
На днях поднимал вопрос сбора логов веб сервера и забыл упомянуть одну систему, которую я знаю уже очень давно. Пользуюсь лет 8. Речь пойдёт про New Relic. Это очень мощная SaaS платформа по мониторингу и аналитике веб приложений и всего, что с ними связано, в том числе серверов. Я не раз уже писал о нём, но можно и ещё раз напомнить.
Сервис постоянно развивается и меняется. Когда я начинал им пользоваться для базового мониторинга серверов, там был бесплатный тарифный план на 10 хостов. В какой-то момент они бесплатный тарифный план совсем убрали, потом вернули в другом виде.
В итоге сейчас есть бесплатный тарифный план без необходимости привязки карты. Просто регистрируетесь на email. Вам даётся 100 ГБ для хранения всех данных с любых сервисов системы. А их там море, они все разные. Это очень удобно и просто для контроля. Хотите мониторить сервера - подключайте хосты, настраивайте метрики. Хотите логи - грузите их. Используется то же доступное пространство.
Вообще говоря, это лучший мониторинг, что мне известен. Нигде я не видел такой простоты, удобства и массы возможностей. Если покупать за деньги, то стоит очень дорого. Отмечу сразу, что вообще он больше заточен под высокоуровневый мониторинг приложений, но и всё остальное в виде мониторинга серверов, сбора логов сделано удобно.
Работа с New Relic по мониторингу сервера и сбора логов выглядит следующим образом. Регистрируетесь в личном кабинете, получаете ключ. Во время установки агента используете этот ключ. Сервер автоматом привязывается к личному кабинету. Дальше за ним наблюдаете оттуда. В настройках агента можно включить сбор логов. Какие - выбираете сами. Можно systemd логи туда отправить, или какие-то отдельные файлы. К примеру, логи Nginx. Если предварительно перевести их в формат json, то потом очень легко настраивать визуализацию в личном кабинете.
Понятное дело, что у такого подхода есть свои риски. Агент newrelic имеет полный доступ к системе. А уж к бесплатному тарифному плану привязываться и подавно опасно. Используйте по месту в каких-то одиночных серверах или временно для дебага.
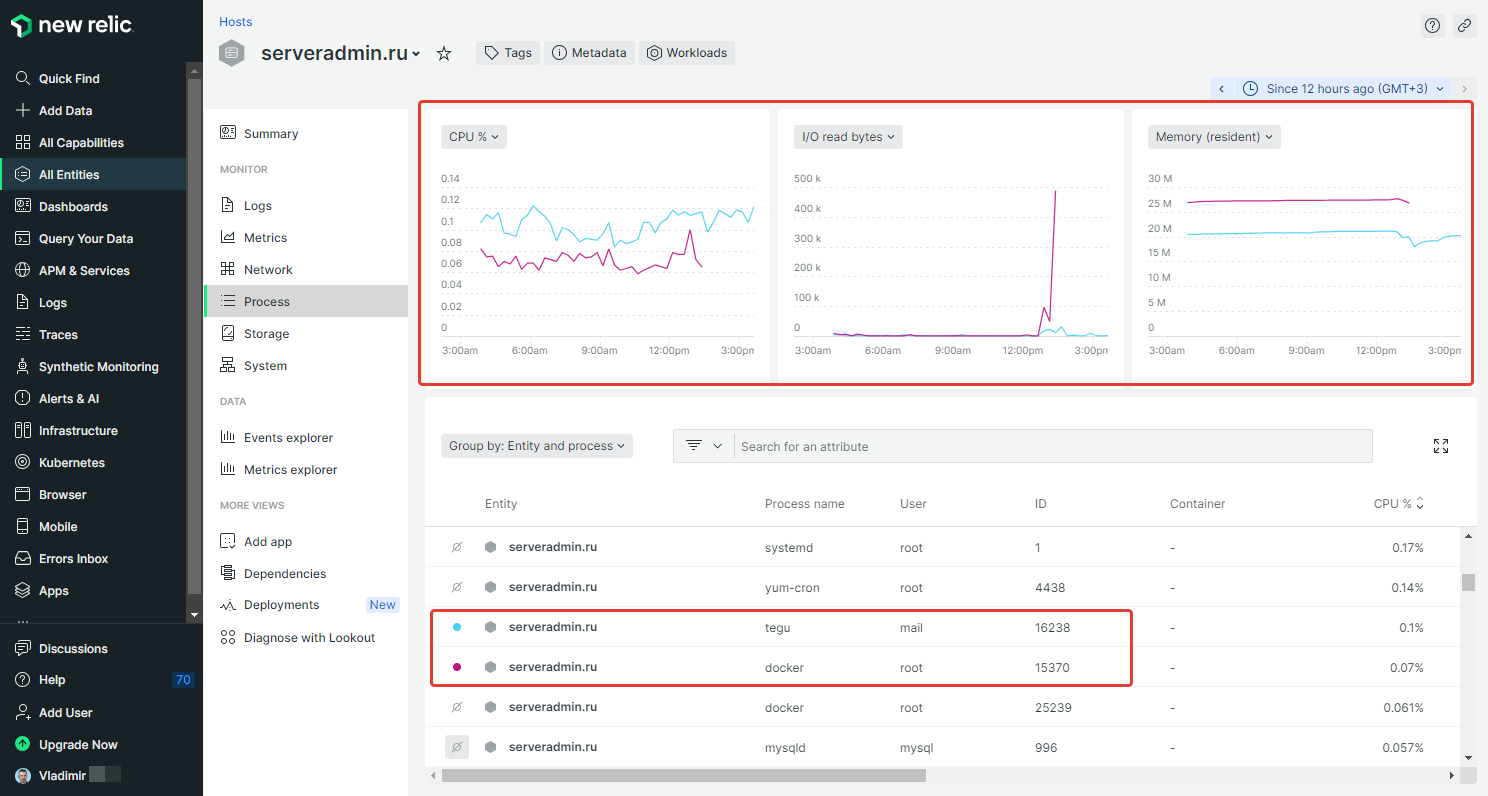
Мониторинг сервера позволяет посмотреть статистику по CPU, I/O, Memory в разрезе отдельных процессов. Это очень удобно и нигде больше не видел такой возможности.
#мониторинг #logs
Сервис постоянно развивается и меняется. Когда я начинал им пользоваться для базового мониторинга серверов, там был бесплатный тарифный план на 10 хостов. В какой-то момент они бесплатный тарифный план совсем убрали, потом вернули в другом виде.
В итоге сейчас есть бесплатный тарифный план без необходимости привязки карты. Просто регистрируетесь на email. Вам даётся 100 ГБ для хранения всех данных с любых сервисов системы. А их там море, они все разные. Это очень удобно и просто для контроля. Хотите мониторить сервера - подключайте хосты, настраивайте метрики. Хотите логи - грузите их. Используется то же доступное пространство.
Вообще говоря, это лучший мониторинг, что мне известен. Нигде я не видел такой простоты, удобства и массы возможностей. Если покупать за деньги, то стоит очень дорого. Отмечу сразу, что вообще он больше заточен под высокоуровневый мониторинг приложений, но и всё остальное в виде мониторинга серверов, сбора логов сделано удобно.
Работа с New Relic по мониторингу сервера и сбора логов выглядит следующим образом. Регистрируетесь в личном кабинете, получаете ключ. Во время установки агента используете этот ключ. Сервер автоматом привязывается к личному кабинету. Дальше за ним наблюдаете оттуда. В настройках агента можно включить сбор логов. Какие - выбираете сами. Можно systemd логи туда отправить, или какие-то отдельные файлы. К примеру, логи Nginx. Если предварительно перевести их в формат json, то потом очень легко настраивать визуализацию в личном кабинете.
Понятное дело, что у такого подхода есть свои риски. Агент newrelic имеет полный доступ к системе. А уж к бесплатному тарифному плану привязываться и подавно опасно. Используйте по месту в каких-то одиночных серверах или временно для дебага.
Мониторинг сервера позволяет посмотреть статистику по CPU, I/O, Memory в разрезе отдельных процессов. Это очень удобно и нигде больше не видел такой возможности.
#мониторинг #logs
{kind=link}
Мой первый настроенный мониторинг в роли системного администратора Linux был на базе rrd графиков, которые рисовались с помощью rrdtool и скриптов, которые забирали информацию с сенсоров и записывали в rrd базу. Было это ещё на Freebsd примерно в 2007-2008 году. Потом переехал на Zabbix версии 1.6 или 1.8, не помню точно.
