
Я регулярно слежу за новостями по Elastic, так как постоянно использую их продукты. Недавно вышло несколько роликов по ELK Stack на русском языке. Не буду говорить, что они прям супер интересные и полезные, но так как на официальном канале на русском языке видео в принципе почти нет, то могу посоветовать к просмотру.
Введение в Машинное обучение в Elastic Stack
https://www.youtube.com/watch?v=V7Lkkh65DFI
ILM: Управление жизненным циклом данных
https://www.youtube.com/watch?v=4nwqXdtoCGo
Alerting в Elastic Stack и Elastic Solutions
https://www.youtube.com/watch?v=qHaS4-U1WAo
Использование Elastic Stack в командах SRE
https://www.youtube.com/watch?v=0u7rsEGb0io
Если у кого-то есть хорошие материалы или видео по теме ELK Stack, поделитесь в комментариях. Я сам почти ничего не изучал, а использую все как придется, методом тыка и своих небольших познаний продукта. Для моих задач хватает. В основном это сбор и анализ логов web севреров.
О том, как я использую ELK Stack можно посмотреть в статьях соответствующего раздела сайта - https://serveradmin.ru/category/elk-stack/
#elk #видео
Введение в Машинное обучение в Elastic Stack
https://www.youtube.com/watch?v=V7Lkkh65DFI
ILM: Управление жизненным циклом данных
https://www.youtube.com/watch?v=4nwqXdtoCGo
Alerting в Elastic Stack и Elastic Solutions
https://www.youtube.com/watch?v=qHaS4-U1WAo
Использование Elastic Stack в командах SRE
https://www.youtube.com/watch?v=0u7rsEGb0io
Если у кого-то есть хорошие материалы или видео по теме ELK Stack, поделитесь в комментариях. Я сам почти ничего не изучал, а использую все как придется, методом тыка и своих небольших познаний продукта. Для моих задач хватает. В основном это сбор и анализ логов web севреров.
О том, как я использую ELK Stack можно посмотреть в статьях соответствующего раздела сайта - https://serveradmin.ru/category/elk-stack/
#elk #видео
YouTube
Введение в Машинное обучение в Elastic Stack
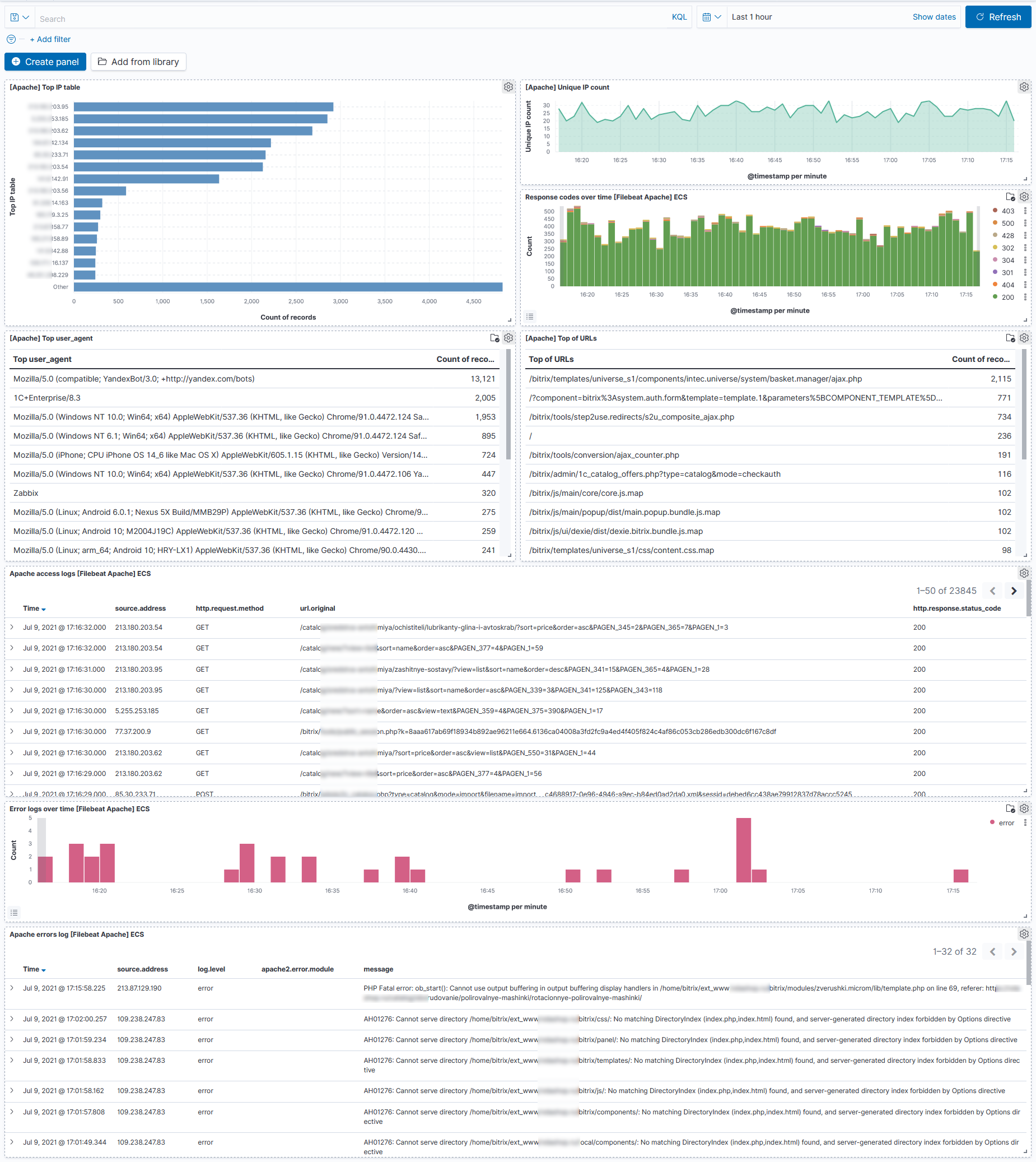
В пятницу пол дня настраивал сбор и анализ логов одного магазина на битриксе. Производительность потихоньку начала в потолок сервера упираться. Надо было внимательно посмотреть, что там происходит. Одного мониторинга уже не хватало.
Собрал вот такой типовой дашборд, основанный на своей практике. Тут есть всё, чтобы быстро оценить и проанализировать активность на сервере:
◽ Топ IP по количеству запросов.
◽ Запросы с уникальными ip на временной шкале.
◽ Коды ответов веб сервера.
◽ Топ юзер агентов.
◽ Топ урлов, к которым обращаются.
◽ Упрощенный лог файл.
◽ Ошибки веб сервера на временной шкале.
◽ Тексты ошибок веб сервера.
Всё это построено на базе elasticsearch + kibana и filebeat. Logstash не стал использовать, так как не было необходимости. Для тех, кто никогда не использовал подобные инструменты, поясню, как это работает.
На данном дашборде можно выбрать, к примеру, конкретный IP и увидите весь дашборд с фильтрацией по этому адресу. То есть все его урлы, что он посетил, все коды ответов, которые получил, все ошибки и т.д. И такая фильтрация работает по всем параметрам.
Еще пример. Вы можете выбрать код ошибки 404 и увидите всю информацию по запросам, клиентам, урлам, юзер агентам и т.д., которые получили ошибку 404. Это очень крутой и удобный инструмент. Правда разобраться с ним не так просто. Придётся потрудиться. Он еще и обновляется достаточно часто. Разница между версиями обычно значительная. Приходится каждый раз разбираться.
С помощью данного дашборда сразу же стало ясно, что основную нагрузку даёт бот Яндекса. Скорее всего от маркета. Я изначально предполагал, что какие-то боты парсеры долбят, но нет.
Некоторую информацию по настройке всего этого можно найти у меня на сайте в отдельном разделе.
#elk #devops
Собрал вот такой типовой дашборд, основанный на своей практике. Тут есть всё, чтобы быстро оценить и проанализировать активность на сервере:
◽ Топ IP по количеству запросов.
