
Информация для пользователей Windows. Когда я перешёл на Windows 11, очень не нравилась панель задач. Меня не устраивали два момента:
1️⃣ Панель задач нельзя перенести на правую сторону. Я очень привык держать панель справа. Современные мониторы и экраны ноутбуков вытянуты по горизонтали. Для того, чтобы рабочая зона была больше по вертикали, особенно при просмотре веб сайтов, очевидно, что лучше панель задач перенести куда-то на боковую сторону. Я это практиковал много лет. В Windows 11 очень не хватало такой возможности.
2️⃣ Мне не нравится, когда на панели задач только значки. Более того, в Windows 11 эти значки, когда активны, слабо выделены. Я уже привык и смирился с этим, но по прежнему не считаю это удобным.
И вот случилось чудо. Я попробовал программу StartAllBack, которая решила все мои задачи.
Меню Пуск и панель задач стали именно такими, 1 в 1, как нужно мне, как я привык и считаю удобным.
Программа платная, стоит недорого (~500 р.) Триал на 100 дней, пока работает он. На сайте увидел возможность оплаты через paypal, который с РФ не работает, и прямой перевод на карту. Надеюсь, последний вариант сработает. Если нет, буду как-то решать, но пользоваться уже не перестану.
#windows
1️⃣ Панель задач нельзя перенести на правую сторону. Я очень привык держать панель справа. Современные мониторы и экраны ноутбуков вытянуты по горизонтали. Для того, чтобы рабочая зона была больше по вертикали, особенно при просмотре веб сайтов, очевидно, что лучше панель задач перенести куда-то на боковую сторону. Я это практиковал много лет. В Windows 11 очень не хватало такой возможности.
2️⃣ Мне не нравится, когда на панели задач только значки. Более того, в Windows 11 эти значки, когда активны, слабо выделены. Я уже привык и смирился с этим, но по прежнему не считаю это удобным.
И вот случилось чудо. Я попробовал программу StartAllBack, которая решила все мои задачи.
> winget install startallbackМеню Пуск и панель задач стали именно такими, 1 в 1, как нужно мне, как я привык и считаю удобным.
Программа платная, стоит недорого (~500 р.) Триал на 100 дней, пока работает он. На сайте увидел возможность оплаты через paypal, который с РФ не работает, и прямой перевод на карту. Надеюсь, последний вариант сработает. Если нет, буду как-то решать, но пользоваться уже не перестану.
#windows
{kind=link}
Среди всех инструментов для управления удалёнными компьютерами есть один, который сильно отличается от остальных - Parsec. Я, честно говоря, про него вообще не слышал, пока несколько раз не увидел упоминания в комментариях к тематическим заметкам. Решил это исправить и попробовать.
Parsec изначально разрабатывался для с прицелом на высокую производительность, чтобы можно было в том числе играть в игры на удалённом компьютере. Работает на всех популярных ОС (Windows, MacOS, Linux и Android). Можно подключаться как через отдельное приложение, так и через браузер.
Основной принцип работы Parsec в том, что он захватывает необработанные кадры рабочего стола, кодирует их, отправляет по сети и декодирует на приёмнике. Для сжатия использует известные кодеки H.264 и H.265, а в качестве ресурсов может задействовать видеокарту. Если её нет, то используется программное декодирование на ресурсах процессора.
В игры я не играю, так что проверить их не смог. Но есть у меня видеосервер с камерами. Если открыть приложение с live потоком, то тормоза будут знатные, чем бы ты не подключался: rdp, anydesk, getscreen. Поставил туда Parsec и подключился. Я бы впечатлён. Он реально работает быстро и отзывчиво. Картинка с камер обновляется бодро, проверить можно по часам на каждой камере. Видно обновление каждой секунды. И при этом поток занимает примерно мегабит, когда я открыл экран с тремя камерами.
Parsec работает в виде сервиса с различными тарифными планами. Есть и бесплатный с самыми базовыми возможностями: поддерживается один монитор и одиночное подключение к компу. Насчёт устройств не увидел ограничения.
Есть только одна проблема. Судя по всему сервис соблюдает какие-то санкции, поэтому страничка с загрузкой клиента недоступна. Скачать можно через VPN, либо зайдя на эту же страницу через web.archive.org. Приложение весит буквально 3 Мб, можно скачать оттуда. Для подключения есть возможность использовать portable клиент. Дальше никаких ограничений ни с регистрацией, ни с подключением я не увидел.
Приложение классное. Странно, что я не слышал о нём раньше. Смущает только наличие ограничений с загрузкой. Как-то стрёмно с такими вводными пользоваться. Но если для личных нужд к каким-то некритичным сервисам, то пойдёт. Для своего видеосервера я приложение оставил, буду пользоваться. Там ничего критичного нет. Стоит в отдельной сетке с подключением по 4G.
⇨ Сайт
#remote
Parsec изначально разрабатывался для с прицелом на высокую производительность, чтобы можно было в том числе играть в игры на удалённом компьютере. Работает на всех популярных ОС (Windows, MacOS, Linux и Android). Можно подключаться как через отдельное приложение, так и через браузер.
Основной принцип работы Parsec в том, что он захватывает необработанные кадры рабочего стола, кодирует их, отправляет по сети и декодирует на приёмнике. Для сжатия использует известные кодеки H.264 и H.265, а в качестве ресурсов может задействовать видеокарту. Если её нет, то используется программное декодирование на ресурсах процессора.
В игры я не играю, так что проверить их не смог. Но есть у меня видеосервер с камерами. Если открыть приложение с live потоком, то тормоза будут знатные, чем бы ты не подключался: rdp, anydesk, getscreen. Поставил туда Parsec и подключился. Я бы впечатлён. Он реально работает быстро и отзывчиво. Картинка с камер обновляется бодро, проверить можно по часам на каждой камере. Видно обновление каждой секунды. И при этом поток занимает примерно мегабит, когда я открыл экран с тремя камерами.
Parsec работает в виде сервиса с различными тарифными планами. Есть и бесплатный с самыми базовыми возможностями: поддерживается один монитор и одиночное подключение к компу. Насчёт устройств не увидел ограничения.
Есть только одна проблема. Судя по всему сервис соблюдает какие-то санкции, поэтому страничка с загрузкой клиента недоступна. Скачать можно через VPN, либо зайдя на эту же страницу через web.archive.org. Приложение весит буквально 3 Мб, можно скачать оттуда. Для подключения есть возможность использовать portable клиент. Дальше никаких ограничений ни с регистрацией, ни с подключением я не увидел.
Приложение классное. Странно, что я не слышал о нём раньше. Смущает только наличие ограничений с загрузкой. Как-то стрёмно с такими вводными пользоваться. Но если для личных нужд к каким-то некритичным сервисам, то пойдёт. Для своего видеосервера я приложение оставил, буду пользоваться. Там ничего критичного нет. Стоит в отдельной сетке с подключением по 4G.
⇨ Сайт
#remote
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
▶️ На днях youtube подкинул в рекомендации забавный shorts. Автор неизвестный и канал у него не айтишный, но мне показался этот ролик забавным. Похоже, линуксоид делал.
https://www.youtube.com/shorts/_LShPDYLX2I
#юмор
https://www.youtube.com/shorts/_LShPDYLX2I
#юмор
Завожу очередную тему выходного дня, так как сам в выходные чаще всего провожу время с семьёй и детьми в частности. К прошлой заметке про развивающие игры для детей один из читателей оставил ссылку на проект piktomir.ru. Это бесплатная игра для детей младшего возраста.
ПиктоМир — свободно распространяемая программная система для изучения азов программирования дошкольниками и младшими школьниками. ПиктоМир позволяет ребенку "собрать" из пиктограмм на экране компьютера несложную программу, управляющую виртуальным исполнителем-роботом. ПиктоМир в первую очередь ориентирован на дошкольников, еще не умеющих писать, или на младшеклассников, не очень любящих писать.
Я поиграл со своим старшим сыном (9 лет). Ему понравилось. Насчёт дошкольников не уверен. Игра не сказать, что сильно простая. Да и в целом я не сторонник сажать за компьютер малышей.
В игре с помощью команд нужно запрограммировать последовательность действий робота, чтобы он закрасил в синий цвет неокрашенные квадраты. В игре никаких подсказок нет, так что я не сразу разобрался, что там делать. Пришлось посмотреть обзор. После него стало понятно, как играть. Начали проходить уровни.
Игра на самом деле интересна не только детям. Мне тоже понравилось проходить уровни. Судя по комментариям к игре в Яндексе, не только мне:
🗣 Очень познавательная и развивающая игра в плане программирования. Причём подходит не только для детей, как было заявлено. Даже я - программист со стажем - с трудом решаю некоторые задачки этой головоломки. Однозначно советую для развития конструктивного мышления.
🗣 Считаю неправильным называть эту программу игрой, так она носит скорее обучающий характер,чем развлекательный. Отлично подходит для начального обучения программированию, развивает логическое и пространственное мышление. Яркое оформление способствует дополнительной мотивации юных программистов.
Если у вас есть дети, обратите внимание. Мне кажется, это хорошая игра, чтобы вовлечь их в мир компьютера и ИТ технологий. Но, как я уже сказал, со школьного возраста. Дошкольников считаю, что нагружать компьютером не обязательно. Насидятся ещё за свою жизнь. Пока лучше пусть в песочнице играют.
