
🎓 На прошлой неделе я рассказывал про репозиторий с обучающими TUI программами с популярными консольными утилитами. Хочу обратить внимание на тренажёр по awk. Я там увидел много полезных примеров с возможностями awk, про которые я даже не знал.
⇨ https://github.com/learnbyexample/TUI-apps/tree/main/AwkExercises
Например, я никогда не использовал awk для того, чтобы вывести строки с определёнными символами. Обычно использовал для этого grep, а потом передавал вывод в awk. Хотя в этом нет никакой необходимости. Awk сам умеет это делать:
Команды делают одно и то же. Выводят строки со словом word. Понятно, что если задача стоит только в этом, то grep использовать проще. Но если нужна дальнейшая обработка, то уже не так однозначно. Например, нам надо вывести только первый столбец в строках со словом word.
Тут с awk уже явно удобнее будет. Ну и так далее. В программе много актуальных примеров обработки текста с awk, которые стоит посмотреть и какие-то записать к себе.
Например, поставить символ . (точка) в конце каждой строки:
Я не понял логику этой конструкции, но работает, проверил. На основе этого примера сделал свой, когда в начало каждой строки ставится знак комментария:
Это хороший пример, который можно совместить с выборкой по строкам и закомментировать что-то конкретное. Чаще для этого используют sed, но мне кажется, что с awk как-то проще и понятнее получается:
Закомментировали строку со словом word. Удобно комментировать какие-то параметры в конфигурационных файлах.
#обучение #bash
⇨ https://github.com/learnbyexample/TUI-apps/tree/main/AwkExercises
Например, я никогда не использовал awk для того, чтобы вывести строки с определёнными символами. Обычно использовал для этого grep, а потом передавал вывод в awk. Хотя в этом нет никакой необходимости. Awk сам умеет это делать:
# grep 'word' file.txt# awk '/word/' file.txtКоманды делают одно и то же. Выводят строки со словом word. Понятно, что если задача стоит только в этом, то grep использовать проще. Но если нужна дальнейшая обработка, то уже не так однозначно. Например, нам надо вывести только первый столбец в строках со словом word.
# grep 'word' file.txt | awk '{print $1}'# awk '/word/{print $1}' file.txtТут с awk уже явно удобнее будет. Ну и так далее. В программе много актуальных примеров обработки текста с awk, которые стоит посмотреть и какие-то записать к себе.
Например, поставить символ . (точка) в конце каждой строки:
# awk '{print $0 "."}' file.txtЯ не понял логику этой конструкции, но работает, проверил. На основе этого примера сделал свой, когда в начало каждой строки ставится знак комментария:
# awk '{print "#" $0}' file.txtЭто хороший пример, который можно совместить с выборкой по строкам и закомментировать что-то конкретное. Чаще для этого используют sed, но мне кажется, что с awk как-то проще и понятнее получается:
# awk '/word/{print "#" $0}' file.txtЗакомментировали строку со словом word. Удобно комментировать какие-то параметры в конфигурационных файлах.
#обучение #bash
{kind=link}
У меня в управлении много различных серверов. Я обычно не заморачивался с типом файловых систем. Выбирал то, что сервер ставит по умолчанию. Для серверов общего назначения особо нет разницы, будет это XFS или EXT4. А выбор обычно из них стоит. RPM дистрибутивы используют по умолчанию XFS, а DEB — EXT4.
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
Она вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
# mountОна вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
df есть нужный ключ:# df -TFilesystem Type 1K-blocks Used Available Use% Mounted onudev devtmpfs 1988408 0 1988408 0% /devtmpfs tmpfs 401244 392 400852 1% /run/dev/sda2 ext4 19948144 2548048 16361456 14% /tmpfs tmpfs 2006220 0 2006220 0% /dev/shmtmpfs tmpfs 5120 0 5120 0% /run/lock/dev/sda1 vfat 523244 5928 517316 2% /boot/efitmpfs tmpfs 401244 0 401244 0% /run/user/0И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
{kind=link}
В комментариях к заметке, где я рассказывал про неудобочитаемый вывод mount один человек посоветовал утилиту column, про которую я раньше вообще не слышал и не видел, чтобы ей пользовались. Не зря говорят: "Век живи, век учись". Ведение канала и сайта очень развивает. Иногда, когда пишу новый текст по трудной теме, чувствую, как шестерёнки в голове скрипят и приходится напрягаться. Это реально развивает мозг и поддерживает его в тонусе.
