
Поделюсь простой и маленькой утилитой, которую я ставлю почти всегда по дефолту на сервера, которые настраиваю сам, наравне с screen, htop и mc. Речь пойдет об iftop - утилита для просмотра загруженности сетевого интерфейса. Она обычно присутствует в стандартных репозиториях linux дистрибутивов. Для Centos живет в epel.
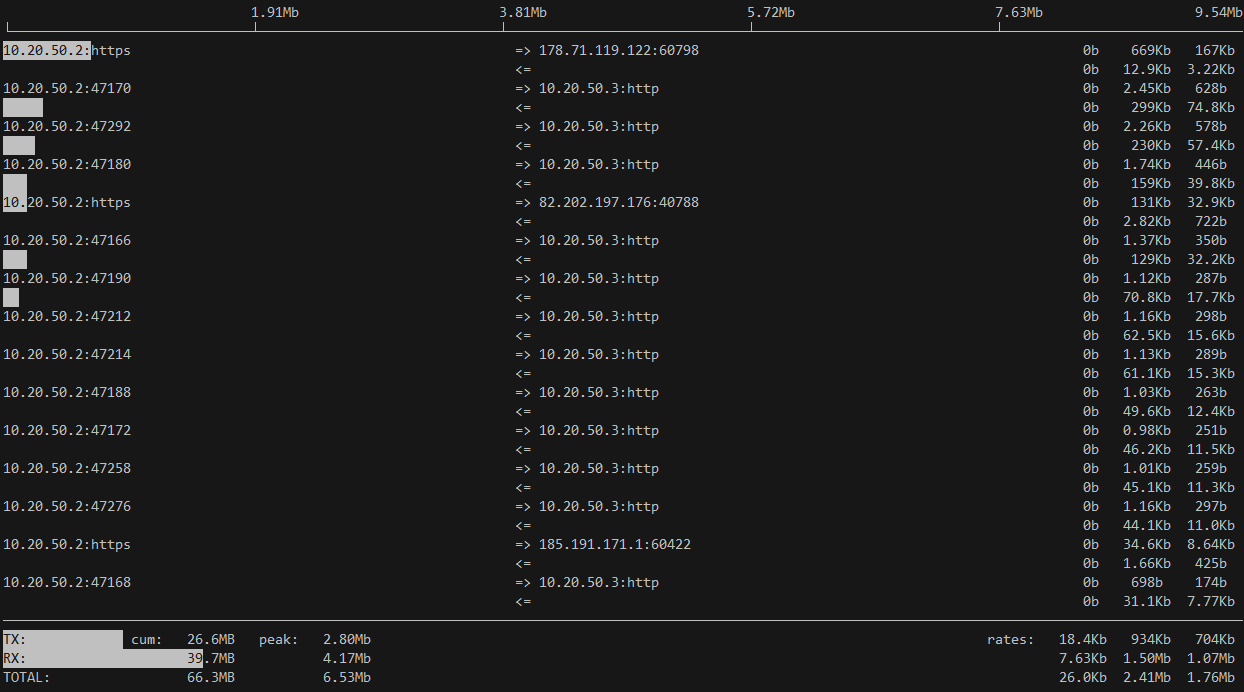
С помощью iftop можно быстро через консоль оценить, кто и как загружает сеть на сервере. В какую сторону и какой трафик идет, по каким портам.
Наиболее частые ключи, которые использую, следующие:
Ключ n отключает резолв ip адресов, а P добавляет в вывод информацию о задействованных портах, i, понятное дело, сетевой интерфейс, который слушаем.
Подозреваю, что подобных утилит существует великое множество. Но я как-то привык к iftop и ничего другого не использую. Меня устраивает полностью. А вы что используете для этих целей?
#утилита
С помощью iftop можно быстро через консоль оценить, кто и как загружает сеть на сервере. В какую сторону и какой трафик идет, по каким портам.
Наиболее частые ключи, которые использую, следующие:
iftop -i ens18 -n -PКлюч n отключает резолв ip адресов, а P добавляет в вывод информацию о задействованных портах, i, понятное дело, сетевой интерфейс, который слушаем.
Подозреваю, что подобных утилит существует великое множество. Но я как-то привык к iftop и ничего другого не использую. Меня устраивает полностью. А вы что используете для этих целей?
#утилита
{kind=link}
Мне очень нравится утилита rsync для синхронизации файлов между Linux серверами. Очень долгое время с ее помощью я бэкапил и файловые сервера Windows, монтируя их по smb к любому linux серверу. А далее запускал локально rsync, копируя файлы с примонтированного диска. В таком режиме бэкап выполнялся медленно, а именно за скорость синхронизации я и предпочитаю rsync. Когда файлов на сервере сотни тысяч разница в скорости заметная.
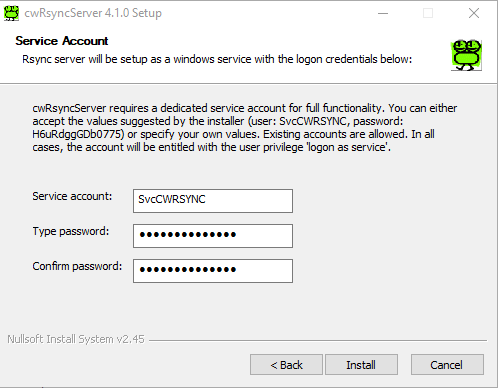
Потом в какой-то момент попробовал установить и настроить rsync сервер напрямую в винде. Оказалось, что это сделать достаточно просто. Есть программа cwRsyncServer, с помощью которой можно запустить как службу rsync сервер на Windows.
Я не знаю историю этой программы. Не понятно, кто разработчик и где официальный сайт. Информация не гуглится. Много ссылок битых. Есть вот такая ссылка - https://itefix.net/cwrsync, но там программу предлагают купить.
У меня давно сохранен архив cwrsyncserver_4.1.0_installer.zip, который я использую в случае необходимости. Скачать его можно, например, вот тут. Ставится обычным инсталлятором, настройка такая же, как в Linux. Формат конфигов один в один, только пути другие.
Вот пример моего конфига для бэкапа двух файловых шар на винде:
Шары, соответственно, в директориях E:\final_projects и D:\documents. Авторизацию не настраиваю, ограничиваю просто по ip. Дополнительно на firewall имеет смысл ограничить доступ к порту rsync.
#утилита #backup
Потом в какой-то момент попробовал установить и настроить rsync сервер напрямую в винде. Оказалось, что это сделать достаточно просто. Есть программа cwRsyncServer, с помощью которой можно запустить как службу rsync сервер на Windows.
Я не знаю историю этой программы. Не понятно, кто разработчик и где официальный сайт. Информация не гуглится. Много ссылок битых. Есть вот такая ссылка - https://itefix.net/cwrsync, но там программу предлагают купить.
У меня давно сохранен архив cwrsyncserver_4.1.0_installer.zip, который я использую в случае необходимости. Скачать его можно, например, вот тут. Ставится обычным инсталлятором, настройка такая же, как в Linux. Формат конфигов один в один, только пути другие.
Вот пример моего конфига для бэкапа двух файловых шар на винде:
uid = 0gid = 0use chroot = falsestrict modes = falsehosts allow = 10.1.3.5 10.1.4.4log file = rsyncd.log[fp]path = /cygdrive/e/final_projectsread only = truetransfer logging = yes[documents]path = /cygdrive/d/documentsread only = truetransfer logging = yesШары, соответственно, в директориях E:\final_projects и D:\documents. Авторизацию не настраиваю, ограничиваю просто по ip. Дополнительно на firewall имеет смысл ограничить доступ к порту rsync.
#утилита #backup
{kind=link}
Существует любопытный инструмент для автоматизации выполнения и планирования задач - Rundeck. Эдакий продвинутый планировщик cron для большого количества задач. С его помощью можно управлять задачами на множестве узлов. Все управление работает через веб интерфейс.
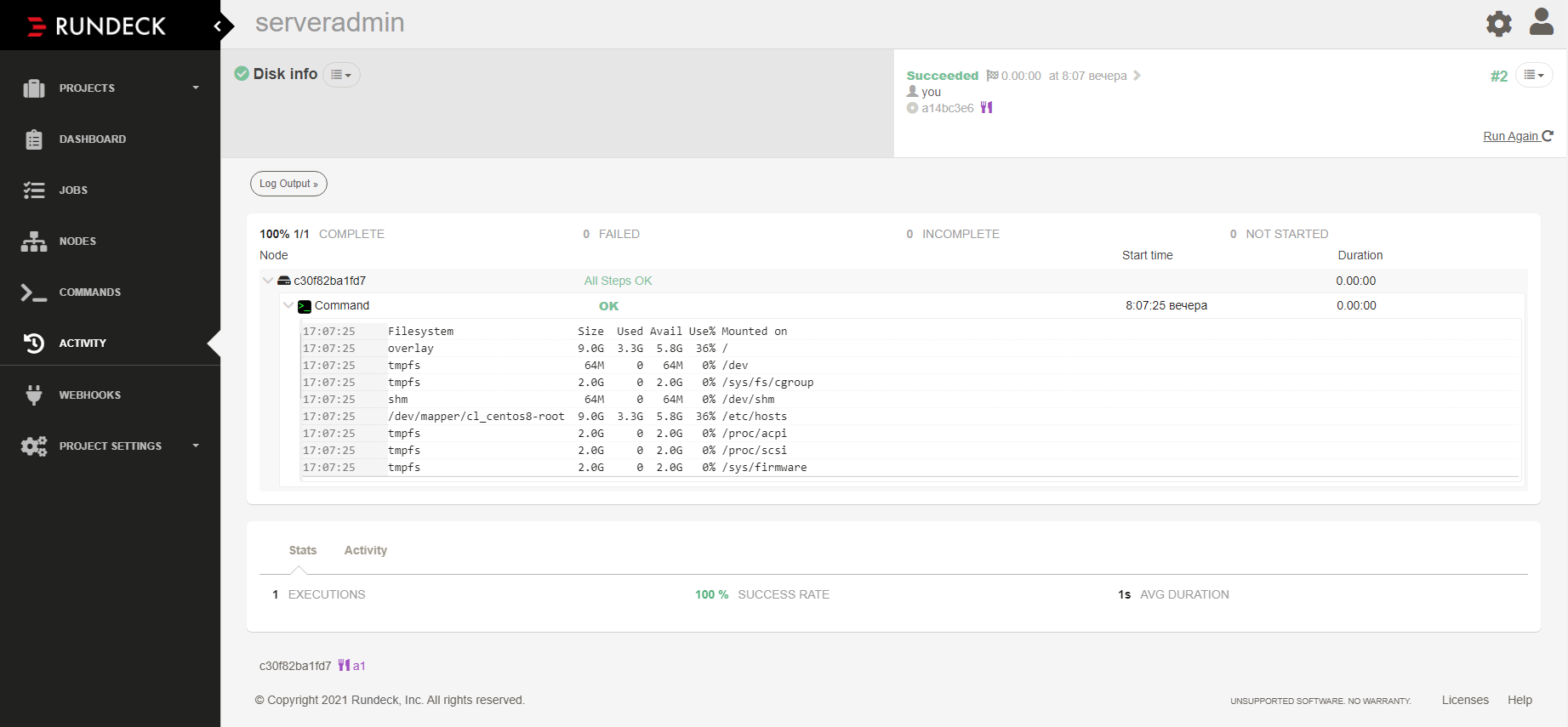
Для того, чтобы быстро познакомиться и попробовать Rundeck, можно запустить его в докере.
docker run --name rundeck -e RUNDECK_GRAILS_URL=http://10.20.1.23:4440 -p 4440:4440 -v data:/home/rundeck/server/data rundeck/rundeck:3.3.10
Не забудьте поменять url на свой. Без его корректного указания работать веб интерфейс не будет, так как там работает редирект на этот url. Учетка по умолчанию admin / admin. Можно сразу заходить и пробовать, как работает эта штука.
