
Расскажу одну историю, которая случилась со мной на днях. Это будет наглядный пример закона подлости и надежды на авось. У меня есть два старых неттопа, которые я время от времени использую. По характеристикам они до сих пор вполне актуальны: i3 cpu + 8GB ram + ssd. Там стоят Windows 10. Один вообще не используется, там чистая настроенная система, второй немного используется и его настройки терять не хочется.
Тот, который используется, бэкапится с помощью Veeam Agent for Windows Free. Архив порядка 100 GB весит. В какой-то момент система начала глючить и периодически виснуть при загрузке. Приходилось систему жёстко выключать, она запускалась снова, проводила какую-то свою диагностику и в итоге загружалась. При этом в журнале ничего информативного. Не понятно, что же не так.
Мне это надоело, решил как-то исправить проблему. Я сразу подумал на железо, поэтому для экономии времени просто перекинул жёсткий диск на второй неттоп. Через некоторое время проблема повторилась. Более того, спустя несколько дней система вообще перестала загружаться, тупо зависая в процессе.
Тогда я почему-то решил, что проблема в жёстком диске, потому что всё остальное я поменял. Взял второй изначально работающий неттоп и решил на него восстановить бэкап нужного. Загрузился с загрузочного диска Veeam, оказалось, что он не видит расшаренные сетевые диски. Пришлось искать внешний диск. Нашёл старый USB-HDD, там USB-2.0. Пару часов копировал на него бэкап.
Подключил диск к системе, начал восстановление бэкапа. При этом бэкапа работающей системы у меня не было. Я перед тем, как начать восстановление, подумал, что наверное неплохо было бы забэкапить чистую систему, чтобы потом не настраивать всё сначала, но поленился.
В итоге, что получилось. Оба неттопа не грузятся. Нет ни чистой работающей системы, ни нужной настроенной. Судя по всему, проблема не в железе, а в самой системе, что я не встречал уже очень давно. Даже не помню, когда у меня окончательно умирала винда. У меня есть бэкап нужной системы, но по факту от него нету толка. При восстановлении из него воспроизводится та же ошибка.
Пока пишу эту заметку, гружу образ винды, буду всё настраивать с нуля. История, как мне кажется, поучительная получилась. Имея как минимум одну работающую систему и бэкап неработающей, я получил две неработающие системы и невозможность воспользоваться бэкапом. По факту систему я потерял. В данном случае это не критично, я потерял только своё время. А вот если в проде такое повториться, то это будет провал.
Причём такие провалы я видел лично, но не по своей вине. Сам я, слава богу 🙏, не сталкивался с этим. Меня привлекали помочь решать проблемы, когда то VM не восстанавливались из бэкапа, то дампы баз данных. Кстати, всегда удавалось решить проблему. У людей просто квалификации не хватало всё сделать правильно, а тренировки они не делали.
❗️Отсюда можно сделать 2 важных коротких вывода:
1️⃣ Надо проверять скорость восстановления бэкапа. В моём случае если бэкап весил бы 500 Гб, то его сутки пришлось бы копировать и восстанавливать.
2️⃣ Бэкапы надо проверять и по возможности хранить как можно бОльшую глубину, так как проблема может появиться очень давно, а проявиться слишком поздно. Если впервые увидели проблемы, сразу сохраните отдельно бэкап ещё рабочей системы.
p.s. Бэкап глючной системы постараюсь починить в виртуалке. Очень интересно узнать, что там случилось. По результатам напишу потом.
#backup
Тот, который используется, бэкапится с помощью Veeam Agent for Windows Free. Архив порядка 100 GB весит. В какой-то момент система начала глючить и периодически виснуть при загрузке. Приходилось систему жёстко выключать, она запускалась снова, проводила какую-то свою диагностику и в итоге загружалась. При этом в журнале ничего информативного. Не понятно, что же не так.
Мне это надоело, решил как-то исправить проблему. Я сразу подумал на железо, поэтому для экономии времени просто перекинул жёсткий диск на второй неттоп. Через некоторое время проблема повторилась. Более того, спустя несколько дней система вообще перестала загружаться, тупо зависая в процессе.
Тогда я почему-то решил, что проблема в жёстком диске, потому что всё остальное я поменял. Взял второй изначально работающий неттоп и решил на него восстановить бэкап нужного. Загрузился с загрузочного диска Veeam, оказалось, что он не видит расшаренные сетевые диски. Пришлось искать внешний диск. Нашёл старый USB-HDD, там USB-2.0. Пару часов копировал на него бэкап.
Подключил диск к системе, начал восстановление бэкапа. При этом бэкапа работающей системы у меня не было. Я перед тем, как начать восстановление, подумал, что наверное неплохо было бы забэкапить чистую систему, чтобы потом не настраивать всё сначала, но поленился.
В итоге, что получилось. Оба неттопа не грузятся. Нет ни чистой работающей системы, ни нужной настроенной. Судя по всему, проблема не в железе, а в самой системе, что я не встречал уже очень давно. Даже не помню, когда у меня окончательно умирала винда. У меня есть бэкап нужной системы, но по факту от него нету толка. При восстановлении из него воспроизводится та же ошибка.
Пока пишу эту заметку, гружу образ винды, буду всё настраивать с нуля. История, как мне кажется, поучительная получилась. Имея как минимум одну работающую систему и бэкап неработающей, я получил две неработающие системы и невозможность воспользоваться бэкапом. По факту систему я потерял. В данном случае это не критично, я потерял только своё время. А вот если в проде такое повториться, то это будет провал.
Причём такие провалы я видел лично, но не по своей вине. Сам я, слава богу 🙏, не сталкивался с этим. Меня привлекали помочь решать проблемы, когда то VM не восстанавливались из бэкапа, то дампы баз данных. Кстати, всегда удавалось решить проблему. У людей просто квалификации не хватало всё сделать правильно, а тренировки они не делали.
❗️Отсюда можно сделать 2 важных коротких вывода:
1️⃣ Надо проверять скорость восстановления бэкапа. В моём случае если бэкап весил бы 500 Гб, то его сутки пришлось бы копировать и восстанавливать.
2️⃣ Бэкапы надо проверять и по возможности хранить как можно бОльшую глубину, так как проблема может появиться очень давно, а проявиться слишком поздно. Если впервые увидели проблемы, сразу сохраните отдельно бэкап ещё рабочей системы.
p.s. Бэкап глючной системы постараюсь починить в виртуалке. Очень интересно узнать, что там случилось. По результатам напишу потом.
#backup
{kind=link}
Для бэкапа баз PostgreSQL существует много различных подходов и решений. Я вам хочу предложить ещё одно, отметив его особенности и преимущества. Да и в целом это одна из самых известных программ для этих целей. А в конце приведу список того, чем ещё можно бэкапить PostgreSQL.
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
Дальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
# apt install pgbackrestДальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
{kind=link}
Если хотите потренироваться и погонять бесплатно S3 хранилище, то у меня есть подходящий сервис для вас с бесплатным тарифным планом - tebi.io. Для регистрации требуется только email, карту не просят. Обещают Free Tier с ограничением на 25 GiB хранилища и 250 GiB исходящего трафика в месяц.
