
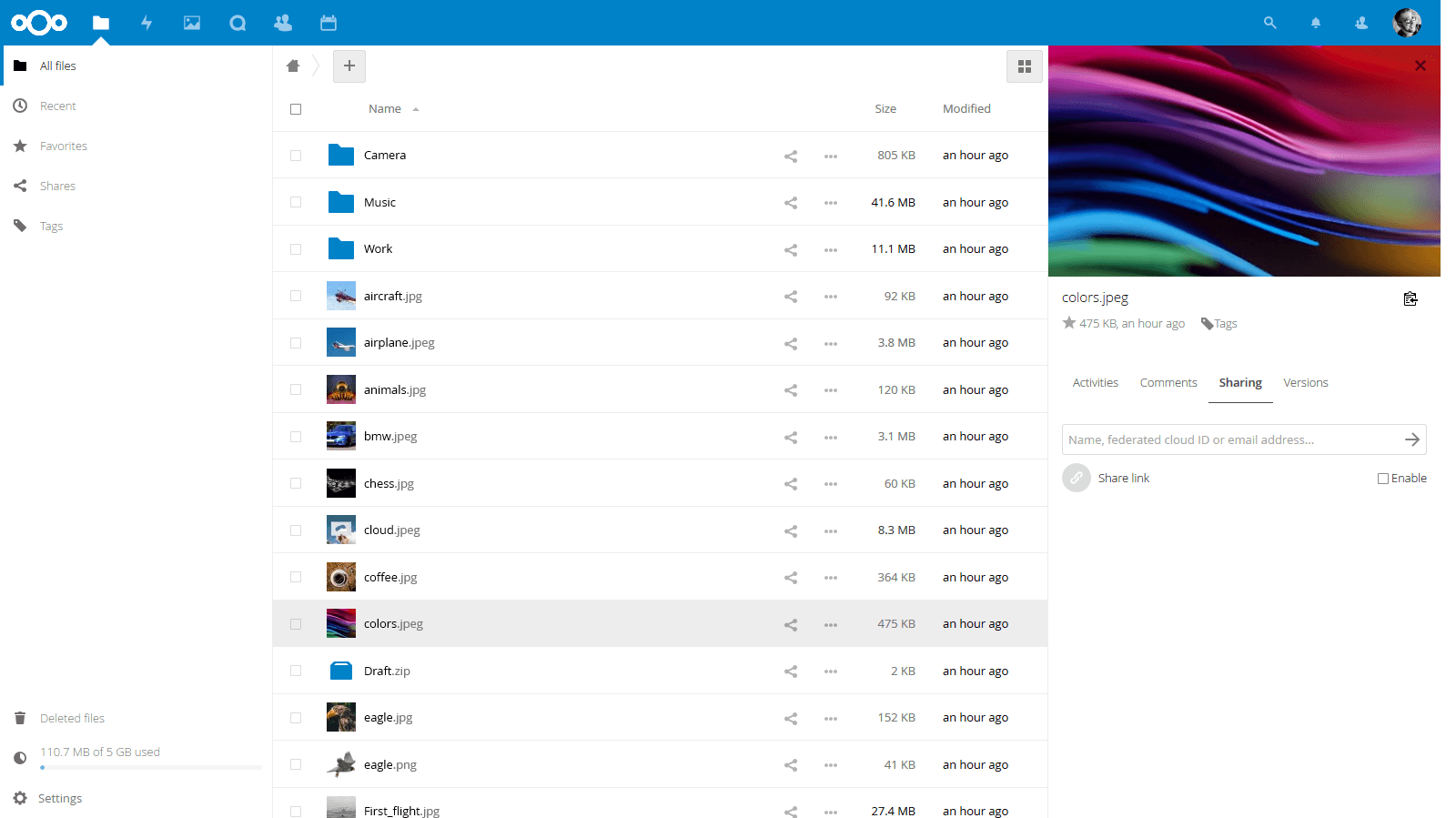
Обратил внимание, что на канале не было ни одной заметки про Nextcloud. Когда продукт известный, кажется, что нет смысла о нём писать. И так все знают. Хотя это далеко не факт. Постараюсь кратко и ёмко описать его своими словами.
Изначально Nextcloud позиционировал себя как бесплатная Open Source замена облачным сервисам по хранению файлов типа Dropbox и Google Drive. Его можно установить на свой сервер, на конечные устройства поставить агенты, которые будут синхронизировать файлы. Не знаю достоверно, насколько надежно в этом плане сейчас работает Nextcloud, но первое время у него были всевозможные баги вплоть до потери всех файлов. Знакомый лично рассказывал, как столкнулся с этим после какого-то обновления. Заторможенная или зависшая синхронизация были обычным делом.
В настоящий момент Nextcloud это не просто сервер для хранения документов. Это полноценная веб платформа для совместной работы. Основной функционал:
▪ Совместная работа с документами, в том числе их редактирование онлайн, работает на базе известных платформ для этого (Collabora Online, Onlyoffice).
▪ Чат сервер с голосовыми и видеозвонками на базе NextCloud Talk.
▪ Управление проектами, задачами, календарями, совместная работа с ними.
▪ Встроенный в веб интерфейс imap клиент для работы с почтой. Встроенного почтового сервера в Nextcloud нет.
▪ Поддержка аутентификации пользователей через LDAP (в том числе Windows AD).
▪ Доступ к файлам пользователя через клиент, веб браузер, WebDAV
▪ Интеграция с Draw.io для рисования схем.
▪ Возможность подключить внешние хранилища: FTP, WebDAV, Nextcloud, SFTP, S3, Dropbox, Google Drive.
Функционал Nextcloud расширяется за счёт дополнений, которые живут во встроенном App Store. Чего там только нет: различные темы, календари, редакторы, чаты, веб сервера, игры, интеграции с другими сервисами и т.д. На глазок их там штук 200-300. Сделано примерно так же, как в Synology.
Если я правильно понимаю, на сегодняшний день Nextcloud - лучшее бесплатное решение для подобного функционала. Если коротко и в современных терминах, то это Groupware с прокачанной функцией хранения файлов. Из аналогов мне известны:
◽ Onlyoffice Workspace. Наиболее развитый с активной разработкой. Но у него существенные ограничения бесплатной версии.
◽ Zimbra. Бесплатная версия доживает свои дни. Новые версии пока не предвидятся. Хотя исходники открыты, но никто не взялся за то, чтобы собирать из них готовый продукт.
◽ Kopano. Разработка бесплатной версии тоже завершилась в 2021 году.
◽ Univention Corporate Server (UCS). Похож на Nextcloud, но выглядит более бледно и не так функционально. На первый взгляд удобство и функционал значительно ниже.
Больше ничего из более ли менее известного не знаю. Если у вас есть опыт эксплуатации подобных систем, поделитесь информацией, чем пользуетесь и удобно ли это на практике.
Мне кажется, что подобного рода продукты лучше покупать за деньги. Когда на них завязана работа всей организации и у вас нет платной техподдержки, можно сильно встрять. Я бы не хотел брать на себя такую ответственность. Внедрял Onlyoffice в небольших компаниях и видел, какие там проблемы могут возникнуть. На небольших масштабах они не так критичны.
Сайт - https://nextcloud.com
Исходники - https://github.com/nextcloud
#docs #fileserver
Изначально Nextcloud позиционировал себя как бесплатная Open Source замена облачным сервисам по хранению файлов типа Dropbox и Google Drive. Его можно установить на свой сервер, на конечные устройства поставить агенты, которые будут синхронизировать файлы. Не знаю достоверно, насколько надежно в этом плане сейчас работает Nextcloud, но первое время у него были всевозможные баги вплоть до потери всех файлов. Знакомый лично рассказывал, как столкнулся с этим после какого-то обновления. Заторможенная или зависшая синхронизация были обычным делом.
В настоящий момент Nextcloud это не просто сервер для хранения документов. Это полноценная веб платформа для совместной работы. Основной функционал:
▪ Совместная работа с документами, в том числе их редактирование онлайн, работает на базе известных платформ для этого (Collabora Online, Onlyoffice).
▪ Чат сервер с голосовыми и видеозвонками на базе NextCloud Talk.
▪ Управление проектами, задачами, календарями, совместная работа с ними.
▪ Встроенный в веб интерфейс imap клиент для работы с почтой. Встроенного почтового сервера в Nextcloud нет.
▪ Поддержка аутентификации пользователей через LDAP (в том числе Windows AD).
▪ Доступ к файлам пользователя через клиент, веб браузер, WebDAV
▪ Интеграция с Draw.io для рисования схем.
▪ Возможность подключить внешние хранилища: FTP, WebDAV, Nextcloud, SFTP, S3, Dropbox, Google Drive.
Функционал Nextcloud расширяется за счёт дополнений, которые живут во встроенном App Store. Чего там только нет: различные темы, календари, редакторы, чаты, веб сервера, игры, интеграции с другими сервисами и т.д. На глазок их там штук 200-300. Сделано примерно так же, как в Synology.
Если я правильно понимаю, на сегодняшний день Nextcloud - лучшее бесплатное решение для подобного функционала. Если коротко и в современных терминах, то это Groupware с прокачанной функцией хранения файлов. Из аналогов мне известны:
◽ Onlyoffice Workspace. Наиболее развитый с активной разработкой. Но у него существенные ограничения бесплатной версии.
◽ Zimbra. Бесплатная версия доживает свои дни. Новые версии пока не предвидятся. Хотя исходники открыты, но никто не взялся за то, чтобы собирать из них готовый продукт.
◽ Kopano. Разработка бесплатной версии тоже завершилась в 2021 году.
◽ Univention Corporate Server (UCS). Похож на Nextcloud, но выглядит более бледно и не так функционально. На первый взгляд удобство и функционал значительно ниже.
Больше ничего из более ли менее известного не знаю. Если у вас есть опыт эксплуатации подобных систем, поделитесь информацией, чем пользуетесь и удобно ли это на практике.
Мне кажется, что подобного рода продукты лучше покупать за деньги. Когда на них завязана работа всей организации и у вас нет платной техподдержки, можно сильно встрять. Я бы не хотел брать на себя такую ответственность. Внедрял Onlyoffice в небольших компаниях и видел, какие там проблемы могут возникнуть. На небольших масштабах они не так критичны.
Сайт - https://nextcloud.com
Исходники - https://github.com/nextcloud
#docs #fileserver
{kind=link}
Если вам нужен простой файловый сервер с доступом к файлам через браузер, то могу посоветовать хорошее решение для этого. Программа так и называется - File Browser. Это open source проект, доступный для установки на Linux, MacOS, Windows. Серверная часть представляет из себя один бинарник и базу данных в одном файле, где хранятся все настройки и пользователи.
Управление File Browser немного непривычное, так что покажу сразу на примере, как его запустить и попробовать. В документации всё это описано. Я там и посмотрел.
Установить File Browser можно через готовый скрипт. Он очень простой, и ничего особенного не делает, только скачивает бинарник и копирует его в системную директорию. Можете это сделать и вручную.
Теперь можно сразу запустить файловый сервер примерно так:
Он запустится на localhost, что не удобно, поэтому поступим по-другому. Создадим сразу готовый конфиг, где укажем некоторые параметры:
Я указал, что надо запуститься на внешнем IP и в качестве директории для обзора указал /var/log. Теперь добавим одного пользователя с полными правами:
serveradmin - имя пользователя, pass - пароль. В директории, где вы запускали команды, будет создан файл filebrowser.db, в котором хранятся все настройки. Можно запускать filebrowser с указанием пути к этому файлу. Все консольные команды по конфигурации и управлению пользователями описаны в документации.
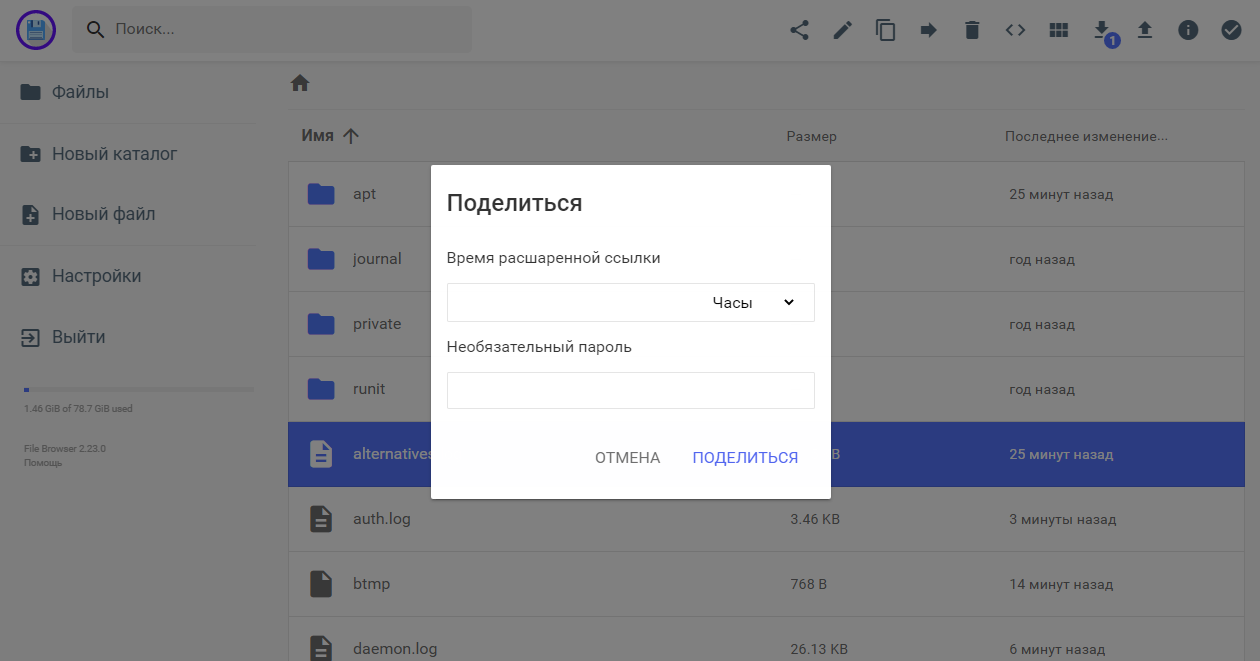
Теперь можно идти http://85.143.175.246:8080, авторизовываться и просматривать файлы. Текстовые можно создавать и редактировать прямо в браузере. Также есть встроенный просмотр картинок.
