
Рассказываю про отличный сервис, который позволит выводить уведомления, к примеру, от системы мониторинга в пуши смартфона или приложение на десктопе. При этом всё бесплатно и можно поднять у себя.
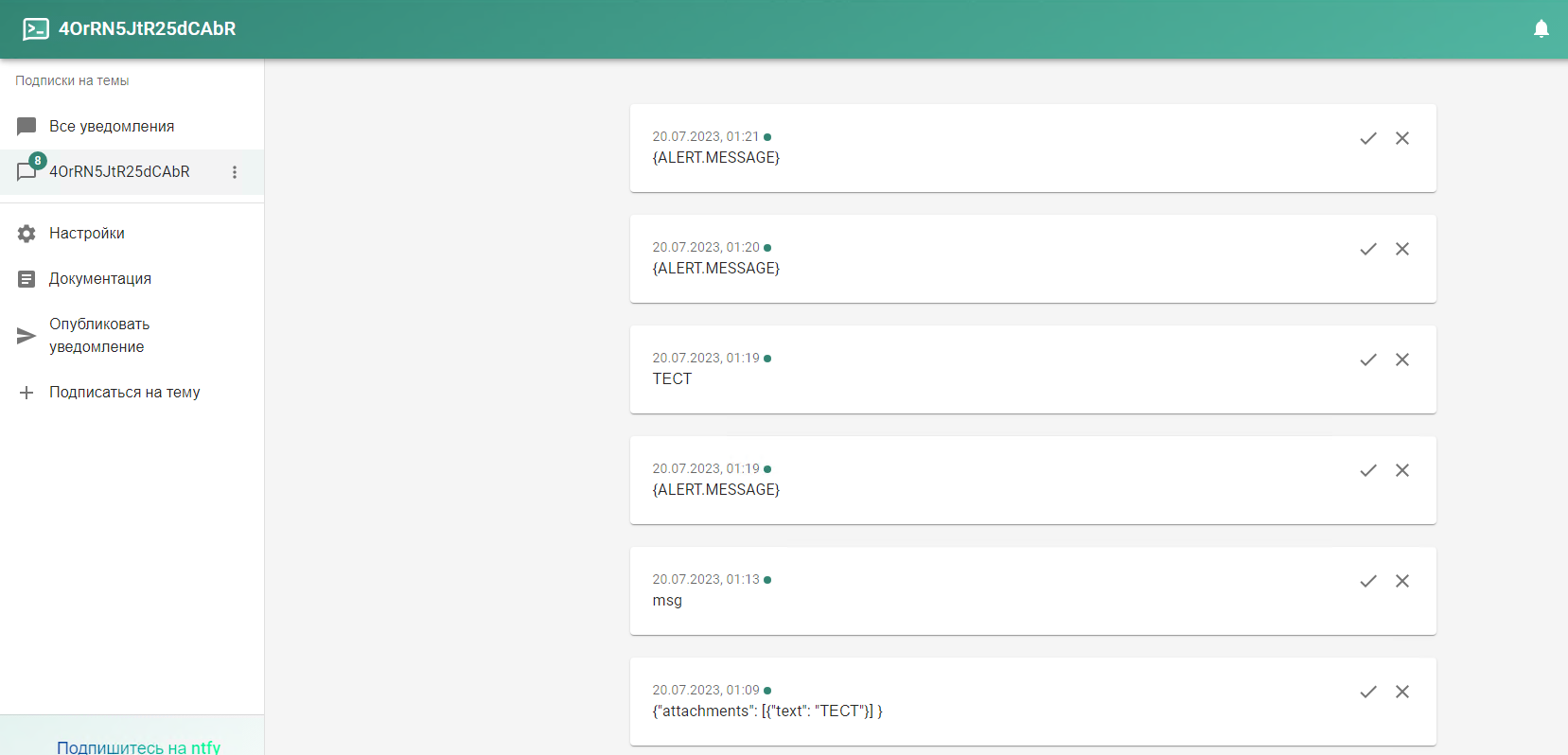
Речь пойдёт про сервис ntfy.sh. Сразу покажу, как им пользоваться, чтобы было понятно, о чём идёт речь. Идёте по ссылке в веб приложение: https://ntfy.sh/app. Разрешаете ему отправлять уведомления. Подписываетесь на новую тему. После этого получаете ссылку вида: ntfy.sh/Stkclnoid6pLCpqU
Теперь идёте в любую консоль и отправляете с помощью curl себе уведомление:
Получаете оповещение от веб приложения. То же самое можно сделать, установив на смартфон приложение. Сервис бесплатный. При этом серверная часть open source. Вы можете развернуть сервер у себя и отправлять уведомления через него. Есть репозитории под все популярные системы. Инструкция прилагается.
Таким образом любой сервис, умеющий выполнять вебхуки, может без проблем отправлять уведомления вам на смартфон или десктоп. Например, в Zabbix достаточно в способах оповещений добавить новый с типом Webhook, в качестве скрипта использовать примерно следующее:
В качестве URL укажите свою подписку в ntfy. Теперь это оповещение можно добавлять пользователям. Им будет приходить уведомление с текстом, который передаёт макрос {ALERT.MESSAGE}.
Либо совсем простой пример для какой-то операции в консоли:
Если бэкап успешен, отправляем одно уведомление, если нет, то другое.
Такой вот простой и удобный сервис.
⇨ Сайт / Исходники
#мониоринг #zabbix #devops
Речь пойдёт про сервис ntfy.sh. Сразу покажу, как им пользоваться, чтобы было понятно, о чём идёт речь. Идёте по ссылке в веб приложение: https://ntfy.sh/app. Разрешаете ему отправлять уведомления. Подписываетесь на новую тему. После этого получаете ссылку вида: ntfy.sh/Stkclnoid6pLCpqU
Теперь идёте в любую консоль и отправляете с помощью curl себе уведомление:
# curl -d "Test Message" ntfy.sh/Stkclnoid6pLCpqUПолучаете оповещение от веб приложения. То же самое можно сделать, установив на смартфон приложение. Сервис бесплатный. При этом серверная часть open source. Вы можете развернуть сервер у себя и отправлять уведомления через него. Есть репозитории под все популярные системы. Инструкция прилагается.
Таким образом любой сервис, умеющий выполнять вебхуки, может без проблем отправлять уведомления вам на смартфон или десктоп. Например, в Zabbix достаточно в способах оповещений добавить новый с типом Webhook, в качестве скрипта использовать примерно следующее:
var response, payload, params = JSON.parse(value), wurl = params.URL, msg = params.Message, request = new CurlHttpRequest(); request.AddHeader('Content-Type: text/plain'); response = request.Post(wurl, msg);В качестве URL укажите свою подписку в ntfy. Теперь это оповещение можно добавлять пользователям. Им будет приходить уведомление с текстом, который передаёт макрос {ALERT.MESSAGE}.
Либо совсем простой пример для какой-то операции в консоли:
# rsync -a /mnt/data user_backup@10.20.1.1:/backups/srv01 \ && curl -H prio:low -d "SRV01 backup succeeded" ntfy.sh/Stkclnoid \ || curl -H tags:warning -H prio:high -d "SRV01 backup failed" ntfy.sh/StkclnoidЕсли бэкап успешен, отправляем одно уведомление, если нет, то другое.
Такой вот простой и удобный сервис.
⇨ Сайт / Исходники
#мониоринг #zabbix #devops
{kind=link}
У Zabbix вчера была рассылка с новостями. Давно ничего не писал про него, потому что новостей особо не было. Буднично проходили новости об очередных обновлениях и конференциях в разных странах. А в этот раз они немного подробностей дали по поводу новой версии 7.0, у которой уже 3-я альфа вышла. Так что работа идёт и релиз всё ближе.
Команда Zabbix показала новые виджеты дашборда, которые будут в новой версии. Можете оценить на прикреплённой картинке. Впечатления двоякие. Вроде бы прикольно, но выглядит как-то колхозно всё это. Не получается им к какому-то единому стилю прийти из-за того, что обновления сильно растянуты. Сначала интерфейс обновили, потом частично графики в виджетах, потом новые виджеты стали добавлять, при этом часть графиков так и осталась в старом дизайне, которому уже около 10-ти лет. Мне кажется, им стоило один раз собраться и в каком-то релизе выкатить полное обновление интерфейса и графиков. А то это так и будет вечно продолжаться.
Помимо новых визуализаций, появится виджет с топом триггеров. Я так понял, что это виджет из отчёта 100 наиболее активных триггеров (в русском интерфейсе). Он показывает триггеры, которые чаще всего меняли своё состояние (срабатывали) за указанный период времени. Кстати, удобный отчёт, который позволяет подредактировать триггеры, которые слишком часто срабатывают.
Из тех обновлений, что точно будут в 7.0, отмечу:
◽увеличится поддержка версий до MySQL 8.1 MariaDB 11
◽появится шаблон для мониторинга за PostgreSQL через ODBC
◽появится шаблон для Cisco SD-WAN
◽появится возможность выполнения удалённых команд при активных проверках
◽некоторые настройки переедут в модальные окна (способы оповещений, скрипты и т.д.)
◽увеличат возможности обработки в aggregation functions
Вот и всё наиболее значимое, что было объявлено в последних трех релизах альфы. Пока как-то негусто изменений. По обещанному обновлению модуля инвентаризации, поддержке сторонних TSDB, асинхронному сбору данных не сделано ничего в тех версиях, что опубликованы.
#zabbix
Команда Zabbix показала новые виджеты дашборда, которые будут в новой версии. Можете оценить на прикреплённой картинке. Впечатления двоякие. Вроде бы прикольно, но выглядит как-то колхозно всё это. Не получается им к какому-то единому стилю прийти из-за того, что обновления сильно растянуты. Сначала интерфейс обновили, потом частично графики в виджетах, потом новые виджеты стали добавлять, при этом часть графиков так и осталась в старом дизайне, которому уже около 10-ти лет. Мне кажется, им стоило один раз собраться и в каком-то релизе выкатить полное обновление интерфейса и графиков. А то это так и будет вечно продолжаться.
Помимо новых визуализаций, появится виджет с топом триггеров. Я так понял, что это виджет из отчёта 100 наиболее активных триггеров (в русском интерфейсе). Он показывает триггеры, которые чаще всего меняли своё состояние (срабатывали) за указанный период времени. Кстати, удобный отчёт, который позволяет подредактировать триггеры, которые слишком часто срабатывают.
Из тех обновлений, что точно будут в 7.0, отмечу:
◽увеличится поддержка версий до MySQL 8.1 MariaDB 11
◽появится шаблон для мониторинга за PostgreSQL через ODBC
◽появится шаблон для Cisco SD-WAN
◽появится возможность выполнения удалённых команд при активных проверках
◽некоторые настройки переедут в модальные окна (способы оповещений, скрипты и т.д.)
◽увеличат возможности обработки в aggregation functions
Вот и всё наиболее значимое, что было объявлено в последних трех релизах альфы. Пока как-то негусто изменений. По обещанному обновлению модуля инвентаризации, поддержке сторонних TSDB, асинхронному сбору данных не сделано ничего в тех версиях, что опубликованы.
#zabbix
{kind=link}
Много раз в заметках упоминал про сервис по рисованию различных схем draw.io. Судя по отзывам, большая часть использует именно его в своей работе. Схемы из draw.io относительно легко можно наложить на мониторинг на базе Grafana. Если вы с ней работаете, то особых проблем не должно возникнуть. Если нет, то не скажу, что настройка будет простой. Но в целом, ничего особенного. Мне когда надо было, освоил Grafana за пару дней для простого мониторинга.
Речь пойдёт про плагин к Графане — flowcharting. Он есть в официальном списке плагинов на сайте, так что с его установкой вопросов не должно возникнуть. Сразу скажу, что с помощью этого плагина можно нарисовать схему и связать через через Графану его с мониторингом на Zabbix.
Последовательность настройки схемы с помощью плагина следующая:
1️⃣ Вы берёте схему в draw.io и выгружаете её в xml формате.
2️⃣ Создаёте dashboard в Grafana и добавляете туда панель flowcharting.
3️⃣ Загружаете xml код схемы в эту панель и получаете визуализацию.
4️⃣ Сопоставляете объекты на схеме с объектами в Графане, сразу переименовывая их так, чтобы было удобно.
5️⃣ Дальше к объектам можно добавлять метрики, как это обычно делается в Grafana. Соответственно, в качестве Data Source можно использовать тот же Zabbix.
Сразу приведу ссылки, которые помогут вам быстро начать действовать, если плагин заинтересовал.
⇨ Страница плагина в Grafana
⇨ Инструкция по настройке
▶️ Плейлист Flowcharting Grafana (29 видео)
Все видео в плейлисте на португальском языке. Можно включить перевод субтитров на русский. В целом, там важно смотреть, как и что он делает. А что говорит, не так важно. В плейлисте полностью раскрыта тема построения мониторинга с помощью этого плагина. В том числе и в связке с Zabbix (26-й ролик).
Плагин давно не обновлялся. Я не уверен, что он нормально заработает на свежих версиях, хотя, по идее должен. Я до сих пор пользуюсь 7-й версией. И там он работает.
#мониторинг #zabbix #grafana
Речь пойдёт про плагин к Графане — flowcharting. Он есть в официальном списке плагинов на сайте, так что с его установкой вопросов не должно возникнуть. Сразу скажу, что с помощью этого плагина можно нарисовать схему и связать через через Графану его с мониторингом на Zabbix.
Последовательность настройки схемы с помощью плагина следующая:
1️⃣ Вы берёте схему в draw.io и выгружаете её в xml формате.
2️⃣ Создаёте dashboard в Grafana и добавляете туда панель flowcharting.
3️⃣ Загружаете xml код схемы в эту панель и получаете визуализацию.
4️⃣ Сопоставляете объекты на схеме с объектами в Графане, сразу переименовывая их так, чтобы было удобно.
5️⃣ Дальше к объектам можно добавлять метрики, как это обычно делается в Grafana. Соответственно, в качестве Data Source можно использовать тот же Zabbix.
Сразу приведу ссылки, которые помогут вам быстро начать действовать, если плагин заинтересовал.