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
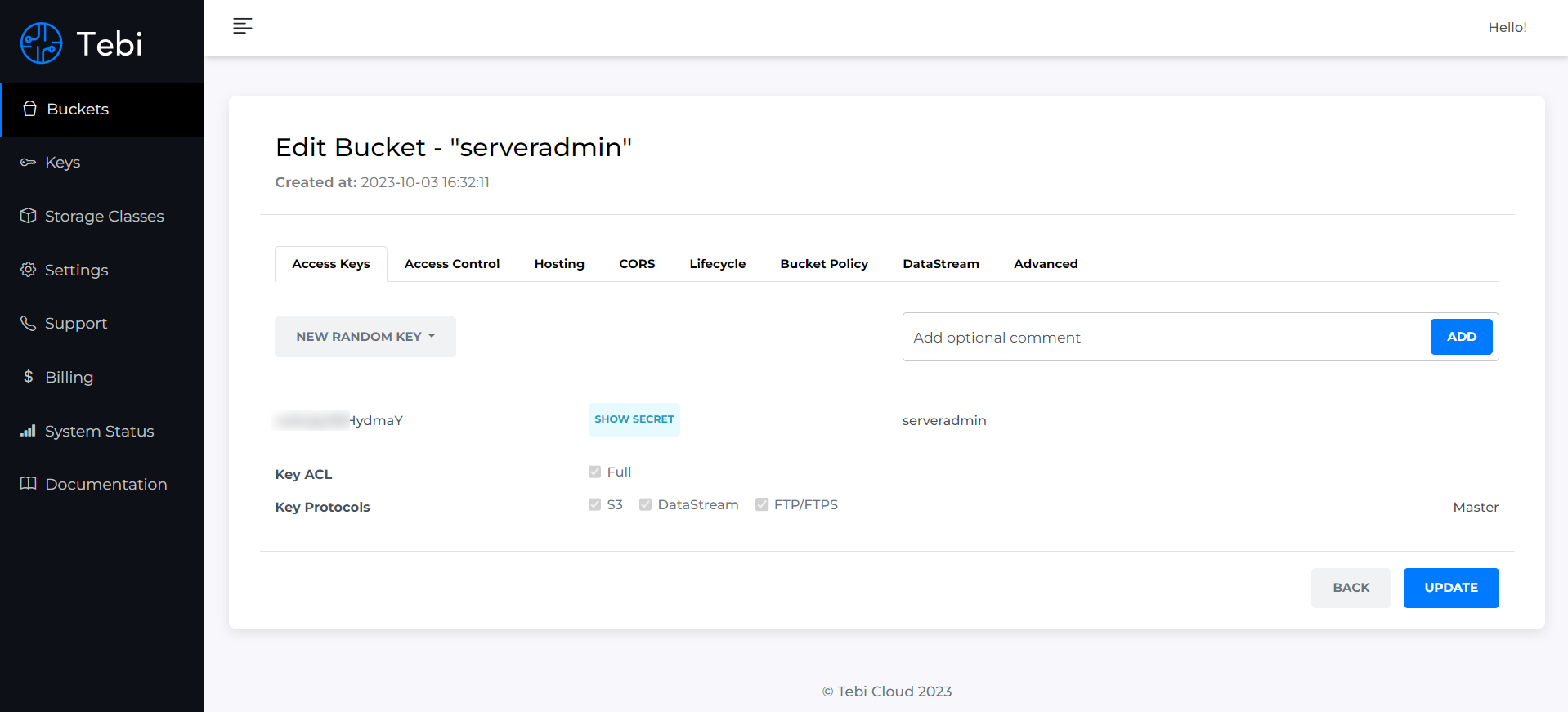
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
И можно грузить файлы или директории:
Для FTP нужны только эти данные:
Третий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
After the Free Trial ends, you can use the Free Tier, or you can switch to a paid subscription.
Я зарегистрировался и погонял этот тариф. Выглядит удобно и функционально. После регистрации вы создаёте новый bucket. Далее заходите в него в режиме редактирования и видите Access key и Secret Key. Они нужны для доступа к хранилищу. Причём доступ этот возможен как по протоколу S3, так и обычному FTP.
Для S3 я взял Rclone и настроил доступ. Достаточно простого конфига:
[tebi]type = s3provider = Otheraccess_key_id = uo5csfdErtydmaYsecret_access_key = vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmendpoint = https://s3.tebi.io/acl = privateИ можно грузить файлы или директории:
# rclone sync -i testfile.exe tebi:bucket_nameДля FTP нужны только эти данные:
server: ftp.tebi.ioport: 21login: uo5csfdErtydmaYpassword: vCFkX9pR785VNyt6Qf1zFJokqTBUFYuHrVX58yOmТретий вариант доступа к данным через веб интерфейс личного кабинета. Если у вас есть, к примеру, небольшие сайты, можете добавить это хранилище в качестве дополнительного места хранения бэкапов. Если уже куда-то складываете по S3, то добавить ещё один бакет в качестве приёмника дело пару минут. А в самом бакете можно настроить политику хранения, чтобы гарантированно не вылезти из лимита 25 GiB. А то ещё заставят деньги платить.
А в целом, это неплохая возможность хотя бы посмотреть, как всё это работает, если не знакомы. Тут полный набор стандартных возможностей типичного S3 хранилища: acl, api, lifecycle, policy, datastream.
📌 Полезные ссылки по теме:
▪ S3 (Simple Storage Service) — плюсы и минусы
▪ Софт для бэкапов в S3
▪ Подключение S3 бакета в качестве диска
▪ Свой S3 сервер на базе MiniO
#беслпатно #S3 #backup
{kind=link}
Недавно один человек у меня попросил совета по поводу программы для бэкапов в Linux на базе rsync, но только чтобы была полноценная поддержка инкрементных архивов, чтобы можно было вернуться назад на заданный день. Я знаю, что базовыми возможностями rsync без костылей и скриптов такое не сделать, поэтому сразу вспомнил про программу rdiff-backup. Хотел скинуть ссылку на свою заметку, но с удивлением обнаружил, что я вообще ни разу про неё не писал, хотя сам лично использовал.
Rdiff-backup по своей сути является python обёрткой вокруг rsync (используется библиотека librsync). Она наследует всю скорость и быстроту синхронизации сотен тысяч файлов, которую обеспечивает rsync. Если нужны бэкапы сырых файлов, без упаковки в архивы, дедупликации, сжатия и т.д., то я всегда предпочитаю использовать именно rsync. С ним быстрее и проще всего получить точную пофайловую копию какого-то файлового хранилища, которое регулярно синхронизируется. Это идеальный инструмент для организации горячего резерва файлового архива. В случае выхода из строя основного сервера или хранилища с файлами, можно очень быстро подмонтировать или организовать подключение копии, создаваемой с помощью rsync.
Особенно это актуально для почтовых серверов с форматом хранения maildir. Там каждое письмо это отдельный файл. В итоге файловое хранилище превращается в сотни тысяч мелких файлов, которые один раз скопировать может и не проблема, но каждый день актуализировать копию уже не так просто, так как надо сравнить источник и приёмник, где с каждой стороны огромное количество файлов и они меняются. По моему опыту, rsync это делает быстрее всех. Я даже на Windows сервера ставлю rsync и бэкаплю большие файловые хранилища с его помощью.
