
В августе было несколько постов с анализом производительности Linux. Хочу немного подвести итог и сгруппировать информацию, чтобы получилась последовательная картинка по теме.
Вам кажется, что сервер тормозит. Первым делом загляните в top или htop (я его предпочитаю). Если понимания, в чём конкретно проблема, не возникло начинаем копать глубже. Типичный пример непонимания - всё тормозит, даже по ssh долгое подключение, load average высокий, а процессор не загружен, память свободная есть.
1️⃣ Используйте dstat, запустив комплексный вывод основных метрик. Это первый пример из заметки:
Там как минимум будет видно, какая и где именно нагрузка. Скорее всего если по top не понятно, в чём проблема, то смотреть надо на диски и сеть.
2️⃣ Я бы в первую очередь посмотрел на диски. Для этого можно воспользоваться заметкой Анализ дисковой активности в Linux. Там конкретные примеры по выводу различной информации с помощью разных утилит. Если они не помогли, то спускаемся на уровень ниже, берём набор утилит perf-tools и используем iolatency и iosnoop. В заметке есть описание с примерами.
3️⃣ Теперь разбираемся с сетью. Берём пакет netsniff-ng и анализируем сетевую активность - трафик, соединения, источники соединений с привязкой к процессам и т.д. В первую очередь понадобятся утилиты Ifpps и flowtop. Чуть более простые и дружелюбные для использования утилиты для анализа сети описаны у меня в посте про программу sniffer. И вот еще список тематических утилит с описанием: Iftop, NetHogs, Iptraf, Bmon.
Я знаю, что многие могут порекомендовать более продвинутые top'ы, типа atop, bashtop, glances и им подобные. Лично я их не очень люблю и обычно не использую. Иду по пути узконаправленных утилит. Возможно это не всегда оправданно, но у меня вот так.
#perfomance #подборка
Вам кажется, что сервер тормозит. Первым делом загляните в top или htop (я его предпочитаю). Если понимания, в чём конкретно проблема, не возникло начинаем копать глубже. Типичный пример непонимания - всё тормозит, даже по ssh долгое подключение, load average высокий, а процессор не загружен, память свободная есть.
1️⃣ Используйте dstat, запустив комплексный вывод основных метрик. Это первый пример из заметки:
# dstat -tldnpms 10Там как минимум будет видно, какая и где именно нагрузка. Скорее всего если по top не понятно, в чём проблема, то смотреть надо на диски и сеть.
2️⃣ Я бы в первую очередь посмотрел на диски. Для этого можно воспользоваться заметкой Анализ дисковой активности в Linux. Там конкретные примеры по выводу различной информации с помощью разных утилит. Если они не помогли, то спускаемся на уровень ниже, берём набор утилит perf-tools и используем iolatency и iosnoop. В заметке есть описание с примерами.
3️⃣ Теперь разбираемся с сетью. Берём пакет netsniff-ng и анализируем сетевую активность - трафик, соединения, источники соединений с привязкой к процессам и т.д. В первую очередь понадобятся утилиты Ifpps и flowtop. Чуть более простые и дружелюбные для использования утилиты для анализа сети описаны у меня в посте про программу sniffer. И вот еще список тематических утилит с описанием: Iftop, NetHogs, Iptraf, Bmon.
Я знаю, что многие могут порекомендовать более продвинутые top'ы, типа atop, bashtop, glances и им подобные. Лично я их не очень люблю и обычно не использую. Иду по пути узконаправленных утилит. Возможно это не всегда оправданно, но у меня вот так.
#perfomance #подборка
Вы знаете, как узнать, кто и насколько активно использует swap в Linux? Можно использовать для этого top, там можно вывести отдельную колонку со swap. Для этого запустите top, нажмите f и выберите колонку со swap, которой по умолчанию нет в отображении. Насколько я слышал, это не совсем корректный способ, поэтому, к примеру, в htop эту колонку вообще убрали, чтобы не вводить людей в заблуждение.