⇨ Страница плагина в Grafana
⇨ Инструкция по настройке
▶️ Плейлист Flowcharting Grafana (29 видео)
Все видео в плейлисте на португальском языке. Можно включить перевод субтитров на русский. В целом, там важно смотреть, как и что он делает. А что говорит, не так важно. В плейлисте полностью раскрыта тема построения мониторинга с помощью этого плагина. В том числе и в связке с Zabbix (26-й ролик).
Плагин давно не обновлялся. Я не уверен, что он нормально заработает на свежих версиях, хотя, по идее должен. Я до сих пор пользуюсь 7-й версией. И там он работает.
#мониторинг #zabbix #grafana
{kind=link}
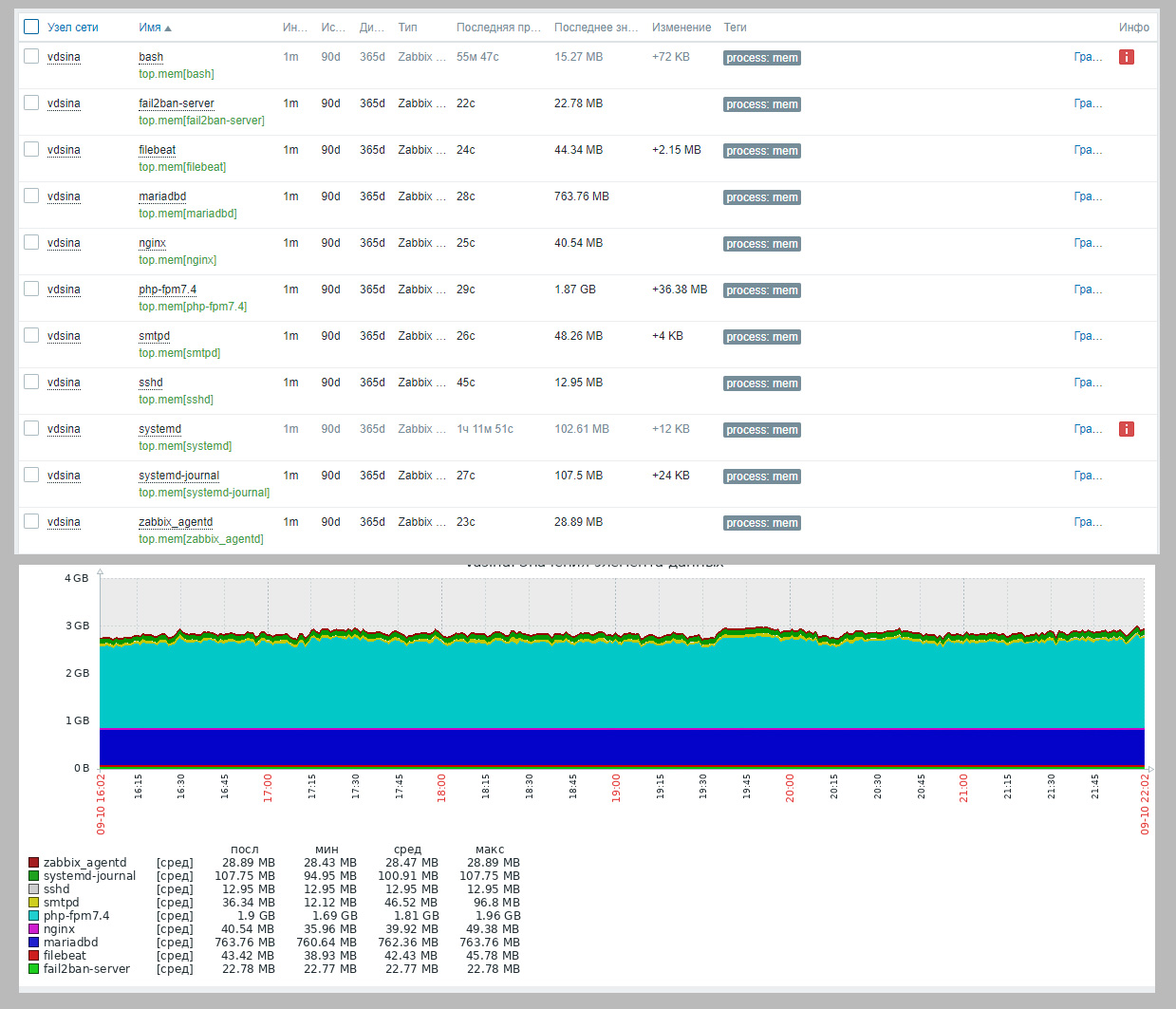
После публикации про мониторинг Newrelic, где можно наблюдать за каждым процессом в системе в отдельности, решил прикинуть, а как подобное реализовать в Zabbix. Итоговое решение по всем метрикам пока не созрело, но контроль использования памяти уже реализовал. Решил поделиться своими наработками. Может кто-то подскажет другие пути решения задачи.
Прикинул, как снимать метрики. Тут особо не пришлось ломать голову, так как сразу родилась идея с утилитами jc и jq, которые я давно знаю. Взял вывод ps, обернул его в json с помощью jc, отсортировал по метрике rss и вывел top 10:
Понравилось, как получилось. Закинул эти данные в отдельный айтем заббикса, но дальше тупик. Не понимаю, как это всё оформить в правила автообнаружения, чтобы автоматически создавались айтемы с именем процесса в названии, чтобы потом можно было для этих айтемов делать выборку с данными об rss из этого json.
Напомню, что у Zabbix свой определённый формат, иерархия и логика работы правил автообнаружения. Чтобы автоматически создавать айтемы, нужно подать на вход json следующего содержания:
Такую строку он сможет взять, на основе переданных значений
Взял вот такую конструкцию, которая анализирует вывод ps, формирует удобный список, который можно отсортировать с помощью sort и взять top 10 самых нагруженных по памяти процессов и в итоге вывести только их имена:
Далее обернул её в скрипт для формирования json для автообнаружения в Zabbix.
top_mem.discovery.sh:
На выходе получаем то, что нам надо:
Сразу же готовим второй скрипт, который будет принимать в качестве параметра имя процесса и отдавать его память (rss).
top_mem.sh:
Проверяем:
Добавляем в конфиг zabbix-agent:
Теперь идём на сервер, создаём шаблон, правило автообнаружения, прототип айтема, графика и сразу делаем панель.
Получилось удобно и функционально. Все нюансы не смог описать, так как лимит на длину поста. Нерешённый момент - особенности реализации LLD не позволяют автоматом закидывать все процессы на один график. Без API не знаю, как это сделать. Текущее решение придумал и опробовал за пару часов.
#zabbix
Прикинул, как снимать метрики. Тут особо не пришлось ломать голову, так как сразу родилась идея с утилитами jc и jq, которые я давно знаю. Взял вывод ps, обернул его в json с помощью jc, отсортировал по метрике rss и вывел top 10:
# ps axu | jc --ps -p | jq 'sort_by(.rss)' | jq .[-10:]..................................] { "user": "servera+", "pid": 1584266, "vsz": 348632, "rss": 109488, "tty": null, "stat": "S", "start": "19:41", "time": "0:28", "command": "php-fpm: pool serveradmin.ru", "cpu_percent": 0.5, "mem_percent": 2.7 }, { "user": "mysql", "pid": 853, "vsz": 2400700, "rss": 782060, "tty": null, "stat": "Ssl", "start": "Aug28", "time": "365:40", "command": "/usr/sbin/mariadbd", "cpu_percent": 1.8, "mem_percent": 19.4 }]..........................................Понравилось, как получилось. Закинул эти данные в отдельный айтем заббикса, но дальше тупик. Не понимаю, как это всё оформить в правила автообнаружения, чтобы автоматически создавались айтемы с именем процесса в названии, чтобы потом можно было для этих айтемов делать выборку с данными об rss из этого json.
Напомню, что у Zabbix свой определённый формат, иерархия и логика работы правил автообнаружения. Чтобы автоматически создавать айтемы, нужно подать на вход json следующего содержания:
[{"{#COMMAND}":"php-fpm7.4"},{"{#COMMAND}":"mariadbd"}.........,{"{#COMMAND}":"smtpd"}]Такую строку он сможет взять, на основе переданных значений
{#COMMAND} создать айтемы. Как мою json от ps приспособить под эти задачи, я не знал. Для этого можно было бы сделать обработку на javascript прямо в айтеме, но мне показалось это слишком сложным для меня путём. Решил всё сделать по старинке на bash.Взял вот такую конструкцию, которая анализирует вывод ps, формирует удобный список, который можно отсортировать с помощью sort и взять top 10 самых нагруженных по памяти процессов и в итоге вывести только их имена:
# ps axo rss,comm | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{print $2}'Далее обернул её в скрипт для формирования json для автообнаружения в Zabbix.
top_mem.discovery.sh:
#!/bin/bashTOPPROC=`ps axo rss,comm | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{print $2}'`JSON=$(for i in ${TOPPROC[@]}; do printf "{\"{#COMMAND}\":\"$i\"},"; done | sed 's/^\(.*\).$/\1/')printf "["printf "$JSON"printf "]"На выходе получаем то, что нам надо:
[{"{#COMMAND}":"php-fpm7.4"},........{"{#COMMAND}":"smtpd"}]Сразу же готовим второй скрипт, который будет принимать в качестве параметра имя процесса и отдавать его память (rss).
top_mem.sh:
#!/bin/bashps axo rss,comm | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | grep $1 | awk '{print $1}'Проверяем:
# ./top_mem.sh mariadbd780840Добавляем в конфиг zabbix-agent:
UserParameter=top.mem.discovery, /bin/bash /etc/zabbix/scripts/top_mem.discovery.shUserParameter=top.mem[*], /bin/bash /etc/zabbix/scripts/top_mem.sh $1Теперь идём на сервер, создаём шаблон, правило автообнаружения, прототип айтема, графика и сразу делаем панель.
Получилось удобно и функционально. Все нюансы не смог описать, так как лимит на длину поста. Нерешённый момент - особенности реализации LLD не позволяют автоматом закидывать все процессы на один график. Без API не знаю, как это сделать. Текущее решение придумал и опробовал за пару часов.
#zabbix
{kind=link}
Провёл аудит своих систем мониторинга Zabbix в связке с Grafana. У меня работают версии LTS 5.0 и 6.0. Промежуточные обычно только для теста ставлю где-то в одном месте. Разбирался в первую очередь с базовым шаблоном для Linux серверов.
У Zabbix есть особенность, что обновление сервера не касается самих шаблонов, а они тоже регулярно обновляются. У этого есть как плюсы, так и минусы. Плюс в том, что всё стабильно и никаких непредвиденных обновлений не будет. Если вы вносили правки в шаблон, они останутся и всё будет работать как раньше с новым сервером. А минус в том, что эти обновления надо проводить вручную.
В процессе аудита понял, что у меня на серверах используются 3 разных версии шаблона. На каких-то серверах все 3 одновременно. У этого есть много причин. Например, у вас есть какая-то удалённая площадка, подключенная по VPN. Я для неё делаю копию стандартного шаблона и в триггерах прописываю зависимость от состояния VPN, чтобы мне не сыпался спам из уведомлений, когда отвалится связь с площадкой. Когда таких изменений много, поддержание актуальной версии шаблонов становится непростой задачей.
Для серверов 6-й версии взял за основу шаблон Linux by Zabbix agent, не забыв указать ветку репозитория 6.0. Методика обновления может быть разной. Безопаснее всего текущий установленный шаблон переименовать, добавив, к примеру, к названию приписку OLD. Потом импортировать новый и вручную накидывать его на хосты, заменяя старый шаблон. Это немного муторно, так как ручной труд.
Проще всего всё сделать автоматом. Отцепить старый шаблон от хостов с удалением всех метрик и соответственно истории к ним. Это обнуляет всю историю метрик по данному шаблону. И потом накатить сверху новый шаблон. Минимум ручной работы, так как нет конфликтов слияния, но потеря всей истории. Если вам не критично, делайте так. Можно не затирая историю применять новый шаблон, перезаписывая старый, но там иногда возникают проблемы, которые нужно опять же вручную разрешать.
У меня хостов не так уж и много, я вручную всё сделал, отключая старый шаблон и подключая новый.