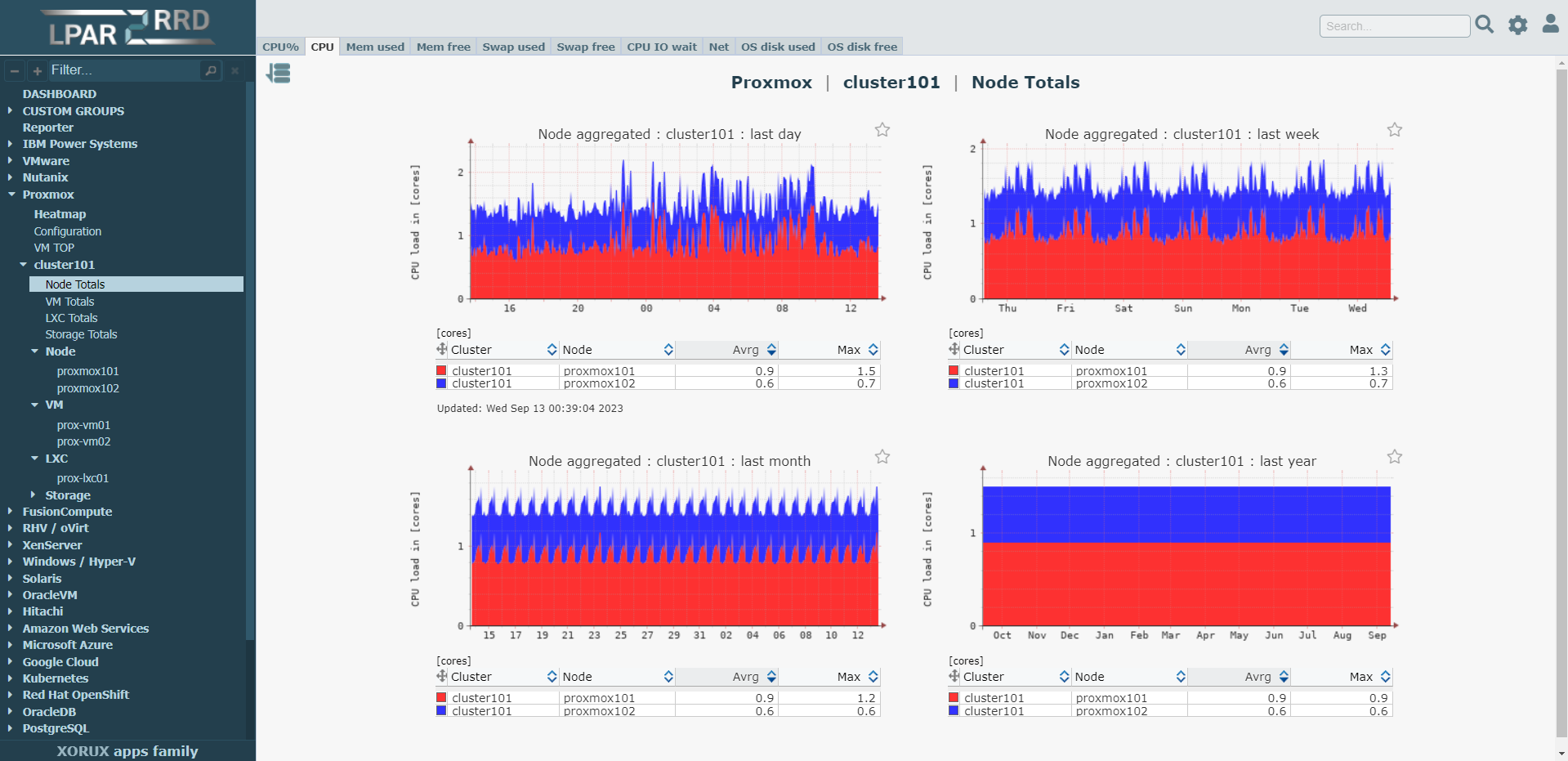
Сейчас rrd графики выглядят старомодно, хотя лично мне их стилистика нравится. Я к чему обо всём этом. Есть неплохой и вполне современный мониторинг LPAR2RRD, у которого все графики rrd. Это старый open source продукт, который монетизируется платной поддержкой этого и ещё одного своего продукта - STOR2RRD.
Отличает lpar2rrd простота установки и настройки. У него есть как свой агент, так и интеграция с популярными программными продуктами. Например, он умеет через API мониторить Proxmox. Просто делаете для lpar2rrd учётку с доступом на чтение к API и он автоматом забирает все необходимые метрики с определённой периодичностью. Другой пример интеграции - PostgreSQL. Тут то же самое. Делаете учётку с доступом на чтение, lpar2rrd забирает всю информацию вплоть до отдельной базы и рисует мониторинг.
Причём поддерживает lpar2rrd всех крупных современных вендоров, коммерческие и open source продукты, облачных провайдеров:
◽IBM Power Systems, VMware, Oracle Solaris, RHV, oVirt, XenServer, Citrix, Hyper-V
◽PostgreSQL, MSSQL, Oracle Database
◽Docker, Kubernetes, OpenShift
◽AWS, Google Cloud, Azure
Ну и обычные агенты под ОС Linux. Выше список не полный. Поддержка Windows тоже есть, но специфичная. Ставится агент на какую-то одну ОС, и он по WMI опрашивает все необходимые машины.
Посмотреть, как всё это выглядит, можно в публичном Demo, где очень удобно представлены все наиболее популярные системы. Можно увидеть в каком виде все метрики будут организованы в мониторинге. Если кто не знает, то временные интервалы задаются мышкой прям на самом графике. Сразу добавлю, что rrd ещё удобен тем, что из него легко картинки графиков автоматом забирать.
Мониторинг, конечно, выглядит простовато по сегодняшним меркам. Пригодится он может в основном тем, кому нужно что-то простое и обзорное, чтобы поставил и не морочился с настройкой и внедрением. И на этот вопрос он реально отвечает. Дал доступ к кластеру Proxmox и получил автоматом мониторинг вплоть до загрузки сетевого интерфейса отдельного lxc контейнера. А так как всё хранится в локальной rrd базе, ему даже полноценная СУБД не нужна.
Можно как дублирующий внешний контур для основного мониторинга использовать. Когда он ляжет, чтобы хоть примерно понимать, как у тебя обстановка.
⇨ Сайт / Demo / Установка
#мониторинг
Сейчас rrd графики выглядят старомодно, хотя лично мне их стилистика нравится. Я к чему обо всём этом. Есть неплохой и вполне современный мониторинг LPAR2RRD, у которого все графики rrd. Это старый open source продукт, который монетизируется платной поддержкой этого и ещё одного своего продукта - STOR2RRD.
Отличает lpar2rrd простота установки и настройки. У него есть как свой агент, так и интеграция с популярными программными продуктами. Например, он умеет через API мониторить Proxmox. Просто делаете для lpar2rrd учётку с доступом на чтение к API и он автоматом забирает все необходимые метрики с определённой периодичностью. Другой пример интеграции - PostgreSQL. Тут то же самое. Делаете учётку с доступом на чтение, lpar2rrd забирает всю информацию вплоть до отдельной базы и рисует мониторинг.
Причём поддерживает lpar2rrd всех крупных современных вендоров, коммерческие и open source продукты, облачных провайдеров:
◽IBM Power Systems, VMware, Oracle Solaris, RHV, oVirt, XenServer, Citrix, Hyper-V
◽PostgreSQL, MSSQL, Oracle Database
◽Docker, Kubernetes, OpenShift
◽AWS, Google Cloud, Azure
Ну и обычные агенты под ОС Linux. Выше список не полный. Поддержка Windows тоже есть, но специфичная. Ставится агент на какую-то одну ОС, и он по WMI опрашивает все необходимые машины.
Посмотреть, как всё это выглядит, можно в публичном Demo, где очень удобно представлены все наиболее популярные системы. Можно увидеть в каком виде все метрики будут организованы в мониторинге. Если кто не знает, то временные интервалы задаются мышкой прям на самом графике. Сразу добавлю, что rrd ещё удобен тем, что из него легко картинки графиков автоматом забирать.
Мониторинг, конечно, выглядит простовато по сегодняшним меркам. Пригодится он может в основном тем, кому нужно что-то простое и обзорное, чтобы поставил и не морочился с настройкой и внедрением. И на этот вопрос он реально отвечает. Дал доступ к кластеру Proxmox и получил автоматом мониторинг вплоть до загрузки сетевого интерфейса отдельного lxc контейнера. А так как всё хранится в локальной rrd базе, ему даже полноценная СУБД не нужна.
