
Меня часто спрашивают, каким образом можно объединить несколько интернет каналов в один общий. То есть настроить не резервирование, не переключение, не балансировку, а именно одновременное использование нескольких каналов для увеличения суммарной пропускной способности. При этом сами каналы чаще всего разного типа. То есть это не то же самое, что объединить порты на свитчах.
У меня никогда не было опыта подобной настройки. Я понимаю, что технически это сложная задача, как логически, так и архитектурно. Честное суммирование каналов будет приводить к явным проблемам. Например, у клиента канал 1000 мегабит, а у сервиса 3 канала по 100 мегабит. Клиент на полной скорости пытается забрать контент с сервера, который вынужден будет для максимальной скорости утилизировать все 3 канала одновременно. Получается один клиент будет забирать контент с трёх разных маршрутов с разными метриками, откликами, source ip шлюзов и т.д.
Ну и в обратную сторону те же самые проблемы, когда у клиента 3 канала, а у сервиса один. Всё это нужно как-то собирать в единую последовательность, чтобы данные не превращались в кашу. А есть ещё привязки аутентификаций и кук к IP. Что с ними будет?
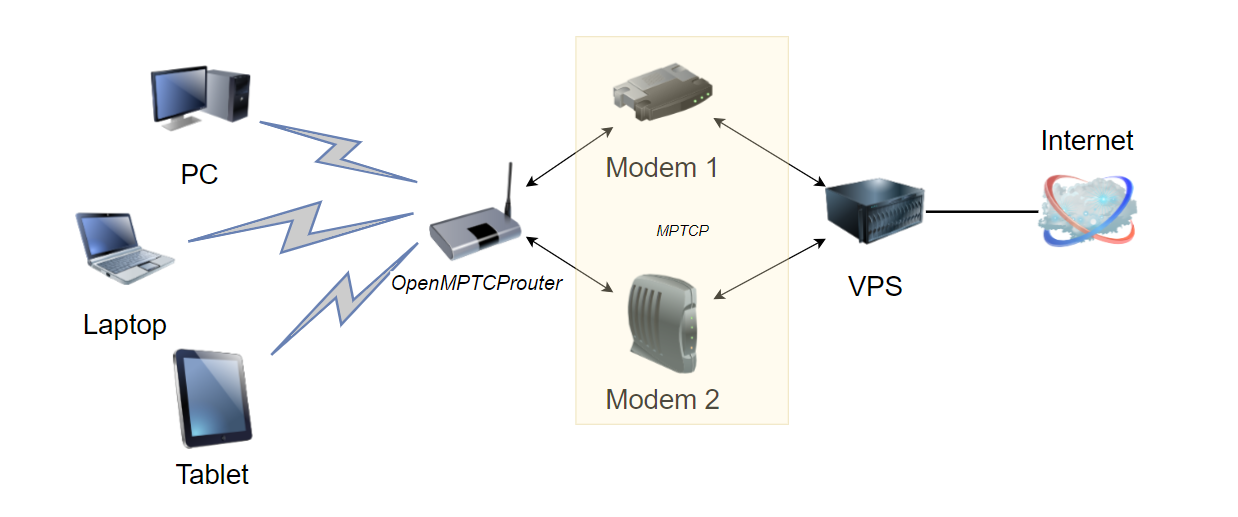
К чему я всё это? Если у вас возникнет подобная задача (постарайтесь от неё отмахнуться), то дам вам подсказку в виде бесплатного OpenMPTCProuter. Это open source проект программного роутера, который умеет честно суммировать интернет каналы. Для этого он состоит из двух частей. Одна клиентская, которую вы ставите там, где суммируете каналы. А вторая часть располагается где-то в интернете для объединения подключений со всех интернет каналов. Только такая схема может обеспечить реальное объединение каналов и возможность приложениям нормально работать при такой схеме без потери пакетов и разрыва соединений.
Клиентская часть, где будут подключены интернет каналы, может быть установлена на обычный x86, x86_64 Linux, Raspberry PI 2B/3B/3B+/4B, Linksys WRT3200ACM/WRT32X, Teltonika RUTX12, Banana PI BPI-R2. Она построена на базе OpenWRT. Суммирующий сервер может быть развёрнут в интернете на обычном VPS на базе Debian или Ubuntu.
Настройка, на удивление для такого продукта, не сложная. Я сам не пробовал, но есть руководство на сайте и инструкции в интернете. Настраивается суммирующий сервер с помощью готового скрипта. Потом поднимаем из образа клиентскую часть. Через веб интерфейс настраиваем интернет каналы и указываем настройки подключения к суммирующему серверу. Этого минимума будет достаточно, чтобы всё заработало.
Это единственное бесплатное решение, которое мне знакомо по данной задаче. Все другие входят в состав дорогих коммерческих продуктов. Из не очень дорогого я когда-то видел коробочку с несколькими USB модемами, но не уверен, что там было честное объединение, а не резервирование и переключение. Да и то название забыл.
Если кто-то пользовался подобными или конкретно этой системой, то дайте обратную связь. Как на практике работает объединение каналов? Тут же куча сопутствующих проблем возникает от банальной настройки файрвола до проброса портов. Не понятно, как это должно работать в таких схемах.
#network
У меня никогда не было опыта подобной настройки. Я понимаю, что технически это сложная задача, как логически, так и архитектурно. Честное суммирование каналов будет приводить к явным проблемам. Например, у клиента канал 1000 мегабит, а у сервиса 3 канала по 100 мегабит. Клиент на полной скорости пытается забрать контент с сервера, который вынужден будет для максимальной скорости утилизировать все 3 канала одновременно. Получается один клиент будет забирать контент с трёх разных маршрутов с разными метриками, откликами, source ip шлюзов и т.д.
Ну и в обратную сторону те же самые проблемы, когда у клиента 3 канала, а у сервиса один. Всё это нужно как-то собирать в единую последовательность, чтобы данные не превращались в кашу. А есть ещё привязки аутентификаций и кук к IP. Что с ними будет?
К чему я всё это? Если у вас возникнет подобная задача (постарайтесь от неё отмахнуться), то дам вам подсказку в виде бесплатного OpenMPTCProuter. Это open source проект программного роутера, который умеет честно суммировать интернет каналы. Для этого он состоит из двух частей. Одна клиентская, которую вы ставите там, где суммируете каналы. А вторая часть располагается где-то в интернете для объединения подключений со всех интернет каналов. Только такая схема может обеспечить реальное объединение каналов и возможность приложениям нормально работать при такой схеме без потери пакетов и разрыва соединений.
Клиентская часть, где будут подключены интернет каналы, может быть установлена на обычный x86, x86_64 Linux, Raspberry PI 2B/3B/3B+/4B, Linksys WRT3200ACM/WRT32X, Teltonika RUTX12, Banana PI BPI-R2. Она построена на базе OpenWRT. Суммирующий сервер может быть развёрнут в интернете на обычном VPS на базе Debian или Ubuntu.
Настройка, на удивление для такого продукта, не сложная. Я сам не пробовал, но есть руководство на сайте и инструкции в интернете. Настраивается суммирующий сервер с помощью готового скрипта. Потом поднимаем из образа клиентскую часть. Через веб интерфейс настраиваем интернет каналы и указываем настройки подключения к суммирующему серверу. Этого минимума будет достаточно, чтобы всё заработало.
Это единственное бесплатное решение, которое мне знакомо по данной задаче. Все другие входят в состав дорогих коммерческих продуктов. Из не очень дорогого я когда-то видел коробочку с несколькими USB модемами, но не уверен, что там было честное объединение, а не резервирование и переключение. Да и то название забыл.
