
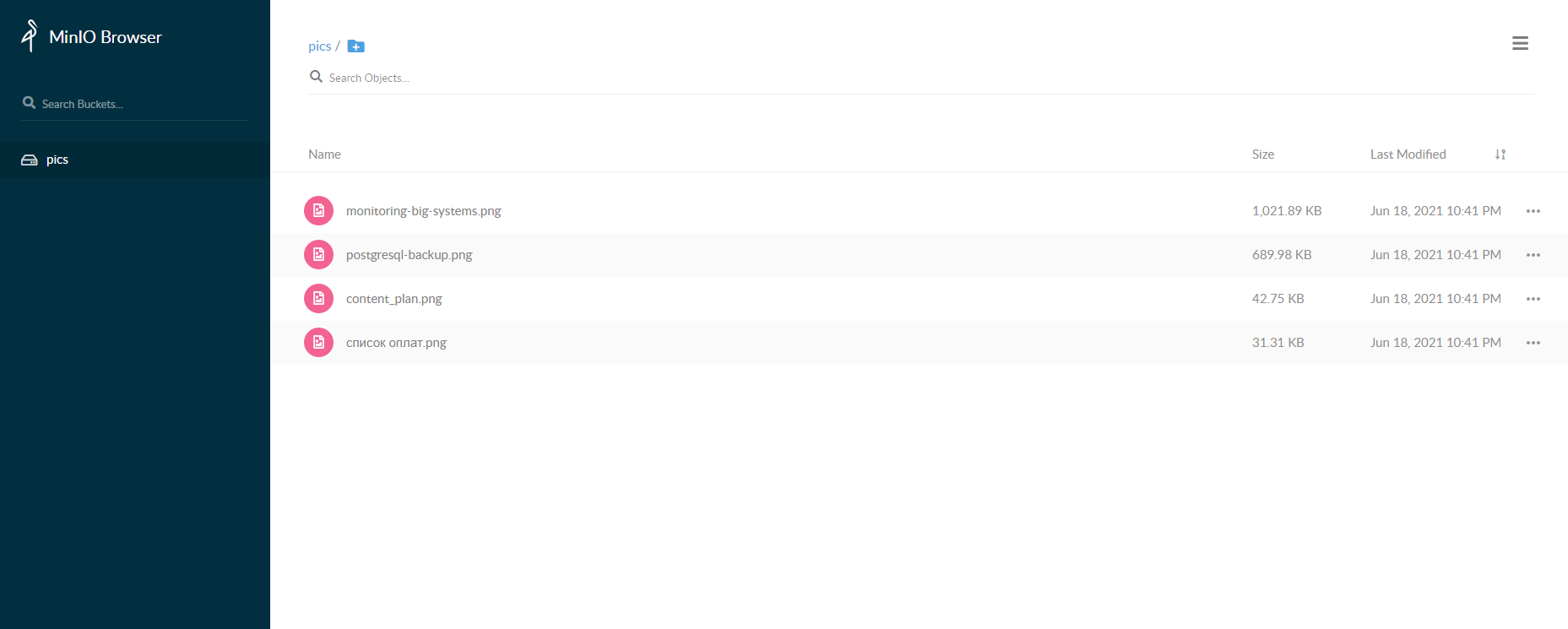
Думаю всем хорошо знакомы объектные хранилища S3. В наше время они активно используются. Изначально подобное хранилище разработал Amazon, но сейчас его api для работы с хранилищем поддерживает огромное количество продуктов и облаков.
Если вам нужен свой сервер хранения S3 рекомендую попробовать MinIO:
https://github.com/minio/minio
Очень простой и бесплатный продукт. На linux запустить его можно вот так:
То есть это просто один бинарник. Далее идёте в веб интерфейс и тестируете - http://ip-adress:9000
На самом сервере файлы хранятся в сыром виде, как есть. То есть он работает поверх обычной файловой системы.
Точно так же MinIO запускается под Windows. Насколько я знаю, это хранилище используется под капотом многих продуктов, таких как Gitlab, Freenas, TrueNAS. Может кто-то еще. Конечно, у сервиса есть масса настроек, необходимых для промышленной эксплуатации. То, как запустил его я, просто для тестов, чтобы посмотреть, как работает и что это такое в принципе.
Подобное хранилище более удобная замена smb и nfs, но, конечно, не во всех случаях. В S3 обычно заливают статику крупных веб проектов или бэкапы. Я тоже там храню одну из копий бэкапов. Покупаю S3 сразу как сервис, потому что выгодно экономически.
#хранение #backup #S3
Если вам нужен свой сервер хранения S3 рекомендую попробовать MinIO:
https://github.com/minio/minio
Очень простой и бесплатный продукт. На linux запустить его можно вот так:
wget https://dl.min.io/server/minio/release/linux-amd64/miniochmod +x minio./minio server /dataТо есть это просто один бинарник. Далее идёте в веб интерфейс и тестируете - http://ip-adress:9000
На самом сервере файлы хранятся в сыром виде, как есть. То есть он работает поверх обычной файловой системы.
Точно так же MinIO запускается под Windows. Насколько я знаю, это хранилище используется под капотом многих продуктов, таких как Gitlab, Freenas, TrueNAS. Может кто-то еще. Конечно, у сервиса есть масса настроек, необходимых для промышленной эксплуатации. То, как запустил его я, просто для тестов, чтобы посмотреть, как работает и что это такое в принципе.
Подобное хранилище более удобная замена smb и nfs, но, конечно, не во всех случаях. В S3 обычно заливают статику крупных веб проектов или бэкапы. Я тоже там храню одну из копий бэкапов. Покупаю S3 сразу как сервис, потому что выгодно экономически.
#хранение #backup #S3
{kind=link}
Типовая ситуация, в которую часто попадаю при аренде выделенных серверов с SSD - нехватка места на дисках. Расширить его зачастую невозможно. Приходится придумывать какие-то другие варианты. Наиболее простым и бюджетным является перенос части холодных данных на S3.
