
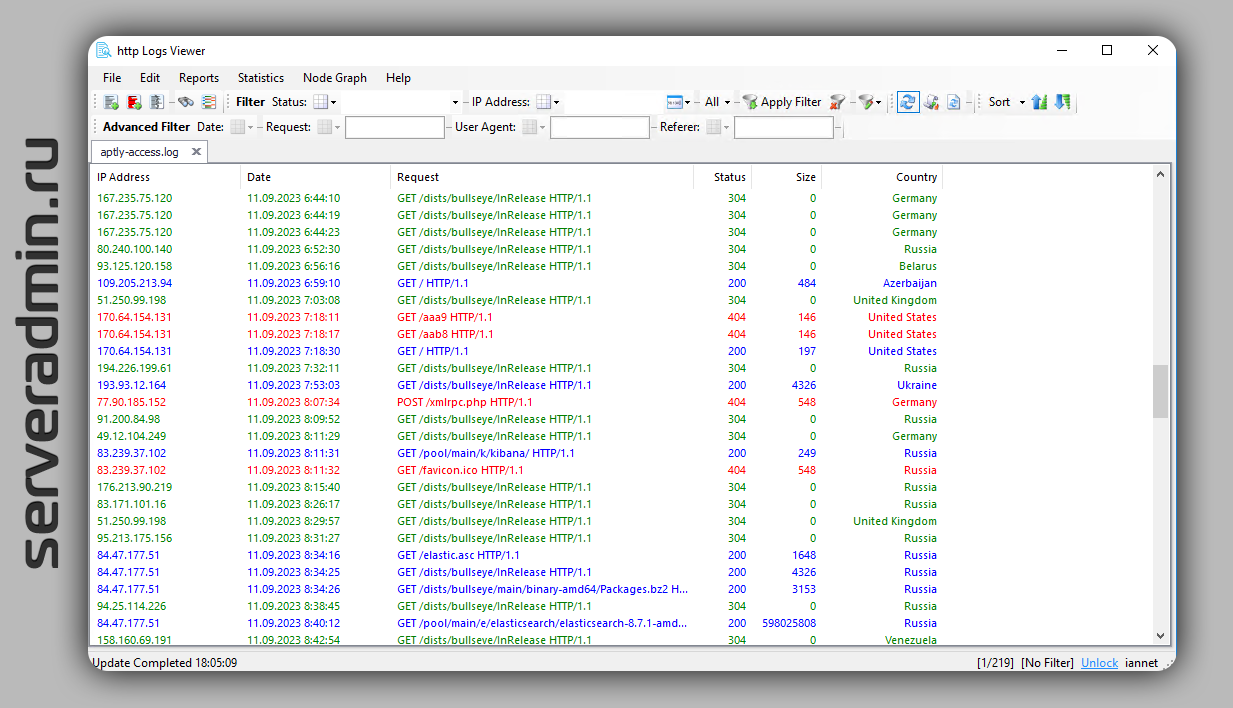
Если у вас есть желание максимально быстро и без лишних телодвижений проанализировать логи веб сервера, то можно воспользоваться типичной windows way программой http Logs Viewer. Скачиваете, устанавливаете, открываете в ней свой лог.
Программа платная, но базовые возможности доступны в бесплатной версии. После открытия лога она автоматом парсит значения из него в виде типовых полей: url, код ответа, IP адрес и т.д. Для IP адреса сразу же определяет страну. Можно тут же сделать сортировку по странам, кодам ответа, урлу и прочим записям в логе.
Если загрузить большой лог, то можно по всем распознанным значениям посмотреть статистику за разные промежутки времени. Тут уже начинается платная функциональность. Бесплатно доступен очень ограниченный набор отчётов.
Программа удобная и простая. Кто привык тыкать мышкой, а не грепать в консоли, будет прям кайфово. Нашёл, отсортировал, скопировал, выгрузил и т.д. Всё наглядно с привычным скролом для больших списков. И никаких вам ELK.
⇨ Сайт
#webserver #logs
Программа платная, но базовые возможности доступны в бесплатной версии. После открытия лога она автоматом парсит значения из него в виде типовых полей: url, код ответа, IP адрес и т.д. Для IP адреса сразу же определяет страну. Можно тут же сделать сортировку по странам, кодам ответа, урлу и прочим записям в логе.
Если загрузить большой лог, то можно по всем распознанным значениям посмотреть статистику за разные промежутки времени. Тут уже начинается платная функциональность. Бесплатно доступен очень ограниченный набор отчётов.
Программа удобная и простая. Кто привык тыкать мышкой, а не грепать в консоли, будет прям кайфово. Нашёл, отсортировал, скопировал, выгрузил и т.д. Всё наглядно с привычным скролом для больших списков. И никаких вам ELK.
⇨ Сайт
#webserver #logs
{kind=link}
Сегодня вышло крупное обновление веб сервера Angie 1.3.0. Кто не читал, посмотрите две мои предыдущие заметки про него (1, 2). Изменения затронули open source версию, так что попробовать и оценить их сможет каждый.
Перечислю наиболее заметные нововведения.
1️⃣ В конфигурации location теперь можно использовать одновременно несколько шаблонов uri. Это упрощает конфигурацию location с одинаковыми настройками. То есть можно сделать примерно вот так:
Сейчас у меня то же самое записано вот так:
Там есть нюанс, что между модификатором и uri не допускается пробел. Немного синтаксис другой получается, не как у одиночных шаблонов. Я возможно что-то с синтаксисом напутал, но идею, думаю, вы поняли. Чуть позже обновится документация и можно будет уже точно смотреть, как это настраивается.
2️⃣ Angie научился самостоятельно экспортировать свою статистику в формате Prometheus, что явно упростит настройку мониторинга. Не нужен отдельный exporter для этих целей. Было бы неплохо сразу и шаблон для Zabbix сделать, не дожидаясь, пока кто-то из энтузиастов это реализует. Достаточно распарсить вывод для Prometheus.
3️⃣ Отдельной настройкой можно включить возможность экспорта содержимого конфигурационных файлов запущенной версии веб сервера через API.
Остальные изменения:
◽детальная информация и метрики по группам проксируемых stream-серверов в интерфейсе статистики, предоставляемом директивой "api"
◽опция "resolve" директивы "server" в блоке "upstream" модуля "stream", позволяющая отслеживать изменения списка IP-адресов, соответствующего доменному имени, и автоматически обновлять его без перезагрузки конфигурации
◽опция "service" директивы "server" в блоке "upstream" модуля "stream", позволяющая получать списки адресов из DNS-записей SRV, с базовой поддержкой приоритета
◽отображение номера поколения конфигурации в именах процессов, что позволяет с помощью утилиты "ps" отслеживать успех перезагрузок конфигурации и количество поколений рабочих процессов с предыдущими версиями конфигурации.
Согласитесь, изменения существенные, которые повышают удобство использования веб сервера. История с мониторингом особенно нравится. Плюс, не забываем, про готовые собранные наиболее популярные модули для веб сервера, которые можно ставить из собранных пакетов разработчиков и подключать в конфигурации. В бесплатной версии Nginx всего этого нет, что требует дополнительные телодвижения при настройке.
#webserver #angie
Перечислю наиболее заметные нововведения.