Если кто-то пользовался подобными или конкретно этой системой, то дайте обратную связь. Как на практике работает объединение каналов? Тут же куча сопутствующих проблем возникает от банальной настройки файрвола до проброса портов. Не понятно, как это должно работать в таких схемах.
#network
{kind=link}
Современные операционные системы сегодня живут своей жизнью. Иногда бывает забавно посмотреть на сетевой трафик и ужаснуться от того, сколько там различных сетевых соединений, которые инициировали не вы. Проще всего их отследить по DNS запросам, настроив свой DNS сервер с логированием всех запросов.
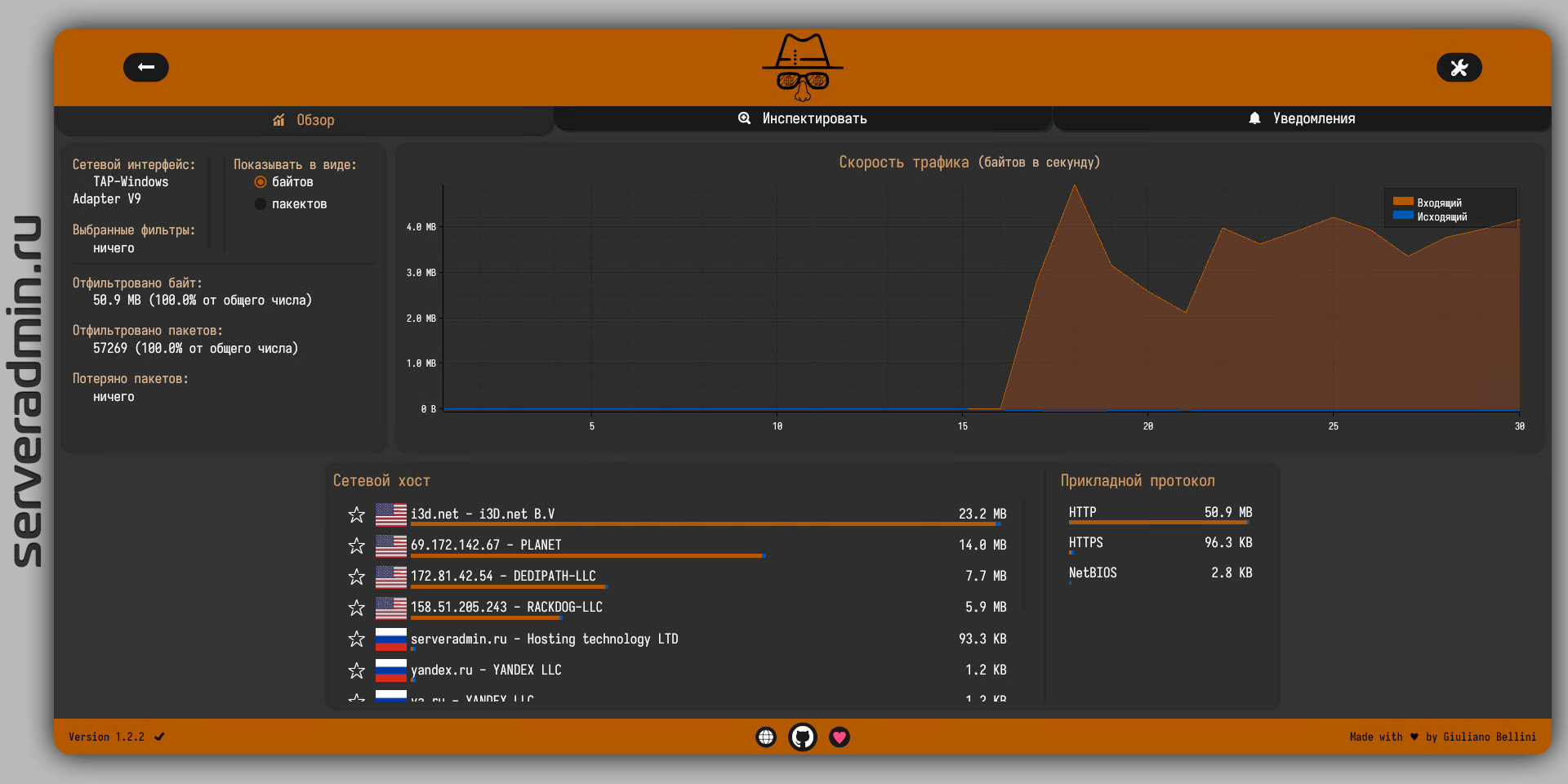
Но есть способы проще. Например, взять open source приложение Sniffnet и посмотреть в удобном виде всю сетевую активность. Причём приложение кроссплатформенное. Я сначала не понял, как такая простая и маленькая программа на Rust может одинаково работать на всех платформах. Оказалось, она использует библиотеку pcap: libpcap в unix и npcap в windows. Для тех, кто не в курсе, поясню, что это та же библиотека, что используется в Nmap и Wireshark.
Sniffnet позволяет подключиться к конкретному сетевому интерфейсу и посмотреть его активность. Работает в том числе с VPN интерфейсами. Например, если вы заворачиваете весь трафик в VPN, то на основном интерфейсе увидите только трафик в сторону VPN сервера. А если заглянете в VPN интерфейс, там уже будет детальна информация. Можно быстро проверить, точно ли весь нужный трафик идёт в VPN.
В Sniffnet можно настроить 3 типа уведомлений:
1️⃣ Превышение порога по частоте передачи пакетов.
2️⃣ Превышение порога полосы пропускания.
3️⃣ Соединение с указанными IP адресами.
Уведомления фиксируются и отображаются в отдельной вкладке интерфейса.
Поддерживаются оба протокола: ipv4 и ipv6. В программе, в принципе, ничего особенного нет. Но сделана добротно и удобно, приятный интерфейс, есть русский язык. Можно взять на заметку, если понадобится подобный функционал. Я, к примеру, так сходу и не вспомню, чем так же трафик посмотреть на Windows. Первыми на ум приходят различные application firewalls, но это немного не то. Более навороченные и функциональные программы.
В Windows предварительно надо будет установить Npcap (installer), в Linux libpcap и звуки со шрифтами:
А потом уже сам Sniffnet.
⇨ Сайт / Исходники
#network
Но есть способы проще. Например, взять open source приложение Sniffnet и посмотреть в удобном виде всю сетевую активность. Причём приложение кроссплатформенное. Я сначала не понял, как такая простая и маленькая программа на Rust может одинаково работать на всех платформах. Оказалось, она использует библиотеку pcap: libpcap в unix и npcap в windows. Для тех, кто не в курсе, поясню, что это та же библиотека, что используется в Nmap и Wireshark.
Sniffnet позволяет подключиться к конкретному сетевому интерфейсу и посмотреть его активность. Работает в том числе с VPN интерфейсами. Например, если вы заворачиваете весь трафик в VPN, то на основном интерфейсе увидите только трафик в сторону VPN сервера. А если заглянете в VPN интерфейс, там уже будет детальна информация. Можно быстро проверить, точно ли весь нужный трафик идёт в VPN.
В Sniffnet можно настроить 3 типа уведомлений:
1️⃣ Превышение порога по частоте передачи пакетов.
2️⃣ Превышение порога полосы пропускания.
3️⃣ Соединение с указанными IP адресами.
Уведомления фиксируются и отображаются в отдельной вкладке интерфейса.
Поддерживаются оба протокола: ipv4 и ipv6. В программе, в принципе, ничего особенного нет. Но сделана добротно и удобно, приятный интерфейс, есть русский язык. Можно взять на заметку, если понадобится подобный функционал. Я, к примеру, так сходу и не вспомню, чем так же трафик посмотреть на Windows. Первыми на ум приходят различные application firewalls, но это немного не то. Более навороченные и функциональные программы.
