
Смотрите, какой любопытный проект у нас появился:
⇨ https://repka-pi.ru
Аналог Raspberry Pi. Выполнен в полностью идентичном форм-факторе, включая габаритные размеры, размеры и расположение основных интерфейсов, места и размеры отверстий для крепления.
Разработка в России. Это не переклеивание шильдиков. Компонентная база китайская, по маркировке всё видно, схемотехника и трассировка российские. Продукт коммерческой компании, без бюджетных денег. Подробное описание разработки лучше почитать от создателей.
Одноплатники в свободной продаже. Заказать можно как на сайте проекта, так и на ozon. ❗️Существенный минус - образы ОС от Raspberry Pi не подходят из-за разных схем питания. У репки свой образ Repka OS на базе Ubuntu. Также поддерживается работа ALT Linux.
Узнал про эти компы вчера вечером. Заинтересовался, почитал информацию, поделился с вами. В сети уже много информации и инструкций по этим одноплатникам. Странно, что я ни разу про них не слышал. Даже свой шаблон под Zabbix есть для мониторинга частоты и температуры процессора.
Мне прям всё понравилось. Цена конкурентная, сайт, описание, упаковка чёткие. Отзывы хорошие, в том числе на качество компонентов, сборки и пайки. Да и в целом хорошо, что подобные компании и продукты есть в России. Это позволяет нарабатывать компетенции, создавать высококвалифицированные рабочие места.
Жаль, что мне одноплатники никогда не были нужны, так бы купил. Цена платы - 7400, сразу с корпусом - 9700. Ждать доставки из Китая не надо. Озон за несколько дней привезёт в любой пункт выдачи.
p.s. Узнал о репке из рекламы в ВК. А кто-то думает, что реклама не работает. Сработала очень даже хорошо для заказчиков.
#железо #отечественное
⇨ https://repka-pi.ru
Аналог Raspberry Pi. Выполнен в полностью идентичном форм-факторе, включая габаритные размеры, размеры и расположение основных интерфейсов, места и размеры отверстий для крепления.
Разработка в России. Это не переклеивание шильдиков. Компонентная база китайская, по маркировке всё видно, схемотехника и трассировка российские. Продукт коммерческой компании, без бюджетных денег. Подробное описание разработки лучше почитать от создателей.
Одноплатники в свободной продаже. Заказать можно как на сайте проекта, так и на ozon. ❗️Существенный минус - образы ОС от Raspberry Pi не подходят из-за разных схем питания. У репки свой образ Repka OS на базе Ubuntu. Также поддерживается работа ALT Linux.
Узнал про эти компы вчера вечером. Заинтересовался, почитал информацию, поделился с вами. В сети уже много информации и инструкций по этим одноплатникам. Странно, что я ни разу про них не слышал. Даже свой шаблон под Zabbix есть для мониторинга частоты и температуры процессора.
Мне прям всё понравилось. Цена конкурентная, сайт, описание, упаковка чёткие. Отзывы хорошие, в том числе на качество компонентов, сборки и пайки. Да и в целом хорошо, что подобные компании и продукты есть в России. Это позволяет нарабатывать компетенции, создавать высококвалифицированные рабочие места.
Жаль, что мне одноплатники никогда не были нужны, так бы купил. Цена платы - 7400, сразу с корпусом - 9700. Ждать доставки из Китая не надо. Озон за несколько дней привезёт в любой пункт выдачи.
p.s. Узнал о репке из рекламы в ВК. А кто-то думает, что реклама не работает. Сработала очень даже хорошо для заказчиков.
#железо #отечественное
{kind=link}
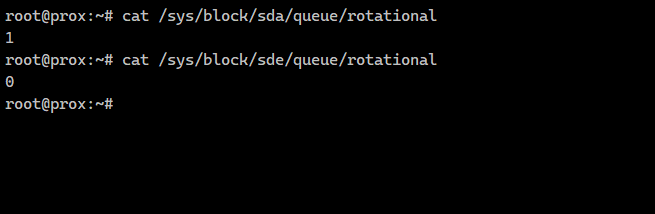
Очень простой и быстрый способ в Linux узнать, какой тип диска у вас в системе, HDD или SSD:
Диск sda — HDD, sde — SSD. Это работает только для железных серверов. То есть параметр буквально указывает, что первый диск с вращением, а второй — без. На основе этих данных ядро системы по возможности избегает одиночного поиска, чтобы лишний раз не дёргать диск. Вместо этого выстраивает запросы в очередь. Для SSD этот механизм становится неактуальным.
В виртуальных машинах могут быть разные значения. Чаще всего они будут показывать, что работают на HDD, если в гипервизоре специально не настроена эмуляция SSD. В Proxmox за это отвечает один из параметров диска — SSD Emulation. Если поставить соответствующую галочку, то виртуалка будет понимать, что работает на SSD. Это имеет смысл делать, хоть и не критично.
Возникает закономерный вопрос, начнёт ли работать технология trim в виртуальной машине, если включена эмуляция SSD. Насколько я смог понять, поискав информацию на эту тему, нет. Включенная эмуляция влияет только на rotational. Trim в виртуальной машине работать по-прежнему не будет.
#железо
# cat /sys/block/sda/queue/rotational1# cat /sys/block/sde/queue/rotational0Диск sda — HDD, sde — SSD. Это работает только для железных серверов. То есть параметр буквально указывает, что первый диск с вращением, а второй — без. На основе этих данных ядро системы по возможности избегает одиночного поиска, чтобы лишний раз не дёргать диск. Вместо этого выстраивает запросы в очередь. Для SSD этот механизм становится неактуальным.
В виртуальных машинах могут быть разные значения. Чаще всего они будут показывать, что работают на HDD, если в гипервизоре специально не настроена эмуляция SSD. В Proxmox за это отвечает один из параметров диска — SSD Emulation. Если поставить соответствующую галочку, то виртуалка будет понимать, что работает на SSD. Это имеет смысл делать, хоть и не критично.
Возникает закономерный вопрос, начнёт ли работать технология trim в виртуальной машине, если включена эмуляция SSD. Насколько я смог понять, поискав информацию на эту тему, нет. Включенная эмуляция влияет только на rotational. Trim в виртуальной машине работать по-прежнему не будет.
#железо
{kind=link}
Хочу продолжить вчерашнюю тему с удалёнными перезагрузками и отрубанием серверов. Немного повспоминал и решил сразу написать, пока не забыл, ещё несколько своих историй по этой теме.
1️⃣ Эту историю я тут описывал и даже статью написал. После обновления сделал штатную перезагрузку виртуалки, а она не поднялась. Немного подождал и пошёл смотреть консоль. Там принудительно началась проверка fsck диска на 3Тб. Длилась она несколько часов. Пришлось понервничать, так как не был уверен, что всё завершится благополучно. С тех пор на больших дисках слежу за этими проверками.
2️⃣ Этот случай был недавно. Достался в наследство сервер с MSSQL, где базы вынесены на отдельный дисковый массив, который представляет из себя внешнюю коробку, подключенную по SCSI разъёму (если не ошибаюсь, точно не помню уже). Проблема в том, что коробочка недорогая. Качество уровня desktop, больше для домашних пользователей. Решили сэкономить. После штатного отключения питания, коробочка не включилась. У неё было своё отдельное питание. Сервер загрузился, базы все лежат. Подключаюсь к серверу, массива нет, соответственно, ничего не работает. Попросил человека на месте проверить, в чём дело. Сказал, что коробка выключена и не включается.
