
Искусственный интеллект – Пифия современности
#ai
Публикация: Savcisens, G., Eliassi-Rad, T., Hansen, L. K., Mortensen, L. H., Lilleholt, L., Rogers, A., ... & Lehmann, S. (2023). Using sequences of life-events to predict human lives. Nature Computational Science, 1-14.
На пятый день после наступления нового года, когда беспечность настоящего постепенно угасает, неизбежно задумываешься о будущем... В долгосрочной перспективе оно кажется неосязаемым и туманным – по крайней мере, для нас. Но не для искусственного интеллекта!
Недавно в Nature Computational Science была представлена модель life2vec, предсказывающая жизнь людей. Модель опиралась на данные жителей Дании от 25 до 70 лет с 2008 по 2016 года. Эти данные представляли собой детализированную последовательность событий в сферах труда и здоровья: получение зарплаты или стипендии, устройство на работу, посещение врачей, постановку диагнозов и т. д. Используя эти данные, расположенные в хронологическом порядке, модель оценивала каждое событие как изолированно, так и в контексте всей последовательности жизни человека целиком. Это и позволяло осуществить предсказание на ближайшие четыре года.
С технической точки зрения важно подчеркнуть, что в модели не использовались традиционные методы предсказания временных рядов, поскольку события жизни человека характеризуются многомерными признаками и не регистрируются через равные промежутки времени. Наконец, само понятие времени в данном случае усложняется, так как представлено и датой события, и возрастом конкретного человека. С учётом всех сложностей была использована архитектура трансформера. Все категории событий жизни человека составили синтетический "вокабуляр", и последовательность событий жизни рассматривались как "предложения", состоящие из элементов этого вокабуляра. Если упрощать, то задача предсказания следующих событий жизни человека сводилась к задаче предсказания следующих "слов" по аналогии с тем, как это делают ИИ-чатботы.
