
В процессе подготовки утренней публикации с антивирусами, пришлось работать с rar архивами. Казалось бы, что может быть проще установки архиватора rar в Debian. Я точно знаю, что он там есть, потому что ранее уже пользовался им.
Помню, что у него имя пакета не просто rar, а что-то ещё добавляется. Нет проблем, воспользуемся поиском:
На экран вываливается тонна пакетов. Такое ощущение, что тут весь список стандартного репозитория. Мотая экран вверх, я даже до буквы R не дошёл, буфер кончился. Читаю описание пакетов из списка, и не понимаю, почему они тут. Никакого rar там нет.
Запускаю другой поиск:
Тут то же самое. Огромный список. Становится понятно, что сюда попали все пакеты, в которых где-то в названии или описании есть rar в составе. То есть все пакеты, где в описании есть слово library, тоже в этом списке. Но не только они. Даже если нигде не видно rar, всё равно где-то в спецификации пакета он есть и пакет выведен в результаты поиска.
Тут мне уже надоело и я тупо загуглил нужный пакет. Он оказался unrar. Ну наконец-то. Ставлю и распаковываю:
Опять какая-то ерунда. Скачиваю этот же архив к себе на комп, нормально открывается с помощью 7zip. То есть архив рабочий, самый обычный. Смотрю версию unrar. Смущает, что она от 2004 года. Полез опять в поиск.
Оказывается, нормальная версия unrar есть в репозитории non-free. Подключаю его, добавляя в sources.list:
Обновляю репы и пакет:
Теперь всё нормально работает.
Я давно знаю, что поиск пакетов через apt или apt-cache работает неудобно. По нему зачастую трудно что-то найти, если название пакета короткое и много где может встречаться в описании. Если знаете какие-то способы, что с этим делать, то поделитесь. Я так всегда и ищу. Если не нахожу, то иду в веб поиск и ищу там. Зачастую это получается быстрее.
Можно немного упростить себе задачу и искать только по названию пакета:
Search в том числе поддерживает регулярки, так что по идее можно ими себе помогать. Но конкретно с rar я не очень понимаю, как могла бы выглядеть регулярка, так как нужен unrar. А если искать обычный rar, то вот так проще всего найти:
А вообще, с rar очень редко приходится иметь дела в Linux. Как-то он тут не прижился. Лично я либо gzip, либо pigz использую, если нужна многопоточность. Что-то другое крайне редко. Даже не припомню, использовал ли какие-то другие архиваторы. Хотя, по идее, сейчас оптимальный алгоритм сжатия - zstd, который используется в том числе в proxmox для создания бэкапов. Да и много где ещё. Он и жмёт хорошо, и самое главное - быстро.
#linux
Помню, что у него имя пакета не просто rar, а что-то ещё добавляется. Нет проблем, воспользуемся поиском:
# apt search rarНа экран вываливается тонна пакетов. Такое ощущение, что тут весь список стандартного репозитория. Мотая экран вверх, я даже до буквы R не дошёл, буфер кончился. Читаю описание пакетов из списка, и не понимаю, почему они тут. Никакого rar там нет.
Запускаю другой поиск:
# apt-cache search rarТут то же самое. Огромный список. Становится понятно, что сюда попали все пакеты, в которых где-то в названии или описании есть rar в составе. То есть все пакеты, где в описании есть слово library, тоже в этом списке. Но не только они. Даже если нигде не видно rar, всё равно где-то в спецификации пакета он есть и пакет выведен в результаты поиска.
Тут мне уже надоело и я тупо загуглил нужный пакет. Он оказался unrar. Ну наконец-то. Ставлю и распаковываю:
# apt install unrar# unrar e anonghost.rarunknown archive type, only plain RAR 2.0 supported(normal and solid archives), SFX and Volumes are NOT supported!Опять какая-то ерунда. Скачиваю этот же архив к себе на комп, нормально открывается с помощью 7zip. То есть архив рабочий, самый обычный. Смотрю версию unrar. Смущает, что она от 2004 года. Полез опять в поиск.
Оказывается, нормальная версия unrar есть в репозитории non-free. Подключаю его, добавляя в sources.list:
deb http://deb.debian.org/debian/ bullseye main non-freeОбновляю репы и пакет:
# apt update# apt upgrade unrarТеперь всё нормально работает.
Я давно знаю, что поиск пакетов через apt или apt-cache работает неудобно. По нему зачастую трудно что-то найти, если название пакета короткое и много где может встречаться в описании. Если знаете какие-то способы, что с этим делать, то поделитесь. Я так всегда и ищу. Если не нахожу, то иду в веб поиск и ищу там. Зачастую это получается быстрее.
Можно немного упростить себе задачу и искать только по названию пакета:
# apt search --names-only rarSearch в том числе поддерживает регулярки, так что по идее можно ими себе помогать. Но конкретно с rar я не очень понимаю, как могла бы выглядеть регулярка, так как нужен unrar. А если искать обычный rar, то вот так проще всего найти:
# apt search ^rar А вообще, с rar очень редко приходится иметь дела в Linux. Как-то он тут не прижился. Лично я либо gzip, либо pigz использую, если нужна многопоточность. Что-то другое крайне редко. Даже не припомню, использовал ли какие-то другие архиваторы. Хотя, по идее, сейчас оптимальный алгоритм сжатия - zstd, который используется в том числе в proxmox для создания бэкапов. Да и много где ещё. Он и жмёт хорошо, и самое главное - быстро.
#linux
Несмотря на то, что Микротики стало сложнее купить, да и стоить они стали больше, особых альтернатив так и не просматривается. Я сам постоянно ими пользуюсь, управляю, как в личных целях, так и на работе. Мне нравятся эти устройства. Очень хочется продолжать ими пользоваться. У меня и дома, и на даче, и у родителей и много где ещё стоят Микротики.
Я когда-то писал про полезный ресурс для Mikrotik - https://buananetpbun.github.io. Там была куча скриптов, утилит, генераторов конфигов для различных настроек. Я им иногда пользовался. Там сначала дизайн поменялся, стало удобнее, появились запросы доната. На днях зашёл, смотрю, а там всё платное стало. Из открытого доступа почти всё исчезло.
Сначала решил через web.archive.org зайти, посмотреть, что там можно достать из полезного контента. Перед этим попробовал поискать по некоторым ключевым словам похожие ресурсы. И не ошибся. Сразу же нашёл копию сайта, когда он был ещё бесплатным. Так что теперь можно пользоваться им:
⇨ https://mikrotiktool.github.io
Основное там - большая структурированная база скриптов для RouterOS. Помимо прям больших и сложных скриптов, там много и простых примеров по типу блокировки сайтов с помощью блокировки DNS запросов, с помощью Layer 7, блокировка торрентов и т.д.
Помимо скриптов там есть генераторы конфигов, которые помогут выполнить настройку устройства. Например:
◽MikroTik Burst Limit Calculator - помогает рассчитать параметры burst при настройке простыл очередей.
◽Port Knocking Generator with (ping) ICMP + Packet Size - простенький генератор правил firewall для настройки Port Knocking.
◽Simple Queue Script Generator - генератор конфигурации для простых очередей.
В общем, там много всего интересного. Если настраиваете Микротики, покопайтесь. Можете найти для себя что-то полезное.
#mikrotik
Я когда-то писал про полезный ресурс для Mikrotik - https://buananetpbun.github.io. Там была куча скриптов, утилит, генераторов конфигов для различных настроек. Я им иногда пользовался. Там сначала дизайн поменялся, стало удобнее, появились запросы доната. На днях зашёл, смотрю, а там всё платное стало. Из открытого доступа почти всё исчезло.
Сначала решил через web.archive.org зайти, посмотреть, что там можно достать из полезного контента. Перед этим попробовал поискать по некоторым ключевым словам похожие ресурсы. И не ошибся. Сразу же нашёл копию сайта, когда он был ещё бесплатным. Так что теперь можно пользоваться им:
⇨ https://mikrotiktool.github.io
Основное там - большая структурированная база скриптов для RouterOS. Помимо прям больших и сложных скриптов, там много и простых примеров по типу блокировки сайтов с помощью блокировки DNS запросов, с помощью Layer 7, блокировка торрентов и т.д.
Помимо скриптов там есть генераторы конфигов, которые помогут выполнить настройку устройства. Например:
◽MikroTik Burst Limit Calculator - помогает рассчитать параметры burst при настройке простыл очередей.
◽Port Knocking Generator with (ping) ICMP + Packet Size - простенький генератор правил firewall для настройки Port Knocking.
◽Simple Queue Script Generator - генератор конфигурации для простых очередей.
В общем, там много всего интересного. Если настраиваете Микротики, покопайтесь. Можете найти для себя что-то полезное.
#mikrotik
{kind=link}
▶️ Вчера посмотрел видео про обзор российских дистрибутивов. Сделано качественно и информативно, так что если вам интересна тема, то рекомендую посмотреть. Я узнал некоторые факты и подробности, про которые не слышал, либо не интересовался.
⇨ https://www.youtube.com/watch?v=ZMHUBc_4Zbw
Добавлю краткие выжимки и приведу список описанных дистрибутивов:
🟢 Astra Linux - сделана на базе Debian. Ориентация в основном на госсектор с повышенными требованиями к безопасности. Куча сертификатов самого высокого уровня доверия. Для многих секторов безальтернативный вариант. На текущий момент лидер рынка российских ОС.
🟢 ALT Linux - старейший дистрибутив из 2000 года, в основу была взята Mandriva. Сейчас это полностью самобытный и самостоятельный дистрибутив с самым большим сообществом в РФ. Дистрибутив ориентирован и на госсектор, и на коммерческие организации. Есть отдельный фокус на продукты в сфере образования. Для домашнего использования почти всё бесплатно.
🟢 Calculate Linux - в основе Gentoo. Относительно старый дистрибутив, разработка начата в 2007 году. Имеет стабильное сообщество, неплохие отзывы и в целом выглядит самобытно. Есть своя экосистема программных продуктов, своя целевая аудитория в виде малого и среднего бизнеса.
🟢 ROSA - в основе Mandriva, используются rpm пакеты, установщик - dnf. Примечательна тем, что разрабатывает свою ОС для смартфонов - РОСА Мобайл. Обещают презентацию уже 14 декабря 2023. Ориентация в основном на госсектор. Есть сертификаты ФСТЭК и Министерства обороны РФ. Тем не менее, предлагает широкую линейку продуктов, где есть в том числе РОСА ФРЕШ - полностью бесплатный продукт для дома.
🟢 RedOS - в основе rpm дистрибутивы, изначально - CentOS. Была сделана под конкретный гос. заказ, который был признан успешным, так что система получила развитие. Чего-то примечательного в этой системе не замечено, похоже просто на переупаковку rpm дистра для получение статуса отечественного.
