
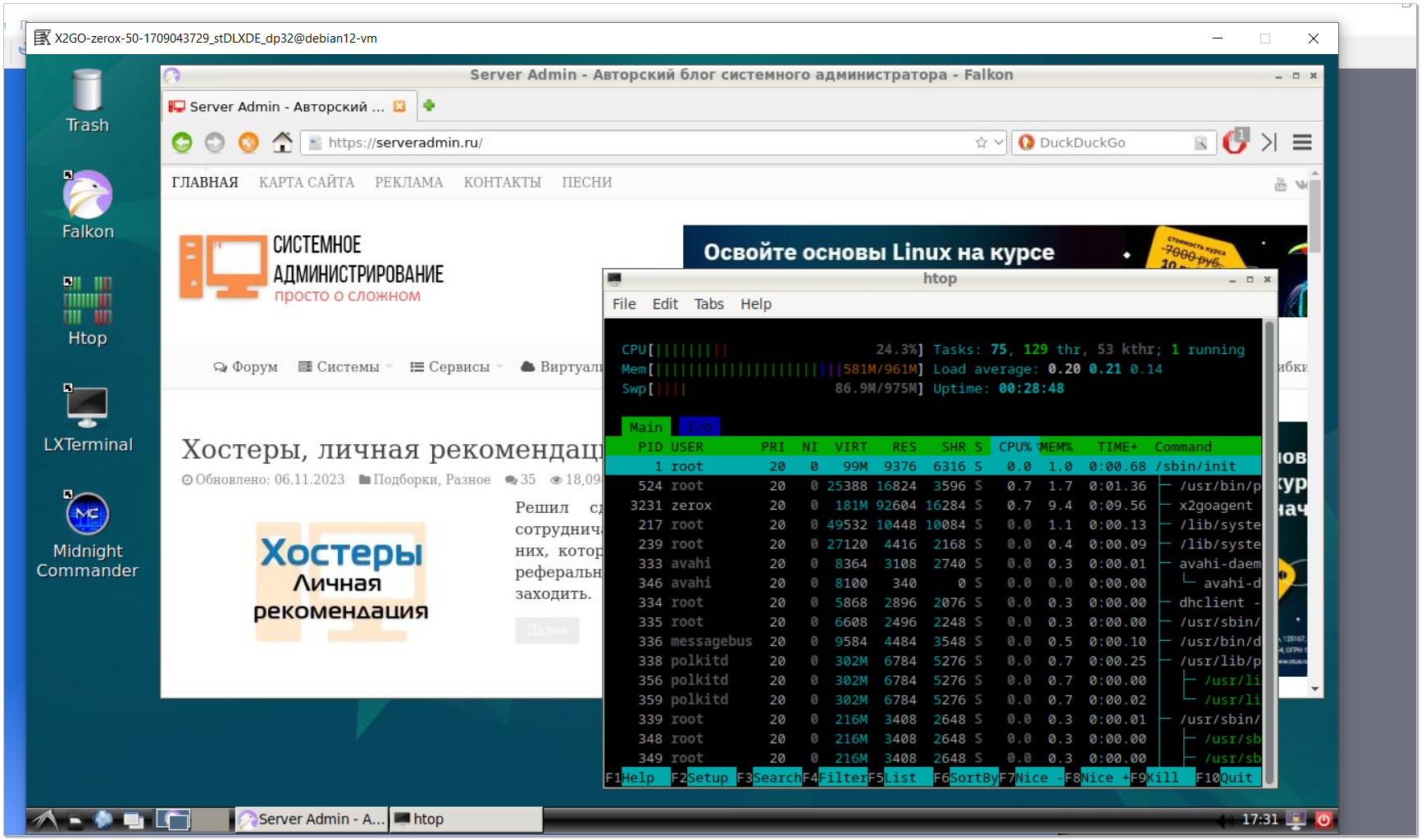
Решил проверить, на какой минимальной VPS можно поднять Linux с рабочим столом и браузером, чтобы можно было подключаться к нему и работать удалённо. Это актуально для тех, у кого есть потребность в рабочем месте, где гарантированно будет нигде не засвеченный ранее твой IP адрес. Если использовать VPN или прокси на основной машине, рано или поздно всё равно спалишь свой IP из-за каких-нибудь ошибок. И получишь блок акка.
Взял VPS 1CPU, 1Gb RAM, 10Gb SSD и у меня всё получилось. Использовал:
▪ Debian 12 minimal в качестве системы
▪ Lxde-core в качестве графического окружения
▪ X2Go в качестве удалённого доступа к системе
Настройка максимально простая, осилит каждый. Устанавливаем lxde-core и x2go:
Уже можно подключаться, скачав клиент x2go под свою систему. В качестве аутентификации используется локальная учётка пользователя, не root, с правами подключения по ssh.
Далее можно установить любой браузер. Я вычитал, что Falkon наименее прожорливый и поставил его:
Понятное дело, что с такими ресурсами всё это работает не очень быстро, но пользоваться можно. Если пользоваться предполагается активно, то надо добавить ещё ядро CPU и еще гиг памяти. Тогда вообще нормально будет.
Я так понимаю, подобную связку lxde-core и falkon можно использовать на старом железе. Можно наверное ещё всё это как-то ужать, используя более специализированные системы и софт, но мне хотелось использовать именно базу, чтобы без заморочек взять и развернуть на стандартном ПО.
#linux
Взял VPS 1CPU, 1Gb RAM, 10Gb SSD и у меня всё получилось. Использовал:
▪ Debian 12 minimal в качестве системы
▪ Lxde-core в качестве графического окружения
▪ X2Go в качестве удалённого доступа к системе
Настройка максимально простая, осилит каждый. Устанавливаем lxde-core и x2go:
# apt install x2goserver x2goserver-xsession lxde-coreУже можно подключаться, скачав клиент x2go под свою систему. В качестве аутентификации используется локальная учётка пользователя, не root, с правами подключения по ssh.
Далее можно установить любой браузер. Я вычитал, что Falkon наименее прожорливый и поставил его:
# apt install falkonПонятное дело, что с такими ресурсами всё это работает не очень быстро, но пользоваться можно. Если пользоваться предполагается активно, то надо добавить ещё ядро CPU и еще гиг памяти. Тогда вообще нормально будет.
Я так понимаю, подобную связку lxde-core и falkon можно использовать на старом железе. Можно наверное ещё всё это как-то ужать, используя более специализированные системы и софт, но мне хотелось использовать именно базу, чтобы без заморочек взять и развернуть на стандартном ПО.
#linux
{kind=link}
В ОС на базе ядра Linux реализован механизм изоляции системных вызовов под названием namespace. С его помощью каждое приложение может быть изолировано от других средствами самого ядра, без сторонних инструментов. Попробую простыми словами рассказать, что это такое.
Покажу сразу на простом примере. Запустим оболочку bash с отдельными namespace PID и mount. То есть мы получим изолированную среду на уровне процессов и точек монтирования. Новый процесс bash в этом namespace получит id 1.
Теперь на условном примере покажу изоляцию mount. Здесь же в изолированных namespaces добавляем монтирование:
При этом на самом хосте вы этого mount не увидите. Если в изолированном namespace создать что-то в /tmp/dir1, оно появится в /mnt/dir1, а если на хосте зайти в /mnt/dir1 там будет пусто, потому что для хоста этого монтирования не существует.
Посмотреть существующие namespaces можно командой
Там будет видно в том числе созданные нами namespaces для форка bash. Это будут mnt и pid. Если у вас на хосте запущены контейнеры, то здесь же их и увидите. Работа контейнеров основана на этом механизме ядра.
Из показанного примера видно, что использовать изоляцию можно и без контейнеров. Можно создавать юниты systemd с использованием namespaces. Базово в системе уже есть некоторые юниты, работающие в своём пространстве. Их видно по
С помощью утилиты nsenter можно запускать процессы в произвольных namespaces. Откроем отдельную консоль и запустим процесс в созданном ранее namespace с bash. Для этого с помощью
#
Возвращаемся в консоль с unshare и смотрим список процессов:
Видим процесс со sleep. Базово всё это попробовать довольно просто, но на самом деле там очень много нюансов. Поэтому все и пользуются готовыми решениями на базе этой технологии, типа Docker.