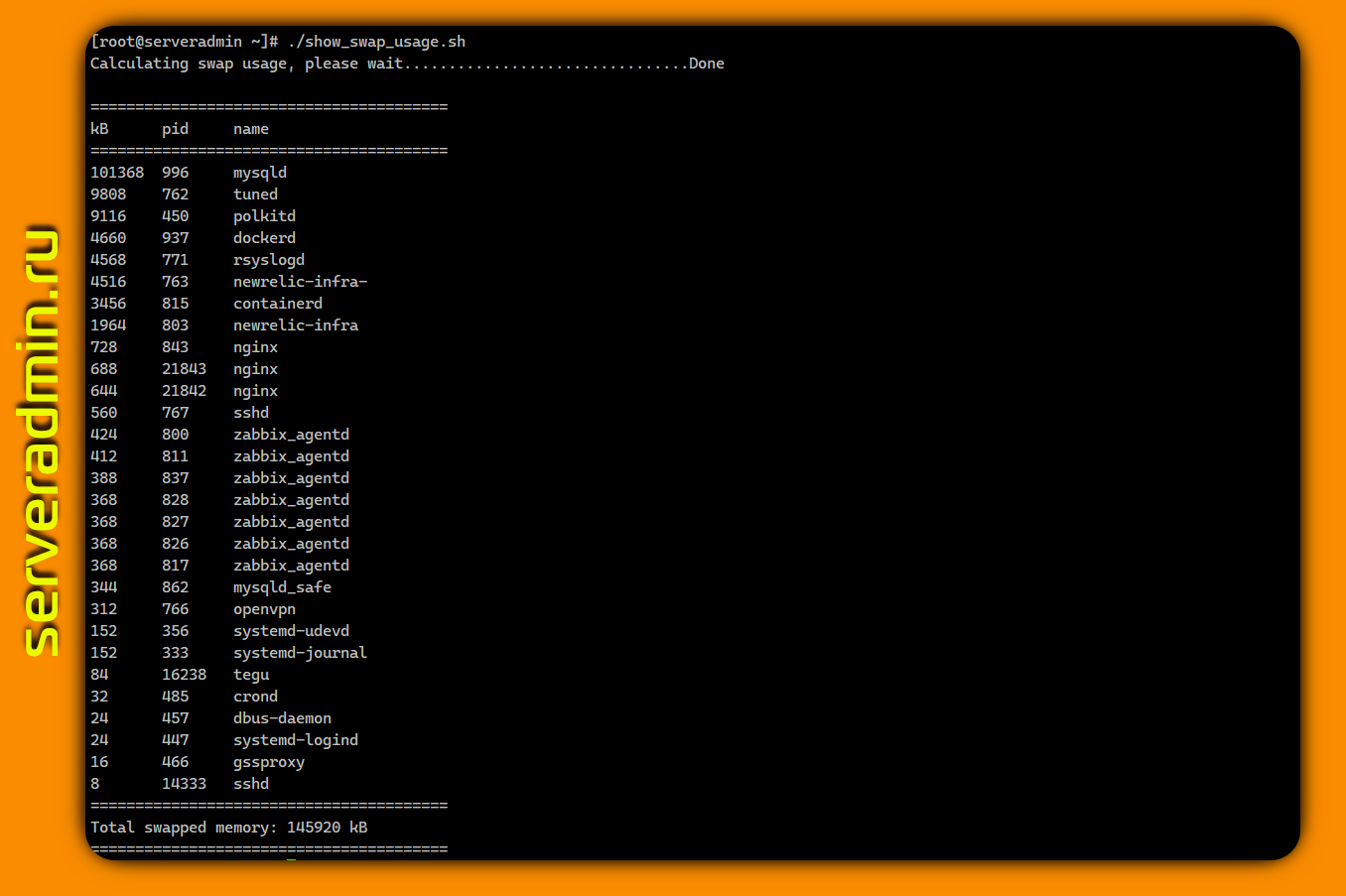
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
#linux #script #perfomance
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
/proc/$PID/smaps или /proc/$PID/status. Первая метрика будет самая точная, но там нужно будет вручную вычислить суммарный объём по отдельным кусочкам используемой памяти. Вторая метрика сразу идёт суммой. В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
#!/bin/bash SUM=0OVERALL=0for DIR in `find /proc/ -maxdepth 1 -type d -regex "^/proc/[0-9]+"`do PID=`echo $DIR | cut -d / -f 3` PROGNAME=`ps -p $PID -o comm --no-headers` for SWAP in `grep VmSwap $DIR/status 2>/dev/null | awk '{ print $2 }'` do let SUM=$SUM+$SWAP done if (( $SUM > 0 )); then echo "PID=$PID swapped $SUM KB ($PROGNAME)" fi let OVERALL=$OVERALL+$SUM SUM=0doneecho "Overall swap used: $OVERALL KB"Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
