
Технический пост, который уже давно нужно было сделать, но всё руки не доходили. На канале много содержательных заметок по различным темам. Иногда сам через поиск ищу то, о чём писал. Ниже набор наиболее популярных тэгов по которым можно найти что-то полезное (и не очень).
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
Когда я только начинал администрировать Linux сервера, первые несколько лет регулярно использовал панель управления Webmin для одной единственной цели - просмотр всевозможных логов. Мне нравился там модуль для этого дела. С его помощью можно было удобно грепать логи, что-то искать, копировать и т.д.
Особенно это было актуально для почтовых серверов на базе postfix. Там постоянно нужно было лазить в лог и что-то проверять: почему письмо не дошло, подключался ли данный клиент, какой был ответ сервера и т.д. Мне было удобно в Webmin задать ID письма или IP сервера и посмотреть всю информацию о них в логах. Обычно там все сильно разбросано по лог файлу, потому что куча повторяющихся и новых событий происходят, а Webmin помогал упорядочить.
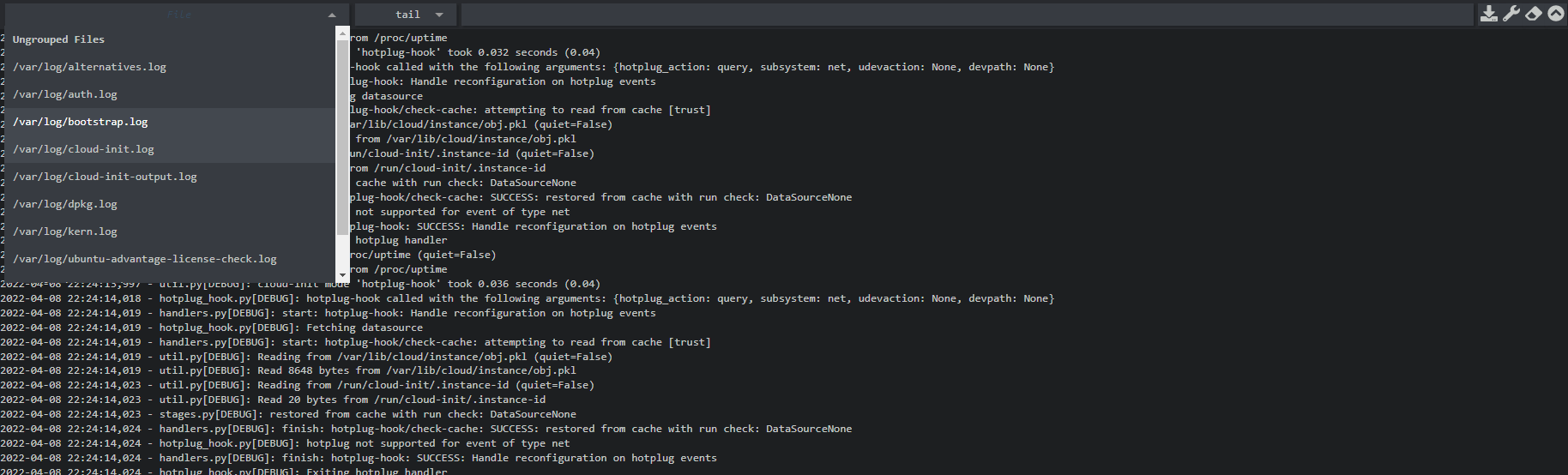
Со временем отказался от Webmin, так как ставить такого монстра только для логов было излишним. Недавно наткнулся на удобную утилиту, которая позволяет делать примерно то же самое - удобно просматривать логи через браузер. Речь идёт про tailon (https://github.com/gvalkov/tailon).
Это маленькая утилита, состоящая из одного бинарника, который можно скачать из репозитория и запустить. Она состоит из веб сервера, который открывает заданные логи, чтобы вы могли посмотреть их через браузер. Поддерживается не только просмотр, но и обработка прямо в браузере стандартными утилитами grep, awk, sed. Сделано всё простенько, но функционально.
Можно сразу все логи директории отправить в браузер, например так:
И выбирать, какой из них открыть на просмотр в веб интерфейсе. Сервер по умолчанию поднимается на порту 8080.
Если вы новичок в Linux и работать в консоли ещё не привыкли, то попробуйте, может понравится инструмент. Да и просто на время отладки может пригодиться, или анализа логов веб сервера в режиме реального времени. В общем, полезная штука.
#linux #logs
Особенно это было актуально для почтовых серверов на базе postfix. Там постоянно нужно было лазить в лог и что-то проверять: почему письмо не дошло, подключался ли данный клиент, какой был ответ сервера и т.д. Мне было удобно в Webmin задать ID письма или IP сервера и посмотреть всю информацию о них в логах. Обычно там все сильно разбросано по лог файлу, потому что куча повторяющихся и новых событий происходят, а Webmin помогал упорядочить.
Со временем отказался от Webmin, так как ставить такого монстра только для логов было излишним. Недавно наткнулся на удобную утилиту, которая позволяет делать примерно то же самое - удобно просматривать логи через браузер. Речь идёт про tailon (https://github.com/gvalkov/tailon).
Это маленькая утилита, состоящая из одного бинарника, который можно скачать из репозитория и запустить. Она состоит из веб сервера, который открывает заданные логи, чтобы вы могли посмотреть их через браузер. Поддерживается не только просмотр, но и обработка прямо в браузере стандартными утилитами grep, awk, sed. Сделано всё простенько, но функционально.
Можно сразу все логи директории отправить в браузер, например так:
# ./tailon /var/log/*.logИ выбирать, какой из них открыть на просмотр в веб интерфейсе. Сервер по умолчанию поднимается на порту 8080.
Если вы новичок в Linux и работать в консоли ещё не привыкли, то попробуйте, может понравится инструмент. Да и просто на время отладки может пригодиться, или анализа логов веб сервера в режиме реального времени. В общем, полезная штука.
#linux #logs
{kind=link}
Продолжаю тему просмотра логов. Нашёл ещё один полезный и популярный проект для просмотра логов в браузере в режиме реального времени - log.io. Написан на Node.js с использованием Socket.io. Ставится через nmp в одну команду. Конфиги хранит в формате json.
Архитектура у приложения клиент серверная. Отдельно ставится сервер приёма сообщений и http сервер. Отдельно ставятся клиенты для отправки логов. Log.io может работать в рамках одного сервера.
Установка и настройка очень простая. Описана целиком на главной сайта с примером конфигурации. Не буду сюда это дублировать.