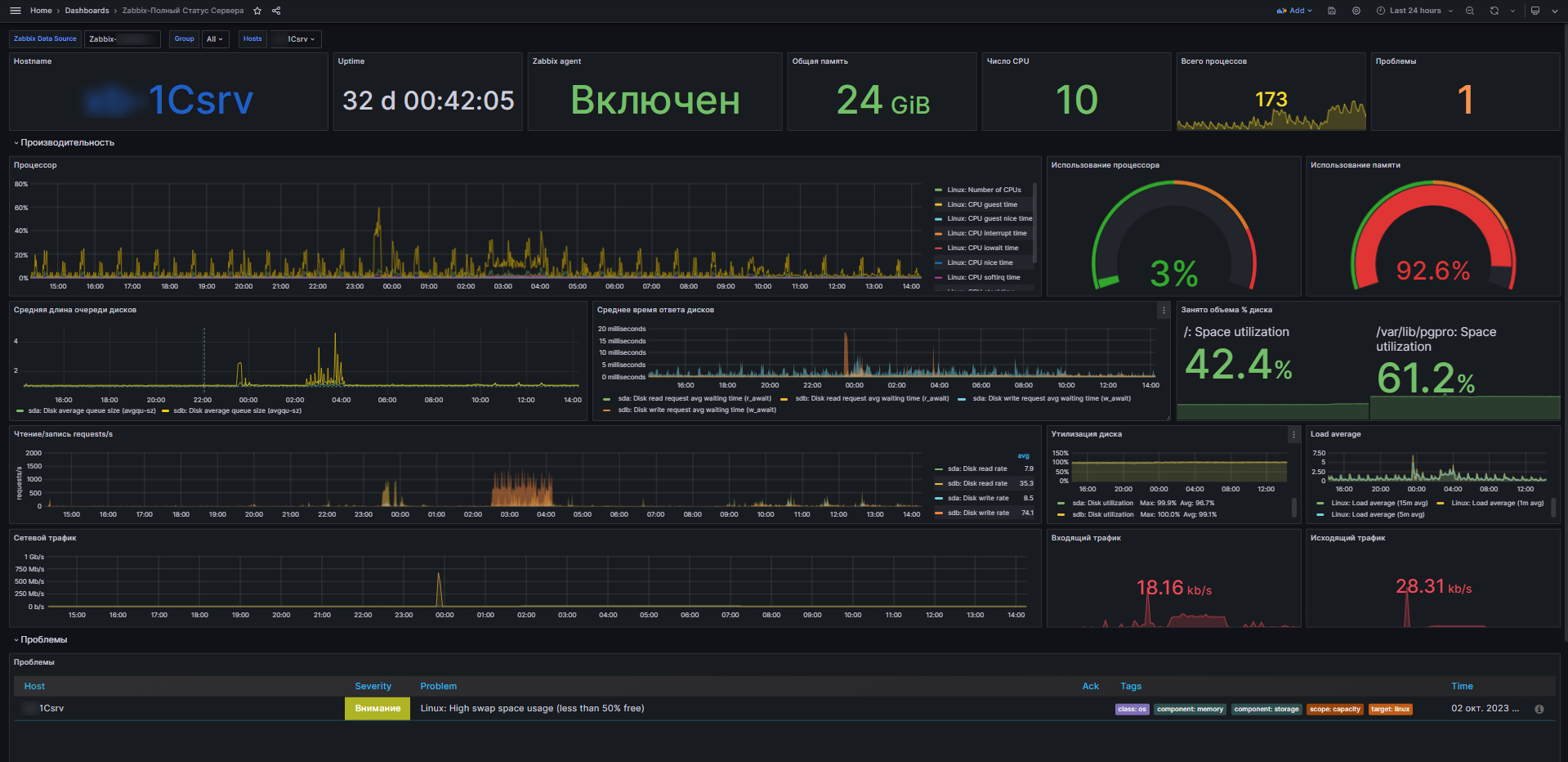
Единообразие шаблонов для Linux позволило сделать единый для всех серверов дашборд в Grafana, куда я вынес наиболее актуальные на мой взгляд метрики, чтобы можно было быстро оценить состояние хоста. Пример, как это выглядит, на картинке. Сам дашборд выложил на сайт, можно скачать. В шаблоне можно выбрать Datasource и конкретный хост. То есть с его помощью можно смотреть все подключенные хосты с такой же версией шаблона Linux. Это намного быстрее и удобнее, чем делать то же самое в самом Zabbix. По настройке Grafana с Zabbix у меня есть отдельная статья.
Ну и в завершении напомню, что обновление шаблонов приносит очень много мелких хлопот на местах, так как опять потребуется калибровка под конкретные хосты. Где-то не нужны какие-то триггеры, например на swap, на отсутствие свободной оперативы, где её и не должно быть, на скорость отклика дисков, потому что они медленные и т.д. Приходится макросы поправлять, триггеры отключать, какие-то изменения в шаблоны и хосты добавлять с зависимостями. Все tun интерфейсы почему-то определяются со скоростью 10 Мегабит в секунду, что приводит к срабатыванию триггеров на загрузку интерфейса. Пока не понял, как это решить, не отключая триггеры.
Из-за всех этих хлопот я всегда сильно откладываю обновление мониторингов, которые в целом и так работают и устраивают. Но всё равно бесконечно отставать от актуальной версии нельзя, приходится обновляться. Вечером будет заметка по обновлению Grafana.
#zabbix #grafana
У Zabbix есть особенность, что обновление сервера не касается самих шаблонов, а они тоже регулярно обновляются. У этого есть как плюсы, так и минусы. Плюс в том, что всё стабильно и никаких непредвиденных обновлений не будет. Если вы вносили правки в шаблон, они останутся и всё будет работать как раньше с новым сервером. А минус в том, что эти обновления надо проводить вручную.
В процессе аудита понял, что у меня на серверах используются 3 разных версии шаблона. На каких-то серверах все 3 одновременно. У этого есть много причин. Например, у вас есть какая-то удалённая площадка, подключенная по VPN. Я для неё делаю копию стандартного шаблона и в триггерах прописываю зависимость от состояния VPN, чтобы мне не сыпался спам из уведомлений, когда отвалится связь с площадкой. Когда таких изменений много, поддержание актуальной версии шаблонов становится непростой задачей.
Для серверов 6-й версии взял за основу шаблон Linux by Zabbix agent, не забыв указать ветку репозитория 6.0. Методика обновления может быть разной. Безопаснее всего текущий установленный шаблон переименовать, добавив, к примеру, к названию приписку OLD. Потом импортировать новый и вручную накидывать его на хосты, заменяя старый шаблон. Это немного муторно, так как ручной труд.
Проще всего всё сделать автоматом. Отцепить старый шаблон от хостов с удалением всех метрик и соответственно истории к ним. Это обнуляет всю историю метрик по данному шаблону. И потом накатить сверху новый шаблон. Минимум ручной работы, так как нет конфликтов слияния, но потеря всей истории. Если вам не критично, делайте так. Можно не затирая историю применять новый шаблон, перезаписывая старый, но там иногда возникают проблемы, которые нужно опять же вручную разрешать.
У меня хостов не так уж и много, я вручную всё сделал, отключая старый шаблон и подключая новый.
Единообразие шаблонов для Linux позволило сделать единый для всех серверов дашборд в Grafana, куда я вынес наиболее актуальные на мой взгляд метрики, чтобы можно было быстро оценить состояние хоста. Пример, как это выглядит, на картинке. Сам дашборд выложил на сайт, можно скачать. В шаблоне можно выбрать Datasource и конкретный хост. То есть с его помощью можно смотреть все подключенные хосты с такой же версией шаблона Linux. Это намного быстрее и удобнее, чем делать то же самое в самом Zabbix. По настройке Grafana с Zabbix у меня есть отдельная статья.
Ну и в завершении напомню, что обновление шаблонов приносит очень много мелких хлопот на местах, так как опять потребуется калибровка под конкретные хосты. Где-то не нужны какие-то триггеры, например на swap, на отсутствие свободной оперативы, где её и не должно быть, на скорость отклика дисков, потому что они медленные и т.д. Приходится макросы поправлять, триггеры отключать, какие-то изменения в шаблоны и хосты добавлять с зависимостями. Все tun интерфейсы почему-то определяются со скоростью 10 Мегабит в секунду, что приводит к срабатыванию триггеров на загрузку интерфейса. Пока не понял, как это решить, не отключая триггеры.
Из-за всех этих хлопот я всегда сильно откладываю обновление мониторингов, которые в целом и так работают и устраивают. Но всё равно бесконечно отставать от актуальной версии нельзя, приходится обновляться. Вечером будет заметка по обновлению Grafana.
#zabbix #grafana
{kind=link}
В процессе актуализации мониторинга обновил также и Grafana до последней 10-й версии. Расскажу, как это делаю я. Это не руководство к действию для вас, а только мой персональный опыт, основанный на том, что у меня немного дашбордов и Data sources.
Всю ценность в Grafana у меня представляют только настройки источников данных и несколько дашбордов, поэтому прорабатывать перенос данных или бэкап нет никакого смысла. Если что-то меняется, то я просто выгружаю json и сохраняю новую версию. А так как это происходит нечасто, меня такая схема устраивает.
Соответственно и обновление у меня выглядит максимально просто и быстро:
1️⃣ Выгружаю Data sources и Dashboards в json.
2️⃣ Обновляю Docker образ grafana:latest и запускаю новый контейнер с ним.
3️⃣ Переключаю на Nginx Proxy трафик на новый контейнер.
4️⃣ Захожу в него и импортирую свои данные.
Если что-то забыл, то заглядываю в старый контейнер, который остаётся некоторое время. Как это всё реализуется технически, описано в моей старой статье:
⇨ Обновление Grafana
В плане экспорта и импорта данных не поменялось ничего. Она полностью актуальна и по ней я переехал с 7-й версии на 10-ю. В конце статьи представлены примеры некоторых моих дашбордов. Они хоть и изменились с того времени, но это уже детали.
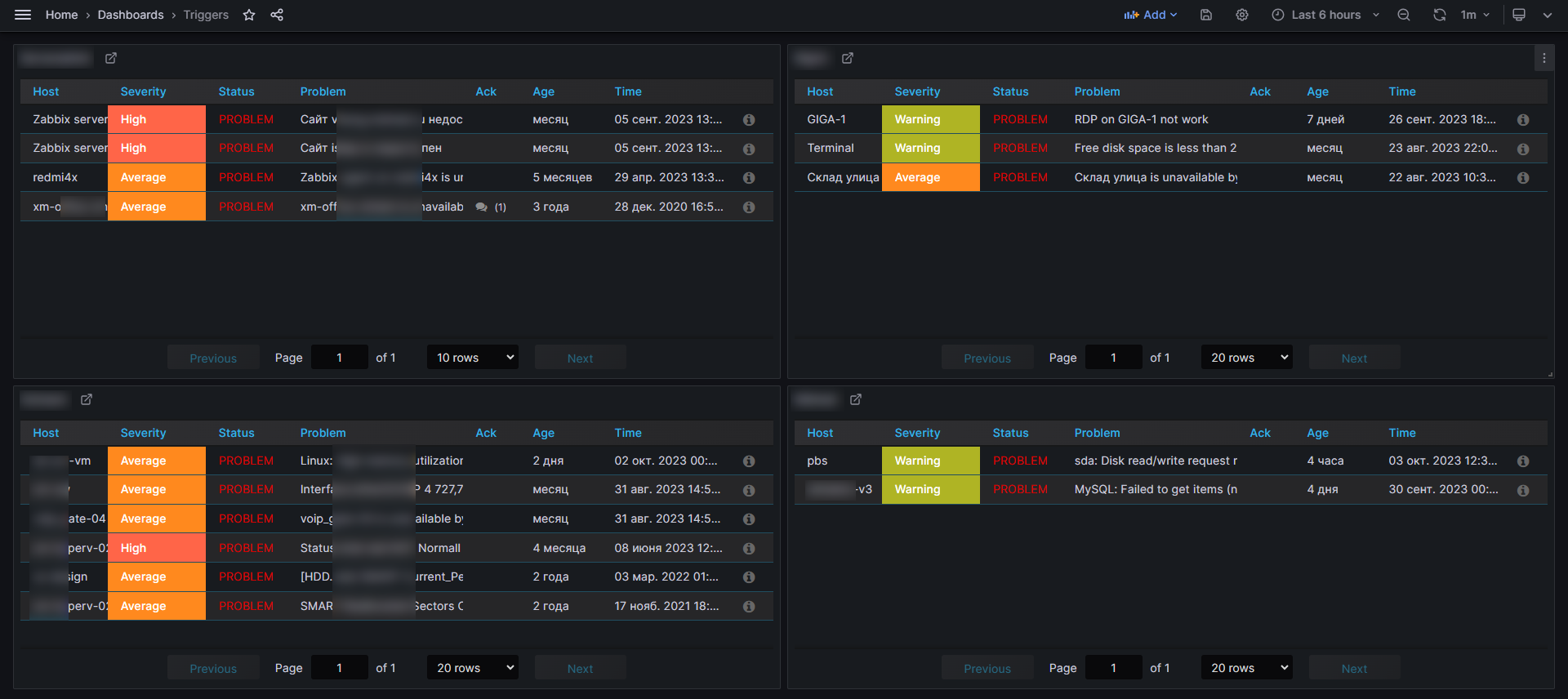
Предвещая вопросы, отвечу, что Grafana использую исключительно для более удобной и простой визуализации данных с Zabbix Server. А также для объединения на одном дашборде информации с разных серверов. Это актуально для триггеров. У меня есть обзорный дашборд с активными триггерами со всех своих серверов. Ну и дополнительно есть несколько дашбордов с другой необходимой мне информации. Один из таких дашбордов с обзорной информацией о сервере я показал в утренней заметке.
Ниже картинка с обзором триггеров.
#grafana #zabbix
Всю ценность в Grafana у меня представляют только настройки источников данных и несколько дашбордов, поэтому прорабатывать перенос данных или бэкап нет никакого смысла. Если что-то меняется, то я просто выгружаю json и сохраняю новую версию. А так как это происходит нечасто, меня такая схема устраивает.
Соответственно и обновление у меня выглядит максимально просто и быстро:
1️⃣ Выгружаю Data sources и Dashboards в json.
2️⃣ Обновляю Docker образ grafana:latest и запускаю новый контейнер с ним.
3️⃣ Переключаю на Nginx Proxy трафик на новый контейнер.
4️⃣ Захожу в него и импортирую свои данные.
Если что-то забыл, то заглядываю в старый контейнер, который остаётся некоторое время. Как это всё реализуется технически, описано в моей старой статье:
⇨ Обновление Grafana
В плане экспорта и импорта данных не поменялось ничего. Она полностью актуальна и по ней я переехал с 7-й версии на 10-ю. В конце статьи представлены примеры некоторых моих дашбордов. Они хоть и изменились с того времени, но это уже детали.
Предвещая вопросы, отвечу, что Grafana использую исключительно для более удобной и простой визуализации данных с Zabbix Server. А также для объединения на одном дашборде информации с разных серверов. Это актуально для триггеров. У меня есть обзорный дашборд с активными триггерами со всех своих серверов. Ну и дополнительно есть несколько дашбордов с другой необходимой мне информации. Один из таких дашбордов с обзорной информацией о сервере я показал в утренней заметке.
Ниже картинка с обзором триггеров.
#grafana #zabbix
{kind=link}
Немного актуальных новостей про Zabbix, которым я постоянно пользуюсь.
1️⃣ В версии 6.0.21 вернулся баг веб проверок. Не работают проверки сайтов, отличных от кодировки UTF-8. У меня есть несколько старых сайтов в WINDOWS-1251. Они нормально работают и трогать их лишний раз не хочется для перекодирования. Для них теперь не работает проверка контрольной строки в коде сайта. Подобный глюк уже был раньше и его вылечили очередным обновлением. Но сейчас уже вышла версия 6.0.22 и этот глюк там остался. Кому актуально, не обновляйтесь с 6.0.20.
