
Рассказываю про отличный сервис, который позволит выводить уведомления, к примеру, от системы мониторинга в пуши смартфона или приложение на десктопе. При этом всё бесплатно и можно поднять у себя.
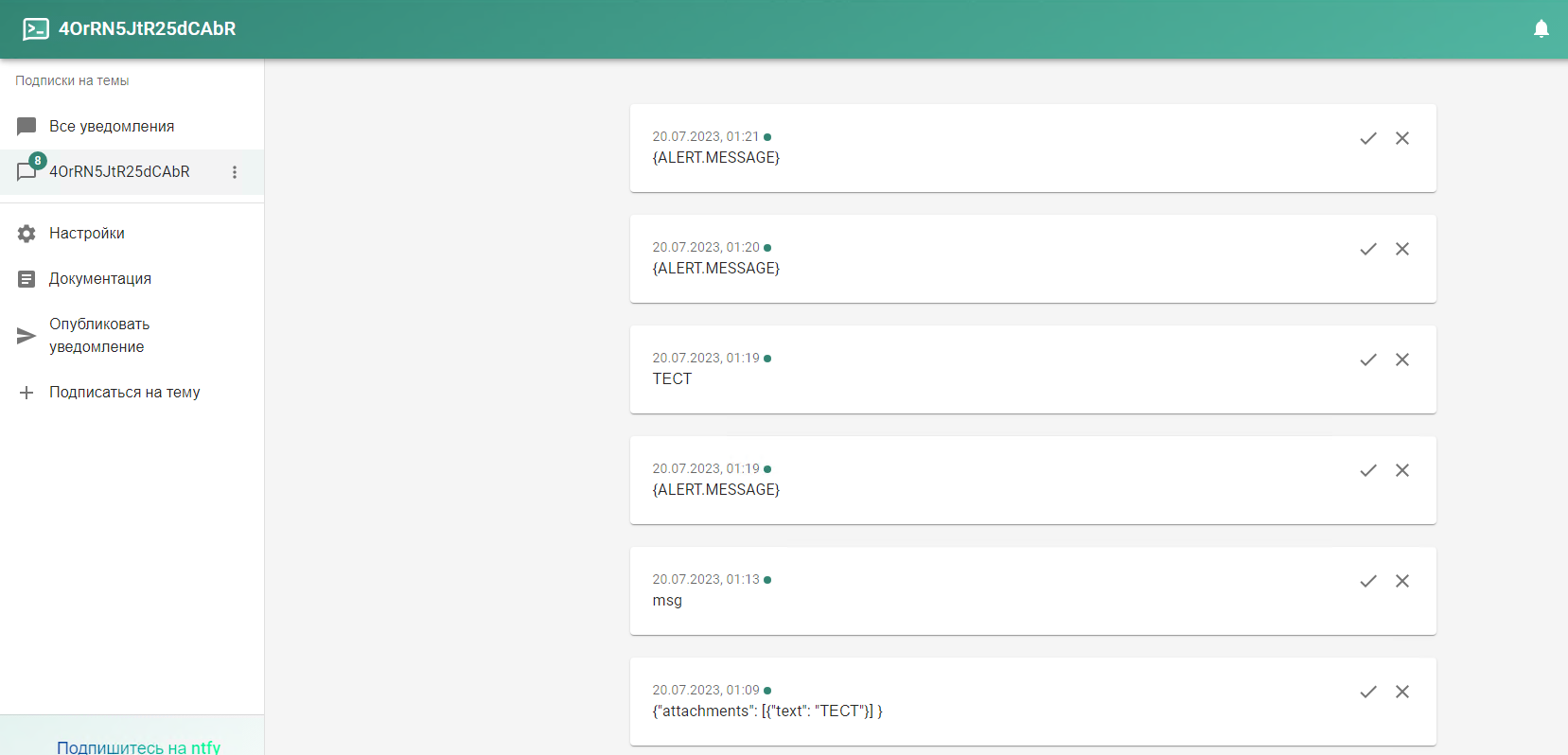
Речь пойдёт про сервис ntfy.sh. Сразу покажу, как им пользоваться, чтобы было понятно, о чём идёт речь. Идёте по ссылке в веб приложение: https://ntfy.sh/app. Разрешаете ему отправлять уведомления. Подписываетесь на новую тему. После этого получаете ссылку вида: ntfy.sh/Stkclnoid6pLCpqU
Теперь идёте в любую консоль и отправляете с помощью curl себе уведомление:
Получаете оповещение от веб приложения. То же самое можно сделать, установив на смартфон приложение. Сервис бесплатный. При этом серверная часть open source. Вы можете развернуть сервер у себя и отправлять уведомления через него. Есть репозитории под все популярные системы. Инструкция прилагается.
Таким образом любой сервис, умеющий выполнять вебхуки, может без проблем отправлять уведомления вам на смартфон или десктоп. Например, в Zabbix достаточно в способах оповещений добавить новый с типом Webhook, в качестве скрипта использовать примерно следующее:
В качестве URL укажите свою подписку в ntfy. Теперь это оповещение можно добавлять пользователям. Им будет приходить уведомление с текстом, который передаёт макрос {ALERT.MESSAGE}.
Либо совсем простой пример для какой-то операции в консоли:
Если бэкап успешен, отправляем одно уведомление, если нет, то другое.
Такой вот простой и удобный сервис.