Можно как дублирующий внешний контур для основного мониторинга использовать. Когда он ляжет, чтобы хоть примерно понимать, как у тебя обстановка.
⇨ Сайт / Demo / Установка
#мониторинг
{kind=link}
У меня написаны заметки по всем более ли менее популярным бесплатным системам мониторинга. И только одну очень старую систему я всегда обходил стороной, за что неоднократно получал комментарии на эту тему. Надо это исправить и дополнить мою статью с обзором систем мониторинга (20 штук).
Речь пойдёт про старичка Cacti, он же Кактус, который хранит данные и рисует графики с помощью очень старой TSDB — RRDTool. Работает Cacti на базе стандартного LAMP стэка, так как написан на PHP, настройки хранит в MySQL. Поднять сервер можно даже на Windows под IIS. Сбор метрик крутится в основном вокруг SNMP, но можно их собирать и другими способами на базе собственных Data Collectors, в качестве которых могут выступать и обычные скрипты. Кактус ориентирован в основном на мониторинг сетевых устройств.
Cacti поддерживает шаблоны, правила автообнаружения, расширяет свои возможности через плагины, имеет разные механизмы аутентификации пользователей, в том числе через LDAP. То есть там полный набор полноценной системы мониторинга. Система очень старая, из 2001 (😎) года, но поддерживается и развивается до сих пор.
Это такая самобытная, добротная, с приятным интерфейсом система мониторинга. Если честно, я не знаю, что может заставить её использовать сейчас. Разве что её интерфейс дашборды. Сказать, что она легко и быстро разворачивается не могу. Чего-то особенного в ней тоже нет. Используется мало где, и мало кому нужна. Не знаю ни одного аргумента, который бы оправдал её использование вместо того же Zabbix или более современных систем.
Если в каких-то других системах мониторинга я могу увидеть простоту установки и настройки, необычный внешний вид или удобные дашборды, то тут ничего такого нет. Настраивать придётся вручную, изучать сбор метрик и принцип работы, разбираться. Материалов не так много, все в основном старые. Это скорее система для тех, кто с ней знаком и работал раньше. Сейчас её изучать смысла не вижу.
Посмотреть внешний вид и основные возможности можно вот в этом обзорном видео: ▶️ https://www.youtube.com/watch?v=Xww5y9V1ikI Возможно вас эта система чем-то зацепит. Как я уже сказал, она самобытная с необычным интерфейсом и дашбордами. Выглядит неплохо. Мне, к примеру, RRD графики нравятся больше чем то, что сейчас есть в Zabbix.
Отдельно отмечу, что у Cacti есть плагин для NetFlow. Можно собирать информацию о трафике с сетевых устройств и смотреть в Кактусе. Пример того, как это может выглядеть в связке с Mikrotik, можно посмотреть в видео. Хотя лично я считаю, что лучше отдельную систему под это, так как это не совсем мониторинг.
В Debian Cacti есть в базовых репах и ставится автоматически весь стек:
После этого идёте в веб интерфейс по адресу http://172.17.196.25/cacti/. Учётка admin / cacti. Для теста можете поставить локально службу snmpd и добавить хост localhost в систему мониторинга.
⇨ Сайт / Исходники / Видеоинструкции
#мониторинг
Речь пойдёт про старичка Cacti, он же Кактус, который хранит данные и рисует графики с помощью очень старой TSDB — RRDTool. Работает Cacti на базе стандартного LAMP стэка, так как написан на PHP, настройки хранит в MySQL. Поднять сервер можно даже на Windows под IIS. Сбор метрик крутится в основном вокруг SNMP, но можно их собирать и другими способами на базе собственных Data Collectors, в качестве которых могут выступать и обычные скрипты. Кактус ориентирован в основном на мониторинг сетевых устройств.
Cacti поддерживает шаблоны, правила автообнаружения, расширяет свои возможности через плагины, имеет разные механизмы аутентификации пользователей, в том числе через LDAP. То есть там полный набор полноценной системы мониторинга. Система очень старая, из 2001 (😎) года, но поддерживается и развивается до сих пор.
Это такая самобытная, добротная, с приятным интерфейсом система мониторинга. Если честно, я не знаю, что может заставить её использовать сейчас. Разве что её интерфейс дашборды. Сказать, что она легко и быстро разворачивается не могу. Чего-то особенного в ней тоже нет. Используется мало где, и мало кому нужна. Не знаю ни одного аргумента, который бы оправдал её использование вместо того же Zabbix или более современных систем.
Если в каких-то других системах мониторинга я могу увидеть простоту установки и настройки, необычный внешний вид или удобные дашборды, то тут ничего такого нет. Настраивать придётся вручную, изучать сбор метрик и принцип работы, разбираться. Материалов не так много, все в основном старые. Это скорее система для тех, кто с ней знаком и работал раньше. Сейчас её изучать смысла не вижу.
Посмотреть внешний вид и основные возможности можно вот в этом обзорном видео: ▶️ https://www.youtube.com/watch?v=Xww5y9V1ikI Возможно вас эта система чем-то зацепит. Как я уже сказал, она самобытная с необычным интерфейсом и дашбордами. Выглядит неплохо. Мне, к примеру, RRD графики нравятся больше чем то, что сейчас есть в Zabbix.
Отдельно отмечу, что у Cacti есть плагин для NetFlow. Можно собирать информацию о трафике с сетевых устройств и смотреть в Кактусе. Пример того, как это может выглядеть в связке с Mikrotik, можно посмотреть в видео. Хотя лично я считаю, что лучше отдельную систему под это, так как это не совсем мониторинг.
В Debian Cacti есть в базовых репах и ставится автоматически весь стек:
# apt install cactiПосле этого идёте в веб интерфейс по адресу http://172.17.196.25/cacti/. Учётка admin / cacti. Для теста можете поставить локально службу snmpd и добавить хост localhost в систему мониторинга.
⇨ Сайт / Исходники / Видеоинструкции
#мониторинг
{kind=link}
Тема мониторинга imap сервера Dovecot всегда обходила меня стороной. Я даже и не знал, что там есть встроенный модуль, который умеет отдавать кучу своих метрик. Не видел особой надобности. Я всегда настраивал fail2ban на перебор учёток Dovecot и мониторинг доступности TCP портов службы. В общем случае мне этого достаточно.
На днях читал новость про обновления в очередной новой версии Dovecot и увидел там изменения в модуле статистики. Заинтересовался и решил изучить его. Оказалось, там всё не так просто, как думалось на первый взгляд. Ожидал там увидеть что-то типа того, что есть в статистике Nginx или Php-fpm. А на самом деле в Dovecot очень много всевозможных метрик и их представлений: в линейных, логарифмических, средних, перцинтильных видах. Плюс фильтры, наборы метрик и т.д. Постараюсь кратко саму суть рассказать. А позже, скорее всего, сделаю небольшой шаблон для Zabbix и настрою мониторинг.