Встроенный веб сервер log.io сам поддерживает http basic auth, так что можно ограничить доступ без применения проксирующего сервера. Как я уже сказал, проект известный, поэтому в сети найдёте много руководств с примерами по установке и настройке. Лично мне хватило информации из документации на guthub.
Обращаю внимание, что сам домен log.io, как я понял, к описываемому продукту не имеет отношения и редиректит на сайт какой-то другой компании.
Сайт - http://logio.org/
Исходники - https://github.com/NarrativeScience/log.io
#logs
Архитектура у приложения клиент серверная. Отдельно ставится сервер приёма сообщений и http сервер. Отдельно ставятся клиенты для отправки логов. Log.io может работать в рамках одного сервера.
Установка и настройка очень простая. Описана целиком на главной сайта с примером конфигурации. Не буду сюда это дублировать.
Встроенный веб сервер log.io сам поддерживает http basic auth, так что можно ограничить доступ без применения проксирующего сервера. Как я уже сказал, проект известный, поэтому в сети найдёте много руководств с примерами по установке и настройке. Лично мне хватило информации из документации на guthub.
Обращаю внимание, что сам домен log.io, как я понял, к описываемому продукту не имеет отношения и редиректит на сайт какой-то другой компании.
Сайт - http://logio.org/
Исходники - https://github.com/NarrativeScience/log.io
#logs
{kind=link}
Поднимал на днях тему просмотра логов в Linux. В комментариях неоднократно получил рекомендацию на утилиту lnav. Попробовал её и оценил. Классный функционал. Расскажу подробнее.
lnav есть в базовых репах Debian и RHEL. В других дистрибутивах не проверял. Ставится просто:
Lnav понимает ряд наиболее популярных форматов логов, таких как access логи веб сервера, syslog, dpkg, strace и некоторые другие. Она их автоматически парсит, подсвечивает, позволяет быстро делать какие-то выборки. Например, посмотреть все ошибки в syslog, показать по ним статистику, вывести информацию по какой-то службе и т.д.
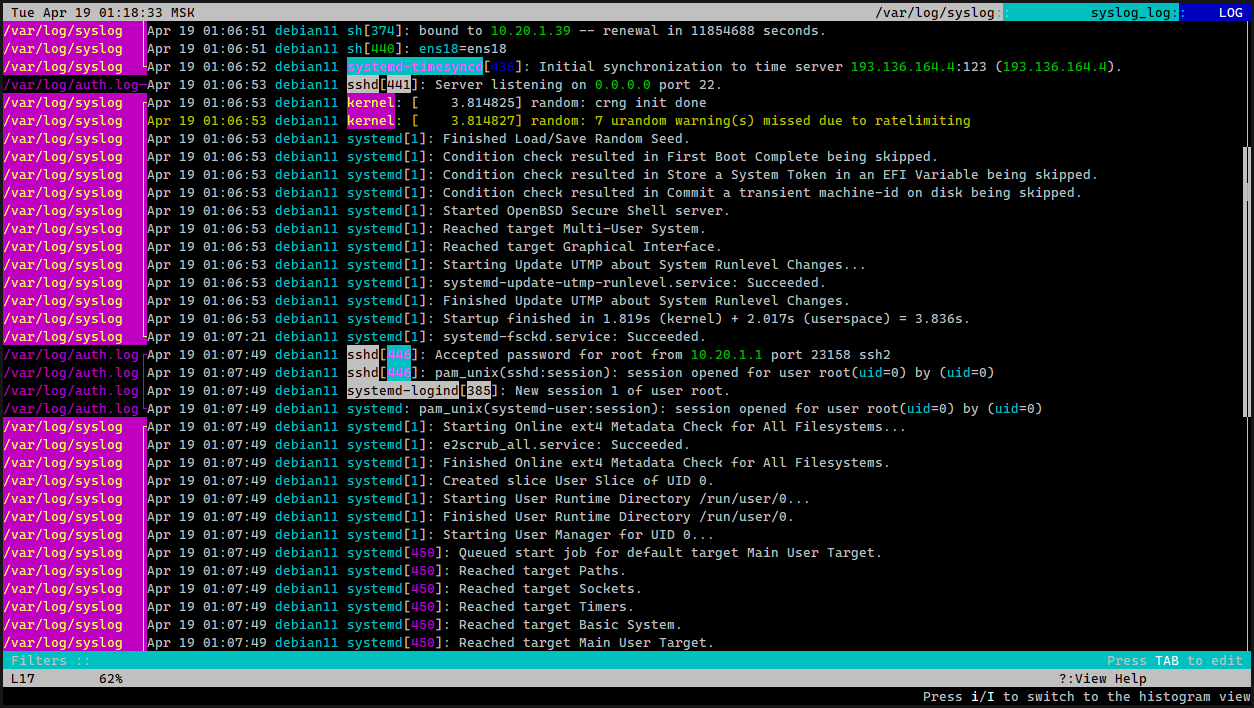
Основное, что очень понравилось в Lnav - возможность открыть сразу несколько логов и увидеть их наложение на одном экране. Это очень удобно в некоторых ситуациях, когда надо что-то расследовать. Нигде раньше не встречал подобного функционала. Когда нужно было сопоставить логи, открывал их либо в соседних вкладках на одном экране, либо как-то ещё. С Lnav просто делаем вот так и смотрим оба лога:
Если утилита распознала формат, то выстроит строки обоих логов в порядке времени событий. На картинке ниже пример.
Помимо прочего Lnav умеет сазу открывать архивные логи, отображать содержимое в режиме реального времени, применять сложные фильтры для отображения нужных строк.
Осталось хорошее впечатление классической консольной программы в Linux с полезным и уникальным функционалом. Рекомендую 👍
#linux #logs
lnav есть в базовых репах Debian и RHEL. В других дистрибутивах не проверял. Ставится просто:
# apt install lnav# dnf install lnavLnav понимает ряд наиболее популярных форматов логов, таких как access логи веб сервера, syslog, dpkg, strace и некоторые другие. Она их автоматически парсит, подсвечивает, позволяет быстро делать какие-то выборки. Например, посмотреть все ошибки в syslog, показать по ним статистику, вывести информацию по какой-то службе и т.д.
Основное, что очень понравилось в Lnav - возможность открыть сразу несколько логов и увидеть их наложение на одном экране. Это очень удобно в некоторых ситуациях, когда надо что-то расследовать. Нигде раньше не встречал подобного функционала. Когда нужно было сопоставить логи, открывал их либо в соседних вкладках на одном экране, либо как-то ещё. С Lnav просто делаем вот так и смотрим оба лога:
# lnav /var/log/auth.log /var/log/syslogЕсли утилита распознала формат, то выстроит строки обоих логов в порядке времени событий. На картинке ниже пример.