#дети #игра
ПиктоМир — свободно распространяемая программная система для изучения азов программирования дошкольниками и младшими школьниками. ПиктоМир позволяет ребенку "собрать" из пиктограмм на экране компьютера несложную программу, управляющую виртуальным исполнителем-роботом. ПиктоМир в первую очередь ориентирован на дошкольников, еще не умеющих писать, или на младшеклассников, не очень любящих писать.
Я поиграл со своим старшим сыном (9 лет). Ему понравилось. Насчёт дошкольников не уверен. Игра не сказать, что сильно простая. Да и в целом я не сторонник сажать за компьютер малышей.
В игре с помощью команд нужно запрограммировать последовательность действий робота, чтобы он закрасил в синий цвет неокрашенные квадраты. В игре никаких подсказок нет, так что я не сразу разобрался, что там делать. Пришлось посмотреть обзор. После него стало понятно, как играть. Начали проходить уровни.
Игра на самом деле интересна не только детям. Мне тоже понравилось проходить уровни. Судя по комментариям к игре в Яндексе, не только мне:
🗣 Очень познавательная и развивающая игра в плане программирования. Причём подходит не только для детей, как было заявлено. Даже я - программист со стажем - с трудом решаю некоторые задачки этой головоломки. Однозначно советую для развития конструктивного мышления.
🗣 Считаю неправильным называть эту программу игрой, так она носит скорее обучающий характер,чем развлекательный. Отлично подходит для начального обучения программированию, развивает логическое и пространственное мышление. Яркое оформление способствует дополнительной мотивации юных программистов.
Если у вас есть дети, обратите внимание. Мне кажется, это хорошая игра, чтобы вовлечь их в мир компьютера и ИТ технологий. Но, как я уже сказал, со школьного возраста. Дошкольников считаю, что нагружать компьютером не обязательно. Насидятся ещё за свою жизнь. Пока лучше пусть в песочнице играют.
#дети #игра
{kind=link}
Во времена развития искусственного интеллекта сидеть и вспоминать команды и ключи консольных утилит Linux уже как-то не солидно. Пусть "вкалывают роботы, а не человек".
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
Извольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
Я не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
sed '1,10d' filenameИзвольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
find ./ -name "*.php" -exec sed -i 's/old/new/g' {} +Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
find /source/directory -type f -mtime +30 -exec ls -s {} \; \| sort -n -r | head -10 | awk '{print $2}' \| xargs -I '{}' mv '{}' /destination/directoryЯ не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
{kind=link}
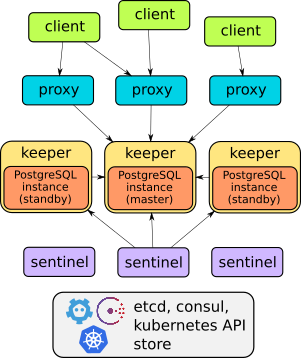
Stolon и Patroni — два наиболее известных решения для построения кластера PostgreSQL типа Leader-Followers. Про Patroni я уже как-то рассказывал. Для него есть готовый плейбук ansible — postgresql_cluster, с помощью которого можно легко и быстро развернуть нужную конфигурацию кластера.
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
{kind=link}
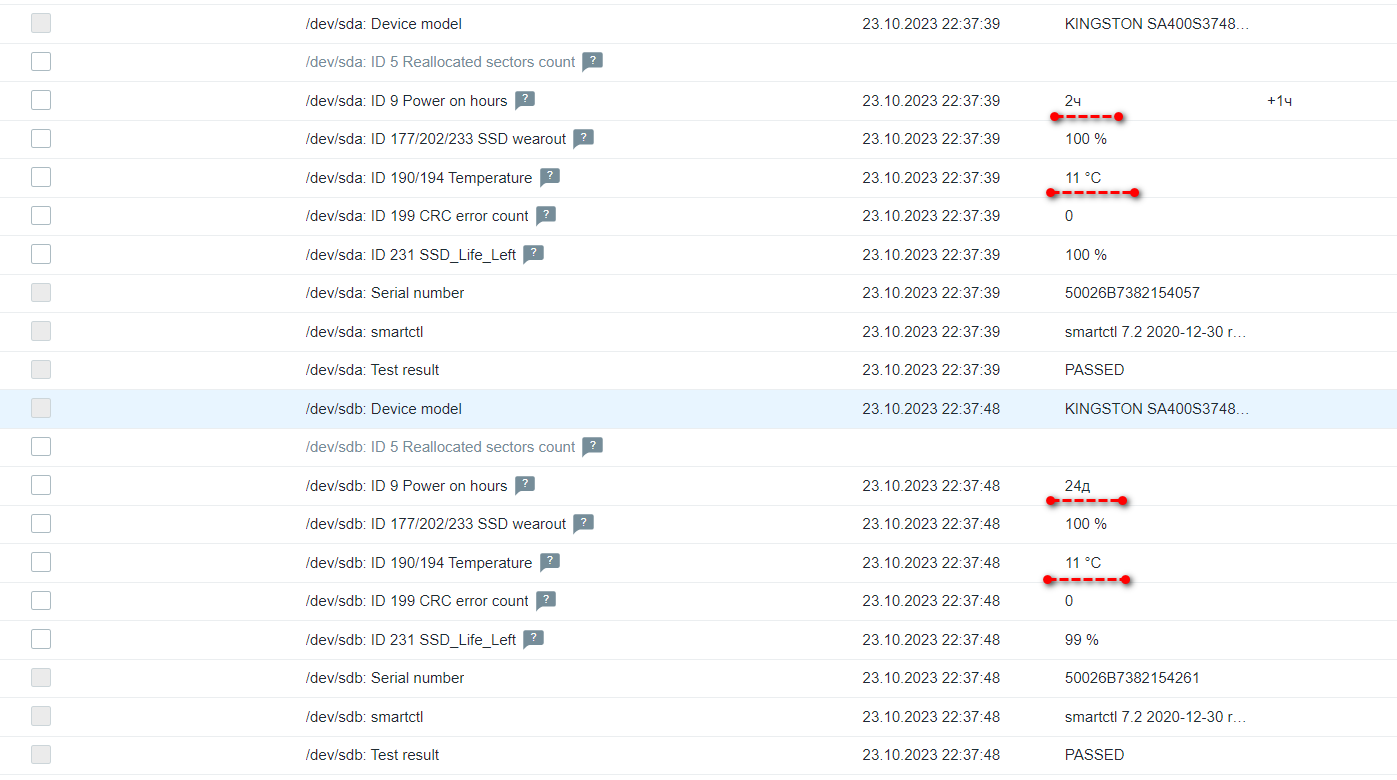
Часто можно слышать рекомендацию, не использовать в рейд массивах диски одной серии, так как для них существует высокий шанс выйти из строя плюс-минус в одно время. Лично я с таким не сталкивался и по сериям никогда диски не разделял. Я просто не очень представляю практически, как это сделать. Чаще всего покупаешь сервер, к нему пачку дисков. Всё это приезжает, монтируешь, запускаешь. А тут получается диски надо в разных магазинах брать? Или вообще разных вендоров? Я никогда так не делаю. Всегда одинаковые беру.
С арендными серверами то же самое. Обычно ставят одинаковые новые диски. Я недавно рассказывал про сервер, где вышел из строя один из идентичных SSD дисков в RAID1. Вот прошло 3 недели, и вышел из строя второй. В принципе, достаточно близко, но явно не одновременно. SMART, кстати, как обычно, не предвещал никаких проблем и не сигналил метриками. По смарту оставалось ещё 18% ресурса, но диск всё равно безвозвратно выпал из системы и перестал отвечать. Это к вопросу, нафиг вообще такой смарт нужен. С него кроме метрики температуры и серийного номера с моделью нечего смотреть. Практической ценности данные не представляют.
Забавно, что сотрудник техподдержки, который обрабатывал заявку, в этот раз уточнил, проверил ли я наличие загрузчика GRUB на живом диске. Судя по всему не раз сталкивался с тем, что люди про это забывают, а потом теряют доступ к серверу после замены единственного диска с загрузчиком. И им надо IP-KVM подключать. Проще заранее напомнить.
Про загрузчик я не забыл, так что в этот раз всё прошло штатно, как обычно по инструкции. После замены сразу же поставил загрузчик на новый диск:
Кстати, отмечу, что когда один диск из системы выпал, вышеприведённая команда не отрабатывала корректно. Завершалась с ошибкой, хотя умершего диска в списке уже не было и загрузчик я не пытался туда ставить. Так как я знал, что GRUB уже стоит на втором диске, на ошибку забил. Можно принудительно его поставить, чтобы наверняка:
Тут уже ошибок быть не должно. Если есть, надо разбираться, в чём проблема.
Теперь снова установлены 2 одинаковых диска, только уже с разницей в 23 дня. Интересно, почему в серверной Selectel так холодно? Если верить дискам, то у них температура 11 градусов сейчас. Под нагрузкой до 16 поднималась. А 3 недели назад первый диск после замены под нагрузкой до 50-ти градусов нагревался. Любопытно, как там серверная устроена, что такие разбросы по температуре.