#linux #отечественное
⇨ https://www.youtube.com/watch?v=ZMHUBc_4Zbw
Добавлю краткие выжимки и приведу список описанных дистрибутивов:
🟢 Astra Linux - сделана на базе Debian. Ориентация в основном на госсектор с повышенными требованиями к безопасности. Куча сертификатов самого высокого уровня доверия. Для многих секторов безальтернативный вариант. На текущий момент лидер рынка российских ОС.
🟢 ALT Linux - старейший дистрибутив из 2000 года, в основу была взята Mandriva. Сейчас это полностью самобытный и самостоятельный дистрибутив с самым большим сообществом в РФ. Дистрибутив ориентирован и на госсектор, и на коммерческие организации. Есть отдельный фокус на продукты в сфере образования. Для домашнего использования почти всё бесплатно.
🟢 Calculate Linux - в основе Gentoo. Относительно старый дистрибутив, разработка начата в 2007 году. Имеет стабильное сообщество, неплохие отзывы и в целом выглядит самобытно. Есть своя экосистема программных продуктов, своя целевая аудитория в виде малого и среднего бизнеса.
🟢 ROSA - в основе Mandriva, используются rpm пакеты, установщик - dnf. Примечательна тем, что разрабатывает свою ОС для смартфонов - РОСА Мобайл. Обещают презентацию уже 14 декабря 2023. Ориентация в основном на госсектор. Есть сертификаты ФСТЭК и Министерства обороны РФ. Тем не менее, предлагает широкую линейку продуктов, где есть в том числе РОСА ФРЕШ - полностью бесплатный продукт для дома.
🟢 RedOS - в основе rpm дистрибутивы, изначально - CentOS. Была сделана под конкретный гос. заказ, который был признан успешным, так что система получила развитие. Чего-то примечательного в этой системе не замечено, похоже просто на переупаковку rpm дистра для получение статуса отечественного.
#linux #отечественное
YouTube
ВСЁ О РУССКИХ ЛИНУКСАХ (2023)
Как много ты знаешь об отечественных вариантах Линукса? В этом видео разберём самые популярные российские дистрибутивы на базе ядра линукс и соберём весь пазл воедино! Приятного просмотра!
Гайд ALT Zero: https://plafon.gitbook.io/alt-zero/alt-zero/start…
Гайд ALT Zero: https://plafon.gitbook.io/alt-zero/alt-zero/start…
Ко мне как то раз обратился человек за помощью в настройке веб сервера. Суть была вот в чём. У него есть контентный сайт, где он пишет хайповые статьи для сбора ситуативного трафика. Монетизируется, соответственно, показами различной рекламы. Чем больше показов, тем больше доход.
И как-то раз одна его статья очень сильно выстрелила, так что трафик полился огромным потоком с различных агрегаторов новостей и ссылок с других статей. В итоге сайт у него начал падать. У него был некий админ-программист, который занимался сайтом. Он с самого начала потока трафика предпринимал какие-то действия, что помогало не очень. Кардинально решить проблему не мог. Сайт всё равно тормозил и часто отдавал 502 ошибку.
Я отказался помогать, потому что в принципе не занимаюсь разовыми задачами, тем более уже в условиях катастрофы, тем более без запланированного заранее времени. Да ещё на сервере, где непонятно кем и как всё настраивалось. Но для себя пометочку сделал, как лучше всего оперативно выкрутиться в такой ситуации. Сейчас с вами поделюсь примерным ходом решения этой задачи.
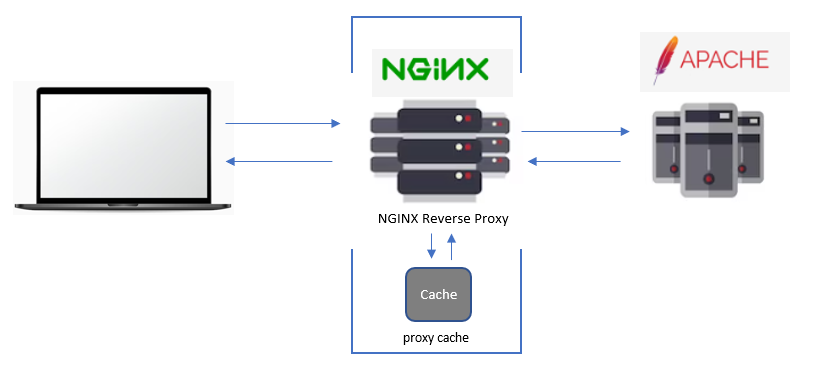
Проще всего в такой ситуации поднять прокси сервер на Nginx и тупо всё закэшировать. Причём настроить кэш так, что если сам сайт лёг, то кэш будет отдавать статические страницы, которые он предварительно сохранил, несмотря на то, что сам сайт динамический. Когда нам во что бы то ни стало надо показывать контент, такой вариант сойдёт. При этом сам прокси сервер можно разместить где угодно, создав виртуалку с достаточными ресурсами. Пока будут обновляться DNS записи, такую же прокси можно воткнуть прямо там же на виртуалке с сайтом, а кэш разместить в оперативной памяти.
Настройка простая и быстрая, так что если ранее вы тестировали такой вариант и сохранили конфиг, то всё настроить можно буквально за 5 минут. Ставим на сервер Nginx, если его ещё нет, и добавляем в основной конфиг, в секцию http:
Создаём директорию
Теперь открываем настройки виртуального хоста и добавляем туда в секцию server и location примерно следующее:
Я не буду описывать эти параметры, так как заметка большая получается. Они все есть в документации Nginx на русском языке.
Основной веб сервер живёт по адресу http://10.20.1.36:81, туда мы проксируем все соединения. Весь кэш складываем в директорию
Я вот прямо сейчас всё это протестировал на тестовом стенде. Поднял в Docker контейнерах сайт на Wordpress, который на php. В качестве веб сервера использовал Apache. И тут же на хосте поднял проксирующий Nginx. Походил по страницам сайта, закешировал их. Убедился, что в директории
Важно понимать, что такое грубое кэширование - это крайний случай. Подойдёт только для полностью статических сайтов, которых сейчас почти нет. Для динамического сайта решать вопросы постоянного кэширования придётся другими методами. Но в случае внезапной нагрузки можно поступить и так. Потом этот кэш отключить. Самое главное, что рабочую инфраструктуру можно не трогать при этом. Просто ставим на вход прокси. Когда она не нужна, отключаем её и работаем как прежде.
#nginx #webserver
И как-то раз одна его статья очень сильно выстрелила, так что трафик полился огромным потоком с различных агрегаторов новостей и ссылок с других статей. В итоге сайт у него начал падать. У него был некий админ-программист, который занимался сайтом. Он с самого начала потока трафика предпринимал какие-то действия, что помогало не очень. Кардинально решить проблему не мог. Сайт всё равно тормозил и часто отдавал 502 ошибку.
Я отказался помогать, потому что в принципе не занимаюсь разовыми задачами, тем более уже в условиях катастрофы, тем более без запланированного заранее времени. Да ещё на сервере, где непонятно кем и как всё настраивалось. Но для себя пометочку сделал, как лучше всего оперативно выкрутиться в такой ситуации. Сейчас с вами поделюсь примерным ходом решения этой задачи.
Проще всего в такой ситуации поднять прокси сервер на Nginx и тупо всё закэшировать. Причём настроить кэш так, что если сам сайт лёг, то кэш будет отдавать статические страницы, которые он предварительно сохранил, несмотря на то, что сам сайт динамический. Когда нам во что бы то ни стало надо показывать контент, такой вариант сойдёт. При этом сам прокси сервер можно разместить где угодно, создав виртуалку с достаточными ресурсами. Пока будут обновляться DNS записи, такую же прокси можно воткнуть прямо там же на виртуалке с сайтом, а кэш разместить в оперативной памяти.
Настройка простая и быстрая, так что если ранее вы тестировали такой вариант и сохранили конфиг, то всё настроить можно буквально за 5 минут. Ставим на сервер Nginx, если его ещё нет, и добавляем в основной конфиг, в секцию http:
http { ... proxy_cache_path /var/cache/nginx keys_zone=my_cache:10m inactive=1w max_size=1G; ...}Создаём директорию
/var/cache/nginx и делаем владельцем пользователя, под которым работает веб сервер. Теперь открываем настройки виртуального хоста и добавляем туда в секцию server и location примерно следующее:
server { ... proxy_cache my_cache; ... location / { proxy_set_header Host $host; proxy_pass http://10.20.1.36:81; proxy_cache_key $scheme://$host$uri$is_args$query_string; proxy_cache_valid 200 30m; proxy_cache_bypass $arg_bypass_cache; proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504 http_429; }}Я не буду описывать эти параметры, так как заметка большая получается. Они все есть в документации Nginx на русском языке.
Основной веб сервер живёт по адресу http://10.20.1.36:81, туда мы проксируем все соединения. Весь кэш складываем в директорию
/var/cache/nginx, можете сходить туда и убедиться. Если используется gzip, то там будут сжатые файлы. Теперь, даже если веб сервер 10.20.1.36:81 умрёт, прокси сервер всё равно будет отдавать статические страницы. Я вот прямо сейчас всё это протестировал на тестовом стенде. Поднял в Docker контейнерах сайт на Wordpress, который на php. В качестве веб сервера использовал Apache. И тут же на хосте поднял проксирующий Nginx. Походил по страницам сайта, закешировал их. Убедился, что в директории
/var/cache/nginx появились эти страницы. Отключил контейнер с Wordpress, сайт продолжил работать в виде закэшированной статики на прокси. Важно понимать, что такое грубое кэширование - это крайний случай. Подойдёт только для полностью статических сайтов, которых сейчас почти нет. Для динамического сайта решать вопросы постоянного кэширования придётся другими методами. Но в случае внезапной нагрузки можно поступить и так. Потом этот кэш отключить. Самое главное, что рабочую инфраструктуру можно не трогать при этом. Просто ставим на вход прокси. Когда она не нужна, отключаем её и работаем как прежде.
#nginx #webserver
{kind=link}
❗️Сразу важное предупреждение перед непосредственно содержательной частью. Всё, что дальше будет изложено, не призыв к действию. Пишу только в качестве информации, с которой каждый сам решает, как поступать. Сразу акцентирую на этом внимание, потому что ко всем подобным заметкам постоянно пишут комментарии на тему того, что бесплатный сыр бывает только в мышеловке, свои данные нельзя ни в какие облака загружать, всё, что в облаке, принадлежит не вам и т.д.
Если вам нужны 1024ГБ в бесплатном облачном хранилище, то можете таким воспользоваться - https://www.terabox.com. Для регистрации нужна только почта. Есть возможность использовать клиент в операционной системе. Ограничение на размер файла в бесплатном тарифе - 4ГБ.
Скорость загрузки и выгрузки высокая. Я протестировал лично на большом и группе мелких файлов. Загружал в облако со скоростью примерно в 50 Мбит/с с пиками до 100 Мбит/с, скачивал к себе на комп примерно со скоростью 20 Мбит/с.
