
Анализ дисковой активности в Linux
Расскажу кратко, с помощью каких консольных инструментов можно всесторонне рассмотреть дисковую активность на сервере под управлением Linux.
Начнём издалека и посмотрим общую дисковую активность отдельного устройства. Для этого можно воспользоваться утилитой btrace из пакета blktrace (есть в стандартных репах)
В течении 60 секунд утилита будет анализировать дисковую активность процессов и потоков ядра. В завершении покажет сводную статистику.
Наглядный вывод статистики по дисковым устройствам в режиме реального времени есть у iostat из пакета sysstat (есть в репозиториях). Я предпочитаю вот такое отображение с использованием watch:
Более детально в режиме реального времени нагрузку на диск отдельных приложений можно посмотреть с помощью iotop (есть в репозиториях). Простой запуск без параметров похож на обычный top, только про диски. Более наглядную информацию можно получить, запустив iotop с ключами:
Ещё один вариант отображения активности процессов в режиме реального времени - pidstat. Она тоже из пакета sysstat. Запускаем с обновлением раз в секунду:
Видим активность всех процессов. Можем конкретизировать, указав один из них по его pid:
Двигаемся дальше и смотрим, в какие файлы производится запись с помощью fatrace (в deb дистрибутивах есть в репозиториях). Проверка очень простая и быстрая через анализ обращений к inotify.
Можно записать всю файловую активность в лог файл и потом спокойно посмотреть:
Более детально разобраться с тем, что пишет процесс на диск можно с помощью strace, указав ему в качестве параметра PID процесса:
Напомню, что PID процесса или процессов можно узнать, например, вот так:
или так:
Смотрим список открытых файлов в конкретной директории с помощью lsof:
Приведённых стандартных инструментов достаточно, чтобы провести основной анализ. Я перечислю ещё несколько удобных инструментов, но их скорее всего придётся ставить вручную, минуя пакетный менеджер, что не очень удобно.
◽ утилита iosnoop из пакета perf-tools, показывает много полезной информации, в том числе latency, чего не делают перечисленные выше утилиты
◽ утилита biosnoop из пакета BPF Tools, показывает активность процессов, в том числе используемые сектора дисков и latency, в этом же пакете к дискам имеют отношения утилиты: biolatency, biotop, bitesize, ext4slower и подобные для других файловых систем.
#bash #perfomance
Расскажу кратко, с помощью каких консольных инструментов можно всесторонне рассмотреть дисковую активность на сервере под управлением Linux.
Начнём издалека и посмотрим общую дисковую активность отдельного устройства. Для этого можно воспользоваться утилитой btrace из пакета blktrace (есть в стандартных репах)
# btrace -w 60 -a write /dev/mapper/rhel-rootВ течении 60 секунд утилита будет анализировать дисковую активность процессов и потоков ядра. В завершении покажет сводную статистику.
Наглядный вывод статистики по дисковым устройствам в режиме реального времени есть у iostat из пакета sysstat (есть в репозиториях). Я предпочитаю вот такое отображение с использованием watch:
# watch -n 1 iostat -xkБолее детально в режиме реального времени нагрузку на диск отдельных приложений можно посмотреть с помощью iotop (есть в репозиториях). Простой запуск без параметров похож на обычный top, только про диски. Более наглядную информацию можно получить, запустив iotop с ключами:
# iotop -obPatЕщё один вариант отображения активности процессов в режиме реального времени - pidstat. Она тоже из пакета sysstat. Запускаем с обновлением раз в секунду:
# pidstat -d 1Видим активность всех процессов. Можем конкретизировать, указав один из них по его pid:
# pidstat -p PID -d 1Двигаемся дальше и смотрим, в какие файлы производится запись с помощью fatrace (в deb дистрибутивах есть в репозиториях). Проверка очень простая и быстрая через анализ обращений к inotify.
# fatrace -f WМожно записать всю файловую активность в лог файл и потом спокойно посмотреть:
# fatrace -t -s 60 -o ~/fatrace.logБолее детально разобраться с тем, что пишет процесс на диск можно с помощью strace, указав ему в качестве параметра PID процесса:
# strace -e trace=write -p PIDНапомню, что PID процесса или процессов можно узнать, например, вот так:
# pgrep mariadbили так:
# ps ax | grep mariadbСмотрим список открытых файлов в конкретной директории с помощью lsof:
# lsof +D /var/logПриведённых стандартных инструментов достаточно, чтобы провести основной анализ. Я перечислю ещё несколько удобных инструментов, но их скорее всего придётся ставить вручную, минуя пакетный менеджер, что не очень удобно.
◽ утилита iosnoop из пакета perf-tools, показывает много полезной информации, в том числе latency, чего не делают перечисленные выше утилиты
◽ утилита biosnoop из пакета BPF Tools, показывает активность процессов, в том числе используемые сектора дисков и latency, в этом же пакете к дискам имеют отношения утилиты: biolatency, biotop, bitesize, ext4slower и подобные для других файловых систем.
#bash #perfomance
Иногда нужно понять, почему какая-то программа или сам сервер на Linux тормозит. Обычно анализ производительности начинается с высокоуровневых средств top, htop, atop и т.д. Если эти инструменты не дают однозначного ответа, в чём проблема, нужно спускаться на уровень ниже.
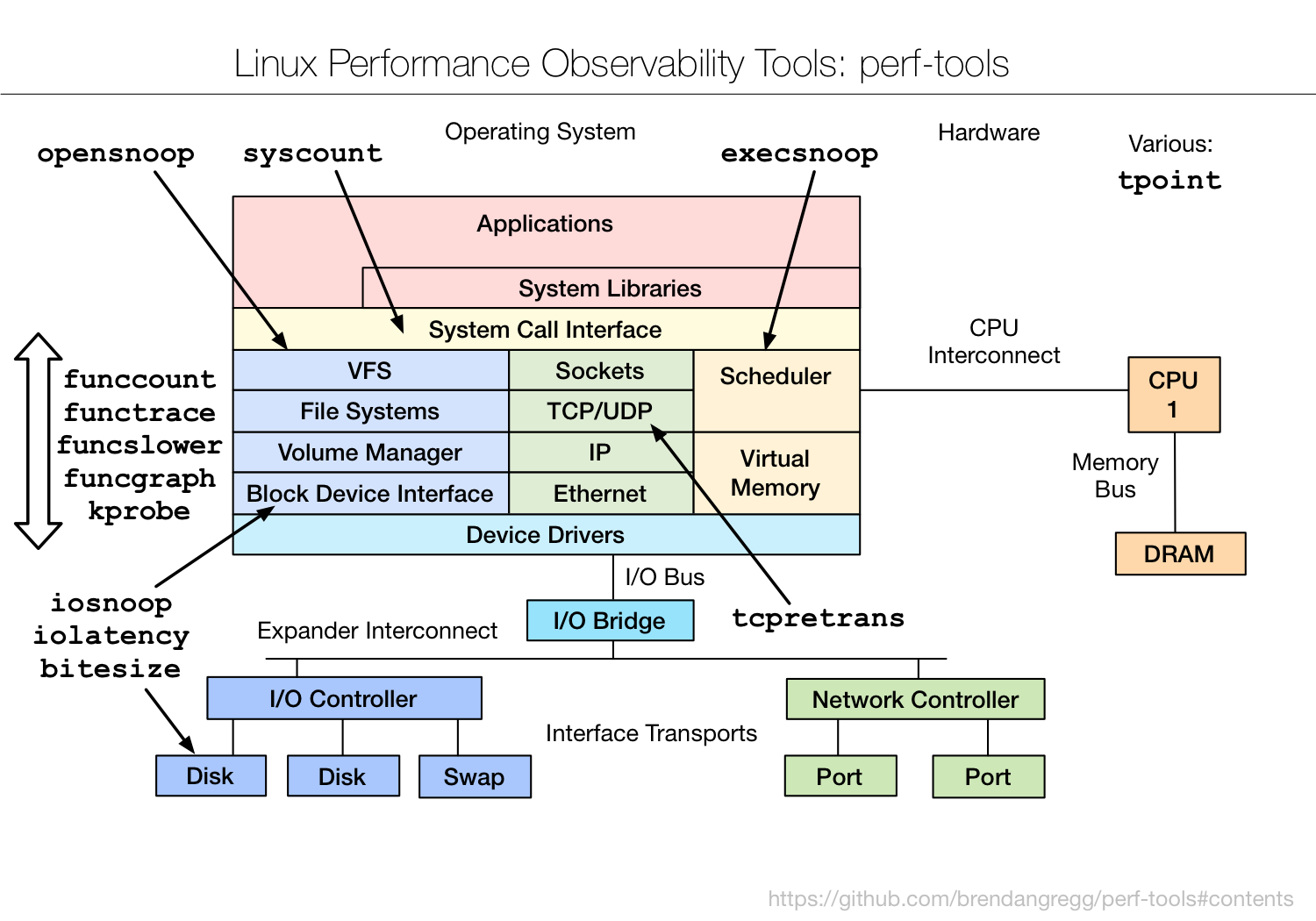
В Linux есть встроенные профилировщики - perf и ftrace. Они входят в состав ядра. На их базе есть большой набор утилит perf-tools, о которых я хочу рассказать. Кратко я уже делал отсылки к ним в разных заметках.