#железо
С арендными серверами то же самое. Обычно ставят одинаковые новые диски. Я недавно рассказывал про сервер, где вышел из строя один из идентичных SSD дисков в RAID1. Вот прошло 3 недели, и вышел из строя второй. В принципе, достаточно близко, но явно не одновременно. SMART, кстати, как обычно, не предвещал никаких проблем и не сигналил метриками. По смарту оставалось ещё 18% ресурса, но диск всё равно безвозвратно выпал из системы и перестал отвечать. Это к вопросу, нафиг вообще такой смарт нужен. С него кроме метрики температуры и серийного номера с моделью нечего смотреть. Практической ценности данные не представляют.
Забавно, что сотрудник техподдержки, который обрабатывал заявку, в этот раз уточнил, проверил ли я наличие загрузчика GRUB на живом диске. Судя по всему не раз сталкивался с тем, что люди про это забывают, а потом теряют доступ к серверу после замены единственного диска с загрузчиком. И им надо IP-KVM подключать. Проще заранее напомнить.
Про загрузчик я не забыл, так что в этот раз всё прошло штатно, как обычно по инструкции. После замены сразу же поставил загрузчик на новый диск:
# dpkg-reconfigure grub-pcКстати, отмечу, что когда один диск из системы выпал, вышеприведённая команда не отрабатывала корректно. Завершалась с ошибкой, хотя умершего диска в списке уже не было и загрузчик я не пытался туда ставить. Так как я знал, что GRUB уже стоит на втором диске, на ошибку забил. Можно принудительно его поставить, чтобы наверняка:
# grub-install /dev/sdb Тут уже ошибок быть не должно. Если есть, надо разбираться, в чём проблема.
Теперь снова установлены 2 одинаковых диска, только уже с разницей в 23 дня. Интересно, почему в серверной Selectel так холодно? Если верить дискам, то у них температура 11 градусов сейчас. Под нагрузкой до 16 поднималась. А 3 недели назад первый диск после замены под нагрузкой до 50-ти градусов нагревался. Любопытно, как там серверная устроена, что такие разбросы по температуре.
#железо
{kind=link}
Последнее время частенько стали попадаться новости, связанные с известной программой для хранения паролей KeePass. Я уже ранее делал заметки по этому поводу. Сейчас попалась очередная новость:
⇨ Фальшивая реклама KeePass использует Punycode и домен, почти неотличимый от настоящего
И как раз недавно вышло обновление Keepass 2.55. Ко всему прочему это ещё и стабильный релиз, на который рекомендуется обновиться. Я сейчас внимательно проверяю все хэши скачанных файлов этой программы, хотя раньше как-то прохладно относился к таким проверкам. Да и вообще обновлял её крайне редко. Типа работает локально и ладно. Потом в какой-то момент почитал изменения новых версий, какие и в каком количестве там баги закрывают. И стал обновляться регулярно.
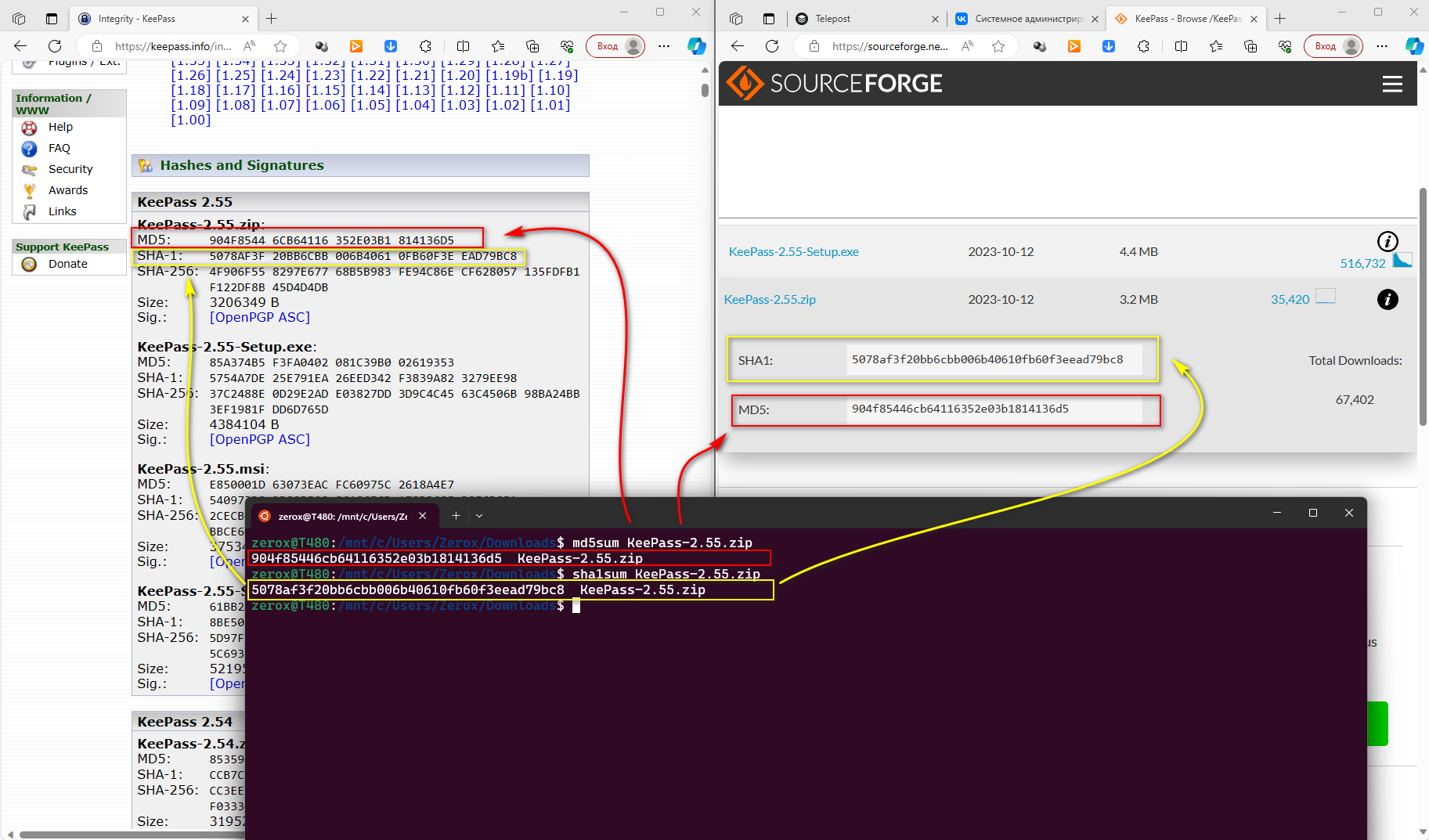
Файлы для загрузки KeePass лежат на sourceforge.net. Там есть возможность посмотреть хэши и сравнить с тем, что к тебе приехало, и с тем, что указано на сайте разработчиков. Я на всякий случай рекомендую делать сверку. В консоли это выполнить проще всего:
Если надо быстро сравнить, то делаем примерно так:
Берём хэш с сайта и выполняем проверку с локальным файлом через ключ
Проверяете файлы по контрольным суммам? Только честно.
#security
⇨ Фальшивая реклама KeePass использует Punycode и домен, почти неотличимый от настоящего
И как раз недавно вышло обновление Keepass 2.55. Ко всему прочему это ещё и стабильный релиз, на который рекомендуется обновиться. Я сейчас внимательно проверяю все хэши скачанных файлов этой программы, хотя раньше как-то прохладно относился к таким проверкам. Да и вообще обновлял её крайне редко. Типа работает локально и ладно. Потом в какой-то момент почитал изменения новых версий, какие и в каком количестве там баги закрывают. И стал обновляться регулярно.
Файлы для загрузки KeePass лежат на sourceforge.net. Там есть возможность посмотреть хэши и сравнить с тем, что к тебе приехало, и с тем, что указано на сайте разработчиков. Я на всякий случай рекомендую делать сверку. В консоли это выполнить проще всего:
# md5sum KeePass-2.55.zip# sha1sum KeePass-2.55.zipЕсли надо быстро сравнить, то делаем примерно так:
# echo "5078AF3F20BB6CBB006B40610FB60F3EEAD79BC8 KeePass-2.55.zip" \| sha1sum -cKeePass-2.55.zip: OKБерём хэш с сайта и выполняем проверку с локальным файлом через ключ
-c. Проверяете файлы по контрольным суммам? Только честно.
#security
{kind=link}
Вчера смотрел очень информативный вебинар Rebrain про оптимизацию запросов MySQL. Планирую сделать по нему заметку, когда запись появится в личном кабинете. Когда автор упомянул свой клиент MySQL Workbench, в чате начали присылать другие варианты клиентов. Я вспомнил, что несколько лет назад делал серию заметок по этой теме. Решил сформировать их в единый список. Думаю, будет полезно. С MySQL постоянно приходится работать в различных приложениях и сайтах.
🟢 MySQL клиенты в виде приложений:
▪ MySQL Workbench - самый навороченный, функциональный и тормозной клиент от авторов непосредственно СУБД MySQL. Если нужен максимум возможностей, то это про него. В большинстве случаев всё это не надо, если вы не разработчик.
▪ HeidiSQL - маленький и шустрый клиент, есть портированная версия. Для типовых задач системного администратора будет достаточно. Я его последнее время использовал, когда нужно было. Но давно это было.
▪ Dbeaver - отличается в первую очередь хорошей поддержкой PostgreSQL и часто используется именно для неё. Если нужно только MySQL, то лучше взять HeidiSQL.
