
14 seconds of April #Nvidia 's CEO speech was generated in silico
Why this important: demand for usage of 3080 and newer GPU models might also get pumped by CGI artists and researchers working in VR / AR tech.
And this raises the bar for #speechsinthesis / #speechgeneration and definately for the rendering of photorealistic picture.
YouTube making of video: https://www.youtube.com/watch?v=1qhqZ9ECm70&t=1430s
Vice article on the subject: https://www.vice.com/en/article/88nbpa/nvidia-reveals-its-ceo-was-computer-generated-in-keynote-speech
Why this important: demand for usage of 3080 and newer GPU models might also get pumped by CGI artists and researchers working in VR / AR tech.
And this raises the bar for #speechsinthesis / #speechgeneration and definately for the rendering of photorealistic picture.
YouTube making of video: https://www.youtube.com/watch?v=1qhqZ9ECm70&t=1430s
Vice article on the subject: https://www.vice.com/en/article/88nbpa/nvidia-reveals-its-ceo-was-computer-generated-in-keynote-speech
YouTube
Connecting in the Metaverse: The Making of the GTC Keynote
See how a small team of artists were able to blur the line between real and rendered in NVIDIA’s #GTC21 keynote in this behind-the-scenes documentary. Read more: https://nvda.ws/3s97Tpy
@NVIDIAOmniverse is an open platform built for virtual collaboration…
@NVIDIAOmniverse is an open platform built for virtual collaboration…
Program Synthesis with Large Language Models
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
{kind=link}
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
#Baidu research proposed a structure-aware interactive graph neural network ( #SIGN ) to better learn representations of protein-ligand complexes, since drug discovery relies on the successful prediction of protein-ligand binding affinity.
Link: https://dl.acm.org/doi/10.1145/3447548.3467311
#biolearning #deeplearning
#Baidu research proposed a structure-aware interactive graph neural network ( #SIGN ) to better learn representations of protein-ligand complexes, since drug discovery relies on the successful prediction of protein-ligand binding affinity.
Link: https://dl.acm.org/doi/10.1145/3447548.3467311
#biolearning #deeplearning
Forwarded from Opensource Findings
⚡️Breeaking news!
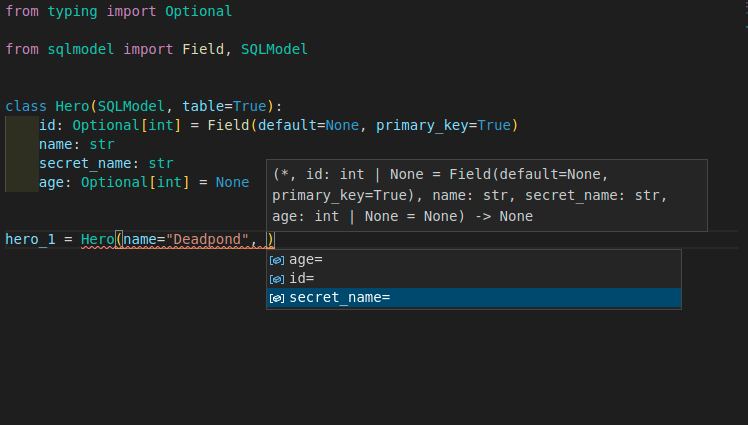
Big project, first public release! From the creator of FastAPI and Typer: SQLModel.
SQLModel is a library for interacting with SQL databases from Python code, with Python objects. It is designed to be intuitive, easy to use, highly compatible, and robust.
SQLModel is based on Python type annotations, and powered by Pydantic and SQLAlchemy.
SQLModel is, in fact, a thin layer on top of Pydantic and SQLAlchemy, carefully designed to be compatible with both.
The key features are:
- Intuitive to write: Great editor support. Completion everywhere. Less time debugging. Designed to be easy to use and learn. Less time reading docs.
- Easy to use: It has sensible defaults and does a lot of work underneath to simplify the code you write.