Сервис всюду предлагает переход на платный тариф, но в целом работает нормально и бесплатно. Можете использовать на своё усмотрение в качестве дополнительного хранилища зашифрованных бэкапов, в качестве хранилища ISO образов (можно делать публичные ссылки), в качестве хранилища публичного медиаконтента и т.д.
Возможно, в случае активного использования бесплатного тарифа, будут введены какие-то скрытые ограничения. Я погонял туда-сюда примерно 10ГБ, никаких изменений не заметил.
#бесплатно #fileserver
Если вам нужны 1024ГБ в бесплатном облачном хранилище, то можете таким воспользоваться - https://www.terabox.com. Для регистрации нужна только почта. Есть возможность использовать клиент в операционной системе. Ограничение на размер файла в бесплатном тарифе - 4ГБ.
Скорость загрузки и выгрузки высокая. Я протестировал лично на большом и группе мелких файлов. Загружал в облако со скоростью примерно в 50 Мбит/с с пиками до 100 Мбит/с, скачивал к себе на комп примерно со скоростью 20 Мбит/с.
Сервис всюду предлагает переход на платный тариф, но в целом работает нормально и бесплатно. Можете использовать на своё усмотрение в качестве дополнительного хранилища зашифрованных бэкапов, в качестве хранилища ISO образов (можно делать публичные ссылки), в качестве хранилища публичного медиаконтента и т.д.
Возможно, в случае активного использования бесплатного тарифа, будут введены какие-то скрытые ограничения. Я погонял туда-сюда примерно 10ГБ, никаких изменений не заметил.
#бесплатно #fileserver
{kind=link}
Расскажу про систему построения отказоустойчивого сервиса из подручных средств по цене аренды железа. Я её когда-то придумал, протестировал и использовал некоторое время для одного сайта. Не могу сказать, что мне понравилось, как всё это работало, но там были частности в виде репликации СУБД, у которой может быть разное решение, которое на саму схему не влияет.
Допустим, у вас условно есть 2 виртуалки в разных датацентрах. Это могут быть и полноценные сервера, и группы серверов. В данном случае это не принципиально. И вы хотите разместить на них сайт, чтобы в случае недоступности одной виртуальной машины, все клиенты автоматом обращались ко второй с минимальным простонем и без какого-либо участия человека, то есть полностью автоматически.
Реализовать это можно следующим образом. На каждой виртуалке настраиваем DNS сервер, например, bind (named). Поднимаем там зону своего сайта, указывая в A записи IP адрес своей виртуалки. То есть каждый DNS сервер резолвит имя сайта в свой IP адрес. TTL записи ставим как можно меньше, в зависимости от того, как быстро вы хотите переключить клиентов. Думаю, имеет смысл поставить 1-2 минуты.
У регистратора сайта в качестве NS серверов указываем 2 своих DNS сервера. Когда клиент будет резолвить адрес сайта, регистратор выдаст ему один из NS серверов, который отрезолвит свой IP адрес и клиент попадёт на сайт. Если один из NS серверов станет недоступен, то клиент снова обратится к регистратору и тот автоматически будет отдавать другой NS сервер, который, если доступен, будет резолвить свой IP адрес. В итоге все запросы будут автоматически попадать на активный NS сервер, и, соответственно, на работающий веб сервер.
Если на одной из виртуалок погасить bind, то весь трафик с него в течении нескольких минут уедет на второй сервер. И можно проводить профилактику.
У такой схемы есть масса нюансов. Первое и самое главное. Если используется СУБД, то вам нужна Master-Master репликация, так как в обычном режиме, когда работают оба сервера, запросы на чтение и запись идут на оба параллельно. Я использовал MySQL и там куча нюансов с репликацией, так что нельзя сказать, что всё работало автоматически. С репликацией приходилось разбираться вручную после аварий, так что полной автоматики не получалось.
Но это, как я уже сказал, частности конкретной реализации. Можно использовать прокси для MySQL на обоих машинах и запись вести с обоих серверов в одну СУБД, которая будет синхронизироваться со второй, а в случае аварии эти прокси переключаются на запись в другую живую СУБД.
С файлами всё проще. Их синхронизация - дело техники. Для статики можно использовать внешнее S3 хранилище или синхронизироваться тем же rsync или csync2. Если хостов больше двух, то вариантов ещё больше. Можно и ceph развернуть. Отдельный вопрос с сессиями пользователей. Это уже нужно решать на уровне приложения.
Схема со своими DNS серверами простая и вполне рабочая. Каких-то особых подводных камней нет. Есть нюансы с итоговой нагрузкой, так как разные регистраторы по разному отдают NS адреса из списка. Кто-то вразнобой, кто-то по алфавиту, кто-то вообще хз как.
Конечно, всё намного проще, когда есть какой-то внешний арбитр, который управляет трафиком. Это может быть какой-то готовый сервис. Но он и будет основной точкой отказа. Ляжет он, ляжет всё остальное. А тут независимая схема, которая, если всё аккуратно настроить, будет работать сама по себе без внешнего арбитра.
Постарался схематично нарисовать, как это примерно выглядит.
#webserver
Допустим, у вас условно есть 2 виртуалки в разных датацентрах. Это могут быть и полноценные сервера, и группы серверов. В данном случае это не принципиально. И вы хотите разместить на них сайт, чтобы в случае недоступности одной виртуальной машины, все клиенты автоматом обращались ко второй с минимальным простонем и без какого-либо участия человека, то есть полностью автоматически.
Реализовать это можно следующим образом. На каждой виртуалке настраиваем DNS сервер, например, bind (named). Поднимаем там зону своего сайта, указывая в A записи IP адрес своей виртуалки. То есть каждый DNS сервер резолвит имя сайта в свой IP адрес. TTL записи ставим как можно меньше, в зависимости от того, как быстро вы хотите переключить клиентов. Думаю, имеет смысл поставить 1-2 минуты.
У регистратора сайта в качестве NS серверов указываем 2 своих DNS сервера. Когда клиент будет резолвить адрес сайта, регистратор выдаст ему один из NS серверов, который отрезолвит свой IP адрес и клиент попадёт на сайт. Если один из NS серверов станет недоступен, то клиент снова обратится к регистратору и тот автоматически будет отдавать другой NS сервер, который, если доступен, будет резолвить свой IP адрес. В итоге все запросы будут автоматически попадать на активный NS сервер, и, соответственно, на работающий веб сервер.
Если на одной из виртуалок погасить bind, то весь трафик с него в течении нескольких минут уедет на второй сервер. И можно проводить профилактику.
У такой схемы есть масса нюансов. Первое и самое главное. Если используется СУБД, то вам нужна Master-Master репликация, так как в обычном режиме, когда работают оба сервера, запросы на чтение и запись идут на оба параллельно. Я использовал MySQL и там куча нюансов с репликацией, так что нельзя сказать, что всё работало автоматически. С репликацией приходилось разбираться вручную после аварий, так что полной автоматики не получалось.
Но это, как я уже сказал, частности конкретной реализации. Можно использовать прокси для MySQL на обоих машинах и запись вести с обоих серверов в одну СУБД, которая будет синхронизироваться со второй, а в случае аварии эти прокси переключаются на запись в другую живую СУБД.
С файлами всё проще. Их синхронизация - дело техники. Для статики можно использовать внешнее S3 хранилище или синхронизироваться тем же rsync или csync2. Если хостов больше двух, то вариантов ещё больше. Можно и ceph развернуть. Отдельный вопрос с сессиями пользователей. Это уже нужно решать на уровне приложения.
Схема со своими DNS серверами простая и вполне рабочая. Каких-то особых подводных камней нет. Есть нюансы с итоговой нагрузкой, так как разные регистраторы по разному отдают NS адреса из списка. Кто-то вразнобой, кто-то по алфавиту, кто-то вообще хз как.
Конечно, всё намного проще, когда есть какой-то внешний арбитр, который управляет трафиком. Это может быть какой-то готовый сервис. Но он и будет основной точкой отказа. Ляжет он, ляжет всё остальное. А тут независимая схема, которая, если всё аккуратно настроить, будет работать сама по себе без внешнего арбитра.
Постарался схематично нарисовать, как это примерно выглядит.
#webserver
{kind=link}
Прикольный мем про Linux. Я, когда первый раз прочитал, подумал, что за херня. Ничего не понятно и не смешно. Потом прочитал ещё раз более осмысленно и проникся. В принципе, неплохая аналогия получилась.
"Но ты забыл примонтировать ногу" 😂
#мем
"Но ты забыл примонтировать ногу" 😂
#мем
🔝 Как вам такие характеристики, сравнение с женщиной и рейтинг Linux дистрибутивов?
Проводя аналогию между своими «бывшими» и Linux, я зашёл так далеко, что умудрился составить рейтинг. Держите!
5️⃣ ПЯТОЕ место (да-да, пятое, у меня не такой большой опыт) — Linux Mint. Заботливая, хозяйственная и простая. Внешне напоминает Windows-жену. С ней хорошо и уютно. Но она быстро наскучит. Если вы не из тех, кто привык топтаться на одном месте — идём дальше.
4️⃣ ЧЕТВЁРТОЕ место — OpenSUSE. Вот, с кем точно не заскучаешь. Имеет два настроения: весёлая меломанка и молчаливая фантазёрка. Но не вздумайте считать её легкомысленной! Постигать внутренний мир этой девушки вы будете не один день, и если у вас получится — это судьба. Если нет, переходим к следующей Linux-женщине.
3️⃣ ТРЕТЬЕ место — Debian. Зрелая, опытная, настроенная на серьёзные отношения дама. Такая в карман за словом не полезет, имеет весомый багаж знаний, ещё бы в свои-то годы… хм, не будем упоминать о её возрасте, тем более, что она старается держать себя в форме. Произвела на свет множество других linux-женщин, из-за чего имеет звание "Мать-героиня". Ради отношений Debian готова на всё, поэтому раздаёт своё программное обеспечение налево-направо абсолютно бесплатно и каждому. Для неё я слишком молод. Но прежде чем перейти к вице-чемпиону рейтинга, уделим внимание ещё двум любопытным особам.
2️⃣ ВТОРОЕ с 1/2 место — Arch Linux. Психованная истеричка. Настолько, что понять ход мыслей этой ненормальной под силу лишь её самым терпеливым поклонникам. Любит разгуливать по дому в одном нижнем белье, из-за чего заводит с полуоборота даже самое ржавое железо (ну вы понимаете о чём я). Кажется глупой, но очень быстро учится. Про такую говорят: «Хочешь нормальную бабу? Сделай её сам!». Избирательна. В отношениях предпочитает умных, зрелых и самодостаточных мужчин. В общем, хотите страсти и огонька, тогда эта дама для вас!