# for file in /proc/*/status ; \do awk '/VmSwap|Name/{printf $2 " " $3} END { print ""}' \$file; done | sort -k 2 -n -r | less#linux #script #perfomance
{kind=link}
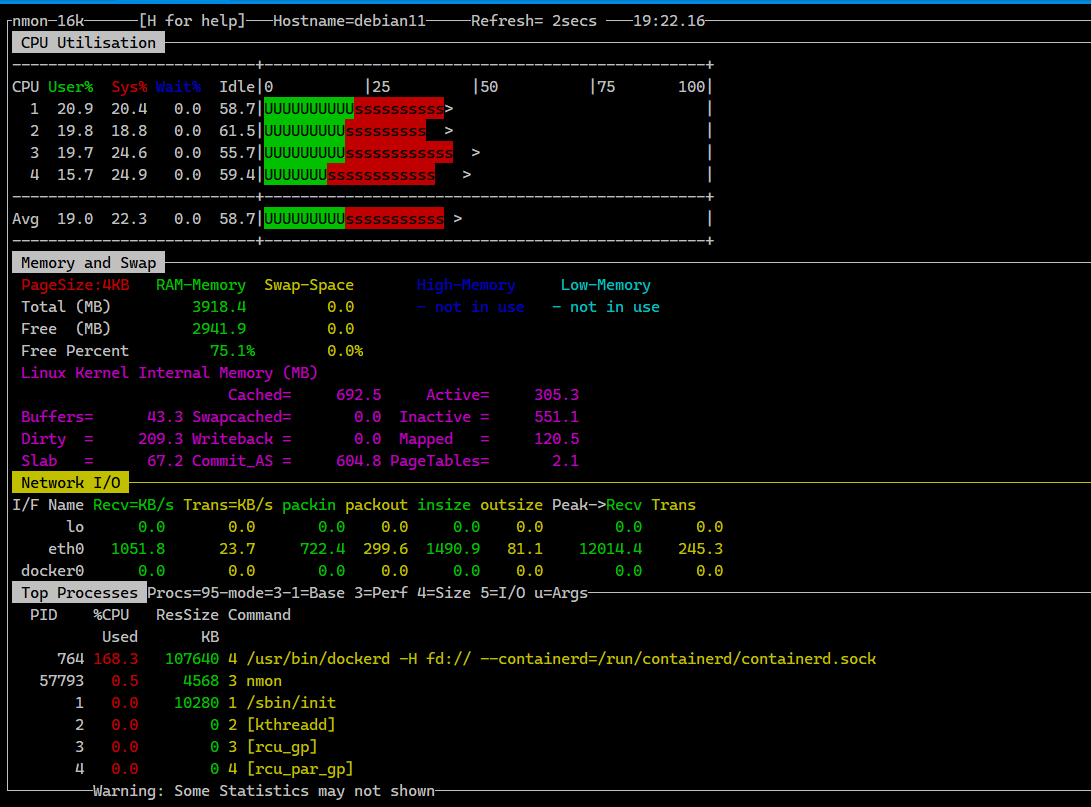
Представляю вашему вниманию очень старую, прямо таки олдскульную программу для анализа нагрузки Linux сервера — nmon. Она периодически всплывает в обсуждениях, рекомендациях. Я почему-то был уверен, что писал о ней. Но поиск по каналу неумолим — ни одного упоминания в заметках. Хотя программа известная, удобная и актуальная по сей день. Не заброшена, развивается, есть в репозиториях популярных дистрибутивов.
По своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
# apt install nmonПо своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
{kind=link}
Утилиту lsof в дистрибутивах Linux чаще всего используют для просмотра открытых файлов. Я и сам так делаю, и много материалов на эту тему видел. Да и название у неё говорящее. Оно как раз образовано от фразы list open files.