В Windows предварительно надо будет установить Npcap (installer), в Linux libpcap и звуки со шрифтами:
# apt install libpcap-dev libasound2-dev libfontconfig1-devА потом уже сам Sniffnet.
⇨ Сайт / Исходники
#network
{kind=link}
Запомнился один момент с недавней конференции, где я присутствовал. Выступающий рассказывал, если не ошибаюсь, про технологию VDI и оптимизацию полосы пропускания, что позволяет комфортно общаться по видеосвязи. В подтверждение своих слов с цифрами показал картинку, где справа окно терминала.
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Когда вы настраиваете VPN, встаёт вопрос выбора размера MTU (maximum transmission unit) внутри туннеля. Это размер полезного блока с данными в одном пакете. Как известно, в сетевом пакете часть информации уходит для служебной информации в заголовках. Различные технологии VPN используют разный объём служебных заголовков. А если VPN пущен поверх другого VPN канала, то этот вопрос встаёт особенно остро.
Если ошибиться с размером MTU, то пакеты начнут разбиваться на несколько, чтобы передать полезный блок с данными. Это очень сильно снижает скорость передачи данных. Минимум в 2 раза, но на деле гораздо больше.
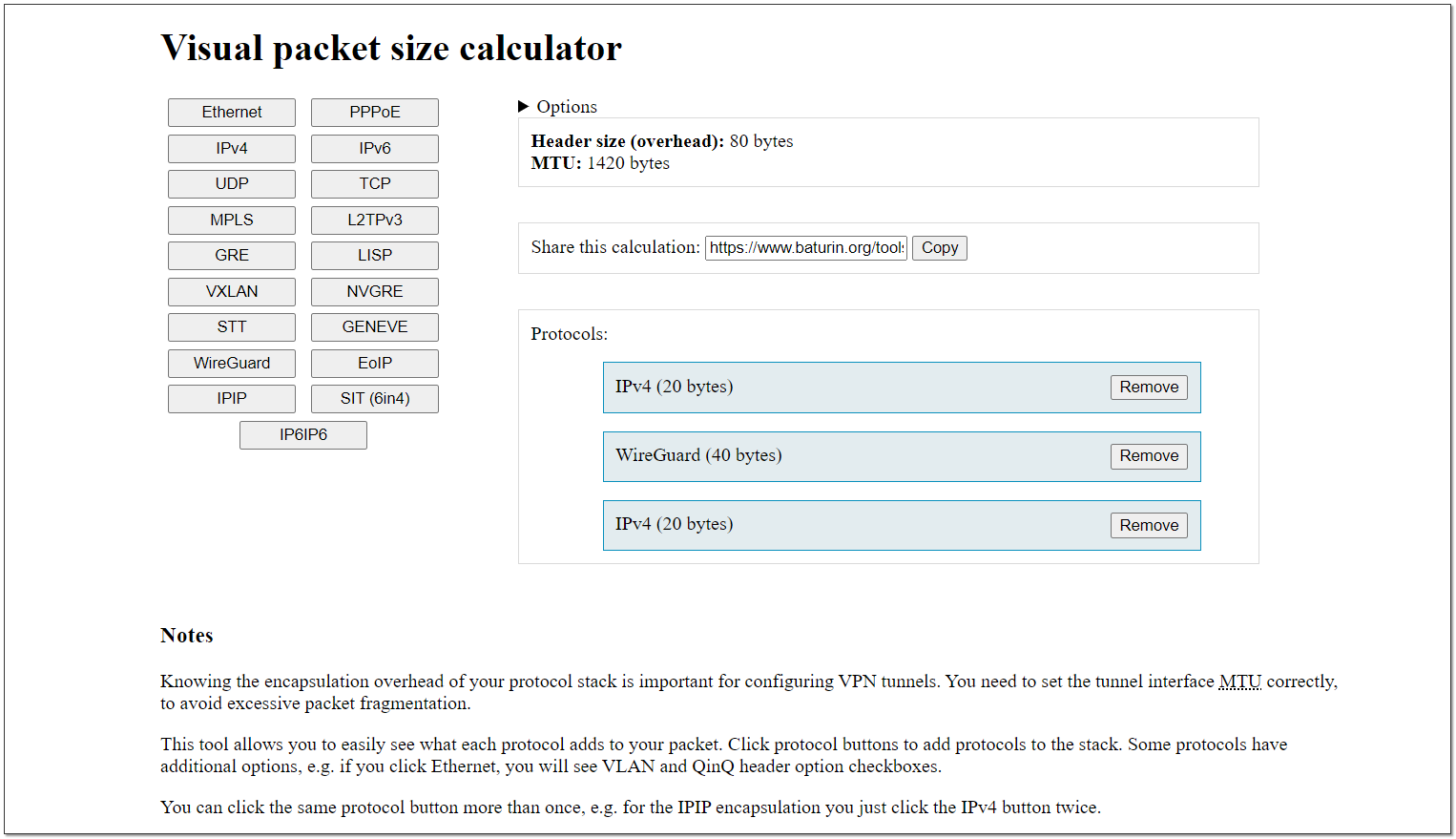
Правильно выбрать размер MTU можно с помощью готового калькулятора - Visual packet size calculator. Его автор, кстати, Даниил Батурин, который иногда ведёт бесплатные вебинары Rebrain, которые я периодически рекламирую. Рекомендую послушать, интересно.
К сожалению, в калькуляторе нет OpenVPN. И я как-то сходу не смог найти информацию, сколько места занимают служебные заголовки этого протокола. Покажу пример для WireGuard, если я всё правильно понимаю. Если ошибаюсь, прошу поправить.
Мы устанавливаем туннель WireGuard, чтобы гонять по нему ipv4 трафик. Идём в калькулятор и выстраиваем там цепочку:
IPv4 (20 bytes) ⇨ WireGuard (40 bytes) ⇨ IPv4 (20 bytes)
Имея на родительском интерфейсе MTU 1500, внутри туннеля нам необходимо установить его 1420. Если не ошибаюсь, это как раз значение по умолчанию для WireGuard.
Тема MTU довольно сложная. Если вы не сетевой инженер и специально ей не интересовались, то вникнуть непросто. На практике я сталкивался с подобными проблемами. Решал их в меру своих сил и способностей - просто уменьшал MTU до некоторых значений, когда проблем пропадала. Если вы не разбираетесь детально в этой теме, рекомендую поступать так же. И важно знать, что если у вас PPPoE соединение от провайдера, то оно дополнительно 8 байт занимает на заголовки. Часто дефолтные значения различного софта не учитывают этого нюанса и нужно будет поправить вручную.
#vpn #network
Если ошибиться с размером MTU, то пакеты начнут разбиваться на несколько, чтобы передать полезный блок с данными. Это очень сильно снижает скорость передачи данных. Минимум в 2 раза, но на деле гораздо больше.
Правильно выбрать размер MTU можно с помощью готового калькулятора - Visual packet size calculator. Его автор, кстати, Даниил Батурин, который иногда ведёт бесплатные вебинары Rebrain, которые я периодически рекламирую. Рекомендую послушать, интересно.
К сожалению, в калькуляторе нет OpenVPN. И я как-то сходу не смог найти информацию, сколько места занимают служебные заголовки этого протокола. Покажу пример для WireGuard, если я всё правильно понимаю. Если ошибаюсь, прошу поправить.
Мы устанавливаем туннель WireGuard, чтобы гонять по нему ipv4 трафик. Идём в калькулятор и выстраиваем там цепочку:
IPv4 (20 bytes) ⇨ WireGuard (40 bytes) ⇨ IPv4 (20 bytes)
Имея на родительском интерфейсе MTU 1500, внутри туннеля нам необходимо установить его 1420. Если не ошибаюсь, это как раз значение по умолчанию для WireGuard.