Возвращаюсь к Rdiff-backup. Он расширяет возможности rsync, позволяя очень быстро организовать полноценные инкрементные бэкапы, используя технологию hard link. Установить программу можно из стандартного репозитория Debian:
Если надо просто сделать копию каких-то данных, то не нужны никакие настройки и ключи. Просто копируем:
Удалённое резервное копирование по SSH с сервера hostname на локальный бэкап-сервер:
Добавляя ключи
Если между первым и вторым запуском бэкапа набор файлов менялся, то в локальной директории
Вы увидите наборы инкрементов и даты, когда они были созданы. С этими инкрементами можно некоторым образом работать. Например, можно посмотреть, какие файлы изменились за последние 5 дней:
Или посмотреть список файлов, которые присутствовали в архиве 5 дней назад. Если список большой, то сразу выводите его в файл и там просматривайте, ищите нужный файл:
Ну и так далее. Подробное описание с примерами есть в документации. Главное, идея понятна. Все изменения от инкремента к инкременту хранятся и их можно анализировать.
Восстановление по сути представляет из себя обычное копирование файлов из актуальной копии. Это если вам нужно взять свежие данные от последней синхронизации. Если же вам нужно восстановиться из какого-то инкремента, то укажите его явно:
Программа простая и функциональная. Рекомендую 👍.
⇨ Сайт / Исходники
Похожие программы, которые тоже используют librsync:
▪ Burp
▪ Duplicity
▪ Csync2
#backup
Rdiff-backup по своей сути является python обёрткой вокруг rsync (используется библиотека librsync). Она наследует всю скорость и быстроту синхронизации сотен тысяч файлов, которую обеспечивает rsync. Если нужны бэкапы сырых файлов, без упаковки в архивы, дедупликации, сжатия и т.д., то я всегда предпочитаю использовать именно rsync. С ним быстрее и проще всего получить точную пофайловую копию какого-то файлового хранилища, которое регулярно синхронизируется. Это идеальный инструмент для организации горячего резерва файлового архива. В случае выхода из строя основного сервера или хранилища с файлами, можно очень быстро подмонтировать или организовать подключение копии, создаваемой с помощью rsync.
Особенно это актуально для почтовых серверов с форматом хранения maildir. Там каждое письмо это отдельный файл. В итоге файловое хранилище превращается в сотни тысяч мелких файлов, которые один раз скопировать может и не проблема, но каждый день актуализировать копию уже не так просто, так как надо сравнить источник и приёмник, где с каждой стороны огромное количество файлов и они меняются. По моему опыту, rsync это делает быстрее всех. Я даже на Windows сервера ставлю rsync и бэкаплю большие файловые хранилища с его помощью.
Возвращаюсь к Rdiff-backup. Он расширяет возможности rsync, позволяя очень быстро организовать полноценные инкрементные бэкапы, используя технологию hard link. Установить программу можно из стандартного репозитория Debian:
# apt install rdiff-backupЕсли надо просто сделать копию каких-то данных, то не нужны никакие настройки и ключи. Просто копируем:
# rdiff-backup /var/www/site.ru/ /backup/site.ru/Удалённое резервное копирование по SSH с сервера hostname на локальный бэкап-сервер:
# rdiff-backup user@hostname::/remote-dir local-dirДобавляя ключи
-v5 и --print-statistics вы можете получать подробную информацию о процессе бэкапа, которую потом удобно парсить, отправлять на хранение, мониторить. Если между первым и вторым запуском бэкапа набор файлов менялся, то в локальной директории
local-dir будет лежать самая последняя копия файлов. А кроме этого в ней же будет находиться директория rdiff-backup-data, которая будет содержать информацию и логи о проводимых бэкапах, а также инкременты, необходимые для отката на любой прошлый выполненный бэкап. Посмотреть инкременты можно вот так:# rdiff-backup -l local-dirВы увидите наборы инкрементов и даты, когда они были созданы. С этими инкрементами можно некоторым образом работать. Например, можно посмотреть, какие файлы изменились за последние 5 дней:
# rdiff-backup list files --changed-since 5D local-dirИли посмотреть список файлов, которые присутствовали в архиве 5 дней назад. Если список большой, то сразу выводите его в файл и там просматривайте, ищите нужный файл:
# rdiff-backup list files --at 5D local-dirНу и так далее. Подробное описание с примерами есть в документации. Главное, идея понятна. Все изменения от инкремента к инкременту хранятся и их можно анализировать.
Восстановление по сути представляет из себя обычное копирование файлов из актуальной копии. Это если вам нужно взять свежие данные от последней синхронизации. Если же вам нужно восстановиться из какого-то инкремента, то укажите его явно:
# rdiff-backup restore \local-dir/rdiff-backup-data/increments.2023-10-29T21:03:37+03:00.dir \/tmp/restoreПрограмма простая и функциональная. Рекомендую 👍.
⇨ Сайт / Исходники
Похожие программы, которые тоже используют librsync:
▪ Burp
▪ Duplicity
▪ Csync2
#backup
{kind=link}
Я обновил популярную подборку со своего сайта:
⇨ Топ бесплатных программ для бэкапа
Обновил не в плане актуализировал все описания, а просто дополнил статью всеми программами, что были упомянуты в моём канале. Я не представляю, как эту подборку можно актуализировать. Слишком хлопотно всё это перепроверять и обновлять описания.
Даже в таком виде статья информативна. Если подбираете себе бесплатный инструмент для бэкапа, то подборка поможет быстро сориентироваться в том, что есть, посмотреть алгоритмы, основные возможности, поддерживаемые платформы, наличие веб интерфейса и т.д.
Плюс, к каждому продукту есть ссылка на обсуждение в Telegram канале, где есть в том числе отзывы и рекомендации от тех, кто пользовался. Именно поэтому я прошу не флудить в комментариях и не превращать чат в болталку. Иногда удаляю то, что считаю бесполезным для читателей (мемы, картинки, ссоры и т.д.), чтобы не занимать зря их время и внимание.
Если считаете, что какой-то полезной программы не хватает, пишите в комментариях здесь или на сайте. Я буду дополнять. В этом обновлении добавил туда ElkarBackup, FBackup. Почему-то их там не было. До этого добавлял ReaR и Restic, но анонса не делал.
#backup #подборка
⇨ Топ бесплатных программ для бэкапа
Обновил не в плане актуализировал все описания, а просто дополнил статью всеми программами, что были упомянуты в моём канале. Я не представляю, как эту подборку можно актуализировать. Слишком хлопотно всё это перепроверять и обновлять описания.
Даже в таком виде статья информативна. Если подбираете себе бесплатный инструмент для бэкапа, то подборка поможет быстро сориентироваться в том, что есть, посмотреть алгоритмы, основные возможности, поддерживаемые платформы, наличие веб интерфейса и т.д.
Плюс, к каждому продукту есть ссылка на обсуждение в Telegram канале, где есть в том числе отзывы и рекомендации от тех, кто пользовался. Именно поэтому я прошу не флудить в комментариях и не превращать чат в болталку. Иногда удаляю то, что считаю бесполезным для читателей (мемы, картинки, ссоры и т.д.), чтобы не занимать зря их время и внимание.
