
Мне для автоматизации с помощью bash скриптов понадобилось получить информацию о прошлом месяце, а именно:
◽ год
◽ номер месяца
◽ первый и последний день
Набросал быстро скрипт, которым делюсь с вами. Оптимальный способ не искал, остановился, как только максимально быстро получил желаемый результат.
Тестировать можно с помощью faketime:
Рекомендую забрать в закладки. Если пишите на bash, рано или поздно пригодится.
#bash #script
◽ год
◽ номер месяца
◽ первый и последний день
Набросал быстро скрипт, которым делюсь с вами. Оптимальный способ не искал, остановился, как только максимально быстро получил желаемый результат.
#!/bin/bashLAST_MONTH=$(date "+%F" -d "$(date +'%Y-%m-01') -1 month")YEAR=$(date "+%Y" -d "$(date +'%Y-%m-01') -1 month")MONTH=$(date "+%m" -d "$(date +'%Y-%m-01') -1 month")DAY_START=$(date "+%d" -d "$(date +'%Y-%m-01') -1 month")DAY_END=$(date "+%d" -d "$LAST_MONTH +1 month -1 day")echo "Полная дата: $LAST_MONTH"echo "Год прошлого месяца: $YEAR"echo "Номер прошлого месяца: $MONTH"echo "Первый день прошлого месяца: $DAY_START"echo "Последний день прошлого месяца: $DAY_END"Тестировать можно с помощью faketime:
# faketime '2021-12-24 08:15:42' last-month.shРекомендую забрать в закладки. Если пишите на bash, рано или поздно пригодится.
#bash #script
{kind=link}
В дистрибутивах на базе Linux по умолчанию нет никакой корзины, куда бы попадали файлы после обычного удаления, как это происходит в Windows. Мне кажется, что механизм корзины очень удобен. Можно было бы по умолчанию в каком-то виде его реализовать. В некоторых десктопных системах это решается тем или иными способом. Я вам хочу предложить самый простой и очевидный подход, который я придумал просто в лоб.
Создаём скрипт trash.sh в домашней директории пользователя примерно следующего содержания:
Создайте директорию для корзины:
Добавьте в .bashrc новый алиас:
Перечитайте .bashrc:
Теперь при удалении файла:
он будет помещаться в /tmp/trash, а к имени будет добавляться маска с датой и временем:
Вы можете её указать, как вам удобно. Варианты формата date я показывал в отдельной заметке.
#linux #terminal #script #bash
Создаём скрипт trash.sh в домашней директории пользователя примерно следующего содержания:
#!/bin/shTRASH_DIR="/tmp/trash"TIMESTAMP=`date +'%d-%b-%Y-%H:%M:%S'`for i in $*; do FILE=`basename $i` mv $i ${TRASH_DIR}/${FILE}.${TIMESTAMP}doneСоздайте директорию для корзины:
# mkdir /tmp/trashДобавьте в .bashrc новый алиас:
alias rm='sh ~/trash.sh'Перечитайте .bashrc:
# source ~/.bashrcТеперь при удалении файла:
# rm filename.txtон будет помещаться в /tmp/trash, а к имени будет добавляться маска с датой и временем:
filename.txt.26-Jan-2023-17:38:01Вы можете её указать, как вам удобно. Варианты формата date я показывал в отдельной заметке.
#linux #terminal #script #bash
{kind=link}
Хочу познакомить вас с простой и крайне полезной консольной утилитой в Linux — basename. Я её регулярно использую при написании bash скриптов для различных задач. В примерах, которыми я с вами делился здесь, она тоже встречалась.
С помощью basename удобно извлечь имя файла из полного пути.
Вместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
Вот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
Очевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
Или ещё раз то же самое, только с помощью find, sed, xargs:
Скрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
С помощью basename удобно извлечь имя файла из полного пути.
