
Прочитал на stackoverflow ответ от DBA Postgresql на тему размещения субд в контейнерах. Ответу уже 3 года, но с тех пор принципиально ничего не изменилось. Кратко смысл такой:
▪ Вам надо монтировать директорию с БД к хосту. Докеровская файловая система вообще не пригодна для интенсивной записи.
▪ Вам надо использовать сеть хостовой системы, чтобы не было снижения производительности на накладные расходы.
Эти 2 условия практически полностью нивелируют удобства Docker. Большого смысла запускать СУБД в контейнере нет. Речь идёт о нагруженной базе данных в проде.
Есть большой опыт использования небольших баз данных и кластеров postgresql в kubernetes у компании Zalando. Я делал отдельную заметку по их выступлению с этой темой на конференции. Там идея такая - большие нагруженные базы в контейнерах не запускают. А вот небольшие базы отдельных микросервисов запускают в kubernetes. Это позволяет организовать удобное централизованное управление и деплой новых баз для различных сервисов и команд.
У меня была еще одна заметка на тему базы данных в Docker. Там я делаю выжимку из статьи компании Percona о её собственных тестах производительности БД в контейнерах. Там вывод такой же, как и в у DBA со stackoverflow. Нужно обязательно использовать сеть хоста, чтобы не было просадки производительности.
В итоге получается, что для хорошей производительности, БД жёстко мапится к самому хосту и сетью, и диском. Ни о каком stateless подходе, на который в первую очередь ориентированы контейнеры, речи не идёт. Польза контейнеров в истории с субд может быть только при использовании большого количества ненагруженных баз, управление которыми может быть организовано с помощью средств оркестрации контейнерами.
У меня в практике как то раз был случай, когда база данных Mysql, запущенная в контейнере, просто исчезла. Разработчики запустили один проект заказчику полностью в контейнерах. В какой-то момент замапленная директория с файлами БД оказалась полностью пустой. Был такой древний баг. Его уже давно пофиксили.
Написал заметку, чтобы вы лишний раз подумали, когда будете использовать докер, а нужен ли он тут. Запускать одиночную субд на хосте в контейнере нет никакого смысла. Точно так же ее можно установить через пакетный менеджер и запустить. Работать будет быстрее, проблем будет меньше.
#postgresql #mysql #docker
▪ Вам надо монтировать директорию с БД к хосту. Докеровская файловая система вообще не пригодна для интенсивной записи.
▪ Вам надо использовать сеть хостовой системы, чтобы не было снижения производительности на накладные расходы.
Эти 2 условия практически полностью нивелируют удобства Docker. Большого смысла запускать СУБД в контейнере нет. Речь идёт о нагруженной базе данных в проде.
Есть большой опыт использования небольших баз данных и кластеров postgresql в kubernetes у компании Zalando. Я делал отдельную заметку по их выступлению с этой темой на конференции. Там идея такая - большие нагруженные базы в контейнерах не запускают. А вот небольшие базы отдельных микросервисов запускают в kubernetes. Это позволяет организовать удобное централизованное управление и деплой новых баз для различных сервисов и команд.
У меня была еще одна заметка на тему базы данных в Docker. Там я делаю выжимку из статьи компании Percona о её собственных тестах производительности БД в контейнерах. Там вывод такой же, как и в у DBA со stackoverflow. Нужно обязательно использовать сеть хоста, чтобы не было просадки производительности.
В итоге получается, что для хорошей производительности, БД жёстко мапится к самому хосту и сетью, и диском. Ни о каком stateless подходе, на который в первую очередь ориентированы контейнеры, речи не идёт. Польза контейнеров в истории с субд может быть только при использовании большого количества ненагруженных баз, управление которыми может быть организовано с помощью средств оркестрации контейнерами.
У меня в практике как то раз был случай, когда база данных Mysql, запущенная в контейнере, просто исчезла. Разработчики запустили один проект заказчику полностью в контейнерах. В какой-то момент замапленная директория с файлами БД оказалась полностью пустой. Был такой древний баг. Его уже давно пофиксили.
Написал заметку, чтобы вы лишний раз подумали, когда будете использовать докер, а нужен ли он тут. Запускать одиночную субд на хосте в контейнере нет никакого смысла. Точно так же ее можно установить через пакетный менеджер и запустить. Работать будет быстрее, проблем будет меньше.
#postgresql #mysql #docker
{kind=link}
Рекомендую к просмотру интересное выступление с HighLoad ++ Даниила Захлыстова (Яндекс) - Надежные и быстрые бэкапы PostgreSQL. Речь там идёт про всем известный инструмент WAL-G для бэкапов баз PostgreSQL.
Выступление короткое и достаточно ёмкое. Рассказано в основном про нововведения готовящегося релиза на момент записи трансляции, так как в целом про WAL-G много информации. Релиз v1.0 в итоге состоялся 31 мая.
WAL-G один из лучших бесплатный инструмент для резервного копирования PostgreSQL. Поддерживает полные и инкрементные бэкапы. Его отличает хорошая поддержка современных облачных хранилищ для хранения архивов.
В видео помимо непосредственно рассказа о WAL-G дана общая информация по бэкапам баз данных, что может быть интересно для тех, кто не сильно разбирается в этой теме.
📌 Полезные ссылки:
Youtube - https://www.youtube.com/watch?v=DcIq7H622dQ
Тэзисы выступления - https://www.highload.ru/spring/2021/abstracts/7276
Исходники WAL-G - https://github.com/wal-g/wal-g
Статья с настройкой и примерами - https://habr.com/ru/post/486188/
В связи с тем, что сейчас многие переезжают на PostgreSQL, в том числе с 1С, информация актуальна. Стоит сохранить в закладках.
#backup #postgresql
Выступление короткое и достаточно ёмкое. Рассказано в основном про нововведения готовящегося релиза на момент записи трансляции, так как в целом про WAL-G много информации. Релиз v1.0 в итоге состоялся 31 мая.
WAL-G один из лучших бесплатный инструмент для резервного копирования PostgreSQL. Поддерживает полные и инкрементные бэкапы. Его отличает хорошая поддержка современных облачных хранилищ для хранения архивов.
В видео помимо непосредственно рассказа о WAL-G дана общая информация по бэкапам баз данных, что может быть интересно для тех, кто не сильно разбирается в этой теме.
📌 Полезные ссылки:
Youtube - https://www.youtube.com/watch?v=DcIq7H622dQ
Тэзисы выступления - https://www.highload.ru/spring/2021/abstracts/7276
Исходники WAL-G - https://github.com/wal-g/wal-g
Статья с настройкой и примерами - https://habr.com/ru/post/486188/
В связи с тем, что сейчас многие переезжают на PostgreSQL, в том числе с 1С, информация актуальна. Стоит сохранить в закладках.
#backup #postgresql
{kind=link}
Если вам вдруг понадобится база данных PostgreSQL для каких-то целей на время, можно воспользоваться готовым сервисом с бесплатным тарифным планом. Например - https://bit.io. Они бесплатно дают PostgreSQL managed database service с ограничением размера базы в 10 Гб и не более 10 миллионов запросов в месяц.
Подобный сервис может быть полезен в первую очередь для каких-то тестов, когда не хочется поднимать и настраивать свою базу данных. В bit.io для регистрации нужен только email. Сразу после регистрации вы получите тестовую базу данных и параметры подключения к ней. Не удаляйте ее. У меня не получилось после удаления заново создать бесплатную базу. То ли глюк, то ли какое-то ограничение, я не понял.