Помимо прочего Lnav умеет сазу открывать архивные логи, отображать содержимое в режиме реального времени, применять сложные фильтры для отображения нужных строк.
Осталось хорошее впечатление классической консольной программы в Linux с полезным и уникальным функционалом. Рекомендую 👍
#linux #logs
{kind=link}
Посмотрел интересное выступление с HighLoad++ 2021, которое весной выложили в открытый доступ - Есть ли жизнь без ELK? Как снизить стоимость Log Management:
https://www.youtube.com/watch?v=BOVuwr43ZTE
Автор детально разбирает тему хранения логов с помощью современных инструментов. Прикидывает нагрузку, стоимость решения. Перебирает различные варианты и в итоге рассказывает, к какому решению пришли сами.
Они решили для экономии денег и ресурсов собрать систему сбора логов самостоятельно на базе сборщика логов Vector (по их тестам он оказался быстрее FluentD), парсинг делают им же, обработка с помощью Kafka, данные хранят в ClickHouse, визуализируют с помощью Grafana.
Если вам интересная данная тема, то рекомендую. Я, например, про Vector вообще впервые услышал. Всегда думал, что оптимальный парсер и доставщик логов это FluentD. Обычно его рекомендуют вместо тормозного Filebeat.
#видео #elk #logs
https://www.youtube.com/watch?v=BOVuwr43ZTE
Автор детально разбирает тему хранения логов с помощью современных инструментов. Прикидывает нагрузку, стоимость решения. Перебирает различные варианты и в итоге рассказывает, к какому решению пришли сами.
Они решили для экономии денег и ресурсов собрать систему сбора логов самостоятельно на базе сборщика логов Vector (по их тестам он оказался быстрее FluentD), парсинг делают им же, обработка с помощью Kafka, данные хранят в ClickHouse, визуализируют с помощью Grafana.
Если вам интересная данная тема, то рекомендую. Я, например, про Vector вообще впервые услышал. Всегда думал, что оптимальный парсер и доставщик логов это FluentD. Обычно его рекомендуют вместо тормозного Filebeat.
#видео #elk #logs
YouTube
Есть ли жизнь без ELK? Как снизить стоимость Log Management / Денис Безкоровайный
Приглашаем на конференцию Saint HighLoad++ 2024, которая пройдет 24 и 25 июня в Санкт-Петербурге!
Программа, подробности и билеты по ссылке: https://vk.cc/cuyIqx
--------
--------
Профессиональная конференция разработчиков высоконагруженных систем
20 и…
Программа, подробности и билеты по ссылке: https://vk.cc/cuyIqx
--------
--------
Профессиональная конференция разработчиков высоконагруженных систем
20 и…
Хочу вас познакомить с отличной современной программой по передаче текстовых данных из одних источников в другие. Речь пойдёт про Vector и проект vector.dev. Это пример простой и качественной программы, которая решает одну задачу - взять данные в одном месте, преобразовать их или оставить в неизменном виде и передать в другое место.
Мне она понравилась в первую очередь своим сайтом с подробной информацией обо всех возможностях и настройках. Буквально за несколько минут разобрался с настройками и запустил в работу.
С помощью Vector можно взять данные из источников: File, Docker logs, JournalD, Kafka, Kubernetes logs, Logstash и ещё 40 различных программ и положить их в один из 50-ти типов поддерживаемых приёмников, среди которых: Console, Elasticsearch, File, HTTP, Loki, Prometheus и т.д.
По пути Vector может делать преобразования. Для каждого источника, преобразования и приёмника есть пример конфигурации, как это можно реализовать. В итоге по частям настраивается полный маршрут.
Вот для примера конфиг для сбора логов JournalD и записи их в файл. Я прямо взял из документации конфиг для JournalD, конфиг для File и совместил их.
Ставим Vector (есть и пакеты, и docker образ):
Рисуем конфиг:
Всё просто и понятно - источник, приёмник, преобразование. Можно текст автоматом в json сконвертировать. Я оставил обычный формат.
Создаём дефолтную директорию для Vector и запускаем его:
В файле /tmp/ntp-%Y-%m-%d.log будет текстовый лог службы ntp, взятый из journald. По такому же принципу работают и другие направления.
Программа очень простая и удобная. По сути она заменяет более именитых и старых товарищей - fluentd, filebeat и т.д. Частично и logstash. Я принял решение использовать её для сбора логов и отправки в ELK.
⇨ Сайт / Исходники / Документация
#logs #devops
Мне она понравилась в первую очередь своим сайтом с подробной информацией обо всех возможностях и настройках. Буквально за несколько минут разобрался с настройками и запустил в работу.
С помощью Vector можно взять данные из источников: File, Docker logs, JournalD, Kafka, Kubernetes logs, Logstash и ещё 40 различных программ и положить их в один из 50-ти типов поддерживаемых приёмников, среди которых: Console, Elasticsearch, File, HTTP, Loki, Prometheus и т.д.
По пути Vector может делать преобразования. Для каждого источника, преобразования и приёмника есть пример конфигурации, как это можно реализовать. В итоге по частям настраивается полный маршрут.
Вот для примера конфиг для сбора логов JournalD и записи их в файл. Я прямо взял из документации конфиг для JournalD, конфиг для File и совместил их.
Ставим Vector (есть и пакеты, и docker образ):
# curl --proto '=https' --tlsv1.2 -sSf https://sh.vector.dev \| bashРисуем конфиг:
[sources.journal_ntp]type = "journald"current_boot_only = trueinclude_units = [ "ntp" ][sinks.log_ntp]type = "file"inputs = [ "journal_ntp" ]path = "/tmp/ntp-%Y-%m-%d.log"[sinks.log_ntp.encoding]codec = "text"Всё просто и понятно - источник, приёмник, преобразование. Можно текст автоматом в json сконвертировать. Я оставил обычный формат.
Создаём дефолтную директорию для Vector и запускаем его:
# mkdir /var/lib/vector/# vector --config /root/.vector/config/vector.tomlВ файле /tmp/ntp-%Y-%m-%d.log будет текстовый лог службы ntp, взятый из journald. По такому же принципу работают и другие направления.
Программа очень простая и удобная. По сути она заменяет более именитых и старых товарищей - fluentd, filebeat и т.д. Частично и logstash. Я принял решение использовать её для сбора логов и отправки в ELK.