◽ Запросы с уникальными ip на временной шкале.
◽ Коды ответов веб сервера.
◽ Топ юзер агентов.
◽ Топ урлов, к которым обращаются.
◽ Упрощенный лог файл.
◽ Ошибки веб сервера на временной шкале.
◽ Тексты ошибок веб сервера.
Всё это построено на базе elasticsearch + kibana и filebeat. Logstash не стал использовать, так как не было необходимости. Для тех, кто никогда не использовал подобные инструменты, поясню, как это работает.
На данном дашборде можно выбрать, к примеру, конкретный IP и увидите весь дашборд с фильтрацией по этому адресу. То есть все его урлы, что он посетил, все коды ответов, которые получил, все ошибки и т.д. И такая фильтрация работает по всем параметрам.
Еще пример. Вы можете выбрать код ошибки 404 и увидите всю информацию по запросам, клиентам, урлам, юзер агентам и т.д., которые получили ошибку 404. Это очень крутой и удобный инструмент. Правда разобраться с ним не так просто. Придётся потрудиться. Он еще и обновляется достаточно часто. Разница между версиями обычно значительная. Приходится каждый раз разбираться.
С помощью данного дашборда сразу же стало ясно, что основную нагрузку даёт бот Яндекса. Скорее всего от маркета. Я изначально предполагал, что какие-то боты парсеры долбят, но нет.
Некоторую информацию по настройке всего этого можно найти у меня на сайте в отдельном разделе.
#elk #devops
{kind=link}
Я неоднократно уже упоминал на канале про ELK Stack. Это достаточно громоздкая, тяжелая в плане ресурсов и не очень простая в плане настройки система хранения и анализа логов. Но она очень функциональная и полезная. Эту услугу можно купить как сервис, а не разворачивать и настраивать на своих мощностях.
Для теста можно взять 14-ти дневный триал и посмотреть, как там всё работает. Если понравится, можно перейти на платный тариф. Самый простой стоит 16$ в месяц. Для начала хватит. Это дешевле стоимости виртуальных машин, которые вам понадобятся, если будете арендовать VPS под них. Для небольшого проекта это однозначно выгоднее, чем устанавливать и поддерживать свой сервер.
У меня есть статья с пошаговым руководством, как всё запустить и потестировать работу с использованием триала. Для примера я собираю логи веб сервера от сайта на bitrix и отправляю в elastic cloud.
https://serveradmin.ru/bystraya-nastrojka-elastic-stack-v-elastic-cloud-dlya-sbora-logov/
#elk #devops
Для теста можно взять 14-ти дневный триал и посмотреть, как там всё работает. Если понравится, можно перейти на платный тариф. Самый простой стоит 16$ в месяц. Для начала хватит. Это дешевле стоимости виртуальных машин, которые вам понадобятся, если будете арендовать VPS под них. Для небольшого проекта это однозначно выгоднее, чем устанавливать и поддерживать свой сервер.
У меня есть статья с пошаговым руководством, как всё запустить и потестировать работу с использованием триала. Для примера я собираю логи веб сервера от сайта на bitrix и отправляю в elastic cloud.
https://serveradmin.ru/bystraya-nastrojka-elastic-stack-v-elastic-cloud-dlya-sbora-logov/
#elk #devops
Server Admin
Сбор логов в Elastic Stack Cloud | serveradmin.ru
Подробное описание регистрации и начала работы с Elastic Cloud для сбора логов с помощью filebeat на примере логов apache.
Узнал вчера про существование проекта для предобработки текста Tremor. Продукт нишевый и нужен только в определенных ситуациях. Это аналог Logstash, который входит в состав ELK. Я Logstash достаточно часто использую. В целом, привык к нему и к его языку парсинга в виде grok фильтров. Значительный минус Logstash - он очень требователен к ресурсам. Такое тяжелое Java приложение. Первого запуска достаточно, чтобы понять, какой он тормозной. Запускается секунд 5-7 даже без нагрузки.
Для тех, кто совсем не понимает, о чём идёт речь, кратко поясню. С помощью подобных инструментов можно брать исходные логи любого формата и приводить их к тому виду, какой вам нужен. Например, с помощью Logstash и его grok фильтров парсится лог веб сервера. Из строк вычленяются ip адреса, урлы, даты и т.д. Все эти данные конвертируются из строковых значений в свои форматы - число, ip адрес, дата и т.д. Далее эти распарсенные и сконвертированные данные можно использовать в построении графиков, отчётах, можно делать агрегации и т.д.
Tremor якобы более легкий и удобный инструмент. У него свой скриптовый язык tremor-script, что лично меня смущает. Хотя в документации говорится, что он более удобен и эффективен. Grok - универсальный фильтр для парсинга, используется много где, а не только в Logstash. А учить новый синтаксис только под один продукт как-то лениво.
Написал эту заметку, чтобы поделиться с вами новым для меня продуктом, а заодно спросить, есть ли тут кто-то, кто использовал Tremor. Имеет смысл его изучать и пробовать как замену Logstash? Я в свое время смотрел на Loki, как более легковесную замену всего ELK в простых ситуациях, но так и не начал пользоваться, так как привык к ELK и неплохо его знаю. Не захотелось распыляться и изучать два продукта. Но этого монстра хотелось бы как-то облегчить.
https://github.com/tremor-rs/tremor-runtime
https://www.tremor.rs/
#devops #elk
Для тех, кто совсем не понимает, о чём идёт речь, кратко поясню. С помощью подобных инструментов можно брать исходные логи любого формата и приводить их к тому виду, какой вам нужен. Например, с помощью Logstash и его grok фильтров парсится лог веб сервера. Из строк вычленяются ip адреса, урлы, даты и т.д. Все эти данные конвертируются из строковых значений в свои форматы - число, ip адрес, дата и т.д. Далее эти распарсенные и сконвертированные данные можно использовать в построении графиков, отчётах, можно делать агрегации и т.д.
Tremor якобы более легкий и удобный инструмент. У него свой скриптовый язык tremor-script, что лично меня смущает. Хотя в документации говорится, что он более удобен и эффективен. Grok - универсальный фильтр для парсинга, используется много где, а не только в Logstash. А учить новый синтаксис только под один продукт как-то лениво.
Написал эту заметку, чтобы поделиться с вами новым для меня продуктом, а заодно спросить, есть ли тут кто-то, кто использовал Tremor. Имеет смысл его изучать и пробовать как замену Logstash? Я в свое время смотрел на Loki, как более легковесную замену всего ELK в простых ситуациях, но так и не начал пользоваться, так как привык к ELK и неплохо его знаю. Не захотелось распыляться и изучать два продукта. Но этого монстра хотелось бы как-то облегчить.
https://github.com/tremor-rs/tremor-runtime
https://www.tremor.rs/
#devops #elk
{kind=link}
Написал статью по настройке Elastic Enterprise Search. Это отдельная служба, которая работает на базе ELK Stack и может быть установлена и интегрирована в указанную инфраструктуру. Но при этом остается независимым, отдельным компонентом.
Если я не ошибаюсь, то когда-то этот продукт был только в платной версии. Почему-то отложилась информация, но нигде не нашёл подтверждения. На текущий момент денег не просит, ставится свободно. Enterprise Search часто используют для настройки продвинутого поиска на большом сайте.
Так как для подключения Enterprise Search необходимо настроить авторизацию через xpack.security, а так же TLS, вынес эти настройки в отдельные подразделы статьи. Они могут быть полезны сами по себе. Я в простых случаях закрываю доступ к ELK через Firewall, а к Kibana на nginx proxy с помощью basic_auth. Это более простое решение, но понятно, что не такое гибкое, как встроенные средства ELK. Но EES хочет видеть настроенными встроенные инструменты, так что пришлось сделать.
https://serveradmin.ru/ustanovka-elastic-enterprise-search/
#elk #devops #статья
Если я не ошибаюсь, то когда-то этот продукт был только в платной версии. Почему-то отложилась информация, но нигде не нашёл подтверждения. На текущий момент денег не просит, ставится свободно. Enterprise Search часто используют для настройки продвинутого поиска на большом сайте.