Что именно может предсказывать модель? Концептуально ограничений нет, поскольку для каждого типа предсказаний на основе сырых данных формируется новое пространство векторов, специфичных для этого типа. То есть каждое событие жизни может быть по-разному представлено в контексте типа предсказания. Это и делает модель в чём-то универсальной. С её помощью удалось предсказать как раннюю смертность для выборки людей от 35 до 65 лет, так и психологически тонкие показатели, связанные с десятью личностными характеристиками экстраверсии. Интересно, что life2vec превзошла модели (рекуррентные нейронные сети), натренированные на данных, относящихся исключительно к предсказываемой переменной.
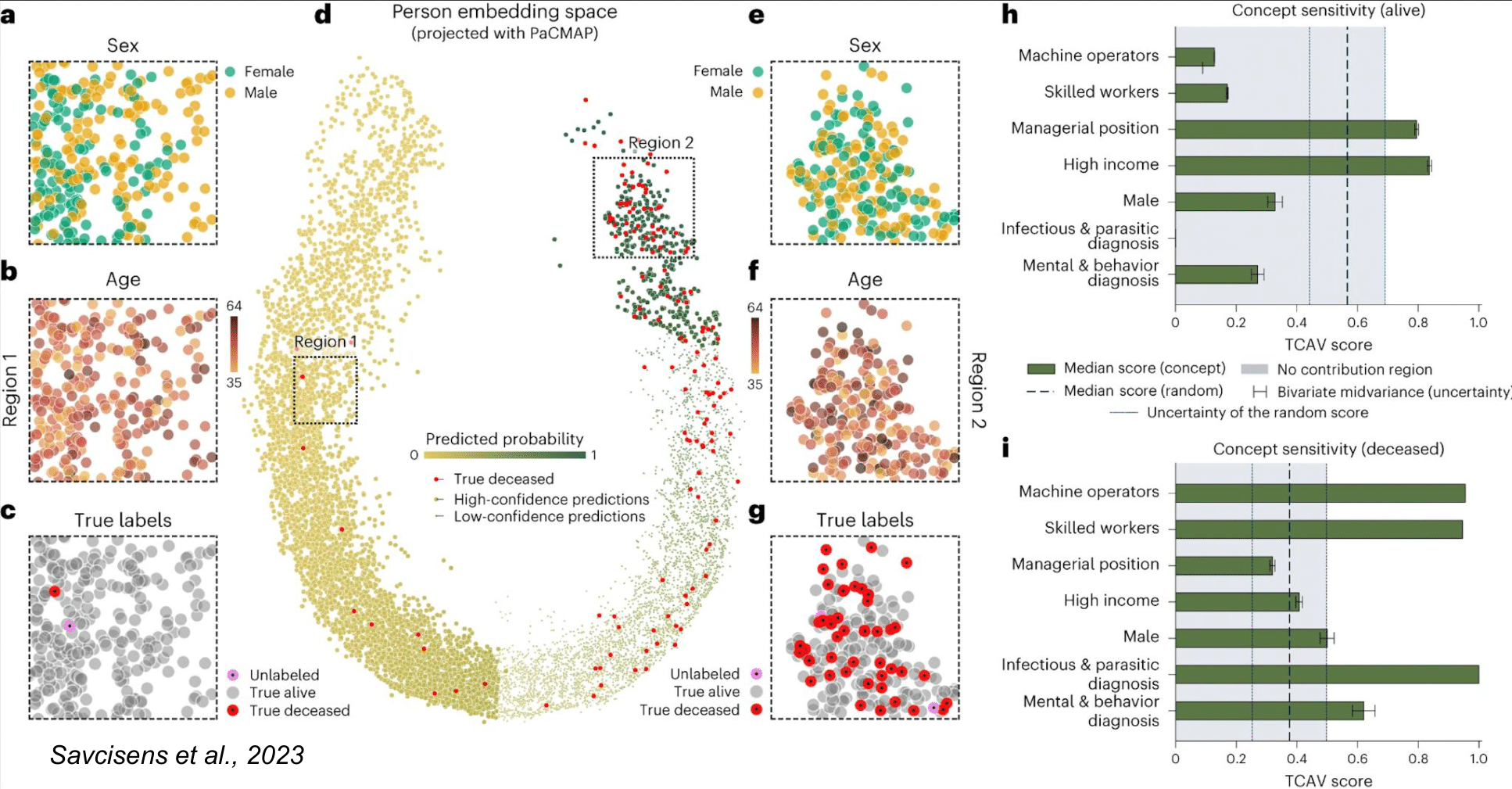
Представляет интерес пример (см. Рис.) двумерной проекции жизней людей для случая с предсказанием смертности. Выделенные на изображении (d) регионы 1 и 2 соответствуют высокой вероятности выживания и смерти соответственно. Примечательно, что в немалая часть региона 2 представлена молодыми людьми (f), которые в действительности умерли (см. красные точки), что указывает на сложный характер предсказаний, с которыми справилась модель. Реальные смерти, близкие к региону 1 (высокая вероятность выживания) и соответствующие ложно-отрицательному результату, объяснялись несчастными случаями, возникновениями новообразований или инфарктом, что действительно сложнее предсказать на основе имеющихся данных.
Из ограничений модели следует отметить использование лишь небольшого промежутка времени длиной в 8 лет, а также возможные социодемографические искажения, связанные с отсутствием данных тех, кто не получает зарплату или не посещает медицинские учреждения. Впрочем, ничто не мешает в дальнейшем использовать и иные источники данных – например, социальные сети.
Этические сомнения также возникают, но они настолько очевидны, что не требуют пояснений.
P. S. Отдельная благодарность подписчице канала Алине за наводку на статью. И для заинтересованных – по этой ссылке можно найти репозиторий с исходным кодом.
#ai
Публикация: Savcisens, G., Eliassi-Rad, T., Hansen, L. K., Mortensen, L. H., Lilleholt, L., Rogers, A., ... & Lehmann, S. (2023). Using sequences of life-events to predict human lives. Nature Computational Science, 1-14.
На пятый день после наступления нового года, когда беспечность настоящего постепенно угасает, неизбежно задумываешься о будущем... В долгосрочной перспективе оно кажется неосязаемым и туманным – по крайней мере, для нас. Но не для искусственного интеллекта!