Чтобы узнать параметры подключения к базе, в личном кабинете слева нажмите на кнопку Connect. Увидите адрес сервера, имя базы, пароль от неё. Доступ к базе возможен как через внешнее подключение, так и через веб интерфейс личного кабинета, что упрощает управление. Я сразу же проверил подключение через HeidiSQL. Без проблем подключился.
#бесплатно #postgresql
Подобный сервис может быть полезен в первую очередь для каких-то тестов, когда не хочется поднимать и настраивать свою базу данных. В bit.io для регистрации нужен только email. Сразу после регистрации вы получите тестовую базу данных и параметры подключения к ней. Не удаляйте ее. У меня не получилось после удаления заново создать бесплатную базу. То ли глюк, то ли какое-то ограничение, я не понял.
Чтобы узнать параметры подключения к базе, в личном кабинете слева нажмите на кнопку Connect. Увидите адрес сервера, имя базы, пароль от неё. Доступ к базе возможен как через внешнее подключение, так и через веб интерфейс личного кабинета, что упрощает управление. Я сразу же проверил подключение через HeidiSQL. Без проблем подключился.
#бесплатно #postgresql
{kind=link}
Технический пост, который уже давно нужно было сделать, но всё руки не доходили. На канале много содержательных заметок по различным темам. Иногда сам через поиск ищу то, о чём писал. Ниже набор наиболее популярных тэгов по которым можно найти что-то полезное (и не очень).
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
Решил написать небольшую шпаргалку по работе в консоли с PostgreSQL. Последнее время всё чаще и чаще приходится иметь с ней дело по двум причинам:
1️⃣ Все новые установки Zabbix Server делаю на postgresql.
2️⃣ Намного чаще стали использовать postgresql в связке с 1С.
PostgreSQL создаёт отдельного пользователя Linux postgres, так что все команды буду делать с указанием этого пользователя. Я обычно работаю так, хотя никто не мешает сразу авторизоваться под ним и запускать команды напрямую. Второй момент - в зависимости от дистрибутива и пакета установки, бинарники postgresql могут находиться в разных местах и не всегда переменная path будет применена. Так что может понадобиться полный путь к исполняемому файлу (pg_dump, psql и т.д.).
📌 Просмотр списка баз:
📌 Создание текстового дампа базы данных:
📌 Сжимаем дамп на лету с помощью pigz (умеет жать всеми ядрами):
📌 Восстановление базы данных в новую базу (сначала создаём её):
Для автоматических бэкапов могу порекомендовать бесплатную программу SQLBackupAndFTP.
📌 Выход из консоли psql (часто забываю):
📌 Создать пользователя:
Задать пароль:
📌 Посмотреть список пользователей:
📌 Дать полные права на базу:
📌 Назначить пользователя владельцем базы:
📌 Выполнить очистку (-f) и анализ (-z) базы данных Postgres Pro:
📌 Переиндексировать базу:
📌 Удалить базу данных:
#postgresql #bash
1️⃣ Все новые установки Zabbix Server делаю на postgresql.
2️⃣ Намного чаще стали использовать postgresql в связке с 1С.
PostgreSQL создаёт отдельного пользователя Linux postgres, так что все команды буду делать с указанием этого пользователя. Я обычно работаю так, хотя никто не мешает сразу авторизоваться под ним и запускать команды напрямую. Второй момент - в зависимости от дистрибутива и пакета установки, бинарники postgresql могут находиться в разных местах и не всегда переменная path будет применена. Так что может понадобиться полный путь к исполняемому файлу (pg_dump, psql и т.д.).
📌 Просмотр списка баз:
# sudo -u postgres psql -U postgres -l📌 Создание текстового дампа базы данных:
# sudo -u postgres pg_dump -U postgres basa01 \> ~/basa01.sql📌 Сжимаем дамп на лету с помощью pigz (умеет жать всеми ядрами):
# sudo -u postgres pg_dump -U postgres basa01 \| pigz > ~/basa01.sql.gz📌 Восстановление базы данных в новую базу (сначала создаём её):
# sudo -u postgres createdb -U postgres \-T template0 basa02# sudo -u postgres psql -U postgres basa02 \< ~/basa01.sqlДля автоматических бэкапов могу порекомендовать бесплатную программу SQLBackupAndFTP.
📌 Выход из консоли psql (часто забываю):
$ \q📌 Создать пользователя:
# sudo -u postgres createuser -U postgres zabbixЗадать пароль:
# sudo -u postgres psql -U postgres -c \"ALTER USER zabbix PASSWORD 'secpasswd'"📌 Посмотреть список пользователей:
# sudo -u postgres psql -U postgres -c \"select * from pg_user"📌 Дать полные права на базу:
# sudo -u postgres psql -U postgres -c \"GRANT ALL PRIVILEGES ON DATABASE zabbixdb to zabbix"📌 Назначить пользователя владельцем базы:
# sudo -u postgres psql -U postgres -c \"ALTER DATABASE zabbixdb OWNER TO zabbix"📌 Выполнить очистку (-f) и анализ (-z) базы данных Postgres Pro:
# sudo -u postgres vacuumdb -U postgres -f -z -d basa01📌 Переиндексировать базу:
# sudo -u postgres reindexdb -U postgres -d basa01📌 Удалить базу данных:
# sudo -u postgres psql -U postgres -c \"DROP DATABASE basa01"#postgresql #bash
{kind=link}
Вчера в комментариях к заметке про PostgreSQL посоветовали утилиту для бэкапа - pg_probackup. Я не знал про неё и никогда не использовал, но решил посмотреть. Оказалось, это очень удобный и надёжный вариант бэкапа баз данных PostgreSQL. Расскажу про особенности и варианты использования этой утилиты.
Авторами pg_probackup является небезызвестная компания Postgres Professional - российская компания, разработчик систем управления базами данных. Утилита поддерживает как ванильные версии postgres, так и собственные платные сборки postgres pro.
📌Pg_probackup умеет:
▪ Выполнять полные и инкрементные бэкапы как отдельных серверов, так и кластеров.
▪ Делать инкрементные бэкапы разными способами: разностное копирование, страничное копирование или копирование изменений. Разные способы дают разную нагрузку на систему и занимают разное количество времени.
▪ Выполнять контроль целостности данных и проверку резервных копий без восстановления самих данных.
▪ Управлять политиками хранения резервных копий в соответствии с заданными параметрами.
▪ Самостоятельно сжимать данные без внешних архиваторов.
▪ Работать в режиме клиент-сервер, то есть настраивается сервер хранения pg_probackup, который сам подключается к хостам с postgresql и забирает бэкапы.
▪ Отдельно поддерживает возможность бэкапа произвольных директорий и файлов. Например, директорию с конфигурацией кластера, с логами или какими-то самописными скриптами.
▪ Вести каталог резервных копий с метаданными архивов, данные о которых может отдавать в формате json.
Продукт многофункциональный, который закрывает полностью вопрос с бэкапами, политикой хранения и мониторинга. Получая информацию об архивах в json, очень легко прикрутить мониторинг к тому же Zabbix Server или Prometheus.
Как можно понять из описания, pg_probackup - универсальный инструмент, который подойдёт как для полного бэкапа одиночных баз и серверов, так и кластеров в различных режимах инкрементов. Архивы можно хранить локально или передавать по сети в единый каталог.
У утилиты есть подробное описание на русском языке. Для установки созданы репозитории под все популярные системы, в том числе отечественные.