Так как для подключения Enterprise Search необходимо настроить авторизацию через xpack.security, а так же TLS, вынес эти настройки в отдельные подразделы статьи. Они могут быть полезны сами по себе. Я в простых случаях закрываю доступ к ELK через Firewall, а к Kibana на nginx proxy с помощью basic_auth. Это более простое решение, но понятно, что не такое гибкое, как встроенные средства ELK. Но EES хочет видеть настроенными встроенные инструменты, так что пришлось сделать.
https://serveradmin.ru/ustanovka-elastic-enterprise-search/
#elk #devops #статья
Server Admin
Установка Elastic Enterprise Search | serveradmin.ru
xpack.security.enabled: true После этого перезапустите службу elasticsearch: # systemctl restart elasticsearch Теперь сгенерируем пароли к встроенным учётным записям (built-in users) elastic. Для...
Многие наверно слышали про разногласия между Elastic и Amazon, в результате чего последний сделал форк ELK Stack на момент действия старой лицензии и начал развивать свой продукт на его основе - OpenSearch. Причём это не то же самое, что они уже ранее анонсировали и поддерживают - Open Distro. Поясню своими словами, так как сам до конца не понимал, что там к чему.
📌 Open Distro - не форк, а самостоятельный продукт на основе Elasticsearch. Он появился в ответ на действия Elastic по объединению в едином репозитории бесплатных продуктов и платных дополнений в виде расширений X-Pack. Из-за этого стало очень неудобно разделять открытую и закрытую лицензию. Open Distro полностью исключил весь код с платной лицензией, сам он публикуется под открытой лицензией Apache 2.0. Дополнительно в нём бесплатно реализована часть наиболее востребованного функционала из X-Pack (security, notifications и т.д.). В ответ на это компании Elastic пришлось сделать сопоставимый функционал бесплатным, чтобы исключить переток пользователей. Именно в этот момент стал доступен функционал разделения доступа на основе пользователей в Kibana. Ранее это покупалось отдельно.
📌 OpenSearch - форк Elasticsearch 7.10. Появился после изменения лицензии, которая запрещает использования Elasticsearch тем, кто на нём зарабатывает, продавая как сервис. Теперь он развивается самостоятельно как независимый движок под открытой лицензией. Из него убрали весь код, связанный с сервисами компании Elastic, а так же платных компонентов от них же. OpenSearch можно использовать компаниям, которые на нём зарабатывают.
Сложилась достаточно интересная ситуация. С одной стороны, вокруг Elasticsearch выстроена большая экосистема различных продуктов и дополнений. С другой стороны, свободно, как раньше, его использовать нельзя. Придётся брать OpenSearch, который только начал развиваться и не имеет такой экосистемы. Но с учётом того, что альтернатив особо нет, она обязательно появится, тем более под крылом такой крупной компании, как Amazon. Как я понимаю, сейчас смысла в Open Distro уже нет и проект будет свёрнут в пользу OpenSearch.
Конечные пользователя, то есть мы с вами, скорее всего от этой истории только выиграем, так как возросла конкуренция. Она и так уже вынудила компании часть платного функционала сделать бесплатным. Посмотрим, как будут дальше развиваться ситуация.
#elk
📌 Open Distro - не форк, а самостоятельный продукт на основе Elasticsearch. Он появился в ответ на действия Elastic по объединению в едином репозитории бесплатных продуктов и платных дополнений в виде расширений X-Pack. Из-за этого стало очень неудобно разделять открытую и закрытую лицензию. Open Distro полностью исключил весь код с платной лицензией, сам он публикуется под открытой лицензией Apache 2.0. Дополнительно в нём бесплатно реализована часть наиболее востребованного функционала из X-Pack (security, notifications и т.д.). В ответ на это компании Elastic пришлось сделать сопоставимый функционал бесплатным, чтобы исключить переток пользователей. Именно в этот момент стал доступен функционал разделения доступа на основе пользователей в Kibana. Ранее это покупалось отдельно.
📌 OpenSearch - форк Elasticsearch 7.10. Появился после изменения лицензии, которая запрещает использования Elasticsearch тем, кто на нём зарабатывает, продавая как сервис. Теперь он развивается самостоятельно как независимый движок под открытой лицензией. Из него убрали весь код, связанный с сервисами компании Elastic, а так же платных компонентов от них же. OpenSearch можно использовать компаниям, которые на нём зарабатывают.
Сложилась достаточно интересная ситуация. С одной стороны, вокруг Elasticsearch выстроена большая экосистема различных продуктов и дополнений. С другой стороны, свободно, как раньше, его использовать нельзя. Придётся брать OpenSearch, который только начал развиваться и не имеет такой экосистемы. Но с учётом того, что альтернатив особо нет, она обязательно появится, тем более под крылом такой крупной компании, как Amazon. Как я понимаю, сейчас смысла в Open Distro уже нет и проект будет свёрнут в пользу OpenSearch.
Конечные пользователя, то есть мы с вами, скорее всего от этой истории только выиграем, так как возросла конкуренция. Она и так уже вынудила компании часть платного функционала сделать бесплатным. Посмотрим, как будут дальше развиваться ситуация.
#elk
{kind=link}
Проверил и актуализировал свою статью про настройку ELK Stack. Добавил информацию про автоматическую очистку индексов встроенными средствами стэка. А также про авторизацию с помощью паролей средствами X-Pack Security.
Статья получилась полным и законченным руководством по внедрению системы сбора логов на базе ELK Stack для одиночного инстанса. Без встроенной авторизации она была незавершённой. Исправил это.
На текущий момент всё можно настроить копипастом из статьи. Я проверил все конфиги. Так что если есть желание познакомиться и изучить, имеет смысл сделать это сейчас. Через некоторое время, как обычно, все изменится с выходом очередной новой версии.
https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
#elk #статья
Статья получилась полным и законченным руководством по внедрению системы сбора логов на базе ELK Stack для одиночного инстанса. Без встроенной авторизации она была незавершённой. Исправил это.
На текущий момент всё можно настроить копипастом из статьи. Я проверил все конфиги. Так что если есть желание познакомиться и изучить, имеет смысл сделать это сейчас. Через некоторое время, как обычно, все изменится с выходом очередной новой версии.
https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
#elk #статья
Server Admin
Установка и настройка Elasticsearch, Logstash, Kibana (ELK Stack)
Подробное описание установки ELK Stack - Elasticsearch, Logstash, Kibana для централизованного сбора логов.