Автором perf-tools является небезызвестный Brendan Gregg. Производительности Linux у него на сайте посвящена отдельная страница, где в том числе упоминаются эти утилиты. Там же есть видео по работе с ними.
Утилиты хорошо структурированы, описаны и приведены примеры, так что работать с ними очень просто. Покажу на конкретном примере. Допустим, нам кажется, что тормозит диск. Надо разобраться, в чём проблема.
Запускаем утилиту iolatency и смотрим latency диска. Если это современный SSD, то большая часть запросов будут укладываться в диапазон 0 -> 1 мс.
Мы видим, что много запросов имеют latency значительно выше. Попробуем разобраться, что именно отвечает медленнее. Запускаем iosnoop и смотрим на отклик приложений:
Я для теста в соседней консоли запустил tar со сжатием, так что все медленные запросы были от него. В данном случае в качестве приложения указана оболочка sh, потому что tar запускает gzip в ней.
Если у вас несколько дисков в системе и они разные - SSD и HDD, то после общего запуска iolatency, можно запустить с анализом конкретного диска. В одном из примеров Brendan Gregg показывает, что отклик обычного HDD со смешанной нагрузкой read/write может быть существенно уменьшен изменением длины очереди со стандартных 128 до 4:
Указанные выше утилиты позволят проанализировать это и оценить результат, подобрать нужное значение.
Расскажу ещё про утилиту opensnoop. Она делают одну простую вещь - с помощью системных вызовов open() показывает открытые файлы и приложения, которые их открывают. Очень удобно для быстрого анализа того, что вообще происходит с диском.
Вывод можно ограничить каким-то отдельным процессом по PID, или посмотреть файлы по маске:
Она же с помощью ключа -x может показать неудавшиеся попытки открыть файл. Это может быть очень полезно в некоторых ситуациях. Например, стартует сервис и не принимает настройки из конфига. Запустив opensnoop с этим ключом можно увидеть, что сервис пытается открыть конфиг по другому пути, а не там, где он у вас лежит.
Утилиты очень простые для освоения и использования. При этом позволяют выполнить низкоуровневый анализ работы системы и найти узкие места. Я показал пример с диском, но там же в репозитории есть инструменты для анализа cpu и сети.
Заметку заберите в закладки. Когда что-то пойдёт не так на сервере, пригодится.
#linux #bash #perfomance
В Linux есть встроенные профилировщики - perf и ftrace. Они входят в состав ядра. На их базе есть большой набор утилит perf-tools, о которых я хочу рассказать. Кратко я уже делал отсылки к ним в разных заметках.
Автором perf-tools является небезызвестный Brendan Gregg. Производительности Linux у него на сайте посвящена отдельная страница, где в том числе упоминаются эти утилиты. Там же есть видео по работе с ними.
Утилиты хорошо структурированы, описаны и приведены примеры, так что работать с ними очень просто. Покажу на конкретном примере. Допустим, нам кажется, что тормозит диск. Надо разобраться, в чём проблема.
Запускаем утилиту iolatency и смотрим latency диска. Если это современный SSD, то большая часть запросов будут укладываться в диапазон 0 -> 1 мс.
# ./iolatency >=(ms) .. <(ms) : I/O |Distribution | 0 -> 1 : 155 |######################################| 1 -> 2 : 10 |### | 2 -> 4 : 19 |##### | 4 -> 8 : 47 |############ | 8 -> 16 : 34 |######### | 16 -> 32 : 5 |## |Мы видим, что много запросов имеют latency значительно выше. Попробуем разобраться, что именно отвечает медленнее. Запускаем iosnoop и смотрим на отклик приложений:
# ./iosnoopTracing block I/O. Ctrl-C to end.COMM PID TYPE DEV BLOCK BYTES LATmsjbd2/sda3-28 286 WS 8,0 10834312 32768 0.72kworker/2:1H 140 WS 8,0 10834376 4096 0.31sh 48839 W 8,0 16379904 1073152 5.23sh 48839 W 8,0 16382000 8192 5.12sh 48839 W 8,0 16382016 1310720 7.71sh 48839 W 8,0 16384576 262144 8.88sh 48839 W 8,0 16387648 229376 11.20sh 48839 W 8,0 16385088 1310720 14.12sh 48839 W 8,0 16388096 1310720 32.67sh 48839 W 8,0 16390656 12288 32.67jbd2/sda3-28 286 WS 8,0 10834384 28672 0.67Я для теста в соседней консоли запустил tar со сжатием, так что все медленные запросы были от него. В данном случае в качестве приложения указана оболочка sh, потому что tar запускает gzip в ней.
Если у вас несколько дисков в системе и они разные - SSD и HDD, то после общего запуска iolatency, можно запустить с анализом конкретного диска. В одном из примеров Brendan Gregg показывает, что отклик обычного HDD со смешанной нагрузкой read/write может быть существенно уменьшен изменением длины очереди со стандартных 128 до 4:
# echo 4 > /sys/block/xvda1/queue/nr_requestsУказанные выше утилиты позволят проанализировать это и оценить результат, подобрать нужное значение.
Расскажу ещё про утилиту opensnoop. Она делают одну простую вещь - с помощью системных вызовов open() показывает открытые файлы и приложения, которые их открывают. Очень удобно для быстрого анализа того, что вообще происходит с диском.