Включаем мониторинг и добавляем некоторый набор метрик, который описывает документация, как пример. Добавляем в конфиг Dovecot:
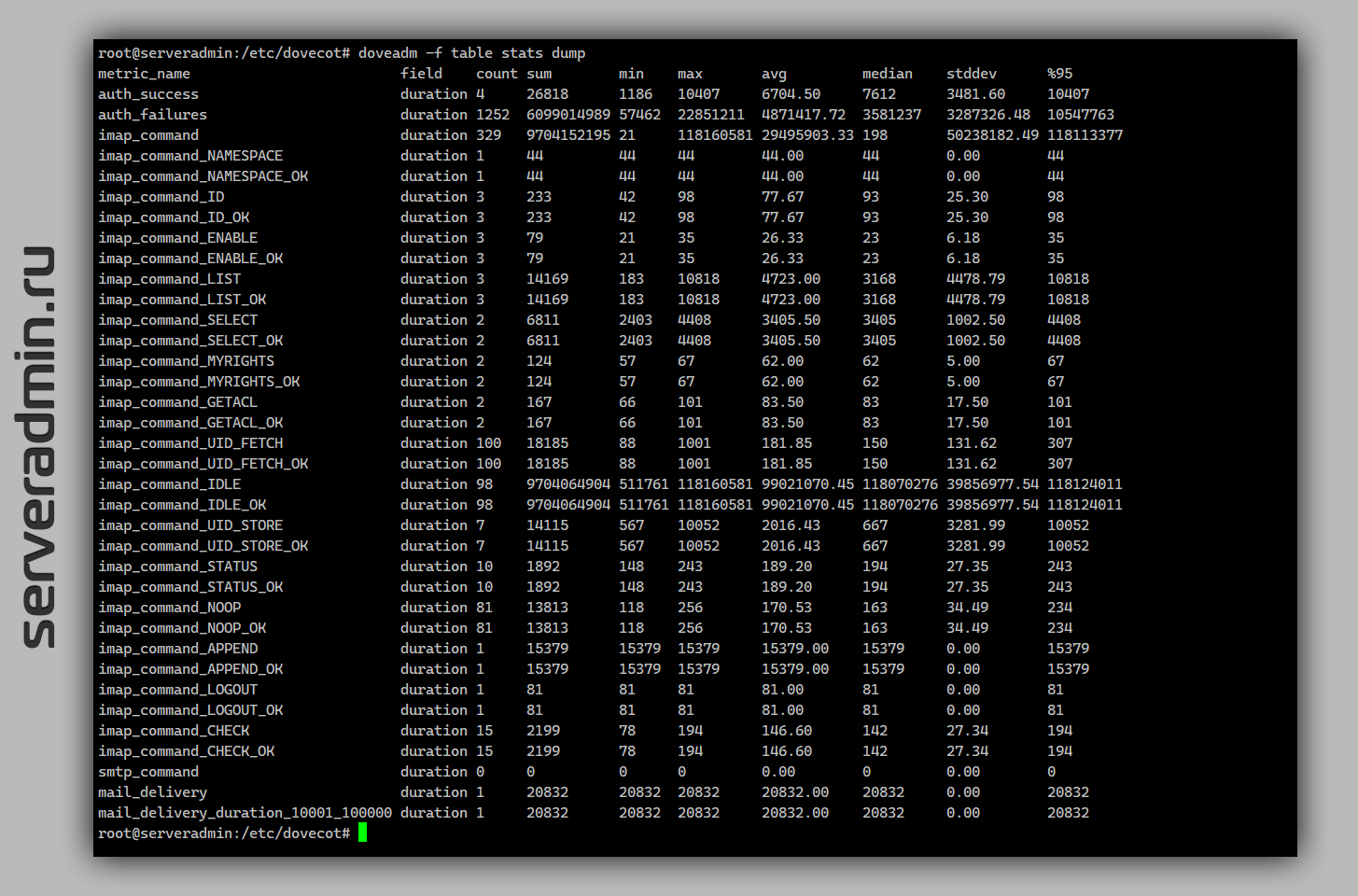
Перезапускаем Dovecot. Метрики можно увидеть по HTTP на порту сервера 9900 (не забудьте настроить ограничение на firewall) или в консоли:
Описание увиденных полей смотрите в документации, в разделе listing-statistic. Все метрики, что не count, выводятся в микросекундах. Я долго не мог понять, что это за огромные числа и зачем они нужны, пока не нашёл описание в документации.
В данном примере мы вывели статистику по успешным и неуспешным аутентификациям, по всем imap и smtp (не понял, что это за smtp метрики, у меня они по нулям) командам, и по успешным доставкам почты в ящики. Полный список событий, которые можно выводить, смотрите в разделе Events. А возможности фильтрации в Event Filtering. В принципе, тут будет вся информация по поводу метрик и их вывода.
Я посмотрел все возможные метрики и прикинул, что реально полезных, за которыми стоит следить, не так много. Перечислю их:
1️⃣ Uptime сервера. Выводится по умолчанию, отдельно настраивать эту метрику не надо. Соответственно, можно делать триггер на перезапуск сервера.
2️⃣ Количество успешных и неудачных аутентификаций. Причём интересны не абсолютные значения, а изменение в минуту. Сделать триггер на превышение среднего значения, например, в 1,5-2 раза. Если у вас резко выросли аутентификации, то, возможно, кто-то наплодил ящиков и заходит в них. А если много неудачных попыток, то, возможно, fail2ban сломался и начался подбор паролей.
3️⃣ Число успешных доставок почты. Если резво выросло число доставленных писем на каком-то большой интервале, то это повод обратить внимание. Интервал надо брать побольше, чем минута, иначе на какие-то легитимные рассылки будет реакция. Взять, думаю, надо интервал 30-60 минут и сравнивать изменения на нём. Можно и накопительную метрику сделать за сутки, чтобы быстро оценить количество входящей почты.
Вот, в принципе, и всё. Остальные метрики это уже тонкая настройка отдельных служб или слежение за производительностью. Dovecot умеет считать выполнение в микросекундах каждой своей команды и выводить min, max, avg, median, персинтили. Можно очень гибко следить за производительностью в разрезе отдельной imap команды, если для вас это важно.
#dovecot #mailserver #мониторинг
На днях читал новость про обновления в очередной новой версии Dovecot и увидел там изменения в модуле статистики. Заинтересовался и решил изучить его. Оказалось, там всё не так просто, как думалось на первый взгляд. Ожидал там увидеть что-то типа того, что есть в статистике Nginx или Php-fpm. А на самом деле в Dovecot очень много всевозможных метрик и их представлений: в линейных, логарифмических, средних, перцинтильных видах. Плюс фильтры, наборы метрик и т.д. Постараюсь кратко саму суть рассказать. А позже, скорее всего, сделаю небольшой шаблон для Zabbix и настрою мониторинг.
Включаем мониторинг и добавляем некоторый набор метрик, который описывает документация, как пример. Добавляем в конфиг Dovecot:
service stats { inet_listener http { port = 9900 }}metric auth_success { filter = event=auth_request_finished AND success=yes}metric auth_failures { filter = event=auth_request_finished AND NOT success=yes}metric imap_command { filter = event=imap_command_finished group_by = cmd_name tagged_reply_state}metric smtp_command { filter = event=smtp_server_command_finished group_by = cmd_name status_code duration:exponential:1:5:10}metric mail_delivery { filter = event=mail_delivery_finished group_by = duration:exponential:1:5:10}Перезапускаем Dovecot. Метрики можно увидеть по HTTP на порту сервера 9900 (не забудьте настроить ограничение на firewall) или в консоли:
# doveadm -f table stats dumpОписание увиденных полей смотрите в документации, в разделе listing-statistic. Все метрики, что не count, выводятся в микросекундах. Я долго не мог понять, что это за огромные числа и зачем они нужны, пока не нашёл описание в документации.
В данном примере мы вывели статистику по успешным и неуспешным аутентификациям, по всем imap и smtp (не понял, что это за smtp метрики, у меня они по нулям) командам, и по успешным доставкам почты в ящики. Полный список событий, которые можно выводить, смотрите в разделе Events. А возможности фильтрации в Event Filtering. В принципе, тут будет вся информация по поводу метрик и их вывода.
Я посмотрел все возможные метрики и прикинул, что реально полезных, за которыми стоит следить, не так много. Перечислю их:
1️⃣ Uptime сервера. Выводится по умолчанию, отдельно настраивать эту метрику не надо. Соответственно, можно делать триггер на перезапуск сервера.
2️⃣ Количество успешных и неудачных аутентификаций. Причём интересны не абсолютные значения, а изменение в минуту. Сделать триггер на превышение среднего значения, например, в 1,5-2 раза. Если у вас резко выросли аутентификации, то, возможно, кто-то наплодил ящиков и заходит в них. А если много неудачных попыток, то, возможно, fail2ban сломался и начался подбор паролей.
3️⃣ Число успешных доставок почты. Если резво выросло число доставленных писем на каком-то большой интервале, то это повод обратить внимание. Интервал надо брать побольше, чем минута, иначе на какие-то легитимные рассылки будет реакция. Взять, думаю, надо интервал 30-60 минут и сравнивать изменения на нём. Можно и накопительную метрику сделать за сутки, чтобы быстро оценить количество входящей почты.
Вот, в принципе, и всё. Остальные метрики это уже тонкая настройка отдельных служб или слежение за производительностью. Dovecot умеет считать выполнение в микросекундах каждой своей команды и выводить min, max, avg, median, персинтили. Можно очень гибко следить за производительностью в разрезе отдельной imap команды, если для вас это важно.