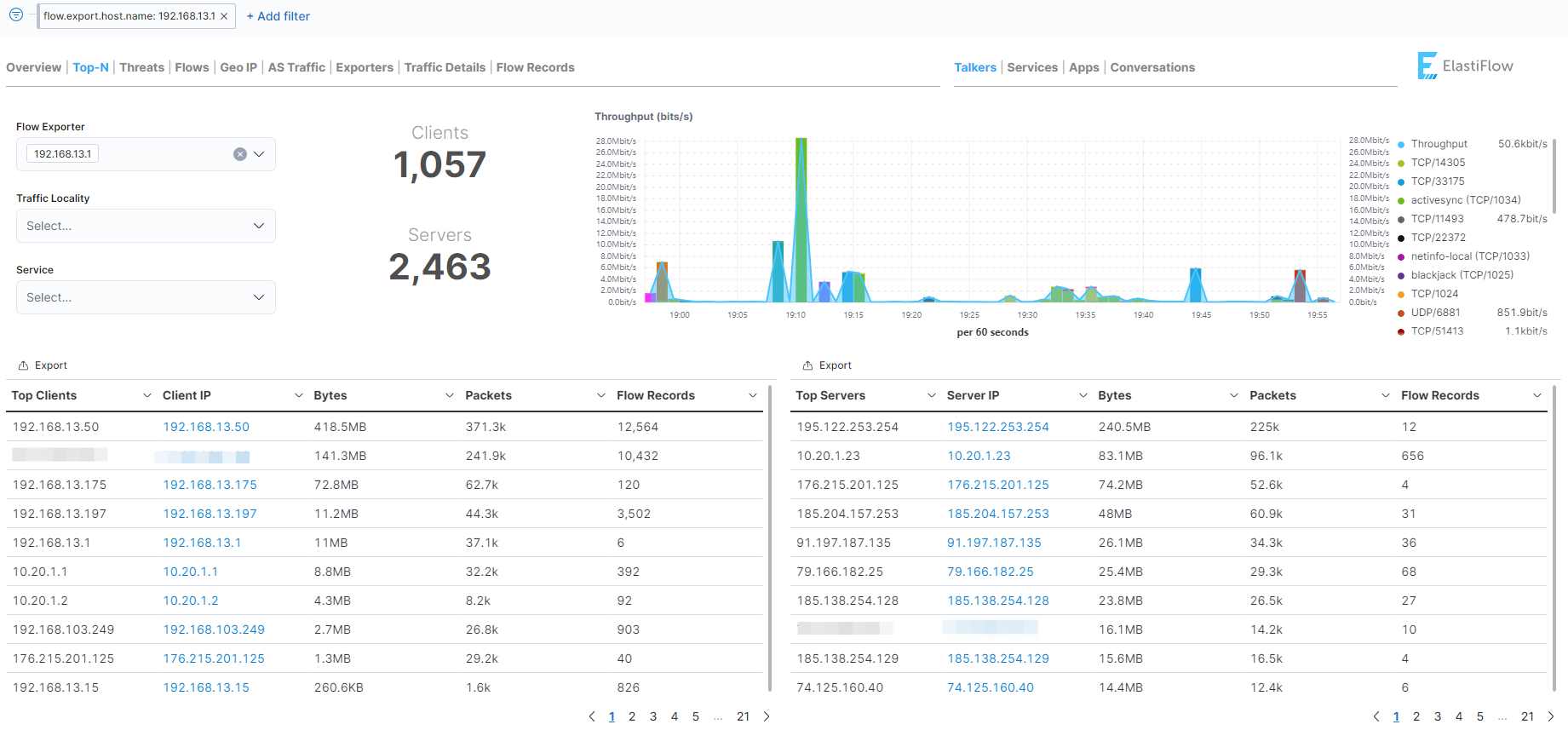
Пока у меня остался свежий стенд с ELK Stack, решил попробовать софт для разбора NetFlow потоков в Elasticsearch - Elastiflow. Идея там такая. Ставите куда угодно коллектор, который собирает NetFlow и принимаете трафик. А этот коллектор передаёт всю информацию в Elasticsearch. В комплекте с Elastiflow идёт все необходимое для визуализации данных - шаблоны, дашборды для Kibana.
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
Последовательность действий для настройки такая:
1️⃣ Устанавливаем Elastiflow, можно в докере. Я так и сделал. Главное не забыть все нужные переменные указать. Основное - разрешить передачу данных в elasticsearch и активировать сбор NetFlow. По дефолту и то, и другое выключено в конфиге, что идёт как пример. Запустить лучше сначала не в режиме демона, чтобы логи смотреть сразу в консоли.
2️⃣ Импортируем объекты Kibana. Шаблоны берём отсюда. Я сначала ошибся и взял шаблоны с репы в github. А там оказывается старая версия, которая больше не развивается. В итоге одни ошибки в веб интерфейсе были.
3️⃣ Направляем NetFlow поток на Elastiflow. Я со своего Mikrotik направил. Подождал пару минут, потом пошел в Kibana и убедился, что полились данные в индекс elastiflow-*
4️⃣ Теперь идём в Dashboard и открываем ElastiFlow: Overview. Это базовый дашборд, где собрана основная информация.
Вот такой простой, бесплатный и функциональный способ сбора и парсинга NetFlow. Я разобрался и все запустил примерно за час. Больше всего времени потратил из-за того, что не те объекты для Kibana взял.
Из минусов - немного сложно разобраться и все запустить тому, кто ELK Stack не знает. Ну и плюс по ресурсам будут высокие требования. Всё это на Java работает, так что железо нужно помощнее.
Недавно был обзор платного Noction Flow Analyzer. Многие спрашивали, как получить то же самое, но бесплатно. Вот бесплатный вариант, но, что ожидаемо, функционал не такой. NFA все же готовый, законченный продукт, а тут только визуализация на базе стороннего решения по хранению и обработке.
Сайт - https://elastiflow.com
Документация - https://docs.elastiflow.com/docs
Kibana Objects - https://docs.elastiflow.com/docs/kibana
#elk #gateway #netflow
{kind=link}
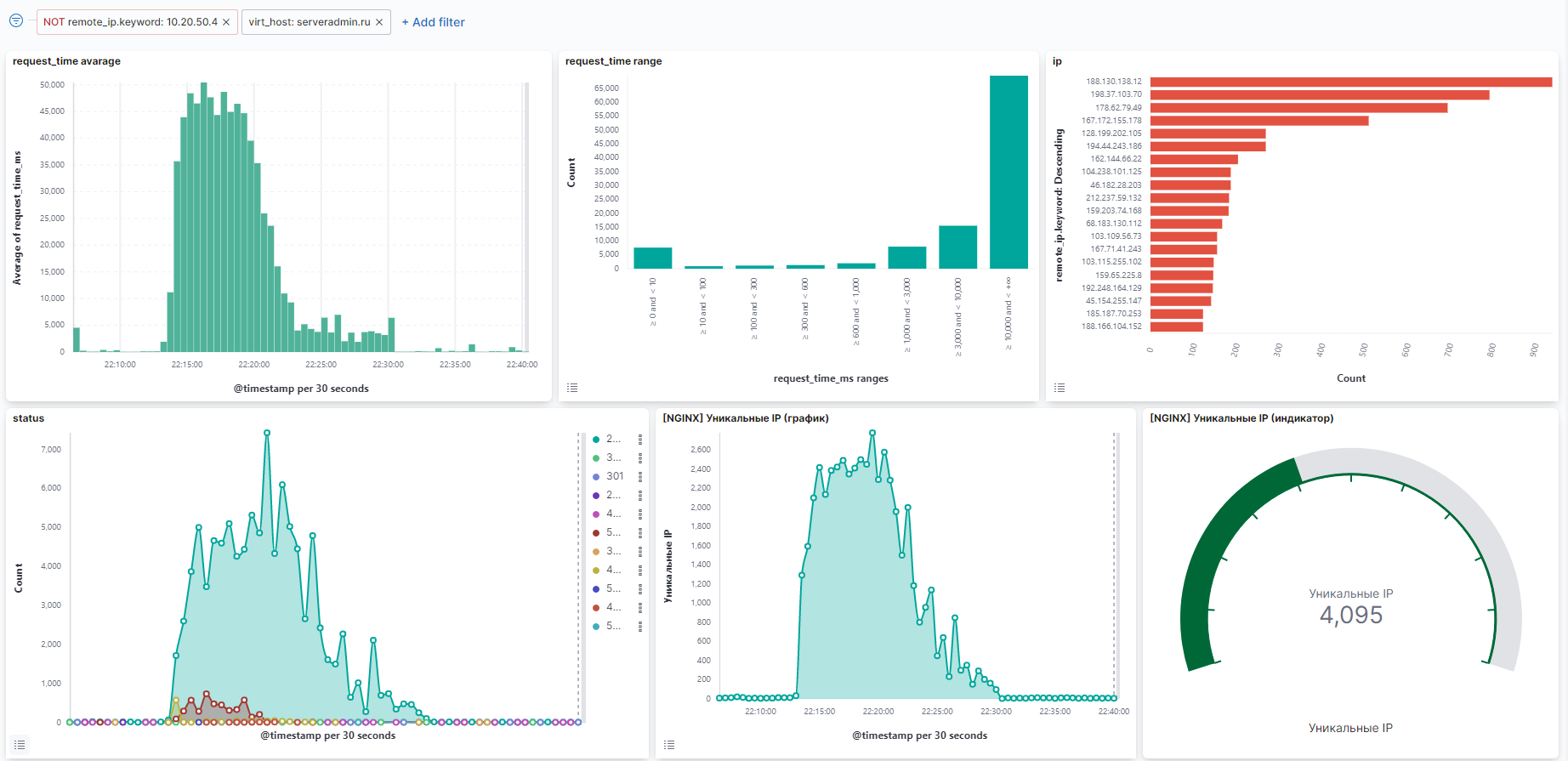
У меня тут сайт на днях ддоснули. Не знаю, специально или нет. Длилось недолго, минут 10-15. Никакой защиты у меня не стоит, так как нет смысла. С меня не убудет, если сайт полежит какое-то время. Защита стоит дороже, чем доход с сайта.