⇨ Сайт / Исходники
#мониоринг #zabbix #devops
Речь пойдёт про сервис ntfy.sh. Сразу покажу, как им пользоваться, чтобы было понятно, о чём идёт речь. Идёте по ссылке в веб приложение: https://ntfy.sh/app. Разрешаете ему отправлять уведомления. Подписываетесь на новую тему. После этого получаете ссылку вида: ntfy.sh/Stkclnoid6pLCpqU
Теперь идёте в любую консоль и отправляете с помощью curl себе уведомление:
# curl -d "Test Message" ntfy.sh/Stkclnoid6pLCpqUПолучаете оповещение от веб приложения. То же самое можно сделать, установив на смартфон приложение. Сервис бесплатный. При этом серверная часть open source. Вы можете развернуть сервер у себя и отправлять уведомления через него. Есть репозитории под все популярные системы. Инструкция прилагается.
Таким образом любой сервис, умеющий выполнять вебхуки, может без проблем отправлять уведомления вам на смартфон или десктоп. Например, в Zabbix достаточно в способах оповещений добавить новый с типом Webhook, в качестве скрипта использовать примерно следующее:
var response, payload, params = JSON.parse(value), wurl = params.URL, msg = params.Message, request = new CurlHttpRequest(); request.AddHeader('Content-Type: text/plain'); response = request.Post(wurl, msg);В качестве URL укажите свою подписку в ntfy. Теперь это оповещение можно добавлять пользователям. Им будет приходить уведомление с текстом, который передаёт макрос {ALERT.MESSAGE}.
Либо совсем простой пример для какой-то операции в консоли:
# rsync -a /mnt/data user_backup@10.20.1.1:/backups/srv01 \ && curl -H prio:low -d "SRV01 backup succeeded" ntfy.sh/Stkclnoid \ || curl -H tags:warning -H prio:high -d "SRV01 backup failed" ntfy.sh/StkclnoidЕсли бэкап успешен, отправляем одно уведомление, если нет, то другое.
Такой вот простой и удобный сервис.
⇨ Сайт / Исходники
#мониоринг #zabbix #devops
{kind=link}
▶️ Я недавно рассказывал про классный сервис отправки оповещений ntfy.sh, который позволяет бесплатно отправлять push уведомления из любых систем мониторинга. Спустя пару недель на одном популярном англоязычном канале, на который я подписан, вышло подробное видео на эту тему:
⇨ Open Source Push Notifications! Get notified of any event you can imagine. Triggers abound!
Автор описывает сам сервис, рассказывает, как его установить у себя и настроить для использования. Размещает его за Reverse Proxy, настраивает TLS сертификат, проверяет работу пушей.
Видео получилось подробное и наглядное. Если вам нужен подобный сервис на своём оборудовании, рекомендую. Не забудьте оставить положительный комментарий, если видео понравится. Я всегда и везде оставляю добрые комментарии. Это ничего не стоит по времени, а автору приятно.
#мониоринг #devops #видео
⇨ Open Source Push Notifications! Get notified of any event you can imagine. Triggers abound!
Автор описывает сам сервис, рассказывает, как его установить у себя и настроить для использования. Размещает его за Reverse Proxy, настраивает TLS сертификат, проверяет работу пушей.
Видео получилось подробное и наглядное. Если вам нужен подобный сервис на своём оборудовании, рекомендую. Не забудьте оставить положительный комментарий, если видео понравится. Я всегда и везде оставляю добрые комментарии. Это ничего не стоит по времени, а автору приятно.
#мониоринг #devops #видео
YouTube
Open Source Push Notifications! Get notified of any event you can imagine. Triggers abound!
=== Links ===
Show Notes
https://wiki.opensourceisawesome.com/books/self-hosted-push-with-ntfysh/page/setupu-ntfysh
Setting Up a Domain, Reverse Proxy, and more...
https://youtu.be/cjJVmAI1Do4
Ntfy.sh Github Page
https://github.com/binwiederhier/ntfy
Ntfy.sh…
Show Notes
https://wiki.opensourceisawesome.com/books/self-hosted-push-with-ntfysh/page/setupu-ntfysh
Setting Up a Domain, Reverse Proxy, and more...
https://youtu.be/cjJVmAI1Do4
Ntfy.sh Github Page
https://github.com/binwiederhier/ntfy
Ntfy.sh…
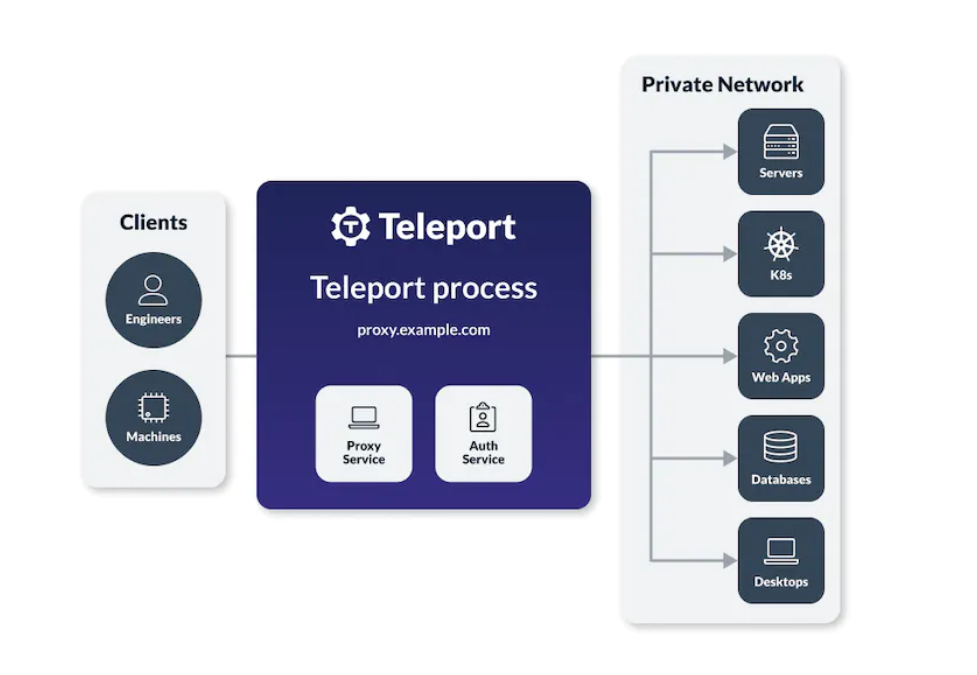
Почти год назад я вам рассказывал про бесплатную open source систему контроля доступа к сервисам и системам — Teleport. У неё недавно вышло несколько крупных обновлений 13-й версии, так что я решил посмотреть на неё повнимательнее и проверить в работе.