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
Получается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
Получается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
# mount | column -tПолучается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
# column -s ":" -t /etc/passwdПолучается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
# column -s ":" -t /etc/passwd | awk '{print $1}'Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
{kind=link}
Во времена развития искусственного интеллекта сидеть и вспоминать команды и ключи консольных утилит Linux уже как-то не солидно. Пусть "вкалывают роботы, а не человек".
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
Извольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
Я не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
sed '1,10d' filenameИзвольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
find ./ -name "*.php" -exec sed -i 's/old/new/g' {} +Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
find /source/directory -type f -mtime +30 -exec ls -s {} \; \| sort -n -r | head -10 | awk '{print $2}' \| xargs -I '{}' mv '{}' /destination/directoryЯ не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
{kind=link}
Смотрите, какая прикольна штука есть для подключения по SSH из консоли - sshto. Это небольшой bash скрипт, который позволяет через псевдографическое меню управлять преднастроенными SSH подключениями. Хорошее решение для самодельного jumphost.
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
Ставим sshto:
Запускаем:
Видим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
~/.ssh/config и выводит список серверов оттуда в псевдографическое меню. Вот пример такого файла:#Host DUMMY #Moscow#Host server-number-one #First ServerHostName 1.2.3.4port 22777user rootHost server-number-two #Second serverHostName 4.3.2.1port 22888user username#Host DUMMY #Saint Petersburg#Host server-number-three #Third serverHostName 5.6.7.8port 22user user01Host server-number-four #Fourth serverHostName 9.8.7.6port 22user user02Ставим sshto:
# git clone https://github.com/vaniacer/sshto# cd sshto/# cp sshto /usr/bin/Запускаем:
# sshtoВидим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
{kind=link}
В Linux есть подсистема ядра, которая позволяет получать уведомления о событиях, связанных с файлами и каталогами файловой системы. Называется Inotify. Я упоминал о ней недавно, когда рассказывал про Lsyncd, которая получает информацию от inotify и запускает синхронизацию при изменениях в файлах.
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
Для наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
Всё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
◽
Откроем рядом ещё одну консоль, создадим, обновим и удалим в директории
В логе при этом будет следующее:
Это уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
Запускаем:
Это самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
И дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
#linux #bash
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
# apt install fswatchДля наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
# fswatch /tmpВсё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
-x - отображать тип событий◽
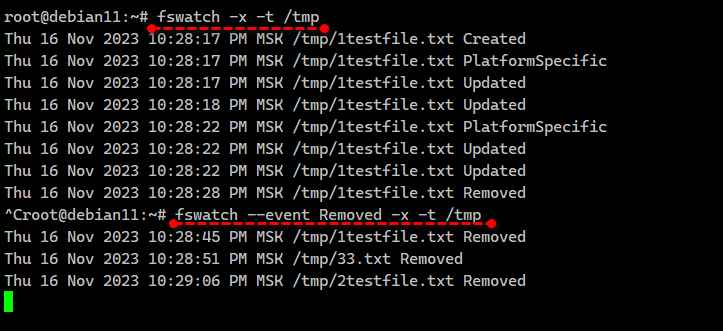
-t - отображать временные метки# fswatch -x -t /tmpОткроем рядом ещё одну консоль, создадим, обновим и удалим в директории
/tmp файл:# echo '123' > file.txt# rm file.txtВ логе при этом будет следующее:
Thu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt CreatedThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt PlatformSpecificThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt UpdatedThu 16 Nov 2023 09:14:25 PM MSK /tmp/file.txt RemovedЭто уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
# fswatch -x -t /tmp >> /var/log/fswatch.log &Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
[Unit]Description=Start fswatch file monitorWants=fswatch.service[Service]ExecStart=fswatch -x -t /tmp[Install]WantedBy=multi-user.targetЗапускаем:
# systemctl start fswatch.serviceЭто самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
# journalctl -u fswatch.serviceИ дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
# fswatch --event Removed -x -t /tmp#linux #bash
{kind=link}