Как-только сайт начал лагать и пришли алерты от мониторинга о том, что на прокси сервере CPU в потолок ушел, сразу же пошел смотреть дашборд в ELK. Картина из него во вложении. Увидел количество запросов и разных IP, сразу расслабился. Я тут сделать ничего не могу. Канал в 1 гиг сразу забили весь. При этом инфра достойно держалась, хотя всё крутится на дешманском сервере chipcore с двумя обычными ssd.
Пользователям отдаётся чистая статика из кэша напрямую через nginx. Так что 500-е полезли из-за того, что на proxy-nginx было всего 2 CPU и они были загружены полностью. Может быть вообще переварили бы весь этот траф. Другое дело, что меня бы провайдер отрубил, если бы атака продлилась чуть дольше.
Важно иметь мониторинг и логи где-то во вне от наблюдаемого объекта. Если бы они висели на том же ip и канале, то посмотреть бы ничего не смог. Пришлось бы разбираться. А так я сразу же всё понял и оценил обстановку. Так как был вечер, приготовился лечь спать 😎
#ddos #elk
Как-только сайт начал лагать и пришли алерты от мониторинга о том, что на прокси сервере CPU в потолок ушел, сразу же пошел смотреть дашборд в ELK. Картина из него во вложении. Увидел количество запросов и разных IP, сразу расслабился. Я тут сделать ничего не могу. Канал в 1 гиг сразу забили весь. При этом инфра достойно держалась, хотя всё крутится на дешманском сервере chipcore с двумя обычными ssd.
Пользователям отдаётся чистая статика из кэша напрямую через nginx. Так что 500-е полезли из-за того, что на proxy-nginx было всего 2 CPU и они были загружены полностью. Может быть вообще переварили бы весь этот траф. Другое дело, что меня бы провайдер отрубил, если бы атака продлилась чуть дольше.
Важно иметь мониторинг и логи где-то во вне от наблюдаемого объекта. Если бы они висели на том же ip и канале, то посмотреть бы ничего не смог. Пришлось бы разбираться. А так я сразу же всё понял и оценил обстановку. Так как был вечер, приготовился лечь спать 😎
#ddos #elk
{kind=link}
Технический пост, который уже давно нужно было сделать, но всё руки не доходили. На канале много содержательных заметок по различным темам. Иногда сам через поиск ищу то, о чём писал. Ниже набор наиболее популярных тэгов по которым можно найти что-то полезное (и не очень).
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
Мне нравится, как работает умная лента новостей Google, когда запускаешь Chrome на смартфоне. Постоянно читаю там новости. Они почти на 100% релевантны моим интересам. Накануне обновлял ELK Stack, пришлось повозиться с Enterprise Search. Так на следующий день мне в ленту насыпало немного информации по ELK, в том числе новость о выходе 8-й версии и изменениях безопасности в ней. Так как я ELK использую постоянно, решил прочитать и поделиться основными изменениями с вами.
Для тех, кто не в курсе, поясню, что изначально в ELK практически всё, что касалось безопасности, было платными дополнениями. Даже банальный доступ к стеку с авторизацией по логину и паролю. Со временем стали появляться форки, где этот функционал был реализован бесплатно, так что разработчикам Elastic пришлось пойти на уступки и тоже потихоньку добавлять этот функционал в бесплатную версию.
На текущий момент в версии 8.0 будет бесплатно доступен следующий функционал:
◽ Аутентификация пользователей
◽ Авторизация пользователей на основе ролей
◽ Kibana multi-tenancy, то есть разный доступ пользователей Kibana к объектам
◽ TLS соединения между нодами elasticsearch
◽ Доступ к Elasticsearch API по HTTPS
Когда я только начинал изучать ELK, всего этого не было и как только не приходилось изворачиваться, чтобы не показать лишнего тому, кому не следует. Приходилось использовать проксирование и basic auth, поднимать разные инстансы для разных команд, чтобы они не видели чужие логи. Сейчас стало очень удобно. Реально весь необходимый функционал есть в бесплатной версии. Я даже не знаю, за что там сейчас люди платят деньги.
У постоянных изменений ELK Stack есть и обратная сторона. Его хлопотно поддерживать. Он часто обновляется и это не всегда проходит легко и гладко. Даже в пределах одной ветки иногда обновления приводят к проблемам и надо очень внимательно готовиться к обновлению стека. У меня по умолчанию пакеты, связанные с ELK, отключаются от обновлений через пакетный менеджер. Всегда делаю это только вручную, чего и вам советую. Недавнее обновление в рамках 7-й версии тоже закончилось падением сервисов, так что пришлось повозиться. Благо, было технологическое окно для этого, и обязательно свежий бэкап и снепшот виртуалки. Если бы понял, что быстро не решу проблему, пришлось бы откатиться.
#elk #devops
Для тех, кто не в курсе, поясню, что изначально в ELK практически всё, что касалось безопасности, было платными дополнениями. Даже банальный доступ к стеку с авторизацией по логину и паролю. Со временем стали появляться форки, где этот функционал был реализован бесплатно, так что разработчикам Elastic пришлось пойти на уступки и тоже потихоньку добавлять этот функционал в бесплатную версию.
На текущий момент в версии 8.0 будет бесплатно доступен следующий функционал:
◽ Аутентификация пользователей
◽ Авторизация пользователей на основе ролей
◽ Kibana multi-tenancy, то есть разный доступ пользователей Kibana к объектам
◽ TLS соединения между нодами elasticsearch
◽ Доступ к Elasticsearch API по HTTPS
Когда я только начинал изучать ELK, всего этого не было и как только не приходилось изворачиваться, чтобы не показать лишнего тому, кому не следует. Приходилось использовать проксирование и basic auth, поднимать разные инстансы для разных команд, чтобы они не видели чужие логи. Сейчас стало очень удобно. Реально весь необходимый функционал есть в бесплатной версии. Я даже не знаю, за что там сейчас люди платят деньги.
У постоянных изменений ELK Stack есть и обратная сторона. Его хлопотно поддерживать. Он часто обновляется и это не всегда проходит легко и гладко. Даже в пределах одной ветки иногда обновления приводят к проблемам и надо очень внимательно готовиться к обновлению стека. У меня по умолчанию пакеты, связанные с ELK, отключаются от обновлений через пакетный менеджер. Всегда делаю это только вручную, чего и вам советую. Недавнее обновление в рамках 7-й версии тоже закончилось падением сервисов, так что пришлось повозиться. Благо, было технологическое окно для этого, и обязательно свежий бэкап и снепшот виртуалки. Если бы понял, что быстро не решу проблему, пришлось бы откатиться.
#elk #devops
{kind=link}
Думаю, вы уже слышали, что компания Elastic, как и многие другие, закрыла доступ к своим репозиториям и пакетам с IP адресов из России. Это создаёт некоторые неудобства. У меня полно комментариев к статьям про ELK, что ничего не устанавливается из реп.
Особых проблем в этом нет, так что какой-то глупый демарш получился. Решений тут несколько:
1️⃣ Перейти на какой-то другой форк: Open Distro или OpenSearch. Что это такое и чем они отличаются, я рассказывал в отдельной заметке.
2️⃣ Настроить работу пакетного менеджера через какой-то иностранный прокси. Лично мне не хочется этим заниматься на сервере.
