
Хочу познакомить вас с простой и крайне полезной консольной утилитой в Linux — basename. Я её регулярно использую при написании bash скриптов для различных задач. В примерах, которыми я с вами делился здесь, она тоже встречалась.
С помощью basename удобно извлечь имя файла из полного пути.
Вместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
Вот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
Очевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
Или ещё раз то же самое, только с помощью find, sed, xargs:
Скрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
С помощью basename удобно извлечь имя файла из полного пути.
# basename /var/log/auth.logauth.logВместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
# basename /var/log/auth.log .logauthВот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
# rsync -av --files-from=<(ssh root@10.20.1.50 '/usr/bin/find /var/lib/pgpro/backup -type f -mtime -1 -exec basename {} \; | egrep -v timestamp') root@10.20.1.5:/var/lib/pgpro/backup/ /data/backup/Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
--files-from. Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
# for file in *.txt; do mv -- "$file" "$(basename $file .txt).log"; doneОчевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
# rename 's/.txt/.log/g' *.txtИли ещё раз то же самое, только с помощью find, sed, xargs:
# find . -type f | sed 'p;s:.txt:.log:g' | xargs -n2 mvСкрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
{kind=link}
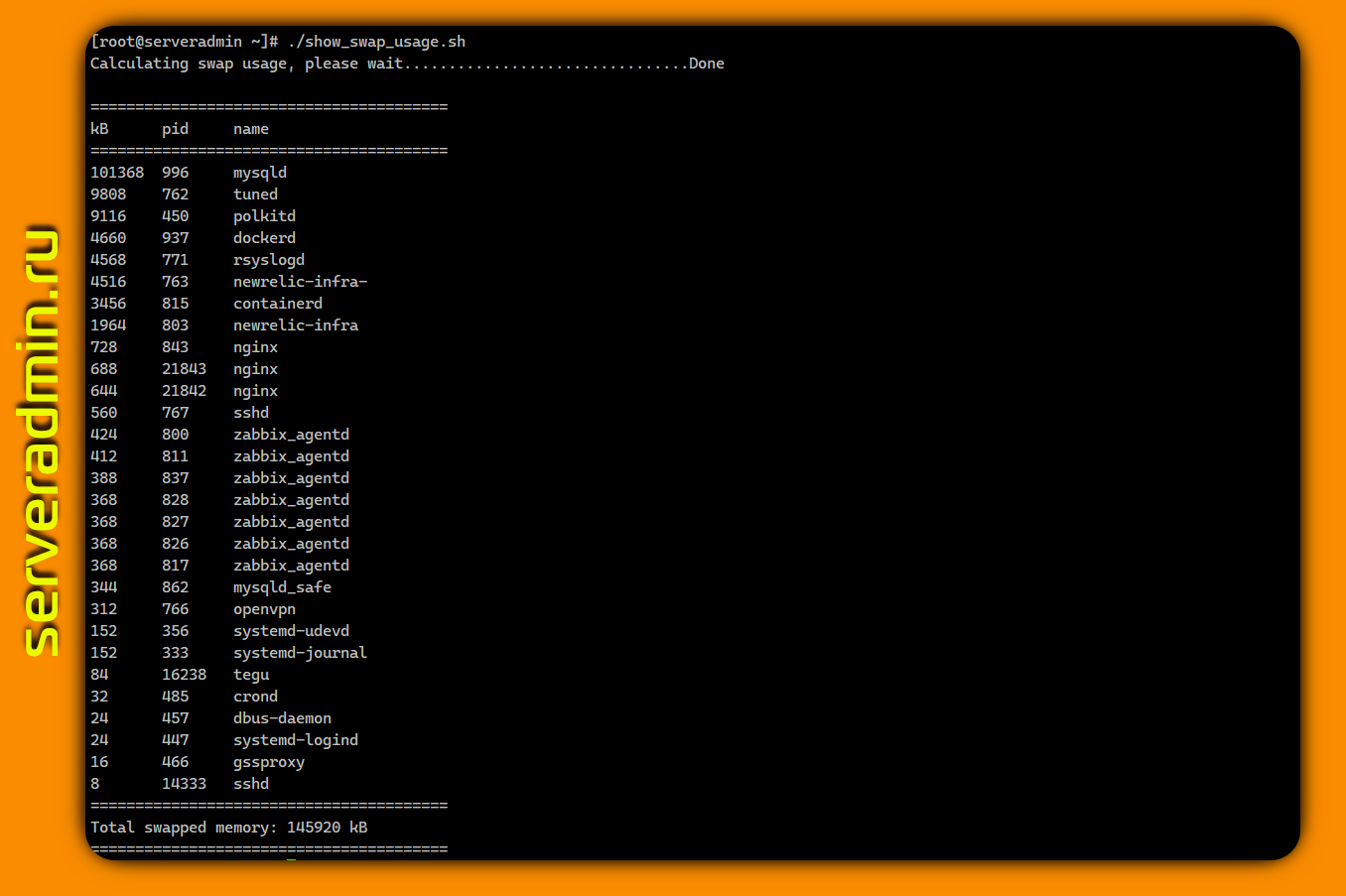
Вы знаете, как узнать, кто и насколько активно использует swap в Linux? Можно использовать для этого top, там можно вывести отдельную колонку со swap. Для этого запустите top, нажмите f и выберите колонку со swap, которой по умолчанию нет в отображении. Насколько я слышал, это не совсем корректный способ, поэтому, к примеру, в htop эту колонку вообще убрали, чтобы не вводить людей в заблуждение.
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
#linux #script #perfomance
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
/proc/$PID/smaps или /proc/$PID/status. Первая метрика будет самая точная, но там нужно будет вручную вычислить суммарный объём по отдельным кусочкам используемой памяти. Вторая метрика сразу идёт суммой. В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
#!/bin/bash SUM=0OVERALL=0for DIR in `find /proc/ -maxdepth 1 -type d -regex "^/proc/[0-9]+"`do PID=`echo $DIR | cut -d / -f 3` PROGNAME=`ps -p $PID -o comm --no-headers` for SWAP in `grep VmSwap $DIR/status 2>/dev/null | awk '{ print $2 }'` do let SUM=$SUM+$SWAP done if (( $SUM > 0 )); then echo "PID=$PID swapped $SUM KB ($PROGNAME)" fi let OVERALL=$OVERALL+$SUM SUM=0doneecho "Overall swap used: $OVERALL KB"Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
# for file in /proc/*/status ; \do awk '/VmSwap|Name/{printf $2 " " $3} END { print ""}' \$file; done | sort -k 2 -n -r | less#linux #script #perfomance
{kind=link}
Сколько вы знаете способов увидеть, под каким пользователем работаете в ОС на базе Linux? На практике эта информация нужна не так часто, если ты работаешь в консоли. Обычно и так знаешь, под каким пользователем подключаешься. Также его видно в строке ввода терминала в bash. Исключения бывают, когда приходится работать под отдельным пользователем для настройки какого-то софта. Например, postgresql. Удобнее зайти под пользователем postgres и работать в его окружении.
Традиционные способы через утилиты:
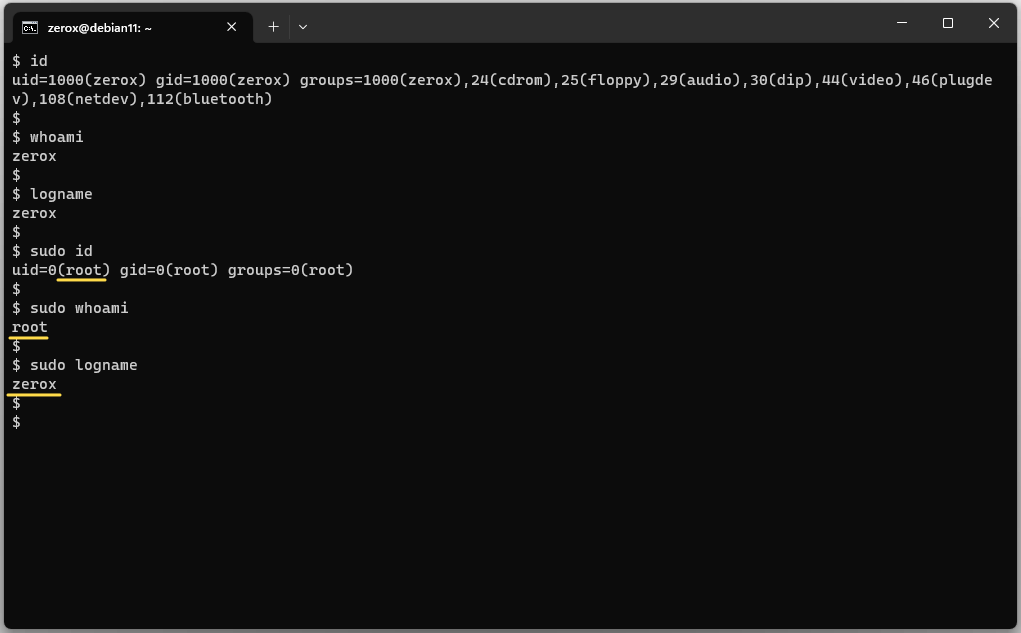
К примеру, если запустить whoami и id под sudo, вы увидите пользователя root, а в logname — пользователя, под которым вы запускаете sudo. Это может быть полезно, если выполняете какой-то скрипт под sudo, и вам нужно сделать проверку пользователя, который его запускает. Например, разрешить запуск скрипта только если он запущен конкретным пользователем (script_allow_user).