Бэкапы все были, начал разворачивать. Проблема в том, что сервер железный. То есть пришлось поднимать новый сервер уже в VM. Пока это делал, инициативный человек на месте отключил коробку, разобрал, продул, собрал и она заработала. Пока работает, но на подхвате уже готов новый сервер, за бэкапами слежу. Переезд уже запланирован.
3️⃣ С подобной ситуацией сталкивался не раз и уже сильно учёный на этот счёт. Все серваки, подключенные к УПСу должны штатно завершать свою работу, когда заряд кончается. Обычно к этому приходят не сразу, а после того, как в один прекрасный день электричество вырубят не на 5 минут, а на пол дня.
И второй важный момент. Они не должны подниматься автоматически. К этому тоже приходят не сразу, а после того, как хапнут проблем. Я всё это проходил. Вырубается электричество, серваки штатно завершают работу, когда батареи пусты. Потом подаётся электричество, серваки включаются, а через 5 минут электричество опять отключают. И всё моментально аварийно падает в момент загрузки. На этом этапе я лично терял VM. С тех пор автоматически запускаются только гипервизоры. А виртуальные машины я или кто-то ещё включает вручную через некоторое время, когда точно понятно, что отключения прекратились и батареи немного зарядились.
❗️ Это просто совет. Когда меняете сетевые настройки, существенные параметры файрвола, либо что-то по железу (добавляете какое-то хранилище, сетевую карту с загрузкой драйвера), либо в системе то, что потенциально может приводить к проблемам загрузки или внешнего доступа. Не откладывайте перезагрузку, а сделайте её по возможности как можно раньше. Иначе может случиться так, что вы через пол года перезагрузите сервер и начнутся проблемы, которые вызваны этими изменениями, а вы про них забыли. Таких примеров у меня была масса.
Например, подключил хранилище, добавил запись в fstab или с ошибкой, или вообще забыл это сделать. А через несколько месяцев перезагрузил сервер. Включаешь его, а данных нет, служба не работает. Начинаешь в панике разбираться, в чём дело.
Либо настраиваешь firewall, применяешь правила, всё в порядке, доступ на месте. И забываешь включить автозапуск файрвола. Через несколько месяцев перезагружаешься и не замечаешь, что правил нет и у тебя всё в открытом доступе. Потом это долго можно не замечать, если не ставил на мониторинг.
Ещё пример. Меняешь сложный dialplan в asterisk. Перезагрузку откладываешь на потом, чтобы не прерывать текущую работу. И забываешь. А при очередной перезагрузке не можешь понять, почему что-то работает неправильно. Трудно быстро вникнуть и вспомнить, что ты менял несколько месяцев назад.
После существенных изменений лучше сразу же перезагрузиться и убедиться, что всё в порядке и работает так, как вы только что настроили.
#железо
1️⃣ Эту историю я тут описывал и даже статью написал. После обновления сделал штатную перезагрузку виртуалки, а она не поднялась. Немного подождал и пошёл смотреть консоль. Там принудительно началась проверка fsck диска на 3Тб. Длилась она несколько часов. Пришлось понервничать, так как не был уверен, что всё завершится благополучно. С тех пор на больших дисках слежу за этими проверками.
2️⃣ Этот случай был недавно. Достался в наследство сервер с MSSQL, где базы вынесены на отдельный дисковый массив, который представляет из себя внешнюю коробку, подключенную по SCSI разъёму (если не ошибаюсь, точно не помню уже). Проблема в том, что коробочка недорогая. Качество уровня desktop, больше для домашних пользователей. Решили сэкономить. После штатного отключения питания, коробочка не включилась. У неё было своё отдельное питание. Сервер загрузился, базы все лежат. Подключаюсь к серверу, массива нет, соответственно, ничего не работает. Попросил человека на месте проверить, в чём дело. Сказал, что коробка выключена и не включается.
Бэкапы все были, начал разворачивать. Проблема в том, что сервер железный. То есть пришлось поднимать новый сервер уже в VM. Пока это делал, инициативный человек на месте отключил коробку, разобрал, продул, собрал и она заработала. Пока работает, но на подхвате уже готов новый сервер, за бэкапами слежу. Переезд уже запланирован.
3️⃣ С подобной ситуацией сталкивался не раз и уже сильно учёный на этот счёт. Все серваки, подключенные к УПСу должны штатно завершать свою работу, когда заряд кончается. Обычно к этому приходят не сразу, а после того, как в один прекрасный день электричество вырубят не на 5 минут, а на пол дня.
И второй важный момент. Они не должны подниматься автоматически. К этому тоже приходят не сразу, а после того, как хапнут проблем. Я всё это проходил. Вырубается электричество, серваки штатно завершают работу, когда батареи пусты. Потом подаётся электричество, серваки включаются, а через 5 минут электричество опять отключают. И всё моментально аварийно падает в момент загрузки. На этом этапе я лично терял VM. С тех пор автоматически запускаются только гипервизоры. А виртуальные машины я или кто-то ещё включает вручную через некоторое время, когда точно понятно, что отключения прекратились и батареи немного зарядились.
❗️ Это просто совет. Когда меняете сетевые настройки, существенные параметры файрвола, либо что-то по железу (добавляете какое-то хранилище, сетевую карту с загрузкой драйвера), либо в системе то, что потенциально может приводить к проблемам загрузки или внешнего доступа. Не откладывайте перезагрузку, а сделайте её по возможности как можно раньше. Иначе может случиться так, что вы через пол года перезагрузите сервер и начнутся проблемы, которые вызваны этими изменениями, а вы про них забыли. Таких примеров у меня была масса.
Например, подключил хранилище, добавил запись в fstab или с ошибкой, или вообще забыл это сделать. А через несколько месяцев перезагрузил сервер. Включаешь его, а данных нет, служба не работает. Начинаешь в панике разбираться, в чём дело.
Либо настраиваешь firewall, применяешь правила, всё в порядке, доступ на месте. И забываешь включить автозапуск файрвола. Через несколько месяцев перезагружаешься и не замечаешь, что правил нет и у тебя всё в открытом доступе. Потом это долго можно не замечать, если не ставил на мониторинг.
Ещё пример. Меняешь сложный dialplan в asterisk. Перезагрузку откладываешь на потом, чтобы не прерывать текущую работу. И забываешь. А при очередной перезагрузке не можешь понять, почему что-то работает неправильно. Трудно быстро вникнуть и вспомнить, что ты менял несколько месяцев назад.
После существенных изменений лучше сразу же перезагрузиться и убедиться, что всё в порядке и работает так, как вы только что настроили.