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
или так:
▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
▪ Смотрим открытые файлы конкретного пользователя:
Часто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
А теперь то же самое, только наоборот исключим открытые файлы пользователя:
Рассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
▪ Список TCP соединений к конкретному IP адресу:
▪ Список TCP соединений конкретного пользователя:
▪ Помимо TCP, можно и UDP соединения смотреть:
Публикацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
# lsof | grep '(deleted)'или так:
# lsof +L1▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
# lsof +D /var/log▪ Смотрим открытые файлы конкретного пользователя:
# lsof -u userЧасто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
# lsof -u user | wc -lА теперь то же самое, только наоборот исключим открытые файлы пользователя:
# lsof -u^user | wc -lРассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
# kill -9 `lsof -t -u user`▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
# lsof -p 94169▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
# lsof -ni▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
# lsof -ni TCP:80 ▪ Список TCP соединений к конкретному IP адресу:
# lsof -ni TCP@172.29.139.228▪ Список TCP соединений конкретного пользователя:
# lsof -ai -u nginx▪ Помимо TCP, можно и UDP соединения смотреть:
# lsof -iUDPПубликацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Вчера слушал вебинар Rebrain на тему диагностики производительности в Linux. Его вёл Лавлинский Николай. Выступление получилось интересное, хотя чего-то принципиально нового я не услышал. Все эти темы так или иначе разбирал в своих заметках в разное время, но всё это сейчас разрознено. Постараюсь оформить на днях в какую-то удобную единую заметку со ссылками. Заодно дополню той информацией, что узнал из вебинара.
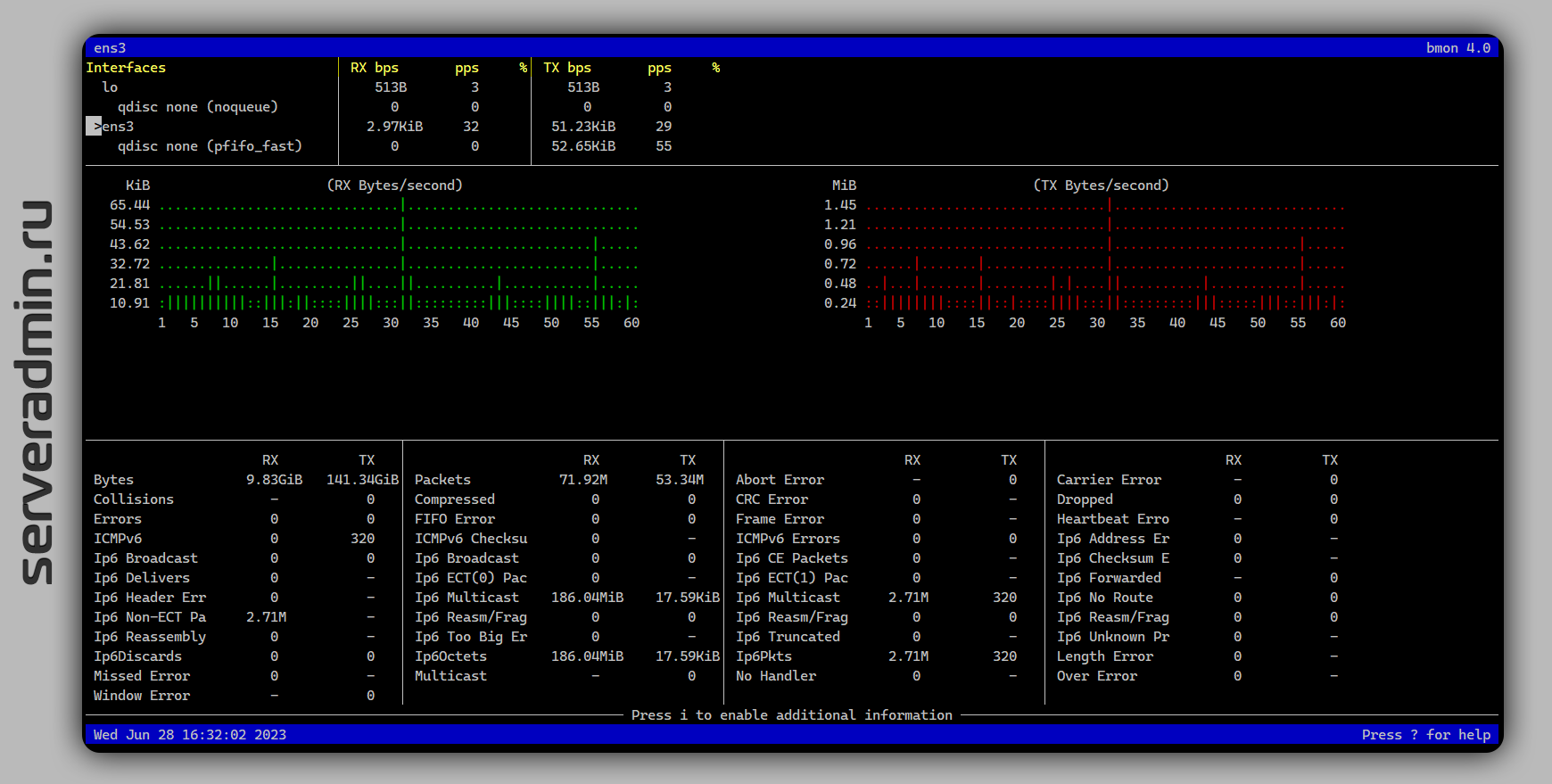
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
Рекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
# apt install bmonРекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
{kind=link}
Как и обещал, подготовил заметку по профилированию нагрузки в Linux. Первое, что нужно понимать — для диагностики нужна методика. Хаотичное использование различных инструментов только в самом простом случае даст положительный результат.
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