Отдельно стоит упомянуть утилиту из состава systemd —
#bash #script
Традиционные способы через утилиты:
whoami, id , logname, w и т. д. Можно посмотреть через переменные окружения: echo $LOGNAME и echo $USER. Все эти способы вроде бы похожи друг на друга, но на самом деле есть некоторые принципиальные отличия. К примеру, если запустить whoami и id под sudo, вы увидите пользователя root, а в logname — пользователя, под которым вы запускаете sudo. Это может быть полезно, если выполняете какой-то скрипт под sudo, и вам нужно сделать проверку пользователя, который его запускает. Например, разрешить запуск скрипта только если он запущен конкретным пользователем (script_allow_user).
if [[ "$(logname)" = 'script_allow_user' ]]then echo "Start script execution..." ...............................................else echo "This user is not allowed to run the script"fiОтдельно стоит упомянуть утилиту из состава systemd —
loginctl. С её помощью можно узнать массу всего не только об активном пользователе, но и о сессиях, и даже управлять ими.# loginctl user-status#bash #script
{kind=link}
На днях в рассылке увидел любопытный инструмент, на который сразу обратил внимание. Название простое и неприметное — Task. Это утилита, написанная на Gо, которая умеет запускать задачи на основе конфигурации в формате yaml. Сейчас сразу на примерах покажу, как это работает, чтобы было понятно, для чего может быть нужно.
Сама программа это просто одиночный бинарник, который можно установить кучей способов, описанных в документации. Его даже в винде можно установить через winget.
Создаём файл с задачами Taskfile.yml:
Сохраняем и запускаем. Для начала посмотрим список задач:
Запустим первую задачу:
Или сразу обе, запустив task без параметров. Запустится задача default, которую мы описали в самом начале:
Идею, думаю, вы поняли. Это более простая и лёгкая в освоении замена утилиты make, которая используется в основном для сбора софта из исходников.
Первое, что приходит в голову, где утилита task может быть полезна, помимо непосредственно сборки из исходников, как замена make — сборка docker образов. Если у вас длинный RUN, который неудобно читать, поддерживать и отлаживать из-за его размера, то его можно заменить одной задачей с task. Это позволит упростить написание и поддержку, а также избавить от необходимости разбивать этот RUN на несколько частей, что порождает создание дополнительных слоёв.
Вместо того, чтобы описывать все свои действия в длиннющем RUN, оформите все свои шаги через task и запустите в RUN только его. Примерно так:
Скопировали бинарник + yaml с задачами и запустили их. А там они могут быть красиво оформлены по шагам. Писать и отлаживать эти задачи будет проще, чем сразу в Dockerfile. Для task написано расширение в Visual Studio Code.
Task поддерживает:
◽переходы по директориям
◽зависимости задач
◽импорт в Taskfile из другого Taskfile
◽динамические переменные
◽особенности OS, можно явно указать Taskfile_linux.yml или Taskfile_windows.yml
и многое другое. Всё это описано в документации.
Я немного поразбирался с Task. Он мне показался более простой заменой одиночных сценариев для ansible. Это когда вам не нужен полноценный playbook, а достаточно простого набора команд в едином файле, чтобы быстро его запустить и выполнить небольшой набор действий. Только в Task нет никаких модулей, только cmds.
#devops #script #docker
Сама программа это просто одиночный бинарник, который можно установить кучей способов, описанных в документации. Его даже в винде можно установить через winget.
Создаём файл с задачами Taskfile.yml:
version: "3"tasks: default: desc: Run all tasks cmds: - task: task01 - task: task02 task01: desc: Task 01 cmds: - echo "Task 01" task02: desc: Task 02 cmds: - echo "Task 02"Сохраняем и запускаем. Для начала посмотрим список задач:
# task --listtask: Available tasks for this project:* default: Run all tasks* task01: Task 01* task02: Task 02Запустим первую задачу:
# task task01task: [task01] echo "Task 01"Или сразу обе, запустив task без параметров. Запустится задача default, которую мы описали в самом начале:
# tasktask: [task01] echo "Task 01"Task 01task: [task02] echo "Task 02"Task 02Идею, думаю, вы поняли. Это более простая и лёгкая в освоении замена утилиты make, которая используется в основном для сбора софта из исходников.
Первое, что приходит в голову, где утилита task может быть полезна, помимо непосредственно сборки из исходников, как замена make — сборка docker образов. Если у вас длинный RUN, который неудобно читать, поддерживать и отлаживать из-за его размера, то его можно заменить одной задачей с task. Это позволит упростить написание и поддержку, а также избавить от необходимости разбивать этот RUN на несколько частей, что порождает создание дополнительных слоёв.
Вместо того, чтобы описывать все свои действия в длиннющем RUN, оформите все свои шаги через task и запустите в RUN только его. Примерно так:
COPY --from=bins /usr/bin/task /usr/local/bin/taskCOPY tasks/Taskfile.yaml ./Taskfile.yamlRUN taskСкопировали бинарник + yaml с задачами и запустили их. А там они могут быть красиво оформлены по шагам. Писать и отлаживать эти задачи будет проще, чем сразу в Dockerfile. Для task написано расширение в Visual Studio Code.
Task поддерживает:
◽переходы по директориям
◽зависимости задач
◽импорт в Taskfile из другого Taskfile
◽динамические переменные
◽особенности OS, можно явно указать Taskfile_linux.yml или Taskfile_windows.yml
и многое другое. Всё это описано в документации.
Я немного поразбирался с Task. Он мне показался более простой заменой одиночных сценариев для ansible. Это когда вам не нужен полноценный playbook, а достаточно простого набора команд в едином файле, чтобы быстро его запустить и выполнить небольшой набор действий. Только в Task нет никаких модулей, только cmds.