Всего существует следующий набор namespaces:
- mount - изоляция на уровне монтирования файловых систем;
- UTS - изоляция hostname и domainname, т.е. в каждом ns может быть своё имя хоста;
- IPC - изоляция межпроцессорного взаимодействия (Inter-process communication);
- network - свои сетевые настройки для разных ns, включая ip адреса, маршруты, правила файрволов;
- PID - изоляция процессов;
- user - изоляция пользовательских UIDs и GIDs;
- cgroup - ограничивает потребляемый объём аппаратных ресурсов, cpu, ram, io и т.д.;
- time - изоляция некоторых параметров времени, а конкретно только MONOTONIC и BOOTTIME, установить разное текущее время в разных ns нельзя.
Все эти ns можно использовать с помощью утилит unshare и nsenter. Также существует отдельный продукт systemd-nspawn, один из компонентов systemd, который реализует возможности для создания легковесных контейнеров. Он как-то не особо распространён, не знаю почему. По идее, благодаря тесной интеграции с systemd это должно быть удобно, так как systemd сейчас везде.
#linux
Покажу сразу на простом примере. Запустим оболочку bash с отдельными namespace PID и mount. То есть мы получим изолированную среду на уровне процессов и точек монтирования. Новый процесс bash в этом namespace получит id 1.
# unshare --pid --fork --mount-proc --mount /bin/bash# ps ax PID TTY STAT TIME COMMAND 1 pts/0 S 0:00 /bin/bash 45 pts/0 R+ 0:00 ps axТеперь на условном примере покажу изоляцию mount. Здесь же в изолированных namespaces добавляем монтирование:
# mkdir /tmp/dir1 /mnt/dir1# mount --bind /tmp/dir1 /mnt/dir1# mount | grep dir1/dev/sda2 on /mnt/dir1 type ext4 (rw,relatime,errors=remount-ro)При этом на самом хосте вы этого mount не увидите. Если в изолированном namespace создать что-то в /tmp/dir1, оно появится в /mnt/dir1, а если на хосте зайти в /mnt/dir1 там будет пусто, потому что для хоста этого монтирования не существует.
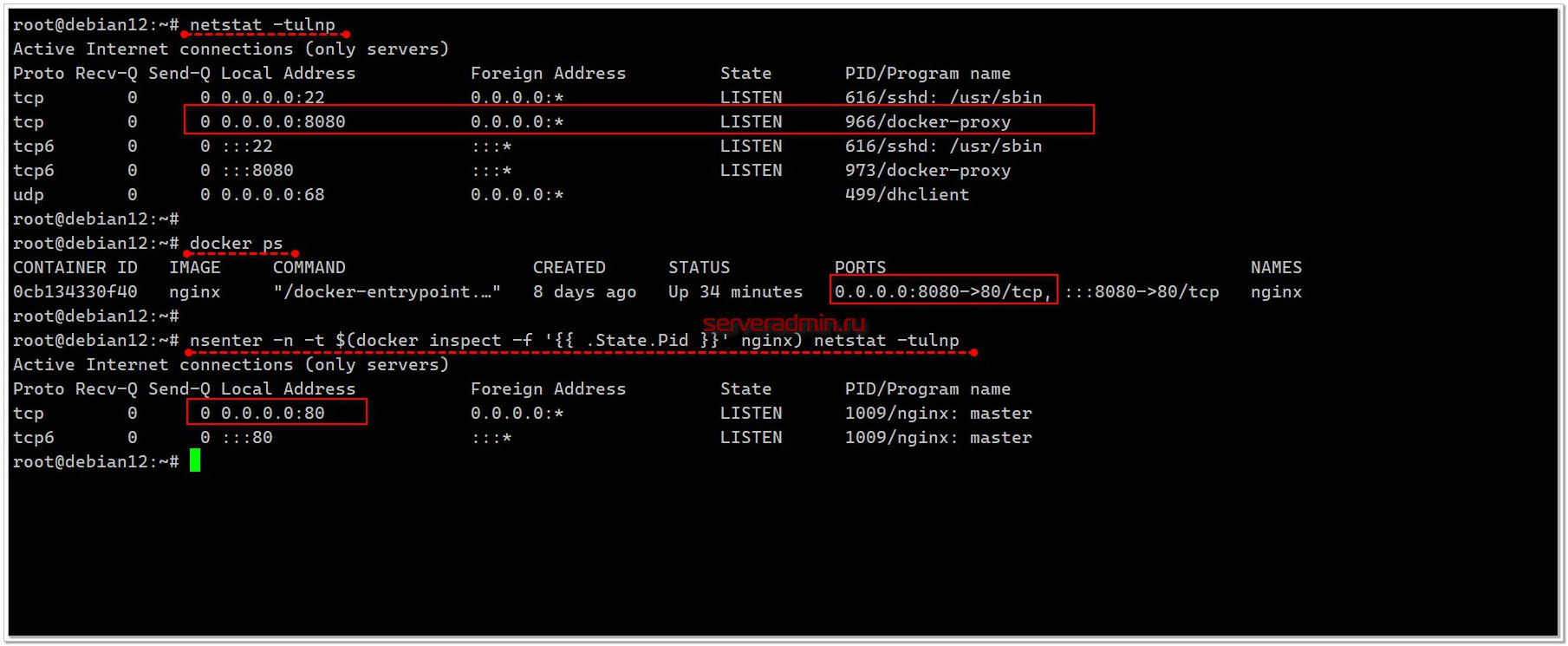
Посмотреть существующие namespaces можно командой
lsns:# lsns................................................4026532129 mnt 2 853 root unshare --pid --fork --mount-proc --mount /bin/bash4026532130 pid 1 854 root └─/bin/bash.................................................Там будет видно в том числе созданные нами namespaces для форка bash. Это будут mnt и pid. Если у вас на хосте запущены контейнеры, то здесь же их и увидите. Работа контейнеров основана на этом механизме ядра.
Из показанного примера видно, что использовать изоляцию можно и без контейнеров. Можно создавать юниты systemd с использованием namespaces. Базово в системе уже есть некоторые юниты, работающие в своём пространстве. Их видно по
lsns. С помощью утилиты nsenter можно запускать процессы в произвольных namespaces. Откроем отдельную консоль и запустим процесс в созданном ранее namespace с bash. Для этого с помощью
lsns узнаём pid процесса в ns pid и подцепляем к нему, к примеру, команду sleep.# lsns | grep /bin/bash4026532129 mnt 2 853 root unshare --pid --fork --mount-proc --mount /bin/bash4026532130 pid 1 854 root └─/bin/bash#
nsenter -t 854 -m -p sleep 60Возвращаемся в консоль с unshare и смотрим список процессов:
# ps ax PID TTY STAT TIME COMMAND 1 pts/0 S 0:00 /bin/bash 50 pts/2 S+ 0:00 sleep 60 51 pts/0 R+ 0:00 ps axВидим процесс со sleep. Базово всё это попробовать довольно просто, но на самом деле там очень много нюансов. Поэтому все и пользуются готовыми решениями на базе этой технологии, типа Docker.
Всего существует следующий набор namespaces:
- mount - изоляция на уровне монтирования файловых систем;
- UTS - изоляция hostname и domainname, т.е. в каждом ns может быть своё имя хоста;
- IPC - изоляция межпроцессорного взаимодействия (Inter-process communication);
- network - свои сетевые настройки для разных ns, включая ip адреса, маршруты, правила файрволов;
- PID - изоляция процессов;
- user - изоляция пользовательских UIDs и GIDs;
- cgroup - ограничивает потребляемый объём аппаратных ресурсов, cpu, ram, io и т.д.;
- time - изоляция некоторых параметров времени, а конкретно только MONOTONIC и BOOTTIME, установить разное текущее время в разных ns нельзя.