⇨ Сайт / Исходники / Документация
#logs #devops
{kind=link}
Некоторое время назад я рассказывал про программу Vector, с помощью которой удобно управлять потоками данных. Сейчас покажу, как с её помощью отправить логи Nginx в сервис axiom.co, где бесплатно можно хранить и обрабатывать до 500 ГБ в месяц. Это отличная возможность быстро собрать дашборд для анализа логов веб сервера.
Сначала зарегистрируйтесь в axiom.co. Там не нужны ни кредитки, ни какая-то ещё информация, кроме email. Сразу получите аккаунт с очень солидными бесплатными лимитами. Там же создайте новый Dataset и к нему API ключ. Это условный аналог облака Elastic на минималках. Я собственно, про него и хотел рассказать, но решил сразу на конкретном примере. К тому же у вектора не очень очевидная документация, особенно в плане преобразований. В своё время долго разбирался, как там парсинг json и grok фильтры правильно настраивать и описывать в конфигах.
Установите Vector любым удобным способом из документации. Настройте логи Nginx в формате json. Это можно не делать, но тогда понадобится grok фильтр для обработки access лога, что дольше и сложнее, чем использование сразу json. Рисуем конфиг для Vector.
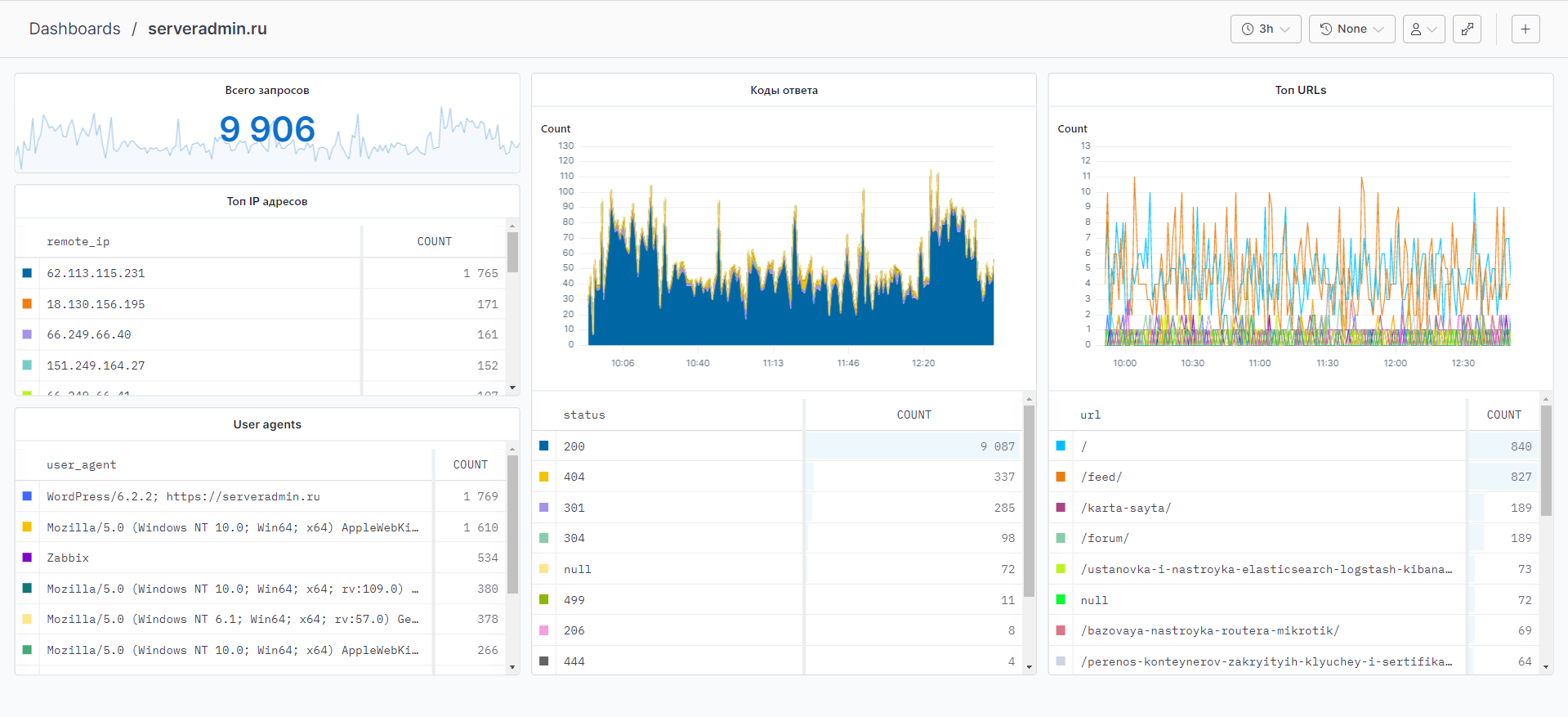
У Vector есть готовая интеграция с axiom, что я и указал в sinks. Теперь запускайте Vector и идите в axiom.co. На вкладке Streams увидите свои логи в режиме реального времени.
Теперь можно зайти в Dashboards и собрать любой дашборд на основе данных лога Nginx. Чем более насыщенный лог, что настраивается в конфиге Nginx, тем больше данных для визуализации. Я для тестового сервера собрал дашборд буквально за 10 минут. Смотрите во вложении к заметке.
Такая вот заметка-инструкция получилась. Vector я уже рекомендовал, теперь советую посмотреть на описанный сервис. Меня никто не просил его рекламировать. Он просто удобный и есть функциональный бесплатный тарифный план. В него включены также 3 оповещения. Например, можно настроить, что если у вас в минуту будет больше 10 500-х ошибок сервера, прилетит оповещение. Или что-то ещё. Там большие возможности для насыщения, аггегации и других манипуляций с данными. Разобраться проще, чем в ELK или OpenSearch.