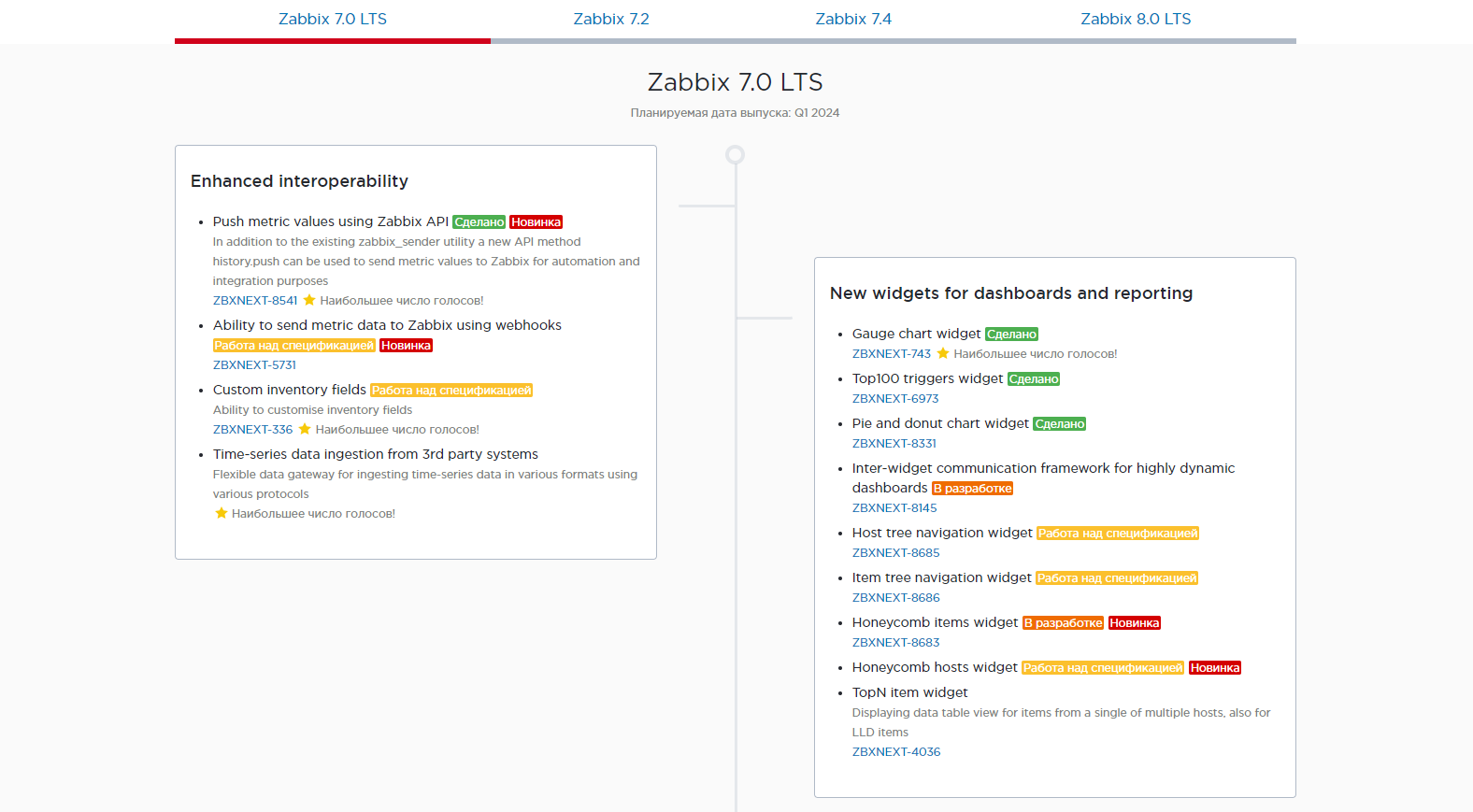
2️⃣ Стала доступна 7.0.0alpha5. Релиз всё ближе. Я уже делал несколько заметок по теме новой 7-й LTS версии (1, 2), ключевые новшества там перечислены. В этой альфе анонсировали возможность настройки таймаутов для каждого айтема отдельно, новый виджет pie chart и новые возможности взаимодействия виджетов, возможность с помощью разных правил LLD делать привязку к одной и той же группе хостов, поддержку mariadb 11.1, добавили шаблон для Acronis Cyber Protect Cloud и много других доработок.
Как я и предполагал ранее, выход 7-й версии перенесли с 2023 года на Q1 2024.
3️⃣ У Wireshark в версии 4.2.0 появилась встроенная поддержка протокола передачи данных Zabbix. Можно перехватывать и анализировать трафик от агентов и прокси. Это поможет выполнить дебаг каких-то проблем со связностью и доставкой информации. Подробно работа с Wireshark описана в статье в официальном блоге Zabbix. Поддерживается в том числе и сжатый, и TLS трафик, при условии, что доступны сессионные ключи. Как это на практике должно работать, не совсем понимаю. Автор обещает выпустить отдельную заметку по разбору TLS трафика.
Вообще, это классная штука. Теперь можно перехватить траффик и заглянуть внутрь пакетов, чтобы понять, какая информация идёт на сервер и почему там это вызывает ошибку или вообще не принимается. А то иногда банально не понятно по тексту ошибки, в чём конкретно проблема. А в wireshark можно увидеть в том числе и полное содержание метрики, которая отправляется.
#zabbix
1️⃣ В версии 6.0.21 вернулся баг веб проверок. Не работают проверки сайтов, отличных от кодировки UTF-8. У меня есть несколько старых сайтов в WINDOWS-1251. Они нормально работают и трогать их лишний раз не хочется для перекодирования. Для них теперь не работает проверка контрольной строки в коде сайта. Подобный глюк уже был раньше и его вылечили очередным обновлением. Но сейчас уже вышла версия 6.0.22 и этот глюк там остался. Кому актуально, не обновляйтесь с 6.0.20.
2️⃣ Стала доступна 7.0.0alpha5. Релиз всё ближе. Я уже делал несколько заметок по теме новой 7-й LTS версии (1, 2), ключевые новшества там перечислены. В этой альфе анонсировали возможность настройки таймаутов для каждого айтема отдельно, новый виджет pie chart и новые возможности взаимодействия виджетов, возможность с помощью разных правил LLD делать привязку к одной и той же группе хостов, поддержку mariadb 11.1, добавили шаблон для Acronis Cyber Protect Cloud и много других доработок.
Как я и предполагал ранее, выход 7-й версии перенесли с 2023 года на Q1 2024.
3️⃣ У Wireshark в версии 4.2.0 появилась встроенная поддержка протокола передачи данных Zabbix. Можно перехватывать и анализировать трафик от агентов и прокси. Это поможет выполнить дебаг каких-то проблем со связностью и доставкой информации. Подробно работа с Wireshark описана в статье в официальном блоге Zabbix. Поддерживается в том числе и сжатый, и TLS трафик, при условии, что доступны сессионные ключи. Как это на практике должно работать, не совсем понимаю. Автор обещает выпустить отдельную заметку по разбору TLS трафика.
Вообще, это классная штука. Теперь можно перехватить траффик и заглянуть внутрь пакетов, чтобы понять, какая информация идёт на сервер и почему там это вызывает ошибку или вообще не принимается. А то иногда банально не понятно по тексту ошибки, в чём конкретно проблема. А в wireshark можно увидеть в том числе и полное содержание метрики, которая отправляется.
#zabbix
{kind=link}
На днях проходил очередной масштабный Zabbix Summit 2023 на английском языке. Сейчас уже выложили полную информацию по нему, в том числе видеозаписи и презентации докладов. Всё это на отдельной странице:
⇨ https://www.zabbix.com/ru/events/zabbix_summit_2023
Было много всяких событий, даже не знаю, о чём конкретно рассказать. В принципе, вы можете сами по программе мероприятия посмотреть то, что вам больше всего интересно и перейти на запись выступления или посмотреть презентацию.
Приведу некоторые интересные факты из выступления основателя компании Алексея Владышева:
🔹Компания Zabbix непрерывно растёт. Сейчас это 150 сотрудников в компании и 250 партнёрских компаний по всему миру.
🔹Zabbix старается покрывать все уровни инфраструктуры от железа до бизнес метрик.
🔹Zabbix следует современным требованиям к безопасности: интеграция с hashicorp vault, 2FA, SSO, Токены к API, работа агентов без прав root и т.д.
🔹Анонсировал изменение в 7-й версии, про которое я не слышал ранее. Раньше было одно соединение на один poller, теперь pollers будут поддерживать множественные соединения, буквально тысячи на каждый poller. Также рассказал про другие нововведения:
◽Хранение метрик для увеличения быстродействия в памяти zabbix-proxy, а не в только в базе, как сейчас.
◽Новые айтемы будут сразу же забирать метрики после создания, в течении минуты, а не через настроенные в них интервалы. Если интервал был час, то час и нужно было ждать до первого обновления, если не сделать его принудительно.
🔹В выступлении Алексей упомянул, что сейчас Zabbix не поддерживает OpenTelemetry, Tracing, полноценный сбор логов. В конце этого блока он сказал, что они будут это исправлять. Было бы неплохо, но хз когда всё это появится.
В целом, мне кажется, что Zabbix как-то забуксовал в развитии. Сейчас в продуктах упор идёт на простоту и скорость настройки. Берём Prometheus, ставим на хост Exporter, забираем все метрики, идём в Grafana, берём готовый дашборд, коих масса под все популярные продукты. И в течении 10 минут у нас всё готово. С Zabbix так не получится. Коллекции публичных дашбордов вообще нет. Мне прям грустно становится, когда настраиваешь какой-то мониторинг и приходится самому вручную собирать дашборд. Это небыстрое занятие.
Графики с виджетами как-то коряво и разномастно смотрятся, даже новые. Нет единства стиля. В дашбордах одни графики через виджеты, в панелях и просто графиках другие. Надо всё это как-то к единообразию привести и дать возможность импорта и экспорта всех этих сущностей, а не только полных шаблонов. Шаблоны это больше про метрики, а визуализации могут быть совсем разные в зависимости от задач. Надо их разделить и создать на сайте раздел с дашбордами, как это есть у Grafana.
Что ещё было интересно из саммита:
🟢 Internal Changes and Improvements in Zabbix 7.0 - Внутренние изменения в работе Zabbix, которые будут в 7-й версии.
🟢 Monitoring Kubernetes Cluster with an External Zabbix Server - Про то, как заббиксом мониторят Kubernetes.
🟢 Logs Go LLD - тут знатные костыли автообнаружения на bash и regex, приправленное перлом.
🟢 Tips and Tricks on using useful features of Zabbix in large scale environments - много интересных примеров и конкретики при построении мониторинга в большой распределённой инфраструктуре.
🟢 Implementing TimescaleDB on large Zabbix without downtime - миграция очень большой базы Zabbix с обычного формата на TimescaleDB без остановки на обслуживание и перенос, и без потери метрик.
#zabbix
⇨ https://www.zabbix.com/ru/events/zabbix_summit_2023
Было много всяких событий, даже не знаю, о чём конкретно рассказать. В принципе, вы можете сами по программе мероприятия посмотреть то, что вам больше всего интересно и перейти на запись выступления или посмотреть презентацию.
Приведу некоторые интересные факты из выступления основателя компании Алексея Владышева:
🔹Компания Zabbix непрерывно растёт. Сейчас это 150 сотрудников в компании и 250 партнёрских компаний по всему миру.
🔹Zabbix старается покрывать все уровни инфраструктуры от железа до бизнес метрик.
🔹Zabbix следует современным требованиям к безопасности: интеграция с hashicorp vault, 2FA, SSO, Токены к API, работа агентов без прав root и т.д.
🔹Анонсировал изменение в 7-й версии, про которое я не слышал ранее. Раньше было одно соединение на один poller, теперь pollers будут поддерживать множественные соединения, буквально тысячи на каждый poller. Также рассказал про другие нововведения:
◽Хранение метрик для увеличения быстродействия в памяти zabbix-proxy, а не в только в базе, как сейчас.
◽Новые айтемы будут сразу же забирать метрики после создания, в течении минуты, а не через настроенные в них интервалы. Если интервал был час, то час и нужно было ждать до первого обновления, если не сделать его принудительно.
🔹В выступлении Алексей упомянул, что сейчас Zabbix не поддерживает OpenTelemetry, Tracing, полноценный сбор логов. В конце этого блока он сказал, что они будут это исправлять. Было бы неплохо, но хз когда всё это появится.
В целом, мне кажется, что Zabbix как-то забуксовал в развитии. Сейчас в продуктах упор идёт на простоту и скорость настройки. Берём Prometheus, ставим на хост Exporter, забираем все метрики, идём в Grafana, берём готовый дашборд, коих масса под все популярные продукты. И в течении 10 минут у нас всё готово. С Zabbix так не получится. Коллекции публичных дашбордов вообще нет. Мне прям грустно становится, когда настраиваешь какой-то мониторинг и приходится самому вручную собирать дашборд. Это небыстрое занятие.
Графики с виджетами как-то коряво и разномастно смотрятся, даже новые. Нет единства стиля. В дашбордах одни графики через виджеты, в панелях и просто графиках другие. Надо всё это как-то к единообразию привести и дать возможность импорта и экспорта всех этих сущностей, а не только полных шаблонов. Шаблоны это больше про метрики, а визуализации могут быть совсем разные в зависимости от задач. Надо их разделить и создать на сайте раздел с дашбордами, как это есть у Grafana.
Что ещё было интересно из саммита:
🟢 Internal Changes and Improvements in Zabbix 7.0 - Внутренние изменения в работе Zabbix, которые будут в 7-й версии.
🟢 Monitoring Kubernetes Cluster with an External Zabbix Server - Про то, как заббиксом мониторят Kubernetes.
🟢 Logs Go LLD - тут знатные костыли автообнаружения на bash и regex, приправленное перлом.
🟢 Tips and Tricks on using useful features of Zabbix in large scale environments - много интересных примеров и конкретики при построении мониторинга в большой распределённой инфраструктуре.