Чтобы быстро понять принцип действия, рекомендую добавить новый проект. В нем создать job. В качестве ноды для установки выбрать локальный сервер. Добавить первый шаг для выполнения в виде какой-то bash команды, например df -h и запустить этот job. Увидите результат работы команды в виде консольного вывода в веб интерфейсе.
Ну а дальше логика следующая - добавляются новые ноды, создаются задачи с множеством шагов и условий, настраивается расписание и т.д. Просто рай для скриптоделов-велосипедистов. Можно копировать файлы, запускать плейбуки ансибла, дергать внешние урлы и т.д. Для всего этого работают оповещения.
Если честно, я до конца не понял, где это может понадобиться сейчас. У меня сложилось впечатление, что это инструмент из прошлого, когда еще только начинали строить системы ci/cd. Сейчас мне кажется, эти велосипеды на bash скриптах заменили всякие Jenkins / Gitlab / Teamcity и т.д. Там в целом все то же самое можно делать, но с упором на разработку. А тут инструмент общего назначения. Например, чтобы дергать скрипты бэкапа в том случае, если нет единой системы.
Кто-нибудь использовал Rundeck? Какие задачи с его помощью решали?
#утилита #devops
Для того, чтобы быстро познакомиться и попробовать Rundeck, можно запустить его в докере.
docker run --name rundeck -e RUNDECK_GRAILS_URL=http://10.20.1.23:4440 -p 4440:4440 -v data:/home/rundeck/server/data rundeck/rundeck:3.3.10
Не забудьте поменять url на свой. Без его корректного указания работать веб интерфейс не будет, так как там работает редирект на этот url. Учетка по умолчанию admin / admin. Можно сразу заходить и пробовать, как работает эта штука.
Чтобы быстро понять принцип действия, рекомендую добавить новый проект. В нем создать job. В качестве ноды для установки выбрать локальный сервер. Добавить первый шаг для выполнения в виде какой-то bash команды, например df -h и запустить этот job. Увидите результат работы команды в виде консольного вывода в веб интерфейсе.
Ну а дальше логика следующая - добавляются новые ноды, создаются задачи с множеством шагов и условий, настраивается расписание и т.д. Просто рай для скриптоделов-велосипедистов. Можно копировать файлы, запускать плейбуки ансибла, дергать внешние урлы и т.д. Для всего этого работают оповещения.
Если честно, я до конца не понял, где это может понадобиться сейчас. У меня сложилось впечатление, что это инструмент из прошлого, когда еще только начинали строить системы ci/cd. Сейчас мне кажется, эти велосипеды на bash скриптах заменили всякие Jenkins / Gitlab / Teamcity и т.д. Там в целом все то же самое можно делать, но с упором на разработку. А тут инструмент общего назначения. Например, чтобы дергать скрипты бэкапа в том случае, если нет единой системы.
Кто-нибудь использовал Rundeck? Какие задачи с его помощью решали?
#утилита #devops
{kind=link}
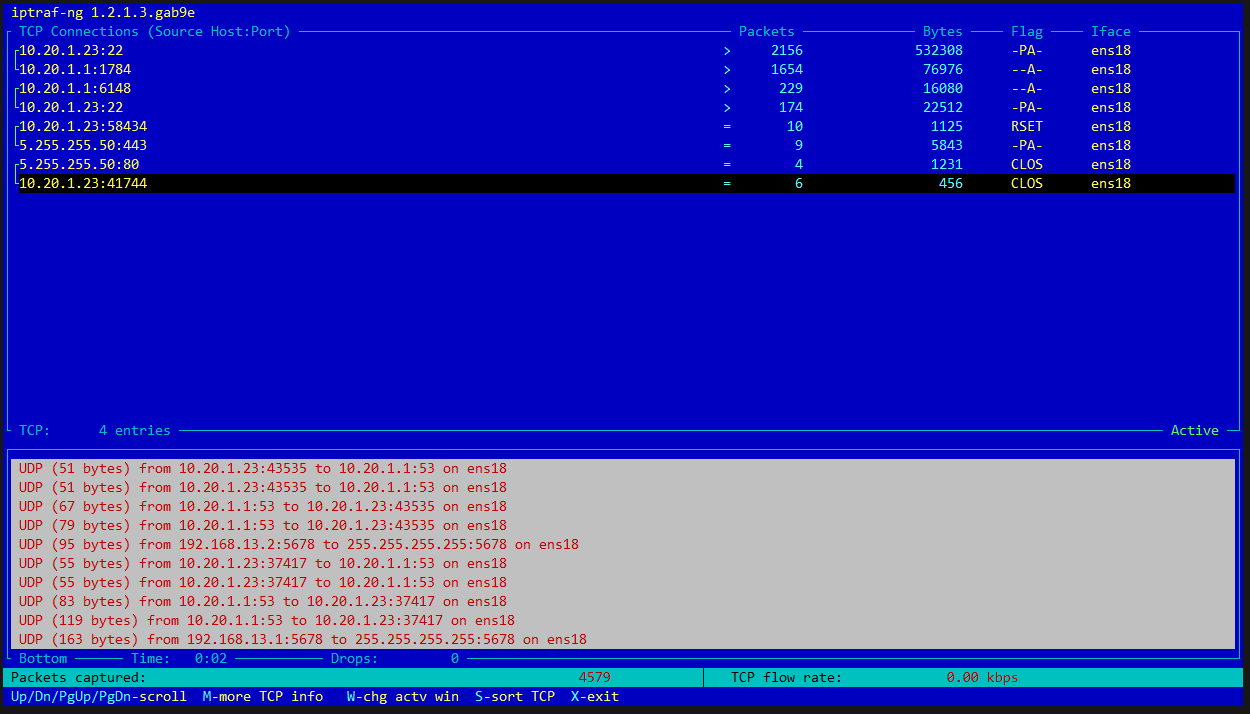
Как быстро и просто проследить за сетевой активностью с помощью консоли Linux? Ранее я для этого предлагал использовать iftop. Но есть более функциональная программа - iptraf, которая живет в стандартных системных репозиториях. Так что с установкой нет проблем.
Если нужна самая свежая версия, то придется собрать самостоятельно: https://github.com/iptraf-ng/iptraf-ng
Далее запускаем:
Программа показывает чуть более расширенную статистику по сравнению с iftop, но основное отличие в том, что может писать информацию в лог файл, который достаточно просто читать. Все очень наглядно. Если хочется выцепить какие-то адреса и порты, то iptraf отлично для этого подходит.
В итоге, наглядно оценить сетевую активность на сервере удобнее с iftop. А если нужно собрать лог за какой-то период и спокойно проанализировать, то удобнее использовать iptraf.
#утилита
dnf install iptrafapt install iptrafЕсли нужна самая свежая версия, то придется собрать самостоятельно: https://github.com/iptraf-ng/iptraf-ng
dnf groupinstall "Development Tools"dnf install ncurses-devel.x86_64git clone https://github.com/iptraf-ng/iptraf-ngcd iptraf-ng/makeДалее запускаем:
./iptraf-ngПрограмма показывает чуть более расширенную статистику по сравнению с iftop, но основное отличие в том, что может писать информацию в лог файл, который достаточно просто читать. Все очень наглядно. Если хочется выцепить какие-то адреса и порты, то iptraf отлично для этого подходит.
В итоге, наглядно оценить сетевую активность на сервере удобнее с iftop. А если нужно собрать лог за какой-то период и спокойно проанализировать, то удобнее использовать iptraf.
