
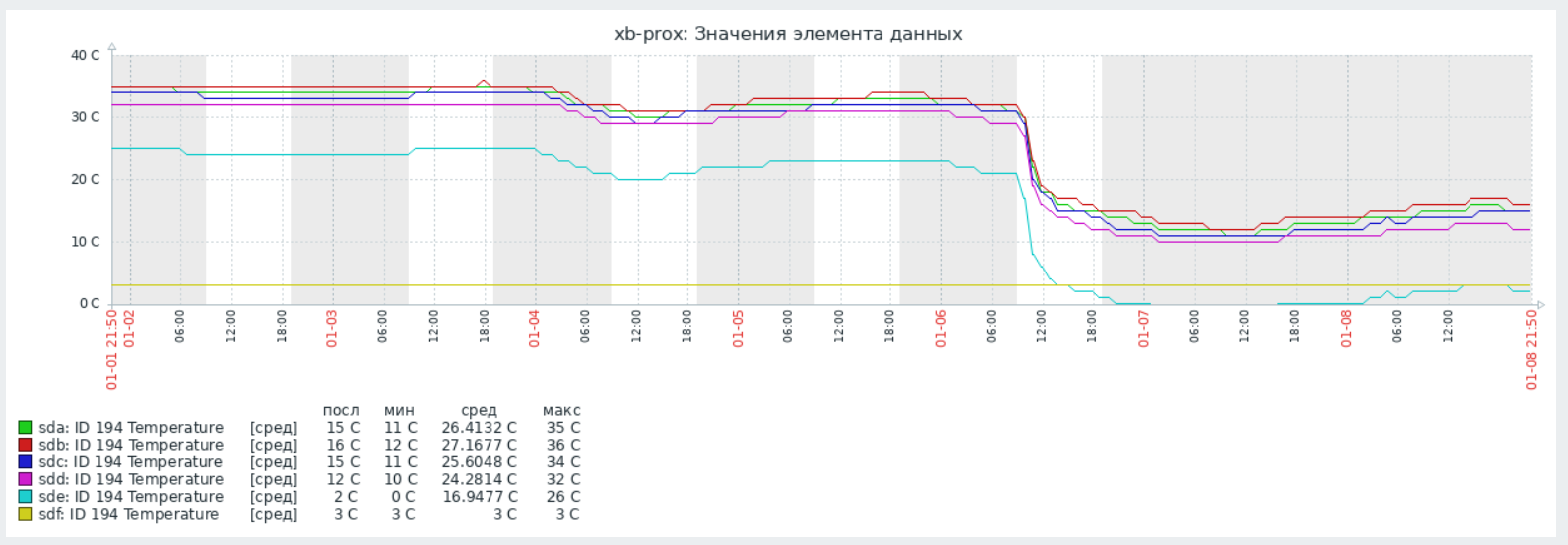
В эти выходные приобрёл новый опыт. Оказывается, триггеры на температуру надо ставить не только на повышенные значения, но и на пониженные. В одном из офисов, судя по всему в нагрянувшие морозы отключилось отопление. Или что-то ещё произошло. Так как там пока никто не работает, информации нет.
Сработал только один триггер на Mikrotik. У Zabbix в стандартном шаблоне есть реакция на температуру устройства ниже 5°C. Я решил проверить температуру серверов. По процессорам всё более ли менее нормально: 12-16°C, для них, как я понимаю, это не проблема. А вот с дисками я не так оптимистичен. Обычные показали 10-12°C, а вот SSD 0-2°C 😱. Надеюсь это их не убьёт.
На будущее учту этот момент. Если шаблон делаю сам, то никогда не настраивают триггеры на низкие температуры. Вообще не ожидал, что серверная может остыть до нуля. Я так понимаю, там и минус может быть, если работающее оборудование остывает почти до нуля. Пост пишу в воскресенье вечером. Если будут подробности, то дам знать в комментариях. Интересно, не заморожены ли там батареи.
#zabbix #мониторинг
Сработал только один триггер на Mikrotik. У Zabbix в стандартном шаблоне есть реакция на температуру устройства ниже 5°C. Я решил проверить температуру серверов. По процессорам всё более ли менее нормально: 12-16°C, для них, как я понимаю, это не проблема. А вот с дисками я не так оптимистичен. Обычные показали 10-12°C, а вот SSD 0-2°C 😱. Надеюсь это их не убьёт.
На будущее учту этот момент. Если шаблон делаю сам, то никогда не настраивают триггеры на низкие температуры. Вообще не ожидал, что серверная может остыть до нуля. Я так понимаю, там и минус может быть, если работающее оборудование остывает почти до нуля. Пост пишу в воскресенье вечером. Если будут подробности, то дам знать в комментариях. Интересно, не заморожены ли там батареи.
#zabbix #мониторинг
{kind=link}
Подготовил сжатый список действий, которые я всегда выполняю при настройке Zabbix Server. Тут нет ничего особенного, пригодится просто чтобы ничего не забыть и разом всё сделать. Все настройки относятся к веб интерфейсу и выполняются там.
1️⃣ Первым делом сразу же создаю нового администратора с другим именем, старого удаляю. Старому админу принадлежат некоторые готовые объекты в виде дашбордов или карт сетей. Чтобы их удалить, нужно назначить владельцем нового админа.
2️⃣ Обычно сразу же настраиваю оповещения на email для администратора. Для этого указываю настройки smtp для этого способа оповещения, добавляю email пользователю администратор и активирую стандартное действие для триггеров, где по умолчанию настроена отправка на почту. После установки это действие изначально отключено.
3️⃣ Иду в шаблоны оповещений и настраиваю шаблон на проблему и на восстановление. Обычно просто удаляю некоторые поля, которые мне не нужны (например, problem ID). Добавляю в тему оповещения макрос {HOST.NAME}, чтобы всегда в заголовке видеть имя хоста, где произошло событие. Иногда перевожу шаблон на русский язык. Там быстро, всего несколько фраз.
4️⃣ В настройках веб интерфейса изменяю "Макс. количество элементов отображаемое в ячейке таблицы" с 50 на 100. Мне так удобнее.
5️⃣ В разделе настроек Опции отображения триггеров меняю значения "Отображать триггеры в состоянии ОК в течении" и "Мигание триггеров при изменении состояния" на 1 минуту. Мне не нравится, когда триггеры на дашборде долго мигают, либо висят уже закрытые.
6️⃣ Удаляю с основного дашборда все виджеты, вместо них добавляю два обязательных: тип "Проблемы". В первом показываю актуальные проблемы, во втором историю проблем. Всё остальное по желанию. Иногда ничего другого на главном дашборде нет. Всё остальное во вкладках. Раньше делал отдельные дашборды, но как только появились вкладки, стал всё делать на основном в них.
7️⃣ Дальше иду в шаблоны и там меняю их в зависимости от объектов мониторинга. Если есть Windows машины, то 100% отключаю в шаблоне правило обнаружения служб. Толку от него мало, а спама будет море. То же самое относится к обнаружению сетевых интерфейсов. Обнаружение в Zabbix шаблоне находит десятки служебных сетевых интерфейсов и все добавляет их в мониторинг. Это ведёт к лишней нагрузке на мониторинг. А данные эти чаще всего не нужны.
На этом всё. Основные настройки сделал. Дальше уже в зависимости от ситуации. Чаще всего настраиваются оповещения в Telegram. Раньше использовал какие-то сторонние скрипты, но последнее время надоело с ними разбираться. Использую стандартный шаблон от разработчиков. Он очень простой и малофункциональный, например, не умеет графики отправлять, использовать markdown разметку. Но мне обычно это и не нужно. Добавляю emoji в шаблон, немного редактирую его, убирая лишнее и пользуюсь.
#zabbix
1️⃣ Первым делом сразу же создаю нового администратора с другим именем, старого удаляю. Старому админу принадлежат некоторые готовые объекты в виде дашбордов или карт сетей. Чтобы их удалить, нужно назначить владельцем нового админа.
2️⃣ Обычно сразу же настраиваю оповещения на email для администратора. Для этого указываю настройки smtp для этого способа оповещения, добавляю email пользователю администратор и активирую стандартное действие для триггеров, где по умолчанию настроена отправка на почту. После установки это действие изначально отключено.
3️⃣ Иду в шаблоны оповещений и настраиваю шаблон на проблему и на восстановление. Обычно просто удаляю некоторые поля, которые мне не нужны (например, problem ID). Добавляю в тему оповещения макрос {HOST.NAME}, чтобы всегда в заголовке видеть имя хоста, где произошло событие. Иногда перевожу шаблон на русский язык. Там быстро, всего несколько фраз.
4️⃣ В настройках веб интерфейса изменяю "Макс. количество элементов отображаемое в ячейке таблицы" с 50 на 100. Мне так удобнее.
5️⃣ В разделе настроек Опции отображения триггеров меняю значения "Отображать триггеры в состоянии ОК в течении" и "Мигание триггеров при изменении состояния" на 1 минуту. Мне не нравится, когда триггеры на дашборде долго мигают, либо висят уже закрытые.
6️⃣ Удаляю с основного дашборда все виджеты, вместо них добавляю два обязательных: тип "Проблемы". В первом показываю актуальные проблемы, во втором историю проблем. Всё остальное по желанию. Иногда ничего другого на главном дашборде нет. Всё остальное во вкладках. Раньше делал отдельные дашборды, но как только появились вкладки, стал всё делать на основном в них.
7️⃣ Дальше иду в шаблоны и там меняю их в зависимости от объектов мониторинга. Если есть Windows машины, то 100% отключаю в шаблоне правило обнаружения служб. Толку от него мало, а спама будет море. То же самое относится к обнаружению сетевых интерфейсов. Обнаружение в Zabbix шаблоне находит десятки служебных сетевых интерфейсов и все добавляет их в мониторинг. Это ведёт к лишней нагрузке на мониторинг. А данные эти чаще всего не нужны.
На этом всё. Основные настройки сделал. Дальше уже в зависимости от ситуации. Чаще всего настраиваются оповещения в Telegram. Раньше использовал какие-то сторонние скрипты, но последнее время надоело с ними разбираться. Использую стандартный шаблон от разработчиков. Он очень простой и малофункциональный, например, не умеет графики отправлять, использовать markdown разметку. Но мне обычно это и не нужно. Добавляю emoji в шаблон, немного редактирую его, убирая лишнее и пользуюсь.
#zabbix
{kind=link}
Понадобилось на днях установить Ceph. У меня есть статья по этому поводу, но как оказалось, она очень сильно устарела. Я потратил целый день на то, чтобы развернуть свежую стабильную версию Ceph. Решил заодно и актуализировать статью.
💡Для тех, кто не знаком с Ceph, поясню, что это программная объектная отказоустойчивая сеть хранения данных. Если по-простому, то это кластер для хранения данных. Причём он может отдавать данные как обычные файлы через свою распределённую файловую систему cephfs, так и в виде блочных устройств. Первое актуально для кластеров, к примеру, под бэкапы или S3, а второе для файловых томов Kubernetes.
Ceph довольно навороченная система и с наскока её не осилить. В статье я постарался дать основную теорию и практику в виде установки кластера и примеров по работе с ним. Если у вас есть базовые навыки работы с Linux, то по статье вы сможете развернуть кластер и попробовать его в деле. Желательно, конечно, и Ansible понимать. Хотя бы на уровне чтения плейбуков и ошибок.
Один из вариантов использования Ceph - вместе с кластером Kubernetes. Достаточно купить любые 3 дешёвые дедика. Поставить туда Proxmox, нарезать виртуалки. На них раскатать Ceph и Kubernetes. Получится очень дешёвый тестовый кластер, который сможет сэкономить кучу денег. Он будет стоит в 3-5 раз дешевле, чем managed kubernetes. И при этом будет выдерживать выход одной ноды из строя. То есть вполне стабильное решение. Кто-то и прод таким образом строит.