#железо
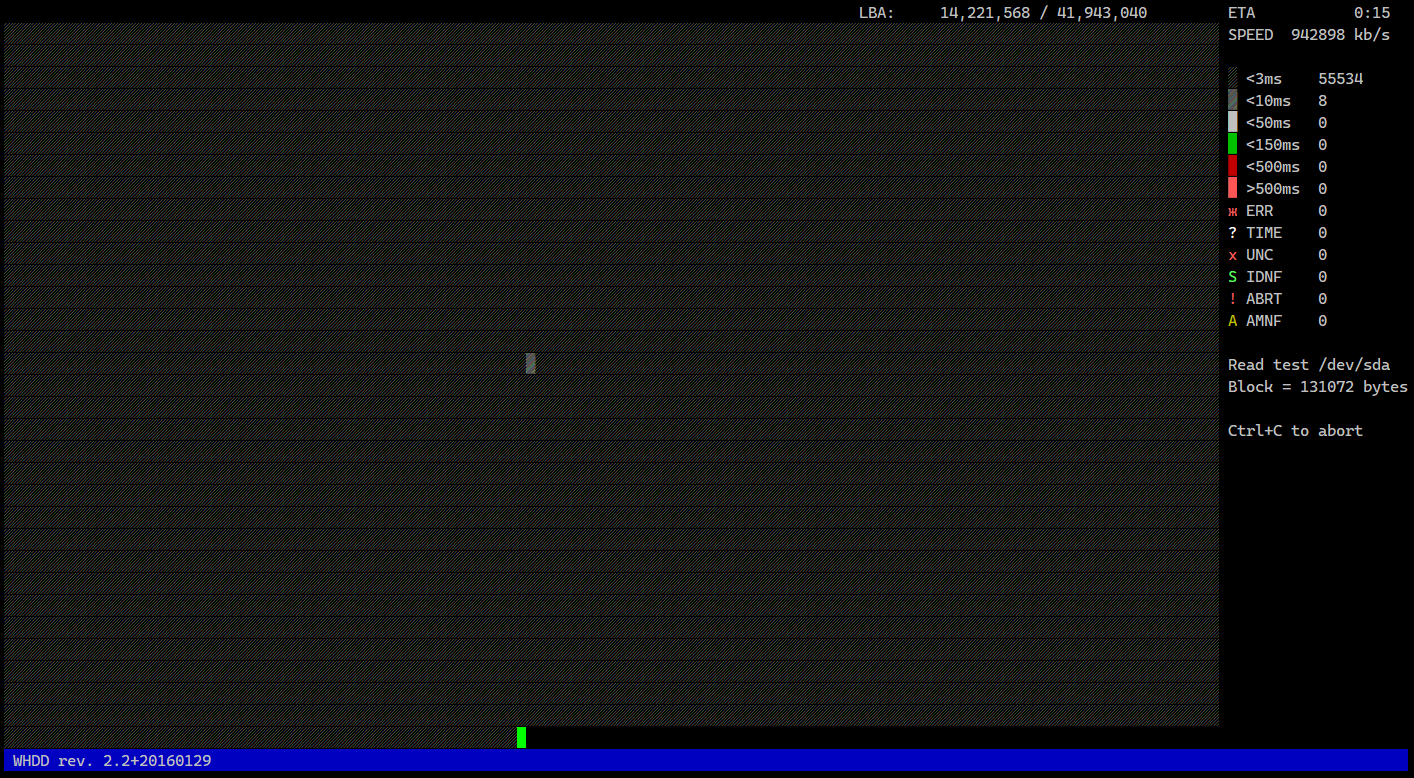
В среде Windows, а точнее ещё даже DOS, была и есть очень популярная программа для тестирования работы диска MHDD. Думаю, если не все, то очень многие её знают. Во времена HDD это было лучшее средство проверить состояние диска, оценить скорость чтения и времени отклика каждого сектора.
В Linux есть похожая программа - whdd. У неё схожие возможности по чтению блочных устройств и выводе информации о них, как и у mhdd. Работает с дисками на низком уровне с помощью ATA команд.
Помимо проверки диска, она умеет делать аккуратные копии повреждённых дисков, а так же безвозвратно удалять данные на них, перезаписывая всё нулями.
Эту утилиту часто используют в составе различных Rescue CD на базе Linux. Но при желании, вы можете воспользоваться любым дистрибутивом и установить whdd туда самостоятельно. Например, в Debian это можно сделать следующим образом.
1️⃣ Ставим зависимости:
2️⃣ Качаем deb пакет под Xenial:
3️⃣ Устанавливаем:
Так что можно взять любой LiveCD на базе deb пакетов и пользоваться. Также пакеты есть под AltLinux, ArchLinux, Gentoo, Slackware. Либо можно собрать из исходников самостоятельно. Проект open source.
⇨ Сайт / Исходники
#железо
В Linux есть похожая программа - whdd. У неё схожие возможности по чтению блочных устройств и выводе информации о них, как и у mhdd. Работает с дисками на низком уровне с помощью ATA команд.
Помимо проверки диска, она умеет делать аккуратные копии повреждённых дисков, а так же безвозвратно удалять данные на них, перезаписывая всё нулями.
Эту утилиту часто используют в составе различных Rescue CD на базе Linux. Но при желании, вы можете воспользоваться любым дистрибутивом и установить whdd туда самостоятельно. Например, в Debian это можно сделать следующим образом.
1️⃣ Ставим зависимости:
# apt install libncursesw5 libtinfo5 smartmontools 2️⃣ Качаем deb пакет под Xenial:
# wget https://launchpad.net/~eugenesan/+archive/ubuntu/ppa/+files/whdd_2.2+20160129-1~eugenesan~xenial1_amd64.deb3️⃣ Устанавливаем:
# dpkg -i whdd_2.2+20160129-1~eugenesan~xenial1_amd64.debТак что можно взять любой LiveCD на базе deb пакетов и пользоваться. Также пакеты есть под AltLinux, ArchLinux, Gentoo, Slackware. Либо можно собрать из исходников самостоятельно. Проект open source.
⇨ Сайт / Исходники
#железо
{kind=link}
⚠ Почему я не люблю работать с железом
Расскажу вам необычную историю из моей практики, которая случилась на днях. Есть у меня компания, с которой я работаю уже очень давно. У неё есть простенькая серверная и несколько своих серверов. К одному из них была подключена бюджетная дисковая полка фирмы HighPoint. Её купили ещё до меня. Лет 10 она честно отработала.
В какой-то момент после планового отключения электричества она не включилась. Человек на месте её покрутил, потряс, не включается. Разобрал, продул, снова включил - заработала. Тогда я сразу понял, что ей конец и форсировал покупку нового сервера. Его купили, оперативно там всё настроил, начали переносить нагрузку. Занимался другой человек. Всё самое основное перенесли.
Вскорости опять обесточивание. Полка не включается уже никак, ничего не помогает. Ничего критичного там уже нет, люди нормально работают. Но остались некоторые данные, которые хотелось бы забрать. Программист не успел перекинуть несколько второстепенных баз. А из бэкапов если доставать, то надо где-то MS SQL разворачивать, так как бэкапились его дампы.
Приехал я и начал шаманить. Стучал, тряс, разбирал, дул. Ничего не помогает. Не включается. Делаю ход конём. Беру сетевой удлинитель, подключаю не в УПС в серверной, а в розетку в соседней комнате. Нажимаю на кнопку - завелась. Просто чудо. Забрали всю инфу оттуда.
В следующий приезд надо было эту полку окончательно отключить и убрать, выключив предварительно сервер, к которому она подключена. Делаю всё очень аккуратно. Погасил сервер, долго не выключается. Переключаюсь на KVM на него, чтобы посмотреть, что на экране. Дождался выключения, возвращаюсь к себе за ноут.