#devops #script #docker
{kind=link}
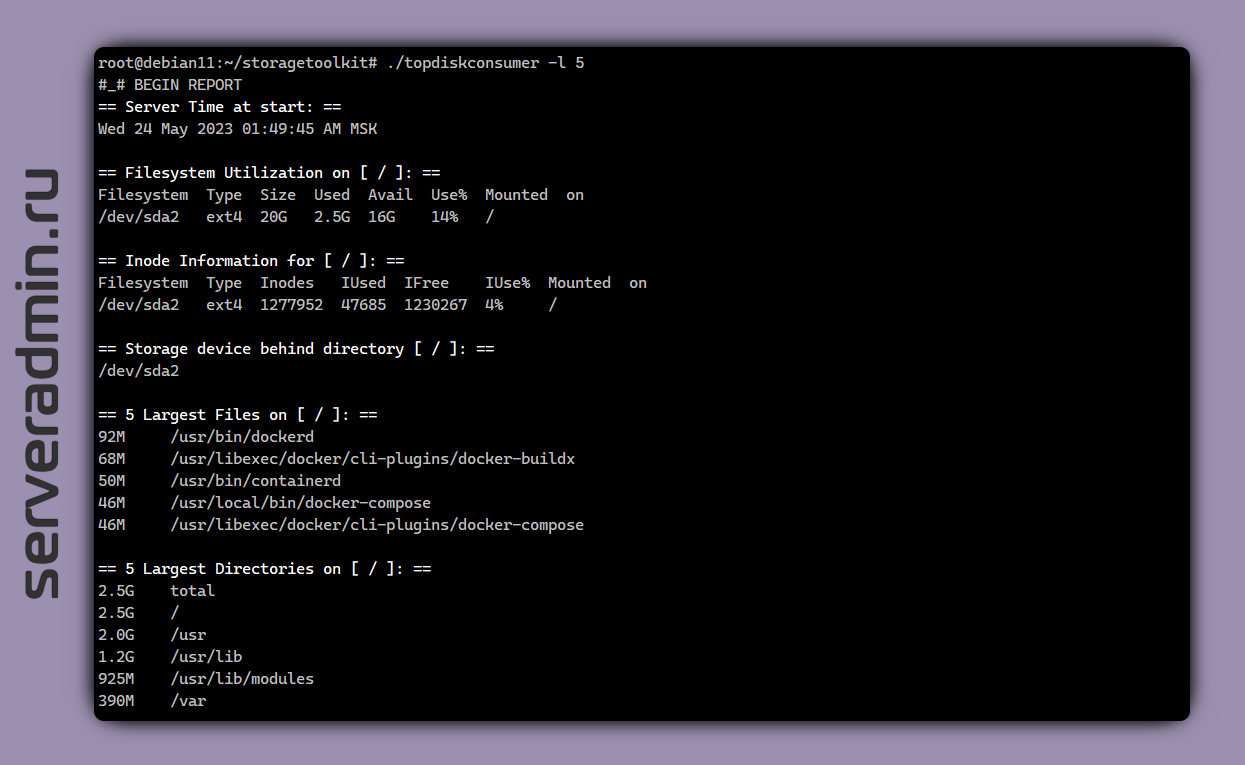
Предлагаю вам сохранить в закладки простой и удобный скрипт для Linux, который поможет быстро разобраться на сервере, кто и чем занял свободное место — topdiskconsumer. Единственный файл в репозитории, кроме README и есть этот скрипт.
Скрипт автоматически определяет mount point, с которого он запущен. Далее идёт в корень диска и вычисляет top:
▪ 20 самых больших файлов
▪ 20 самых объёмных директорий
▪ 20 самых больших файлов, старше 30-ти дней
▪ 20 самых больших удалённых файлов с незакрытыми handles (удалёнными, но реально всё ещё занимающими место, потому что дескриптор не закрыт)
При этом скрипт ничего не ставит и не использует сторонний софт. Всё реализовано через привычный функционал системы. Например, топ 20 директорий вычисляет вот такая конструкция:
Топ 20 файлов:
Топ 20 старых файлов:
Для удалённых файлов длинная конструкция с использованием lsof. Не буду всю её приводить, можете сами в скрипте посмотреть функцию fnLargestUnlinked.
Размер топа задаётся переменной intNumFiles в самом начале скрипта. Можете изменить при желании на любое другое число. Оно же указывается, если запустить скрипт с ключом
Там много всего полезного.
Скрипт очень понравился, сразу сохранил себе в коллекцию. Когда куда-то утекло место на сервере, поможет быстро оценить обстановку, не вспоминая все эти команды самостоятельно. Я их в разное время и в разных публикациях уже приводил здесь. Причём все, что используются. А тут всё в одном месте собрали.
#script #bash
Скрипт автоматически определяет mount point, с которого он запущен. Далее идёт в корень диска и вычисляет top:
▪ 20 самых больших файлов
▪ 20 самых объёмных директорий
▪ 20 самых больших файлов, старше 30-ти дней
▪ 20 самых больших удалённых файлов с незакрытыми handles (удалёнными, но реально всё ещё занимающими место, потому что дескриптор не закрыт)
При этом скрипт ничего не ставит и не использует сторонний софт. Всё реализовано через привычный функционал системы. Например, топ 20 директорий вычисляет вот такая конструкция:
# du -hcx --max-depth=6 / 2>/dev/null | sort -rh | head -n 20Топ 20 файлов:
# find / -mount -ignore_readdir_race -type f -exec du -h "{}" + 2>&1 \| sort -rh | head -n 20Топ 20 старых файлов:
# find / -mount -ignore_readdir_race -type f -mtime +30 -exec du -h "{}" + 2>&1 \| sort -rh | head -20Для удалённых файлов длинная конструкция с использованием lsof. Не буду всю её приводить, можете сами в скрипте посмотреть функцию fnLargestUnlinked.
Размер топа задаётся переменной intNumFiles в самом начале скрипта. Можете изменить при желании на любое другое число. Оно же указывается, если запустить скрипт с ключом
-l. Описание всех возможностей можно посмотреть вот так:# ./topdiskconsumer --helpТам много всего полезного.
Скрипт очень понравился, сразу сохранил себе в коллекцию. Когда куда-то утекло место на сервере, поможет быстро оценить обстановку, не вспоминая все эти команды самостоятельно. Я их в разное время и в разных публикациях уже приводил здесь. Причём все, что используются. А тут всё в одном месте собрали.
#script #bash
{kind=link}
Буквально на днях узнал, что в bash квадратная скобка [ и утилита test это одно и то же. Точнее, я вообще не знал, что существует эта встроенная утилита. Всегда и везде в скриптах видел и сам использовал именно скобку.
Синтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
Сделаем проверку, что он существует, как я обычно это делаю:
А теперь то же самое, только через test:
Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
# type testtest is a shell builtin# type [[ is a shell builtinСинтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
# touch file.txtСделаем проверку, что он существует, как я обычно это делаю:
#!/bin/bashif [ -e file.txt]then echo "File exist"else echo "There is no testfile"А теперь то же самое, только через test:
#!/bin/bashif test -e file.txtthen echo "File exist"else echo "There is no testfile"Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
Хочу дать пару простых советов, которые не все знают и используют, но они могут сильно упростить жизнь при работе со стандартными утилитами Unix в консоли.
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
Тут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
Получится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
В этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
А если c $, получим то, что надо:
Можно совместить:
А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
#bash #script
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
# grep -E -v '^#' nginx.confТут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
# grep -E -v '^ #' nginx.confПолучится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
# ls | grep ^errorerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngВ этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
# ls | grep .pngerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngА если c $, получим то, что надо:
# ls | grep .png$error-windows-10-share-110x75.pngerror-windows-10-share-150x150.pngМожно совместить:
# ls | grep ^error | grep png$А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
# grep -E -v '^#|^$' nginx.conf#bash #script
{kind=link}
Провёл небольшое исследование на тему того, чем в консоли bash быстрее всего удалить большое количество директорий и файлов. Думаю, не все знают, что очень много файлов могут стать большой проблемой. Пока с этим не столкнёшься, не думаешь об этом. Если у тебя сервер бэкапов на обычных дисках и надо удалить миллионы файлов, это может оказаться непростой задачей.
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
И последняя команда, ради которой всё затевалось:
Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
Создаю 500 000 файлов в цикле по 50 000 с помощью
и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
Для второго теста сделал такой скрипт:
Создаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
# rm -r test/# rm -r test/*# find test/ -type f -delete# cd test/ ; ls . | xargs -n 100 rm #только для файлов работаетИ последняя команда, ради которой всё затевалось:
# rsync -a --delete empty/ test/Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
#!/bin/bashmkdir testcount=1while test $count -le 10do touch test/file$count-{000..50000}count=$(( $count + 1 ))donels test | wc -lСоздаю 500 000 файлов в цикле по 50 000 с помощью
touch. Больше за раз не получается создать, touch ругается на слишком большой список аргументов. После этого запускаю приведённые выше команды с подсчётом времени их выполнения с помощью time:# time rm -r test/и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
rm -r test/* в какой-то момент перестанет работать и будет ругаться на большое количество аргументов.Для второго теста сделал такой скрипт:
#!/bin/bashcount=1while test $count -le 10do mkdir -p test/dir$count-{000..500}touch test/dir$count-{000..500}/file-{000..100}count=$(( $count + 1 ))donefind test/ | wc -lСоздаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync
Linux всегда меня восхищал и радовал простыми решениями по возможностям работы с текстовыми файлами через командную строку. Слово простые можно было бы взять в кавычки, так как в реальности не просто изучить синтаксис подходящих консольных утилит. Но никто не мешает найти готовое выражение и использовать его. В Windows чаще всего можно решить эти же задачи с помощью своих программ, но обычно это занимает больше времени.