# basename /var/log/auth.logauth.logВместо полного пути к файлу вы получаете только его имя. Можете сразу убрать расширение файла, если оно вам не нужно:
# basename /var/log/auth.log .logauthВот пример из реального скрипта, которым пользуюсь. Мне нужно было с помощью rsync передать с одного сервера на другой бэкапы прошлого дня. Более старые не трогать. Забирать файлы нужно было строго со стороннего сервера, а не копировать их со стороны исходного, где лежат файлы. При этом нужно было добавить еще и исключение в файлах, чтобы забрать только то, что нужно. Сделал так:
# rsync -av --files-from=<(ssh root@10.20.1.50 '/usr/bin/find /var/lib/pgpro/backup -type f -mtime -1 -exec basename {} \; | egrep -v timestamp') root@10.20.1.5:/var/lib/pgpro/backup/ /data/backup/Список нужных файлов для копирования формирую на удаленном сервере с помощью find, оставляю только имена через basename, добавляю исключение через egrep и передаю этот список на целевой сервер через параметр rysnc
--files-from. Сходу не вспомнил ещё свои примеры с basename. Обычно она как раз с find используется. Причём, не удивлюсь, если у find есть какой-то ключ, чтобы вывести список файлов без полных путей. Я привык в итоге использовать basename. Ещё пример был недавно с импровизированной корзиной в Linux, где я тоже использовал basename, чтобы все удалённые файлы класть в отдельную папку в общую кучу, без сохранения путей. Мне так показалось удобнее.
С помощью basename можно однострочником сменить расширение у всех файлов .txt на .log в директории:
# for file in *.txt; do mv -- "$file" "$(basename $file .txt).log"; doneОчевидно, что это не самый оптимальный и быстрый способ. Показал просто для примера. То же самое можно сделать с помощью rename, которая не везде есть по умолчанию, может понадобится установить отдельно.
# rename 's/.txt/.log/g' *.txtИли ещё раз то же самое, только с помощью find, sed, xargs:
# find . -type f | sed 'p;s:.txt:.log:g' | xargs -n2 mvСкрипты в Linux — бесконечный простор для творчества, особенно если писать их в bash. Там можно десяток различных способов придумать для решения одной и той же задачи. Чем больше утилит знаешь, тем больше вариантов.
#bash #script