Примеры запуска и использования приводить не буду, так как всё подробно и по-русски описано в документации. В общем случае сначала надо инициализировать каталог резервных копий, потом добавить туда сервер PostgreSQL, настроить политику хранения, запустить бэкап.
❓Напрашивается важный вопрос. А когда стоит переходить к подобным бэкапам от простых дампов. Однозначного ответа тут нет. Ориентироваться нужно по следующим признакам:
1️⃣ Вам нужна возможность откатить состояние базы на любой момент в прошлом. Тогда дампы вообще не подходят.
2️⃣ Размер базы данных такой, что выполнение дампа занимает значительное время и снижает производительность сервера.
3️⃣ Хочется иметь большую глубину хранения резервных копий, но в полных дампах она будет занимать слишком много места.
По моим прикидкам, если сжатый дамп начинает занимать более 5 Гб, стоит думать о других способах создания и хранения резервных копий БД.
Исходники / Документация
#postgresql #backup
Авторами pg_probackup является небезызвестная компания Postgres Professional - российская компания, разработчик систем управления базами данных. Утилита поддерживает как ванильные версии postgres, так и собственные платные сборки postgres pro.
📌Pg_probackup умеет:
▪ Выполнять полные и инкрементные бэкапы как отдельных серверов, так и кластеров.
▪ Делать инкрементные бэкапы разными способами: разностное копирование, страничное копирование или копирование изменений. Разные способы дают разную нагрузку на систему и занимают разное количество времени.
▪ Выполнять контроль целостности данных и проверку резервных копий без восстановления самих данных.
▪ Управлять политиками хранения резервных копий в соответствии с заданными параметрами.
▪ Самостоятельно сжимать данные без внешних архиваторов.
▪ Работать в режиме клиент-сервер, то есть настраивается сервер хранения pg_probackup, который сам подключается к хостам с postgresql и забирает бэкапы.
▪ Отдельно поддерживает возможность бэкапа произвольных директорий и файлов. Например, директорию с конфигурацией кластера, с логами или какими-то самописными скриптами.
▪ Вести каталог резервных копий с метаданными архивов, данные о которых может отдавать в формате json.
Продукт многофункциональный, который закрывает полностью вопрос с бэкапами, политикой хранения и мониторинга. Получая информацию об архивах в json, очень легко прикрутить мониторинг к тому же Zabbix Server или Prometheus.
Как можно понять из описания, pg_probackup - универсальный инструмент, который подойдёт как для полного бэкапа одиночных баз и серверов, так и кластеров в различных режимах инкрементов. Архивы можно хранить локально или передавать по сети в единый каталог.
У утилиты есть подробное описание на русском языке. Для установки созданы репозитории под все популярные системы, в том числе отечественные.
Примеры запуска и использования приводить не буду, так как всё подробно и по-русски описано в документации. В общем случае сначала надо инициализировать каталог резервных копий, потом добавить туда сервер PostgreSQL, настроить политику хранения, запустить бэкап.
❓Напрашивается важный вопрос. А когда стоит переходить к подобным бэкапам от простых дампов. Однозначного ответа тут нет. Ориентироваться нужно по следующим признакам:
1️⃣ Вам нужна возможность откатить состояние базы на любой момент в прошлом. Тогда дампы вообще не подходят.
2️⃣ Размер базы данных такой, что выполнение дампа занимает значительное время и снижает производительность сервера.
3️⃣ Хочется иметь большую глубину хранения резервных копий, но в полных дампах она будет занимать слишком много места.
По моим прикидкам, если сжатый дамп начинает занимать более 5 Гб, стоит думать о других способах создания и хранения резервных копий БД.
Исходники / Документация
#postgresql #backup
Существуют разные подходы к мониторингу. Можно настраивать одну универсальную систему и всё замыкать на неё. Это удобно в том плане, что всё в одном месте. Но мониторинг каждого отдельного элемента будет не самым лучшим.
Другой подход - для каждого продукта использовать тот мониторинг, который заточен именно под него. Например, такой мониторинг есть для Nginx - NGINX Amplify. Или мониторинг для баз данных от Percona - Percona Monitoring and Management (PMM). Про последний я и хочу сегодня рассказать.
Percona Monitoring and Management - open source мониторинг для баз данных MySQL, PostgreSQL и MongoDB. Построен на базе своего PMM Server и PMM Agent. Визуализация метрик реализована через Grafana.
Благодаря тому, что это узкоспециализированный продукт, его очень легко установить и настроить. По сути и настраивать то нечего. Достаточно установить сервер, агенты на хосты с БД и дальше смотреть метрики в готовых дашбордах Графаны.
Это не сравнится с тем, что предлагает Zabbix по мониторингу баз данных. Да, все те же метрики в него тоже можно передать. Но настроить всё это в готовую систему с метриками, триггерами, оповещениями, графиками и дашбордами очень хлопотно. А в PMM всё это работает сразу после установки. Времени нужно минимум, чтобы запустить мониторинг.
В принципе, если для вас важны базы данных, подобные мониторинги можно и отдельно разворачивать рядом с основным, а потом события со всех мониторингов собирать в одном месте. Например, с помощью OnCall.
Как я уже сказал, установить PMM очень просто. Можете сами оценить сложность и трудозатраты - Install Percona Monitoring and Management. Буквально 10 минут копипасты: ставим сервер, ставим клиент, соединяем клиента с сервером, добавляем в базу пользователя для сбора метрик. Если я правильно понял, то PMM построен на базе prometheus и использует метрики с его exporters.
Как всё это выглядит, можете посмотреть в публичном Demo. Там даже аутентификация не нужна. Помимо метрик баз данных PMM может собирать типовые метрики сервера Linux, HAProxy, выполнять внешние проверки tcp портов или забирать метрики по http.
Проект относительно свежий (2019 год) и очень активно развивается.
⇨ Сайт / Установка / Demo / Исходники
#мониторинг #mysql #postgresql
Другой подход - для каждого продукта использовать тот мониторинг, который заточен именно под него. Например, такой мониторинг есть для Nginx - NGINX Amplify. Или мониторинг для баз данных от Percona - Percona Monitoring and Management (PMM). Про последний я и хочу сегодня рассказать.
Percona Monitoring and Management - open source мониторинг для баз данных MySQL, PostgreSQL и MongoDB. Построен на базе своего PMM Server и PMM Agent. Визуализация метрик реализована через Grafana.
Благодаря тому, что это узкоспециализированный продукт, его очень легко установить и настроить. По сути и настраивать то нечего. Достаточно установить сервер, агенты на хосты с БД и дальше смотреть метрики в готовых дашбордах Графаны.
Это не сравнится с тем, что предлагает Zabbix по мониторингу баз данных. Да, все те же метрики в него тоже можно передать. Но настроить всё это в готовую систему с метриками, триггерами, оповещениями, графиками и дашбордами очень хлопотно. А в PMM всё это работает сразу после установки. Времени нужно минимум, чтобы запустить мониторинг.
В принципе, если для вас важны базы данных, подобные мониторинги можно и отдельно разворачивать рядом с основным, а потом события со всех мониторингов собирать в одном месте. Например, с помощью OnCall.
Как я уже сказал, установить PMM очень просто. Можете сами оценить сложность и трудозатраты - Install Percona Monitoring and Management. Буквально 10 минут копипасты: ставим сервер, ставим клиент, соединяем клиента с сервером, добавляем в базу пользователя для сбора метрик. Если я правильно понял, то PMM построен на базе prometheus и использует метрики с его exporters.