🟢 Implementing TimescaleDB on large Zabbix without downtime - миграция очень большой базы Zabbix с обычного формата на TimescaleDB без остановки на обслуживание и перенос, и без потери метрик.
#zabbix
{kind=link}
Решил не откладывать в долгий ящик и перевести один из веб серверов на Angie. Как и обещали разработчики, с конфигами Nginx полная совместимость. Установил Angie и скопировал основной конфиг сервиса, а также виртуальных хостов. Виртуальные хосты вообще не трогал, а основной конфиг немного подредактировал, изменив в include пути с
Остановил Nginx, запустил Angie. Никаких проблем. Всё мгновенно подхватилось новым веб серверов. Простой пару секунд.
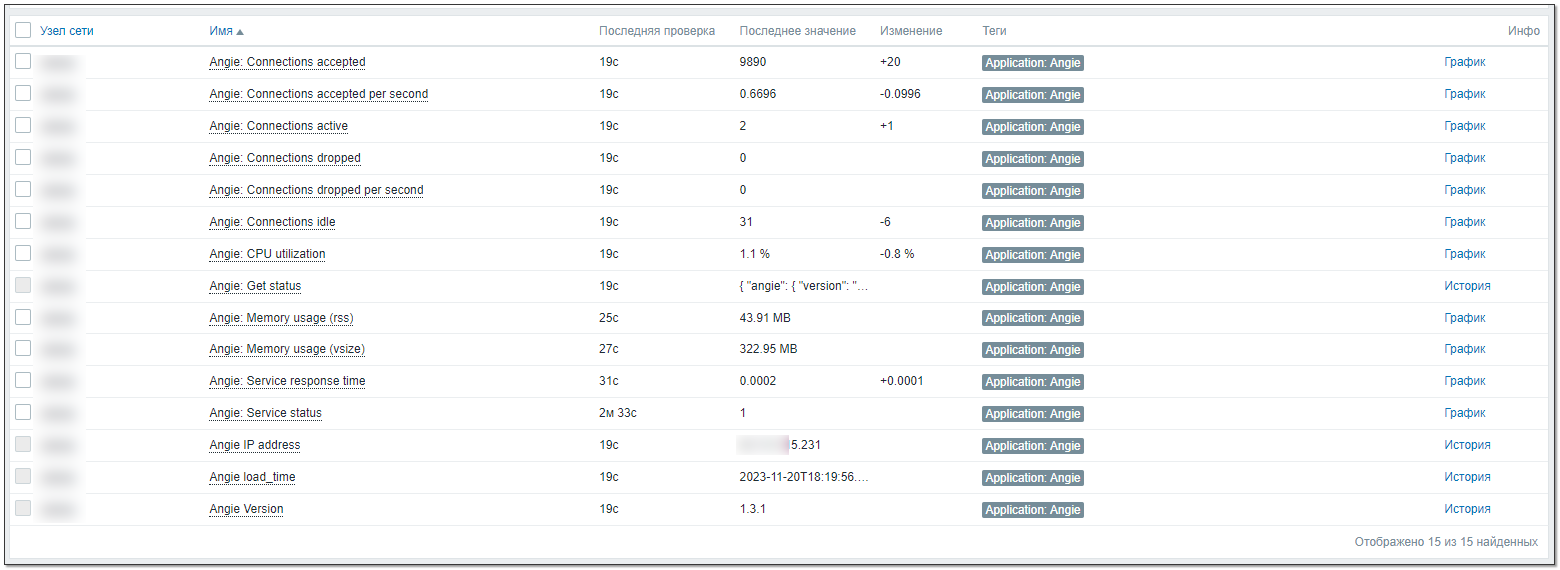
Заметку пишу не про переход, а про мониторинг. Согласно документации настроил передачу метрик сервера через API, веб консоль и метрики Prometheus. С прометеусом пока не разбирался, веб консоль просто для красоты включил, а внимание уделил API. Настроил шаблон Zabbix для сбора метрик через API. Сделал по аналогии с Nginx, но кое-что изменил по своему усмотрению. Шаблон можно скачать тут. Это первая версия. Немного попользуюсь и надеюсь, что оформлю всё это в полноценную статью с какими-то правками, которые наверняка накопятся по мере использования.
В шаблоне используются 2 макроса:
◽{$STATUS_HOST} - ip адрес сервера
◽{$STATUS_PATH} - часть урла для API.
У меня доступ к API настроен по IP, а полный путь выглядит так: http://1.2.3.4/status/. Соответственно, первый макрос - 1.2.3.4, второй - /status/.
На картинке ниже метрики, которые я посчитал полезными и добавил в шаблон. Триггера сделал три: не отвечает внешний порт веб сервера, нет ни одного процесса angie на сервере, не поступают данные от API в мониторинг. Также добавил 4 графика и оформил всё в панель. Картинку панели покажу в комментариях.
#angie #zabbix
/etc/nginx на /etc/angie. Ещё параметр pid изменил с /var/run/nginx.pid на /run/angie.pid. Больше ничего не менял. Остановил Nginx, запустил Angie. Никаких проблем. Всё мгновенно подхватилось новым веб серверов. Простой пару секунд.
Заметку пишу не про переход, а про мониторинг. Согласно документации настроил передачу метрик сервера через API, веб консоль и метрики Prometheus. С прометеусом пока не разбирался, веб консоль просто для красоты включил, а внимание уделил API. Настроил шаблон Zabbix для сбора метрик через API. Сделал по аналогии с Nginx, но кое-что изменил по своему усмотрению. Шаблон можно скачать тут. Это первая версия. Немного попользуюсь и надеюсь, что оформлю всё это в полноценную статью с какими-то правками, которые наверняка накопятся по мере использования.
В шаблоне используются 2 макроса:
◽{$STATUS_HOST} - ip адрес сервера
◽{$STATUS_PATH} - часть урла для API.
У меня доступ к API настроен по IP, а полный путь выглядит так: http://1.2.3.4/status/. Соответственно, первый макрос - 1.2.3.4, второй - /status/.
На картинке ниже метрики, которые я посчитал полезными и добавил в шаблон. Триггера сделал три: не отвечает внешний порт веб сервера, нет ни одного процесса angie на сервере, не поступают данные от API в мониторинг. Также добавил 4 графика и оформил всё в панель. Картинку панели покажу в комментариях.
#angie #zabbix
{kind=link}
Один из читателей канала давно мне скидывал информацию про скрипт для Zabbix, который отправляет оповещения с графиками в Telegram. Он его сам написал. У меня как-то затерялась эта информация и только сейчас дошли руки посмотреть. Я проверил, всё работает нормально. В целом, таких скриптов немало, я сам пользуюсь и в статье рассказываю про настройку. Тут отличие в том, что он полностью на Bash, в то время как я использую решения, написанные на Python. Вариант с башем лично для мне выглядит более привлекательным.
В принципе, всё описание есть в репозитории и в отдельной статье от автора. Я по ним без проблем настроил. Если раньше уведомления в Telegram не настраивали, то, возможно, придётся повозиться. Там надо бота создать, с токеном ничего не напутать и т.д. Судя по количеству комментариев с вопросами к моей статье по этой теме, у многих не получается быстро с этим разобраться.
Отмечу несколько моментов, с которыми сам столкнулся.
1️⃣ Скрипт по умолчанию пишет лог файл в директорию
2️⃣ Второй момент - когда будете добавлять новый способ оповещений (media type), не забудьте добавить туда шаблоны. По умолчанию они не создаются. Я забыл об этом и не сразу догадался, почему ошибку при отправке через этот тип сообщений получаю.
3️⃣ Для айтема должен существовать график, чтобы он прилетел в оповещения. Иначе графика не будет. Если что-то не будет получаться, то почитайте комментарии к статье. Там автор подробно объясняет нюансы и показывает, как дебажить отсутствие графиков
#zabbix
В принципе, всё описание есть в репозитории и в отдельной статье от автора. Я по ним без проблем настроил. Если раньше уведомления в Telegram не настраивали, то, возможно, придётся повозиться. Там надо бота создать, с токеном ничего не напутать и т.д. Судя по количеству комментариев с вопросами к моей статье по этой теме, у многих не получается быстро с этим разобраться.
Отмечу несколько моментов, с которыми сам столкнулся.
1️⃣ Скрипт по умолчанию пишет лог файл в директорию
/usr/lib/zabbix/alertscripts, владельцем которой является root, соответственно у скрипта нет прав на запись туда. Либо сделайте владельцем пользователя Zabbix, либо вынесите лог куда-то в другое место. 2️⃣ Второй момент - когда будете добавлять новый способ оповещений (media type), не забудьте добавить туда шаблоны. По умолчанию они не создаются. Я забыл об этом и не сразу догадался, почему ошибку при отправке через этот тип сообщений получаю.
3️⃣ Для айтема должен существовать график, чтобы он прилетел в оповещения. Иначе графика не будет. Если что-то не будет получаться, то почитайте комментарии к статье. Там автор подробно объясняет нюансы и показывает, как дебажить отсутствие графиков
#zabbix
{kind=link}
Zabbix последнее время не сильно радует новостями или какими-то событиями. Как-будто у компании проблемы. Раньше регулярно были рассылки с множеством событий: обновления, статьи в блоге, ролики в ютубе, новые шаблоны, вебинары и т.д.
Сейчас и количество рассылок сократилось, и количество событий в них. В блоге давно не вижу ничего интересного, на ютубе тоже в основном пусто. Вчера была рассылка, там единственное интересное событие - одно из обновлений в новой версии 7.0.
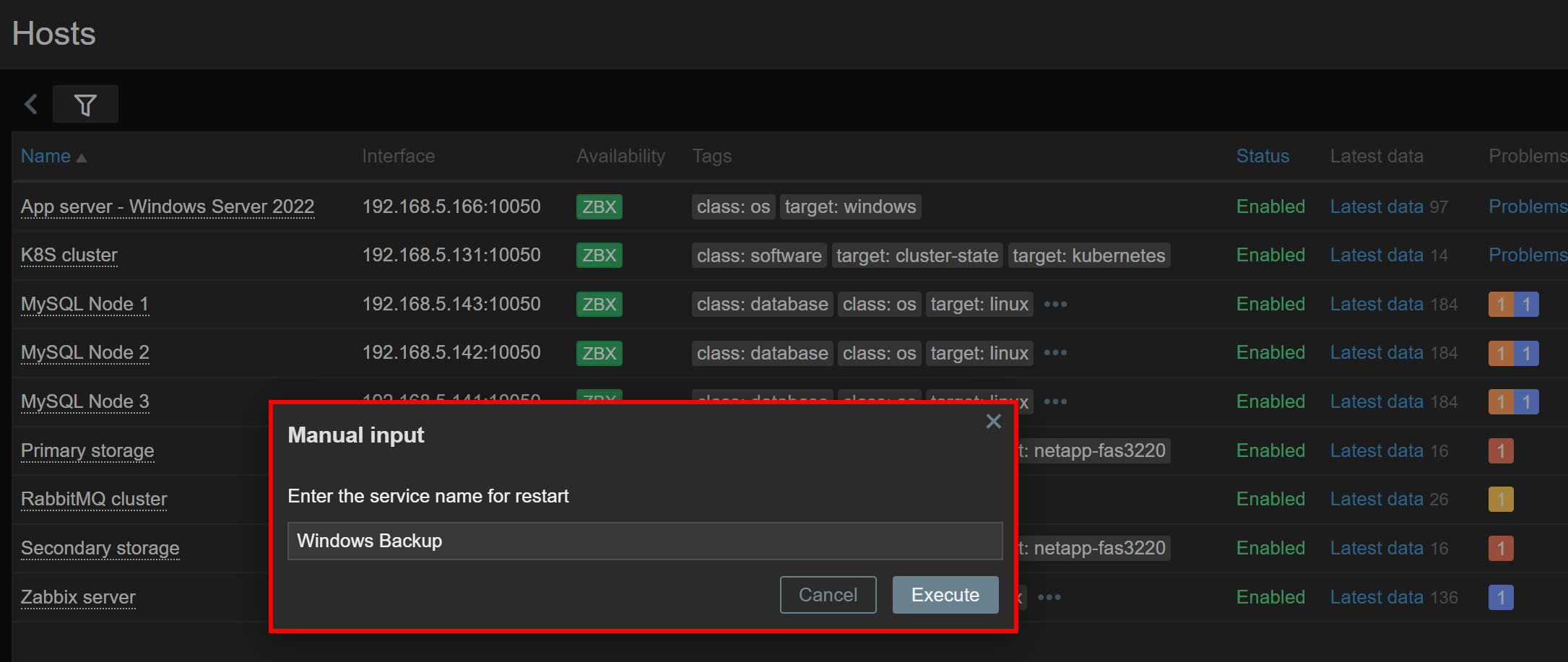
✔️ Рассказывают, что реализовали возможность передавать параметры к скриптам прямо из веб интерфейса. Если я правильно понял, то можно добавить какой-то скрипт, к примеру, для перезапуска службы. В случае необходимости, можно через веб интерфейс к нему обратиться и передать что-то в качестве параметра. Например, адрес сервера и/или имя службы. И скрипт выполнит перезапуск на целевом сервере. Подробного описания нет. Свою интерпретацию сделал на основе вот этих строк: "The latest alpha release introduces the ability to pass custom input to frontend scripts, enabling many new host administration scenarios directly from the Zabbix frontend." и картинки, что будет в конце публикации.
✔️ Посмотрел список остальных нововведений. Понравился новый тип проверки net.dns.perf. С его помощью можно проверять DNS записи. Это полезная штука, так как зачастую изменение записей может обрушить всю систему. За этим важно следить.
✔️ Ещё из полезного - добавили возможность пушить метрики через Zabbix API. Раньше для этого можно было только zabbix_sender использовать. Теперь можно без него обойтись. Это позволит быстро и просто передавать метрики из других систем через их вебхуки. В будущем обещают виджет на дашборд для ввода метрик вручную. Это, кстати, было бы полезно. Сейчас нет простых способов передать вручную в айтем значение.
▶️ Zabbix 7.0 - History Push API Feature
В видео в том числе можно увидеть новый интерфейс в Zabbix 7.0. Всё левое меню существенно изменилось.