#утилита
{kind=link}
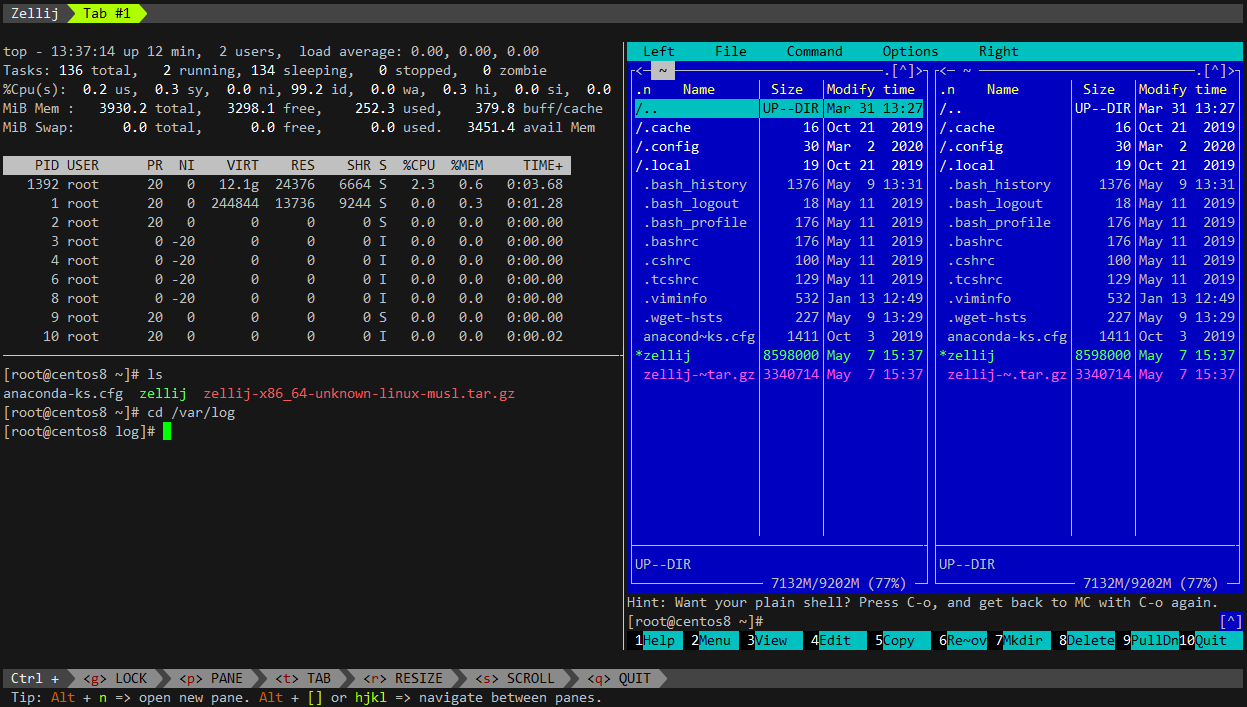
Познакомился с любопытной утилитой, которая недавно вышла в свет. Первая альфа версия была в январе этого года. Речь идет о Zellij - https://zellij.dev. Опенсорсный продукт с репой на гитхабе https://github.com/zellij-org/zellij.
Она умеет в рамках одной ssh сессии открывать несколько панелей с командной строкой. Посмотреть, как это выглядит, можно тут - https://zellij.dev/screenshots/
Для запуска, достаточно скачать бинарник из релизов на github. Я немного потестил, в целом понравилось. То же самое привык делать с помощью отдельных сессий ssh в клиенте.
Из особенностей можно выделить:
🔹 преднастройка с помощью yaml конфига
🔹 поддержка плагинов
В будущем обещают сделать веб клиент для работы в консоли через браузери шаринг своей сессии зрителям.
#утилита
Она умеет в рамках одной ssh сессии открывать несколько панелей с командной строкой. Посмотреть, как это выглядит, можно тут - https://zellij.dev/screenshots/
Для запуска, достаточно скачать бинарник из релизов на github. Я немного потестил, в целом понравилось. То же самое привык делать с помощью отдельных сессий ssh в клиенте.
Из особенностей можно выделить:
🔹 преднастройка с помощью yaml конфига
🔹 поддержка плагинов
В будущем обещают сделать веб клиент для работы в консоли через браузери шаринг своей сессии зрителям.
#утилита
{kind=link}
Вчера потестировал любопытную утилиту, которая умеет отправлять логи напрямую в Telegram. Называется Logram - https://github.com/mxseev/logram
Ставится и настраивается очень просто. Качаем deb или rpm пакет из репозитория и ставим на машину:
wget https://github.com/mxseev/logram/releases/download/v2.0.0/logram-2.0.0.amd64.deb
dpkg -i logram-2.0.0.amd64.deb
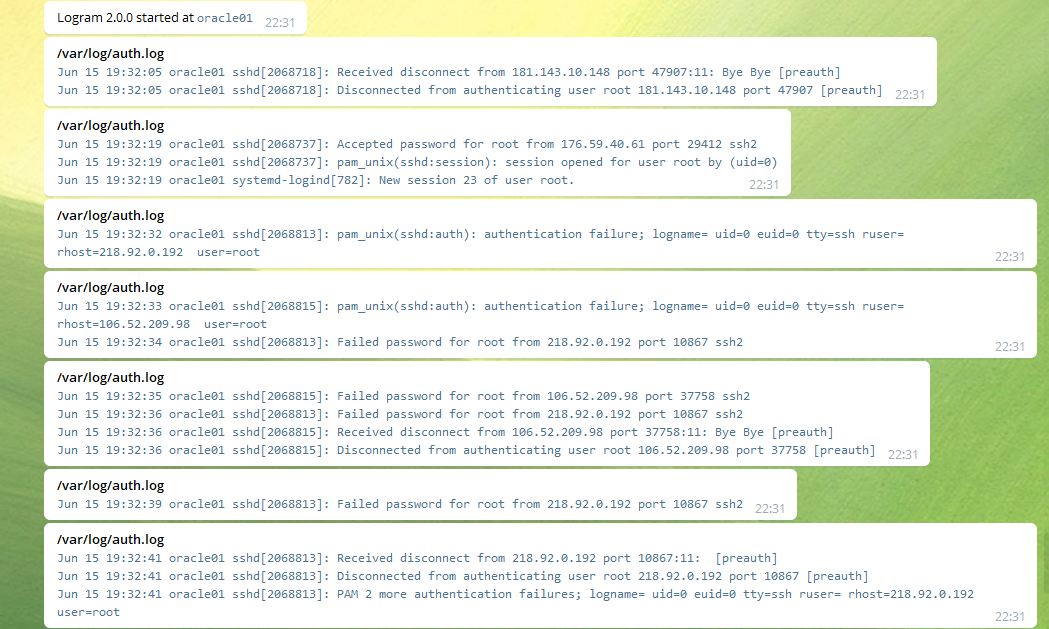
Далее редактируем конфиг /etc/logram.yaml. Я поменял только следующие строки:
telegram:
token: <bot_token>
chat_id: <id чата>
filesystem:
enabled: true
entries:
- /var/log/auth.log
С такой настройкой бот будет отправлять вам в чат все новые строки лога /var/log/auth.log
Остается только запустить его:
systemctl start logram
Быстро узнать id чата можно с помощью бота и logram. Добавьте вашего бота в чат и запустите в консоли:
logram echo_id -t <bot_token>
The chat ID of group "srvadmin_zabbix_group": -1001998787756
На Centos 7 у меня эта штука не завелась, ругнулась на неподходящую версию glibc:
/usr/bin/logram: /lib64/libc.so.6: version `GLIBC_2.32' not found (required by /usr/bin/logram)
А вот на ubuntu 20 сразу заработала.
#утилита
Ставится и настраивается очень просто. Качаем deb или rpm пакет из репозитория и ставим на машину:
wget https://github.com/mxseev/logram/releases/download/v2.0.0/logram-2.0.0.amd64.deb
dpkg -i logram-2.0.0.amd64.deb
Далее редактируем конфиг /etc/logram.yaml. Я поменял только следующие строки:
telegram:
token: <bot_token>
chat_id: <id чата>
filesystem:
enabled: true
entries:
- /var/log/auth.log
С такой настройкой бот будет отправлять вам в чат все новые строки лога /var/log/auth.log
Остается только запустить его:
systemctl start logram
Быстро узнать id чата можно с помощью бота и logram. Добавьте вашего бота в чат и запустите в консоли:
logram echo_id -t <bot_token>
The chat ID of group "srvadmin_zabbix_group": -1001998787756
На Centos 7 у меня эта штука не завелась, ругнулась на неподходящую версию glibc:
/usr/bin/logram: /lib64/libc.so.6: version `GLIBC_2.32' not found (required by /usr/bin/logram)
А вот на ubuntu 20 сразу заработала.
#утилита
{kind=link}
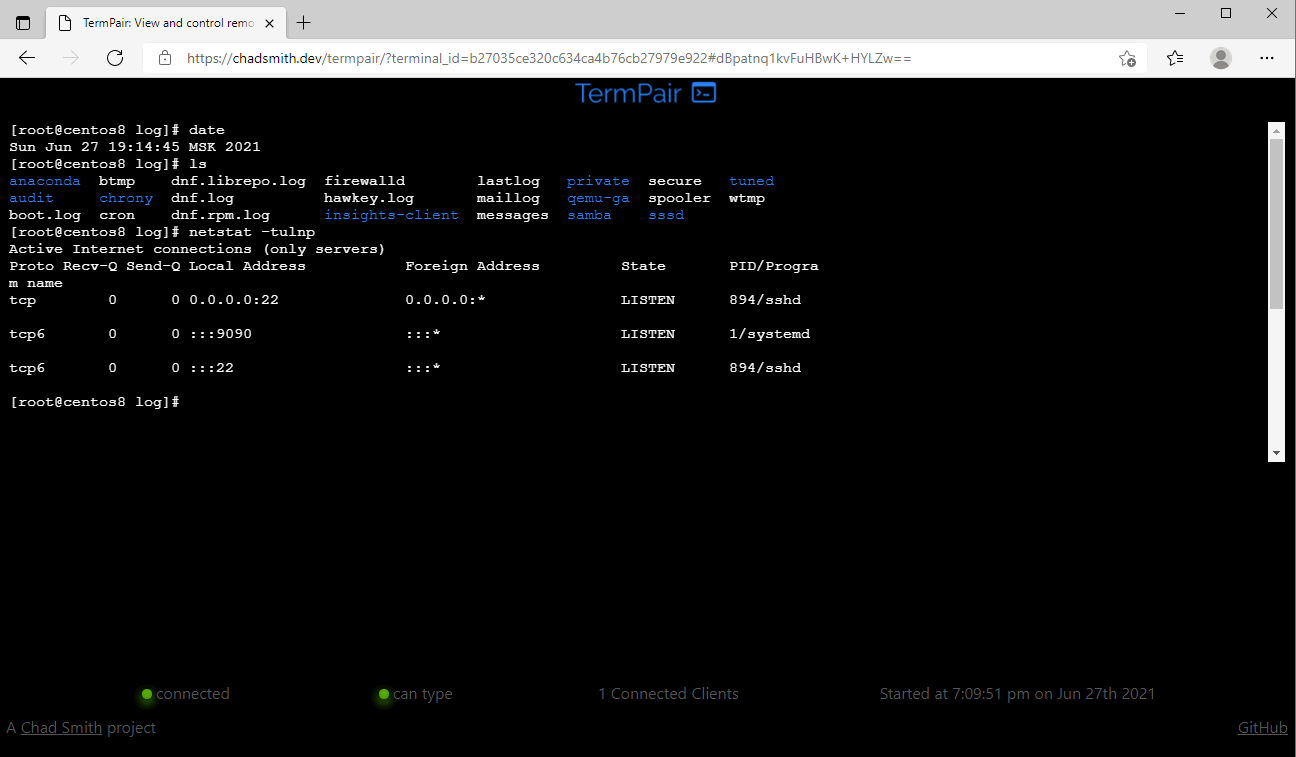
Любопытный проект на github для совместной работы в консоли - TermPair.
https://github.com/cs01/termpair
Идея такая. Ты запускаешь у себя в консоли сервер:
Дальше можно расшарить консоль:
Вы получите ссылку вида:
Можно подключаться через браузер и смотреть, что происходит в консоли, либо управлять ей. Очевидно, что для доступа через интернет нужен либо белый ip, либо придётся пробрасывать порт через nat. Клиентов может подключиться сколько угодно.
