
Хочу предложить вашему вниманию bash скрипт по проверке статуса работы Nginx. Обращаю внимание именно на него, потому что он классно написан и его можно взять за основу для любой похожей задачи. Сейчас подробно расскажу, что там происходит.
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
Для начала отмечу, что этот скрипт check_nginx_running.sh из репозитория Linux scripts. Его ведёт автор сайта https://blog.programs74.ru. Я с ним не знаком, но часто пользовался его материалами и скриптами. Всё классно написано и рассказано. Так что рекомендую.
Что делает этот скрипт:
1. Проверяет, запущен ли он под root.
2. Проверяет существование master и worker процессов nginx.
3. Проверяет занимаемую ими оперативную память.
4. Записывает все свои действия в текстовый файл.
5. Перезапускает службу, если она не запущена.
6. Перед перезапуском проверяет конфигурацию на отсутствие ошибок.
Возможность логирования и перезапуска включается или отключается по желанию.
Этот скрипт легко адаптировать под мониторинг любых других процессов Linux. Какие-то проверки можно убрать, логику упростить. Пример с Nginx как раз удобен, так как тут и 2 разных процесса, и проверка конфигурации. Сразу сложный пример разобран.
Если у вас есть какая-то система мониторинга, и она не умеет мониторить процессы Linux, можно использовать подобный скрипт. Проще всего настроить анализ лог файла и выдавать оповещения в зависимости от его содержимого. Не придётся особо ломать голову, как реализовать. Уже всё реализовано.
Например, в Zabbix из коробки для мониторинга служб есть ключи proc.num и proc.mem, которые считают количество запущенных процессов с заданным именем и используемую память. Это всё, что есть встроенного по части процессов. Если нужна какая-то реакция, например, запуск упавшего процесса, то нужно всё равно писать bash скрипт для этого, который будет запускаться триггером.
Соответственно, у вас есть 2 пути по настройке контроля за процессом: использовать скрипт типа этого про крону и в мониторинге наблюдать за ним, либо следить за состоянием процесса через мониторинг и отдельным скриптом совершать какие-то действия. Что удобнее, решать по месту в зависимости от используемой архитектуры инфраструктуры. Позволять через Zabbix запускать скрипты на удалённых машинах не всегда удобно и безопасно. У локального скрипта в cron тоже есть свои минусы. Решать надо по ситуации.
#script #bash #мониторинг
{kind=link}
Один подписчик поделился полезным сервисом, про который я ранее не слышал:
⇨ https://cmdgenerator.phphe.com.
С его помощью можно подготовить итоговую команду для популярных утилит командной строки Linux с набором параметров. Сделано добротно и удобно. Это такая продвинутая замена man, которая позволяет быстрее сформировать нужные параметры. Единственное, заметил, что некоторые ключи не совпадают с ключами этой утилиты в том же Debian. Не понятно, для какой версии они актуальны. Стоило бы указать.
Что-то похожее я как будто уже видел, но сходу не могу вспомнить. На ум приходит другой сервис, который действует наоборот. Длинную консольную команду разбирает на отдельные части и поясняет, что каждая из них делает:
⇨ https://explainshell.com
Похожие на первый сервисы есть для отдельных утилит. Например, я знаю для find удобную штуку:
⇨ find-command-generator
Он тоже неплохо сделан и может существенно помочь. У find куча параметров, которые невозможно запомнить. Надо либо готовые команды записывать, либо открывать man и искать нужное. Этот помощник может сэкономить время. Для cron ещё полно похожих сервисов.
#bash #terminal
⇨ https://cmdgenerator.phphe.com.
С его помощью можно подготовить итоговую команду для популярных утилит командной строки Linux с набором параметров. Сделано добротно и удобно. Это такая продвинутая замена man, которая позволяет быстрее сформировать нужные параметры. Единственное, заметил, что некоторые ключи не совпадают с ключами этой утилиты в том же Debian. Не понятно, для какой версии они актуальны. Стоило бы указать.
Что-то похожее я как будто уже видел, но сходу не могу вспомнить. На ум приходит другой сервис, который действует наоборот. Длинную консольную команду разбирает на отдельные части и поясняет, что каждая из них делает:
⇨ https://explainshell.com
Похожие на первый сервисы есть для отдельных утилит. Например, я знаю для find удобную штуку:
⇨ find-command-generator
Он тоже неплохо сделан и может существенно помочь. У find куча параметров, которые невозможно запомнить. Надо либо готовые команды записывать, либо открывать man и искать нужное. Этот помощник может сэкономить время. Для cron ещё полно похожих сервисов.
