
Администраторам Linux постоянно приходится сталкиваться с регулярными выражениями. Разобраться в них - та ещё задача. Лично я не умею писать регулярки. Что-то простое, конечно, могу придумать, или расшифровать чужую, но не всегда. Как по мне, регулярки - настоящий вынос мозга. Я их просто записываю и собираю свою коллекцию.
Упростить понимание и написание регулярок может старый известный сервис regex101.com. Рекомендую забрать его в закладки. Странно, что я ещё ни разу о нём не написал. Рассмотрим простой пример 😁
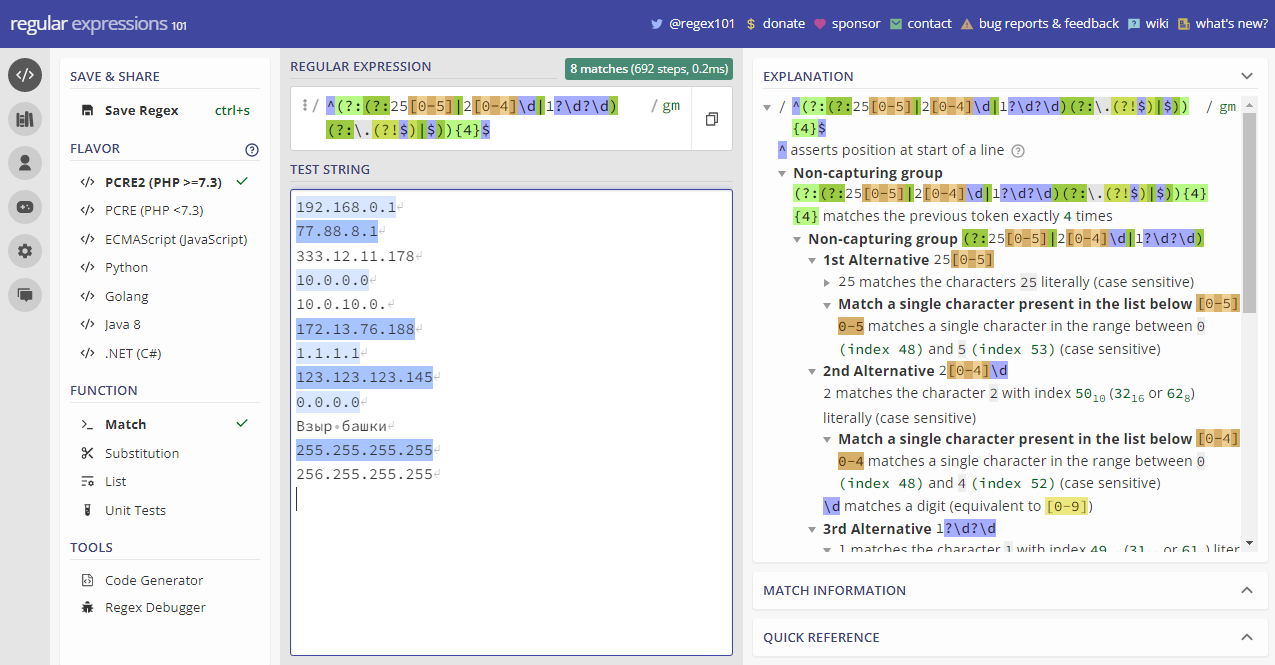
Есть хоть один вменяемый человек, который сможет понять, что это такое? Это же натуральная обфускация, чтобы никто не понял, о чём тут речь. Но на самом деле это регулярка для проверки IP адреса. Результат работы сервиса по этой регулярке можете посмотреть на картинке.
Помимо непосредственно проверки, в этом сервисе есть большая коллекция готовых выражений, по которой работает поиск. Там можно найти много полезных штук, которые не придётся придумывать самому или искать где-то ещё.
Один народный умелец так проникся этим сервисом, что упаковал его в офлайн приложение для PC под все системы:
⇨ https://github.com/nedrysoft/regex101
Кстати, у меня даже ни одного знакомого нет, кто мог бы написать какую-то более ли менее сложную регулярку. Либо я об этом не знаю. Это какое-то тайное знание, которое передаётся как магия из рук в руки между хранителями исходников.
❓Вы можете сами написать регулярку, наподобие той, что проверяет ip адреса?
