
RecSim: A Configurable Simulation Platform for Recommender Systems
It's a configurable platform for authoring simulation environments to facilitate the study of RL algorithms in recommender systems (and CIRs in particular).
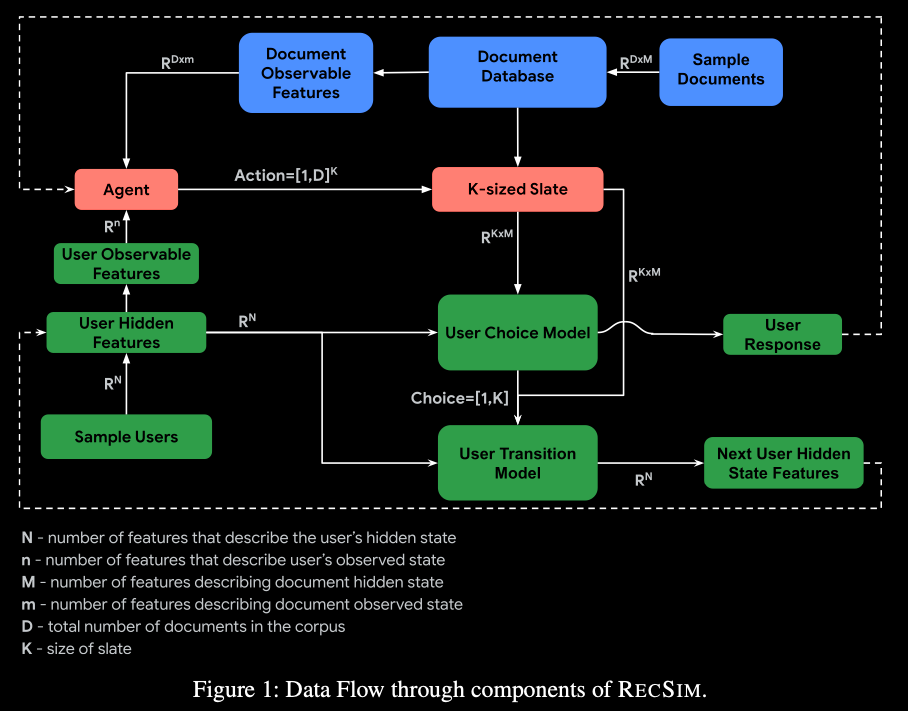
RᴇᴄSɪᴍ allows both researchers and practitioners to test the limits of existing RL methods in synthetic recommender settings. RecSim’s aim is to support simulations that mirror specific aspects of user behavior found in real recommender systems and serve as a controlled environment for developing, evaluating and comparing recommender models and algorithms, especially RL systems designed for sequential user-system interaction.
As an open-source platform, RᴇᴄSɪᴍ:
* facilitates research at the intersection of RL and recommender systems
* encourages reproducibility and model-sharing
* aids the recommender-systems practitioner, interested in applying RL to rapidly test and refine models and algorithms in simulation, before incurring the potential cost (e.g., time, user impact) of live experiments
* serves as a resource for academic-industry collaboration through the release of “realistic” stylized models of user behavior without revealing user data or sensitive industry strategies.
blog: https://ai.googleblog.com/2019/11/recsim-configurable-simulation-platform.html
paper: https://arxiv.org/abs/1909.04847
code: https://github.com/google-research/recsim
#rs #rl
It's a configurable platform for authoring simulation environments to facilitate the study of RL algorithms in recommender systems (and CIRs in particular).
RᴇᴄSɪᴍ allows both researchers and practitioners to test the limits of existing RL methods in synthetic recommender settings. RecSim’s aim is to support simulations that mirror specific aspects of user behavior found in real recommender systems and serve as a controlled environment for developing, evaluating and comparing recommender models and algorithms, especially RL systems designed for sequential user-system interaction.
As an open-source platform, RᴇᴄSɪᴍ:
* facilitates research at the intersection of RL and recommender systems
* encourages reproducibility and model-sharing
* aids the recommender-systems practitioner, interested in applying RL to rapidly test and refine models and algorithms in simulation, before incurring the potential cost (e.g., time, user impact) of live experiments
* serves as a resource for academic-industry collaboration through the release of “realistic” stylized models of user behavior without revealing user data or sensitive industry strategies.
blog: https://ai.googleblog.com/2019/11/recsim-configurable-simulation-platform.html
paper: https://arxiv.org/abs/1909.04847
code: https://github.com/google-research/recsim
#rs #rl
{kind=link}
Dream to Control: Learning Behaviors by Latent Imagination
Abstract: Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs are becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.
Dreamer learns long-horizon behaviors from images purely by latent imagination. For this, it backpropagates value estimates through trajectories imagined in the compact latent space of a learned world model. Dreamer solves visual control tasks using substantially fewer episodes than strong model-free agents.
Dreamer learns a world model from past experiences that can predict the future. It then learns action and value models in its compact latent space. The value model optimizes Bellman's consistency of imagined trajectories. The action model maximizes value estimates by propagating their analytic gradients back through imagined trajectories. When interacting with the environment, it simply executes the action model.
paper: https://arxiv.org/abs/1912.01603
github: https://github.com/google-research/dreamer
site: https://danijar.com/dreamer
#RL #Dreams #Imagination #DL #GoogleBrain #DeepMind
Abstract: Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs are becoming feasible through deep learning, there are many potential ways for deriving behaviors from them. We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model. On 20 challenging visual control tasks, Dreamer exceeds existing approaches in data-efficiency, computation time, and final performance.
Dreamer learns long-horizon behaviors from images purely by latent imagination. For this, it backpropagates value estimates through trajectories imagined in the compact latent space of a learned world model. Dreamer solves visual control tasks using substantially fewer episodes than strong model-free agents.
Dreamer learns a world model from past experiences that can predict the future. It then learns action and value models in its compact latent space. The value model optimizes Bellman's consistency of imagined trajectories. The action model maximizes value estimates by propagating their analytic gradients back through imagined trajectories. When interacting with the environment, it simply executes the action model.
paper: https://arxiv.org/abs/1912.01603
github: https://github.com/google-research/dreamer
site: https://danijar.com/dreamer
#RL #Dreams #Imagination #DL #GoogleBrain #DeepMind