1️⃣ В конфигурации location теперь можно использовать одновременно несколько шаблонов uri. Это упрощает конфигурацию location с одинаковыми настройками. То есть можно сделать примерно вот так:
location =~/.git ~*^/(\.ht|xmlrpc\.php)${ return 404;}Сейчас у меня то же самое записано вот так:
location ~ /.git {return 404;}location ~* ^/(\.ht|xmlrpc\.php)$ { return 404;}Там есть нюанс, что между модификатором и uri не допускается пробел. Немного синтаксис другой получается, не как у одиночных шаблонов. Я возможно что-то с синтаксисом напутал, но идею, думаю, вы поняли. Чуть позже обновится документация и можно будет уже точно смотреть, как это настраивается.
2️⃣ Angie научился самостоятельно экспортировать свою статистику в формате Prometheus, что явно упростит настройку мониторинга. Не нужен отдельный exporter для этих целей. Было бы неплохо сразу и шаблон для Zabbix сделать, не дожидаясь, пока кто-то из энтузиастов это реализует. Достаточно распарсить вывод для Prometheus.
3️⃣ Отдельной настройкой можно включить возможность экспорта содержимого конфигурационных файлов запущенной версии веб сервера через API.
Остальные изменения:
◽детальная информация и метрики по группам проксируемых stream-серверов в интерфейсе статистики, предоставляемом директивой "api"
◽опция "resolve" директивы "server" в блоке "upstream" модуля "stream", позволяющая отслеживать изменения списка IP-адресов, соответствующего доменному имени, и автоматически обновлять его без перезагрузки конфигурации
◽опция "service" директивы "server" в блоке "upstream" модуля "stream", позволяющая получать списки адресов из DNS-записей SRV, с базовой поддержкой приоритета
◽отображение номера поколения конфигурации в именах процессов, что позволяет с помощью утилиты "ps" отслеживать успех перезагрузок конфигурации и количество поколений рабочих процессов с предыдущими версиями конфигурации.
Согласитесь, изменения существенные, которые повышают удобство использования веб сервера. История с мониторингом особенно нравится. Плюс, не забываем, про готовые собранные наиболее популярные модули для веб сервера, которые можно ставить из собранных пакетов разработчиков и подключать в конфигурации. В бесплатной версии Nginx всего этого нет, что требует дополнительные телодвижения при настройке.
#webserver #angie
{kind=link}
Ко мне как то раз обратился человек за помощью в настройке веб сервера. Суть была вот в чём. У него есть контентный сайт, где он пишет хайповые статьи для сбора ситуативного трафика. Монетизируется, соответственно, показами различной рекламы. Чем больше показов, тем больше доход.
И как-то раз одна его статья очень сильно выстрелила, так что трафик полился огромным потоком с различных агрегаторов новостей и ссылок с других статей. В итоге сайт у него начал падать. У него был некий админ-программист, который занимался сайтом. Он с самого начала потока трафика предпринимал какие-то действия, что помогало не очень. Кардинально решить проблему не мог. Сайт всё равно тормозил и часто отдавал 502 ошибку.
Я отказался помогать, потому что в принципе не занимаюсь разовыми задачами, тем более уже в условиях катастрофы, тем более без запланированного заранее времени. Да ещё на сервере, где непонятно кем и как всё настраивалось. Но для себя пометочку сделал, как лучше всего оперативно выкрутиться в такой ситуации. Сейчас с вами поделюсь примерным ходом решения этой задачи.
Проще всего в такой ситуации поднять прокси сервер на Nginx и тупо всё закэшировать. Причём настроить кэш так, что если сам сайт лёг, то кэш будет отдавать статические страницы, которые он предварительно сохранил, несмотря на то, что сам сайт динамический. Когда нам во что бы то ни стало надо показывать контент, такой вариант сойдёт. При этом сам прокси сервер можно разместить где угодно, создав виртуалку с достаточными ресурсами. Пока будут обновляться DNS записи, такую же прокси можно воткнуть прямо там же на виртуалке с сайтом, а кэш разместить в оперативной памяти.
Настройка простая и быстрая, так что если ранее вы тестировали такой вариант и сохранили конфиг, то всё настроить можно буквально за 5 минут. Ставим на сервер Nginx, если его ещё нет, и добавляем в основной конфиг, в секцию http:
Создаём директорию
Теперь открываем настройки виртуального хоста и добавляем туда в секцию server и location примерно следующее:
Я не буду описывать эти параметры, так как заметка большая получается. Они все есть в документации Nginx на русском языке.
Основной веб сервер живёт по адресу http://10.20.1.36:81, туда мы проксируем все соединения. Весь кэш складываем в директорию
Я вот прямо сейчас всё это протестировал на тестовом стенде. Поднял в Docker контейнерах сайт на Wordpress, который на php. В качестве веб сервера использовал Apache. И тут же на хосте поднял проксирующий Nginx. Походил по страницам сайта, закешировал их. Убедился, что в директории
Важно понимать, что такое грубое кэширование - это крайний случай. Подойдёт только для полностью статических сайтов, которых сейчас почти нет. Для динамического сайта решать вопросы постоянного кэширования придётся другими методами. Но в случае внезапной нагрузки можно поступить и так. Потом этот кэш отключить. Самое главное, что рабочую инфраструктуру можно не трогать при этом. Просто ставим на вход прокси. Когда она не нужна, отключаем её и работаем как прежде.
#nginx #webserver
И как-то раз одна его статья очень сильно выстрелила, так что трафик полился огромным потоком с различных агрегаторов новостей и ссылок с других статей. В итоге сайт у него начал падать. У него был некий админ-программист, который занимался сайтом. Он с самого начала потока трафика предпринимал какие-то действия, что помогало не очень. Кардинально решить проблему не мог. Сайт всё равно тормозил и часто отдавал 502 ошибку.
Я отказался помогать, потому что в принципе не занимаюсь разовыми задачами, тем более уже в условиях катастрофы, тем более без запланированного заранее времени. Да ещё на сервере, где непонятно кем и как всё настраивалось. Но для себя пометочку сделал, как лучше всего оперативно выкрутиться в такой ситуации. Сейчас с вами поделюсь примерным ходом решения этой задачи.
Проще всего в такой ситуации поднять прокси сервер на Nginx и тупо всё закэшировать. Причём настроить кэш так, что если сам сайт лёг, то кэш будет отдавать статические страницы, которые он предварительно сохранил, несмотря на то, что сам сайт динамический. Когда нам во что бы то ни стало надо показывать контент, такой вариант сойдёт. При этом сам прокси сервер можно разместить где угодно, создав виртуалку с достаточными ресурсами. Пока будут обновляться DNS записи, такую же прокси можно воткнуть прямо там же на виртуалке с сайтом, а кэш разместить в оперативной памяти.
Настройка простая и быстрая, так что если ранее вы тестировали такой вариант и сохранили конфиг, то всё настроить можно буквально за 5 минут. Ставим на сервер Nginx, если его ещё нет, и добавляем в основной конфиг, в секцию http:
http { ... proxy_cache_path /var/cache/nginx keys_zone=my_cache:10m inactive=1w max_size=1G; ...}Создаём директорию
/var/cache/nginx и делаем владельцем пользователя, под которым работает веб сервер. Теперь открываем настройки виртуального хоста и добавляем туда в секцию server и location примерно следующее:
server { ... proxy_cache my_cache; ... location / { proxy_set_header Host $host; proxy_pass http://10.20.1.36:81; proxy_cache_key $scheme://$host$uri$is_args$query_string; proxy_cache_valid 200 30m; proxy_cache_bypass $arg_bypass_cache; proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504 http_429; }}Я не буду описывать эти параметры, так как заметка большая получается. Они все есть в документации Nginx на русском языке.