3️⃣ Вручную скачать пакеты через vpn на своей машине и залить на сервер. Мне этот вариант кажется наиболее простым. Обновления приходится делать не часто, тестируя их предварительно. Так что всё равно готовиться надо. Плюс, продукты elastic в своих пакетах содержат практически все, что им надо для работы. В 7-й и 8-й версии даже Java уже запакована в них, не надо ставить отдельно. То есть они автономны.
Ссылки для скачивания:
Elasticsearch, Kibana, Logstash.
Я зашёл через американский vpn, всё скачал и установил.
#elk
Особых проблем в этом нет, так что какой-то глупый демарш получился. Решений тут несколько:
1️⃣ Перейти на какой-то другой форк: Open Distro или OpenSearch. Что это такое и чем они отличаются, я рассказывал в отдельной заметке.
2️⃣ Настроить работу пакетного менеджера через какой-то иностранный прокси. Лично мне не хочется этим заниматься на сервере.
3️⃣ Вручную скачать пакеты через vpn на своей машине и залить на сервер. Мне этот вариант кажется наиболее простым. Обновления приходится делать не часто, тестируя их предварительно. Так что всё равно готовиться надо. Плюс, продукты elastic в своих пакетах содержат практически все, что им надо для работы. В 7-й и 8-й версии даже Java уже запакована в них, не надо ставить отдельно. То есть они автономны.
Ссылки для скачивания:
Elasticsearch, Kibana, Logstash.
Я зашёл через американский vpn, всё скачал и установил.
#elk
{kind=link}
Я давно подписан на канал практикующего DevOps инженера Be Geek, но, если не ошибаюсь, ни разу о нём не упоминал. На днях у него вышел обзорный ролик на тему Elasticsearch, так что появился повод.
Как собрать кластер Elasticsearch. Какие есть роли у нод Elasticsearch.
https://www.youtube.com/watch?v=-e0M9X6uD_4
Мне он показался полезным, так как сам я с кластером никогда не работал, хотя Elasticsearch использую активно и очень давно. Под мои задачи хватает одиночного инстанса.
В видео автор разбирает кластерные роли хостов и теорию по организации кластера Elasticsearch. Основные темы:
- Из чего состоит кластер
- Какие роли есть у узлов
- Разбор основных ролей узлов кластера
- Как грамотно организовать кластер
Видео обзорное, можно просто послушать на ходу или в машине.
Презентация из видео
#video #elk
Как собрать кластер Elasticsearch. Какие есть роли у нод Elasticsearch.
https://www.youtube.com/watch?v=-e0M9X6uD_4
Мне он показался полезным, так как сам я с кластером никогда не работал, хотя Elasticsearch использую активно и очень давно. Под мои задачи хватает одиночного инстанса.
В видео автор разбирает кластерные роли хостов и теорию по организации кластера Elasticsearch. Основные темы:
- Из чего состоит кластер
- Какие роли есть у узлов
- Разбор основных ролей узлов кластера
- Как грамотно организовать кластер
Видео обзорное, можно просто послушать на ходу или в машине.
Презентация из видео
#video #elk
{kind=link}
Посмотрел интересное выступление с HighLoad++ 2021, которое весной выложили в открытый доступ - Есть ли жизнь без ELK? Как снизить стоимость Log Management:
https://www.youtube.com/watch?v=BOVuwr43ZTE
Автор детально разбирает тему хранения логов с помощью современных инструментов. Прикидывает нагрузку, стоимость решения. Перебирает различные варианты и в итоге рассказывает, к какому решению пришли сами.
Они решили для экономии денег и ресурсов собрать систему сбора логов самостоятельно на базе сборщика логов Vector (по их тестам он оказался быстрее FluentD), парсинг делают им же, обработка с помощью Kafka, данные хранят в ClickHouse, визуализируют с помощью Grafana.
Если вам интересная данная тема, то рекомендую. Я, например, про Vector вообще впервые услышал. Всегда думал, что оптимальный парсер и доставщик логов это FluentD. Обычно его рекомендуют вместо тормозного Filebeat.
#видео #elk #logs
https://www.youtube.com/watch?v=BOVuwr43ZTE
Автор детально разбирает тему хранения логов с помощью современных инструментов. Прикидывает нагрузку, стоимость решения. Перебирает различные варианты и в итоге рассказывает, к какому решению пришли сами.
Они решили для экономии денег и ресурсов собрать систему сбора логов самостоятельно на базе сборщика логов Vector (по их тестам он оказался быстрее FluentD), парсинг делают им же, обработка с помощью Kafka, данные хранят в ClickHouse, визуализируют с помощью Grafana.
Если вам интересная данная тема, то рекомендую. Я, например, про Vector вообще впервые услышал. Всегда думал, что оптимальный парсер и доставщик логов это FluentD. Обычно его рекомендуют вместо тормозного Filebeat.
#видео #elk #logs
YouTube
Есть ли жизнь без ELK? Как снизить стоимость Log Management / Денис Безкоровайный
Приглашаем на конференцию HighLoad++ 2024, которая пройдет 2 и 3 декабря в Москве!
Программа, подробности и билеты по ссылке: https://clck.ru/3DD4yb
--------
Профессиональная конференция разработчиков высоконагруженных систем
20 и 21 сентября 2021. Санкт…
Программа, подробности и билеты по ссылке: https://clck.ru/3DD4yb
--------
Профессиональная конференция разработчиков высоконагруженных систем
20 и 21 сентября 2021. Санкт…
В последнее время навводили кучу запретов на загрузку софта с IP адресов РФ. Я покажу на наглядном примере, как поднять свой deb репозиторий, наполнить его санкционным софтом и использовать в своей инфраструктуре.
Пример будет не гипотетический, а самый что ни на есть актуальный. Допустим, нам надо на парке серверов обновить filebeat от компании elastic, которая закрыла доступ к своим публичным репозиториям с территории РФ. Я включил прокси, скачал через браузер пакет filebeat-8.4.3-amd64.deb.
Далее идём на сервер с Debian, где будем настраивать локальный репозиторий с помощью aptly.
Создаём конфиг /etc/aptly.conf. Содержимое берём из документации, где меняем только rootDir и имя FileSystemPublishEndpoints.
Создаём необходимые директории:
Создаю репозиторий для Debian 11:
Копирую на сервер пакет и добавляю его в репозиторий:
Создаю gpg ключ для репозитория:
Публикуем репозиторий с этим ключом:
Далее вам нужно поднять любой веб сервер и настроить через него доступ к директории /var/www/aptly. Если не хочется это делать, можно запустить сам aptly как веб сервер (дефолтный порт 8080):
Он автоматом создаст и опубликует директорию /mnt/repo/public. Для удобства можно туда выгрузить публичный ключ:
Можно зайти браузером на 8080 порт сервера и посмотреть содержимое репозитория вместе с gpg ключом.
Теперь идём на клиенты и подключаем репозиторий. Для этого создаём файл /etc/apt/sources.list.d/elk_repo.list:
Обновляем пакеты и устанавливаем или обновляем filebeat:
Инструкцию написал и проверил лично, так как надо было для дела. Можете заполнить этот репозиторий всеми пакетами elastic и пользоваться.
#debian #elk
Пример будет не гипотетический, а самый что ни на есть актуальный. Допустим, нам надо на парке серверов обновить filebeat от компании elastic, которая закрыла доступ к своим публичным репозиториям с территории РФ. Я включил прокси, скачал через браузер пакет filebeat-8.4.3-amd64.deb.
Далее идём на сервер с Debian, где будем настраивать локальный репозиторий с помощью aptly.
# apt install aptlyСоздаём конфиг /etc/aptly.conf. Содержимое берём из документации, где меняем только rootDir и имя FileSystemPublishEndpoints.