{kind=link}
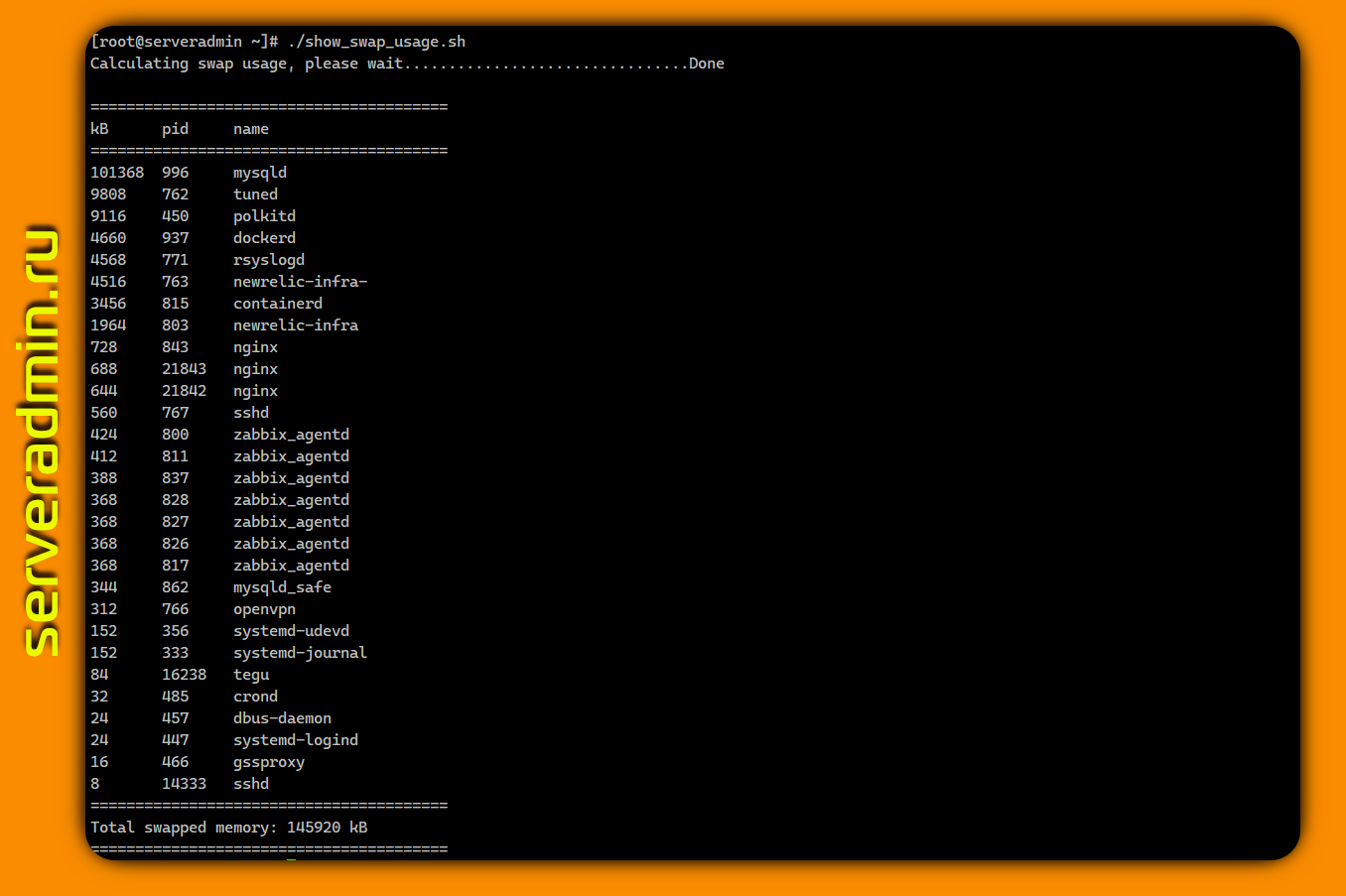
Вы знаете, как узнать, кто и насколько активно использует swap в Linux? Можно использовать для этого top, там можно вывести отдельную колонку со swap. Для этого запустите top, нажмите f и выберите колонку со swap, которой по умолчанию нет в отображении. Насколько я слышал, это не совсем корректный способ, поэтому, к примеру, в htop эту колонку вообще убрали, чтобы не вводить людей в заблуждение.
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
#linux #script #perfomance
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
/proc/$PID/smaps или /proc/$PID/status. Первая метрика будет самая точная, но там нужно будет вручную вычислить суммарный объём по отдельным кусочкам используемой памяти. Вторая метрика сразу идёт суммой. В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
#!/bin/bash SUM=0OVERALL=0for DIR in `find /proc/ -maxdepth 1 -type d -regex "^/proc/[0-9]+"`do PID=`echo $DIR | cut -d / -f 3` PROGNAME=`ps -p $PID -o comm --no-headers` for SWAP in `grep VmSwap $DIR/status 2>/dev/null | awk '{ print $2 }'` do let SUM=$SUM+$SWAP done if (( $SUM > 0 )); then echo "PID=$PID swapped $SUM KB ($PROGNAME)" fi let OVERALL=$OVERALL+$SUM SUM=0doneecho "Overall swap used: $OVERALL KB"Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
# for file in /proc/*/status ; \do awk '/VmSwap|Name/{printf $2 " " $3} END { print ""}' \$file; done | sort -k 2 -n -r | less#linux #script #perfomance
{kind=link}
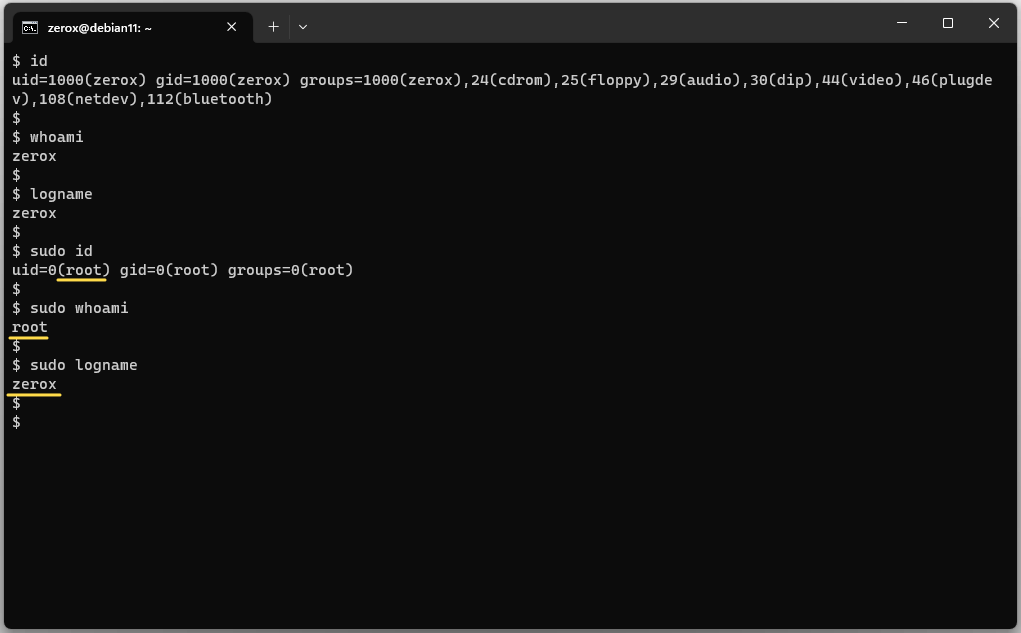
Сколько вы знаете способов увидеть, под каким пользователем работаете в ОС на базе Linux? На практике эта информация нужна не так часто, если ты работаешь в консоли. Обычно и так знаешь, под каким пользователем подключаешься. Также его видно в строке ввода терминала в bash. Исключения бывают, когда приходится работать под отдельным пользователем для настройки какого-то софта. Например, postgresql. Удобнее зайти под пользователем postgres и работать в его окружении.