Сделать это можно с помощью софта s3fs-fuse: https://github.com/s3fs-fuse/s3fs-fuse
Он обычно есть в стандартных репозиториях:
Далее необходимо создать файл с учётными данными для подключения к облаку:
И можно монтировать:
Показал на примере S3 хранилища в Selectel. Я обычно им пользуюсь, потому что дёшево.
#s3
Сделать это можно с помощью софта s3fs-fuse: https://github.com/s3fs-fuse/s3fs-fuse
Он обычно есть в стандартных репозиториях:
# dnf install s3fs-fuse# apt install s3fsДалее необходимо создать файл с учётными данными для подключения к облаку:
# echo user:password > ~/.passwd-s3fs# chmod 600 ~/.passwd-s3fsИ можно монтировать:
# s3fs mybucket /mnt/s3 -o passwd_file=~/.passwd-s3fs \-o url=https://s3.storage.selcloud.ru \-o use_path_request_styleПоказал на примере S3 хранилища в Selectel. Я обычно им пользуюсь, потому что дёшево.
#s3
GitHub
GitHub - s3fs-fuse/s3fs-fuse: FUSE-based file system backed by Amazon S3
FUSE-based file system backed by Amazon S3. Contribute to s3fs-fuse/s3fs-fuse development by creating an account on GitHub.
Постоянно пользуюсь утилитой rclone для загрузки данных в S3 хранилище. Вспомнил, что ни разу не писал про неё отдельно. Решил исправить. Думаю, многие знают про неё, так как программа старая, удобная, популярная. Она есть под все известные ОС: Windows, macOS, Linux, FreeBSD, NetBSD, OpenBSD, Plan9, Solaris.
Я использую её исключительно в консоли Linux. Она есть в базовых репозиториях, так что ставится стандартно:
Самую свежую версию можно поставить вот так:
Далее рисуем простой конфиг в файле ~/.config/rclone/rclone.conf:
Это пример для S3 хранилища от Selectel. Все учётные данные получите в ЛК. Я давно им пользуюсь. Когда выбирал, он был самым дешёвым. Сейчас не знаю как, не сравнивал. Для объёмов до 100 Гб там цены небольшие. За этот объём заплатите рублей 300 примерно (стандартное хранилище, холодное ещё дешевле), так что не критично. Рекомендую дублировать бэкапы сайтов, магазинов в S3. У меня это всегда второе, холодное хранилище, куда уезжают полные архивы с определённой периодичностью.
Бэкап директории /mnt/backup/day делается следующим образом:
Я обычно делаю 3 контейнера: day, week, month с настройкой хранения копий 7, 30 дней и бессрочно. Контейнер с месячными архивами чищу вручную время от времени, либо вообще не чищу. А первые два очищаются самостоятельно в соответствии со своими настройками. Следить самому за этим не надо. Если у вас это будет единственное хранилище, то очистку лучше настроить не по времени, а по количеству файлов в контейнере. Иначе если не уследите за бэкапами и они по какой-то причине не будут выполняться, через какое-то время все старые будут удалены, а новые не приедут.
В S3 от Selectel данные заходят очень быстро. Скорость до Гигабита в секунду. Скачивать редко приходится, так что не знаю, какая там реальная скорость, но проблем никогда не было. Думаю тоже что-то в районе гигабита, обычно сам интернет медленнее, куда грузить будете. Можно через панель управления зайти и открыть веб доступ к какому-нибудь файлу, сделать одноразовую ссылку. Также доступ к файлам есть через личный кабинет напрямую в браузере, либо по FTP. Я для визуального контроля и загрузки файлов обычно по FTP захожу.
Сайт - https://rclone.org
#backup #s3
Я использую её исключительно в консоли Linux. Она есть в базовых репозиториях, так что ставится стандартно:
# apt install rclone# dnf install rcloneСамую свежую версию можно поставить вот так:
# curl https://rclone.org/install.sh | bashДалее рисуем простой конфиг в файле ~/.config/rclone/rclone.conf:
[selectel]type = swiftuser = 79167_usernamekey = uO6GdPZ97auth = https://api.selcdn.ru/v3tenant = 79167_usernameauth_version = 3endpoint_type = publicЭто пример для S3 хранилища от Selectel. Все учётные данные получите в ЛК. Я давно им пользуюсь. Когда выбирал, он был самым дешёвым. Сейчас не знаю как, не сравнивал. Для объёмов до 100 Гб там цены небольшие. За этот объём заплатите рублей 300 примерно (стандартное хранилище, холодное ещё дешевле), так что не критично. Рекомендую дублировать бэкапы сайтов, магазинов в S3. У меня это всегда второе, холодное хранилище, куда уезжают полные архивы с определённой периодичностью.
Бэкап директории /mnt/backup/day делается следующим образом:
# /usr/bin/rclone copy /mnt/backup/day selectel:websrv-dayЯ обычно делаю 3 контейнера: day, week, month с настройкой хранения копий 7, 30 дней и бессрочно. Контейнер с месячными архивами чищу вручную время от времени, либо вообще не чищу. А первые два очищаются самостоятельно в соответствии со своими настройками. Следить самому за этим не надо. Если у вас это будет единственное хранилище, то очистку лучше настроить не по времени, а по количеству файлов в контейнере. Иначе если не уследите за бэкапами и они по какой-то причине не будут выполняться, через какое-то время все старые будут удалены, а новые не приедут.
В S3 от Selectel данные заходят очень быстро. Скорость до Гигабита в секунду. Скачивать редко приходится, так что не знаю, какая там реальная скорость, но проблем никогда не было. Думаю тоже что-то в районе гигабита, обычно сам интернет медленнее, куда грузить будете. Можно через панель управления зайти и открыть веб доступ к какому-нибудь файлу, сделать одноразовую ссылку. Также доступ к файлам есть через личный кабинет напрямую в браузере, либо по FTP. Я для визуального контроля и загрузки файлов обычно по FTP захожу.