# ./opensnoopВывод можно ограничить каким-то отдельным процессом по PID, или посмотреть файлы по маске:
# ./opensnoop -p 181# ./opensnoop 'log$'Она же с помощью ключа -x может показать неудавшиеся попытки открыть файл. Это может быть очень полезно в некоторых ситуациях. Например, стартует сервис и не принимает настройки из конфига. Запустив opensnoop с этим ключом можно увидеть, что сервис пытается открыть конфиг по другому пути, а не там, где он у вас лежит.
Утилиты очень простые для освоения и использования. При этом позволяют выполнить низкоуровневый анализ работы системы и найти узкие места. Я показал пример с диском, но там же в репозитории есть инструменты для анализа cpu и сети.
Заметку заберите в закладки. Когда что-то пойдёт не так на сервере, пригодится.
#linux #bash #perfomance
{kind=link}
Я рассказывал про удобные и простые в использовании утилиты профилирования производительности Linux - perf-tools. Расскажу вам про похожий набор утилит, только заточенные на анализ сетевой активности. Речь пойдёт про netsniff-ng. Это довольно старый и известный пакет, который можно установить через пакетный менеджер популярных дистрибутивов.
В состав netsniff-ng входит несколько утилит, реализующих различный функционал. Их 8, я перечислю только то, что сам иногда использую:
▪ Непосредственно netsniff-ng, который является аналогом tcpdump, сниффер сетевого трафика. Я пробовал, но лично мне tcpdump больше нравится.
▪ Trafgen - генератор сетевого трафика с гибкими настройками. Например, с его помощью можно налить кучу synflood трафика. Примеры шаблонов конфигов под разный трафик можно найти в сети.
▪ Ifpps - показывает статистику по загрузке сетевого интерфейса. Очень точные данные, получаемые напрямую из ядра. Наглядное отображение информации по трафику, пакетам, ошибкам, нагрузке cpu, задержек и т.д. Запускать так:
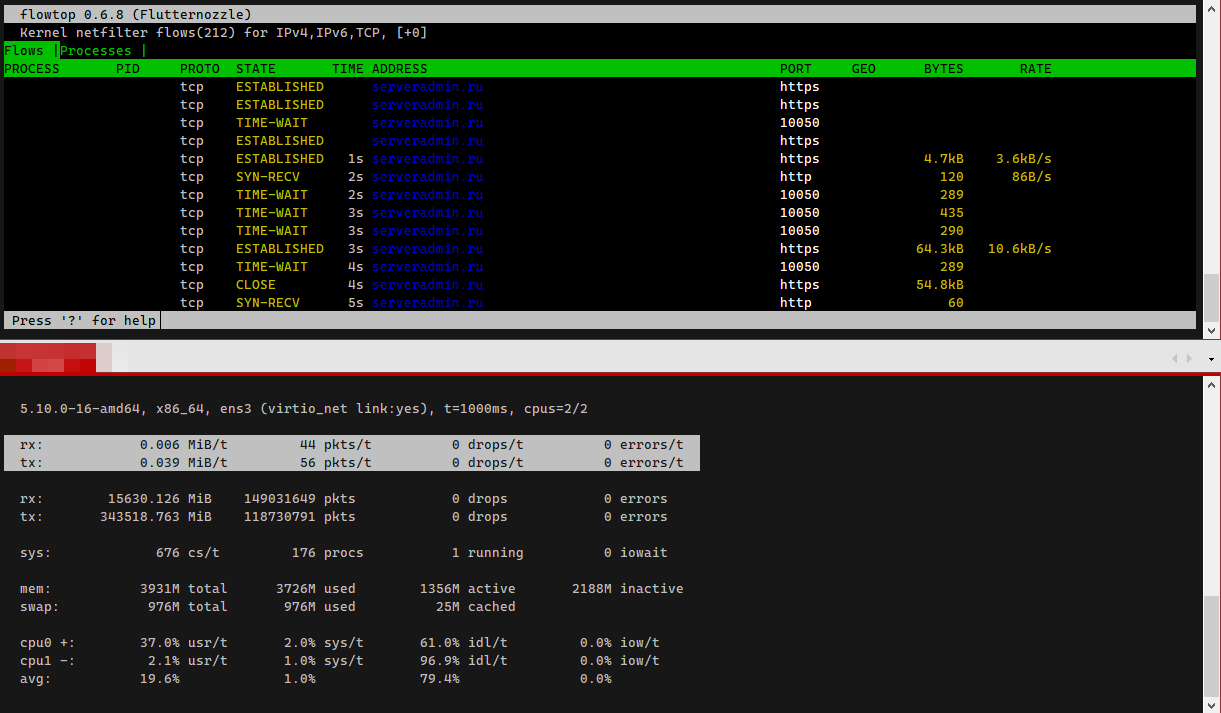
▪ Flowtop - показывает список сетевых соединений с информацией о процессе, удалённом адресе, к которому подключались, статистику по трафику и кое-что ещё. Отображение удобное и наглядное. Похоже на связку Iftop + NetHogs. Закрывает функционал обоих утилит. Запускать с ключом -G, чтобы не подключалась GeoIP4 база. Её надо отдельно качать.
Остальные утилиты:
◽ mausezahn - генератор пакетов с Cisco-like CLI;
◽ bpfc - компилятор Berkeley Packet Filter, даже не знаю, для чего он на практике нужен;
◽ curvetun - лёгкий, высокопроизводительный туннель на базе TUN/TAP интерфейсов;
◽ astraceroute - трассировщик с выводом информации в том числе об autonomous system (AS).
Для анализа сети достаточно установить только netsniff-ng. В нём есть всё, что может пригодиться для получения всей полноты информации.
Сайт - http://www.netsniff-ng.org/
Исходники - https://github.com/netsniff-ng/netsniff-ng
#linux #bash #perfomance #network
# apt install netsniff-ng# dnf install netsniff-ngВ состав netsniff-ng входит несколько утилит, реализующих различный функционал. Их 8, я перечислю только то, что сам иногда использую:
▪ Непосредственно netsniff-ng, который является аналогом tcpdump, сниффер сетевого трафика. Я пробовал, но лично мне tcpdump больше нравится.
▪ Trafgen - генератор сетевого трафика с гибкими настройками. Например, с его помощью можно налить кучу synflood трафика. Примеры шаблонов конфигов под разный трафик можно найти в сети.
▪ Ifpps - показывает статистику по загрузке сетевого интерфейса. Очень точные данные, получаемые напрямую из ядра. Наглядное отображение информации по трафику, пакетам, ошибкам, нагрузке cpu, задержек и т.д. Запускать так:
# ifpps -d ens18▪ Flowtop - показывает список сетевых соединений с информацией о процессе, удалённом адресе, к которому подключались, статистику по трафику и кое-что ещё. Отображение удобное и наглядное. Похоже на связку Iftop + NetHogs. Закрывает функционал обоих утилит. Запускать с ключом -G, чтобы не подключалась GeoIP4 база. Её надо отдельно качать.
# flowtop -GОстальные утилиты:
◽ mausezahn - генератор пакетов с Cisco-like CLI;
◽ bpfc - компилятор Berkeley Packet Filter, даже не знаю, для чего он на практике нужен;
◽ curvetun - лёгкий, высокопроизводительный туннель на базе TUN/TAP интерфейсов;
◽ astraceroute - трассировщик с выводом информации в том числе об autonomous system (AS).
Для анализа сети достаточно установить только netsniff-ng. В нём есть всё, что может пригодиться для получения всей полноты информации.