Самый простой пример того, о чём я говорю — автоматическая замена определённого текста в заданных файлах. Мне лично чаще всего это нужно, когда что-то делаешь с исходниками сайтов. Помню, как свои первые сайты делал более 20-ти лет назад на чистом html в Dreamweaver. При этом страниц там было сотни. Обновлял вручную копипастом. Это было тяжело, но в то время большинство сайтов были статичными, так как бесплатных хостингов на php не существовало. Но это я отвлёкся, заметка планируется про другое.
Допустим, у вас есть какой-то большой сайт на php и вам надо во всех файлах заменить устаревшую функцию на новую. В общем случае замену текста можно сделать с помощью sed, примерно так:
Или посложнее пример с вырезанием вредоносного куска кода из всех файлов, которые заразил какой-то вирус. Допустим, это некий код следующего содержания:
Текста между тэгами script может быть много, поэтому искать проще всего по этому тэгу и началу строки с function aeaab19d(a).
Тут я использую ключ -r для поддержки регулярных выражений, конкретно
Можно ещё усложнить и выполнить замену кода между каких-то строк. Для усложнения возьмём какой-нибудь XML:
Заменим user01 на user02
Тут важны круглые скобки и \1 и \2. Мы в первой части выражения запомнили текст в круглых скобках, а во второй части его использовали — сначала первую скобку, потом вторую.
Это были примеры для одиночных файлов, а теперь добавляем сюда find и используем sed на любом наборе файлов, который найдёт find.
Добавляем к sed ключ -i для того, чтобы он сразу изменял файл. Кстати, для find наиболее популярные примеры можете посмотреть через тэг #find.
Очень аккуратно выполняйте массовые действия. Сначала всё отладьте на тестовых файлах. Потом сделайте бэкап исходных файлов. И только потом выполняйте массовые изменения. И будьте готовы быстро всё откатить обратно.
Примеры рекомендую записать. Если надо быстро что-то сделать, то сходу правильно регулярку вы так просто не наберёте. К тому же в таком использовании есть свои нюансы. К примеру, я так и не смог победить команду sed, которая удаляет весь код <script>, если внутри есть переход на новую строку. Вроде бы легко найти, как заставить
Не забывайте про сервисы, которые помогают отлаживать регулярки. Собрал их в отдельной заметке.
#linux #bash #script
Самый простой пример того, о чём я говорю — автоматическая замена определённого текста в заданных файлах. Мне лично чаще всего это нужно, когда что-то делаешь с исходниками сайтов. Помню, как свои первые сайты делал более 20-ти лет назад на чистом html в Dreamweaver. При этом страниц там было сотни. Обновлял вручную копипастом. Это было тяжело, но в то время большинство сайтов были статичными, так как бесплатных хостингов на php не существовало. Но это я отвлёкся, заметка планируется про другое.
Допустим, у вас есть какой-то большой сайт на php и вам надо во всех файлах заменить устаревшую функцию на новую. В общем случае замену текста можно сделать с помощью sed, примерно так:
# sed 's/old_function/new_function/g' oldfilename > newfilenameИли посложнее пример с вырезанием вредоносного куска кода из всех файлов, которые заразил какой-то вирус. Допустим, это некий код следующего содержания:
<script>function aeaab19d(a)...................</script>Текста между тэгами script может быть много, поэтому искать проще всего по этому тэгу и началу строки с function aeaab19d(a).
# sed -r 's/<script>function aeaab19d\(a\).*?<\/script>//' test.phpТут я использую ключ -r для поддержки регулярных выражений, конкретно
.*?. Можно ещё усложнить и выполнить замену кода между каких-то строк. Для усложнения возьмём какой-нибудь XML:
<username><![CDATA[user01]]></username><password><![CDATA[password01]]></password><dbname><![CDATA[database]]></dbname>Заменим user01 на user02
# sed -r 's/(<username>.+)user01(.+<\/username>)/\1user02\2/' test.xmlТут важны круглые скобки и \1 и \2. Мы в первой части выражения запомнили текст в круглых скобках, а во второй части его использовали — сначала первую скобку, потом вторую.
Это были примеры для одиночных файлов, а теперь добавляем сюда find и используем sed на любом наборе файлов, который найдёт find.
# find /var/www/ -type f -name \*.php -exec \sed -i -r 's/<script>function aeaab19d\(a\).*?<\/script>//' {} \;Добавляем к sed ключ -i для того, чтобы он сразу изменял файл. Кстати, для find наиболее популярные примеры можете посмотреть через тэг #find.
Очень аккуратно выполняйте массовые действия. Сначала всё отладьте на тестовых файлах. Потом сделайте бэкап исходных файлов. И только потом выполняйте массовые изменения. И будьте готовы быстро всё откатить обратно.
Примеры рекомендую записать. Если надо быстро что-то сделать, то сходу правильно регулярку вы так просто не наберёте. К тому же в таком использовании есть свои нюансы. К примеру, я так и не смог победить команду sed, которая удаляет весь код <script>, если внутри есть переход на новую строку. Вроде бы легко найти, как заставить
. в регулярках учитывать и переход на новую строку, но на практике у меня это не получилось сделать. Я не понял, как правильно составить выражение для sed. Не забывайте про сервисы, которые помогают отлаживать регулярки. Собрал их в отдельной заметке.
#linux #bash #script
{kind=link}
Рекомендую очень полезный скрипт для Mysql, который помогает настраивать параметры сервера в зависимости от имеющейся памяти. Я уже неоднократно писал в заметках примерный алгоритм действий для этого. Подробности можно посмотреть в статье про настройку сервера под Битрикс в разделе про Mysql. Можно вот эту заметку посмотреть, где я частично эту же тему поднимаю.
Скрипт простой в плане функциональности, так как только парсит внутреннюю статистику Mysql и выводит те параметры, что больше всего нужны для оптимизации потребления памяти. Но сделано аккуратно и удобно. Сразу показывает, сколько памяти потребляет каждое соединение.
Причём автор поддерживает этот скрипт. Я в апреле на одном из серверов заметил, что он даёт ошибку деления на ноль. Не стал разбираться, в чём там проблема. А сейчас зашёл и вижу, что автор внёс исправление как раз по этой части. Похоже, какое-то обновление Mysql сломало работу.
Вот прямая ссылка на код: mysql-stat.sh. Результат работы на картинке ниже. Добавить к нему нечего. Использовать так:
Не забудьте поставить пробел перед командой, чтобы она вместе с паролем не залетела в history. Либо почистите её после работы скрипта, так как пробел не всегда работает. Зависит от настроек. Это при условии, что у вас парольное подключение к MySQL.
#bash #script #mysql
Скрипт простой в плане функциональности, так как только парсит внутреннюю статистику Mysql и выводит те параметры, что больше всего нужны для оптимизации потребления памяти. Но сделано аккуратно и удобно. Сразу показывает, сколько памяти потребляет каждое соединение.
Причём автор поддерживает этот скрипт. Я в апреле на одном из серверов заметил, что он даёт ошибку деления на ноль. Не стал разбираться, в чём там проблема. А сейчас зашёл и вижу, что автор внёс исправление как раз по этой части. Похоже, какое-то обновление Mysql сломало работу.
Вот прямая ссылка на код: mysql-stat.sh. Результат работы на картинке ниже. Добавить к нему нечего. Использовать так:
# ./mysql-stat.sh --user root --password "superpass"Не забудьте поставить пробел перед командой, чтобы она вместе с паролем не залетела в history. Либо почистите её после работы скрипта, так как пробел не всегда работает. Зависит от настроек. Это при условии, что у вас парольное подключение к MySQL.
#bash #script #mysql
{kind=link}
Смотрите, какая интересная коллекция приёмов на bash для выполнения различных обработок строк, массивов, файлов и т.д.:
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
Использовать следующим образом:
Примерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
Используем для примера:
Понятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
pure bash bible
⇨ https://github.com/dylanaraps/pure-bash-bible
Вообще не видел раньше, чтобы кто-то подобным заморачивался. Тут смысл в том, что все преобразования производятся на чистом bash, без каких-то внешних утилит, типа sed, awk, grep или языка программирования perl. То есть нет никаких внешних зависимостей.