✅ Также вышла новая версия Zabbix Server 6.0.25, в которой наконец-то исправили баг, когда не работали веб проверки сайтов в кодировке, отличной от utf8. В комментариях кто-то писал, что тоже заметил эту проблему. Так вот теперь её исправили. У меня наконец-то заработали проверки старых сайтов в кодировке Windows-1251. Раньше Битрикс по умолчанию в ней устанавливался и до сих пор успешно работает и обновляется с этой кодировкой.
У Zabbix изменились сроки поддержки не LTS версий, то есть версий X.2 и X.4. Теперь это будет 6 месяцев полной поддержки и 6 месяцев исправлений критичных багов и проблем с безопасностью. То есть поддержка будет 1 год со времени выхода нового релиза. Напомню, что у LTS версии поддержка 5 лет. Я обычно на LTS версиях сижу. Редко обновляю на промежуточные релизы. Только если интересно потестить какие-то нововведения.
⇨ Zabbix Life Cycle and Release Policy.
Ждём версию 7.0. Пока что только alpha, потом ещё несколько месяцев будут beta выходить. К весне, наверное, зарелизятся.
#zabbix
Сейчас и количество рассылок сократилось, и количество событий в них. В блоге давно не вижу ничего интересного, на ютубе тоже в основном пусто. Вчера была рассылка, там единственное интересное событие - одно из обновлений в новой версии 7.0.
✔️ Рассказывают, что реализовали возможность передавать параметры к скриптам прямо из веб интерфейса. Если я правильно понял, то можно добавить какой-то скрипт, к примеру, для перезапуска службы. В случае необходимости, можно через веб интерфейс к нему обратиться и передать что-то в качестве параметра. Например, адрес сервера и/или имя службы. И скрипт выполнит перезапуск на целевом сервере. Подробного описания нет. Свою интерпретацию сделал на основе вот этих строк: "The latest alpha release introduces the ability to pass custom input to frontend scripts, enabling many new host administration scenarios directly from the Zabbix frontend." и картинки, что будет в конце публикации.
✔️ Посмотрел список остальных нововведений. Понравился новый тип проверки net.dns.perf. С его помощью можно проверять DNS записи. Это полезная штука, так как зачастую изменение записей может обрушить всю систему. За этим важно следить.
✔️ Ещё из полезного - добавили возможность пушить метрики через Zabbix API. Раньше для этого можно было только zabbix_sender использовать. Теперь можно без него обойтись. Это позволит быстро и просто передавать метрики из других систем через их вебхуки. В будущем обещают виджет на дашборд для ввода метрик вручную. Это, кстати, было бы полезно. Сейчас нет простых способов передать вручную в айтем значение.
▶️ Zabbix 7.0 - History Push API Feature
В видео в том числе можно увидеть новый интерфейс в Zabbix 7.0. Всё левое меню существенно изменилось.
✅ Также вышла новая версия Zabbix Server 6.0.25, в которой наконец-то исправили баг, когда не работали веб проверки сайтов в кодировке, отличной от utf8. В комментариях кто-то писал, что тоже заметил эту проблему. Так вот теперь её исправили. У меня наконец-то заработали проверки старых сайтов в кодировке Windows-1251. Раньше Битрикс по умолчанию в ней устанавливался и до сих пор успешно работает и обновляется с этой кодировкой.
У Zabbix изменились сроки поддержки не LTS версий, то есть версий X.2 и X.4. Теперь это будет 6 месяцев полной поддержки и 6 месяцев исправлений критичных багов и проблем с безопасностью. То есть поддержка будет 1 год со времени выхода нового релиза. Напомню, что у LTS версии поддержка 5 лет. Я обычно на LTS версиях сижу. Редко обновляю на промежуточные релизы. Только если интересно потестить какие-то нововведения.
⇨ Zabbix Life Cycle and Release Policy.
Ждём версию 7.0. Пока что только alpha, потом ещё несколько месяцев будут beta выходить. К весне, наверное, зарелизятся.
#zabbix
{kind=link}
Расскажу про очень простой и быстрый способ мониторить размер какой-нибудь директории или файла на сервере с помощью Zabbix. Способов реализации может быть очень много. Предлагаю наиболее простой, который подойдёт для директорий, где проверку надо делать не часто, и она относительно быстро выполнится. В пределах настроенных таймаутов для агента.
Смотрим размер директории в килобайтах:
Эту цифру надо передать на Zabbix Server. Для этого открываем конфиг zabbix_agentd.conf и добавляем туда:
Перезапускаем агента и проверяем работу метрики:
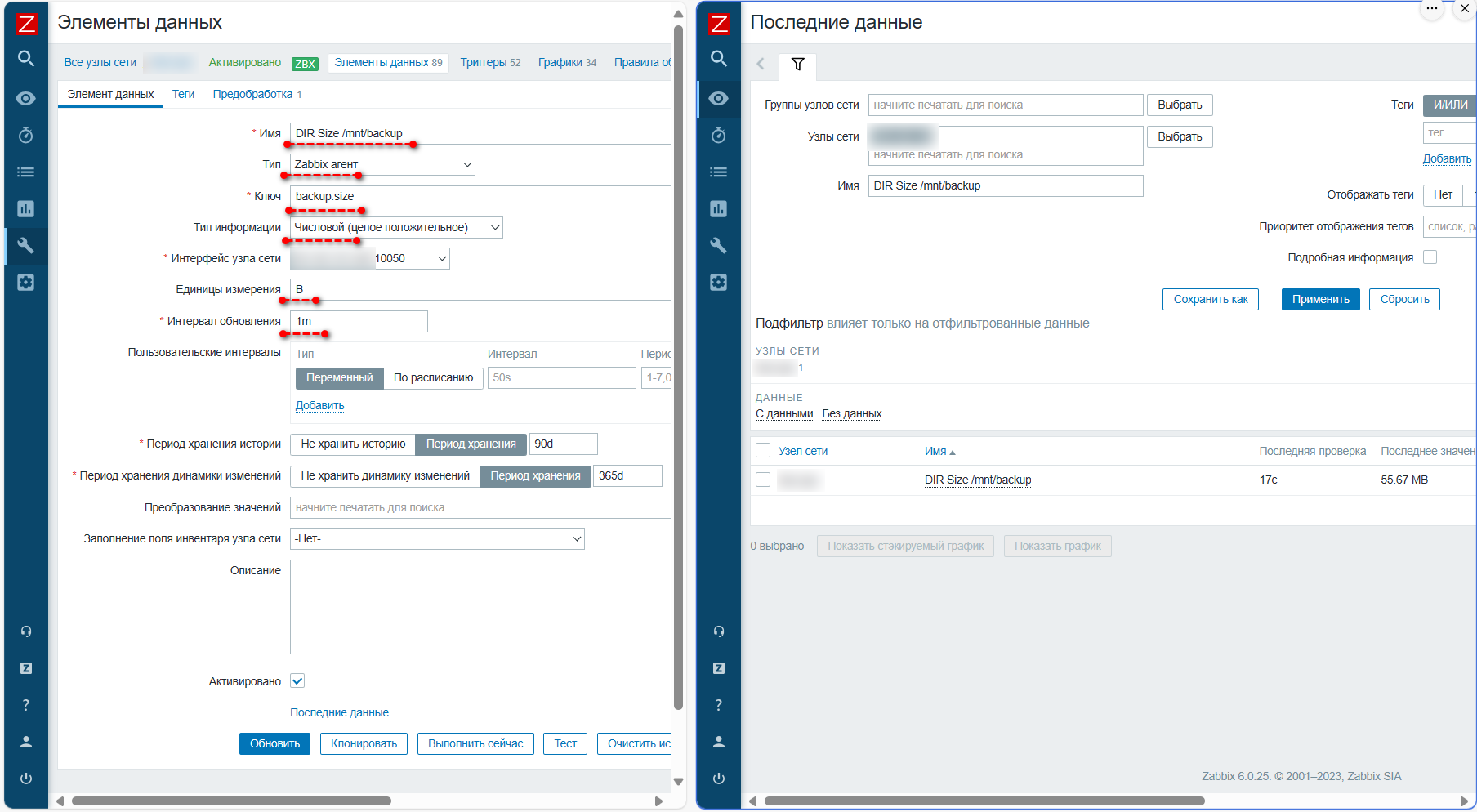
Отлично, метрика работает. Идём на Zabbix Server, создаём новый шаблон или добавляем айтем напрямую в нужный хост (лучше всегда делать шаблоны). Указываем:
◽Имя: DIR Size /mnt/backup (указываете любое)
◽Тип: Zabbix agent
◽Ключ: backup.size
◽Тип информации: целое положительное
◽Единицы измерения: B (латинская B - байты)
Единица измерения байты указана для того, чтобы Zabbix понимал, что речь идёт о размере данных. Тогда он будет автоматически их переводить на графиках в килобайты, мегабайты, гигабайты, что удобно. Единственный нюанс, у нас данные приходят не в байтах, а килобайтах, поэтому нам нужно добавить множитель 1024. Для этого переходим в настройках айтема на вкладку Предобработка и добавляем шаг:
◽Пользовательский множитель: 1024
Сохраняем айтем. Теперь шаблон можно прикрепить к хосту, где настраивали агента и проверить, как работает. При необходимости можно сделать триггер на этот размер. Не знаю, за чем конкретно вам нужно будет следить, за превышением или наоборот за уменьшением размера, или за изменениями в день. В зависимости от этого настраивается триггер. Там всё интуитивно и по-русски, не трудно разобраться.
По аналогии можно следить за размером отдельного файла. Для этого достаточно указать именно его, а не директорию:
Ну и точно так же добавляем потом в UserParameter новый айтем, настраиваем его на сервере.
Если в UserParameter написать примерно так:
То в качестве имени файла можно передавать значения из ключа айтема, который настраивается на сервере. Примерно так будет выглядеть ключ:
Вот это значение из квадратных скобок приедет на агента вместо
Такой простой механизм передачи в Zabbix любых значений с сервера. Это открывает безграничные возможности для мониторинга всего, что только можно придумать.
Отдельно отмечу, что если директорий у вас много, там много файлов, и частота проверок приличная, то сажайте эти подсчёты на cron, записывайте результаты в файл, а в Zabbix забирайте уже из файла. Так будет надёжнее и проще для сервера мониторинга. Не будет его нагружать лишними соединениями и ожиданиями результата.
Если у кого-то есть вопросы по Zabbix, можете позадавать. Если что, подскажу. Особенно если надо придумать мониторинг какой-нибудь нестандартной метрики. Я чего только не мониторил с ним. От давления жидкости в контуре с контроллера по Modbus протоколу до числа подписчиков в Telegram группе.
#zabbix
Смотрим размер директории в килобайтах:
# du -s /mnt/backup | awk '{print $1}'57004Эту цифру надо передать на Zabbix Server. Для этого открываем конфиг zabbix_agentd.conf и добавляем туда:
UserParameter=backup.size, du -s /mnt/backup | awk '{print $1}'Перезапускаем агента и проверяем работу метрики:
# systemctl restart zabbix-agent# zabbix_agentd -t backup.sizebackup.size [t|57004]Отлично, метрика работает. Идём на Zabbix Server, создаём новый шаблон или добавляем айтем напрямую в нужный хост (лучше всегда делать шаблоны). Указываем:
◽Имя: DIR Size /mnt/backup (указываете любое)
◽Тип: Zabbix agent
◽Ключ: backup.size
◽Тип информации: целое положительное
◽Единицы измерения: B (латинская B - байты)
Единица измерения байты указана для того, чтобы Zabbix понимал, что речь идёт о размере данных. Тогда он будет автоматически их переводить на графиках в килобайты, мегабайты, гигабайты, что удобно. Единственный нюанс, у нас данные приходят не в байтах, а килобайтах, поэтому нам нужно добавить множитель 1024. Для этого переходим в настройках айтема на вкладку Предобработка и добавляем шаг:
◽Пользовательский множитель: 1024
Сохраняем айтем. Теперь шаблон можно прикрепить к хосту, где настраивали агента и проверить, как работает. При необходимости можно сделать триггер на этот размер. Не знаю, за чем конкретно вам нужно будет следить, за превышением или наоборот за уменьшением размера, или за изменениями в день. В зависимости от этого настраивается триггер. Там всё интуитивно и по-русски, не трудно разобраться.
По аналогии можно следить за размером отдельного файла. Для этого достаточно указать именно его, а не директорию:
# du -s /mnt/backup/daily/mysql/daily_mysql_2024-03-01_16h13m_Friday.sql.gz530004Ну и точно так же добавляем потом в UserParameter новый айтем, настраиваем его на сервере.
Если в UserParameter написать примерно так:
UserParameter=file.size[*], du -s $1 | awk '{print $1}'То в качестве имени файла можно передавать значения из ключа айтема, который настраивается на сервере. Примерно так будет выглядеть ключ:
file.size[/mnt/backup/daily/mysql/daily_mysql_2024-03-01_16h13m_Friday.sql.gz]Вот это значение из квадратных скобок приедет на агента вместо
* в квадратные скобки, и вместо $1 в консольную команду.. То есть не придётся для каждого файла настраивать UserParameter. Звёздочка будет разворачиваться в переданное значение.Такой простой механизм передачи в Zabbix любых значений с сервера. Это открывает безграничные возможности для мониторинга всего, что только можно придумать.
Отдельно отмечу, что если директорий у вас много, там много файлов, и частота проверок приличная, то сажайте эти подсчёты на cron, записывайте результаты в файл, а в Zabbix забирайте уже из файла. Так будет надёжнее и проще для сервера мониторинга. Не будет его нагружать лишними соединениями и ожиданиями результата.
Если у кого-то есть вопросы по Zabbix, можете позадавать. Если что, подскажу. Особенно если надо придумать мониторинг какой-нибудь нестандартной метрики. Я чего только не мониторил с ним. От давления жидкости в контуре с контроллера по Modbus протоколу до числа подписчиков в Telegram группе.