ВТОРОЕ с 1/4 место — Mandriva Linux. Типичная брошенка. За всё время вашего знакомства будет жаловаться на несправедливость жизни, рассказывая о несбыточных мечтах и проклиная всех своих бывших. Она обаятельна, дружелюбна и интересна, много знает и имеет французские корни, но не смотря на перечисленные заслуги вы поступите с Mandriva Linux так же, как до вас это сделали остальные. Брошенные Linux-девушки мало кого привлекают. Долгожданный вице-чемпион.
ВТОРОЕ место — Ubuntu. Привлекательна, умна и популярна. Мечтает идти в ногу с модными тенденциями, из-за чего не сильно держится за стабильные отношения. Такая девушка будет либо первой, либо, если у вас что-нибудь родится — единственной. Третьего не дано.
1️⃣ И, наконец, ПЕРВОЕ место моего рейтинга ТА-ДАМ! (да простит меня Карим, но это не Kali Linux, хотя она чертовски хороша) — Elementary OS. Внешне как Ubuntu, но под толстым слоем макияжа. Да, она тратит много времени на косметические процедуры и забывает о личностном росте, зато имеет горы поклонников. Да, она молода и не опытна, но в сравнении с глупой фотомоделью, вроде Deepin, у Elementary есть эстетический вкус. Да, она, кажется, простой, но минимализм этой девушки подкупает вас, и чем дольше вы на неё смотрите, тем сильнее влюбляетесь. Может после работы с этим дистрибутивом моё мнение в корне изменится, но созерцать сей продукт человеческого гения — сплошное удовольствие для любознательных глаз!
Это фрагмент из книги people > /dev/null, про которую я писал ранее. Видел уже, что некоторые её прочитали.
#юмор
Проводя аналогию между своими «бывшими» и Linux, я зашёл так далеко, что умудрился составить рейтинг. Держите!
5️⃣ ПЯТОЕ место (да-да, пятое, у меня не такой большой опыт) — Linux Mint. Заботливая, хозяйственная и простая. Внешне напоминает Windows-жену. С ней хорошо и уютно. Но она быстро наскучит. Если вы не из тех, кто привык топтаться на одном месте — идём дальше.
4️⃣ ЧЕТВЁРТОЕ место — OpenSUSE. Вот, с кем точно не заскучаешь. Имеет два настроения: весёлая меломанка и молчаливая фантазёрка. Но не вздумайте считать её легкомысленной! Постигать внутренний мир этой девушки вы будете не один день, и если у вас получится — это судьба. Если нет, переходим к следующей Linux-женщине.
3️⃣ ТРЕТЬЕ место — Debian. Зрелая, опытная, настроенная на серьёзные отношения дама. Такая в карман за словом не полезет, имеет весомый багаж знаний, ещё бы в свои-то годы… хм, не будем упоминать о её возрасте, тем более, что она старается держать себя в форме. Произвела на свет множество других linux-женщин, из-за чего имеет звание "Мать-героиня". Ради отношений Debian готова на всё, поэтому раздаёт своё программное обеспечение налево-направо абсолютно бесплатно и каждому. Для неё я слишком молод. Но прежде чем перейти к вице-чемпиону рейтинга, уделим внимание ещё двум любопытным особам.
2️⃣ ВТОРОЕ с 1/2 место — Arch Linux. Психованная истеричка. Настолько, что понять ход мыслей этой ненормальной под силу лишь её самым терпеливым поклонникам. Любит разгуливать по дому в одном нижнем белье, из-за чего заводит с полуоборота даже самое ржавое железо (ну вы понимаете о чём я). Кажется глупой, но очень быстро учится. Про такую говорят: «Хочешь нормальную бабу? Сделай её сам!». Избирательна. В отношениях предпочитает умных, зрелых и самодостаточных мужчин. В общем, хотите страсти и огонька, тогда эта дама для вас!
ВТОРОЕ с 1/4 место — Mandriva Linux. Типичная брошенка. За всё время вашего знакомства будет жаловаться на несправедливость жизни, рассказывая о несбыточных мечтах и проклиная всех своих бывших. Она обаятельна, дружелюбна и интересна, много знает и имеет французские корни, но не смотря на перечисленные заслуги вы поступите с Mandriva Linux так же, как до вас это сделали остальные. Брошенные Linux-девушки мало кого привлекают. Долгожданный вице-чемпион.
ВТОРОЕ место — Ubuntu. Привлекательна, умна и популярна. Мечтает идти в ногу с модными тенденциями, из-за чего не сильно держится за стабильные отношения. Такая девушка будет либо первой, либо, если у вас что-нибудь родится — единственной. Третьего не дано.
1️⃣ И, наконец, ПЕРВОЕ место моего рейтинга ТА-ДАМ! (да простит меня Карим, но это не Kali Linux, хотя она чертовски хороша) — Elementary OS. Внешне как Ubuntu, но под толстым слоем макияжа. Да, она тратит много времени на косметические процедуры и забывает о личностном росте, зато имеет горы поклонников. Да, она молода и не опытна, но в сравнении с глупой фотомоделью, вроде Deepin, у Elementary есть эстетический вкус. Да, она, кажется, простой, но минимализм этой девушки подкупает вас, и чем дольше вы на неё смотрите, тем сильнее влюбляетесь. Может после работы с этим дистрибутивом моё мнение в корне изменится, но созерцать сей продукт человеческого гения — сплошное удовольствие для любознательных глаз!
Это фрагмент из книги people > /dev/null, про которую я писал ранее. Видел уже, что некоторые её прочитали.
#юмор
На днях посмотрел вроде как юмористическое видео, но на самом деле не смешно:
⇨ Вампиры средней полосы. Ремонт ПК.
Проблема с разводом людей на ремонте компьютеров уже до телевидения добралась. Я так понял, это фрагмент из популярного сериала. Печальная история.
Я всегда знакомым, родственникам говорю, чтобы мне звонили, если что-то сломается. Сам хоть и не имею возможности и времени всем чинить компы и ноуты, но хотя бы советом всегда помогу. Если куда-то еду и люди просят посмотреть их компьютер или ноутбук, то всегда предлагаю привезти оборудование, чтобы я смог хотя бы глянуть и что-то посоветовать.
Одно время как-то не любил этим заниматься. Я же не ремонтник компьютеров. Но с жизненным опытом пришло понимание, что в мире всё взаимосвязано. Если ты можешь кому-то помочь, то помоги. Это тебе самому поможет в будущем. Понимаю, что для неразбирающегося человека сломавшийся компьютер - реальная проблема. Нет возможности гарантированно получить ремонт за вменяемые деньги. Рынок наводнён мошенниками и разводилами.
Мне с моими знаниями, что-то быстро посмотреть и посоветовать практически ничего не стоит. А для другого человека это может оказаться большой помощью.
#железо #мысли
⇨ Вампиры средней полосы. Ремонт ПК.
Проблема с разводом людей на ремонте компьютеров уже до телевидения добралась. Я так понял, это фрагмент из популярного сериала. Печальная история.
Я всегда знакомым, родственникам говорю, чтобы мне звонили, если что-то сломается. Сам хоть и не имею возможности и времени всем чинить компы и ноуты, но хотя бы советом всегда помогу. Если куда-то еду и люди просят посмотреть их компьютер или ноутбук, то всегда предлагаю привезти оборудование, чтобы я смог хотя бы глянуть и что-то посоветовать.
Одно время как-то не любил этим заниматься. Я же не ремонтник компьютеров. Но с жизненным опытом пришло понимание, что в мире всё взаимосвязано. Если ты можешь кому-то помочь, то помоги. Это тебе самому поможет в будущем. Понимаю, что для неразбирающегося человека сломавшийся компьютер - реальная проблема. Нет возможности гарантированно получить ремонт за вменяемые деньги. Рынок наводнён мошенниками и разводилами.
Мне с моими знаниями, что-то быстро посмотреть и посоветовать практически ничего не стоит. А для другого человека это может оказаться большой помощью.
#железо #мысли
YouTube
#вампиры средней полосы ремонт пк
Я на днях затрагивал тему, где нужно было держать в идентичном виде несколько веб серверов. Есть много решений, которые позволяют синхронизировать файлы в режиме онлайн или почти онлайн, так как на самом деле не всегда нужно синхронизировать каталоги в тот же момент, как они изменились. Можно это делать и с периодичностью в 1-2 минуты.
Одним из самых простых и эффективных решений по синхронизации файлов практически в режиме реального времени - Lsyncd. Он работает на базе rsync, есть в базовых репозиториях большинства дистрибутивов. Имеет стандартные конфигурационные файлы и небольшой набор базовых настроек. Работает на базе подсистемы ядра inotify (Linux) или fsevents (MacOS).
Сразу сделаю важную ремарку. С помощью Lsyncd и других подобных утилит можно гарантированно настроить только одностороннюю онлайн синхронизацию. Это архитектурное ограничение и в рамках синхронизации сырых файлов не имеет простого решения, если не использовать специализированный софт на обоих устройствах. Допустим, вы синхронизируете большой файл с источника на приёмник. Приёмник не знает ничего об этом файле и как только он появится, будет пытаться его тоже синхронизировать в обратную сторону, если синхронизация двусторонняя. В итоге файл побьётся и будет испорчен с обоих сторон. Я рассмотрю на этой неделе также софт для двусторонней синхронизации. Самое надёжное решение для этого - DRBD, которое я уже описывал и использовал.
Покажу сразу на примере, как Lsyncd настраивается и работает. Синхронизировать каталоги будем между двумя серверами по SSH.
Устанавливаем Lsyncd:
Он автоматически подтянет за собой rsync. На сервере приёмнике нужно будет rsync установить отдельно:
Копировать файлы будем по SSH, так что источник должен ходить на приёмник с настроенной аутентификацией по ключам. Не буду на этом останавливаться, настройка стандартная. Пакет почему-то не создал никаких каталогов и конфигов. Утилита по старинке использует для запуска скрипты инициализации init.d, так что просто заглянул в
Настроил синхронизацию директории
Теперь можете положить файл в директорию
По своей сути Lsyncd это удобная обёртка вокруг rsync, которая позволяет быстро настроить нужную конфигурацию и запустить по ней синхронизацию в режиме службы по событиям от inotify. Это отличное решение для поддержания каталогов с сотнями тысяч и миллионов файлов. Лучше я даже не знаю.
⇨ Сайт / Исходники
#rsync
Одним из самых простых и эффективных решений по синхронизации файлов практически в режиме реального времени - Lsyncd. Он работает на базе rsync, есть в базовых репозиториях большинства дистрибутивов. Имеет стандартные конфигурационные файлы и небольшой набор базовых настроек. Работает на базе подсистемы ядра inotify (Linux) или fsevents (MacOS).
Сразу сделаю важную ремарку. С помощью Lsyncd и других подобных утилит можно гарантированно настроить только одностороннюю онлайн синхронизацию. Это архитектурное ограничение и в рамках синхронизации сырых файлов не имеет простого решения, если не использовать специализированный софт на обоих устройствах. Допустим, вы синхронизируете большой файл с источника на приёмник. Приёмник не знает ничего об этом файле и как только он появится, будет пытаться его тоже синхронизировать в обратную сторону, если синхронизация двусторонняя. В итоге файл побьётся и будет испорчен с обоих сторон. Я рассмотрю на этой неделе также софт для двусторонней синхронизации. Самое надёжное решение для этого - DRBD, которое я уже описывал и использовал.
