
Cut and Learn for Unsupervised Object Detection and Instance Segmentation
CutLER (Cut-and-LEaRn) is a new approach for training unsupervised object detection and segmentation models without using any human labels. It uses a combination of a MaskCut approach to generate object masks and a robust loss function to learn a detector. The model is simple and compatible with different detection architectures and can detect multiple objects. It is a zero-shot detector, meaning it performs well without additional in-domain data and is robust against domain shifts across various types of images. CutLER can also be used as a pretrained model for supervised detection and improves performance on few-shot benchmarks. Results show improved performance over previous work, including being a zero-shot unsupervised detector and surpassing other low-shot detectors with finetuning.
Paper: https://arxiv.org/abs/2301.11320
Code link: https://github.com/facebookresearch/CutLER1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cutler
#deeplearning #cv #objectdetection #imagesegmentation
CutLER (Cut-and-LEaRn) is a new approach for training unsupervised object detection and segmentation models without using any human labels. It uses a combination of a MaskCut approach to generate object masks and a robust loss function to learn a detector. The model is simple and compatible with different detection architectures and can detect multiple objects. It is a zero-shot detector, meaning it performs well without additional in-domain data and is robust against domain shifts across various types of images. CutLER can also be used as a pretrained model for supervised detection and improves performance on few-shot benchmarks. Results show improved performance over previous work, including being a zero-shot unsupervised detector and surpassing other low-shot detectors with finetuning.
Paper: https://arxiv.org/abs/2301.11320
Code link: https://github.com/facebookresearch/CutLER1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cutler
#deeplearning #cv #objectdetection #imagesegmentation
{kind=link}
Forwarded from Spark in me (Alexander)
An interesting perspective here. What if LLMs are viewed though the lens of Microsoft willing to take some part of the search market?
Trends in the dollar training cost of machine learning systems - https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems
The Inference Cost Of Search Disruption – Large Language Model Cost Analysis - https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
The AI Brick Wall – A Practical Limit For Scaling Dense Transformer Models, and How GPT 4 Will Break Past It - https://www.semianalysis.com/p/the-ai-brick-wall-a-practical-limit