- Compatible: It is designed to be compatible with FastAPI, Pydantic, and SQLAlchemy.
- Extensible: You have all the power of SQLAlchemy and Pydantic underneath.
- Short: Minimize code duplication. A single type annotation does a lot of work. No need to duplicate models in SQLAlchemy and Pydantic.
https://github.com/tiangolo/sqlmodel
Big project, first public release! From the creator of FastAPI and Typer: SQLModel.
SQLModel is a library for interacting with SQL databases from Python code, with Python objects. It is designed to be intuitive, easy to use, highly compatible, and robust.
SQLModel is based on Python type annotations, and powered by Pydantic and SQLAlchemy.
SQLModel is, in fact, a thin layer on top of Pydantic and SQLAlchemy, carefully designed to be compatible with both.
The key features are:
- Intuitive to write: Great editor support. Completion everywhere. Less time debugging. Designed to be easy to use and learn. Less time reading docs.
- Easy to use: It has sensible defaults and does a lot of work underneath to simplify the code you write.
- Compatible: It is designed to be compatible with FastAPI, Pydantic, and SQLAlchemy.
- Extensible: You have all the power of SQLAlchemy and Pydantic underneath.
- Short: Minimize code duplication. A single type annotation does a lot of work. No need to duplicate models in SQLAlchemy and Pydantic.
https://github.com/tiangolo/sqlmodel
{kind=link}
Forwarded from Silero News (Alexander)
New German V4 Model and English V5 Models
New and improved models in Silero-models! Community edition versions available here: https://github.com/snakers4/silero-models
Huge performance improvements for two new models:
- English V5 (quality)
- German V3 (quality)
The models currently are available in the following flavors:
- English V5
The quality growth visualization:
New and improved models in Silero-models! Community edition versions available here: https://github.com/snakers4/silero-models
Huge performance improvements for two new models:
- English V5 (quality)
- German V3 (quality)
The models currently are available in the following flavors:
- English V5
jit (small), onnx (small), jit_q (small, quantized), jit_xlarge, onnx_xlarge
- German V3 jit_large, onnx_large
The xsmall model family for English in on the way.The quality growth visualization:
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
iRobot with poop detection
iRobot (company building cleaning house robots) had a problem with robots regarding pet poops. So they built a special model along with physical models of poop to test the product.
iRobot official YouTube: https://www.youtube.com/watch?v=2rj3VUmRNnU
TechCrunch: https://techcrunch.com/2021/09/09/actuator-4/
#aiproduct #marketinggurus
iRobot (company building cleaning house robots) had a problem with robots regarding pet poops. So they built a special model along with physical models of poop to test the product.
iRobot official YouTube: https://www.youtube.com/watch?v=2rj3VUmRNnU
TechCrunch: https://techcrunch.com/2021/09/09/actuator-4/
#aiproduct #marketinggurus
{kind=link}
New attempt at proving P≠NP
Martin Dowd published a 5-page paper claiming to contain a proof that P ≠ NP. This is a fundamental question, comparing quickly checkable against quickly solvalble problems.
Basically, proving P != NP would mean that there will be unlimited demand alphago-like solutions in different spheres, because that will mean (as a scientific fact) that there are problems not having fast [enough] analytical solutions.
ResearchGate: https://www.researchgate.net/publication/354423778_P_Does_Not_Equal_NP
Wiki on the problem: https://en.wikipedia.org/wiki/P_versus_NP_problem
#fundamental #pnenp #computerscience
Martin Dowd published a 5-page paper claiming to contain a proof that P ≠ NP. This is a fundamental question, comparing quickly checkable against quickly solvalble problems.
Basically, proving P != NP would mean that there will be unlimited demand alphago-like solutions in different spheres, because that will mean (as a scientific fact) that there are problems not having fast [enough] analytical solutions.