Кратко расскажу, в чём суть этой системы. Это условно точка входа в вашу инфраструктуру. Работает в виде службы, веб сервиса и клиентов. Вы ставите Teleport на управляющий сервер, создаёте там пользователей, подключаете другие системы и сервисы. Используя двухфакторную аутентификацию с помощью OTP authenticator пользователь логинится в систему. Это может быть либо браузер, либо консольный клиент. Далее пользователь прямо через браузер может подключиться к SSH разрешённого сервера, либо с помощью специального консольного SSH клиента. Все сессии логируются и записываются. Помимо SSH поддерживаются и другие виды подключений.
Кратко покажу, как это всё развернуть и запустить в работу. Для начала устанавливаем Teleport на Linux сервер:
Создаём самоподписанные сертификаты для домена teleport.local, так как в примере я использую сервер в локальной сети. Можно взять бесплатные сертификаты от Let's Encrypt.
На выходе получите два файла privkey.pem и fullchain.pem. Используем их для создания файла конфигурации:
Запускаем службу:
Все клиенты должны иметь DNS запись teleport.local, чтобы обращаться к серверу Teleport только по доменному имени. Откройте в браузере страницу https://teleport.local. Если увидите окно аутентификации, значит сервис запустился. Идём обратно в консоль сервера и добавляем туда администратора системы с именем teleport-admin, разрешая ему использовать пользователя root для своих подключений. Если подключаетесь не под root, укажите своего пользователя, или перечислите их через запятую.
В ответ получите ссылку вида https://teleport.local/web/invite/296a7fab9182d7525a6f3f456ed3b074. Пройдите по ней. Тут нам понадобится любой OTP аутентификатор со сканером QR кода. Я стандартно взял Google Authenticator, но можно использовать любой другой. Сканируем QR код смартфоном и вводим код в поле регистрации. Пользователь teleport-admin добавлен.
Теперь можно зайти в веб интерфейс и подключиться по SSH к управляющему серверу, который по умолчанию уже добавлен. В разделе Management ⇨ Session Recordings будут записи сессий. Записывается всё, в том числе работа в MC.
Расскажу, как использовать консольный клиент для подключений по SSH. Он есть под все системы. Показываю пример с Linux. Ставим клиента:
Проходим аутентификацию на сервере Teleport:
Тут опять понадобится аутентификатор от гугла и одноразовый код. После успешной аутентификации, можно подключаться по SSH к серверу teleport.local:
Список доступных серверов для вашей учётной записи можно посмотреть вот так:
Информацию об аутентификации и время её жизни так:
Таким образом можно организовать безопасный и контролируемый доступ к закрытой инфраструктуре без VPN и пробросов портов. Но лучше Teleport тоже скрыть от посторонних глаз.
⇨ Сайт / Исходники
#security #управление #devops
Кратко расскажу, в чём суть этой системы. Это условно точка входа в вашу инфраструктуру. Работает в виде службы, веб сервиса и клиентов. Вы ставите Teleport на управляющий сервер, создаёте там пользователей, подключаете другие системы и сервисы. Используя двухфакторную аутентификацию с помощью OTP authenticator пользователь логинится в систему. Это может быть либо браузер, либо консольный клиент. Далее пользователь прямо через браузер может подключиться к SSH разрешённого сервера, либо с помощью специального консольного SSH клиента. Все сессии логируются и записываются. Помимо SSH поддерживаются и другие виды подключений.
Кратко покажу, как это всё развернуть и запустить в работу. Для начала устанавливаем Teleport на Linux сервер:
# curl https://goteleport.com/static/install.sh | bash -s 13.3.2Создаём самоподписанные сертификаты для домена teleport.local, так как в примере я использую сервер в локальной сети. Можно взять бесплатные сертификаты от Let's Encrypt.
# cd /var/lib/teleport# openssl req -x509 -newkey rsa:4096 -keyout privkey.pem \-out fullchain.pem -sha256 -days 3650 -nodes \ -subj "/C=RU/ST=Russia/L=Moscow/O=Homelab/OU=ITdep/CN=*.teleport.local"На выходе получите два файла privkey.pem и fullchain.pem. Используем их для создания файла конфигурации:
# teleport configure -o file \ --cluster-name=teleport.local \ --public-addr=teleport.local:443 \ --cert-file=/var/lib/teleport/fullchain.pem \ --key-file=/var/lib/teleport/privkey.pemЗапускаем службу:
# systemctl start teleportВсе клиенты должны иметь DNS запись teleport.local, чтобы обращаться к серверу Teleport только по доменному имени. Откройте в браузере страницу https://teleport.local. Если увидите окно аутентификации, значит сервис запустился. Идём обратно в консоль сервера и добавляем туда администратора системы с именем teleport-admin, разрешая ему использовать пользователя root для своих подключений. Если подключаетесь не под root, укажите своего пользователя, или перечислите их через запятую.
# tctl users add teleport-admin --roles=editor,access --logins=rootВ ответ получите ссылку вида https://teleport.local/web/invite/296a7fab9182d7525a6f3f456ed3b074. Пройдите по ней. Тут нам понадобится любой OTP аутентификатор со сканером QR кода. Я стандартно взял Google Authenticator, но можно использовать любой другой. Сканируем QR код смартфоном и вводим код в поле регистрации. Пользователь teleport-admin добавлен.