Training Compute-Optimal Large Language Models - https://arxiv.org/pdf/2203.15556.pdf
Trends in the dollar training cost of machine learning systems - https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems
The Inference Cost Of Search Disruption – Large Language Model Cost Analysis - https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
The AI Brick Wall – A Practical Limit For Scaling Dense Transformer Models, and How GPT 4 Will Break Past It - https://www.semianalysis.com/p/the-ai-brick-wall-a-practical-limit
Training Compute-Optimal Large Language Models - https://arxiv.org/pdf/2203.15556.pdf
Epoch AI
Trends in the Dollar Training Cost of Machine Learning Systems
I combine training compute and GPU price-performance data to estimate the cost of compute in US dollars for the final training run of 124 machine learning systems published between 2009 and 2022, and find that the cost has grown by approximately 0.5 orders…
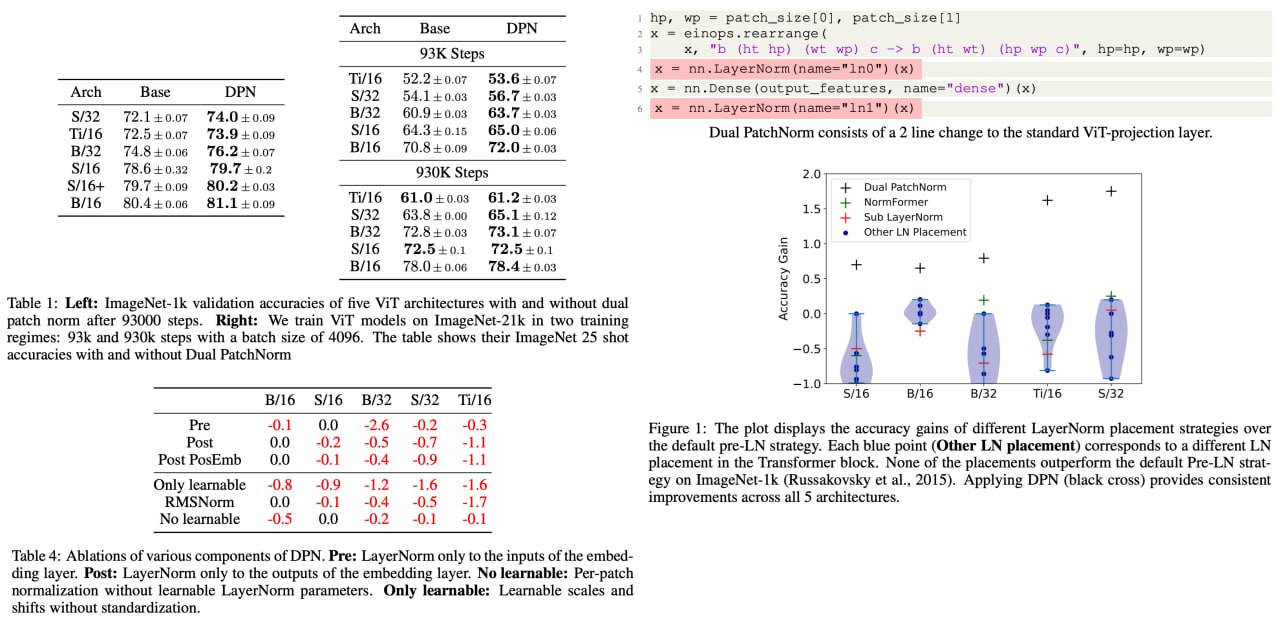
Dual PatchNorm
The authors propose a new method, Dual PatchNorm, for Vision Transformers which involves adding two Layer Normalization layers before and after the patch embedding layer. Experiments across three datasets show that this method improves the performance of well-tuned ViT models, and qualitative experiments support this.
Paper: https://arxiv.org/abs/2302.01327
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dual-patch-norm
#deeplearning #cv #transformer
The authors propose a new method, Dual PatchNorm, for Vision Transformers which involves adding two Layer Normalization layers before and after the patch embedding layer. Experiments across three datasets show that this method improves the performance of well-tuned ViT models, and qualitative experiments support this.
Paper: https://arxiv.org/abs/2302.01327
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dual-patch-norm
#deeplearning #cv #transformer
{kind=link}
We really love machine learning competitions! Competitions help us to explore new methods and solve problems that are not available at work.
We are organizing a new semester of ML training.
We are waiting for you online and offline in Moscow.
When: February 16, 2023, (19:00 Moscow time, 16:00 UTC)
Registration is required, the language is Russian.
We are organizing a new semester of ML training.
We are waiting for you online and offline in Moscow.
When: February 16, 2023, (19:00 Moscow time, 16:00 UTC)
Registration is required, the language is Russian.
Data Dojo [февраль]
Data Dojo — тренировки по машинному обучению и место встречи специалистов в сфере анализа данных. Приглашаем вас присоединиться к первой тренировке сезона 2023.