Для любителей grok, как я, покажу пример transforms в Vector своего формата логов Nginx. Вот пример формата лога, который я обычно использую, где есть всё, что мне надо:
log_format full '$remote_addr - $host [$time_local] "$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';
Вот grok фильтр в Vector:
[transforms.nginx_access_logs_parsed]
type = "remap"
inputs = ["nginx_access_logs"]
source = '''
. = parse_grok!(.message, "%{IPORHOST:remote_ip} - %{DATA:virt_host} \\[%{HTTPDATE:access_time}\\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" request_length=%{INT:request_length} status=%{INT:status} bytes_sent=%{INT:bytes_sent} body_bytes_sent=%{NUMBER:body_bytes_sent} referer=%{DATA:referer} user_agent=\"%{DATA:user_agent}\" upstream_status=%{DATA:upstream_status} request_time=%{NUMBER:request_time} upstream_response_time=%{DATA:upstream_response_time} upstream_connect_time=%{DATA:upstream_connect_time} upstream_header_time=%{DATA:upstream_header_time}")
'''
#nginx #logs #devops
Сначала зарегистрируйтесь в axiom.co. Там не нужны ни кредитки, ни какая-то ещё информация, кроме email. Сразу получите аккаунт с очень солидными бесплатными лимитами. Там же создайте новый Dataset и к нему API ключ. Это условный аналог облака Elastic на минималках. Я собственно, про него и хотел рассказать, но решил сразу на конкретном примере. К тому же у вектора не очень очевидная документация, особенно в плане преобразований. В своё время долго разбирался, как там парсинг json и grok фильтры правильно настраивать и описывать в конфигах.
Установите Vector любым удобным способом из документации. Настройте логи Nginx в формате json. Это можно не делать, но тогда понадобится grok фильтр для обработки access лога, что дольше и сложнее, чем использование сразу json. Рисуем конфиг для Vector.
[sources.nginx_access_logs]type = "file"include = ["/var/log/nginx/access.log"][transforms.nginx_access_logs_parsed]type = "remap"inputs = ["nginx_access_logs"]source = '''. = parse_json!(.message)'''[sinks.axiom]inputs = ["nginx_access_logs_parsed"]type = "axiom"token = "xaat-36c1ff8f-447f-454e-99fd-abe804aeebf3"dataset = "webserver"У Vector есть готовая интеграция с axiom, что я и указал в sinks. Теперь запускайте Vector и идите в axiom.co. На вкладке Streams увидите свои логи в режиме реального времени.
Теперь можно зайти в Dashboards и собрать любой дашборд на основе данных лога Nginx. Чем более насыщенный лог, что настраивается в конфиге Nginx, тем больше данных для визуализации. Я для тестового сервера собрал дашборд буквально за 10 минут. Смотрите во вложении к заметке.
Такая вот заметка-инструкция получилась. Vector я уже рекомендовал, теперь советую посмотреть на описанный сервис. Меня никто не просил его рекламировать. Он просто удобный и есть функциональный бесплатный тарифный план. В него включены также 3 оповещения. Например, можно настроить, что если у вас в минуту будет больше 10 500-х ошибок сервера, прилетит оповещение. Или что-то ещё. Там большие возможности для насыщения, аггегации и других манипуляций с данными. Разобраться проще, чем в ELK или OpenSearch.
Для любителей grok, как я, покажу пример transforms в Vector своего формата логов Nginx. Вот пример формата лога, который я обычно использую, где есть всё, что мне надо:
log_format full '$remote_addr - $host [$time_local] "$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';
Вот grok фильтр в Vector:
[transforms.nginx_access_logs_parsed]
type = "remap"
inputs = ["nginx_access_logs"]
source = '''
. = parse_grok!(.message, "%{IPORHOST:remote_ip} - %{DATA:virt_host} \\[%{HTTPDATE:access_time}\\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" request_length=%{INT:request_length} status=%{INT:status} bytes_sent=%{INT:bytes_sent} body_bytes_sent=%{NUMBER:body_bytes_sent} referer=%{DATA:referer} user_agent=\"%{DATA:user_agent}\" upstream_status=%{DATA:upstream_status} request_time=%{NUMBER:request_time} upstream_response_time=%{DATA:upstream_response_time} upstream_connect_time=%{DATA:upstream_connect_time} upstream_header_time=%{DATA:upstream_header_time}")
'''
#nginx #logs #devops
{kind=link}
В логировании современных систем и программ в основном используют два подхода к распределению логов и событий по важности. Один из них поддерживает 8 уровней важности, или значимости. Не знаю, как правильно перевести severity levels, передав их смысл. Эти уровни пришли из формата логов syslog, появившемся в 80-х годах. Вот эти уровни:
▪ Emergency
▪ Alert
▪ Critical
▪ Error
▪ Warning
▪ Notice
▪ Informational
▪ Debug
Чем ниже идти по приведённому списку, тем больше информации будет в логах. Соответственно, если настраиваете систему логирования, то внимательно смотрите, какой уровень логов будете собирать.
Debug чаще всего не предназначен для долговременного хранения, а включается только во время отладки приложения. Если забудете отключить этот уровень, потом с удивлением обнаружите, что ваши логи разрослись до огромных размеров и работать с ними неудобно. Надо чистить. Постоянно информация уровня Debug обычно не нужна.
Например, такой формат логов поддерживает Nginx или Apache. В них явно можно указать, какого уровня события будут логироваться.
В современной разработке прижилась немного упрощённая и более конкретная схема важности логирования или ошибок:
▪ Fatal
▪ Error
▪ Warn
▪ Info
▪ Debug
▪ Trace
Уровни Trace и Debug нужны чаще всего для разработчиков, которые занимаются отладкой. Иногда они объединены в один уровень Debug. С остальными четырьмя уровнями приходится работать уже сопровождению или поддержке.
Уровень Info это обычно информация о работе сервиса: запуск, остановка, перезагрузка и т.д. Реакция на это не нужна. А вот на уровень Warn и выше уже может потребоваться реакция, хотя и не всегда. К примеру, если у вас почтовый сервер Postfix смотрит в интернет, то все неудачные попытки аутентификации будут уровня Warn. И реагировать на это не обязательно. А вот если у вас система в закрытом контуре и неудачных аутентификаций там быть не должно, то на подобное событие нужна реакция.
Уровни Error и Fatal самые критичные. Очевидно, что на них реакция требуется всегда. В соответствии с уровнями событий, настраиваются разные реакции. К примеру, я события типа Info в Zabbix собираю, но никаких реакций и оповещений на них не делаю. С дашбордов обычно тоже их убираю, либо делаю отдельные информационные панели. Например, со списком действий пользователей VPN, подключения и отключения. Реакция на это не нужна, но иногда бывает нужно быстро посмотреть, кто сейчас подключен. Отлично подойдёт виджет с такой информацией.
Так что рекомендую осмысленно подходить к классификации событий. Это помогает и упрощает настройку систем мониторинга и оповещений.
#linux #logs
▪ Emergency
▪ Alert
▪ Critical
▪ Error
▪ Warning
▪ Notice
▪ Informational
▪ Debug
Чем ниже идти по приведённому списку, тем больше информации будет в логах. Соответственно, если настраиваете систему логирования, то внимательно смотрите, какой уровень логов будете собирать.