Традиционные способы через утилиты:
К примеру, если запустить whoami и id под sudo, вы увидите пользователя root, а в logname — пользователя, под которым вы запускаете sudo. Это может быть полезно, если выполняете какой-то скрипт под sudo, и вам нужно сделать проверку пользователя, который его запускает. Например, разрешить запуск скрипта только если он запущен конкретным пользователем (script_allow_user).
Отдельно стоит упомянуть утилиту из состава systemd —
#bash #script
Традиционные способы через утилиты:
whoami, id , logname, w и т. д. Можно посмотреть через переменные окружения: echo $LOGNAME и echo $USER. Все эти способы вроде бы похожи друг на друга, но на самом деле есть некоторые принципиальные отличия. К примеру, если запустить whoami и id под sudo, вы увидите пользователя root, а в logname — пользователя, под которым вы запускаете sudo. Это может быть полезно, если выполняете какой-то скрипт под sudo, и вам нужно сделать проверку пользователя, который его запускает. Например, разрешить запуск скрипта только если он запущен конкретным пользователем (script_allow_user).
if [[ "$(logname)" = 'script_allow_user' ]]then echo "Start script execution..." ...............................................else echo "This user is not allowed to run the script"fiОтдельно стоит упомянуть утилиту из состава systemd —
loginctl. С её помощью можно узнать массу всего не только об активном пользователе, но и о сессиях, и даже управлять ими.# loginctl user-status#bash #script
{kind=link}
На днях в рассылке увидел любопытный инструмент, на который сразу обратил внимание. Название простое и неприметное — Task. Это утилита, написанная на Gо, которая умеет запускать задачи на основе конфигурации в формате yaml. Сейчас сразу на примерах покажу, как это работает, чтобы было понятно, для чего может быть нужно.
Сама программа это просто одиночный бинарник, который можно установить кучей способов, описанных в документации. Его даже в винде можно установить через winget.
Создаём файл с задачами Taskfile.yml:
Сохраняем и запускаем. Для начала посмотрим список задач:
Запустим первую задачу:
Или сразу обе, запустив task без параметров. Запустится задача default, которую мы описали в самом начале:
Идею, думаю, вы поняли. Это более простая и лёгкая в освоении замена утилиты make, которая используется в основном для сбора софта из исходников.
Первое, что приходит в голову, где утилита task может быть полезна, помимо непосредственно сборки из исходников, как замена make — сборка docker образов. Если у вас длинный RUN, который неудобно читать, поддерживать и отлаживать из-за его размера, то его можно заменить одной задачей с task. Это позволит упростить написание и поддержку, а также избавить от необходимости разбивать этот RUN на несколько частей, что порождает создание дополнительных слоёв.
Вместо того, чтобы описывать все свои действия в длиннющем RUN, оформите все свои шаги через task и запустите в RUN только его. Примерно так:
Скопировали бинарник + yaml с задачами и запустили их. А там они могут быть красиво оформлены по шагам. Писать и отлаживать эти задачи будет проще, чем сразу в Dockerfile. Для task написано расширение в Visual Studio Code.
Task поддерживает:
◽переходы по директориям
◽зависимости задач
◽импорт в Taskfile из другого Taskfile
◽динамические переменные
◽особенности OS, можно явно указать Taskfile_linux.yml или Taskfile_windows.yml
и многое другое. Всё это описано в документации.