Сайт - https://rclone.org
#backup #s3
{kind=link}
Бэкапы в S3
Вчера в чате один читатель попросил совет на тему бесплатных решений для бэкапа шифрованных архивов в хранилище на базе S3. Я описывал много различных продуктов для бэкапа и довольно быстро нашёл именно те, что умеют в S3 складывать данные. Думаю, эта информация будет полезна всем, так что решил оформить в отдельную заметку.
🟢 Kopia. Поставил на первое место, так как это классное кроссплатформенное решение с управлением как через web, так и cli. Можно в одном месте собрать бэкапы с разных систем. Настраивается просто, функционал обширный. Я использовал этот софт лично, мне понравился.
🟢 Restic. Простая и быстрая консольная программа, состоящая из одного бинарника. Как и Kopia, есть под все системы. В Debian можно из базовой репы поставить. Есть поддержка снепшотов и дедупликации. Отличное решение под автоматизацию на базе самописных скриптов.
🟢 Duplicati. Очень популярная программа. Тоже кроссплатформенная, есть cli и веб интерфейс. Поддерживает много бэкендов в качестве хранилища, типа Dropbox, OneDrive, Google Drive и т.д. Умеет делать инкрементные бэкапы, поддерживает дедупликацию. Функционально и архитектурно похожа на Kopia.
🟢 Duplicity. Программа только под Linux с управлением через cli. Работает на базе библиотеки librsync, как и rsync, а значит синхронизирует данные очень быстро. Плюс поддерживает работу с rsync сервером. То есть вы можете поднять привычный rsync сервер и с помощью Duplicity забирать с него данные. Это удобно и функционально.
🟢 Rclone. Консольная программа под Linux. Она не совсем для бэкапов, а скорее просто для передачи данных. Я её использую, чтобы складывать в S3 уже подготовленные данные, например шифрованный дамп базы данных. Удобно использовать в своих скриптах.
💡 В дополнение отмечу, что если вам нужен свой сервер на базе S3, то рекомендую поднять его с помощью MinIO. Очень простой в настройке и функциональный продукт.
Если знаете и используете ещё какие-то хорошие продукты по данной тематике, поделитесь информацией. А этот пост рекомендую забрать в закладки.
#backup #S3 #подборка
Вчера в чате один читатель попросил совет на тему бесплатных решений для бэкапа шифрованных архивов в хранилище на базе S3. Я описывал много различных продуктов для бэкапа и довольно быстро нашёл именно те, что умеют в S3 складывать данные. Думаю, эта информация будет полезна всем, так что решил оформить в отдельную заметку.
🟢 Kopia. Поставил на первое место, так как это классное кроссплатформенное решение с управлением как через web, так и cli. Можно в одном месте собрать бэкапы с разных систем. Настраивается просто, функционал обширный. Я использовал этот софт лично, мне понравился.
🟢 Restic. Простая и быстрая консольная программа, состоящая из одного бинарника. Как и Kopia, есть под все системы. В Debian можно из базовой репы поставить. Есть поддержка снепшотов и дедупликации. Отличное решение под автоматизацию на базе самописных скриптов.
🟢 Duplicati. Очень популярная программа. Тоже кроссплатформенная, есть cli и веб интерфейс. Поддерживает много бэкендов в качестве хранилища, типа Dropbox, OneDrive, Google Drive и т.д. Умеет делать инкрементные бэкапы, поддерживает дедупликацию. Функционально и архитектурно похожа на Kopia.
🟢 Duplicity. Программа только под Linux с управлением через cli. Работает на базе библиотеки librsync, как и rsync, а значит синхронизирует данные очень быстро. Плюс поддерживает работу с rsync сервером. То есть вы можете поднять привычный rsync сервер и с помощью Duplicity забирать с него данные. Это удобно и функционально.
🟢 Rclone. Консольная программа под Linux. Она не совсем для бэкапов, а скорее просто для передачи данных. Я её использую, чтобы складывать в S3 уже подготовленные данные, например шифрованный дамп базы данных. Удобно использовать в своих скриптах.
💡 В дополнение отмечу, что если вам нужен свой сервер на базе S3, то рекомендую поднять его с помощью MinIO. Очень простой в настройке и функциональный продукт.
Если знаете и используете ещё какие-то хорошие продукты по данной тематике, поделитесь информацией. А этот пост рекомендую забрать в закладки.
#backup #S3 #подборка
❓Неоднократно получал вопросы на тему современных S3 (Simple Storage Service) совместимых хранилищ. Для чего они нужны, почему такие популярные и чем лучше того же NFS или SMB?
Консерваторы считают это хипстерской поделкой для девопсов, которые не хотят и не умеют ни в чём разбираться, а хотят просто денежки чужие заплатить и получить результат, не прилагая усилий.
Я неоднократно в комментариях отвечал на этот вопрос, поэтому решил вынести его в отдельную заметку и своими словами пояснить, чем удобны подобные хранилища и за счёт чего завоевали популярность.