⇨ https://serveradmin.ru/ustanovka-i-nastrojka-ceph
#ceph #devops
💡Для тех, кто не знаком с Ceph, поясню, что это программная объектная отказоустойчивая сеть хранения данных. Если по-простому, то это кластер для хранения данных. Причём он может отдавать данные как обычные файлы через свою распределённую файловую систему cephfs, так и в виде блочных устройств. Первое актуально для кластеров, к примеру, под бэкапы или S3, а второе для файловых томов Kubernetes.
Ceph довольно навороченная система и с наскока её не осилить. В статье я постарался дать основную теорию и практику в виде установки кластера и примеров по работе с ним. Если у вас есть базовые навыки работы с Linux, то по статье вы сможете развернуть кластер и попробовать его в деле. Желательно, конечно, и Ansible понимать. Хотя бы на уровне чтения плейбуков и ошибок.
Один из вариантов использования Ceph - вместе с кластером Kubernetes. Достаточно купить любые 3 дешёвые дедика. Поставить туда Proxmox, нарезать виртуалки. На них раскатать Ceph и Kubernetes. Получится очень дешёвый тестовый кластер, который сможет сэкономить кучу денег. Он будет стоит в 3-5 раз дешевле, чем managed kubernetes. И при этом будет выдерживать выход одной ноды из строя. То есть вполне стабильное решение. Кто-то и прод таким образом строит.
⇨ https://serveradmin.ru/ustanovka-i-nastrojka-ceph
#ceph #devops
Server Admin
Установка, настройка и эксплуатация Ceph | serveradmin.ru
Подробное описание установки, настройки и эксплуатации ceph своими словами для новичков и тех, кто только знакомится с ceph.
Заметил любопытную особенность в работе DHCP с которой раньше не был знаком. Когда клонировал виртуальные машины, заметил, что они получают одни и те же IP адреса, хотя я менял у сетевых интерфейсов MAC адреса. Я всегда был уверен, что выдача IP зависит от мака. Оказывается, что не только.
В качестве DHCP сервера выступал Mikrotik. Несмотря на изменение маков, он выдавал один и тот же IP адрес разным виртуалкам. Я выяснил, что выдача у него привязана к Client ID. Пока не изменить его, адрес не изменится.
В Linux этот ID указан в файле /etc/machine-id. Для того, чтобы его изменить, надо его удалить и сгенерировать заново:
Таким образом, после клонирования виртуальной машины нужно:
1️⃣ Изменить MAC адрес сетевого интерфейса.
2️⃣ Изменить hostname:
3️⃣ Отредактировать файл /etc/hosts, изменив там имя сервреа.
4️⃣ Сгенерировать новый machine-id.
Вроде всё. Может ещё что-то забыл? Мне не так часто приходится этим заниматься. Даже если и приходится делать клон вируталки, то обычно для тестов и запускается всё это в изолированной сети. А так, чтобы делать клон и запускать его тут же, я не практикую.
#dhcp
В качестве DHCP сервера выступал Mikrotik. Несмотря на изменение маков, он выдавал один и тот же IP адрес разным виртуалкам. Я выяснил, что выдача у него привязана к Client ID. Пока не изменить его, адрес не изменится.
В Linux этот ID указан в файле /etc/machine-id. Для того, чтобы его изменить, надо его удалить и сгенерировать заново:
# rm -f /etc/machine-id# dbus-uuidgen --ensure=/etc/machine-idТаким образом, после клонирования виртуальной машины нужно:
1️⃣ Изменить MAC адрес сетевого интерфейса.
2️⃣ Изменить hostname:
# hostnamectl set-hostname server-clone3️⃣ Отредактировать файл /etc/hosts, изменив там имя сервреа.
4️⃣ Сгенерировать новый machine-id.
Вроде всё. Может ещё что-то забыл? Мне не так часто приходится этим заниматься. Даже если и приходится делать клон вируталки, то обычно для тестов и запускается всё это в изолированной сети. А так, чтобы делать клон и запускать его тут же, я не практикую.
#dhcp
Некоторое время назад я рассказывал про любопытный сервис под названием Tailscale. Возвращаюсь к нему вновь, чтобы рассказать тем, кто про него не знает, о его существовании. А так же поделиться любопытными новостями, связанными с ним.
Кратко поясню, что это вообще такое. Очень условно Tailscale можно назвать аналогом популярного Hamachi. Его можно использовать в том же качестве, как и Хамачи, но не только. Это децентрализованная VPN-сеть, построенная на базе опенсорсного VPN-клиента WireGuard по принципу mesh-сети.
Для работы с Tailscale, вы ставите клиента на свои устройства (поддерживаются все популярные системы), и они объединяются в единую VPN сеть. Ничего настраивать не надо, работает максимально просто для пользователя. Всё взаимодействие с сетью происходит через сервер управления и веб интерфейс разработчиков. А вот это уже закрытый функционал, который продаётся за деньги. Есть бесплатный тариф для индивидуального использования с 20-ю устройствами.
Для личного использования бесплатного тарифа за глаза. Я проверял его, очень удобно. Недавно вышло нововведение - Tailscale SSH. Это встроенный в браузер SSH клиент, с помощью которого можно подключаться к своим серверам прямо из веб интерфейса. Реализовано удобно. Посмотреть, как работает, можно в демонстрационном ролике.
Со временем появилась open source реализация управляющего сервера - Headscale. Причём разработчики Tailscale отнеслись к нему благосклонно и помогают в разработке. Информируют об изменениях протокола. Палки в колёса не ставят. Проект очень живой, постоянно обновляется.
Мы имеем open source реализацию клиентов Tailscale от самих разработчиков, и серверную часть Headscale, которую можно развернуть на своих серверах. Отдельно есть репозиторий с веб интерфейсом для Headscale - headscale-ui. То есть практически весь функционал платного сервиса можно поднять бесплатно на своих серверах. В сети уже есть описания и руководства (пример 1, 2).
На вид всё это выглядит очень удобно и функционально. Если Headscale на практике без багов и особых проблем реализует функционал Tailscale, то такая система будет актуальна для больших установок. Там есть и внешняя аутентификация, и управление доступом на основе ACL, и управление маршрутами. Много всего, что требуется для больших коллективов.
⇨ Сайт / Исходники Tailscale / Headscale / Headscale-ui
#vpn #tailscale
Кратко поясню, что это вообще такое. Очень условно Tailscale можно назвать аналогом популярного Hamachi. Его можно использовать в том же качестве, как и Хамачи, но не только. Это децентрализованная VPN-сеть, построенная на базе опенсорсного VPN-клиента WireGuard по принципу mesh-сети.
Для работы с Tailscale, вы ставите клиента на свои устройства (поддерживаются все популярные системы), и они объединяются в единую VPN сеть. Ничего настраивать не надо, работает максимально просто для пользователя. Всё взаимодействие с сетью происходит через сервер управления и веб интерфейс разработчиков. А вот это уже закрытый функционал, который продаётся за деньги. Есть бесплатный тариф для индивидуального использования с 20-ю устройствами.
Для личного использования бесплатного тарифа за глаза. Я проверял его, очень удобно. Недавно вышло нововведение - Tailscale SSH. Это встроенный в браузер SSH клиент, с помощью которого можно подключаться к своим серверам прямо из веб интерфейса. Реализовано удобно. Посмотреть, как работает, можно в демонстрационном ролике.
Со временем появилась open source реализация управляющего сервера - Headscale. Причём разработчики Tailscale отнеслись к нему благосклонно и помогают в разработке. Информируют об изменениях протокола. Палки в колёса не ставят. Проект очень живой, постоянно обновляется.
Мы имеем open source реализацию клиентов Tailscale от самих разработчиков, и серверную часть Headscale, которую можно развернуть на своих серверах. Отдельно есть репозиторий с веб интерфейсом для Headscale - headscale-ui. То есть практически весь функционал платного сервиса можно поднять бесплатно на своих серверах. В сети уже есть описания и руководства (пример 1, 2).
На вид всё это выглядит очень удобно и функционально. Если Headscale на практике без багов и особых проблем реализует функционал Tailscale, то такая система будет актуальна для больших установок. Там есть и внешняя аутентификация, и управление доступом на основе ACL, и управление маршрутами. Много всего, что требуется для больших коллективов.
⇨ Сайт / Исходники Tailscale / Headscale / Headscale-ui
#vpn #tailscale
{kind=link}
Чтобы два раза не вставать, продолжу тему Tailscale. Покажу пару конкретных примеров личного пользования на базе бесплатного тарифного плана. Оба примера могут использоваться одновременно.
1️⃣ По умолчанию Tailscale заворачивает в VPN туннель только трафик своей сети. Но вы можете сделать так, что подключенное устройство весь свой внешний трафик (например, сёрфинг в интернете) будет заворачивать на одно из устройств сети.
К примеру, у вас есть какой-то внешний сервер для обхода блокировок. Вы добавляете все свои устройства в Tailscale, а для внешней виртуалки указываете настройку exit node. Выбранные вами устройства (например, смартфоны) после подключения будут заворачивать весь свой трафик на эту виртуалку по умолчанию. Описание настройки.
2️⃣ Если вы используете блокировщики рекламы, то можно настроить свой собственный сервер Pi-hole и использовать его возможности. Для этого надо добавить машину с настроенным Pi-hole. Далее в настройках Tailscale добавить DNS сервер, указав внутренний IP адрес Pi-hole сервера. И отдельно указать, что подключенным клиентам надо заменять их локальный DNS сервер на настроенный.
При сёрфинге с подключенным Tailscale все DNS запросы будут проходить через ваш Pi-hole и очищаться от рекламных доменов. Особенно это актуально для смартфонов. Если блокировку надо отключить, то просто отключаетесь от Tailscale. Описание настройки.
Ещё больше примеров и готовых инструкций можно посмотреть в документации в разделе How-to Guides.
Показанные выше примеры без проблем можно реализовать с помощью OpenVPN. Он умеет и настройки DNS, и маршруты передавать клиенту. Я неоднократно это настраивал. Но всё это делается в консоли, а для этого нужно хорошее понимание и знание работы OpenVPN. С Tailscale всё это делается за 5-10 минут через настройки в веб интерфейсе. Единственное, что надо будет настроить — включить маршрутизацию трафика на exit node. Но есть одно очень важное принципиальное отличие. OpenVPN весь трафик пропускает через себя, а Tailscale напрямую соединяет устройства. Трафик между ними идёт минуя управляющий сервер.
#vpn #tailscale
1️⃣ По умолчанию Tailscale заворачивает в VPN туннель только трафик своей сети. Но вы можете сделать так, что подключенное устройство весь свой внешний трафик (например, сёрфинг в интернете) будет заворачивать на одно из устройств сети.
К примеру, у вас есть какой-то внешний сервер для обхода блокировок. Вы добавляете все свои устройства в Tailscale, а для внешней виртуалки указываете настройку exit node. Выбранные вами устройства (например, смартфоны) после подключения будут заворачивать весь свой трафик на эту виртуалку по умолчанию. Описание настройки.
2️⃣ Если вы используете блокировщики рекламы, то можно настроить свой собственный сервер Pi-hole и использовать его возможности. Для этого надо добавить машину с настроенным Pi-hole. Далее в настройках Tailscale добавить DNS сервер, указав внутренний IP адрес Pi-hole сервера. И отдельно указать, что подключенным клиентам надо заменять их локальный DNS сервер на настроенный.