Можно расшарить консоль и через внешний хост. Для этого надо будет воспользоваться каким-то внешним сервером. Например, вот так:
Сразу получите внешнюю ссылку и через браузер окажетесь в консоли.
Программа написана на python, так что поставить можно через pip:
Перед установкой обновите pip до последней версии. У меня сначала не прошла установка из-за каких-то проблем с криптографией. Когда обновил pip, все прошло успешно.
Гифка с демонстрацией работы - https://raw.githubusercontent.com/cs01/termpair/master/termpair_browser.gif
#утилита
https://github.com/cs01/termpair
Идея такая. Ты запускаешь у себя в консоли сервер:
termpair serve --port 8000Дальше можно расшарить консоль:
termpair share --port 8000Вы получите ссылку вида:
http://ip-server:8000/?terminal_id=fd96c0f8476872950e19cМожно подключаться через браузер и смотреть, что происходит в консоли, либо управлять ей. Очевидно, что для доступа через интернет нужен либо белый ip, либо придётся пробрасывать порт через nat. Клиентов может подключиться сколько угодно.
Можно расшарить консоль и через внешний хост. Для этого надо будет воспользоваться каким-то внешним сервером. Например, вот так:
termpair share --host "https://chadsmith.dev/termpair/" --port 443Сразу получите внешнюю ссылку и через браузер окажетесь в консоли.
Программа написана на python, так что поставить можно через pip:
pip install termpairПеред установкой обновите pip до последней версии. У меня сначала не прошла установка из-за каких-то проблем с криптографией. Когда обновил pip, все прошло успешно.
Гифка с демонстрацией работы - https://raw.githubusercontent.com/cs01/termpair/master/termpair_browser.gif
#утилита
{kind=link}
Есть в линуксе полезный архиватор - pigz (Parallel Implementation of GZip). На мой взгляд, он не очень известный. Редко его вижу где-то в статьях или чьих то скриптах. Сам я его использую постоянно. Главная его особенность - он жмёт всеми ядрами. Большинство привычных консольных архиваторов жмут только одним ядром. Когда архивируете большие объемы, разница в скорости огромная.
С установкой pigz проблем нет, живёт в стандартных репах популярных дистрибутивов. Использовать, как это обычно бывает в линукс, можно разными способами.
Одиночный файл:
Распаковываем:
Либо сразу дамп базы:
Жмём директорию:
Распаковываем:
Жмём несколько файлов по маске:
Распаковываем:
Для архивации больших дампов баз данных очень актуально. На серваках с БД обычно много ядер. Если жать только одним, это может длиться слишком долго. Pigz жмёт огромные дампы на максимальной скорости, которую могут обеспечить все ядра процессора.
#утилита
С установкой pigz проблем нет, живёт в стандартных репах популярных дистрибутивов. Использовать, как это обычно бывает в линукс, можно разными способами.
Одиночный файл:
pigz -c filename > /tmp/filename.gzРаспаковываем:
unpigz filename.gzЛибо сразу дамп базы:
pg_dump -U postgres base | pigz > /tmp/base.sql.gzЖмём директорию:
tar cf - directory | pigz - > directory.tar.gzРаспаковываем:
cat directory.tar.gz | unpigz - | tar xf -Жмём несколько файлов по маске:
find /data -type f -name *filemask* -exec pigz -c '{}' \;Распаковываем:
find /data -type f -name *filemask.gz -exec unpigz '{}' \;Для архивации больших дампов баз данных очень актуально. На серваках с БД обычно много ядер. Если жать только одним, это может длиться слишком долго. Pigz жмёт огромные дампы на максимальной скорости, которую могут обеспечить все ядра процессора.
#утилита
{kind=link}
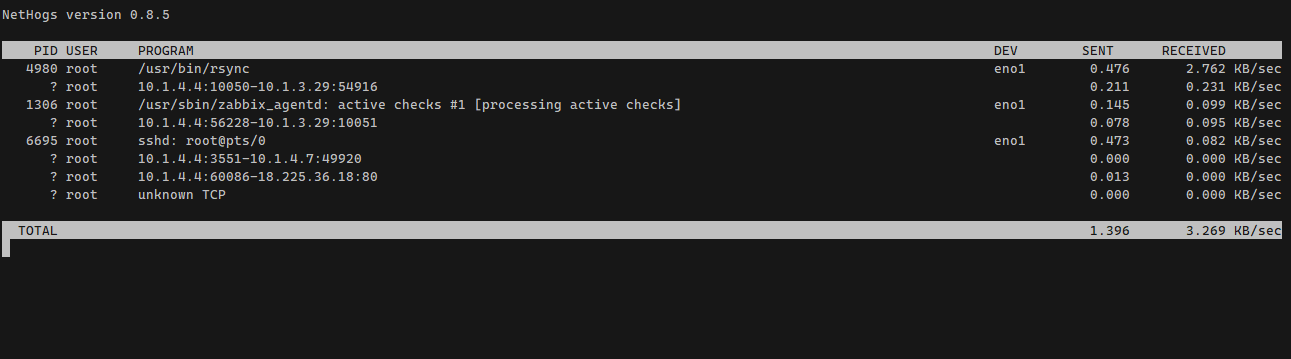
Очень удобная и простая утилита наподобие top, только для пропускной способности сети - nethogs.
После запуска в командной строке вы увидите pid процесса, его название, сетевой интерфейс и пропускную способность сети, которую в данный момент занимает конкретный процесс.
Утилита очень удобна для того, чтобы быстро понять, кто конкретно нагружает сеть на сервере или вирутальной машине.
Особо даже добавить нечего. Просто сохраните название утилиты и используйте, когда понадобится подобный функционал.
#утилита #сеть
dnf install nethogs (живёт в epel)apt install nethogsПосле запуска в командной строке вы увидите pid процесса, его название, сетевой интерфейс и пропускную способность сети, которую в данный момент занимает конкретный процесс.
Утилита очень удобна для того, чтобы быстро понять, кто конкретно нагружает сеть на сервере или вирутальной машине.
Особо даже добавить нечего. Просто сохраните название утилиты и используйте, когда понадобится подобный функционал.
#утилита #сеть
{kind=link}
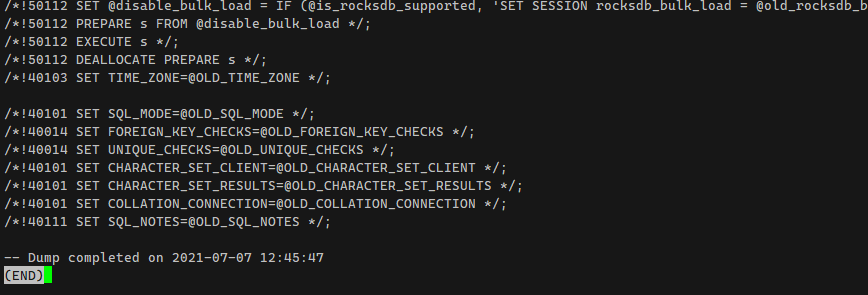
Просматривал вчера в консоли большие дампы mysql с помощью утилиты less и подумал, что неплохо было бы о ней рассказать. Я её чаще всего использую, чтобы быстро посмотреть начало или конец какого-то объемного файла с текстовой информацией. Если файл небольшой (до 100 мб), то сразу открываю в mcedit или vi и смотрю там.
А вот если у вас дамп на пару гигов, к примеру, и хочется посмотреть, он вообще корректно завершился, то less очень подходит. Открываете файл, дальше жмёте shift + G и оказываетесь сразу в самом конце файла. Альтернативным способом можно сделать так:
Но с less быстрее и удобнее, как по мне.
Плюс, с помощью less удобно листать файлы. Можно сразу экранами перемещаться, прыгать на конкретную строку, или быстро в начало или конец переходить, что-то искать.
Горячие клавиши:
▪ Стрелка вверх – перемещение на одну строку вверх
▪ Стрелка вниз – перемещение на одну строку вниз
▪ Пробел или PgDn – перемещение на одну страницу вниз
▪ b или PgUp – переместить на одну страницу вверх
▪ g – переместить в начало файла
▪ G – переместить в конец файла
▪ ng – перейти на n-ю строку
В целом, подобный функционал доступен в огромном количестве редакторов и утилит, но лично я привык к less и постоянно её использую.
#bash #утилита
А вот если у вас дамп на пару гигов, к примеру, и хочется посмотреть, он вообще корректно завершился, то less очень подходит. Открываете файл, дальше жмёте shift + G и оказываетесь сразу в самом конце файла. Альтернативным способом можно сделать так:
tail -n 10 20210707_12-35_vdakernel.sqlНо с less быстрее и удобнее, как по мне.
Плюс, с помощью less удобно листать файлы. Можно сразу экранами перемещаться, прыгать на конкретную строку, или быстро в начало или конец переходить, что-то искать.
Горячие клавиши:
▪ Стрелка вверх – перемещение на одну строку вверх
▪ Стрелка вниз – перемещение на одну строку вниз
▪ Пробел или PgDn – перемещение на одну страницу вниз
▪ b или PgUp – переместить на одну страницу вверх
▪ g – переместить в начало файла
▪ G – переместить в конец файла
▪ ng – перейти на n-ю строку
В целом, подобный функционал доступен в огромном количестве редакторов и утилит, но лично я привык к less и постоянно её использую.