ResearchGate: https://www.researchgate.net/publication/354423778_P_Does_Not_Equal_NP
Wiki on the problem: https://en.wikipedia.org/wiki/P_versus_NP_problem
#fundamental #pnenp #computerscience
ResearchGate
130+ million publications organized by topic on ResearchGate
ResearchGate is a network dedicated to science and research. Connect, collaborate and discover scientific publications, jobs and conferences. All for free.
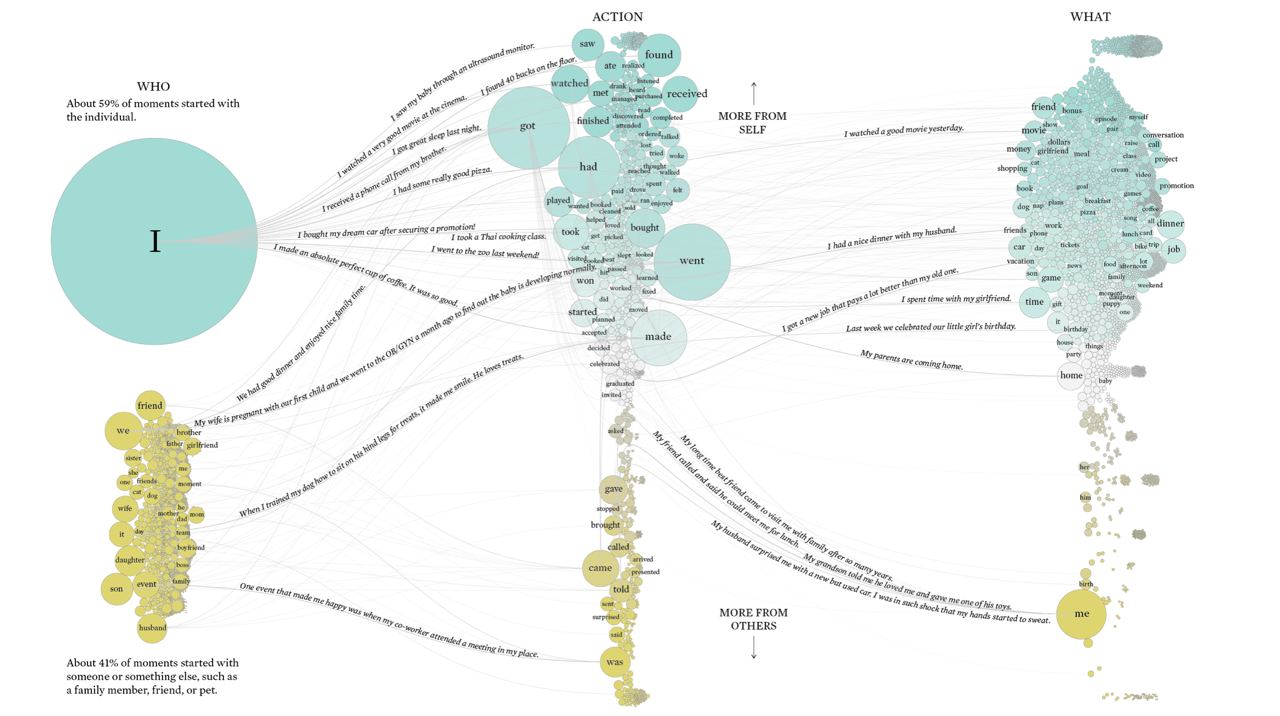
Counting Happiness and Where it Comes From
Researches asked 10 000 Mechanical Turk participants to name 10 things which are making them happy, resulting in creation of HappyDB.
And since that DB is open, Nathan Yau analyzed and vizualized this database in the perspective of subjects and actions, producing intersting visualization.
Hope that daily reading @opendatascience makes you at least content, if not happy.
Happines reason visualization link: https://flowingdata.com/2021/07/29/counting-happiness
HappyDB link: https://megagon.ai/projects/happydb-a-happiness-database-of-100000-happy-moments/
#dataset #emotions #visualization
Researches asked 10 000 Mechanical Turk participants to name 10 things which are making them happy, resulting in creation of HappyDB.