Основной веб сервер живёт по адресу http://10.20.1.36:81, туда мы проксируем все соединения. Весь кэш складываем в директорию
/var/cache/nginx, можете сходить туда и убедиться. Если используется gzip, то там будут сжатые файлы. Теперь, даже если веб сервер 10.20.1.36:81 умрёт, прокси сервер всё равно будет отдавать статические страницы. Я вот прямо сейчас всё это протестировал на тестовом стенде. Поднял в Docker контейнерах сайт на Wordpress, который на php. В качестве веб сервера использовал Apache. И тут же на хосте поднял проксирующий Nginx. Походил по страницам сайта, закешировал их. Убедился, что в директории
/var/cache/nginx появились эти страницы. Отключил контейнер с Wordpress, сайт продолжил работать в виде закэшированной статики на прокси. Важно понимать, что такое грубое кэширование - это крайний случай. Подойдёт только для полностью статических сайтов, которых сейчас почти нет. Для динамического сайта решать вопросы постоянного кэширования придётся другими методами. Но в случае внезапной нагрузки можно поступить и так. Потом этот кэш отключить. Самое главное, что рабочую инфраструктуру можно не трогать при этом. Просто ставим на вход прокси. Когда она не нужна, отключаем её и работаем как прежде.
#nginx #webserver
{kind=link}
Расскажу про систему построения отказоустойчивого сервиса из подручных средств по цене аренды железа. Я её когда-то придумал, протестировал и использовал некоторое время для одного сайта. Не могу сказать, что мне понравилось, как всё это работало, но там были частности в виде репликации СУБД, у которой может быть разное решение, которое на саму схему не влияет.
Допустим, у вас условно есть 2 виртуалки в разных датацентрах. Это могут быть и полноценные сервера, и группы серверов. В данном случае это не принципиально. И вы хотите разместить на них сайт, чтобы в случае недоступности одной виртуальной машины, все клиенты автоматом обращались ко второй с минимальным простонем и без какого-либо участия человека, то есть полностью автоматически.
Реализовать это можно следующим образом. На каждой виртуалке настраиваем DNS сервер, например, bind (named). Поднимаем там зону своего сайта, указывая в A записи IP адрес своей виртуалки. То есть каждый DNS сервер резолвит имя сайта в свой IP адрес. TTL записи ставим как можно меньше, в зависимости от того, как быстро вы хотите переключить клиентов. Думаю, имеет смысл поставить 1-2 минуты.
У регистратора сайта в качестве NS серверов указываем 2 своих DNS сервера. Когда клиент будет резолвить адрес сайта, регистратор выдаст ему один из NS серверов, который отрезолвит свой IP адрес и клиент попадёт на сайт. Если один из NS серверов станет недоступен, то клиент снова обратится к регистратору и тот автоматически будет отдавать другой NS сервер, который, если доступен, будет резолвить свой IP адрес. В итоге все запросы будут автоматически попадать на активный NS сервер, и, соответственно, на работающий веб сервер.
Если на одной из виртуалок погасить bind, то весь трафик с него в течении нескольких минут уедет на второй сервер. И можно проводить профилактику.
У такой схемы есть масса нюансов. Первое и самое главное. Если используется СУБД, то вам нужна Master-Master репликация, так как в обычном режиме, когда работают оба сервера, запросы на чтение и запись идут на оба параллельно. Я использовал MySQL и там куча нюансов с репликацией, так что нельзя сказать, что всё работало автоматически. С репликацией приходилось разбираться вручную после аварий, так что полной автоматики не получалось.
Но это, как я уже сказал, частности конкретной реализации. Можно использовать прокси для MySQL на обоих машинах и запись вести с обоих серверов в одну СУБД, которая будет синхронизироваться со второй, а в случае аварии эти прокси переключаются на запись в другую живую СУБД.
С файлами всё проще. Их синхронизация - дело техники. Для статики можно использовать внешнее S3 хранилище или синхронизироваться тем же rsync или csync2. Если хостов больше двух, то вариантов ещё больше. Можно и ceph развернуть. Отдельный вопрос с сессиями пользователей. Это уже нужно решать на уровне приложения.
Схема со своими DNS серверами простая и вполне рабочая. Каких-то особых подводных камней нет. Есть нюансы с итоговой нагрузкой, так как разные регистраторы по разному отдают NS адреса из списка. Кто-то вразнобой, кто-то по алфавиту, кто-то вообще хз как.
Конечно, всё намного проще, когда есть какой-то внешний арбитр, который управляет трафиком. Это может быть какой-то готовый сервис. Но он и будет основной точкой отказа. Ляжет он, ляжет всё остальное. А тут независимая схема, которая, если всё аккуратно настроить, будет работать сама по себе без внешнего арбитра.
Постарался схематично нарисовать, как это примерно выглядит.
#webserver
Допустим, у вас условно есть 2 виртуалки в разных датацентрах. Это могут быть и полноценные сервера, и группы серверов. В данном случае это не принципиально. И вы хотите разместить на них сайт, чтобы в случае недоступности одной виртуальной машины, все клиенты автоматом обращались ко второй с минимальным простонем и без какого-либо участия человека, то есть полностью автоматически.
Реализовать это можно следующим образом. На каждой виртуалке настраиваем DNS сервер, например, bind (named). Поднимаем там зону своего сайта, указывая в A записи IP адрес своей виртуалки. То есть каждый DNS сервер резолвит имя сайта в свой IP адрес. TTL записи ставим как можно меньше, в зависимости от того, как быстро вы хотите переключить клиентов. Думаю, имеет смысл поставить 1-2 минуты.
У регистратора сайта в качестве NS серверов указываем 2 своих DNS сервера. Когда клиент будет резолвить адрес сайта, регистратор выдаст ему один из NS серверов, который отрезолвит свой IP адрес и клиент попадёт на сайт. Если один из NS серверов станет недоступен, то клиент снова обратится к регистратору и тот автоматически будет отдавать другой NS сервер, который, если доступен, будет резолвить свой IP адрес. В итоге все запросы будут автоматически попадать на активный NS сервер, и, соответственно, на работающий веб сервер.
Если на одной из виртуалок погасить bind, то весь трафик с него в течении нескольких минут уедет на второй сервер. И можно проводить профилактику.
У такой схемы есть масса нюансов. Первое и самое главное. Если используется СУБД, то вам нужна Master-Master репликация, так как в обычном режиме, когда работают оба сервера, запросы на чтение и запись идут на оба параллельно. Я использовал MySQL и там куча нюансов с репликацией, так что нельзя сказать, что всё работало автоматически. С репликацией приходилось разбираться вручную после аварий, так что полной автоматики не получалось.
Но это, как я уже сказал, частности конкретной реализации. Можно использовать прокси для MySQL на обоих машинах и запись вести с обоих серверов в одну СУБД, которая будет синхронизироваться со второй, а в случае аварии эти прокси переключаются на запись в другую живую СУБД.