При сёрфинге с подключенным Tailscale все DNS запросы будут проходить через ваш Pi-hole и очищаться от рекламных доменов. Особенно это актуально для смартфонов. Если блокировку надо отключить, то просто отключаетесь от Tailscale. Описание настройки.
Ещё больше примеров и готовых инструкций можно посмотреть в документации в разделе How-to Guides.
Показанные выше примеры без проблем можно реализовать с помощью OpenVPN. Он умеет и настройки DNS, и маршруты передавать клиенту. Я неоднократно это настраивал. Но всё это делается в консоли, а для этого нужно хорошее понимание и знание работы OpenVPN. С Tailscale всё это делается за 5-10 минут через настройки в веб интерфейсе. Единственное, что надо будет настроить — включить маршрутизацию трафика на exit node. Но есть одно очень важное принципиальное отличие. OpenVPN весь трафик пропускает через себя, а Tailscale напрямую соединяет устройства. Трафик между ними идёт минуя управляющий сервер.
#vpn #tailscale
{kind=link}
Хочу вас познакомить с очередной готовой сборкой почтового сервера, которую я развернул и потестировал лично. Результат мне понравился, так что делюсь подробностями. Речь пойдёт о сборке Mail-in-a-Box.
Автор сборки позиционирует её как максимально простую систему, устанавливаемую в один клик. Настроек через панель управления нет практически никаких. И это правда. Лично для меня это минус, а для тех, кто не очень знаком с почтовыми серверами — плюс, так как предлагаемая настройка является универсальной, покрывающей основные потребности в почтовой системе. Можно не вникая в подробности получить надёжный почтовый сервер.
📌 Mail-in-a-Box состоит из следующих компонентов:
◽традиционные Postfix + Dovecot
◽веб интерфейс Roudcube + адресная книга от Nextcloud
◽z-push для Exchange ActiveSync
◽spamassassin и postgrey для борьбы со спамом
◽остальные компоненты: OpenDKIM, сертификаты от Let's Encrypt, duplicity для бэкапов, ufw в качестве фаервола, fail2ban, munin в качестве мониторинга, nsd4 в качестве DNS сервера.
Полная схема взаимодействия всех компонентов
Ставится всё это традиционно из пакетов, без Docker. Есть простой скрипт установщик, который всё это дело разворачивает на голой Ubuntu 22.04. Я на ней и проверял. Не знаю, заработает ли корректно автоматическая установка на других системах. Из всех настроек спросят только имя почтового сервера.
После установки всё управление выполняется через веб интерфейс. Сервер автоматически проверит все DNS записи, а также возможность отправки через 25-й порт. Если у вас провайдер его блокирует, то сразу об этом узнаете. Из настроек доступно только управление TLS сертификатами, в том числе автоматическое получение и установка Let's Encrypt, а также бэкапы, которые можно передавать с помощью rsync на любой сервер по SSH, либо складывать на S3 совместимое хранилище.
Компонент Postgrey реализует функционал Greylisting для новых отправителей. Я лично не люблю его и обычно не использую. Через веб интерфейс настроек никаких нет, но можно строку в конфиге postfix убрать, и он работать не будет. Ещё мне остался непонятен механизм управления spamassasin. Вообще ничего на нашёл на этот счёт. Автоматически подключен список zen.spamhaus.org для проверки отправителей. Отключить можно только через конфигурацию postfix.
Всё остальное сделано удобно. Через админку можно добавлять почтовые ящики, либо DNS записи. Настроенный сервер может выступать в качестве DNS сервера. Для пользователей доступны веб интерфейсы Roundcube для работы с почтой и Nextcloud для календаря и контактов. Поддерживаются почтовые адреса вида you+anythinghere@yourdomain.com. То есть к ящику you@yourdomain.com через + добавляется любая маска, а все письма с разными масками попадают в ящик you@yourdomain.com.
Дополнительно на сервере можно хостить статические страницы добавленных доменов. Там как веб интерфейс и так работает на веб сервере (nginx), плюс тут же есть управление DNS, разработчики решили добавить возможности простенького хостинга. Отдельно отмечу, что есть API для управления почтовыми ящиками.
Как я уже сказал, настроек через веб интерфейс почти нет, но все компоненты являются обычными пакетами, установленными в систему. Так что при желании, вы можете поменять любые настройки, если понимаете как и для чего это делать. В этом плане система удобна. Никаких лишних компонентов, слоёв и абстракций. По сути с помощью обвязки на bash и python вы автоматически устанавливаете классический почтовый сервер на Linux, типа того, что я описываю в своей статье.
Сборка мне понравилась. Опыта эксплуатации, понятное дело, у меня нет. Но я не вижу тут каких-то подводных камней, так как под капотом там типовые компоненты. Продукт известный, сообщество большое, идёт постоянное развитие и обновление. В репозитории большая активность. Из тех сборок, что мне известны на текущий момент, я бы рекомендовал именно эту. Она мне понравилась больше, чем бесплатная версия Iredmail.
⇨ Сайт / Исходники
#mailserver
Автор сборки позиционирует её как максимально простую систему, устанавливаемую в один клик. Настроек через панель управления нет практически никаких. И это правда. Лично для меня это минус, а для тех, кто не очень знаком с почтовыми серверами — плюс, так как предлагаемая настройка является универсальной, покрывающей основные потребности в почтовой системе. Можно не вникая в подробности получить надёжный почтовый сервер.
📌 Mail-in-a-Box состоит из следующих компонентов:
◽традиционные Postfix + Dovecot
◽веб интерфейс Roudcube + адресная книга от Nextcloud
◽z-push для Exchange ActiveSync
◽spamassassin и postgrey для борьбы со спамом
◽остальные компоненты: OpenDKIM, сертификаты от Let's Encrypt, duplicity для бэкапов, ufw в качестве фаервола, fail2ban, munin в качестве мониторинга, nsd4 в качестве DNS сервера.
Полная схема взаимодействия всех компонентов
Ставится всё это традиционно из пакетов, без Docker. Есть простой скрипт установщик, который всё это дело разворачивает на голой Ubuntu 22.04. Я на ней и проверял. Не знаю, заработает ли корректно автоматическая установка на других системах. Из всех настроек спросят только имя почтового сервера.
После установки всё управление выполняется через веб интерфейс. Сервер автоматически проверит все DNS записи, а также возможность отправки через 25-й порт. Если у вас провайдер его блокирует, то сразу об этом узнаете. Из настроек доступно только управление TLS сертификатами, в том числе автоматическое получение и установка Let's Encrypt, а также бэкапы, которые можно передавать с помощью rsync на любой сервер по SSH, либо складывать на S3 совместимое хранилище.
Компонент Postgrey реализует функционал Greylisting для новых отправителей. Я лично не люблю его и обычно не использую. Через веб интерфейс настроек никаких нет, но можно строку в конфиге postfix убрать, и он работать не будет. Ещё мне остался непонятен механизм управления spamassasin. Вообще ничего на нашёл на этот счёт. Автоматически подключен список zen.spamhaus.org для проверки отправителей. Отключить можно только через конфигурацию postfix.
Всё остальное сделано удобно. Через админку можно добавлять почтовые ящики, либо DNS записи. Настроенный сервер может выступать в качестве DNS сервера. Для пользователей доступны веб интерфейсы Roundcube для работы с почтой и Nextcloud для календаря и контактов. Поддерживаются почтовые адреса вида you+anythinghere@yourdomain.com. То есть к ящику you@yourdomain.com через + добавляется любая маска, а все письма с разными масками попадают в ящик you@yourdomain.com.
Дополнительно на сервере можно хостить статические страницы добавленных доменов. Там как веб интерфейс и так работает на веб сервере (nginx), плюс тут же есть управление DNS, разработчики решили добавить возможности простенького хостинга. Отдельно отмечу, что есть API для управления почтовыми ящиками.
Как я уже сказал, настроек через веб интерфейс почти нет, но все компоненты являются обычными пакетами, установленными в систему. Так что при желании, вы можете поменять любые настройки, если понимаете как и для чего это делать. В этом плане система удобна. Никаких лишних компонентов, слоёв и абстракций. По сути с помощью обвязки на bash и python вы автоматически устанавливаете классический почтовый сервер на Linux, типа того, что я описываю в своей статье.
Сборка мне понравилась. Опыта эксплуатации, понятное дело, у меня нет. Но я не вижу тут каких-то подводных камней, так как под капотом там типовые компоненты. Продукт известный, сообщество большое, идёт постоянное развитие и обновление. В репозитории большая активность. Из тех сборок, что мне известны на текущий момент, я бы рекомендовал именно эту. Она мне понравилась больше, чем бесплатная версия Iredmail.
⇨ Сайт / Исходники
#mailserver
{kind=link}
▶️ Для тех, кому любопытно получить объяснение и принципы работы машинного обучения (ML, Machine Learning), рекомендую видео Дениса Астахова. Там он очень доступно даёт теорию по этой теме. Я так понял, что он начал изучать какой-то курс по ML, поэтому решил записать ролик на эту тему.
⇨ Основы Машинного Обучения на примере Распознавание Кота на картинке | MACHINE LEARNING
Для тех, кто не знает Дениса, рекомендую посмотреть его канал. Я раньше все его видео смотрел, пока не появился цикл про AWS, который в наше время для жителей РФ стал не актуален. Его пропускаю.
Автор кратко и доступно раскрывает темы, так как сам является практикующим специалистом, а ютуб канал — его хобби. При этом он вырос самостоятельно сначала из программиста, потом системного администратора в DevOps инженера, а потом стал архитектором.
Меня позабавил один момент в его ролике. Он сам, если не ошибаюсь, родился в Крыму, потом переехал в Израиль. Жил там и работал несколько лет, знает иврит. Потом переехал в Канаду. Живёт и работает там уже много лет, общается, как я понимаю, на английском. А диск в его компьютере называется RAZNOE, как и у меня 😀 Не Various, не Разное, а Raznoe.
Как я уже сказал, на канале много полезных обучающих роликов, объединённых в законченные циклы обучения. Посмотреть их можно в плейлистах. Обращаю внимание на Terraform, Ansible, Jenkins, Git.
Отдельно отмечу ролики общей тематики, которые понравились мне лично:
◽Junior, Middle, Senior Девопс Инженер - Настоящие Примеры Задач
◽Чем пользуется DevOps Инженер на Работе: Tools, Software, Hardware
◽Как стать DevOps Инженером с Нуля, что учить и в каком порядке
#видео #обучение #devops
⇨ Основы Машинного Обучения на примере Распознавание Кота на картинке | MACHINE LEARNING
Для тех, кто не знает Дениса, рекомендую посмотреть его канал. Я раньше все его видео смотрел, пока не появился цикл про AWS, который в наше время для жителей РФ стал не актуален. Его пропускаю.
Автор кратко и доступно раскрывает темы, так как сам является практикующим специалистом, а ютуб канал — его хобби. При этом он вырос самостоятельно сначала из программиста, потом системного администратора в DevOps инженера, а потом стал архитектором.
Меня позабавил один момент в его ролике. Он сам, если не ошибаюсь, родился в Крыму, потом переехал в Израиль. Жил там и работал несколько лет, знает иврит. Потом переехал в Канаду. Живёт и работает там уже много лет, общается, как я понимаю, на английском. А диск в его компьютере называется RAZNOE, как и у меня 😀 Не Various, не Разное, а Raznoe.
Как я уже сказал, на канале много полезных обучающих роликов, объединённых в законченные циклы обучения. Посмотреть их можно в плейлистах. Обращаю внимание на Terraform, Ansible, Jenkins, Git.