Все эти ns можно использовать с помощью утилит unshare и nsenter. Также существует отдельный продукт systemd-nspawn, один из компонентов systemd, который реализует возможности для создания легковесных контейнеров. Он как-то не особо распространён, не знаю почему. По идее, благодаря тесной интеграции с systemd это должно быть удобно, так как systemd сейчас везде.
#linux
{kind=link}
▶️ Очередная подборка авторских IT роликов, которые я лично посмотрел и посчитал интересными/полезными. Как раз к выходным.
▪ Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox
Новое прохождение задания на Hackthebox по взлому операционной системы. Не буду подробно описывать видео. Оно по структуре и тематике такое же как прошлое, где я подробно разобрал, о чём там речь. Только тут задача посложнее и подольше. Смотреть интересно, но только если понимаешь, что там происходит. В целом, контент очень качественный, рекомендую.
▪ Как в Synology просто и быстро развернуть несколько сайтов в пару кликов
Автор рассказывает, как в Synology настроить веб сервер и захостить там сайты. Когда-то давным-давно мой сайт некоторое время жил у меня в квартире на Synology. В целом, работал нормально, но мне быстро надоел постоянно работающий сервер. Убрал сайт на хостинг, а NAS стал периодически выключать.
▪ Организация компьютерных сетей
▪ Терминология сетей
Андрей Созыкин начал работу над новой актуальной версией курса по компьютерным сетям. Первые уроки уже смонтированы, можно посмотреть.
▪ Proxmox Установка и обзор функций WebUI
Простая установка и разбор возможностей веб интерфейса Proxmox. Конкретно в этом видео ничего особо нового и интересного нет. Автор обещает дальше настройку кластера, настройку бэкапов в PBS. Так что имеет смысл подписаться и следить, если интересна эта тема.
▪ Monitor Storage S.M.A.R.T With ZABBIX - Tutorial
Инструкция от Dmitry Lambert о том, как мониторить показатели SMART с помощью Zabbix agent 2. В инструкции он показывает на примере системы Windows. То есть это решение в основном для мониторинга за рабочими станциями.
🔥Running Windows in a Docker Container!
История о том, как на Linux запустить любую версию Windows с помощью Docker контейнера и зайти в неё через браузер. Сначала подумал, что за магия? На самом деле никакой магии. Контейнер поднимает KVM, создаёт виртуалку и запускает. Весь процесс автоматизирован. По этой теме имеет смысл сделать отдельную публикацию с описанием. Очень интересное решение получилось. Я пока только посмотрел, сам не пробовал запускать.
Если посмотрите видео, то не забудьте зайти в комментарии и поблагодарить авторов. Вам это ничего не стоит, а им приятно.
#видео
▪ Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox
Новое прохождение задания на Hackthebox по взлому операционной системы. Не буду подробно описывать видео. Оно по структуре и тематике такое же как прошлое, где я подробно разобрал, о чём там речь. Только тут задача посложнее и подольше. Смотреть интересно, но только если понимаешь, что там происходит. В целом, контент очень качественный, рекомендую.
▪ Как в Synology просто и быстро развернуть несколько сайтов в пару кликов
Автор рассказывает, как в Synology настроить веб сервер и захостить там сайты. Когда-то давным-давно мой сайт некоторое время жил у меня в квартире на Synology. В целом, работал нормально, но мне быстро надоел постоянно работающий сервер. Убрал сайт на хостинг, а NAS стал периодически выключать.
▪ Организация компьютерных сетей
▪ Терминология сетей
Андрей Созыкин начал работу над новой актуальной версией курса по компьютерным сетям. Первые уроки уже смонтированы, можно посмотреть.
▪ Proxmox Установка и обзор функций WebUI
Простая установка и разбор возможностей веб интерфейса Proxmox. Конкретно в этом видео ничего особо нового и интересного нет. Автор обещает дальше настройку кластера, настройку бэкапов в PBS. Так что имеет смысл подписаться и следить, если интересна эта тема.
▪ Monitor Storage S.M.A.R.T With ZABBIX - Tutorial
Инструкция от Dmitry Lambert о том, как мониторить показатели SMART с помощью Zabbix agent 2. В инструкции он показывает на примере системы Windows. То есть это решение в основном для мониторинга за рабочими станциями.
🔥Running Windows in a Docker Container!
История о том, как на Linux запустить любую версию Windows с помощью Docker контейнера и зайти в неё через браузер. Сначала подумал, что за магия? На самом деле никакой магии. Контейнер поднимает KVM, создаёт виртуалку и запускает. Весь процесс автоматизирован. По этой теме имеет смысл сделать отдельную публикацию с описанием. Очень интересное решение получилось. Я пока только посмотрел, сам не пробовал запускать.
Если посмотрите видео, то не забудьте зайти в комментарии и поблагодарить авторов. Вам это ничего не стоит, а им приятно.
#видео
YouTube
Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox | КАК ПРОЙТИ #DRIVE.HTB
Как решить машину DRIVE на HackTheBox?
Drive — это сложная(средняя) машина Linux, которая включает в себя сервис обмена файлами, подверженный уязвимости #IDOR (Insecure Direct Object Reference), через который обнаруживается простой текстовый пароль, приводящий…
Drive — это сложная(средняя) машина Linux, которая включает в себя сервис обмена файлами, подверженный уязвимости #IDOR (Insecure Direct Object Reference), через который обнаруживается простой текстовый пароль, приводящий…
В Linux относительно просто назначить выполнение того или иного процесса на заданном количестве ядер процессора. Для этого используется утилита taskset. Она может "сажать" на указанные ядра как запущенный процесс, так и запустить новый с заданными параметрами.
1️⃣ Покажу сразу на примерах. Допустим, у вас есть какой-то процесс, который по умолчанию может занимать ресурсы всех ядер процессора. Допустим, вы хотите разрешить ему работать только на первых двух. Для того, чтобы это сделать, нам необходимо узнать pid процесса:
Выбирайте любой способ, какой больше нравится. Смотрим, какие у нас процессоры и ядра в системе:
Видим четыре CPU с 0 по 3. Посадим наш процесс на первые два ядра:
Где 927 - это pid процесса. Видим, что привязка изменилась с 0-3 на 0,1.
2️⃣ Менять привязку уже запущенных процессов мне кажется не таким полезным, как иметь возможность запустить процесс с заданными параметрами. Это более практичная возможность, для которой нетрудно придумать реальный пример.
Я активно использую архиватор pigz, который умеет жать всеми доступными ядрами. Ему можно задать ограничение на использование ядер, но он будет случайным образом занимать ядра и почти всегда нулевое будет занято. А его желательно оставить свободным для остальных задач. Особенно если вы снимаете дампы СУБД и сразу жмёте в каком-то нагруженном сервере. В таком случае можно явно во время запуска указать pigz, какие ядра использовать.