🔥 Для файлов можно открывать внешний доступ с ограничением по времени или доступом по паролю.
Filebrowser имеет простой и удобный веб интерфейс. Есть русский язык. В общем и целом оставляет приятное впечатление. Для работы с файлами через браузер отличный вариант, который легко и быстро запускается и настраивается. Рекомендую обратить внимание, если нужен подобный функционал.
⇨ Сайт / Исходники
#fileserver
Управление File Browser немного непривычное, так что покажу сразу на примере, как его запустить и попробовать. В документации всё это описано. Я там и посмотрел.
Установить File Browser можно через готовый скрипт. Он очень простой, и ничего особенного не делает, только скачивает бинарник и копирует его в системную директорию. Можете это сделать и вручную.
# curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh \| bashТеперь можно сразу запустить файловый сервер примерно так:
# filebrowser -r /path/to/your/filesОн запустится на localhost, что не удобно, поэтому поступим по-другому. Создадим сразу готовый конфиг, где укажем некоторые параметры:
# filebrowser config init --address 85.143.175.246 -r /var/logЯ указал, что надо запуститься на внешнем IP и в качестве директории для обзора указал /var/log. Теперь добавим одного пользователя с полными правами:
# filebrowser users add serveradmin pass --perm.adminserveradmin - имя пользователя, pass - пароль. В директории, где вы запускали команды, будет создан файл filebrowser.db, в котором хранятся все настройки. Можно запускать filebrowser с указанием пути к этому файлу. Все консольные команды по конфигурации и управлению пользователями описаны в документации.
Теперь можно идти http://85.143.175.246:8080, авторизовываться и просматривать файлы. Текстовые можно создавать и редактировать прямо в браузере. Также есть встроенный просмотр картинок.
🔥 Для файлов можно открывать внешний доступ с ограничением по времени или доступом по паролю.
Filebrowser имеет простой и удобный веб интерфейс. Есть русский язык. В общем и целом оставляет приятное впечатление. Для работы с файлами через браузер отличный вариант, который легко и быстро запускается и настраивается. Рекомендую обратить внимание, если нужен подобный функционал.
⇨ Сайт / Исходники
#fileserver
{kind=link}
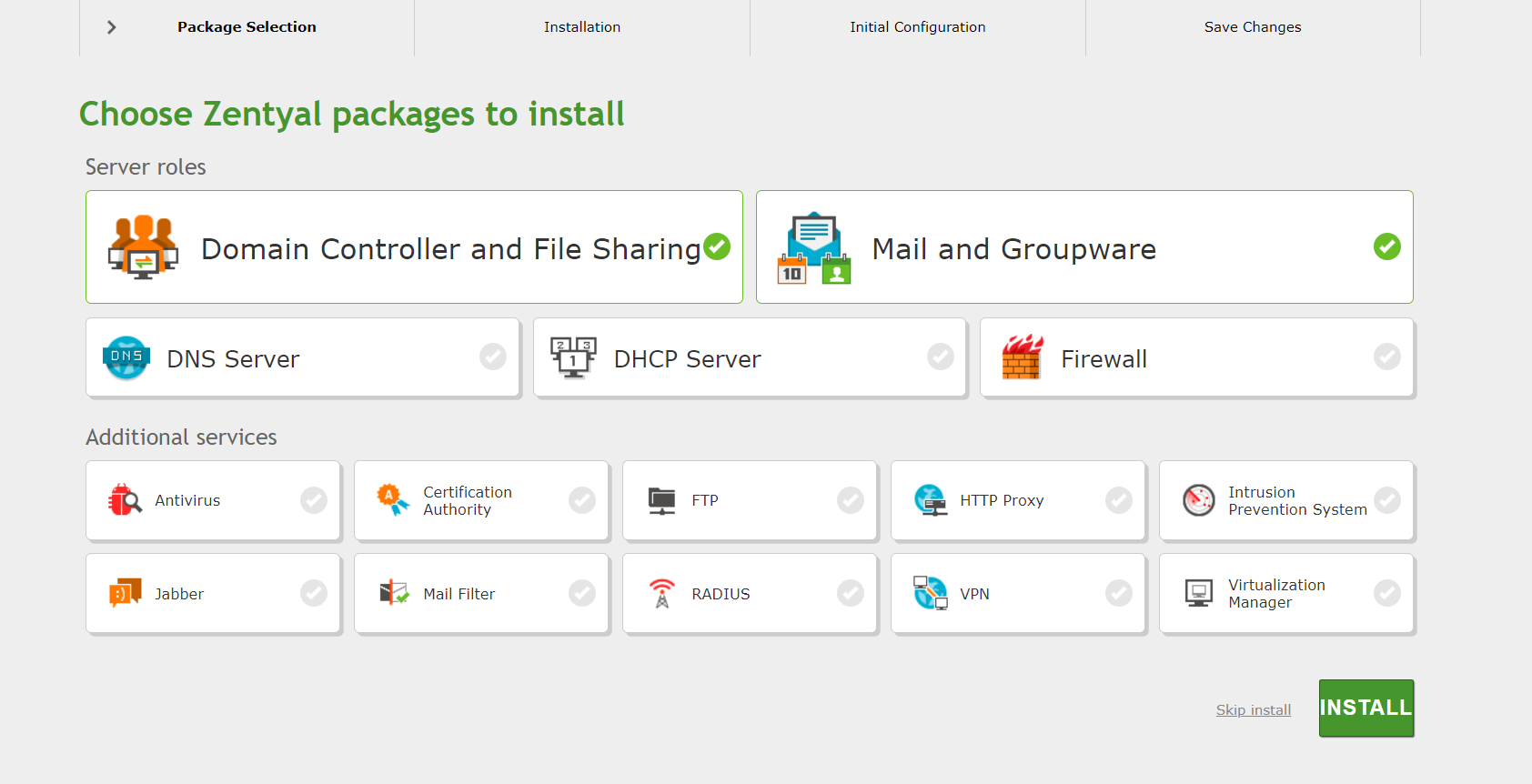
Существует старый и известный продукт на основе Linux по типу всё в одном - Zentyal. Он время от времени мелькает в комментариях и рекомендациях как замена AD или в качестве почтового сервера. Решил вам рассказать о нём, так как и то, и другое сейчас актуально.
Стоит сразу сказать, что Zentyal в первую очередь коммерческий продукт, продающийся по подписке. Но у него, как это часто бывает, есть бесплатная community версия, которую они в какой-то момент переименовали в Development Edition. Полное название бесплатной версии - Zentyal Server Development Edition.
У бесплатной версии сильно ограничен функционал, но всё основное есть. То есть его можно использовать в качестве контроллера домена для Windows машин и почтового сервера. Дистрибутив основан на ОС Ubuntu, установщик полностью от неё. После установки в консоль лазить не обязательно, всё управление через веб интерфейс. Причём стандартный установщик автоматически разворачивает графическое окружение и ставит браузер Firefox, так что управлять сервером можно сразу через консоль VM.
После установки настройка и управление осуществляются через веб интерфейс: https://ip_address:8443, учётка та, что была создана в качестве пользователя во время установки системы. Там вы сможете установить пакеты для:
▪ Контроллера домена на основе Samba 4.
▪ Почтового сервера на базе SOGo с поддержкой IMAP, Microsoft Exchange ActiveSync, CalDAV и CardDAV.
▪ Шлюза Linux с Firewall и NAT, DNS, DHCP, VPN и т.д.
Всё остальное не перечисляю, там уже не так интересно. Насколько всё это хорошо работает, трудно судить. В целом, домен работает. Много видел отзывов об этом в том числе и в комментариях к своим заметкам. Но нужно понимать, что это всё та же Samba и там могут быть проблемы. Но виндовые машины в домен зайдут и будет работать аутентификация, в том числе во все связанные сервисы (почта, файлы и т.д.). Можно будет файловые шары создать с доступом по пользователям и группам.
Сами разработчики позиционируют Zentyal как альтернатива Windows Server для малого и среднего бизнеса. Насколько я могу судить, это одна из самых удачных реализаций Linux all-in-box.
Аналоги:
◽ UCS
◽ ClearOS
⇨ Сайт / Исходники
#docs #fileserver #mailserver #ldap #samba
Стоит сразу сказать, что Zentyal в первую очередь коммерческий продукт, продающийся по подписке. Но у него, как это часто бывает, есть бесплатная community версия, которую они в какой-то момент переименовали в Development Edition. Полное название бесплатной версии - Zentyal Server Development Edition.
У бесплатной версии сильно ограничен функционал, но всё основное есть. То есть его можно использовать в качестве контроллера домена для Windows машин и почтового сервера. Дистрибутив основан на ОС Ubuntu, установщик полностью от неё. После установки в консоль лазить не обязательно, всё управление через веб интерфейс. Причём стандартный установщик автоматически разворачивает графическое окружение и ставит браузер Firefox, так что управлять сервером можно сразу через консоль VM.
После установки настройка и управление осуществляются через веб интерфейс: https://ip_address:8443, учётка та, что была создана в качестве пользователя во время установки системы. Там вы сможете установить пакеты для:
▪ Контроллера домена на основе Samba 4.
▪ Почтового сервера на базе SOGo с поддержкой IMAP, Microsoft Exchange ActiveSync, CalDAV и CardDAV.
▪ Шлюза Linux с Firewall и NAT, DNS, DHCP, VPN и т.д.
Всё остальное не перечисляю, там уже не так интересно. Насколько всё это хорошо работает, трудно судить. В целом, домен работает. Много видел отзывов об этом в том числе и в комментариях к своим заметкам. Но нужно понимать, что это всё та же Samba и там могут быть проблемы. Но виндовые машины в домен зайдут и будет работать аутентификация, в том числе во все связанные сервисы (почта, файлы и т.д.). Можно будет файловые шары создать с доступом по пользователям и группам.
Сами разработчики позиционируют Zentyal как альтернатива Windows Server для малого и среднего бизнеса. Насколько я могу судить, это одна из самых удачных реализаций Linux all-in-box.
Аналоги:
◽ UCS
◽ ClearOS
⇨ Сайт / Исходники
#docs #fileserver #mailserver #ldap #samba
{kind=link}
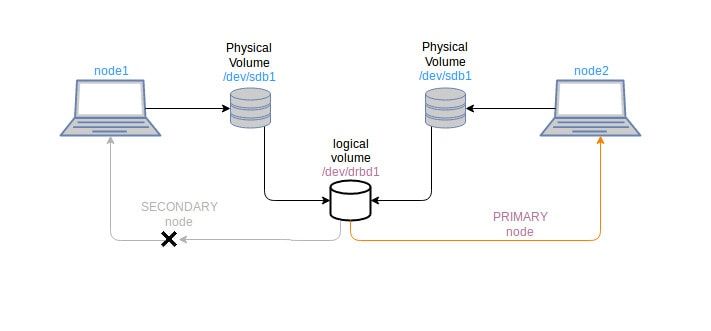
Расскажу про простую схему построения отказоустойчивой системы на уровне файлового хранения с помощью DRBD (Distributed Replicated Block Device — распределённое реплицируемое блочное устройство). Это очень простое и известное решение в том числе из-за того, что поддержка DRBD входит в стандартное ядро Linux.
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
/dev/sdb будут использоваться под DRBD. Запускаете инициализацию и получаете новое блочное устройство на каждом сервере, которое автоматически синхронизируется.Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
{kind=link}
Хочу подкинуть вам идею, которая может когда-нибудь пригодиться. Подключение к NFS серверу можно организовать через проброс портов по SSH и это нормально работает. Когда есть sshfs, может показаться, что в этом нет никакого смысла. Могу привести свой пример, когда мне это пригодилось.