Недавно в Nature Computational Science была представлена модель life2vec, предсказывающая жизнь людей. Модель опиралась на данные жителей Дании от 25 до 70 лет с 2008 по 2016 года. Эти данные представляли собой детализированную последовательность событий в сферах труда и здоровья: получение зарплаты или стипендии, устройство на работу, посещение врачей, постановку диагнозов и т. д. Используя эти данные, расположенные в хронологическом порядке, модель оценивала каждое событие как изолированно, так и в контексте всей последовательности жизни человека целиком. Это и позволяло осуществить предсказание на ближайшие четыре года.
С технической точки зрения важно подчеркнуть, что в модели не использовались традиционные методы предсказания временных рядов, поскольку события жизни человека характеризуются многомерными признаками и не регистрируются через равные промежутки времени. Наконец, само понятие времени в данном случае усложняется, так как представлено и датой события, и возрастом конкретного человека. С учётом всех сложностей была использована архитектура трансформера. Все категории событий жизни человека составили синтетический "вокабуляр", и последовательность событий жизни рассматривались как "предложения", состоящие из элементов этого вокабуляра. Если упрощать, то задача предсказания следующих событий жизни человека сводилась к задаче предсказания следующих "слов" по аналогии с тем, как это делают ИИ-чатботы.
Что именно может предсказывать модель? Концептуально ограничений нет, поскольку для каждого типа предсказаний на основе сырых данных формируется новое пространство векторов, специфичных для этого типа. То есть каждое событие жизни может быть по-разному представлено в контексте типа предсказания. Это и делает модель в чём-то универсальной. С её помощью удалось предсказать как раннюю смертность для выборки людей от 35 до 65 лет, так и психологически тонкие показатели, связанные с десятью личностными характеристиками экстраверсии. Интересно, что life2vec превзошла модели (рекуррентные нейронные сети), натренированные на данных, относящихся исключительно к предсказываемой переменной.
Представляет интерес пример (см. Рис.) двумерной проекции жизней людей для случая с предсказанием смертности. Выделенные на изображении (d) регионы 1 и 2 соответствуют высокой вероятности выживания и смерти соответственно. Примечательно, что в немалая часть региона 2 представлена молодыми людьми (f), которые в действительности умерли (см. красные точки), что указывает на сложный характер предсказаний, с которыми справилась модель. Реальные смерти, близкие к региону 1 (высокая вероятность выживания) и соответствующие ложно-отрицательному результату, объяснялись несчастными случаями, возникновениями новообразований или инфарктом, что действительно сложнее предсказать на основе имеющихся данных.
Из ограничений модели следует отметить использование лишь небольшого промежутка времени длиной в 8 лет, а также возможные социодемографические искажения, связанные с отсутствием данных тех, кто не получает зарплату или не посещает медицинские учреждения. Впрочем, ничто не мешает в дальнейшем использовать и иные источники данных – например, социальные сети.
Этические сомнения также возникают, но они настолько очевидны, что не требуют пояснений.
P. S. Отдельная благодарность подписчице канала Алине за наводку на статью. И для заинтересованных – по этой ссылке можно найти репозиторий с исходным кодом.
{kind=link}
Доверчивые ученые и искусственный интеллект
#metascience #ai
Публикация: Messeri, L., Crockett, M.J. Artificial intelligence and illusions of understanding in scientific research. Nature 627, 49–58 (2024).
Сложно представить сферу деятельности, в профессиональную обыденность которой не внедрился искусственный интеллект. Наука не стала исключением. Уже не раз обсуждалась проблематичность этого феномена на примере "галлюцинирующего" GPT, плохой интерпретируемости многих моделей и набивших оскомину этических ограничений. Авторы же вышедшей на днях публикации, проанализировав литературу с примерами использования ИИ в науке, вынесли на поверхность проблемы, относящиеся не столько непосредственно к ИИ как к технологии, сколько к тому, какие ложные ожидания на него накладывают сами учёные.
Авторы выделили роли, которые ИИ уже выполняет в практике учёных:
1. "Оракул": изучение бесконечно растущего пласта научных публикаций, его обобщение, выдвижение гипотез (реальный пример – предсказание комплексных биологических структур);
2. "Суррогат": синтез или аугментация данных, сбор которых в реальности сопряжен с временными и финансовыми затратами;
3. "Аналитик данных": наиболее привычная роль ИИ –автоматизированная обработка огромных массивов данных;
4. "Арбитр": роль, схожая с "оракулом" – анализ отправляемых на рецензию статей (в этом случае ИИ должен быть непредвзятым, уметь оценивать реплицируемость исследования и устранять publication biases).