Если считаете, что какой-то полезной программы не хватает, пишите в комментариях здесь или на сайте. Я буду дополнять. В этом обновлении добавил туда ElkarBackup, FBackup. Почему-то их там не было. До этого добавлял ReaR и Restic, но анонса не делал.
#backup #подборка
Server Admin
Топ 12 бесплатных программ для бэкапа | serveradmin.ru
Подборка бесплатных программ для бэкапа. Краткое описание, возможности, отзывы реальных людей об использовании.
Не так давно я рассказывал про простую и надёжную систему для бэкапов - rdiff-backup на базе rsync. Система хорошая, сам её использовал. Один из читателей поделился информацией про продукт Minarca. Это клиент-серверное приложение с веб интерфейсом на основе rdiff-backup. Я его установил и немного потетисровал. Понравилась идея и реализация.
Установить сервер очень просто. Для DEB дистрибутивов есть репозитории. На Debian ставим так:
И всё, можно идти в веб интерфейс на порт 8080. Учётка по умолчанию:
Для того, чтобы что-то забэкапить, надо скачать и установить агента. Есть версия под Windows, Linux, MacOS. Можно всех бэкапить под одной учёткой, либо под разными. Дальше будет понятно, в чём отличие. Устанавливаем клиента, указываем адрес сервера, логин, пароль.
Приложение очень простое. Выбираем что бэкапим на уровне файлов и каталогов, задаём расписание и запускаем бэкап. Когда он будет закончен, на сервере в веб интерфейсе вы увидите репозиторий этого агента и информацию по бэкапам. Там же можно посмотреть файлы.
Восстановление можно сделать как с сервера с помощью админской учётки, так и с клиента под его собственной учёткой. То есть у каждого клиента может быть доступ к своим бэкапам, если он знает учётную запись, под которой эти бэкапы делались. На сервере можно настроить политику хранения бэкапа для каждого репозитория, посмотреть статистику, настроить уведомления. Есть графики, логи.
Каких-то особенных возможностей нет, но в базе по бэкапам есть всё необходимое. При желании, можно настроить 2FA и спрятать сервис за прокси. Отмечу ещё раз, что под капотом там rdiff-backup, соответственно, все возможности по хранению там те же: бэкап только на уровне файлов, дедупликации, бэкапа дисков и всей системы нет. Хранятся инкрементные бэкапы в экономичном формате с помощью линуксовых hard links. Репозитроий для хранения - обычная директория Linux на сервере. По умолчанию -
Мне система понравилась. Не знаю, что там по надёжности и удобству использования. Это надо попользоваться, чтобы понять. Больше всего понравилось то, что можно легко дать пользователям доступ к бэкапам. А также ежедневные или еженедельные отчёты по бэкапам, которые можно настроить в уведомлениях.
⇨ Сайт / Исходники / Demo / Видеообзор
#backup
Установить сервер очень просто. Для DEB дистрибутивов есть репозитории. На Debian ставим так:
# curl -L https://www.ikus-soft.com/archive/minarca/public.key | gpg --dearmor > /usr/share/keyrings/minarca-keyring.gpg# echo "deb [arch=amd64 signed-by=/usr/share/keyrings/minarca-keyring.gpg] https://nexus.ikus-soft.com/repository/apt-release-$(lsb_release -sc)/ $(lsb_release -sc) main" > /etc/apt/sources.list.d/minarca.list# apt update# apt install minarca-serverИ всё, можно идти в веб интерфейс на порт 8080. Учётка по умолчанию:
admin / admin123. Для того, чтобы что-то забэкапить, надо скачать и установить агента. Есть версия под Windows, Linux, MacOS. Можно всех бэкапить под одной учёткой, либо под разными. Дальше будет понятно, в чём отличие. Устанавливаем клиента, указываем адрес сервера, логин, пароль.
Приложение очень простое. Выбираем что бэкапим на уровне файлов и каталогов, задаём расписание и запускаем бэкап. Когда он будет закончен, на сервере в веб интерфейсе вы увидите репозиторий этого агента и информацию по бэкапам. Там же можно посмотреть файлы.
Восстановление можно сделать как с сервера с помощью админской учётки, так и с клиента под его собственной учёткой. То есть у каждого клиента может быть доступ к своим бэкапам, если он знает учётную запись, под которой эти бэкапы делались. На сервере можно настроить политику хранения бэкапа для каждого репозитория, посмотреть статистику, настроить уведомления. Есть графики, логи.
Каких-то особенных возможностей нет, но в базе по бэкапам есть всё необходимое. При желании, можно настроить 2FA и спрятать сервис за прокси. Отмечу ещё раз, что под капотом там rdiff-backup, соответственно, все возможности по хранению там те же: бэкап только на уровне файлов, дедупликации, бэкапа дисков и всей системы нет. Хранятся инкрементные бэкапы в экономичном формате с помощью линуксовых hard links. Репозитроий для хранения - обычная директория Linux на сервере. По умолчанию -
/backups.Мне система понравилась. Не знаю, что там по надёжности и удобству использования. Это надо попользоваться, чтобы понять. Больше всего понравилось то, что можно легко дать пользователям доступ к бэкапам. А также ежедневные или еженедельные отчёты по бэкапам, которые можно настроить в уведомлениях.
⇨ Сайт / Исходники / Demo / Видеообзор
#backup
{kind=link}
До появления Proxmox Backup Server я часто отдавал предпочтение при выборе гипервизора Hyper-V из-за того, что для Proxmox VE не было функционального инструмента для бэкапов VM, кроме его встроенного средства, которое делало только полные бэкапы.
С выходом PBS этот вопрос был закрыт, причём бескомпромиссно. Предложенное решение было лучше, чем любое другое бесплатное. Так что связка Proxmox VE + PBS аналогов сейчас не имеет по удобству, простоте настройки и эксплуатации.
Отдельно отметить и рассказать более подробно я хочу про Proxmox Backup Client. Это консольная утилита для Linux, которая позволяет делать бэкап на уровне файлов из виртуальной машины в PBS, даже если система находится на другом гипервизоре. То есть это полностью отвязанный от инфраструктуры Proxmox клиент, который позволяет складывать резервные копии в PBS. Таким образом этот сервер бэкапов может объединять в себе разнородную инфраструктуру.
Сразу перечислю основные ограничения этого клиента:
▪ бэкап только на уровне файлов или образов дисков, не системы целиком;
▪ официальная поддержка только deb дистрибутивов, для rpm люди сами собирают пакеты, так как исходники открыты;
▪ нет поддержки windows, вариант бэкапа данных оттуда только один - монтирование диска по smb к linux машине и бэкап этого примонтированного диска.
Использовать proxmox-backup-client очень просто. Я не буду подробно описывать его возможности, так как в оригинальной документации представлена исчерпывающая информация. Если хочется на русском, то можно обратиться к документации от altlinux. Кратко покажу пример установки и бэкапа.