Как всё это выглядит, можете посмотреть в публичном Demo. Там даже аутентификация не нужна. Помимо метрик баз данных PMM может собирать типовые метрики сервера Linux, HAProxy, выполнять внешние проверки tcp портов или забирать метрики по http.
Проект относительно свежий (2019 год) и очень активно развивается.
⇨ Сайт / Установка / Demo / Исходники
#мониторинг #mysql #postgresql
{kind=link}
Те, кто постоянно работают с Postgresql наверняка знают про такой параметр, как stats_temp_directory. В самой документации по СУБД сказано, что его перенос в ОЗУ снизит нагрузку на файловое хранилище и увеличит быстродействие.
Я в обязательном порядке переносил это хранилище для временных данных статистики в tmpfs, потому что при использовании SSD этот каталог очень быстро съедал его ресурс. И это не пустые опасения, как часто бывает с SSD. Я реально видел по мониторингу, как утекал ресурс. Там идёт постоянная активная перезапись.
Хорошая новость в том, что в Postgres 15 больше не потребуется это делать. Там все подсчёты статистики выполняются в памяти по умолчанию. Такого параметра, как stats_temp_directory больше нет.
Сейчас уже активно обновляют или ставят 1С вместе с Postgres 15, так что информирую. Сборку postgresql для 1С можно скачать тут - https://1c.postgres.ru. 15-я уже в наличии.
#postgresql
Я в обязательном порядке переносил это хранилище для временных данных статистики в tmpfs, потому что при использовании SSD этот каталог очень быстро съедал его ресурс. И это не пустые опасения, как часто бывает с SSD. Я реально видел по мониторингу, как утекал ресурс. Там идёт постоянная активная перезапись.
Хорошая новость в том, что в Postgres 15 больше не потребуется это делать. Там все подсчёты статистики выполняются в памяти по умолчанию. Такого параметра, как stats_temp_directory больше нет.
Сейчас уже активно обновляют или ставят 1С вместе с Postgres 15, так что информирую. Сборку postgresql для 1С можно скачать тут - https://1c.postgres.ru. 15-я уже в наличии.
#postgresql
Я обновил и актуализировал популярную на сайте статью по настройке сервера 1С:
Установка и настройка 1С на Debian с PostgreSQL
⇨ https://serveradmin.ru/ustanovka-i-nastrojka-1s-na-debian-s-postgresql/
Статья подробная. Позволяет простым копированием и ставкой настроить указанную связку. В ней показаны:
✅ Установка и настройка свежей версии сервера 1С и PosgtreSQL 15 на Debian 11.
✅ Пример создания баз данных на этом сервере и подключение к ним.
✅ Бэкап и обслуживание postgresql баз утилитами сервера бд. Рассказываю про свой подход к этому процессу и привожу скрипты автоматизации.
✅ Как я тестирую восстановление из sql дампов и делаю контрольную проверку в виде выгрузки баз в .dt файлы в консоли Linux. Всё это автоматизируется скриптами.
✅ Рассказываю про свои подходы к мониторингу этих бэкапов и выгрузок, чтобы всегда быть уверенным в том, что у тебя есть гарантированно рабочие бэкапы.
Всё описанное основано на личном опыте настройки и эксплуатации подобных систем. Ни у кого ничего не смотрел, лучших практик не знаю. Придумал всё сам и сделал, как посчитал нужным. Так что не нужно это воспринимать как оптимальное решение.
#1с #postgresql
Установка и настройка 1С на Debian с PostgreSQL
⇨ https://serveradmin.ru/ustanovka-i-nastrojka-1s-na-debian-s-postgresql/
Статья подробная. Позволяет простым копированием и ставкой настроить указанную связку. В ней показаны:
✅ Установка и настройка свежей версии сервера 1С и PosgtreSQL 15 на Debian 11.
✅ Пример создания баз данных на этом сервере и подключение к ним.
✅ Бэкап и обслуживание postgresql баз утилитами сервера бд. Рассказываю про свой подход к этому процессу и привожу скрипты автоматизации.
✅ Как я тестирую восстановление из sql дампов и делаю контрольную проверку в виде выгрузки баз в .dt файлы в консоли Linux. Всё это автоматизируется скриптами.
✅ Рассказываю про свои подходы к мониторингу этих бэкапов и выгрузок, чтобы всегда быть уверенным в том, что у тебя есть гарантированно рабочие бэкапы.
Всё описанное основано на личном опыте настройки и эксплуатации подобных систем. Ни у кого ничего не смотрел, лучших практик не знаю. Придумал всё сам и сделал, как посчитал нужным. Так что не нужно это воспринимать как оптимальное решение.
#1с #postgresql
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
Очень простой в установке и использовании инструмент для анализа работы СУБД Postgres — pgCenter. Это open source разработка нашего соотечественника Алексея Лесовского, который сейчас трудится в PostgresPro. Он давно известен своим проектом zabbix-extensions (проект давно заброшен и неактуален), где собрана куча скриптов для мониторинга всего и вся в Linux.
PgCenter — набор утилит командной строки, которые позволяют анализировать состояние СУБД в режиме реального времени, наподобие программы top и других подобных инструментов.
PgCenter пригодится как обычным админам, чтобы быстро оценить состояние СУБД (использование ресурсов, просмотр ошибок и т.д.), так и DBA для детального изучения (встроенная статистика) и решения проблем (долгие транзакции, конфликты репликации и т.д.).
В репозитории автоматически собираются rpm и deb пакеты для локальной установки, а также Docker образы. Попробовать проще всего вот так:
У автора есть ещё несколько полезных утилит. Скорее всего напишу о них отдельно:
◽Noisia — генератор нагрузки PostgreSQL.
◽pgSCV — экспортёр метрик для Prometheus и Victoriametrics.
◽pgstats.dev — веб проект с описанием метрик Postgres для мониторинга.
⇨ Исходники
#postgresql
PgCenter — набор утилит командной строки, которые позволяют анализировать состояние СУБД в режиме реального времени, наподобие программы top и других подобных инструментов.
PgCenter пригодится как обычным админам, чтобы быстро оценить состояние СУБД (использование ресурсов, просмотр ошибок и т.д.), так и DBA для детального изучения (встроенная статистика) и решения проблем (долгие транзакции, конфликты репликации и т.д.).
В репозитории автоматически собираются rpm и deb пакеты для локальной установки, а также Docker образы. Попробовать проще всего вот так:
# docker run -it --rm lesovsky/pgcenter:latest pgcenter top \-h 1.2.3.4 -U user -d dbnameУ автора есть ещё несколько полезных утилит. Скорее всего напишу о них отдельно:
◽Noisia — генератор нагрузки PostgreSQL.
◽pgSCV — экспортёр метрик для Prometheus и Victoriametrics.
◽pgstats.dev — веб проект с описанием метрик Postgres для мониторинга.
⇨ Исходники
#postgresql
{kind=link}
Если хотите посмотреть, попробовать, изучить работу кластера PostgreSQL, можно воспользоваться готовым плейбуком ansible — postgresql_cluster. Это production ready решение, которое просто и легко устанавливается. У меня получилось базовую версию без балансировки на haproxy и consul развернуть сходу.
Всё описание есть в репозитории. Если нет опыта в этом хозяйстве, то развернуть лучше Type B: один мастер и две реплики. Это будет обычный HA кластер на базе Patroni. Если не ошибаюсь, на текущий момент это самое популярное решение для построения кластеров PostgreSQL.