And since that DB is open, Nathan Yau analyzed and vizualized this database in the perspective of subjects and actions, producing intersting visualization.
Hope that daily reading @opendatascience makes you at least content, if not happy.
Happines reason visualization link: https://flowingdata.com/2021/07/29/counting-happiness
HappyDB link: https://megagon.ai/projects/happydb-a-happiness-database-of-100000-happy-moments/
#dataset #emotions #visualization
{kind=link}
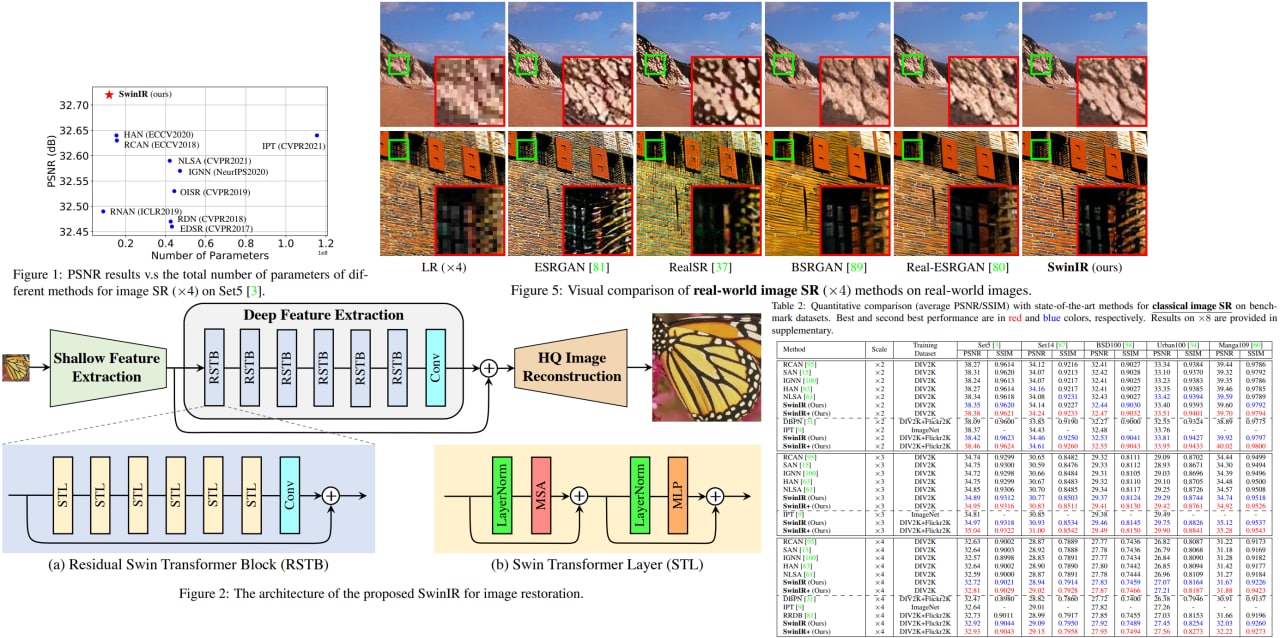
SwinIR: Image Restoration Using Swin Transformer
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy, and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers, which show impressive performance on high-level vision tasks.
The authors use a model SwinIR based on the Swin Transformers. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks (image super-resolution, image denoising, and JPEG compression artifact reduction) by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
Paper: https://arxiv.org/abs/2108.10257
Code: https://github.com/JingyunLiang/SwinIR
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swinir
#deeplearning #cv #transformer #superresolution #imagerestoration
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy, and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers, which show impressive performance on high-level vision tasks.