Ставим Proxmox Backup Client на Debian:
Вставляем туда для Debian 12
Для Debian 11:
Для Debian 10:
Ставим клиента:
Теперь бэкапим корень сервера без примонтированных дисков. То есть делаем бэкап системы:
Здесь мы указали:
◽root.pxar - имя архива в формате pbs
◽/ - бэкапим корень системы
◽10.20.1.47 - адрес pbs сервера
◽main - имя datastore
По умолчанию используется учётная запись root@pam, то есть дефолтный админ. Разумеется, на проде так делать не надо, потому что у него полные права, в том числе на удаление архивов. Делайте отдельные учётки для разных систем с ограниченными правами. В PBS это организовано удобно и просто, так что разобраться не трудно. Для указания имени пользователя, нужно использовать такой вид репозитория:
Для того, чтобы не вводить пароль пользователя вручную, можно задать его через переменную окружения
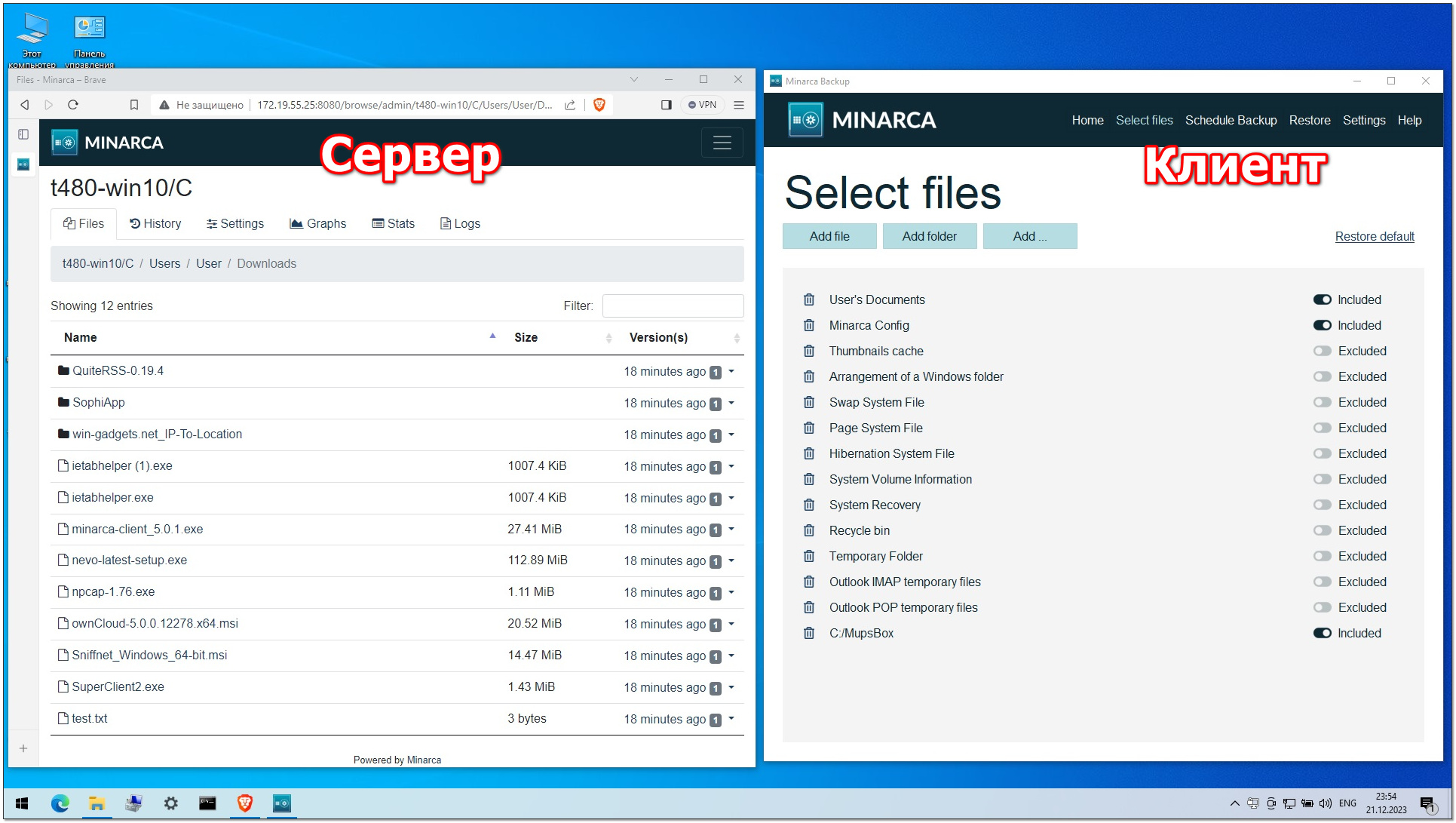
Смотреть содержимое бэкапов можно как через веб интерфейс, так и тут локально. Причём бэкап можно примонтировать через fuse. Сморим снэпшоты и выбираем любой для монтирования:
Очень быстро и удобно. При желании бэкапы можно шифровать.
#proxmox #backup
С выходом PBS этот вопрос был закрыт, причём бескомпромиссно. Предложенное решение было лучше, чем любое другое бесплатное. Так что связка Proxmox VE + PBS аналогов сейчас не имеет по удобству, простоте настройки и эксплуатации.
Отдельно отметить и рассказать более подробно я хочу про Proxmox Backup Client. Это консольная утилита для Linux, которая позволяет делать бэкап на уровне файлов из виртуальной машины в PBS, даже если система находится на другом гипервизоре. То есть это полностью отвязанный от инфраструктуры Proxmox клиент, который позволяет складывать резервные копии в PBS. Таким образом этот сервер бэкапов может объединять в себе разнородную инфраструктуру.
Сразу перечислю основные ограничения этого клиента:
▪ бэкап только на уровне файлов или образов дисков, не системы целиком;
▪ официальная поддержка только deb дистрибутивов, для rpm люди сами собирают пакеты, так как исходники открыты;
▪ нет поддержки windows, вариант бэкапа данных оттуда только один - монтирование диска по smb к linux машине и бэкап этого примонтированного диска.
Использовать proxmox-backup-client очень просто. Я не буду подробно описывать его возможности, так как в оригинальной документации представлена исчерпывающая информация. Если хочется на русском, то можно обратиться к документации от altlinux. Кратко покажу пример установки и бэкапа.
Ставим Proxmox Backup Client на Debian:
# wget https://enterprise.proxmox.com/debian/proxmox-release-bookworm.gpg -O /etc/apt/trusted.gpg.d/proxmox-release-bookworm.gpg# mcedit /etc/apt/sources.list.d/pbs-client.listВставляем туда для Debian 12
deb http://download.proxmox.com/debian/pbs-client bookworm mainДля Debian 11:
deb http://download.proxmox.com/debian/pbs-client bullseye mainДля Debian 10:
deb http://download.proxmox.com/debian/pbs-client buster mainСтавим клиента:
# apt update && apt install proxmox-backup-clientТеперь бэкапим корень сервера без примонтированных дисков. То есть делаем бэкап системы:
# proxmox-backup-client backup root.pxar:/ --repository 10.20.1.47:mainЗдесь мы указали:
◽root.pxar - имя архива в формате pbs
◽/ - бэкапим корень системы
◽10.20.1.47 - адрес pbs сервера
◽main - имя datastore
По умолчанию используется учётная запись root@pam, то есть дефолтный админ. Разумеется, на проде так делать не надо, потому что у него полные права, в том числе на удаление архивов. Делайте отдельные учётки для разных систем с ограниченными правами. В PBS это организовано удобно и просто, так что разобраться не трудно. Для указания имени пользователя, нужно использовать такой вид репозитория:
user01@pbs@10.20.1.47. То есть мы указали созданного вручную пользователя user01@pbs.Для того, чтобы не вводить пароль пользователя вручную, можно задать его через переменную окружения
PBS_PASSWORD. Смотреть содержимое бэкапов можно как через веб интерфейс, так и тут локально. Причём бэкап можно примонтировать через fuse. Сморим снэпшоты и выбираем любой для монтирования:
# proxmox-backup-client snapshot list --repository 10.20.1.47:main# proxmox-backup-client mount host/debian12-vm/2024-02-06T19:19:12Z root.pxar --repository 10.20.1.47:main /mnt/backupОчень быстро и удобно. При желании бэкапы можно шифровать.