Я немного поразбирался с Task. Он мне показался более простой заменой одиночных сценариев для ansible. Это когда вам не нужен полноценный playbook, а достаточно простого набора команд в едином файле, чтобы быстро его запустить и выполнить небольшой набор действий. Только в Task нет никаких модулей, только cmds.
#devops #script #docker
Сама программа это просто одиночный бинарник, который можно установить кучей способов, описанных в документации. Его даже в винде можно установить через winget.
Создаём файл с задачами Taskfile.yml:
version: "3"tasks: default: desc: Run all tasks cmds: - task: task01 - task: task02 task01: desc: Task 01 cmds: - echo "Task 01" task02: desc: Task 02 cmds: - echo "Task 02"Сохраняем и запускаем. Для начала посмотрим список задач:
# task --listtask: Available tasks for this project:* default: Run all tasks* task01: Task 01* task02: Task 02Запустим первую задачу:
# task task01task: [task01] echo "Task 01"Или сразу обе, запустив task без параметров. Запустится задача default, которую мы описали в самом начале:
# tasktask: [task01] echo "Task 01"Task 01task: [task02] echo "Task 02"Task 02Идею, думаю, вы поняли. Это более простая и лёгкая в освоении замена утилиты make, которая используется в основном для сбора софта из исходников.
Первое, что приходит в голову, где утилита task может быть полезна, помимо непосредственно сборки из исходников, как замена make — сборка docker образов. Если у вас длинный RUN, который неудобно читать, поддерживать и отлаживать из-за его размера, то его можно заменить одной задачей с task. Это позволит упростить написание и поддержку, а также избавить от необходимости разбивать этот RUN на несколько частей, что порождает создание дополнительных слоёв.
Вместо того, чтобы описывать все свои действия в длиннющем RUN, оформите все свои шаги через task и запустите в RUN только его. Примерно так:
COPY --from=bins /usr/bin/task /usr/local/bin/taskCOPY tasks/Taskfile.yaml ./Taskfile.yamlRUN taskСкопировали бинарник + yaml с задачами и запустили их. А там они могут быть красиво оформлены по шагам. Писать и отлаживать эти задачи будет проще, чем сразу в Dockerfile. Для task написано расширение в Visual Studio Code.
Task поддерживает:
◽переходы по директориям
◽зависимости задач
◽импорт в Taskfile из другого Taskfile
◽динамические переменные
◽особенности OS, можно явно указать Taskfile_linux.yml или Taskfile_windows.yml
и многое другое. Всё это описано в документации.
Я немного поразбирался с Task. Он мне показался более простой заменой одиночных сценариев для ansible. Это когда вам не нужен полноценный playbook, а достаточно простого набора команд в едином файле, чтобы быстро его запустить и выполнить небольшой набор действий. Только в Task нет никаких модулей, только cmds.
#devops #script #docker