#regex #сервис
Упростить понимание и написание регулярок может старый известный сервис regex101.com. Рекомендую забрать его в закладки. Странно, что я ещё ни разу о нём не написал. Рассмотрим простой пример 😁
^(?:(?:25[0-5]|2[0-4]\d|1?\d?\d)(?:\.(?!$)|$)){4}$Есть хоть один вменяемый человек, который сможет понять, что это такое? Это же натуральная обфускация, чтобы никто не понял, о чём тут речь. Но на самом деле это регулярка для проверки IP адреса. Результат работы сервиса по этой регулярке можете посмотреть на картинке.
Помимо непосредственно проверки, в этом сервисе есть большая коллекция готовых выражений, по которой работает поиск. Там можно найти много полезных штук, которые не придётся придумывать самому или искать где-то ещё.
Один народный умелец так проникся этим сервисом, что упаковал его в офлайн приложение для PC под все системы:
⇨ https://github.com/nedrysoft/regex101
Кстати, у меня даже ни одного знакомого нет, кто мог бы написать какую-то более ли менее сложную регулярку. Либо я об этом не знаю. Это какое-то тайное знание, которое передаётся как магия из рук в руки между хранителями исходников.
❓Вы можете сами написать регулярку, наподобие той, что проверяет ip адреса?
#regex #сервис
{kind=link}
Ранее я уже затрагивал тему работы с регулярными выражениями, рассказав про сервис regex101.com. Хочу её немного развить и дополнить ещё несколькими полезными ссылками, которые имеет смысл собрать в одном месте, чтобы воспользоваться, когда нужно будет написать очередную регулярку.
Есть очень удобный сервис, который на основе введённых вами данных сам напишет регулярку. Звучит, как фантастика, но он действительно это умеет. Это программа grex, которую можно запустить у себя, либо воспользоваться публичным сервисом — https://pemistahl.github.io/grex-js.
Приведу простой пример для наглядности. Вам нужна регулярка, которая покрывает IP адреса из подсети 192.168.0.0/24. Мне не очевидно, как её сделать. А с помощью этого сервиса никаких проблем. Пишу простой скрипт, который мне сформирует строку со всеми 256 адресами:
Копирую полученную строку в grex, получаю регулярку:
Для проверки прогоняю её через regex101.com и убеждаюсь, что пример рабочий.
Конечно, какие-то сложные выражения с помощью этого сервиса не составить, но что-то простое запросто можно сделать, особенно если вы не особо разбираетесь в самостоятельном написании. Я буквально за 5 минут решил поставленную задачу. Сам бы точно ковырялся дольше с составлением.
И ещё несколько ссылок. Сервис https://regexper.com наглядно разбирает регулярку с картинками. Удобно для изучения и понимания. А в сервисе https://ihateregex.io можно посмотреть примеры наиболее востребованных регулярок тоже с примерами разбора правил. Также хочу порекомендовать вам хороший бесплатный курс по изучению регулярных выражений — https://stepik.org/course/107335/promo.
📌 А теперь всё кратко одним списком:
▪ regex101.com — проверка регулярных выражений
▪ grex — автоматическое составление регулярок
▪ regexper.com — схематическое изображение регулярок
▪ ihateregex.io — готовые примеры регулярных выражений
▪ stepik.org — бесплатный курс для изучения регулярок
#regex #сервис
Есть очень удобный сервис, который на основе введённых вами данных сам напишет регулярку. Звучит, как фантастика, но он действительно это умеет. Это программа grex, которую можно запустить у себя, либо воспользоваться публичным сервисом — https://pemistahl.github.io/grex-js.
Приведу простой пример для наглядности. Вам нужна регулярка, которая покрывает IP адреса из подсети 192.168.0.0/24. Мне не очевидно, как её сделать. А с помощью этого сервиса никаких проблем. Пишу простой скрипт, который мне сформирует строку со всеми 256 адресами:
#!/bin/bashcount=1while [ $count -le 256 ]doecho 192.168.0.$countcount=$(( $count + 1 ))doneКопирую полученную строку в grex, получаю регулярку:
^192\.168\.0\.(?:2(?:5[0-6]|[6-9])|(?:1[0-9]|2[0-4]|[3-9])[0-9]?|25?|1)$Для проверки прогоняю её через regex101.com и убеждаюсь, что пример рабочий.
Конечно, какие-то сложные выражения с помощью этого сервиса не составить, но что-то простое запросто можно сделать, особенно если вы не особо разбираетесь в самостоятельном написании. Я буквально за 5 минут решил поставленную задачу. Сам бы точно ковырялся дольше с составлением.
И ещё несколько ссылок. Сервис https://regexper.com наглядно разбирает регулярку с картинками. Удобно для изучения и понимания. А в сервисе https://ihateregex.io можно посмотреть примеры наиболее востребованных регулярок тоже с примерами разбора правил. Также хочу порекомендовать вам хороший бесплатный курс по изучению регулярных выражений — https://stepik.org/course/107335/promo.