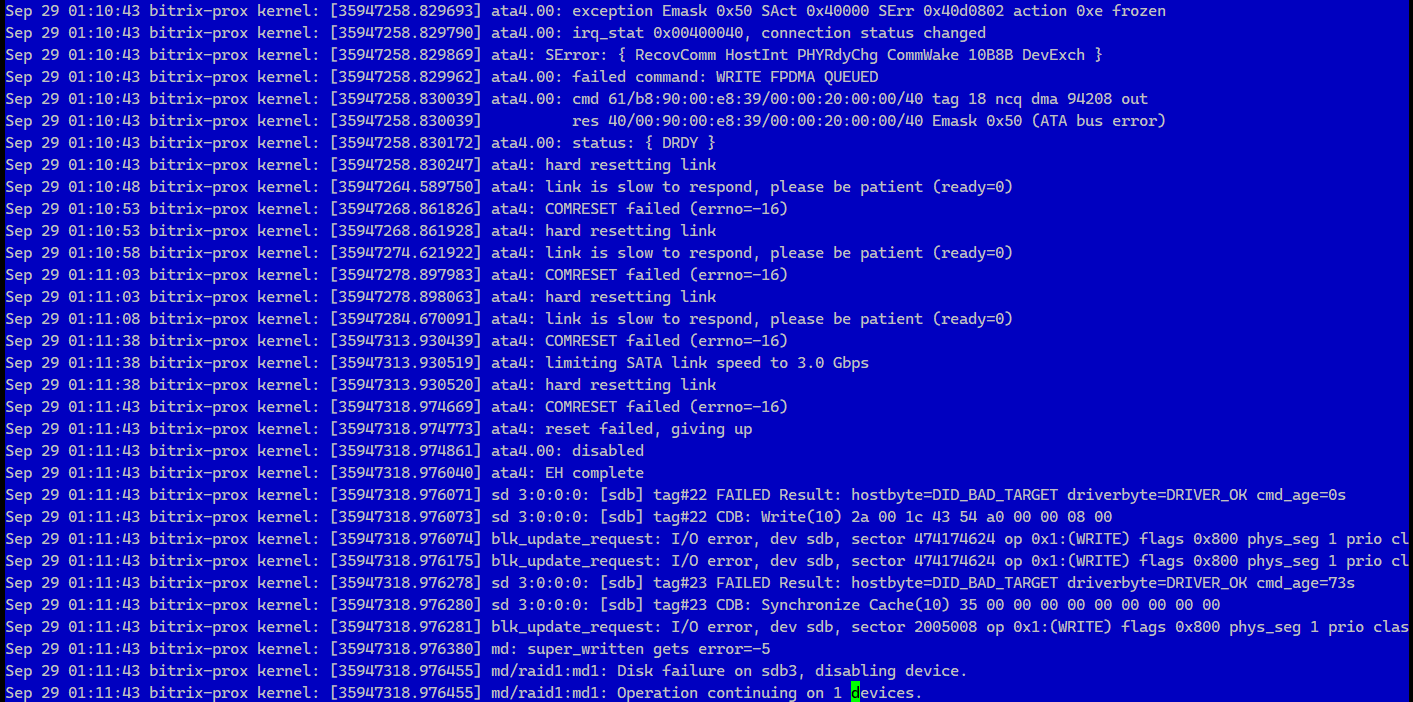
⚡️Прилетают алерты. На соседнем сервере вылетел диск из рейда. I/O улетает в потолок, сервак фактически зависает. Виснет и SSH подключение, и с консоли логинишься, оболочка не загружается. Минут 10 подождал, понял, что дело труба. Судя по таймингам, проблемы спровоцировало нажатие кнопок на KVM. Я там ничего не дергал, железо не двигал. Просто подошёл и немного поработал за клавой с мышкой. Как это могло привести к тому, что начались сбои на HDD диске соседнего сервера, я хз. Какая-то статика что ли или ещё что-то. Даже идей нет.
С таким я сталкивался не раз. Очень не люблю работать с железом, особенно с серверами, которые работают 24/7 не в специализированном помещении. Если не соблюдается режим по температуре и влажности, то серверы или другое оборудование нередко не включается, после обесточивания.
Зависший сервер пришлось гасить принудительно. Скрестил пальцы, включаю. RAID10 живой, диск на месте, начался ребилд. Пока пишу заметку, rebuild на 75% закончен. На вид всё в порядке. Что это было - х.з.
Такие вот незапланированные приключения на ровном месте. Я уже давно не покупаю железо и не устраиваю серверные. Всё это наследство прошлого. Всегда стараюсь убедить арендовать железо в ЦОД, или своё на colocation поставить. Если всё аккуратно считать, то это не обязательно будет дороже. Но точно стабильнее и надёжнее.
Если у кого-то есть идеи, что могло спровоцировать проблемы с диском на соседнем сервере, поделитесь. Точно не было случайных ударов, пинков, каких-то сильных вибраций и т.д. Провода не задевал и не дёргал. Возможно соседний сервер выключился и каких-то колебаний добавил. Может в этом дело.
#железо
Расскажу вам необычную историю из моей практики, которая случилась на днях. Есть у меня компания, с которой я работаю уже очень давно. У неё есть простенькая серверная и несколько своих серверов. К одному из них была подключена бюджетная дисковая полка фирмы HighPoint. Её купили ещё до меня. Лет 10 она честно отработала.
В какой-то момент после планового отключения электричества она не включилась. Человек на месте её покрутил, потряс, не включается. Разобрал, продул, снова включил - заработала. Тогда я сразу понял, что ей конец и форсировал покупку нового сервера. Его купили, оперативно там всё настроил, начали переносить нагрузку. Занимался другой человек. Всё самое основное перенесли.
Вскорости опять обесточивание. Полка не включается уже никак, ничего не помогает. Ничего критичного там уже нет, люди нормально работают. Но остались некоторые данные, которые хотелось бы забрать. Программист не успел перекинуть несколько второстепенных баз. А из бэкапов если доставать, то надо где-то MS SQL разворачивать, так как бэкапились его дампы.
Приехал я и начал шаманить. Стучал, тряс, разбирал, дул. Ничего не помогает. Не включается. Делаю ход конём. Беру сетевой удлинитель, подключаю не в УПС в серверной, а в розетку в соседней комнате. Нажимаю на кнопку - завелась. Просто чудо. Забрали всю инфу оттуда.
В следующий приезд надо было эту полку окончательно отключить и убрать, выключив предварительно сервер, к которому она подключена. Делаю всё очень аккуратно. Погасил сервер, долго не выключается. Переключаюсь на KVM на него, чтобы посмотреть, что на экране. Дождался выключения, возвращаюсь к себе за ноут.
⚡️Прилетают алерты. На соседнем сервере вылетел диск из рейда. I/O улетает в потолок, сервак фактически зависает. Виснет и SSH подключение, и с консоли логинишься, оболочка не загружается. Минут 10 подождал, понял, что дело труба. Судя по таймингам, проблемы спровоцировало нажатие кнопок на KVM. Я там ничего не дергал, железо не двигал. Просто подошёл и немного поработал за клавой с мышкой. Как это могло привести к тому, что начались сбои на HDD диске соседнего сервера, я хз. Какая-то статика что ли или ещё что-то. Даже идей нет.