Мне нужно было перекинуть бэкапы виртуалок с внешнего сервера Proxmox домой на мой NFS сервер. Тут вариант либо порты пробрасывать на домашний сервер, но это если у тебя белый IP, либо как раз воспользоваться пробросом портов, подключившись из дома к внешнему серверу по SSH.
Настраивать тут особо ничего не надо. Если NFS сервер уже настроен, то достаточно сделать обратный проброс локального порта 2049 на внешний сервер:
Если на той стороне уже есть nfs сервер и порт 2049 занят, то можно указать другой. Только надо аккуратно поменять ровно то, что нужно. Я обычно путаюсь в пробросе портов по SSH, так как тут неинтуитивно. Должно быть вот так:
Останется только на удалённом сервере подмонтировать том:
Тут ещё стоит понимать, что nfs и sshfs принципиально разные вещи. Первое — это полноценная сетевая файловая система со своими службами, хранением метаданных и т.д., а второе — реализация доступа к файлам по протоколу SFTP на базе FUSE (Filesystem in Userspace). SFTP обычно используется для разовой передачи файлов. NFS же можно ставить на постоянку. Это стабильное решение (но не через SSH 😀).
#nfs #ssh #fileserver
Мне нужно было перекинуть бэкапы виртуалок с внешнего сервера Proxmox домой на мой NFS сервер. Тут вариант либо порты пробрасывать на домашний сервер, но это если у тебя белый IP, либо как раз воспользоваться пробросом портов, подключившись из дома к внешнему серверу по SSH.
Настраивать тут особо ничего не надо. Если NFS сервер уже настроен, то достаточно сделать обратный проброс локального порта 2049 на внешний сервер:
# ssh -R 2049:127.0.0.1:2049 root@server-ipЕсли на той стороне уже есть nfs сервер и порт 2049 занят, то можно указать другой. Только надо аккуратно поменять ровно то, что нужно. Я обычно путаюсь в пробросе портов по SSH, так как тут неинтуитивно. Должно быть вот так:
# ssh -R 3049:127.0.0.1:2049 root@server-ipОстанется только на удалённом сервере подмонтировать том:
# mount -t nfs -o port=3049 localhost:/data /mnt/nfs-shareТут ещё стоит понимать, что nfs и sshfs принципиально разные вещи. Первое — это полноценная сетевая файловая система со своими службами, хранением метаданных и т.д., а второе — реализация доступа к файлам по протоколу SFTP на базе FUSE (Filesystem in Userspace). SFTP обычно используется для разовой передачи файлов. NFS же можно ставить на постоянку. Это стабильное решение (но не через SSH 😀).
#nfs #ssh #fileserver
Расскажу вам про полезный инструмент, которым с одной стороны можно будет пользоваться самим, а с другой стороны для понимания того, как этот инструмент могут использовать другие. В том числе и против вас.
Речь пойдёт про сервис для обмена файлами pwndrop, который можно развернуть у себя. Это open source проект, исходники на github. В базе это простой и удобный сервис для обмена файлами. Ставится в пару действий, имеет простой конфиг, приятный и удобный веб интерфейс. Служба написана на Go, веб интерфейс на JavaScript. Работает шустро.
Основной функционал у pwndrop типичный для таких сервисов. Загружаете файл, получаете ссылку и делитесь ею с другими людьми. Причём загрузить ваш файл они могут как по http, так и по webdav. Из удобств — автоматически получает сертификат от let's encrypt, если развёрнут на реальном доменном имени с DNS записью.
А теперь его особенности, так как позиционируется он как инструмент для пентестеров. Я не буду перечислять всё, что в есть в описании, так как некоторые вещи не понимаю. Расскажу, что попробовал сам.
◽У pwndrop можно изменить url админки, чтобы скрыть её от посторонних глаз. Обращение на основной домен можно перенаправить в любое другое место. То есть наличие самого сервиса на конкретном домене можно спрятать, оставив только доступ по прямым ссылкам, которые заранее известны.
◽Pwndrop умеет подменять изначально загруженный файл на какой-то другой. То есть вы можете загрузить файл, отдать кому-то ссылку. А потом в настройках доступа к этому файлу указать для загрузки другой файл. В итоге по одной и той же ссылке в разное время можно загружать разные файлы. Всё это управляется из админки и может включаться и выключаться по вашему усмотрению.
◽В настройках загруженного файла можно указать любой другой url, куда будет выполняться редирект при обращении по ссылке на скачивание. То есть вместо подмены файла, описанной выше, происходит редирект на произвольный url.
На примере подобного сервиса можно легко понять, как загружая по известной ссылке какой-то файл, можно получить совсем не то, что ожидаешь. Понятно, что подобные вещи не представляют какой-то особой сложности и при желании всегда можно сделать такую подмену. Но с такими готовыми серверами, это доступно любому школьнику. Так что будьте внимательны.
Pwndrop ставится скриптом, либо вручную скачиванием архива со всеми файлами. По умолчанию он устанавливает себя в /usr/local/pwndrop, там и конфиг, и бинарник. Также создаёт systemd службу. Формат конфига очень простой, примеры настроек есть в репозитории. Их буквально несколько штук (порты, директории, ip и т.д.). Также запустить сервер можно в Docker с помощью готового образа от linuxserver.io.
Я попробовал. Сервис реально простой, удобный, легко ставится, легко настраивается. Может оказаться полезным и для личного использования, и для совместной работы с кем-то. Веб интерфейс адаптивен для смартфонов.
⇨ Сайт / Исходники
#fileserver
Речь пойдёт про сервис для обмена файлами pwndrop, который можно развернуть у себя. Это open source проект, исходники на github. В базе это простой и удобный сервис для обмена файлами. Ставится в пару действий, имеет простой конфиг, приятный и удобный веб интерфейс. Служба написана на Go, веб интерфейс на JavaScript. Работает шустро.
Основной функционал у pwndrop типичный для таких сервисов. Загружаете файл, получаете ссылку и делитесь ею с другими людьми. Причём загрузить ваш файл они могут как по http, так и по webdav. Из удобств — автоматически получает сертификат от let's encrypt, если развёрнут на реальном доменном имени с DNS записью.
А теперь его особенности, так как позиционируется он как инструмент для пентестеров. Я не буду перечислять всё, что в есть в описании, так как некоторые вещи не понимаю. Расскажу, что попробовал сам.
◽У pwndrop можно изменить url админки, чтобы скрыть её от посторонних глаз. Обращение на основной домен можно перенаправить в любое другое место. То есть наличие самого сервиса на конкретном домене можно спрятать, оставив только доступ по прямым ссылкам, которые заранее известны.
◽Pwndrop умеет подменять изначально загруженный файл на какой-то другой. То есть вы можете загрузить файл, отдать кому-то ссылку. А потом в настройках доступа к этому файлу указать для загрузки другой файл. В итоге по одной и той же ссылке в разное время можно загружать разные файлы. Всё это управляется из админки и может включаться и выключаться по вашему усмотрению.
◽В настройках загруженного файла можно указать любой другой url, куда будет выполняться редирект при обращении по ссылке на скачивание. То есть вместо подмены файла, описанной выше, происходит редирект на произвольный url.
На примере подобного сервиса можно легко понять, как загружая по известной ссылке какой-то файл, можно получить совсем не то, что ожидаешь. Понятно, что подобные вещи не представляют какой-то особой сложности и при желании всегда можно сделать такую подмену. Но с такими готовыми серверами, это доступно любому школьнику. Так что будьте внимательны.
Pwndrop ставится скриптом, либо вручную скачиванием архива со всеми файлами. По умолчанию он устанавливает себя в /usr/local/pwndrop, там и конфиг, и бинарник. Также создаёт systemd службу. Формат конфига очень простой, примеры настроек есть в репозитории. Их буквально несколько штук (порты, директории, ip и т.д.). Также запустить сервер можно в Docker с помощью готового образа от linuxserver.io.
Я попробовал. Сервис реально простой, удобный, легко ставится, легко настраивается. Может оказаться полезным и для личного использования, и для совместной работы с кем-то. Веб интерфейс адаптивен для смартфонов.
⇨ Сайт / Исходники
#fileserver
{kind=link}
Для создания своего "облачного" хранилища файлов, похожего на Dropbox, Google Drive, Yandex.Disk и т.д. можно воспользоваться известным open source решением Seafile. Это популярный сервер, про который я вообще ни разу не упоминал, хотя услышал про него впервые очень давно, ещё до того как появился owncloud, который породил форк Nextcloud — наиболее известный на сегодняшний день продукт для автономного файлового хранилища.
Seafile существует как в коммерческой, так и в Community редакции с открытым исходным кодом. Код также открыт и для клиентов под все популярные системы: Windows, Linux, Macos, Android. Для Linux версии есть консольный клиент. Для самого сервера есть веб интерфейс, через который осуществляется управление.
Основной особенностью Seafile можно считать маленькие требования к ресурсам, так что его можно запускать на Raspberry Pi. Для этого существует отдельная сборка сервера.
Несмотря на свою простоту и лёгкость, Seafile предлагает неплохой бесплатный функционал:
◽создание и управление аккаунтами пользователей
◽версионирование файлов и логирование доступа к ним
◽мобильный клиент
◽возможность подключать хранилище в виде виртуального диска
◽создание ссылок для общего доступа к файлам или по паролю
◽шифрование файлов
◽просмотр медиа файлов через веб интерфейс
◽онлайн редактор для совместной работы над текстовыми файлами в формате Markdown (другие форматы, типа docx, xlsx и т.д. не поддерживаются).
Оценить функционал можно в публичном demo - https://demo.seafile.com.
Запустить у себя тоже нет никаких проблем. Есть готовый docker-compose.yml от разработчиков. Там же все инструкции.
Ядро сервера Seafile написано на C 😎 (вспомнилось Папа может в си). Этим объясняется его легкость и быстродействие. Веб интерфейс на Python (django) и JavaScript.
Я сам никогда не использовал этот сервер, поэтому не могу поделиться информацией по эксплуатации. Если кто-то активно пользовался, то дайте обратную связь. Если рассматривать только хранение файлов, на текущий день это решение лучше или хуже Nextcloud?
⇨ Сайт / Исходники / Демо
#fileserver
Seafile существует как в коммерческой, так и в Community редакции с открытым исходным кодом. Код также открыт и для клиентов под все популярные системы: Windows, Linux, Macos, Android. Для Linux версии есть консольный клиент. Для самого сервера есть веб интерфейс, через который осуществляется управление.
Основной особенностью Seafile можно считать маленькие требования к ресурсам, так что его можно запускать на Raspberry Pi. Для этого существует отдельная сборка сервера.
Несмотря на свою простоту и лёгкость, Seafile предлагает неплохой бесплатный функционал:
◽создание и управление аккаунтами пользователей
◽версионирование файлов и логирование доступа к ним
◽мобильный клиент
◽возможность подключать хранилище в виде виртуального диска
◽создание ссылок для общего доступа к файлам или по паролю
◽шифрование файлов
◽просмотр медиа файлов через веб интерфейс
◽онлайн редактор для совместной работы над текстовыми файлами в формате Markdown (другие форматы, типа docx, xlsx и т.д. не поддерживаются).
Оценить функционал можно в публичном demo - https://demo.seafile.com.
Запустить у себя тоже нет никаких проблем. Есть готовый docker-compose.yml от разработчиков. Там же все инструкции.
Ядро сервера Seafile написано на C 😎 (вспомнилось Папа может в си). Этим объясняется его легкость и быстродействие. Веб интерфейс на Python (django) и JavaScript.
Я сам никогда не использовал этот сервер, поэтому не могу поделиться информацией по эксплуатации. Если кто-то активно пользовался, то дайте обратную связь. Если рассматривать только хранение файлов, на текущий день это решение лучше или хуже Nextcloud?
⇨ Сайт / Исходники / Демо
#fileserver
{kind=link}
В операционной системе на базе Linux существуют два разных способа назначения прав доступа к файлам. Не все начинающие администраторы об этом знают. Недавно один читатель попросил помочь настроить права доступа к файловой шаре samba. Он описал задачу на основе того, как привык раздавать права на директории в Windows. В Linux у него не получалось настроить так же в рамках стандартных прав доступа через локальных пользователей, групп и утилит
В Linux, помимо основных прав доступа, которые вы видите при просмотре директории с помощью
После установки данного пакета у вас появятся две основные утилиты, которые будут нужны для управления доступом:
Я не буду сейчас подробно расписывать как всем этим пользоваться. В интернете масса руководств. Просто знайте, что в Linux правами на файлы и директории можно управлять практически точно так же, как в домене Windows. Есть нюансы и различия, но в базовых случаях несущественные. Если добавить Linux сервер с Samba и ACL в домен, то через систему Windows можно будет управлять доступом к файлами через её свойства папки с галочками и списками групп.
Пример того, как всё это может выглядеть, есть в моей статье:
⇨ https://serveradmin.ru/nastroyka-samba-s-integratsiey-v-ad/
Она очень старая и скорее всего уже неактуальна в технической части. Я сам давно файловые сервера в Linux в домене не настраивал и не эксплуатировал. Но общее понимание картины можно получить. Соответственно, вместо Microsoft AD может выступать любой другой LDAP каталог пользователей и групп.