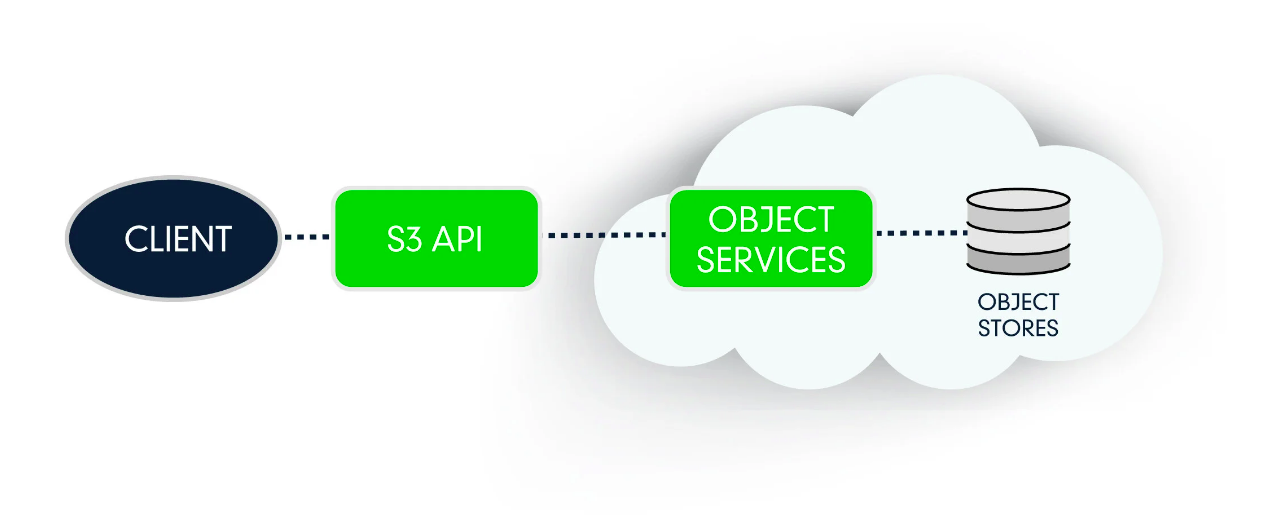
Замечал, что некоторые люди путают и считают, что когда речь идёт о S3 хранилище данных, подразумевается объектное хранилище Amazon S3. Да, Amazon придумал и внедрил подобное хранилище, оснастив его S3 RESTful API. Сейчас появилось огромное количество продуктов и сервисов, которые на 100% поддерживают S3 API. Именно их и называют S3 хранилищами. Можно выбирать на любой вкус и кошелёк. Практически у всех крупных провайдеров есть подобный сервис.
➕Преимущества объектного хранилища S3 (Object storage S3):
🟢 Возможность быстро обратиться к файлу по его идентификатору, получить его метаданные. При этом в бэкенде у хранилища может быть всё, что угодно, API запросов будет везде одинаковый.
🟢 Удобные для провайдера возможности тарификации в зависимости от активности клиентов. Это позволяет клиентам получать необходимый объём, линейно его изменяя, и платить только за потребляемые ресурсы: объём, трафик, количество запросов.
🟢 Данные могут храниться в отдельных контейнерах со своими настройками доступа, хранения, производительности и т.д. То есть их удобно структурировать и разделять информацию по различным типам.
🟢 Все объекты хранилища располагаются в плоском адресном пространстве, без иерархии, которая присутствует в обычной файловой системе. Это упрощает доступ и работу с файлами. Нет проблем с ограничением на длину пути к файлу или с именем файла.
➖Минусы:
🟠 Больше накладных расходов на хранение информации.
🟠 Ниже скорость работы с файлами по сравнению с блочными хранилищами.
Несмотря на то, что хранение файлов в объектных хранилищах дороже, чем в блочных или файловых, за счёт более гибкой и точной тарификации для клиента это всё равно выходит выгоднее, так как он платит только за то, что реально использовал. А минус в скорости работы компенсируется простотой горизонтального масштабирования S3 хранилищ.
❗️Нужно хорошо понимать, что S3 это не про скорость доступа, а про объём и унификацию.
Расписал всё своими словами. Надеюсь понятно объяснил. На практике S3 лучше всего подходит под хранение статических файлов больших сайтов, архивов видеонаблюдения, логов, бэкапов. Конкретно я именно для холодных бэкапов их использую. Обычно это бэкапы бэкапов, копируются с помощью rclone.
#s3
Консерваторы считают это хипстерской поделкой для девопсов, которые не хотят и не умеют ни в чём разбираться, а хотят просто денежки чужие заплатить и получить результат, не прилагая усилий.
Я неоднократно в комментариях отвечал на этот вопрос, поэтому решил вынести его в отдельную заметку и своими словами пояснить, чем удобны подобные хранилища и за счёт чего завоевали популярность.
Замечал, что некоторые люди путают и считают, что когда речь идёт о S3 хранилище данных, подразумевается объектное хранилище Amazon S3. Да, Amazon придумал и внедрил подобное хранилище, оснастив его S3 RESTful API. Сейчас появилось огромное количество продуктов и сервисов, которые на 100% поддерживают S3 API. Именно их и называют S3 хранилищами. Можно выбирать на любой вкус и кошелёк. Практически у всех крупных провайдеров есть подобный сервис.
➕Преимущества объектного хранилища S3 (Object storage S3):
🟢 Возможность быстро обратиться к файлу по его идентификатору, получить его метаданные. При этом в бэкенде у хранилища может быть всё, что угодно, API запросов будет везде одинаковый.
🟢 Удобные для провайдера возможности тарификации в зависимости от активности клиентов. Это позволяет клиентам получать необходимый объём, линейно его изменяя, и платить только за потребляемые ресурсы: объём, трафик, количество запросов.
🟢 Данные могут храниться в отдельных контейнерах со своими настройками доступа, хранения, производительности и т.д. То есть их удобно структурировать и разделять информацию по различным типам.
🟢 Все объекты хранилища располагаются в плоском адресном пространстве, без иерархии, которая присутствует в обычной файловой системе. Это упрощает доступ и работу с файлами. Нет проблем с ограничением на длину пути к файлу или с именем файла.
➖Минусы:
🟠 Больше накладных расходов на хранение информации.
🟠 Ниже скорость работы с файлами по сравнению с блочными хранилищами.
Несмотря на то, что хранение файлов в объектных хранилищах дороже, чем в блочных или файловых, за счёт более гибкой и точной тарификации для клиента это всё равно выходит выгоднее, так как он платит только за то, что реально использовал. А минус в скорости работы компенсируется простотой горизонтального масштабирования S3 хранилищ.
❗️Нужно хорошо понимать, что S3 это не про скорость доступа, а про объём и унификацию.
Расписал всё своими словами. Надеюсь понятно объяснил. На практике S3 лучше всего подходит под хранение статических файлов больших сайтов, архивов видеонаблюдения, логов, бэкапов. Конкретно я именно для холодных бэкапов их использую. Обычно это бэкапы бэкапов, копируются с помощью rclone.