#proxmox #backup
{kind=link}
Яндекс.Диск – одно из самых дешёвых файловых хранилищ. При этом с хорошей скоростью. У него есть полнофункциональный Linux клиент, который умеет работать только в консоли. Его без проблем можно установить на сервер без gui и складывать туда бэкапы.
Установить его просто, так как есть репозиторий под это дело:
После этого запускаете:
Дальше следуете указаниям мастера, проходите авторизацию устройства, указываете директорию, которая будет синхронизироваться с диском. После этого все файлы, положенные в эту директорию, будут синхронизироваться с облаком.
При работе таким образом важно понимать нюансы. Нельзя бэкапы держать только на Яндекс.Диске. Если у него будет сбой и повредятся или пропадут файлы, то и у вас они пропадут, так как синхронизация двусторонняя. Я лично с таким сталкивался. Так что это в первую очередь холодное хранение одной из копий. Нельзя полагаться только на неё. И хотя фактически данные хранятся в двух местах – у вас на диске и в облаке. Потеряете и там, и тут, если не предпримете отдельных действий.
Второй нюанс в том, что все синхронизируемые данные лежат и на сервере, и на диске. А на сервере зачастую нет большого количества свободного места, так как оно тоже денег стоит, особенно если он арендуется. Из этой ситуации можно выйти, отправляя файлы напрямую в диск через API, без родного клиента. Это умеет делать rclone, либо можно самостоятельно передавать туда файлы с помощью простейшего bash скрипта.
Я не раз видел отзывы, что у Яндекс.Диска плохая скорость. Вот конкретно в Москве никогда такого не наблюдал. Он канал до 100 мегабит спокойно утилизирует весь. Я им пользуюсь постоянно, проверял не единожды. Так что могу смело его рекомендовать с поправкой на то, что данные там могут быть утеряны. Ну а где этого не может случиться? Везде можно потерять, поэтому храните несколько копий.
И ещё такой момент. Сам Яндекс через техподдержку всегда говорит, что максимальную скорость гарантирует только при использовании родного клиента. Все остальные способы доступа к файлам работают как получится. Возможно в каких-то случаях скорость сознательно урезается. С webdav это точно происходит.
#backup
Установить его просто, так как есть репозиторий под это дело:
# echo "deb http://repo.yandex.ru/yandex-disk/deb/ stable main" | tee -a /etc/apt/sources.list.d/yandex-disk.list > /dev/null# wget http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | apt-key add - # apt update && apt install yandex-diskПосле этого запускаете:
# yandex-disk setupДальше следуете указаниям мастера, проходите авторизацию устройства, указываете директорию, которая будет синхронизироваться с диском. После этого все файлы, положенные в эту директорию, будут синхронизироваться с облаком.
При работе таким образом важно понимать нюансы. Нельзя бэкапы держать только на Яндекс.Диске. Если у него будет сбой и повредятся или пропадут файлы, то и у вас они пропадут, так как синхронизация двусторонняя. Я лично с таким сталкивался. Так что это в первую очередь холодное хранение одной из копий. Нельзя полагаться только на неё. И хотя фактически данные хранятся в двух местах – у вас на диске и в облаке. Потеряете и там, и тут, если не предпримете отдельных действий.
Второй нюанс в том, что все синхронизируемые данные лежат и на сервере, и на диске. А на сервере зачастую нет большого количества свободного места, так как оно тоже денег стоит, особенно если он арендуется. Из этой ситуации можно выйти, отправляя файлы напрямую в диск через API, без родного клиента. Это умеет делать rclone, либо можно самостоятельно передавать туда файлы с помощью простейшего bash скрипта.
Я не раз видел отзывы, что у Яндекс.Диска плохая скорость. Вот конкретно в Москве никогда такого не наблюдал. Он канал до 100 мегабит спокойно утилизирует весь. Я им пользуюсь постоянно, проверял не единожды. Так что могу смело его рекомендовать с поправкой на то, что данные там могут быть утеряны. Ну а где этого не может случиться? Везде можно потерять, поэтому храните несколько копий.
И ещё такой момент. Сам Яндекс через техподдержку всегда говорит, что максимальную скорость гарантирует только при использовании родного клиента. Все остальные способы доступа к файлам работают как получится. Возможно в каких-то случаях скорость сознательно урезается. С webdav это точно происходит.
#backup
{kind=link}
На днях триггер в Zabbix сработал на то, что дамп Mysql базы не создался. Это бывает редко, давно его не видел. Решил по этому поводу рассказать, как у меня устроена проверка создания дампов с контролем этого процесса через Zabbix. Здесь будет только теория в общих словах. Пример реализации описан у меня в статье:
⇨ https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
Она старя, что-то уже переделывалась, но общий смысл примерно тот же. К сожалению, нет времени обновлять и актуализировать статьи. Да и просмотров там не очень много. Тема узкая, не очень популярная. Хотя как по мне, без мониторинга этих дампов просто нельзя. Можно годами не знать, что у тебя дампы битые, если хотя бы не проверять их создание.
Описание ниже будет актуально для любых текстовых дампов sql серверов. Как минимум, один и тот же подход я применяю как к Mysql, так и Postgresql.
1️⃣ В любом дампе sql обычно есть служебные строки в начале и в конце. Для Mysql это обычно в начале
2️⃣ Если строки есть, пишу в отдельный лог файл что-то типа
3️⃣ В Zabbix настраиваю отдельный шаблон, где в айтем забираю этот лог. И делаю для него триггер, что если есть слово corrupted, то срабатывает триггер.
Вот и всё. Если срабатывает триггер, иду на сервер и смотрю результат работы дампа. Я его тоже в отдельный файл сохраняю. Можно и его забирать в Zabbix, но я не вижу большого смысла в этой информации, чтобы забивать ей базу заббикса.
В логе увидел ошибку:
Не знаю, с чем она была связана. Проверил лог mysql в это время, там тоже ошибка:
Проверил таблицу, там всё в порядке:
Следующий дамп прошёл уже без ошибок, так что я просто забил. Если повторится, буду разбираться детальнее.
Делать такую проверку можно как угодно. Я люблю всё замыкать на Zabbix, а он уже шлёт уведомления. Можно в скрипте с проверкой сразу отправлять информацию на почту, и, к примеру, мониторить почтовый ящик. Если кто-то тоже мониторит создание дампов, то расскажите, как это делаете вы.
Ну и не забываем, что это только мониторинг создания. Даже если не было ошибок, это ещё не гарантия того, что дамп реально рабочий, хотя лично я ни разу не сталкивался с тем, что корректно созданный дамп не восстанавливается.