Теперь можно зайти в веб интерфейс и подключиться по SSH к управляющему серверу, который по умолчанию уже добавлен. В разделе Management ⇨ Session Recordings будут записи сессий. Записывается всё, в том числе работа в MC.
Расскажу, как использовать консольный клиент для подключений по SSH. Он есть под все системы. Показываю пример с Linux. Ставим клиента:
# curl -O https://cdn.teleport.dev/teleport-v13.3.2-linux-amd64-bin.tar.gz# tar -xzf teleport-v13.3.2-linux-amd64-bin.tar.gz# cd teleport# ./installПроходим аутентификацию на сервере Teleport:
# tsh login --proxy=teleport.local --user=teleport-admin --insecureТут опять понадобится аутентификатор от гугла и одноразовый код. После успешной аутентификации, можно подключаться по SSH к серверу teleport.local:
# tsh ssh teleport.localСписок доступных серверов для вашей учётной записи можно посмотреть вот так:
# tsh lsИнформацию об аутентификации и время её жизни так:
# tsh statusТаким образом можно организовать безопасный и контролируемый доступ к закрытой инфраструктуре без VPN и пробросов портов. Но лучше Teleport тоже скрыть от посторонних глаз.
⇨ Сайт / Исходники
#security #управление #devops
{kind=link}
Недавно рассказывал про open source систему контроля доступа к сервисам и системам Teleport. На днях как по заказу вышел подробный ролик с описанием его установки за проксируемым сервером Traefik. Это, кстати, фича последних версий. Раньше Teleport не удавалось разместить за прокси.
⇨ Installing Teleport + Traefik (Letsencrypt TLS certs)
Видео наглядное и подробное. Автор на наших глазах разворачивает всё хозяйство в Docker и настраивает. В качестве примера Application настраивает доступ к серверу Proxmox. Всё как мы любим. Не хватает только Mikrotik. Доступ через web, при желании, к нему настраивается по аналогии. Мне очень интересно узнать, записывает ли Teleport сессии к Application так же как к серверам по SSH. На своём стенде забыл это проверить.
Если не понимаете на слух английский, включите субтитры или синхронный перевод от Яндекса. Я с ним слушал, всё понятно. Качество перевода приемлемое. Я бы даже сказал хорошее, если бы он "teleport" не переводил как "телепортация".
#security #управление #devops
⇨ Installing Teleport + Traefik (Letsencrypt TLS certs)
Видео наглядное и подробное. Автор на наших глазах разворачивает всё хозяйство в Docker и настраивает. В качестве примера Application настраивает доступ к серверу Proxmox. Всё как мы любим. Не хватает только Mikrotik. Доступ через web, при желании, к нему настраивается по аналогии. Мне очень интересно узнать, записывает ли Teleport сессии к Application так же как к серверам по SSH. На своём стенде забыл это проверить.
Если не понимаете на слух английский, включите субтитры или синхронный перевод от Яндекса. Я с ним слушал, всё понятно. Качество перевода приемлемое. Я бы даже сказал хорошее, если бы он "teleport" не переводил как "телепортация".
#security #управление #devops
YouTube
Installing Teleport + Traefik (Letsencrypt TLS certs)
In this video, I'll show you how to install Traefik and Teleport in a few easy steps! I'll walk you through setting up the Docker projects, creating a custom network, adding an API token, configuring the cert resolver, and more. Plus, I'll show you how to…
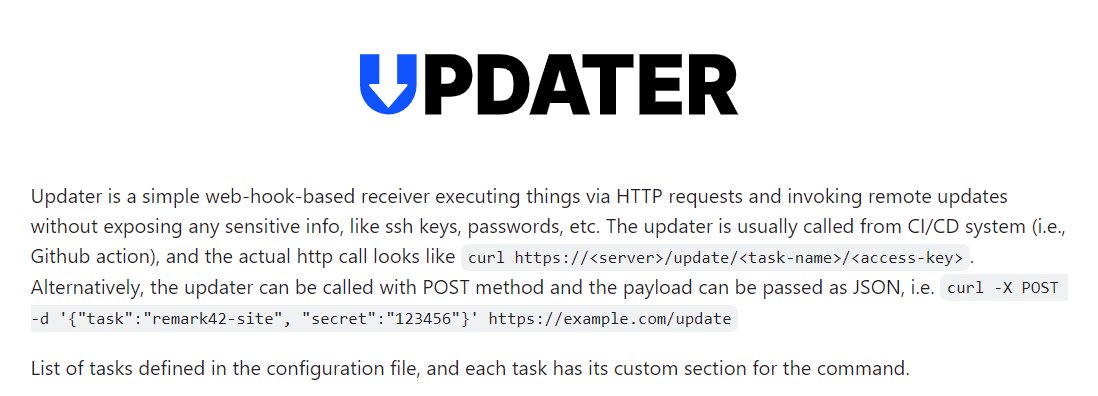
Предлагаю вашему вниманию любопытную утилиту, которую мне давно посоветовали посмотреть в контексте обсуждения темы Port knocking. На практике она может пригодиться в очень широком диапазоне костылей.
Речь пойдёт про программу updater. Она слушает запросы на специальный url и выполняет заданные действия, если запрос легитимный. То есть курлом можно дёрнуть какой-то урл и на сервере выполнится определённое действие. Например, iptables создаст разрешающее правила для подключения по ssh. Урлы можно выбирать любые, в том числе те, что не поддаются подбору. А также наличие аутентификации через токен, делают этот инструмент замаскированным и относительно безопасным. Можно посадить его за прокси, чтобы совсем спрятать.