top ,atop или любом другом менеджере процессов. Это универсальная метрика, с которой обязательно надо разобраться и понять, что конкретно она показывает. У меня есть заметка по ней. ✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
free -m. С памятью в Linux тоже не всё так просто. Недавно делал заметку на эту тему в рамках рассказа о pmon. Там же подробности того, как оценивать используемую и доступную память. Наряду с памятью стоит заглянуть в swap и посмотреть, кто и как его использует.✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
{kind=link}
Небольшой совет по быстродействию сайтов и веб приложений, который очень простой, но если вы его не знаете, то можете потратить уйму времени на поиски причин медленного ответа веб сервера.
Всегда проверяйте внешние ссылки на ресурсы и, по возможности, копируйте их к себе на веб сервер. Особенно много проблем может доставить какой-нибудь curl к внешнему ресурсу в самом коде. Это вообще бомба замедленного действия, которую потом очень трудно и неочевидно отлаживать. Если внешний ресурс начнёт отвечать с задержкой в 5-10 секунд, то при определённых обстоятельствах, у вас вся страница будет ждать это же время, прежде чем уедет к клиенту.
В коде за такие штуки можно только бить по рукам программистов. А вот если это статика для сайта в виде шрифтов, js кода, стилей, то это можно исправить и самостоятельно. К примеру, я давно и успешно практикую загрузку javascript кода от Яндекс.Метрики локально со своего сервера. Для этого сделал простенький скрипт:
Он работает по расписанию раз в день. В коде счётчика на сайте указан не внешний адрес mc.yandex.ru/metrika/watch.js к скрипту, а локальный serveradmin.ru/watch.js. Подобная конструкция у меня работает уже не один год и никаких проблем с работой статистики нет. При этом минус лишний запрос к внешнему источнику. Причём очень медленный запрос.
То же самое делаю с внешними шрифтами и другими скриптами. Всё, что можно, копирую локально. А то, что не нужно, отключаю. К примеру, я видел сайт, где был подключен код от reCaptcha, но она не использовалась. В какой-то момент отключили, а код оставили. Он очень сильно замедляет загрузку страницы, так как там куча внешних запросов к сторонним серверам.
Внешние запросы статики легко отследить с помощью типовых сервисов по проверке скорости загрузки сайта, типа webpagetest, gtmetrix, или обычной панели разработчика в браузере. Если это в коде используется, то всё намного сложнее. Надо либо код смотреть, либо как-то профилировать работу скриптов и смотреть, где там задержки.