Отдельно отмечу ролики общей тематики, которые понравились мне лично:
◽Junior, Middle, Senior Девопс Инженер - Настоящие Примеры Задач
◽Чем пользуется DevOps Инженер на Работе: Tools, Software, Hardware
◽Как стать DevOps Инженером с Нуля, что учить и в каком порядке
#видео #обучение #devops
{kind=link}
🎓 Мне на глаза попалась очень интересная русскоязычная научная публикация белорусского издания на тему:
Исследование производительности различных имплементаций Ingress контроллеров в кластере Kubernetes
⇨ http://www.vsbel.by/Portico/2021/3/130_Шуляк.pdf
Понравилось в первую очередь оформление, так как раньше с подобного рода исследованиями в IT мне сталкиваться не приходилось. Я сохранил себе документ, чтобы если придётся делать какие-то сравнительные тесты, постараться оформить их похожим образом. Выполнено очень качественно и наглядно. Информации немного и всё по делу. Я прям наслаждение получил от прочтения.
Выводы тоже получились интересными. Сравнивали обратные прокси серверы в дефолтных настройках:
◽Traefik;
◽NGINX;
◽NGINX Inc.;
◽Envoy (управляющий слой Contour);
◽HAProxy.
Я так понял, что NGINX Inc. это платная версия Nginx.
💡Выводы получились следующие:
Ingress контроллер, построенный на обратном прокси сервере HAProxy, имеет наилучшую производительность с точки зрения количества запросов в секунду, а также наименьшую нагрузку на центральный процессор. С точки зрения задержки в обработке запросов наилучшим образом показывает себя Ingress-контроллер на базе обратного проксисервера Traefik.
Зарекомендовавшие себя на рынке Ingress-контроллеры на базе обратных прокси-серверов NGINX имеют наихудшие показатели в стандартной конфигурации без модификаций.
❗️Так что если не умеете крутить настройки прокси, то разумнее всего выбрать HAProxy и не ломать голову над выбором.
#webserver
Исследование производительности различных имплементаций Ingress контроллеров в кластере Kubernetes
⇨ http://www.vsbel.by/Portico/2021/3/130_Шуляк.pdf
Понравилось в первую очередь оформление, так как раньше с подобного рода исследованиями в IT мне сталкиваться не приходилось. Я сохранил себе документ, чтобы если придётся делать какие-то сравнительные тесты, постараться оформить их похожим образом. Выполнено очень качественно и наглядно. Информации немного и всё по делу. Я прям наслаждение получил от прочтения.
Выводы тоже получились интересными. Сравнивали обратные прокси серверы в дефолтных настройках:
◽Traefik;
◽NGINX;
◽NGINX Inc.;
◽Envoy (управляющий слой Contour);
◽HAProxy.
Я так понял, что NGINX Inc. это платная версия Nginx.
💡Выводы получились следующие:
Ingress контроллер, построенный на обратном прокси сервере HAProxy, имеет наилучшую производительность с точки зрения количества запросов в секунду, а также наименьшую нагрузку на центральный процессор. С точки зрения задержки в обработке запросов наилучшим образом показывает себя Ingress-контроллер на базе обратного проксисервера Traefik.
Зарекомендовавшие себя на рынке Ingress-контроллеры на базе обратных прокси-серверов NGINX имеют наихудшие показатели в стандартной конфигурации без модификаций.
❗️Так что если не умеете крутить настройки прокси, то разумнее всего выбрать HAProxy и не ломать голову над выбором.
#webserver
{kind=link}
Существует простой и эффективный метод борьбы со спамом — Greylisting. Его переводят на русский как серый список. Расскажу вам простыми словами, как он работает, а также поделюсь своим опытом его использования.
Принцип работы Greylisting очень прост. Когда на сервер поступает письмо от нового адресата, с которым он ещё не взаимодействовал, письмо отклоняется с временным кодом ошибки 4ХХ, обычно 450. Согласно rfc5321, отправитель, получив такую ошибку, должен выполнить повторную отправку через некоторое время. В rfc оно указано как не менее 30 минут, если я правильно понял (the retry interval SHOULD be at least 30 minutes). На практике обычно это время меньше. В postfix по умолчанию оно равно 3 минутам.
Вот тут и кроется главная проблема. Не все серверы делают повторную отправку через 3 минуты. Это всё может настраиваться индивидуально, а rfc не указывает конкретные значения. В итоге может так получиться, что пользователь в течении 10-20 минут не сможет получить письмо от нового контрагента, что очень раздражает. Случается такое не часто, но бывает.
Способ реально простой и рабочий. Отсекает спам эффективно, так как спамеры обычно не обрабатывают коды ошибок и не держат у себя очередь, так как это накладно. Рассылка идёт по сотням тысяч адресов с каких-то взломанных машин или временных почтовых серверов. Надо за короткий промежуток времени разослать как можно больше почты, пока тебя не забанили. Поэтому обработкой ошибок обычно не занимаются.
Так что Greylisting очень дешёвый и эффективный способ борьбы со спамом, который не требует особых настроек. Достаточно где-то хранить список всех серверов, с которых вы уже получали почту и принимать от них её сразу. А всем остальным на первый раз выдавать 450 ошибку. Если они повторно делают отправку к вам, то принимается письмо, а сервер добавляется в этот список.
Во многих готовых почтовый сборках этот механизм включён по умолчанию. Например в Iredmail или Mail-in-a-Box. Я лично всегда его отключают, потому что даже задержка письма на 5-10 минут хотя бы раз в месяц вынудит пользователя сообщить поддержке, что с доставкой какие-то проблемы. И надо будет разбираться, объяснять в чём тут дело. Популярна ситуация, когда пользователь разговаривает с кем-то по телефону и тут же обменивается почтой. И письмо не приходит сразу. Для разговора в режиме реального времени задержка в 3 минуты значительна и раздражает. Приходится ждать, обновлять ящик, отправлять ещё раз и т.д.
Если для вас это не критично, то рекомендую обратить внимание на Greylisting. Он один способен отсечь большую часть спама. И не нужно будет разбираться с другими системами, особенно бальными, где надо поначалу тратить время на калибровку системы. Конкретных реализаций подхода Greylisting много. Под каждый почтовый сервер написаны свои. В каких-то сборках это собственным решением реализовано. На Postfix легко гуглится настройка.
#mailserver
Принцип работы Greylisting очень прост. Когда на сервер поступает письмо от нового адресата, с которым он ещё не взаимодействовал, письмо отклоняется с временным кодом ошибки 4ХХ, обычно 450. Согласно rfc5321, отправитель, получив такую ошибку, должен выполнить повторную отправку через некоторое время. В rfc оно указано как не менее 30 минут, если я правильно понял (the retry interval SHOULD be at least 30 minutes). На практике обычно это время меньше. В postfix по умолчанию оно равно 3 минутам.
Вот тут и кроется главная проблема. Не все серверы делают повторную отправку через 3 минуты. Это всё может настраиваться индивидуально, а rfc не указывает конкретные значения. В итоге может так получиться, что пользователь в течении 10-20 минут не сможет получить письмо от нового контрагента, что очень раздражает. Случается такое не часто, но бывает.
Способ реально простой и рабочий. Отсекает спам эффективно, так как спамеры обычно не обрабатывают коды ошибок и не держат у себя очередь, так как это накладно. Рассылка идёт по сотням тысяч адресов с каких-то взломанных машин или временных почтовых серверов. Надо за короткий промежуток времени разослать как можно больше почты, пока тебя не забанили. Поэтому обработкой ошибок обычно не занимаются.
Так что Greylisting очень дешёвый и эффективный способ борьбы со спамом, который не требует особых настроек. Достаточно где-то хранить список всех серверов, с которых вы уже получали почту и принимать от них её сразу. А всем остальным на первый раз выдавать 450 ошибку. Если они повторно делают отправку к вам, то принимается письмо, а сервер добавляется в этот список.
Во многих готовых почтовый сборках этот механизм включён по умолчанию. Например в Iredmail или Mail-in-a-Box. Я лично всегда его отключают, потому что даже задержка письма на 5-10 минут хотя бы раз в месяц вынудит пользователя сообщить поддержке, что с доставкой какие-то проблемы. И надо будет разбираться, объяснять в чём тут дело. Популярна ситуация, когда пользователь разговаривает с кем-то по телефону и тут же обменивается почтой. И письмо не приходит сразу. Для разговора в режиме реального времени задержка в 3 минуты значительна и раздражает. Приходится ждать, обновлять ящик, отправлять ещё раз и т.д.
Если для вас это не критично, то рекомендую обратить внимание на Greylisting. Он один способен отсечь большую часть спама. И не нужно будет разбираться с другими системами, особенно бальными, где надо поначалу тратить время на калибровку системы. Конкретных реализаций подхода Greylisting много. Под каждый почтовый сервер написаны свои. В каких-то сборках это собственным решением реализовано. На Postfix легко гуглится настройка.
#mailserver
{kind=link}
Для быстрой и простой проверки Docker образов на уязвимости существует популярный Open Source инструмент — Trivy. Я покажу на примере, как им пользоваться. Получится готовая мини инструкция по установке и использованию.
Установить Trivy можно разными способами: из репозитория с пакетами, собрать с помощью Nix, воспользоваться bash скриптом, запустить в Docker. Все способы описаны в документации. Я установлю в Debian из репозитория.
Теперь скачиваем любой образ и проверяем его на уязвимости. Покажу на примере заведомо уязвимого образа.
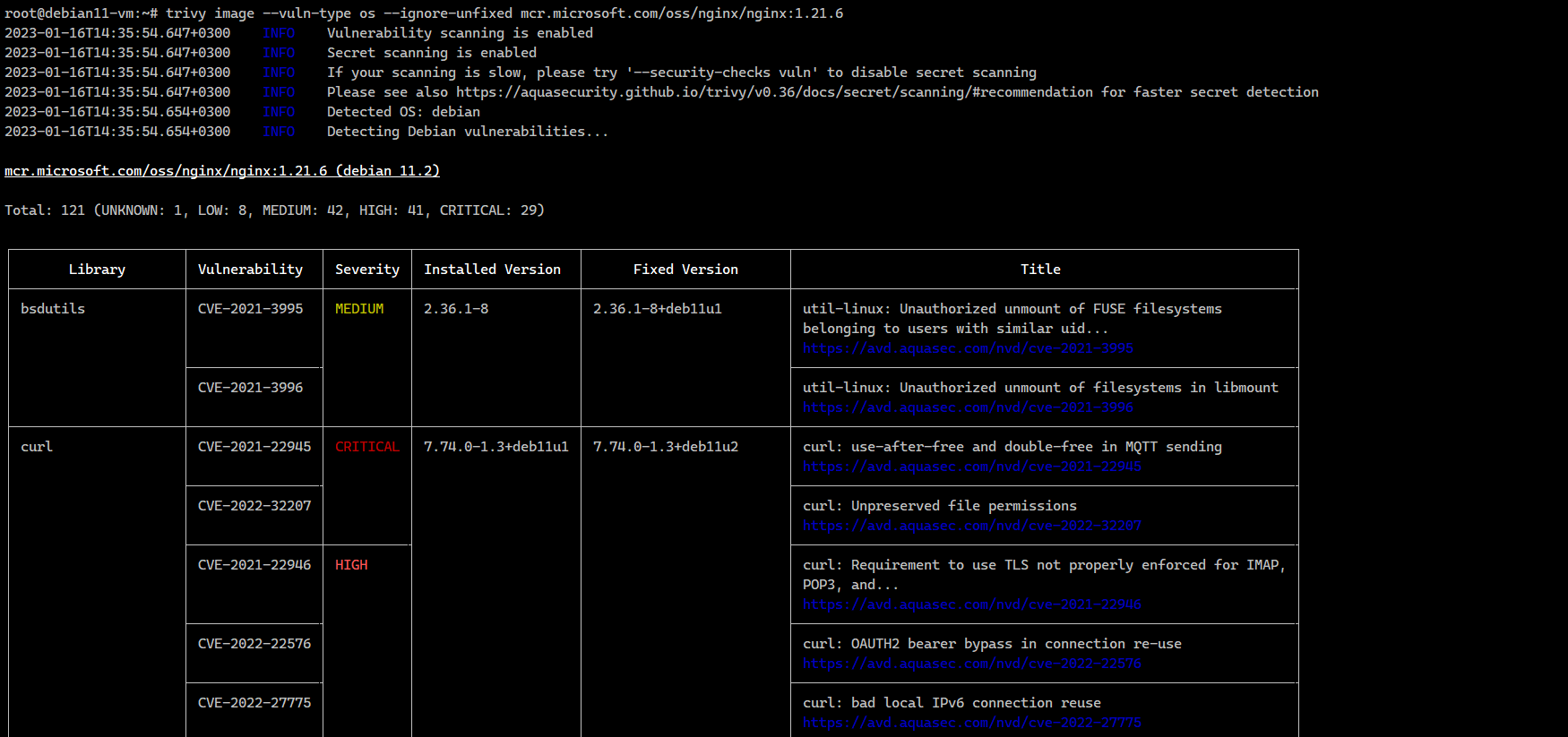
Результат проверки будет в файле nginx.1.21.6.json, что удобно для последующего автоматического анализа. Можно наглядно посмотреть результат в консоли:
Trivy отлично подходит для автоматической проверки образов перед их отправкой в registry. Да и просто для быстрого анализа созданного или скачанного образа. Помимо проверки образов, он умеет сканировать git репозитории, файлы с зависимостями (Gemfile.lock, Pipfile.lock, composer.lock, package-lock.json, yarn.lock, Cargo.lock).