🟡 MySQL клиенты в виде скриптов:
▪ PhpMyAdmin - думаю, не нуждается в представлении. Я почти всегда использую именно его. Его же обычно просят и разработчики. В публичный доступ не рекомендую его выставлять. Если хочется разово запустить, но не хочется настраивать веб сервер, то можно быстро запустить через встроенный в php веб сервер.
▪ Adminer - простенький php скрипт из одного файла. Очень удобно, если не хочется ничего настраивать, а нужно быстро зайти в базу и что-то там сделать. Как закончишь, скрипт можно просто удалить.
Тру админы наверняка начнут сейчас писать в комментариях, что не надо никаких внешних клиентов. Заходим консольным клиентом и делаем всё, что надо. Иногда я так делаю, но приходится вспоминать синтаксис, так как нужен он редко. Время тратится больше. Тот же adminer быстрее закинуть, чем вспомнить, как правильно написать запрос на создание пользователя и выставление для него прав на базу. Другое дело, если копипастишь откуда-то команды. Тогда можно и в консольный клиент.
#mysql #подборка
🟢 MySQL клиенты в виде приложений:
▪ MySQL Workbench - самый навороченный, функциональный и тормозной клиент от авторов непосредственно СУБД MySQL. Если нужен максимум возможностей, то это про него. В большинстве случаев всё это не надо, если вы не разработчик.
▪ HeidiSQL - маленький и шустрый клиент, есть портированная версия. Для типовых задач системного администратора будет достаточно. Я его последнее время использовал, когда нужно было. Но давно это было.
▪ Dbeaver - отличается в первую очередь хорошей поддержкой PostgreSQL и часто используется именно для неё. Если нужно только MySQL, то лучше взять HeidiSQL.
🟡 MySQL клиенты в виде скриптов:
▪ PhpMyAdmin - думаю, не нуждается в представлении. Я почти всегда использую именно его. Его же обычно просят и разработчики. В публичный доступ не рекомендую его выставлять. Если хочется разово запустить, но не хочется настраивать веб сервер, то можно быстро запустить через встроенный в php веб сервер.
▪ Adminer - простенький php скрипт из одного файла. Очень удобно, если не хочется ничего настраивать, а нужно быстро зайти в базу и что-то там сделать. Как закончишь, скрипт можно просто удалить.
Тру админы наверняка начнут сейчас писать в комментариях, что не надо никаких внешних клиентов. Заходим консольным клиентом и делаем всё, что надо. Иногда я так делаю, но приходится вспоминать синтаксис, так как нужен он редко. Время тратится больше. Тот же adminer быстрее закинуть, чем вспомнить, как правильно написать запрос на создание пользователя и выставление для него прав на базу. Другое дело, если копипастишь откуда-то команды. Тогда можно и в консольный клиент.
#mysql #подборка
{kind=link}
Предлагаю вашему вниманию любопытный проект по мониторингу одиночного хоста с Docker - domolo. Сразу скажу, что это продукт уровня курсовой работы с каких-нибудь курсов по DevOps на тему мониторинга. Он представляет из себя преднастроенный набор контейнеров на современном стеке.
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
Идём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
# git clone https://github.com/ductnn/domolo.git# cd domolo# docker-compose up -dИдём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
{kind=link}
Я посмотрел два больших информативных вебинара про оптимизацию запросов в MySQL. Понятно, что в формате заметки невозможно раскрыть тему, поэтому я сделаю выжимку основных этапов и инструментов, которые используются. Кому нужна будет эта тема, сможет раскрутить её на основе этих вводных.
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
log_error = /var/log/mysql/error.logslow_query_logslow_query_log_file = /var/log/mysql/slow.loglong_query_time = 2.0Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
{kind=link}
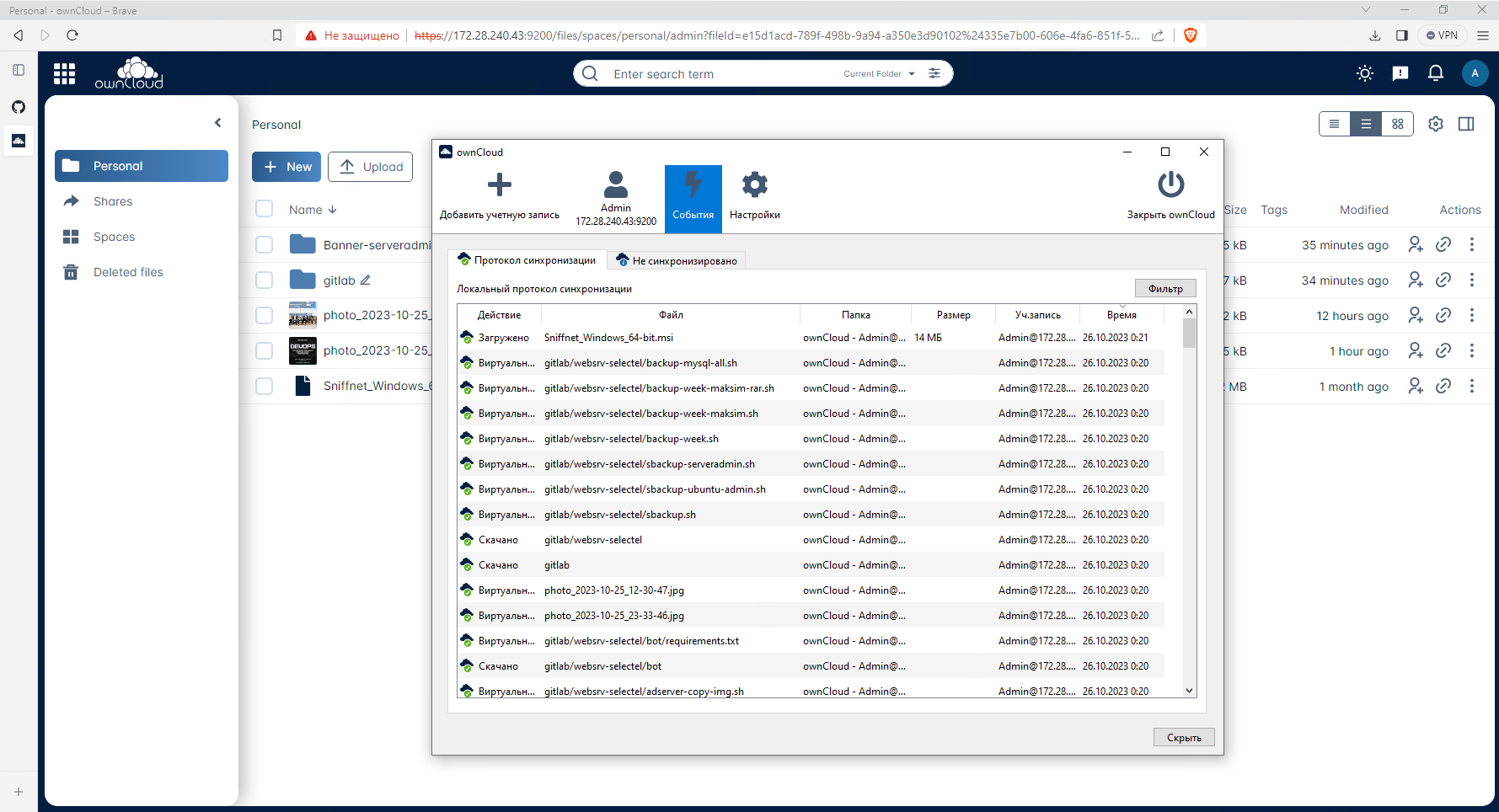
Кто-нибудь ещё помнит, использует такой продукт, как OwnCloud? Это прародитель файлового сервера Nextcloud, который появился после того, как часть разработчиков что-то не поделила в коллективе owncloud, отделилась и начала его развивать. С тех пор этот форк стал более популярен прародителя. А сам owncloud растерял всю свою популярность.
Недавно я случайно и с удивлением узнал, что оказывается OwnCloud выпустили новый продукт, написав его с нуля на Go (бэк) и Vue.js (фронт). Я не видел ни новостей, ни какой-то ещё информации на эту тему. Случайно прочитал в комментариях в каком-то обсуждении.
Заинтересовался и решил попробовать. Так как продукт относительно новый, функциональности там немного. Получился простой файловый сервер под Linux с клиентами под все популярные системы. Ну или не файловый сервер, а облачный, как их сейчас называют. Ставите себе клиентскую часть, и она автоматически синхронизирует заданные файлы с серверной частью, как яндекс.диск, dropbox, gdrive и т.д.
Основной упор сделан на производительность, отзывчивость, скорость работы. В целом, получилось неплохо. Так как ownCloud Infinite Scale 4.0, а именно так полностью называется продукт, написан на Go, то представляет из себя одиночный бинарник, который достаточно скачать и запустить:
Скачали, создали конфиг, передали некоторые переменные перед запуском и запустили сервер прямо в консоли. Для запуска в фоне нужно будет юнит systemd сделать или использовать Docker контейнер. Учётку для доступа увидите в консоли после
Я скачал и установил ownCloud client для Windows. Приложение небольшое, всего 21 мегабайт. Установил, указал IP сервера, подключился, синхронизировал файлы. Закинул туда несколько папок с 500 файлами. Переварил всё нормально и быстро, каких-то лагов, тормозов не заметил. Понятно, что объём и количество небольшое, но полноценные тесты проводить хлопотно и конкретно мне нет большого смысла.