{ "rootDir": "/mnt/repo", "downloadConcurrency": 4, "downloadSpeedLimit": 0, "architectures": [], "dependencyFollowSuggests": false, "dependencyFollowRecommends": false, "dependencyFollowAllVariants": false, "dependencyFollowSource": false, "dependencyVerboseResolve": false, "gpgDisableSign": false, "gpgDisableVerify": false, "gpgProvider": "gpg", "downloadSourcePackages": false, "skipLegacyPool": true, "ppaDistributorID": "elk", "ppaCodename": "", "FileSystemPublishEndpoints": { "elkrepo": { "rootDir": "/var/www/aptly", "linkMethod": "symlink", "verifyMethod": "md5" } }, "enableMetricsEndpoint": false}Создаём необходимые директории:
# mkdir -p /mnt/repo /var/www/aptlyСоздаю репозиторий для Debian 11:
# aptly repo create -distribution="bullseye" elkКопирую на сервер пакет и добавляю его в репозиторий:
# aptly repo add elk ~/filebeat-8.4.3-amd64.debСоздаю gpg ключ для репозитория:
# gpg --default-new-key-algo rsa4096 --gen-key --keyring pubringReal name: elkrepoПубликуем репозиторий с этим ключом:
# aptly publish repo elkДалее вам нужно поднять любой веб сервер и настроить через него доступ к директории /var/www/aptly. Если не хочется это делать, можно запустить сам aptly как веб сервер (дефолтный порт 8080):
# aptly serveОн автоматом создаст и опубликует директорию /mnt/repo/public. Для удобства можно туда выгрузить публичный ключ:
# gpg --export --armor > /mnt/repo/public/elkrepo.ascМожно зайти браузером на 8080 порт сервера и посмотреть содержимое репозитория вместе с gpg ключом.
Теперь идём на клиенты и подключаем репозиторий. Для этого создаём файл /etc/apt/sources.list.d/elk_repo.list:
deb http://10.20.1.56:8080 bullseye mainОбновляем пакеты и устанавливаем или обновляем filebeat:
# apt update && apt install filebeatИнструкцию написал и проверил лично, так как надо было для дела. Можете заполнить этот репозиторий всеми пакетами elastic и пользоваться.
#debian #elk
С удивлением узнал, что существует полноценная бесплатная open source SIEM-система (менеджмент информации и событий безопасности) - Wazuh. Она состоит из агентов для сбора данных под все популярные системы и серверной части с дашбордом и просмотром информации через браузер.
С помощью Wazuh можно решать следующие задачи:
◽ анализ журналов
◽ мониторинг файлов
◽ обнаружение вторжений
◽ сканирование запущенных процессов
◽ реагирование на инциденты
◽ проверка соответствия систем заданным политикам
◽ проверка уязвимостей CVE
Сама система Wazuh построена на базе Linux, но позволяет наблюдать в том числе за хостами под Windows.
Wazuh зрелый и известный проект. Имеет интеграцию с ELK, в том числе плагин для Kibana с готовыми дашбордами. Яндекс.Облако предлагает использовать Wazuh как готовую DevSecOps платформу и развернуть в несколько кликов через свой готовый образ.
Развернуть Wazuh можно на своём железе. В документации всё подробно описано. Можно использовать скрипты установки, пакеты из репозиториев, либо готовый образ виртуальной машины, docker контейнеры, готовый deployment для kubernetes.
Для тех, кто не совсем понимает, что это за система и как работает, поясню на небольших примерах. Это не антивирус, который автоматически обновляет базы и что-то делает за вас. Эта система собирает данные и предлагает вам настроить оповещения и какие-то действия на конкретные события. При этом она может получать данные и от антивирусов.
Допустим, какой-то ваш сервис брутят, пытаясь подобрать учётную запись. Вы видите это в логах. Заранее или по факту пишите какой-то скрипт, правило или что-то ещё, что управляет вашим фаерволом. Потом применяете это правило блокировки злоумышленника на основе данных из логов как реакцию на событие. Другой пример. С помощью агента вы знаете список софта и его версии. В какой-то момент появляется CVE для одной из версий. Вы видите это на основе отчёта. Далее создаёте политику на обновление уязвимых программ и распространяете её.
Сам я Wazuh никогда не использовал и даже не видел. Собрал информацию по ходу написания заметки. Если вы использовали, дайте обратную связь. На вид всё выглядит неплохо. Я даже задумался, какой смысл устанавливать и настраивать только ELK для сбора и анализа логов, если можно сразу Wazuh развернуть и получить не только обзор логов, но и всё остальное. Под капотом там тот же Elasticsearch и Kibana.
⇨ Сайт / Документация / Исходники
#security #elk #devops
С помощью Wazuh можно решать следующие задачи:
◽ анализ журналов
◽ мониторинг файлов
◽ обнаружение вторжений
◽ сканирование запущенных процессов
◽ реагирование на инциденты
◽ проверка соответствия систем заданным политикам
◽ проверка уязвимостей CVE
Сама система Wazuh построена на базе Linux, но позволяет наблюдать в том числе за хостами под Windows.
Wazuh зрелый и известный проект. Имеет интеграцию с ELK, в том числе плагин для Kibana с готовыми дашбордами. Яндекс.Облако предлагает использовать Wazuh как готовую DevSecOps платформу и развернуть в несколько кликов через свой готовый образ.
Развернуть Wazuh можно на своём железе. В документации всё подробно описано. Можно использовать скрипты установки, пакеты из репозиториев, либо готовый образ виртуальной машины, docker контейнеры, готовый deployment для kubernetes.
Для тех, кто не совсем понимает, что это за система и как работает, поясню на небольших примерах. Это не антивирус, который автоматически обновляет базы и что-то делает за вас. Эта система собирает данные и предлагает вам настроить оповещения и какие-то действия на конкретные события. При этом она может получать данные и от антивирусов.
Допустим, какой-то ваш сервис брутят, пытаясь подобрать учётную запись. Вы видите это в логах. Заранее или по факту пишите какой-то скрипт, правило или что-то ещё, что управляет вашим фаерволом. Потом применяете это правило блокировки злоумышленника на основе данных из логов как реакцию на событие. Другой пример. С помощью агента вы знаете список софта и его версии. В какой-то момент появляется CVE для одной из версий. Вы видите это на основе отчёта. Далее создаёте политику на обновление уязвимых программ и распространяете её.
Сам я Wazuh никогда не использовал и даже не видел. Собрал информацию по ходу написания заметки. Если вы использовали, дайте обратную связь. На вид всё выглядит неплохо. Я даже задумался, какой смысл устанавливать и настраивать только ELK для сбора и анализа логов, если можно сразу Wazuh развернуть и получить не только обзор логов, но и всё остальное. Под капотом там тот же Elasticsearch и Kibana.
⇨ Сайт / Документация / Исходники
#security #elk #devops
{kind=link}
Наконец-то собрался с силами и обновил статью по настройке ELK Stack. Он так часто обновляется, что материал устаревает практически полностью в течение года.
Мне регулярно приходится его настраивать, так что не только обновил статью, но и поднял свой deb репозиторий для всех пакетов, что используются в инструкции. Теперь не придётся через VPN или прокси копировать вручную пакеты. В Debian 11 можно автоматически устанавливать через менеджер пакетов, а для всех остальных deb систем можно зайти по адресу репо или просто по IP (тупит DNS, не было времени разобраться) и скачать вручную пакет.
Полный ELK Stack довольно навороченная и сложная система. Так что сделать пошаговую настройку не так просто. Надеюсь нигде сильно не ошибался. Написал по горячим следам после очередной настройки. Конфиги брал с работающих серверов, но разных, так как одновременно и Linux, и Windows логи встречаются редко. Некоторые некритичные картинки остались от 7-й версии. Отличия не сильные, не стал переделывать.
⇨ Установка и настройка ELK Stack
#elk #devops
Мне регулярно приходится его настраивать, так что не только обновил статью, но и поднял свой deb репозиторий для всех пакетов, что используются в инструкции. Теперь не придётся через VPN или прокси копировать вручную пакеты. В Debian 11 можно автоматически устанавливать через менеджер пакетов, а для всех остальных deb систем можно зайти по адресу репо или просто по IP (тупит DNS, не было времени разобраться) и скачать вручную пакет.
Полный ELK Stack довольно навороченная и сложная система. Так что сделать пошаговую настройку не так просто. Надеюсь нигде сильно не ошибался. Написал по горячим следам после очередной настройки. Конфиги брал с работающих серверов, но разных, так как одновременно и Linux, и Windows логи встречаются редко. Некоторые некритичные картинки остались от 7-й версии. Отличия не сильные, не стал переделывать.