Debug чаще всего не предназначен для долговременного хранения, а включается только во время отладки приложения. Если забудете отключить этот уровень, потом с удивлением обнаружите, что ваши логи разрослись до огромных размеров и работать с ними неудобно. Надо чистить. Постоянно информация уровня Debug обычно не нужна.
Например, такой формат логов поддерживает Nginx или Apache. В них явно можно указать, какого уровня события будут логироваться.
В современной разработке прижилась немного упрощённая и более конкретная схема важности логирования или ошибок:
▪ Fatal
▪ Error
▪ Warn
▪ Info
▪ Debug
▪ Trace
Уровни Trace и Debug нужны чаще всего для разработчиков, которые занимаются отладкой. Иногда они объединены в один уровень Debug. С остальными четырьмя уровнями приходится работать уже сопровождению или поддержке.
Уровень Info это обычно информация о работе сервиса: запуск, остановка, перезагрузка и т.д. Реакция на это не нужна. А вот на уровень Warn и выше уже может потребоваться реакция, хотя и не всегда. К примеру, если у вас почтовый сервер Postfix смотрит в интернет, то все неудачные попытки аутентификации будут уровня Warn. И реагировать на это не обязательно. А вот если у вас система в закрытом контуре и неудачных аутентификаций там быть не должно, то на подобное событие нужна реакция.
Уровни Error и Fatal самые критичные. Очевидно, что на них реакция требуется всегда. В соответствии с уровнями событий, настраиваются разные реакции. К примеру, я события типа Info в Zabbix собираю, но никаких реакций и оповещений на них не делаю. С дашбордов обычно тоже их убираю, либо делаю отдельные информационные панели. Например, со списком действий пользователей VPN, подключения и отключения. Реакция на это не нужна, но иногда бывает нужно быстро посмотреть, кто сейчас подключен. Отлично подойдёт виджет с такой информацией.
Так что рекомендую осмысленно подходить к классификации событий. Это помогает и упрощает настройку систем мониторинга и оповещений.
#linux #logs
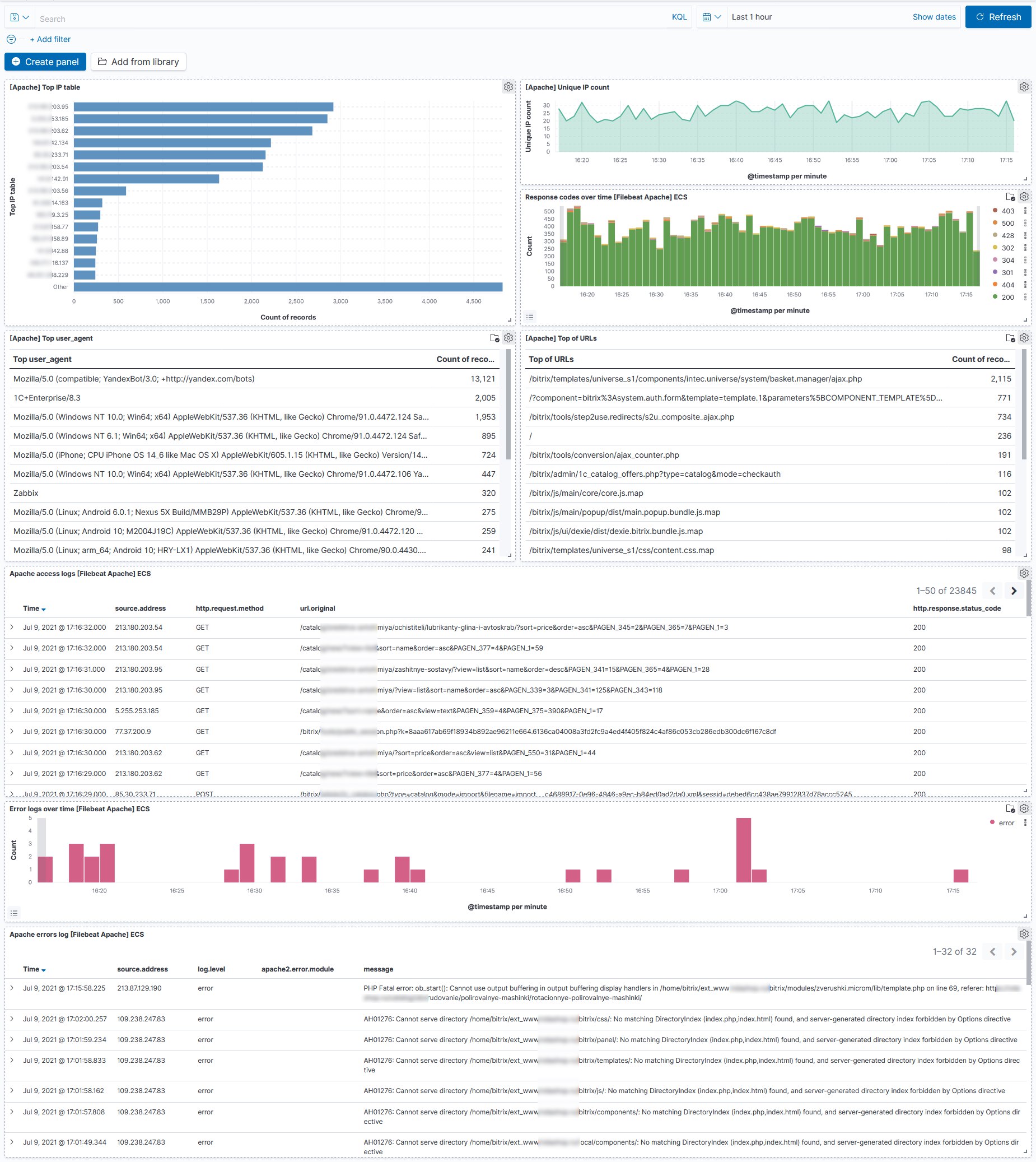
Постоянно приходится заниматься вопросами сбора и анализа логов веб серверов. Решил сделать подборку инструментов для этих целей от самых навороченных, типа ELK, до одиночных консольных утилит.
✅ Сам я чаще всего использую именно ELK, потому что привык к нему, умею настраивать, есть все заготовки и понимание, как собрать необходимые дашборды. Минусов у этого решения два:
◽ELK очень прожорливый.
◽Порог входа довольно высокий. Но тем не менее, ничего запредельного там нет. У меня знакомый с нуля по моей статье за несколько дней во всём разобрался. Немного позадавал мне вопросов, чтобы побыстрее вникнуть в суть. А дальше сам. В итоге всю базу освоил, логи собрал, дашборды сделал. В общем, было бы желание, можно и без дорогих курсов разобраться с основами. Сразу плюс к резюме и будущей зарплате.