📌 А теперь всё кратко одним списком:
▪ regex101.com — проверка регулярных выражений
▪ grex — автоматическое составление регулярок
▪ regexper.com — схематическое изображение регулярок
▪ ihateregex.io — готовые примеры регулярных выражений
▪ stepik.org — бесплатный курс для изучения регулярок
#regex #сервис
{kind=link}
Закрою тему с регулярными выражениями ещё парой полезных ссылок, которыми поделились в комментариях. Первое — сервис на основе OpenAI, который английский текст переводит в регулярные выражения. Причём делает он это неплохо.
⇨ https://www.autoregex.xyz
Я попробовал пару примеров. Сделать регулярку по маске телефона +7903ххххххх. Прям так и написал в запрос: Phone number regexp by mask +7903ххххххх. Выдал ответ:
Вот ещё пример. Минимум восемь символов, по крайней мере, одна заглавная английская буква, одна строчная английская буква, одна цифра и один специальный символ. Запрос написал так: Minimum eight characters, at least one upper case English letter, one lower case English letter, one number and one special character. Регулярку получил такую 😱:
Проверил через regex101.com, регулярка верная. По крайней мере не смог подобрать неподходящий вариант. Спецсимволы, как я понял, перечислены тут - [@$!%*#?&]
И ещё одна полезная ссылка:
⇨ https://regexlearn.com/ru
Это хорошая обучающая программа на русском языке для изучения регулярок. По своей сути это open source проект, переведённый на разные языки.
📌 Все ресурсы по regexp одним списком:
▪️ regex101.com — проверка регулярных выражений
▪️ grex — автоматическое составление регулярок
▪️ regexper.com — схематическое изображение регулярок
▪️ ihateregex.io — готовые примеры регулярных выражений
▪️ autoregex.xyz — построение регулярок с помощью ИИ
▪️ stepik.org — бесплатный курс для изучения регулярок
▪️ regexlearn.com — обучение regex на русском языке
#regex
⇨ https://www.autoregex.xyz
Я попробовал пару примеров. Сделать регулярку по маске телефона +7903ххххххх. Прям так и написал в запрос: Phone number regexp by mask +7903ххххххх. Выдал ответ:
\+7903\d{6}. В целом верно, только должно быть \+7903\d{7}. Вот ещё пример. Минимум восемь символов, по крайней мере, одна заглавная английская буква, одна строчная английская буква, одна цифра и один специальный символ. Запрос написал так: Minimum eight characters, at least one upper case English letter, one lower case English letter, one number and one special character. Регулярку получил такую 😱:
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*#?&])[A-Za-z\d@$!#%*?&]{8,}$Проверил через regex101.com, регулярка верная. По крайней мере не смог подобрать неподходящий вариант. Спецсимволы, как я понял, перечислены тут - [@$!%*#?&]
И ещё одна полезная ссылка:
⇨ https://regexlearn.com/ru
Это хорошая обучающая программа на русском языке для изучения регулярок. По своей сути это open source проект, переведённый на разные языки.
📌 Все ресурсы по regexp одним списком:
▪️ regex101.com — проверка регулярных выражений
▪️ grex — автоматическое составление регулярок
▪️ regexper.com — схематическое изображение регулярок
▪️ ihateregex.io — готовые примеры регулярных выражений
▪️ autoregex.xyz — построение регулярок с помощью ИИ
▪️ stepik.org — бесплатный курс для изучения регулярок
▪️ regexlearn.com — обучение regex на русском языке
#regex
{kind=link}
Освоить синтаксис регулярных выражений – непростая задача. Не то, чтобы она очень сложная, но не так много людей работают с ними постоянно. Большинству сисадминов и девопсов они нужны время от времени для разовых задач. В связи с этим сильно погружаться в них и разбираться зачастую не имеет смысла. Через полгода отсутствия практики всё забудешь.
Предлагаю запомнить, если ещё не запомнили, несколько простых вещей, которые требуются более-менее регулярно. По крайней мере я их помню. Покажу на примере парсинга вывода команды
🟢 В регулярных выражениях используются так называемые якоря, или анкоры. Наиболее часто встречающиеся:
Если убрать
Регулярно залетаю в бан на своём сайте, когда тестирую что-то. Команду на разбан всегда подсматриваю.