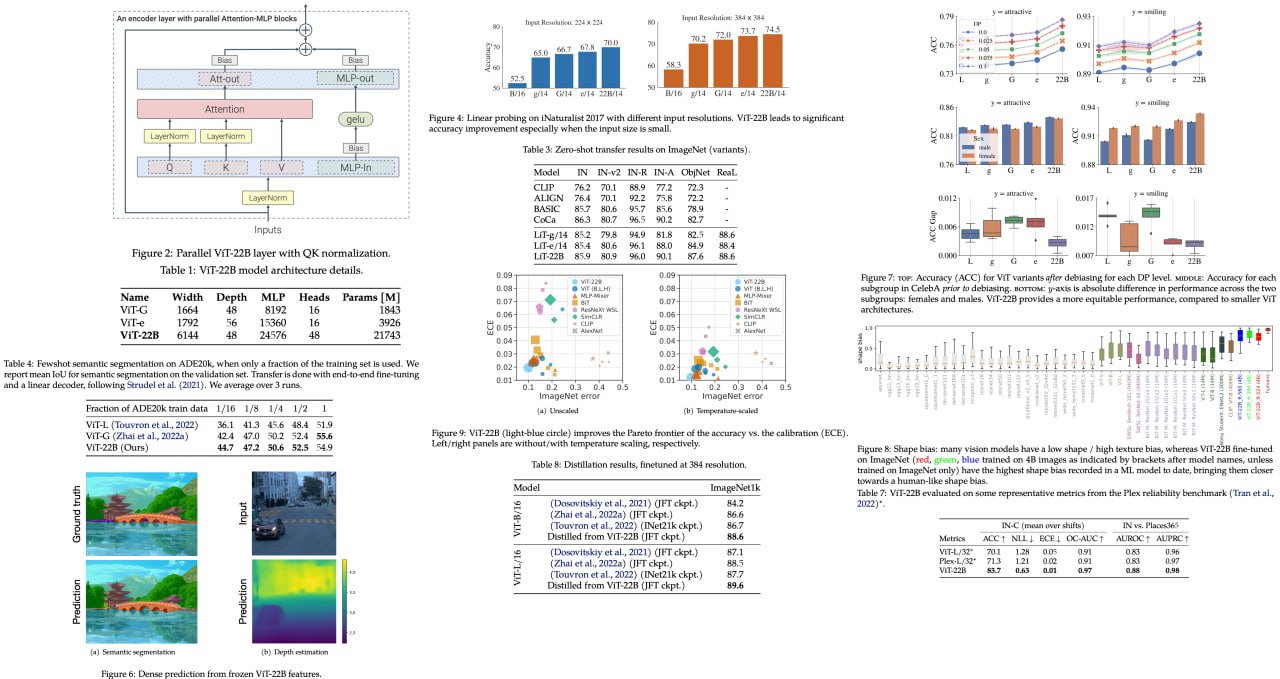
Scaling Vision Transformers to 22 Billion Parameters
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
{kind=link}
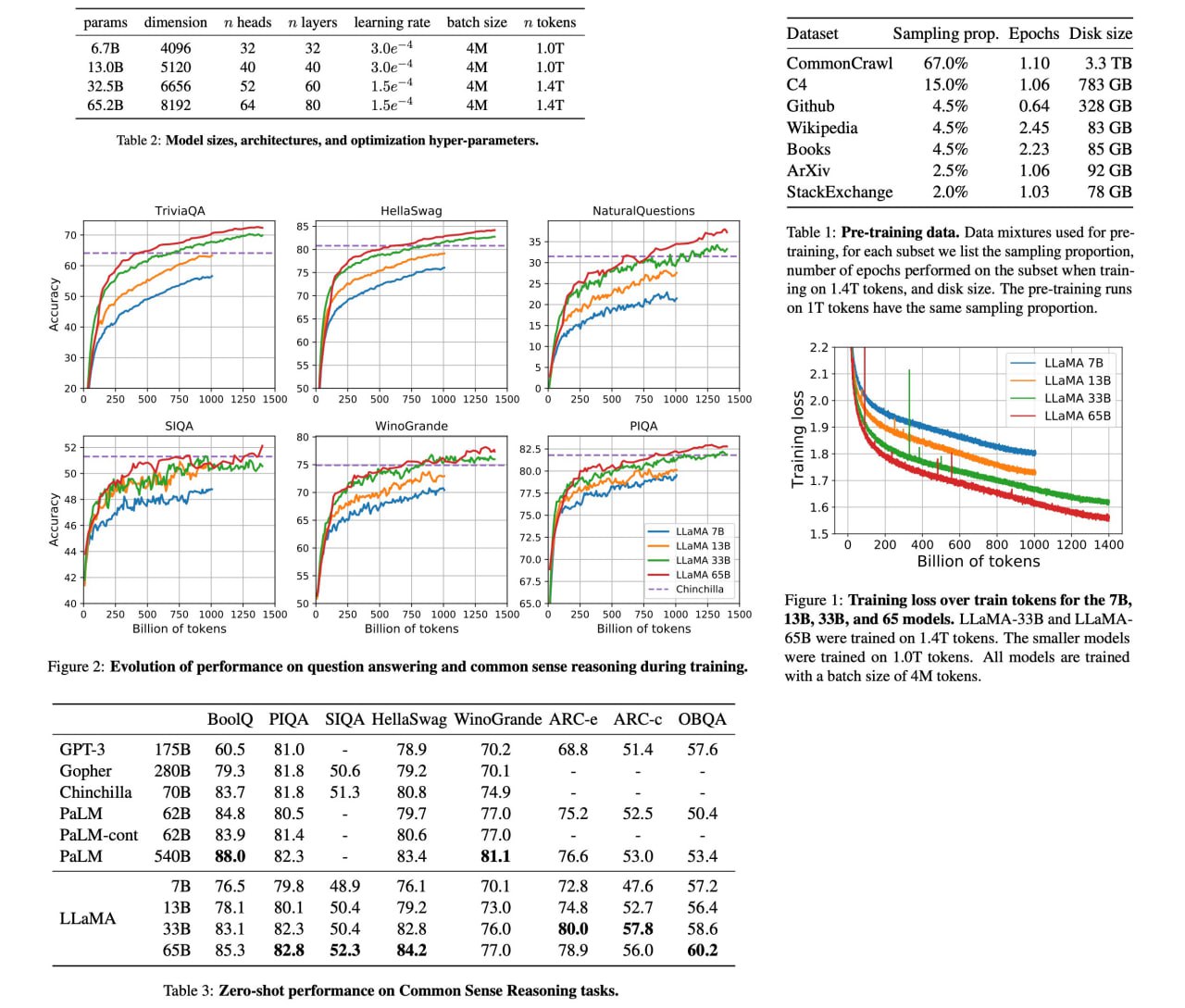
LLaMA: Open and Efficient Foundation Language Models
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
Forwarded from gonzo-обзоры ML статей
Hot news: https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
Training smaller foundation models like LLaMA is desirable in the large language model space because it requires far less computing power and resources to test new approaches, validate others’ work, and explore new use cases. Foundation models train on a large set of unlabeled data, which makes them ideal for fine-tuning for a variety of tasks. We are making LLaMA available at several sizes (7B, 13B, 33B, and 65B parameters) and also sharing a LLAMA model card that details how we built the model in keeping with our approach to Responsible AI practices.
In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B. We release all our models to the research community.
Model card: https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Form to apply: https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform
Unfortunately, it's only for non-commercial purposes :(
"You will not, and will not permit, assist or cause any third party to:
a. use, modify, copy, reproduce, create derivative works of, or distribute the Software Products (or any derivative works thereof, works incorporating the Software Products, or any data produced by the Software), in whole or in part, for (i) any commercial or production purposes ... "
Training smaller foundation models like LLaMA is desirable in the large language model space because it requires far less computing power and resources to test new approaches, validate others’ work, and explore new use cases. Foundation models train on a large set of unlabeled data, which makes them ideal for fine-tuning for a variety of tasks. We are making LLaMA available at several sizes (7B, 13B, 33B, and 65B parameters) and also sharing a LLAMA model card that details how we built the model in keeping with our approach to Responsible AI practices.
In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla70B and PaLM-540B. We release all our models to the research community.
Model card: https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Form to apply: https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform
Unfortunately, it's only for non-commercial purposes :(
"You will not, and will not permit, assist or cause any third party to:
a. use, modify, copy, reproduce, create derivative works of, or distribute the Software Products (or any derivative works thereof, works incorporating the Software Products, or any data produced by the Software), in whole or in part, for (i) any commercial or production purposes ... "
Meta
Introducing LLaMA: A foundational, 65-billion-parameter language model
Today, we’re releasing our LLaMA (Large Language Model Meta AI) foundational model with a gated release. LLaMA is more efficient and competitive with previously published models of a similar size on existing benchmarks.