С файлами всё проще. Их синхронизация - дело техники. Для статики можно использовать внешнее S3 хранилище или синхронизироваться тем же rsync или csync2. Если хостов больше двух, то вариантов ещё больше. Можно и ceph развернуть. Отдельный вопрос с сессиями пользователей. Это уже нужно решать на уровне приложения.
Схема со своими DNS серверами простая и вполне рабочая. Каких-то особых подводных камней нет. Есть нюансы с итоговой нагрузкой, так как разные регистраторы по разному отдают NS адреса из списка. Кто-то вразнобой, кто-то по алфавиту, кто-то вообще хз как.
Конечно, всё намного проще, когда есть какой-то внешний арбитр, который управляет трафиком. Это может быть какой-то готовый сервис. Но он и будет основной точкой отказа. Ляжет он, ляжет всё остальное. А тут независимая схема, которая, если всё аккуратно настроить, будет работать сама по себе без внешнего арбитра.
Постарался схематично нарисовать, как это примерно выглядит.
#webserver
{kind=link}
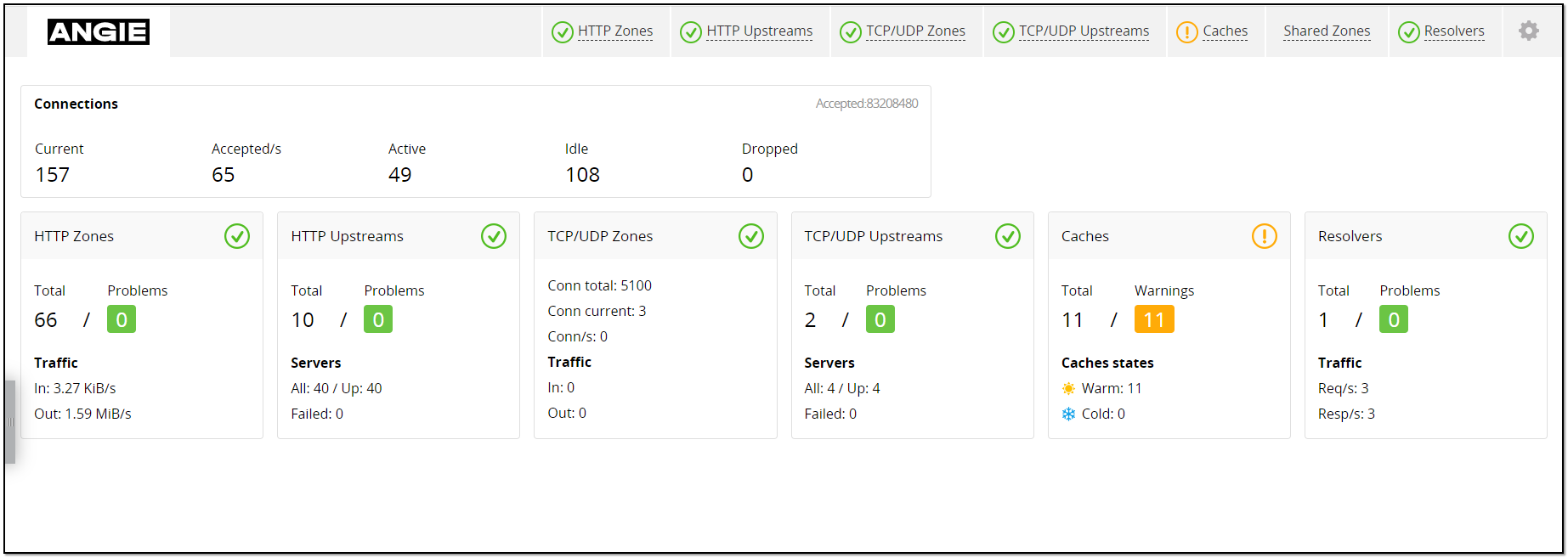
В предпоследнем обновлении веб сервера Angie, которое я из-за занятости пропустил, была анонсирована удобная веб панель наблюдения за сервером - Console Light. Только в последнем обновлении заметил это и решил навести справки.
Сразу покажу как поставить, потому что сам это проделал для того, чтобы оценить. Пример для Debian 12:
Добавляем в конфиг виртуального хоста:
Доступ лучше ограничить списком адресов. Я убрал ограничение для локального теста. Набор доступных виджетов и метрик в них зависит от настроек панели. К примеру, если хотите видеть через веб интерфейс конфигурационные файлы Angie с красивым форматированием и подсветкой синтаксиса, добавьте в location /console/api/ параметр api_config_files:
Удобное новшество. Можно быстро оценить всю рабочую конфигурацию, собранную из всех присоединённых файлов. Очень удобно для окружения Bitrix, где этих конфигов десятки.
На тестовом сервере смотреть особо не на что, кроме базовых метрик по соединениям. Оценить функциональность панели можно в публичном демо:
⇨ https://console.angie.software
Статья с подробным описанием этой панели и всего мониторинга в целом есть на хабре:
⇨ Многогранный мониторинг Angie
И там же свежее интервью с руководителем отдела разработки:
⇨ Интервью с Валентином Бартеневым: как бывшие сотрудники Nginx разрабатывают отечественный веб-сервер Angie
В принципе, в панели представлена та же информация, что и во встроенном модуле метрик для Prometheus, который был анонсирован в более старых обновлениях. Особенность встроенной панели в том, что там метрики можно смотреть практически в режиме реального времени, без задержки попадания метрик в привычный мониторинг.
Мне немного лениво работающие сервера переводить на Angie, но если что-то новое придётся настраивать, буду делать на нём. Плюсы относительно Nginx очевидны и наглядны. Готовый мониторинг и веб панель - это прям самый сок.
#angie #webserver #отечественное
Сразу покажу как поставить, потому что сам это проделал для того, чтобы оценить. Пример для Debian 12:
# curl -o /etc/apt/trusted.gpg.d/angie-signing.gpg https://angie.software/keys/angie-signing.gpg# echo "deb https://download.angie.software/angie/debian/ `lsb_release -cs` main" | tee /etc/apt/sources.list.d/angie.list > /dev/null# apt update && apt install angie angie-console-lightДобавляем в конфиг виртуального хоста:
location /console { #allow 127.0.0.1; #deny all; alias /usr/share/angie-console-light/html; index index.html; location /console/api/ { api /status/; } }Доступ лучше ограничить списком адресов. Я убрал ограничение для локального теста. Набор доступных виджетов и метрик в них зависит от настроек панели. К примеру, если хотите видеть через веб интерфейс конфигурационные файлы Angie с красивым форматированием и подсветкой синтаксиса, добавьте в location /console/api/ параметр api_config_files:
location /console/api/ { api /status/; api_config_files on; }Удобное новшество. Можно быстро оценить всю рабочую конфигурацию, собранную из всех присоединённых файлов. Очень удобно для окружения Bitrix, где этих конфигов десятки.