{kind=link}
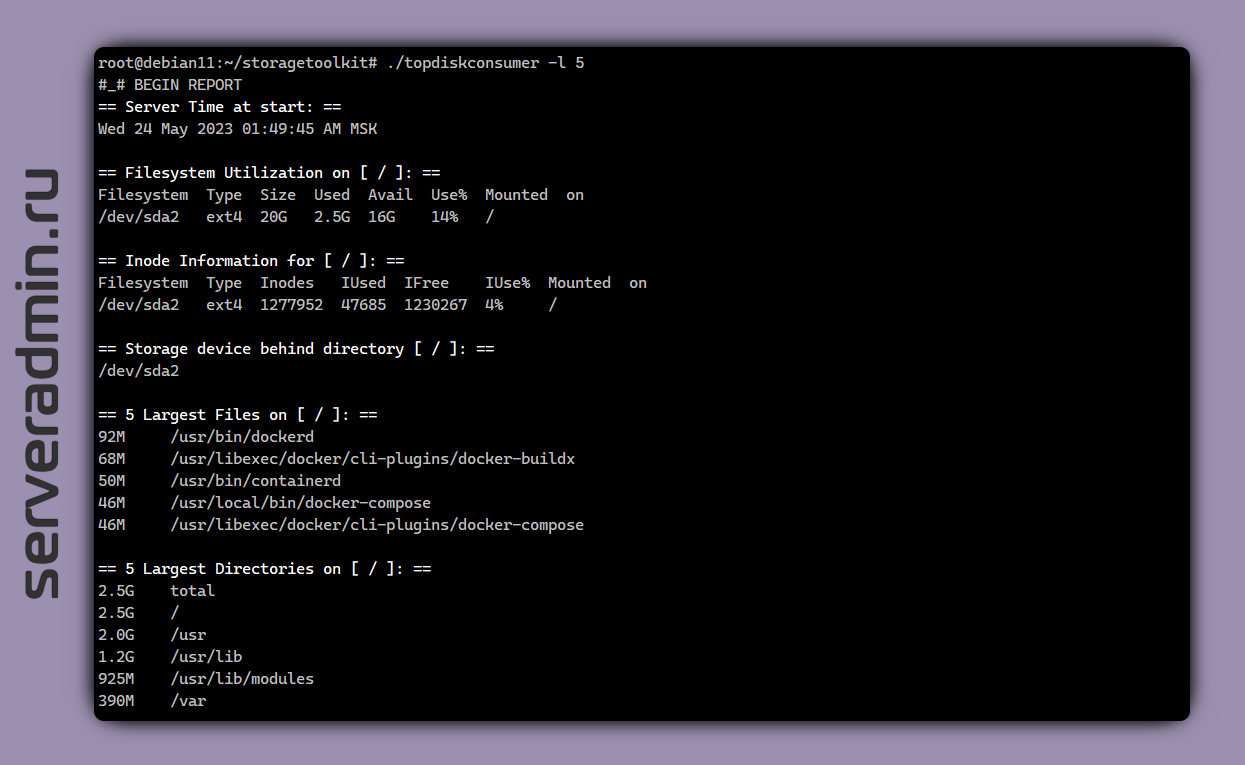
Предлагаю вам сохранить в закладки простой и удобный скрипт для Linux, который поможет быстро разобраться на сервере, кто и чем занял свободное место — topdiskconsumer. Единственный файл в репозитории, кроме README и есть этот скрипт.
Скрипт автоматически определяет mount point, с которого он запущен. Далее идёт в корень диска и вычисляет top:
▪ 20 самых больших файлов
▪ 20 самых объёмных директорий
▪ 20 самых больших файлов, старше 30-ти дней
▪ 20 самых больших удалённых файлов с незакрытыми handles (удалёнными, но реально всё ещё занимающими место, потому что дескриптор не закрыт)
При этом скрипт ничего не ставит и не использует сторонний софт. Всё реализовано через привычный функционал системы. Например, топ 20 директорий вычисляет вот такая конструкция:
Топ 20 файлов:
Топ 20 старых файлов:
Для удалённых файлов длинная конструкция с использованием lsof. Не буду всю её приводить, можете сами в скрипте посмотреть функцию fnLargestUnlinked.
Размер топа задаётся переменной intNumFiles в самом начале скрипта. Можете изменить при желании на любое другое число. Оно же указывается, если запустить скрипт с ключом
Там много всего полезного.
Скрипт очень понравился, сразу сохранил себе в коллекцию. Когда куда-то утекло место на сервере, поможет быстро оценить обстановку, не вспоминая все эти команды самостоятельно. Я их в разное время и в разных публикациях уже приводил здесь. Причём все, что используются. А тут всё в одном месте собрали.
#script #bash
Скрипт автоматически определяет mount point, с которого он запущен. Далее идёт в корень диска и вычисляет top:
▪ 20 самых больших файлов
▪ 20 самых объёмных директорий
▪ 20 самых больших файлов, старше 30-ти дней
▪ 20 самых больших удалённых файлов с незакрытыми handles (удалёнными, но реально всё ещё занимающими место, потому что дескриптор не закрыт)
При этом скрипт ничего не ставит и не использует сторонний софт. Всё реализовано через привычный функционал системы. Например, топ 20 директорий вычисляет вот такая конструкция:
# du -hcx --max-depth=6 / 2>/dev/null | sort -rh | head -n 20Топ 20 файлов:
# find / -mount -ignore_readdir_race -type f -exec du -h "{}" + 2>&1 \| sort -rh | head -n 20Топ 20 старых файлов:
# find / -mount -ignore_readdir_race -type f -mtime +30 -exec du -h "{}" + 2>&1 \| sort -rh | head -20Для удалённых файлов длинная конструкция с использованием lsof. Не буду всю её приводить, можете сами в скрипте посмотреть функцию fnLargestUnlinked.
Размер топа задаётся переменной intNumFiles в самом начале скрипта. Можете изменить при желании на любое другое число. Оно же указывается, если запустить скрипт с ключом
-l. Описание всех возможностей можно посмотреть вот так:# ./topdiskconsumer --helpТам много всего полезного.