#bash #terminal
{kind=link}
🎓 Сегодня пятница, а пятница — это почти выходной, когда уже не хочется заниматься делами. Лучше это время потратить с пользой и заняться самообразованием. А в этом нам может помочь набор TUI программ для обучения в консоли.
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
Запускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
Ответ правильный и мне предлагают ещё вариант:
С sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
Я ошибся и срезал только 4 строки. Поправился:
Утилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
Тоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
#обучение #terminal #bash
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
# python3 -m venv textual_apps# cd textual_apps# source bin/activate# pip install cliexercises# cliexercisesЗапускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
head -n 5 ip.txtОтвет правильный и мне предлагают ещё вариант:
sed '5q' ip.txtС sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
tail -n +5 blocks.txt Я ошибся и срезал только 4 строки. Поправился:
tail -n +6 blocks.txtУтилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
sed '1,5d' blocks.txtТоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
awk 'NR>5' blocks.txt Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
%=%=, надо вывести 3-й блок. Для меня это уже сложно, чтобы что-то сходу придумать. Вот решение:awk '$0 == \"%=%=\"{c++} c==3' blocks.txt#обучение #terminal #bash
{kind=link}
🎓 На прошлой неделе я рассказывал про репозиторий с обучающими TUI программами с популярными консольными утилитами. Хочу обратить внимание на тренажёр по awk. Я там увидел много полезных примеров с возможностями awk, про которые я даже не знал.
⇨ https://github.com/learnbyexample/TUI-apps/tree/main/AwkExercises
Например, я никогда не использовал awk для того, чтобы вывести строки с определёнными символами. Обычно использовал для этого grep, а потом передавал вывод в awk. Хотя в этом нет никакой необходимости. Awk сам умеет это делать:
Команды делают одно и то же. Выводят строки со словом word. Понятно, что если задача стоит только в этом, то grep использовать проще. Но если нужна дальнейшая обработка, то уже не так однозначно. Например, нам надо вывести только первый столбец в строках со словом word.
Тут с awk уже явно удобнее будет. Ну и так далее. В программе много актуальных примеров обработки текста с awk, которые стоит посмотреть и какие-то записать к себе.
Например, поставить символ . (точка) в конце каждой строки:
Я не понял логику этой конструкции, но работает, проверил. На основе этого примера сделал свой, когда в начало каждой строки ставится знак комментария:
Это хороший пример, который можно совместить с выборкой по строкам и закомментировать что-то конкретное. Чаще для этого используют sed, но мне кажется, что с awk как-то проще и понятнее получается:
Закомментировали строку со словом word. Удобно комментировать какие-то параметры в конфигурационных файлах.
#обучение #bash
⇨ https://github.com/learnbyexample/TUI-apps/tree/main/AwkExercises
Например, я никогда не использовал awk для того, чтобы вывести строки с определёнными символами. Обычно использовал для этого grep, а потом передавал вывод в awk. Хотя в этом нет никакой необходимости. Awk сам умеет это делать:
# grep 'word' file.txt# awk '/word/' file.txtКоманды делают одно и то же. Выводят строки со словом word. Понятно, что если задача стоит только в этом, то grep использовать проще. Но если нужна дальнейшая обработка, то уже не так однозначно. Например, нам надо вывести только первый столбец в строках со словом word.
# grep 'word' file.txt | awk '{print $1}'# awk '/word/{print $1}' file.txtТут с awk уже явно удобнее будет. Ну и так далее. В программе много актуальных примеров обработки текста с awk, которые стоит посмотреть и какие-то записать к себе.
Например, поставить символ . (точка) в конце каждой строки:
# awk '{print $0 "."}' file.txtЯ не понял логику этой конструкции, но работает, проверил. На основе этого примера сделал свой, когда в начало каждой строки ставится знак комментария:
# awk '{print "#" $0}' file.txtЭто хороший пример, который можно совместить с выборкой по строкам и закомментировать что-то конкретное. Чаще для этого используют sed, но мне кажется, что с awk как-то проще и понятнее получается:
# awk '/word/{print "#" $0}' file.txtЗакомментировали строку со словом word. Удобно комментировать какие-то параметры в конфигурационных файлах.
#обучение #bash
{kind=link}
У меня в управлении много различных серверов. Я обычно не заморачивался с типом файловых систем. Выбирал то, что сервер ставит по умолчанию. Для серверов общего назначения особо нет разницы, будет это XFS или EXT4. А выбор обычно из них стоит. RPM дистрибутивы используют по умолчанию XFS, а DEB — EXT4.