Какие риски сопровождают эти роли?
Первый риск – это иллюзия глубины понимания (illusion of explanatory depth). Люди не могут охватить все доступные знания, поэтому склонны полагаться на экспертизу других лиц, которых считают авторитетными. Ощущение, что другое лицо понимает изучаемый феномен глубоко, может создавать иллюзию, что и сам человек обладает этим пониманием. Перенос этой иллюзии в сферу ИИ формирует ситуации, в которых высокая точность предсказания модели может создавать ложное ощущение объяснимости феномена. При этом самая точная модель не обязательно должна соотноситься с реальными механизмами, порождающими изучаемые данные. Это может подтверждаться, в частности, существованием эффекта Расёмона в машинном обучении, в соответствии с которым одинаково точные модели могут опираться на взаимоисключающие принципы связей входных данных и целевых переменных.
Второй риск – иллюзия широты исследования (illusion of exploratory breadth). В этом случае учёные ограничивают спектр гипотез только теми, которые возможно адаптировать под использование ИИ. В частности, используя ИИ как "суррогат", симулирующий данные поведения людей, мы можем отдавать предпочтение тем данным, которые моделируются менее проблематично (напр., результаты опросников против данных физически осуществляемых движений). Другие проблемы связаны и с тем, что алгоритмы могут требовать упрощения данных и при универсальном использовании на широком спектре данных порождать не самые точные предсказания.
Третий риск – иллюзия объективности. ИИ может восприниматься как агент, не имеющий точки зрения или учитывающий все возможные точки зрения. На самом же деле ИИ содержит в себе все искажения данных, на которых он обучался, и способов, которыми его обучали и ограничивали.
Все перечисленные риски имеют отношение к исходно существующим когнитивным искажениям, связанным с ситуациями, когда мы делегируем те или иные элементы процесса научного познания как социальной практики или оказываемся частью научной "монокультуры". Грядущая ИИ-центрированность этой монокультуры может снизить разнообразие тестируемых гипотез или используемых подходов, но при этом не исключено, что в ней и без того присутствует большое количество деформаций, которые уже сложно чем-либо испортить.
А пока что самыми безопасными условиями использования ИИ в науке оказываются рутинность выполняемых задач, связь задач с областью экспертизы использующего ИИ учёного, а также осведомлённость учёного о технических и концептуальных ограничениях ИИ в целом.
#metascience #ai
Публикация: Messeri, L., Crockett, M.J. Artificial intelligence and illusions of understanding in scientific research. Nature 627, 49–58 (2024).
Сложно представить сферу деятельности, в профессиональную обыденность которой не внедрился искусственный интеллект. Наука не стала исключением. Уже не раз обсуждалась проблематичность этого феномена на примере "галлюцинирующего" GPT, плохой интерпретируемости многих моделей и набивших оскомину этических ограничений. Авторы же вышедшей на днях публикации, проанализировав литературу с примерами использования ИИ в науке, вынесли на поверхность проблемы, относящиеся не столько непосредственно к ИИ как к технологии, сколько к тому, какие ложные ожидания на него накладывают сами учёные.
Авторы выделили роли, которые ИИ уже выполняет в практике учёных:
1. "Оракул": изучение бесконечно растущего пласта научных публикаций, его обобщение, выдвижение гипотез (реальный пример – предсказание комплексных биологических структур);
2. "Суррогат": синтез или аугментация данных, сбор которых в реальности сопряжен с временными и финансовыми затратами;
3. "Аналитик данных": наиболее привычная роль ИИ –автоматизированная обработка огромных массивов данных;
4. "Арбитр": роль, схожая с "оракулом" – анализ отправляемых на рецензию статей (в этом случае ИИ должен быть непредвзятым, уметь оценивать реплицируемость исследования и устранять publication biases).
Какие риски сопровождают эти роли?