Скрипт очень понравился, сразу сохранил себе в коллекцию. Когда куда-то утекло место на сервере, поможет быстро оценить обстановку, не вспоминая все эти команды самостоятельно. Я их в разное время и в разных публикациях уже приводил здесь. Причём все, что используются. А тут всё в одном месте собрали.
#script #bash
{kind=link}
Буквально на днях узнал, что в bash квадратная скобка [ и утилита test это одно и то же. Точнее, я вообще не знал, что существует эта встроенная утилита. Всегда и везде в скриптах видел и сам использовал именно скобку.
Синтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
Сделаем проверку, что он существует, как я обычно это делаю:
А теперь то же самое, только через test:
Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
# type testtest is a shell builtin# type [[ is a shell builtinСинтаксис с квадратными скобками в bash терпеть не могу. Всё время, когда пишу, думаю, кто же это всё придумал. Вообще неинтуитивно и нечитаемо. Простой пример. Создадим файл:
# touch file.txtСделаем проверку, что он существует, как я обычно это делаю:
#!/bin/bashif [ -e file.txt]then echo "File exist"else echo "There is no testfile"А теперь то же самое, только через test:
#!/bin/bashif test -e file.txtthen echo "File exist"else echo "There is no testfile"Вам какой вариант кажется более понятным и читаемым? Мне кажется, что второй скрипт явно понятнее. К тому же скобки могут быть как одинарными, так и двойными.
Bash максимально непонятный язык программирования. Если неподготовленному человеку показать какой-то более ли менее сложный скрипт на bash, он ничего не поймёт. Но если посмотреть код python или go, то он вполне читаемый. Помню как-то писал про программу, которая делает обфускацию bash скриптов. Понравился к ней комментарий, где человек написал, что разве bash коду нужна какая-то обфускация? Его и так невозможно понять. Пример:
ps axo rss,comm,pid | awk '{ proc_list[$2] += $1; } END { for (proc in proc_list) { printf("%d\t%s\n", proc_list[proc],proc); }}' | sort -n | tail -n 10 | sort -rn | awk '{$1/=1024;printf "%.0fMB\t",$1}{print $2}'
Что тут происходит? 😲 Всего-то посмотрели топ 10 пожирателей оперативной памяти на сервере. Кстати, скрипт сохраните, пригодится.
Не знаю, в чём феномен bash и почему он стал таким популярным в повседневном использовании. На нём трудно и муторно писать и отлаживать. Я лично не могу сходу написать что-то на bash. Мне нужно сесть, подумать, посмотреть, как я что-то похожее делал раньше, вспомнить синтаксис условий, вспомнить, чем одинарные скобки отличаются от двойных, посмотреть логические операторы. И только после этого я готов с копипастом что-то писать.
А у вас какие с bash отношения?
#bash #script
Хочу дать пару простых советов, которые не все знают и используют, но они могут сильно упростить жизнь при работе со стандартными утилитами Unix в консоли.
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
Тут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
Получится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
В этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
А если c $, получим то, что надо:
Можно совместить:
А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
#bash #script
1️⃣ Первое это символ ^, который означает начало строки. Например, можно в каком-то конфиге исключить все строки с комментариями, которые начинаются на #:
# grep -E -v '^#' nginx.confТут важно именно в начале строки найти #, потому что он может быть и в рабочей строке конфига, когда комментарий стоит после какого-то параметра, и его убирать не надо.
Когда проверял этот пример, заметил, что в стандартном пакете Nginx в Debian, конфиг по умолчанию включает в себя комментарии, где в начале строки идёт табуляция, потом #. Соответственно, пример выше не помог избавиться от комментариев. При этом в консоли bash вы просто так не введёте табуляцию в строку. Чтобы это получилось, необходимо ввести команду выше, навести указатель на символ сразу после ^, нажать Ctrl-V и потом уже на tab. Таким образом вы сможете найти все строки, которые начинаются с табуляции и символа #. Это очень удобно чистит конфигурационные файлы от комментариев.
# grep -E -v '^ #' nginx.confПолучится что-то типа такого, но если вы скопируете эту команду, то она у вас не сработает. Нужно именно в своей консоли нажать Ctrl-V и tab.
Также символ начала строки удобно использовать в поиске, когда надо найти что-то по началу имени файла.
# ls | grep ^errorerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngВ этой директории были файлы со словом error не только в начале имени.