Для установки желательно знать Ansible, но в целом можно и копипастом развернуть, но без понимания основ скорее всего не получится по инструкции правильно заполнить инвентарь и переменные. Это как раз пример того, почему важно знать Ansible, даже если у вас под управлением нет десятков хостов, для которых будет актуальна автоматизация процессов, и вы сами не пишите плейбуки. Очень много готовых продуктов устанавливаются через Ansible.
Patroni известный продукт, по которому много статей и руководств в интернете. Как пример, вот мастер-класс по нему от самих авторов. Предложенный репозиторий тоже распространён. Можно нагуглить статьи с его участием. Например, вот тут тестируют отставание реплики на кластере, развёрнутом из этого репозитория.
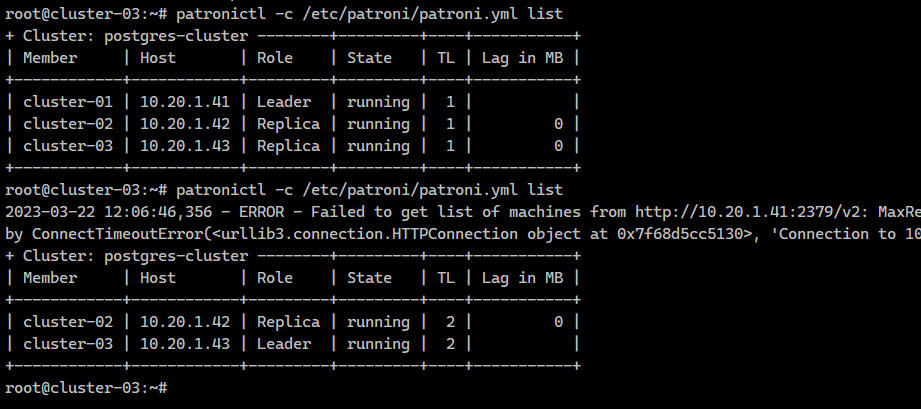
После установки статус кластера смотрите командой:
Можете отключать ноды и смотреть, как кластер будет на это реагировать.
#postgresql
Всё описание есть в репозитории. Если нет опыта в этом хозяйстве, то развернуть лучше Type B: один мастер и две реплики. Это будет обычный HA кластер на базе Patroni. Если не ошибаюсь, на текущий момент это самое популярное решение для построения кластеров PostgreSQL.
Для установки желательно знать Ansible, но в целом можно и копипастом развернуть, но без понимания основ скорее всего не получится по инструкции правильно заполнить инвентарь и переменные. Это как раз пример того, почему важно знать Ansible, даже если у вас под управлением нет десятков хостов, для которых будет актуальна автоматизация процессов, и вы сами не пишите плейбуки. Очень много готовых продуктов устанавливаются через Ansible.
Patroni известный продукт, по которому много статей и руководств в интернете. Как пример, вот мастер-класс по нему от самих авторов. Предложенный репозиторий тоже распространён. Можно нагуглить статьи с его участием. Например, вот тут тестируют отставание реплики на кластере, развёрнутом из этого репозитория.
После установки статус кластера смотрите командой:
# patronictl -c /etc/patroni/patroni.yml listМожете отключать ноды и смотреть, как кластер будет на это реагировать.
#postgresql
{kind=link}
Когда настраиваете сервер или кластер PostgreSQL, перед тем, как нагрузить его рабочей нагрузкой, хочется как-то протестировать его и посмотреть, как он себя поведёт под нагрузкой или в случае каких-то ошибок. Особенно это актуально, если у вас ещё и мониторинг настроен. Хочется на деле посмотреть, как он отработает.
Сделать подобное тестирование с имитацией рабочей нагрузки и ошибок можно с помощью утилиты Noisia. Она написала на Gо, есть в виде бинарника или rpm, deb пакета. Забрать можно из репозитория. Либо запустить через Docker.
Автор утилиты подробно рассказывает про принцип работы и функциональность на онлайн вебинаре — Noisia - генератор аварийных и нештатных ситуаций в PostgreSQL (текстовая расшифровка). Там описаны основные возможности и параметры для использования.
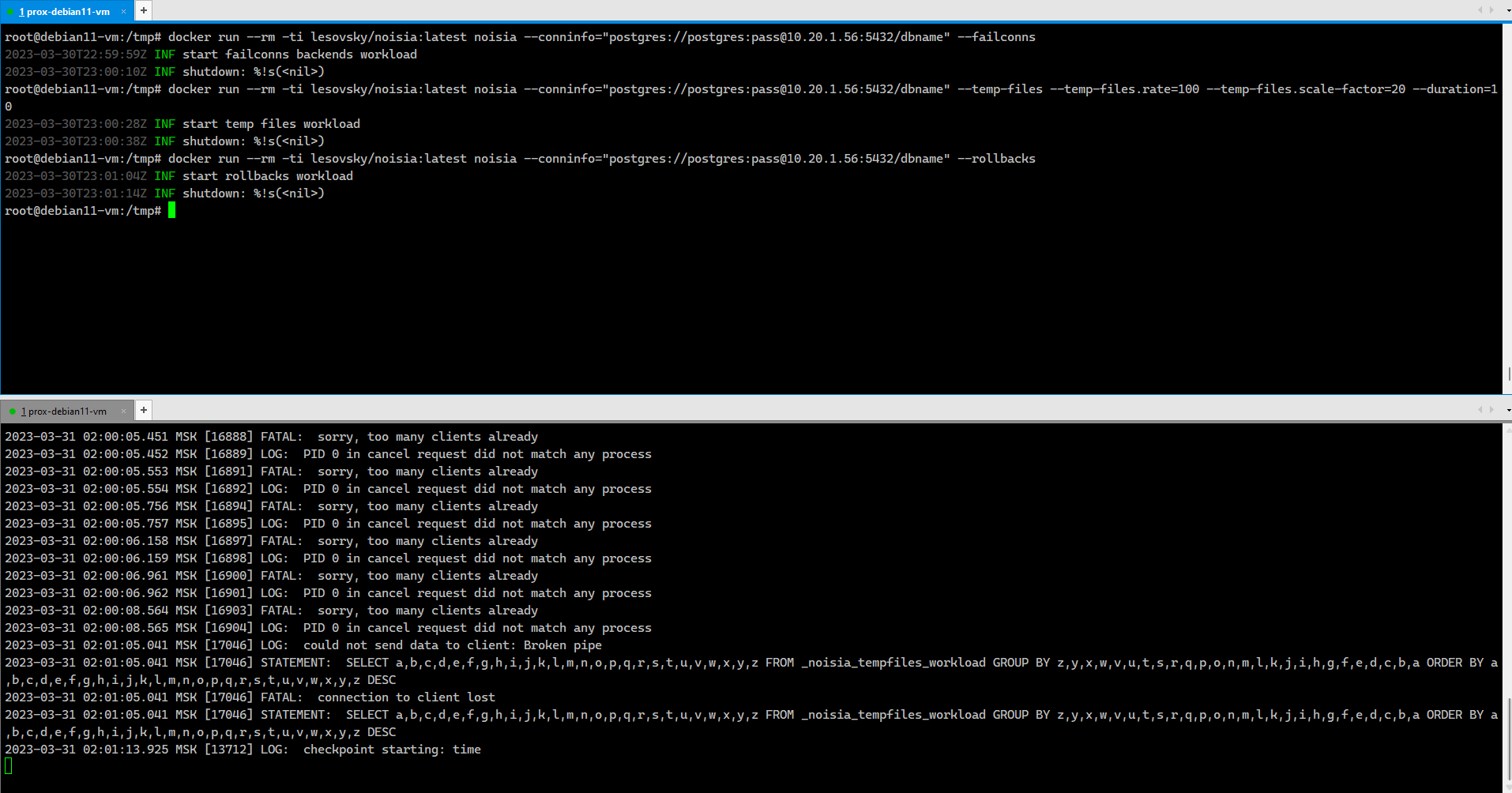
Вот простой пример исчерпания всех доступных подключений к базе, которые обязательно должны мониториться, чтобы своевременно увеличить лимит подключений, или разобраться, куда они все ушли.