The authors use a model SwinIR based on the Swin Transformers. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks (image super-resolution, image denoising, and JPEG compression artifact reduction) by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
Paper: https://arxiv.org/abs/2108.10257
Code: https://github.com/JingyunLiang/SwinIR
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swinir
#deeplearning #cv #transformer #superresolution #imagerestoration
{kind=link}
Summarizing Books with Human Feedback
#OpenAI fine-tuned #GPT3 to summarize books well enough to be human-readable. Main approach: recursively split text into parts and then meta-summarize summaries.
This is really important because once there will be a great summarization #SOTA we won't need editors to write posts for you. And researchers ultimatively will have some asisstance interpreting models' results.
BlogPost: https://openai.com/blog/summarizing-books/
ArXiV: https://arxiv.org/abs/2109.10862
#summarization #NLU #NLP
#OpenAI fine-tuned #GPT3 to summarize books well enough to be human-readable. Main approach: recursively split text into parts and then meta-summarize summaries.
This is really important because once there will be a great summarization #SOTA we won't need editors to write posts for you. And researchers ultimatively will have some asisstance interpreting models' results.
BlogPost: https://openai.com/blog/summarizing-books/
ArXiV: https://arxiv.org/abs/2109.10862
#summarization #NLU #NLP
{kind=link}
AI Generated Pokemon Sprites with GPT-2
Author trained #GPT2 model to generate #pokemon sprites, encoding them as the lines of characters (including color). Surprisingly, results were decent, so this leaves us wonder if #GPT3 results would be better.
YouTube: https://www.youtube.com/watch?v=Z9K3cwSL6uM
GitHub: https://github.com/MatthewRayfield/pokemon-gpt-2
Article: https://matthewrayfield.com/articles/ai-generated-pokemon-sprites-with-gpt-2/
Example: https://matthewrayfield.com/projects/ai-pokemon/
#NLU #NLP #generation #neuralart
Author trained #GPT2 model to generate #pokemon sprites, encoding them as the lines of characters (including color). Surprisingly, results were decent, so this leaves us wonder if #GPT3 results would be better.
YouTube: https://www.youtube.com/watch?v=Z9K3cwSL6uM
GitHub: https://github.com/MatthewRayfield/pokemon-gpt-2
Article: https://matthewrayfield.com/articles/ai-generated-pokemon-sprites-with-gpt-2/
Example: https://matthewrayfield.com/projects/ai-pokemon/
#NLU #NLP #generation #neuralart
{kind=link}
This Olesya doesn't exist
Author trained StyleGAN2-ADA network on 2445 personal photos to generate new photo on the site each time there is a refresh or click.
Website: http://thisolesyadoesnotexist.glitch.me
Olesya's personal site: https://monolesan.com
#StyleGAN2 #StyleGAN2ADA #generation #thisXdoesntexist
Author trained StyleGAN2-ADA network on 2445 personal photos to generate new photo on the site each time there is a refresh or click.
Website: http://thisolesyadoesnotexist.glitch.me
Olesya's personal site: https://monolesan.com
#StyleGAN2 #StyleGAN2ADA #generation #thisXdoesntexist
{kind=link}
Real numbers, data science and chaos: How to fit any dataset with a single parameter
Gentle reminder that measure of information is bit and that single parameter can contain more information than multiple parameters.
ArXiV: https://arxiv.org/abs/1904.12320
#cs #bits #math
Gentle reminder that measure of information is bit and that single parameter can contain more information than multiple parameters.
ArXiV: https://arxiv.org/abs/1904.12320
#cs #bits #math
{kind=link}
Interesting idea for using GitHub panes for data #visualization
Source: https://twitter.com/levelsio/status/1443133071230791680
Live: https://nomadlist.com/open
Source: https://twitter.com/levelsio/status/1443133071230791680
Live: https://nomadlist.com/open
Experimenting with CLIP+VQGAN to Create AI Generated Art
Tips and tricks on prompts to #vqclip. TLDR:
* Adding
* Using the pipe to split a prompt into separate prompts that are steered towards independently may be counterproductive.