На тестовом сервере смотреть особо не на что, кроме базовых метрик по соединениям. Оценить функциональность панели можно в публичном демо:
⇨ https://console.angie.software
Статья с подробным описанием этой панели и всего мониторинга в целом есть на хабре:
⇨ Многогранный мониторинг Angie
И там же свежее интервью с руководителем отдела разработки:
⇨ Интервью с Валентином Бартеневым: как бывшие сотрудники Nginx разрабатывают отечественный веб-сервер Angie
В принципе, в панели представлена та же информация, что и во встроенном модуле метрик для Prometheus, который был анонсирован в более старых обновлениях. Особенность встроенной панели в том, что там метрики можно смотреть практически в режиме реального времени, без задержки попадания метрик в привычный мониторинг.
Мне немного лениво работающие сервера переводить на Angie, но если что-то новое придётся настраивать, буду делать на нём. Плюсы относительно Nginx очевидны и наглядны. Готовый мониторинг и веб панель - это прям самый сок.
#angie #webserver #отечественное
{kind=link}
Как это обычно бывает в обслуживании и поддержке, длинные выходные случаются не только лишь у всех. Я всегда стараюсь выстроить рабочий процесс так, чтобы в выходные всё же не работать. Но почти никогда это не получается. В этот раз поступила просьба, которой я не стал отказывать.
Сторонним разработчикам, нанятым незадолго до НГ, нужна была копия сайта для разработки. Пока с ними договаривались (не я), обсуждали детали, наметили план, наступило 28-е, четверг. В пятницу я уже не успел ничего сделать и благоразумно отложил решение всех вопросов на рабочие дни после праздников, так как не предполагал, что в праздники кто-то будет что-то делать. Но разработчики очень попросили всё сделать заранее, так как планировали начать работы уже 2-го января. Вот ещё категория трудоголиков, которая любит работать в праздники.
В итоге 1-го вечером я уже трудился за ноутом. В целом, задача не трудная, поэтому не стал динамить и всё сделал. В процессе возникло несколько затруднений, которые я решил. Об этом и хочу написать. Там ничего особенного, обычная рутина админа, но это может быть интересным и полезным.
Основная проблема в том, что сайт относительно большой, а свободных мощностей у компании мало. Все арендованные и дорогие. Нужно порядка 400 Гб места на дисках под сам сайт и база данных mysql примерно 10 гигов. Да ещё и сайт планировали с php 7.4 перенести на 8.0, так что нужна была отдельная виртуалка, где можно будет обновлять пакеты и будет полный доступ у разработчиков. Я перед началом работ прикинул и понял, что развернуть копию на длительное время тупо негде.
Что-то докупать или заказывать в праздники не получится, потому что нужно согласовывать расходы, оплачивать и заказывать. Начал искать варианты. У сайта есть директория с пользовательскими прикреплёнными файлами. Для разработки они не нужны, так что решил поднимать без них. Нашёл сервер, где было немного свободного места. Развернул там виртуалку, скопировал сайт без лишних файлов. Начал разворачивать базу, не хватает места. И сам дамп большой, и во время разворачивания надо много места.
Посмотрел, что в базе. Понял, что большая часть информации — это данные, которые регулярно обновляются и удаляются, и для разработки не нужны. Возникла задача из обычного текстового sql дампа вырезать содержимое некоторых таблиц. Так как файл текстовый, то придумал такое решение. Я уже когда-то делал похожую заметку, но раньше мне приходилось вытаскивать отдельную таблицу из дампа, а тут надо наоборот, удалить содержимое таблицы, но сохранить всю структуру базы.
Решил таким образом. Все данные таблицы в дампе располагаются между строк Dumping data for table нужной таблицы и Table structure, где начинается новая таблица. Вывел все такие строки в отдельный текстовый файл:
Нашёл там нужную таблицу и номера первой и второй указанных строк. И потом вырезал всё, что между ними с помощью sed. Первое число — номер строки Dumping data for table, которую нужно удалить и всё, что за ней. Второе — номер строки, предшествующей записи Table structure, так как эту строку нужно оставить. Она относится к структуре новой таблицы.
Таким образом можно очистить все ненужные таблицы, оставив только их структуру.
Места в итоге всё равно не хватило. Посмотрел, на каких виртуалках на этом сервере есть свободное место. Нашёл одну, где его было много. Поднял там nfs сервер, примонтировал каталог к новому серверу, разместил там сайт. Всё заработало. Далее настроил проксирование к этому сайту, пробросил со шлюза порты ssh для разработчиков и всё им отправил. Надеюсь, они успешно поработают, а мои праздничные костыли не окажутся напрасными.
❓Кто ещё работает в праздники? Чем занимаетесь? Я обычно что-то обновляю, переношу, пока никто не мешает. Но на этот НГ ничего не планировал. Столько лет всегда что-то делаю, что решил в этот раз отдохнуть.
#webserver
Сторонним разработчикам, нанятым незадолго до НГ, нужна была копия сайта для разработки. Пока с ними договаривались (не я), обсуждали детали, наметили план, наступило 28-е, четверг. В пятницу я уже не успел ничего сделать и благоразумно отложил решение всех вопросов на рабочие дни после праздников, так как не предполагал, что в праздники кто-то будет что-то делать. Но разработчики очень попросили всё сделать заранее, так как планировали начать работы уже 2-го января. Вот ещё категория трудоголиков, которая любит работать в праздники.
В итоге 1-го вечером я уже трудился за ноутом. В целом, задача не трудная, поэтому не стал динамить и всё сделал. В процессе возникло несколько затруднений, которые я решил. Об этом и хочу написать. Там ничего особенного, обычная рутина админа, но это может быть интересным и полезным.
Основная проблема в том, что сайт относительно большой, а свободных мощностей у компании мало. Все арендованные и дорогие. Нужно порядка 400 Гб места на дисках под сам сайт и база данных mysql примерно 10 гигов. Да ещё и сайт планировали с php 7.4 перенести на 8.0, так что нужна была отдельная виртуалка, где можно будет обновлять пакеты и будет полный доступ у разработчиков. Я перед началом работ прикинул и понял, что развернуть копию на длительное время тупо негде.
Что-то докупать или заказывать в праздники не получится, потому что нужно согласовывать расходы, оплачивать и заказывать. Начал искать варианты. У сайта есть директория с пользовательскими прикреплёнными файлами. Для разработки они не нужны, так что решил поднимать без них. Нашёл сервер, где было немного свободного места. Развернул там виртуалку, скопировал сайт без лишних файлов. Начал разворачивать базу, не хватает места. И сам дамп большой, и во время разворачивания надо много места.
Посмотрел, что в базе. Понял, что большая часть информации — это данные, которые регулярно обновляются и удаляются, и для разработки не нужны. Возникла задача из обычного текстового sql дампа вырезать содержимое некоторых таблиц. Так как файл текстовый, то придумал такое решение. Я уже когда-то делал похожую заметку, но раньше мне приходилось вытаскивать отдельную таблицу из дампа, а тут надо наоборот, удалить содержимое таблицы, но сохранить всю структуру базы.
Решил таким образом. Все данные таблицы в дампе располагаются между строк Dumping data for table нужной таблицы и Table structure, где начинается новая таблица. Вывел все такие строки в отдельный текстовый файл:
# grep -n 'Table structure\|Dumping data for table' dump.sql > tables.txtНашёл там нужную таблицу и номера первой и второй указанных строк. И потом вырезал всё, что между ними с помощью sed. Первое число — номер строки Dumping data for table, которую нужно удалить и всё, что за ней. Второе — номер строки, предшествующей записи Table structure, так как эту строку нужно оставить. Она относится к структуре новой таблицы.