У автора в репозитории примеры сразу в составе с docker-compose с использованием reproxy в качестве reversed proxy. Если хотите просто погонять утилиту и посмотреть, как работает, может приспособить для своих простых задач, то можете просто запустить в одиночном контейнере:
Создаёте директорию etc там, откуда будете запускать команду. В неё положите конфиг
Формат yaml, так что будьте аккуратны с пробелами. Теперь проверяем, как работает:
Думаю, принцип понятен. Автор пишет, что написал этот софт для использования в CI/CD без необходимости работы по SSH, а следовательно передачи паролей или ключей. По его задумке с помощью updater можно выполнять обновление и перезапуск docker контейнеров. Для этого в составе его контейнера есть docker client и туда пробрасывается docker.sock.
Кстати, его идею я сразу понял, так как в простых случаях я именно так и костылил в Teamcity. Заходил по SSH, обновлял и перезапускал контейнер консольными командами. В целом, это не очень хорошая практика, но задачу решает быстро и в лоб. Для небольших проектов нормальная тема. До этого разработчики руками это делали. Потом попросили настроить что-нибудь для автоматизации. Я воткнул бесплатный Teamcity и автоматизировал в лоб все их действия. Они были довольны.
Для работы на хосте updater нужно вытащить из контейнера и запустить напрямую. Это не трудно сделать, так как updater обычное приложение на GO, состоящее из одного бинарника. Ключи описаны автором в репозитории.
Теперь можно запускать локально. Полезная небольшая утилита. Рекомендую запомнить её. Напомню, что есть похожая программа, про которую я пару раз писал и использую сам - labean.
⇨ Исходники
#security #cicd #devops
Речь пойдёт про программу updater. Она слушает запросы на специальный url и выполняет заданные действия, если запрос легитимный. То есть курлом можно дёрнуть какой-то урл и на сервере выполнится определённое действие. Например, iptables создаст разрешающее правила для подключения по ssh. Урлы можно выбирать любые, в том числе те, что не поддаются подбору. А также наличие аутентификации через токен, делают этот инструмент замаскированным и относительно безопасным. Можно посадить его за прокси, чтобы совсем спрятать.
У автора в репозитории примеры сразу в составе с docker-compose с использованием reproxy в качестве reversed proxy. Если хотите просто погонять утилиту и посмотреть, как работает, может приспособить для своих простых задач, то можете просто запустить в одиночном контейнере:
# docker run -p 8080:8080 -e LISTEN=0.0.0.0:8080 \-e KEY=super-secret-password \-e CONF=/srv/etc/updater.yml \--name=updater -v ./etc:/srv/etc \ghcr.io/umputun/updater:masterСоздаёте директорию etc там, откуда будете запускать команду. В неё положите конфиг
updater.yml для простейшего задания с echo:tasks: - name: echo-test command: | echo "Test updater work"Формат yaml, так что будьте аккуратны с пробелами. Теперь проверяем, как работает:
# curl 172.17.196.25:8080/update/echo-test/super-secret-password{"task":"echo-test","updated":"ok"}Думаю, принцип понятен. Автор пишет, что написал этот софт для использования в CI/CD без необходимости работы по SSH, а следовательно передачи паролей или ключей. По его задумке с помощью updater можно выполнять обновление и перезапуск docker контейнеров. Для этого в составе его контейнера есть docker client и туда пробрасывается docker.sock.
Кстати, его идею я сразу понял, так как в простых случаях я именно так и костылил в Teamcity. Заходил по SSH, обновлял и перезапускал контейнер консольными командами. В целом, это не очень хорошая практика, но задачу решает быстро и в лоб. Для небольших проектов нормальная тема. До этого разработчики руками это делали. Потом попросили настроить что-нибудь для автоматизации. Я воткнул бесплатный Teamcity и автоматизировал в лоб все их действия. Они были довольны.
Для работы на хосте updater нужно вытащить из контейнера и запустить напрямую. Это не трудно сделать, так как updater обычное приложение на GO, состоящее из одного бинарника. Ключи описаны автором в репозитории.
# docker cp f41a990d84c0:/srv/updater updaterТеперь можно запускать локально. Полезная небольшая утилита. Рекомендую запомнить её. Напомню, что есть похожая программа, про которую я пару раз писал и использую сам - labean.
⇨ Исходники
#security #cicd #devops
{kind=link}
Когда-то давно на одном из обучений услышал необычное сравнение работы классических сисадминов и девопсов, как разницу между домашними животными и крупным рогатым скотом - pet vs cattle. Многие, наверное, уже знают, о чём тут речь. Напишу для тех, кто, возможно, об этом не слышал.
Идея в том, что в стародавние времена инфраструктура состояла из отдельных серверов и ими занимались админы как с домашними животными. Каждого знали лично, занимались ими, настраивали, обновляли и т.д. Даже имена давали осмысленно, иногда что-то красивое выдумывали.
С приходом методологии DevOps отношение к серверам поменялось. Ими управляют массово, как крупным рогатым скотом. Никто по отдельности не занимается каждой единицей, а вместо этого создаёт инструменты автоматизации, чтобы решать вопросы массово. И имена обычно по шаблону задаются, как и все основные настройки, обслуживание и т.д.
У меня лично сейчас все сервера, как домашние животные. Из-за того, что их немного (штук 50-60 VPS и 15 железных в сумме, но всё сильно разнородное и принадлежащее разным юр. лицам), я всех знаю лично, регулярно подключаюсь по SSH и что-то делаю вручную. Мне так больше нравится. Потребность в таких услугах всё равно есть, поэтому я остался в этой нише.