Сайт - http://www.netsniff-ng.org/
Исходники - https://github.com/netsniff-ng/netsniff-ng
#linux #bash #perfomance #network
{kind=link}
Расскажу про ещё одну отличную утилиту для локального мониторинга и поиска узких мест в производительности Linux. Я её уже упоминал в разных заметках, но не было единой публикации, чтобы забрать в закладки. Речь пойдёт про dstat.
Утилита есть в стандартных репозиториях дистрибутивов. Ставим так:
Dstat - универсальный инструмент, который частично перекрывает функционал iostat, vmstat, netstat и ifstat. У утилиты есть отдельно свои односимвольные ключи, которые вызываются одиночным тире и список плагинов, которые вызываются через двойное тире. Их можно комбинировать.
Покажу сразу пример из свой шпаргалки, которой постоянно пользуюсь:
При этом будет выводиться с интервалом в 10 секунд:
◽ текущее время – t
◽ средняя загрузка системы – l
◽ использования дисков – d
◽ загрузка сетевых устройств – n
◽ активность процессов – p
◽ использование памяти – m
◽ использование подкачки – s
Очень удобная команда, которая позволяет быстро и комплексно оценить загрузку системы по всем основным характеристикам.
Нагрузка на диск с разбивкой по процессам:
Пример того, как можно настроить вывод информации в удобном для себя формате:
◽ load average -l
◽ использование памяти -m
◽ использование swap -s
◽ процесс, занимающий больше всего памяти --top-mem
У утилиты очень много разнообразных ключей для той или иной информации. Комбинируя их, можно настраивать необходимый вам вывод.
Набор метрик для анализа нагрузки на CPU:
Любопытный ключ:
Утилита покажет того, кого OOM Killer грохнет первого, если закончится оперативная память. Не знаю, чем это отличается от ключа --top-mem. По идее, одно и то же должно быть.
Ну и так далее. Комбинаций ключей может быть много. Список всех доступных плагинов можно посмотреть так:
или в man.
К слову, развитие этой утилиты прекратилось в 2019 году из-за того, что Red Hat взяли это же название для своего продукта из набора Performance Co-Pilot. Об этом автор написал в репозитории. Я не знаю, что в современных дистрибутивах, основанных на RHEL, ставится под этим названием пакета. В Debian по прежнему старый dstat. В Centos 7 тоже он же ставился, я постоянно пользовался. Что интересно, замену можно и не заметить, так как все ключи и вывод команды Red Hat повторили в своём продукте. То есть сознательно так поступили, заняв известное имя.
#perfomance
Утилита есть в стандартных репозиториях дистрибутивов. Ставим так:
# apt install dstat# dnf install dstatDstat - универсальный инструмент, который частично перекрывает функционал iostat, vmstat, netstat и ifstat. У утилиты есть отдельно свои односимвольные ключи, которые вызываются одиночным тире и список плагинов, которые вызываются через двойное тире. Их можно комбинировать.
Покажу сразу пример из свой шпаргалки, которой постоянно пользуюсь:
# dstat -tldnpms 10При этом будет выводиться с интервалом в 10 секунд:
◽ текущее время – t
◽ средняя загрузка системы – l
◽ использования дисков – d
◽ загрузка сетевых устройств – n
◽ активность процессов – p
◽ использование памяти – m
◽ использование подкачки – s
Очень удобная команда, которая позволяет быстро и комплексно оценить загрузку системы по всем основным характеристикам.
Нагрузка на диск с разбивкой по процессам:
# dstat --top-ioПример того, как можно настроить вывод информации в удобном для себя формате:
# dstat -l -m -s --top-mem◽ load average -l
◽ использование памяти -m
◽ использование swap -s
◽ процесс, занимающий больше всего памяти --top-mem
У утилиты очень много разнообразных ключей для той или иной информации. Комбинируя их, можно настраивать необходимый вам вывод.
Набор метрик для анализа нагрузки на CPU:
# dstat -c -y -l --proc-count --top-cpuЛюбопытный ключ:
# dstat --top-oomУтилита покажет того, кого OOM Killer грохнет первого, если закончится оперативная память. Не знаю, чем это отличается от ключа --top-mem. По идее, одно и то же должно быть.
Ну и так далее. Комбинаций ключей может быть много. Список всех доступных плагинов можно посмотреть так:
# dstat --listили в man.
К слову, развитие этой утилиты прекратилось в 2019 году из-за того, что Red Hat взяли это же название для своего продукта из набора Performance Co-Pilot. Об этом автор написал в репозитории. Я не знаю, что в современных дистрибутивах, основанных на RHEL, ставится под этим названием пакета. В Debian по прежнему старый dstat. В Centos 7 тоже он же ставился, я постоянно пользовался. Что интересно, замену можно и не заметить, так как все ключи и вывод команды Red Hat повторили в своём продукте. То есть сознательно так поступили, заняв известное имя.
#perfomance
{kind=link}
В августе было несколько постов с анализом производительности Linux. Хочу немного подвести итог и сгруппировать информацию, чтобы получилась последовательная картинка по теме.
Вам кажется, что сервер тормозит. Первым делом загляните в top или htop (я его предпочитаю). Если понимания, в чём конкретно проблема, не возникло начинаем копать глубже. Типичный пример непонимания - всё тормозит, даже по ssh долгое подключение, load average высокий, а процессор не загружен, память свободная есть.
1️⃣ Используйте dstat, запустив комплексный вывод основных метрик. Это первый пример из заметки:
Там как минимум будет видно, какая и где именно нагрузка. Скорее всего если по top не понятно, в чём проблема, то смотреть надо на диски и сеть.
2️⃣ Я бы в первую очередь посмотрел на диски. Для этого можно воспользоваться заметкой Анализ дисковой активности в Linux. Там конкретные примеры по выводу различной информации с помощью разных утилит. Если они не помогли, то спускаемся на уровень ниже, берём набор утилит perf-tools и используем iolatency и iosnoop. В заметке есть описание с примерами.
3️⃣ Теперь разбираемся с сетью. Берём пакет netsniff-ng и анализируем сетевую активность - трафик, соединения, источники соединений с привязкой к процессам и т.д. В первую очередь понадобятся утилиты Ifpps и flowtop. Чуть более простые и дружелюбные для использования утилиты для анализа сети описаны у меня в посте про программу sniffer. И вот еще список тематических утилит с описанием: Iftop, NetHogs, Iptraf, Bmon.
Я знаю, что многие могут порекомендовать более продвинутые top'ы, типа atop, bashtop, glances и им подобные. Лично я их не очень люблю и обычно не использую. Иду по пути узконаправленных утилит. Возможно это не всегда оправданно, но у меня вот так.
#perfomance #подборка
Вам кажется, что сервер тормозит. Первым делом загляните в top или htop (я его предпочитаю). Если понимания, в чём конкретно проблема, не возникло начинаем копать глубже. Типичный пример непонимания - всё тормозит, даже по ssh долгое подключение, load average высокий, а процессор не загружен, память свободная есть.
1️⃣ Используйте dstat, запустив комплексный вывод основных метрик. Это первый пример из заметки:
# dstat -tldnpms 10Там как минимум будет видно, какая и где именно нагрузка. Скорее всего если по top не понятно, в чём проблема, то смотреть надо на диски и сеть.