В целом, впечатление неплохое производит. Из возможностей пока увидел только управление пользователями и создание совместных пространств для них. Подкупает лёгкость и простота установки, настройки, за счёт того, что это одиночный бинарник и единый конфиг формата yaml.
Продукт скорее всего сыроват и имеет баги. В русскоязычном интернете не нашёл вообще ни одного отзыва на него. Репозиторий продукта живой, много commits, issues. Обновления выходят регулярно. Может что и получится в итоге дельное.
⇨ Сайт / Исходники
#fileserver
Недавно я случайно и с удивлением узнал, что оказывается OwnCloud выпустили новый продукт, написав его с нуля на Go (бэк) и Vue.js (фронт). Я не видел ни новостей, ни какой-то ещё информации на эту тему. Случайно прочитал в комментариях в каком-то обсуждении.
Заинтересовался и решил попробовать. Так как продукт относительно новый, функциональности там немного. Получился простой файловый сервер под Linux с клиентами под все популярные системы. Ну или не файловый сервер, а облачный, как их сейчас называют. Ставите себе клиентскую часть, и она автоматически синхронизирует заданные файлы с серверной частью, как яндекс.диск, dropbox, gdrive и т.д.
Основной упор сделан на производительность, отзывчивость, скорость работы. В целом, получилось неплохо. Так как ownCloud Infinite Scale 4.0, а именно так полностью называется продукт, написан на Go, то представляет из себя одиночный бинарник, который достаточно скачать и запустить:
# wget -O /usr/local/bin/ocis \ https://download.owncloud.com/ocis/ocis/stable/4.0.2/ocis-4.0.2-linux-amd64# chmod +x /usr/local/bin/ocis# ocis init# OCIS_INSECURE=true \IDM_CREATE_DEMO_USERS=true \PROXY_HTTP_ADDR=0.0.0.0:9200 \OCIS_URL=https://172.28.240.43:9200 \ocis serverСкачали, создали конфиг, передали некоторые переменные перед запуском и запустили сервер прямо в консоли. Для запуска в фоне нужно будет юнит systemd сделать или использовать Docker контейнер. Учётку для доступа увидите в консоли после
ocis init. Дальше можно идти в веб интерфейс на порт хоста 9200. Я скачал и установил ownCloud client для Windows. Приложение небольшое, всего 21 мегабайт. Установил, указал IP сервера, подключился, синхронизировал файлы. Закинул туда несколько папок с 500 файлами. Переварил всё нормально и быстро, каких-то лагов, тормозов не заметил. Понятно, что объём и количество небольшое, но полноценные тесты проводить хлопотно и конкретно мне нет большого смысла.
В целом, впечатление неплохое производит. Из возможностей пока увидел только управление пользователями и создание совместных пространств для них. Подкупает лёгкость и простота установки, настройки, за счёт того, что это одиночный бинарник и единый конфиг формата yaml.
Продукт скорее всего сыроват и имеет баги. В русскоязычном интернете не нашёл вообще ни одного отзыва на него. Репозиторий продукта живой, много commits, issues. Обновления выходят регулярно. Может что и получится в итоге дельное.
⇨ Сайт / Исходники
#fileserver
{kind=link}
В это трудно поверить, но я никогда не проверял, что в реальности будет, если сделать
И вот решил на тестовой виртуалке посмотреть, а что реально произойдёт после
И всё реально удалилось, кроме раздела
Работают только те утилиты, что встроены в оболочку. Например echo, pwd, type, cd и т.д.:
То есть переместиться в /sys/module/ можно. А вот что-то сделать там - нет. Подключиться новой сессией или залогоиниться через терминал уже не получится. Даже команду
После перезагрузки отработает загрузчик в boot разделе, так как его мы не трогали, он вне корня / и увидим консоль grub rescue. Сделать там уже ничего не получится, потому что данных нет. Грузиться неоткуда. Хотя встроенные в grub утилиты тоже работают. Через ls можно увидеть разделы диска и даже оставшееся содержимое:
Некоторые директории выжили.
С виртуалкой больше делать нечего. Мы её гарантированно прибили.
#linux
rm -rf на весь корневой раздел. Однажды на заре карьеры я ошибся с удалением и запустил удаление по корню. Но это была не команда rm, а что-то другое. Уже не помню подробностей. Тогда ещё сервера были железные и это реально стало проблемой. Сервер ещё не ввели в прод, но я на нём уже что-настроил. Ошибку сразу заметил и отменил команду. Сначала подумал, что обошлось, но потом заметил, что пропали все символьные ссылки, хотя в целом система работала и нормально перезагружалась. Пришлось всё равно всё переделать. И вот решил на тестовой виртуалке посмотреть, а что реально произойдёт после
rm -rf /. В таком виде команда не отработала и попросила добавить ключ --no-preserve-root. Я это сделал:# rm -rf / --no-preserve-rootИ всё реально удалилось, кроме раздела
/dev и загруженных системных модулей в /sys/module/. Причём так буднично, без каких-то особых сообщений, фатальных ошибок или чего-то ещё. Сидишь в системе, где нет ничего, кроме того, что было загружено в память. Оболочка bash работает, можно что-то поделать, но не сильно много. Бинарников то нет. Работают только те утилиты, что встроены в оболочку. Например echo, pwd, type, cd и т.д.:
# type cdcd is a shell builtinТо есть переместиться в /sys/module/ можно. А вот что-то сделать там - нет. Подключиться новой сессией или залогоиниться через терминал уже не получится. Даже команду
reboot не сделать. Это бинарник, а его нет. Тем не менее, сервер всё ещё можно штатно отправить в reboot. Интересно, много ли людей знают, как это сделать? Пишите предложения в комментарии. Я потом напишу ответ, если его не будет. После перезагрузки отработает загрузчик в boot разделе, так как его мы не трогали, он вне корня / и увидим консоль grub rescue. Сделать там уже ничего не получится, потому что данных нет. Грузиться неоткуда. Хотя встроенные в grub утилиты тоже работают. Через ls можно увидеть разделы диска и даже оставшееся содержимое:
# ls (hd0,msdos1)/./ ../ var/ tmp/ dev/ proc/ run/ sys/Некоторые директории выжили.
С виртуалкой больше делать нечего. Мы её гарантированно прибили.
#linux
{kind=link}
▶️ Традиционная пятничная тема на вечер. Я когда-то давно смотрел (писал об этом) сериал ITить-КОЛОТИТЬ, снятый одним облачным провайдером. Не могу сказать, что он прям сильно интересный и смешной, но, в целом, нормально. Отдельные серии мне понравились. С учётом того, что подобных русскоязычных работ я вообще не знаю, то и сравнивать не с чем. Можно глянуть.
Они сняли второй сезон, который я недавно увидел и посмотрел. В целом - так себе, мне показалось, похуже первого. Какой-то муженавистнический получился (директор и ибэшник - женщины, издеваются над админом, а он вяло над ними). Но это субъективно, так что кому-то может и зайдёт. Посмотрите, если будет желание:
⇨ ITить-КОЛОТИТЬ 2 сезон
К следующей пятнице планирую собрать подборку из англоязычных похожих сериалов. Сразу вспоминается Nick Burns и скетчи Bored про магазин компьютерных комплектующих. Если у кого-то есть на примете что-то интересное на IT тему, поделитесь в комментариях.
#юмор
Они сняли второй сезон, который я недавно увидел и посмотрел. В целом - так себе, мне показалось, похуже первого. Какой-то муженавистнический получился (директор и ибэшник - женщины, издеваются над админом, а он вяло над ними). Но это субъективно, так что кому-то может и зайдёт. Посмотрите, если будет желание:
⇨ ITить-КОЛОТИТЬ 2 сезон
К следующей пятнице планирую собрать подборку из англоязычных похожих сериалов. Сразу вспоминается Nick Burns и скетчи Bored про магазин компьютерных комплектующих. Если у кого-то есть на примете что-то интересное на IT тему, поделитесь в комментариях.
#юмор
{kind=link}
Я знаю, что меня читают многие авторы Telegram каналов. И также я знаю как минимум 2 IT канала, которые читаю, и которые у авторов в итоге увели мошенники. Cегодня закончил общаться с одним мошенником, который понял, что не смог меня развести и сразу же удалил всю переписку. Делаю эту публикацию, чтобы предупредить остальных.
С самого начала предполагал, что разговариваю с мошенником, поэтому под конец диалога успел его сохранить и выгрузить через стандартный экспорт Telegram. Основная идея разводки в том, что вам предлагают сразу много рекламных публикаций. Идёт проверка на жадность. Как известно, жадность - это порок, не надо ей поддаваться. Некоторые проверку не проходят, так как мысленно уже начинают считать доходы от заказанных 5 или 10 рекламных публикаций.
Ну а дальше вам либо ссылку на какой-то левый сайт дают для заполнения анкеты, либо на Telegram бота, как в моём случае. Что делает этот бот, я не знаю, не заходил туда. Сразу понял, что тема мутная и это развод. Ниже диалог выкладываю. Аккаунт мошенника: @avdeev1Dm
Виктор Авдеев
Добрый день!!Интересуюсь размещениями на вашем канале.Можем обговорить ценники?
Vladimir Zp
Добрый день. Вся информация есть в боте. Если будут дополнительные вопросы, задавайте.
Виктор Авдеев
Хорошо,а где я могу более детально ознакомиться со статистикой канала?
(*тут я уже понял, что это развод)
Vladimir Zp
А чем недостаточна статистика на tgstat? Она очень подробная. Я не знаю, где есть более полная.