#bash #утилита
{kind=link}
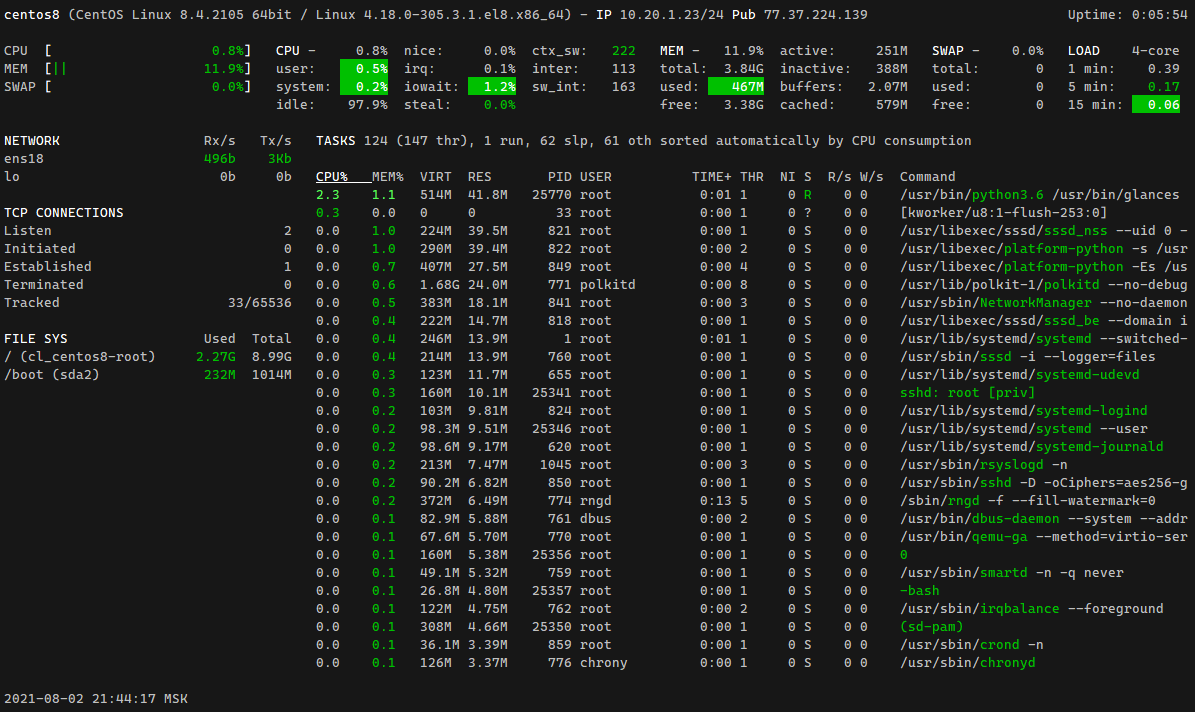
Я тут затестил на удивление удобную утилиту. Даже не знаю, как её обозвать. Это такой top с кучей информации не только по процессам. Речь идёт про glances.
https://github.com/nicolargo/glances
Не слышал о ней раньше, хотя на вид мне сразу показалась удобной и живет в стандартных репах. Для Centos и форков в репозитории epel. Установить можно как оттуда, так и через pip.
Утилита написана под все современные linux системы и даже freebsd. Для нее существует куча расширений для увеличения метрик, и не только. Можно поставить веб интерфейс, чтобы через него смотреть за метриками, либо модуль для экспорта метрик в формате prometheus или elasticsearch. Через pip это ставится примерно так:
Такую штуку можно по дефолту ставить вместо htop. Последний я неизменно ставлю почти на все сервера под моим управлением. Очень привык, в первую очередь к древовидному отображению процессов. Очень наглядно и удобно, как по мне.
#terminal #утилита
https://github.com/nicolargo/glances
Не слышал о ней раньше, хотя на вид мне сразу показалась удобной и живет в стандартных репах. Для Centos и форков в репозитории epel. Установить можно как оттуда, так и через pip.
# dnf install epel-release# dnf install python python-devel# dnf install glancesУтилита написана под все современные linux системы и даже freebsd. Для нее существует куча расширений для увеличения метрик, и не только. Можно поставить веб интерфейс, чтобы через него смотреть за метриками, либо модуль для экспорта метрик в формате prometheus или elasticsearch. Через pip это ставится примерно так:
pip install 'glances[browser,docker,export]'Такую штуку можно по дефолту ставить вместо htop. Последний я неизменно ставлю почти на все сервера под моим управлением. Очень привык, в первую очередь к древовидному отображению процессов. Очень наглядно и удобно, как по мне.
#terminal #утилита
{kind=link}
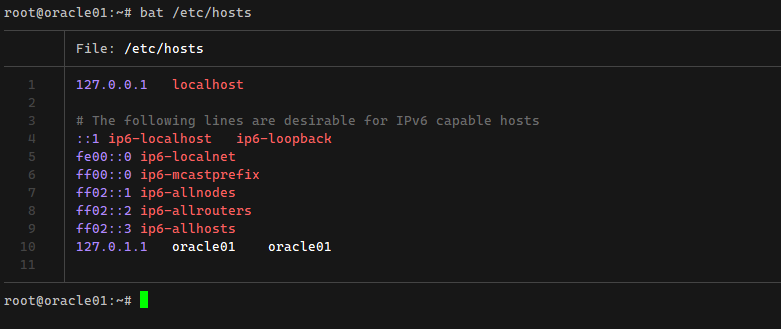
Знакомлю вас с утилитой командной строки, которая мне очень понравилась. Речь пойдёт про bat, аналоге cat, только с подсветкой синтаксиса и не только. Лично я утилиту cat использую постоянно. Сформировалась привычка при поиске чего-то делать сначала cat, потом grep. Например:
По идее, логичнее и проще сделать так:
Но я привык к первому варианту и cat использую постоянно. И при грепанье, и просто при просмотре чего-то в консоли. Перед тем, как что-то скопировать из файла, вывожу через cat в консоль.
Bat очень классно подсвечивает вывод в консоли. Нет смысла рассказывать, на картинке к посту все и так видно:
Репозиторий утилиты - https://github.com/sharkdp/bat. В Debian/Ubuntu bat ставится из стандартных реп:
В Centos 8 (на 7 не заработает из-за устаревших пакетов) и форках придется бинарник качать:
# wget https://github.com/sharkdp/bat/releases/download/v0.18.2/bat-v0.18.2-x86_64-unknown-linux-gnu.tar.gz
Жаль, что подобного рода утилиты либо вообще не доедут до состава стандартного дистрибутива, либо появятся там лет через 20, когда оттуда наконец-то выпилят vi и им подобное. Так что использовать получится только на своих серверах, которых обычно не много.
#terminal #утилита
# cat /var/log/messages | grep kernelПо идее, логичнее и проще сделать так:
# egrep "kernel" /var/log/messagesНо я привык к первому варианту и cat использую постоянно. И при грепанье, и просто при просмотре чего-то в консоли. Перед тем, как что-то скопировать из файла, вывожу через cat в консоль.
Bat очень классно подсвечивает вывод в консоли. Нет смысла рассказывать, на картинке к посту все и так видно:
# bat /etc/hostsРепозиторий утилиты - https://github.com/sharkdp/bat. В Debian/Ubuntu bat ставится из стандартных реп:
# apt install bat# ln -s /usr/bin/batcat /usr/bin/batВ Centos 8 (на 7 не заработает из-за устаревших пакетов) и форках придется бинарник качать:
# wget https://github.com/sharkdp/bat/releases/download/v0.18.2/bat-v0.18.2-x86_64-unknown-linux-gnu.tar.gz
# tar xzvf bat-v0.18.2-x86_64-unknown-linux-gnu.tar.gz# cd bat-v0.18.2-x86_64-unknown-linux-gnu# cp bat /usr/bin/Жаль, что подобного рода утилиты либо вообще не доедут до состава стандартного дистрибутива, либо появятся там лет через 20, когда оттуда наконец-то выпилят vi и им подобное. Так что использовать получится только на своих серверах, которых обычно не много.
#terminal #утилита
{kind=link}
Существует очень известная и популярная программа для удаленного сканирования хостов - Nmap. Лично у меня она стоит и на рабочем ноутбуке и на некоторых серверах. Используется как для разовых проверок открытых портов какого-то сервера, так и для регулярных автоматических проверок.
Я даже статью как-то написал на тему регулярных проверок своей же инфраструктуры с помощью nmap. Рекомендую ознакомиться. Бывает, что поднимается временно какой-то сервис для теста в отдельной виртуальной машине. Для простоты к нему просто пробрасывается определенный порт. После теста виртуальная машина удаляется, а проброс порта остается.
Через некоторое время на этот же ip адрес может приехать что-то другое. Например, у меня приехал новый сервер и на этот ip был посажен idrac. Каково же было мое удивление, когда я, сканируя внешний ip, увидел доступ к консоли управления сервером. Сначала перепугался, думал кто-то что-то сломал. Полез разбираться, оказалось, что старый проброс 443 порта остался на этом внешнем ip.
Можете настроить что-то простое и банальное, типа подобной проверки и засунуть её в крон:
nmap -T4 87.250.250.242 | mail -s "Nmap Scan 87.250.250.242" serveradmin@gmail.com
Раз в неделю будете получать отчёты на почту по проверке своих IP. И более детальную и подробную проверку сделать. Например, так:
nmap -T0 -A -v 87.250.250.242 | mail -s "Nmap Scan 87.250.250.242" serveradmin@gmail.com
Полный список параметров можно посмотреть в документации - https://nmap.org/man/ru/man-briefoptions.html
Добавлю для информации еще несколько ходовых примеров, чтобы за ними в документацию не лазить.
Сканирование подсети или отдельных адресов:
nmap 192.168.1.0/24 или nmap 192.168.1.*
nmap 192.168.1.1,2,3
Быстрый скан сети пингом. Позволяет сразу увидеть, какие хосты в сети запущены и отвечают на пинг.
nmap -sP 192.168.1.0/24
Скан хоста, не отвечающего на пинг. Актуально, если открытые порты есть, но хост не отвечает на icmp запросы.
nmap -Pn 192.168.1.1
Быстрое сканирование. Если не добавить ключи, увеличивающие скорость, дефолтный скан будет длиться очень долго.
nmap -F 192.168.1.1
nmap -T4 192.168.1.1
Подробный скан всех портов хоста. Небольшой скрипт nmap.sh, который по очереди подробно сканирует все открытые порты. Процесс может длиться долго.
#!/bin/bash
ports=$(nmap -p- --min-rate=500 $1 | grep ^[0-9] | cut -d '/' -f 1 | tr '\n' ',' | sed s/,$//)
nmap -p$ports -A $1
Использовать
./nmap.sh 192.168.1.1
Как обычно, не забываем забрать в закладки.