Подскажите, кто скрещивает Linux с Windows. На текущий момент нет проблем с добавлением Linux в AD под управлением свежих Windows Server? Интеграция упростилась или усложнилась? Давно уже не слежу за этой темой. Я где-то видел новость, что Ubuntu для платных подписчиков выпустила какой-то свой инструмент для упрощения работы в AD.
#linux #fileserver
chown, chmod. В Linux, помимо основных прав доступа, которые вы видите при просмотре директории с помощью
ls -l, существуют дополнительные списки доступа ACL (access control list). Они позволяют очень гибко управлять доступом. По умолчанию инструменты для управления этими списками в минимальной установке Debian отсутствуют. Устанавливаются так:# apt install aclПосле установки данного пакета у вас появятся две основные утилиты, которые будут нужны для управления доступом:
getfacl - посмотреть права доступа, setfacl - установить права доступа. Я не буду сейчас подробно расписывать как всем этим пользоваться. В интернете масса руководств. Просто знайте, что в Linux правами на файлы и директории можно управлять практически точно так же, как в домене Windows. Есть нюансы и различия, но в базовых случаях несущественные. Если добавить Linux сервер с Samba и ACL в домен, то через систему Windows можно будет управлять доступом к файлами через её свойства папки с галочками и списками групп.
Пример того, как всё это может выглядеть, есть в моей статье:
⇨ https://serveradmin.ru/nastroyka-samba-s-integratsiey-v-ad/
Она очень старая и скорее всего уже неактуальна в технической части. Я сам давно файловые сервера в Linux в домене не настраивал и не эксплуатировал. Но общее понимание картины можно получить. Соответственно, вместо Microsoft AD может выступать любой другой LDAP каталог пользователей и групп.
Подскажите, кто скрещивает Linux с Windows. На текущий момент нет проблем с добавлением Linux в AD под управлением свежих Windows Server? Интеграция упростилась или усложнилась? Давно уже не слежу за этой темой. Я где-то видел новость, что Ubuntu для платных подписчиков выпустила какой-то свой инструмент для упрощения работы в AD.
#linux #fileserver
{kind=link}
Некоторое время назад в ядро Linux завезли реализацию файлового сервера на базе протокола smb - ksmbd. Давно хотел его попробовать, но всё руки не доходили. А тут возникла потребность в простом файловом сервере для обмена файлами. Решил его попробовать.
Для поддержки ksmbd нужно относительно свежее ядро. В Ubuntu 22 и Debian 12 оно уже точно подходящей версии. Я как раз из анонсов Debian 12 про этот сервер и узнал. А вот в Debian 11 наверняка не знаю, надо уточнять, приехала ли туда поддержка ksmbd. Если нет, то лучше обойтись привычной самбой.
Настроить ksmbd реально очень просто и быстро. Показываю по шагам. Устанавливаем службу:
Рисуем конфиг
Ksmbd использует сопоставление с системным пользователем, так что добавляем его:
И сопоставляем с пользователем ksmbd:
После изменения конфигурации, необходимо перезапустить службу:
В автозагрузку она добавляется автоматически после установки.
После этого зашёл через свежий Windows Server 2022. Всё заработало сразу без танцев с бубнами, что бывает нередко, когда настраиваешь самбу. Не забудьте только права проверить, чтобы пользователи ksmbd имели доступ к директории, которую вы расшарили.
Погуглил немного настройки ksmbd. Хотел узнать, можно ли там, как в самбе, делать сразу в конфигурации ограничения на доступ не по пользователям, а по IP. Не увидел таких настроек. В принципе, они не сильно актуальны, так как сейчас почти во всех системах закрыт по умолчанию анонимный доступ по smb. Так что всё равно надо настраивать аутентификацию, а если надо ограничить доступ на уровне сети, использовать firewall.
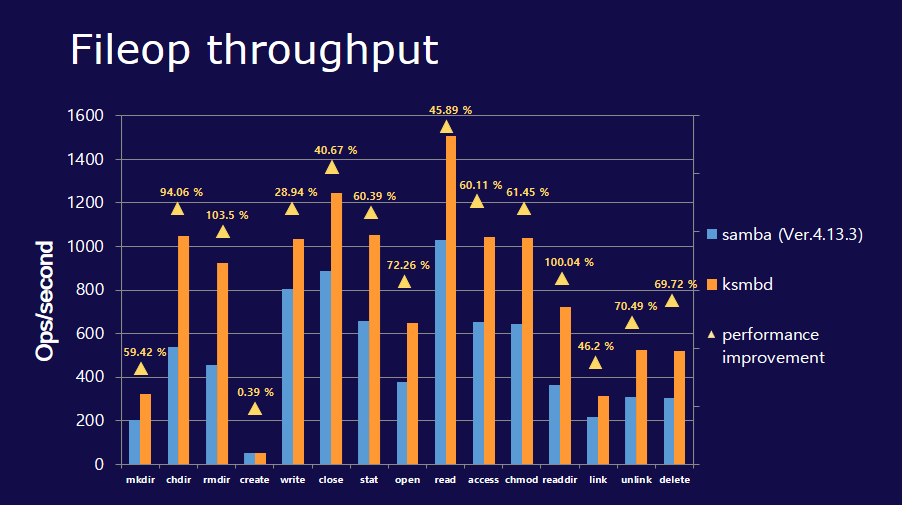
Кстати, поддержка Win-ACL, Kerberos есть, судя по документации. Если верить тестам из репозитория разработчиков, то ksmbd работает заметно быстрее samba. Так что если для вас это критично, попробуйте.
#fileserver #linux #smb
Для поддержки ksmbd нужно относительно свежее ядро. В Ubuntu 22 и Debian 12 оно уже точно подходящей версии. Я как раз из анонсов Debian 12 про этот сервер и узнал. А вот в Debian 11 наверняка не знаю, надо уточнять, приехала ли туда поддержка ksmbd. Если нет, то лучше обойтись привычной самбой.
Настроить ksmbd реально очень просто и быстро. Показываю по шагам. Устанавливаем службу:
# apt install ksmbd-toolsРисуем конфиг
/etc/ksmbd/ksmbd.conf:[global] netbios name = 1cbackup map to guest = never[backup] comment = 1C_backup path = /mnt/backup writeable = yes users = ksmbduserKsmbd использует сопоставление с системным пользователем, так что добавляем его:
# useradd -s /sbin/nologin ksmbduserИ сопоставляем с пользователем ksmbd:
# ksmbd.adduser --add-user=ksmbduserПосле изменения конфигурации, необходимо перезапустить службу:
# systemctl restart ksmbdВ автозагрузку она добавляется автоматически после установки.
После этого зашёл через свежий Windows Server 2022. Всё заработало сразу без танцев с бубнами, что бывает нередко, когда настраиваешь самбу. Не забудьте только права проверить, чтобы пользователи ksmbd имели доступ к директории, которую вы расшарили.
Погуглил немного настройки ksmbd. Хотел узнать, можно ли там, как в самбе, делать сразу в конфигурации ограничения на доступ не по пользователям, а по IP. Не увидел таких настроек. В принципе, они не сильно актуальны, так как сейчас почти во всех системах закрыт по умолчанию анонимный доступ по smb. Так что всё равно надо настраивать аутентификацию, а если надо ограничить доступ на уровне сети, использовать firewall.
Кстати, поддержка Win-ACL, Kerberos есть, судя по документации. Если верить тестам из репозитория разработчиков, то ksmbd работает заметно быстрее samba. Так что если для вас это критично, попробуйте.
#fileserver #linux #smb
{kind=link}
Решил сделать подборку self-hosted решений хранения большого количества фотографий для совместной работы с ними и просмотра. Я одно время заморочился и перетащил весь семейный фотоархив во встроенное приложение в Synology. Но со временем надоело туда вносить правки, всё устарело и потеряло актуальность. Сейчас решил возобновить эту тему, но без привязки к какому-то вендору, на базе open source.
Если кто-то пользуется чем-то и ему оно нравится, то поделитесь своим продуктом. Я и на работе не раз видел потребность в каких-то общих галереях. Например, для выездных специалистов, которые фотографируют объекты. Или просто перетащить куда-то в одно место фотки с корпоративов, которые забивают общие сетевые диски и расползаются по личным папкам пользователей, занимая огромные объёмы. Практически везде с этим сталкивался.
Вот подборка, которую я собрал:
◽Photoprism - самый масштабный и известный продукт. Выглядит монструозно и функционально. Умеет распознавать лица, классифицировать фотографии по содержанию и координатам. Запустить можно быстро через Docker. Написан на Go. Есть мобильное приложение. На первый взгляд хороший вариант.
◽Lychee в противовес предыдущей галерее предлагает более простую функциональность базе PHP фреймворка Laravel, который работает на стандартном стэке LAMP, настройки хранит в MySQL/MariaDB, PostgreSQL или SQLite базе. Каких-то особых фишек нет, просто публичные, либо закрытые альбомы. Если не нужны навороты, то неплохой вариант. Мне нравится Laravel, на его базе получаются простые и шустрые приложения.
◽Librephotos - эта галерея написана на Python. Есть распознавание и классификация лиц, анализ и группировка по гео меткам, анализ сцены, объектов в фотках. В репе есть ссылки на все open source продукты, что используются для распознавания. На вид ничего особенного, интерфейс посмотрел. Но количество звёзд на гитхабе очень много.
◽Photoview на вид простая и лаконичная галерея. Минималистичный, но удобный для своих задач дизайн. Написан на Go и JavaScript примерно в равных пропорциях. Из анализа содержимого заявлено только распознавание лиц. Есть мобильное приложение, но только под iOS. На вид выглядит как середнячок на современном стэке с простой функциональностью.
◽Piwigo - ещё одна галерея на PHP под LAMP. Старичок из далёкого 2002 года, который развивается до сих пор. Есть темы и плагины, API, развитая система управления пользователями и их правами. За время существования проекта накопилось огромное количество плагинов. Я немного полистал список, чего там только нет. Например, плагин аутентификации пользователей через LDAP каталог.
Как я уже написал, лидером выглядит Photoprism, но лично мне, судя по всему, больше подойдёт Photoview, так как распознавания лиц мне будет достаточно.
#fileserver #подборка
Если кто-то пользуется чем-то и ему оно нравится, то поделитесь своим продуктом. Я и на работе не раз видел потребность в каких-то общих галереях. Например, для выездных специалистов, которые фотографируют объекты. Или просто перетащить куда-то в одно место фотки с корпоративов, которые забивают общие сетевые диски и расползаются по личным папкам пользователей, занимая огромные объёмы. Практически везде с этим сталкивался.
Вот подборка, которую я собрал:
◽Photoprism - самый масштабный и известный продукт. Выглядит монструозно и функционально. Умеет распознавать лица, классифицировать фотографии по содержанию и координатам. Запустить можно быстро через Docker. Написан на Go. Есть мобильное приложение. На первый взгляд хороший вариант.
◽Lychee в противовес предыдущей галерее предлагает более простую функциональность базе PHP фреймворка Laravel, который работает на стандартном стэке LAMP, настройки хранит в MySQL/MariaDB, PostgreSQL или SQLite базе. Каких-то особых фишек нет, просто публичные, либо закрытые альбомы. Если не нужны навороты, то неплохой вариант. Мне нравится Laravel, на его базе получаются простые и шустрые приложения.
◽Librephotos - эта галерея написана на Python. Есть распознавание и классификация лиц, анализ и группировка по гео меткам, анализ сцены, объектов в фотках. В репе есть ссылки на все open source продукты, что используются для распознавания. На вид ничего особенного, интерфейс посмотрел. Но количество звёзд на гитхабе очень много.
◽Photoview на вид простая и лаконичная галерея. Минималистичный, но удобный для своих задач дизайн. Написан на Go и JavaScript примерно в равных пропорциях. Из анализа содержимого заявлено только распознавание лиц. Есть мобильное приложение, но только под iOS. На вид выглядит как середнячок на современном стэке с простой функциональностью.
◽Piwigo - ещё одна галерея на PHP под LAMP. Старичок из далёкого 2002 года, который развивается до сих пор. Есть темы и плагины, API, развитая система управления пользователями и их правами. За время существования проекта накопилось огромное количество плагинов. Я немного полистал список, чего там только нет. Например, плагин аутентификации пользователей через LDAP каталог.
Как я уже написал, лидером выглядит Photoprism, но лично мне, судя по всему, больше подойдёт Photoview, так как распознавания лиц мне будет достаточно.