# sed '22826,26719 d' dump.sql > cleanup.sqlТаким образом можно очистить все ненужные таблицы, оставив только их структуру.
Места в итоге всё равно не хватило. Посмотрел, на каких виртуалках на этом сервере есть свободное место. Нашёл одну, где его было много. Поднял там nfs сервер, примонтировал каталог к новому серверу, разместил там сайт. Всё заработало. Далее настроил проксирование к этому сайту, пробросил со шлюза порты ssh для разработчиков и всё им отправил. Надеюсь, они успешно поработают, а мои праздничные костыли не окажутся напрасными.
❓Кто ещё работает в праздники? Чем занимаетесь? Я обычно что-то обновляю, переношу, пока никто не мешает. Но на этот НГ ничего не планировал. Столько лет всегда что-то делаю, что решил в этот раз отдохнуть.
#webserver
Я уже много раз упоминал про использование простейшего http сервера на базе python:
Я его постоянно использую, когда надо быстро откуда-то забрать файлы без лишних телодвижений. Просто перехожу в нужную директорию, запускаю веб сервер, скачиваю файлы, открыв их по ip адресу сервера и завершаю работу веб сервера.
Мне понадобилось для проверки одного приложения запустить https сервер, так как по http оно не работает. Было лень настраивать для этого Nginx. Подумал, что наверное его так же можно быстро поднять с помощью python. Быстро нашёл решение.
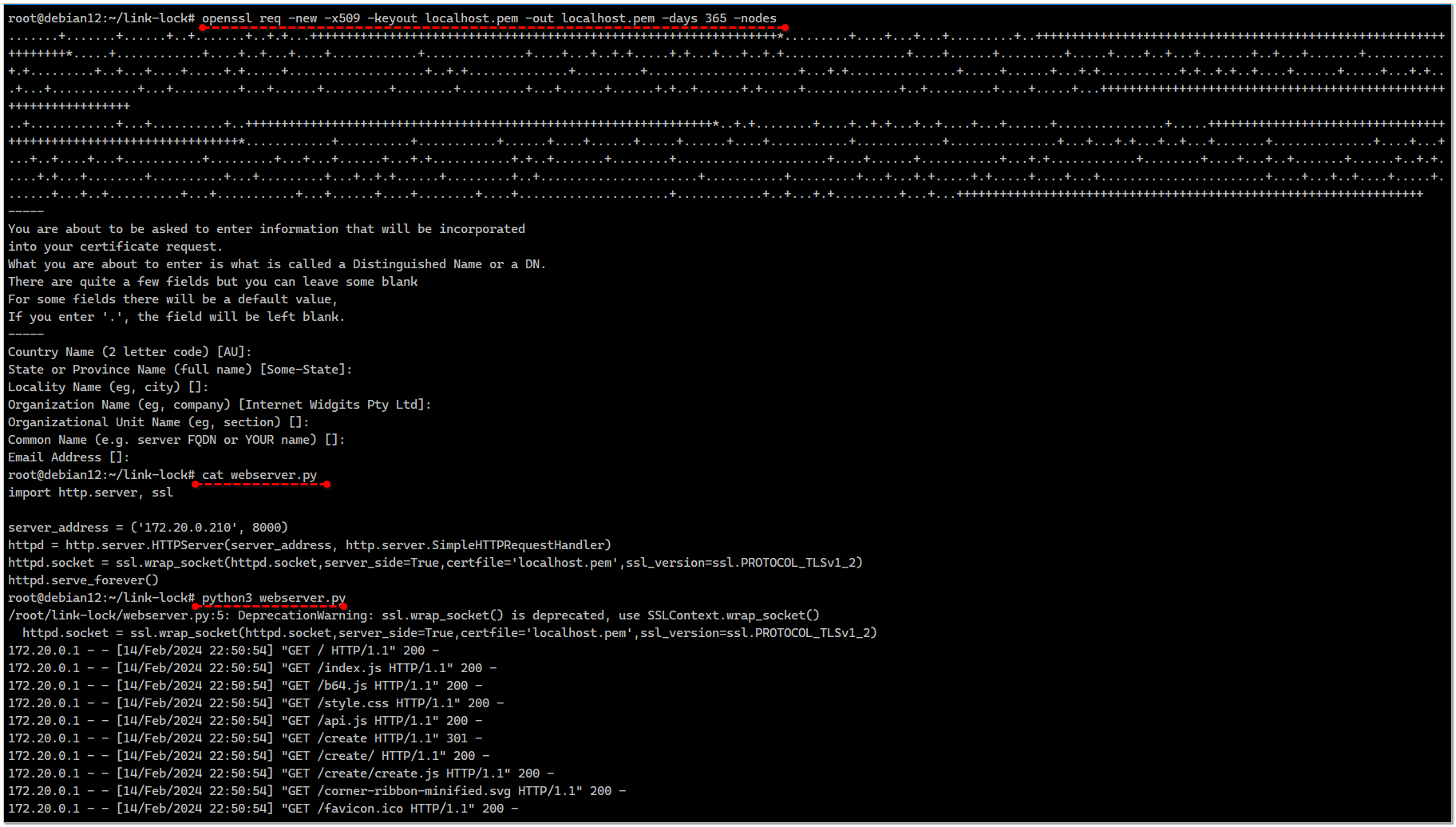
Генерируем самоподписный ключ и сертификат в один файл:
Создаём файл
Запускаем веб сервер:
Идём по адресу https://172.20.0.210:8000 и видим содержимое директории или какой-то сайт, если в ней лежит index.html.
В принципе, можно сохранить этот файл и использовать для передачи файлов, если вам важно передавать по https. Я люблю такие простые и быстрые решения. Так что обязательно сохраню и буду использовать.
#webserver #python
# python3 -m http.server 8000Я его постоянно использую, когда надо быстро откуда-то забрать файлы без лишних телодвижений. Просто перехожу в нужную директорию, запускаю веб сервер, скачиваю файлы, открыв их по ip адресу сервера и завершаю работу веб сервера.
Мне понадобилось для проверки одного приложения запустить https сервер, так как по http оно не работает. Было лень настраивать для этого Nginx. Подумал, что наверное его так же можно быстро поднять с помощью python. Быстро нашёл решение.
Генерируем самоподписный ключ и сертификат в один файл:
# openssl req -new -x509 -keyout localhost.pem -out localhost.pem -days 365 -nodesСоздаём файл
webserver.py следующего содержания:import http.server, sslserver_address = ('172.20.0.210', 8000)httpd = http.server.HTTPServer(server_address, http.server.SimpleHTTPRequestHandler)httpd.socket = ssl.wrap_socket(httpd.socket,server_side=True,certfile='localhost.pem',ssl_version=ssl.PROTOCOL_TLSv1_2)httpd.serve_forever()Запускаем веб сервер:
# python3 webserver.pyИдём по адресу https://172.20.0.210:8000 и видим содержимое директории или какой-то сайт, если в ней лежит index.html.
В принципе, можно сохранить этот файл и использовать для передачи файлов, если вам важно передавать по https. Я люблю такие простые и быстрые решения. Так что обязательно сохраню и буду использовать.