#zabbix
{kind=link}
Заглядывал на днях на один из серверов 1С, который настраивал примерно 3 года назад. Купил туда бюджетные серверные диски KINGSTON SEDC500M 960G в RAID1. Стоят они очень умеренно, а по ресурсу значительно преворсходят десктопные модели. Раньше там каждые год-два меняли SSD. В принципе, хватало производительности, но при интенсивной записи во время дампов баз всё подтормаживало. С этими стало намного лучше.
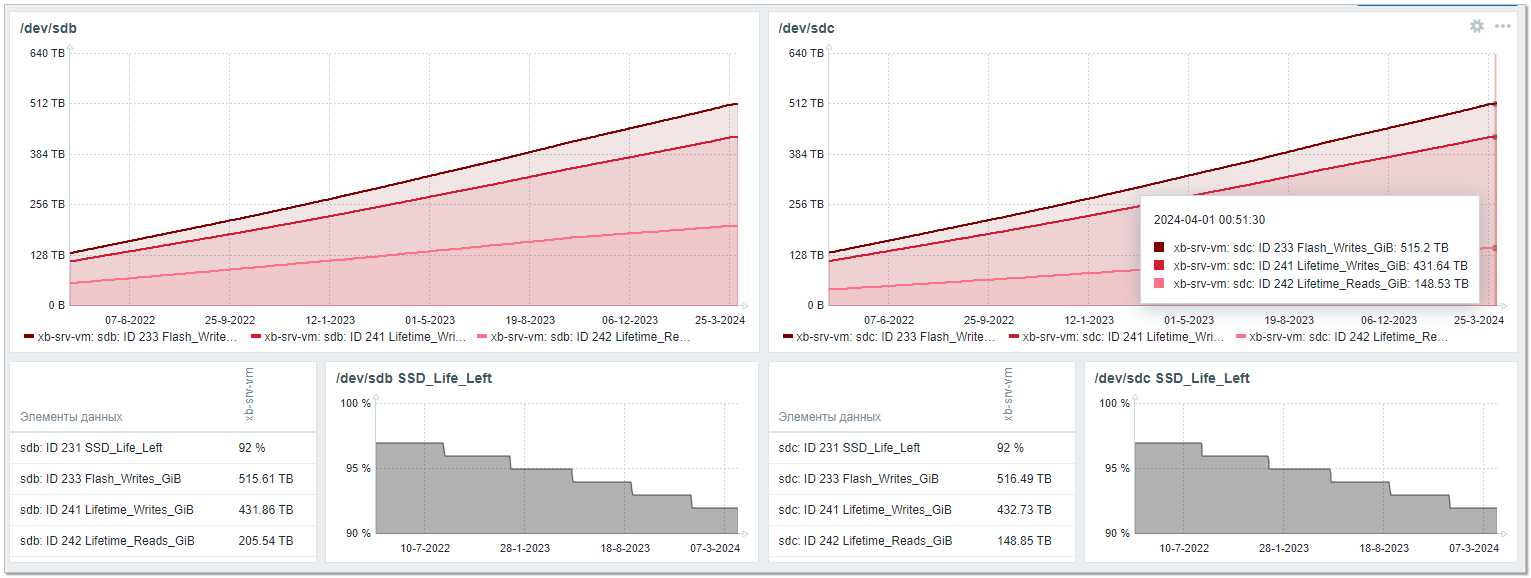
Я, собственно, зашёл проверить ресурс и статистику по записи. Просто любопытно стало. Решил и с вами поделиться цифрами. У меня все метрики SMART собирал Zabbix, а основные выведены на дашборд. Так что удобно оценить разом.
Основные метрики, за которыми следил:
▪️ Flash_Writes_GiB - количество сырых данных, записанных в NAND flash.
▪️ Lifetime_Writes_GiB - количество записанных данных, прошедших через ATA интерфейс.
▪️ Lifetime_Reads_GiB - количество прочитанных данных.
▪️ SSD_Life_Left - остаток ресурса жизни SSD.
По записи для обоих дисков получились примерно одинаковые значения:
sdb: ID 233 Flash_Writes_GiB 515.61 TB
sdb: ID 241 Lifetime_Writes_GiB 431.86 TB
sdc: ID 233 Flash_Writes_GiB 516.49 TB
sdc: ID 241 Lifetime_Writes_GiB 432.73 TB
Сырых данных на флеш пишется значительно больше, чем переданных на диск реальных, прошедших через интерфейс передачи данных. Если я правильно понимаю, это связно с тем, что данные записываются не как есть, а в зависимости от кратности ячеек памяти, куда происходит запись. То есть реально на диск пишется больше данных, чем передаётся.
А вот по чтению данные сильно разнятся:
sdb: ID 242 Lifetime_Reads_GiB 205.54 TB
sdc: ID 242 Lifetime_Reads_GiB 148.85 TB
С одного диска данные читались на четверть чаще, чем с другого. Рейд организован средствами mdadm. То есть обычный софтовый RAID1.
Ну и по ресурсу там запас ещё огромный. SMART показывает 92%. За последние два года изменение с 97% до 92%. Если смарт не врёт, то скорее заменят сервер с дисками, чем они израсходуют свой ресурс. В день там примерно по 400 GB пишется.
Мониторится всё это через парсинг вывода smartctl:
Примерный вариант настройки можно в моей статье посмотреть:
⇨ Настройка мониторинга SMART жесткого диска в zabbix
#железо #zabbix
Я, собственно, зашёл проверить ресурс и статистику по записи. Просто любопытно стало. Решил и с вами поделиться цифрами. У меня все метрики SMART собирал Zabbix, а основные выведены на дашборд. Так что удобно оценить разом.
Основные метрики, за которыми следил:
▪️ Flash_Writes_GiB - количество сырых данных, записанных в NAND flash.
▪️ Lifetime_Writes_GiB - количество записанных данных, прошедших через ATA интерфейс.
▪️ Lifetime_Reads_GiB - количество прочитанных данных.
▪️ SSD_Life_Left - остаток ресурса жизни SSD.
По записи для обоих дисков получились примерно одинаковые значения:
sdb: ID 233 Flash_Writes_GiB 515.61 TB
sdb: ID 241 Lifetime_Writes_GiB 431.86 TB
sdc: ID 233 Flash_Writes_GiB 516.49 TB
sdc: ID 241 Lifetime_Writes_GiB 432.73 TB
Сырых данных на флеш пишется значительно больше, чем переданных на диск реальных, прошедших через интерфейс передачи данных. Если я правильно понимаю, это связно с тем, что данные записываются не как есть, а в зависимости от кратности ячеек памяти, куда происходит запись. То есть реально на диск пишется больше данных, чем передаётся.
А вот по чтению данные сильно разнятся:
sdb: ID 242 Lifetime_Reads_GiB 205.54 TB
sdc: ID 242 Lifetime_Reads_GiB 148.85 TB
С одного диска данные читались на четверть чаще, чем с другого. Рейд организован средствами mdadm. То есть обычный софтовый RAID1.
Ну и по ресурсу там запас ещё огромный. SMART показывает 92%. За последние два года изменение с 97% до 92%. Если смарт не врёт, то скорее заменят сервер с дисками, чем они израсходуют свой ресурс. В день там примерно по 400 GB пишется.
Мониторится всё это через парсинг вывода smartctl:
# smartctl -A /dev/sdbПримерный вариант настройки можно в моей статье посмотреть:
⇨ Настройка мониторинга SMART жесткого диска в zabbix
#железо #zabbix
{kind=link}
Давно не писал ничего про Zabbix. Всё жду, когда выйдет обещанная 7-я версия, а её всё нет. Решил навести справки, почитать имеющуюся информацию. От Zabbix последнее время мало новостей, так что я и следить перестал.
🔹Основная новость в том, что Zabbix, как и многие другие open source проекты в последнее время, изменил свою лицензию. Об этом была заметка в блоге от владельца компании. Расскажу, в чём суть замены лицензии GPL на AGPL и что это означает на практике.
Сразу отмечу, что для обычных пользователей Zabbix изменения не будут заметны. Для них ничего не меняется. Изменения, как и в случае с другими продуктами, коснутся тех, кто продаёт услуги на основе Zabbix другим людям. То есть компании таким образом защищают свои коммерческие интересы. С GPL вы обязаны выкладывать свои исходники только если продаёте готовый продукт на основе другого продукта с лицензией GPL. Если я правильно понял, то можно взять продукт под лицензией GPL, реализовать на его основе какой-то сервис и продавать этот сервис пользователям. Лицензия GPL позволяет вам его использовать таким образом и не выкладывать исходники своего сервиса.
AGPL убирает такую возможность. Если вы продаёте какой-то сервис, к примеру, по модели saas, где используется продукт с лицензией AGPL, вы обязаны опубликовать исходники своего сервиса. В целом, выглядит вполне логично для авторов продукта. По такой же схеме в своё время меняли лицензию MongoDB, Elastic, HashiCorp, Redis. Там хоть и другие лицензии используются, но общий смысл такой же и по своей сути лицензии похожи друг на друга, но со своими нюансами. Основной посыл - запретить облачным сервисам предоставлять услуги на основе open source продуктов без покупки коммерческой версии или открытия своего кода.
🔹К другим новостям. Недавно вышла версия 7.0.0beta3. В целом, релиз движется к публикации. Думаю, к лету он состоится. Изначально стояла дата Q4 2023, потом перенесли на Q1 2024, сейчас уже на Q2 2024. В целом, ничего необычного. У Zabbix релизы всегда откладываются. Кто-то уже сейчас пользуется 7-й версией. Видел такие комментарии не раз. Я так понимаю, что она вполне стабильна. Если делать новую установку, то можно уже 7-ю версию ставить.
🔹Zabbix периодически проводит вебинары на русском языке. Ближайший назначен на 2 мая, тема - Расширение возможностей Zabbix. Речь там пойдёт про userparametres и плагины агента 2. Тема полезная, если с ней не знакомы.
🔹Из последних статей в блоге была одна реально полезная. Там рассказано, как сгенерировать самоподписанный сертификат, чтобы по HTTPS ходить на веб интерфейс по DNS имени или IP адресу и не получать предупреждения браузера. Там ничего особенного, просто все команды и конфиги собраны в одно место, что удобно. Надо будет оформить в небольшую заметку. Обычно лень с этим возиться и получаешь сертификаты от Let's Encrypt. Но зачастую проще и удобнее выпустить свои с условно бесконечным сроком действия и забыть про этот вопрос.
#zabbix
🔹Основная новость в том, что Zabbix, как и многие другие open source проекты в последнее время, изменил свою лицензию. Об этом была заметка в блоге от владельца компании. Расскажу, в чём суть замены лицензии GPL на AGPL и что это означает на практике.
Сразу отмечу, что для обычных пользователей Zabbix изменения не будут заметны. Для них ничего не меняется. Изменения, как и в случае с другими продуктами, коснутся тех, кто продаёт услуги на основе Zabbix другим людям. То есть компании таким образом защищают свои коммерческие интересы. С GPL вы обязаны выкладывать свои исходники только если продаёте готовый продукт на основе другого продукта с лицензией GPL. Если я правильно понял, то можно взять продукт под лицензией GPL, реализовать на его основе какой-то сервис и продавать этот сервис пользователям. Лицензия GPL позволяет вам его использовать таким образом и не выкладывать исходники своего сервиса.
AGPL убирает такую возможность. Если вы продаёте какой-то сервис, к примеру, по модели saas, где используется продукт с лицензией AGPL, вы обязаны опубликовать исходники своего сервиса. В целом, выглядит вполне логично для авторов продукта. По такой же схеме в своё время меняли лицензию MongoDB, Elastic, HashiCorp, Redis. Там хоть и другие лицензии используются, но общий смысл такой же и по своей сути лицензии похожи друг на друга, но со своими нюансами. Основной посыл - запретить облачным сервисам предоставлять услуги на основе open source продуктов без покупки коммерческой версии или открытия своего кода.
🔹К другим новостям. Недавно вышла версия 7.0.0beta3. В целом, релиз движется к публикации. Думаю, к лету он состоится. Изначально стояла дата Q4 2023, потом перенесли на Q1 2024, сейчас уже на Q2 2024. В целом, ничего необычного. У Zabbix релизы всегда откладываются. Кто-то уже сейчас пользуется 7-й версией. Видел такие комментарии не раз. Я так понимаю, что она вполне стабильна. Если делать новую установку, то можно уже 7-ю версию ставить.
🔹Zabbix периодически проводит вебинары на русском языке. Ближайший назначен на 2 мая, тема - Расширение возможностей Zabbix. Речь там пойдёт про userparametres и плагины агента 2. Тема полезная, если с ней не знакомы.
🔹Из последних статей в блоге была одна реально полезная. Там рассказано, как сгенерировать самоподписанный сертификат, чтобы по HTTPS ходить на веб интерфейс по DNS имени или IP адресу и не получать предупреждения браузера. Там ничего особенного, просто все команды и конфиги собраны в одно место, что удобно. Надо будет оформить в небольшую заметку. Обычно лень с этим возиться и получаешь сертификаты от Let's Encrypt. Но зачастую проще и удобнее выпустить свои с условно бесконечным сроком действия и забыть про этот вопрос.
#zabbix
{kind=link}
Вчера был релиз новой версии Zabbix Server 7.0. Это LTS версия со сроком поддержки 5 лет. Я буду обновлять все свои сервера со временем на эту версию. Почти всегда на рабочих серверах держу LTS версии, на промежуточные не обновляюсь.
Не буду перечислять все нововведения этой версии. Их можно посмотреть в официальном пресс-релизе. Они сейчас много где будут опубликованы. На русском языке можно прочитать в новости на opennet. Отмечу и прокомментирую то, что мне показалось наиболее интересным и полезным.
1️⃣ Обновился мониторинг веб сайтов. Очень давно ждал это. Почти все настроенные мной сервера так или иначе мониторили веб сайты или какие-то другие веб службы. Функциональность востребована, а не обновлялась очень давно. Как в версии то ли 1.8, то ли 2.0 я её увидел, так она и оставалось неизменной. Появился новый тип айтема для этого мониторинга - Browser.