#dovecot #mailserver #мониторинг
{kind=link}
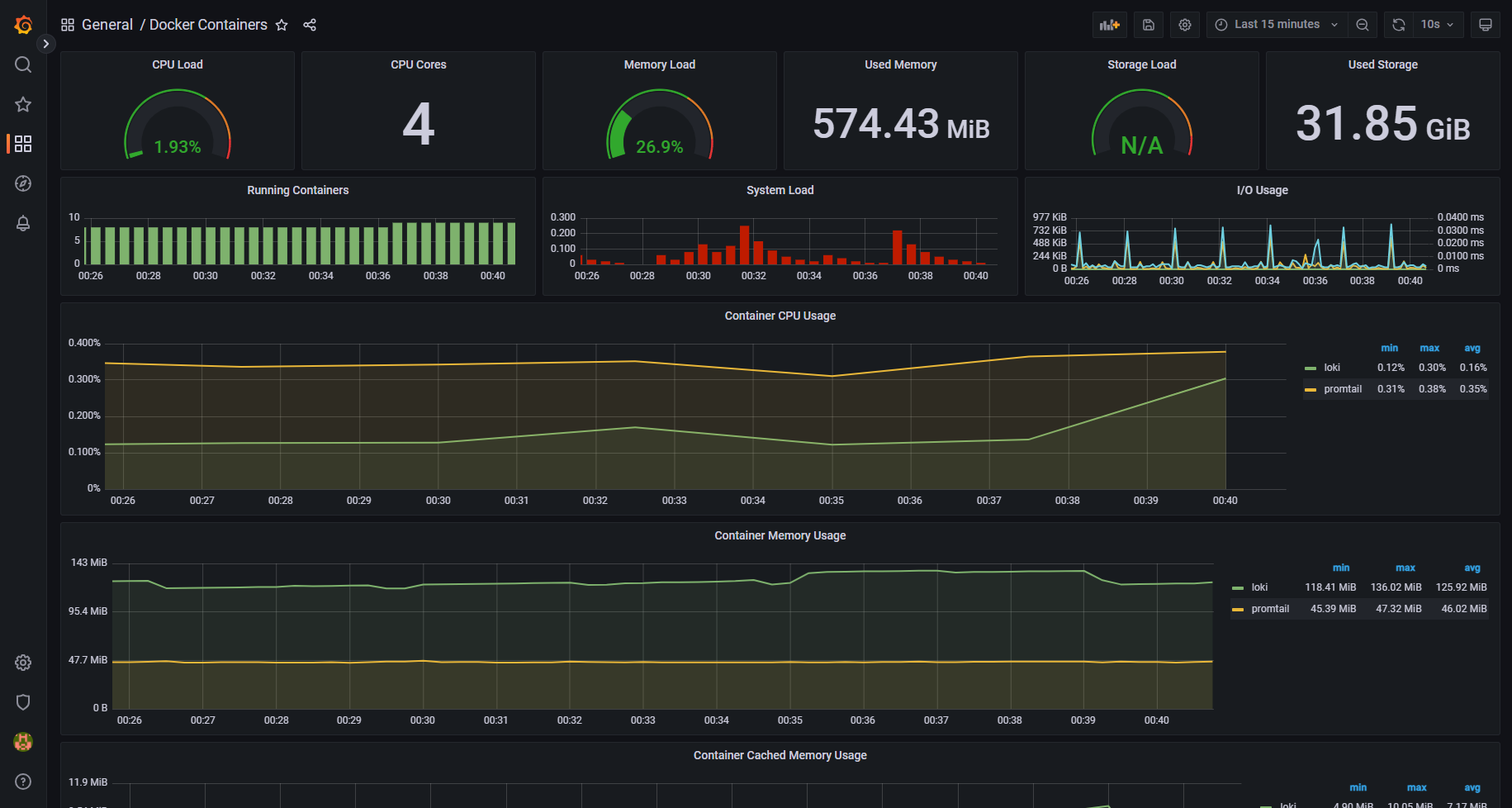
Предлагаю вашему вниманию любопытный проект по мониторингу одиночного хоста с Docker - domolo. Сразу скажу, что это продукт уровня курсовой работы с каких-нибудь курсов по DevOps на тему мониторинга. Он представляет из себя преднастроенный набор контейнеров на современном стеке.
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
Идём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
# git clone https://github.com/ductnn/domolo.git# cd domolo# docker-compose up -dИдём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
{kind=link}
Выбирая между софтовым или железным рейдом, я чаще всего выберу софтовый, если не будет остро стоять вопрос быстродействия дисковой подсистемы. А в бюджетном сегменте обычно и выбирать не приходится. Хотя и дорогой сервер могу взять без встроенного рейд контроллера, особенно если там быстрые ssd или nvme диски.
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
и выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
Получаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
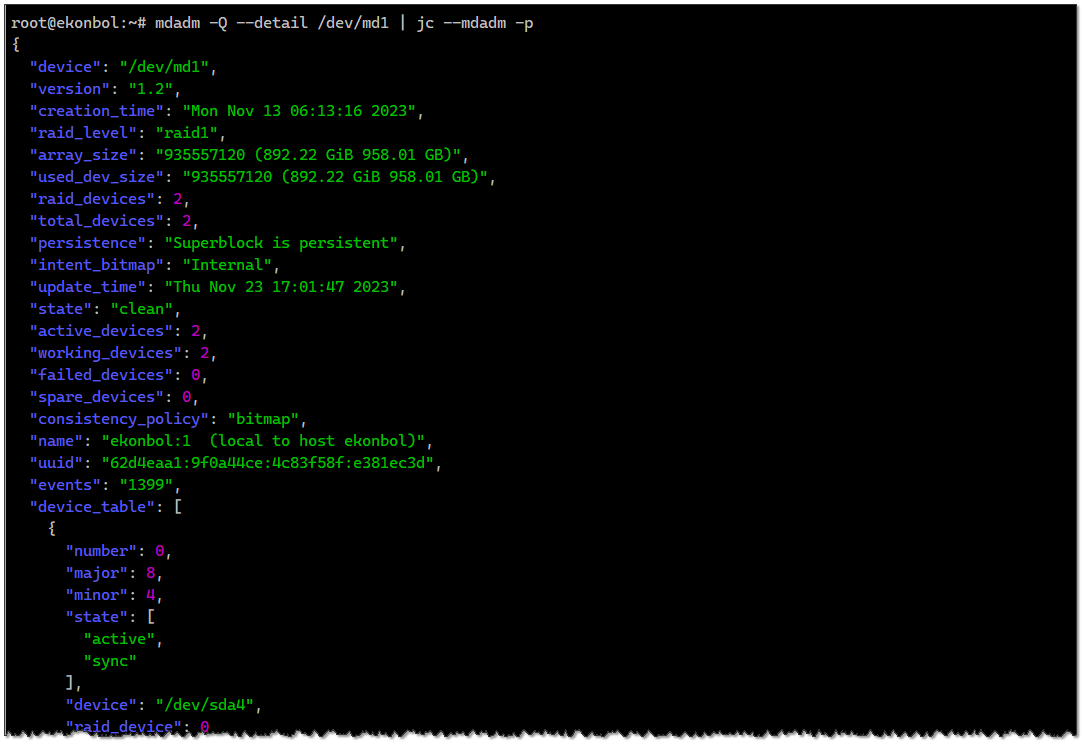
То же самое с mdadm. Смотрим состояние:
Добавляем утилиту jc:
Выгружаем полную информацию о массиве в формате json:
И отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
# apt install smartmontoolsи выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
# smartctl -i /dev/sdd -j# smartctl -A /dev/sdd -jПолучаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
То же самое с mdadm. Смотрим состояние:
# mdadm -Q --detail /dev/md1Добавляем утилиту jc:
# apt install jcВыгружаем полную информацию о массиве в формате json:
# mdadm -Q --detail /dev/md1 | jc --mdadm -pИ отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
{kind=link}
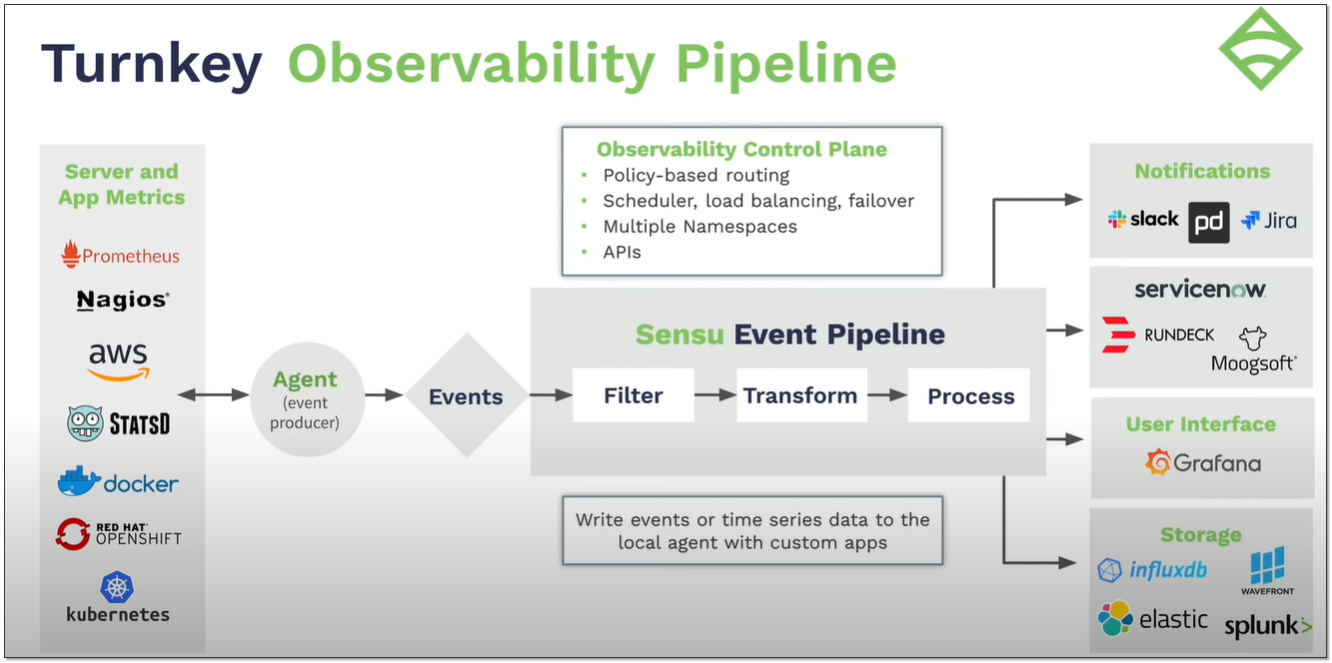
Существует довольно старая система мониторинга под названием Sensu. Ей лет 10 точно есть. Изначально она была написана на Ruby. На этом же языке писались и самостоятельные проверки, дополнения и т.д. Судя по всему в какой-то момент разработчики поняли, что это не самая удачная реализация и переписали всё на Go, а язык для проверок реализовали на JavaScript.