Первый риск – это иллюзия глубины понимания (illusion of explanatory depth). Люди не могут охватить все доступные знания, поэтому склонны полагаться на экспертизу других лиц, которых считают авторитетными. Ощущение, что другое лицо понимает изучаемый феномен глубоко, может создавать иллюзию, что и сам человек обладает этим пониманием. Перенос этой иллюзии в сферу ИИ формирует ситуации, в которых высокая точность предсказания модели может создавать ложное ощущение объяснимости феномена. При этом самая точная модель не обязательно должна соотноситься с реальными механизмами, порождающими изучаемые данные. Это может подтверждаться, в частности, существованием эффекта Расёмона в машинном обучении, в соответствии с которым одинаково точные модели могут опираться на взаимоисключающие принципы связей входных данных и целевых переменных.
Второй риск – иллюзия широты исследования (illusion of exploratory breadth). В этом случае учёные ограничивают спектр гипотез только теми, которые возможно адаптировать под использование ИИ. В частности, используя ИИ как "суррогат", симулирующий данные поведения людей, мы можем отдавать предпочтение тем данным, которые моделируются менее проблематично (напр., результаты опросников против данных физически осуществляемых движений). Другие проблемы связаны и с тем, что алгоритмы могут требовать упрощения данных и при универсальном использовании на широком спектре данных порождать не самые точные предсказания.
Третий риск – иллюзия объективности. ИИ может восприниматься как агент, не имеющий точки зрения или учитывающий все возможные точки зрения. На самом же деле ИИ содержит в себе все искажения данных, на которых он обучался, и способов, которыми его обучали и ограничивали.
Все перечисленные риски имеют отношение к исходно существующим когнитивным искажениям, связанным с ситуациями, когда мы делегируем те или иные элементы процесса научного познания как социальной практики или оказываемся частью научной "монокультуры". Грядущая ИИ-центрированность этой монокультуры может снизить разнообразие тестируемых гипотез или используемых подходов, но при этом не исключено, что в ней и без того присутствует большое количество деформаций, которые уже сложно чем-либо испортить.
А пока что самыми безопасными условиями использования ИИ в науке оказываются рутинность выполняемых задач, связь задач с областью экспертизы использующего ИИ учёного, а также осведомлённость учёного о технических и концептуальных ограничениях ИИ в целом.
{kind=link}
Please open Telegram to view this post
VIEW IN TELEGRAM
ИИ среди чужих и своих
#ai #social_psychology
Публикация: Hu, T., Kyrychenko, Y., Rathje, S., Collier, N., van der Linden, S., & Roozenbeek, J. (2024). Generative language models exhibit social identity biases. Nature Computational Science, 1-11.
Кажется, я нашла себе занятие на случай, если востребованность нейроучёных, занимающихся людскими мозгами, снизится — буду выявлятьбеды с башкой когнитивные искажения у искусственных мозгов. Если же оставить иронию, то свежие исследования действительно выявляют многочисленные предубеждения у языковых моделей, в т. ч. гендерные и этнические стереотипы. Недавнее же исследование было посвящено обнаружению у ИИ более глубокого социального искажения — склонности к делению мира на “своих” и “чужих”.
❓ Что это значит?
В основе многих форм социальной дискриминации лежит эффект социальной идентичности — когнитивный механизм, который побуждает нас воспринимать членов своей группы как более достойных доверия (внутригрупповой фаворитизм), а представителей чужой группы — с предвзятостью и подозрением (внегрупповая враждебность). Это универсальный эффект: он проявляется не только в политике и межкультурных различиях, но даже в разделении людей по более произвольным признакам — например, по любви к живописи Клее или Кандинского.
‼️ Эксперименты над ИИ
С помощью 77 языковых моделей (GPT, Llama, Pythia, Gemma и др.) авторы исследования сгенерировали 2000 утверждений с использованием конструктов “мы” и “они”. Например, “Мы боремся с дезинформацией” или “Они предотвращают попытки к примирению”. Затем тональность фраз анализировалась с помощью автоматических классификаторов. Было установлено, что большинство моделей были склонны к эффектам социальной идентичности, а уровни внутригруппового фаворитизма и внегрупповой враждебности были сопоставимы с показателями, наблюдаемыми у людей.