Следующей будет заметка с описанием автоматического исправления уязвимостей в образах на основе отчётов trivy.
⇨ Сайт / Исходники
#security #docker #devops
Установить Trivy можно разными способами: из репозитория с пакетами, собрать с помощью Nix, воспользоваться bash скриптом, запустить в Docker. Все способы описаны в документации. Я установлю в Debian из репозитория.
# apt install wget apt-transport-https gnupg lsb-release# wget -qO - https://aquasecurity.github.io/trivy-repo/deb/public.key \| gpg --dearmor | tee /usr/share/keyrings/trivy.gpg > /dev/null# echo "deb [signed-by=/usr/share/keyrings/trivy.gpg] \ https://aquasecurity.github.io/trivy-repo/deb $(lsb_release -sc) main" \| tee -a /etc/apt/sources.list.d/trivy.list# apt update# apt install trivyТеперь скачиваем любой образ и проверяем его на уязвимости. Покажу на примере заведомо уязвимого образа.
# docker pull mcr.microsoft.com/oss/nginx/nginx:1.21.6# trivy image --vuln-type os --ignore-unfixed \-f json -o nginx.1.21.6.json mcr.microsoft.com/oss/nginx/nginx:1.21.6Результат проверки будет в файле nginx.1.21.6.json, что удобно для последующего автоматического анализа. Можно наглядно посмотреть результат в консоли:
# trivy image --vuln-type os \--ignore-unfixed mcr.microsoft.com/oss/nginx/nginx:1.21.6Trivy отлично подходит для автоматической проверки образов перед их отправкой в registry. Да и просто для быстрого анализа созданного или скачанного образа. Помимо проверки образов, он умеет сканировать git репозитории, файлы с зависимостями (Gemfile.lock, Pipfile.lock, composer.lock, package-lock.json, yarn.lock, Cargo.lock).
Следующей будет заметка с описанием автоматического исправления уязвимостей в образах на основе отчётов trivy.
⇨ Сайт / Исходники
#security #docker #devops
{kind=link}
Хотите научиться работать в DevSecOps проектах?
⚡️ Приглашаем 19 января в 20:00 мск на бесплатный вебинар «Сервисная сетка на базе Istio в Kubernetes».
На занятии мы:
✅ Рассмотрим один из базовых инструментов для обеспечения безопасности Kubernetes-кластеров — сервисная сетка (service mesh) на базе opensource-инструмента Istio.
✅ Посмотрим, из каких компонентов состоит сервисная сетка, как устроен инструмент Istio (control и data plane, sidecar, envoy), как осуществляется и внедряется термин наблюдаемости (observability).
✅ Продемонстрируем, как развернуть k3d-кластер, проинсталировать Istio и добавить в сервисную сетку свое первое приложение, развернутое в Kubernetes-кластер.
👉🏻 Регистрация на вебинар: https://otus.pw/GYpK/
⚡️ Приглашаем 19 января в 20:00 мск на бесплатный вебинар «Сервисная сетка на базе Istio в Kubernetes».
На занятии мы:
✅ Рассмотрим один из базовых инструментов для обеспечения безопасности Kubernetes-кластеров — сервисная сетка (service mesh) на базе opensource-инструмента Istio.
✅ Посмотрим, из каких компонентов состоит сервисная сетка, как устроен инструмент Istio (control и data plane, sidecar, envoy), как осуществляется и внедряется термин наблюдаемости (observability).
✅ Продемонстрируем, как развернуть k3d-кластер, проинсталировать Istio и добавить в сервисную сетку свое первое приложение, развернутое в Kubernetes-кластер.
👉🏻 Регистрация на вебинар: https://otus.pw/GYpK/
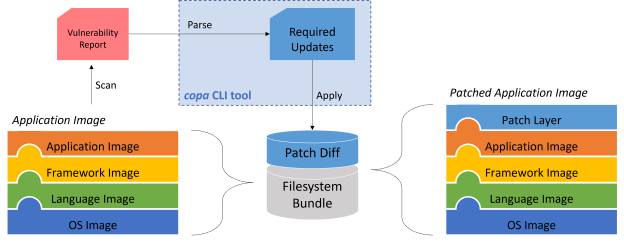
Продолжаю тему безопасности Docker контейнеров. С помощью Trivy можно проверить образ на уязвимости. Теперь расскажу, как их автоматически исправить. Для этого нам понадобится Copacetic. Он будет брать информацию из отчётов Trivy. Для запуска copa cli нам нужно:
1️⃣ Установить Go v1.19 или новее.
2️⃣ Собрать и установить runc.
3️⃣ Установить buildkit v0.10.5 или новее.
4️⃣ Собрать и установить copa.
Я кратко без пояснений покажу как это сделать на примере Debian. Все подробности есть в самих репозиториях программ.
✅ Устанавливаем GO.
✅ Устанавливаем runc.
✅ Устанавливаем buildkit.
✅ Устанавливаем copacetic.
Все необходимые компоненты установили. Теперь патчим уязвимый контейнер. Для этого предварительно в фоне запускаем buildkitd:
Copa не перезаписывает старый образ, а создаёт новый с тэгом patched. Можете сразу его посмотреть и проверить:
Ну и убедиться, что он нормально запускается:
Copa, используя информацию о версиях пакетов из отчёта Trivy, обновила все уязвимые системные пакеты в образе. Можете проверить уже пропатченный образ:
Я показал набор софта и пример обновления контейнера. Получилась готовая инструкция, которую я лично проверил. Используя эту информацию и информацию из репозиториев, можно настроить подобные обновления для своей среды.
⇨ Исходники Copacetic
#security #docker #devops
1️⃣ Установить Go v1.19 или новее.
2️⃣ Собрать и установить runc.
3️⃣ Установить buildkit v0.10.5 или новее.
4️⃣ Собрать и установить copa.
Я кратко без пояснений покажу как это сделать на примере Debian. Все подробности есть в самих репозиториях программ.
✅ Устанавливаем GO.
# wget https://go.dev/dl/go1.19.5.linux-amd64.tar.gz# tar -C /usr/local -xzf go1.19.5.linux-amd64.tar.gz# ln -s /usr/local/go/bin/go /usr/bin/go# go version✅ Устанавливаем runc.
# apt install make git gcc build-essential pkgconf libtool libsystemd-dev \libprotobuf-c-dev libcap-dev libseccomp-dev libyajl-dev libgcrypt20-dev \go-md2man autoconf python3 automake# git clone https://github.com/opencontainers/runc# cd runc# make# make install✅ Устанавливаем buildkit.
# wget https://github.com/moby/buildkit/releases/download/v0.11.0/buildkit-v0.11.0.linux-amd64.tar.gz# tar -C /usr -xzf buildkit-v0.11.0.linux-amd64.tar.gz✅ Устанавливаем copacetic.
# git clone https://github.com/project-copacetic/copacetic# cd copacetic# make# mv dist/linux_amd64/release/copa /usr/local/bin/Все необходимые компоненты установили. Теперь патчим уязвимый контейнер. Для этого предварительно в фоне запускаем buildkitd:
# buildkitd &# copa patch -i mcr.microsoft.com/oss/nginx/nginx:1.21.6 -r nginx.1.21.6.json -t 1.21.6-patchedCopa не перезаписывает старый образ, а создаёт новый с тэгом patched. Можете сразу его посмотреть и проверить:
# docker images# docker history mcr.microsoft.com/oss/nginx/nginx:1.21.6-patchedНу и убедиться, что он нормально запускается:
# docker run -it --rm --name nginx-test mcr.microsoft.com/oss/nginx/nginx:1.21.6-patchedCopa, используя информацию о версиях пакетов из отчёта Trivy, обновила все уязвимые системные пакеты в образе. Можете проверить уже пропатченный образ:
# trivy image --vuln-type os --ignore-unfixed mcr.microsoft.com/oss/nginx/nginx:1.21.6-patchedЯ показал набор софта и пример обновления контейнера. Получилась готовая инструкция, которую я лично проверил. Используя эту информацию и информацию из репозиториев, можно настроить подобные обновления для своей среды.
⇨ Исходники Copacetic
#security #docker #devops
{kind=link}
Все или почти все системные администраторы знают такой инструмент как Nmap. Если не знаете, познакомьтесь. Я сам не раз писал о нём на канале. Основной его минус — медленное сканирование. Есть альтернативная программа — Zmap, где проблема скорости решена, но и функционал у программы намного беднее.
А если хочется сканировать ещё быстрее? Чем вообще сканируют весь интернет? Сейчас это обычное дело. Для этого используют тоже open source программу — masscan. Она написана изначально под Linux, но можно собрать и под другую систему. В репозитории нет готовых сборок, но, к примеру, в Debian, поставить можно из стандартного репозитория:
Дополнительно понадобится библиотека Libpcap для анализа сетевых пакетов:
Masscan очень быстрый за счёт того, что использует свой собственный TCP/IP стек. Из-за этого он не может ничего делать, кроме как выполнять простое сканирование. В противном случае будут возникать проблемы с локальным TCP/IP стеком операционной системы. Для быстрого сканирования используются массовые асинхронные SYN пакеты только для обнаружения. А чтобы собирать полноценную информацию, как умеет Nmap, нужно устанавливать полноценные TCP соединения и ждать информацию.