По сути сейчас это новая система мониторинга, полностью заточенная на реализацию подхода IaC в виде его уточнения - Monitoring-as-Code. Я изучил сайт, посмотрел возможности, обзорное видео, инструкцию по разворачиванию. Выглядит современно и удобно. Сами они себя позиционируют как инструмент для DevOps и SRE команд. При этом я вообще нигде и никогда не видел упоминание про этот мониторинг ни в современных статьях, ни где-то в выступлениях на тему мониторинга.
Базовый продукт open source. То есть можно спокойно развернуть у себя. Sensu состоит из следующих компонентов:
◽Sensu Backend - основной компонент, который собирает, обрабатывает и хранит данные.
◽Sensu API - интерфейс для взаимодействия с бэкендом.
◽Sensuctl - CLI интерфейс для взаимодействия с бэкендом через API.
◽Sensu Agent - агенты, которые устанавливаются на конечные хосты для сбора и отправки данных.
Из архитектуры понятно, что это агентский мониторинг. Реализован он немного необычно, с акцентом на простоту и скорость разворачивания агентов. Все правила по сбору метрик вы настраиваете на сервере. Каждое правило - отдельный yaml файл. Когда вы разворачиваете агент, указываете только url апишки и набор подписок на сервере. Всё, на агенте больше ничего настраивать не надо.
На самом сервере абсолютно все настройки расположены в yaml файлах: интеграции, проверки, хранилища, оповещения и т.д. Под каждую настройку создаётся отдельный yaml файл. Примерно так это выглядит:
Создали конфигурацию хранилища, добавили оповещения и метрику для сбора информации о нагрузке на cpu. Теперь настройки этой метрики можно опубликовать, а агенты на неё подпишутся и будут отправлять данные. После каждой выполненной команды будет создан соответствующий yaml файл, где можно будет настроить параметры. Sensu поддерживает namespaces для разделения доступа на большой системе. Примерно так, как это реализовано в Kubernetes. Sensu вообще в плане организации работы сильно похожа на кубер.
Подобная схема идеально подходит под современный подход к разработке и эксплуатации со встраиванием мониторинга в пайплайны. При этом Sensu объединяет в себе метрики, логи и трейсы. То есть закрывает все задачи разом.
Сам сервер Sensu под Linux. Есть как deb и rpm пакеты, так и Docker контейнер. Агенты тоже есть под все Linux, а также под Windows. У Sensu много готовых интеграций и плагинов. К примеру, он умеет забирать метрики с экспортеров Prometheus или плагинов Nagios. Может складывать данные в Elasticsearch, InfluxDB, TimescaleDB. Имеет интеграцию с Grafana.
В комплекте c бэкендом есть свой веб интерфейс, где можно наблюдать состояние всей системы. Всё, что вы создали через CLI и Yaml файлы, а также все агенты будут там видны.
По описанию и возможностям система выглядит очень привлекательно. Разработчики заявляют, что она покрывает всё, от baremetal до кластеров Kubernetes. Мне не совсем понятна её малая распространённость и известность. Может это особенность русскоязычной среды. Я вообще ничего не знаю и не слышал про этот мониторинг. Если кто-то использовал его, поделитесь информацией на этот счёт.
⇨ Сайт / Исходники / Видеообзор
#мониторинг
По сути сейчас это новая система мониторинга, полностью заточенная на реализацию подхода IaC в виде его уточнения - Monitoring-as-Code. Я изучил сайт, посмотрел возможности, обзорное видео, инструкцию по разворачиванию. Выглядит современно и удобно. Сами они себя позиционируют как инструмент для DevOps и SRE команд. При этом я вообще нигде и никогда не видел упоминание про этот мониторинг ни в современных статьях, ни где-то в выступлениях на тему мониторинга.
Базовый продукт open source. То есть можно спокойно развернуть у себя. Sensu состоит из следующих компонентов:
◽Sensu Backend - основной компонент, который собирает, обрабатывает и хранит данные.
◽Sensu API - интерфейс для взаимодействия с бэкендом.
◽Sensuctl - CLI интерфейс для взаимодействия с бэкендом через API.
◽Sensu Agent - агенты, которые устанавливаются на конечные хосты для сбора и отправки данных.
Из архитектуры понятно, что это агентский мониторинг. Реализован он немного необычно, с акцентом на простоту и скорость разворачивания агентов. Все правила по сбору метрик вы настраиваете на сервере. Каждое правило - отдельный yaml файл. Когда вы разворачиваете агент, указываете только url апишки и набор подписок на сервере. Всё, на агенте больше ничего настраивать не надо.
На самом сервере абсолютно все настройки расположены в yaml файлах: интеграции, проверки, хранилища, оповещения и т.д. Под каждую настройку создаётся отдельный yaml файл. Примерно так это выглядит:
# sensuctl create -f metric-storage/influxdb.yaml# sensuctl create -f alert/slack.yaml# sensuctl create -r -f system/linux/cpuСоздали конфигурацию хранилища, добавили оповещения и метрику для сбора информации о нагрузке на cpu. Теперь настройки этой метрики можно опубликовать, а агенты на неё подпишутся и будут отправлять данные. После каждой выполненной команды будет создан соответствующий yaml файл, где можно будет настроить параметры. Sensu поддерживает namespaces для разделения доступа на большой системе. Примерно так, как это реализовано в Kubernetes. Sensu вообще в плане организации работы сильно похожа на кубер.
Подобная схема идеально подходит под современный подход к разработке и эксплуатации со встраиванием мониторинга в пайплайны. При этом Sensu объединяет в себе метрики, логи и трейсы. То есть закрывает все задачи разом.
Сам сервер Sensu под Linux. Есть как deb и rpm пакеты, так и Docker контейнер. Агенты тоже есть под все Linux, а также под Windows. У Sensu много готовых интеграций и плагинов. К примеру, он умеет забирать метрики с экспортеров Prometheus или плагинов Nagios. Может складывать данные в Elasticsearch, InfluxDB, TimescaleDB. Имеет интеграцию с Grafana.
В комплекте c бэкендом есть свой веб интерфейс, где можно наблюдать состояние всей системы. Всё, что вы создали через CLI и Yaml файлы, а также все агенты будут там видны.