🙂 Можно ли это исправить?
Хорошая новость заключается в том, что описываемый эффект возможно контролировать. Было установлено, что модели, использующие fine-tuning на основе обратной связи от пользователей (например, ChatGPT), показывают сниженную предвзятость. Однако тут же выяснилось, что если дообучить модель на политически окрашенных постах республиканцев и демократов из одной известной социальной сети, то её внегрупповая враждебность в среднем увеличивается в пять раз.
😡 Кто кого?
В финальной части исследования авторы проанализировали реальные диалоги пользователей с языковыми моделями (из открытых баз WildChat и LMSYS-Chat-1M), подтвердив сохранение тех же уровней внутригрупповой и внегрупповой предвзятости, что и на синтезированных данных. В качестве спекуляции можно поразмышлять о том, насколько такие модели не просто поддерживают, но и усиливают наши когнитивные и социальные искажения в процессе диалога.
Не исключено, что подобные исследования дадут нам возможность выйти за рамки одной лишь задачи снижения предвзятости алгоритмов и глубже разобраться в природе нормализуемых социальных границ, используя ИИ как увеличительное стекло или зеркало. Если при этом мы сумеем настроить модели так, чтобы сохранялся гибкий плюрализм, не перетекающий в дискриминацию, то полученные выводы могут подсказать пути к более конструктивным изменениям в разных сферах человеческого взаимодействия.
#ai #social_psychology
Публикация: Hu, T., Kyrychenko, Y., Rathje, S., Collier, N., van der Linden, S., & Roozenbeek, J. (2024). Generative language models exhibit social identity biases. Nature Computational Science, 1-11.
Кажется, я нашла себе занятие на случай, если востребованность нейроучёных, занимающихся людскими мозгами, снизится — буду выявлять
В основе многих форм социальной дискриминации лежит эффект социальной идентичности — когнитивный механизм, который побуждает нас воспринимать членов своей группы как более достойных доверия (внутригрупповой фаворитизм), а представителей чужой группы — с предвзятостью и подозрением (внегрупповая враждебность). Это универсальный эффект: он проявляется не только в политике и межкультурных различиях, но даже в разделении людей по более произвольным признакам — например, по любви к живописи Клее или Кандинского.
С помощью 77 языковых моделей (GPT, Llama, Pythia, Gemma и др.) авторы исследования сгенерировали 2000 утверждений с использованием конструктов “мы” и “они”. Например, “Мы боремся с дезинформацией” или “Они предотвращают попытки к примирению”. Затем тональность фраз анализировалась с помощью автоматических классификаторов. Было установлено, что большинство моделей были склонны к эффектам социальной идентичности, а уровни внутригруппового фаворитизма и внегрупповой враждебности были сопоставимы с показателями, наблюдаемыми у людей.
Хорошая новость заключается в том, что описываемый эффект возможно контролировать. Было установлено, что модели, использующие fine-tuning на основе обратной связи от пользователей (например, ChatGPT), показывают сниженную предвзятость. Однако тут же выяснилось, что если дообучить модель на политически окрашенных постах республиканцев и демократов из одной известной социальной сети, то её внегрупповая враждебность в среднем увеличивается в пять раз.
В финальной части исследования авторы проанализировали реальные диалоги пользователей с языковыми моделями (из открытых баз WildChat и LMSYS-Chat-1M), подтвердив сохранение тех же уровней внутригрупповой и внегрупповой предвзятости, что и на синтезированных данных. В качестве спекуляции можно поразмышлять о том, насколько такие модели не просто поддерживают, но и усиливают наши когнитивные и социальные искажения в процессе диалога.
Не исключено, что подобные исследования дадут нам возможность выйти за рамки одной лишь задачи снижения предвзятости алгоритмов и глубже разобраться в природе нормализуемых социальных границ, используя ИИ как увеличительное стекло или зеркало. Если при этом мы сумеем настроить модели так, чтобы сохранялся гибкий плюрализм, не перетекающий в дискриминацию, то полученные выводы могут подсказать пути к более конструктивным изменениям в разных сферах человеческого взаимодействия.
Please open Telegram to view this post
VIEW IN TELEGRAM