
Torch Dataloader With Workers Leaking RAM
Everyone has faced this issue for HUGE datasets. Is is just because of python itself. If you faced it - you know what I am talking about.
I do not claim this to be a definitive solution, but it worked for me.
If you just need the whole dict, it has some methods to access the whole dict in one big object, which is fast.
#pytorch
#deep_learning
Everyone has faced this issue for HUGE datasets. Is is just because of python itself. If you faced it - you know what I am talking about.
I do not claim this to be a definitive solution, but it worked for me.
import timeBe careful with manager dict though. Though it behaves like a dict, if you just try to iterate over its keys, it will be slow, because it has some overhead for inter-process communication.
import torch
import random
import string
from multiprocessing import Manager
from torch.utils.data import Dataset, DataLoader
def id_gen(size=6,
chars=string.ascii_uppercase):
return ''.join(random.choice(chars)
for _ in range(size))
class DataIter(Dataset):
def __init__(self):
m = Manager()
self.data = m.dict({i: {'key': random.random(),
'path': id_gen(size=10)}
for i in range(1000000)})
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data = self.data[idx]
return torch.tensor(data['cer']), data['path']
train_data = DataIter()
train_loader = DataLoader(train_data,
batch_size=60,
shuffle=False,
drop_last=False,
pin_memory=False,
num_workers=10)
tic = time.time()
for i, item in enumerate(train_loader):
if (i + 1) % 1000 == 0:
toc = time.time()
print(f"Time for 1000 batches in {toc - tic} s")
tic = time.time()
If you just need the whole dict, it has some methods to access the whole dict in one big object, which is fast.
#pytorch
#deep_learning
New Benchmarking Tool in PyTorch
https://pytorch.org/tutorials/recipes/recipes/benchmark.html#pytorch-benchmark
Looks a bit over-complicated at the first glance (why provide classes for random tensor generation, I have no idea), but it has a few very nice features:
- Automated
- Automated CUDA synchronization
- Report generation, storing the results, comparing the results
But I suppose there is nothing wrong just using
#deep_learning
https://pytorch.org/tutorials/recipes/recipes/benchmark.html#pytorch-benchmark
Looks a bit over-complicated at the first glance (why provide classes for random tensor generation, I have no idea), but it has a few very nice features:
- Automated
num_threads handling- Automated CUDA synchronization
- Report generation, storing the results, comparing the results
But I suppose there is nothing wrong just using
%%timeit manually setting num_threads.#deep_learning
Forwarded from Data Science by ODS.ai 🦜
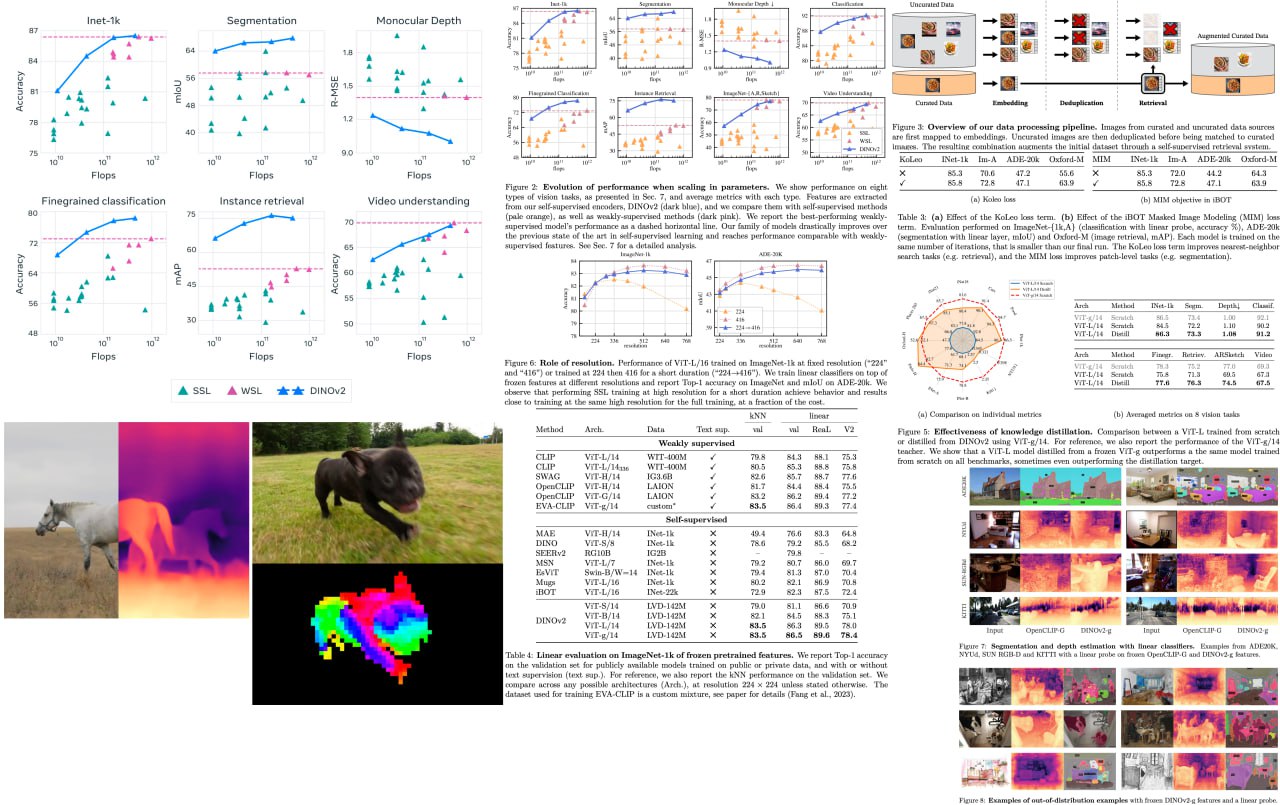
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}