Виктор Авдеев
Ладно.Наши аналитики сверяют данные.Я вам напишу!
Виктор Авдеев
Здравствуйте!Нам подходит.Интересуемся оптовой закупок в количестве 5 постов.Какой будет конечный ценник?
Vladimir Zp
У меня нет скидок за объём.
Виктор Авдеев
Ладно.
Какие ближайшие даты свободны?
Vladimir Zp
Давайте для начала рекламные посты посмотрим. Вы что хотите рекламировать? Если по содержанию всё ок будет, обсудим дальше дела.
Виктор Авдеев
(*присылает несколько постов с рекламой ноубуков в магазине Эльдорадо)
Маркировки требуются?
Vladimir Zp
По содержимому ОК. Я готов это публиковать. Маркировка будет.
Виктор Авдеев
Отлично!
С чьей стороны будет маркировка?
Vladimir Zp
Я могу всё сам промаркировать. Это не проблема.
Виктор Авдеев
Договорились,Владимир. Какие ближайшие даты свободны?
Vladimir Zp
(*отправляю картинку с календарём)
Это ноябрь. То, что красное, уже занято. Раньше 9-го ноября свободных дат нет.
Виктор Авдеев
Нас интересуют даты начиная с 11 числа.По 1 посту с интервалом в 3 дня.Так можно будет сделать?
Vladimir Zp
Календарь я скинул, те даты, что красным отмечены, уже забронированы и оплачены. Остальные вы можете выбрать.
Виктор Авдеев
Хорошо. Ещё один момент нас интересует.Сколько постов схожей тематики будут конкурировать с нашими?
Vladimir Zp
Рекламы ноутбуков у меня вообще нет и не было никогда.
Виктор Авдеев
Отлично! Нам все подходит!Для оформления нашего сотрудничества вам нужно будет составить рекламную анкету в нашем официальном телеграмм боте - @Acer_corporation_bot
После прохождения модерации,в течении 15-20 минут старший менеджер подтвердит заявку и средства будут начислены внутри бота,после чего у вас открывается возможность вывода денег на вашу карту/криптовалюту
Vladimir Zp
Спасибо, мне это не интересно.
Дальше были ещё прикольные моменты, но диалог не сохранился, так как мошенник почти сразу же его удалил, в том числе и у меня. Это отвратительная возможность Telegram. Из-за этого часто приходится сохранять переписку и делать скрины, иначе потом невозможно подтвердить что-то из разговора, который удалит вторая сторона.
#разное
С самого начала предполагал, что разговариваю с мошенником, поэтому под конец диалога успел его сохранить и выгрузить через стандартный экспорт Telegram. Основная идея разводки в том, что вам предлагают сразу много рекламных публикаций. Идёт проверка на жадность. Как известно, жадность - это порок, не надо ей поддаваться. Некоторые проверку не проходят, так как мысленно уже начинают считать доходы от заказанных 5 или 10 рекламных публикаций.
Ну а дальше вам либо ссылку на какой-то левый сайт дают для заполнения анкеты, либо на Telegram бота, как в моём случае. Что делает этот бот, я не знаю, не заходил туда. Сразу понял, что тема мутная и это развод. Ниже диалог выкладываю. Аккаунт мошенника: @avdeev1Dm
Виктор Авдеев
Добрый день!!Интересуюсь размещениями на вашем канале.Можем обговорить ценники?
Vladimir Zp
Добрый день. Вся информация есть в боте. Если будут дополнительные вопросы, задавайте.
Виктор Авдеев
Хорошо,а где я могу более детально ознакомиться со статистикой канала?
(*тут я уже понял, что это развод)
Vladimir Zp
А чем недостаточна статистика на tgstat? Она очень подробная. Я не знаю, где есть более полная.
Виктор Авдеев
Ладно.Наши аналитики сверяют данные.Я вам напишу!
Виктор Авдеев
Здравствуйте!Нам подходит.Интересуемся оптовой закупок в количестве 5 постов.Какой будет конечный ценник?
Vladimir Zp
У меня нет скидок за объём.
Виктор Авдеев
Ладно.
Какие ближайшие даты свободны?
Vladimir Zp
Давайте для начала рекламные посты посмотрим. Вы что хотите рекламировать? Если по содержанию всё ок будет, обсудим дальше дела.
Виктор Авдеев
(*присылает несколько постов с рекламой ноубуков в магазине Эльдорадо)
Маркировки требуются?
Vladimir Zp
По содержимому ОК. Я готов это публиковать. Маркировка будет.
Виктор Авдеев
Отлично!
С чьей стороны будет маркировка?
Vladimir Zp
Я могу всё сам промаркировать. Это не проблема.
Виктор Авдеев
Договорились,Владимир. Какие ближайшие даты свободны?
Vladimir Zp
(*отправляю картинку с календарём)
Это ноябрь. То, что красное, уже занято. Раньше 9-го ноября свободных дат нет.
Виктор Авдеев
Нас интересуют даты начиная с 11 числа.По 1 посту с интервалом в 3 дня.Так можно будет сделать?
Vladimir Zp
Календарь я скинул, те даты, что красным отмечены, уже забронированы и оплачены. Остальные вы можете выбрать.
Виктор Авдеев
Хорошо. Ещё один момент нас интересует.Сколько постов схожей тематики будут конкурировать с нашими?
Vladimir Zp
Рекламы ноутбуков у меня вообще нет и не было никогда.
Виктор Авдеев
Отлично! Нам все подходит!Для оформления нашего сотрудничества вам нужно будет составить рекламную анкету в нашем официальном телеграмм боте - @Acer_corporation_bot
После прохождения модерации,в течении 15-20 минут старший менеджер подтвердит заявку и средства будут начислены внутри бота,после чего у вас открывается возможность вывода денег на вашу карту/криптовалюту
Vladimir Zp
Спасибо, мне это не интересно.
Дальше были ещё прикольные моменты, но диалог не сохранился, так как мошенник почти сразу же его удалил, в том числе и у меня. Это отвратительная возможность Telegram. Из-за этого часто приходится сохранять переписку и делать скрины, иначе потом невозможно подтвердить что-то из разговора, который удалит вторая сторона.
#разное
Недавно один человек у меня попросил совета по поводу программы для бэкапов в Linux на базе rsync, но только чтобы была полноценная поддержка инкрементных архивов, чтобы можно было вернуться назад на заданный день. Я знаю, что базовыми возможностями rsync без костылей и скриптов такое не сделать, поэтому сразу вспомнил про программу rdiff-backup. Хотел скинуть ссылку на свою заметку, но с удивлением обнаружил, что я вообще ни разу про неё не писал, хотя сам лично использовал.
Rdiff-backup по своей сути является python обёрткой вокруг rsync (используется библиотека librsync). Она наследует всю скорость и быстроту синхронизации сотен тысяч файлов, которую обеспечивает rsync. Если нужны бэкапы сырых файлов, без упаковки в архивы, дедупликации, сжатия и т.д., то я всегда предпочитаю использовать именно rsync. С ним быстрее и проще всего получить точную пофайловую копию какого-то файлового хранилища, которое регулярно синхронизируется. Это идеальный инструмент для организации горячего резерва файлового архива. В случае выхода из строя основного сервера или хранилища с файлами, можно очень быстро подмонтировать или организовать подключение копии, создаваемой с помощью rsync.
Особенно это актуально для почтовых серверов с форматом хранения maildir. Там каждое письмо это отдельный файл. В итоге файловое хранилище превращается в сотни тысяч мелких файлов, которые один раз скопировать может и не проблема, но каждый день актуализировать копию уже не так просто, так как надо сравнить источник и приёмник, где с каждой стороны огромное количество файлов и они меняются. По моему опыту, rsync это делает быстрее всех. Я даже на Windows сервера ставлю rsync и бэкаплю большие файловые хранилища с его помощью.
Возвращаюсь к Rdiff-backup. Он расширяет возможности rsync, позволяя очень быстро организовать полноценные инкрементные бэкапы, используя технологию hard link. Установить программу можно из стандартного репозитория Debian:
Если надо просто сделать копию каких-то данных, то не нужны никакие настройки и ключи. Просто копируем:
Удалённое резервное копирование по SSH с сервера hostname на локальный бэкап-сервер:
Добавляя ключи
Если между первым и вторым запуском бэкапа набор файлов менялся, то в локальной директории
Вы увидите наборы инкрементов и даты, когда они были созданы. С этими инкрементами можно некоторым образом работать. Например, можно посмотреть, какие файлы изменились за последние 5 дней:
Или посмотреть список файлов, которые присутствовали в архиве 5 дней назад. Если список большой, то сразу выводите его в файл и там просматривайте, ищите нужный файл:
Ну и так далее. Подробное описание с примерами есть в документации. Главное, идея понятна. Все изменения от инкремента к инкременту хранятся и их можно анализировать.
Восстановление по сути представляет из себя обычное копирование файлов из актуальной копии. Это если вам нужно взять свежие данные от последней синхронизации. Если же вам нужно восстановиться из какого-то инкремента, то укажите его явно:
Программа простая и функциональная. Рекомендую 👍.