Вот пример сканирования в сети 80-го порта с ограничением в 100 пакетов в секунду:
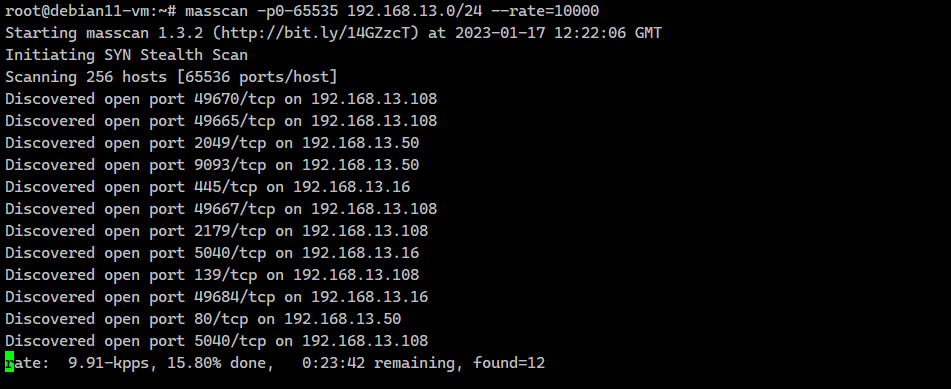
Вся сеть просканирована за пару секунд. А теперь немного ускоримся до 10000 пакетов в секунду и просканируем весь диапазон портов в той же сети:
На это уйдёт примерно 30 минут. Нагрузка на железо будет значительная, так что аккуратнее. Лучше начинать с более низких значений. Виртуалка на Proxmox без проблем переварила 10000 пакетов в секунду, а вот если запустить на рабочем ноуте в виртуалке HyperV, то начинает подтормаживать хостовая система.
Процесс сканирования можно в любой момент прервать по CTRL + C. Результат будет сохранён в файл paused.conf. Возобновить сканирование можно следующим образом:
Если получите ошибку
то это баг более старой версии. В репах Debian именно она. Строку с nocapture = servername надо просто удалить из файла и всё заработает.
Если будете сканировать через NAT, то не забудьте, что существует ограничение на количество возможных одновременных соединений в роутере. Это если надумаете сканировать весь интернет с домашнего компьютера😀 Быстро всё равно не получится. За обещанные 5 минут не уложитесь. Если вы всё же настроены просканировать весь интернет, то в отдельной доке есть подсказки, как это лучше сделать.
Я первый раз попробовал masscan, хотя знал про него давно. Быстро просканировать всю локалку и найти вообще все открытые порты действительно удобно и быстро по сравнению с тем же Nmap.
После сканирования хорошо бы было как-то автоматически все открытые порты скормить в nmap для более детального анализа. Но пока не прорабатывал этот вопрос. Если у кого-то есть готовые решения по этой теме, поделитесь.
#network
А если хочется сканировать ещё быстрее? Чем вообще сканируют весь интернет? Сейчас это обычное дело. Для этого используют тоже open source программу — masscan. Она написана изначально под Linux, но можно собрать и под другую систему. В репозитории нет готовых сборок, но, к примеру, в Debian, поставить можно из стандартного репозитория:
# apt install masscanДополнительно понадобится библиотека Libpcap для анализа сетевых пакетов:
# apt install libpcap-devMasscan очень быстрый за счёт того, что использует свой собственный TCP/IP стек. Из-за этого он не может ничего делать, кроме как выполнять простое сканирование. В противном случае будут возникать проблемы с локальным TCP/IP стеком операционной системы. Для быстрого сканирования используются массовые асинхронные SYN пакеты только для обнаружения. А чтобы собирать полноценную информацию, как умеет Nmap, нужно устанавливать полноценные TCP соединения и ждать информацию.
Вот пример сканирования в сети 80-го порта с ограничением в 100 пакетов в секунду:
# masscan -p80 192.168.13.0/24 --rate=100Scanning 256 hosts [1 port/host]Discovered open port 80/tcp on 192.168.13.2 Discovered open port 80/tcp on 192.168.13.50Вся сеть просканирована за пару секунд. А теперь немного ускоримся до 10000 пакетов в секунду и просканируем весь диапазон портов в той же сети:
# masscan -p0-65535 192.168.13.0/24 --rate=10000На это уйдёт примерно 30 минут. Нагрузка на железо будет значительная, так что аккуратнее. Лучше начинать с более низких значений. Виртуалка на Proxmox без проблем переварила 10000 пакетов в секунду, а вот если запустить на рабочем ноуте в виртуалке HyperV, то начинает подтормаживать хостовая система.
Процесс сканирования можно в любой момент прервать по CTRL + C. Результат будет сохранён в файл paused.conf. Возобновить сканирование можно следующим образом:
# masscan --resume paused.confЕсли получите ошибку
CONF: unknown config option: nocapture=servernameто это баг более старой версии. В репах Debian именно она. Строку с nocapture = servername надо просто удалить из файла и всё заработает.
Если будете сканировать через NAT, то не забудьте, что существует ограничение на количество возможных одновременных соединений в роутере. Это если надумаете сканировать весь интернет с домашнего компьютера😀 Быстро всё равно не получится. За обещанные 5 минут не уложитесь. Если вы всё же настроены просканировать весь интернет, то в отдельной доке есть подсказки, как это лучше сделать.
Я первый раз попробовал masscan, хотя знал про него давно. Быстро просканировать всю локалку и найти вообще все открытые порты действительно удобно и быстро по сравнению с тем же Nmap.
После сканирования хорошо бы было как-то автоматически все открытые порты скормить в nmap для более детального анализа. Но пока не прорабатывал этот вопрос. Если у кого-то есть готовые решения по этой теме, поделитесь.
#network
{kind=link}
Почти любой пользователь Linux знаком с консольной командой cat, соавтором которой является легендарный Richard Matthew Stallman. Хочу рассказать об одной небольшой возможности этой программы, про которую не все знают. Более того, чаще всего люди как раз об этом не знают.
Cat может выступать как простой текстовый редактор. С помощью неё можно быстро создать пустой файл, либо добавить в конец новые строки. Создаём файл:
Проверяем:
Создавать пустые файлы с помощью cat не имеет большого смысла, так как то же самое делает команда touch:
Я обычно создаю файлы с её помощью.
С помощью cat можно сразу добавить несколько строк в файл, как в новый, так и в существующий.
Записали в файл строку testfile и вышли из редактора. Проверяем:
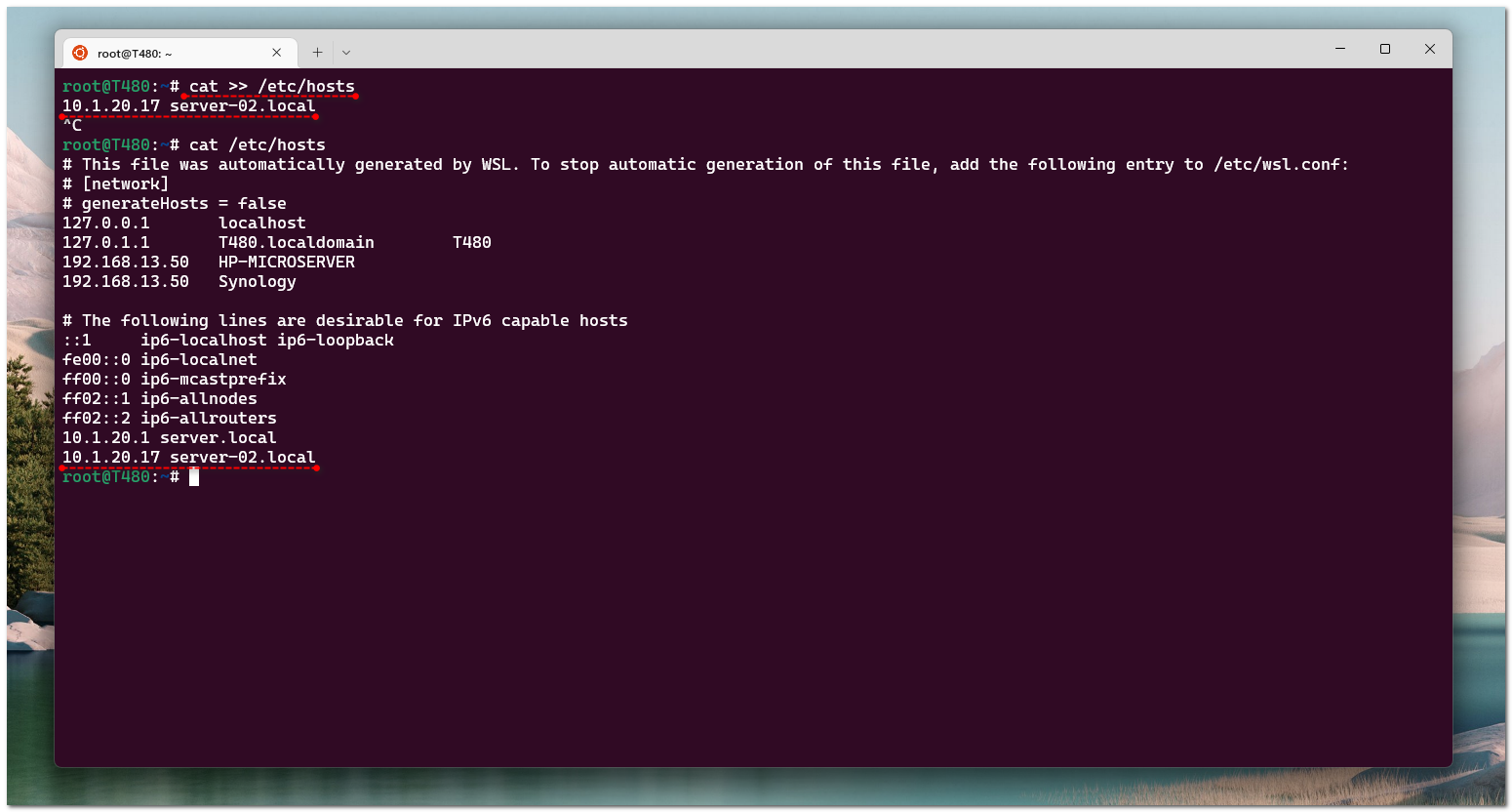
Cat может не только записать что-то в новый файл, но и добавить в конец уже существующего. А вот это уже удобно в некоторых случаях. Например, нужно добавить новую запись в hosts. С помощью cat это удобно сделать:
Добавили в конец файла новую строку
И в завершение напомню, что с помощью cat удобно объединить несколько файлов в один:
Интересно узнать, вы знали, что cat позволяет редактировать файлы? Обычно его используют только для просмотра.
#terminal
Cat может выступать как простой текстовый редактор. С помощью неё можно быстро создать пустой файл, либо добавить в конец новые строки. Создаём файл:
# cat > file1CTRL + CПроверяем:
# ls -lh file1-rw-r--r-- 1 root root 0 Jan 16 16:24 file1Создавать пустые файлы с помощью cat не имеет большого смысла, так как то же самое делает команда touch:
# touch file2Я обычно создаю файлы с её помощью.
С помощью cat можно сразу добавить несколько строк в файл, как в новый, так и в существующий.
# cat > file3testfileCTRL + CЗаписали в файл строку testfile и вышли из редактора. Проверяем:
# cat file3testfileCat может не только записать что-то в новый файл, но и добавить в конец уже существующего. А вот это уже удобно в некоторых случаях. Например, нужно добавить новую запись в hosts. С помощью cat это удобно сделать:
# cat >> /etc/hosts10.1.20.1 server.localCTRL + CДобавили в конец файла новую строку
10.1.20.1 server.local. Нет необходимости открывать файл в текстовом редакторе. Не забудьте добавить сразу переход на новую строку. И главное не перепутать и поставить два перенаправления ввода >>, а не одно >. С одним просто перезапишите файл, что тоже иногда случается 😁 Если не уверены в своей внимательности, не пользуйтесь.И в завершение напомню, что с помощью cat удобно объединить несколько файлов в один:
# cat file1 file2 > file_1_2Интересно узнать, вы знали, что cat позволяет редактировать файлы? Обычно его используют только для просмотра.