Покажу на паре примеров, как этой библиотекой пользоваться. Там всё реализовано через функции bash. Возьмём что-то простое. Например, перевод текста в нижний регистр. Видим в библиотеке функцию:
lower() { printf '%s\n' "${1,,}"}Чтобы её использовать в скрипте, необходимо его создать примерно такого содержания:
#!/bin/bashlower() { printf '%s\n' "${1,,}"}lower "$1"Использовать следующим образом:
# ./lower.sh HELLOhelloПримерно таким образом можно работать с этой коллекцией. Возьмём более сложный и прикладной пример. Вычленим из полного пути файла только его имя. Мне такое в скриптах очень часто приходится делать.
#!/bin/bashbasename() { local tmp tmp=${1%"${1##*[!/]}"} tmp=${tmp##*/} tmp=${tmp%"${2/"$tmp"}"} printf '%s\n' "${tmp:-/}"}Используем для примера:
# ./basename.sh /var/log/syslog.2.gzsyslog.2.gzПонятное дело, что пример синтетический, для демонстрации работы. Вам скорее всего понадобится вычленять имя файла в большом скрипте для дальнейшего использования, а не выводить его имя в консоль.
Более того, чаще всего в большинстве дистрибутивов Unix будут отдельные утилиты
basename и dirname для вычленения имени файла или пути директории, в котором лежит файл. Но это будут внешние зависимости к отдельным бинарникам, а не код на bash.Этот репозиторий настоящая находка для меня. Мало того, что тут в принципе очень много всего полезного. Так ещё и реализация на чистом bash. Плохо только то, что я тут практически не понимаю, что происходит и как реализовано. С применением утилит мне проще разобраться. Так что тут только брать сразу всю функцию, без попытки изменить или написать свою.
#bash #script
{kind=link}
Если вам нужно заблокировать какую-то страну, чтобы ограничить доступ к вашим сервисам, например, с помощью iptables или nginx, потребуется список IP адресов по странам.
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
Тут я создаю список IP адресов для ipset, а потом использую его в iptables:
Если в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
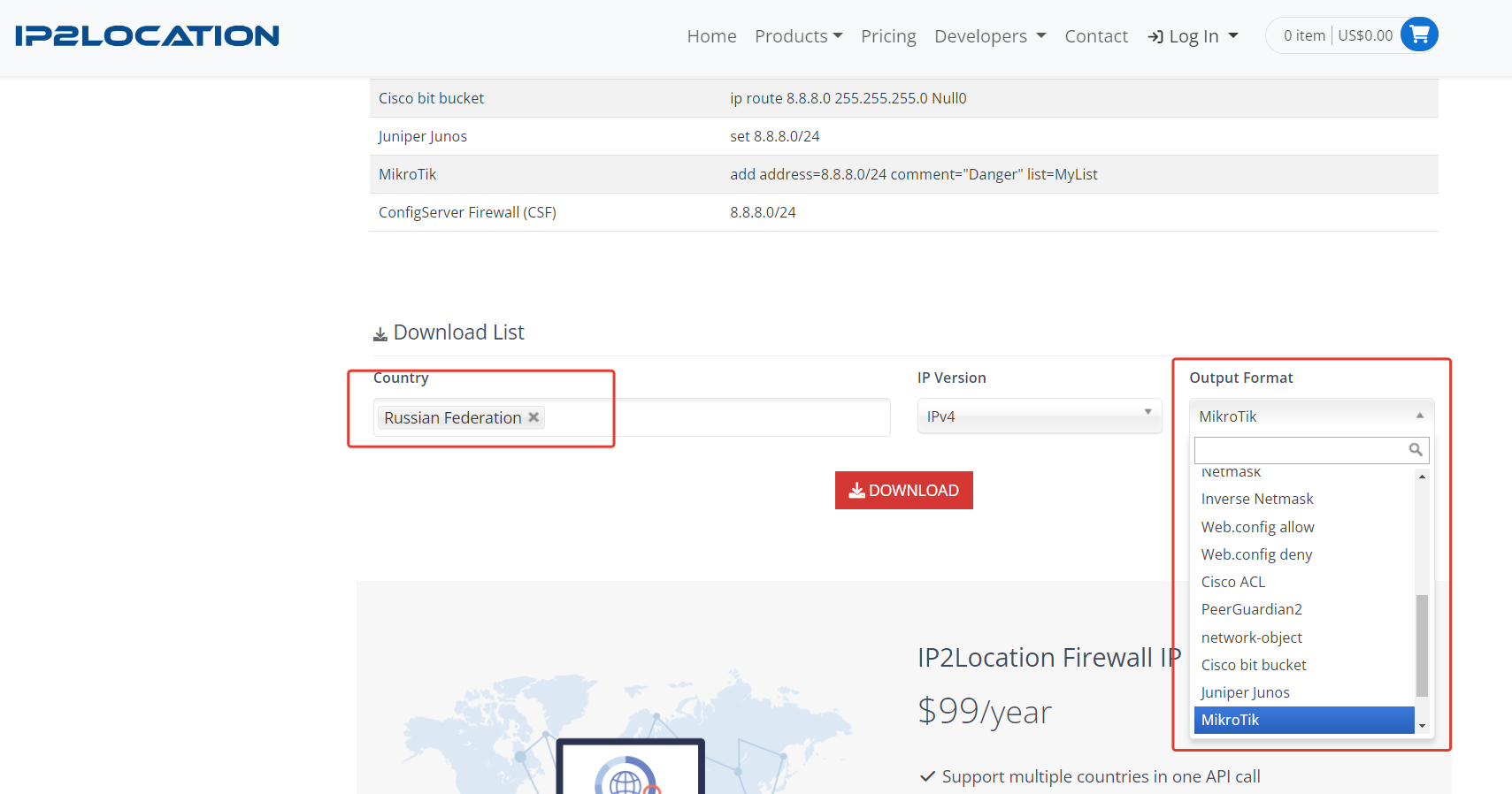
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
Я сам всегда использую вот эти списки:
⇨ https://www.ipdeny.com/ipblocks
Конкретно в скриптах забираю их по урлам. Например, для России:
⇨ https://www.ipdeny.com/ipblocks/data/countries/ru.zone
Это удобно, потому что списки уже готовы к использованию — одна строка, одно значение. Можно удобно интегрировать в скрипты. Например, вот так:
#!/bin/bash# Удаляем список, если он уже естьipset -X whitelist# Создаем новый списокipset -N whitelist nethash# Скачиваем файлы тех стран, что нас интересуют и сразу объединяем в единый списокwget -O netwhite http://www.ipdeny.com/ipblocks/data/countries/{ru,ua,kz,by,uz,md,kg,de,am,az,ge,ee,tj,lv}.zoneecho -n "Загружаем белый список в IPSET..."# Читаем список сетей и построчно добавляем в ipsetlist=$(cat netwhite)for ipnet in $list do ipset -A whitelist $ipnet doneecho "Завершено"# Выгружаем созданный список в файл для проверки составаipset -L whitelist > w-exportТут я создаю список IP адресов для ipset, а потом использую его в iptables:
iptables -A INPUT -i $WAN -m set --match-set whitenet src -p tcp --dport 80 -j ACCEPTЕсли в списке адресов более 1-2 тысяч значений, использовать ipset обязательно. Iptables начнёт отжирать очень много памяти, если загружать огромные списки в него напрямую.
Есть ещё вот такой сервис:
⇨ https://www.ip2location.com/free/visitor-blocker
Там можно сразу конфиг получить для конкретного сервиса: Apache, Nginx, правил Iptables и других. Даже правила в формате Mikrotik есть.
☝ Ссылки рекомендую в закладки забрать.
#iptables #nginx #security #script
{kind=link}
Хочу предложить вашему вниманию bash скрипт по проверке статуса работы Nginx. Обращаю внимание именно на него, потому что он классно написан и его можно взять за основу для любой похожей задачи. Сейчас подробно расскажу, что там происходит.
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
{kind=link}
Делюсь с вами очень классным скриптом для Linux, с помощью которого можно быстро и в удобном виде посмотреть использование оперативной памяти программами (не процессами!). Я изначально нашёл только скрипт на Python и использовал его, а потом понял, что этот же скрипт есть и в стандартных репозиториях некоторых дистрибутивов.