⇨ Сайт / Исходники
Похожие программы, которые тоже используют librsync:
▪ Burp
▪ Duplicity
▪ Csync2
#backup
Rdiff-backup по своей сути является python обёрткой вокруг rsync (используется библиотека librsync). Она наследует всю скорость и быстроту синхронизации сотен тысяч файлов, которую обеспечивает rsync. Если нужны бэкапы сырых файлов, без упаковки в архивы, дедупликации, сжатия и т.д., то я всегда предпочитаю использовать именно rsync. С ним быстрее и проще всего получить точную пофайловую копию какого-то файлового хранилища, которое регулярно синхронизируется. Это идеальный инструмент для организации горячего резерва файлового архива. В случае выхода из строя основного сервера или хранилища с файлами, можно очень быстро подмонтировать или организовать подключение копии, создаваемой с помощью rsync.
Особенно это актуально для почтовых серверов с форматом хранения maildir. Там каждое письмо это отдельный файл. В итоге файловое хранилище превращается в сотни тысяч мелких файлов, которые один раз скопировать может и не проблема, но каждый день актуализировать копию уже не так просто, так как надо сравнить источник и приёмник, где с каждой стороны огромное количество файлов и они меняются. По моему опыту, rsync это делает быстрее всех. Я даже на Windows сервера ставлю rsync и бэкаплю большие файловые хранилища с его помощью.
Возвращаюсь к Rdiff-backup. Он расширяет возможности rsync, позволяя очень быстро организовать полноценные инкрементные бэкапы, используя технологию hard link. Установить программу можно из стандартного репозитория Debian:
# apt install rdiff-backupЕсли надо просто сделать копию каких-то данных, то не нужны никакие настройки и ключи. Просто копируем:
# rdiff-backup /var/www/site.ru/ /backup/site.ru/Удалённое резервное копирование по SSH с сервера hostname на локальный бэкап-сервер:
# rdiff-backup user@hostname::/remote-dir local-dirДобавляя ключи
-v5 и --print-statistics вы можете получать подробную информацию о процессе бэкапа, которую потом удобно парсить, отправлять на хранение, мониторить. Если между первым и вторым запуском бэкапа набор файлов менялся, то в локальной директории
local-dir будет лежать самая последняя копия файлов. А кроме этого в ней же будет находиться директория rdiff-backup-data, которая будет содержать информацию и логи о проводимых бэкапах, а также инкременты, необходимые для отката на любой прошлый выполненный бэкап. Посмотреть инкременты можно вот так:# rdiff-backup -l local-dirВы увидите наборы инкрементов и даты, когда они были созданы. С этими инкрементами можно некоторым образом работать. Например, можно посмотреть, какие файлы изменились за последние 5 дней:
# rdiff-backup list files --changed-since 5D local-dirИли посмотреть список файлов, которые присутствовали в архиве 5 дней назад. Если список большой, то сразу выводите его в файл и там просматривайте, ищите нужный файл:
# rdiff-backup list files --at 5D local-dirНу и так далее. Подробное описание с примерами есть в документации. Главное, идея понятна. Все изменения от инкремента к инкременту хранятся и их можно анализировать.
Восстановление по сути представляет из себя обычное копирование файлов из актуальной копии. Это если вам нужно взять свежие данные от последней синхронизации. Если же вам нужно восстановиться из какого-то инкремента, то укажите его явно:
# rdiff-backup restore \local-dir/rdiff-backup-data/increments.2023-10-29T21:03:37+03:00.dir \/tmp/restoreПрограмма простая и функциональная. Рекомендую 👍.
⇨ Сайт / Исходники
Похожие программы, которые тоже используют librsync:
▪ Burp
▪ Duplicity
▪ Csync2
#backup
{kind=link}
Для Linux есть замечательный локальный веб сервер, который можно запустить с помощью python:
Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
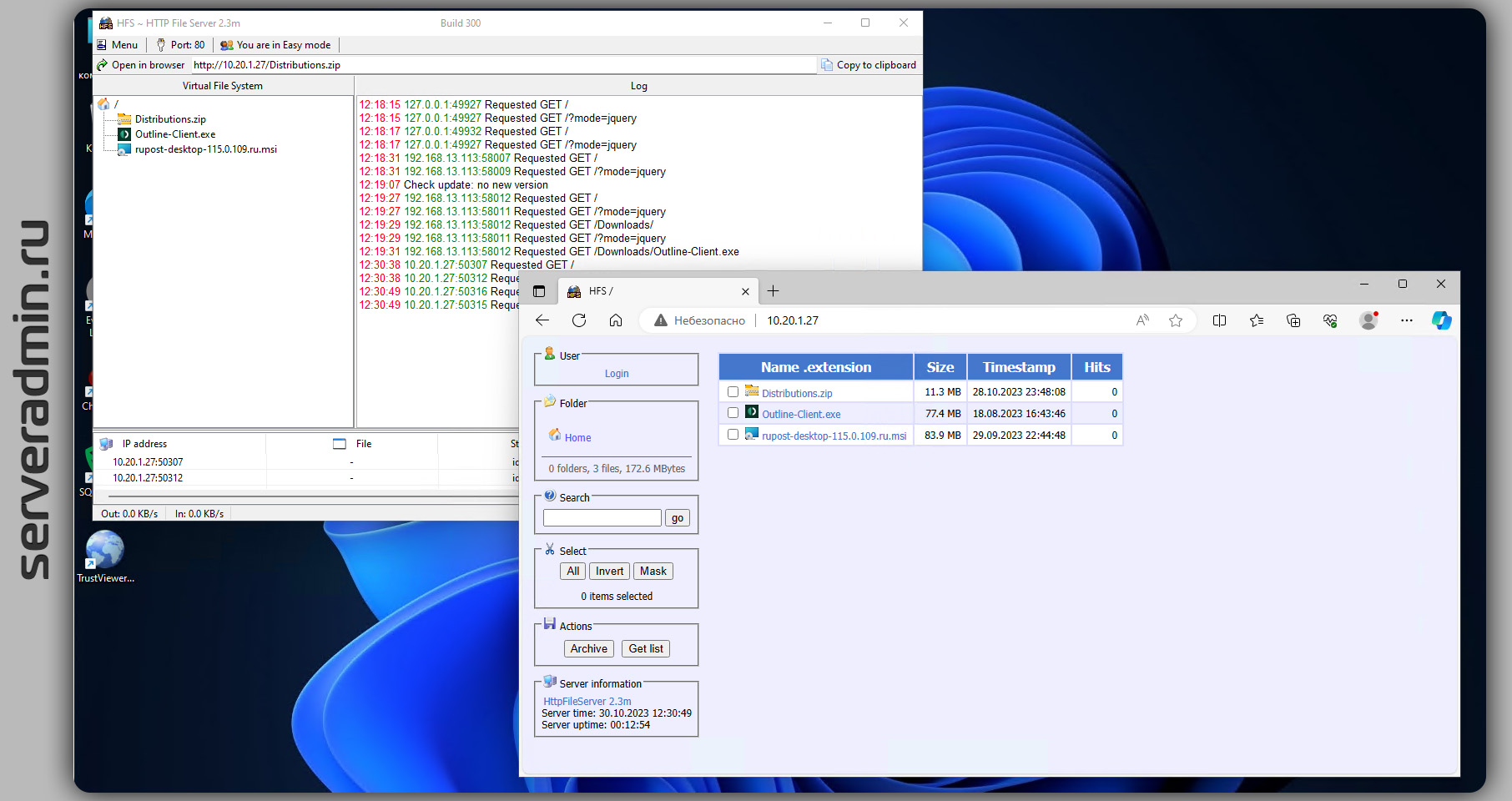
Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
# cd /var/log# python3 -m http.server 8181Переходим браузером на 8181 порт сервера по IP адресу и видим содержимое директории
/var/log. Когда скачали, завершаем работу. Это очень простой способ быстро передать файлы, когда не хочется ничего настраивать. Я регулярно им пользуюсь. Для Windows есть похожий инструмент из далёкого прошлого, работающий и поддерживающийся до сих пор - HFS (HTTP File Server). Это одиночный исполняемый файл весом 2,1 Мб. Работает на любой системе вплоть до современной Windows 11. Скачиваете, запускаете и заходите через браузер на IP адрес машины, предварительно отключив или настроив firewall. Когда всё скачаете, сервер можно выключить, завершив работу приложения.
Сделано всё максимально просто. Никаких настроек не надо. Можете опубликовать какую-то директорию на компьютере или просто мышкой накидать список файлов. Это быстрее и удобнее, чем по SMB что-то передавать, так как надо настраивать аутентификацию. Плюс не всегда получается без проблем зайти с одной системы на другую. То версии SMB не совпадают, то учётка пользователя без пароля и SMB не работает, то просто гостевые подключения не разрешены. Из простого механизма, через который было удобно шарить папки, он превратился в какой-то геморрой. Мне проще через WSL по SCP передать данные, если есть SSH, что я и делаю, чем по SMB.
☝ Причём у этого веб сервера на самом деле очень много возможностей. Вот некоторые из них:
◽ Аутентификация пользователей
◽ Логирование
◽ Возможность настроить внешний вид с помощью HTML шаблонов
◽ Контроль полосы пропускания и отображение загрузки в режиме реального времени
◽ Может работать в фоновом режиме
В общем, это хорошая добротная программа для решения конкретной задачи. И ко всему прочему - open source. Обращаю внимание, что программа изначально написана на Delphi. На сайте скачивается именно она. А на гитхабе то же самое, только переписанное на JavaScript. Но есть и на Delphi репа.