Покажу сразу на примере, как Lsyncd настраивается и работает. Синхронизировать каталоги будем между двумя серверами по SSH.
Устанавливаем Lsyncd:
# apt install lsyncd Он автоматически подтянет за собой rsync. На сервере приёмнике нужно будет rsync установить отдельно:
# apt install rsyncКопировать файлы будем по SSH, так что источник должен ходить на приёмник с настроенной аутентификацией по ключам. Не буду на этом останавливаться, настройка стандартная. Пакет почему-то не создал никаких каталогов и конфигов. Утилита по старинке использует для запуска скрипты инициализации init.d, так что просто заглянул в
/etc/init.d/lsyncd и увидел, что конфиг должен быть в /etc/lsyncd/lsyncd.conf.lua. Создал каталог и файл конфигурации следующего содержания:settings { logfile = "/var/log/lsyncd.log", statusFile = "/var/log/lsyncd.stat", statusInterval = 5, insist = true, nodaemon = false,}sync { default.rsyncssh, source="/mnt/sync", host = "syncuser@1.2.3.4", targetdir = "/mnt/sync", ssh = { port = 22777 }}Настроил синхронизацию директории
/mnt/sync с локального сервера на удалённый 1.2.3.4. Сразу для примера показал, как указать нестандартный порт SSH. В данном случае 22777. Примерно так же можно передать какие-то ключи rsync:rsync = {compress = true,archive = true,_extra = {"--bwlimit=50000"}}Теперь можете положить файл в директорию
/mnt/sync. Через 2-3 секунды он приедет на приёмник. Информация о всех передачах отражается в log файле. По своей сути Lsyncd это удобная обёртка вокруг rsync, которая позволяет быстро настроить нужную конфигурацию и запустить по ней синхронизацию в режиме службы по событиям от inotify. Это отличное решение для поддержания каталогов с сотнями тысяч и миллионов файлов. Лучше я даже не знаю.
⇨ Сайт / Исходники
#rsync
{kind=link}
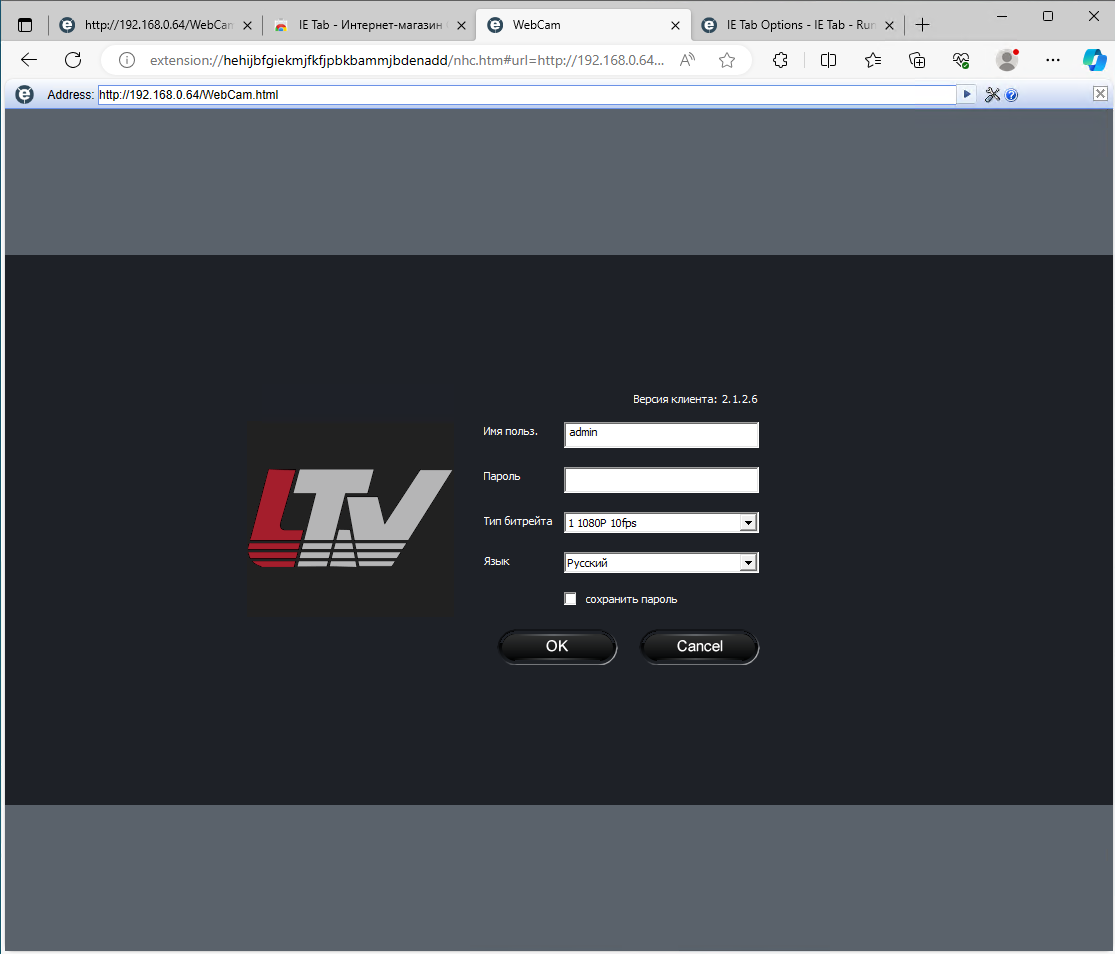
Понадобилось зайти на старую камеру LTV, которая просит установить какой-то плагин при входе по IP адресу и работает только в Internet Explorer, с которым в современных системах стало туго. У меня для всякого мусора есть отдельная виртуалка с виндой, но оттуда каким-то обновлением выпили IE.
Я знаю, что есть удобное решение таких проблем - плагин IE Tab для хромоподобных браузеров. Раньше я им уже пользовался. Решил воспользоваться и в этот раз. Без проблем поставил в Edge и с удивлением обнаружил, что это расширение стало платным. Он мне сообщил, что проработает в режиме trial 2 недели, а потом надо платить. Раньше он вроде бы бесплатным был.
При этом работает он отлично. Я без проблем зашёл на эту камеру. Всё работает, как и должно. Хотя live картинку не показал, но в настройки зашёл и сделал всё, что надо было.
А вы как сейчас выкручиваетесь в таких ситуациях?
Я знаю, что есть удобное решение таких проблем - плагин IE Tab для хромоподобных браузеров. Раньше я им уже пользовался. Решил воспользоваться и в этот раз. Без проблем поставил в Edge и с удивлением обнаружил, что это расширение стало платным. Он мне сообщил, что проработает в режиме trial 2 недели, а потом надо платить. Раньше он вроде бы бесплатным был.
При этом работает он отлично. Я без проблем зашёл на эту камеру. Всё работает, как и должно. Хотя live картинку не показал, но в настройки зашёл и сделал всё, что надо было.
А вы как сейчас выкручиваетесь в таких ситуациях?
{kind=link}
Продолжу тему синхронизации файлов. На этот раз расскажу про утилиту Unison, которая позволяет выполнять двухстороннюю синхронизацию, в отличие от Lsyncd, которая выполняет только одностороннюю.
Unison я знаю и использую очень давно. Статья про её использование написана в далёком 2015 году. Там ничего интересного нет, так как она планировалась как вводная для дальнейшего развития темы, но почему-то не срослось, хотя я помню, что тогда активно использовал её, поэтому и планировал написать. Это одна из старых статей, которую я написал вскоре после того, как с FreeBSD переехал в Linux.
🟢 Основные возможности Unison:
◽Кроссплатформенная программа. Поддерживает Linux, Windows, MacOS, FreeBSD и прочие *BSD. Соответственно, между ними возможна синхронизация.
◽Честная двухсторонняя синхронизация. Конфликтующие файлы обнаруживаются и отображаются.
◽Синхронизирует на уровне файлов как обычная пользовательская программа, не требует прав суперпользователя.
◽Для передачи больших файлов использует тот же подход, что и rsync, то есть передаёт только изменения, а не весь файл.
◽Работает как поверх SSH, так и напрямую по TCP (без шифрования, так что не рекомендуется использовать).
◽Использует такую же реализацию передачи данных, как и rsync. Насколько я понял, реализация написана самостоятельно, а не через использование готовой библиотеки, как в других похожих программах.
В Debian живёт в базовых репозиториях, поэтому установка очень простая:
Установить нужно на обе машины одну и ту же версию. А также настроить аутентификацию по SSH с помощью ключей в обе стороны.
Далее с любой машины тестируем подключение к другой:
Сразу показал пример с использованием нестандартного порта SSH. В данном случае я проверяю возможность синхронизации локального и удалённого каталога
Если всё ОК, то дальше можно пробовать запускать непосредственно синхронизацию:
При первой синхронизации вам выдадут некоторое предупреждение с информацией о синхронизации. А потом попросят подтвердить синхронизацию каждого файла. Понятное дело, что нам это не подходит.
После синхронизации в директории
Каталоги на обоих сторонах будут приведены к единому содержанию. Запускать Unison достаточно на каком-то одном хосте. По умолчанию для него нет готовой службы, так что настраивать запуск придётся вручную либо с помощью cron, либо с помощью systemd timers. В заметке как раз приведён пример, который хорошо подходит для ситуации с Unison.
Если на обоих хостах появится файл с одним и тем же именем, но разным содержанием, то синхронизирован он не будет. В результатах синхронизации будет отображено, что файл был пропущен.
Хорошее руководство по unison с примерами есть в arch wiki. А вот прямая ссылка на официальную документацию. У программы очень много возможностей. Например, можно указать, куда будут бэкапиться изменённые файлы. Работает примерно так же, как ключ
⇨ Исходники
#rsync
Unison я знаю и использую очень давно. Статья про её использование написана в далёком 2015 году. Там ничего интересного нет, так как она планировалась как вводная для дальнейшего развития темы, но почему-то не срослось, хотя я помню, что тогда активно использовал её, поэтому и планировал написать. Это одна из старых статей, которую я написал вскоре после того, как с FreeBSD переехал в Linux.
🟢 Основные возможности Unison:
◽Кроссплатформенная программа. Поддерживает Linux, Windows, MacOS, FreeBSD и прочие *BSD. Соответственно, между ними возможна синхронизация.
◽Честная двухсторонняя синхронизация. Конфликтующие файлы обнаруживаются и отображаются.
◽Синхронизирует на уровне файлов как обычная пользовательская программа, не требует прав суперпользователя.
◽Для передачи больших файлов использует тот же подход, что и rsync, то есть передаёт только изменения, а не весь файл.