Не забудьте настроить удалённые подключения к базе, либо запускайте нагрузку локально, не через docker.
Запуск транзакций, которые завершаются откатом (ROLLBACK), то есть заканчиваются с ошибкой. За ними обычно тоже следят (pg_stat_database.xact_rollback).
Ну и так далее. Все параметры можно посмотреть в help:
#postgresql
Сделать подобное тестирование с имитацией рабочей нагрузки и ошибок можно с помощью утилиты Noisia. Она написала на Gо, есть в виде бинарника или rpm, deb пакета. Забрать можно из репозитория. Либо запустить через Docker.
Автор утилиты подробно рассказывает про принцип работы и функциональность на онлайн вебинаре — Noisia - генератор аварийных и нештатных ситуаций в PostgreSQL (текстовая расшифровка). Там описаны основные возможности и параметры для использования.
Вот простой пример исчерпания всех доступных подключений к базе, которые обязательно должны мониториться, чтобы своевременно увеличить лимит подключений, или разобраться, куда они все ушли.
# docker run --rm -ti lesovsky/noisia:latest noisia \--conninfo="postgres://postgres:pass@10.20.1.56:5432/dbname" \--failconnsНе забудьте настроить удалённые подключения к базе, либо запускайте нагрузку локально, не через docker.
Запуск транзакций, которые завершаются откатом (ROLLBACK), то есть заканчиваются с ошибкой. За ними обычно тоже следят (pg_stat_database.xact_rollback).
# docker run --rm -ti lesovsky/noisia:latest noisia \--conninfo="postgres://postgres:pass@10.20.1.56:5432/dbname" \--rollbacks \--rollbacks.min-rate=10 \--jobs=3 \--duration=20Ну и так далее. Все параметры можно посмотреть в help:
# docker run --rm -ti lesovsky/noisia:latest noisia --help#postgresql
{kind=link}
Пока занимался с PostgreSQL, вспомнил про простой и быстрый способ посмотреть статистику по запросам, который я использовал очень давно. Ещё во времена, когда не пользовался централизованными системами по сбору и анализу логов. Проверил методику, на удивление всё работает до сих пор, так что расскажу вам.
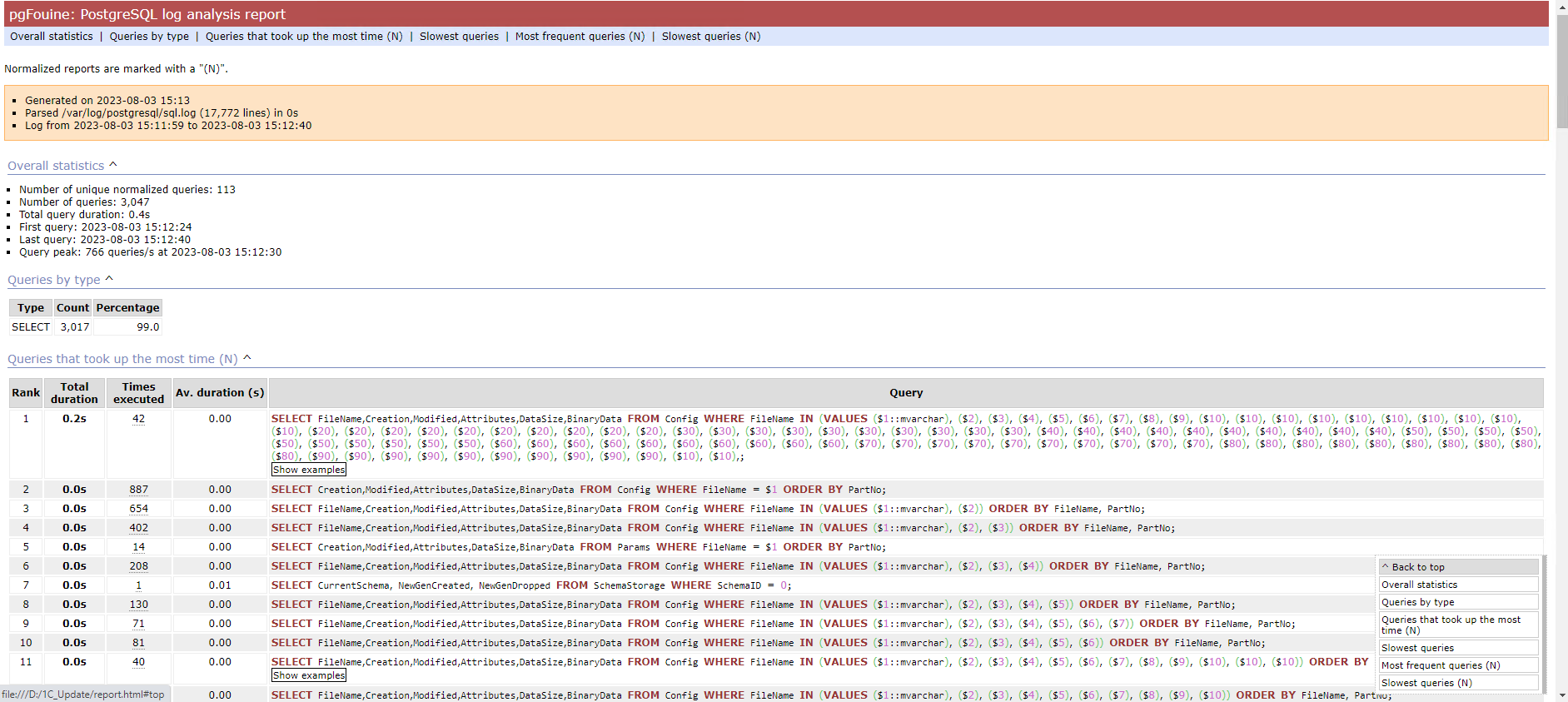
Речь пойдёт про анализатор запросов pgFouine. Продукт старый, последняя версия от 2010-го года. Обновление есть только для совместимости с версией php 7. Сам анализатор - это одиночный скрипт на php, который на входе берёт лог с запросами, а на выходе формирует одну html страницу со статистикой, которая включает в себя:
◽общую статистику по запросам, в том числе по их типам
◽запросы, которые занимают больше всего времени СУБД
◽топ медленных запросов
◽счётчик повторяющихся запросов
Для того, чтобы включить сбор логов, в конфигурационный файл PostgreSQL нужно добавить следующие параметры:
Это мы собираем только медленные запросы, дольше трех секунд. Если указать
Имеет смысл также отключить запись этих логов в общий лог, добавив
Перезапускаем сервисы:
Ждём, когда заполнится лог и отправляем его в pgFouine. Для этого достаточно скопировать себе файл pgfouine.php или весь репозиторий:
Теперь файл report.html можно открыть в браузере и посмотреть статистику. Предварительно нужно установить php, либо передать лог с запросами на машину, где php установлен. У меня нормально отработал на версии php 7.4.