#s3
{kind=link}
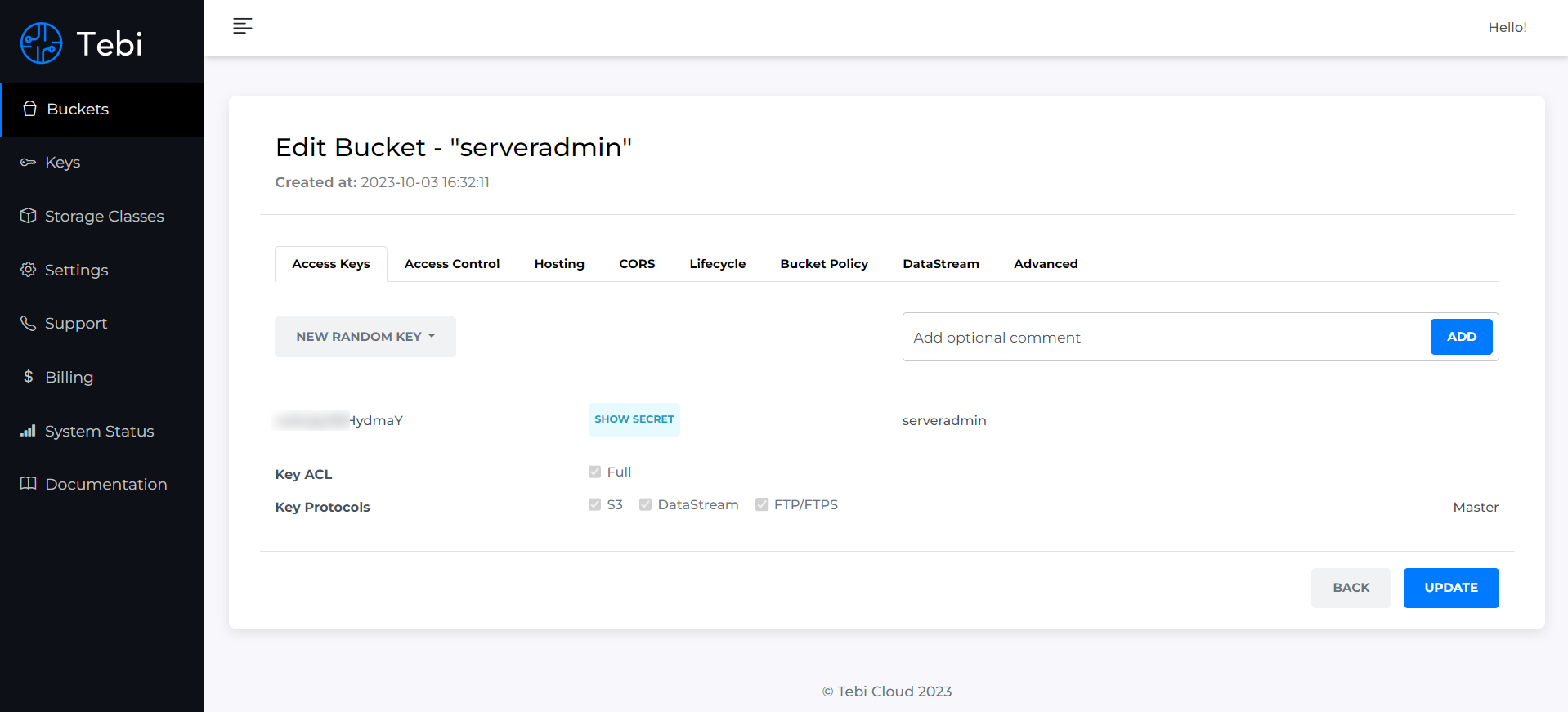
Если хотите потренироваться и погонять бесплатно S3 хранилище, то у меня есть подходящий сервис для вас с бесплатным тарифным планом - tebi.io. Для регистрации требуется только email, карту не просят. Обещают Free Tier с ограничением на 25 GiB хранилища и 250 GiB исходящего трафика в месяц.
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
И можно грузить файлы или директории:
Для FTP нужны только эти данные:
Третий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
[tebi]type = s3provider = Otheraccess_key_id = uo5csfdErtydmaYsecret_access_key = vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmendpoint = https://s3.tebi.io/acl = privateИ можно грузить файлы или директории:
# rclone sync -i testfile.exe tebi:bucket_nameДля FTP нужны только эти данные:
server: ftp.tebi.ioport: 21login: uo5csfdErtydmaYpassword: vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmТретий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
{kind=link}
Немного поизучал тему self-hosted решений для S3 и понял, что аналогов MiniO по сути и нет. Всё, что есть, либо малофункционально, либо малоизвестно. Нет ни руководств, ни отзывов. Но в процессе заметил любопытный продукт от известной компании Zenko, которая специализируется на multi-cloud решениях.
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
Примеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
Речь пойдёт про их open source продукт Zenko CloudServer. Заявлено, что он полностью совместим и заменяем для Amazon S3 хранилищ. Он может выступать как обычный S3 сервер с сохранением файлов локально, так и использовать для хранения другие публичные или приватные бэкенды. То есть его назначение в том числе выступать неким прокси для S3 запросов.
CloudServer может принимать запросы на сохранение в одно место, а реально сохранять в другое, либо сразу в несколько. Это ложится в концепцию продуктов Zenko по мультиоблачной работе. Допустим, у вас приложение настроено на сохранение данных в конкретный бакет AWS. Вы можете настроить CloudServer так, что приложение будет считать его за AWS, а реально данные будут складываться, к примеру, в локальный кластер, а их копия в какой-то другой сервис, отличный от AWS. Надеюсь, идею поняли.
Я немного погонял этот сервер локально и могу сказать, что настроить его непросто. Запустить у меня получилось, но вот полноценно настроить хранение на внешнем бэкенде при обращении к локальному серверу я не смог. Документация не очень подробная, готовых полных примеров не увидел, только отрывки конфигов. Часа два провозился и бросил.
В целом инструмент рабочий. Есть живой репозиторий, документация, да и самому серверу уже много лет. Если вам реально нужна подобная функциональность, то можно разобраться. Можно один раз настроить CloudServer, а потом у него переключать различные бэкенды для управления хранением.