Для этого нужно запустить программу через taskset, указав ядра, на которых она будет работать. К сожалению, для этого не получится использовать простой список ядер, типа 1,2,3. Нужно использовать bitmask в полном или сокращённом виде. Например, использование только 0-го ядра будет выглядеть вот так:
или просто
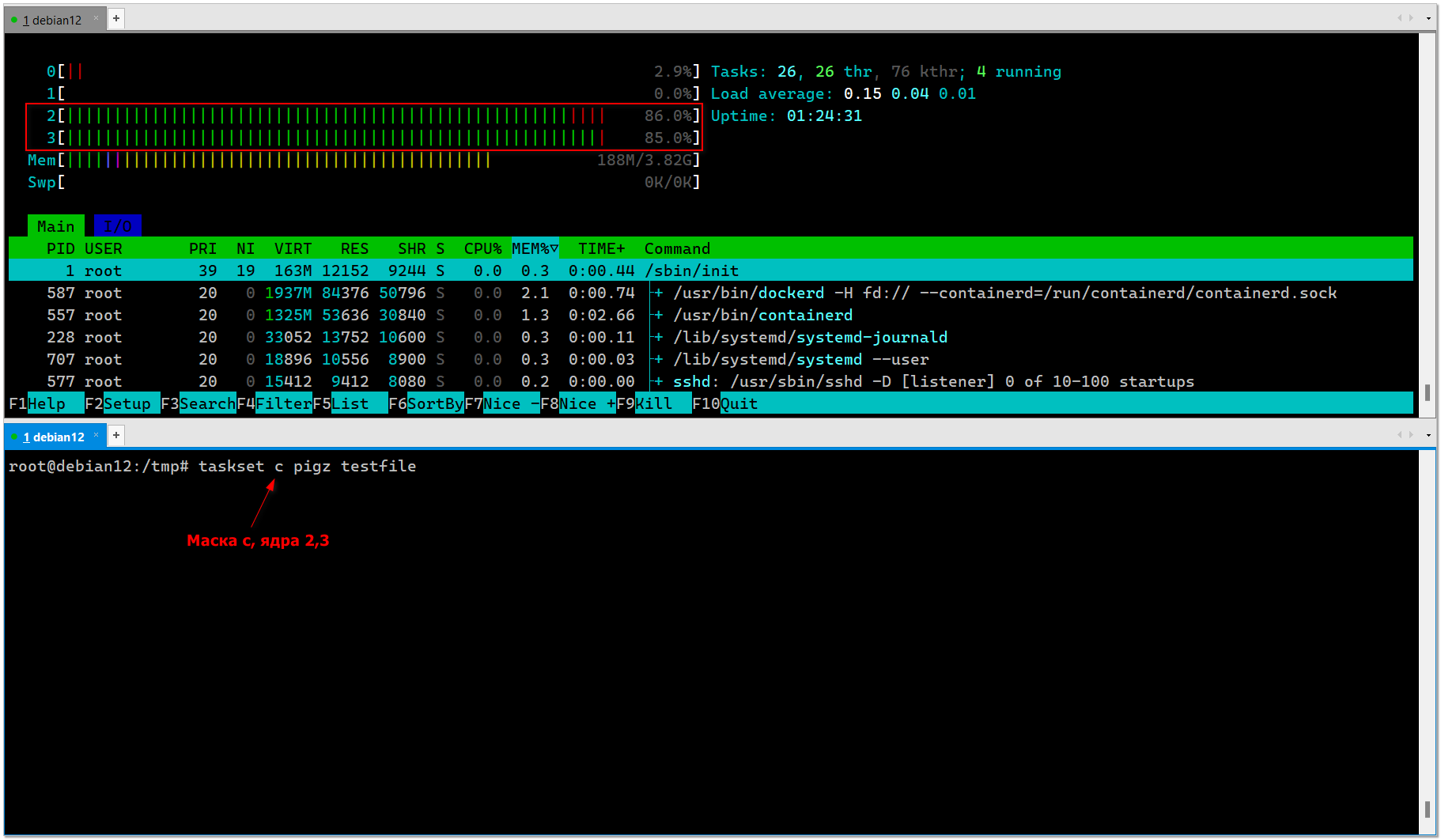
Pigz будет жать только одним, нулевым ядром. Я до конца не разобрался, как быстро понять, какая маска тебе нужна. Самый простой способ это узнать, проверить на каком-то работающем процессе. Ему можно задать список ядер не маской, а явно. Допустим, нам нужна запустить архиватор только на 2 и 3 ядре. Для этого назначим, к примеру, эти ядра для htop и посмотрим нужную маску:
Маска
Я взял для примера именно pigz, потому что на нём наглядно видны все настройки. Какие ядра задал, такие он и использует. Для этого достаточно создать небольшой тестовый файл и понаблюдать через htop его поведение:
Список масок, которые имеют отношение к первым 4-м ядрам:
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
#linux #system
1️⃣ Покажу сразу на примерах. Допустим, у вас есть какой-то процесс, который по умолчанию может занимать ресурсы всех ядер процессора. Допустим, вы хотите разрешить ему работать только на первых двух. Для того, чтобы это сделать, нам необходимо узнать pid процесса:
# ps ax | grep mc# ps -T -C mc | awk '{print $2}' | grep -E '[0-9]'# pidof mcВыбирайте любой способ, какой больше нравится. Смотрим, какие у нас процессоры и ядра в системе:
# lscpu | grep -i CPU\(s\)# lscpu | grep -i numaNUMA node(s): 1NUMA node0 CPU(s): 0-3Видим четыре CPU с 0 по 3. Посадим наш процесс на первые два ядра:
# taskset -pc 0-1 927pid 927's current affinity list: 0-3pid 927's new affinity list: 0,1Где 927 - это pid процесса. Видим, что привязка изменилась с 0-3 на 0,1.
2️⃣ Менять привязку уже запущенных процессов мне кажется не таким полезным, как иметь возможность запустить процесс с заданными параметрами. Это более практичная возможность, для которой нетрудно придумать реальный пример.
Я активно использую архиватор pigz, который умеет жать всеми доступными ядрами. Ему можно задать ограничение на использование ядер, но он будет случайным образом занимать ядра и почти всегда нулевое будет занято. А его желательно оставить свободным для остальных задач. Особенно если вы снимаете дампы СУБД и сразу жмёте в каком-то нагруженном сервере. В таком случае можно явно во время запуска указать pigz, какие ядра использовать.
Для этого нужно запустить программу через taskset, указав ядра, на которых она будет работать. К сожалению, для этого не получится использовать простой список ядер, типа 1,2,3. Нужно использовать bitmask в полном или сокращённом виде. Например, использование только 0-го ядра будет выглядеть вот так:
# taskset 0x00000001 pigz testfileили просто
# taskset 1 pigz testfilePigz будет жать только одним, нулевым ядром. Я до конца не разобрался, как быстро понять, какая маска тебе нужна. Самый простой способ это узнать, проверить на каком-то работающем процессе. Ему можно задать список ядер не маской, а явно. Допустим, нам нужна запустить архиватор только на 2 и 3 ядре. Для этого назначим, к примеру, эти ядра для htop и посмотрим нужную маску:
# taskset -pc 2-3 `pidof htop`pid 984's current affinity list: 0-3pid 984's new affinity list: 2,3Смотрим маску:# taskset -p `pidof htop`pid 984's current affinity mask: cМаска
c. Запускаем pigz с этой маской, чтобы он жал только на 2 и 3 ядрах, оставив первые два свободными:# taskset c pigz testfileЯ взял для примера именно pigz, потому что на нём наглядно видны все настройки. Какие ядра задал, такие он и использует. Для этого достаточно создать небольшой тестовый файл и понаблюдать через htop его поведение:
# dd if=/dev/zero of=/tmp/testfile bs=1024 count=2000000# taskset 6 pigz testfileСписок масок, которые имеют отношение к первым 4-м ядрам:
◽
1 - ядро 0◽
2 - ядро 1◽
3 - ядра 0,1◽
4 - ядро 2◽
5 - ядра 0,2◽
6 - ядра 1,2◽
7 - ядра 1,2,3◽
8 - ядро 3◽
9 - ядра 0,3◽
a - ядра 1,3◽
b - ядра 0,1,3◽
с - ядра 2,3◽
d - ядра 0,2,3#linux #system
{kind=link}
В ОС на базе Linux есть разные способы измерить время выполнения той или иной команды. Самый простой с помощью утилиты time:
Сразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
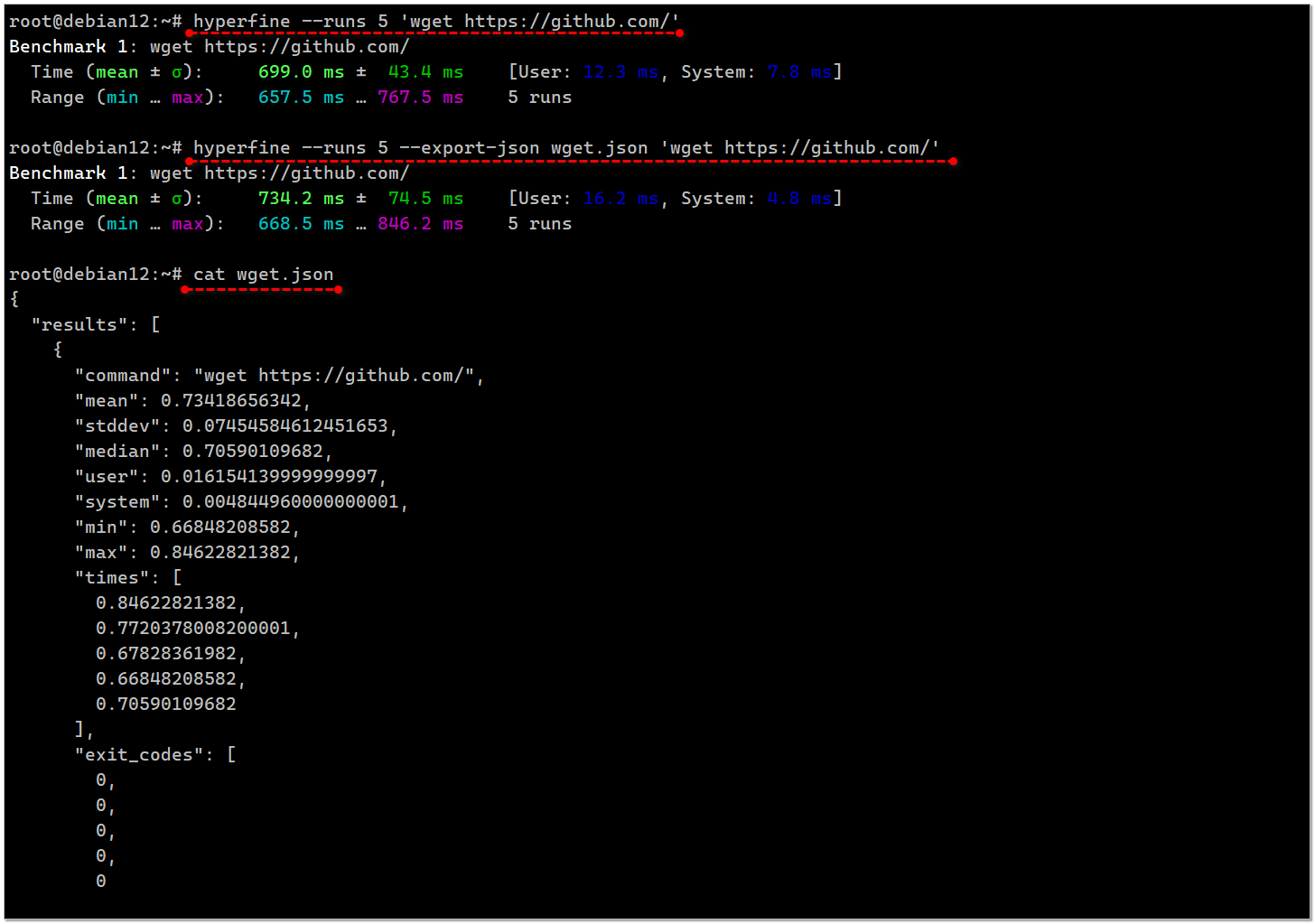
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
С его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
На выходе получаем файл
Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