Тема MTU довольно сложная. Если вы не сетевой инженер и специально ей не интересовались, то вникнуть непросто. На практике я сталкивался с подобными проблемами. Решал их в меру своих сил и способностей - просто уменьшал MTU до некоторых значений, когда проблем пропадала. Если вы не разбираетесь детально в этой теме, рекомендую поступать так же. И важно знать, что если у вас PPPoE соединение от провайдера, то оно дополнительно 8 байт занимает на заголовки. Часто дефолтные значения различного софта не учитывают этого нюанса и нужно будет поправить вручную.
#vpn #network
{kind=link}
Часто слышал выражение, что трафик отправляют в blackhole. Обычно это делает провайдер, когда вас ддосят. Вас просто отключают, отбрасывая весь адресованный вам трафик. А что за сущность такая blackhole, я не знал. Решил узнать, заодно и вам рассказать.
Я изначально думал, что это какое-то образное выражение, которое переводится как чёрная дыра. А на деле предполагал, что соединения просто дропают где-то на файрволе, да и всё. Оказывается, blackhole это реальная запись в таблице маршрутизации. Вы на своём Linux сервере тоже можете отправить весь трафик в blackhole, просто создав соответствующий маршрут:
Проверяем:
Все пакеты с маршрутом до 1.2.3.4 будут удалены с причиной No route to host. На практике на своём сервере кого-то отправлять в blackhole большого смысла нет. Если я правильно понимаю, это провайдеры отправляют в blackhole весь трафик, адресованный какому-то хосту, которого ддосят. Таким образом они разгружают своё оборудование. И это более эффективно и просто, чем что-то делать на файрволе.
Если я правильно понимаю, подобные маршруты где-то у себя имеет смысл использовать, чтобы гарантированно отсечь какой-то исходящий трафик в случае динамических маршрутов. Например, у вас есть какой-то трафик по vpn, который должен уходить строго по определённому маршруту. Если этого маршрута не будет, то трафик не должен никуда идти. В таком случае делаете blackhole маршрут с максимальной дистанцией, а легитимные маршруты с дистанцией меньше. В итоге если легитимного маршрута не будет, весь трафик пойдёт в blackhole. Таким образом можно подстраховывать себя от ошибок в файрволе.
#network
Я изначально думал, что это какое-то образное выражение, которое переводится как чёрная дыра. А на деле предполагал, что соединения просто дропают где-то на файрволе, да и всё. Оказывается, blackhole это реальная запись в таблице маршрутизации. Вы на своём Linux сервере тоже можете отправить весь трафик в blackhole, просто создав соответствующий маршрут:
# ip route add blackhole 1.2.3.4Проверяем:
# ip r | grep blackholeblackhole 1.2.3.4Все пакеты с маршрутом до 1.2.3.4 будут удалены с причиной No route to host. На практике на своём сервере кого-то отправлять в blackhole большого смысла нет. Если я правильно понимаю, это провайдеры отправляют в blackhole весь трафик, адресованный какому-то хосту, которого ддосят. Таким образом они разгружают своё оборудование. И это более эффективно и просто, чем что-то делать на файрволе.
Если я правильно понимаю, подобные маршруты где-то у себя имеет смысл использовать, чтобы гарантированно отсечь какой-то исходящий трафик в случае динамических маршрутов. Например, у вас есть какой-то трафик по vpn, который должен уходить строго по определённому маршруту. Если этого маршрута не будет, то трафик не должен никуда идти. В таком случае делаете blackhole маршрут с максимальной дистанцией, а легитимные маршруты с дистанцией меньше. В итоге если легитимного маршрута не будет, весь трафик пойдёт в blackhole. Таким образом можно подстраховывать себя от ошибок в файрволе.
#network
{kind=link}
В Linux существует относительно простой способ шейпирования (ограничения) трафика с помощью утилиты tc (traffic control) из пакета iproute2. Простой в том плане, что какие-то базовые вещи делаются просто и быстро. Но в то же время это очень мощный инструмент с иерархической структурой, который позволяет очень гибко управлять трафиком.
Сразу сделаю важную ремарку, суть которой некоторые не понимают. Шейпировать можно только исходящий трафик. Управлять входящим трафиком без его потери невозможно. На входе вы можете только отбрасывать пакеты, но не выстраивать в определённые очереди.
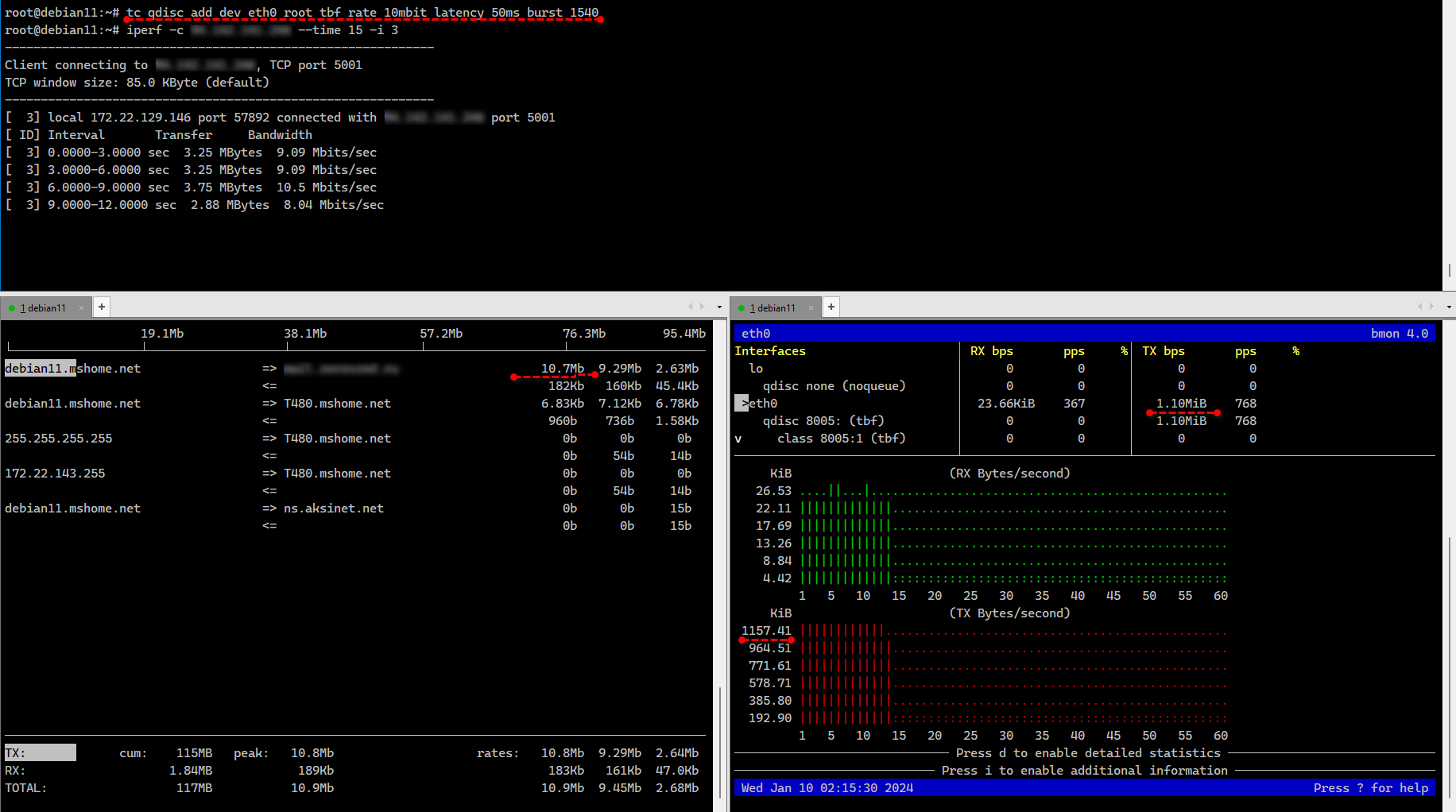
Я не буду подробно рассказывать, как tc работает, потому что это долго и в целом не имеет смысла в рамках заметки. В интернете очень много материала по этой теме. Покажу для начала простой пример ограничения исходящего трафика на конкретном интерфейсе с помощью алгоритма TBF. В минимальной установке Debian tc уже присутствует, так что отдельно ставить не надо.
