
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
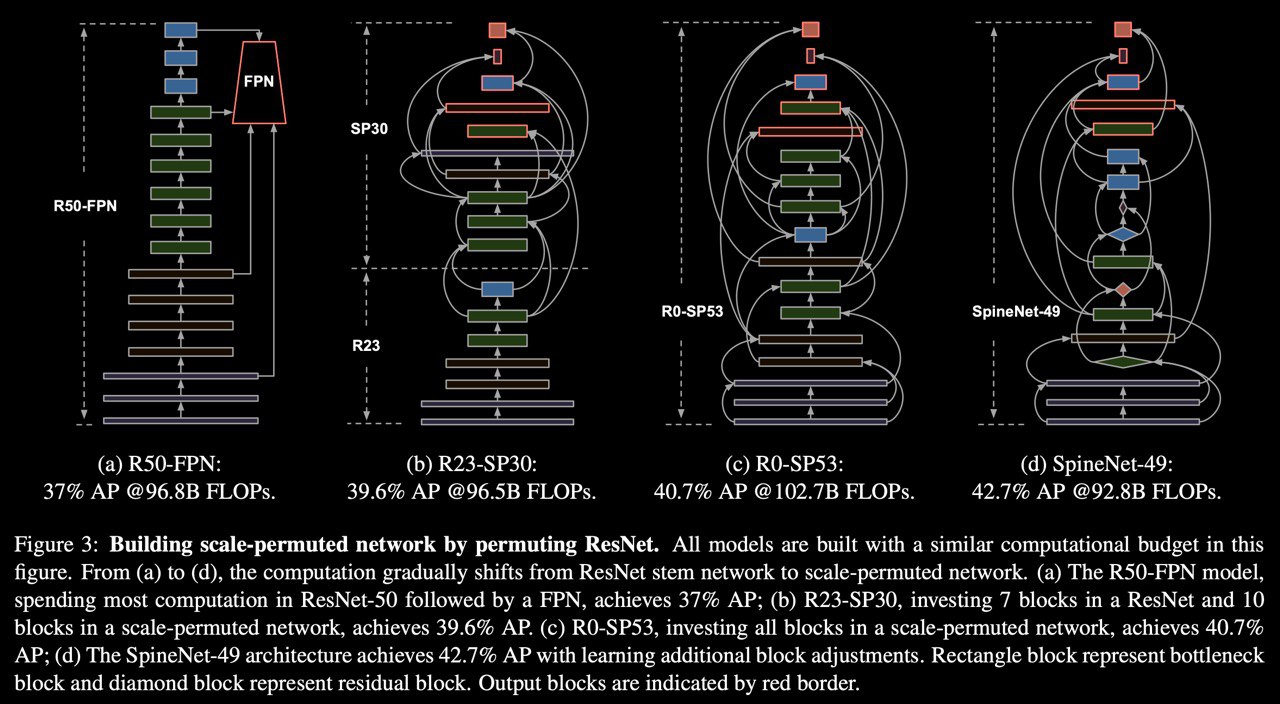
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
{kind=link}
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
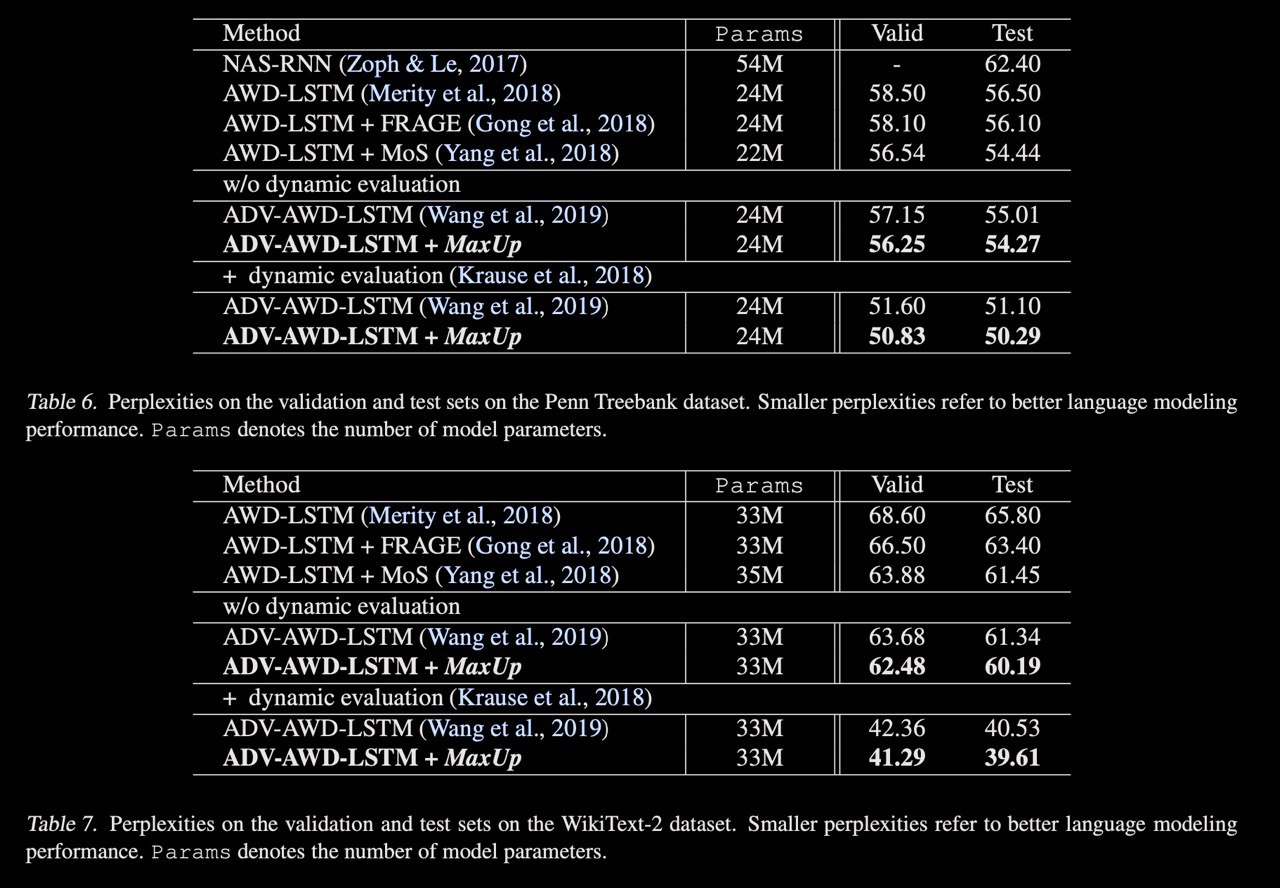
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
m times and then found aug with maximum loss and does backprop only through that. i.e. minimizing max loss.There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
augs without the overhead. Only m times to forward pass on the sample but one time to backprop. paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
{kind=link}