2️⃣ Я бы в первую очередь посмотрел на диски. Для этого можно воспользоваться заметкой Анализ дисковой активности в Linux. Там конкретные примеры по выводу различной информации с помощью разных утилит. Если они не помогли, то спускаемся на уровень ниже, берём набор утилит perf-tools и используем iolatency и iosnoop. В заметке есть описание с примерами.
3️⃣ Теперь разбираемся с сетью. Берём пакет netsniff-ng и анализируем сетевую активность - трафик, соединения, источники соединений с привязкой к процессам и т.д. В первую очередь понадобятся утилиты Ifpps и flowtop. Чуть более простые и дружелюбные для использования утилиты для анализа сети описаны у меня в посте про программу sniffer. И вот еще список тематических утилит с описанием: Iftop, NetHogs, Iptraf, Bmon.
Я знаю, что многие могут порекомендовать более продвинутые top'ы, типа atop, bashtop, glances и им подобные. Лично я их не очень люблю и обычно не использую. Иду по пути узконаправленных утилит. Возможно это не всегда оправданно, но у меня вот так.
#perfomance #подборка
Вы знаете, как узнать, кто и насколько активно использует swap в Linux? Можно использовать для этого top, там можно вывести отдельную колонку со swap. Для этого запустите top, нажмите f и выберите колонку со swap, которой по умолчанию нет в отображении. Насколько я слышал, это не совсем корректный способ, поэтому, к примеру, в htop эту колонку вообще убрали, чтобы не вводить людей в заблуждение.
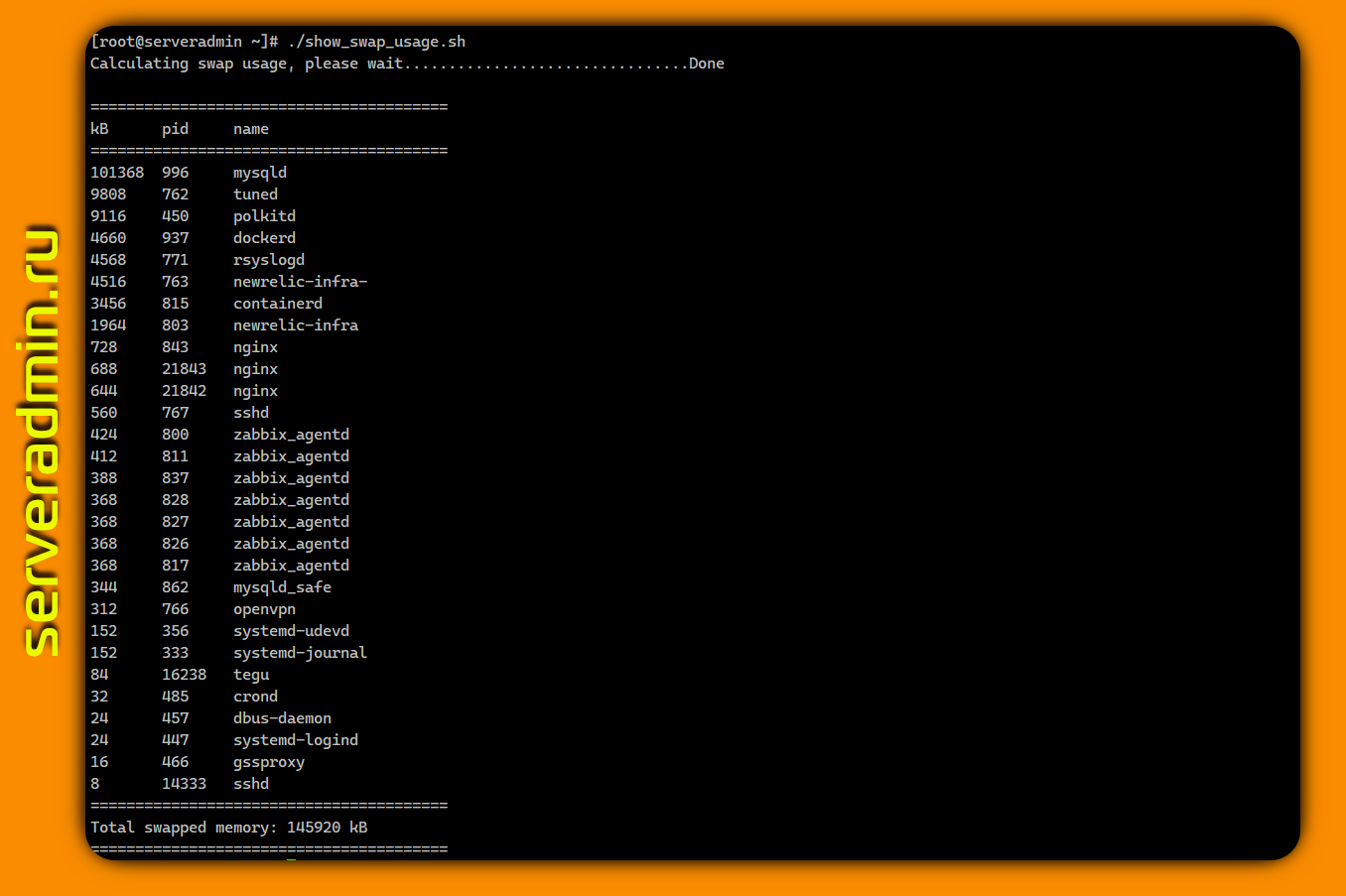
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
#linux #script #perfomance
Самый надёжный способ узнать, сколько процесс занимает места в swap, проверить
/proc/$PID/smaps или /proc/$PID/status. Первая метрика будет самая точная, но там нужно будет вручную вычислить суммарный объём по отдельным кусочкам используемой памяти. Вторая метрика сразу идёт суммой. В сети много различных скриптов, которые вычисляют суммарный объем памяти в swap для процессов и выводят его в различном виде. Вот наиболее простой и короткий:
#!/bin/bash SUM=0OVERALL=0for DIR in `find /proc/ -maxdepth 1 -type d -regex "^/proc/[0-9]+"`do PID=`echo $DIR | cut -d / -f 3` PROGNAME=`ps -p $PID -o comm --no-headers` for SWAP in `grep VmSwap $DIR/status 2>/dev/null | awk '{ print $2 }'` do let SUM=$SUM+$SWAP done if (( $SUM > 0 )); then echo "PID=$PID swapped $SUM KB ($PROGNAME)" fi let OVERALL=$OVERALL+$SUM SUM=0doneecho "Overall swap used: $OVERALL KB"Здесь просто выводятся значения метрики VmSwap из /proc/$PID/status. А тут пример скрипта, где суммируются значения для swap из /proc/$PID/smaps и далее сортируются от самого большого потребителя к наименьшему. Не стал показывать его, потому что он значительно длиннее. Главное, что идею вы поняли. Наколхозить скрипт можно и самому так, как тебе больше нравится.
Можно по-быстрому в консоли посмотреть:
# for file in /proc/*/status ; \do awk '/VmSwap|Name/{printf $2 " " $3} END { print ""}' \$file; done | sort -k 2 -n -r | less#linux #script #perfomance
{kind=link}
Представляю вашему вниманию очень старую, прямо таки олдскульную программу для анализа нагрузки Linux сервера — nmon. Она периодически всплывает в обсуждениях, рекомендациях. Я почему-то был уверен, что писал о ней. Но поиск по каналу неумолим — ни одного упоминания в заметках. Хотя программа известная, удобная и актуальная по сей день. Не заброшена, развивается, есть в репозиториях популярных дистрибутивов.