◽Работает как поверх SSH, так и напрямую по TCP (без шифрования, так что не рекомендуется использовать).
◽Использует такую же реализацию передачи данных, как и rsync. Насколько я понял, реализация написана самостоятельно, а не через использование готовой библиотеки, как в других похожих программах.
В Debian живёт в базовых репозиториях, поэтому установка очень простая:
# apt install unisonУстановить нужно на обе машины одну и ту же версию. А также настроить аутентификацию по SSH с помощью ключей в обе стороны.
Далее с любой машины тестируем подключение к другой:
# unison -testServer /mnt/sync ssh://syncuser@1.2.3.4:22777//mnt/sync Unison 2.51.3 (ocaml 4.11.1): Contacting server...Connected [//1.2.3.4:22777//mnt/sync -> //debian11//mnt/sync]Сразу показал пример с использованием нестандартного порта SSH. В данном случае я проверяю возможность синхронизации локального и удалённого каталога
/mnt/sync. Если всё ОК, то дальше можно пробовать запускать непосредственно синхронизацию:
# unison /mnt/sync ssh://syncuser@1.2.3.4:22777//mnt/syncПри первой синхронизации вам выдадут некоторое предупреждение с информацией о синхронизации. А потом попросят подтвердить синхронизацию каждого файла. Понятное дело, что нам это не подходит.
После синхронизации в директории
~/.unison появится файл конфигурации default.prf, в котором можно настроить поведение программы при синхронизации. Чтобы вам не задавали никаких вопросов, достаточно добавить туда:auto=truebatch=trueКаталоги на обоих сторонах будут приведены к единому содержанию. Запускать Unison достаточно на каком-то одном хосте. По умолчанию для него нет готовой службы, так что настраивать запуск придётся вручную либо с помощью cron, либо с помощью systemd timers. В заметке как раз приведён пример, который хорошо подходит для ситуации с Unison.
Если на обоих хостах появится файл с одним и тем же именем, но разным содержанием, то синхронизирован он не будет. В результатах синхронизации будет отображено, что файл был пропущен.
Хорошее руководство по unison с примерами есть в arch wiki. А вот прямая ссылка на официальную документацию. У программы очень много возможностей. Например, можно указать, куда будут бэкапиться изменённые файлы. Работает примерно так же, как ключ
-backup у rsync, только настроек больше. ⇨ Исходники
#rsync
{kind=link}
Смотрите, какая прикольна штука есть для подключения по SSH из консоли - sshto. Это небольшой bash скрипт, который позволяет через псевдографическое меню управлять преднастроенными SSH подключениями. Хорошее решение для самодельного jumphost.
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
Ставим sshto:
Запускаем:
Видим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
~/.ssh/config и выводит список серверов оттуда в псевдографическое меню. Вот пример такого файла:#Host DUMMY #Moscow#Host server-number-one #First ServerHostName 1.2.3.4port 22777user rootHost server-number-two #Second serverHostName 4.3.2.1port 22888user username#Host DUMMY #Saint Petersburg#Host server-number-three #Third serverHostName 5.6.7.8port 22user user01Host server-number-four #Fourth serverHostName 9.8.7.6port 22user user02Ставим sshto:
# git clone https://github.com/vaniacer/sshto# cd sshto/# cp sshto /usr/bin/Запускаем:
# sshtoВидим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
{kind=link}
В рамках темы по синхронизации файлов расскажу про необычный инструмент на основе git - git-annex. Это система управления файлами без индексации содержимого. С помощью git индексируются только имена, пути файлов и хэш содержимого. Для использования необходимо понимание работы git. Эта система больше всего подойдёт для индивидуального или семейного хранения файлов в разных хранилищах.
Я не буду расписывать, как эта штука работает, так как она довольно заморочена, а сразу покажу на примере. Так будет понятнее. Программа есть под все популярные ОС, но под Windows всё ещё в бете, так что запускать лучше Linux версию в WSL. В Debian и Ubuntu ставим стандартно из базовой репы:
Переходим в директорию
Добавляем файлы в репу:
Все файлы превратились в символьные ссылки, а их содержимое уехало
Скопируем этот репозиторий на условный ноутбук, который будет периодически забирать нужные файлы с сервера и пушить туда какие-то свои новые или изменения старых. Для этого он должен ходить на сервер по SSH с аутентификацией по ключу.
На ноутбуке копируем репозиторий с сервера и сразу синхронизируем:
Мы получили на ноутбуке копию репозитория, но вместо файлов у нас битые ссылки. Так и должно быть. Если вы хотите синхронизировать все реальные файлы, то сделать это можно так:
А если только один файл, то так:
Когда у вас несколько устройств работают с репозиторием, то узнать, где физически находится файл можно так:
Вернёмся на сервер и добавим в него информацию о ноуте:
Теперь репозитории знают друг о друге. На ноутбук он был клонирован с сервера, а на сервер мы вручную добавили ноутбук. Добавим новый файл в репозиторий с ноутбука:
Проверим его местонахождение:
Он только на ноутбуке. Идём на сервер, делаем там синхронизацию и поверяем местонахождение файла:
Теперь он располагается в двух местах.
Надеюсь, у меня получилось хоть немного показать, как эта штука работает. У неё много настроек. Можно очень гибко указать какие файлы по весу, количеству копий, типу папок, имени, типу содержимого нужны в каждом репозитории. Есть преднастроенные группы: backup, archive, client, transfer. Например, можно принудительно скачивать все файлы при синхронизации:
Git-annex удобен для хранения нескольких копий файлов в разных репозиториях. Вы можете подключать внешние носители и периодически синхронизировать файлы с ними, обозвав каждый носитель своим именем. В репозитории будет храниться информация о том, где какой файл лежит и сколько копий файла имеется. Вся информация о всех файлах хранится в одном общем репозитории, а физически файлы могут располагаться выборочно в разных местах.
И не забываем, что у нас все преимущества git в виде версионирования. Более подробно о работе можно почитать в документации. На первый взгляд кажется, что система слишком сложная. Для тех, кто не знаком с git, да. Но я не раз видел восторженные отзывы о системе тех, кто в ней разобрался и активно пользуется.
⇨ Сайт / Обучалка
#git #fileserver
Я не буду расписывать, как эта штука работает, так как она довольно заморочена, а сразу покажу на примере. Так будет понятнее. Программа есть под все популярные ОС, но под Windows всё ещё в бете, так что запускать лучше Linux версию в WSL. В Debian и Ubuntu ставим стандартно из базовой репы:
# apt install git-annexПереходим в директорию
/mnt/annex, где хранятся какие-то файлы и инициализируем там репозиторий, пометив его как server:# git config --global user.email "root@serveradmin.ru"# git config --global user.name "Serveradmin"# git init .# git annex init 'server'Добавляем файлы в репу:
# git annex add .# git commit -m "Добавил новые файлы"Все файлы превратились в символьные ссылки, а их содержимое уехало
.git/annex/objects.Скопируем этот репозиторий на условный ноутбук, который будет периодически забирать нужные файлы с сервера и пушить туда какие-то свои новые или изменения старых. Для этого он должен ходить на сервер по SSH с аутентификацией по ключу.
На ноутбуке копируем репозиторий с сервера и сразу синхронизируем:
# git clone ssh://user@1.2.3.4/mnt/annex# git annex init 'notebook'# git annex syncМы получили на ноутбуке копию репозитория, но вместо файлов у нас битые ссылки. Так и должно быть. Если вы хотите синхронизировать все реальные файлы, то сделать это можно так:
# git annex get .А если только один файл, то так:
# git annex get docker-iptables.shКогда у вас несколько устройств работают с репозиторием, то узнать, где физически находится файл можно так:
# git annex whereis file.txtwhereis file.txt (2 copies) 01f4d93-480af476 -- server [origin] 13f223a-e75b6a69 -- notebook [here]Вернёмся на сервер и добавим в него информацию о ноуте:
# git remote add notebook ssh://user@4.3.2.1/mnt/annex# git annex syncТеперь репозитории знают друг о друге. На ноутбук он был клонирован с сервера, а на сервер мы вручную добавили ноутбук. Добавим новый файл в репозиторий с ноутбука:
# git annex add nout.txt# git commit -m "add nout.txt"Проверим его местонахождение:
# git annex whereis nout.txtwhereis nout.txt (1 copy) 637597c-3f54f8746 -- notebook [here]Он только на ноутбуке. Идём на сервер, делаем там синхронизацию и поверяем местонахождение файла:
# git annex sync# git annex get nout.txt# git annex whereis nout.txtwhereis nout.txt (2 copies) 6307597c-3f54f5ff8746 -- [notebook] edeab032-7091559a6ca4 -- server [here]Теперь он располагается в двух местах.
Надеюсь, у меня получилось хоть немного показать, как эта штука работает. У неё много настроек. Можно очень гибко указать какие файлы по весу, количеству копий, типу папок, имени, типу содержимого нужны в каждом репозитории. Есть преднастроенные группы: backup, archive, client, transfer. Например, можно принудительно скачивать все файлы при синхронизации:
# git annex sync --contentGit-annex удобен для хранения нескольких копий файлов в разных репозиториях. Вы можете подключать внешние носители и периодически синхронизировать файлы с ними, обозвав каждый носитель своим именем. В репозитории будет храниться информация о том, где какой файл лежит и сколько копий файла имеется. Вся информация о всех файлах хранится в одном общем репозитории, а физически файлы могут располагаться выборочно в разных местах.
И не забываем, что у нас все преимущества git в виде версионирования. Более подробно о работе можно почитать в документации. На первый взгляд кажется, что система слишком сложная. Для тех, кто не знаком с git, да. Но я не раз видел восторженные отзывы о системе тех, кто в ней разобрался и активно пользуется.
⇨ Сайт / Обучалка
#git #fileserver
{kind=link}
Вчера посмотрел новое видео на канале RomNero про open source сервис Planka. Я все видео у него смотрю, потому что интересно и полезно. Про Guacamole у него пару месяцев назад хорошее видео вышло.
Planka - очень близкий аналог Trello. Он пытается повторить как функциональность, так и внешний вид. И получается неплохо. Можете сами оценить в публичном Demo. Написана Planka на React (библиотека JavaScript).
Акцент на этом видео я сделал потому, что оно поучительно записано. Там внимание не только на самом сервисе, но и на том, как его запустить с помощью docker-compose, как дебажить ошибки. Автор разбирает файл композа, дописывает настройки, разделяет сервисы на подсети и т.д. В общем интересно и поучительно.
Плюс, лично мне всегда любопытно посмотреть на рабочее окружение других специалистов. Какой у них терминал, консоль, в каком редакторе предпочитают работать и как.
⇨ Сайт / Исходники
#заметки
Planka - очень близкий аналог Trello. Он пытается повторить как функциональность, так и внешний вид. И получается неплохо. Можете сами оценить в публичном Demo. Написана Planka на React (библиотека JavaScript).