С таким я сталкивался не раз. Очень не люблю работать с железом, особенно с серверами, которые работают 24/7 не в специализированном помещении. Если не соблюдается режим по температуре и влажности, то серверы или другое оборудование нередко не включается, после обесточивания.
Зависший сервер пришлось гасить принудительно. Скрестил пальцы, включаю. RAID10 живой, диск на месте, начался ребилд. Пока пишу заметку, rebuild на 75% закончен. На вид всё в порядке. Что это было - х.з.
Такие вот незапланированные приключения на ровном месте. Я уже давно не покупаю железо и не устраиваю серверные. Всё это наследство прошлого. Всегда стараюсь убедить арендовать железо в ЦОД, или своё на colocation поставить. Если всё аккуратно считать, то это не обязательно будет дороже. Но точно стабильнее и надёжнее.
Если у кого-то есть идеи, что могло спровоцировать проблемы с диском на соседнем сервере, поделитесь. Точно не было случайных ударов, пинков, каких-то сильных вибраций и т.д. Провода не задевал и не дёргал. Возможно соседний сервер выключился и каких-то колебаний добавил. Может в этом дело.
#железо
Ещё одну историю про железо расскажу. Как-то кучно было на прошлой неделе. В одном сервере для бэкапов вылетел диск из рейд массива. Он сначала помигал параметром SMART Current_Pending_Sector. То появлялся, то исчезал. В принципе, это не критично. Я видел много дисков, которые годами работают в массивах с этими метриками, и с ними в целом всё в порядке. Главное, чтобы всё стабильно было, не прыгало туда сюда в значениях.
Этот немного попрыгал и вывалился из массива. Он был в составе RAID6. Я для бэкапов обычно делаю его. Иногда RAID10 для увеличения производительности. Но только с RAID6 чувствую себя спокойно, так как он позволяет штатно пережить выход двух дисков из строя. Потеря одного совершенно некритична, нет нужды срочно менять диск, что не так для других уровней. RAID5 лично я вообще не использую и вам не советую.
Здесь рейд был создан на базе mdadm, так что замена прошла штатно. Я уже описывал её в заметке, которую сам постоянно использую:
⇨ https://t.me/srv_admin/723
Только в заметке диски SSD и меньше 2TB, поэтому там работает утилита sfdisk для копирования разметки. Для больших дисков она не подходит, надо использовать sgdisk. Скопировать таблицу разделов с /dev/sda на /dev/sdb:
Важно не перепутать диски. Таблица разделов склонируется вместе с GUID, что в данном случае нам не надо. Поэтому меняем GUID:
Если боитесь напортачить с автоматической разметкой нового диска, то сделайте это вручную с помощью parted. Посмотрите разметку существующего диска и создайте вручную такую же на новом.
Дальше всё то же самое по инструкции, что я привёл выше. Ребилд длился часов 14 в итоге. Всё прошло штатно. Если всё же надумаете когда-нибудь использовать RAID5, то делайте это с SSD дисками размером не больше 1-2 TB. Думаю там это может быть обоснованно.
Мониторинг SMART в случае с mdadm обычно делаю примерно так:
⇨ https://serveradmin.ru/monitoring-smart-v-zabbix/
Если рейд железный и сервер с bmc, то в зависимости от возможностей платформы. Некоторые передают параметры смарт, некоторые нет. Если контроллер данные не передаёт, то уже ничего не поделать. Приходится довольствоваться его метриками. Я поэтому и люблю mdadm. Диски и его статус легко обложить метриками, какими пожелаешь. И поведение более чем предсказуемое.
#железо
Этот немного попрыгал и вывалился из массива. Он был в составе RAID6. Я для бэкапов обычно делаю его. Иногда RAID10 для увеличения производительности. Но только с RAID6 чувствую себя спокойно, так как он позволяет штатно пережить выход двух дисков из строя. Потеря одного совершенно некритична, нет нужды срочно менять диск, что не так для других уровней. RAID5 лично я вообще не использую и вам не советую.
Здесь рейд был создан на базе mdadm, так что замена прошла штатно. Я уже описывал её в заметке, которую сам постоянно использую:
⇨ https://t.me/srv_admin/723
Только в заметке диски SSD и меньше 2TB, поэтому там работает утилита sfdisk для копирования разметки. Для больших дисков она не подходит, надо использовать sgdisk. Скопировать таблицу разделов с /dev/sda на /dev/sdb:
# sgdisk -R /dev/sdb /dev/sdaВажно не перепутать диски. Таблица разделов склонируется вместе с GUID, что в данном случае нам не надо. Поэтому меняем GUID:
# sgdisk -G /dev/sdbЕсли боитесь напортачить с автоматической разметкой нового диска, то сделайте это вручную с помощью parted. Посмотрите разметку существующего диска и создайте вручную такую же на новом.
Дальше всё то же самое по инструкции, что я привёл выше. Ребилд длился часов 14 в итоге. Всё прошло штатно. Если всё же надумаете когда-нибудь использовать RAID5, то делайте это с SSD дисками размером не больше 1-2 TB. Думаю там это может быть обоснованно.
Мониторинг SMART в случае с mdadm обычно делаю примерно так:
⇨ https://serveradmin.ru/monitoring-smart-v-zabbix/
Если рейд железный и сервер с bmc, то в зависимости от возможностей платформы. Некоторые передают параметры смарт, некоторые нет. Если контроллер данные не передаёт, то уже ничего не поделать. Приходится довольствоваться его метриками. Я поэтому и люблю mdadm. Диски и его статус легко обложить метриками, какими пожелаешь. И поведение более чем предсказуемое.
#железо
Последнее время кучно пошли поломки железа. Расскажу про ещё один случай, но уже с арендованным сервером в Selectel. У заказчика арендован уже несколько лет сервер CL21-SSD (Intel Core i7-8700: 6 × 3.2ГГц, 32 ГБ DDR4, 2 × 480 ГБ SSD SATA). Сейчас его стоимость 5450 р. в месяц.
Он был заказан сразу с предустановленным Proxmox на софтовом рейде mdadm. Очень удобно. Ничего не надо самому колхозить. Заказал и сразу получил настроенный гипервизор. Единственное, сразу отмечу, что на всякий случай проверяйте, установлен ли загрузчик на оба диска. У меня были случаи, когда загрузчик стоял только на sda. Похоже не учли этот момент создатели шаблона. Сейчас может уже исправили.
На этом сервере крутятся 5 виртуалок. Три виртуалки с веб серверами. Они сильно разные по стекам, поэтому пришлось разнести. Один сайт на Bitrix довольно тяжёлый и нагруженный. Одна виртуалка с Zabbix, который мониторит всю инфраструктуру. И ещё одна виртуалка с WinSrv и файловыми базами 1С, которые опубликованы через HTTP. Работают примерно 5 человек. И вот этот дешёвый дедик без проблем тянет всё это хозяйство и каждая отдельная виртуалка работает значительно быстрее, чем то же самое было бы при аренде по отдельности виртуальных машин.
Из массива выпал один диск. Узнал из мониторинга. В нём же посмотрел информацию о дисках. На сервере стояли идентичные диски Patriot Burst. Насколько я понимаю, это самый дешман. Но даже он без проблем отработал 5 лет на этом сервере. Информация тоже из мониторинга. Там же видно по показателям SMART, что у одного диска осталось 19% ресурса, а у второго, который вышел из строя - 25%. Толку от этого SMART никакого нет.