Про #elk я много писал как здесь, так и на сайте есть разные статьи.
🟢 Альтернатива ELK - Loki от Grafana. Сразу скажу, что опыта с ним у меня нет. Так и не собрался, нигде его не внедрил. Всё как-то лениво. Использую привычные и знакомые инструменты. Плюсы у Loki по сравнению с ELK существенные, а конкретно:
◽кушает меньше ресурсов;
◽проще настроить и разобраться.
Из минусов — меньше гибкости и возможностей по сравнению с ELK, но во многих случаях всего этого и не надо. Если бы сейчас мне нужно было собрать логи веб сервера и я бы выбирал из незнакомых инструментов, начал бы с Loki.
🟢 Ещё один вариант — облачный сервис axiom.co. У него есть бесплатный тарифный план, куда можно очень быстро настроить отправку и хранение логов общим объёмом до 500 ГБ!!! Зачастую этого хватает за глаза. В него можно отправить распарсенные grok фильтром логи, как в ELK и настроить простенькие дашборды, которых во многих случаях хватит для простого анализа. Мне понравился этот сервис, использую его как дубль некоторых других систем. Денег же не просит, почему бы не использовать.
Далее упомяну системы попроще, для одиночных серверов. Даже не системы, а утилиты, которых иногда может оказаться достаточно.
🟡 Классная бесплатная утилита goaccess, которая умеет показывать статистику логов веб сервера в режиме онлайн в консоли. Либо генерировать статические html страницы для просмотра статистики в браузере. Устанавливается и настраивается очень легко и быстро. Подробности есть в моей заметке. Интересная программа, рекомендую. Пример html страницы.
🟡 Ещё один вариант консольной программы — lnav. Он заточен не только под веб сервер, но понимает и его формат в виде базовых настроек access логов.
Перечислю ещё несколько решений по теме для полноты картины, с которыми я сам не работал, но знаю про них: Graylog, OpenSearch.
❗️Если забыл что-то известное, удобное, подходящее, дополните в комментариях.
#logs #webserver #подборка
✅ Сам я чаще всего использую именно ELK, потому что привык к нему, умею настраивать, есть все заготовки и понимание, как собрать необходимые дашборды. Минусов у этого решения два:
◽ELK очень прожорливый.
◽Порог входа довольно высокий. Но тем не менее, ничего запредельного там нет. У меня знакомый с нуля по моей статье за несколько дней во всём разобрался. Немного позадавал мне вопросов, чтобы побыстрее вникнуть в суть. А дальше сам. В итоге всю базу освоил, логи собрал, дашборды сделал. В общем, было бы желание, можно и без дорогих курсов разобраться с основами. Сразу плюс к резюме и будущей зарплате.
Про #elk я много писал как здесь, так и на сайте есть разные статьи.
🟢 Альтернатива ELK - Loki от Grafana. Сразу скажу, что опыта с ним у меня нет. Так и не собрался, нигде его не внедрил. Всё как-то лениво. Использую привычные и знакомые инструменты. Плюсы у Loki по сравнению с ELK существенные, а конкретно:
◽кушает меньше ресурсов;
◽проще настроить и разобраться.
Из минусов — меньше гибкости и возможностей по сравнению с ELK, но во многих случаях всего этого и не надо. Если бы сейчас мне нужно было собрать логи веб сервера и я бы выбирал из незнакомых инструментов, начал бы с Loki.
🟢 Ещё один вариант — облачный сервис axiom.co. У него есть бесплатный тарифный план, куда можно очень быстро настроить отправку и хранение логов общим объёмом до 500 ГБ!!! Зачастую этого хватает за глаза. В него можно отправить распарсенные grok фильтром логи, как в ELK и настроить простенькие дашборды, которых во многих случаях хватит для простого анализа. Мне понравился этот сервис, использую его как дубль некоторых других систем. Денег же не просит, почему бы не использовать.
Далее упомяну системы попроще, для одиночных серверов. Даже не системы, а утилиты, которых иногда может оказаться достаточно.
🟡 Классная бесплатная утилита goaccess, которая умеет показывать статистику логов веб сервера в режиме онлайн в консоли. Либо генерировать статические html страницы для просмотра статистики в браузере. Устанавливается и настраивается очень легко и быстро. Подробности есть в моей заметке. Интересная программа, рекомендую. Пример html страницы.
🟡 Ещё один вариант консольной программы — lnav. Он заточен не только под веб сервер, но понимает и его формат в виде базовых настроек access логов.
Перечислю ещё несколько решений по теме для полноты картины, с которыми я сам не работал, но знаю про них: Graylog, OpenSearch.
❗️Если забыл что-то известное, удобное, подходящее, дополните в комментариях.