Такой вот олдскул. Сейчас не знаю, кто так статистику смотрит. Есть парсеры логов для ELK или Graylog. Но для этого у вас должны быть эти системы. Надо туда отправить логи, распарсить, собрать дашборды. Это пуд соли съесть. А подобный разовый анализ можно сделать за 10 минут.
#postgresql
Речь пойдёт про анализатор запросов pgFouine. Продукт старый, последняя версия от 2010-го года. Обновление есть только для совместимости с версией php 7. Сам анализатор - это одиночный скрипт на php, который на входе берёт лог с запросами, а на выходе формирует одну html страницу со статистикой, которая включает в себя:
◽общую статистику по запросам, в том числе по их типам
◽запросы, которые занимают больше всего времени СУБД
◽топ медленных запросов
◽счётчик повторяющихся запросов
Для того, чтобы включить сбор логов, в конфигурационный файл PostgreSQL нужно добавить следующие параметры:
log_destination = 'syslog'syslog_facility = 'LOCAL0'syslog_ident = 'postgres'log_min_duration_statement = 3000 # 3000 мс = 3 секундыlog_duration = offlog_statement = 'none'Это мы собираем только медленные запросы, дольше трех секунд. Если указать
log_min_duration_statement = 0, будут логироваться все запросы. Логи будут писаться в syslog. Имеет смысл поместить их в отдельный файл. Для этого добавляем в конфигурационный файл rsyslog:LOCAL0.* -/var/log/postgresql/sql.logИмеет смысл также отключить запись этих логов в общий лог, добавив
LOCAL0.none:*.*;auth,authpriv.none;LOCAL0.none -/var/log/syslog*.=info;*.=notice;*.=warn;\ auth,authpriv.none;\ cron,daemon.none;\ mail,news.none;\ LOCAL0.none -/var/log/messagesПерезапускаем сервисы:
# systemctl restart postgresql# systemctl restart rsyslogЖдём, когда заполнится лог и отправляем его в pgFouine. Для этого достаточно скопировать себе файл pgfouine.php или весь репозиторий:
# git clone https://github.com/milo/pgFouine# cd pgFouine# php pgfouine.php -file /var/log/postgresql/sql.log > report.htmlТеперь файл report.html можно открыть в браузере и посмотреть статистику. Предварительно нужно установить php, либо передать лог с запросами на машину, где php установлен. У меня нормально отработал на версии php 7.4.
Такой вот олдскул. Сейчас не знаю, кто так статистику смотрит. Есть парсеры логов для ELK или Graylog. Но для этого у вас должны быть эти системы. Надо туда отправить логи, распарсить, собрать дашборды. Это пуд соли съесть. А подобный разовый анализ можно сделать за 10 минут.
#postgresql
{kind=link}
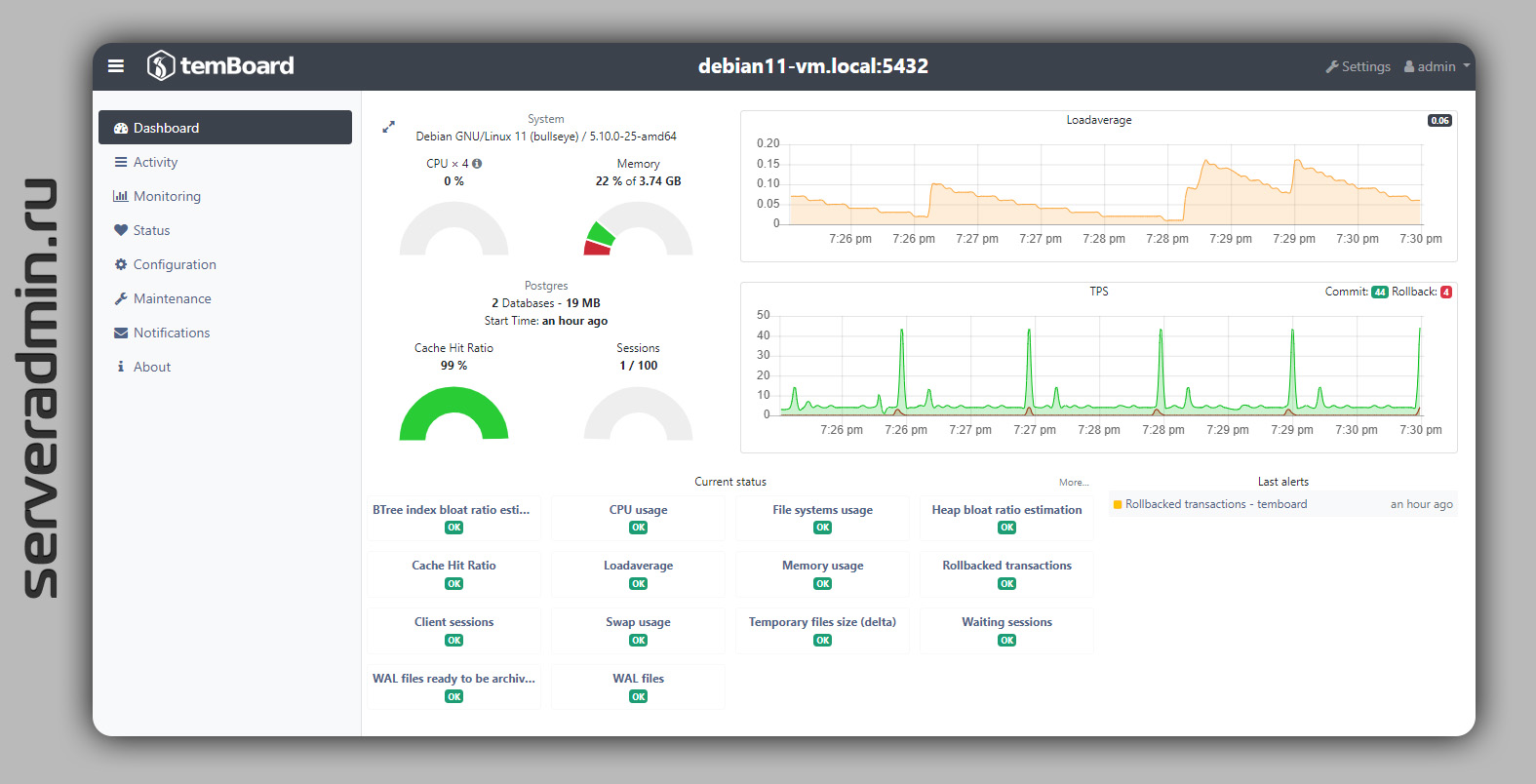
Существует удобный веб интерфейс для управления и мониторинга СУБД Postgresql - temBoard. Он по смыслу напоминает специализированный мониторинг Percona Monitoring and Management (PMM). Но почему-то не очень популярен, хотя написан людьми, которые контрибьютят в PostgreSQL. Есть новость на сайте postgresql от них с анонсом очередного релиза.
У меня есть несколько одиночных серверов PostgreSQL для работы с 1С, так что я решил проверить работу сразу с ними. В сети нет готовых инструкций по настройке temBoard, а с учётом того, что сборка PostgreSQL для 1С не совсем типовая, пришлось немного повозиться с настройкой. В итоге всё получилось.
С помощью temBoard можно:
◽подключить множество экземпляров СУБД в единую веб панель;
◽смотреть основные метрики мониторинга серверов;
◽управлять активными сеансами пользователей;
◽запускать операции vacuum, reindex, analyze;
◽отслеживать запросы к СУБД;
◽выполнять некоторые настройки СУБД.