Например в Centos или форках RHEL:
В deb дистрибутивах нет, но можно поставить через pip:
Либо просто скопировать исходный код на Python:
https://github.com/pixelb/ps_mem/blob/master/ps_mem.py
и запустить:
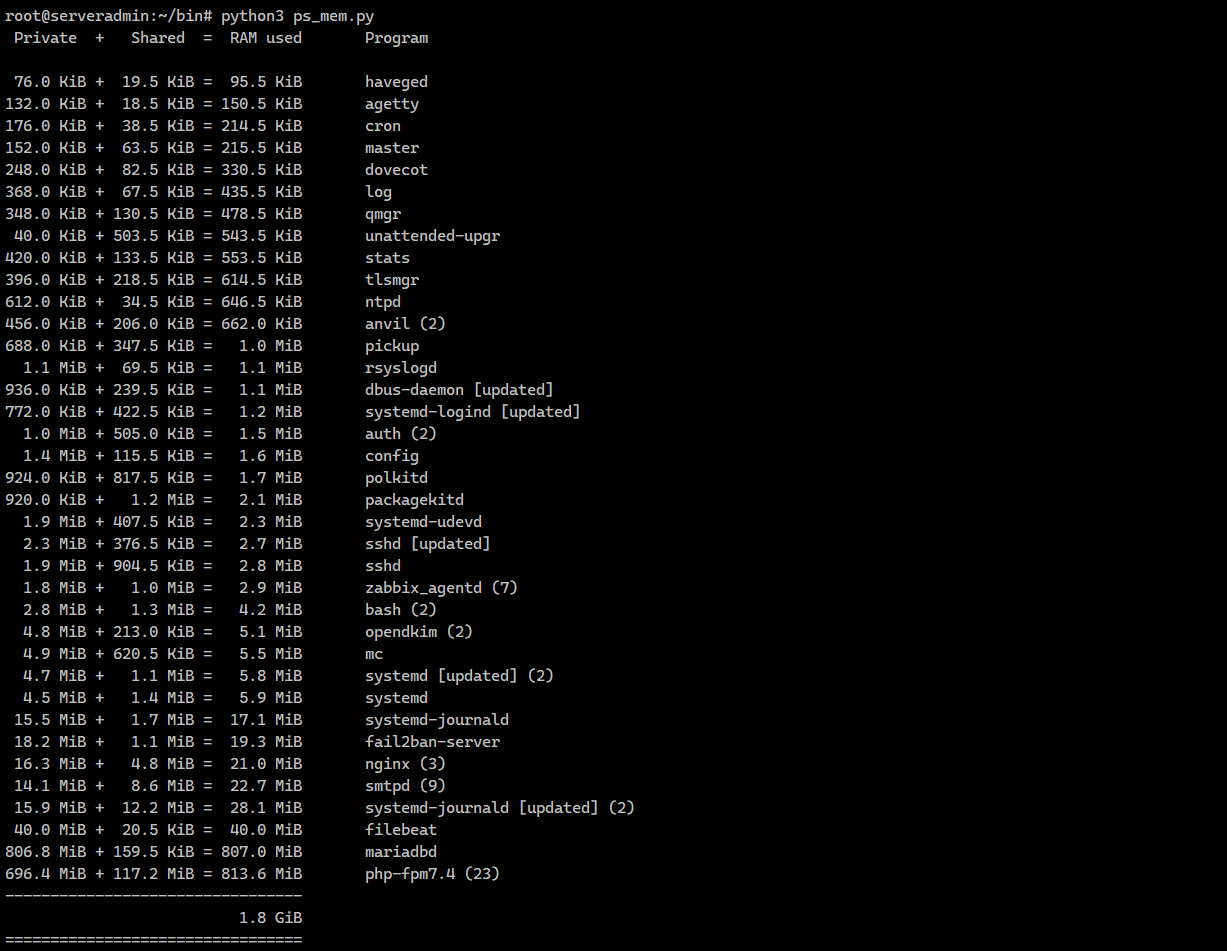
Увидите примерно такой список. Я не разобрался, как конкретно этот скрипт считает потребление памяти. Сам автор пишет:
In detail it reports: sum(private RAM for program processes) + sum(Shared RAM for program processes). The shared RAM is problematic to calculate, and this script automatically selects the most accurate method available for your kernel.
Если взять, к примеру, один из предыдущих вариантов, который я предлагал для подсчёта памяти программы и всех её процессов:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
То разница в результатах для программ, которые порождают множество подпроцессов, будет существенная. В принципе, это логично, потому что реально потребляемая память будет меньше, чем сумма RSS всех процессов программы. Для одиночных процессов данные совпадают.
У меня была заметка про потребление памяти в Linux: https://t.me/srv_admin/2859
Там рассказано, как вручную с помощью pmap разобраться в потреблении памяти программами в Linux. Я вручную проверил все процессы Nginx и сравнил с результатом скрипта ps_mem. Результаты не совпадали полностью, но были близки. Так что этот скрипт выдаёт хорошую информацию.
Я себе сохранил скрипт к себе в коллекцию.
#linux #script
Например в Centos или форках RHEL:
# yum/dnf install ps_memВ deb дистрибутивах нет, но можно поставить через pip:
# pip install ps_memЛибо просто скопировать исходный код на Python:
https://github.com/pixelb/ps_mem/blob/master/ps_mem.py
и запустить:
# python3 ps_mem.py Private + Shared = RAM used Program 18.2 MiB + 1.1 MiB = 19.2 MiB fail2ban-server 16.3 MiB + 4.7 MiB = 21.0 MiB nginx (3) 17.5 MiB + 5.5 MiB = 23.0 MiB smtpd (11) 15.5 MiB + 10.3 MiB = 25.8 MiB systemd-journald [updated] (2) 39.2 MiB + 18.5 KiB = 39.2 MiB filebeat806.8 MiB + 145.5 KiB = 806.9 MiB mariadbd709.4 MiB + 120.2 MiB = 829.5 MiB php-fpm7.4 (23)Увидите примерно такой список. Я не разобрался, как конкретно этот скрипт считает потребление памяти. Сам автор пишет:
In detail it reports: sum(private RAM for program processes) + sum(Shared RAM for program processes). The shared RAM is problematic to calculate, and this script automatically selects the most accurate method available for your kernel.
Если взять, к примеру, один из предыдущих вариантов, который я предлагал для подсчёта памяти программы и всех её процессов:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
То разница в результатах для программ, которые порождают множество подпроцессов, будет существенная. В принципе, это логично, потому что реально потребляемая память будет меньше, чем сумма RSS всех процессов программы. Для одиночных процессов данные совпадают.
У меня была заметка про потребление памяти в Linux: https://t.me/srv_admin/2859
Там рассказано, как вручную с помощью pmap разобраться в потреблении памяти программами в Linux. Я вручную проверил все процессы Nginx и сравнил с результатом скрипта ps_mem. Результаты не совпадали полностью, но были близки. Так что этот скрипт выдаёт хорошую информацию.
Я себе сохранил скрипт к себе в коллекцию.
#linux #script
{kind=link}
Смотрите, какая прикольна штука есть для подключения по SSH из консоли - sshto. Это небольшой bash скрипт, который позволяет через псевдографическое меню управлять преднастроенными SSH подключениями. Хорошее решение для самодельного jumphost.
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
Ставим sshto:
Запускаем:
Видим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
~/.ssh/config и выводит список серверов оттуда в псевдографическое меню. Вот пример такого файла:#Host DUMMY #Moscow#Host server-number-one #First ServerHostName 1.2.3.4port 22777user rootHost server-number-two #Second serverHostName 4.3.2.1port 22888user username#Host DUMMY #Saint Petersburg#Host server-number-three #Third serverHostName 5.6.7.8port 22user user01Host server-number-four #Fourth serverHostName 9.8.7.6port 22user user02Ставим sshto:
# git clone https://github.com/vaniacer/sshto# cd sshto/# cp sshto /usr/bin/Запускаем:
# sshtoВидим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
{kind=link}
Хочу напомнить про 2 очень полезные утилиты Linux, с помощью которых удобно в скриптах делать проверки наличия подключенных и примонтированных блочных устройств и файловых систем. Речь пойдёт про findmnt и findfs.