2️⃣ Второй символ $, который означает конец строки. Можно сразу же продолжить последний пример. Там есть файлы с двойным расширением. Это пример с реального веб севера, где модуль конвертации файлов в webp породил такого рода имена файлов. Выведем файлы только с расширением png. Если действовать в лоб, то получится вот так:
# ls | grep .pngerror-windows-10-share-110x75.pngerror-windows-10-share-110x75.png.webperror-windows-10-share-150x150.pngА если c $, получим то, что надо:
# ls | grep .png$error-windows-10-share-110x75.pngerror-windows-10-share-150x150.pngМожно совместить:
# ls | grep ^error | grep png$А вместе символы ^$ означают пустую строку, что тоже удобно для чистки конфигурационных файлов. Удалим строки, начинающиеся на # и пустые:
# grep -E -v '^#|^$' nginx.conf#bash #script
{kind=link}
Провёл небольшое исследование на тему того, чем в консоли bash быстрее всего удалить большое количество директорий и файлов. Думаю, не все знают, что очень много файлов могут стать большой проблемой. Пока с этим не столкнёшься, не думаешь об этом. Если у тебя сервер бэкапов на обычных дисках и надо удалить миллионы файлов, это может оказаться непростой задачей.
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
И последняя команда, ради которой всё затевалось:
Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
Создаю 500 000 файлов в цикле по 50 000 с помощью
и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
Для второго теста сделал такой скрипт:
Создаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync
Основные проблемы будут в том, что либо команда на удаление будет выполняться очень долго, либо она вообще не будет запускаться и писать что-то типа Argument list too long. Даже если команда запустится, то выполняться может часами и вы не будете понимать, что происходит.
Я взял несколько наиболее популярных способов для удаления файлов и каталогов и протестировал скорость их работы. Среди них будут вот такие:
# rm -r test/# rm -r test/*# find test/ -type f -delete# cd test/ ; ls . | xargs -n 100 rm #только для файлов работаетИ последняя команда, ради которой всё затевалось:
# rsync -a --delete empty/ test/Мы создаём пустой каталог empty/ и копируем его в целевой каталог test/ с файлами. Пустота затирает эти файлы.
Я провёл два разных теста. В первом в одном каталоге лежат 500 тыс. файлов, во втором создана иерархия каталогов одного уровня, где в каждом лежит немного файлов. Для первого теста написал в лоб такой скрипт:
#!/bin/bashmkdir testcount=1while test $count -le 10do touch test/file$count-{000..50000}count=$(( $count + 1 ))donels test | wc -lСоздаю 500 000 файлов в цикле по 50 000 с помощью
touch. Больше за раз не получается создать, touch ругается на слишком большой список аргументов. После этого запускаю приведённые выше команды с подсчётом времени их выполнения с помощью time:# time rm -r test/и т.д.
Я не буду приводить все результаты, скажу только, что вариант с rsync самый быстрый. И чем больше файлов, тем сильнее разница. Вариант с
rm -r test/* в какой-то момент перестанет работать и будет ругаться на большое количество аргументов.Для второго теста сделал такой скрипт:
#!/bin/bashcount=1while test $count -le 10do mkdir -p test/dir$count-{000..500}touch test/dir$count-{000..500}/file-{000..100}count=$(( $count + 1 ))donefind test/ | wc -lСоздаю те же 500 000 файлов, только не в одной директории, а в 50 000, в каждой из которых внутри по 100 файлов. В такой конфигурации все команды отрабатывают примерно одинаково. Если директорий сделать те же 500 000, а суммарное количество файлов увеличить до 5 000 000, то разницы всё равно нет. Не знаю почему. Если будете тестировать, не забудьте увеличить стандартное количество inodes, быстро упрётесь в лимит в ext4.
☝Резюме такое. Если вам нужно удалить очень много файлов в одной директории, то используйте rsync. В остальных случаях не принципиально.
Кстати, насчёт rsync я когда-то давно писал заметку и делал мем. Как раз на тему случайного удаления полезных данных, если перепутать в аргументах источник и приёмник. Если сначала, как в моём примере, указать пустую директорию, то вы очень быстро удалите все свои полезные файлы, которые собирались скопировать.
Сохраните скрипты для тестов, чтобы потом свои не колхозить. Часто бывает нужно, чтобы что-то протестировать. Например, нагрузку на жёсткий диск. Создание и удаление файлов нормально его нагружают.
#linux #bash #script #rsync