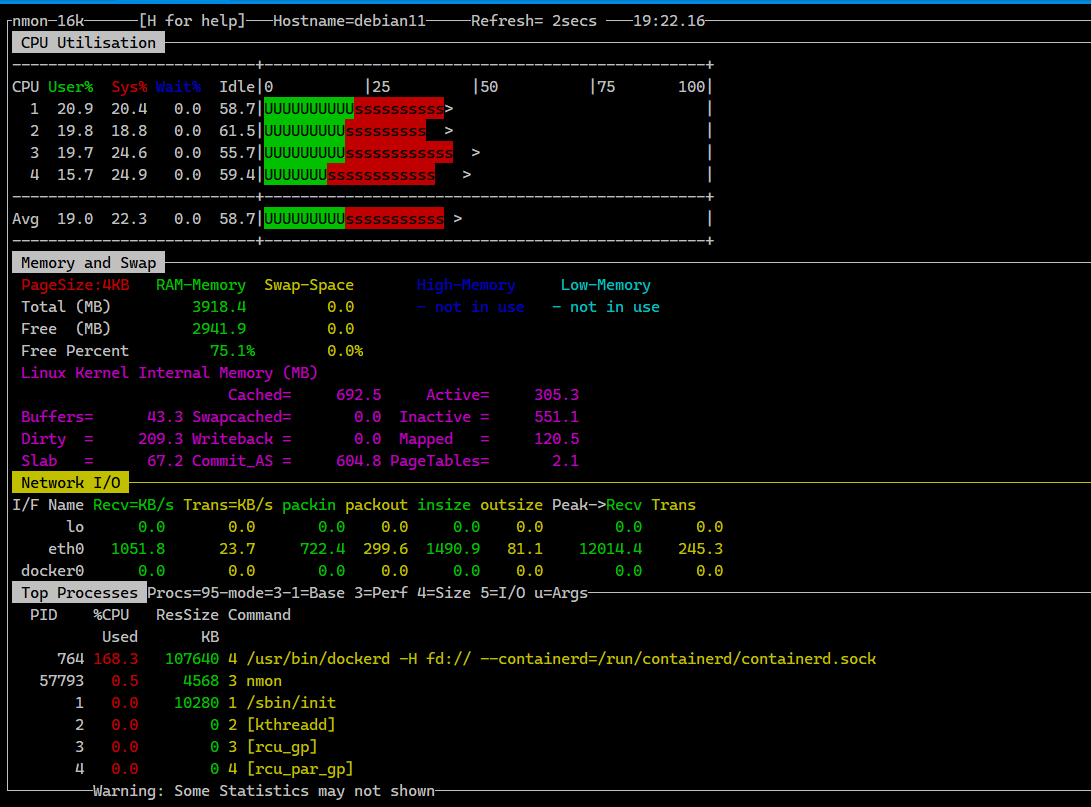
По своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
# apt install nmonПо своей сути nmon — консольная программа, объединяющая частичную функциональность top, iostat, bmon и других подобных утилит. Удобство nmon в первую очередь в том, что вы можете вывести на экран только те метрики, которые вам нужны. К примеру, нагрузку на CPU и Disk, а остальное проигнорировать. Работает это про принципу виджетов, только в данном случае вся информация отображается в консоли. Вы можете собрать интересующий вас дашборд под конкретную задачу.
Nmon умеет показывать:
◽Использование CPU, в том числе в виде псевдографика
◽Использование оперативной памяти и swap
◽Использование сети
◽Нагрузку на диски
◽Статистику ядра
◽Частоту ядер CPU
◽Информацию о NFS подключении (I/O)
◽Список процессов с информацией об использовании ресурсов каждым
И некоторые другие менее значимые метрики.
Помимо работы в режиме реального времени, nmon умеет работать в фоне и собирать информацию в csv файл по заданным параметрам. Например, в течении часа с записью метрик каждую минуту. Смотреть собранную статистику можно через браузер с помощью nmonchart, которую написал этот же разработчик. Nmonchart анализирует csv файл и генерирует на его основе html страницы, которые можно посмотреть браузером. Вот пример подобного отчёта.
Помимо nmon, у автора есть более современная утилита njmon, которая делает всё то же самое, только умеет выгружать данные в json формате. Потом их легко скормить любой современной time-series db. Например, InfluxDB, точно так же, как я это делал с glances.
Помимо всего прочего, для nmon есть конвертер cvs файлов в json, экспортёр данных в InfluxDB, дашборд для Grafana, чтобы вывести метрики из InfluxDB. В общем, полный набор. Всё это собрано на отдельной странице.
Может возникнуть вопрос, а зачем всё это надо? Можно же просто развернуть мониторинг и пользоваться. Мне лично не надо, но вот буквально недавно мне написал человек и предложил работу. Надо было разобраться в их инфраструктуре из трех железных серверов и набора виртуалок, которые их не устраивали по производительности. Надо было сделать анализ и предложить модернизацию. Я сразу же спросил, есть ли мониторинг. Его не было вообще никакого. Я отказался, так как нет свободного времени на эту задачу. Но если бы согласился, то первичный анализ нагрузки пришлось бы делать какими-то подобными утилитами. А потом уже проектировать полноценный мониторинг. В малом и среднем бизнесе отсутствие мониторинга — обычное дело. Я постоянно с этим сталкиваюсь.
#monitoring #terminal #perfomance
{kind=link}
Утилиту lsof в дистрибутивах Linux чаще всего используют для просмотра открытых файлов. Я и сам так делаю, и много материалов на эту тему видел. Да и название у неё говорящее. Оно как раз образовано от фразы list open files.
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
или так:
▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
▪ Смотрим открытые файлы конкретного пользователя:
Часто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
А теперь то же самое, только наоборот исключим открытые файлы пользователя:
Рассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
▪ Список TCP соединений к конкретному IP адресу:
▪ Список TCP соединений конкретного пользователя:
▪ Помимо TCP, можно и UDP соединения смотреть:
Публикацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Тем не менее, её можно использовать не только для этого.
▪ Но сначала про основную функциональность. Лично я чаще всего запускаю lsof для просмотра открытых файлов, которые удалили, но забыли закрыть файловый дескриптор. Например, наживую удалили лог nginx или docker и не перезапустили сервис. В итоге файла нет, а место он занимает. Такие файлы будет видно вот так:
# lsof | grep '(deleted)'или так:
# lsof +L1▪ Смотрим кем и что конкретно открыто из файлов в указанной директории:
# lsof +D /var/log▪ Смотрим открытые файлы конкретного пользователя:
# lsof -u userЧасто бывает нужно быстро узнать, сколько файлов у него открыто, чтобы понять, если с ним проблема или нет:
# lsof -u user | wc -lА теперь то же самое, только наоборот исключим открытые файлы пользователя:
# lsof -u^user | wc -lРассмотрим ситуацию, когда под пользователем плодятся процессы, которые открывают кучу файлов и нам всё это надо быстро прибить. Добавляем ключ -t к lsof, который позволяет выводить только PID процессов. И отправляем вывод в kill:
# kill -9 `lsof -t -u user`▪ Файлы, открытые конкретным процессом, для которого указан его PID. Очень востребованная функциональность.