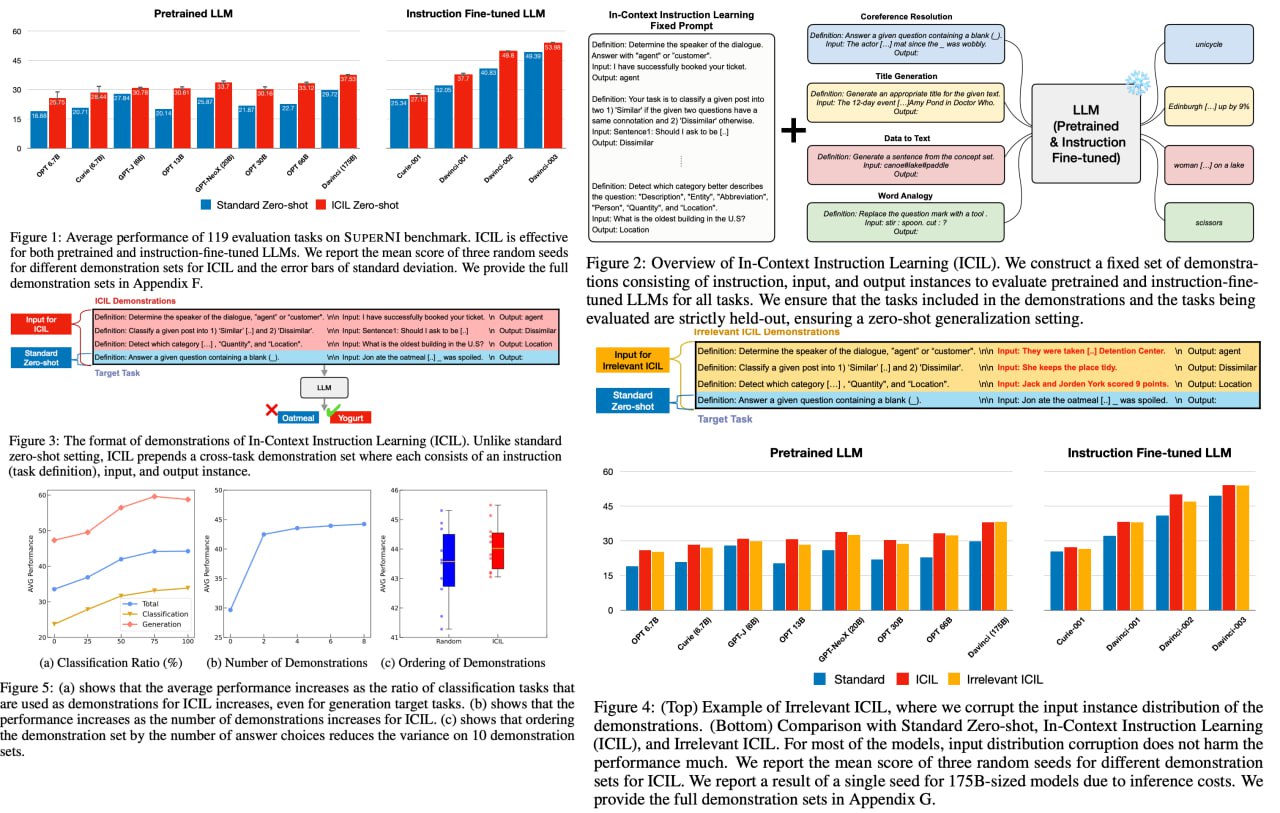
In-Context Instruction Learning
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
Forwarded from ml4se
ChatML
OpenAI released ChatGPT API with Chat Markup Language. The basic idea behind ChatML is ensure the LLM model inputs are sent in structured format following ChatML and not as unstructured text.
https://github.com/openai/openai-python/blob/main/chatml.md
OpenAI released ChatGPT API with Chat Markup Language. The basic idea behind ChatML is ensure the LLM model inputs are sent in structured format following ChatML and not as unstructured text.