⇨ Сайт / Исходники
#windows #fileserver
{kind=link}
Попереживал тут на днях из-за своей неаккуратности. Настроил сервер 1С примерно так же, как описано у меня в статье:
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
3️⃣ Проверяю, создалась ли база:
4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
# sudo -u postgres /usr/bin/createdb -U postgres -T template0 base1C-restored3️⃣ Проверяю, создалась ли база:
# sudo -u postgres /usr/bin/psql -U postgres -l4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
# sudo -u postgres /usr/bin/psql -U postgres base1C-restored < /tmp/backup.sql5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
Погрузитесь в мир 🐳 DevOps и станьте devops-инженером за рекордные 4 месяца с курсом от Merion Academy!
Все, кому интересно, получат 🚀 2 бесплатных урока, где расскажут, кто такой DevOps-инженер, какие инструменты использует, куда и как развивает карьеру. Познакомитесь с Docker и контейнирезацией и закрепите знания.
🎁 Бонус – интенсив по развитию карьеры, где HR-эксперты расскажут как создавать сильные резюме и проходить собеседования.
📜 Плюс гайд по командам Docker.
🕺У ребят одна из самых доступных цен, которая в разы ниже, чем в других онлайн-школах, а еще есть рассрочка для тех, кто хочет учиться сейчас и платить по чуть-чуть ежемесячно.
👉 Регистрируйтесь по ссылке чтобы забирать бесплатные уроки, интенсив по карьере и гайд.
Merion Academy – это экосистема доступного образования, которая включает в себя:
📍IT-базу знаний с полезными статьями.
📍Youtube-канал ,где простыми словами говорят о сложных вещах.
📍 IT-академию, где обучат востребованным направлениям по самым доступным ценам.
#реклама
Все, кому интересно, получат 🚀 2 бесплатных урока, где расскажут, кто такой DevOps-инженер, какие инструменты использует, куда и как развивает карьеру. Познакомитесь с Docker и контейнирезацией и закрепите знания.
🎁 Бонус – интенсив по развитию карьеры, где HR-эксперты расскажут как создавать сильные резюме и проходить собеседования.
📜 Плюс гайд по командам Docker.
🕺У ребят одна из самых доступных цен, которая в разы ниже, чем в других онлайн-школах, а еще есть рассрочка для тех, кто хочет учиться сейчас и платить по чуть-чуть ежемесячно.
👉 Регистрируйтесь по ссылке чтобы забирать бесплатные уроки, интенсив по карьере и гайд.
Merion Academy – это экосистема доступного образования, которая включает в себя:
📍IT-базу знаний с полезными статьями.
📍Youtube-канал ,где простыми словами говорят о сложных вещах.
📍 IT-академию, где обучат востребованным направлениям по самым доступным ценам.
#реклама
Протестировал новый для себя инструмент, с которым раньше не был знаком. Он очень понравился и показался удобнее аналогичных, про которые знал и использовал раньше. Речь пойдёт про систему планирования и управления задачами серверов Cronicle. Условно его можно назвать продвинутым Cron с веб интерфейсом. Очень похож на Rundeck, про который когда-то писал.
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽автоматически находить соседние сервера;
◽запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
Теперь ставим сам Cronicle. Для этого есть готовый скрипт:
Установка будет выполнена в директорию
А потом запустите:
Теперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#scripts #devops
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽автоматически находить соседние сервера;
◽запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
# apt update# apt install ca-certificates curl gnupg# mkdir -p /etc/apt/keyrings# curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key \| gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg# NODE_MAJOR=20# echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_$NODE_MAJOR.x nodistro main" \| tee /etc/apt/sources.list.d/nodesource.list# apt update# apt install nodejsТеперь ставим сам Cronicle. Для этого есть готовый скрипт:
# curl -s https://raw.githubusercontent.com/jhuckaby/Cronicle/master/bin/install.js \| nodeУстановка будет выполнена в директорию
/opt/cronicle. Если ставите master сервер, то после установки выполните setup:# /opt/cronicle/bin/control.sh setupА потом запустите:
# /opt/cronicle/bin/control.sh startТеперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
/opt/cronicle/conf/config.json с master сервера. Там прописаны ключи, которые должны везде быть одинаковые. В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#scripts #devops
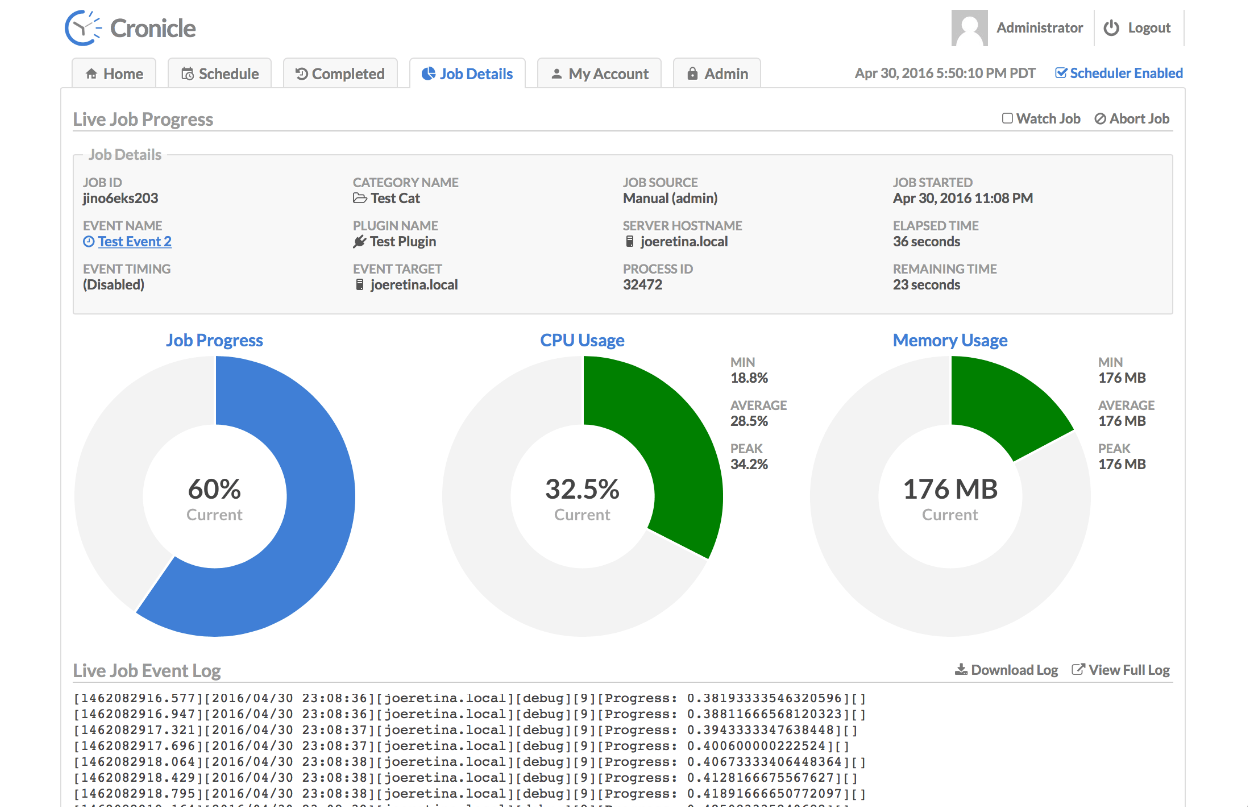{kind=link}
🔝 Очередной ТОП постов за прошедший месяц. Для тех, кто недавно присоединился к каналу, напомню, что он выходит регулярно уже более года. Все самые популярные публикации можно почитать со соответствующему хэштэгу #топ
📌 Больше всего просмотров:
◽️Мем про бэкап Шрёдингера (10984)
◽️Сервис-пинговалка ping.pe (9147)
◽️Заметка про ownCloud Infinite Scale 4.0 (9097)
📌 Больше всего комментариев:
◽️Отмена бесплатных лицензий 1C сервера на Linux (106)
◽️Почтовый сервер RuPost (104)
◽️Обновление Windows Server 2012 и 2012 R2 (95)
📌 Больше всего пересылок:
◽️Скрипт ps_mem для просмотра памяти приложений (371)
◽️Заметка про rdiff-backup (307)
◽️Нейронка для составления консольных команд (296)
📌 Больше всего реакций:
◽️Заметка про утилиту column (212)
◽️Мем про бэкап Шрёдингера (167)
◽️Как я делал rm -rf / (164)
◽️Заметка про увод Telegram каналов (152)
#топ
📌 Больше всего просмотров:
◽️Мем про бэкап Шрёдингера (10984)
◽️Сервис-пинговалка ping.pe (9147)
◽️Заметка про ownCloud Infinite Scale 4.0 (9097)
📌 Больше всего комментариев:
◽️Отмена бесплатных лицензий 1C сервера на Linux (106)
◽️Почтовый сервер RuPost (104)
◽️Обновление Windows Server 2012 и 2012 R2 (95)
📌 Больше всего пересылок:
◽️Скрипт ps_mem для просмотра памяти приложений (371)
◽️Заметка про rdiff-backup (307)
◽️Нейронка для составления консольных команд (296)
📌 Больше всего реакций:
◽️Заметка про утилиту column (212)
◽️Мем про бэкап Шрёдингера (167)
◽️Как я делал rm -rf / (164)
◽️Заметка про увод Telegram каналов (152)
#топ