# time curl http://127.0.0.1/server-statusActive connections: 1 server accepts handled requests 6726 6726 4110 Reading: 0 Writing: 1 Waiting: 0 real 0m0.015suser 0m0.006ssys 0m0.009sСразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
# apt install hyperfineС его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
# hyperfine --runs 1 --export-json mysqldump.json 'mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql'На выходе получаем файл
mysqldump.json с информацией:{ "results": [ { "command": "mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql", "mean": 2.7331184105, "stddev": null, "median": 2.7331184105, "user": 2.1372425799999997, "system": 0.35953332, "min": 2.7331184105, "max": 2.7331184105, "times": [ 2.7331184105 ], "exit_codes": [ 0 ] } ]}Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
# hyperfine --runs 3 'curl -s https://github.com/'Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
{kind=link}
Нравятся тенденции последних лет по принятию разных полезных современных утилит в базовые репозитории популярных дистрибутивов. Недавно рассказывал про hyperfine и bat. К ним можно теперь добавить утилиту duf, как замену df. Она теперь тоже переехала в базовый репозиторий:
Когда первый раз про неё писал, её там не было. Качал бинарник вручную. Рассказывать про неё особо нечего. Так же, как и df, duf показывает использование диска разных устройств и точек монтирования. Вывод более наглядный, чем в df. Плюс, есть несколько дополнительных возможностей, которые могут быть полезны:
▪️ Умеет делать вывод в формате json:
▪️ Умеет сразу сортировать по разным признакам:
▪️ Умеет группировать и сортировать устройства:
и т.д.
То есть эта штука удобна не только для визуального просмотра через консоль, но и для использования в различных костылях, велосипедах и мониторингах. Не нужно парсить регулярками вывод df, а можно отфильтровать, выгрузить в json и обработать jq. Написана duf на GO, работает шустро. Хороший софт, можно брать на вооружение.
#linux #terminal
# apt install dufКогда первый раз про неё писал, её там не было. Качал бинарник вручную. Рассказывать про неё особо нечего. Так же, как и df, duf показывает использование диска разных устройств и точек монтирования. Вывод более наглядный, чем в df. Плюс, есть несколько дополнительных возможностей, которые могут быть полезны:
▪️ Умеет делать вывод в формате json:
# duf -json▪️ Умеет сразу сортировать по разным признакам:
# duf -sort size# duf -sort used# duf -sort avail▪️ Умеет группировать и сортировать устройства:
# duf --only local# duf --only network# duf --hide local# duf --only-mp /,/mnt/backupи т.д.
То есть эта штука удобна не только для визуального просмотра через консоль, но и для использования в различных костылях, велосипедах и мониторингах. Не нужно парсить регулярками вывод df, а можно отфильтровать, выгрузить в json и обработать jq. Написана duf на GO, работает шустро. Хороший софт, можно брать на вооружение.
#linux #terminal
{kind=link}
Начиная с пятницы, в сети наперебой постили новости с шокирующей уязвимостью в OpenSSH сервере CVE-2024-3094, которая позволяет получить доступ к SSH-серверу без аутентификации (на самом деле это не так). Якобы ей подвержены почти все современные системы. Я всю пятницу и субботу в сборах и дороге был, так что только вчера смог спокойно сесть и разобраться, что там случилось.
Сразу скажу, что если у вас Debian 11 или 12 можно вообще не переживать и не торопиться обновляться. Никаких проблем с найденной уязвимостью в этих системах нет. Заражённый пакет успел приехать только в тестовый репозиторий sid.
Расскажу своими словами, в чём там дело. OpenSSH сервер использует библиотеку liblzma. Насколько я понял, не все сервера её используют, но большая часть. Проверить можно так:
Уязвимой является версия библиотеки 5.6.0 и 5.6.1. Проверяем установленную у себя версию через пакетный менеджер. Для deb вот так:
Или напрямую через просмотр версии xz:
В Debian 12 указанной уязвимости нет, можно не переживать. В security-tracker есть отдельная страница по этой уязвимости. Там видно, что версия 5.6.1 была только в sid.
В rpm дистрибутивах нужно проверять версию пакета xz-libs:
Для 8-й ветки форков RHEL проблема тоже неактуальна. 9-й у меня нигде нет, там не проверял.
Вообще, история с этой уязвимостью очень любопытная. На самом деле она позвоялет выполнить произвольный код в системе, не оставляя следов в логах sshd. Подробный разбор работы есть на opennet. Сделано всё очень мудрёно и запутанно не без использования bash портянки, которая выглядит как обфускация. А обнаружили уязвимость случайно, потому что sshd стал чуток медленнее работать, чем раньше. А сколько таких уязвимостей есть в системах, которые ещё никто случайно не заметил?
#linux #security
Сразу скажу, что если у вас Debian 11 или 12 можно вообще не переживать и не торопиться обновляться. Никаких проблем с найденной уязвимостью в этих системах нет. Заражённый пакет успел приехать только в тестовый репозиторий sid.