#terminal #утилита #nmap
Я даже статью как-то написал на тему регулярных проверок своей же инфраструктуры с помощью nmap. Рекомендую ознакомиться. Бывает, что поднимается временно какой-то сервис для теста в отдельной виртуальной машине. Для простоты к нему просто пробрасывается определенный порт. После теста виртуальная машина удаляется, а проброс порта остается.
Через некоторое время на этот же ip адрес может приехать что-то другое. Например, у меня приехал новый сервер и на этот ip был посажен idrac. Каково же было мое удивление, когда я, сканируя внешний ip, увидел доступ к консоли управления сервером. Сначала перепугался, думал кто-то что-то сломал. Полез разбираться, оказалось, что старый проброс 443 порта остался на этом внешнем ip.
Можете настроить что-то простое и банальное, типа подобной проверки и засунуть её в крон:
nmap -T4 87.250.250.242 | mail -s "Nmap Scan 87.250.250.242" serveradmin@gmail.com
Раз в неделю будете получать отчёты на почту по проверке своих IP. И более детальную и подробную проверку сделать. Например, так:
nmap -T0 -A -v 87.250.250.242 | mail -s "Nmap Scan 87.250.250.242" serveradmin@gmail.com
Полный список параметров можно посмотреть в документации - https://nmap.org/man/ru/man-briefoptions.html
Добавлю для информации еще несколько ходовых примеров, чтобы за ними в документацию не лазить.
Сканирование подсети или отдельных адресов:
nmap 192.168.1.0/24 или nmap 192.168.1.*
nmap 192.168.1.1,2,3
Быстрый скан сети пингом. Позволяет сразу увидеть, какие хосты в сети запущены и отвечают на пинг.
nmap -sP 192.168.1.0/24
Скан хоста, не отвечающего на пинг. Актуально, если открытые порты есть, но хост не отвечает на icmp запросы.
nmap -Pn 192.168.1.1
Быстрое сканирование. Если не добавить ключи, увеличивающие скорость, дефолтный скан будет длиться очень долго.
nmap -F 192.168.1.1
nmap -T4 192.168.1.1
Подробный скан всех портов хоста. Небольшой скрипт nmap.sh, который по очереди подробно сканирует все открытые порты. Процесс может длиться долго.
#!/bin/bash
ports=$(nmap -p- --min-rate=500 $1 | grep ^[0-9] | cut -d '/' -f 1 | tr '\n' ',' | sed s/,$//)
nmap -p$ports -A $1
Использовать
./nmap.sh 192.168.1.1
Как обычно, не забываем забрать в закладки.
#terminal #утилита #nmap
Server Admin
Проверка открытых портов с помощью Nmap | serveradmin.ru
Небольшой практический совет. Время от времени рекомендую сканировать свои внешние ip адреса какими-нибудь сканерами портов, например, nmap. Можно это делать на регулярной основе с помощью...
Существует программа для тестирования производительности сервера - sysbench. Она умеет всякими разными способами нагружать систему, но мне обычно это не надо. Да и в целом софта для теста процессора, памяти, дисков существует много. Гораздо полезнее другая ее возможность - тестирование производительности Mysql или Postgresql сервера.
Программа бесплатная, живет на github. Можно самому собирать, можно поставить из репозитория. Есть под все популярные системы. Быстро добавить репу можно через скрипт. Содержимое небольшое, можно проверить перед установкой:
# curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
# yum install sysbench
Список доступных тестов можно посмотреть в директории /usr/share/sysbench/. Перед началом тестов, надо создать тестовую базу:
Я буду подключаться локально, авторизация через root уже настроена. Наполняем тестовую базу данными. Будут 16 таблиц по 10000 строк в каждой.
Смотрим, что получилось:
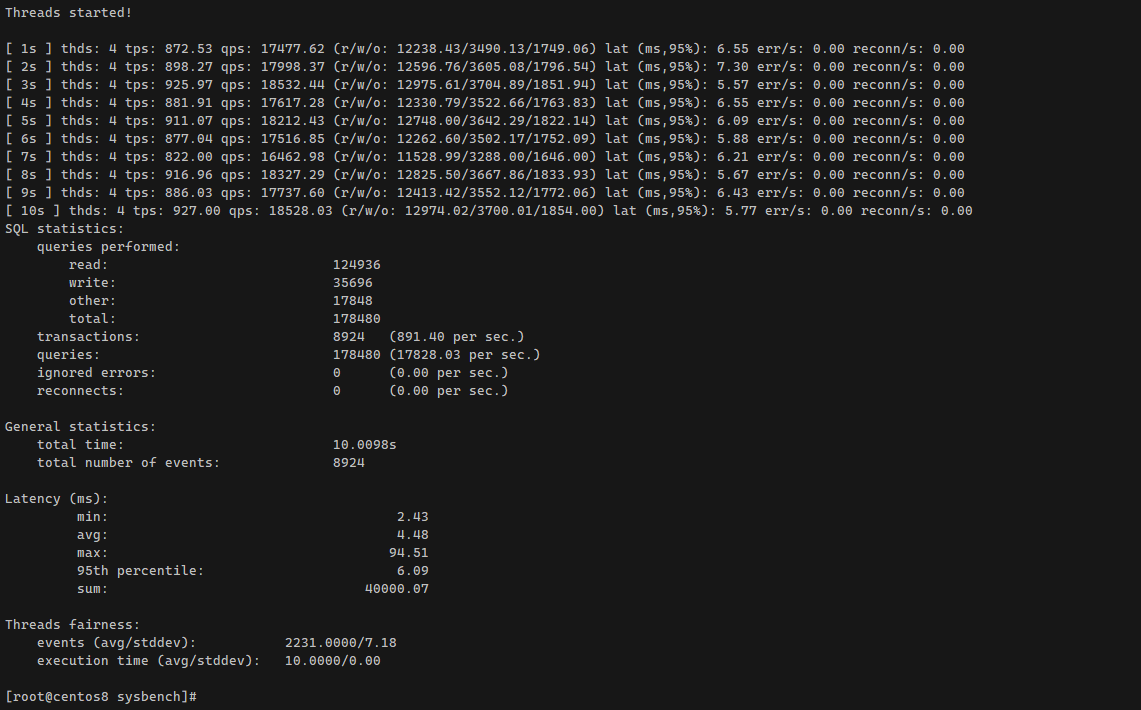
После этого запускаем сам тест oltp_read_write на 10 секунд:
На выходе получите количество транзакций в секунду и некоторые другие данные. Настроек и возможностей у sysbench много, в рамках заметки это всё не рассказать. Надеюсь, показал главное - этой утилитой достаточно легко пользоваться. Не надо долго разбираться. Можно быстро оценить производительность, сравнить разные виртуальные машины или конфигурации mysql / postgresql.
#terminal #утилита
Программа бесплатная, живет на github. Можно самому собирать, можно поставить из репозитория. Есть под все популярные системы. Быстро добавить репу можно через скрипт. Содержимое небольшое, можно проверить перед установкой:
# curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash
# yum install sysbench
Список доступных тестов можно посмотреть в директории /usr/share/sysbench/. Перед началом тестов, надо создать тестовую базу:
> create database sbtest;Я буду подключаться локально, авторизация через root уже настроена. Наполняем тестовую базу данными. Будут 16 таблиц по 10000 строк в каждой.
# sysbench \--db-driver=mysql \--mysql-user=root \--mysql-db=sbtest \--mysql-host=127.0.0.1 \--mysql-port=3306 \--tables=16 \--table-size=10000 \/usr/share/sysbench/oltp_read_write.lua prepareСмотрим, что получилось:
# du -sh /var/lib/mysql/sbtest/161M /var/lib/mysql/sbtest/После этого запускаем сам тест oltp_read_write на 10 секунд:
# sysbench \--db-driver=mysql \--mysql-user=root \--mysql-db=sbtest \--mysql-host=127.0.0.1 \--mysql-port=3306 \--tables=16 \--table-size=10000 \--threads=4 \--time=10 \--events=0 \--report-interval=1 \/usr/share/sysbench/oltp_read_write.lua runНа выходе получите количество транзакций в секунду и некоторые другие данные. Настроек и возможностей у sysbench много, в рамках заметки это всё не рассказать. Надеюсь, показал главное - этой утилитой достаточно легко пользоваться. Не надо долго разбираться. Можно быстро оценить производительность, сравнить разные виртуальные машины или конфигурации mysql / postgresql.
#terminal #утилита
{kind=link}
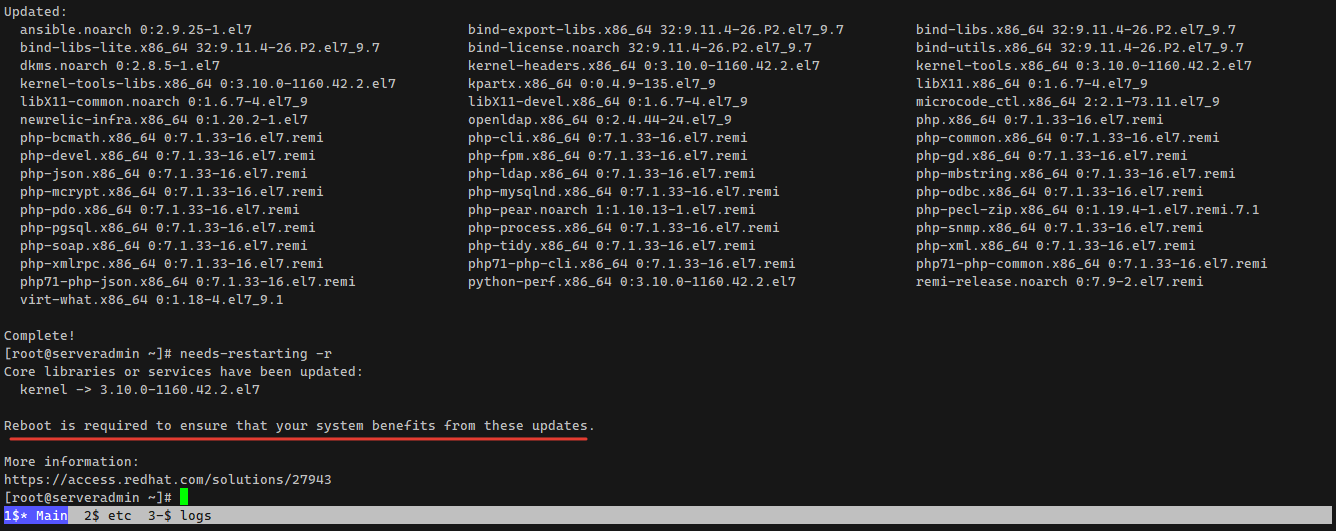
Вы знали, что в rpm-based дистрибутивах есть утилита, которая определяет, нужна серверу в данный момент перезагрузка или нет? Она живет в базовом репозитории (baseos) и называется needs-restarting. Входит в состав пакета yum-utils.