#terminal
{kind=link}
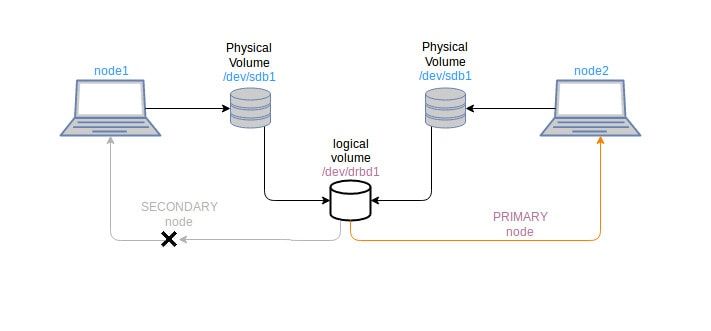
Расскажу про простую схему построения отказоустойчивой системы на уровне файлового хранения с помощью DRBD (Distributed Replicated Block Device — распределённое реплицируемое блочное устройство). Это очень простое и известное решение в том числе из-за того, что поддержка DRBD входит в стандартное ядро Linux.
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
На мой взгляд DRBD наиболее быстрое в настройке средство для репликации данных. Вы условно получаете сетевой RAID1. Есть возможность построить его на двух устройствах и вручную или автоматически разрешать ситуации с splitbrain. Эта ситуация характерна для двух узлов, когда в случае выхода из строя одного из них, а потом возврата, нужно решить, какие данные считать актуальными. Без внешнего арбитра это нетривиальная задача. К примеру, чтобы не было такой истории, в ceph рекомендуется иметь минимум 3 ноды.
Расскажу на простых словах, как выглядит работа с DRBD. Вы устанавливаете пакет drbd-utils в систему и создаёте по два одинаковых конфига на двух серверах. В конфигах указываете, что, к примеру, устройства
/dev/sdb будут использоваться под DRBD. Запускаете инициализацию и получаете новое блочное устройство на каждом сервере, которое автоматически синхронизируется.Далее на этих устройствах вы создаёте любую файловую систему, например ext4, монтируете в систему и пользуетесь. Данные будут автоматически синхронизироваться. Получившийся "кластер" может работать в режиме Primary/Secondary с ручным управлением, либо в режиме Primary/Primary с автоматическим выбором мастера.
Расскажу, как я использовал в своё время DRBD, когда ещё не было решений по репликации виртуалок уровня Veeam. Покупались два одинаковых сервера с двумя гигабтными сетевыми картами, на них устанавливались любые гипервизоры. На одном гипервизоре настраивались все виртуалки с DRBD дисками. Потом эти виртуалки клонировались на второй гипервизор. Там немного правились настройки IP, hostname, hosts, а также DRBD. И всё это запускалось.
Одна сетевая карта работала на локальную сеть, вторая только на обмен данными DRBD. Гигабита вполне хватало для серверных потребностей небольшого офиса на 50-100 человек. Там был файловый сервер, почтовый и остальное по мелочи без больших файловых хранилищ.
Если выходил из строя основной сервер, то нужно было вручную на втором сервере пометить, что DRBD устройства стали Primary, поправить DNS записи на IP виртуалок второго сервера. И вся нагрузка переходила на второй сервер. После починки первый сервер запускался в работу, его DRBD помечались как Secondary. Дожидались окончания синхронизации и либо оставались на втором сервере в качестве мастера, либо обратно переключались на первый и меняли приоритет DRBD.
Так работала схема с ручным переключением. Рассказал свой опыт. Это не инструкция для применения. Я просто не рисковал настраивать автоматическое переключение, так как реальной потребности в HA кластере не было. Мне было важно иметь под рукой горячую копию всех данных с возможностью быстро на неё переключиться. И быть уверенным в том, что данные реально не перемешаются, а я аккуратно сам всё переключу и проконтролирую, что не будет рассинхронизации и задвоения или перезаписи новых данных. Основные проблемы были с аварийным выключением серверов. Нужно было вручную потом заходить на каждый и разбираться со статусом DRBD дисков. Поэтому важно в этой схеме иметь упсы и корректное завершение работы. Но даже с аварийным выключением реальных потерь данных не было, просто нужно было вручную разбираться. Так что в плане надёжности и сохранности данных решение хорошее.
DRBD старый и известный продукт. В сети много готовых инструкций под все популярные системы. Так что если надумаете его попробовать, проблем с настройкой не будет.
Есть множество реализаций на базе DRBD. Можно, к примеру, с одного из блочных устройств снимать бэкапы, чтобы не нагружать прод. Можно с помощью Virtual IP создавать HA кластеры. Тот же Proxmox раньше предлагал свой двухнодовый HA Cluster на базе DRBD.
#fileserver #linux #drbd
{kind=link}
Открытый практикум DevOps by Rebrain: Развёртывание kubernetes на своих машинках с помощью kubeadm
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
🗓 24 Января (Вторник) в 20:00 по МСК
Программа практикума:
🔹Зачем нужен карманный kubernetes?
🔹Популярные альтернативы kubeadm (MicroK8s, Docker Desktop)
🔹Kubernetes за десять минут, первый сервис за одну
Кто ведет?
Павел Фискович - Инженер с 2009. Мечтатель. Отец. He/him
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
🗓 24 Января (Вторник) в 20:00 по МСК
Программа практикума:
🔹Зачем нужен карманный kubernetes?
🔹Популярные альтернативы kubeadm (MicroK8s, Docker Desktop)
🔹Kubernetes за десять минут, первый сервис за одну
Кто ведет?
Павел Фискович - Инженер с 2009. Мечтатель. Отец. He/him
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Отследить сетевую активность конкретного приложения Linux, а также сетевые адреса, куда оно стучится, не тривиальная задача. Мне на ум не приходят какие-то известные простые программы. Решения по наблюдению за сетевым трафиком обычно оперируют IP адресами хостов и портами служб, но не локальными приложениями, потому что берут трафик со шлюзов.
Если вам нужно собирать на машине сетевую активность приложений, то можно воспользоваться open source утилитой picosnitch. Она позволяет через простой веб интерфейс просматривать статистику с группировкой по приложению, порту или удалённому IP адресу. Выбирая приложение, можно посмотреть, на какие IP адреса оно стучалось и посмотреть статистику по конкретному адресу.
Picosnitch создаёт впечатления простого pet проекта, но тем не менее заявленный функционал выполняется. Я протестировал. Автор поддерживает репозиторий пакетов для Ubuntu. Я же пробовал на Debian. Установка возможна через pip. Дополнительно понадобятся пакеты для работы с BPF.
Веб интерфейс запускается отдельной командой:
По умолчанию он работает на http://localhost:5100. Чтобы иметь доступ по сети к веб интерфейсу, задаётся IP адрес сервера через переменную окружения HOST перед запуском интерфейса. Примерно так:
На первый взгляд веб интерфейс выглядит как-то коряво и непривычно. Я даже подумал, что работает криво и не выводит информацию. Надо немного разобраться и понять логику работы. На самом деле всё работает. Можно выбрать конкретное приложение, IP адрес, домен, порт. Например, для того, чтобы посмотреть к каким IP адресам обращается какое-то приложение, необходимо выбрать группировку по Destination IP, в условии указать Where Process Name и в выпадающем списке выбрать приложение. Получите его статистику.
Picosnitch хранит информацию в SQLite базе. Сама база, настройки и лог файл лежит в директории пользователя (не root) ~/.config/picosnitch. Можно настроить глубину хранения статистики в днях. Все параметры подробно описаны в репозитории. Дополнительно программа умеет оповещать о том, что какое-то приложение полезло в сеть, либо изменился его исполняемый файл.
Для просмотра сетевой активности приложений в терминале, можно воспользоваться программой sniffer, которую я уже описывал ранее. Она более простая, без веб интерфейса и хранения статистики.
⇨ Исходники
#network
Если вам нужно собирать на машине сетевую активность приложений, то можно воспользоваться open source утилитой picosnitch. Она позволяет через простой веб интерфейс просматривать статистику с группировкой по приложению, порту или удалённому IP адресу. Выбирая приложение, можно посмотреть, на какие IP адреса оно стучалось и посмотреть статистику по конкретному адресу.
Picosnitch создаёт впечатления простого pet проекта, но тем не менее заявленный функционал выполняется. Я протестировал. Автор поддерживает репозиторий пакетов для Ubuntu. Я же пробовал на Debian. Установка возможна через pip. Дополнительно понадобятся пакеты для работы с BPF.
# apt install python3-pip bpfcc-tools libbpfcc libbpfcc-dev \linux-headers-$(uname -r)# pip3 install "picosnitch[full]" --upgrade --user# picosnitch systemd# systemctl start picosnitchВеб интерфейс запускается отдельной командой:
# picosnitch dashПо умолчанию он работает на http://localhost:5100. Чтобы иметь доступ по сети к веб интерфейсу, задаётся IP адрес сервера через переменную окружения HOST перед запуском интерфейса. Примерно так:
# export HOST='172.27.51.252'# picosnitch dashНа первый взгляд веб интерфейс выглядит как-то коряво и непривычно. Я даже подумал, что работает криво и не выводит информацию. Надо немного разобраться и понять логику работы. На самом деле всё работает. Можно выбрать конкретное приложение, IP адрес, домен, порт. Например, для того, чтобы посмотреть к каким IP адресам обращается какое-то приложение, необходимо выбрать группировку по Destination IP, в условии указать Where Process Name и в выпадающем списке выбрать приложение. Получите его статистику.
Picosnitch хранит информацию в SQLite базе. Сама база, настройки и лог файл лежит в директории пользователя (не root) ~/.config/picosnitch. Можно настроить глубину хранения статистики в днях. Все параметры подробно описаны в репозитории. Дополнительно программа умеет оповещать о том, что какое-то приложение полезло в сеть, либо изменился его исполняемый файл.
Для просмотра сетевой активности приложений в терминале, можно воспользоваться программой sniffer, которую я уже описывал ранее. Она более простая, без веб интерфейса и хранения статистики.
⇨ Исходники
#network
{kind=link}
Вчера один человек попросил посоветовать простенький, максимально легкий и простой в настройке мониторинг для одиночного сервера. Задача быстро настроить и смотреть красивые картинки в веб интерфейсе. Я быстро накидал вариантов, про которые вспомнил. Решил их оформить отдельным постом. Думаю, будет полезно не только ему.
🔥 Munin — очень простой мониторинг одиночного или небольшой группы серверов на perl. Данные хранятся в rrdtool. Настраивается очень просто и быстро, за что его любят некоторые разработчики, устанавливая на свои сервера для каких-то собственных проектов. Munin используют разработчики BitrixEnv, включили его в комплект своего окружения. А также авторы Mail-in-a-Box.
🟡 Monitorix — похожий на Munin мониторинг и тоже на основе perl и rrdtool. Подойдёт для одиночного сервера. Отличительная черта в том, что он потребляет очень мало ресурсов. Графики рендерятся сразу в png картинки. Помимо базовых системных и сетевых метрик, из коробки поддерживает мониторинг наиболее популярного софта - postfix, exim, apache, nginx, php-fpm, nfs, zfs, mysql, postgresql, redis и т.д.
🟡 Monit — похож на Munin и Monitorix. Такой же легковесный с акцентом на мониторинг одиночного сервера. Умеет не только мониторить, но и выполнять какие-то заскриптованные действия. Данные хранит в SQLite. Monit для тех, кто просто хочет мониторить свой локалхост, получать алерты, перезапускать сервисы, когда они падают. И при этом тратить минимум ресурсов. Писать oldschool конфиги без учёта отступов, пробелов, скобок.