Дам немного подсказок, чтобы сэкономить время тем, кому это реально нужно будет. Запускал через Docker вот так:
docker run -p 8000:8000 --name=cloudserver \ -v $(pwd)/config.json:/usr/src/app/config.json \ -v $(pwd)/locationConfig.json /usr/src/app/locationConfig.json \ -v $(pwd)/data:/usr/src/app/localData \ -v $(pwd)/metadata:/usr/src/app/localMetadata \ -e REMOTE_MANAGEMENT_DISABLE=1 -d zenko/cloudserverПримеры конфигов есть в репозитории, а описание в документации. Конфигурация rclone для работы с сервером:
[remote]type = s3env_auth = falseaccess_key_id = accessKey1secret_access_key = verySecretKey1region = other-v2-signatureendpoint = http://localhost:8000location_constraint =acl = privateserver_side_encryption =storage_class =Соответственно используются дефолтные секреты accessKey1 и verySecretKey1. Их можно переназначить через conf/authdata.json, пример конфига тоже есть в репозитории. По умолчанию управление только через конфиги и API, веб интерфейса нет. В качестве веб интерфейса может выступать Zenko Orbit, входящий в состав продукта multi-cloud data controller. Он опенсорсный, но это уже отдельная история.
⇨ Сайт / Исходники / Документация
#S3 #devops
{kind=link}
Вчера бился часа 3-4 над одной проблемой. Уже спать пора было ложиться, но не могу уснуть, когда не доделано дело. Не даст спокойно спать, а на следующий день всё равно придётся доделывать. Не могу бросить нерешённые задачи, даже если они не очень важные. Особенно, когда кажется, что ещё чуть-чуть и всё заработает.
Мне нужно было настроить aws-cli для работы со сторонними S3 сервисами. В целом, проблем особых нет. У Yandex.Cloud или Selectel есть для этого инструкции. Важная особенность в том, что эта утилита заточена на использование с сервисами AWS. Для подключения к сторонним сервисам есть консольный ключ
Мне нужно было настроить работу без этого ключа. Для этого нужно правильно настроить
Я пробовал и на локальном WSL под Ubuntu, и на виртуалке под Debian 12. Никак не получалось настроить. Не буду вас утомлять дальнейшем рассказом. Сразу скажу, в чём было дело. Есть параметр для файла credentials:
Но появился он не так давно. Версии aws-cli на обоих системах, что я настраивал, были старее, где этого параметра ещё не было. При этом утилита на него не ругалась. Я такого накрутил в настройках и переменных, что даже когда обновил утилиту до последней версии, не заработало.
Потом всё обнулил, начал с самого начала с новой версией и всё получилось. Поначалу даже мысли не было, что версия слишком старая. Обычно на неподдерживаемые параметры программы ругаются. А тут тишина. Тупо не принимает его, хоть ты что делай. Я уже не знал, что и думать. Всё перепробовал.
Вот описание настроек в документации. Тут и намека нет на версию, начиная с которой это поддерживается. В версии 2.9.19 не работает, в последней 2.13.39 - работает. Появилось это только в июле этого года в версии 2.13.0. А обсуждение этой фичи есть аж с 2015 года.
Обидно потерять столько времени на такой ерунде.
#s3
Мне нужно было настроить aws-cli для работы со сторонними S3 сервисами. В целом, проблем особых нет. У Yandex.Cloud или Selectel есть для этого инструкции. Важная особенность в том, что эта утилита заточена на использование с сервисами AWS. Для подключения к сторонним сервисам есть консольный ключ
--endpoint-url=https://s3.ru-1.storage.selcloud.ru. Это вариант для Selectel. Он работает нормально.Мне нужно было настроить работу без этого ключа. Для этого нужно правильно настроить
~/.aws/config и ~/.aws/credentials. Начал гуглить решение задачи. Наткнулся на множество вопросов, где люди спрашивают, как подобное настроить. Где-то есть инструкции, как это предположительно может работать, как обойти этот вопрос, например добавлением алиаса с уже настроенным эндпоинтом, чтобы его не набирать. Можно использовать переменные окружения типа export AWS_ENDPOINT_URL=https://s3.ru-1.storage.selcloud.ru, но у меня они почему-то никак не работали.Я пробовал и на локальном WSL под Ubuntu, и на виртуалке под Debian 12. Никак не получалось настроить. Не буду вас утомлять дальнейшем рассказом. Сразу скажу, в чём было дело. Есть параметр для файла credentials:
endpoint_url = https://s3.ru-1.storage.selcloud.ruНо появился он не так давно. Версии aws-cli на обоих системах, что я настраивал, были старее, где этого параметра ещё не было. При этом утилита на него не ругалась. Я такого накрутил в настройках и переменных, что даже когда обновил утилиту до последней версии, не заработало.
Потом всё обнулил, начал с самого начала с новой версией и всё получилось. Поначалу даже мысли не было, что версия слишком старая. Обычно на неподдерживаемые параметры программы ругаются. А тут тишина. Тупо не принимает его, хоть ты что делай. Я уже не знал, что и думать. Всё перепробовал.
Вот описание настроек в документации. Тут и намека нет на версию, начиная с которой это поддерживается. В версии 2.9.19 не работает, в последней 2.13.39 - работает. Появилось это только в июле этого года в версии 2.13.0. А обсуждение этой фичи есть аж с 2015 года.
Обидно потерять столько времени на такой ерунде.
#s3
{kind=link}
Озадачился вопросом GUI клиента для S3 под Windows. Обычно у всех сервисов есть веб интерфейс, так что для разовых задач можно и им воспользоваться. Но локальным клиентом всё равно удобнее.