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
Она вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
# mountОна вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
df есть нужный ключ:# df -TFilesystem Type 1K-blocks Used Available Use% Mounted onudev devtmpfs 1988408 0 1988408 0% /devtmpfs tmpfs 401244 392 400852 1% /run/dev/sda2 ext4 19948144 2548048 16361456 14% /tmpfs tmpfs 2006220 0 2006220 0% /dev/shmtmpfs tmpfs 5120 0 5120 0% /run/lock/dev/sda1 vfat 523244 5928 517316 2% /boot/efitmpfs tmpfs 401244 0 401244 0% /run/user/0И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
{kind=link}
В комментариях к заметке, где я рассказывал про неудобочитаемый вывод mount один человек посоветовал утилиту column, про которую я раньше вообще не слышал и не видел, чтобы ей пользовались. Не зря говорят: "Век живи, век учись". Ведение канала и сайта очень развивает. Иногда, когда пишу новый текст по трудной теме, чувствую, как шестерёнки в голове скрипят и приходится напрягаться. Это реально развивает мозг и поддерживает его в тонусе.
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
Получается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
Получается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
# mount | column -tПолучается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
# column -s ":" -t /etc/passwdПолучается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
# column -s ":" -t /etc/passwd | awk '{print $1}'Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
{kind=link}
Во времена развития искусственного интеллекта сидеть и вспоминать команды и ключи консольных утилит Linux уже как-то не солидно. Пусть "вкалывают роботы, а не человек".
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
Извольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
Я не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
sed '1,10d' filenameИзвольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
find ./ -name "*.php" -exec sed -i 's/old/new/g' {} +Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
find /source/directory -type f -mtime +30 -exec ls -s {} \; \| sort -n -r | head -10 | awk '{print $2}' \| xargs -I '{}' mv '{}' /destination/directoryЯ не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
{kind=link}
Смотрите, какая прикольна штука есть для подключения по SSH из консоли - sshto. Это небольшой bash скрипт, который позволяет через псевдографическое меню управлять преднастроенными SSH подключениями. Хорошее решение для самодельного jumphost.
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
Ставим sshto:
Запускаем:
Видим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
Это когда вы используете промежуточный сервер для подключения к целевым серверам. Такой подход позволяет гибко управлять доступом на основе пользователей jump севера, логировать команды и записывать вывод консоли. И всё без каких-то специализированных решений. В основном средствами самого Linux и его небольших утилит. У меня в разное время были различные заметки по этой теме. Если интересно, могу собрать их в одну.
Вернёмся к sshto. Как я уже сказал, это bash скрипт, который читает конфигурацию из файла
~/.ssh/config и выводит список серверов оттуда в псевдографическое меню. Вот пример такого файла:#Host DUMMY #Moscow#Host server-number-one #First ServerHostName 1.2.3.4port 22777user rootHost server-number-two #Second serverHostName 4.3.2.1port 22888user username#Host DUMMY #Saint Petersburg#Host server-number-three #Third serverHostName 5.6.7.8port 22user user01Host server-number-four #Fourth serverHostName 9.8.7.6port 22user user02Ставим sshto:
# git clone https://github.com/vaniacer/sshto# cd sshto/# cp sshto /usr/bin/Запускаем:
# sshtoВидим меню, такое же как, в приложенной картинке. Помимо непосредственно подключений по SSH, скрипт умеет там же, на удалённых серверах, сразу же выполнять некоторые команды.
#ssh #bash #script
{kind=link}
В Linux есть подсистема ядра, которая позволяет получать уведомления о событиях, связанных с файлами и каталогами файловой системы. Называется Inotify. Я упоминал о ней недавно, когда рассказывал про Lsyncd, которая получает информацию от inotify и запускает синхронизацию при изменениях в файлах.
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
Для наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
Всё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
◽
Откроем рядом ещё одну консоль, создадим, обновим и удалим в директории
В логе при этом будет следующее:
Это уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
Запускаем:
Это самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
И дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
#linux #bash
На основе inotify можно организовать простой мониторинг за изменениями файлов. Реализовать это можно, к примеру, с помощью утилиты fswatch, которая есть в базовых репозиториях практически всех популярных систем (GNU/Linux, *BSD, Mac OS X, Solaris). В каждой системе она выбирает свой механизм ядра для уведомлений. В Linux это inotify.