#webserver #python
{kind=link}
Обращаю ваше внимание на сервис по генерации конфигов для Nginx. Я когда-то давно уже о нём рассказывал, но с тех пор прошло много лет.
⇨ https://www.digitalocean.com/community/tools/nginx
Сам я на постоянку не пользуюсь такими сервисами, потому что у меня уже на все случаи жизни есть свои конфигурации. Но время от времени их имеет смысл проверять и актуализировать. Вот и в этот раз я решил этим заняться.
Указанный сервис очень удобен. Видно, что развивается. Раньше немного не так работал. Через форму на сайте указываете все нужные параметры и на выходе получается готовый набор конфигурационных файлов, разбитых по смыслу на части: отдельно общий конфиг, конфиг по безопасности, конфиг для специфических настроек wordpress, если укажите, что делаете конфигурацию для этой cms, отдельно настройки для letsencrypt и так далее.
В конце вам предложат скачать весь набор правил и покажут последовательность действий, для того, чтобы всё заработало. В зависимости от настроек, это будут команды для:
◽генерации файла dhparam.pem, нужного для работы https с параметром ssl_dhparam:
◽создания каталога letsencrypt для подтверждения сертификатов;
◽инструкции по настройке certbot.
Я создал типовой для меня конфиг и сверился со своим. Увидел некоторые опции, которые раньше не использовал. Например:
▪ log_not_found - разрешает или запрещает записывать в error_log ошибки о том, что файл не найден. По умолчанию в nginx параметр включён и в error_log пишутся эти ошибки, сервис предлагает по умолчанию отключать. В принципе, смысл в этом есть. На практике error_log реально забивается этими записями, хотя чаще всего они не нужны, так как на работающий сайт постоянно кто-то стучится по несуществующим урлам. К себе тоже добавил этот параметр глобально
▪ ssl_ciphers - обновил себе набор шифров. Я не вникаю в подробности набора, так как не особо в этом разбираюсь, да и не вижу большого смысла. Только учтите, что этот набор должен согласовываться с параметром ssl_protocols, где вы указываете список поддерживаемых версий TLS. Сейчас считается, что ниже TLSv1.2 использовать небезопасно.
▪ отдельно глобально вынесена блокировка всего, что начинается с точки, кроме директории .well-known, которую использует letsencrypt, и подключается ко всем виртуальным хостам:
Я обычно в каждом виртуальном хосте сначала разрешал .well-known, а потом блокировал всё, что начинается с точки:
То, как предлагает сервис, сделано удобнее. Тоже забрал себе.
Ну и так далее. Не буду всё расписывать, так как у каждого свои шаблоны. В общем, сервис удобный и полезный. Рекомендую не просто забрать в закладки, но и провести аудит своих конфигов на предмет улучшения. А если настраиваете nginx редко, то просто пользуйтесь этим сервисов. Он рисует абсолютно адекватные и качественные конфиги.
#nginx #webserver
⇨ https://www.digitalocean.com/community/tools/nginx
Сам я на постоянку не пользуюсь такими сервисами, потому что у меня уже на все случаи жизни есть свои конфигурации. Но время от времени их имеет смысл проверять и актуализировать. Вот и в этот раз я решил этим заняться.
Указанный сервис очень удобен. Видно, что развивается. Раньше немного не так работал. Через форму на сайте указываете все нужные параметры и на выходе получается готовый набор конфигурационных файлов, разбитых по смыслу на части: отдельно общий конфиг, конфиг по безопасности, конфиг для специфических настроек wordpress, если укажите, что делаете конфигурацию для этой cms, отдельно настройки для letsencrypt и так далее.
В конце вам предложат скачать весь набор правил и покажут последовательность действий, для того, чтобы всё заработало. В зависимости от настроек, это будут команды для:
◽генерации файла dhparam.pem, нужного для работы https с параметром ssl_dhparam:
◽создания каталога letsencrypt для подтверждения сертификатов;
◽инструкции по настройке certbot.
Я создал типовой для меня конфиг и сверился со своим. Увидел некоторые опции, которые раньше не использовал. Например:
▪ log_not_found - разрешает или запрещает записывать в error_log ошибки о том, что файл не найден. По умолчанию в nginx параметр включён и в error_log пишутся эти ошибки, сервис предлагает по умолчанию отключать. В принципе, смысл в этом есть. На практике error_log реально забивается этими записями, хотя чаще всего они не нужны, так как на работающий сайт постоянно кто-то стучится по несуществующим урлам. К себе тоже добавил этот параметр глобально
log_not_found off; Раньше отключал только по месту для отдельных location, типа /favicon.ico или /robots.txt ▪ ssl_ciphers - обновил себе набор шифров. Я не вникаю в подробности набора, так как не особо в этом разбираюсь, да и не вижу большого смысла. Только учтите, что этот набор должен согласовываться с параметром ssl_protocols, где вы указываете список поддерживаемых версий TLS. Сейчас считается, что ниже TLSv1.2 использовать небезопасно.
▪ отдельно глобально вынесена блокировка всего, что начинается с точки, кроме директории .well-known, которую использует letsencrypt, и подключается ко всем виртуальным хостам:
location ~ /\.(?!well-known) { deny all;Я обычно в каждом виртуальном хосте сначала разрешал .well-known, а потом блокировал всё, что начинается с точки:
location ~ /\.well-known\/acme-challenge { allow all;}location ~ /\. { deny all; return 404;}То, как предлагает сервис, сделано удобнее. Тоже забрал себе.
Ну и так далее. Не буду всё расписывать, так как у каждого свои шаблоны. В общем, сервис удобный и полезный. Рекомендую не просто забрать в закладки, но и провести аудит своих конфигов на предмет улучшения. А если настраиваете nginx редко, то просто пользуйтесь этим сервисов. Он рисует абсолютно адекватные и качественные конфиги.
#nginx #webserver
{kind=link}
Для получения бесплатных TLS сертификатов от Let's Encrypt существуют два набора скриптов: certbot и acme.sh. Может ещё какие-то есть, но эти самые популярные. Certbot написан на python, acme.sh полностью на bash.
Я всегда использовал certbot. Просто привычка. Начал с него и всегда пользуюсь именно им. Много раз слышал, что acme.sh более удобен и функционален. Плюс, не привязан к версии python. Он вообще не нужен, хотя для базовых систем это не принципиально. Python обычно есть на всех полноценных системах Linux.
Решил я посмотреть на acme.sh и сравнить с certbot. Устанавливается он просто:
Обязательно измените email. С указанным доменом example потом ничего выпустить не получится. Установщик делает 3 вещи:
1️⃣ Копирует скрипт acme.sh и некоторые конфиги в домашнюю директорию ~/.acme.sh/
2️⃣ Подключает в .bashrc окружение из ~/.acme.sh/acme.sh.env. По сути просто делает алиас
3️⃣ Добавляет в cron пользователя задачу на ежедневную попытку обновления сертификатов.
После этого можно сразу пробовать получить сертификат. Acme.sh поддерживает разные CA, поэтому надо явно указать letsencrypt:
Если всё прошло без ошибок, то в директории ~/.acme.sh появится папка с именем домена, где будет лежать сертификат, ключ и некоторые настройки для этого домена. Теперь можно куда-то скопировать этот сертификат с ключом и перезапустить веб сервер. Например, в директорию /etc/nginx/certs/. Можно это сделать вручную, а можно через тот же acme.sh:
Если ранее Nginx был настроен на использование сертификата и ключа для этого домена из указанной директории, то он перечитает свой конфиг и автоматически подхватит новые файлы.