Казалось бы, что может быть проще копирования файлов из одной директории в другую. Тем не менее в консоли Linux это не всегда простая и очевидная процедура. Для этого существует небольшая утилита
Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
Но так скопируются только файлы, без вложенных директорий. Добавляем ключ
По моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
На длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
Ещё засаду с
Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
Тут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
cp, которая обычно присутствует во всех дистрибутивах. Лично у меня сложности возникают с тем, что я начинаю вспоминать, нужно ли использовать *, ставить или нет слеш на конце директории и т.д. Всё это влияет на конечный результат. Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
# cp /dir_a/* /dir_bНо так скопируются только файлы, без вложенных директорий. Добавляем ключ
-r или сразу -a, чтобы и все атрибуты скопировать:# cp -a /dir_a/* /dir_bПо моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
# cp -a /dir_a/file1 /dir_a/file2 /dir_a/file3 ...... /dir_bНа длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
* в командах, запускаемых в bash, работает именно так.Ещё засаду с
cp можно получить, если в директории будут файлы, начинающиеся с точки. Те же .htaccess. Если скопируем предложенной выше командой со *, то все файлы с точкой в начале имени потеряем. Будет неприятно. Это опять же особенность bash, которая по умолчанию трактует такие файлы как скрытые. Такое поведение можно изменить.Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
* :# cp -aT /dir_a /dir_bТут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
Вчера в заметке про копирование с помощью
Мы всё содержимое директории
В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
Можно сделать:
и остаться в текущем каталоге, либо:
и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
Явно указываем на скрипт, который запускаем. Иначе оболочка проверит
Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
Создали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
cp в комментариях справедливо привели ещё один вариант копирования. Причём самый простой и удобный. Я про него знал, но не стал упоминать, потому что нужны будут пояснения для тех, кто не знает про некоторые особенности псевдопапок в виде точки или двух точек. Речь идёт о примерно такой конструкции:# cp -a /dir_a/. /dir_bМы всё содержимое директории
dir_a со всеми скрытыми файлами скопировали в dir_b. В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
ls -la, то мы их увидим вместе с остальными директориями:# ls -latotal 56drwx------ 8 root root 4096 Nov 22 21:37 .drwxr-xr-x 18 root root 4096 Oct 13 12:30 ..-rw------- 1 root root 6115 Nov 22 16:02 .bash_history-rw-r--r-- 1 root root 571 Apr 10 2021 .bashrcdrwx------ 3 root root 4096 Dec 9 2022 .cachedrwx------ 4 root root 4096 Nov 16 21:22 .config-rw-r--r-- 1 root root 56 Nov 15 00:19 .gitconfigdrwx------ 3 root root 4096 Dec 9 2022 .local-rw-r--r-- 1 root root 161 Jul 9 2019 .profile-rw-r--r-- 1 root root 72 Dec 9 2022 .selected_editordrwx------ 2 root root 4096 Nov 15 00:21 .sshМожно сделать:
# cd .и остаться в текущем каталоге, либо:
# cd .. и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
# ./script.shЯвно указываем на скрипт, который запускаем. Иначе оболочка проверит
$PATH, там не окажется текущего каталога и скрипт не будет выполнен. Так что надо написать либо полный путь, либо использовать точку, если скрипт в текущем каталоге. Точно помню, что вот эту тему с точкой я очень долго не понимал и просто использовал. Даже мысли не было, что это я текущий каталог указываю. Думал, это какой-то признак исполняемого файла.Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
# touch ../file.nameСоздали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
Хочу напомнить про 2 очень полезные утилиты Linux, с помощью которых удобно в скриптах делать проверки наличия подключенных и примонтированных блочных устройств и файловых систем. Речь пойдёт про findmnt и findfs.