Я когда-то давно писал статью по поводу ускорения работы сайта. Там описана в том числе и эта проблема. Пробежал глазами по статье. Она не устарела. Всё, что там перечислено, актуально и по сей день. Если поддерживаете сайты, почитайте, будет полезно. Там такие вещи, на которые некоторые в принципе не обращают внимания, так как на работу в целом это никак не влияет. Только на скорость отдачи страниц.
#webserver #perfomance
Всегда проверяйте внешние ссылки на ресурсы и, по возможности, копируйте их к себе на веб сервер. Особенно много проблем может доставить какой-нибудь curl к внешнему ресурсу в самом коде. Это вообще бомба замедленного действия, которую потом очень трудно и неочевидно отлаживать. Если внешний ресурс начнёт отвечать с задержкой в 5-10 секунд, то при определённых обстоятельствах, у вас вся страница будет ждать это же время, прежде чем уедет к клиенту.
В коде за такие штуки можно только бить по рукам программистов. А вот если это статика для сайта в виде шрифтов, js кода, стилей, то это можно исправить и самостоятельно. К примеру, я давно и успешно практикую загрузку javascript кода от Яндекс.Метрики локально со своего сервера. Для этого сделал простенький скрипт:
#!/bin/bashcurl -o /web/sites/serveradmin.ru/www/watch.js https://mc.yandex.ru/metrika/watch.jschown serveradmin.ru:nginx /web/sites/serveradmin.ru/www/watch.jsОн работает по расписанию раз в день. В коде счётчика на сайте указан не внешний адрес mc.yandex.ru/metrika/watch.js к скрипту, а локальный serveradmin.ru/watch.js. Подобная конструкция у меня работает уже не один год и никаких проблем с работой статистики нет. При этом минус лишний запрос к внешнему источнику. Причём очень медленный запрос.
То же самое делаю с внешними шрифтами и другими скриптами. Всё, что можно, копирую локально. А то, что не нужно, отключаю. К примеру, я видел сайт, где был подключен код от reCaptcha, но она не использовалась. В какой-то момент отключили, а код оставили. Он очень сильно замедляет загрузку страницы, так как там куча внешних запросов к сторонним серверам.
Внешние запросы статики легко отследить с помощью типовых сервисов по проверке скорости загрузки сайта, типа webpagetest, gtmetrix, или обычной панели разработчика в браузере. Если это в коде используется, то всё намного сложнее. Надо либо код смотреть, либо как-то профилировать работу скриптов и смотреть, где там задержки.
Я когда-то давно писал статью по поводу ускорения работы сайта. Там описана в том числе и эта проблема. Пробежал глазами по статье. Она не устарела. Всё, что там перечислено, актуально и по сей день. Если поддерживаете сайты, почитайте, будет полезно. Там такие вещи, на которые некоторые в принципе не обращают внимания, так как на работу в целом это никак не влияет. Только на скорость отдачи страниц.
#webserver #perfomance
Server Admin
Оптимизация скорости сайта, аудит сайта | serveradmin.ru
На конкретном примере тестирую работу сайта, показываю инструменты для этого и выполняю оптимизацию скорости загрузки сайта.