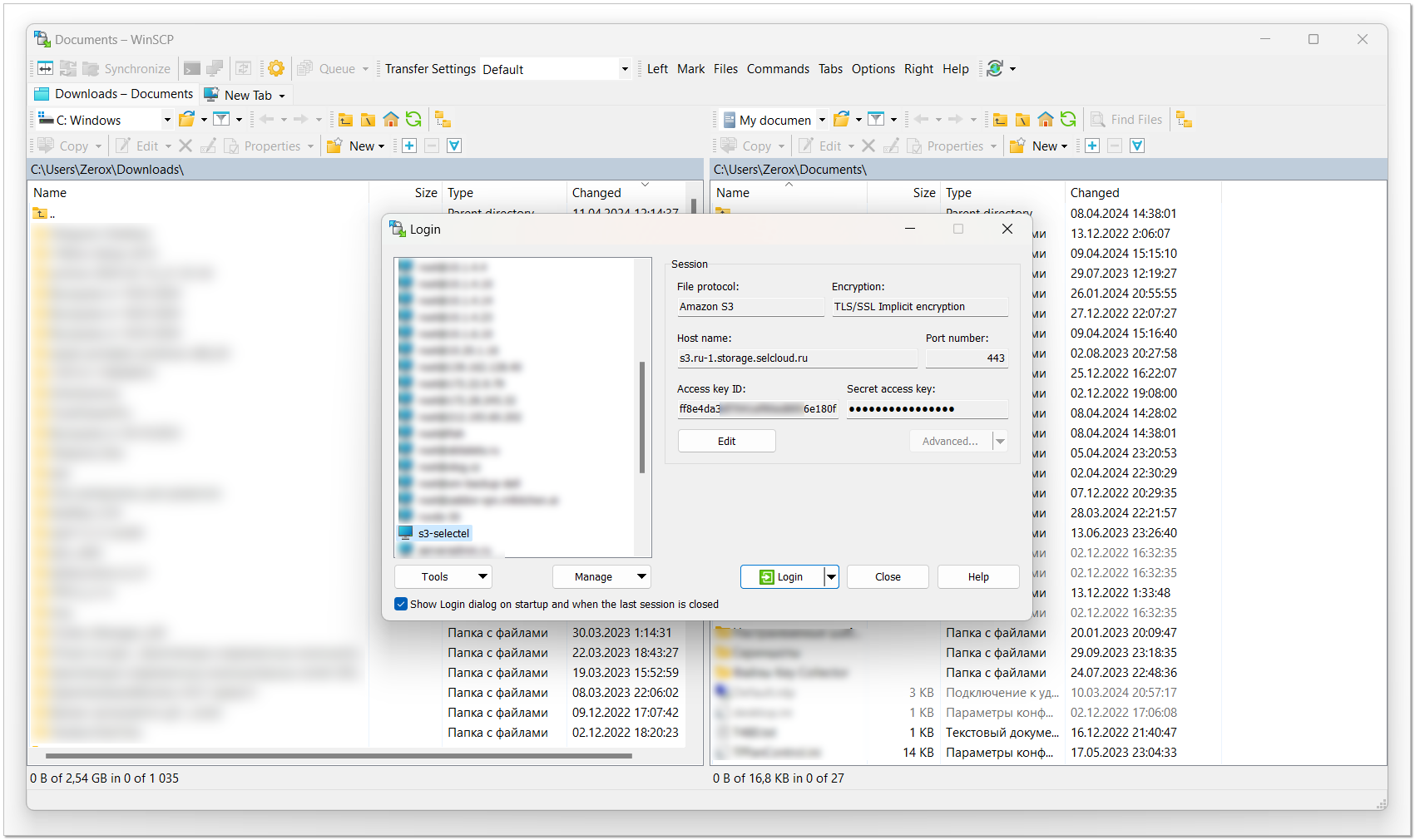
Быстро посмотрел в поиске и практически сразу же увидел, что WinSCP оказывается поддерживает S3. Я этой программой пользуюсь с незапамятных времён для подключений по SFTP, другие протоколы даже не смотрел. Для FTP привык к Total Commander, так что у меня эта связка очень давно. Посмотрел на свою портированную версию WinSCP, она от 2020 года. Обновил до свежей и попробовал.
WinSCP реально поддерживает S3 совместимые хранилища, хоть в настройках и указано, что протокол Amazon S3. Я подключился к хранилищу Selectel, просто указав s3.ru-1.storage.selcloud.ru и access key, secret key от сервисного пользователя с соответствующим доступом. Единственный нюанс был - надо включить Virtual-Hosted адресацию в конфигурации контейнера. Без этого хоть и подключался, но не мог в контейнеры заходить.
Других провайдеров не пробовал, но видел, что WinSCP с Яндекс облаком тоже без проблем работает. Думаю, что и со всеми остальными всё в порядке будет.
#s3
Быстро посмотрел в поиске и практически сразу же увидел, что WinSCP оказывается поддерживает S3. Я этой программой пользуюсь с незапамятных времён для подключений по SFTP, другие протоколы даже не смотрел. Для FTP привык к Total Commander, так что у меня эта связка очень давно. Посмотрел на свою портированную версию WinSCP, она от 2020 года. Обновил до свежей и попробовал.
WinSCP реально поддерживает S3 совместимые хранилища, хоть в настройках и указано, что протокол Amazon S3. Я подключился к хранилищу Selectel, просто указав s3.ru-1.storage.selcloud.ru и access key, secret key от сервисного пользователя с соответствующим доступом. Единственный нюанс был - надо включить Virtual-Hosted адресацию в конфигурации контейнера. Без этого хоть и подключался, но не мог в контейнеры заходить.
Других провайдеров не пробовал, но видел, что WinSCP с Яндекс облаком тоже без проблем работает. Думаю, что и со всеми остальными всё в порядке будет.
#s3
{kind=link}
▶️ Сегодня у нас пятница, и это будет день видео. Вечером будет подборка роликов, а сейчас я хочу рассказать про одно конкретное выступление, потому что оно мне понравилось, как по тематике, так и по изложению:
⇨ Свой распределённый S3 на базе MinIO — практический опыт наступания на грабли / Алексей Плетнёв
Выступление двухгодичной давности, но я его посмотрел только на днях. У крупной компании возникла потребность в большом файловом хранилище (100 TБ данных и 100 ТБ трафика в месяц). Готовые решения отбросили из-за дороговизны. Решили строить своё на базе известного сервера MinIO.