Оба анкора вместе
🟢 Далее стоит знать специальные символы
Можно заменить переход на новую строку пробелом или удалить все табуляции:
или просто
Удаляем табы:
🟢 Часто приходится использовать оператор или в виде прямой черты
Выведет все строки, где встречается либо postfix, либо dovecot. Здесь же я сразу упомянул ещё один специальный символ регулярных выражений, который занимается экранированием -
И поиск нормально сработает. Дело в том, что у регулярных выражений существуют разные диалекты. Ключ
В общем-то, это всё, что лично я помню. Если нужно использовать шаблоны, диапазоны, условия, открываю шпаргалки. Сходу правильно написать регулярку у меня не получится.
📌 Полезные ссылки по теме:
▪️ regex101.com — проверка регулярных выражений
▪️ grex — автоматическое составление регулярок
▪️ regexper.com — схематическое изображение регулярок
▪️ ihateregex.io — готовые примеры регулярных выражений
▪️ autoregex.xyz — построение регулярок с помощью ИИ
▪️ stepik.org — бесплатный курс для изучения регулярок
▪️ regexlearn.com — обучение regex на русском языке
#regex
Предлагаю запомнить, если ещё не запомнили, несколько простых вещей, которые требуются более-менее регулярно. По крайней мере я их помню. Покажу на примере парсинга вывода команды
history. Это подходящий вариант для демонстрации. 🟢 В регулярных выражениях используются так называемые якоря, или анкоры. Наиболее часто встречающиеся:
^ - начало строки, $ - конец. Сразу пример. Допустим, мы когда-то использовали certbot в консоли. Если сделать grep по этому имени, то вылезут строки, где мы его устанавливали или запускали службу с таким именем, где смотрели логи и т.д. А нам нужна команда, которая в консоли начиналась с certbot:# grep '^certbot' ~/.bash_historycertbot certonlyЕсли убрать
^, то будут выведены все строки, в которых где угодно встречалось слово certbot. То же самое, только с концом строки. Выведу команду, где в конце указан IP адрес:# grep '75.35.224.135$' ~/.bash_historyfail2ban-client set nginx-limit-conn unbanip 75.35.224.135Регулярно залетаю в бан на своём сайте, когда тестирую что-то. Команду на разбан всегда подсматриваю.
Оба анкора вместе
^$ означают пустую строку. Удобно использовать для чистки конфигов, логов от пустых строк.🟢 Далее стоит знать специальные символы
\n - новая строка, \t - табуляция. Это бывает нужно, когда стоит задача удалить эти табуляции, или наоборот добавить. Примерно так:# echo -e '\tThis is line with tab' >> file.txt# echo -e '\nThis is new line' >> file.txtМожно заменить переход на новую строку пробелом или удалить все табуляции:
# cat file.txt | tr '\n' ' ' или просто
# tr '\n' ' ' < file.txtУдаляем табы:
# tr -d '\t' < file.txt🟢 Часто приходится использовать оператор или в виде прямой черты
|. Это прям самое популярное из регулярок. Грепаем что-то с набором условий:# grep 'postfix\|dovecot' ~/.bash_historyВыведет все строки, где встречается либо postfix, либо dovecot. Здесь же я сразу упомянул ещё один специальный символ регулярных выражений, который занимается экранированием -
\. Если его не поставить, то grep будет искать буквально фразу postfix|dovecot и ничего не найдёт. Но при этом можно сделать вот так:# grep -E "postfix|dovecot" ~/.bash_historyИ поиск нормально сработает. Дело в том, что у регулярных выражений существуют разные диалекты. Ключ
-E включает реализацию Extended Regular Expression (ERE), где получается всё наоборот. Метасимвол или | экранировать не надо. А вот если мы хотим найти слово с этим символом, то нам его надо экранировать. По умолчанию grep использует диалект Basic Regular Expressions (BRE). Всё это зачастую добавляет путаницу и приходится постоянно пробовать, то так, то эдак экранировать, когда использует разные утилиты и перенаправления потоков.В общем-то, это всё, что лично я помню. Если нужно использовать шаблоны, диапазоны, условия, открываю шпаргалки. Сходу правильно написать регулярку у меня не получится.
📌 Полезные ссылки по теме:
▪️ regex101.com — проверка регулярных выражений
▪️ grex — автоматическое составление регулярок
▪️ regexper.com — схематическое изображение регулярок
▪️ ihateregex.io — готовые примеры регулярных выражений
▪️ autoregex.xyz — построение регулярок с помощью ИИ
▪️ stepik.org — бесплатный курс для изучения регулярок
▪️ regexlearn.com — обучение regex на русском языке
#regex