Тем не менее, восстановление я тоже проверяю. Тут уже могут быть различные реализации в зависимости от инфраструктуры. Самый более ли менее приближённый к реальности вариант такой. Копируете этот дамп вместе с бэкапом исходников на запасной веб сервер, там скриптами разворачиваете и проверяете тем же Zabbix, что развёрнутый из бэкапов сайт работает и актуален по свежести. Пример, как это может выглядеть, я когда-то тоже описывал в старой статье.
#mysql #backup
⇨ https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
Она старя, что-то уже переделывалась, но общий смысл примерно тот же. К сожалению, нет времени обновлять и актуализировать статьи. Да и просмотров там не очень много. Тема узкая, не очень популярная. Хотя как по мне, без мониторинга этих дампов просто нельзя. Можно годами не знать, что у тебя дампы битые, если хотя бы не проверять их создание.
Описание ниже будет актуально для любых текстовых дампов sql серверов. Как минимум, один и тот же подход я применяю как к Mysql, так и Postgresql.
1️⃣ В любом дампе sql обычно есть служебные строки в начале и в конце. Для Mysql это обычно в начале
-- MySQL dump и в конце -- Dump completed. После создания дампа я банальным grep проверяю, что там эти строки есть. 2️⃣ Если строки есть, пишу в отдельный лог файл что-то типа
${BASE01} backup is OK, если хоть одной строки нет, то ${BASE01} backup is corrupted.3️⃣ В Zabbix настраиваю отдельный шаблон, где в айтем забираю этот лог. И делаю для него триггер, что если есть слово corrupted, то срабатывает триггер.
Вот и всё. Если срабатывает триггер, иду на сервер и смотрю результат работы дампа. Я его тоже в отдельный файл сохраняю. Можно и его забирать в Zabbix, но я не вижу большого смысла в этой информации, чтобы забивать ей базу заббикса.
В логе увидел ошибку:
mysqldump: Error 2013: Lost connection to MySQL server during query when dumping table `b_stat_session_data` at row: 1479887Не знаю, с чем она была связана. Проверил лог mysql в это время, там тоже ошибка:
Aborted connection 1290694 to db: 'db01' user: 'user01' host: 'localhost' (Got timeout writing communication packets)Проверил таблицу, там всё в порядке:
> check table b_stat_session_data;Следующий дамп прошёл уже без ошибок, так что я просто забил. Если повторится, буду разбираться детальнее.
Делать такую проверку можно как угодно. Я люблю всё замыкать на Zabbix, а он уже шлёт уведомления. Можно в скрипте с проверкой сразу отправлять информацию на почту, и, к примеру, мониторить почтовый ящик. Если кто-то тоже мониторит создание дампов, то расскажите, как это делаете вы.
Ну и не забываем, что это только мониторинг создания. Даже если не было ошибок, это ещё не гарантия того, что дамп реально рабочий, хотя лично я ни разу не сталкивался с тем, что корректно созданный дамп не восстанавливается.
Тем не менее, восстановление я тоже проверяю. Тут уже могут быть различные реализации в зависимости от инфраструктуры. Самый более ли менее приближённый к реальности вариант такой. Копируете этот дамп вместе с бэкапом исходников на запасной веб сервер, там скриптами разворачиваете и проверяете тем же Zabbix, что развёрнутый из бэкапов сайт работает и актуален по свежести. Пример, как это может выглядеть, я когда-то тоже описывал в старой статье.
#mysql #backup
Server Admin
Настройка mysqldump, проверка и мониторинг бэкапов mysql |...
Создание и проверка бэкапов MySQL с помощью mysqldump. Мониторинг бэкапов в Zabbix с уведомлением об ошибках создания.
Для бэкапа серверов под управлением Linux существует отличное бесплатное решение - Veeam Agent for Linux FREE. Я очень давно его знаю, но конкретно для Linux давно не пользовался. У меня есть статья по работе с ним:
⇨ Бэкап и перенос linux (centos, debian, ubuntu) сервера с помощью Veeam Agent for Linux
Она написана давно, поэтому я решил проверить, насколько актуален тот метод восстановления, что там описан. Забегая вперёд скажу, что актуален. Изменились некоторые детали, но в основном всё то же самое.
Я себе поставил задачу – перенести виртуальную машину от обычного хостера, где используется стандартная услуга VPS и больше ничего. То есть у вас система на одном жёстком диске заданного размера. Задача перенести её в исходном виде к себе на локальный гипервизор Proxmox. В итоге у меня всё получилось. Рассказываю по шагам, что делал.
1️⃣ Скачал с сайта Veeam файл с репозиторием для Debian veeam-release-deb_1.0.8_amd64.deb и загрузочный ISO для восстановления Veeam Linux Recovery Media. Для загрузки нужна регистрация.
2️⃣ Скопировал файл с репозиторием на целевой сервер и подключил его:
3️⃣ Установил veeam и дополнительные пакеты:
4️⃣ К сожалению, понадобилась перезагрузка сервера. Без перезагрузки не создавался бэкап. Veeam ругался, что не загружен модуль для снепшота диска. У меня так и не получилось его загрузить вручную. Вроде всё делал, что надо, но не заработало. Пришлось перезагрузиться и проблема ушла.
5️⃣ Так как на сервере у нас только один диск, мы не можем на него же класть бэкап, когда будем делать образ всей системы. Я решил использовать сетевой smb диск с другой виртуальной машины, которая запущена на целевом Proxmox, куда буду переносить систему. Для этого на ней поднял и настроил ksmbd, затем с помощью ssh настроил VPN туннель между машинами. Всё делал прям по инструкциям из указанных заметок. Заняло буквально 5-10 минут.