🟡 Monitoror — очень простой мониторинг, который состоит всего лишь из одного бинарника и конфигурационного файла к нему. Отдельным конфигом настраивается web интерфейс. Используется формат json. Настраивать проверки быстро и просто. Monitoror отличает простота парсинга и сбора текстовых данных по http с возможностью их вывести в плитках на дашбодр. Это отличный инструмент для всяких чисел, получаемых из API.
🟡 Netdata — мониторинг с очень простой установкой и настройкой. Скрипт сам в автоматическом режиме развернёт сервер на Linux машине. Работает на основе агентов и коллекторов, которые ставятся очень просто, автоматически регистрируют себя на сервере и начинают отправлять данные. Это не легковесный вариант мониторинга локалхоста, но за счёт простоты установки и настройки, а так же готовых дашбордов в комплекте, добавил его в эту подборку. Для одиночного сервера он тоже подойдёт.
🟡 Glances — не совсем мониторинг, но для обозначенных в заметке задач может подойти. Это продвинутый монитор системных ресурсов с возможностью вывода информации через веб сервер. Эдакий прокачанный диспетчер ресурсов и процессов с веб интерфейсом и экспортёрами метрик в prometheus или elasticsearch.
Если забыл что-то интересное и полезное, то поделитесь в комментариях.
#мониторинг #подборка
🔥 Munin — очень простой мониторинг одиночного или небольшой группы серверов на perl. Данные хранятся в rrdtool. Настраивается очень просто и быстро, за что его любят некоторые разработчики, устанавливая на свои сервера для каких-то собственных проектов. Munin используют разработчики BitrixEnv, включили его в комплект своего окружения. А также авторы Mail-in-a-Box.
🟡 Monitorix — похожий на Munin мониторинг и тоже на основе perl и rrdtool. Подойдёт для одиночного сервера. Отличительная черта в том, что он потребляет очень мало ресурсов. Графики рендерятся сразу в png картинки. Помимо базовых системных и сетевых метрик, из коробки поддерживает мониторинг наиболее популярного софта - postfix, exim, apache, nginx, php-fpm, nfs, zfs, mysql, postgresql, redis и т.д.
🟡 Monit — похож на Munin и Monitorix. Такой же легковесный с акцентом на мониторинг одиночного сервера. Умеет не только мониторить, но и выполнять какие-то заскриптованные действия. Данные хранит в SQLite. Monit для тех, кто просто хочет мониторить свой локалхост, получать алерты, перезапускать сервисы, когда они падают. И при этом тратить минимум ресурсов. Писать oldschool конфиги без учёта отступов, пробелов, скобок.
🟡 Monitoror — очень простой мониторинг, который состоит всего лишь из одного бинарника и конфигурационного файла к нему. Отдельным конфигом настраивается web интерфейс. Используется формат json. Настраивать проверки быстро и просто. Monitoror отличает простота парсинга и сбора текстовых данных по http с возможностью их вывести в плитках на дашбодр. Это отличный инструмент для всяких чисел, получаемых из API.
🟡 Netdata — мониторинг с очень простой установкой и настройкой. Скрипт сам в автоматическом режиме развернёт сервер на Linux машине. Работает на основе агентов и коллекторов, которые ставятся очень просто, автоматически регистрируют себя на сервере и начинают отправлять данные. Это не легковесный вариант мониторинга локалхоста, но за счёт простоты установки и настройки, а так же готовых дашбордов в комплекте, добавил его в эту подборку. Для одиночного сервера он тоже подойдёт.
🟡 Glances — не совсем мониторинг, но для обозначенных в заметке задач может подойти. Это продвинутый монитор системных ресурсов с возможностью вывода информации через веб сервер. Эдакий прокачанный диспетчер ресурсов и процессов с веб интерфейсом и экспортёрами метрик в prometheus или elasticsearch.
Если забыл что-то интересное и полезное, то поделитесь в комментариях.
#мониторинг #подборка
{kind=link}
⚠ Я долго это терпел, но не выдержал. Надоело то, что не грузятся аватарки в youtube. Для всех других сайтов обходился редким включением VPN, так как не часто хожу по запрещёнке. Но ютубом пользуюсь каждый день.
✅ В итоге настроил:
◽ OpenVPN сервер на американском VPS.
◽ Подключил его к домашнему Микротику.
◽ Создал Address List со списком доменов, запросы к которым хочу заворачивать в VPN туннель.
◽ Промаркировал все запросы к этому списку.
◽ Настроил в routes маршрут через OpenVPN туннель для всех промаркированных запросов.
И о чудо, спустя почти год я постоянно вижу все картинки с ютуба.
Подробно весь процесс настройки показан вот в этом видео:
Wireguard + Mikrotik. Частичное перенаправление трафика
⇨ https://www.youtube.com/watch?v=RA8mICgGcs0
Единственное отличие — у автора уже RouterOS 7 и настроен WireGuard. Мне пока не хочется экспериментов с 7-й версией, поэтому я до сих пор везде использую 6-ю. А там поддержки WG нет, поэтому подключаюсь по OpenVPN.
#vpn #mikrotik
✅ В итоге настроил:
◽ OpenVPN сервер на американском VPS.
◽ Подключил его к домашнему Микротику.
◽ Создал Address List со списком доменов, запросы к которым хочу заворачивать в VPN туннель.
◽ Промаркировал все запросы к этому списку.
◽ Настроил в routes маршрут через OpenVPN туннель для всех промаркированных запросов.
И о чудо, спустя почти год я постоянно вижу все картинки с ютуба.
Подробно весь процесс настройки показан вот в этом видео:
Wireguard + Mikrotik. Частичное перенаправление трафика
⇨ https://www.youtube.com/watch?v=RA8mICgGcs0
Единственное отличие — у автора уже RouterOS 7 и настроен WireGuard. Мне пока не хочется экспериментов с 7-й версией, поэтому я до сих пор везде использую 6-ю. А там поддержки WG нет, поэтому подключаюсь по OpenVPN.
#vpn #mikrotik
YouTube
Wireguard + Mikrotik. Частичное перенаправление трафика
Ссылка на первый выпуск о Wireguard https://youtu.be/inx_dVfjadI
Мой сайт https://matiashov.ru
Телеграм канал https://t.me/amatyashov
Мой телеграм бот: https://t.me/amatyashov_bot
Добро пожаловать на мой канал, друзья! Здесь я делюсь информацией в разных…
Мой сайт https://matiashov.ru
Телеграм канал https://t.me/amatyashov
Мой телеграм бот: https://t.me/amatyashov_bot
Добро пожаловать на мой канал, друзья! Здесь я делюсь информацией в разных…
В операционной системе Linux существует полезная утилита touch, которую по моим наблюдениям чаще всего используют не по её прямому назначению. Когда-то давно я увидел, что с её помощью можно создать пустой файл. Запомнил это и сам постоянно её использую, хотя есть способы проще. А изначально touch была создана для обновления информации о времени изменения и доступа к файлу. Об этом прямо написано в man этой утилиты: Update the access and modification times of each FILE to the current time.
С помощью touch можно создать пустой файл или несколько файлов сразу:
А с помощью дополнительных ключей можно обновить информацию о времени последнего доступа к файлу:
Посмотрели старое время доступа, обновили его до актуального и посмотрели ещё раз. Время будет обновлено.
То же самое для времени изменения файла:
Несмотря на то, что сам файл мы не меняли, его метка о времени изменения обновилась на текущее время, когда выполнялась команда.
Подобный функционал с изменением меток времени можно использовать в скриптах, когда нужно после выполнения какого-то действия явно указать, что изменения произошли, даже если файлы не поменялись. Например, взять какой-то файл за образец того, когда выполнялся последний бэкап и перед его выполнением менять дату доступа к файлу. Отслеживая изменение этого файла можно следить за выполнением процесса синхронизации. Это пример того, как я сам использую подобный функционал. Суть в том, что если файлы в неизменном виде приезжают на бэкап сервер со своими исходными метками доступа и изменения, то в случае если в источнике файлы не изменились за время между бэкапами, на приёмнике трудно понять, а была ли реально выполнена синхронизация. Может файлы не изменились, а может и копирования не было. А если вы какой-то файл на источнике принудительно пометите с помощью touch, то проверив его изменение на приёмнике вы хотя бы будете знать, что синхронизация реально произошла, просто файлы не изменились.
Также с помощью touch можно явно указать дату изменения файла. Можно его существенно состарить:
Установили дату изменения файла - 21 марта 2019 года 16:55. Формат даты в команде - YYMMDDhhmm. Данный приём активно использую всякие зловреды на сайтах, чтобы затеряться среди старых файлов. Обычно когда разбираются во взломе, первым делом ищут все недавно изменённые файлы. А после такого изменения файл может разом состариться на пару лет.
Но если внимательно посмотреть на изменяемый файл с помощью stat, то можно увидеть время его создания и изменения атрибутов (change и birth):
Наверное их тоже можно поменять, но я не разбирался с этим. Если кто-то знает, как это сделать, подскажите.
#linux #bash
С помощью touch можно создать пустой файл или несколько файлов сразу:
# touch file01.txt# touch file01.txt file02.txt file03.txt# touch file0{1,2,3}.txtА с помощью дополнительных ключей можно обновить информацию о времени последнего доступа к файлу:
# ls -l file01.txt --time=atime# touch -a file01.txt# ls -l file01.txt --time=atimeПосмотрели старое время доступа, обновили его до актуального и посмотрели ещё раз. Время будет обновлено.
То же самое для времени изменения файла:
# ls -l file01.txt# touch -m file01.txt# ls -l file01.txtНесмотря на то, что сам файл мы не меняли, его метка о времени изменения обновилась на текущее время, когда выполнялась команда.
Подобный функционал с изменением меток времени можно использовать в скриптах, когда нужно после выполнения какого-то действия явно указать, что изменения произошли, даже если файлы не поменялись. Например, взять какой-то файл за образец того, когда выполнялся последний бэкап и перед его выполнением менять дату доступа к файлу. Отслеживая изменение этого файла можно следить за выполнением процесса синхронизации. Это пример того, как я сам использую подобный функционал. Суть в том, что если файлы в неизменном виде приезжают на бэкап сервер со своими исходными метками доступа и изменения, то в случае если в источнике файлы не изменились за время между бэкапами, на приёмнике трудно понять, а была ли реально выполнена синхронизация. Может файлы не изменились, а может и копирования не было. А если вы какой-то файл на источнике принудительно пометите с помощью touch, то проверив его изменение на приёмнике вы хотя бы будете знать, что синхронизация реально произошла, просто файлы не изменились.
Также с помощью touch можно явно указать дату изменения файла. Можно его существенно состарить:
# touch -t 201903211655 file01.txt # ls -l file01.txt-rw-r--r-- 1 root root 0 Mar 21 2019 file01.txtУстановили дату изменения файла - 21 марта 2019 года 16:55. Формат даты в команде - YYMMDDhhmm. Данный приём активно использую всякие зловреды на сайтах, чтобы затеряться среди старых файлов. Обычно когда разбираются во взломе, первым делом ищут все недавно изменённые файлы. А после такого изменения файл может разом состариться на пару лет.
Но если внимательно посмотреть на изменяемый файл с помощью stat, то можно увидеть время его создания и изменения атрибутов (change и birth):
# stat file01.txt File: file01.txt Size: 0 Blocks: 0 IO Block: 4096 regular empty fileDevice: 802h/2050d Inode: 790197 Links: 1Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)Access: 2019-03-21 16:55:00.000000000 +0300Modify: 2019-03-21 16:55:00.000000000 +0300Change: 2023-01-19 01:09:17.084405177 +0300 Birth: 2023-01-19 00:50:59.789606107 +0300Наверное их тоже можно поменять, но я не разбирался с этим. Если кто-то знает, как это сделать, подскажите.
#linux #bash