Расскажу своими словами, в чём там дело. OpenSSH сервер использует библиотеку liblzma. Насколько я понял, не все сервера её используют, но большая часть. Проверить можно так:
# ldd "$(command -v sshd)" | grep liblzma liblzma.so.5 => /lib/x86_64-linux-gnu/liblzma.so.5 (0x00007f4f01c9d000)Уязвимой является версия библиотеки 5.6.0 и 5.6.1. Проверяем установленную у себя версию через пакетный менеджер. Для deb вот так:
# dpkg -l | grep liblzmaii liblzma5:amd64 5.4.1-0.2 amd64 XZ-format compression libraryИли напрямую через просмотр версии xz:
# xz --versionxz (XZ Utils) 5.4.1liblzma 5.4.1В Debian 12 указанной уязвимости нет, можно не переживать. В security-tracker есть отдельная страница по этой уязвимости. Там видно, что версия 5.6.1 была только в sid.
В rpm дистрибутивах нужно проверять версию пакета xz-libs:
# rpm -qa | grep xz-libsxz-libs-5.2.4-4.el8_6.x86_64Для 8-й ветки форков RHEL проблема тоже неактуальна. 9-й у меня нигде нет, там не проверял.
Вообще, история с этой уязвимостью очень любопытная. На самом деле она позвоялет выполнить произвольный код в системе, не оставляя следов в логах sshd. Подробный разбор работы есть на opennet. Сделано всё очень мудрёно и запутанно не без использования bash портянки, которая выглядит как обфускация. А обнаружили уязвимость случайно, потому что sshd стал чуток медленнее работать, чем раньше. А сколько таких уязвимостей есть в системах, которые ещё никто случайно не заметил?
#linux #security
www.opennet.ru
Разбор логики активации и работы бэкдора в пакете xz
Доступны предварительные результаты обратного инжиниринга вредоносного объектного файла, встроенного в liblzma в результате кампании по продвижению бэкдора в пакет xz. Бэкдор затрагивает только системы x86_64 на базе ядра Linux и Си-библиотеки Glibc, в которых…
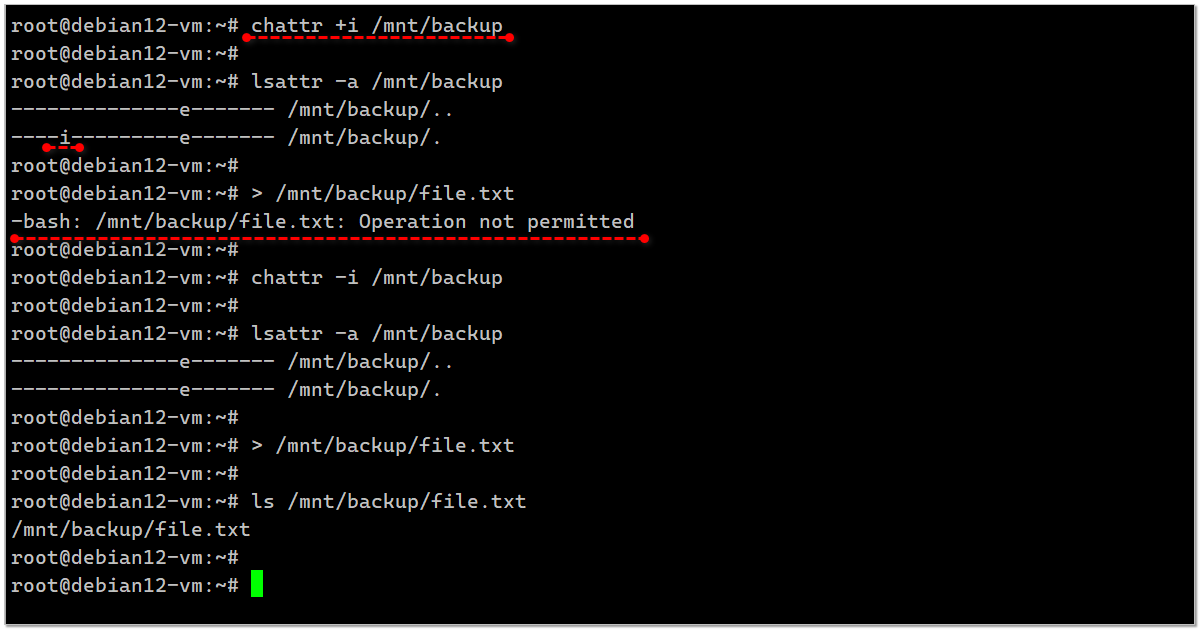
В популярных файловых системах на Linux есть одна полезная особенность. Любой файл или каталог можно сделать неизменяемым с помощью атрибута immutable. Его ещё называют immutable bit. Его может установить только root. Он же его может и убрать.
Сразу покажу на примере, где это может быть актуально. Я уже как-то делал ранее заметки на тему заполнения локальной файловой системы, когда вы копируете что-то в точку монтирования, например,
Бороться с этим можно разными способами. Например, проверять перед копированием монтирование с помощью findmnt. А можно просто с помощью флага immutable запретить запись в директорию:
Так как это признак файловой системы, то когда сетевой диск будет смонтирован поверх, писать в директорию можно будет. А если диск не примонтирован, то в локальную директорию записать не получится:
Убираем бит и пробуем ещё раз:
Посмотреть наличие этого бита можно командой lsattr. Для директории необходимо добавлять ключ
Буква
Можно придумать разное применение этого бита. В основном это будут какие-то костыли, которыми не стоит сильно увлекаться. Например, можно очень просто запретить изменение паролей пользователям. Достаточно установить immutable bit на файл
Теперь если пользователь попытается поменять пароль, то у него ничего не выйдет. Даже у root:
Необходимо вручную снять бит. Можно запретить изменение какого-то конфига на сайте или в системе. Когда-то давно видел, как публичные хостинги использовали этот бит, чтобы запретить пользователям удалять некоторые файлы, которые доступны в их домашних директориях.
Также читал, что некоторые трояны и прочие зловреды защищают себя от удаления или изменения с помощью immutable bit. Так что если расследуете взлом, имеет смысл рекурсивно пройтись по всем системным бинарям и проверить у них этот бит. Отсюда следует параноидальный способ защиты от вирусов - использование этого бита на всех важных системных файлах. Нужно только понимать, что для обновления системы, этот бит нужно будет снимать и потом ставить заново.
Если знаете ещё какое-то полезное применение immutable, поделитесь в комментах. Я видел, что некоторые
Вообще, это неплохой вопрос для собеседований или шуток над каким-то незнающим человеком. Обычно в Unix root может удалить всё, что угодно, даже работающую систему. А тут он вдруг по какой-то причине не может удалить или изменить файл, записать в директорию.
#linux
Сразу покажу на примере, где это может быть актуально. Я уже как-то делал ранее заметки на тему заполнения локальной файловой системы, когда вы копируете что-то в точку монтирования, например,
/mnt/backup, которая подключает сетевой диск. В случае, если диск по какой-то причине не подключился, а вы в точку монтирования /mnt/backup залили кучу файлов, они всё лягут локально в корень и заполнят его. Бороться с этим можно разными способами. Например, проверять перед копированием монтирование с помощью findmnt. А можно просто с помощью флага immutable запретить запись в директорию:
# chattr +i /mnt/backupТак как это признак файловой системы, то когда сетевой диск будет смонтирован поверх, писать в директорию можно будет. А если диск не примонтирован, то в локальную директорию записать не получится:
# > /mnt/backup/file.txtbash: /mnt/backup/file.txt: Operation not permittedУбираем бит и пробуем ещё раз:
# chattr -i /mnt/backup# > /mnt/backup/file.txt# ls /mnt/backup/file.txt/mnt/backup/file.txtПосмотреть наличие этого бита можно командой lsattr. Для директории необходимо добавлять ключ
-a, для отдельных файлов он не нужен.# lsattr -a /mnt/backup--------------e------- /mnt/backup/..----i---------e------- /mnt/backup/.Буква
i указывает, что immutable bit установлен. Про псевдопапки точка и две точки читайте отдельную заметку. Можно придумать разное применение этого бита. В основном это будут какие-то костыли, которыми не стоит сильно увлекаться. Например, можно очень просто запретить изменение паролей пользователям. Достаточно установить immutable bit на файл
/etc/shadow:# chattr +i /etc/shadowТеперь если пользователь попытается поменять пароль, то у него ничего не выйдет. Даже у root:
# passwd rootpasswd: Authentication token manipulation errorpasswd: password unchangedНеобходимо вручную снять бит. Можно запретить изменение какого-то конфига на сайте или в системе. Когда-то давно видел, как публичные хостинги использовали этот бит, чтобы запретить пользователям удалять некоторые файлы, которые доступны в их домашних директориях.
