
Trick for image preprocessing - histogram equalization
- http://scikit-image.org/docs/dev/auto_examples/color_exposure/plot_equalize.html
#cv
- http://scikit-image.org/docs/dev/auto_examples/color_exposure/plot_equalize.html
#cv
Playing with multi-GPU small batch-sizes
If you play with SemSeg with a big model with large images (HD, FullHD) - you may face a situation when only one image fits to one GPU.
Also this is useful if your train-test split is far from ideal and or you are using pre-trained imagenet encoders for a SemSeg task - so you cannot really update your bnorm params.
Also AFAIK - all the major deep-learning frameworks:
(0) do not have batch norm freeze options on evaluation (batch-norm contains 2 sets of parameters - learnable and updated on inference
(1) calculate batch-norm for each GPU separately
It all may mean, that your models may severely underperform in inference for these situations.
Solutions?
(0) Sync batch-norm. I believe to do it properly you will have to modify the framework you are using, but there is a PyTorch implementation done for the CVPR 2018 - also an explanation here http://hangzh.com/PyTorch-Encoding/notes/syncbn.html - I guess if its multi-GPU wrappers for model can be used for any models - then we are in the money)
(1) Use
(2) Freeze your encoder batch-norm params completely
https://discuss.pytorch.org/t/how-to-train-with-frozen-batchnorm/12106/10 (though I am not sure - they do not seem to be freezing the running mean parameters) - probably this also needs
(3) Use recent Facebook group norm - https://arxiv.org/pdf/1803.08494.pdf
This is a finicky topic - please tell in comments about your experiences and tests
#deep_learning
#cv
Like this post or have something to say => tell us more in the comments or donate!
If you play with SemSeg with a big model with large images (HD, FullHD) - you may face a situation when only one image fits to one GPU.
Also this is useful if your train-test split is far from ideal and or you are using pre-trained imagenet encoders for a SemSeg task - so you cannot really update your bnorm params.
Also AFAIK - all the major deep-learning frameworks:
(0) do not have batch norm freeze options on evaluation (batch-norm contains 2 sets of parameters - learnable and updated on inference
(1) calculate batch-norm for each GPU separately
It all may mean, that your models may severely underperform in inference for these situations.
Solutions?
(0) Sync batch-norm. I believe to do it properly you will have to modify the framework you are using, but there is a PyTorch implementation done for the CVPR 2018 - also an explanation here http://hangzh.com/PyTorch-Encoding/notes/syncbn.html - I guess if its multi-GPU wrappers for model can be used for any models - then we are in the money)
(1) Use
affine=False in your batch-norm. But probably in this case imagenet initialization will not help - you will have to train your model from scratch completely(2) Freeze your encoder batch-norm params completely
https://discuss.pytorch.org/t/how-to-train-with-frozen-batchnorm/12106/10 (though I am not sure - they do not seem to be freezing the running mean parameters) - probably this also needs
m.trainable = False or something like this(3) Use recent Facebook group norm - https://arxiv.org/pdf/1803.08494.pdf
This is a finicky topic - please tell in comments about your experiences and tests
#deep_learning
#cv
Like this post or have something to say => tell us more in the comments or donate!
PyTorch Forums
How to train with frozen BatchNorm?
Since pytorch does not support syncBN, I hope to freeze mean/var of BN layer while trainning. Mean/Var in pretrained model are used while weight/bias are learnable. In this way, calculation of bottom_grad in BN will be different from that of the novel trainning…
Forwarded from Варим МЛ
От меня тут давно ничего не было, потому что переезжал в другую страну (начал ещё в мае и только сейчас всё устаканилось). Долго думал о чём бы написать пост, но так как сейчас на работе пишу библиотеку для метрик лёрнинга, а о такой задаче знает не очень много людей, про неё и будет пост.
#Миша #обзор #CV
#Миша #обзор #CV
GitHub
GitHub - OML-Team/open-metric-learning: Metric learning and retrieval pipelines, models and zoo.
Metric learning and retrieval pipelines, models and zoo. - OML-Team/open-metric-learning
Forwarded from Data Science by ODS.ai 🦜
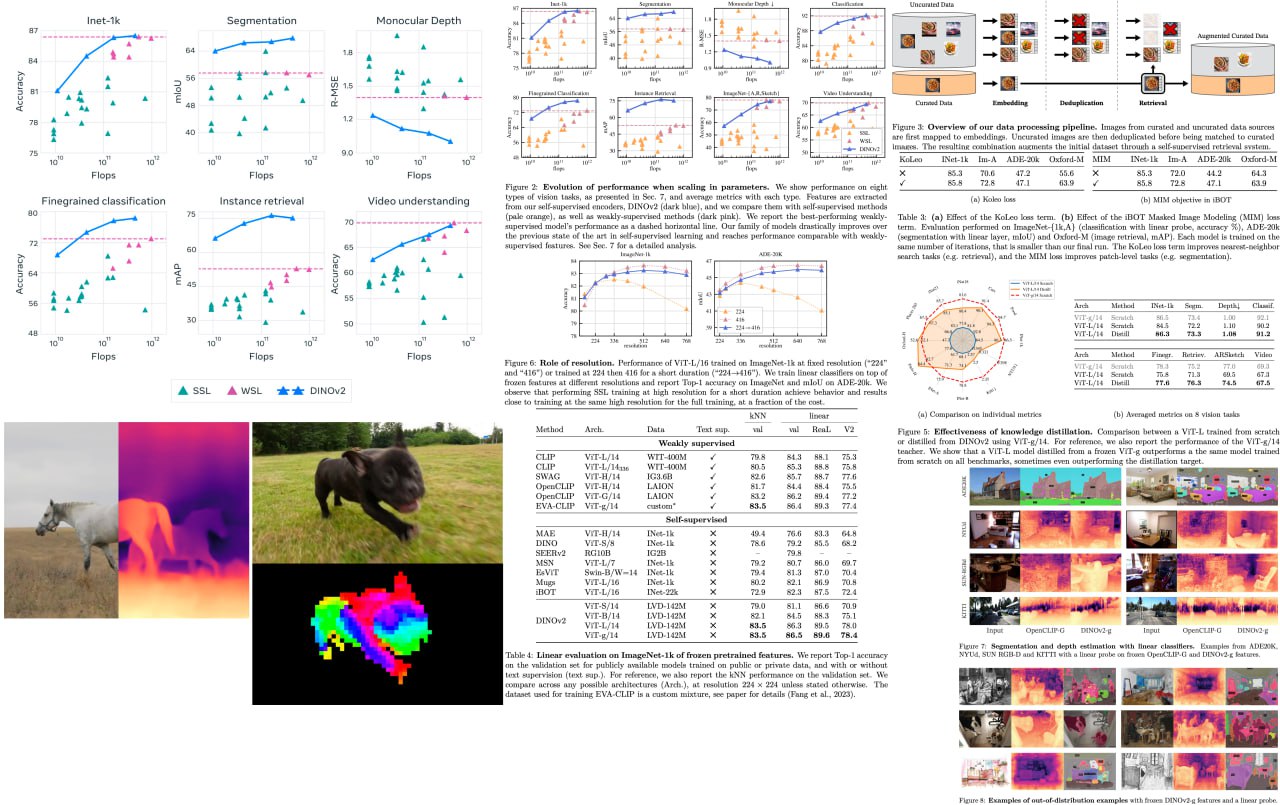
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
Fast Segment Anything
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
{kind=link}