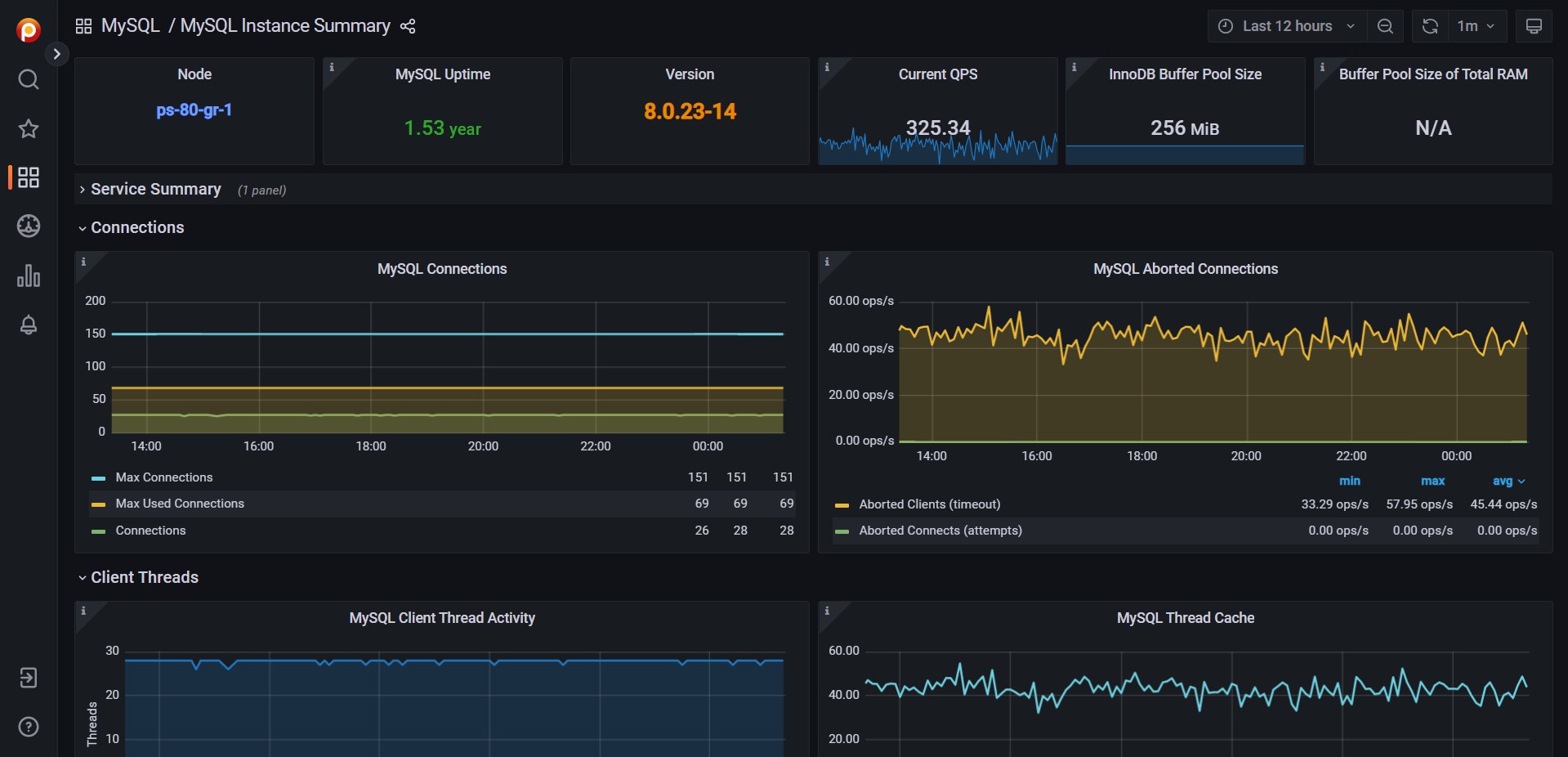
Я посмотрел два больших информативных вебинара про оптимизацию запросов в MySQL. Понятно, что в формате заметки невозможно раскрыть тему, поэтому я сделаю выжимку основных этапов и инструментов, которые используются. Кому нужна будет эта тема, сможет раскрутить её на основе этих вводных.
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
log_error = /var/log/mysql/error.logslow_query_logslow_query_log_file = /var/log/mysql/slow.loglong_query_time = 2.0Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
{kind=link}
Запомнился один момент с недавней конференции, где я присутствовал. Выступающий рассказывал, если не ошибаюсь, про технологию VDI и оптимизацию полосы пропускания, что позволяет комфортно общаться по видеосвязи. В подтверждение своих слов с цифрами показал картинку, где справа окно терминала.
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Я сразу же узнал, чем они измеряли скорость. Это утилита iftop, которую я сам почти всегда ставлю на сервера под своим управлением. Привык к ней. Удобно быстро посмотреть потоки трафика на сервере с разбивкой по IP адресам и портам.
Ну и чтобы добавить пользы посту, приведу список утилит со схожей функциональностью, но не идентичной. То есть они дополняют друг друга: bmon, Iptraf, sniffer, netsniff-ng.
#network #perfomance
Почти во всех популярных дистрибутивах Linux в составе присутствует утилита vmstat. С её помощью можно узнать подробную информацию по использованию оперативной памяти, cpu и дисках. Лично я её не люблю, потому что вывод неинформативен. Утилита больше для какой-то глубокой диагностики или мониторинга, нежели простого использования в консоли.