Также читал, что некоторые трояны и прочие зловреды защищают себя от удаления или изменения с помощью immutable bit. Так что если расследуете взлом, имеет смысл рекурсивно пройтись по всем системным бинарям и проверить у них этот бит. Отсюда следует параноидальный способ защиты от вирусов - использование этого бита на всех важных системных файлах. Нужно только понимать, что для обновления системы, этот бит нужно будет снимать и потом ставить заново.
Если знаете ещё какое-то полезное применение immutable, поделитесь в комментах. Я видел, что некоторые
/etc/hosts или /etc/resolve.conf им защищают от изменений. Вообще, это неплохой вопрос для собеседований или шуток над каким-то незнающим человеком. Обычно в Unix root может удалить всё, что угодно, даже работающую систему. А тут он вдруг по какой-то причине не может удалить или изменить файл, записать в директорию.
#linux
{kind=link}
Для управления Linux сервером через браузер существуют два наиболее популярных решения:
▪️ webmin
▪️ cockpit
Webmin очень старый продукт, написанный на Perl. Он же наиболее функциональный. Развивается до сих пор. Удивительный долгожитель. Сколько работаю с Linux, столько его знаю. Под него существует большое количество плагинов. Вся базовая функциональность сервера им покрывается: файрвол, samba, postfix и dovecot, dns и dhcp, логи, обновления и т.д. Я знал админов, которые успешно управлялись с сервером только через вебмин, не умея и не работая в консоли вообще. Удивился, когда не нашёл на своём канале отдельной заметки про эту панель. Неплохо её знаю, доводилось работать, хотя на свои сервера не устанавливал.
Cockpit более молодой проект, который принадлежит Red Hat. Ими же и развивается. Он более компактный и целостный, возможностей поменьше, чем у Webmin, но лично я бы для базовых задач отдал ему предпочтение. Но только если вам хватает его возможностей. В cockpit удобный просмотр логов, установка обновлений, выполнение базовых настроек системы — переименовать, настроить сеть, посмотреть автозагрузку, остановить или запустить какую-то службу, посмотреть таймеры systemd, отредактировать пользователя и т.д. Можно поставить и отдать сервер в управление кому-то далёкому от консоли человеку. Он сможет решать какие-то простые задачи, типа установки обновлений и настройки пользователей.
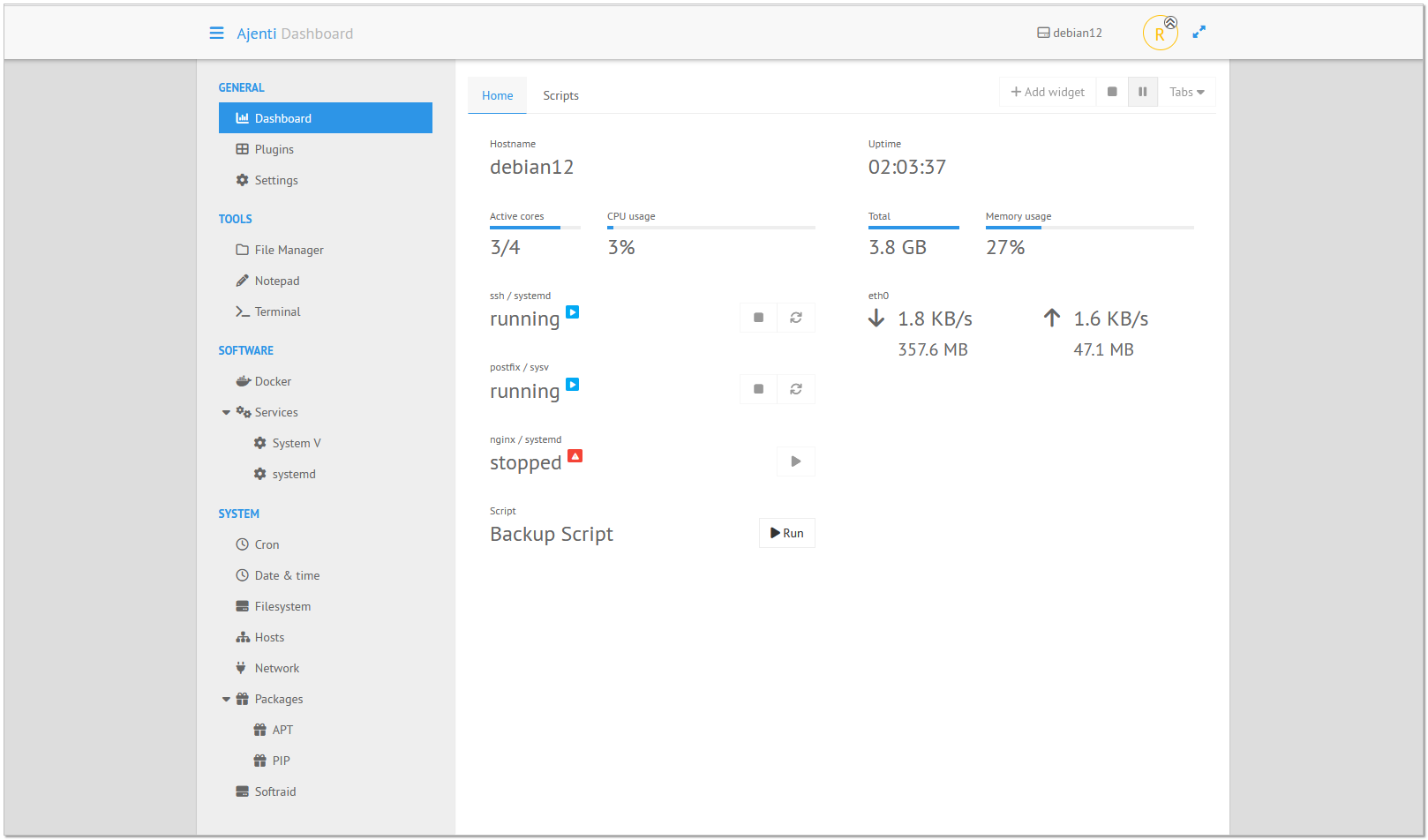
Сегодня хочу немного расширить эту тему и познакомить вас с ещё одной панелью управления сервером - Ajenti. Сразу скажу, что это проект намного меньше и проще описанных выше, но у него есть некоторые свои полезные особенности. Базовые возможности там примерно такие же, как у Cockpit без модулей. Функциональность расширяется плагинами, которые устанавливаются через веб интерфейс.
Я развернул на тестовом сервере Ajenti и внимательно посмотрел на неё. Отметил следующие полезные возможности:
◽двухфакторная аутентификация через TOTP;
◽аутентификация по сертификатам;
🔥настраиваемые дашборды с табами и виджетами, куда можно добавить запуск служб или выполнение каких-то скриптов;
◽удобный файловый менеджер;
◽есть русский язык;
◽адаптивный интерфейс, работает и на смартфонах.
Устанавливается панель просто. Есть инструкция, где описан автоматический и ручной способ установки. Панель написана на Python, так что установка через pip. Есть простой скрипт, который автоматизирует её в зависимости от используемого дистрибутива:
Скрипт определяет дистрибутив, устанавливает необходимые пакеты и панель через pip, создаёт systemd службу.
Далее можно идти по IP адресу сервера на порт 8000 и логиниться под root в панель. Сразу имеет смысл сгенерировать самоподписанный TLS сертификат, включить принудительную работу по HTTPS. Всё это в админке делается.