Акцент на этом видео я сделал потому, что оно поучительно записано. Там внимание не только на самом сервисе, но и на том, как его запустить с помощью docker-compose, как дебажить ошибки. Автор разбирает файл композа, дописывает настройки, разделяет сервисы на подсети и т.д. В общем интересно и поучительно.
Плюс, лично мне всегда любопытно посмотреть на рабочее окружение других специалистов. Какой у них терминал, консоль, в каком редакторе предпочитают работать и как.
⇨ Сайт / Исходники
#заметки
YouTube
Planka (docker) - управлять задачами и проектами просто. Kanban Board для себя и для работы.
Planka - это интуитивно понятное и эффективное приложение для управления задачами и проектами. Он обеспечивает удобство использования досок Kanban для отслеживания задач, организации проектов и управления рабочим процессом.
https://planka.app/
~~~~~~~~…
https://planka.app/
~~~~~~~~…
В комментариях к заметкам про синхронизацию файлов не раз упоминались отказоустойчивые сетевые файловые системы. Прямым представителем такой файловой системы является GlusterFS. Это условный аналог Ceph, которая по своей сути не файловая система, а отказоустойчивая сеть хранения данных. Но в целом обе эти системы используются для решения одних и тех же задач. Про Ceph я писал (#ceph) уже не раз, а вот про GlusterFS не было ни одного упоминания.
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
На все 3 сервера устанавливаем glusterfs-server:
Запускаем также на всех серверах:
На server1 добавляем в пул два других сервера:
На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
На каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
Создаём на этой точке монтирования том glusterfs:
Если получите ошибку:
то проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
Если всё пошло без ошибок, то можно запускать том:
Смотрим о нём информацию:
Теперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
Можете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
/etc/hosts на каждый сервер примерно такие записи:server1 10.20.1.1server2 10.20.1.2server3 10.20.1.3На все 3 сервера устанавливаем glusterfs-server:
# apt install glusterfs-serverЗапускаем также на всех серверах:
# service glusterd startНа server1 добавляем в пул два других сервера:
# gluster peer probe server2# gluster peer probe server3На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
# gluster peer statusНа каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
/mnt/gv0.# mkfs.ext4 /dev/sdb1# mkdir /mnt/gv0# mount /dev/sdb1 /mnt/gv0Создаём на этой точке монтирования том glusterfs:
# gluster volume create gv0 replica 3 server1:/mnt/gv0 server2:/mnt/gv0 server3:/mnt/gv0Если получите ошибку:
volume create: gv0: failed: Host server1 is not in 'Peer in Cluster' stateто проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
/var/lib/glusterd.Если всё пошло без ошибок, то можно запускать том:
# gluster volume start gv0Смотрим о нём информацию:
# gluster volume infoТеперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
# mkdir /mnt/gluster-test# mount -t glusterfs server1:/gv0 /mnt/gluster-testМожете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
/mnt/gv0. По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
{kind=link}
Я не раз делал заметки про различные способы создания загрузочных флешек с набором необходимых дистрибутивов. К примеру, сделать это можно с помощью:
◽Ventoy
◽YUMI – Multiboot USB Creator
◽Easy2Boot (внутри в том числе Ventoy)
Сейчас почти все рабочие места оснащены доступом в интернет. И чаще всего он вполне скоростной, особенно домашний. Есть бесплатный проект netboot.xyz, который позволяет создать загрузочную флешку с возможностью установить систему через интернет. Достаточно загрузиться с этой флешки и выбрать нужную систему. При этом также есть возможность развернуть сервис у себя в локальной сети и выполнять установку с него.
По умолчанию, скачанный с сайта образ содержит набор ОС Linux с возможностью загрузки из официальных репозиториев. Windows системы тоже можно устанавливать через netboot, но для этого нужна собственная Служба развертывания Windows (Windows Deployment Services). Это отдельная серверная роль. Также в стандартном образе есть набор бесплатных программ и утилит, которые можно использовать для диагностики (memtest, system rescue cd и д.р.) или копирования информации (Rescuezilla, Clonezilla).
Для создания собственного меню с системами в загрузочном диске можно использовать отдельный репозиторий с инструкцией. А для настройки своего сервера есть ansible palybook или docker-образ. Управление сервером через веб интерфейс. Настройка простая и быстрая.
Сервис весьма популярен, в сети много материалов по нему. Просто знайте, что он такой есть. Я узнал о нём случайно буквально недавно. Потребности в нём не было, так что информация проходила мимо меня. Подобный образ удобно использовать в том числе в гипервизорах для установки различных систем. Вместо того, чтобы вручную качать образы для разных ОС, можно обновлять один единственный netboot.xyz.iso.
⇨ Сайт / Исходники / Список всех ОС
◽Ventoy
◽YUMI – Multiboot USB Creator
◽Easy2Boot (внутри в том числе Ventoy)
Сейчас почти все рабочие места оснащены доступом в интернет. И чаще всего он вполне скоростной, особенно домашний. Есть бесплатный проект netboot.xyz, который позволяет создать загрузочную флешку с возможностью установить систему через интернет. Достаточно загрузиться с этой флешки и выбрать нужную систему. При этом также есть возможность развернуть сервис у себя в локальной сети и выполнять установку с него.
По умолчанию, скачанный с сайта образ содержит набор ОС Linux с возможностью загрузки из официальных репозиториев. Windows системы тоже можно устанавливать через netboot, но для этого нужна собственная Служба развертывания Windows (Windows Deployment Services). Это отдельная серверная роль. Также в стандартном образе есть набор бесплатных программ и утилит, которые можно использовать для диагностики (memtest, system rescue cd и д.р.) или копирования информации (Rescuezilla, Clonezilla).
Для создания собственного меню с системами в загрузочном диске можно использовать отдельный репозиторий с инструкцией. А для настройки своего сервера есть ansible palybook или docker-образ. Управление сервером через веб интерфейс. Настройка простая и быстрая.
Сервис весьма популярен, в сети много материалов по нему. Просто знайте, что он такой есть. Я узнал о нём случайно буквально недавно. Потребности в нём не было, так что информация проходила мимо меня. Подобный образ удобно использовать в том числе в гипервизорах для установки различных систем. Вместо того, чтобы вручную качать образы для разных ОС, можно обновлять один единственный netboot.xyz.iso.
⇨ Сайт / Исходники / Список всех ОС
{kind=link}
В Linux есть подсистема ядра, которая позволяет получать уведомления о событиях, связанных с файлами и каталогами файловой системы. Называется Inotify. Я упоминал о ней недавно, когда рассказывал про Lsyncd, которая получает информацию от inotify и запускает синхронизацию при изменениях в файлах.
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
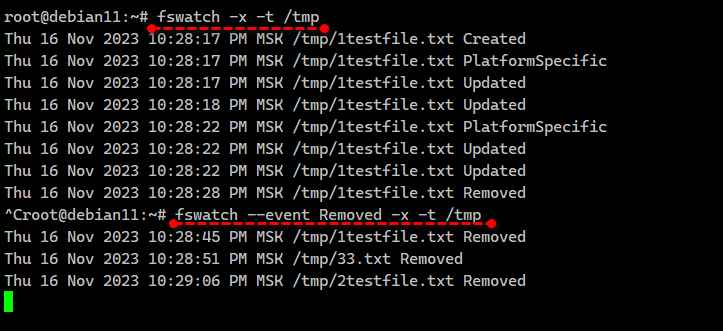
Для наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
Всё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
◽
Откроем рядом ещё одну консоль, создадим, обновим и удалим в директории
В логе при этом будет следующее:
Это уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
Запускаем:
Это самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
И дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
#linux #bash
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
# apt install fswatchДля наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
# fswatch /tmpВсё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
-x - отображать тип событий◽
-t - отображать временные метки# fswatch -x -t /tmpОткроем рядом ещё одну консоль, создадим, обновим и удалим в директории
/tmp файл:# echo '123' > file.txt# rm file.txtВ логе при этом будет следующее:
Thu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt CreatedThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt PlatformSpecificThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt UpdatedThu 16 Nov 2023 09:14:25 PM MSK /tmp/file.txt RemovedЭто уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
# fswatch -x -t /tmp >> /var/log/fswatch.log &Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
[Unit]Description=Start fswatch file monitorWants=fswatch.service[Service]ExecStart=fswatch -x -t /tmp[Install]WantedBy=multi-user.targetЗапускаем:
# systemctl start fswatch.serviceЭто самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
# journalctl -u fswatch.serviceИ дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
# fswatch --event Removed -x -t /tmp#linux #bash
{kind=link}
Сел сегодня подготовить какой-то мемчик, но когда увидел такую картинку, понял, что к ней не требуется редактирование. Можно в таком виде брать и публиковать к каждой второй моей статье на сайте или заметке тут.
Эту картинку можно смело публиковать вот к этим комментариям:
https://t.me/srv_admin/2536
https://t.me/srv_admin/2604
https://t.me/srv_admin/362
Удивительно, конечно, как сейчас некоторые люди не способны воспринимать написанное. Буквально вчера делал заметку про netboot.xyz, где в самом начале упомянул про Ventoy и сделал ссылку на заметку про него. А человек мне пишет и спрашивает, что я могу сказать про Ventoy? Я ему говорю, так я же написал об этом в самом начале заметки, на что он попросил прислать ему ссылку 🤦.
Сталкиваюсь с подобным регулярно. Пишешь заметку, где явно отвечаешь на какой-то вопрос. А тебе в комментариях его задают. Я в целом не негативлю по этому поводу. Воспринимаю как факт. Странно просто, как у других так получается. Сам в такую ситуацию не попадал.
#мем
Эту картинку можно смело публиковать вот к этим комментариям:
https://t.me/srv_admin/2536
https://t.me/srv_admin/2604
https://t.me/srv_admin/362
Удивительно, конечно, как сейчас некоторые люди не способны воспринимать написанное. Буквально вчера делал заметку про netboot.xyz, где в самом начале упомянул про Ventoy и сделал ссылку на заметку про него. А человек мне пишет и спрашивает, что я могу сказать про Ventoy? Я ему говорю, так я же написал об этом в самом начале заметки, на что он попросил прислать ему ссылку 🤦.
Сталкиваюсь с подобным регулярно. Пишешь заметку, где явно отвечаешь на какой-то вопрос. А тебе в комментариях его задают. Я в целом не негативлю по этому поводу. Воспринимаю как факт. Странно просто, как у других так получается. Сам в такую ситуацию не попадал.
#мем
Тема выходного дня по IT, но на самом деле про людей. Давно хотел написать, но всё откладывал. Неоднократно сталкивался с тем, что взрослые люди иногда ведут себя как дети или подростки.
Я как-то раз ввязался в один проект, условия которого по ходу дела начали меняться в сторону существенного увеличения масштаба и объёма работ, которые я уже тянуть не мог и не хотел. Не вижу смысла в таких случаях межеваться и морозиться, сразу об этом прямо сказал заказчику и предложил варианты, как я должен из него выйти.
