого можно воспользоваться официальным руководством:
⇨ Shrink Qcow2 Disk Files
Достаточно указать тип дискового контроллера Virtio-SCSI, а для самого диска установить параметр Discard. После этого внутри VM с Linux выполнить команду:
Все современные дистрибутивы Linux имеют systemd службу с fstrim и таймер для запуска. Диск на самом гипервизоре ужмётся до реального размера данных внутри VM. Проверить это можно так:
Если внутри витуалки добавить занимаемый объём, то это сразу же будет видно на гипервизоре:
Смотрим ещё раз на файл диска:
Удаляем в виртуалке файл:
Смотрим на размер диска:
Ничего не поменялось. А если сделаем fstrim внутри VM, реальный размер диска уменьшится.
То же самое можно сделать и с уровня гипервизора, но для этого нужно будет выключить виртуальную машину, что неудобно, но иногда тоже может пригодиться. Это можно сделать с помощью утилиты virt-sparsify из комплекта libguests-tools:
Для успешной работы этой команды, на диске гипервизора должно быть место для создания копии образа диска, так как по факту команда делает копию, работает с ней и потом заменяет основной файл.
#proxmox #виртуализация
Я раньше решал эту задачу для HyperV и виртуалок с Linux. Сейчас уже не помню точную реализацию, но смысл был в том, что незанятое пространство внутри VM надо было принудительно заполнить нулями и выполнить что-то со стороны гипервизора. Помню виртуалку в 500 ГБ, где реально использовалось 40 ГБ. Она была очень критичная, там был самописный call центр на базе Elastix. Интересно, кто-нибудь помнит его? Хороший был продукт для VOIP. Так вот, эта виртуалка занимала на диске гипервизора реальные 500 ГБ и не получалось её перенести в доступное для этого окно. Call центр почти круглые сутки работал. Ужать по размеру диска её не получилось, но когда она стала занимать реальные 40 ГБ, переносить её стало значительно проще и быстрее.
С Proxmox сейчас стало всё намного проще. Никаких ручных действий. Если у вас в виртуалках динамические диски, а это иногда оправданно для экономии места, когда есть возможность расселять виртуалки, когда на гипервизоре заканчивается место (так делают почти все хостеры VPS), то достаточно выполнить пару простых действий, чтобы виртуалки занимали тот объём, сколько реальных данных там есть.
Для этого можно воспользоваться официальным руководством:
⇨ Shrink Qcow2 Disk Files
Достаточно указать тип дискового контроллера Virtio-SCSI, а для самого диска установить параметр Discard. После этого внутри VM с Linux выполнить команду:
# fstrim -avВсе современные дистрибутивы Linux имеют systemd службу с fstrim и таймер для запуска. Диск на самом гипервизоре ужмётся до реального размера данных внутри VM. Проверить это можно так:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 1.32 GiBcluster_size: 65536Если внутри витуалки добавить занимаемый объём, то это сразу же будет видно на гипервизоре:
# dd if=/dev/urandom of=testfile bs=1M count=2048Смотрим ещё раз на файл диска:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 3.32 GiBcluster_size: 65536Удаляем в виртуалке файл:
# rm testfileСмотрим на размер диска:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 3.32 GiBcluster_size: 65536Ничего не поменялось. А если сделаем fstrim внутри VM, реальный размер диска уменьшится.
То же самое можно сделать и с уровня гипервизора, но для этого нужно будет выключить виртуальную машину, что неудобно, но иногда тоже может пригодиться. Это можно сделать с помощью утилиты virt-sparsify из комплекта libguests-tools:
# virt-sparsify --in-place vm-100-disk-0.qcow2Для успешной работы этой команды, на диске гипервизора должно быть место для создания копии образа диска, так как по факту команда делает копию, работает с ней и потом заменяет основной файл.
#proxmox #виртуализация