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
А если в чём-то ошибётесь, то получите ошибку:
Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
Если файловая система не будет найдена, код будет 1:
Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
Вместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
Проверяем:
Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
-x ещё и позволяет проверить отредактированный файл fstab на наличие в нём ошибок. Рекомендую запомнить эту возможность и использовать:# findmnt -xSuccess, no errors or warnings detectedА если в чём-то ошибётесь, то получите ошибку:
# findmnt -x/mnt/backup [E] unreachable on boot required source: UUID=151ea24d-977a-412c-818f-0d374baa5012Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5013"/dev/sda2Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
# echo $?0Если файловая система не будет найдена, код будет 1:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5012"findfs: unable to resolve 'UUID=151ea24d-977a-412c-818f-0d374baa5012'# echo $?1Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
if findfs "UUID=$1" >/dev/null; then echo "$1 connected."elseecho "$1 not connected."fiВместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
# ./check-fs.sh 151ea24d-977a-412c-818f-0d374baa5013151ea24d-977a-412c-818f-0d374baa5013 connected.И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
if findmnt -rno TARGET "$1" >/dev/null; then echo "$1 mounted."elseecho "$1 not mounted."fiПроверяем:
# ./check-mnt.sh /mnt/extbackup/mnt/extbackup not mounted.Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
Кажется, я ни разу не упоминал про простой и быстрый способ отладки bash скрипта. Для этого достаточно в самое начало написать:
В этом случай bash начнёт выводить в консоль каждую команду, которую он выполняет. Успешно выполненная команда помечается плюсом в начале строки. Не сказать, что это прям очень сильно помогает отладить, если есть ошибка, но в целом проще и удобнее. Особенно если скрипт большой, с условиями, вычислением переменных и т.д. Вы всё будете видеть на каждом этапе.
Покажу как это работает на простом скрипте по добавлению swap в систему:
Запускаем скрипт:
Благодаря
Когда не знал про
#bash #script
set -xВ этом случай bash начнёт выводить в консоль каждую команду, которую он выполняет. Успешно выполненная команда помечается плюсом в начале строки. Не сказать, что это прям очень сильно помогает отладить, если есть ошибка, но в целом проще и удобнее. Особенно если скрипт большой, с условиями, вычислением переменных и т.д. Вы всё будете видеть на каждом этапе.
Покажу как это работает на простом скрипте по добавлению swap в систему:
#!/bin/bashset -xread -p 'Enter swap size in megabytes: ' size_mbsize_kb=$((1024*${size_mb}))dd if=/dev/zero of=/swap bs=1024 count=${size_kb}chmod 0600 /swapmkswap /swapswapon /swapif [ "$(grep '/swap' /etc/fstab)" ]; then echo "Error: file /etc/fstab already has 'Swap' record"else echo "Add Swap record to /etc/fstab" echo -e '\n/swap swap swap defaults 0 0' >> /etc/fstabfiswapon --showЗапускаем скрипт:
# ./script.sh + read -p 'Enter swap size in megabytes: ' size_mbEnter swap size in megabytes: 512+ size_kb=524288+ dd if=/dev/zero of=/swap bs=1024 count=524288524288+0 records in524288+0 records out536870912 bytes (537 MB, 512 MiB) copied, 1.26859 s, 423 MB/s+ chmod 0600 /swap+ mkswap /swapSetting up swapspace version 1, size = 512 MiB (536866816 bytes)no label, UUID=e873faad-881e-4df0-b25f-23580b952738+ swapon /swap++ grep /swap /etc/fstab+ '[' '' ']'+ echo 'Add Swap record to /etc/fstab'Add Swap record to /etc/fstab+ echo -e '\n/swap swap swap defaults 0 0'+ swapon --showNAME TYPE SIZE USED PRIO/swap file 512M 0B -2Благодаря
set -x мы видим каждое действие, которое выполняет скрипт. Оно начинается с +, а дальше виден стандартный вывод после этого действия. Так разбирать работу скрипта проще, потому что в командах видны все переменные. В этом примере это не очень актуально, а когда они будут неявно указаны, а вычисляемые, то это может сильно помочь. Когда не знал про
set -x, выводил нужные мне переменные в разных местах скрипта с помощью echo во время отладки, чтобы понимать, что там происходит после каждой команды. Но этот путь намного проще.#bash #script
{kind=link}
Почти во всех популярных дистрибутивах Linux в составе присутствует утилита vmstat. С её помощью можно узнать подробную информацию по использованию оперативной памяти, cpu и дисках. Лично я её не люблю, потому что вывод неинформативен. Утилита больше для какой-то глубокой диагностики или мониторинга, нежели простого использования в консоли.