Article: https://blog.roboflow.com/ai-generated-art/
Colab Notebook: https://colab.research.google.com/drive/1go6YwMFe5MX6XM9tv-cnQiSTU50N9EeT
#visualization #gan #generation #generatinveart #vqgan #clip
Tips and tricks on prompts to #vqclip. TLDR:
* Adding
rendered in unreal engine, trending on artstation, top of /r/art improves image quality significally.* Using the pipe to split a prompt into separate prompts that are steered towards independently may be counterproductive.
Article: https://blog.roboflow.com/ai-generated-art/
Colab Notebook: https://colab.research.google.com/drive/1go6YwMFe5MX6XM9tv-cnQiSTU50N9EeT
#visualization #gan #generation #generatinveart #vqgan #clip
Forwarded from Towards NLP🇺🇦
RoBERTa English Toxicity Classifier
We have released our fine-tuned RoBERTa based toxicity classifier for English language on🤗:
https://huggingface.co/SkolkovoInstitute/roberta_toxicity_classifier
The model was trained on the merge of the English parts of the three datasets by Jigsaw. The classifiers perform closely on the test set of the first Jigsaw competition, reaching the AUC-ROC of 0.98 and F1-score of 0.76.
So, you can use it now conveniently for any of your research or industrial tasks☺️
We have released our fine-tuned RoBERTa based toxicity classifier for English language on🤗:
https://huggingface.co/SkolkovoInstitute/roberta_toxicity_classifier
The model was trained on the merge of the English parts of the three datasets by Jigsaw. The classifiers perform closely on the test set of the first Jigsaw competition, reaching the AUC-ROC of 0.98 and F1-score of 0.76.
So, you can use it now conveniently for any of your research or industrial tasks☺️
huggingface.co
s-nlp/roberta_toxicity_classifier · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
It's All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
Forwarded from Silero News (Alexander)
We Have Published a Model For Text Repunctuation and Recapitalization
The model works with SINGLE sentences (albeit long ones) and:
- Inserts capital letters and basic punctuation marks (dot, comma, hyphen, question mark, exclamation mark, dash for Russian);
- Works for 4 languages (Russian, English, German, Spanish) and can be extended;
- By design is domain agnostic and is not based on any hard-coded rules;
- Has non-trivial metrics and succeeds in the task of improving text readability;
Links:
- Model repo - https://github.com/snakers4/silero-models#text-enhancement
- Colab notebook - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_te.ipynb
- Russian article - https://habr.com/ru/post/581946/
- English article - https://habr.com/ru/post/581960/
The model works with SINGLE sentences (albeit long ones) and:
- Inserts capital letters and basic punctuation marks (dot, comma, hyphen, question mark, exclamation mark, dash for Russian);
- Works for 4 languages (Russian, English, German, Spanish) and can be extended;
- By design is domain agnostic and is not based on any hard-coded rules;
- Has non-trivial metrics and succeeds in the task of improving text readability;
Links:
- Model repo - https://github.com/snakers4/silero-models#text-enhancement
- Colab notebook - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_te.ipynb
- Russian article - https://habr.com/ru/post/581946/
- English article - https://habr.com/ru/post/581960/
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
AI for Earth Monitoring course
Course is about how to apply data science to datasets of Earth images collected by satellites. This course would benefit people interested in jumping into the real world application and working with real Earth observation image data.
Start date: 18 Oct. 2021
Duration: 6 weeks
Cost: Free
Link: https://bit.ly/3lerMti
Course is about how to apply data science to datasets of Earth images collected by satellites. This course would benefit people interested in jumping into the real world application and working with real Earth observation image data.
Start date: 18 Oct. 2021
Duration: 6 weeks
Cost: Free
Link: https://bit.ly/3lerMti
FutureLearn
Artificial Intelligence (AI) for Earth Monitoring - AI Course - FutureLearn
Explore how artificial intelligence (AI) and machine learning (ML) technologies are helping to advance Earth monitoring with this online AI course.