Пишу в тот же день в техподдержку информацию о том, что диск сломан, выпал из массива. Прикладываю кусок лога из
Вечером актуализировал бэкапы данных, снял бэкапы виртуалок, потушил сервер, написал в техподдержку, что можно менять. Буквально за 10 минут заменили диск, включили сервер. Я зашёл по SSH, убедился, что всё ОК, увидел, что диск заменили на KINGSTON SA400S37480G того же объёма. Запустил ребилд массива. Первые несколько минут он ребилдился со скоростью 200 МБ в секунду, потом со 100 МБ/c. Судя по всему кэш забился. Скорость записи очень низкая, диски дешёвые. Но при этом явно видна вся прелесть SSD. Несмотря на дешивизну, они вполне функциональны и тянут типовую нагрузку, где преимущественно чтение данных. В конце не забыл установить загрузчик на новый диск, так как очевидно, что скоро второй старый тоже выйдет из строя.
Написал заметку в таком ключе, чтобы продемонстрировать удобство и дешевизну бюджетных серверов с SSD. Они стоят очень мало по сравнению с полноценными брендовыми серверами, но типовую нагрузку спокойно тянут. Они намного выгоднее по деньгам аренды VPS, и при этом имеют вполне приемлемую отказоустойчивость на уровне дисков. Само железо у меня ни разу не выходило из строя в Selectel, а диски регулярно.
Я всем заказчикам арендую сервера в Selectel, потому что нравится соотношение цены и качества железа, а так же уровень техподдержки. Плохо только, что конфигурации только с двумя дисками, либо SSD, либо HDD. Очень не хватает серверов с 4-мя дисками, чтобы можно было миксовать SSD и большой объём HDD. Раньше у них такие сервера были и они до сих пор есть у меня в управлении. Но больше их не будет. Специально интересовался. Все платформы бюджетных серверов теперь поддерживают только 2 диска.
Если будете пробовать Selectel, зарегистрируйтесь через мою реф. ссылку. Вам всё равно, а мне приятно. Из услуг я там использую ещё S3 хранилища и бесплатный DNS хостинг. Больше ничего.
#железо #хостинг
Он был заказан сразу с предустановленным Proxmox на софтовом рейде mdadm. Очень удобно. Ничего не надо самому колхозить. Заказал и сразу получил настроенный гипервизор. Единственное, сразу отмечу, что на всякий случай проверяйте, установлен ли загрузчик на оба диска. У меня были случаи, когда загрузчик стоял только на sda. Похоже не учли этот момент создатели шаблона. Сейчас может уже исправили.
На этом сервере крутятся 5 виртуалок. Три виртуалки с веб серверами. Они сильно разные по стекам, поэтому пришлось разнести. Один сайт на Bitrix довольно тяжёлый и нагруженный. Одна виртуалка с Zabbix, который мониторит всю инфраструктуру. И ещё одна виртуалка с WinSrv и файловыми базами 1С, которые опубликованы через HTTP. Работают примерно 5 человек. И вот этот дешёвый дедик без проблем тянет всё это хозяйство и каждая отдельная виртуалка работает значительно быстрее, чем то же самое было бы при аренде по отдельности виртуальных машин.
Из массива выпал один диск. Узнал из мониторинга. В нём же посмотрел информацию о дисках. На сервере стояли идентичные диски Patriot Burst. Насколько я понимаю, это самый дешман. Но даже он без проблем отработал 5 лет на этом сервере. Информация тоже из мониторинга. Там же видно по показателям SMART, что у одного диска осталось 19% ресурса, а у второго, который вышел из строя - 25%. Толку от этого SMART никакого нет.
Пишу в тот же день в техподдержку информацию о том, что диск сломан, выпал из массива. Прикладываю кусок лога из
/var/log/syslog с ошибками диска и скрин из мониторинга с информацией об износе и серийном номере диска. Техподдержка подтверждает, что готова заменить диск, просит погасить сервер и написать, когда можно начинать замену. Вечером актуализировал бэкапы данных, снял бэкапы виртуалок, потушил сервер, написал в техподдержку, что можно менять. Буквально за 10 минут заменили диск, включили сервер. Я зашёл по SSH, убедился, что всё ОК, увидел, что диск заменили на KINGSTON SA400S37480G того же объёма. Запустил ребилд массива. Первые несколько минут он ребилдился со скоростью 200 МБ в секунду, потом со 100 МБ/c. Судя по всему кэш забился. Скорость записи очень низкая, диски дешёвые. Но при этом явно видна вся прелесть SSD. Несмотря на дешивизну, они вполне функциональны и тянут типовую нагрузку, где преимущественно чтение данных. В конце не забыл установить загрузчик на новый диск, так как очевидно, что скоро второй старый тоже выйдет из строя.
Написал заметку в таком ключе, чтобы продемонстрировать удобство и дешевизну бюджетных серверов с SSD. Они стоят очень мало по сравнению с полноценными брендовыми серверами, но типовую нагрузку спокойно тянут. Они намного выгоднее по деньгам аренды VPS, и при этом имеют вполне приемлемую отказоустойчивость на уровне дисков. Само железо у меня ни разу не выходило из строя в Selectel, а диски регулярно.
Я всем заказчикам арендую сервера в Selectel, потому что нравится соотношение цены и качества железа, а так же уровень техподдержки. Плохо только, что конфигурации только с двумя дисками, либо SSD, либо HDD. Очень не хватает серверов с 4-мя дисками, чтобы можно было миксовать SSD и большой объём HDD. Раньше у них такие сервера были и они до сих пор есть у меня в управлении. Но больше их не будет. Специально интересовался. Все платформы бюджетных серверов теперь поддерживают только 2 диска.
Если будете пробовать Selectel, зарегистрируйтесь через мою реф. ссылку. Вам всё равно, а мне приятно. Из услуг я там использую ещё S3 хранилища и бесплатный DNS хостинг. Больше ничего.
#железо #хостинг
{kind=link}
Часто можно слышать рекомендацию, не использовать в рейд массивах диски одной серии, так как для них существует высокий шанс выйти из строя плюс-минус в одно время. Лично я с таким не сталкивался и по сериям никогда диски не разделял. Я просто не очень представляю практически, как это сделать. Чаще всего покупаешь сервер, к нему пачку дисков. Всё это приезжает, монтируешь, запускаешь. А тут получается диски надо в разных магазинах брать? Или вообще разных вендоров? Я никогда так не делаю. Всегда одинаковые беру.