⇨ Установка и настройка ELK Stack
#elk #devops
Server Admin
Установка и настройка Elasticsearch, Logstash, Kibana (ELK Stack)
Подробное описание установки ELK Stack - Elasticsearch, Logstash, Kibana для централизованного сбора логов.
Расскажу своими словами про особенности и удобство сбора логов в ELK Stack или любое подобное хранилище на его основе. Продукт сложный и многокомпонентный. Те, кто с ним не работали, зачастую не понимают, что это такое и зачем оно нужно. Ведь логи можно хранить и просматривать много где. Зачем этот тяжелющий монстр? Я поясню своими словами на простом примере.
Вои пример фрагмента лога web сервера стандартного формата:
180.163.220.100 - travvels.ru [05/Sep/2021:14:45:52 +0300] "GET /assets/galleries/26/1.png HTTP/1.1" 304 0 "https://travvels.ru/ru/glavnaya/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"
Он состоит из отдельных частей, каждая из которых содержит какую-то информацию - ip адрес, дата, тип запроса, url, метод, код ответа, количество переданных байт, реферер, user-agent. Это стандартный формат лога Nginx или Apache.
ELK Stack не просто собирает эти логи и хранит у себя. Он распознаёт каждое значение из каждой строки и индексирует эти данные, чтобы потом можно было быстро с ними работать. Например, подсчитать количество 500-х кодов ответов, или количество запросов к какому-то урлу. Для типовых форматов данных есть готовые фильтры парсинга. Но нет проблем написать и свои, хоть и не так просто, но посильно. Я в своё время разобрался, когда надо было. В частности, Logstash использует фильтры GROK.
Чтобы было удобно работать с логами, я обычно делаю следующее. Собираю дашборд, куда вывожу в виджетах информацию о топе урлов, к которым идут запросы, о топе ip адресов, с которых идут запросы, о топе user-agent, графики кодов ответов и т.д. В общем, всё, что может быть интересно.
Когда нужно разобраться с каким-нибудь инцидентом, этот дашборд очень выручает. Если честно, я так привык к ним, что даже не представляю, как обслуживать веб сервер без подобного сбора и анализа логов. Так вот, я открываю этот дашборд и вижу, к примеру, что к какому-то урлу идёт вал запросов. В поиске тут же в дашборде делаю группировку данных на основе этого урла и дашборд со всеми виджетами перестраивается, выводя информацию только по этому урлу.
В итоге я вижу все IP адреса, которые к нему обращались, все коды ответов, все user-agents и т.д. Например, я могу увидеть, что все запросы к этому урлу идут с одного и того же IP адреса и это какой-то бот. Можно его забанить. Также, например, можно заметить, что резко выросло количество 404 ошибок. Делаю группировку по ним и вижу, что все 404 коды ответов выдаются какому-то боту с отличительным user-agent, который занимается перебором. Баним его по user-agent.
Надеюсь, понятно объяснил принцип. Видя какую-то аномалию, мы без проблем можем детально её рассмотреть со всеми подробностями. Ещё актуальный пример из практики. В веб сервере сайта на Bitrix можно добавить ID сессии пользователя в лог веб сервера. Затем подредактировать стандартный фильтр парсинга Logstash, чтобы он индексировал и это поле. После этого вы сможете делать группировку логов по этой сессии. Очень удобно, когда надо просмотреть все действия пользователя. Эту настройку я описывал в отдельной статье.
Подводя итог скажу, что ELK Stack очень полезный инструмент даже в небольшой инфраструктуре. Не обязательно собирать кластер о хранить тонны логов. Даже логи с одного сайта очень помогут в его поддержке. Админам инфраструктуры на Windows тоже советую обратить внимание на ELK. С его помощью удобно разбирать журналы Windows, которые он тоже умеет парсить и индексировать. По винде я делал отдельную статью, где описывал принцип и показывал примеры.
Если захотите изучить ELK Stack и попробовать в работе, воспользуйтесь моей статьёй. С её помощью простым копипастом можно поднять весь стек и попробовать с ним поработать. Ничего супер сложного в этом нет. Когда я задался целью, то сам с нуля всё изучил, не ходил ни на какие курсы и никто мне не помогал. Просто сел и разобрался понемногу. Было тяжело, конечно, особенно с фильтрами, но дорогу осилит идущий.
#elk
Вои пример фрагмента лога web сервера стандартного формата:
180.163.220.100 - travvels.ru [05/Sep/2021:14:45:52 +0300] "GET /assets/galleries/26/1.png HTTP/1.1" 304 0 "https://travvels.ru/ru/glavnaya/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"
Он состоит из отдельных частей, каждая из которых содержит какую-то информацию - ip адрес, дата, тип запроса, url, метод, код ответа, количество переданных байт, реферер, user-agent. Это стандартный формат лога Nginx или Apache.
ELK Stack не просто собирает эти логи и хранит у себя. Он распознаёт каждое значение из каждой строки и индексирует эти данные, чтобы потом можно было быстро с ними работать. Например, подсчитать количество 500-х кодов ответов, или количество запросов к какому-то урлу. Для типовых форматов данных есть готовые фильтры парсинга. Но нет проблем написать и свои, хоть и не так просто, но посильно. Я в своё время разобрался, когда надо было. В частности, Logstash использует фильтры GROK.
Чтобы было удобно работать с логами, я обычно делаю следующее. Собираю дашборд, куда вывожу в виджетах информацию о топе урлов, к которым идут запросы, о топе ip адресов, с которых идут запросы, о топе user-agent, графики кодов ответов и т.д. В общем, всё, что может быть интересно.
Когда нужно разобраться с каким-нибудь инцидентом, этот дашборд очень выручает. Если честно, я так привык к ним, что даже не представляю, как обслуживать веб сервер без подобного сбора и анализа логов. Так вот, я открываю этот дашборд и вижу, к примеру, что к какому-то урлу идёт вал запросов. В поиске тут же в дашборде делаю группировку данных на основе этого урла и дашборд со всеми виджетами перестраивается, выводя информацию только по этому урлу.
В итоге я вижу все IP адреса, которые к нему обращались, все коды ответов, все user-agents и т.д. Например, я могу увидеть, что все запросы к этому урлу идут с одного и того же IP адреса и это какой-то бот. Можно его забанить. Также, например, можно заметить, что резко выросло количество 404 ошибок. Делаю группировку по ним и вижу, что все 404 коды ответов выдаются какому-то боту с отличительным user-agent, который занимается перебором. Баним его по user-agent.
Надеюсь, понятно объяснил принцип. Видя какую-то аномалию, мы без проблем можем детально её рассмотреть со всеми подробностями. Ещё актуальный пример из практики. В веб сервере сайта на Bitrix можно добавить ID сессии пользователя в лог веб сервера. Затем подредактировать стандартный фильтр парсинга Logstash, чтобы он индексировал и это поле. После этого вы сможете делать группировку логов по этой сессии. Очень удобно, когда надо просмотреть все действия пользователя. Эту настройку я описывал в отдельной статье.
Подводя итог скажу, что ELK Stack очень полезный инструмент даже в небольшой инфраструктуре. Не обязательно собирать кластер о хранить тонны логов. Даже логи с одного сайта очень помогут в его поддержке. Админам инфраструктуры на Windows тоже советую обратить внимание на ELK. С его помощью удобно разбирать журналы Windows, которые он тоже умеет парсить и индексировать. По винде я делал отдельную статью, где описывал принцип и показывал примеры.
Если захотите изучить ELK Stack и попробовать в работе, воспользуйтесь моей статьёй. С её помощью простым копипастом можно поднять весь стек и попробовать с ним поработать. Ничего супер сложного в этом нет. Когда я задался целью, то сам с нуля всё изучил, не ходил ни на какие курсы и никто мне не помогал. Просто сел и разобрался понемногу. Было тяжело, конечно, особенно с фильтрами, но дорогу осилит идущий.
#elk
{kind=link}