https://github.com/openai/openai-python/blob/main/chatml.md
PaLM-E: An Embodied Multimodal Language Model
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
{kind=link}
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
{kind=link}
Forwarded from Machinelearning
OpenOccupancy first surrounding semantic occupancy perception benchmar.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from ml4se
Software Vulnerability Prediction Knowledge Transferring Between Programming Languages
One of the biggest challenges in this area is the lack of code samples for all different programming languages. In this study, authors address this issue by proposing a transfer learning technique to leverage available datasets and generate a model to detect common vulnerabilities in different programming languages. They use C source code samples to train a CNN model, then, they use Java source code samples to adopt and evaluate the learned model. The authors use code samples from two benchmark datasets: NIST Software Assurance Reference Dataset (SARD) and Draper VDISC dataset. The results show that proposed model detects vulnerabilities in both C and Java codes with average recall of 72%.
One of the biggest challenges in this area is the lack of code samples for all different programming languages. In this study, authors address this issue by proposing a transfer learning technique to leverage available datasets and generate a model to detect common vulnerabilities in different programming languages. They use C source code samples to train a CNN model, then, they use Java source code samples to adopt and evaluate the learned model. The authors use code samples from two benchmark datasets: NIST Software Assurance Reference Dataset (SARD) and Draper VDISC dataset. The results show that proposed model detects vulnerabilities in both C and Java codes with average recall of 72%.
Forwarded from gonzo-обзоры ML статей
In the meantime, some slides from my talks on NLP in 2022
https://docs.google.com/presentation/d/1m7Wpzaowbvi2je6nQERXyfQ0bzzS0dD0OArWznfOjHE/edit
https://docs.google.com/presentation/d/1m7Wpzaowbvi2je6nQERXyfQ0bzzS0dD0OArWznfOjHE/edit
Google Docs
NLP in 2022 / Intento
NLP in 2022 Grigory Sapunov Internal talks / 2023.03.01-2023.03.08 gs@inten.to
Hyena Hierarchy: Towards Larger Convolutional Language Models
Attention has been a cornerstone of deep learning, but it comes at a steep cost: quadratic expense in sequence length. This can limit the amount of context accessible, making it challenging for subquadratic methods like low-rank and sparse approximations to achieve comparable performance. That's where Hyena comes in!
Hyena is a revolutionary subquadratic drop-in replacement for attention that combines implicitly parametrized long convolutions and data-controlled gating. And the results speak for themselves! Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
In fact, Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. And that's not all! Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
Paper: https://arxiv.org/abs/2302.10866
Code link: https://github.com/HazyResearch/safari
Project link: https://hazyresearch.stanford.edu/blog/2023-03-07-hyena
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hyena
#deeplearning #nlp #cv #languagemodel #convolution
Attention has been a cornerstone of deep learning, but it comes at a steep cost: quadratic expense in sequence length. This can limit the amount of context accessible, making it challenging for subquadratic methods like low-rank and sparse approximations to achieve comparable performance. That's where Hyena comes in!
Hyena is a revolutionary subquadratic drop-in replacement for attention that combines implicitly parametrized long convolutions and data-controlled gating. And the results speak for themselves! Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
In fact, Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. And that's not all! Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
Paper: https://arxiv.org/abs/2302.10866
Code link: https://github.com/HazyResearch/safari
Project link: https://hazyresearch.stanford.edu/blog/2023-03-07-hyena
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hyena
#deeplearning #nlp #cv #languagemodel #convolution
{kind=link}
Forwarded from ml4se
Tracking the Fake GitHub Star Black Market with Dagster, dbt and BigQuery
This is a simple Dagster project to analyze the number of fake GitHub stars on any GitHub repository:
https://github.com/dagster-io/fake-star-detector
This is a simple Dagster project to analyze the number of fake GitHub stars on any GitHub repository:
https://github.com/dagster-io/fake-star-detector
dagster.io
Tracking the Fake GitHub Star Black Market with Dagster, dbt and BigQuery | Dagster Blog
It's easy for an open-source project to buy fake GitHub stars. We share two approaches for detecting them.
Interview of Ilya Sutskver
TLDR: thereotically #chatgpt can learn a lot and eventually converge to #AGI given the proper dataset and help of #RLHF (Reinforcement Learning from Human Feedback).