Ограничили исходящую скорость на интерфейсе eth0 10Mbit/s или примерно 1,25MB/s. В данном случае параметры latency - максимальное время пакета в очереди и burst - размер буфера, обязательны. Посмотреть применённые настройки можно так:
Тестировать ограничение скорость проще всего с помощью iperf или speedtest-cli. Удалить правило можно так же, как и добавляли, только вместо add указать del:
В примере выше мы использовали бесклассовую дисциплину с алгоритмом TBF. Его можно применять только к интерфейсу без возможности фильтрации пакетов. Если нужно настроить ограничение по порту или ip адресу, то воспользуемся другим алгоритмом. Укажем ограничение скорости для конкретного TCP порта с помощью классовой дисциплины HTB. Например, ограничим порт 5001, который использует по умолчанию iperf:
Так как это классовая дисциплина, мы вначале создали общий класс по умолчанию для всего трафика без ограничений. Потом создали класс с идентификатором 1:1 с ограничением скорости. Затем в этот класс с ограничением добавили порт 5001. По аналогии можно создавать другие классы и добавлять туда фильтры на основе разных признаков: порты, ip адреса, протоколы. Примерно так же назначаются и приоритеты трафика.
Подробно настройка tc описана в этом how-to. Разделы 9, 10, 11, 12.
Для tc есть небольшая python обёртка, которая упрощает настройку - traffictoll. Там конфигурацию можно в yaml файлах писать. Причём эта штука поддерживает в том числе фильтрацию по процессам. Честно говоря, я не понял, как там это реализовано. Насколько я знаю, tc по процессам фильтровать не умеет. Поковырялся в исходниках traffictoll, но реализацию так и не нашёл. Вижу, что используется библиотека psutil для получения информации о процессе, подгружается модуль ядра ifb numifbs=1, но где правила для процессов задаются, не понял.
#network
Сразу сделаю важную ремарку, суть которой некоторые не понимают. Шейпировать можно только исходящий трафик. Управлять входящим трафиком без его потери невозможно. На входе вы можете только отбрасывать пакеты, но не выстраивать в определённые очереди.
Я не буду подробно рассказывать, как tc работает, потому что это долго и в целом не имеет смысла в рамках заметки. В интернете очень много материала по этой теме. Покажу для начала простой пример ограничения исходящего трафика на конкретном интерфейсе с помощью алгоритма TBF. В минимальной установке Debian tc уже присутствует, так что отдельно ставить не надо.
# tc qdisc add dev eth0 root tbf rate 10mbit latency 50ms burst 10kОграничили исходящую скорость на интерфейсе eth0 10Mbit/s или примерно 1,25MB/s. В данном случае параметры latency - максимальное время пакета в очереди и burst - размер буфера, обязательны. Посмотреть применённые настройки можно так:
# tc qdisc show dev eth0Тестировать ограничение скорость проще всего с помощью iperf или speedtest-cli. Удалить правило можно так же, как и добавляли, только вместо add указать del:
# tc qdisc del dev eth0 root tbf rate 10mbit latency 50ms burst 10kВ примере выше мы использовали бесклассовую дисциплину с алгоритмом TBF. Его можно применять только к интерфейсу без возможности фильтрации пакетов. Если нужно настроить ограничение по порту или ip адресу, то воспользуемся другим алгоритмом. Укажем ограничение скорости для конкретного TCP порта с помощью классовой дисциплины HTB. Например, ограничим порт 5001, который использует по умолчанию iperf:
# tc qdisc add dev eth0 root handle 1: htb default 20# tc class add dev eth0 parent 1: classid 1:1 htb rate 10mbit ceil 10mbit# tc filter add dev eth0 protocol ip parent 1: prio 1 u32 match ip dport 5001 0xffff flowid 1:1Так как это классовая дисциплина, мы вначале создали общий класс по умолчанию для всего трафика без ограничений. Потом создали класс с идентификатором 1:1 с ограничением скорости. Затем в этот класс с ограничением добавили порт 5001. По аналогии можно создавать другие классы и добавлять туда фильтры на основе разных признаков: порты, ip адреса, протоколы. Примерно так же назначаются и приоритеты трафика.
Подробно настройка tc описана в этом how-to. Разделы 9, 10, 11, 12.
Для tc есть небольшая python обёртка, которая упрощает настройку - traffictoll. Там конфигурацию можно в yaml файлах писать. Причём эта штука поддерживает в том числе фильтрацию по процессам. Честно говоря, я не понял, как там это реализовано. Насколько я знаю, tc по процессам фильтровать не умеет. Поковырялся в исходниках traffictoll, но реализацию так и не нашёл. Вижу, что используется библиотека psutil для получения информации о процессе, подгружается модуль ядра ifb numifbs=1, но где правила для процессов задаются, не понял.
#network
{kind=link}
Расскажу своими словами о такой характеристики сетевого пакета как TTL (Time to live). Думаю, многие если что-то и знают или слышали об этом, то не вдавались в подробности, так как базово системному администратору не так часто приходится подробно разбираться с временем жизни пакета.
Вообще, я впервые познакомился с этим термином, когда купил свой первый модем Yota и захотел не просто пользоваться интернетом на одном устройстве, но и раздать его другим. В то время у Yota был безлимит только для конкретного устройства, в который воткнут модем или сим карта. А одним из способов определить, что интернет раздаётся, был анализ его TTL. Но не только. Из забавного расскажу, что также был контроль ресурсов, к которым обращается пользователь. Я тогда ещё иногда админил Freebsd, а на ноуте была тестовая виртуалка с ней. Как только я пытался обновить список портов (это аналог обновления репозитория в Linux), мне провайдер отключал интернет за нарушение условий использования. Видимо какой-то местный админ, настраивавший ограничения, решил, что пользователь Yota с usb модемом не может обновлять пакеты для Freebsd. Обходил это VPN соединением. Сразу весь траф в него заворачивал, чтобы не палить.
Возвращаюсь к TTL. Это число, которое присутствует в отдельном поле IP заголовка сетевого пакета. После прохождения каждого маршрутизатора этот параметр уменьшается на единицу. Как только это число станет равно 0, пакет уничтожается. Сделано это для того, чтобы ограничить способность пакета бесконечно перемещаться по сети. Рано или поздно он будет уничтожен, если не достигнет адресата.
Как это работает на практике, наглядно можно показать на примере ограничений Yota того периода. У разных устройств и систем по умолчанию устанавливается разное TTL. Для Linux, Android обычно это 64, для Windows 128. Если вы используете интернет напрямую на смартфоне, то TTL выходящего из вашего устройства пакета будет 64. Если же вы раздаёте интернет другому смартфону, то на вашем устройстве TTL будет 64, на втором устройстве, которому раздали интернет, будет 63. И провайдер на своём оборудовании увидит TTL 63, а не 64. Это позволяет ему определить раздачу. Способ простой, но эффективный для большей части абонентов.