Проверяем, нужна ли перезагрузка:
После установки обновлений вывод меняется:
Debian и Ubuntu эту информацию выдают обычно в приветствии после ssh подключения. Не знаю, на основе чего там реализован этот функционал, не разбирался.
#terminal #утилита
# yum install yum-utilsПроверяем, нужна ли перезагрузка:
# needs-restarting -rNo core libraries or services have been updated since boot-up.Reboot should not be necessary.После установки обновлений вывод меняется:
# needs-restarting -rCore libraries or services have been updated: kernel -> 3.10.0-1160.42.2.el7Reboot is required to ensure that your system benefits from these updates.More information:https://access.redhat.com/solutions/27943Debian и Ubuntu эту информацию выдают обычно в приветствии после ssh подключения. Не знаю, на основе чего там реализован этот функционал, не разбирался.
#terminal #утилита
{kind=link}
В репозиториях популярных дистрибутивов живёт небольшая утилита exa, которая делает всё то же самое, что и ls, только красиво окрашивает вывод. В Debian/Ubuntu она в unstable репе. В rpm-based дистрах в федореном репозитории.
https://github.com/ogham/exa
https://the.exa.website/
Утилита состоит из одного бинарника, так что можно просто скачать и запустить. Есть поддержка git, так что можно увидеть статус (modified, Untracked) каждого файла.
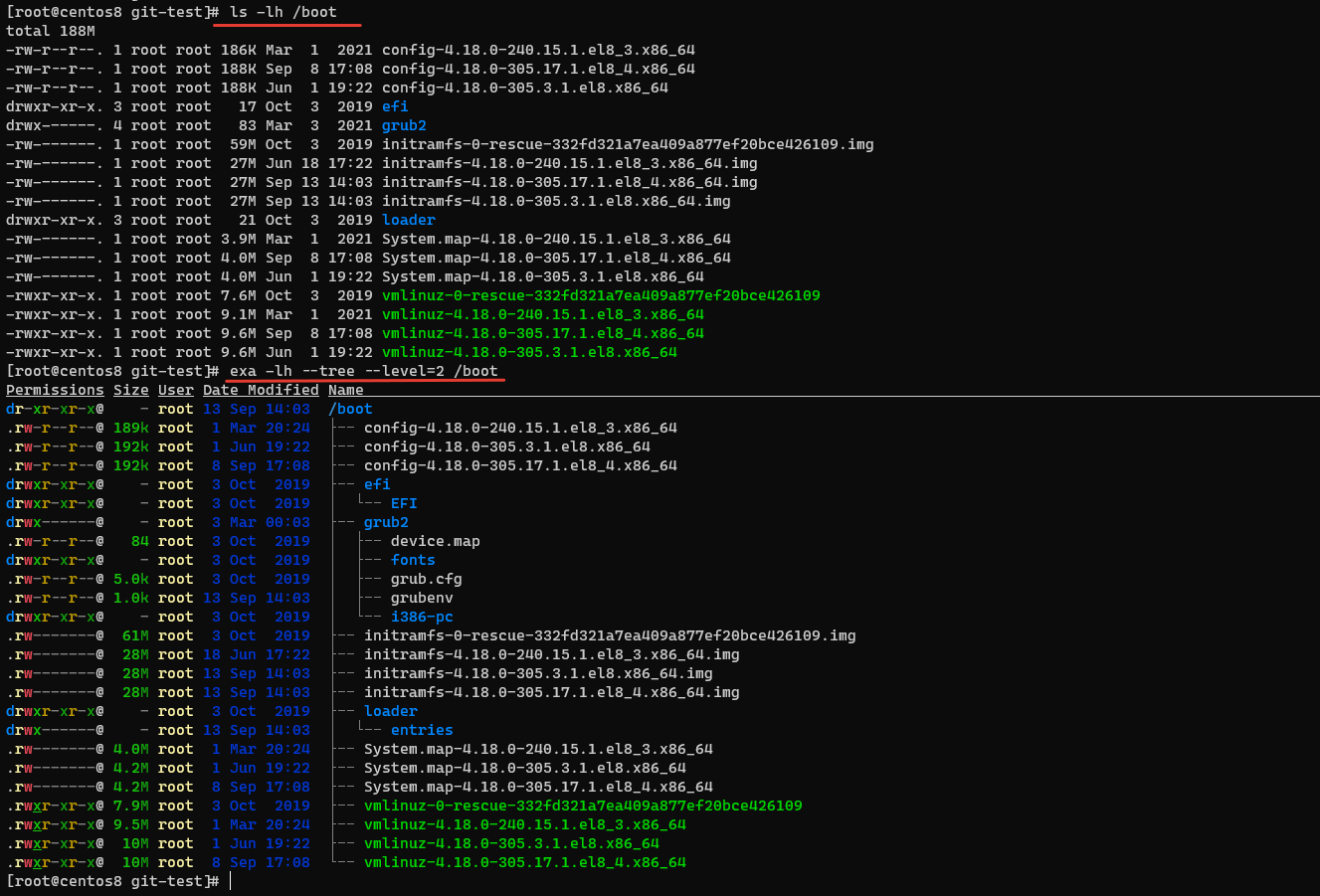
Exa умеет делать древовидное отображение каталогов и файлов с возможностью ограничивать глубину. Например:
# exa --tree --level=2 /boot
Удобная и функциональная утилита. Можно просто заменить ls символьной ссылкой и пользоваться только exa. Работает так же быстро.
#terminal #утилита
https://github.com/ogham/exa
https://the.exa.website/
Утилита состоит из одного бинарника, так что можно просто скачать и запустить. Есть поддержка git, так что можно увидеть статус (modified, Untracked) каждого файла.
Exa умеет делать древовидное отображение каталогов и файлов с возможностью ограничивать глубину. Например:
# exa --tree --level=2 /boot
Удобная и функциональная утилита. Можно просто заменить ls символьной ссылкой и пользоваться только exa. Работает так же быстро.
#terminal #утилита
{kind=link}
Одна из программ командной строки Linux, которую часто приходится использовать - find. При этом у неё не очень простой синтаксис. Я лично постоянно его забываю, поэтому всегда использую шпаргалку с наиболее часто используемыми конструкциями.
Существует утилита fd (https://github.com/sharkdp/fd), которая упрощает использование поиска через консоль. Она есть под все популярные системы, даже windows. В репе перечислены все способы установки, а также ссылки на готовые пакеты. Бинарник после установки будет называться fdfind, так как в некоторых системах имя fd уже занято. Чтобы использовать короткое обозначение придётся либо алиас, либо символьную ссылку сделать.
Основные особенности утилиты:
◽ интуитивный синтаксис и дефолтные значения
◽ быстрый параллельный поиск
◽ возможность выполнить внешнюю команду не с каждым результатом поиска, а отправить весь результат, как аргумент (это может существенно ускорить удаление огромного кол-ва файлов, но это не точно 😁)
◽ расцветка вывода
Примеры использования.
Поиск файла в текущей директории:
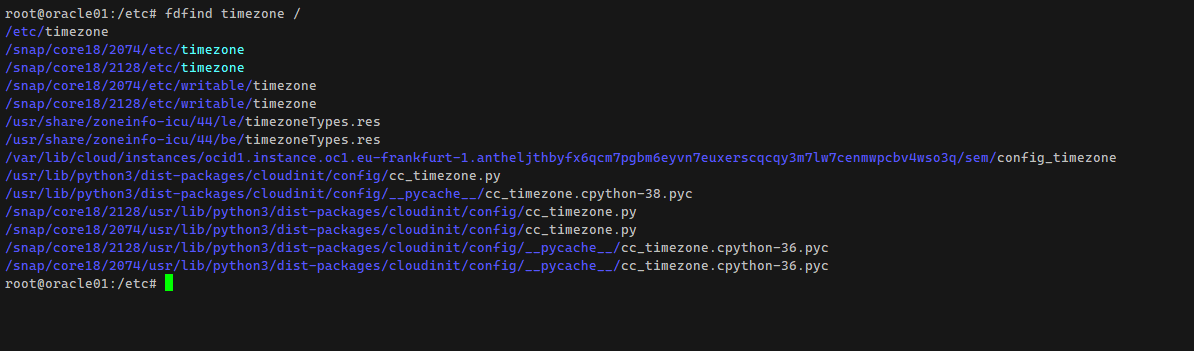
Поиск файла в конкретной директории. По умолчанию он будет рекурсивный. Для поиска по всему серверу можно использовать корень.
Поиск файлов с определённым расширением:
Найти все архивы и распаковать их:
Найти файлы и удалить одной командой:
Еще больше примеров разобраны в описании репозитория. Для простого поиска этой утилитой реально удобнее пользоваться, чем стандартным find. Более сложные конструкции я не тестировал. Они обычно в скриптах используются, а там уже не критично, где один раз собрать команду.
#terminal #утилита
Существует утилита fd (https://github.com/sharkdp/fd), которая упрощает использование поиска через консоль. Она есть под все популярные системы, даже windows. В репе перечислены все способы установки, а также ссылки на готовые пакеты. Бинарник после установки будет называться fdfind, так как в некоторых системах имя fd уже занято. Чтобы использовать короткое обозначение придётся либо алиас, либо символьную ссылку сделать.
Основные особенности утилиты:
◽ интуитивный синтаксис и дефолтные значения
◽ быстрый параллельный поиск
◽ возможность выполнить внешнюю команду не с каждым результатом поиска, а отправить весь результат, как аргумент (это может существенно ускорить удаление огромного кол-ва файлов, но это не точно 😁)
◽ расцветка вывода
Примеры использования.