2️⃣ Появилась централизованная настройка таймаутов в GUI. На функциональность особо не влияет, но на самом деле нужная штука. Таймауты постоянно приходится менять и подгонять значения под конкретные типы проверок на разных серверах. Удобно, что это можно будет делать не в конфигурационном файле, а в веб интерфейсе. И эти настройки будут иметь приоритет перед всеми остальными.
3️⃣ Добавили много разных виджетов. Не скажу, что это прям сильно нужно лично мне при настройке мониторинга. Скорее больше для эстетического удовольствия их делаю. Для анализа реальных данных обычно достаточно очень простых дашбордов с конкретным набором графиков, а не различные красивые виджеты в виде спидометров или сот. Но ситуации разные бывают. Например, виджет с географической картой активно используется многими компаниями. Из новых виджетов наиболее интересные - навигаторы хостов и айтемов.
4️⃣ Появилась мультифакторная аутентификация из коробки для веб интерфейса. Так как он часто смотрит напрямую в интернет, особенно у аутсорсеров, которые могут давать доступ заказчикам к мониторингу, это удобно.
5️⃣ Добавилось много менее значительных изменений по мониторингу. Такие как мониторинг DNS записей, возможность передавать метрики напрямую в мониторинг через API с помощью метода history.push, объекты, обнаруженные через discovery, теперь могут автоматически отключаться, если они больше не обнаруживаются, выборку через JSONPath теперь можно делать и в функциях триггеров, а не только в предобработке, можно выполнять удалённые команды через агенты, работающие в активном режиме.
Много работы проделано для увеличения производительности системы в целом. Перечислять всё это не стал, можно в новости от вендора всё это увидеть. Новость, в целом приятная. Мне нравится Zabbix как продукт. Буду обновляться потихоньку и изучать новые возможности.
Если что-то ещё значительное заметили среди изменений, дайте знать. А то я иногда что-то пропускаю, а потом через год-два после релиза вдруг обнаруживаю, что какая-то полезная возможность, про которую я не знал, реализована. Много раз с таким сталкивался.
#zabbix
Не буду перечислять все нововведения этой версии. Их можно посмотреть в официальном пресс-релизе. Они сейчас много где будут опубликованы. На русском языке можно прочитать в новости на opennet. Отмечу и прокомментирую то, что мне показалось наиболее интересным и полезным.
1️⃣ Обновился мониторинг веб сайтов. Очень давно ждал это. Почти все настроенные мной сервера так или иначе мониторили веб сайты или какие-то другие веб службы. Функциональность востребована, а не обновлялась очень давно. Как в версии то ли 1.8, то ли 2.0 я её увидел, так она и оставалось неизменной. Появился новый тип айтема для этого мониторинга - Browser.
2️⃣ Появилась централизованная настройка таймаутов в GUI. На функциональность особо не влияет, но на самом деле нужная штука. Таймауты постоянно приходится менять и подгонять значения под конкретные типы проверок на разных серверах. Удобно, что это можно будет делать не в конфигурационном файле, а в веб интерфейсе. И эти настройки будут иметь приоритет перед всеми остальными.
3️⃣ Добавили много разных виджетов. Не скажу, что это прям сильно нужно лично мне при настройке мониторинга. Скорее больше для эстетического удовольствия их делаю. Для анализа реальных данных обычно достаточно очень простых дашбордов с конкретным набором графиков, а не различные красивые виджеты в виде спидометров или сот. Но ситуации разные бывают. Например, виджет с географической картой активно используется многими компаниями. Из новых виджетов наиболее интересные - навигаторы хостов и айтемов.
4️⃣ Появилась мультифакторная аутентификация из коробки для веб интерфейса. Так как он часто смотрит напрямую в интернет, особенно у аутсорсеров, которые могут давать доступ заказчикам к мониторингу, это удобно.
5️⃣ Добавилось много менее значительных изменений по мониторингу. Такие как мониторинг DNS записей, возможность передавать метрики напрямую в мониторинг через API с помощью метода history.push, объекты, обнаруженные через discovery, теперь могут автоматически отключаться, если они больше не обнаруживаются, выборку через JSONPath теперь можно делать и в функциях триггеров, а не только в предобработке, можно выполнять удалённые команды через агенты, работающие в активном режиме.
Много работы проделано для увеличения производительности системы в целом. Перечислять всё это не стал, можно в новости от вендора всё это увидеть. Новость, в целом приятная. Мне нравится Zabbix как продукт. Буду обновляться потихоньку и изучать новые возможности.
Если что-то ещё значительное заметили среди изменений, дайте знать. А то я иногда что-то пропускаю, а потом через год-два после релиза вдруг обнаруживаю, что какая-то полезная возможность, про которую я не знал, реализована. Много раз с таким сталкивался.
#zabbix
{kind=link}
Вчера обновил один из своих серверов Zabbix до версии 7.0. Сразу же оформил всю информацию в статью. У меня сервер был установлен на систему Oracle Linux Server 8.10. Процедура прошла штатно и без заминок. Основные моменты, на которые нужно обратить внимание:
▪️ Версия 6.0 требовала php 7.2, эта требует 8.0. Не забудьте отдельно обновить и php. Напрямую к Zabbix Server это не относится, так что само не обновится. Мне пришлось подключить отдельный репозиторий Remi и поставить php 8.0 оттуда. В более свежих системах этого делать не потребуется, так как там 8.0+ в базовых репах. Особо заморачиваться не придётся.
▪️ Обновление самого сервера прошло штатно. Подключил репу новой версии и обновил пакеты. Можно воспользоваться официальной инструкцией, но она куцая.
💥Прямое обновление до 7.0 возможно практически в любой прошлой версии. Дословно с сайта Zabbix: Direct upgrade to Zabbix 7.0.x is possible from Zabbix 6.4.x, 6.2.x, 6.0.x, 5.4.x, 5.2.x, 5.0.x, 4.4.x, 4.2.x, 4.0.x, 3.4.x, 3.2.x, 3.0.x, 2.4.x, 2.2.x and 2.0.x. For upgrading from earlier versions consult Zabbix documentation for 2.0 and earlier.
▪️ Шаблоны мониторинга, оповещений и интеграций нужно обновлять отдельно, если хотите получить свежую версию. С самим сервером они автоматически не обновляются. В статье я написал, как можно провести эту процедуру.
▪️ Обновлять агенты до новой версии не обязательно. Всё будет нормально работать и со старыми версиями агентов. Обновление агентов опционально, но не обязательно.
▪️ Обновлять прокси тоже не обязательно, но крайне рекомендуется. Полная поддержка прокси сервером возможна только в рамках одной релизной ветки. Прокси прошлого релиза поддерживаются в ограниченном формате.
#zabbix
▪️ Версия 6.0 требовала php 7.2, эта требует 8.0. Не забудьте отдельно обновить и php. Напрямую к Zabbix Server это не относится, так что само не обновится. Мне пришлось подключить отдельный репозиторий Remi и поставить php 8.0 оттуда. В более свежих системах этого делать не потребуется, так как там 8.0+ в базовых репах. Особо заморачиваться не придётся.
▪️ Обновление самого сервера прошло штатно. Подключил репу новой версии и обновил пакеты. Можно воспользоваться официальной инструкцией, но она куцая.
💥Прямое обновление до 7.0 возможно практически в любой прошлой версии. Дословно с сайта Zabbix: Direct upgrade to Zabbix 7.0.x is possible from Zabbix 6.4.x, 6.2.x, 6.0.x, 5.4.x, 5.2.x, 5.0.x, 4.4.x, 4.2.x, 4.0.x, 3.4.x, 3.2.x, 3.0.x, 2.4.x, 2.2.x and 2.0.x. For upgrading from earlier versions consult Zabbix documentation for 2.0 and earlier.
▪️ Шаблоны мониторинга, оповещений и интеграций нужно обновлять отдельно, если хотите получить свежую версию. С самим сервером они автоматически не обновляются. В статье я написал, как можно провести эту процедуру.
▪️ Обновлять агенты до новой версии не обязательно. Всё будет нормально работать и со старыми версиями агентов. Обновление агентов опционально, но не обязательно.
▪️ Обновлять прокси тоже не обязательно, но крайне рекомендуется. Полная поддержка прокси сервером возможна только в рамках одной релизной ветки. Прокси прошлого релиза поддерживаются в ограниченном формате.
#zabbix
Server Admin
Обновление Zabbix 6.0 до 7.0 | serveradmin.ru
Подробное описание процесса обновления Zabbix Server с версии 6 до актуальной 7 на примере реального сервера.
Вчера вечером сел за компьютер посмотреть почту, в том числе сообщения от мониторинга. Всегда это делаю вечером в воскресенье, чтобы оценить состояние инфраструктуры перед понедельником. Привлёк внимание триггер от Zabbix с одной виртуалки. Там в течении почти 6-ти часов было высокие метрики по Load Average. Потом прошло.
Посмотрел остальные метрики за это время. Ни повышенного трафика, ни чтения/записи диска, ни жора памяти или swap не было. В логах тоже ничего. Выяснить, что же там было, теперь не представляется возможным. К сожалению, это существенный пробел Zabbix, так как стандартными шаблонами этот вопрос никак не решается.
Когда-то давно я придумал решение этой задачи в лоб:
1️⃣ Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
2️⃣ Разрешаю на zabbix agent запуск внешних команд.
3️⃣Настраиваю на Zabbix Server действие при срабатывании триггера на загрузку CPU. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
Решение очень простое в реализации и главное удобное в анализе. Список процессов получается в наглядном виде. И при этом постоянно не собираются эти данные, а запрашиваются только в нужные моменты.
Описал этот способ в статье:
⇨ Мониторинг списка запущенных процессов в Zabbix
Способ рабочий, я им одно время пользовался, а потом забил по нескольким причинам:
1️⃣ По возможности стараюсь не использовать скрипты на хостах, потому что это усложняет настройку, неудобно быстро разворачивать и переносить настройки.
2️⃣ Настройка
Попытался придумать какую-то другую реализацию, но в голове не сложилась итоговая картинка, как это может выглядеть, поэтому прошу помощи тех, кто возможно уже решал такую задачу, либо есть идеи, как это можно сделать.
В Zabbix Server 6.2 появился новый айтем:
◽proc.get[<name>,<user>,<cmdline>,<mode>]
С его помощью можно вывести подробную информацию либо обо всех процессах системы, либо о заданных. Описание параметров есть в документации. Посмотреть через консоль, как он работает и что выводит, можно так:
Вся информация в json. Теоретически её можно собрать обо всех процессах, обработать, отсортировать по CPU или различным метрикам памяти и как-то вывести. Но наглядность будет сильно хуже, чем отсортированный вывод
Если у кого-то есть идеи, поделитесь. Ну а кому интересно подобное настроить, то решение в статье вполне рабочее. Нужно только сделать поправку на то, что статья писалась давно, а интерфейс Zabbix Server с тех пор изменился. Некоторые настройки изменили своё положение. Но сам подход через скрипт и EnableRemoteCommands сработает и сейчас.
#zabbix
Посмотрел остальные метрики за это время. Ни повышенного трафика, ни чтения/записи диска, ни жора памяти или swap не было. В логах тоже ничего. Выяснить, что же там было, теперь не представляется возможным. К сожалению, это существенный пробел Zabbix, так как стандартными шаблонами этот вопрос никак не решается.
Когда-то давно я придумал решение этой задачи в лоб:
1️⃣ Добавляю в стандартный шаблон новый айтем типа Zabbix Trapper.
2️⃣ Разрешаю на zabbix agent запуск внешних команд.
3️⃣Настраиваю на Zabbix Server действие при срабатывании триггера на загрузку CPU. В действии указываю выполнение команды на целевом сервере, которая сформирует список процессов и отправит его на сервер мониторинга с помощью zabbix-sender.
# ps aux --sort=-pcpu,+pmem | head -10Решение очень простое в реализации и главное удобное в анализе. Список процессов получается в наглядном виде. И при этом постоянно не собираются эти данные, а запрашиваются только в нужные моменты.
Описал этот способ в статье:
⇨ Мониторинг списка запущенных процессов в Zabbix
Способ рабочий, я им одно время пользовался, а потом забил по нескольким причинам:
1️⃣ По возможности стараюсь не использовать скрипты на хостах, потому что это усложняет настройку, неудобно быстро разворачивать и переносить настройки.
2️⃣ Настройка
EnableRemoteCommands=1 потенциально небезопасна. По возможности её лучше не использовать. А если используешь, то надо и за фаерволом следить, и за tls. А если что-то от root запускаешь, то через мониторинг тебе вообще всю инфру положить могут. Попытался придумать какую-то другую реализацию, но в голове не сложилась итоговая картинка, как это может выглядеть, поэтому прошу помощи тех, кто возможно уже решал такую задачу, либо есть идеи, как это можно сделать.
В Zabbix Server 6.2 появился новый айтем:
◽proc.get[<name>,<user>,<cmdline>,<mode>]
С его помощью можно вывести подробную информацию либо обо всех процессах системы, либо о заданных. Описание параметров есть в документации. Посмотреть через консоль, как он работает и что выводит, можно так:
# zabbix_agentd -t proc.get[zabbix_server,,,]# zabbix_agentd -t proc.get[zabbix_server,,,summary]# zabbix_agentd -t proc.get[]Вся информация в json. Теоретически её можно собрать обо всех процессах, обработать, отсортировать по CPU или различным метрикам памяти и как-то вывести. Но наглядность будет сильно хуже, чем отсортированный вывод
ps aux. Плюс, не совсем понимаю, как всё это организовать в рамках Zabbix Server без скриптов на хосте с привязкой к триггеру, чтобы не постоянно это всё собирать, а только когда нужно. Если у кого-то есть идеи, поделитесь. Ну а кому интересно подобное настроить, то решение в статье вполне рабочее. Нужно только сделать поправку на то, что статья писалась давно, а интерфейс Zabbix Server с тех пор изменился. Некоторые настройки изменили своё положение. Но сам подход через скрипт и EnableRemoteCommands сработает и сейчас.
#zabbix
Server Admin
Мониторинг списка запущенных процессов в Zabbix | serveradmin.ru
Получение информации о топ 10 нагруженных процессов в Linux в момент срабатывания триггера в Zabbix на нагрузку CPU.