Изменить TTL довольно просто, если у вас есть навыки и инструменты системы. Можно поменять настройки по умолчанию TTL на системе, раздающей интернет. Просто увеличить значение на 1. Пример для Linux:
Но будет неудобно, если вы выходите с этого устройства в интернет напрямую. Можно на ходу с помощью iptables править время жизни пакетов. Настройка будет зависеть от того, раздающее это устройство или использующее интернет. Пример для раздающего:
Для android устройств (рутованных) и многих usb модемов (перепрошитых) выпускали патчи, где как раз с помощью параметра системы или iptables решали этот вопрос. Под Windows он решался таким же способом, только другими инструментами.
Сейчас, по идее, всё это неактуально стало, так как законодательно запретили провайдерам ограничивать раздачу интернета. Но для понимания TTL этот пример актуален, так как не знаю, где ещё можно с этим столкнуться. В обычных сетевых задачах с TTL мне не приходилось сталкиваться.
#network
Вообще, я впервые познакомился с этим термином, когда купил свой первый модем Yota и захотел не просто пользоваться интернетом на одном устройстве, но и раздать его другим. В то время у Yota был безлимит только для конкретного устройства, в который воткнут модем или сим карта. А одним из способов определить, что интернет раздаётся, был анализ его TTL. Но не только. Из забавного расскажу, что также был контроль ресурсов, к которым обращается пользователь. Я тогда ещё иногда админил Freebsd, а на ноуте была тестовая виртуалка с ней. Как только я пытался обновить список портов (это аналог обновления репозитория в Linux), мне провайдер отключал интернет за нарушение условий использования. Видимо какой-то местный админ, настраивавший ограничения, решил, что пользователь Yota с usb модемом не может обновлять пакеты для Freebsd. Обходил это VPN соединением. Сразу весь траф в него заворачивал, чтобы не палить.
Возвращаюсь к TTL. Это число, которое присутствует в отдельном поле IP заголовка сетевого пакета. После прохождения каждого маршрутизатора этот параметр уменьшается на единицу. Как только это число станет равно 0, пакет уничтожается. Сделано это для того, чтобы ограничить способность пакета бесконечно перемещаться по сети. Рано или поздно он будет уничтожен, если не достигнет адресата.
Как это работает на практике, наглядно можно показать на примере ограничений Yota того периода. У разных устройств и систем по умолчанию устанавливается разное TTL. Для Linux, Android обычно это 64, для Windows 128. Если вы используете интернет напрямую на смартфоне, то TTL выходящего из вашего устройства пакета будет 64. Если же вы раздаёте интернет другому смартфону, то на вашем устройстве TTL будет 64, на втором устройстве, которому раздали интернет, будет 63. И провайдер на своём оборудовании увидит TTL 63, а не 64. Это позволяет ему определить раздачу. Способ простой, но эффективный для большей части абонентов.
Изменить TTL довольно просто, если у вас есть навыки и инструменты системы. Можно поменять настройки по умолчанию TTL на системе, раздающей интернет. Просто увеличить значение на 1. Пример для Linux:
# sysctl -w net.ipv4.ip_default_ttl=65Но будет неудобно, если вы выходите с этого устройства в интернет напрямую. Можно на ходу с помощью iptables править время жизни пакетов. Настройка будет зависеть от того, раздающее это устройство или использующее интернет. Пример для раздающего:
# iptables -t mangle -A POSTROUTING -j TTL --ttl-set 65Для android устройств (рутованных) и многих usb модемов (перепрошитых) выпускали патчи, где как раз с помощью параметра системы или iptables решали этот вопрос. Под Windows он решался таким же способом, только другими инструментами.
Сейчас, по идее, всё это неактуально стало, так как законодательно запретили провайдерам ограничивать раздачу интернета. Но для понимания TTL этот пример актуален, так как не знаю, где ещё можно с этим столкнуться. В обычных сетевых задачах с TTL мне не приходилось сталкиваться.
#network
❓Как бы вы решили следующую задачу.
Как проверить, есть ли обращение клиента на порт TCP 22 сервера с определённого IP адреса и порта?
Это, кстати, вопрос из того же списка, что я публиковал ранее, но я решил его вынести в отдельную публикацию, потому что он объёмный, а там уже лимит сообщения был превышен.
В таком виде этот вопрос выглядит довольно просто, так как тут речь скорее всего про службу sshd, которая по умолчанию логируется практически везде. Можно просто зайти в её лог и посмотреть, какие там были подключения.
Если же речь идёт о любом другом соединении, то если оно активно, посмотреть его можно с помощью
Нужный адрес и порт можно грепнуть:
Менее очевидный вариант с помощью
Если же речь вести про прошлые, а не активные соединения, то первое, что мне приходит на ум из подручных системных средств - логирование с помощью firewall. В iptables я это делаю примерно так:
Сделал отдельную цепочку для логирования и отправил туда запись всех пакетов с портом назначения 22. Логи будут по умолчанию собираться в системном логе syslog. При желании можно в отдельный файл вынести через правило в rsyslog. Отдельную цепочку для каждой службы я обычно не делаю. Вместо этого создаю три цепочки - input, output, forward, куда добавляю правила для тех адресов и портов, которые я хочу логировать.
Это всё, что мне пришло в голову по данному вопросу. Если знаете ещё какие-то способы, то напишите. Будет интересно посмотреть.
Пока заканчивал материал, вспомнил про ещё один:
В принципе, это тот же самый ss или netstat. Они скорее всего отсюда и берут информацию.
#network #terminal
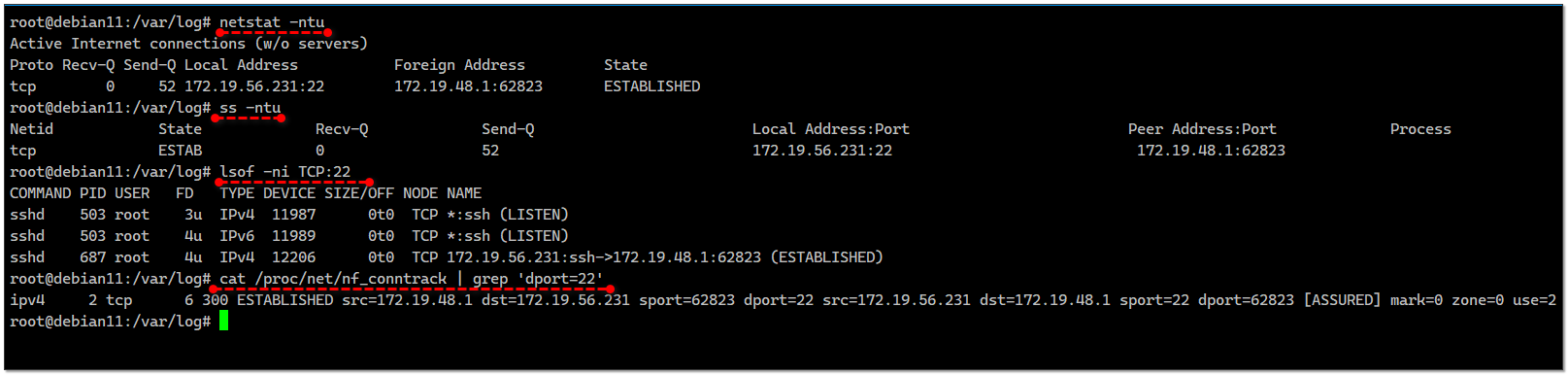
Как проверить, есть ли обращение клиента на порт TCP 22 сервера с определённого IP адреса и порта?