С учётом перечисленных возможностей понятно, что у панели есть почти полный доступ к СУБД, так что использовать её надо аккуратно. Это может быть точкой отказа или утечки данных.
Для установки temBoard необходимо установить веб интерфейс и настроить хранение данных в одной из баз данных PostgreSQL, существующей или отдельной. На хосты с СУБД ставится небольшой агент. Для temBoard есть репозитории разработчиков, так что установка не представляет особых сложностей, но есть нюансы.
Я развернул всё на Debian 11. В моём случае наблюдаемый сервер PostgreSQL будет стоять на этом же хосте. Нужно убедиться, что все хосты имеют FQDN имена. Без них ничего не заработает, так как будут выпущены сертификаты. А скрипты генерации сертификатов ожидают FQDN имена, без них будут ошибки.
Для установки использовал официальную инструкцию. Ставим утилиты, которые пригодятся:
Подключаем репозиторий и устанавливаем temBoard:
Теперь нужно запустить скрипт настройки. Он берёт все значения PostgreSQL по умолчанию. Если используете сборку от Postgrespro для 1С, то сокет для подключения она открывает в
Скрипт генерирует сертификаты, конфиги, службу systemd, создаёт себе базу данных в СУБД и что-то ещё, соответственно, в
Если всё прошло без ошибок, то можно открывать веб интерфейс https://temboard.local:8888, учётка - admin / admin. Там будет пусто, так как нет ни одного подключенного хоста.
Теперь нужно установить агента. Если это одна и та же машина, то пакет ставится из того же репозитория. Если хост другой, то подключите туда репозиторий:
Запускаем скрипт для конфигурирования агента:
Тут он у меня постоянно вываливался с неинформативной ошибкой. Анализируя скрипт понял, что идёт проверка доступности ключа
Если доступа нет, настройте. После этого всё получится. Далее забираем ключ с сервера, запускаем агента и регистрируемся на сервере:
Идём в веб интерфейс и наблюдаем там свой хост.
⇨ Сайт / Исходники
#монитроинг #postgresql
У меня есть несколько одиночных серверов PostgreSQL для работы с 1С, так что я решил проверить работу сразу с ними. В сети нет готовых инструкций по настройке temBoard, а с учётом того, что сборка PostgreSQL для 1С не совсем типовая, пришлось немного повозиться с настройкой. В итоге всё получилось.
С помощью temBoard можно:
◽подключить множество экземпляров СУБД в единую веб панель;
◽смотреть основные метрики мониторинга серверов;
◽управлять активными сеансами пользователей;
◽запускать операции vacuum, reindex, analyze;
◽отслеживать запросы к СУБД;
◽выполнять некоторые настройки СУБД.
С учётом перечисленных возможностей понятно, что у панели есть почти полный доступ к СУБД, так что использовать её надо аккуратно. Это может быть точкой отказа или утечки данных.
Для установки temBoard необходимо установить веб интерфейс и настроить хранение данных в одной из баз данных PostgreSQL, существующей или отдельной. На хосты с СУБД ставится небольшой агент. Для temBoard есть репозитории разработчиков, так что установка не представляет особых сложностей, но есть нюансы.
Я развернул всё на Debian 11. В моём случае наблюдаемый сервер PostgreSQL будет стоять на этом же хосте. Нужно убедиться, что все хосты имеют FQDN имена. Без них ничего не заработает, так как будут выпущены сертификаты. А скрипты генерации сертификатов ожидают FQDN имена, без них будут ошибки.
Для установки использовал официальную инструкцию. Ставим утилиты, которые пригодятся:
# apt install gnupg curl sudoПодключаем репозиторий и устанавливаем temBoard:
# echo deb http://apt.dalibo.org/labs $(lsb_release -cs)-dalibo main \> /etc/apt/sources.list.d/dalibo-labs.list# curl https://apt.dalibo.org/labs/debian-dalibo.asc | apt-key add -# apt update# apt install temboardТеперь нужно запустить скрипт настройки. Он берёт все значения PostgreSQL по умолчанию. Если используете сборку от Postgrespro для 1С, то сокет для подключения она открывает в
/tmp, а не в /var/run. Нужно это передать скрипту. Сразу покажу и переменную для tcp порта postgresql, если у вас используется нестандартный.# PGPORT=5432 PGHOST=/tmp /usr/share/temboard/auto_configure.shСкрипт генерирует сертификаты, конфиги, службу systemd, создаёт себе базу данных в СУБД и что-то ещё, соответственно, в
pg_hba.conf нужно настроить доступ для юзера postgres. После того, как скрипт отработает, запускаем службу:# systemctl enable --now temboardЕсли всё прошло без ошибок, то можно открывать веб интерфейс https://temboard.local:8888, учётка - admin / admin. Там будет пусто, так как нет ни одного подключенного хоста.
Теперь нужно установить агента. Если это одна и та же машина, то пакет ставится из того же репозитория. Если хост другой, то подключите туда репозиторий:
# apt install temboard-agentЗапускаем скрипт для конфигурирования агента:
# /usr/share/temboard-agent/auto_configure.sh https://temboard.local:8888Тут он у меня постоянно вываливался с неинформативной ошибкой. Анализируя скрипт понял, что идёт проверка доступности ключа
/etc/ssl/private/ssl-cert-snakeoil.key пользователем postgresql. Проверить так:# sudo -u postgres cat /etc/ssl/private/ssl-cert-snakeoil.key Если доступа нет, настройте. После этого всё получится. Далее забираем ключ с сервера, запускаем агента и регистрируемся на сервере:
# sudo -u postgres temboard-agent -c \/etc/temboard-agent/15/pg5432/temboard-agent.conf fetch-key# systemctl enable --now temboard-agent@15-pg5432# sudo -u postgres temboard-agent -c \/etc/temboard-agent/15/pg5432/temboard-agent.conf register --groups defaultИдём в веб интерфейс и наблюдаем там свой хост.
⇨ Сайт / Исходники
#монитроинг #postgresql
{kind=link}
Для бэкапа баз PostgreSQL существует много различных подходов и решений. Я вам хочу предложить ещё одно, отметив его особенности и преимущества. Да и в целом это одна из самых известных программ для этих целей. А в конце приведу список того, чем ещё можно бэкапить PostgreSQL.
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
Дальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
# apt install pgbackrestДальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
{kind=link}
Stolon и Patroni — два наиболее известных решения для построения кластера PostgreSQL типа Leader-Followers. Про Patroni я уже как-то рассказывал. Для него есть готовый плейбук ansible — postgresql_cluster, с помощью которого можно легко и быстро развернуть нужную конфигурацию кластера.
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
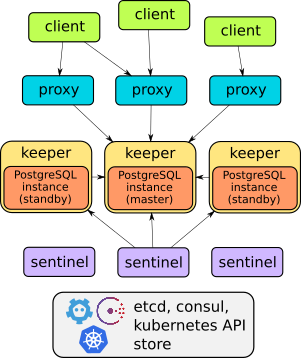
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
{kind=link}
Попереживал тут на днях из-за своей неаккуратности. Настроил сервер 1С примерно так же, как описано у меня в статье:
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
3️⃣ Проверяю, создалась ли база:
4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
# sudo -u postgres /usr/bin/createdb -U postgres -T template0 base1C-restored3️⃣ Проверяю, создалась ли база:
# sudo -u postgres /usr/bin/psql -U postgres -l4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
# sudo -u postgres /usr/bin/psql -U postgres base1C-restored < /tmp/backup.sql5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.