Поиск файла в текущей директории:
fdfind fileПоиск файла в конкретной директории. По умолчанию он будет рекурсивный. Для поиска по всему серверу можно использовать корень.
fdfind file /varfdfind file /Поиск файлов с определённым расширением:
fdfind -e phpНайти все архивы и распаковать их:
fdfind -e zip -x unzipНайти файлы и удалить одной командой:
fdfind -e log -X rmЕще больше примеров разобраны в описании репозитория. Для простого поиска этой утилитой реально удобнее пользоваться, чем стандартным find. Более сложные конструкции я не тестировал. Они обычно в скриптах используются, а там уже не критично, где один раз собрать команду.
#terminal #утилита
{kind=link}
Существует крутой консольный просмотрщик логов Lnav. Он умеет объединять логи из разных источников, подсвечивать их, распаковывать из архивов, фильтровать по регуляркам и многое другое. При этом пользоваться им достаточно просто. Не надо изучать и вникать в работу. Всё интуитивно и максимально просто.
Lnav это просто одиночный бинарник, который можно загрузить из github - https://github.com/tstack/lnav/releases.
# wget https://github.com/tstack/lnav/releases/download/v0.10.0/lnav-0.10.0-musl-64bit.zip
# unzip lnav-0.10.0-musl-64bit.zip
# mv lnav-0.10.0/lnav /usr/local/bin
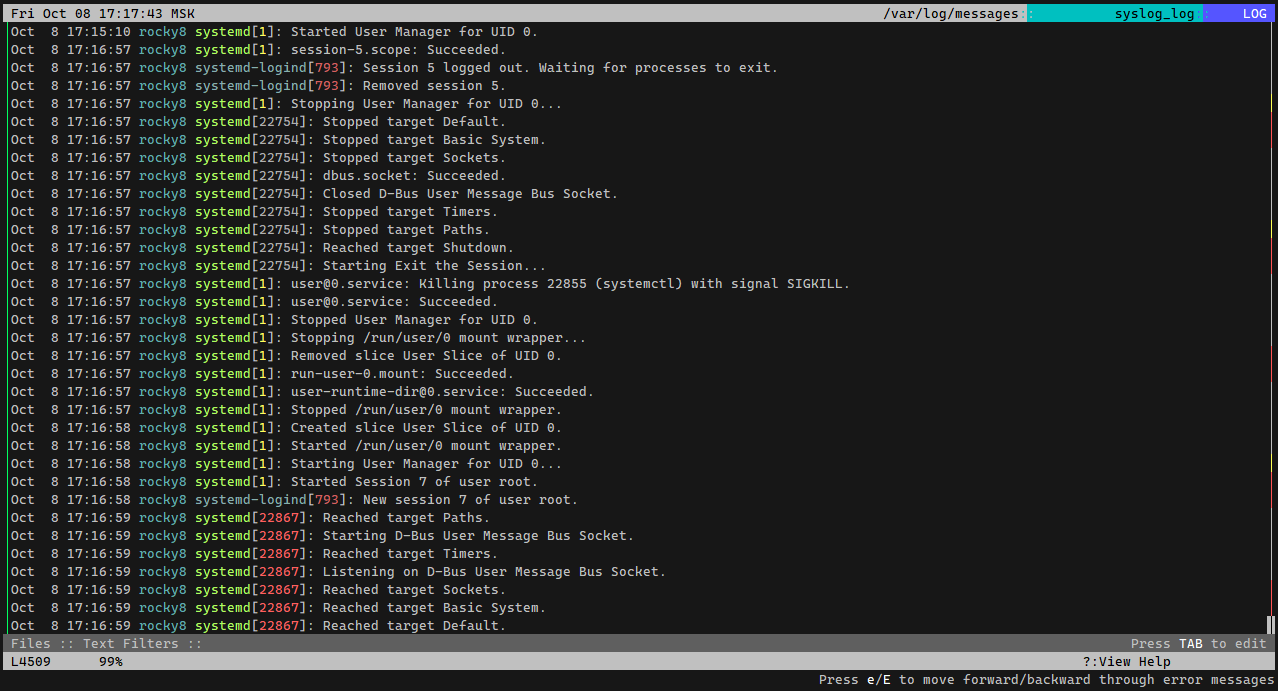
Теперь, к примеру, можно разом посмотреть все логи /var/log/messages, в том числе и сжатые, ротированные файлы:
Можно неудобочитаемый вывод journalctl направить в lnav:
При просмотре логов автоматически работает всторенная навигация на перемещение к ошибкам по горячей клавише e (error) или предупреждениям по клавише w (warning). Новые строки логов автоматически отображаются, то есть lnav можно использовать вместо tail -f.
Для корректной работы lnav нужен 256 цветный терминал. Если у вас используется обычный term, то надо добавить в ~/.bashrc и перезайти:
Сайт программы - https://lnav.org На нём описаны все возможности этой утилиты.
#утилита #terminal
Lnav это просто одиночный бинарник, который можно загрузить из github - https://github.com/tstack/lnav/releases.
# wget https://github.com/tstack/lnav/releases/download/v0.10.0/lnav-0.10.0-musl-64bit.zip
# unzip lnav-0.10.0-musl-64bit.zip
# mv lnav-0.10.0/lnav /usr/local/bin
Теперь, к примеру, можно разом посмотреть все логи /var/log/messages, в том числе и сжатые, ротированные файлы:
# lnav /var/log/messages*Можно неудобочитаемый вывод journalctl направить в lnav:
# journalctl | lnavПри просмотре логов автоматически работает всторенная навигация на перемещение к ошибкам по горячей клавише e (error) или предупреждениям по клавише w (warning). Новые строки логов автоматически отображаются, то есть lnav можно использовать вместо tail -f.
Для корректной работы lnav нужен 256 цветный терминал. Если у вас используется обычный term, то надо добавить в ~/.bashrc и перезайти:
export TERM=xterm-256colorСайт программы - https://lnav.org На нём описаны все возможности этой утилиты.
#утилита #terminal
{kind=link}
Существует любопытная консольная утилита для пинга хостов - gping. Казалось бы, что тут можно придумать. Утилита ping есть почти во всех системах и работает примерно одинаково. Что еще можно ожидать от обычного пинга?
Авторы gping сумели наполнить обычный ping новым функционалом. Утилита умеет:
◽ Строить график времени отклика хоста
◽ Одновременно пинговать и строить график для нескольких хостов
Последнее особенно полезно, когда надо понять, это у тебя проблемы с сетью или у какого-то удаленного хоста. Можно для теста пингануть несколько разных серверов и проверить.
Утилиты нет в стандартных репозиториях систем, но можно найти в сторонних.
# dnf copr enable atim/gping
# dnf install gping
# echo "deb http://packages.azlux.fr/debian/ buster main" | sudo tee /etc/apt/sources.list.d/azlux.list
# wget -qO - https://azlux.fr/repo.gpg.key | sudo apt-key add -
# apt update && apt install gping
Gping есть и под Windows. Поставить можно через choco:
# choco install gping
Или просто скачать бинарник.
Github - https://github.com/orf/gping
#terminal #утилита
Авторы gping сумели наполнить обычный ping новым функционалом. Утилита умеет:
◽ Строить график времени отклика хоста
◽ Одновременно пинговать и строить график для нескольких хостов
Последнее особенно полезно, когда надо понять, это у тебя проблемы с сетью или у какого-то удаленного хоста. Можно для теста пингануть несколько разных серверов и проверить.
Утилиты нет в стандартных репозиториях систем, но можно найти в сторонних.
# dnf copr enable atim/gping
# dnf install gping
# echo "deb http://packages.azlux.fr/debian/ buster main" | sudo tee /etc/apt/sources.list.d/azlux.list
# wget -qO - https://azlux.fr/repo.gpg.key | sudo apt-key add -
# apt update && apt install gping
Gping есть и под Windows. Поставить можно через choco:
# choco install gping
Или просто скачать бинарник.
Github - https://github.com/orf/gping
#terminal #утилита
{kind=link}
Простая и современная утилита для шифрования данных - age. Написана в духе Unix-style. Никаких конфигов. Всё управление ключами. Для шифрования используется связка приватного и публичного ключа.
Отлично подходит для автоматизации, юниксовых пайпов и скриптов. В стандартных репах ubuntu / centos я ее не нашел, так что ставить придётся с гитхаба. Утилита представляет из себя два бинарника - непосредственно шифровальщик и keygen для паролей.
Установка:
# wget https://github.com/FiloSottile/age/releases/download/v1.0.0/age-v1.0.0-linux-amd64.tar.gz
# tar xzvf age-v1.0.0-linux-amd64.tar.gz
# mv age/* /usr/local/bin
Использование. Сформируем ключи:
# age-keygen -o key.txt
Шифруем обычный файл с использованием публичного ключа:
# echo "Actually Good Encryption" > file.txt
# age -r age1ql3z7hjy54pw3hyww5ayyfg7zqgvc7w3j2elw8zmrj2kg5sfn9aqmcac8p file.txt > file.txt.age
Убеждаемся, что файл зашифрован и затем расшифровываем его закрытым ключом:
# cat file.txt.age
# age -d -i key.txt file.txt.age > file_decrypted.txt
# cat file_decrypted.txt
Если используете ключи для подключения по ssh, то age может использовать их точно так же, как и свои. Никакой разницы не будет.
github - https://github.com/FiloSottile/age
#terminal #утилита
Отлично подходит для автоматизации, юниксовых пайпов и скриптов. В стандартных репах ubuntu / centos я ее не нашел, так что ставить придётся с гитхаба. Утилита представляет из себя два бинарника - непосредственно шифровальщик и keygen для паролей.
Установка:
# wget https://github.com/FiloSottile/age/releases/download/v1.0.0/age-v1.0.0-linux-amd64.tar.gz
# tar xzvf age-v1.0.0-linux-amd64.tar.gz
# mv age/* /usr/local/bin
Использование. Сформируем ключи:
# age-keygen -o key.txt
Шифруем обычный файл с использованием публичного ключа:
# echo "Actually Good Encryption" > file.txt
# age -r age1ql3z7hjy54pw3hyww5ayyfg7zqgvc7w3j2elw8zmrj2kg5sfn9aqmcac8p file.txt > file.txt.age
Убеждаемся, что файл зашифрован и затем расшифровываем его закрытым ключом:
# cat file.txt.age
# age -d -i key.txt file.txt.age > file_decrypted.txt
# cat file_decrypted.txt
Если используете ключи для подключения по ssh, то age может использовать их точно так же, как и свои. Никакой разницы не будет.
github - https://github.com/FiloSottile/age
#terminal #утилита
{kind=link}