#fileserver #подборка
{kind=link}
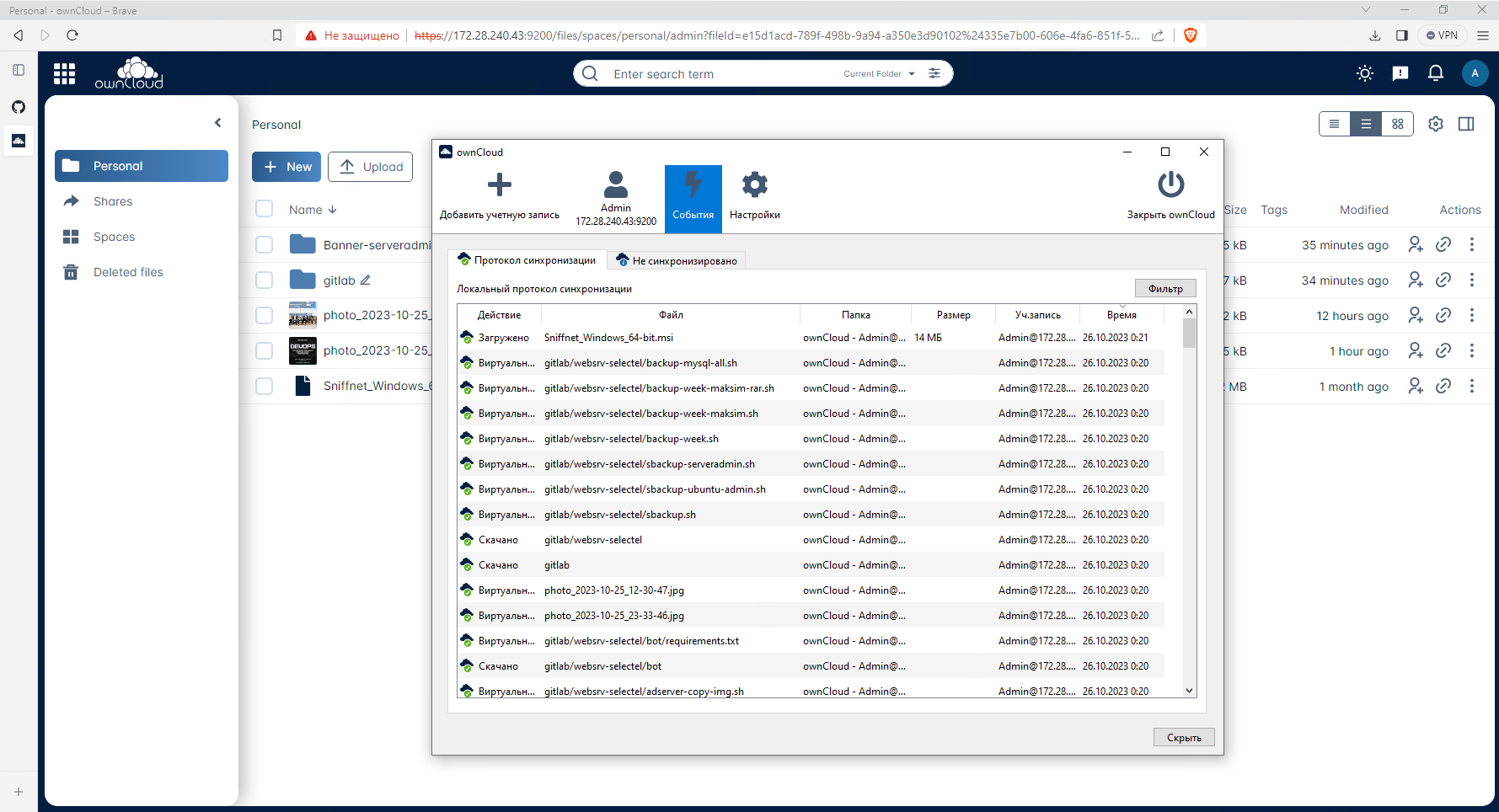
Кто-нибудь ещё помнит, использует такой продукт, как OwnCloud? Это прародитель файлового сервера Nextcloud, который появился после того, как часть разработчиков что-то не поделила в коллективе owncloud, отделилась и начала его развивать. С тех пор этот форк стал более популярен прародителя. А сам owncloud растерял всю свою популярность.
Недавно я случайно и с удивлением узнал, что оказывается OwnCloud выпустили новый продукт, написав его с нуля на Go (бэк) и Vue.js (фронт). Я не видел ни новостей, ни какой-то ещё информации на эту тему. Случайно прочитал в комментариях в каком-то обсуждении.
Заинтересовался и решил попробовать. Так как продукт относительно новый, функциональности там немного. Получился простой файловый сервер под Linux с клиентами под все популярные системы. Ну или не файловый сервер, а облачный, как их сейчас называют. Ставите себе клиентскую часть, и она автоматически синхронизирует заданные файлы с серверной частью, как яндекс.диск, dropbox, gdrive и т.д.
Основной упор сделан на производительность, отзывчивость, скорость работы. В целом, получилось неплохо. Так как ownCloud Infinite Scale 4.0, а именно так полностью называется продукт, написан на Go, то представляет из себя одиночный бинарник, который достаточно скачать и запустить:
Скачали, создали конфиг, передали некоторые переменные перед запуском и запустили сервер прямо в консоли. Для запуска в фоне нужно будет юнит systemd сделать или использовать Docker контейнер. Учётку для доступа увидите в консоли после
Я скачал и установил ownCloud client для Windows. Приложение небольшое, всего 21 мегабайт. Установил, указал IP сервера, подключился, синхронизировал файлы. Закинул туда несколько папок с 500 файлами. Переварил всё нормально и быстро, каких-то лагов, тормозов не заметил. Понятно, что объём и количество небольшое, но полноценные тесты проводить хлопотно и конкретно мне нет большого смысла.
В целом, впечатление неплохое производит. Из возможностей пока увидел только управление пользователями и создание совместных пространств для них. Подкупает лёгкость и простота установки, настройки, за счёт того, что это одиночный бинарник и единый конфиг формата yaml.
Продукт скорее всего сыроват и имеет баги. В русскоязычном интернете не нашёл вообще ни одного отзыва на него. Репозиторий продукта живой, много commits, issues. Обновления выходят регулярно. Может что и получится в итоге дельное.
⇨ Сайт / Исходники
#fileserver
Недавно я случайно и с удивлением узнал, что оказывается OwnCloud выпустили новый продукт, написав его с нуля на Go (бэк) и Vue.js (фронт). Я не видел ни новостей, ни какой-то ещё информации на эту тему. Случайно прочитал в комментариях в каком-то обсуждении.
Заинтересовался и решил попробовать. Так как продукт относительно новый, функциональности там немного. Получился простой файловый сервер под Linux с клиентами под все популярные системы. Ну или не файловый сервер, а облачный, как их сейчас называют. Ставите себе клиентскую часть, и она автоматически синхронизирует заданные файлы с серверной частью, как яндекс.диск, dropbox, gdrive и т.д.
Основной упор сделан на производительность, отзывчивость, скорость работы. В целом, получилось неплохо. Так как ownCloud Infinite Scale 4.0, а именно так полностью называется продукт, написан на Go, то представляет из себя одиночный бинарник, который достаточно скачать и запустить:
# wget -O /usr/local/bin/ocis \ https://download.owncloud.com/ocis/ocis/stable/4.0.2/ocis-4.0.2-linux-amd64# chmod +x /usr/local/bin/ocis# ocis init# OCIS_INSECURE=true \IDM_CREATE_DEMO_USERS=true \PROXY_HTTP_ADDR=0.0.0.0:9200 \OCIS_URL=https://172.28.240.43:9200 \ocis serverСкачали, создали конфиг, передали некоторые переменные перед запуском и запустили сервер прямо в консоли. Для запуска в фоне нужно будет юнит systemd сделать или использовать Docker контейнер. Учётку для доступа увидите в консоли после
ocis init. Дальше можно идти в веб интерфейс на порт хоста 9200. Я скачал и установил ownCloud client для Windows. Приложение небольшое, всего 21 мегабайт. Установил, указал IP сервера, подключился, синхронизировал файлы. Закинул туда несколько папок с 500 файлами. Переварил всё нормально и быстро, каких-то лагов, тормозов не заметил. Понятно, что объём и количество небольшое, но полноценные тесты проводить хлопотно и конкретно мне нет большого смысла.
В целом, впечатление неплохое производит. Из возможностей пока увидел только управление пользователями и создание совместных пространств для них. Подкупает лёгкость и простота установки, настройки, за счёт того, что это одиночный бинарник и единый конфиг формата yaml.
Продукт скорее всего сыроват и имеет баги. В русскоязычном интернете не нашёл вообще ни одного отзыва на него. Репозиторий продукта живой, много commits, issues. Обновления выходят регулярно. Может что и получится в итоге дельное.
⇨ Сайт / Исходники
#fileserver
{kind=link}
Для Linux есть замечательный локальный веб сервер, который можно запустить с помощью python:
Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
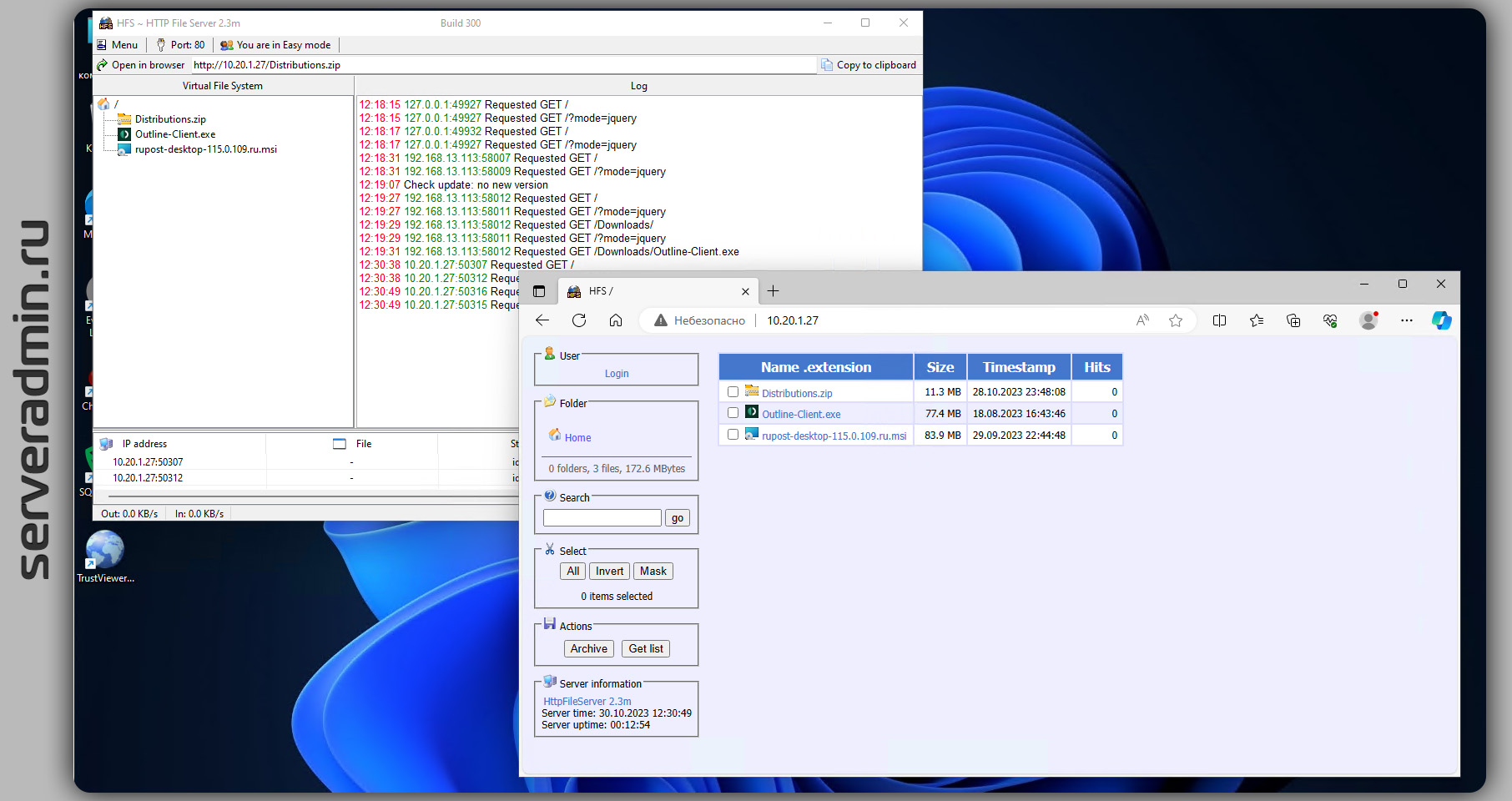
Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
# cd /var/log# python3 -m http.server 8181Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
/var/log. Когда скачали, завершаем работу. Это очень простой способ быстро передать файлы, когда не хочется ничего настраивать. Я регулярно им пользуюсь. Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
{kind=link}
❗️Сразу важное предупреждение перед непосредственно содержательной частью. Всё, что дальше будет изложено, не призыв к действию. Пишу только в качестве информации, с которой каждый сам решает, как поступать. Сразу акцентирую на этом внимание, потому что ко всем подобным заметкам постоянно пишут комментарии на тему того, что бесплатный сыр бывает только в мышеловке, свои данные нельзя ни в какие облака загружать, всё, что в облаке, принадлежит не вам и т.д.