Он в целом нормально на это отреагировал и мы стали работать. Он начал искать других людей, я готовил свои дела к передаче. Заказчик нашёл человека. К моему удивлению, это был тоже публичный и немного известный в узких кругах человек. Я обрадовался, думаю, что отлично, передам дела ответственному человеку.
Созвонились, всё обсудили. Я честно как есть расписал весь проект со всеми плюсами и минусами, передал дела. Человек по мере того, как вник во все дела понял, что не тянет, не хочет или не может. Это не знаю. Но, вместо того, чтобы прямо об этом сказать, начал морозиться. Через какое-то время заявил, что надо ехать в командировку, времени нет, проект вести не может.
Заказчик опять вышел на меня и попросил помочь передать всё новому исполнителю. Я проделал всю процедуру ещё раз. Нашли человека, всё рассказали, расписали и т.д. Он немного поработал и тоже отморозился. Уже не помню, чем именно. То ли заболел, то ли ещё что-то. Факт в том, что не сказал прямо, что я отказываюсь работать по такой-то причине. Зачем соглашался, не понятно.
При этом заказчик адекватный. У меня с ним не было проблем ни с оплатой, ни с чем-то ещё. Встречался лично. Он в итоге плюнул и нанял уже компанию, с которой проект и завершил в итоге. Хотел просто отделаться меньшими затратами по времени, деньгам, бюрократии, работая напрямую, но не вышло.
И вот с такими историями я сталкивался не раз. У меня вообще сложилось впечатление, что у людей из сферы IT много какого-то инфантилизма, боязни говорить правду, спорить, не в комментариях к постам, а по рабочим делам. Вроде всё обсудили, обо всём договорились, всех всё устроило. А потом начинаются отговорки, оправдания, переносы сроков и т.д. Не знаю, может это везде так, но я такие вещи замечал постоянно в том числе со стороны своих знакомых.
У меня как-то была ситуация, когда мой небольшой косяк привёл к большим проблемам. Первая мысль в голове была, как придумать отмазку, чтобы как-бы не я был виноват. Вот реально, первое, что пришло в голову. Но понимаю, что это контрпродуктивно. Позвонил директору и сказал, всё как есть. Смысл в том, что директор умный человек и в том числе с его помощью получилось быстро и относительно безпроблемно решить вопрос. Он сразу сориентировался и выдал нужные указания. А если бы я морозился и оправдывался, прикрывая себя, то всё равно бы остался виноват, но последствия были бы хуже.
Даже не знаю, чем подвести итог сказанному. Наверное так. Мужчины, будьте мужчинами. Держите слово, отвечайте за себя и свои поступки. Будьте прямолинейны. Оправдания некоторых людей выглядят так же, как оправдывается школьник перед учителем, или ребёнок перед родителем. Один мой знакомый вообще провернул финт. Он мне как-то рассказал, как ловко придумал историю, чтобы уволиться с одной работы, где у него были обязательства. А потом через несколько лет по похожей схеме обманул меня, когда нужно было съехать с одной темы. Он либо забыл, либо не догадался, что я банально прочитаю эту историю на основании того, что мы давно знакомы. Выглядит глупо, конечно. Общение с ним прекратил.
Опытные и умные люди вот так же читают оправдания других. Лучше прямо обо всём рассказать. В плюсе останутся все ☝.
#мысли
Я как-то раз ввязался в один проект, условия которого по ходу дела начали меняться в сторону существенного увеличения масштаба и объёма работ, которые я уже тянуть не мог и не хотел. Не вижу смысла в таких случаях межеваться и морозиться, сразу об этом прямо сказал заказчику и предложил варианты, как я должен из него выйти.
Он в целом нормально на это отреагировал и мы стали работать. Он начал искать других людей, я готовил свои дела к передаче. Заказчик нашёл человека. К моему удивлению, это был тоже публичный и немного известный в узких кругах человек. Я обрадовался, думаю, что отлично, передам дела ответственному человеку.
Созвонились, всё обсудили. Я честно как есть расписал весь проект со всеми плюсами и минусами, передал дела. Человек по мере того, как вник во все дела понял, что не тянет, не хочет или не может. Это не знаю. Но, вместо того, чтобы прямо об этом сказать, начал морозиться. Через какое-то время заявил, что надо ехать в командировку, времени нет, проект вести не может.
Заказчик опять вышел на меня и попросил помочь передать всё новому исполнителю. Я проделал всю процедуру ещё раз. Нашли человека, всё рассказали, расписали и т.д. Он немного поработал и тоже отморозился. Уже не помню, чем именно. То ли заболел, то ли ещё что-то. Факт в том, что не сказал прямо, что я отказываюсь работать по такой-то причине. Зачем соглашался, не понятно.
При этом заказчик адекватный. У меня с ним не было проблем ни с оплатой, ни с чем-то ещё. Встречался лично. Он в итоге плюнул и нанял уже компанию, с которой проект и завершил в итоге. Хотел просто отделаться меньшими затратами по времени, деньгам, бюрократии, работая напрямую, но не вышло.
И вот с такими историями я сталкивался не раз. У меня вообще сложилось впечатление, что у людей из сферы IT много какого-то инфантилизма, боязни говорить правду, спорить, не в комментариях к постам, а по рабочим делам. Вроде всё обсудили, обо всём договорились, всех всё устроило. А потом начинаются отговорки, оправдания, переносы сроков и т.д. Не знаю, может это везде так, но я такие вещи замечал постоянно в том числе со стороны своих знакомых.
У меня как-то была ситуация, когда мой небольшой косяк привёл к большим проблемам. Первая мысль в голове была, как придумать отмазку, чтобы как-бы не я был виноват. Вот реально, первое, что пришло в голову. Но понимаю, что это контрпродуктивно. Позвонил директору и сказал, всё как есть. Смысл в том, что директор умный человек и в том числе с его помощью получилось быстро и относительно безпроблемно решить вопрос. Он сразу сориентировался и выдал нужные указания. А если бы я морозился и оправдывался, прикрывая себя, то всё равно бы остался виноват, но последствия были бы хуже.
Даже не знаю, чем подвести итог сказанному. Наверное так. Мужчины, будьте мужчинами. Держите слово, отвечайте за себя и свои поступки. Будьте прямолинейны. Оправдания некоторых людей выглядят так же, как оправдывается школьник перед учителем, или ребёнок перед родителем. Один мой знакомый вообще провернул финт. Он мне как-то рассказал, как ловко придумал историю, чтобы уволиться с одной работы, где у него были обязательства. А потом через несколько лет по похожей схеме обманул меня, когда нужно было съехать с одной темы. Он либо забыл, либо не догадался, что я банально прочитаю эту историю на основании того, что мы давно знакомы. Выглядит глупо, конечно. Общение с ним прекратил.
Опытные и умные люди вот так же читают оправдания других. Лучше прямо обо всём рассказать. В плюсе останутся все ☝.
#мысли
В предпоследнем обновлении веб сервера Angie, которое я из-за занятости пропустил, была анонсирована удобная веб панель наблюдения за сервером - Console Light. Только в последнем обновлении заметил это и решил навести справки.
Сразу покажу как поставить, потому что сам это проделал для того, чтобы оценить. Пример для Debian 12:
Добавляем в конфиг виртуального хоста:
Доступ лучше ограничить списком адресов. Я убрал ограничение для локального теста. Набор доступных виджетов и метрик в них зависит от настроек панели. К примеру, если хотите видеть через веб интерфейс конфигурационные файлы Angie с красивым форматированием и подсветкой синтаксиса, добавьте в location /console/api/ параметр api_config_files:
Удобное новшество. Можно быстро оценить всю рабочую конфигурацию, собранную из всех присоединённых файлов. Очень удобно для окружения Bitrix, где этих конфигов десятки.
На тестовом сервере смотреть особо не на что, кроме базовых метрик по соединениям. Оценить функциональность панели можно в публичном демо:
⇨ https://console.angie.software
Статья с подробным описанием этой панели и всего мониторинга в целом есть на хабре:
⇨ Многогранный мониторинг Angie
И там же свежее интервью с руководителем отдела разработки:
⇨ Интервью с Валентином Бартеневым: как бывшие сотрудники Nginx разрабатывают отечественный веб-сервер Angie
В принципе, в панели представлена та же информация, что и во встроенном модуле метрик для Prometheus, который был анонсирован в более старых обновлениях. Особенность встроенной панели в том, что там метрики можно смотреть практически в режиме реального времени, без задержки попадания метрик в привычный мониторинг.
Мне немного лениво работающие сервера переводить на Angie, но если что-то новое придётся настраивать, буду делать на нём. Плюсы относительно Nginx очевидны и наглядны. Готовый мониторинг и веб панель - это прям самый сок.
#angie #webserver #отечественное
Сразу покажу как поставить, потому что сам это проделал для того, чтобы оценить. Пример для Debian 12:
# curl -o /etc/apt/trusted.gpg.d/angie-signing.gpg https://angie.software/keys/angie-signing.gpg# echo "deb https://download.angie.software/angie/debian/ `lsb_release -cs` main" | tee /etc/apt/sources.list.d/angie.list > /dev/null# apt update && apt install angie angie-console-lightДобавляем в конфиг виртуального хоста:
location /console { #allow 127.0.0.1; #deny all; alias /usr/share/angie-console-light/html; index index.html; location /console/api/ { api /status/; } }Доступ лучше ограничить списком адресов. Я убрал ограничение для локального теста. Набор доступных виджетов и метрик в них зависит от настроек панели. К примеру, если хотите видеть через веб интерфейс конфигурационные файлы Angie с красивым форматированием и подсветкой синтаксиса, добавьте в location /console/api/ параметр api_config_files:
location /console/api/ { api /status/; api_config_files on; }Удобное новшество. Можно быстро оценить всю рабочую конфигурацию, собранную из всех присоединённых файлов. Очень удобно для окружения Bitrix, где этих конфигов десятки.
На тестовом сервере смотреть особо не на что, кроме базовых метрик по соединениям. Оценить функциональность панели можно в публичном демо:
⇨ https://console.angie.software
Статья с подробным описанием этой панели и всего мониторинга в целом есть на хабре:
⇨ Многогранный мониторинг Angie
И там же свежее интервью с руководителем отдела разработки:
⇨ Интервью с Валентином Бартеневым: как бывшие сотрудники Nginx разрабатывают отечественный веб-сервер Angie
В принципе, в панели представлена та же информация, что и во встроенном модуле метрик для Prometheus, который был анонсирован в более старых обновлениях. Особенность встроенной панели в том, что там метрики можно смотреть практически в режиме реального времени, без задержки попадания метрик в привычный мониторинг.
Мне немного лениво работающие сервера переводить на Angie, но если что-то новое придётся настраивать, буду делать на нём. Плюсы относительно Nginx очевидны и наглядны. Готовый мониторинг и веб панель - это прям самый сок.
#angie #webserver #отечественное
{kind=link}