По описанию и возможностям система выглядит очень привлекательно. Разработчики заявляют, что она покрывает всё, от baremetal до кластеров Kubernetes. Мне не совсем понятна её малая распространённость и известность. Может это особенность русскоязычной среды. Я вообще ничего не знаю и не слышал про этот мониторинг. Если кто-то использовал его, поделитесь информацией на этот счёт.
⇨ Сайт / Исходники / Видеообзор
#мониторинг
{kind=link}
Я активно использую технологию wake on lan в личных целях. Запускаю разное железо дома, когда это нужно. Сам для этого использую Mikrotik и его функциональность в виде tool wol и встроенной системы скриптов. Скрипт выглядит вот так:
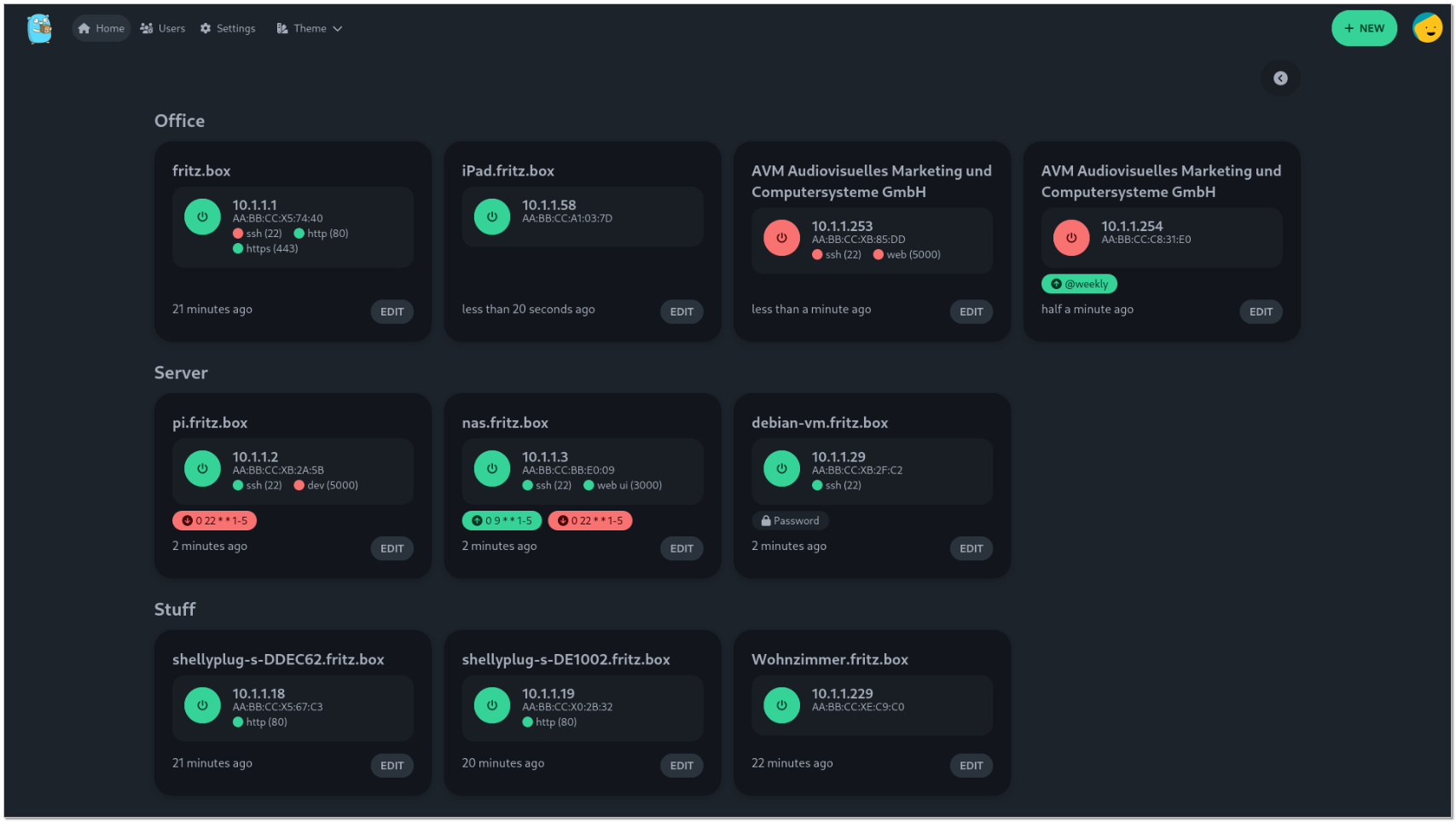
Что-то вручную запускаю, что-то по таймеру. Если у вас нету Микротика, либо хочется что-то более красивое, удобное, то можно воспользоваться готовой панелькой для этого - UpSnap. Это простенькая веб панель с приятным внешним видом. Запустить можно в Docker:
Всё, можно идти смотреть на http://172.20.4.92:8090/_/. Это админский url, где нужно будет зарегистрироваться. Сам дашборд будет доступен под той же учёткой, только по адресу без подчёркивания: http://172.20.4.92:8090/
Основные возможности UpSnap:
▪ Общий Dashboard со всеми добавленными устройствами, с которыми можно выполнять настроенные действия: будить, завершать работу, наблюдать за открытыми портами и т.д.
▪ Использовать планировщик для запланированных действий
▪ Сканировать сеть с помощью nmap
▪ Разделение прав с помощью пользователей
Выглядит симпатично. Подойдёт и в качестве простого мониторинга. Не знаю, насколько эти применимо где-то в работе, а для дома нормально. У меня всё то же самое реализовано на базе, как уже сказал, Mikrotik и Zabbix. Я и включаю, и выключаю, и слежу за запущенными устройствами с его помощью. Обычно перед сном смотрю, что в доме включенным осталось. Если дети или жена забыли свои компы выключить, могу это сделать удалённо. То же самое с дачей, котлом, компом и камерами там. Понятно, что для личного пользования Zabbix для этих целей перебор, но так как это один из основных моих рабочих инструментов, использую его везде.
UpSnap может заменить простенький мониторинг с проверкой хостов пингом и наличием настроенных открытых tcp портов. Разбираться не придётся, настроек минимум. Можно развернуть и сходу всё настроить.
⇨ Исходники
#мониторинг
tool wol interface=ether1 mac=00:25:21:BC:39:42Что-то вручную запускаю, что-то по таймеру. Если у вас нету Микротика, либо хочется что-то более красивое, удобное, то можно воспользоваться готовой панелькой для этого - UpSnap. Это простенькая веб панель с приятным внешним видом. Запустить можно в Docker:
# git clone https://github.com/seriousm4x/UpSnap# cd UpSnap# docker compose upВсё, можно идти смотреть на http://172.20.4.92:8090/_/. Это админский url, где нужно будет зарегистрироваться. Сам дашборд будет доступен под той же учёткой, только по адресу без подчёркивания: http://172.20.4.92:8090/
Основные возможности UpSnap:
▪ Общий Dashboard со всеми добавленными устройствами, с которыми можно выполнять настроенные действия: будить, завершать работу, наблюдать за открытыми портами и т.д.
▪ Использовать планировщик для запланированных действий
▪ Сканировать сеть с помощью nmap
▪ Разделение прав с помощью пользователей
Выглядит симпатично. Подойдёт и в качестве простого мониторинга. Не знаю, насколько эти применимо где-то в работе, а для дома нормально. У меня всё то же самое реализовано на базе, как уже сказал, Mikrotik и Zabbix. Я и включаю, и выключаю, и слежу за запущенными устройствами с его помощью. Обычно перед сном смотрю, что в доме включенным осталось. Если дети или жена забыли свои компы выключить, могу это сделать удалённо. То же самое с дачей, котлом, компом и камерами там. Понятно, что для личного пользования Zabbix для этих целей перебор, но так как это один из основных моих рабочих инструментов, использую его везде.
UpSnap может заменить простенький мониторинг с проверкой хостов пингом и наличием настроенных открытых tcp портов. Разбираться не придётся, настроек минимум. Можно развернуть и сходу всё настроить.