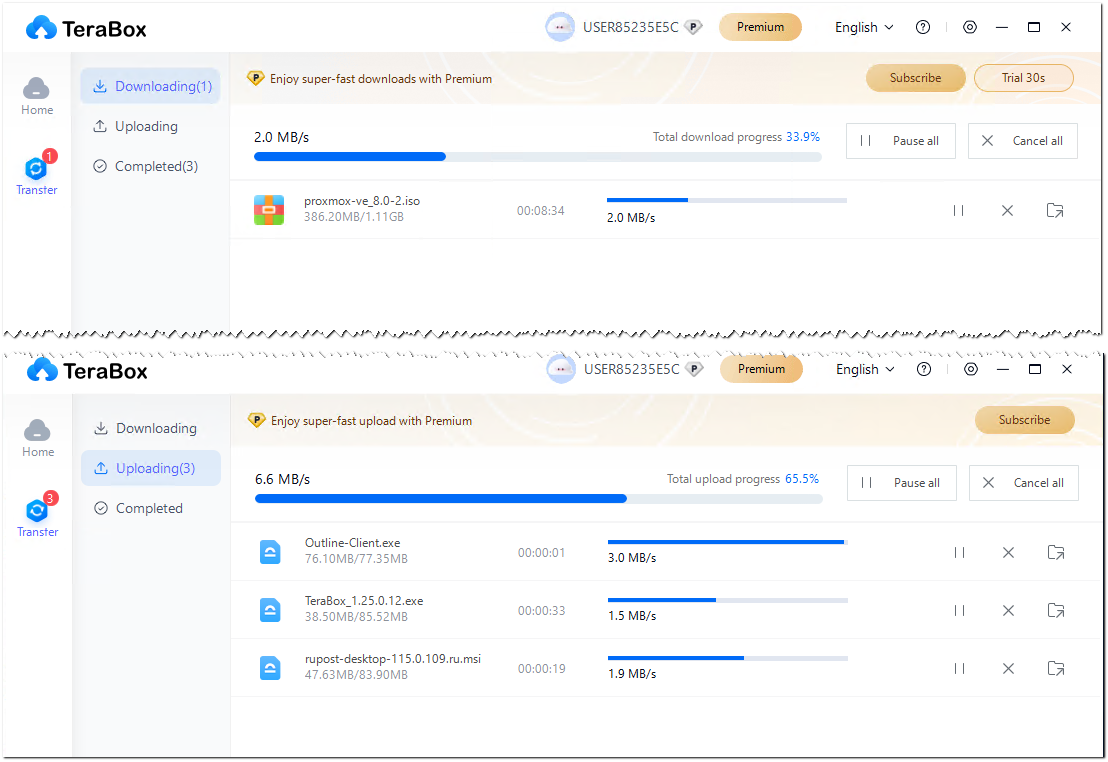
Если вам нужны 1024ГБ в бесплатном облачном хранилище, то можете таким воспользоваться - https://www.terabox.com. Для регистрации нужна только почта. Есть возможность использовать клиент в операционной системе. Ограничение на размер файла в бесплатном тарифе - 4ГБ.
Скорость загрузки и выгрузки высокая. Я протестировал лично на большом и группе мелких файлов. Загружал в облако со скоростью примерно в 50 Мбит/с с пиками до 100 Мбит/с, скачивал к себе на комп примерно со скоростью 20 Мбит/с.
Сервис всюду предлагает переход на платный тариф, но в целом работает нормально и бесплатно. Можете использовать на своё усмотрение в качестве дополнительного хранилища зашифрованных бэкапов, в качестве хранилища ISO образов (можно делать публичные ссылки), в качестве хранилища публичного медиаконтента и т.д.
Возможно, в случае активного использования бесплатного тарифа, будут введены какие-то скрытые ограничения. Я погонял туда-сюда примерно 10ГБ, никаких изменений не заметил.
#бесплатно #fileserver
Если вам нужны 1024ГБ в бесплатном облачном хранилище, то можете таким воспользоваться - https://www.terabox.com. Для регистрации нужна только почта. Есть возможность использовать клиент в операционной системе. Ограничение на размер файла в бесплатном тарифе - 4ГБ.
Скорость загрузки и выгрузки высокая. Я протестировал лично на большом и группе мелких файлов. Загружал в облако со скоростью примерно в 50 Мбит/с с пиками до 100 Мбит/с, скачивал к себе на комп примерно со скоростью 20 Мбит/с.
Сервис всюду предлагает переход на платный тариф, но в целом работает нормально и бесплатно. Можете использовать на своё усмотрение в качестве дополнительного хранилища зашифрованных бэкапов, в качестве хранилища ISO образов (можно делать публичные ссылки), в качестве хранилища публичного медиаконтента и т.д.
Возможно, в случае активного использования бесплатного тарифа, будут введены какие-то скрытые ограничения. Я погонял туда-сюда примерно 10ГБ, никаких изменений не заметил.
#бесплатно #fileserver
{kind=link}
В рамках темы по синхронизации файлов расскажу про необычный инструмент на основе git - git-annex. Это система управления файлами без индексации содержимого. С помощью git индексируются только имена, пути файлов и хэш содержимого. Для использования необходимо понимание работы git. Эта система больше всего подойдёт для индивидуального или семейного хранения файлов в разных хранилищах.
Я не буду расписывать, как эта штука работает, так как она довольно заморочена, а сразу покажу на примере. Так будет понятнее. Программа есть под все популярные ОС, но под Windows всё ещё в бете, так что запускать лучше Linux версию в WSL. В Debian и Ubuntu ставим стандартно из базовой репы:
Переходим в директорию
Добавляем файлы в репу:
Все файлы превратились в символьные ссылки, а их содержимое уехало
Скопируем этот репозиторий на условный ноутбук, который будет периодически забирать нужные файлы с сервера и пушить туда какие-то свои новые или изменения старых. Для этого он должен ходить на сервер по SSH с аутентификацией по ключу.
На ноутбуке копируем репозиторий с сервера и сразу синхронизируем:
Мы получили на ноутбуке копию репозитория, но вместо файлов у нас битые ссылки. Так и должно быть. Если вы хотите синхронизировать все реальные файлы, то сделать это можно так:
А если только один файл, то так:
Когда у вас несколько устройств работают с репозиторием, то узнать, где физически находится файл можно так:
Вернёмся на сервер и добавим в него информацию о ноуте:
Теперь репозитории знают друг о друге. На ноутбук он был клонирован с сервера, а на сервер мы вручную добавили ноутбук. Добавим новый файл в репозиторий с ноутбука:
Проверим его местонахождение:
Он только на ноутбуке. Идём на сервер, делаем там синхронизацию и поверяем местонахождение файла:
Теперь он располагается в двух местах.
Надеюсь, у меня получилось хоть немного показать, как эта штука работает. У неё много настроек. Можно очень гибко указать какие файлы по весу, количеству копий, типу папок, имени, типу содержимого нужны в каждом репозитории. Есть преднастроенные группы: backup, archive, client, transfer. Например, можно принудительно скачивать все файлы при синхронизации:
Git-annex удобен для хранения нескольких копий файлов в разных репозиториях. Вы можете подключать внешние носители и периодически синхронизировать файлы с ними, обозвав каждый носитель своим именем. В репозитории будет храниться информация о том, где какой файл лежит и сколько копий файла имеется. Вся информация о всех файлах хранится в одном общем репозитории, а физически файлы могут располагаться выборочно в разных местах.
И не забываем, что у нас все преимущества git в виде версионирования. Более подробно о работе можно почитать в документации. На первый взгляд кажется, что система слишком сложная. Для тех, кто не знаком с git, да. Но я не раз видел восторженные отзывы о системе тех, кто в ней разобрался и активно пользуется.
⇨ Сайт / Обучалка
#git #fileserver
Я не буду расписывать, как эта штука работает, так как она довольно заморочена, а сразу покажу на примере. Так будет понятнее. Программа есть под все популярные ОС, но под Windows всё ещё в бете, так что запускать лучше Linux версию в WSL. В Debian и Ubuntu ставим стандартно из базовой репы:
# apt install git-annexПереходим в директорию
/mnt/annex, где хранятся какие-то файлы и инициализируем там репозиторий, пометив его как server:# git config --global user.email "root@serveradmin.ru"# git config --global user.name "Serveradmin"# git init .# git annex init 'server'Добавляем файлы в репу:
# git annex add .# git commit -m "Добавил новые файлы"Все файлы превратились в символьные ссылки, а их содержимое уехало
.git/annex/objects.Скопируем этот репозиторий на условный ноутбук, который будет периодически забирать нужные файлы с сервера и пушить туда какие-то свои новые или изменения старых. Для этого он должен ходить на сервер по SSH с аутентификацией по ключу.
На ноутбуке копируем репозиторий с сервера и сразу синхронизируем:
# git clone ssh://user@1.2.3.4/mnt/annex# git annex init 'notebook'# git annex syncМы получили на ноутбуке копию репозитория, но вместо файлов у нас битые ссылки. Так и должно быть. Если вы хотите синхронизировать все реальные файлы, то сделать это можно так:
# git annex get .А если только один файл, то так:
# git annex get docker-iptables.shКогда у вас несколько устройств работают с репозиторием, то узнать, где физически находится файл можно так:
# git annex whereis file.txtwhereis file.txt (2 copies) 01f4d93-480af476 -- server [origin] 13f223a-e75b6a69 -- notebook [here]Вернёмся на сервер и добавим в него информацию о ноуте:
# git remote add notebook ssh://user@4.3.2.1/mnt/annex# git annex syncТеперь репозитории знают друг о друге. На ноутбук он был клонирован с сервера, а на сервер мы вручную добавили ноутбук. Добавим новый файл в репозиторий с ноутбука:
# git annex add nout.txt# git commit -m "add nout.txt"Проверим его местонахождение:
# git annex whereis nout.txtwhereis nout.txt (1 copy) 637597c-3f54f8746 -- notebook [here]Он только на ноутбуке. Идём на сервер, делаем там синхронизацию и поверяем местонахождение файла:
# git annex sync# git annex get nout.txt# git annex whereis nout.txtwhereis nout.txt (2 copies) 6307597c-3f54f5ff8746 -- [notebook] edeab032-7091559a6ca4 -- server [here]Теперь он располагается в двух местах.
Надеюсь, у меня получилось хоть немного показать, как эта штука работает. У неё много настроек. Можно очень гибко указать какие файлы по весу, количеству копий, типу папок, имени, типу содержимого нужны в каждом репозитории. Есть преднастроенные группы: backup, archive, client, transfer. Например, можно принудительно скачивать все файлы при синхронизации:
# git annex sync --contentGit-annex удобен для хранения нескольких копий файлов в разных репозиториях. Вы можете подключать внешние носители и периодически синхронизировать файлы с ними, обозвав каждый носитель своим именем. В репозитории будет храниться информация о том, где какой файл лежит и сколько копий файла имеется. Вся информация о всех файлах хранится в одном общем репозитории, а физически файлы могут располагаться выборочно в разных местах.
И не забываем, что у нас все преимущества git в виде версионирования. Более подробно о работе можно почитать в документации. На первый взгляд кажется, что система слишком сложная. Для тех, кто не знаком с git, да. Но я не раз видел восторженные отзывы о системе тех, кто в ней разобрался и активно пользуется.
⇨ Сайт / Обучалка
#git #fileserver
{kind=link}
В комментариях к заметкам про синхронизацию файлов не раз упоминались отказоустойчивые сетевые файловые системы. Прямым представителем такой файловой системы является GlusterFS. Это условный аналог Ceph, которая по своей сути не файловая система, а отказоустойчивая сеть хранения данных. Но в целом обе эти системы используются для решения одних и тех же задач. Про Ceph я писал (#ceph) уже не раз, а вот про GlusterFS не было ни одного упоминания.