Video provides valuable insights into the current state and future of artificial intelligence. The conversation explores the progress of AI, its limitations, and the importance of reinforcement learning and ethics in AI development. Ilia also discusses the potential benefits of AI in democracy and its potential role in helping humans manage society. This interview offers a comprehensive and thought-provoking overview of the AI landscape, making it a must-watch for anyone interested in understanding the impact of AI on our lives and the world at large.
Youtube: https://www.youtube.com/watch?v=SjhIlw3Iffs
#youtube #Sutskever #OpenAI #GPTEditor
TLDR: thereotically #chatgpt can learn a lot and eventually converge to #AGI given the proper dataset and help of #RLHF (Reinforcement Learning from Human Feedback).
Video provides valuable insights into the current state and future of artificial intelligence. The conversation explores the progress of AI, its limitations, and the importance of reinforcement learning and ethics in AI development. Ilia also discusses the potential benefits of AI in democracy and its potential role in helping humans manage society. This interview offers a comprehensive and thought-provoking overview of the AI landscape, making it a must-watch for anyone interested in understanding the impact of AI on our lives and the world at large.
Youtube: https://www.youtube.com/watch?v=SjhIlw3Iffs
#youtube #Sutskever #OpenAI #GPTEditor
YouTube
The Mastermind Behind GPT-4 and the Future of AI | Ilya Sutskever
In this podcast episode, Ilya Sutskever, the co-founder and chief scientist at OpenAI, discusses his vision for the future of artificial intelligence (AI), including large language models like GPT-4.
Sutskever starts by explaining the importance of AI research…
Sutskever starts by explaining the importance of AI research…
lecun-20230324-nyuphil.pdf
30.5 MB
ReBotNet: Fast Real-time Video Enhancement
The authors introduce a novel Recurrent Bottleneck Mixer Network (ReBotNet) method, designed for real-time video enhancement in practical scenarios, such as live video calls and video streams. ReBotNet employs a dual-branch framework, where one branch focuses on learning spatio-temporal features, and the other aims to enhance temporal consistency. A common decoder combines the features from both branches to generate the improved frame. This method incorporates a recurrent training approach that utilizes predictions from previous frames for more efficient enhancement and superior temporal consistency.
To assess ReBotNet, the authors use two new datasets that simulate real-world situations and show that their technique surpasses existing methods in terms of reduced computations, decreased memory requirements, and quicker inference times.
Paper: https://arxiv.org/abs/2303.13504
Project link: https://jeya-maria-jose.github.io/rebotnet-web/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rebotnet
#deeplearning #cv #MachineLearning #VideoEnhancement #AI #Innovation #RealTimeVideo
The authors introduce a novel Recurrent Bottleneck Mixer Network (ReBotNet) method, designed for real-time video enhancement in practical scenarios, such as live video calls and video streams. ReBotNet employs a dual-branch framework, where one branch focuses on learning spatio-temporal features, and the other aims to enhance temporal consistency. A common decoder combines the features from both branches to generate the improved frame. This method incorporates a recurrent training approach that utilizes predictions from previous frames for more efficient enhancement and superior temporal consistency.
To assess ReBotNet, the authors use two new datasets that simulate real-world situations and show that their technique surpasses existing methods in terms of reduced computations, decreased memory requirements, and quicker inference times.
Paper: https://arxiv.org/abs/2303.13504
Project link: https://jeya-maria-jose.github.io/rebotnet-web/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rebotnet
#deeplearning #cv #MachineLearning #VideoEnhancement #AI #Innovation #RealTimeVideo
{kind=link}
Forwarded from Spark in me (Alexander)
My experience with PyTorch 2.0 so far:
[1] - packaging?
[2] - compilation errors
We will test other models as well.
[1] - packaging?
[2] - compilation errors
We will test other models as well.
PyTorch Forums
How to serialize models with torch.compile properly
Hi, Despite the main points in the torch.compile pitch, we faced some issues with jit, but they were tolerable, and we adopted torch.jit.save and torch packages as a model serialization / obfuscation / freezing methods (and ONNX as well). It may be seen…