Отличить подход pet от cattle очень просто. Если у вас какой-то сервер сломался и работа сервиса нарушена, а вы начинаете думать, как быстрее его восстановить и в каком состоянии бэкапы, то у вас домашние животные. Если вы просто прибили упавший сервер и подняли новый, автоматически накатив на него всё, что надо, то у вас крупный рогатый скот. Очевидно, что для подхода cattle нужны бОльшие масштабы и бОльшие бюджеты. До какого-то уровня это будет экономически не оправданно.
А вам какой подход больше по душе? Ручной или массовое управление с автоматизацией? У меня, как я уже сказал, ручной. Поэтому и вся тематика канала соответствующая. Думаю, это и так заметно.
#разное #devops
Идея в том, что в стародавние времена инфраструктура состояла из отдельных серверов и ими занимались админы как с домашними животными. Каждого знали лично, занимались ими, настраивали, обновляли и т.д. Даже имена давали осмысленно, иногда что-то красивое выдумывали.
С приходом методологии DevOps отношение к серверам поменялось. Ими управляют массово, как крупным рогатым скотом. Никто по отдельности не занимается каждой единицей, а вместо этого создаёт инструменты автоматизации, чтобы решать вопросы массово. И имена обычно по шаблону задаются, как и все основные настройки, обслуживание и т.д.
У меня лично сейчас все сервера, как домашние животные. Из-за того, что их немного (штук 50-60 VPS и 15 железных в сумме, но всё сильно разнородное и принадлежащее разным юр. лицам), я всех знаю лично, регулярно подключаюсь по SSH и что-то делаю вручную. Мне так больше нравится. Потребность в таких услугах всё равно есть, поэтому я остался в этой нише.
Отличить подход pet от cattle очень просто. Если у вас какой-то сервер сломался и работа сервиса нарушена, а вы начинаете думать, как быстрее его восстановить и в каком состоянии бэкапы, то у вас домашние животные. Если вы просто прибили упавший сервер и подняли новый, автоматически накатив на него всё, что надо, то у вас крупный рогатый скот. Очевидно, что для подхода cattle нужны бОльшие масштабы и бОльшие бюджеты. До какого-то уровня это будет экономически не оправданно.
А вам какой подход больше по душе? Ручной или массовое управление с автоматизацией? У меня, как я уже сказал, ручной. Поэтому и вся тематика канала соответствующая. Думаю, это и так заметно.
#разное #devops
{kind=link}
Немного поизучал тему self-hosted решений для S3 и понял, что аналогов MiniO по сути и нет. Всё, что есть, либо малофункционально, либо малоизвестно. Нет ни руководств, ни отзывов. Но в процессе заметил любопытный продукт от известной компании Zenko, которая специализируется на multi-cloud решениях.
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
Примеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
docker run -p 8000:8000 --name=cloudserver \ -v $(pwd)/config.json:/usr/src/app/config.json \ -v $(pwd)/locationConfig.json /usr/src/app/locationConfig.json \ -v $(pwd)/data:/usr/src/app/localData \ -v $(pwd)/metadata:/usr/src/app/localMetadata \ -e REMOTE_MANAGEMENT_DISABLE=1 -d zenko/cloudserverПримеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
[remote]type = s3env_auth = falseaccess_key_id = accessKey1secret_access_key = verySecretKey1region = other-v2-signatureendpoint = http://localhost:8000location_constraint =acl = privateserver_side_encryption =storage_class =Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
{kind=link}
Я не так давно рассказывал про сервис рисования схем excalidraw.com. Тогда впервые о нём узнал, и он мне очень понравился. В комментариях кто-то упомянул, что у него есть плагин для VSCode, но я не придал значения.
На канале realmanual вышло наглядное видео, где показано, как работает этот плагин. А работает он очень круто. Там идея такая. У вас есть репозиторий, где вы в том числе храните схему в виде картинки. Плагин позволяет рисовать схему прямо в редакторе, управляя изменениями через GIT. Но это не всё. На файл со схемой можно оставить ссылку в другом документе, например README.md и по этой ссылке схема будет автоматически отрисовываться в статичную картинку.
По описанию возможно не очень понятно, как это работает. Лучше посмотреть короткое видео (13 мин):
⇨ Рисуем документацию прямо внутри IDE - excalidraw
Это реально очень удобно. Причём нет никакой привязки к онлайн сервису. Мало того, что вы excalidraw можете развернуть у себя, так в плагине VSCode он уже запускается полностью автономно, без привязки к внешнему сервису.
По идее это получается наиболее красивый и удобный сервис для рисования схем. Я поставил себе плагин. Схемы теперь в нём буду рисовать.
#схемы #devops
На канале realmanual вышло наглядное видео, где показано, как работает этот плагин. А работает он очень круто. Там идея такая. У вас есть репозиторий, где вы в том числе храните схему в виде картинки. Плагин позволяет рисовать схему прямо в редакторе, управляя изменениями через GIT. Но это не всё. На файл со схемой можно оставить ссылку в другом документе, например README.md и по этой ссылке схема будет автоматически отрисовываться в статичную картинку.
По описанию возможно не очень понятно, как это работает. Лучше посмотреть короткое видео (13 мин):
⇨ Рисуем документацию прямо внутри IDE - excalidraw
Это реально очень удобно. Причём нет никакой привязки к онлайн сервису. Мало того, что вы excalidraw можете развернуть у себя, так в плагине VSCode он уже запускается полностью автономно, без привязки к внешнему сервису.
По идее это получается наиболее красивый и удобный сервис для рисования схем. Я поставил себе плагин. Схемы теперь в нём буду рисовать.
