
Old news ... but Attention works
Funny enough, but in the past my models :
- Either did not need attention;
- Attention was implemented by @thinline72 ;
- The domain was so complicated (NMT) so that I had to resort to boilerplate with key-value attention;
It was the first time I / we tried manually building a model with plain self attention from scratch.
An you know - it really adds 5-10% to all of the tracked metrics.
Best plain attention layer in PyTorch - simple, well documented ... and it works in real life applications:
https://gist.github.com/cbaziotis/94e53bdd6e4852756e0395560ff38aa4
#nlp
#deep_learning
Funny enough, but in the past my models :
- Either did not need attention;
- Attention was implemented by @thinline72 ;
- The domain was so complicated (NMT) so that I had to resort to boilerplate with key-value attention;
It was the first time I / we tried manually building a model with plain self attention from scratch.
An you know - it really adds 5-10% to all of the tracked metrics.
Best plain attention layer in PyTorch - simple, well documented ... and it works in real life applications:
https://gist.github.com/cbaziotis/94e53bdd6e4852756e0395560ff38aa4
#nlp
#deep_learning
Gist
SelfAttention implementation in PyTorch
SelfAttention implementation in PyTorch. GitHub Gist: instantly share code, notes, and snippets.
Russian thesaurus that really works
https://nlpub.ru/Russian_Distributional_Thesaurus#.D0.93.D1.80.D0.B0.D1.84_.D0.BF.D0.BE.D0.B4.D0.BE.D0.B1.D0.B8.D1.8F_.D1.81.D0.BB.D0.BE.D0.B2
It knows so many peculiar / old-fashioned and cheeky synonyms for obscene words!
#nlp
https://nlpub.ru/Russian_Distributional_Thesaurus#.D0.93.D1.80.D0.B0.D1.84_.D0.BF.D0.BE.D0.B4.D0.BE.D0.B1.D0.B8.D1.8F_.D1.81.D0.BB.D0.BE.D0.B2
It knows so many peculiar / old-fashioned and cheeky synonyms for obscene words!
#nlp
nlpub.ru
Russian Distributional Thesaurus — NLPub
Russian Distributional Thesaurus (сокр. RDT) — проект создания открытого дистрибутивного тезауруса русского языка. На данный момент ресурс содержит несколько компонент: вектора слов (word embeddings), граф подобия слов (дистрибутивный тезаурус), множество…
PyTorch NLP best practices
Very simple ideas, actually.
(1) Multi GPU parallelization and FP16 training
Do not bother reinventing the wheel.
Just use nvidia's
Best examples [here](https://github.com/huggingface/pytorch-pretrained-BERT).
(2) Put as much as possible INSIDE of the model
Implement the as much as possible of your logic inside of
Why?
So that you can seamleassly you all the abstractions from (1) with ease.
Also models are more abstract and reusable in general.
(3) Why have a separate train/val loop?
PyTorch 0.4 introduced context handlers.
You can simplify your train / val / test loops, and merge them into one simple function.
(4) EmbeddingBag
Use EmbeddingBag layer for morphologically rich languages. Seriously!
(5) Writing trainers / training abstractions
This is waste of time imho if you follow (1), (2) and (3).
(6) Nice bonus
If you follow most of these, you can train on as many GPUs and machines as you wan for any language)
(7) Using tensorboard for logging
This goes without saying.
#nlp
#deep_learning
Very simple ideas, actually.
(1) Multi GPU parallelization and FP16 training
Do not bother reinventing the wheel.
Just use nvidia's
apex, DistributedDataParallel, DataParallel.Best examples [here](https://github.com/huggingface/pytorch-pretrained-BERT).
(2) Put as much as possible INSIDE of the model
Implement the as much as possible of your logic inside of
nn.module.Why?
So that you can seamleassly you all the abstractions from (1) with ease.
Also models are more abstract and reusable in general.
(3) Why have a separate train/val loop?
PyTorch 0.4 introduced context handlers.
You can simplify your train / val / test loops, and merge them into one simple function.
context = torch.no_grad() if loop_type=='Val' else torch.enable_grad()
if loop_type=='Train':
model.train()
elif loop_type=='Val':
model.eval()
with context:
for i, (some_tensor) in enumerate(tqdm(train_loader)):
# do your stuff here
pass
(4) EmbeddingBag
Use EmbeddingBag layer for morphologically rich languages. Seriously!
(5) Writing trainers / training abstractions
This is waste of time imho if you follow (1), (2) and (3).
(6) Nice bonus
If you follow most of these, you can train on as many GPUs and machines as you wan for any language)
(7) Using tensorboard for logging
This goes without saying.
#nlp
#deep_learning
GitHub
GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
Dependency parsing and POS tagging in Russian
Less popular set of NLP tasks.
Popular tools reviewed
https://habr.com/ru/company/sberbank/blog/418701/
Only morphology:
(0) Well known
Only POS tags and morphology:
(0) https://github.com/IlyaGusev/rnnmorph (easy to use);
(1) https://github.com/nlpub/pymystem3 (easy to use);
Full dependency parsing
(0) Russian spacy plugin:
- https://github.com/buriy/spacy-ru - installation
- https://github.com/buriy/spacy-ru/blob/master/examples/POS_and_syntax.ipynb - usage with examples
(1) Malt parser based solution (drawback - no examples)
- https://github.com/oxaoo/mp4ru
(2) Google's syntaxnet
- https://github.com/tensorflow/models/tree/master/research/syntaxnet
#nlp
Less popular set of NLP tasks.
Popular tools reviewed
https://habr.com/ru/company/sberbank/blog/418701/
Only morphology:
(0) Well known
pymorphy2 package;Only POS tags and morphology:
(0) https://github.com/IlyaGusev/rnnmorph (easy to use);
(1) https://github.com/nlpub/pymystem3 (easy to use);
Full dependency parsing
(0) Russian spacy plugin:
- https://github.com/buriy/spacy-ru - installation
- https://github.com/buriy/spacy-ru/blob/master/examples/POS_and_syntax.ipynb - usage with examples
(1) Malt parser based solution (drawback - no examples)
- https://github.com/oxaoo/mp4ru
(2) Google's syntaxnet
- https://github.com/tensorflow/models/tree/master/research/syntaxnet
#nlp
Хабр
Изучаем синтаксические парсеры для русского языка
Привет! Меня зовут Денис Кирьянов, я работаю в Сбербанке и занимаюсь проблемами обработки естественного языка (NLP). Однажды нам понадобилось выбрать синтаксический парсер для работы с русским языком....
Our Transformer post was featured by Towards Data Science
https://medium.com/p/complexity-generalization-computational-cost-in-nlp-modeling-of-morphologically-rich-languages-7fa2c0b45909?source=email-f29885e9bef3--writer.postDistributed&sk=a56711f1436d60283d4b672466ba258b
#nlp
https://medium.com/p/complexity-generalization-computational-cost-in-nlp-modeling-of-morphologically-rich-languages-7fa2c0b45909?source=email-f29885e9bef3--writer.postDistributed&sk=a56711f1436d60283d4b672466ba258b
#nlp
Towards Data Science
Comparing complex NLP models for complex languages on a set of real tasks
Transformer is not yet really usable in practice for languages with rich morphology, but we take the first step in this direction
Normalization techniques other than batch norm:
(https://pics.spark-in.me/upload/aecc2c5fb356b6d803b4218fcb0bc3ec.png)
Weight normalization (used in TCN http://arxiv.org/abs/1602.07868):
- Decouples length of weight vectors from their direction;
- Does not introduce any dependencies between the examples in a minibatch;
- Can be applied successfully to recurrent models such as LSTMs;
- Tested only on small datasets (CIFAR + VAES + DQN);
Instance norm (used in [style transfer](https://arxiv.org/abs/1607.08022))
- Proposed for style transfer;
- Essentially is batch-norm for one image;
- The mean and standard-deviation are calculated per-dimension separately for each object in a mini-batch;
Layer norm (used in Transformers, [paper](https://arxiv.org/abs/1607.06450))
- Designed especially for sequntial networks;
- Computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case;
- The mean and standard-deviation are calculated separately over the last certain number dimensions;
- Unlike Batch Normalization and Instance Normalization, which applies scalar scale and bias for each entire channel/plane with the affine option, Layer Normalization applies per-element scale and bias;
#deep_learning
#nlp
(https://pics.spark-in.me/upload/aecc2c5fb356b6d803b4218fcb0bc3ec.png)
Weight normalization (used in TCN http://arxiv.org/abs/1602.07868):
- Decouples length of weight vectors from their direction;
- Does not introduce any dependencies between the examples in a minibatch;
- Can be applied successfully to recurrent models such as LSTMs;
- Tested only on small datasets (CIFAR + VAES + DQN);
Instance norm (used in [style transfer](https://arxiv.org/abs/1607.08022))
- Proposed for style transfer;
- Essentially is batch-norm for one image;
- The mean and standard-deviation are calculated per-dimension separately for each object in a mini-batch;
Layer norm (used in Transformers, [paper](https://arxiv.org/abs/1607.06450))
- Designed especially for sequntial networks;
- Computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case;
- The mean and standard-deviation are calculated separately over the last certain number dimensions;
- Unlike Batch Normalization and Instance Normalization, which applies scalar scale and bias for each entire channel/plane with the affine option, Layer Normalization applies per-element scale and bias;
#deep_learning
#nlp
{kind=link}
Spark in me
Sentiment datasets in Russian Just randomly found several links. - http://study.mokoron.com/ - annotated tweets - http://text-machine.cs.uml.edu/projects/rusentiment/ - some more posts from VK - https://github.com/dkulagin/kartaslov/tree/master/dataset/emo_dict…
Russian sentiment dataset
In a typical Russian fashion - one of these datasets was deleted by the request of bad people, whom I shall not name.
Luckily, some
Anyway - use it.
Yeah, it is small. But it is free, so whatever.
#nlp
#data_science
In a typical Russian fashion - one of these datasets was deleted by the request of bad people, whom I shall not name.
Luckily, some
anonymous backed the dataset up.Anyway - use it.
Yeah, it is small. But it is free, so whatever.
#nlp
#data_science
Miniaturize / optimize your ... NLP models?
For CV applications there literally dozens of ways to make your models smaller.
And yeah, I do not mean some "moonshots" or special limited libraries (matrix decompositions, some custom pruning, etc etc).
I mean cheap and dirty hacks, that work in 95% of cases regardless of your stack / device / framework:
- Smaller images (x3-x4 easy);
- FP16 inference (30-40% maybe);
- Knowledge distillation into smaller networks (x3-x10);
- Naïve cascade optimizations (feed only Nth frame using some heuristic);
But what can you do with NLP networks?
Turns out not much.
But here are my ideas:
- Use a simpler model - embedding bag + plain self-attention + LSTM can solve 90% of tasks;
- Decrease embedding size from 300 to 50 (or maybe even more). Tried and tested, works like a charm. For harder tasks you lose just 1-3pp of your target metric, for smaller tasks - it is just the same;
- FP16 inference is supported in PyTorch for
- If you have very long sentences or large batches - try distilling / swapping your recurrent network with a CNN / TCN. This way you can also trade model size vs. inference time but probably in a different direction;
#nlp
#deep_learning
For CV applications there literally dozens of ways to make your models smaller.
And yeah, I do not mean some "moonshots" or special limited libraries (matrix decompositions, some custom pruning, etc etc).
I mean cheap and dirty hacks, that work in 95% of cases regardless of your stack / device / framework:
- Smaller images (x3-x4 easy);
- FP16 inference (30-40% maybe);
- Knowledge distillation into smaller networks (x3-x10);
- Naïve cascade optimizations (feed only Nth frame using some heuristic);
But what can you do with NLP networks?
Turns out not much.
But here are my ideas:
- Use a simpler model - embedding bag + plain self-attention + LSTM can solve 90% of tasks;
- Decrease embedding size from 300 to 50 (or maybe even more). Tried and tested, works like a charm. For harder tasks you lose just 1-3pp of your target metric, for smaller tasks - it is just the same;
- FP16 inference is supported in PyTorch for
nn.Embedding, but not for nn.EmbeddingBag. But you get the idea;_embedding_bag is not implemented for type torch.HalfTensor- You can try distilling your vocabulary / embedding-bag model into a char level model. If it works, you can trade model size vs. inference time;
- If you have very long sentences or large batches - try distilling / swapping your recurrent network with a CNN / TCN. This way you can also trade model size vs. inference time but probably in a different direction;
#nlp
#deep_learning
Archive team ... makes monthly Twitter archives
With all the BS with politics / "Russian hackers" / Arab spring - twitter how has closed its developer API.
No problem.
Just pay a visit to archive team page
https://archive.org/details/twitterstream?and[]=year%3A%222018%22
Donate them here
https://archive.org/donate/
#data_science
#nlp
#nlp
With all the BS with politics / "Russian hackers" / Arab spring - twitter how has closed its developer API.
No problem.
Just pay a visit to archive team page
https://archive.org/details/twitterstream?and[]=year%3A%222018%22
Donate them here
https://archive.org/donate/
#data_science
#nlp
#nlp
archive.org
Archive Team: The Twitter Stream Grab : Free Web : Free Download, Borrow and Streaming : Internet Archive
A simple collection of JSON grabbed from the general twitter stream, for the purposes of research, history, testing and memory. This is the Spritzer version, the most light and shallow of Twitter grabs. Unfortunately, we do not currently have access to the…
Extreme NLP network miniaturization
Tried some plain RNNs on a custom in the wild NER task.
The dataset is huge - literally infinite, but manually generated to mimick in-the-wild data.
I use EmbeddingBag + 1m n-grams (an optimal cut-off). Yeah, on NER / classification it is a handy trick that makes your pipeline totally misprint / error / OOV agnostic. Also FAIR themselves just guessed this too. Very cool! Just add PyTorch and you are golden.
What is interesting:
- Model works with embedding sizes 300, 100, 50 and even 5! 5 is dangerously close to OHE, but doing OHE on 1m n-grams kind-of does not make sense;
- Model works with various hidden sizes
- Naturally all of the models run on CPU very fast, but the smallest model also is very light in terms of its weights;
- The only difference is - convergence time. It kind of scales as a log of model size, i.e. model with 5 takes 5-7x more time to converge compared to model with 50. I wonder what if I use embedding size of 1?;
As added bonus - you can just store such miniature model in git w/o lfs.
What is with training transformers on US$250k worth of compute credits you say?)
#nlp
#data_science
#deep_learning
Tried some plain RNNs on a custom in the wild NER task.
The dataset is huge - literally infinite, but manually generated to mimick in-the-wild data.
I use EmbeddingBag + 1m n-grams (an optimal cut-off). Yeah, on NER / classification it is a handy trick that makes your pipeline totally misprint / error / OOV agnostic. Also FAIR themselves just guessed this too. Very cool! Just add PyTorch and you are golden.
What is interesting:
- Model works with embedding sizes 300, 100, 50 and even 5! 5 is dangerously close to OHE, but doing OHE on 1m n-grams kind-of does not make sense;
- Model works with various hidden sizes
- Naturally all of the models run on CPU very fast, but the smallest model also is very light in terms of its weights;
- The only difference is - convergence time. It kind of scales as a log of model size, i.e. model with 5 takes 5-7x more time to converge compared to model with 50. I wonder what if I use embedding size of 1?;
As added bonus - you can just store such miniature model in git w/o lfs.
What is with training transformers on US$250k worth of compute credits you say?)
#nlp
#data_science
#deep_learning
Facebook
A new model for word embeddings that are resilient to misspellings
Misspelling Oblivious Embeddings (MOE) is a new model for word embeddings that are resilient to misspellings, improving the ability to apply word embeddings to real-world situations, where misspellings are common.
Playing with name NER
Premise
So, I needed to separate street names that are actual name + surname. Do not ask me why.
Yeah I know that maybe 70% of streets are human names more or less.
So you need 99% precision and at least 30-40% recall.
Or you can imagine a creepy soviet name like
So, today making a NER parser is easy, take out our favourite framework (plan PyTorch ofc) of choice.
Even use FastText or something even less true. Add data and boom you have it.
The pain
But not so fast. Turns our there is a reason why cutting out proper names is a pain.
For Russian there is the natasha library, but since it works on YARGY, it has some assumptions about data structure.
I.e. names should be capitalized, come in pairs (name - surname), etc etc - I did not look their rules under the hood, but I would write it like this.
So probably this would be a name -
Ofc no, it just assumes some stuff that may not hold for your dataset.
And yeah it works for streets just fine.
Also recognizing a proper name without context does not really work. And good luck finding (or generating) corpora for that.
Why deep learning may not work
So I downloaded some free databases with names (VK.com respects your secutity lol - the 100M leaked database is available, but useless, too much noise) and surnames.
Got 700k surnames of different origin, around 100-200k male and female names. Used just random words from CC + wiki + taiga for hard negative mining.
Got 92% accuracy on 4 classes (just word, female name, male name, surname) with some naive models.
... and it works .... kind of. If you give it 10M unique word forms, it can distinguish name-like stuff in 90% of cases.
But for addresses it is useless more or less and heuristics from natasha work much better.
The moral
- A tool that works on one case may be 90% useless on another;
- Heuristics have very high precision, low recall and are fragile;
- Neural networks are superior, but you should match your artifically created dataset to the real data (it may take a month to pull off properly);
- In any case, properly cracking both approaches may take time, but both heuristics and NNs are very fast to create, but sometimes 3 plain rules give you 100% precision with 10% recall and sometimes generating a fake dataset that matches your domain is a no-brainer. It depends.
#data_science
#nlp
#deep_learning
Premise
So, I needed to separate street names that are actual name + surname. Do not ask me why.
Yeah I know that maybe 70% of streets are human names more or less.
So you need 99% precision and at least 30-40% recall.
Or you can imagine a creepy soviet name like
Трактор.So, today making a NER parser is easy, take out our favourite framework (plan PyTorch ofc) of choice.
Even use FastText or something even less true. Add data and boom you have it.
The pain
But not so fast. Turns our there is a reason why cutting out proper names is a pain.
For Russian there is the natasha library, but since it works on YARGY, it has some assumptions about data structure.
I.e. names should be capitalized, come in pairs (name - surname), etc etc - I did not look their rules under the hood, but I would write it like this.
So probably this would be a name -
Иван Иванов
But this probably would not ванечка иванофф
Is it bad? Ofc no, it just assumes some stuff that may not hold for your dataset.
And yeah it works for streets just fine.
Also recognizing a proper name without context does not really work. And good luck finding (or generating) corpora for that.
Why deep learning may not work
So I downloaded some free databases with names (VK.com respects your secutity lol - the 100M leaked database is available, but useless, too much noise) and surnames.
Got 700k surnames of different origin, around 100-200k male and female names. Used just random words from CC + wiki + taiga for hard negative mining.
Got 92% accuracy on 4 classes (just word, female name, male name, surname) with some naive models.
... and it works .... kind of. If you give it 10M unique word forms, it can distinguish name-like stuff in 90% of cases.
But for addresses it is useless more or less and heuristics from natasha work much better.
The moral
- A tool that works on one case may be 90% useless on another;
- Heuristics have very high precision, low recall and are fragile;
- Neural networks are superior, but you should match your artifically created dataset to the real data (it may take a month to pull off properly);
- In any case, properly cracking both approaches may take time, but both heuristics and NNs are very fast to create, but sometimes 3 plain rules give you 100% precision with 10% recall and sometimes generating a fake dataset that matches your domain is a no-brainer. It depends.
#data_science
#nlp
#deep_learning
GitHub
GitHub - natasha/yargy: Rule-based facts extraction for Russian language
Rule-based facts extraction for Russian language. Contribute to natasha/yargy development by creating an account on GitHub.
New Workhorse Tokenization Method for Morphologically Rich Languages?
Some time ago I read an NMT paper by the Chinese researchers where they effectively use some stemmer for the Russian language and predict the STEM and the SUFFIX (не только суффикс в нашем понимании, но и окончание, что на самом деле разумно) separately. They claim that this reduces complexity and makes Russian more similar to languages with less variation.
For the Russian language, approx.
So separately tokenizing "endings" (300 is a very small number) and using BPE or embedding bags to model the "stems" so far seems to be the best of both worlds.
There is no proper subword tokenizer for Russian (приставка, корень, суффикс, окончание), but with this approach you can just get away with
Without endings (cases) and suffixes (conjugation) - you effectively get something very similar to English or German. With the power of embedding bags or BPE you can model the rest.
If anyone is doing experiments now - please tell if this scheme is:
- Superior to embedding bags
- Plain BPE
#deep_learning
#nlp
Some time ago I read an NMT paper by the Chinese researchers where they effectively use some stemmer for the Russian language and predict the STEM and the SUFFIX (не только суффикс в нашем понимании, но и окончание, что на самом деле разумно) separately. They claim that this reduces complexity and makes Russian more similar to languages with less variation.
For the Russian language, approx.
300 endings (full word minus its stem) cover 99% of all cases.So separately tokenizing "endings" (300 is a very small number) and using BPE or embedding bags to model the "stems" so far seems to be the best of both worlds.
There is no proper subword tokenizer for Russian (приставка, корень, суффикс, окончание), but with this approach you can just get away with
snowball stemmer from nltk.Without endings (cases) and suffixes (conjugation) - you effectively get something very similar to English or German. With the power of embedding bags or BPE you can model the rest.
If anyone is doing experiments now - please tell if this scheme is:
- Superior to embedding bags
- Plain BPE
#deep_learning
#nlp
Russian Text Normalization for Speech Recognition
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
- De-Normalization (
We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
пять);- De-Normalization (
пять => 5);We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
Russian Speech Recognition
You may have heard about our dataset, Open STT.
And yeah, if you have not guessed we have built a Speech-To-Text system that is better / on par with alleged "market leaders", the only difference being that we publish something for the common good and we do not need 100 Tesla GPUs (wink-wink, Oleg).
Also if it is not super obvious, this thing is already deployed into production and it really works.
Now we decided to go out of stealth mode a bit and publish a series of publications in online Russian / English publications:
- A piece on Habr.com - just published https://habr.com/ru/post/494006/ - it is very short and abridged, you know habr;
- 2 more detailed pieces on https://thegradient.pub - coming soon!
If you want more gory details, you can see a couple of posts on our project's website:
- STT system quality benchmarks - https://www.silero.ai/russian-stt-benchmarks/
- STT system speed https://www.silero.ai/stt-system-speed/
- How to measure quality in STT https://www.silero.ai/stt-quality-metrics/
If you would like to test our system, you may first want to:
- Try a demo http://demo.silero.ai/ (more beautiful mobile demo coming up!)
- See the API https://api.silero.ai/docs
#deep_learning
#speech
#nlp
You may have heard about our dataset, Open STT.
And yeah, if you have not guessed we have built a Speech-To-Text system that is better / on par with alleged "market leaders", the only difference being that we publish something for the common good and we do not need 100 Tesla GPUs (wink-wink, Oleg).
Also if it is not super obvious, this thing is already deployed into production and it really works.
Now we decided to go out of stealth mode a bit and publish a series of publications in online Russian / English publications:
- A piece on Habr.com - just published https://habr.com/ru/post/494006/ - it is very short and abridged, you know habr;
- 2 more detailed pieces on https://thegradient.pub - coming soon!
If you want more gory details, you can see a couple of posts on our project's website:
- STT system quality benchmarks - https://www.silero.ai/russian-stt-benchmarks/
- STT system speed https://www.silero.ai/stt-system-speed/
- How to measure quality in STT https://www.silero.ai/stt-quality-metrics/
If you would like to test our system, you may first want to:
- Try a demo http://demo.silero.ai/ (more beautiful mobile demo coming up!)
- See the API https://api.silero.ai/docs
#deep_learning
#speech
#nlp
Silero
🥇 Сравнение Нашей Системы STT с Остальными Системами на Рынке по Качеству
Если вы еще не познакомились с нашей статьей, то самое время прочитать. Обязатально прочитайте и возвращайтесь!
⌛ Как Правильно Измерять Качество STT?> Мы часто сталкиваемся с заблуждениями по поводу того как ”правильно” проверятькачество STT систем. В этой…
⌛ Как Правильно Измерять Качество STT?> Мы часто сталкиваемся с заблуждениями по поводу того как ”правильно” проверятькачество STT систем. В этой…
Sentence / Word Tokenizer for Russian
Looks like razdel just got a decent facelift:
- https://github.com/natasha/razdel#sentencies
- https://github.com/natasha/razdel#tokens
Nice! Well, it is very cool that such libraries exist if your need a one-liner for a tedious task!
But probably you could just get away with
#nlp
Looks like razdel just got a decent facelift:
- https://github.com/natasha/razdel#sentencies
- https://github.com/natasha/razdel#tokens
Nice! Well, it is very cool that such libraries exist if your need a one-liner for a tedious task!
But probably you could just get away with
nltk.sent_tokenize + some cleaning (remove non-printables, space punctuation, remove extra spaces) + embedding bags =) #nlp
GitHub
GitHub - natasha/razdel: Rule-based token, sentence segmentation for Russian language
Rule-based token, sentence segmentation for Russian language - natasha/razdel
A Blog ... about Building Your Own Search Engine
You heard it right - https://0x65.dev/
And this is not some highly sophisticated blockchain technology that would work on if everyone adopts it. A few facts:
- They are open that their team exists at least starting from 2013 and is financed by Burda (I wonder why Burda finances this, they raised this question, but did not answer it)
- They do not rely on Google or Bing (unlike other alternative engines)
- The methods they describe - are down-to-earth, sane and hacky sometimes
- Biggest corner cutting ideas / what makes them different:
-- Aggressive no tracking policies - i.e. they have an assessor network, but the data is aggregated on the client side, not server side
-- Build first approximate search using KNN on search queries only
-- Then results are refined using ad hoc filters (i.e. date, porn, language, etc etc), page content, page popularity
-- Mine for search queries aggressively using other SEs, artificial data, own assessor network
-- They store vectors for word separately and then just sum them
-- Their KNN index ... would fit in your RAM (100 - 200 GB) =)
-- Emphasis on mining data from anchors - it arguably he best annotation in search
-- Looks like they do not use any explicit PageRank like algorithms
About the quality of their search. It kind of sucks, except when it does not, except when it does. I.e. it works well for well defined topics like wikipedia, looking up some docs for python, looking up cat photos etc
It does not really work
- For Russian
- For new content - there is a noticeable lag
- For rarer topics
Also it is a bit slow. Also I hope they do not perish and this becomes a decent alternative.
#nlp
You heard it right - https://0x65.dev/
And this is not some highly sophisticated blockchain technology that would work on if everyone adopts it. A few facts:
- They are open that their team exists at least starting from 2013 and is financed by Burda (I wonder why Burda finances this, they raised this question, but did not answer it)
- They do not rely on Google or Bing (unlike other alternative engines)
- The methods they describe - are down-to-earth, sane and hacky sometimes
- Biggest corner cutting ideas / what makes them different:
-- Aggressive no tracking policies - i.e. they have an assessor network, but the data is aggregated on the client side, not server side
-- Build first approximate search using KNN on search queries only
-- Then results are refined using ad hoc filters (i.e. date, porn, language, etc etc), page content, page popularity
-- Mine for search queries aggressively using other SEs, artificial data, own assessor network
-- They store vectors for word separately and then just sum them
-- Their KNN index ... would fit in your RAM (100 - 200 GB) =)
-- Emphasis on mining data from anchors - it arguably he best annotation in search
-- Looks like they do not use any explicit PageRank like algorithms
About the quality of their search. It kind of sucks, except when it does not, except when it does. I.e. it works well for well defined topics like wikipedia, looking up some docs for python, looking up cat photos etc
It does not really work
- For Russian
- For new content - there is a noticeable lag
- For rarer topics
Also it is a bit slow. Also I hope they do not perish and this becomes a decent alternative.
#nlp
0x65.dev
Tech @ Cliqz
Cliqz 0x65 – Tech Blog
Building Scalable, Explainable, and Adaptive NLP Models with Retrieval
I am so tired of "trillion param model go brrr" bs. It is nice to see that at least some people are trying to create something useful for a change.
Is retrieval “all you need”?
http://ai.stanford.edu/blog/retrieval-based-NLP/
#deep_learing
#nlp
I am so tired of "trillion param model go brrr" bs. It is nice to see that at least some people are trying to create something useful for a change.
Is retrieval “all you need”?
The black-box nature of large language models like T5 and GPT-3 makes them inefficient to train and deploy, opaque in their knowledge representations and in backing their claims with provenance, and static in facing a constantly evolving world and diverse downstream contexts. This post explores retrieval-based NLP, where models retrieve information pertinent to solving their tasks from a plugged-in text corpus. This paradigm allows NLP models to leverage the representational strengths of language models, while needing much smaller architectures, offering transparent provenance for claims, and enabling efficient updates and adaptation.
We surveyed much of the existing and emerging work in this space and highlighted some of our work at Stanford, including ColBERT for scaling up expressive retrieval to massive corpora via late interaction, ColBERT-QA for accurately answering open-domain questions by adapting high-recall retrieval to the task, and Baleen for solving tasks that demand information from several independent sources using a condensed retrieval architecture. We continue to actively maintain our code as open source.
http://ai.stanford.edu/blog/retrieval-based-NLP/
#deep_learing
#nlp
ai.stanford.edu
Building Scalable, Explainable, and Adaptive NLP Models with Retrieval
Forwarded from Data Science by ODS.ai 🦜
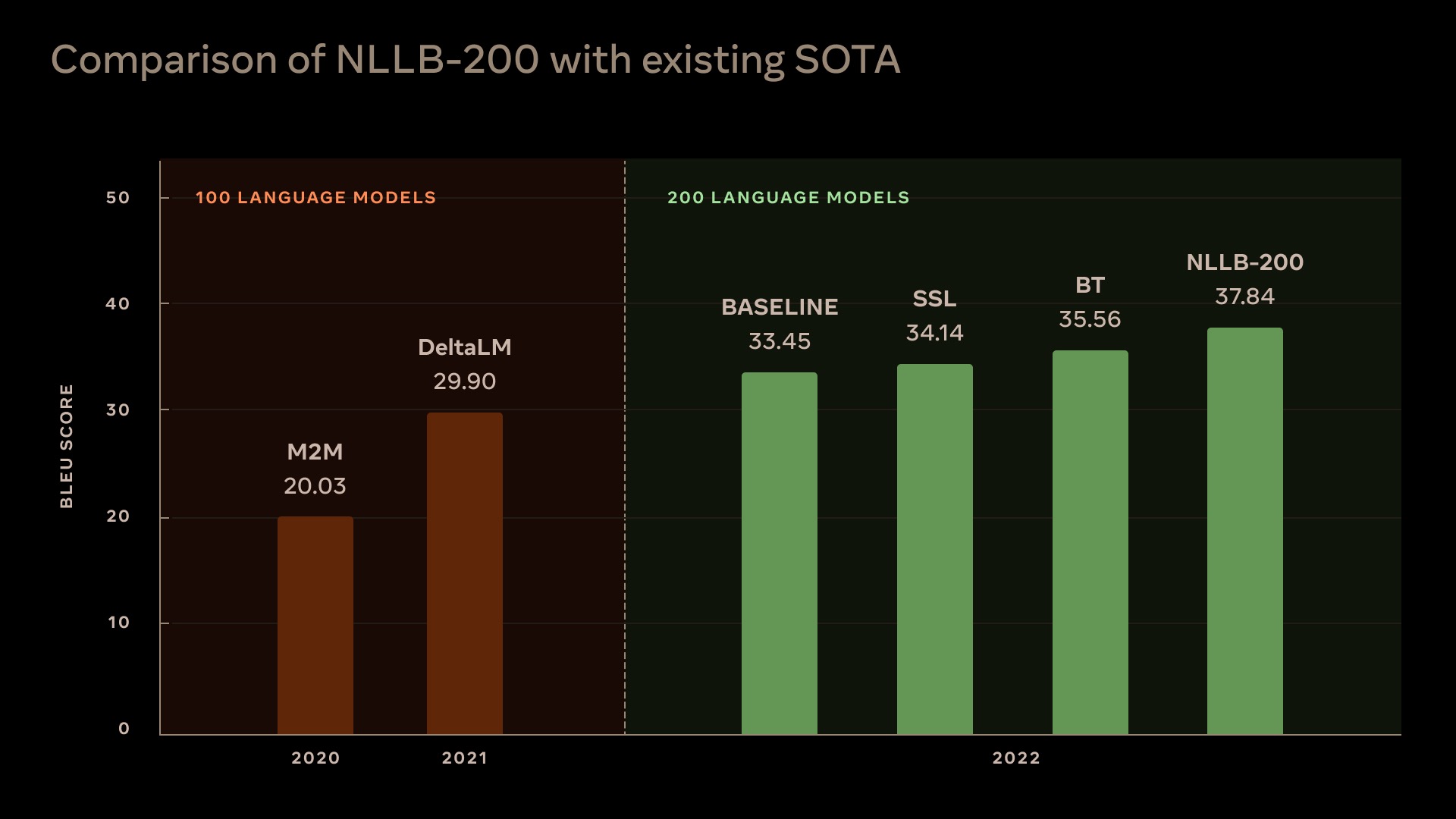
No Language Left Behind
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
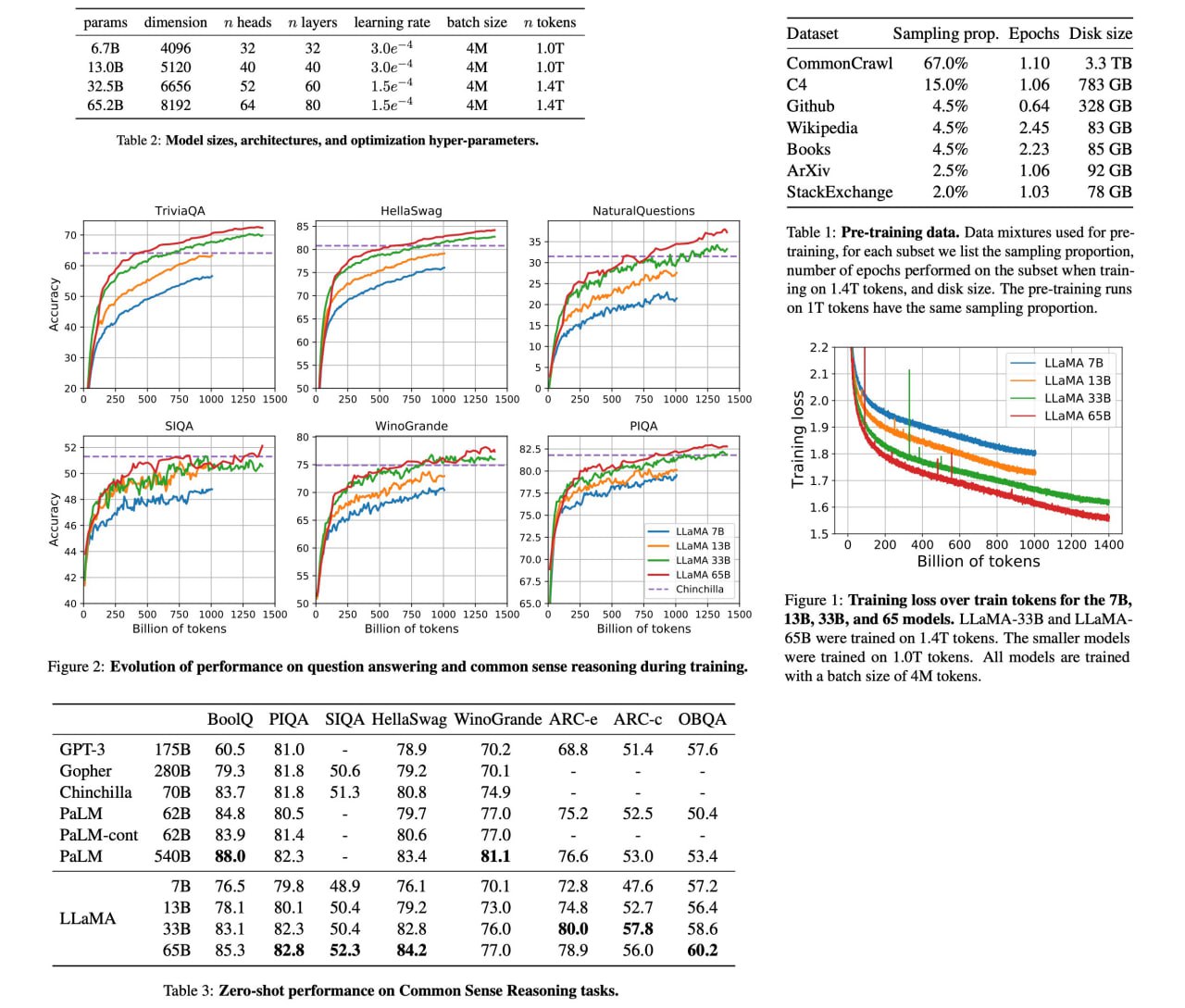
LLaMA: Open and Efficient Foundation Language Models
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
Scaling Transformer to 1M tokens and beyond with RMT
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
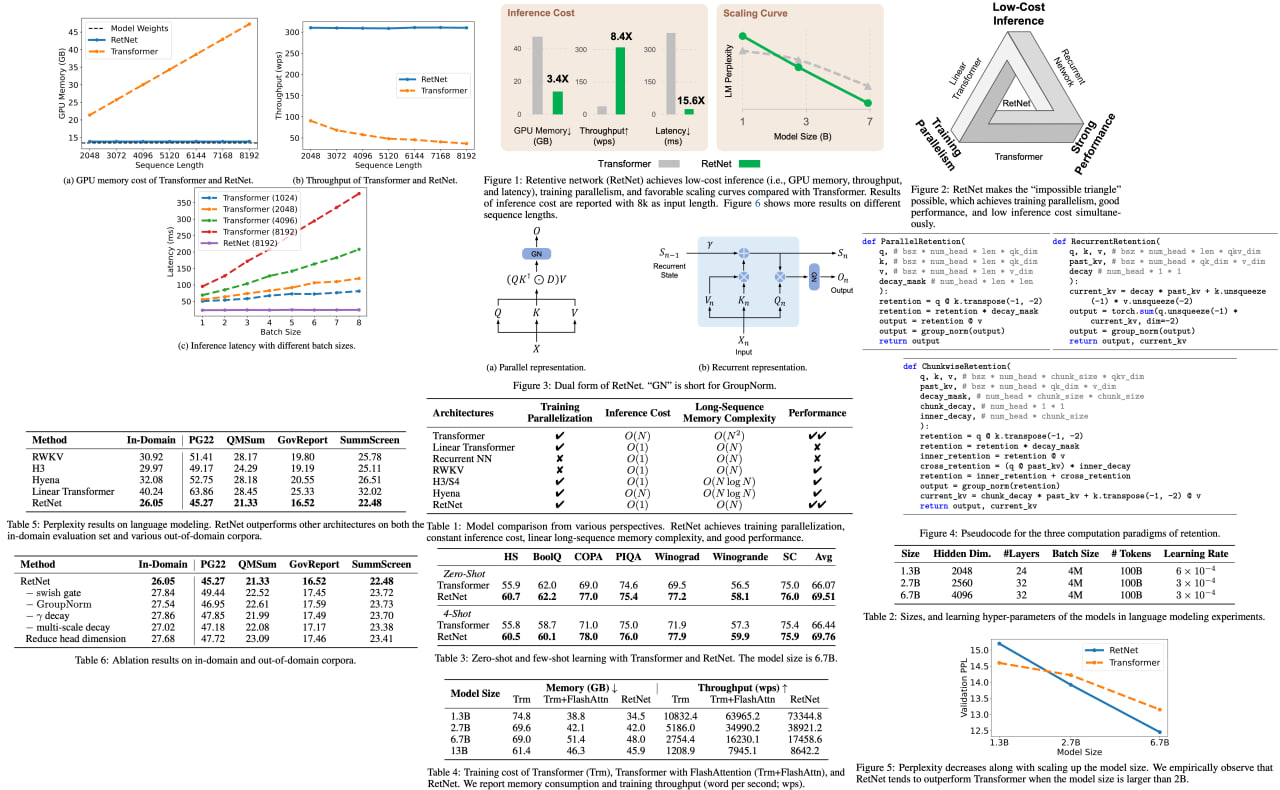
Retentive Network: A Successor to Transformer for Large Language Models
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
{kind=link}