📌 Причины, почему выбрали MinIO:
◽Open Source
◽Производительный
◽Распределённая архитектура
◽Легко масштабируется и разворачивается
◽Сжатие файлов на лету
◽Общая популярность проекта
📌 Проблемы, с которыми столкнулись при внедрении и эксплуатации:
▪️ Не очень информативная документация
▪️ По умолчанию модель отказоустойчивости такова, что при неудачном стечении обстоятельств выход из строя буквально нескольких дисков на одном сервере может привести к потере информации, хотя на первый взгляд кажется, что чуть ли не потеря половины кластера не приведёт к этому
▪️ Нельзя расширить существующий кластер. Можно только создать новый и присоединить его к текущему.
▪️ При обновлении нельзя перезапускать ноды по очереди. Рестартить надо разом весь кластер, так что без простоя сервиса не обойтись.
▪️ Вылезла куча критических багов, когда пропадали все пользователи и политики, бились сжатые файлы, неверно работало кэширование и т.д.
▪️ Реальный срок восстановления после замены диска непрогнозируемый. Нагрузка при этом на диски сопоставима с эксплуатацией RAID5.
▪️ Нет мониторинга производительности дисков. Если один диск жёстко тормозит, тормозит весь кластер. Эту проблему ты должен решать самостоятельно.
Для полноценного теста отказоустойчивого распределённого хранилища достаточно следующего железа. 3 одинаковые ноды:
- 8 CPU
- 16G RAM
- SSD NVME для горячих данных
- HDD для холодных
MinIO поверх ZFS работает значительно лучше, чем на обычной файловой системе, хотя разработчики это не рекомендуют. При расширении ZFS пулов, MinIO адекватно это переваривает и расширяется сам. Это позволяет решать вопрос с расширением кластера налету. Для дополнительной отказоустойчивости и возможности обновления без даунтайма автор к каждой ноде MinIO поставил кэш на базе Nginx. Пока сервер перезапускается, кэши отдают горячие данные.
В итоге автор делает следующий вывод. Minio неплохое локальное решение в рамках одной стойки или дата центра, но для большого распределённого кластера он плохо подходит из-за архитектуры и багов.
Отдельно было интересно узнать мнение автора о Ceph. Они от него отказались из-за сложности в обслуживании. MinIO настроили один раз и он работает практически без присмотра. Ceph требует постоянного наблюдения силами специально обученных людей.
#S3
⇨ Свой распределённый S3 на базе MinIO — практический опыт наступания на грабли / Алексей Плетнёв
Выступление двухгодичной давности, но я его посмотрел только на днях. У крупной компании возникла потребность в большом файловом хранилище (100 TБ данных и 100 ТБ трафика в месяц). Готовые решения отбросили из-за дороговизны. Решили строить своё на базе известного сервера MinIO.
📌 Причины, почему выбрали MinIO:
◽Open Source
◽Производительный
◽Распределённая архитектура
◽Легко масштабируется и разворачивается
◽Сжатие файлов на лету
◽Общая популярность проекта
📌 Проблемы, с которыми столкнулись при внедрении и эксплуатации:
▪️ Не очень информативная документация
▪️ По умолчанию модель отказоустойчивости такова, что при неудачном стечении обстоятельств выход из строя буквально нескольких дисков на одном сервере может привести к потере информации, хотя на первый взгляд кажется, что чуть ли не потеря половины кластера не приведёт к этому
▪️ Нельзя расширить существующий кластер. Можно только создать новый и присоединить его к текущему.
▪️ При обновлении нельзя перезапускать ноды по очереди. Рестартить надо разом весь кластер, так что без простоя сервиса не обойтись.
▪️ Вылезла куча критических багов, когда пропадали все пользователи и политики, бились сжатые файлы, неверно работало кэширование и т.д.
▪️ Реальный срок восстановления после замены диска непрогнозируемый. Нагрузка при этом на диски сопоставима с эксплуатацией RAID5.
▪️ Нет мониторинга производительности дисков. Если один диск жёстко тормозит, тормозит весь кластер. Эту проблему ты должен решать самостоятельно.
Для полноценного теста отказоустойчивого распределённого хранилища достаточно следующего железа. 3 одинаковые ноды:
- 8 CPU
- 16G RAM
- SSD NVME для горячих данных
- HDD для холодных
MinIO поверх ZFS работает значительно лучше, чем на обычной файловой системе, хотя разработчики это не рекомендуют. При расширении ZFS пулов, MinIO адекватно это переваривает и расширяется сам. Это позволяет решать вопрос с расширением кластера налету. Для дополнительной отказоустойчивости и возможности обновления без даунтайма автор к каждой ноде MinIO поставил кэш на базе Nginx. Пока сервер перезапускается, кэши отдают горячие данные.
В итоге автор делает следующий вывод. Minio неплохое локальное решение в рамках одной стойки или дата центра, но для большого распределённого кластера он плохо подходит из-за архитектуры и багов.
Отдельно было интересно узнать мнение автора о Ceph. Они от него отказались из-за сложности в обслуживании. MinIO настроили один раз и он работает практически без присмотра. Ceph требует постоянного наблюдения силами специально обученных людей.
#S3
YouTube
Свой распределённый S3 на базе MinIO — практический опыт наступания на грабли / Алексей Плетнёв
Приглашаем на конференцию HighLoad++ 2024, которая пройдет 2 и 3 декабря в Москве!
Программа, подробности и билеты по ссылке: https://clck.ru/3DD4yb
--------
Saint HighLoad++ 2022
Презентация и тезисы:
https://highload.ru/spb/2022/abstracts/9072
Любому…
Программа, подробности и билеты по ссылке: https://clck.ru/3DD4yb
--------
Saint HighLoad++ 2022
Презентация и тезисы:
https://highload.ru/spb/2022/abstracts/9072
Любому…