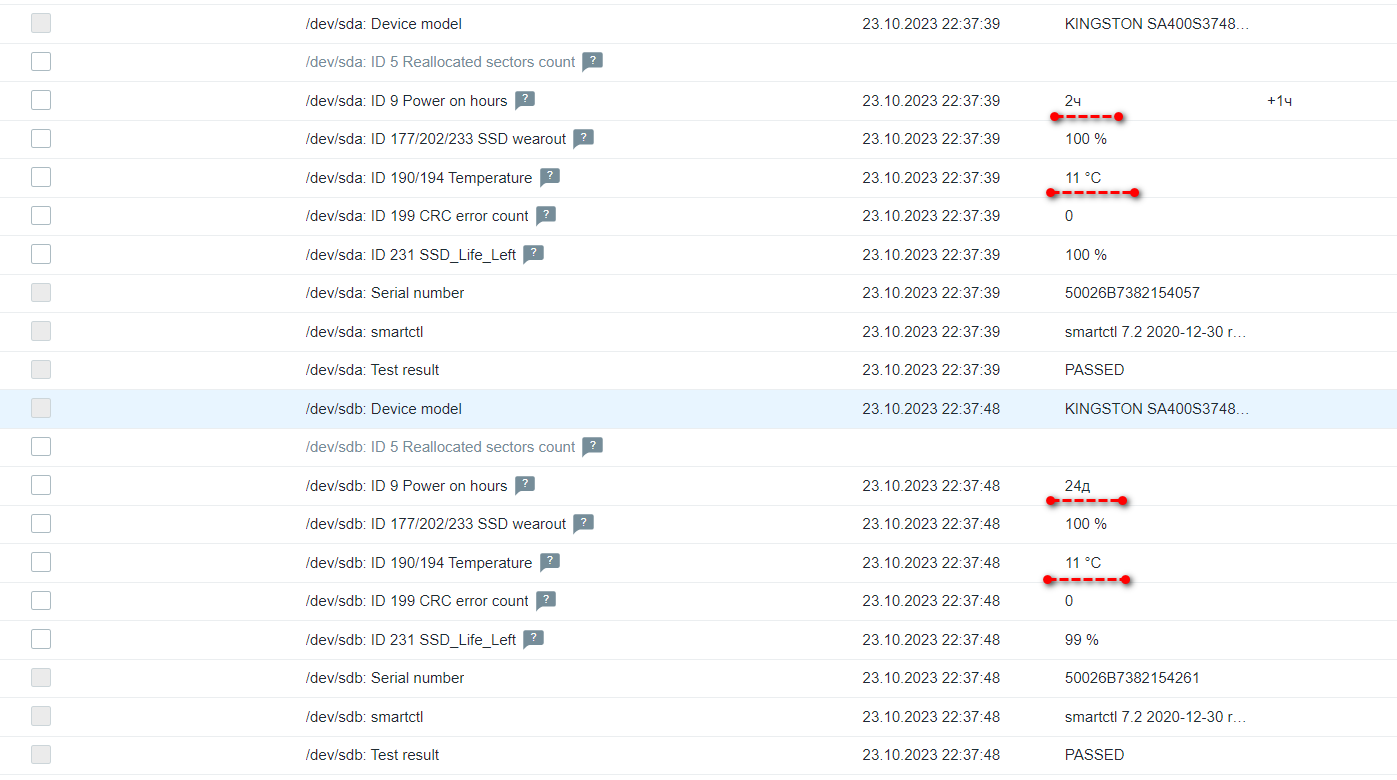
С арендными серверами то же самое. Обычно ставят одинаковые новые диски. Я недавно рассказывал про сервер, где вышел из строя один из идентичных SSD дисков в RAID1. Вот прошло 3 недели, и вышел из строя второй. В принципе, достаточно близко, но явно не одновременно. SMART, кстати, как обычно, не предвещал никаких проблем и не сигналил метриками. По смарту оставалось ещё 18% ресурса, но диск всё равно безвозвратно выпал из системы и перестал отвечать. Это к вопросу, нафиг вообще такой смарт нужен. С него кроме метрики температуры и серийного номера с моделью нечего смотреть. Практической ценности данные не представляют.
Забавно, что сотрудник техподдержки, который обрабатывал заявку, в этот раз уточнил, проверил ли я наличие загрузчика GRUB на живом диске. Судя по всему не раз сталкивался с тем, что люди про это забывают, а потом теряют доступ к серверу после замены единственного диска с загрузчиком. И им надо IP-KVM подключать. Проще заранее напомнить.
Про загрузчик я не забыл, так что в этот раз всё прошло штатно, как обычно по инструкции. После замены сразу же поставил загрузчик на новый диск:
Кстати, отмечу, что когда один диск из системы выпал, вышеприведённая команда не отрабатывала корректно. Завершалась с ошибкой, хотя умершего диска в списке уже не было и загрузчик я не пытался туда ставить. Так как я знал, что GRUB уже стоит на втором диске, на ошибку забил. Можно принудительно его поставить, чтобы наверняка:
Тут уже ошибок быть не должно. Если есть, надо разбираться, в чём проблема.
Теперь снова установлены 2 одинаковых диска, только уже с разницей в 23 дня. Интересно, почему в серверной Selectel так холодно? Если верить дискам, то у них температура 11 градусов сейчас. Под нагрузкой до 16 поднималась. А 3 недели назад первый диск после замены под нагрузкой до 50-ти градусов нагревался. Любопытно, как там серверная устроена, что такие разбросы по температуре.
#железо
С арендными серверами то же самое. Обычно ставят одинаковые новые диски. Я недавно рассказывал про сервер, где вышел из строя один из идентичных SSD дисков в RAID1. Вот прошло 3 недели, и вышел из строя второй. В принципе, достаточно близко, но явно не одновременно. SMART, кстати, как обычно, не предвещал никаких проблем и не сигналил метриками. По смарту оставалось ещё 18% ресурса, но диск всё равно безвозвратно выпал из системы и перестал отвечать. Это к вопросу, нафиг вообще такой смарт нужен. С него кроме метрики температуры и серийного номера с моделью нечего смотреть. Практической ценности данные не представляют.
Забавно, что сотрудник техподдержки, который обрабатывал заявку, в этот раз уточнил, проверил ли я наличие загрузчика GRUB на живом диске. Судя по всему не раз сталкивался с тем, что люди про это забывают, а потом теряют доступ к серверу после замены единственного диска с загрузчиком. И им надо IP-KVM подключать. Проще заранее напомнить.
Про загрузчик я не забыл, так что в этот раз всё прошло штатно, как обычно по инструкции. После замены сразу же поставил загрузчик на новый диск:
# dpkg-reconfigure grub-pcКстати, отмечу, что когда один диск из системы выпал, вышеприведённая команда не отрабатывала корректно. Завершалась с ошибкой, хотя умершего диска в списке уже не было и загрузчик я не пытался туда ставить. Так как я знал, что GRUB уже стоит на втором диске, на ошибку забил. Можно принудительно его поставить, чтобы наверняка:
# grub-install /dev/sdb Тут уже ошибок быть не должно. Если есть, надо разбираться, в чём проблема.
Теперь снова установлены 2 одинаковых диска, только уже с разницей в 23 дня. Интересно, почему в серверной Selectel так холодно? Если верить дискам, то у них температура 11 градусов сейчас. Под нагрузкой до 16 поднималась. А 3 недели назад первый диск после замены под нагрузкой до 50-ти градусов нагревался. Любопытно, как там серверная устроена, что такие разбросы по температуре.
#железо
{kind=link}
На днях посмотрел вроде как юмористическое видео, но на самом деле не смешно:
⇨ Вампиры средней полосы. Ремонт ПК.
Проблема с разводом людей на ремонте компьютеров уже до телевидения добралась. Я так понял, это фрагмент из популярного сериала. Печальная история.
Я всегда знакомым, родственникам говорю, чтобы мне звонили, если что-то сломается. Сам хоть и не имею возможности и времени всем чинить компы и ноуты, но хотя бы советом всегда помогу. Если куда-то еду и люди просят посмотреть их компьютер или ноутбук, то всегда предлагаю привезти оборудование, чтобы я смог хотя бы глянуть и что-то посоветовать.