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
Как можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
# vmstat 1 -w -S MКак можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
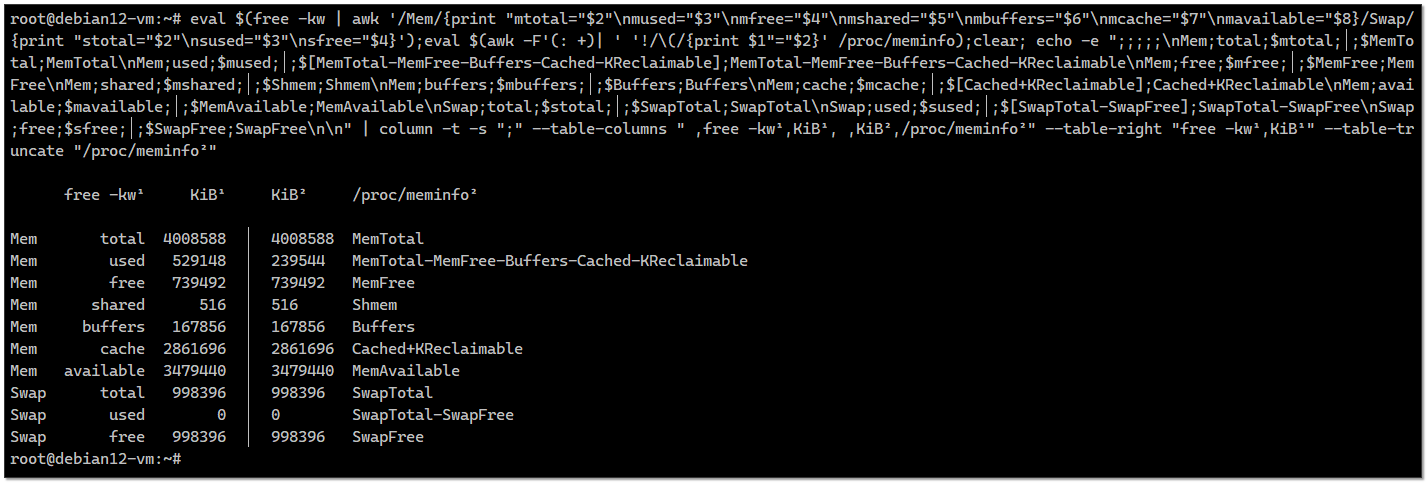
man vmstat они подробно описаны, так что с интерпретацией проблем не должно возникать.А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
free и cat /proc/meminfo: # eval $(free -kw | awk '/Mem/{print "mtotal="$2"\nmused="$3"\nmfree="$4"\nmshared="$5"\nmbuffers="$6"\nmcache="$7"\nmavailable="$8}/Swap/{print "stotal="$2"\nsused="$3"\nsfree="$4}');eval $(awk -F'(: +)| ' '!/\(/{print $1"="$2}' /proc/meminfo);clear; echo -e ";;;;;\nMem;total;$mtotal;│;$MemTotal;MemTotal\nMem;used;$mused;│;$[MemTotal-MemFree-Buffers-Cached-KReclaimable];MemTotal-MemFree-Buffers-Cached-KReclaimable\nMem;free;$mfree;│;$MemFree;MemFree\nMem;shared;$mshared;│;$Shmem;Shmem\nMem;buffers;$mbuffers;│;$Buffers;Buffers\nMem;cache;$mcache;│;$[Cached+KReclaimable];Cached+KReclaimable\nMem;available;$mavailable;│;$MemAvailable;MemAvailable\nSwap;total;$stotal;│;$SwapTotal;SwapTotal\nSwap;used;$sused;│;$[SwapTotal-SwapFree];SwapTotal-SwapFree\nSwap;free;$sfree;│;$SwapFree;SwapFree\n\n" | column -t -s ";" --table-columns " ,free -kw¹,KiB¹, ,KiB²,/proc/meminfo²" --table-right "free -kw¹,KiB¹" --table-truncate "/proc/meminfo²"Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
{kind=link}