⇨ Исходники
#мониторинг
{kind=link}
В ОС на базе Linux есть разные способы измерить время выполнения той или иной команды. Самый простой с помощью утилиты time:
Сразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
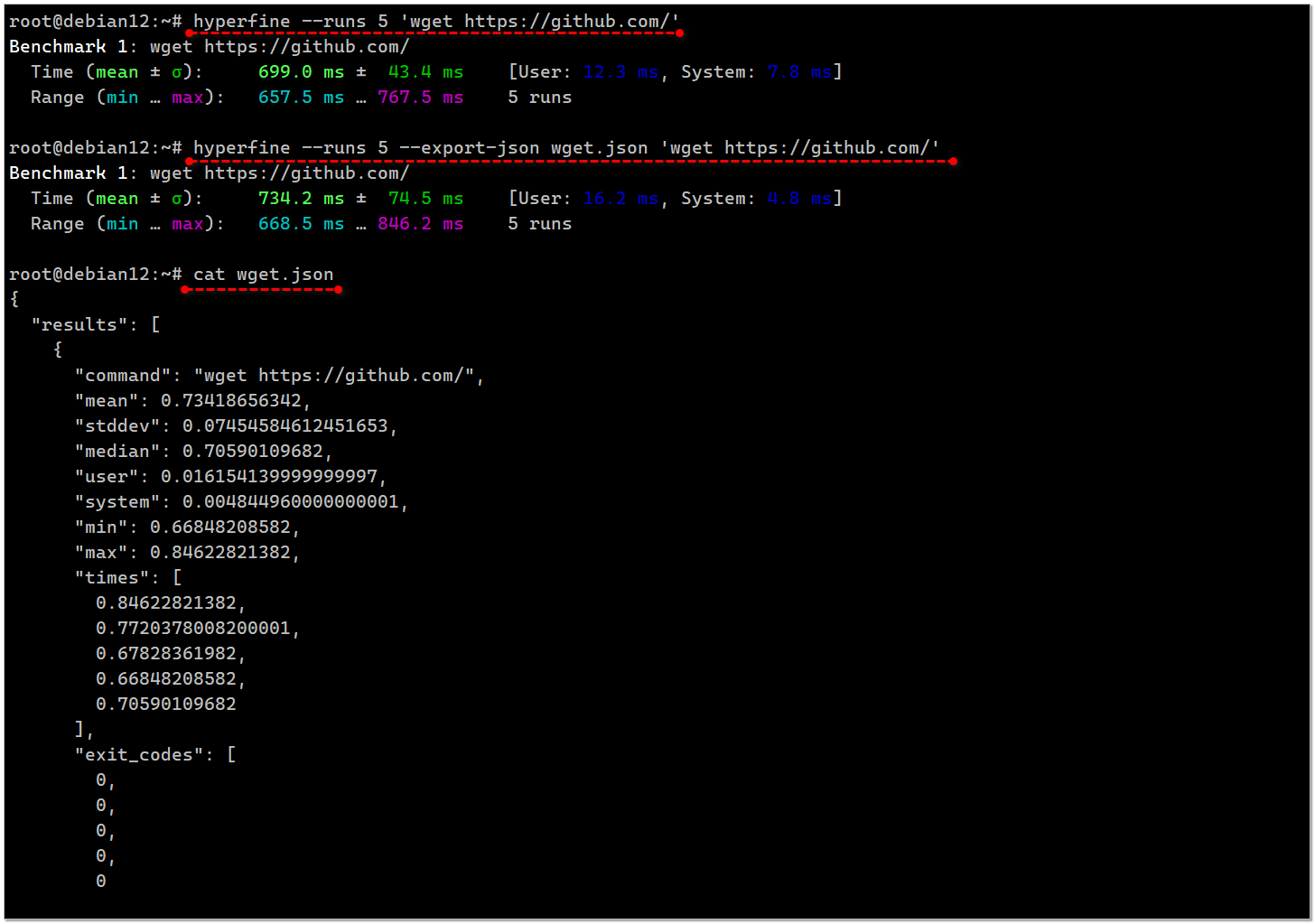
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
С его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
На выходе получаем файл
Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
# time curl http://127.0.0.1/server-statusActive connections: 1 server accepts handled requests 6726 6726 4110 Reading: 0 Writing: 1 Waiting: 0 real 0m0.015suser 0m0.006ssys 0m0.009sСразу показал на конкретном примере, как я это использовал в мониторинге. Через curl обращаюсь на страницу со статистикой веб сервера Nginx. Дальше распарсиваю вывод и забираю в том числе метрику real, которая показывает реальное выполнение запроса. Сама по себе в абсолютном значении эта метрика не важна, но важна динамика. Когда сервер работает штатно, то эта метрика плюс-минус одна и та же. И если начинаются проблемы, то отклик запроса страницы растёт. А это уже реальный сигнал, что с сервером какие-то проблемы.
Сейчас в репозитории современных систем приехал более продвинутый инструмент для отслеживания времени выполнения консольных команд - hyperfine:
# apt install hyperfineС его помощью можно не только измерять время выполнения разовой задачи, но и прогонять множественные тесты, сравнивать выполнение разных команд, выгружать результаты в различные форматы, в том числе json. В репозитории много примеров. Hyperfine заточен в основном на оптимизацию консольных команд, сравнение и выявление узких мест. Лично мне он больше интересен как инструмент мониторинга.
Например, в hyperfine можно обернуть какую-то команду и получить информацию по её выполнению. Покажу на примере создания дампа mysql базы:
# hyperfine --runs 1 --export-json mysqldump.json 'mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql'На выходе получаем файл
mysqldump.json с информацией:{ "results": [ { "command": "mysqldump --opt -v --no-create-db db01 -u'user01' -p'pass01' > ~/db01.sql", "mean": 2.7331184105, "stddev": null, "median": 2.7331184105, "user": 2.1372425799999997, "system": 0.35953332, "min": 2.7331184105, "max": 2.7331184105, "times": [ 2.7331184105 ], "exit_codes": [ 0 ] } ]}Получаем команду, время выполнения и код выхода. Эти данные можно забирать в систему мониторинга или сбора логов. Удобно настроить мониторинг на среднее время выполнения команды или на код выхода. Если не нулевой, то срабатывает триггер.
Точно так же можно собирать информацию о реальном отклике сайта:
# hyperfine --runs 3 'curl -s https://github.com/'Можно раз в минуту прогонять по 3 теста с нужной вам локации, записывать результат и сравнивать со средним или с заданным пределом.
Я привел примеры только для мониторинга. Так то hyperfine многофункционален. Так что берите на вооружение.
#linux #мониторинг #perfomance
{kind=link}
Я когда-то давно уже рассказывал про сервис мониторинга UptimeRobot. Хочу лишний раз про него напомнить, так как сам с тех пор им так и пользуюсь для личных нужд.
По своей сути это простая пинговалка, проверка открытых TCP портов и доступности сайтов. У неё есть бесплатный тарифный план на 50 проверок с периодичностью не чаще одного раза в 5 минут. Для личных нужд этого за глаза.
В целом, ничего особенного, если бы не приятный внешний вид и самое главное - 🔥мобильное приложение. Я вообще не знаю бесплатных мониторингов с мобильным приложением. А тут оно не просто бесплатное, оно ещё и красивое, удобное. В бесплатном тарифном плане есть отправка пушей.
Я туда загнал всякие свои личные проверки типа интернета в квартире и на даче, личные VPS и т.д. Для работы как-то особо не надо. Там и так везде разные мониторинги. А для себя просто по кайфу этим приложением пользоваться.
Если кто-то знает ещё хорошие приложения мониторинга для смартфона, поделитесь информацией. Не понимаю, почему Zabbix не запилит какое-нибудь родное приложение. Для него вообще ничего на смартфоне нет. Какие-то отдельные приложения есть от одиночных авторов, но они никакущие. Я все их пробовал.
#мониторинг #бесплатно
По своей сути это простая пинговалка, проверка открытых TCP портов и доступности сайтов. У неё есть бесплатный тарифный план на 50 проверок с периодичностью не чаще одного раза в 5 минут. Для личных нужд этого за глаза.
В целом, ничего особенного, если бы не приятный внешний вид и самое главное - 🔥мобильное приложение. Я вообще не знаю бесплатных мониторингов с мобильным приложением. А тут оно не просто бесплатное, оно ещё и красивое, удобное. В бесплатном тарифном плане есть отправка пушей.
Я туда загнал всякие свои личные проверки типа интернета в квартире и на даче, личные VPS и т.д. Для работы как-то особо не надо. Там и так везде разные мониторинги. А для себя просто по кайфу этим приложением пользоваться.
Если кто-то знает ещё хорошие приложения мониторинга для смартфона, поделитесь информацией. Не понимаю, почему Zabbix не запилит какое-нибудь родное приложение. Для него вообще ничего на смартфоне нет. Какие-то отдельные приложения есть от одиночных авторов, но они никакущие. Я все их пробовал.
#мониторинг #бесплатно
{kind=link}