Это, кстати, вопрос из того же списка, что я публиковал ранее, но я решил его вынести в отдельную публикацию, потому что он объёмный, а там уже лимит сообщения был превышен.
В таком виде этот вопрос выглядит довольно просто, так как тут речь скорее всего про службу sshd, которая по умолчанию логируется практически везде. Можно просто зайти в её лог и посмотреть, какие там были подключения.
Если же речь идёт о любом другом соединении, то если оно активно, посмотреть его можно с помощью
netstat или более современного ss:# netstat -ntu# ss -ntuНужный адрес и порт можно грепнуть:
# netstat -ntu | grep ':22'Менее очевидный вариант с помощью
lsof:# lsof -ni TCP:22Если же речь вести про прошлые, а не активные соединения, то первое, что мне приходит на ум из подручных системных средств - логирование с помощью firewall. В iptables я это делаю примерно так:
# iptables -N ssh_in# iptables -A INPUT -j ssh_in# iptables -A ssh_in -j LOG --log-level info --log-prefix "--IN--SSH--"# iptables -A INPUT -p tcp --dport 22 -j ACCEPTСделал отдельную цепочку для логирования и отправил туда запись всех пакетов с портом назначения 22. Логи будут по умолчанию собираться в системном логе syslog. При желании можно в отдельный файл вынести через правило в rsyslog. Отдельную цепочку для каждой службы я обычно не делаю. Вместо этого создаю три цепочки - input, output, forward, куда добавляю правила для тех адресов и портов, которые я хочу логировать.
Это всё, что мне пришло в голову по данному вопросу. Если знаете ещё какие-то способы, то напишите. Будет интересно посмотреть.
Пока заканчивал материал, вспомнил про ещё один:
# cat /proc/net/nf_conntrack | grep 'dport=22'В принципе, это тот же самый ss или netstat. Они скорее всего отсюда и берут информацию.
#network #terminal
{kind=link}
Тема с Portmaster получила очень живой отклик в виде сохранений заметки. Решил её немного развить и предложить альтернативу этому хоть и удобному, но очень объёмному и тяжёлому приложению. Тяжёл прежде всего интерфейс на Electron, само ядро там на Go. В противовес можно поставить simplewall. Это обёртка над Windows Filtering Platform (WFP) весом буквально в мегабайт. В репозитории все скрины на русском языке, так что автор, судя по всему, русскоязычный.
Компания Microsoft действует очень разумно и логично в своей массовой системе Windows. Закрывает наиболее актуальные потребности людей, замыкая их в своей экосистеме. Отрезает всех остальных от бигдаты пользователей. Её встроенных средств безопасности и защиты достаточно среднестатистическому пользователю. Нет необходимости ставить сторонние антивирусы или прочие приложения.
WFP - это набор системных служб для фильтрации трафика, охватывающий все основные сетевые уровни, от транспортного (TCP/UDP) до канального (Ethernet). Simplewall взаимодействует с WFP через встроенный API. То есть это не обёртка над Windows Firewall, как может показаться вначале.
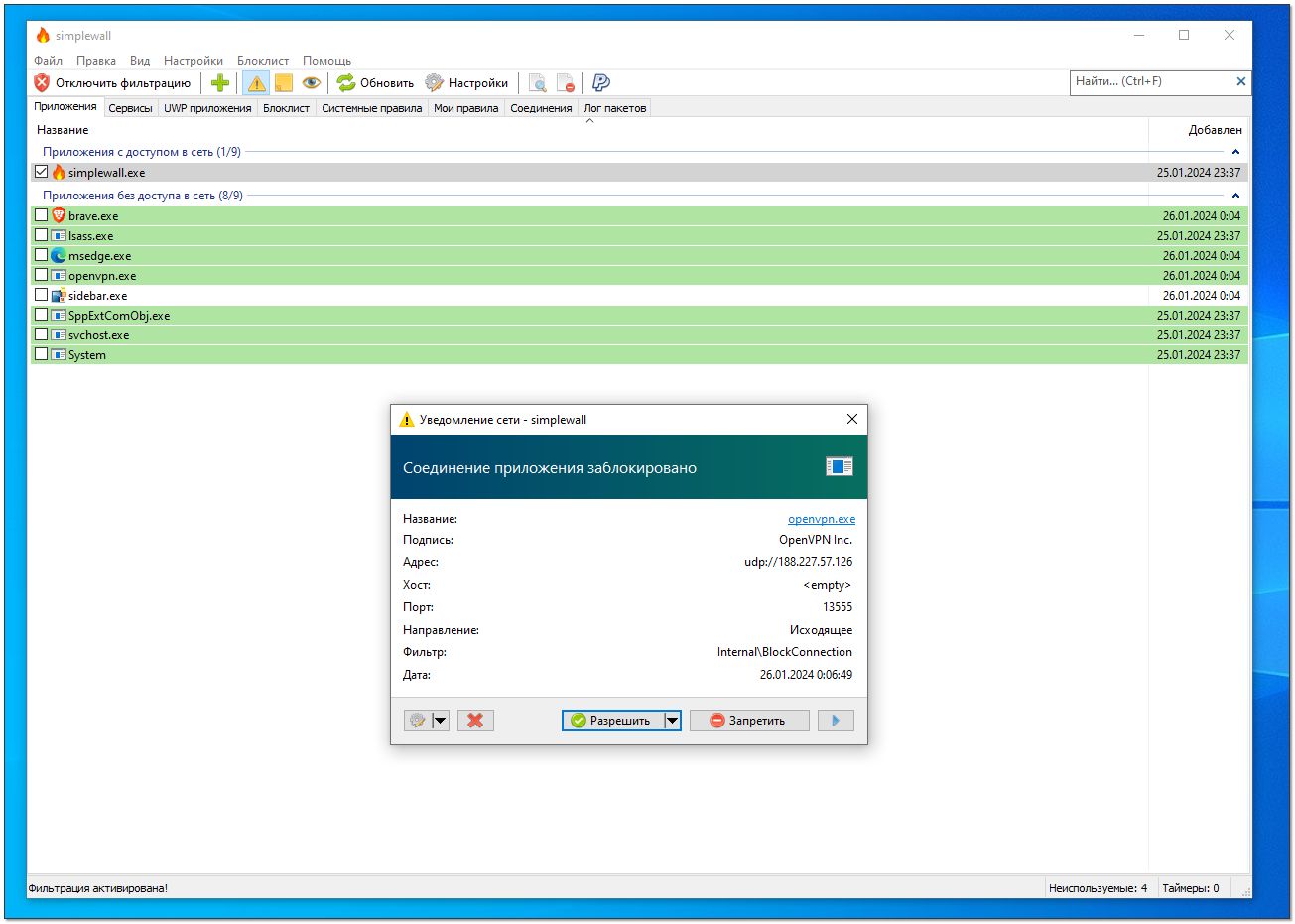
Основная функция Simplewall - контроль сетевой активности. Вы можете заблокировать весь сетевой доступ, а при попытке какого-то приложения получить этот доступ, увидите сообщение от программы, где можно либо разрешить активность, либо запретить. Можно создавать готовые правила для тех или иных приложений.
Simplewall поддерживает работу с системными службами, приложениями из магазина, WSL, с обычными приложениями. Можно логировать сетевую активность приложений или служб. Несмотря на то, что используется встроенный системный инструмент, он позволяет заблокировать в том числе и обновления системы с телеметрией.
Особенность Simplewall в том, что все настроенные правила будут действовать даже если приложение не запущено. Реальная фильтрация выполняется с помощью WFP по преднастроенным правилам. По умолчанию, после запуска фильтрации, программа заблокирует всю сетевую активность. На каждое приложение, которое попросится в сеть, будет выскакивать окно с запросом разрешения или запрета сетевой активности. То есть это очень простой способ заблокировать все запросы с машины во вне.