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
Как можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
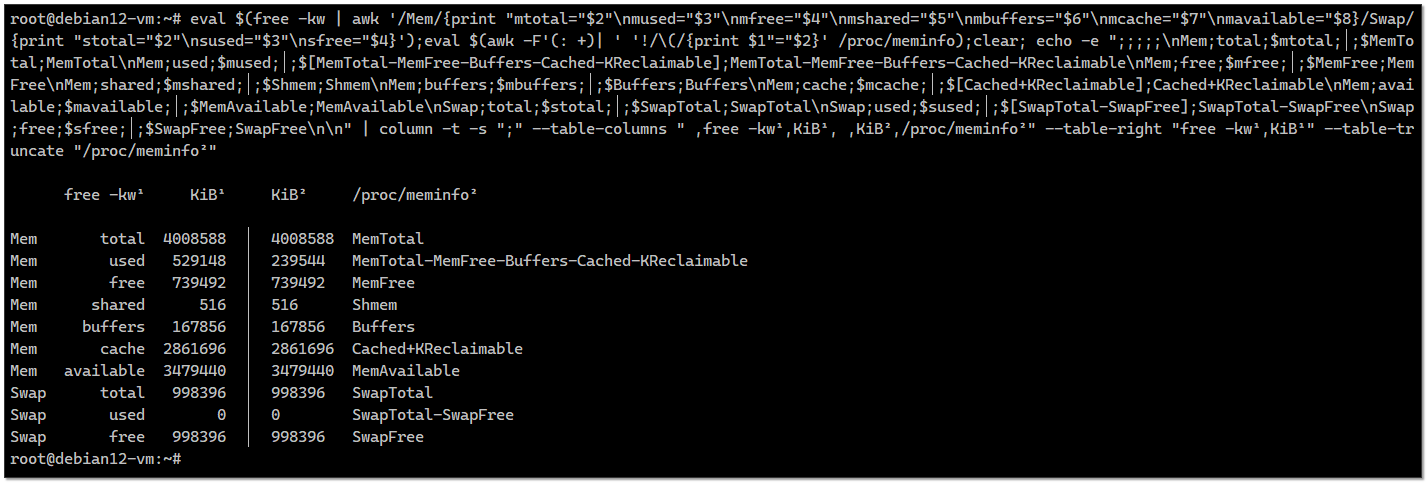
А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
# vmstat 1 -w -S MКак можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
man vmstat они подробно описаны, так что с интерпретацией проблем не должно возникать.А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
free и cat /proc/meminfo: # eval $(free -kw | awk '/Mem/{print "mtotal="$2"\nmused="$3"\nmfree="$4"\nmshared="$5"\nmbuffers="$6"\nmcache="$7"\nmavailable="$8}/Swap/{print "stotal="$2"\nsused="$3"\nsfree="$4}');eval $(awk -F'(: +)| ' '!/\(/{print $1"="$2}' /proc/meminfo);clear; echo -e ";;;;;\nMem;total;$mtotal;│;$MemTotal;MemTotal\nMem;used;$mused;│;$[MemTotal-MemFree-Buffers-Cached-KReclaimable];MemTotal-MemFree-Buffers-Cached-KReclaimable\nMem;free;$mfree;│;$MemFree;MemFree\nMem;shared;$mshared;│;$Shmem;Shmem\nMem;buffers;$mbuffers;│;$Buffers;Buffers\nMem;cache;$mcache;│;$[Cached+KReclaimable];Cached+KReclaimable\nMem;available;$mavailable;│;$MemAvailable;MemAvailable\nSwap;total;$stotal;│;$SwapTotal;SwapTotal\nSwap;used;$sused;│;$[SwapTotal-SwapFree];SwapTotal-SwapFree\nSwap;free;$sfree;│;$SwapFree;SwapFree\n\n" | column -t -s ";" --table-columns " ,free -kw¹,KiB¹, ,KiB²,/proc/meminfo²" --table-right "free -kw¹,KiB¹" --table-truncate "/proc/meminfo²"Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
{kind=link}