В целом, по использованию плюс-минус то же самое, что и в certbot. Какого-то явного удобства не увидел. Плюс только один - простая установка, так как это обычный bash скрипт без зависимостей. Но я по-прежнему буду использовать certbot, потому что мне больше нравится делать вот так:
а не так:
Если кто-то пользуется acme.sh и знает его явные преимущества, прошу поделиться информацией.
⇨ Исходники
#webserver
Я всегда использовал certbot. Просто привычка. Начал с него и всегда пользуюсь именно им. Много раз слышал, что acme.sh более удобен и функционален. Плюс, не привязан к версии python. Он вообще не нужен, хотя для базовых систем это не принципиально. Python обычно есть на всех полноценных системах Linux.
Решил я посмотреть на acme.sh и сравнить с certbot. Устанавливается он просто:
# curl https://get.acme.sh | sh -s email=my@example.comОбязательно измените email. С указанным доменом example потом ничего выпустить не получится. Установщик делает 3 вещи:
1️⃣ Копирует скрипт acme.sh и некоторые конфиги в домашнюю директорию ~/.acme.sh/
2️⃣ Подключает в .bashrc окружение из ~/.acme.sh/acme.sh.env. По сути просто делает алиас
alias acme.sh="/root/.acme.sh/acme.sh".3️⃣ Добавляет в cron пользователя задачу на ежедневную попытку обновления сертификатов.
После этого можно сразу пробовать получить сертификат. Acme.sh поддерживает разные CA, поэтому надо явно указать letsencrypt:
# acme.sh --issue --server letsencrypt -d 329415.simplecloud.ru -w /var/www/htmlЕсли всё прошло без ошибок, то в директории ~/.acme.sh появится папка с именем домена, где будет лежать сертификат, ключ и некоторые настройки для этого домена. Теперь можно куда-то скопировать этот сертификат с ключом и перезапустить веб сервер. Например, в директорию /etc/nginx/certs/. Можно это сделать вручную, а можно через тот же acme.sh:
acme.sh --install-cert -d 329415.simplecloud.ru \--key-file /etc/nginx/certs/key.pem \--fullchain-file /etc/nginx/certs/cert.pem \--reloadcmd "service nginx force-reload"Если ранее Nginx был настроен на использование сертификата и ключа для этого домена из указанной директории, то он перечитает свой конфиг и автоматически подхватит новые файлы.
В целом, по использованию плюс-минус то же самое, что и в certbot. Какого-то явного удобства не увидел. Плюс только один - простая установка, так как это обычный bash скрипт без зависимостей. Но я по-прежнему буду использовать certbot, потому что мне больше нравится делать вот так:
# apt install certbotа не так:
# curl https://get.acme.sh | sh -Если кто-то пользуется acme.sh и знает его явные преимущества, прошу поделиться информацией.
⇨ Исходники
#webserver
{kind=link}
Как быстро и малыми усилиями попытаться выяснить, почему что-то тормозит в php коде сайта? Расскажу, с чего уместнее всего начать расследование, если вы используете php-fpm. Если нет каких-то особых требований, то лично я всегда исользую именно его.
У него есть две простые настройки, которые можно применить в нужном пуле, когда проводите расследование:
Таймаут выставляете под свои требования. Если сайт в целом тормозной (bitrix, админка wordpress), то 1 секунда слишком малый интервал, но в идеале хочется, чтобы весь код выполнялся быстрее этого времени.
Далее необходимо перезаустить php-fpm и идти смотреть лог:
В логе запросов будет не только информация о скрипте, который долго выполняется, но и его трассировака. Она будет включать в себя все инклюды и функции. То, что было вызвано сначала, будет внизу трейса, последняя функция - в самом верху. Причём верхней функцией будет та, что выполнялась в момент наступления времени, указанного в request_slowlog_timeout. Часто именно она и причина тормозов.
Разобраться во всём этом не такая простая задача, но в целом выполнимая даже админом. Самое главное, что иногда можно сразу получить подсказку, которая ответит на ворос о том, что именно томозит. Бывает не понятно, какой именно запрос приводит к выполнению того или иного скрипта. Нужно сопоставить по времени запрос в access.log веб сервера и slowlog php-fpm.
Очень часто тормозят какие-то заросы к внешним сервисам. Они могут делаться, к примеру, через curl_exec. И вы это сразу увидите в slowlog в самом верху трейса. Нужно будет только пройтись по функуциям и зависимостям, и найти то место, откуда функция с curl вызывается. Также часто в самом верху трейса можно увидеть функцию mysqli_query или что-то в этом роде. Тогда понятно, что тормозят запросы к базе.
По факту это самый простой инструмент, который имеет смысл использовать в самом начале разборов. Зачастую с его помощью можно сразу найти проблему. Ну а если нет, то можно подключать strace и смотреть более детально, что там внутри происходит. Но это уже сложнее, хотя какие-то простые вещи тоже можно сразу отловить. Тот же внешний тормозящий запрос тоже будет виден сразу.
#php #webserver #perfomance
У него есть две простые настройки, которые можно применить в нужном пуле, когда проводите расследование:
slowlog = /var/log/php-fpm/site01.ru.slow.logrequest_slowlog_timeout = 1sТаймаут выставляете под свои требования. Если сайт в целом тормозной (bitrix, админка wordpress), то 1 секунда слишком малый интервал, но в идеале хочется, чтобы весь код выполнялся быстрее этого времени.
Далее необходимо перезаустить php-fpm и идти смотреть лог:
# systemctl restart php8.0-fpmВ логе запросов будет не только информация о скрипте, который долго выполняется, но и его трассировака. Она будет включать в себя все инклюды и функции. То, что было вызвано сначала, будет внизу трейса, последняя функция - в самом верху. Причём верхней функцией будет та, что выполнялась в момент наступления времени, указанного в request_slowlog_timeout. Часто именно она и причина тормозов.
Разобраться во всём этом не такая простая задача, но в целом выполнимая даже админом. Самое главное, что иногда можно сразу получить подсказку, которая ответит на ворос о том, что именно томозит. Бывает не понятно, какой именно запрос приводит к выполнению того или иного скрипта. Нужно сопоставить по времени запрос в access.log веб сервера и slowlog php-fpm.
Очень часто тормозят какие-то заросы к внешним сервисам. Они могут делаться, к примеру, через curl_exec. И вы это сразу увидите в slowlog в самом верху трейса. Нужно будет только пройтись по функуциям и зависимостям, и найти то место, откуда функция с curl вызывается. Также часто в самом верху трейса можно увидеть функцию mysqli_query или что-то в этом роде. Тогда понятно, что тормозят запросы к базе.
По факту это самый простой инструмент, который имеет смысл использовать в самом начале разборов. Зачастую с его помощью можно сразу найти проблему. Ну а если нет, то можно подключать strace и смотреть более детально, что там внутри происходит. Но это уже сложнее, хотя какие-то простые вещи тоже можно сразу отловить. Тот же внешний тормозящий запрос тоже будет виден сразу.
#php #webserver #perfomance
{kind=link}