# lsof -p 94169▪ А теперь немного того, что от lsof не ожидаешь. Список TCP соединений, причём очень наглядный и удобный для восприятия.
# lsof -ni▪ Смотрим подробную информацию о том, кто открыл 80-й порт:
# lsof -ni TCP:80 ▪ Список TCP соединений к конкретному IP адресу:
# lsof -ni TCP@172.29.139.228▪ Список TCP соединений конкретного пользователя:
# lsof -ai -u nginx▪ Помимо TCP, можно и UDP соединения смотреть:
# lsof -iUDPПубликацию имеет смысл сохранить в закладки.
#linux #terminal #perfomance
Вчера слушал вебинар Rebrain на тему диагностики производительности в Linux. Его вёл Лавлинский Николай. Выступление получилось интересное, хотя чего-то принципиально нового я не услышал. Все эти темы так или иначе разбирал в своих заметках в разное время, но всё это сейчас разрознено. Постараюсь оформить на днях в какую-то удобную единую заметку со ссылками. Заодно дополню той информацией, что узнал из вебинара.
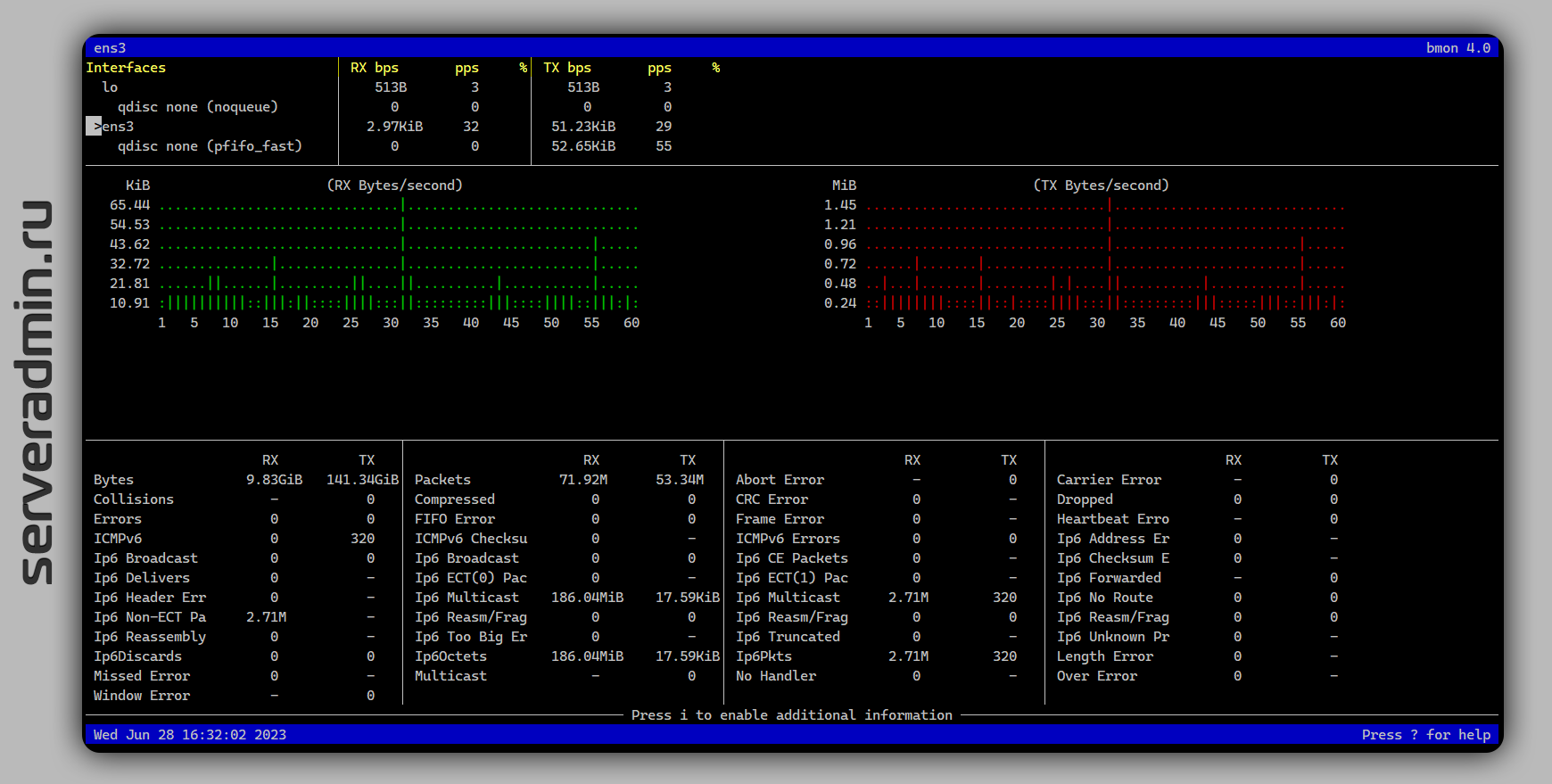
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
Рекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
Там не рассмотрели анализ сетевой активности, хотя автор упомянул утилиту bmon. Точнее, я ему подсказал точное название в чате. Я её давно знаю, упоминал в заметках вскользь, а отдельно не писал. Решил это исправить.
Bmon (bandwidth monitor) — классическая unix утилита для просмотра статистики сетевых интерфейсов. Показывает только трафик, не направления. Основное удобство bmon — сразу показывает разбивку по интерфейсам, что удобно, если у вас их несколько. Плюс, удобная визуализация и наглядный вид статистики.
Утилита простая и маленькая, живёт в стандартных репозиториях, так что с установкой никаких проблем нет:
# apt install bmonРекомендую обратить внимание. По наглядности и удобству использования, она мне больше всего нравится из подобных. Привожу список других полезных утилит по этой теме:
◽Iftop — эту утилиту ставлю по дефолту почти на все сервера. Показывает только скорость соединений к удалённым хостам без привязки к приложениям.
◽NetHogs — немного похожа по внешнему виду на iftop, только разбивает трафик не по направлениям, а по приложениям. В связке с iftop закрывает вопрос анализа полосы пропускания сервера. Можно оценить и по приложениям загрузку, и по удалённым хостам.
◽Iptraf — показывает более подробную информацию, в отличие от первых двух утилит. Плюс, умеет писать информацию в файл для последующего анализа. Трафик разбивает по удалённым подключениям, не по приложениям.
◽sniffer — показывает сетевую активность и по направлениям, и по приложениям, и просто список всех сетевых соединений. Программа удобная и функциональная. Минус в том, что нет в репах, надо ставить вручную с github.
А что касается профилирования производительности сетевой подсистемы, то тут поможет набор инструментов netsniff-ng. В заметке разобрано их применение. Это условный аналог perf-tools, только для сети.
#network #perfomance
{kind=link}
Как и обещал, подготовил заметку по профилированию нагрузки в Linux. Первое, что нужно понимать — для диагностики нужна методика. Хаотичное использование различных инструментов только в самом простом случае даст положительный результат.