#схемы #devops
YouTube
Рисуем документацию прямо внутри IDE - excalidraw
Рассмотрим: интеграцию рисовалки для документации в вашем любимом vscode (phpstorm)
Ближайшие и доступные курсы можно посмотреть в школе https://realmanual.ru
Ближайшие и доступные курсы можно посмотреть в школе https://realmanual.ru
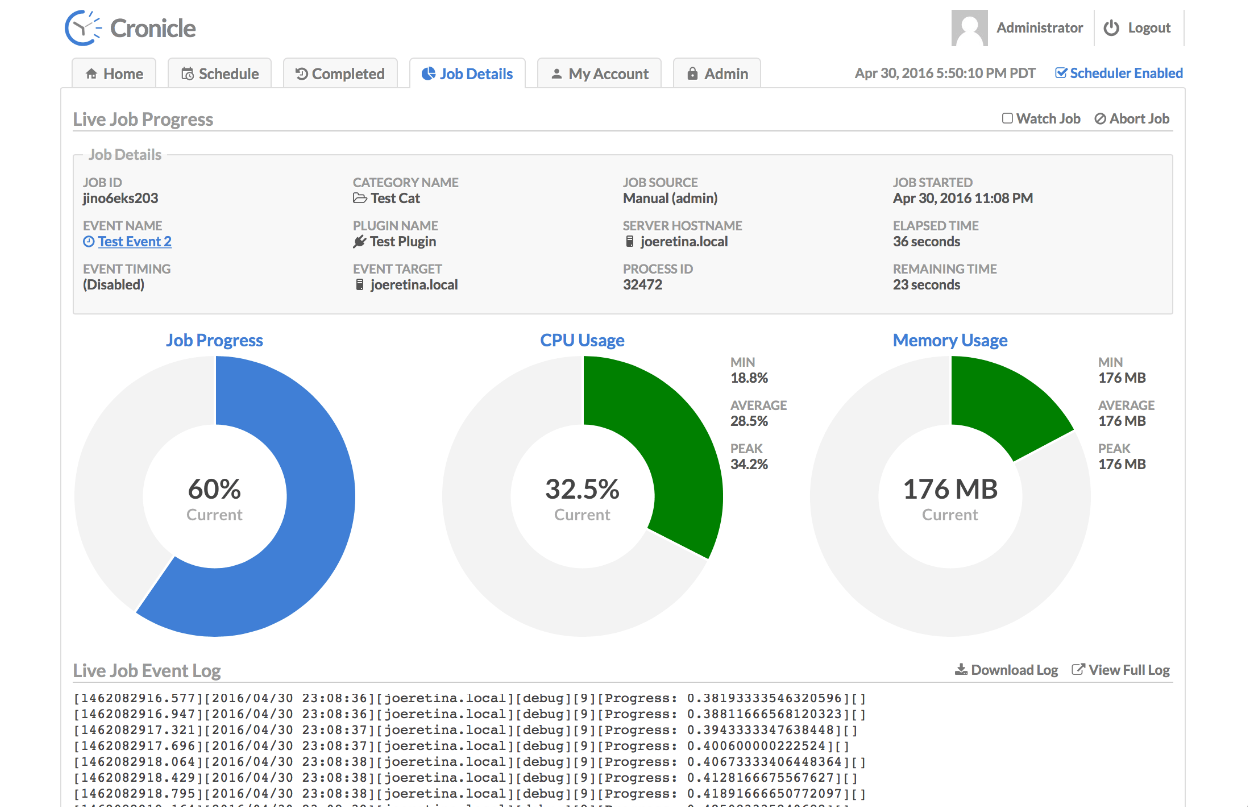
Протестировал новый для себя инструмент, с которым раньше не был знаком. Он очень понравился и показался удобнее аналогичных, про которые знал и использовал раньше. Речь пойдёт про систему планирования и управления задачами серверов Cronicle. Условно его можно назвать продвинутым Cron с веб интерфейсом. Очень похож на Rundeck, про который когда-то писал.
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽автоматически находить соседние сервера;
◽запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
Теперь ставим сам Cronicle. Для этого есть готовый скрипт:
Установка будет выполнена в директорию
А потом запустите:
Теперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#scripts #devops
С помощью Cronicle вы можете создавать различные задачи, тип которых зависит от подключенных плагинов. Например, это может быть SHELL скрипт или HTTP запрос. Управление всё через веб интерфейс, там же и отслеживание результатов в виде логов и другой статистики. Помимо перечисленного Cronicle умеет:
◽работать с распределённой сетью машин, объединённых в единый веб интерфейс;
◽работать в отказоустойчивом режиме по схеме master ⇨ backup сервер;
◽автоматически находить соседние сервера;
◽запускать задачи в веб интерфейсе с отслеживанием работы в режиме онлайн;
◽подсчитывать затраты CPU и Memory и управлять лимитами на каждую задачу;
◽отправлять уведомления и выполнять вебхуки по результатам выполнения задач;
◽поддерживает API для управления задачами извне.
Возможности хорошие, плюс всё это просто и быстро настраивается. Я разобрался буквально за час, установив сначала локально и погоняв задачи, а потом и подключив дополнительный сервер. Не сразу понял, как это сделать.
Cronicle написана на JavaScript, поэтому для работы надо установить на сервер NodeJS версии 16+. Я тестировал на Debian, версию взял 20 LTS. Вот краткая инструкция:
# apt update# apt install ca-certificates curl gnupg# mkdir -p /etc/apt/keyrings# curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key \| gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg# NODE_MAJOR=20# echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_$NODE_MAJOR.x nodistro main" \| tee /etc/apt/sources.list.d/nodesource.list# apt update# apt install nodejsТеперь ставим сам Cronicle. Для этого есть готовый скрипт:
# curl -s https://raw.githubusercontent.com/jhuckaby/Cronicle/master/bin/install.js \| nodeУстановка будет выполнена в директорию
/opt/cronicle. Если ставите master сервер, то после установки выполните setup:# /opt/cronicle/bin/control.sh setupА потом запустите:
# /opt/cronicle/bin/control.sh startТеперь можно идти в веб интерфейс на порт сервера 3012. Учётка по умолчанию - admin / admin. В веб интерфейсе всё понятно, разобраться не составит труда. Для подключения второго сервера, на него надо так же установить Cronicle, но не выполнять setup, а сразу запустить, скопировав на него конфиг
/opt/cronicle/conf/config.json с master сервера. Там прописаны ключи, которые должны везде быть одинаковые. В веб интерфейсе можно добавить новое задание, настроить расписание, выбрать в качестве типа shell script и прям тут же в веб интерфейсе написать его. Дальше выбрать сервер, где он будет исполняться и вручную запустить для проверки. Я потестировал, работает нормально.
На выходе получилось довольно удобная и практичная система управления задачами. Насколько она безопасна архитектурно, не берусь судить. По идее не очень. В любом случае на серверах доступ к службе cronicle нужно ограничить на уровне firewall запросами только с master сервера. Ну а его тоже надо скрыть от посторонних глаз и лишнего доступа.
Если кто-то использовал эту систему, дайте обратную связь. Мне идея понравилась, потому что я любитель всевозможных скриптов и костылей.
⇨ Сайт / Исходники
#scripts #devops
{kind=link}
В комментариях к заметкам про синхронизацию файлов не раз упоминались отказоустойчивые сетевые файловые системы. Прямым представителем такой файловой системы является GlusterFS. Это условный аналог Ceph, которая по своей сути не файловая система, а отказоустойчивая сеть хранения данных. Но в целом обе эти системы используются для решения одних и тех же задач. Про Ceph я писал (#ceph) уже не раз, а вот про GlusterFS не было ни одного упоминания.
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
На все 3 сервера устанавливаем glusterfs-server:
Запускаем также на всех серверах:
На server1 добавляем в пул два других сервера:
На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
На каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
Создаём на этой точке монтирования том glusterfs:
Если получите ошибку:
то проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
Если всё пошло без ошибок, то можно запускать том:
Смотрим о нём информацию:
Теперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
Можете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
Вообще, когда выбирают, на основе чего построить распределённое файловое хранилище, выбирают и сравнивают как раз GlusterFS и Ceph. Между ними есть серьёзные отличия. Первое и самое основное, GlusterFS - это файловая система Linux. При этом Ceph - объектное, файловое и блочное хранилище с доступом через собственное API, минуя операционную систему. Архитектурно для настройки и использования GlusterFS более простая система и это видно на практике, когда начинаешь её настраивать и сравнивать с Ceph.
Я покажу на конкретном примере, как быстро поднять и потестировать GlusterFS на трёх нодах. Для этого нам понадобятся три идентичных сервера на базе Debian с двумя жёсткими дисками. Один под систему, второй под GlusterFS. Вообще, GlusterFS - детище в том числе RedHat. На её основе у них построен продукт Red Hat Gluster Storage. Поэтому часто можно увидеть рекомендацию настраивать GlusterFS на базе форков RHEL с использованием файловой системы xfs, но это не обязательно.
❗️ВАЖНО. Перед тем, как настраивать, убедитесь, что все 3 сервера доступны друг другу по именам. Добавьте в
/etc/hosts на каждый сервер примерно такие записи:server1 10.20.1.1server2 10.20.1.2server3 10.20.1.3На все 3 сервера устанавливаем glusterfs-server:
# apt install glusterfs-serverЗапускаем также на всех серверах:
# service glusterd startНа server1 добавляем в пул два других сервера:
# gluster peer probe server2# gluster peer probe server3На остальных серверах делаем то же самое, только указываем соответствующие имена серверов.
Проверяем статус пиров пула:
# gluster peer statusНа каждом сервере вы должны видеть два других сервера.
На всех серверах на втором жёстком диске создайте отдельный раздел, отформатируйте его в файловую систему xfs или ext4. Я в своём тесте использовал ext4. И примонтируйте в
/mnt/gv0.# mkfs.ext4 /dev/sdb1# mkdir /mnt/gv0# mount /dev/sdb1 /mnt/gv0Создаём на этой точке монтирования том glusterfs:
# gluster volume create gv0 replica 3 server1:/mnt/gv0 server2:/mnt/gv0 server3:/mnt/gv0Если получите ошибку:
volume create: gv0: failed: Host server1 is not in 'Peer in Cluster' stateто проверьте ещё раз файл hosts. На каждом хосте должны быть указаны все три ноды кластера. После исправления ошибок, если есть, остановите службу glusterfs и почистите каталог
/var/lib/glusterd.Если всё пошло без ошибок, то можно запускать том:
# gluster volume start gv0Смотрим о нём информацию:
# gluster volume infoТеперь этот volume можно подключить любому клиенту, в роли которого может выступать один из серверов:
# mkdir /mnt/gluster-test# mount -t glusterfs server1:/gv0 /mnt/gluster-testМожете зайти в эту директорию и добавить файлы. Они автоматически появятся на всех нодах кластера в директории
/mnt/gv0. По этому руководству наглядно видно, что запустить glusterfs реально очень просто. Чего нельзя сказать о настройке и промышленно эксплуатации. В подобных системах очень много нюансов, которые трудно учесть и сразу всё сделать правильно. Нужен реальный опыт работы, чтобы правильно отрабатывать отказы, подбирать настройки под свою нагрузку, расширять тома и пулы и т.д. Поэтому в простых ситуациях, если есть возможность, лучше обойтись синхронизацией на базе lsyncd, unison и т.д. Особенно, если хосты территориально разнесены. И отдельное внимание нужно уделить ситуациям, когда у вас сотни тысяч мелких файлов. Настройка распределённых хранилищ будет нетривиальной задачей, так как остро встанет вопрос хранения и репликации метаданных.
⇨ Сайт / Исходники
#fileserver #devops
{kind=link}