6️⃣ Запустил на целевой машине veeam:
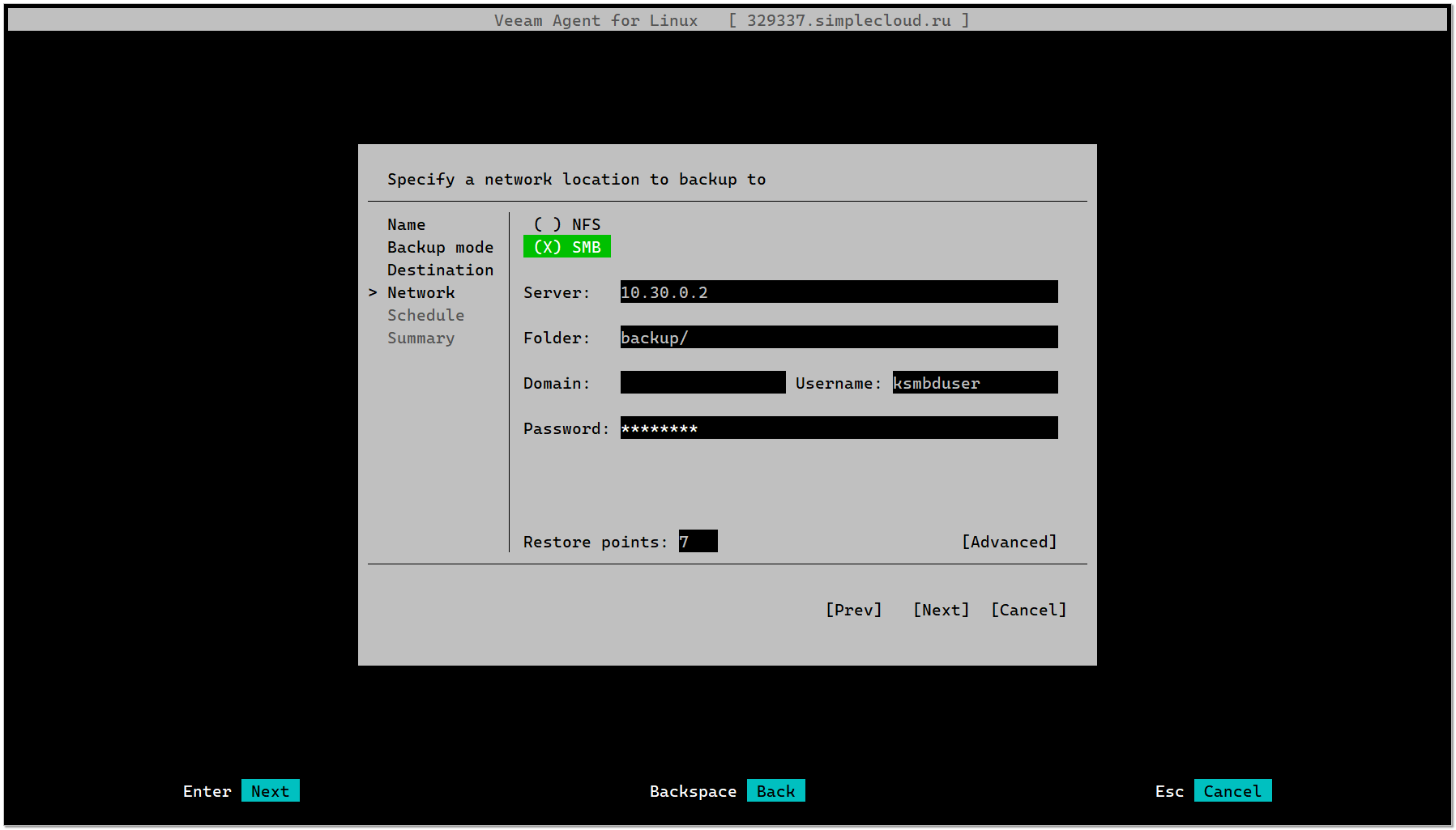
И с помощью псевдографического интерфейса настроил задание для бэкапа в сетевую папку smb. Там всё просто. Немного затупил с правильностью указания настроек для smb, так как не сразу понял формат, в котором надо записать путь к серверу (на картинке снизу скриншот правильных настроек). Но быстро разобрался. И ещё важный момент. На smb шару у вас должны быть права на запись. Если их нет, получите неинформативную ошибку. Я с этим проковырялся немного, пока не догадался проверить. Оказалось, что забыл дать права на запись в директорию, которая монтировалась по smb.
7️⃣ Запустил задание бэкапа и убедился, что он прошёл без ошибок.
8️⃣ Сделал на Proxmox новую виртуальную машину с диском, у которого размер не меньше исходной машины, которую бэкапили. Это важно. Даже если на диске занято очень мало места, перераспределить его при восстановлении на меньший диск не получится. Veeam просто не умеет этого делать.
9️⃣ Загрузил новую виртуалку с Veeam Linux Recovery Media, подключил туда по smb тот же сетевой диск, куда делал бэкап и успешно выполнил восстановление. Всё прошло без сучка и задоринки. Виртуалка сразу же загрузилась с восстановленного диска и заработала без каких-то дополнительных действий.
Такой вот полезный инструмент. Если локально ещё есть разные варианты, чем забэкапить машину, то с арендованными VPS всё не так просто. Veeam Agent for Linux позволяет из без проблем бэкапить и в случае необходимости восстанавливать локально.
#backup #veeam
⇨ Бэкап и перенос linux (centos, debian, ubuntu) сервера с помощью Veeam Agent for Linux
Она написана давно, поэтому я решил проверить, насколько актуален тот метод восстановления, что там описан. Забегая вперёд скажу, что актуален. Изменились некоторые детали, но в основном всё то же самое.
Я себе поставил задачу – перенести виртуальную машину от обычного хостера, где используется стандартная услуга VPS и больше ничего. То есть у вас система на одном жёстком диске заданного размера. Задача перенести её в исходном виде к себе на локальный гипервизор Proxmox. В итоге у меня всё получилось. Рассказываю по шагам, что делал.
1️⃣ Скачал с сайта Veeam файл с репозиторием для Debian veeam-release-deb_1.0.8_amd64.deb и загрузочный ISO для восстановления Veeam Linux Recovery Media. Для загрузки нужна регистрация.
2️⃣ Скопировал файл с репозиторием на целевой сервер и подключил его:
# dpkg -i veeam-release-deb_1.0.8_amd64.deb3️⃣ Установил veeam и дополнительные пакеты:
# apt install blksnap veeam cifs-utils4️⃣ К сожалению, понадобилась перезагрузка сервера. Без перезагрузки не создавался бэкап. Veeam ругался, что не загружен модуль для снепшота диска. У меня так и не получилось его загрузить вручную. Вроде всё делал, что надо, но не заработало. Пришлось перезагрузиться и проблема ушла.
5️⃣ Так как на сервере у нас только один диск, мы не можем на него же класть бэкап, когда будем делать образ всей системы. Я решил использовать сетевой smb диск с другой виртуальной машины, которая запущена на целевом Proxmox, куда буду переносить систему. Для этого на ней поднял и настроил ksmbd, затем с помощью ssh настроил VPN туннель между машинами. Всё делал прям по инструкциям из указанных заметок. Заняло буквально 5-10 минут.
6️⃣ Запустил на целевой машине veeam:
# veeamИ с помощью псевдографического интерфейса настроил задание для бэкапа в сетевую папку smb. Там всё просто. Немного затупил с правильностью указания настроек для smb, так как не сразу понял формат, в котором надо записать путь к серверу (на картинке снизу скриншот правильных настроек). Но быстро разобрался. И ещё важный момент. На smb шару у вас должны быть права на запись. Если их нет, получите неинформативную ошибку. Я с этим проковырялся немного, пока не догадался проверить. Оказалось, что забыл дать права на запись в директорию, которая монтировалась по smb.
7️⃣ Запустил задание бэкапа и убедился, что он прошёл без ошибок.
8️⃣ Сделал на Proxmox новую виртуальную машину с диском, у которого размер не меньше исходной машины, которую бэкапили. Это важно. Даже если на диске занято очень мало места, перераспределить его при восстановлении на меньший диск не получится. Veeam просто не умеет этого делать.
9️⃣ Загрузил новую виртуалку с Veeam Linux Recovery Media, подключил туда по smb тот же сетевой диск, куда делал бэкап и успешно выполнил восстановление. Всё прошло без сучка и задоринки. Виртуалка сразу же загрузилась с восстановленного диска и заработала без каких-то дополнительных действий.
Такой вот полезный инструмент. Если локально ещё есть разные варианты, чем забэкапить машину, то с арендованными VPS всё не так просто. Veeam Agent for Linux позволяет из без проблем бэкапить и в случае необходимости восстанавливать локально.
#backup #veeam
{kind=link}