
Forwarded from Data Science by ODS.ai 🦜
Retentive Network: A Successor to Transformer for Large Language Models
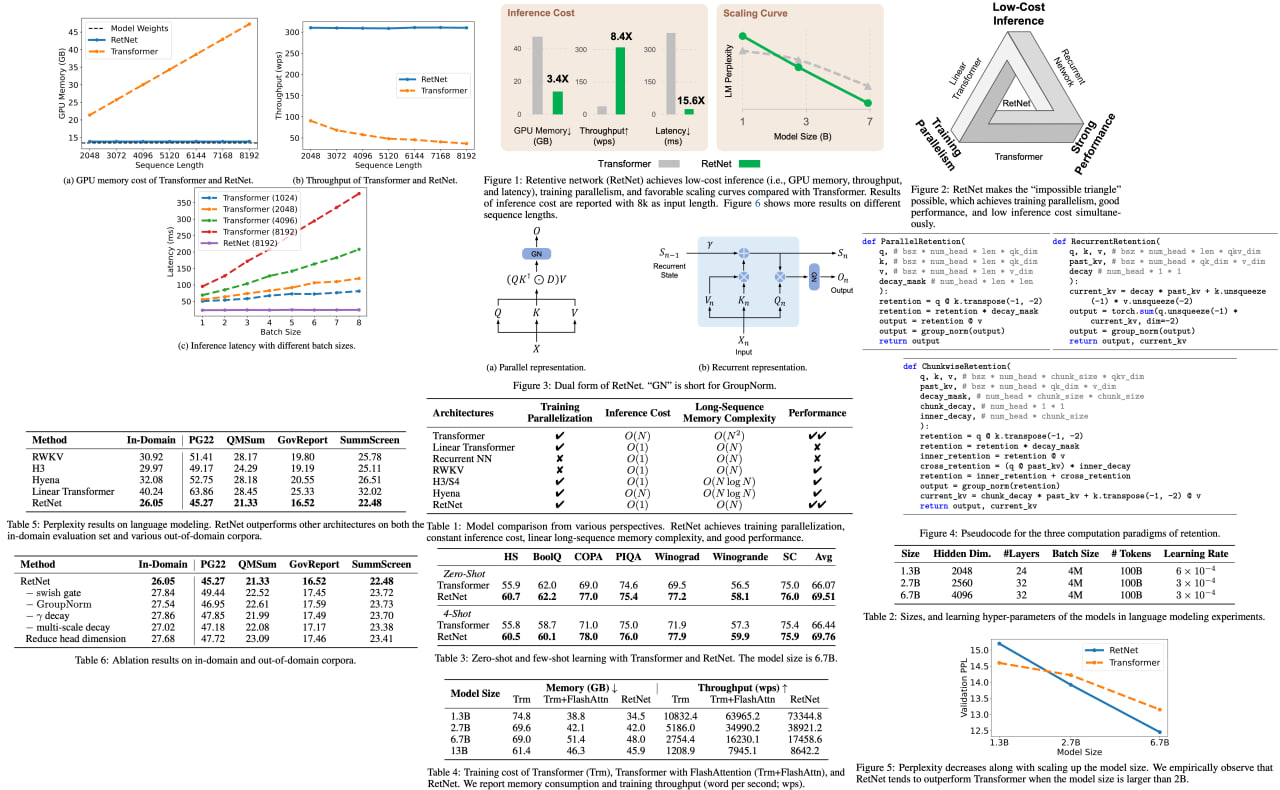
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
{kind=link}