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
А если в чём-то ошибётесь, то получите ошибку:
Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
Если файловая система не будет найдена, код будет 1:
Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
Вместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
Проверяем:
Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
-x ещё и позволяет проверить отредактированный файл fstab на наличие в нём ошибок. Рекомендую запомнить эту возможность и использовать:# findmnt -xSuccess, no errors or warnings detectedА если в чём-то ошибётесь, то получите ошибку:
# findmnt -x/mnt/backup [E] unreachable on boot required source: UUID=151ea24d-977a-412c-818f-0d374baa5012Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5013"/dev/sda2Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
# echo $?0Если файловая система не будет найдена, код будет 1:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5012"findfs: unable to resolve 'UUID=151ea24d-977a-412c-818f-0d374baa5012'# echo $?1Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
if findfs "UUID=$1" >/dev/null; then echo "$1 connected."elseecho "$1 not connected."fiВместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
# ./check-fs.sh 151ea24d-977a-412c-818f-0d374baa5013151ea24d-977a-412c-818f-0d374baa5013 connected.И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
if findmnt -rno TARGET "$1" >/dev/null; then echo "$1 mounted."elseecho "$1 not mounted."fiПроверяем:
# ./check-mnt.sh /mnt/extbackup/mnt/extbackup not mounted.Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
Кажется, я ни разу не упоминал про простой и быстрый способ отладки bash скрипта. Для этого достаточно в самое начало написать:
В этом случай bash начнёт выводить в консоль каждую команду, которую он выполняет. Успешно выполненная команда помечается плюсом в начале строки. Не сказать, что это прям очень сильно помогает отладить, если есть ошибка, но в целом проще и удобнее. Особенно если скрипт большой, с условиями, вычислением переменных и т.д. Вы всё будете видеть на каждом этапе.
Покажу как это работает на простом скрипте по добавлению swap в систему:
Запускаем скрипт:
Благодаря
Когда не знал про
#bash #script
set -xВ этом случай bash начнёт выводить в консоль каждую команду, которую он выполняет. Успешно выполненная команда помечается плюсом в начале строки. Не сказать, что это прям очень сильно помогает отладить, если есть ошибка, но в целом проще и удобнее. Особенно если скрипт большой, с условиями, вычислением переменных и т.д. Вы всё будете видеть на каждом этапе.
Покажу как это работает на простом скрипте по добавлению swap в систему:
#!/bin/bashset -xread -p 'Enter swap size in megabytes: ' size_mbsize_kb=$((1024*${size_mb}))dd if=/dev/zero of=/swap bs=1024 count=${size_kb}chmod 0600 /swapmkswap /swapswapon /swapif [ "$(grep '/swap' /etc/fstab)" ]; then echo "Error: file /etc/fstab already has 'Swap' record"else echo "Add Swap record to /etc/fstab" echo -e '\n/swap swap swap defaults 0 0' >> /etc/fstabfiswapon --showЗапускаем скрипт:
# ./script.sh + read -p 'Enter swap size in megabytes: ' size_mbEnter swap size in megabytes: 512+ size_kb=524288+ dd if=/dev/zero of=/swap bs=1024 count=524288524288+0 records in524288+0 records out536870912 bytes (537 MB, 512 MiB) copied, 1.26859 s, 423 MB/s+ chmod 0600 /swap+ mkswap /swapSetting up swapspace version 1, size = 512 MiB (536866816 bytes)no label, UUID=e873faad-881e-4df0-b25f-23580b952738+ swapon /swap++ grep /swap /etc/fstab+ '[' '' ']'+ echo 'Add Swap record to /etc/fstab'Add Swap record to /etc/fstab+ echo -e '\n/swap swap swap defaults 0 0'+ swapon --showNAME TYPE SIZE USED PRIO/swap file 512M 0B -2Благодаря
set -x мы видим каждое действие, которое выполняет скрипт. Оно начинается с +, а дальше виден стандартный вывод после этого действия. Так разбирать работу скрипта проще, потому что в командах видны все переменные. В этом примере это не очень актуально, а когда они будут неявно указаны, а вычисляемые, то это может сильно помочь. Когда не знал про
set -x, выводил нужные мне переменные в разных местах скрипта с помощью echo во время отладки, чтобы понимать, что там происходит после каждой команды. Но этот путь намного проще.#bash #script
{kind=link}
Почти во всех популярных дистрибутивах Linux в составе присутствует утилита vmstat. С её помощью можно узнать подробную информацию по использованию оперативной памяти, cpu и дисках. Лично я её не люблю, потому что вывод неинформативен. Утилита больше для какой-то глубокой диагностики или мониторинга, нежели простого использования в консоли.
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
Как можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
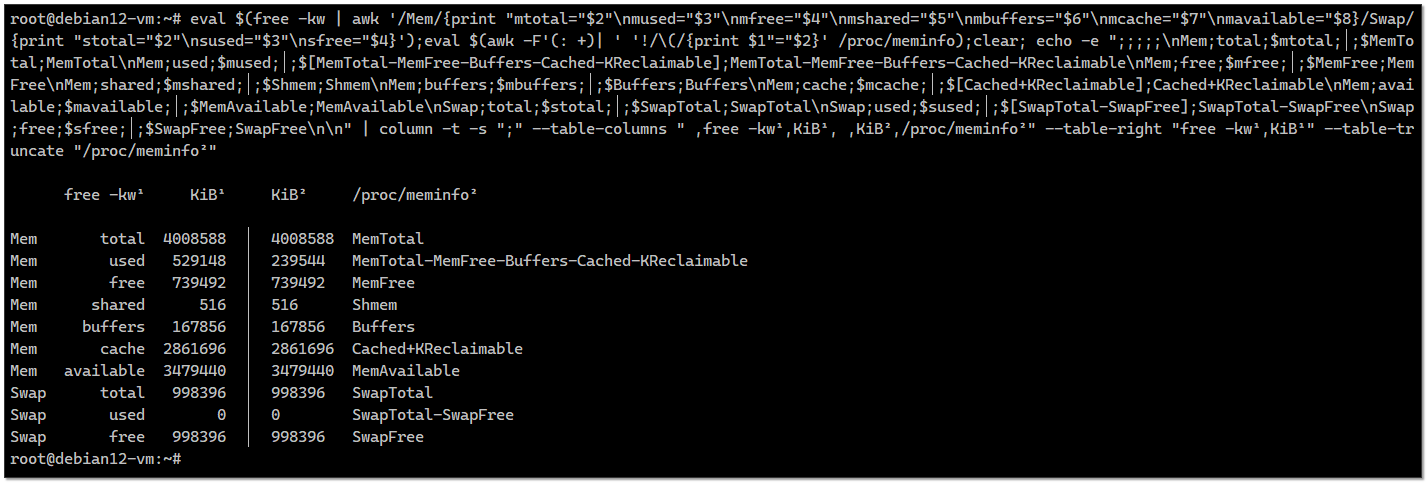
А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
# vmstat 1 -w -S MКак можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
man vmstat они подробно описаны, так что с интерпретацией проблем не должно возникать.А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
free и cat /proc/meminfo: # eval $(free -kw | awk '/Mem/{print "mtotal="$2"\nmused="$3"\nmfree="$4"\nmshared="$5"\nmbuffers="$6"\nmcache="$7"\nmavailable="$8}/Swap/{print "stotal="$2"\nsused="$3"\nsfree="$4}');eval $(awk -F'(: +)| ' '!/\(/{print $1"="$2}' /proc/meminfo);clear; echo -e ";;;;;\nMem;total;$mtotal;│;$MemTotal;MemTotal\nMem;used;$mused;│;$[MemTotal-MemFree-Buffers-Cached-KReclaimable];MemTotal-MemFree-Buffers-Cached-KReclaimable\nMem;free;$mfree;│;$MemFree;MemFree\nMem;shared;$mshared;│;$Shmem;Shmem\nMem;buffers;$mbuffers;│;$Buffers;Buffers\nMem;cache;$mcache;│;$[Cached+KReclaimable];Cached+KReclaimable\nMem;available;$mavailable;│;$MemAvailable;MemAvailable\nSwap;total;$stotal;│;$SwapTotal;SwapTotal\nSwap;used;$sused;│;$[SwapTotal-SwapFree];SwapTotal-SwapFree\nSwap;free;$sfree;│;$SwapFree;SwapFree\n\n" | column -t -s ";" --table-columns " ,free -kw¹,KiB¹, ,KiB²,/proc/meminfo²" --table-right "free -kw¹,KiB¹" --table-truncate "/proc/meminfo²"Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
{kind=link}
Если вам необходимо кому-то передать свой bash скрипт, но при этом вы не хотите, чтобы этот кто-то видел его содержимое, то есть простое решение. С помощью утилиты shc его можно транслировать в язык C и скомпилировать. На выходе будет обычный бинарник, который будет успешно работать практически на любой ОС Linux.