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
На все 3 сервера устанавливаем glusterfs-server:
Запускаем также на всех серверах:
На server1 добавляем в пул два других сервера:
На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
На каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
Создаём на этой точке монтирования том glusterfs:
Если получите ошибку:
то проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
Если всё пошло без ошибок, то можно запускать том:
Смотрим о нём информацию:
Теперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
Можете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
/etc/hosts на каждый сервер примерно такие записи:server1 10.20.1.1server2 10.20.1.2server3 10.20.1.3На все 3 сервера устанавливаем glusterfs-server:
# apt install glusterfs-serverЗапускаем также на всех серверах:
# service glusterd startНа server1 добавляем в пул два других сервера:
# gluster peer probe server2# gluster peer probe server3На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
# gluster peer statusНа каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
/mnt/gv0.# mkfs.ext4 /dev/sdb1# mkdir /mnt/gv0# mount /dev/sdb1 /mnt/gv0Создаём на этой точке монтирования том glusterfs:
# gluster volume create gv0 replica 3 server1:/mnt/gv0 server2:/mnt/gv0 server3:/mnt/gv0Если получите ошибку:
volume create: gv0: failed: Host server1 is not in 'Peer in Cluster' stateто проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
/var/lib/glusterd.Если всё пошло без ошибок, то можно запускать том:
# gluster volume start gv0Смотрим о нём информацию:
# gluster volume infoТеперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
# mkdir /mnt/gluster-test# mount -t glusterfs server1:/gv0 /mnt/gluster-testМожете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
/mnt/gv0. По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
{kind=link}
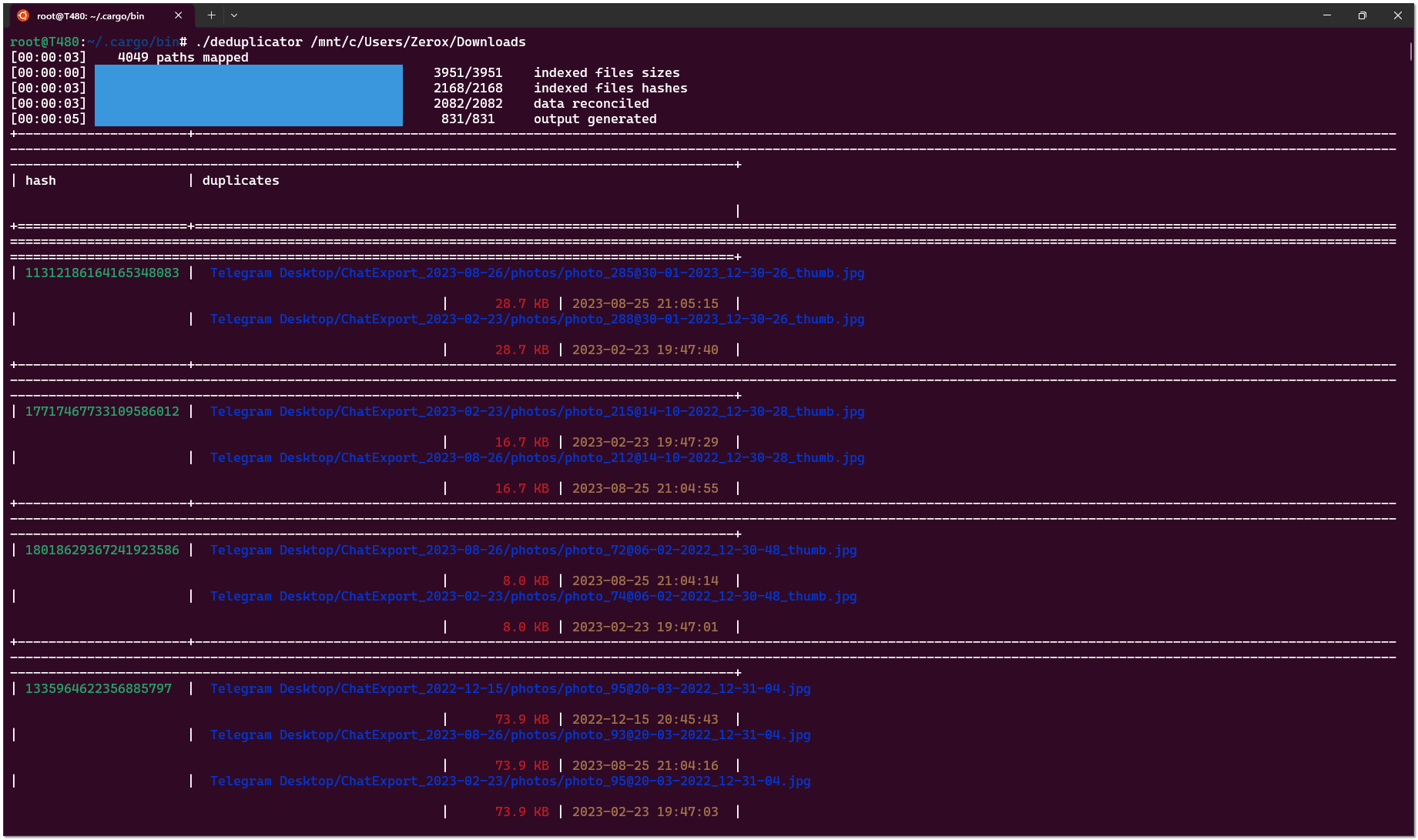
Мне неизвестны какие-то простые и эффективные способы поиска дубликатов файлов в Linux с использованием стандартного набора системных программ и утилит. Если встаёт такая задача, то приходится искать какие-то сторонние средства. Я предлагаю один из них - Deduplicator.
Deduplicator - небольшая open source программа, написанная на Rust. Написана в основном силами одного человека. Им же и поддерживается. Пока регулярно. Автор, судя по всему, любит свой продукт, поэтому старается обновлять.
Основная особенность Deduplicator - очень быстрая работа. Используется сравнение по размеру и хешам, полученных с помощью растовского алгоритма fxhash (впервые слышу о таком).
Использовать лучше самую свежую версию, потому что там появился вывод результата в json, плюс в одной из недавних версий стали выводиться полные пути дубликатов. До этого выводились обрезанные и было неудобно. Есть проблема с тем, что в репозитории собранная под Linux версия есть только годовой давности. Более свежие предлагается собирать самостоятельно. Не знаю, зачем так сделано, но я в итоге собрал сам, благо сделать это не трудно через растовый пакетный менеджер:
На выходе получаем одиночный бинарник, который можно скопировать на целевой сервер. Сразу скажу про ещё один момент, с которым столкнулся. Deduplicator хочет свежую версию glibc. Не понял точно, какую именно, но на Centos 7 не заработал. Не получилось прогнать на месте. В итоге проверку сделал на бэкап сервере. Там более свежая система - Debian 12, уже успел обновить. На Ubuntu 22 тоже завелась, почистил на своём ноуте дубликаты и домашнем медиасервере. Там дубликатов море было.
Вывод удобно направить сразу в текстовый файл и там уже смотреть:
Он будет в табличном виде. Удобен для ручного просмотра. А если нужна автоматизация, то есть вывод в
Сразу скажу, что на файловых серверах проверил дубликаты чисто для информации. Я не знаю, как системно решать проблемы с дубликатами и надо ли. Можно заменять дубликаты символьными ссылками, но в какой-то момент это может выйти боком.
⇨ Исходники
#fileserver
Deduplicator - небольшая open source программа, написанная на Rust. Написана в основном силами одного человека. Им же и поддерживается. Пока регулярно. Автор, судя по всему, любит свой продукт, поэтому старается обновлять.
Основная особенность Deduplicator - очень быстрая работа. Используется сравнение по размеру и хешам, полученных с помощью растовского алгоритма fxhash (впервые слышу о таком).
Использовать лучше самую свежую версию, потому что там появился вывод результата в json, плюс в одной из недавних версий стали выводиться полные пути дубликатов. До этого выводились обрезанные и было неудобно. Есть проблема с тем, что в репозитории собранная под Linux версия есть только годовой давности. Более свежие предлагается собирать самостоятельно. Не знаю, зачем так сделано, но я в итоге собрал сам, благо сделать это не трудно через растовый пакетный менеджер:
# apt install cargo# cargo install deduplicatorНа выходе получаем одиночный бинарник, который можно скопировать на целевой сервер. Сразу скажу про ещё один момент, с которым столкнулся. Deduplicator хочет свежую версию glibc. Не понял точно, какую именно, но на Centos 7 не заработал. Не получилось прогнать на месте. В итоге проверку сделал на бэкап сервере. Там более свежая система - Debian 12, уже успел обновить. На Ubuntu 22 тоже завелась, почистил на своём ноуте дубликаты и домашнем медиасервере. Там дубликатов море было.
Вывод удобно направить сразу в текстовый файл и там уже смотреть:
# ./deduplicator /mnt/backup/design > deduplicator.txtОн будет в табличном виде. Удобен для ручного просмотра. А если нужна автоматизация, то есть вывод в
--json с помощью соответствующего ключа.Сразу скажу, что на файловых серверах проверил дубликаты чисто для информации. Я не знаю, как системно решать проблемы с дубликатами и надо ли. Можно заменять дубликаты символьными ссылками, но в какой-то момент это может выйти боком.
⇨ Исходники
#fileserver
{kind=link}
У меня дома есть NAS и на всех компах и ноутах подключены сетевые папки. Домашние слабо представляют, как всё это работает. На смартфоне использую TotalCommander с плагином для доступа к тем же сетевым папкам. Жена наверное через TG или VK перекидывает файлы. По-другому вряд ли умеет. Детям это пока не надо.
Есть простое и удобное open source решение для этого вопроса - LocalSend. Поддерживает все операционные системы, в том числе на смартфонах. Это небольшое приложение, которое запускается на определённом порту (53317), принимает входящие соединения и с помощью нескольких методов (описание протокола, в основе поиска Multicast UDP, если не помогает, то POST запрос на все адреса локальной сети) осуществляет поиск таких же серверов в локальной сети. Передача данных осуществляется по протоколу HTTP.
На практике всё это работает автоматически. Приложение под Windows можно поставить, к примеру, через wingwet или скачать portable версию. На смартфоне ставим через Google Play, F-Droid или просто качаем apk. Работает всё в локальной сети, без необходимости каких-то внешних сервисов в интернете. Запускаем на обоих устройствах приложение, они сразу же находят друг друга. Можно передавать файлы. При этом можно на том же компе настроить такой режим, чтобы он автоматом принимал файлы со смартфона и складывал в определённую директорию.
Каждое устройство в приложении можно обозвать своим именем и передавать файлы между ними. Не знаю, где это в работе может пригодиться, но для дома очень удобно. В первую очередь простотой и поддержкой всех платформ. В программе хороший русский язык, пользоваться просто и понятно.
Мне иногда надо сыну передать со своего смартфона из родительского чата информацию от учителя с пояснениями по домашке. Я для этого делал скриншот чата, клал его на NAS, на компе с NAS копировал сыну. Через приложение передать в разы удобнее. Запустил прогу и перекинул на комп с именем СЫН. Всё. Мессенджеров и соц. сетей у него пока нет.
Это приложение, которое я попробовал и сразу развернул на всех устройствах. Жене очень понравилось.
Отдельно отмечу, что приложение написано на языке программирования Dart. Впервые о нём услышал. Сначала показалось, что это типичное приложение на JavaScript под NodeJS. Но смутил небольшой размер. После этого и пошёл смотреть, на чём написано. Оказалось, что этот язык программирования разрабатывает Google как раз для замены JavaScript, взяв от него всё лучшее, но исправив недостатки. В целом, выглядит всё это неплохо.
⇨ Сайт / Исходники
#fileserver
Есть простое и удобное open source решение для этого вопроса - LocalSend. Поддерживает все операционные системы, в том числе на смартфонах. Это небольшое приложение, которое запускается на определённом порту (53317), принимает входящие соединения и с помощью нескольких методов (описание протокола, в основе поиска Multicast UDP, если не помогает, то POST запрос на все адреса локальной сети) осуществляет поиск таких же серверов в локальной сети. Передача данных осуществляется по протоколу HTTP.
На практике всё это работает автоматически. Приложение под Windows можно поставить, к примеру, через wingwet или скачать portable версию. На смартфоне ставим через Google Play, F-Droid или просто качаем apk. Работает всё в локальной сети, без необходимости каких-то внешних сервисов в интернете. Запускаем на обоих устройствах приложение, они сразу же находят друг друга. Можно передавать файлы. При этом можно на том же компе настроить такой режим, чтобы он автоматом принимал файлы со смартфона и складывал в определённую директорию.
Каждое устройство в приложении можно обозвать своим именем и передавать файлы между ними. Не знаю, где это в работе может пригодиться, но для дома очень удобно. В первую очередь простотой и поддержкой всех платформ. В программе хороший русский язык, пользоваться просто и понятно.
Мне иногда надо сыну передать со своего смартфона из родительского чата информацию от учителя с пояснениями по домашке. Я для этого делал скриншот чата, клал его на NAS, на компе с NAS копировал сыну. Через приложение передать в разы удобнее. Запустил прогу и перекинул на комп с именем СЫН. Всё. Мессенджеров и соц. сетей у него пока нет.
Это приложение, которое я попробовал и сразу развернул на всех устройствах. Жене очень понравилось.
Отдельно отмечу, что приложение написано на языке программирования Dart. Впервые о нём услышал. Сначала показалось, что это типичное приложение на JavaScript под NodeJS. Но смутил небольшой размер. После этого и пошёл смотреть, на чём написано. Оказалось, что этот язык программирования разрабатывает Google как раз для замены JavaScript, взяв от него всё лучшее, но исправив недостатки. В целом, выглядит всё это неплохо.