#windows #security #network
Компания Microsoft действует очень разумно и логично в своей массовой системе Windows. Закрывает наиболее актуальные потребности людей, замыкая их в своей экосистеме. Отрезает всех остальных от бигдаты пользователей. Её встроенных средств безопасности и защиты достаточно среднестатистическому пользователю. Нет необходимости ставить сторонние антивирусы или прочие приложения.
WFP - это набор системных служб для фильтрации трафика, охватывающий все основные сетевые уровни, от транспортного (TCP/UDP) до канального (Ethernet). Simplewall взаимодействует с WFP через встроенный API. То есть это не обёртка над Windows Firewall, как может показаться вначале.
Основная функция Simplewall - контроль сетевой активности. Вы можете заблокировать весь сетевой доступ, а при попытке какого-то приложения получить этот доступ, увидите сообщение от программы, где можно либо разрешить активность, либо запретить. Можно создавать готовые правила для тех или иных приложений.
Simplewall поддерживает работу с системными службами, приложениями из магазина, WSL, с обычными приложениями. Можно логировать сетевую активность приложений или служб. Несмотря на то, что используется встроенный системный инструмент, он позволяет заблокировать в том числе и обновления системы с телеметрией.
Особенность Simplewall в том, что все настроенные правила будут действовать даже если приложение не запущено. Реальная фильтрация выполняется с помощью WFP по преднастроенным правилам. По умолчанию, после запуска фильтрации, программа заблокирует всю сетевую активность. На каждое приложение, которое попросится в сеть, будет выскакивать окно с запросом разрешения или запрета сетевой активности. То есть это очень простой способ заблокировать все запросы с машины во вне.
#windows #security #network
{kind=link}
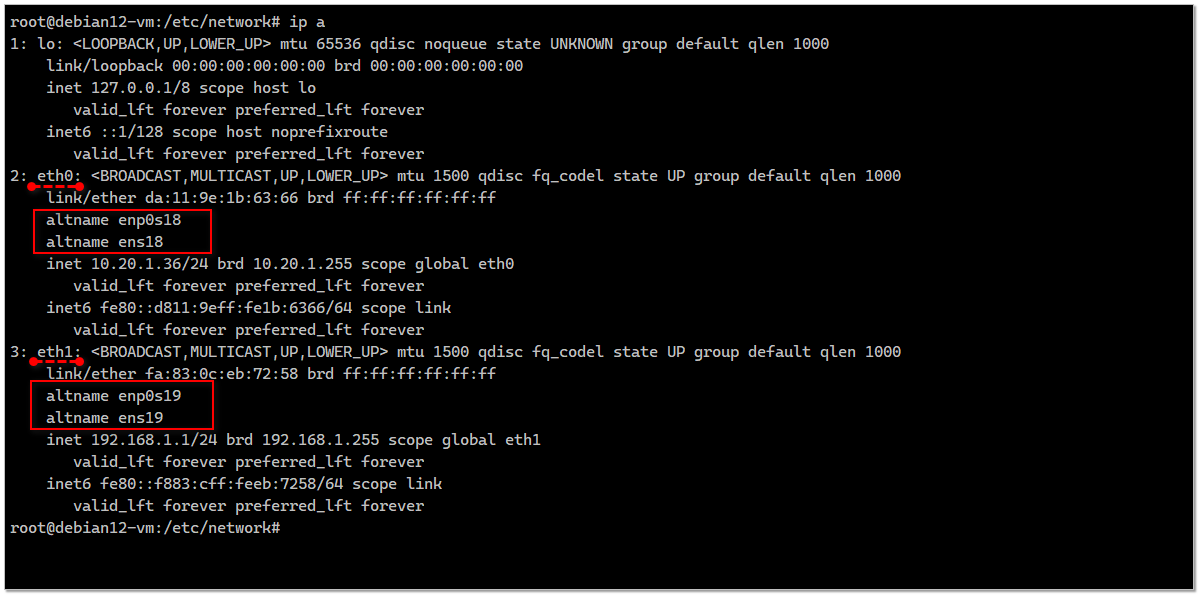
Если вам по какой-то причине не нравится современное именование сетевых интерфейсов в Linux вида ens18, enp0s18 и т.д. то вы можете довольно просто вернуться к привычным названиям eth0, eth1 и т.д. Только сразу предупрежу, что не стоит это делать на уже работающем сервере. Если уж вам так хочется переименовать сетевые интерфейсы, то делайте это сразу после установки системы.
Итак, если вам хочется вернуть старое именование интерфейсов, то в файле конфигурации grub
У вас уже могут быть указаны какие-то другие значения. Новые добавьте через пробел. Изначально их вообще может не быть, а параметр указан вот так:
Или могут быть какие-то другие значения:
После этого нужно обновить загрузчик. В зависимости от дистрибутива, это может выглядеть по-разному. В deb дистрибутивах то выглядит так:
В rpm уже точно не помню, специально не проверял, но вроде бы раньше это выглядело так:
Как в современных версиях уже не знаю, так как не использую их.
После этого нужно везде в сетевых настройках изменить имена интерфейсов со старых на новые. Для Debian достаточно отредактировать
Теперь можно перезагружать сервер. Загрузится он со старыми названиями сетевых интерфейсов.
Попутно задам вопрос, на который у меня нет ответа. Я не понимаю, почему в некоторых виртуалках по умолчанию используется старое именование сетевых интерфейсов, а в некоторых новое. Причём, это не зависит от версии ОС. У меня прямо сейчас есть две одинаковые Debian 11, где на одной eth0, а на другой ens18. Первая на HyperV, вторая на Proxmox. Подозреваю, что это зависит от типа эмулируемой сетевухи и драйвера, который используется в системе.
#linux #network
Итак, если вам хочется вернуть старое именование интерфейсов, то в файле конфигурации grub
/etc/default/grub добавьте в параметр GRUB_CMDLINE_LINUX дополнительные значения net.ifnames и biosdevname:GRUB_CMDLINE_LINUX="net.ifnames=0 biosdevname=0"У вас уже могут быть указаны какие-то другие значения. Новые добавьте через пробел. Изначально их вообще может не быть, а параметр указан вот так:
GRUB_CMDLINE_LINUX=""Или могут быть какие-то другие значения:
GRUB_CMDLINE_LINUX="crashkernel=auto rhgb quiet"После этого нужно обновить загрузчик. В зависимости от дистрибутива, это может выглядеть по-разному. В deb дистрибутивах то выглядит так:
# dpkg-reconfigure grub-pc В rpm уже точно не помню, специально не проверял, но вроде бы раньше это выглядело так:
# grub2-mkconfig -o /boot/grub2/grub.cfgКак в современных версиях уже не знаю, так как не использую их.
После этого нужно везде в сетевых настройках изменить имена интерфейсов со старых на новые. Для Debian достаточно отредактировать
/etc/network/interfaces. Не забудьте про firewall, если у вас правила привязаны к именам интерфейсов. Теперь можно перезагружать сервер. Загрузится он со старыми названиями сетевых интерфейсов.
Попутно задам вопрос, на который у меня нет ответа. Я не понимаю, почему в некоторых виртуалках по умолчанию используется старое именование сетевых интерфейсов, а в некоторых новое. Причём, это не зависит от версии ОС. У меня прямо сейчас есть две одинаковые Debian 11, где на одной eth0, а на другой ens18. Первая на HyperV, вторая на Proxmox. Подозреваю, что это зависит от типа эмулируемой сетевухи и драйвера, который используется в системе.
#linux #network
{kind=link}