
Расскажу про простую схему построения отказоустойчивой системы на уровне файлового хранения с помощью DRBD (Distributed Replicated Block Device — распределённое реплицируемое блочное устройство). Это очень простое и известное решение в том числе из-за того, что поддержка DRBD входит в стандартное ядро Linux.
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
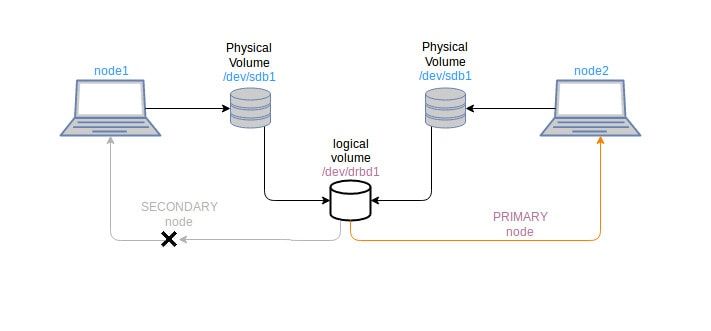
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
/dev/sdb будут использоваться под DRBD. Запускаете инициализацию и получаете новое блочное устройство на каждом сервере, которое автоматически синхронизируется.Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
{kind=link}