#linux
▪️ webmin
▪️ cockpit
Webmin очень старый продукт, написанный на Perl. Он же наиболее функциональный. Развивается до сих пор. Удивительный долгожитель. Сколько работаю с Linux, столько его знаю. Под него существует большое количество плагинов. Вся базовая функциональность сервера им покрывается: файрвол, samba, postfix и dovecot, dns и dhcp, логи, обновления и т.д. Я знал админов, которые успешно управлялись с сервером только через вебмин, не умея и не работая в консоли вообще. Удивился, когда не нашёл на своём канале отдельной заметки про эту панель. Неплохо её знаю, доводилось работать, хотя на свои сервера не устанавливал.
Cockpit более молодой проект, который принадлежит Red Hat. Ими же и развивается. Он более компактный и целостный, возможностей поменьше, чем у Webmin, но лично я бы для базовых задач отдал ему предпочтение. Но только если вам хватает его возможностей. В cockpit удобный просмотр логов, установка обновлений, выполнение базовых настроек системы — переименовать, настроить сеть, посмотреть автозагрузку, остановить или запустить какую-то службу, посмотреть таймеры systemd, отредактировать пользователя и т.д. Можно поставить и отдать сервер в управление кому-то далёкому от консоли человеку. Он сможет решать какие-то простые задачи, типа установки обновлений и настройки пользователей.
Сегодня хочу немного расширить эту тему и познакомить вас с ещё одной панелью управления сервером - Ajenti. Сразу скажу, что это проект намного меньше и проще описанных выше, но у него есть некоторые свои полезные особенности. Базовые возможности там примерно такие же, как у Cockpit без модулей. Функциональность расширяется плагинами, которые устанавливаются через веб интерфейс.
Я развернул на тестовом сервере Ajenti и внимательно посмотрел на неё. Отметил следующие полезные возможности:
◽двухфакторная аутентификация через TOTP;
◽аутентификация по сертификатам;
🔥настраиваемые дашборды с табами и виджетами, куда можно добавить запуск служб или выполнение каких-то скриптов;
◽удобный файловый менеджер;
◽есть русский язык;
◽адаптивный интерфейс, работает и на смартфонах.
Устанавливается панель просто. Есть инструкция, где описан автоматический и ручной способ установки. Панель написана на Python, так что установка через pip. Есть простой скрипт, который автоматизирует её в зависимости от используемого дистрибутива:
# curl https://raw.githubusercontent.com/ajenti/ajenti/master/scripts/install-venv.sh | bash -s -Скрипт определяет дистрибутив, устанавливает необходимые пакеты и панель через pip, создаёт systemd службу.
Далее можно идти по IP адресу сервера на порт 8000 и логиниться под root в панель. Сразу имеет смысл сгенерировать самоподписанный TLS сертификат, включить принудительную работу по HTTPS. Всё это в админке делается.
#linux
{kind=link}
Ранее я делал шпаргалку по mtime, ctime, atime и crtime. Кто иногда путается в этих характеристиках, как я, рекомендую почитать и сохранить. Я там постарался кратко рассказать о них, чтобы не ошибаться на практике. Хотя путаться всё равно не перестал. Расскажу недавнюю историю.
Надо было периодически чистить корзину от Samba. Сама шара регулярно бэкапится, так что большого смысла в корзине нет. Сделал её больше для себя, чтобы если что, можно было быстро локально восстановить случайно удалённые файлы, а не тянуть с бэкапа. Засунул в крон простую команду по очистке:
Тип - каталог, указал, потому что если удалять только файлы, остаются пустые каталоги. Решил удалять сразу их. Плюс, там есть ещё такой момент с файлами, что они прилетают в корзину с исходным mtime, с которым они лежали на шаре. То есть файл может быть удалён сегодня, но mtime у него будет годовалой давности. Так тоже не подходит. С каталогами более подходящий вариант. Там скорее лишнее будет оставаться слишком долго, нежели свежее будет удаляться.
В какой-то момент был удалён сам каталог .trash/. Я, не вникая в суть проблемы, на автомате решил, что достаточно в корне этого каталога раз в сутки обновлять какой-нибудь файл, чтобы mtime каталога обновлялся, и скрипт его не удалял. Добавил перед удалением обновление одного и того же файла через touch:
Через некоторое время каталог .trash/ опять был удалён. Тут уже решил разобраться. Оказалось, обновление mtime файла внутри каталога недостаточно, чтобы обновился mtime самого каталога. Нужно, чтобы был удалён или добавлен какой-то файл. То есть надо файл timestamp удалить и добавить снова. Тогда mtime каталога обновится. В итоге сделал так:
Надеюсь теперь всё будет работать так, как задумано.
Такой вот небольшой нюанс, о котором я ранее не знал. Изменения mtime файла внутри каталога недостаточно для изменения mtime каталога, в котором находится этот файл. Необходимо добавить, удалить или переименовать файл или каталог внутри родительского каталога.
Если я правильно понимаю, то так происходит, потому что каталог это по сути набор информации о всех директориях и файлах внутри. Информация эта состоит из имени и номера inode. Когда я через touch дёргаю файл, его номер inode не меняется. Поэтому и родительский каталог остаётся неизменным. А если файл удалить и создать снова, даже точно такой же, то его номер inode поменяется, поэтому и mtime каталога изменяется.
Век живи - век учись. С такими вещами пока не столкнёшься, не познакомишься. Просто так со всем этим разбираться вряд ли захочется. Я вроде всю теорию по файлам, директориям и айнодам когда-то изучал, но уже всё забыл. Теория без практики мертва.
#linux
Надо было периодически чистить корзину от Samba. Сама шара регулярно бэкапится, так что большого смысла в корзине нет. Сделал её больше для себя, чтобы если что, можно было быстро локально восстановить случайно удалённые файлы, а не тянуть с бэкапа. Засунул в крон простую команду по очистке:
/usr/bin/find /mnt/shara/.trash/ -type d -mtime +7 -exec rm -rf {} \;Тип - каталог, указал, потому что если удалять только файлы, остаются пустые каталоги. Решил удалять сразу их. Плюс, там есть ещё такой момент с файлами, что они прилетают в корзину с исходным mtime, с которым они лежали на шаре. То есть файл может быть удалён сегодня, но mtime у него будет годовалой давности. Так тоже не подходит. С каталогами более подходящий вариант. Там скорее лишнее будет оставаться слишком долго, нежели свежее будет удаляться.
В какой-то момент был удалён сам каталог .trash/. Я, не вникая в суть проблемы, на автомате решил, что достаточно в корне этого каталога раз в сутки обновлять какой-нибудь файл, чтобы mtime каталога обновлялся, и скрипт его не удалял. Добавил перед удалением обновление одного и того же файла через touch:
/usr/bin/touch /mnt/shara/.trash/timestampЧерез некоторое время каталог .trash/ опять был удалён. Тут уже решил разобраться. Оказалось, обновление mtime файла внутри каталога недостаточно, чтобы обновился mtime самого каталога. Нужно, чтобы был удалён или добавлен какой-то файл. То есть надо файл timestamp удалить и добавить снова. Тогда mtime каталога обновится. В итоге сделал так:
/usr/bin/rm /mnt/shara/.trash/timestamp/usr/bin/touch /mnt/shara/.trash/timestamp/usr/bin/find /mnt/shara/.trash/ -type d -mtime +7 -exec rm -rf {} \;Надеюсь теперь всё будет работать так, как задумано.
Такой вот небольшой нюанс, о котором я ранее не знал. Изменения mtime файла внутри каталога недостаточно для изменения mtime каталога, в котором находится этот файл. Необходимо добавить, удалить или переименовать файл или каталог внутри родительского каталога.
Если я правильно понимаю, то так происходит, потому что каталог это по сути набор информации о всех директориях и файлах внутри. Информация эта состоит из имени и номера inode. Когда я через touch дёргаю файл, его номер inode не меняется. Поэтому и родительский каталог остаётся неизменным. А если файл удалить и создать снова, даже точно такой же, то его номер inode поменяется, поэтому и mtime каталога изменяется.
Век живи - век учись. С такими вещами пока не столкнёшься, не познакомишься. Просто так со всем этим разбираться вряд ли захочется. Я вроде всю теорию по файлам, директориям и айнодам когда-то изучал, но уже всё забыл. Теория без практики мертва.
#linux