Одно время как-то не любил этим заниматься. Я же не ремонтник компьютеров. Но с жизненным опытом пришло понимание, что в мире всё взаимосвязано. Если ты можешь кому-то помочь, то помоги. Это тебе самому поможет в будущем. Понимаю, что для неразбирающегося человека сломавшийся компьютер - реальная проблема. Нет возможности гарантированно получить ремонт за вменяемые деньги. Рынок наводнён мошенниками и разводилами.
Мне с моими знаниями, что-то быстро посмотреть и посоветовать практически ничего не стоит. А для другого человека это может оказаться большой помощью.
#железо #мысли
⇨ Вампиры средней полосы. Ремонт ПК.
Проблема с разводом людей на ремонте компьютеров уже до телевидения добралась. Я так понял, это фрагмент из популярного сериала. Печальная история.
Я всегда знакомым, родственникам говорю, чтобы мне звонили, если что-то сломается. Сам хоть и не имею возможности и времени всем чинить компы и ноуты, но хотя бы советом всегда помогу. Если куда-то еду и люди просят посмотреть их компьютер или ноутбук, то всегда предлагаю привезти оборудование, чтобы я смог хотя бы глянуть и что-то посоветовать.
Одно время как-то не любил этим заниматься. Я же не ремонтник компьютеров. Но с жизненным опытом пришло понимание, что в мире всё взаимосвязано. Если ты можешь кому-то помочь, то помоги. Это тебе самому поможет в будущем. Понимаю, что для неразбирающегося человека сломавшийся компьютер - реальная проблема. Нет возможности гарантированно получить ремонт за вменяемые деньги. Рынок наводнён мошенниками и разводилами.
Мне с моими знаниями, что-то быстро посмотреть и посоветовать практически ничего не стоит. А для другого человека это может оказаться большой помощью.
#железо #мысли
YouTube
#вампиры средней полосы ремонт пк
Выбирая между софтовым или железным рейдом, я чаще всего выберу софтовый, если не будет остро стоять вопрос быстродействия дисковой подсистемы. А в бюджетном сегменте обычно и выбирать не приходится. Хотя и дорогой сервер могу взять без встроенного рейд контроллера, особенно если там быстрые ssd или nvme диски.
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
и выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
Получаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
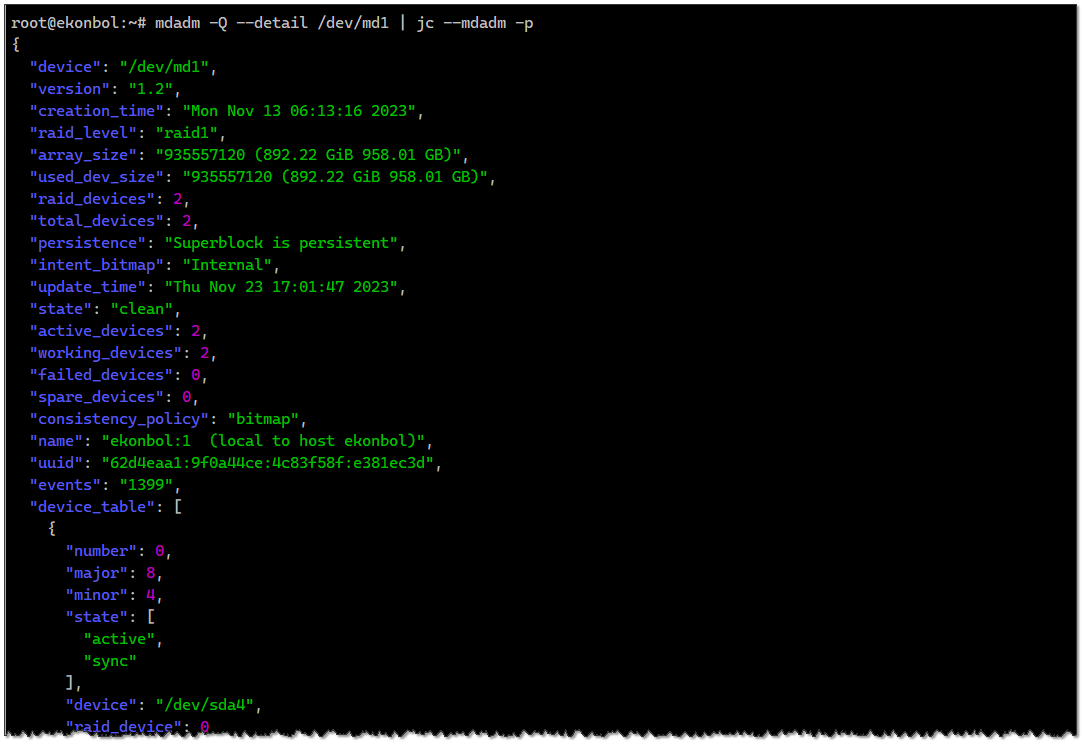
То же самое с mdadm. Смотрим состояние:
Добавляем утилиту jc:
Выгружаем полную информацию о массиве в формате json:
И отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
Под софтовым рейдом я в первую очередь подразумеваю реализацию на базе mdadm, потому что сам её использую, либо zfs. Удобство программных реализаций в том, что диски и массивы полностью видны в системе, поэтому для них очень легко и просто настроить мониторинг, в отличие от железных рейдов, где иногда вообще невозможно замониторить состояние рейда или дисков. А к дискам может не быть доступа. То есть со стороны системы они просто не видны. Хорошо, если есть развитый BMC (Baseboard Management Controller) и данные можно вытянуть через IPMI.
С софтовыми рейдами таких проблем нет. Диски видны из системы, и их мониторинг не представляет каких-то сложностей. Берём smartmontools
# apt install smartmontoolsи выгружаем всю информацию о диске вместе с моделью, серийным номером и смартом:
# smartctl -i /dev/sdd -j# smartctl -A /dev/sdd -jПолучаем вывод в формате json, с которым можно делать всё, что угодно. Например, отправить в Zabbix и там распарсить с помощью jsonpath в предобработке. К тому же автообнаружение блочных устройств там уже реализовано штатным шаблоном.
То же самое с mdadm. Смотрим состояние:
# mdadm -Q --detail /dev/md1Добавляем утилиту jc:
# apt install jcВыгружаем полную информацию о массиве в формате json:
# mdadm -Q --detail /dev/md1 | jc --mdadm -pИ отправляем это в мониторинг.
Настройка простая и гибкая. У вас полный контроль за всеми устройствами и массивами. Замена тоже проста и понятна и не зависит от модели сервера, рейд контроллера, вендора и т.д. Всё везде одинаково. Я за эту осень уже 4 диска менял в составе mdadm на разных серверах и всё везде прошло одинаково: вовремя отработал мониторинг, планово сделал замену.
Надеюсь найду время и напишу когда-нибудь подробную статью по этой теме. Есть старая: https://serveradmin.ru/monitoring-smart-v-zabbix, но сейчас я уже делаю не так. В статье до сих пор скрипт на perl и парсинг консольными утилитами. Сейчас я всё вывожу в json и парсю уже на сервере мониторинга.
#железо #mdadm #мониторинг
{kind=link}