⇨ Сайт / Исходники
#fileserver
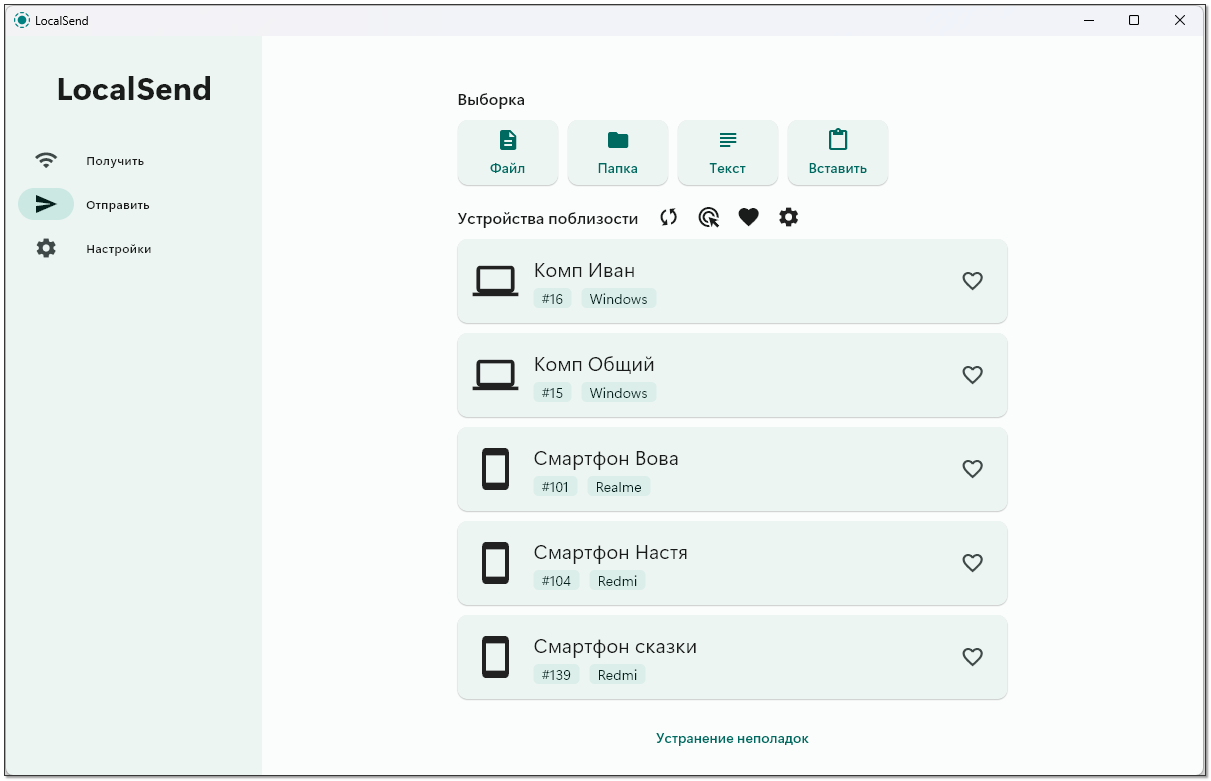{kind=link}
Когда мне нужно было быстро поднять smb сервер, чтобы разово перекинуть какие-то файлы, раньше я устанавливал samba и делал для неё простейший конфиг.
Потом в Linux появилась поддержка протокола smb и сервера на его основе в ядре в виде пакета ksmbd. Стал использовать его. Хотя принципиально ни по времени настройки, ни по удобству он особо не выигрывает у самбы. Настройка плюс-минус такая же. В нём основное преимущество в скорости по сравнению с samba, что для разовых задач непринципиально.
На днях в комментариях поделились информацией о том, что есть простой smb сервер на базе python. Решил его попробовать. Он реализован в отдельном пакете python3-impacket.
Это довольно обширный набор сетевых утилит, которые обычно используют пентестеры. В том числе там есть и smb сервер. Запустить его можно в одну строку примерно так:
◽share - имя шары
◽/mnt/share - директория для smb сервера, не забудьте на неё сделать права 777, так как доступ анонимный
◽smb2support - использовать 2-ю версию протокола, если это не добавить, то с Windows 11 подключиться не получится.
Запуск сервера реально простой и быстрый. Не нужны ни конфиги, ни службы. Запускаем в консоли команду, делаем свои дела и завершаем работу сервера. Для разовых задач идеально, если бы не довольно жирный сам пакет impacket.
Если нужна аутентификация, то её можно добавить:
Только учтите, что винда по какой-то причине не предлагает ввести имя пользователя и пароль, а пытается автоматически подключиться, используя имя пользователя и пароль, под которыми вы находитесь в системе в данный момент. Я не очень понял, почему так происходит. Если кто-то знает, поделитесь информацией. По идее, должно вылезать окно аутентификации. Но по логам smbserver вижу, что винда автоматически случится под той учёткой, от которой пытаешься подключиться.
Если подключаться с Linux, то таких проблем нет. Смотрим информацию о сетевых папках сервера:
Подключаемся к настроенной шаре:
Такой вот инструмент. В принципе, удобно. Можно использовать наравне с веб сервером.
#python #fileserver
Потом в Linux появилась поддержка протокола smb и сервера на его основе в ядре в виде пакета ksmbd. Стал использовать его. Хотя принципиально ни по времени настройки, ни по удобству он особо не выигрывает у самбы. Настройка плюс-минус такая же. В нём основное преимущество в скорости по сравнению с samba, что для разовых задач непринципиально.
На днях в комментариях поделились информацией о том, что есть простой smb сервер на базе python. Решил его попробовать. Он реализован в отдельном пакете python3-impacket.
# apt install python3-impacketЭто довольно обширный набор сетевых утилит, которые обычно используют пентестеры. В том числе там есть и smb сервер. Запустить его можно в одну строку примерно так:
# cd /usr/share/doc/python3-impacket/examples/# python3 smbserver.py share /mnt/share -smb2support◽share - имя шары
◽/mnt/share - директория для smb сервера, не забудьте на неё сделать права 777, так как доступ анонимный
◽smb2support - использовать 2-ю версию протокола, если это не добавить, то с Windows 11 подключиться не получится.
Запуск сервера реально простой и быстрый. Не нужны ни конфиги, ни службы. Запускаем в консоли команду, делаем свои дела и завершаем работу сервера. Для разовых задач идеально, если бы не довольно жирный сам пакет impacket.
Если нужна аутентификация, то её можно добавить:
# python3 smbserver.py share /mnt/share -smb2support -username user -password 123Только учтите, что винда по какой-то причине не предлагает ввести имя пользователя и пароль, а пытается автоматически подключиться, используя имя пользователя и пароль, под которыми вы находитесь в системе в данный момент. Я не очень понял, почему так происходит. Если кто-то знает, поделитесь информацией. По идее, должно вылезать окно аутентификации. Но по логам smbserver вижу, что винда автоматически случится под той учёткой, от которой пытаешься подключиться.
Если подключаться с Linux, то таких проблем нет. Смотрим информацию о сетевых папках сервера:
# smbclient -L 172.20.204.133 --user user --password=123Подключаемся к настроенной шаре:
# smbclient //172.20.204.133/share --user user --password=123Такой вот инструмент. В принципе, удобно. Можно использовать наравне с веб сервером.
#python #fileserver
{kind=link}
Прочитал интересную серию статей Building A 'Mini' 100TB NAS, где человек в трёх частях рассказывает, как он себе домой NAS собирал и обновлял. Железо там хорошее для дома. Было интересно почитать.
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
И после этого запускаете синхронизацию:
Данные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
Меня в третьей части привлёк один проект для создания хранилища с дублированием информации - SnapRAID. Я раньше не слышал про него. Это такая необычная штука не то бэкапилка, не то рейд массив. Наполовину и то, и другое. Расскажу, как она работает.
Образно SnapRAID можно сравнить с RAID 5 или RAID 6, но с ручной синхронизацией. И реализован он программно поверх уже существующей файловой системы.
Допустим, у вас сервер с четырьмя дисками. Вы хотите быть готовым к тому, что выход из строя одного из дисков не приведёт к потере данных. Тогда вы настраиваете SnapRAID следующим образом:
/mnt/diskp <- диск для контроля чётности
/mnt/disk1 <- первый диск с данными
/mnt/disk2 <- второй диск с данными
/mnt/disk3 <- третий диск с данными
Принцип получается как в обычном RAID5. Вы создаёте настройки для SnapRAID в
/etc/snapraid.conf:parity /mnt/diskp/snapraid.paritycontent /var/snapraid/snapraid.contentcontent /mnt/disk1/snapraid.contentcontent /mnt/disk2/snapraid.contentdata d1 /mnt/disk1/data d2 /mnt/disk2/data d3 /mnt/disk3/И после этого запускаете синхронизацию:
# snapraid syncДанные на дисках могут уже присутствовать. Это не принципиально. SnapRAID запустит процесс пересчёта чётности файлов, как в обычном RAID 5. Только проходит это не в режиме онлайн, а после запуска команды.
После того, как вся чётность пересчитана, данные защищены на всех дисках. Если любой из дисков выйдет из строя, у вас будет возможность восстановить данные на момент последней синхронизации.
Звучит это немного странно и я до конца не могу осознать, как это работает, потому что толком не понимаю, как контроль чётности помогает восстанавливать файлы. Но в общем это работает. Получается классический RAID 5 с ручной синхронизацией.
Надеюсь основной принцип работы я передал. Насколько я понял, подобная штука может быть очень удобной для дома. К примеру, для хранения медиа контента, к которому доступ в основном в режиме чтения. Не нужны никакие рейд контроллеры и массивы. Берём любые диски, объединяем их в SnapRAID, синхронизируем данные раз в сутки по ночам и спокойно спим. Если выйдет из строя один диск, вы ничего не теряете. Имеете честный RAID 5 с ручной синхронизацией, что для дома приемлемо. Да и не только для дома. Можно ещё где-то придумать применение.
Одной из возможностей SnapRAID является создание некоего пула, который будет объединять символьными ссылками в режиме чтения данные со всех дисков в одну точку монтирования, которую можно расшарить в сеть. То есть берёте NAS из четырёх дисков. Один диск отдаёте на контроль чётности. Три Остальных заполняете, как вам вздумается. Потом создаёте пул, шарите его по сети, подключаете к телевизору. Он видит контент со всех трёх дисков.
Выглядит эта тема на самом деле неплохо. У меня дома как раз NAS на 4 диска и у меня там 2 зеркала RAID 1 на базе mdadm. В основном хранится контент для медиацентра, фотки и немного других файлов. Вариант со SnapRAID смотрится в этом случае более привлекательным, чем два рейд массива.
Я прочитал весь Getting Started. Настраивается и управляется эта штука очень просто. Небольшой конфиг и набор простых команд. Понятен процесс восстановления файлов, добавления новых дисков. Даже если что-то пойдёт не так, то больше данных, чем было на сломавшемся диске, вы не потеряете. Не выйдет так, что массив развалился и вы остались без данных, так как они лежат в исходном виде на файловой системе.
SnapRAID есть в составе openmediavault. Он там очень давно присутствует в виде плагина. Программа представляет из себя один исполняемый файл и конфигурацию к нему. Есть как под Linux, так и Windows.
⇨ Сайт / Исходники
#fileserver #backup
{kind=link}
Регулярно приходится настраивать NFS сервер для различных прикладных задач. Причём в основном не на постоянное использование, а временное. На практике именно по nfs достигается максимальная скорость копирования, быстрее чем по scp, ssh, smb или http.
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
Устанавливаем пакет для nfs-server:
Добавляем в файл
Для всей подсети просто добавляем маску:
Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
Перезапускаем сервер
Проверяем работу:
Для работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
Проверяем, видит ли клиент что-то на сервере:
Всё в порядке, видим ресурс для нас. Монтируем его к себе:
Проверяем:
Смотрим версию протокола. Желательно, чтобы работало по v4:
Создаём файл:
При желании можно в fstab добавить на постоянку:
Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
/mnt:# mkdir /mnt/nfs# chown nobody:nogroup /mnt/nfsУстанавливаем пакет для nfs-server:
# apt install nfs-kernel-serverДобавляем в файл
/etc/exports описание экспортируемой файловой системы только для ip адреса 10.20.1.56:/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)Для всей подсети просто добавляем маску:
/mnt/nfs 10.20.1.56/24(rw,all_squash,no_subtree_check,crossmnt)Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)/mnt/nfs 10.20.1.52(rw,all_squash,no_subtree_check,crossmnt)Перезапускаем сервер
# systemctl restart nfs-serverПроверяем работу:
# systemctl status nfs-serverДля работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
# apt install nfs-commonПроверяем, видит ли клиент что-то на сервере:
# showmount -e 10.20.1.36Export list for 10.20.1.36:/mnt/nfs 10.20.1.56Всё в порядке, видим ресурс для нас. Монтируем его к себе:
# mkdir /mnt/nfs# mount 10.20.1.36:/mnt/nfs /mnt/nfsПроверяем:
# df -h | grep nfs10.20.1.36:/mnt/nfs 48G 3.2G 43G 7% /mnt/nfsСмотрим версию протокола. Желательно, чтобы работало по v4:
# mount -t nfs410.20.1.36:/ on /mnt/nfs type nfs4 (rw,relatime,vers=4.2,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.20.1.56,local_lock=none,addr=10.20.1.36)Создаём файл:
# echo "test" > /mnt/nfs/testfileПри желании можно в fstab добавить на постоянку:
10.20.1.36:/mnt/nfs /mnt/nfs nfs4 defaults 0 0Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs