
Артефакты и размер эффекта
#resources #statistics
Нашла отличный интерактивный тулбокс от Matthew B. Jané по визуализации статистических артефактов, которые искажают размер эффекта. Сопровождающие теоретические материалы с формулами и кодом можно найти здесь. В этих материалах рассматриваются такие артефакты, как небольшая величина выборки, ошибки измерения, понижающие показатели связи между факторами, а также ограничения доступного диапазона величин. Для каждого случая предлагаются способы коррекции возникших искажений.
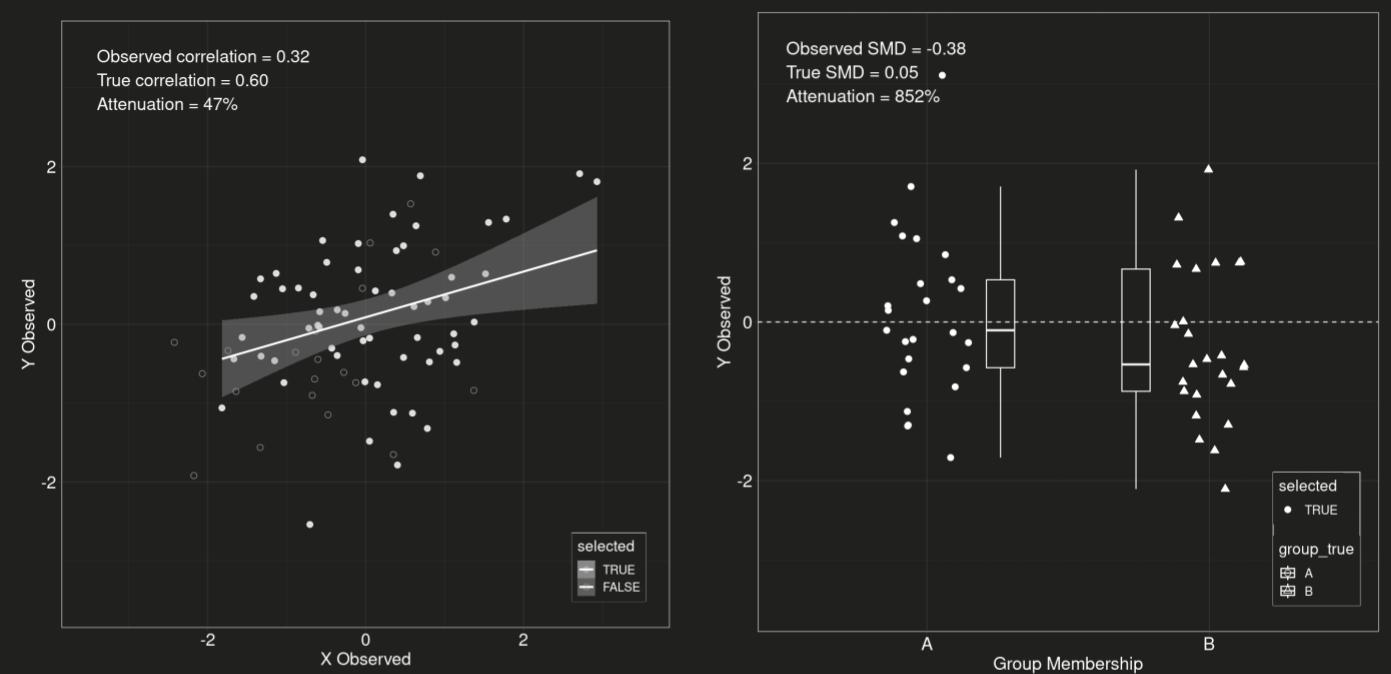
Один из простейших примеров работы тулбокса (см. скрин): демонстрация того, как недостаточный объем выборки приводит к заниженным показателям корреляции и завышенным показателям стандартизованной разницы средних.
#resources #statistics
Нашла отличный интерактивный тулбокс от Matthew B. Jané по визуализации статистических артефактов, которые искажают размер эффекта. Сопровождающие теоретические материалы с формулами и кодом можно найти здесь. В этих материалах рассматриваются такие артефакты, как небольшая величина выборки, ошибки измерения, понижающие показатели связи между факторами, а также ограничения доступного диапазона величин. Для каждого случая предлагаются способы коррекции возникших искажений.
Один из простейших примеров работы тулбокса (см. скрин): демонстрация того, как недостаточный объем выборки приводит к заниженным показателям корреляции и завышенным показателям стандартизованной разницы средних.
{kind=link}
Голодные судьи против статистики
#psychology #resources #statistics
На очень полезном ресурсе по статистике Д. Лакенса приведен пример того, как можно пойти на поводу у слишком красивых результатов.
Нередко в качестве иллюстрации того, как сильно наши решения зависят от косвенных факторов, упоминается исследование, в котором обнаружилось, что судьи выносят более жесткие приговоры до обеда, чем после обеда. Напрашивается простая интерпретация: справедливости не существует, когда ты голоден (не обессудьте – клише). Однако не все так просто.
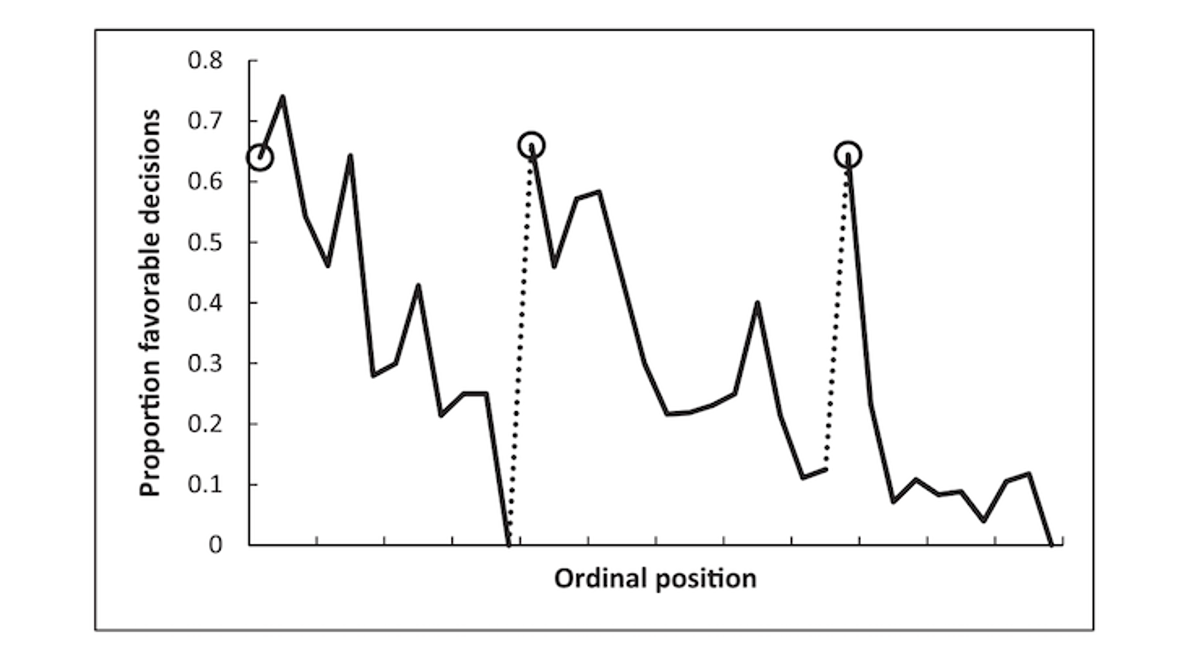
Во-первых, обратимся к графику из статьи. Он показывает пропорцию решений в пользу подсудимых в течение всего дня (общее количество анализируемых дней составило 50). Мы видим, что в самом начале дня судьи отпускали на волю 65 % подсудимых, а затем этот показатель резко падал до нуля. После перерыва показатель cнова возвращался к 65 % и так же быстро падал. После второго перерыва ситуация повторялась. Такая повторяемость и такие резкие спады выглядят очень подозрительно.
Во-вторых, выяснилось, что размер эффекта у наблюдаемых тенденций чрезмерно высокий. Напомню, что хоть мы все подспудно и гонимся на значимыми p-values, они констатируют лишь наличие эффекта, а его размер нужно количественно оценивать дополнительно. Например, если разница в среднем росте между детьми и подростками составит 60 см, то это станет размером эффекта. Поделив эту разность на стандартное отклонение, мы получим стандартизованную оценку (Cohen's d, d Коэна). Если d=1, то это значит, что две группы отличаются на одно стандартное отклонение. d=0.2 считают малым размером эффекта, d=0.5 – средним, d>0.8 – большим.
В исследовании про судей размер эффекта составил d=1.96! В психологических экспериментах такие размеры эффекта едва ли достижимы. В частности, Лакенс приводит пример исследования, в котором d=2 соответствует различию в росте 21-летнего взрослого мужчины и женщины в Нидерландах. Оно составляет 13 сантиметров, что весьма ощутимо. Если же переключаться на размеры эффекта в психологии, то близкие значения d Коэна могли достигаться лишь в тех случаях, когда независимая и зависимая переменные составляли чуть ли не тавтологию (например, взаимодействие харизмы и лидерства, социальной девиации и исключения из общества и т. д.)
Таким образом, обнаруженный эффект явно не может объясняться такими опосредованными механизмами, как голод и усталость. Было бы это так, мы бы наблюдали этот огромный эффект напрямую в виде хаоса и ментальных провалов в предобеденное время. Впрочем, если обращаться к нашему внутрилабораторному опыту, иногда это похоже на правду, но точно не дотягивает до d=1.96.
Наиболее вероятным объяснением полученных результатов может являться то, что рассмотрение дел в суде в каждой из сессий производилось не в случайном порядке: например, "простые" дела, в результате которых подсудимый с большой вероятностью заслуживал освобождение, могли рассматриваться первыми.
Это наглядный пример того, что красивая статистика без правдоподобной интерпретации, соответствующей ей, приводит к заблуждениям. И такие примеры могут послужить поводом к включению в эксперименты 'maximum positive controls' – экспериментальных условий, которые задают верхнюю границу возможного размера эффекта в заданной парадигме.
#psychology #resources #statistics
На очень полезном ресурсе по статистике Д. Лакенса приведен пример того, как можно пойти на поводу у слишком красивых результатов.
Нередко в качестве иллюстрации того, как сильно наши решения зависят от косвенных факторов, упоминается исследование, в котором обнаружилось, что судьи выносят более жесткие приговоры до обеда, чем после обеда. Напрашивается простая интерпретация: справедливости не существует, когда ты голоден (не обессудьте – клише). Однако не все так просто.
Во-первых, обратимся к графику из статьи. Он показывает пропорцию решений в пользу подсудимых в течение всего дня (общее количество анализируемых дней составило 50). Мы видим, что в самом начале дня судьи отпускали на волю 65 % подсудимых, а затем этот показатель резко падал до нуля. После перерыва показатель cнова возвращался к 65 % и так же быстро падал. После второго перерыва ситуация повторялась. Такая повторяемость и такие резкие спады выглядят очень подозрительно.
Во-вторых, выяснилось, что размер эффекта у наблюдаемых тенденций чрезмерно высокий. Напомню, что хоть мы все подспудно и гонимся на значимыми p-values, они констатируют лишь наличие эффекта, а его размер нужно количественно оценивать дополнительно. Например, если разница в среднем росте между детьми и подростками составит 60 см, то это станет размером эффекта. Поделив эту разность на стандартное отклонение, мы получим стандартизованную оценку (Cohen's d, d Коэна). Если d=1, то это значит, что две группы отличаются на одно стандартное отклонение. d=0.2 считают малым размером эффекта, d=0.5 – средним, d>0.8 – большим.
В исследовании про судей размер эффекта составил d=1.96! В психологических экспериментах такие размеры эффекта едва ли достижимы. В частности, Лакенс приводит пример исследования, в котором d=2 соответствует различию в росте 21-летнего взрослого мужчины и женщины в Нидерландах. Оно составляет 13 сантиметров, что весьма ощутимо. Если же переключаться на размеры эффекта в психологии, то близкие значения d Коэна могли достигаться лишь в тех случаях, когда независимая и зависимая переменные составляли чуть ли не тавтологию (например, взаимодействие харизмы и лидерства, социальной девиации и исключения из общества и т. д.)
Таким образом, обнаруженный эффект явно не может объясняться такими опосредованными механизмами, как голод и усталость. Было бы это так, мы бы наблюдали этот огромный эффект напрямую в виде хаоса и ментальных провалов в предобеденное время. Впрочем, если обращаться к нашему внутрилабораторному опыту, иногда это похоже на правду, но точно не дотягивает до d=1.96.
Наиболее вероятным объяснением полученных результатов может являться то, что рассмотрение дел в суде в каждой из сессий производилось не в случайном порядке: например, "простые" дела, в результате которых подсудимый с большой вероятностью заслуживал освобождение, могли рассматриваться первыми.
Это наглядный пример того, что красивая статистика без правдоподобной интерпретации, соответствующей ей, приводит к заблуждениям. И такие примеры могут послужить поводом к включению в эксперименты 'maximum positive controls' – экспериментальных условий, которые задают верхнюю границу возможного размера эффекта в заданной парадигме.
{kind=link}
Ловушка больших данных и корреляций
#metascience #statistics
"Всё со всем связано".
В статистическом смысле это означает, что в реалистичных сценариях практически невозможно обнаружить две переменные, взаимодействия между которыми будут характеризоваться нулевым коэффициентом корреляции. Ненулевые же статистически значимые корреляции будут сохраняться и с увеличением выборки.
В связи с данным феноменом был введён термин 'crud-фактор' или – более нейтрально – "окружающий шум" (ambient noise). Несмотря на отсутствие чёткой формализации, под crud-фактором подразумевают среднее значение всех коэффициентов корреляции между всеми возможными парами переменных.
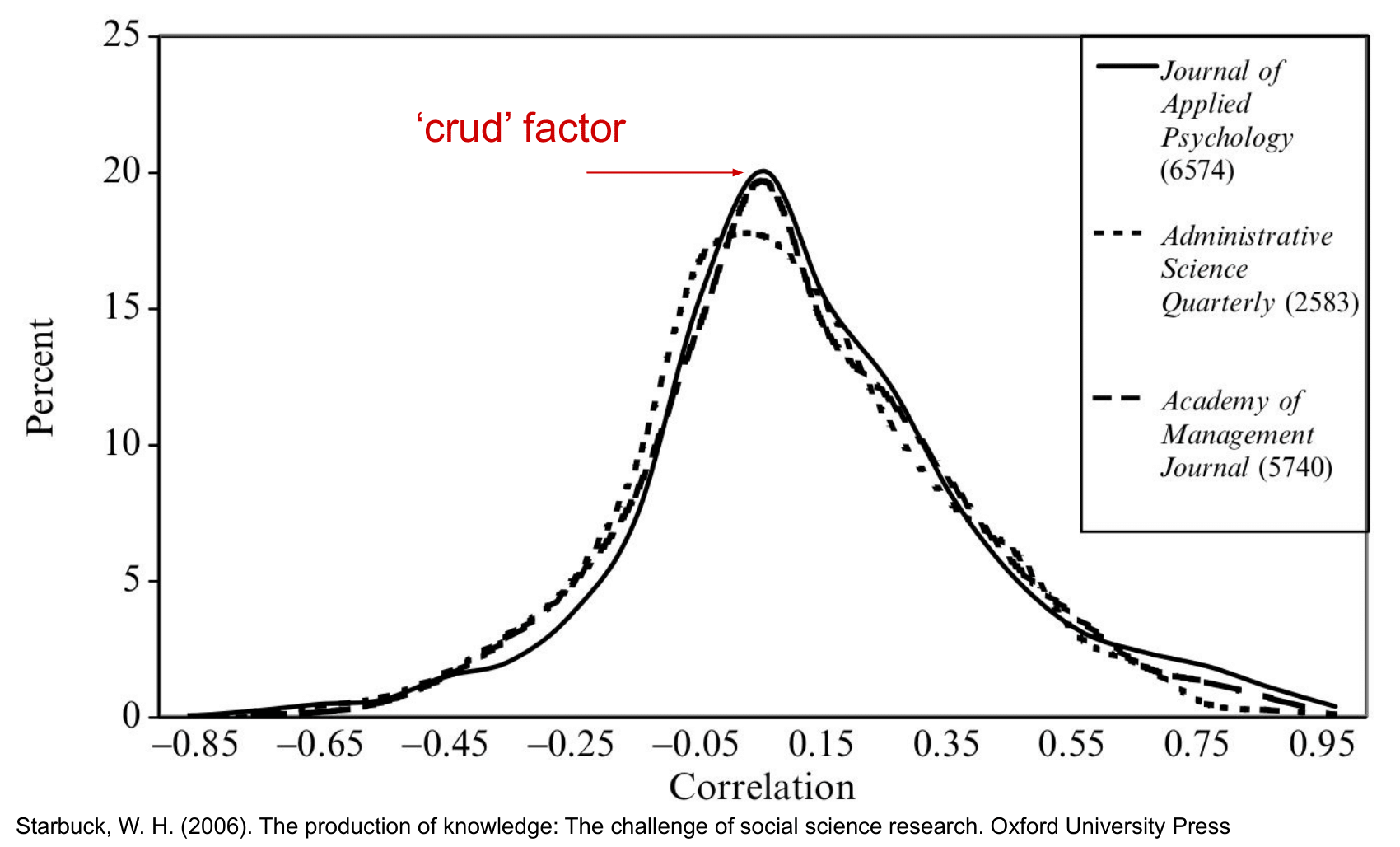
Пример численного значения crud-фактора можно обнаружить в анализе ~ 15 000 корреляций из ~ 260 исследований, опубликованных в трёх журналах, связанных с социологией и психологией: Administrative Science Quarterly, Academy of Management Journal и Journal of Applied Psychology. На графике представлены три распределения коэффициентов корреляции, соответствующие трём журналам. Заметна их схожесть, достаточно большое стандартное отклонение и выделяющийся пик около коэффициента корреляции 0.1, что и возможно обозначить как crud-фактор. Таким образом, мы наблюдаем, что, вопреки нулевой гипотезе, вовсе не нулевая корреляция является "дефолтным" значением для такого числа сопоставляемых переменных.
Каковы следствия такого наблюдения?
1. Психологические и социальные науки во многом базируются на нулевых гипотезах. Существование crud-фактора указывает на то, что едва ли не любая нулевая гипотеза, фиксирующая коэффициент корреляции в нуле, неизбежно будет опровергнута с увеличением выборки. Получается, что более оптимальным вариантом было бы рассматривать только те корреляции, которые не попадают в диапазон, скажем, одного стандартного отклонения от значения ненулевого crud-фактора.
2. Имеет смысл уделять внимание каузальному сетевому анализу, потому что эмпирически наблюдаемые ненулевые корреляции между концептуально отличными переменными могут указывать на наличие дополнительных латентных факторов, опосредованно влияющих на взаимодействие этих переменных (достаточно вспомнить влияние генотипа на некоторые психологические характеристики).
3. С учётом наблюдаемого crud-фактора обнаружение переменных, которые, напротив, не коррелируют с большинством других переменных, может указывать на их "бессмысленность", проблемы со сбором данных или дополнительные искажения, в частности:
- парадокс Симпсона, в котором значимые тренды, присутствующие в нескольких группах, уничтожаются при их объединении;
- или влияние так называемой константы ящера (lizardman constant), обозначающей процент респондентов, нарочно заполняющих опросники неверно.
Как исследователи могут себя полностью обезопасить от crud-фактора, пока не вполне очевидно. Путь к решению должен включать в себя и более точное понимание механизмов, порождающих ненулевые корреляции, и реструктуризацию статистических основ для тестирования гипотез.
P. S. В качестве снижения градуса серьёзности оставляю ссылку на сайт c примерами абсурдных корреляций. Так вы сможете узнать, что число разводов в некоторых штатах США коррелирует с потреблением маргарина, а годовое число людей, утонувших в бассейне, коррелирует с числом фильмов, в которых снимался Николас Кейдж.
#metascience #statistics
"Всё со всем связано".
В статистическом смысле это означает, что в реалистичных сценариях практически невозможно обнаружить две переменные, взаимодействия между которыми будут характеризоваться нулевым коэффициентом корреляции. Ненулевые же статистически значимые корреляции будут сохраняться и с увеличением выборки.
В связи с данным феноменом был введён термин 'crud-фактор' или – более нейтрально – "окружающий шум" (ambient noise). Несмотря на отсутствие чёткой формализации, под crud-фактором подразумевают среднее значение всех коэффициентов корреляции между всеми возможными парами переменных.
Пример численного значения crud-фактора можно обнаружить в анализе ~ 15 000 корреляций из ~ 260 исследований, опубликованных в трёх журналах, связанных с социологией и психологией: Administrative Science Quarterly, Academy of Management Journal и Journal of Applied Psychology. На графике представлены три распределения коэффициентов корреляции, соответствующие трём журналам. Заметна их схожесть, достаточно большое стандартное отклонение и выделяющийся пик около коэффициента корреляции 0.1, что и возможно обозначить как crud-фактор. Таким образом, мы наблюдаем, что, вопреки нулевой гипотезе, вовсе не нулевая корреляция является "дефолтным" значением для такого числа сопоставляемых переменных.
Каковы следствия такого наблюдения?
1. Психологические и социальные науки во многом базируются на нулевых гипотезах. Существование crud-фактора указывает на то, что едва ли не любая нулевая гипотеза, фиксирующая коэффициент корреляции в нуле, неизбежно будет опровергнута с увеличением выборки. Получается, что более оптимальным вариантом было бы рассматривать только те корреляции, которые не попадают в диапазон, скажем, одного стандартного отклонения от значения ненулевого crud-фактора.
2. Имеет смысл уделять внимание каузальному сетевому анализу, потому что эмпирически наблюдаемые ненулевые корреляции между концептуально отличными переменными могут указывать на наличие дополнительных латентных факторов, опосредованно влияющих на взаимодействие этих переменных (достаточно вспомнить влияние генотипа на некоторые психологические характеристики).
3. С учётом наблюдаемого crud-фактора обнаружение переменных, которые, напротив, не коррелируют с большинством других переменных, может указывать на их "бессмысленность", проблемы со сбором данных или дополнительные искажения, в частности:
- парадокс Симпсона, в котором значимые тренды, присутствующие в нескольких группах, уничтожаются при их объединении;
- или влияние так называемой константы ящера (lizardman constant), обозначающей процент респондентов, нарочно заполняющих опросники неверно.
Как исследователи могут себя полностью обезопасить от crud-фактора, пока не вполне очевидно. Путь к решению должен включать в себя и более точное понимание механизмов, порождающих ненулевые корреляции, и реструктуризацию статистических основ для тестирования гипотез.
P. S. В качестве снижения градуса серьёзности оставляю ссылку на сайт c примерами абсурдных корреляций. Так вы сможете узнать, что число разводов в некоторых штатах США коррелирует с потреблением маргарина, а годовое число людей, утонувших в бассейне, коррелирует с числом фильмов, в которых снимался Николас Кейдж.
{kind=link}