#logs #webserver #подборка
{kind=link}
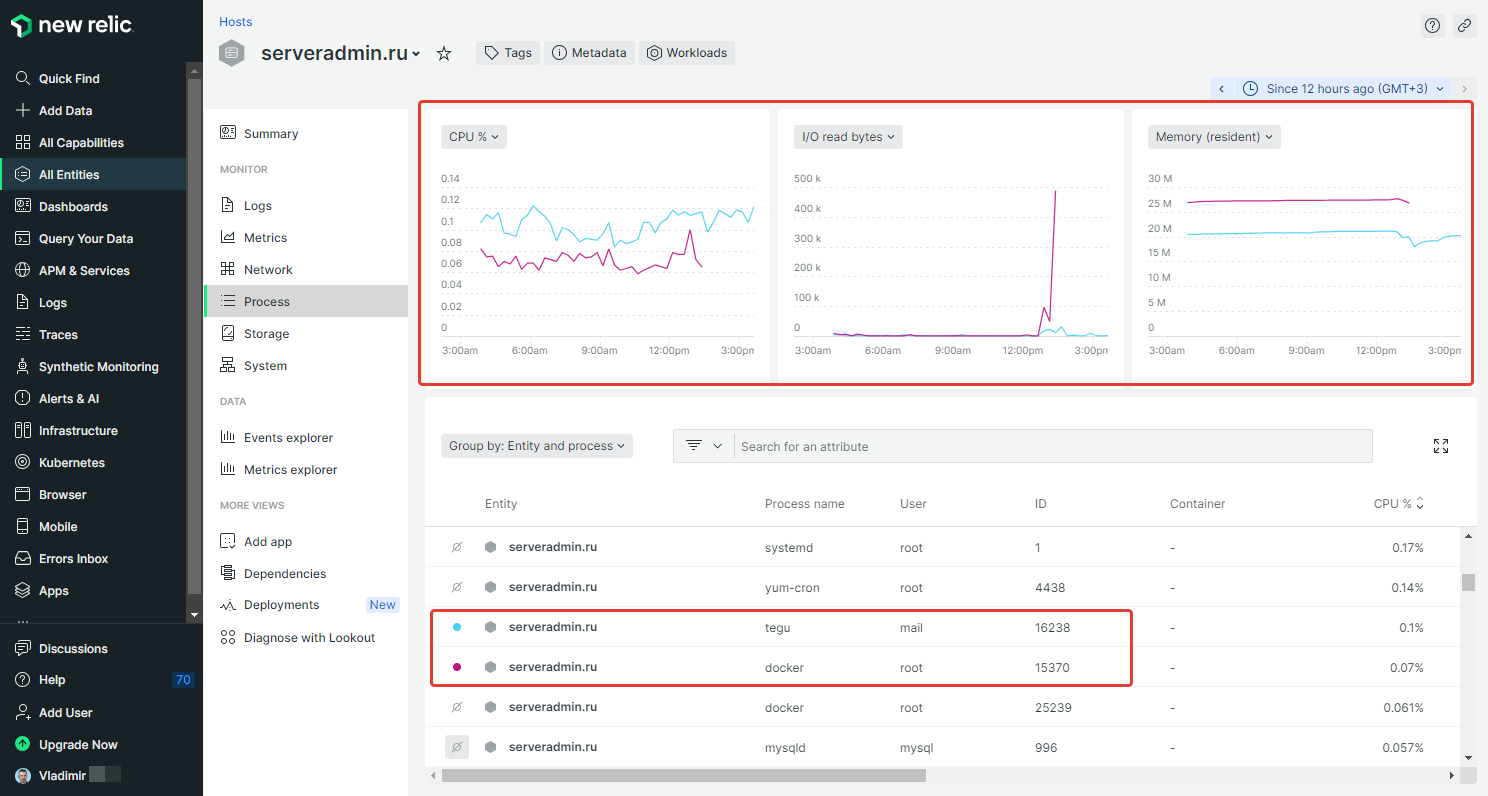
На днях поднимал вопрос сбора логов веб сервера и забыл упомянуть одну систему, которую я знаю уже очень давно. Пользуюсь лет 8. Речь пойдёт про New Relic. Это очень мощная SaaS платформа по мониторингу и аналитике веб приложений и всего, что с ними связано, в том числе серверов. Я не раз уже писал о нём, но можно и ещё раз напомнить.
Сервис постоянно развивается и меняется. Когда я начинал им пользоваться для базового мониторинга серверов, там был бесплатный тарифный план на 10 хостов. В какой-то момент они бесплатный тарифный план совсем убрали, потом вернули в другом виде.
В итоге сейчас есть бесплатный тарифный план без необходимости привязки карты. Просто регистрируетесь на email. Вам даётся 100 ГБ для хранения всех данных с любых сервисов системы. А их там море, они все разные. Это очень удобно и просто для контроля. Хотите мониторить сервера - подключайте хосты, настраивайте метрики. Хотите логи - грузите их. Используется то же доступное пространство.
Вообще говоря, это лучший мониторинг, что мне известен. Нигде я не видел такой простоты, удобства и массы возможностей. Если покупать за деньги, то стоит очень дорого. Отмечу сразу, что вообще он больше заточен под высокоуровневый мониторинг приложений, но и всё остальное в виде мониторинга серверов, сбора логов сделано удобно.
Работа с New Relic по мониторингу сервера и сбора логов выглядит следующим образом. Регистрируетесь в личном кабинете, получаете ключ. Во время установки агента используете этот ключ. Сервер автоматом привязывается к личному кабинету. Дальше за ним наблюдаете оттуда. В настройках агента можно включить сбор логов. Какие - выбираете сами. Можно systemd логи туда отправить, или какие-то отдельные файлы. К примеру, логи Nginx. Если предварительно перевести их в формат json, то потом очень легко настраивать визуализацию в личном кабинете.
Понятное дело, что у такого подхода есть свои риски. Агент newrelic имеет полный доступ к системе. А уж к бесплатному тарифному плану привязываться и подавно опасно. Используйте по месту в каких-то одиночных серверах или временно для дебага.
Мониторинг сервера позволяет посмотреть статистику по CPU, I/O, Memory в разрезе отдельных процессов. Это очень удобно и нигде больше не видел такой возможности.
#мониторинг #logs
Сервис постоянно развивается и меняется. Когда я начинал им пользоваться для базового мониторинга серверов, там был бесплатный тарифный план на 10 хостов. В какой-то момент они бесплатный тарифный план совсем убрали, потом вернули в другом виде.
В итоге сейчас есть бесплатный тарифный план без необходимости привязки карты. Просто регистрируетесь на email. Вам даётся 100 ГБ для хранения всех данных с любых сервисов системы. А их там море, они все разные. Это очень удобно и просто для контроля. Хотите мониторить сервера - подключайте хосты, настраивайте метрики. Хотите логи - грузите их. Используется то же доступное пространство.
Вообще говоря, это лучший мониторинг, что мне известен. Нигде я не видел такой простоты, удобства и массы возможностей. Если покупать за деньги, то стоит очень дорого. Отмечу сразу, что вообще он больше заточен под высокоуровневый мониторинг приложений, но и всё остальное в виде мониторинга серверов, сбора логов сделано удобно.
Работа с New Relic по мониторингу сервера и сбора логов выглядит следующим образом. Регистрируетесь в личном кабинете, получаете ключ. Во время установки агента используете этот ключ. Сервер автоматом привязывается к личному кабинету. Дальше за ним наблюдаете оттуда. В настройках агента можно включить сбор логов. Какие - выбираете сами. Можно systemd логи туда отправить, или какие-то отдельные файлы. К примеру, логи Nginx. Если предварительно перевести их в формат json, то потом очень легко настраивать визуализацию в личном кабинете.
Понятное дело, что у такого подхода есть свои риски. Агент newrelic имеет полный доступ к системе. А уж к бесплатному тарифному плану привязываться и подавно опасно. Используйте по месту в каких-то одиночных серверах или временно для дебага.
Мониторинг сервера позволяет посмотреть статистику по CPU, I/O, Memory в разрезе отдельных процессов. Это очень удобно и нигде больше не видел такой возможности.
#мониторинг #logs
{kind=link}