Это может быть актуально, если вы делаете кому-то что-то на заказ и надо продемонстрировать работоспособность решения. Если сразу отдать скрипт, то недобросовестные заказчики могут не заплатить, так как всё решение это и есть текст скрипта. Возможно, вы просто захотите от кого-то скрыть чувствительные данные или идею реализации той или иной функциональности.
Shc живёт в базовых репозиториях Debian или Ubuntu, возможно и в других дистрибутивах. Для сборки также понадобится пакет gcc.
Пользоваться ей очень просто. Покажу на примере небольшого скрипта с вводом переменной в консоли.
Запускаем:
Теперь компилируем его в бинарник:
На выходе получаем два файла:
- script.sh.x - бинарник
- script.sh.x.c - исходный код
Запускаем бинарь:
Отработал точно так же, как и bash скрипт. С помощью shc можно указать дату, после которой скрипт запускаться не будет. Выглядит это примерно так:
Я подозреваю, что прятать какие-то важные пароли таким образом опасно. Наверняка есть способ, чтобы его вытащить оттуда. Мне даже кажется, что это и не слишком сложно. В памяти то всё равно содержимое будет в каком-то виде отображаться. Можно сдампить память в момент запуска и посмотреть.
Быстро поискал и нашёл готовое решение по расшифровке таких файлов:
⇨ https://github.com/yanncam/UnSHc
Так что имейте ввиду, что это в основном защита от дурака.
#bash #script
Это может быть актуально, если вы делаете кому-то что-то на заказ и надо продемонстрировать работоспособность решения. Если сразу отдать скрипт, то недобросовестные заказчики могут не заплатить, так как всё решение это и есть текст скрипта. Возможно, вы просто захотите от кого-то скрыть чувствительные данные или идею реализации той или иной функциональности.
Shc живёт в базовых репозиториях Debian или Ubuntu, возможно и в других дистрибутивах. Для сборки также понадобится пакет gcc.
# apt install shc gccПользоваться ей очень просто. Покажу на примере небольшого скрипта с вводом переменной в консоли.
#!/bin/bashv=$1echo "Simple BASH script. Entered VARIABLE: $v"Запускаем:
# ./script.sh 111Simple BASH script. Entered VARIABLE: 111Теперь компилируем его в бинарник:
# shc -f -r script.shНа выходе получаем два файла:
- script.sh.x - бинарник
- script.sh.x.c - исходный код
Запускаем бинарь:
# ./script.sh.x 123Simple BASH script. Entered VARIABLE: 123Отработал точно так же, как и bash скрипт. С помощью shc можно указать дату, после которой скрипт запускаться не будет. Выглядит это примерно так:
# shc -e 31/12/2023 -m "Извини, но ты опоздал!" -f -r script.sh# ./script.sh.x./script.sh.x: has expired!Извини, но ты опоздал!Я подозреваю, что прятать какие-то важные пароли таким образом опасно. Наверняка есть способ, чтобы его вытащить оттуда. Мне даже кажется, что это и не слишком сложно. В памяти то всё равно содержимое будет в каком-то виде отображаться. Можно сдампить память в момент запуска и посмотреть.
Быстро поискал и нашёл готовое решение по расшифровке таких файлов:
⇨ https://github.com/yanncam/UnSHc
Так что имейте ввиду, что это в основном защита от дурака.
#bash #script
{kind=link}
Если вам нужно хорошенько нагрузить интернет канал и желательно с возможностью некоторого управления суммарным объёмом трафика, то предлагаю вам свой простенький скрипт, который набросал на днях. Он использует публичные Looking Glass российских хостеров, у которых сервер проверки стоит в Москве. Мне так надо было. Подобрать нужных хостеров можно тут.
Запускаем скрипт, указывая нужное количество проходок скачивания указанных файлов:
И скрипт 5 раз пройдёт по этому списку, скачав 500 мегабайт за проход. Чаще всего у хостеров есть там же файлы по 1000MB. Так что зачастую просто добавив нолик в урле, можно увеличить размер файла. Мне не надо было, поэтому качал по 100. Сам список тоже можно сделать очень длинным.
Скрипт удобно использовать для отладки триггеров в мониторинге на загрузку сетевого интерфейса.
#script
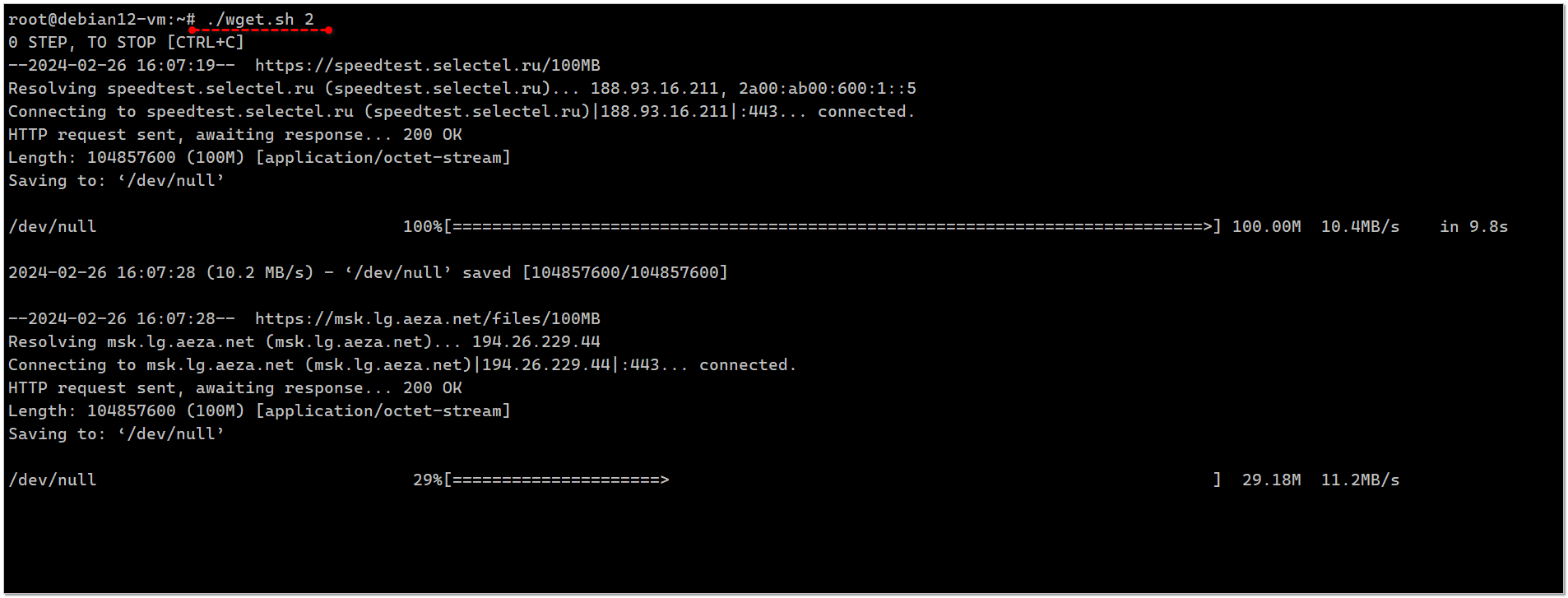
#!/bin/bashsteps=$1for ((i=0;i<$steps;i++))do echo "$i STEP, TO STOP [CTRL+C]" wget -O /dev/null https://speedtest.selectel.ru/100MB wget -O /dev/null https://msk.lg.aeza.net/files/100MB wget -O /dev/null https://45-67-230-12.lg.looking.house/100.mb wget -O /dev/null https://185-43-4-155.lg.looking.house/100.mb wget -O /dev/null https://185-231-154-182.lg.looking.house/100.mbdoneЗапускаем скрипт, указывая нужное количество проходок скачивания указанных файлов:
# ./wget.sh 5И скрипт 5 раз пройдёт по этому списку, скачав 500 мегабайт за проход. Чаще всего у хостеров есть там же файлы по 1000MB. Так что зачастую просто добавив нолик в урле, можно увеличить размер файла. Мне не надо было, поэтому качал по 100. Сам список тоже можно сделать очень длинным.
Скрипт удобно использовать для отладки триггеров в мониторинге на загрузку сетевого интерфейса.
#script
{kind=link}