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
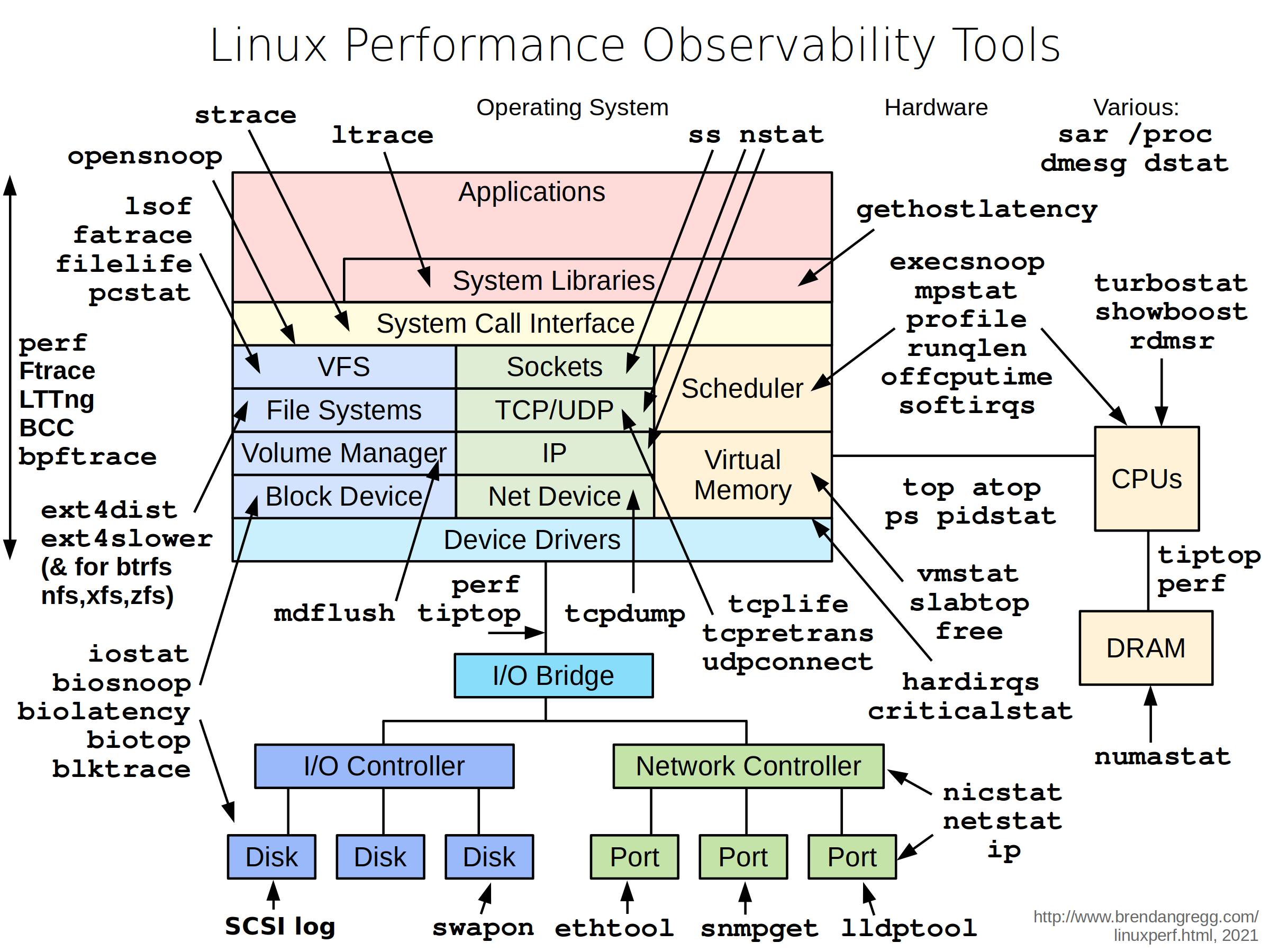
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
Наиболее известные методики диагностики:
🟢 USE от Brendan Gregg — Utilization, Saturation, Errors. Подходит больше для мониторинга ресурсов. Почитать подробности можно на сайте автора.
🟢 RED от Tom Wilkie — Requests, Errors, Durations. Больше подходит для сервисов и приложений. Описание метода можно посмотреть в выступлении автора.
Очень хороший разбор этих методик на примере анализа производительности PostgreSQL есть в выступлении Павла Труханова из Okmeter — Мониторинг Postgres по USE и RED. Очень рекомендую к прочтению или просмотру.
Прежде чем решать какую-то проблему производительности, имеет смысл ответить на несколько вопросов:
1️⃣ На основе каких данных вы считаете, что есть проблема? В чём она выражается?
2️⃣ Когда система работала хорошо?
3️⃣ Что изменилось с тех пор? Железо, софт, настройки, нагрузка?
4️⃣ Вы можете измерить деградацию производительности в каких-то единицах?
После положительного ответа на эти вопросы переходите к решению проблем. Без этого можно ходить по кругу, что-то изменять, перезапускать, но не будет чёткого понимания, что меняется и становится ли лучше. Иногда может быть достаточно просто откатиться по софту на старую версию и проблема сразу же решится.
❗️Важное замечание. Ниже я буду приводить инструменты для диагностики. Нужно понимать, что их использование — крайний случай, когда ничего другое не помогает решить вопрос. В общем случае проблемы производительности решаются с помощью той или иной системы мониторинга, которая должна быть предварительно развёрнута для хранения метрик из прошлого. Отсутствие исторических данных сильно усложняет диагностику и поиск проблем.
✅ Диагностику стоит начать с просмотра Load Average в том же
top ,atop или любом другом менеджере процессов. Это универсальная метрика, с которой обязательно надо разобраться и понять, что конкретно она показывает. У меня есть заметка по ней. ✅ Дальше имеет смысл посмотреть, что с памятью. Либо в том же менеджере процессов, либо отдельно, набрав в терминале
free -m. С памятью в Linux тоже не всё так просто. Недавно делал заметку на эту тему в рамках рассказа о pmon. Там же подробности того, как оценивать используемую и доступную память. Наряду с памятью стоит заглянуть в swap и посмотреть, кто и как его использует.✅ Если LA и Память не дали ответа на вопрос, в чём проблемы, переходим к дисковой подсистеме. Здесь можно использовать dstat или набор других утилит для анализа дисковой активности (btrace, iotop, lsof и т.д.). Отдельно отмечу lsof, с помощью которой удобно исследовать открытые и используемые файлы.
✅ Если представленные выше утилиты не помогли, то нужно спускаться на уровень ниже и подключать встроенные системные профилировщики perf и ftrace. Удобнее всего использовать набор утилит на их основе — perf-tools от того же Brendan Gregg. В отдельной заметке я показывал пример, как разобраться с дисковыми тормозами с их помощью.
✅ Для диагностики сетевых проблем начать можно с простых утилит анализа сетевой активности хостов и приложений. В этом помогут: Iftop, bmon, Iptraf, sniffer, vnStat, nethogs. Если указанные программы не помогли, подключайте более низкоуровневые из пакета netsniff-ng. Там есть как утилиты для диагностики, так и для тестовой нагрузки. Отдельно отмечу консольные команды для анализа сетевого стека. С их помощью можно быстро посмотреть количество сетевых соединений, в том числе с конкретных IP адресов, число соединений в различном состоянии.
На этом у меня всё. Постарался вспомнить и собрать, о чём писал и использовал по этой теме. Разумеется, список не претендует на полноту. Это только мой опыт и знания. Дополнения приветствуются.
☝ Подборку имеет смысл сохранить в закладки!
#perfomance #подборка
{kind=link}