Устанавливаем fswatch:
# apt install fswatchДля наблюдения за файлом или каталогом достаточно просто запустить fswatch в консоли:
# fswatch /tmpВсё, что будет происходить с файлами и директориями в /tmp, будет выводиться в консоль. Но в таком виде утилита малоинформативна и на практике бесполезна. Запускать лучше сразу с парочкой дополнительных ключей:
◽
-x - отображать тип событий◽
-t - отображать временные метки# fswatch -x -t /tmpОткроем рядом ещё одну консоль, создадим, обновим и удалим в директории
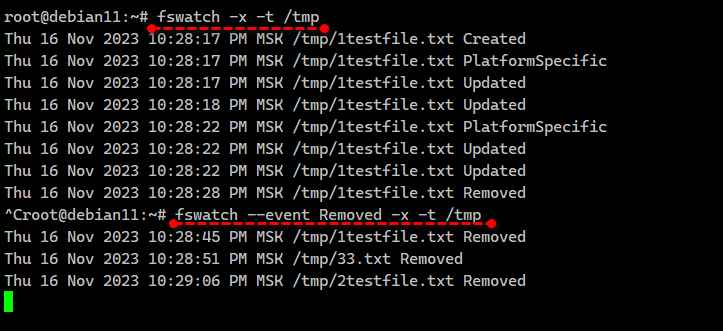
/tmp файл:# echo '123' > file.txt# rm file.txtВ логе при этом будет следующее:
Thu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt CreatedThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt PlatformSpecificThu 16 Nov 2023 09:14:10 PM MSK /tmp/file.txt UpdatedThu 16 Nov 2023 09:14:25 PM MSK /tmp/file.txt RemovedЭто уже более прикладное решение. Можно запустить fswatch в фоне, вывод направить, например, в текстовый файл и анализировать его с помощью Zabbix, реагируя на какие-то события. В статье рассказано в том числе как настроить триггеры. Первое, что приходит в голову, это сделать вот так:
# fswatch -x -t /tmp >> /var/log/fswatch.log &Утилита будет работать в фоне и писать в файл изменения. Можно добавить запуск через cron по событию @reboot, чтобы запускать при старте системы.
Надёжнее написать запуск через systemd, создав файл /etc/systemd/system/fswatch.service:
[Unit]Description=Start fswatch file monitorWants=fswatch.service[Service]ExecStart=fswatch -x -t /tmp[Install]WantedBy=multi-user.targetЗапускаем:
# systemctl start fswatch.serviceЭто самый простой вариант. Лог будет писаться сюда же, в journald. Смотреть можно так:
# journalctl -u fswatch.serviceИ дальше обрабатывать как обычные systemd логи. Можно вывести эти логи в отдельный namespace и отправить в централизованное хранилище.
Простой и эффективный способ решения задачи минимальными сторонними средствами. Можно обернуть в любую логику с помощью bash и использовать по потребностям. Например, на почту что-то слать при удалении файла, или сразу в Telegram. Тип событий указывается отдельным ключом:
# fswatch --event Removed -x -t /tmp#linux #bash
{kind=link}
Казалось бы, что может быть проще копирования файлов из одной директории в другую. Тем не менее в консоли Linux это не всегда простая и очевидная процедура. Для этого существует небольшая утилита
Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
Но так скопируются только файлы, без вложенных директорий. Добавляем ключ
По моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
На длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
Ещё засаду с
Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
Тут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
cp, которая обычно присутствует во всех дистрибутивах. Лично у меня сложности возникают с тем, что я начинаю вспоминать, нужно ли использовать *, ставить или нет слеш на конце директории и т.д. Всё это влияет на конечный результат. Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
# cp /dir_a/* /dir_bНо так скопируются только файлы, без вложенных директорий. Добавляем ключ
-r или сразу -a, чтобы и все атрибуты скопировать:# cp -a /dir_a/* /dir_bПо моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
# cp -a /dir_a/file1 /dir_a/file2 /dir_a/file3 ...... /dir_bНа длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
* в командах, запускаемых в bash, работает именно так.Ещё засаду с
cp можно получить, если в директории будут файлы, начинающиеся с точки. Те же .htaccess. Если скопируем предложенной выше командой со *, то все файлы с точкой в начале имени потеряем. Будет неприятно. Это опять же особенность bash, которая по умолчанию трактует такие файлы как скрытые. Такое поведение можно изменить.Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
* :# cp -aT /dir_a /dir_bТут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash