
Forwarded from Graph Machine Learning
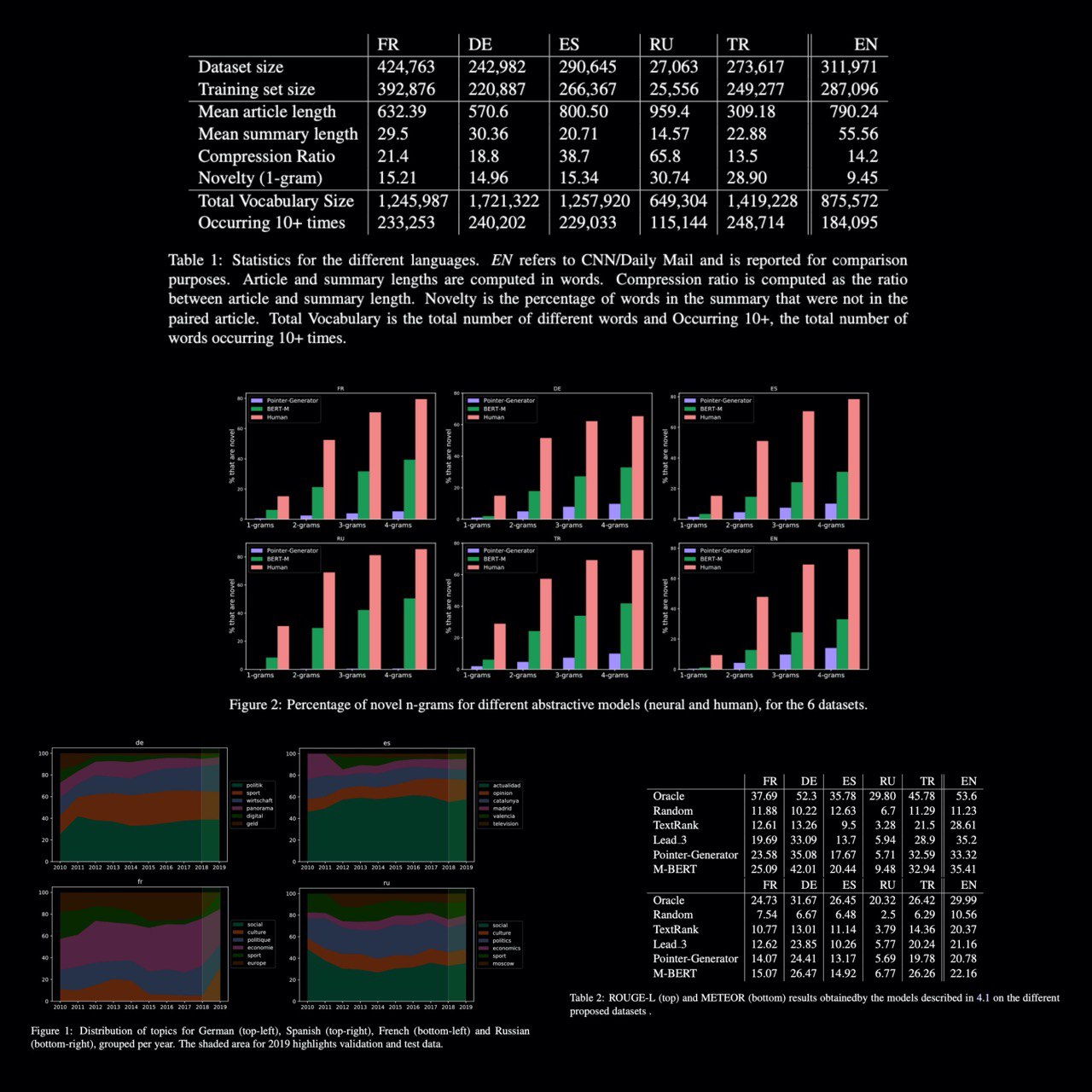
MLSUM: The Multilingual Summarization Corpus
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
{kind=link}
Shear, Torsion and Pressure Tactile Sensor via Plastic Optofiber Guided Imaging
CNN applied to tactile sensing
YouTube: https://youtu.be/7wsURXJrq7U
Paper: https://ieeexplore.ieee.org/abstract/document/8990014
CNN applied to tactile sensing
YouTube: https://youtu.be/7wsURXJrq7U
Paper: https://ieeexplore.ieee.org/abstract/document/8990014
YouTube
ICRA2020 Baimukashev Optical Tactile Sensor
Submitted to RA-L with ICRA2020 option
Martin Calvino's AI-inspired art is such an evoking meta-narrative of "art imitating tech imitating art"
https://www.martincalvino.co/paintings
#ai #art #abstract
https://www.martincalvino.co/paintings
#ai #art #abstract
{kind=link}
🤖 The NetHack Learning Environment
#Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft (as a matter of fact one might say «console NetHack game» to go ‘all in’ in a word pun game).
NetHack is a wonderful RPG adventure game, happening in dungeon. Players control
#NLE uses python and ZeroMQ and we are looking forward to interesting applications or showcases to arise from this release.
Github: https://github.com/facebookresearch/nle
NetHack official page: http://nethack.org
#RL
#Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft (as a matter of fact one might say «console NetHack game» to go ‘all in’ in a word pun game).
NetHack is a wonderful RPG adventure game, happening in dungeon. Players control
@ sign moving in ASCII-based environment, fighting enemies and doing quests. If you haven’t played it you are missing a whole piece of gaming culture and our editorial team kindly cheers you on at least trying to play it. Though now there lots of wikis and playing guides, canonicial way to play it is to dive into source code for looking up the keys and getting the whole idea of what to expect from different situations.#NLE uses python and ZeroMQ and we are looking forward to interesting applications or showcases to arise from this release.
Github: https://github.com/facebookresearch/nle
NetHack official page: http://nethack.org
#RL
The Cost of Training NLP Models: A Concise Overview
The authors review the cost of training large-scale language models, and the drivers of these costs.
More at the paper: https://arxiv.org/abs/2004.08900
#nlp #language
The authors review the cost of training large-scale language models, and the drivers of these costs.
More at the paper: https://arxiv.org/abs/2004.08900
#nlp #language
{kind=link}
By the coincedence we received a couple of help requests with trivial questions.
Thank you for using @opendatasciencebot and we will address the issue in our upcoming Ultimate Post on Where To Start with Data Science.
Our channel doesn’t advertise or spam, so our editorial team runs only on enthuasism (and because we want to give back to the community and spread worthy information). Therefore we do not have enough resources to provide response on technical questions regarding syntax and other errors and we can not help with your requests.
We can only advice to try stackoverflow for getting down to the source of your problems.
Thank you for using @opendatasciencebot and we will address the issue in our upcoming Ultimate Post on Where To Start with Data Science.
Our channel doesn’t advertise or spam, so our editorial team runs only on enthuasism (and because we want to give back to the community and spread worthy information). Therefore we do not have enough resources to provide response on technical questions regarding syntax and other errors and we can not help with your requests.
We can only advice to try stackoverflow for getting down to the source of your problems.
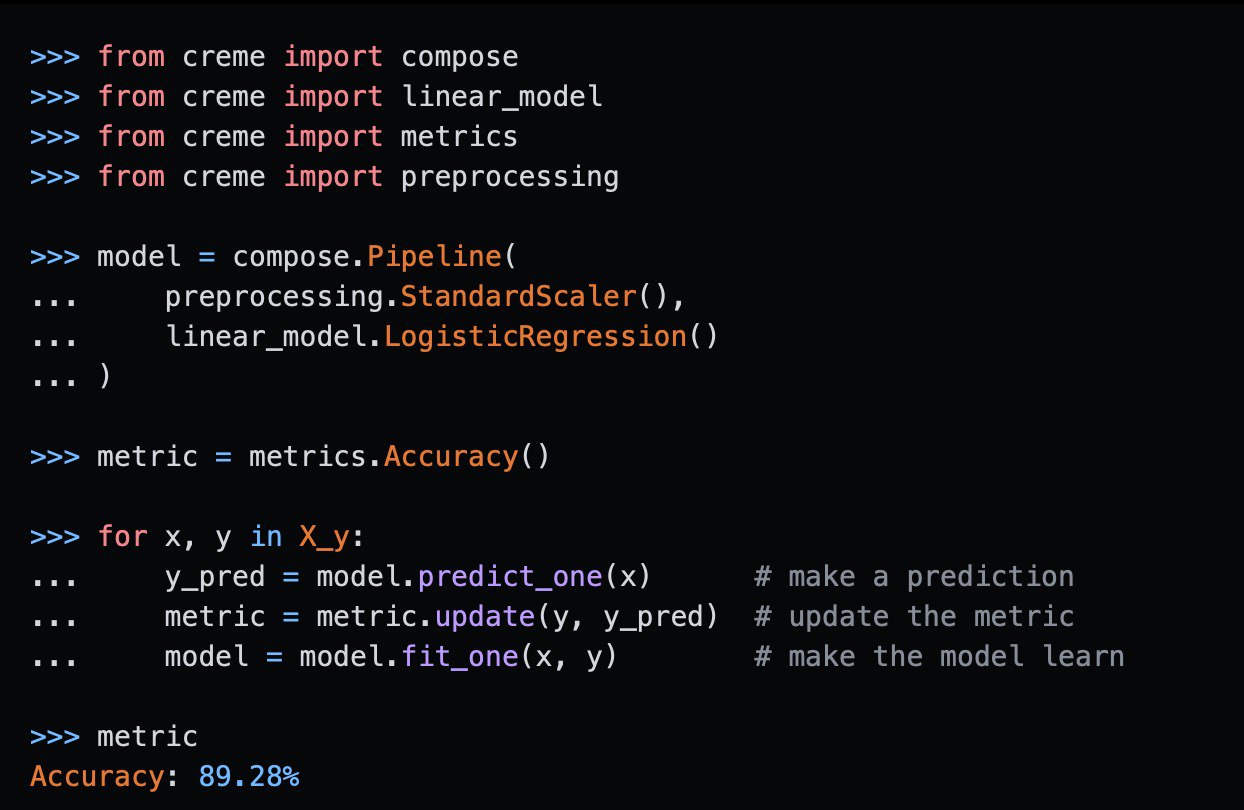
CREME – python library for online ML
All the tools in the library can be updated with a single observation at a time, and can therefore be used to learn from streaming data.
The model learns from one observation at a time, and can therefore be updated on the fly. This allows to learn from massive datasets that don't fit in main memory. Online machine learning also integrates nicely in cases where new data is constantly arriving. It shines in many use cases, such as time series forecasting, spam filtering, recommender systems, CTR prediction, and IoT applications. If you're bored with retraining models and want to instead build dynamic models, then online machine learning might be what you're looking for.
Here are some benefits of using creme (and online machine learning in general):
• incremental – models can update themselves in real-time
• adaptive – models can adapt to concept drift
• production-ready – working with data streams makes it simple to replicate production scenarios during model development
• efficient – models don't have to be retrained and require little compute power, which lowers their carbon footprint
api reference: https://creme-ml.github.io/content/api.html
github: https://github.com/creme-ml/creme
#ml #online #learning
All the tools in the library can be updated with a single observation at a time, and can therefore be used to learn from streaming data.
The model learns from one observation at a time, and can therefore be updated on the fly. This allows to learn from massive datasets that don't fit in main memory. Online machine learning also integrates nicely in cases where new data is constantly arriving. It shines in many use cases, such as time series forecasting, spam filtering, recommender systems, CTR prediction, and IoT applications. If you're bored with retraining models and want to instead build dynamic models, then online machine learning might be what you're looking for.
Here are some benefits of using creme (and online machine learning in general):
• incremental – models can update themselves in real-time
• adaptive – models can adapt to concept drift
• production-ready – working with data streams makes it simple to replicate production scenarios during model development
• efficient – models don't have to be retrained and require little compute power, which lowers their carbon footprint
api reference: https://creme-ml.github.io/content/api.html
github: https://github.com/creme-ml/creme
#ml #online #learning
{kind=link}
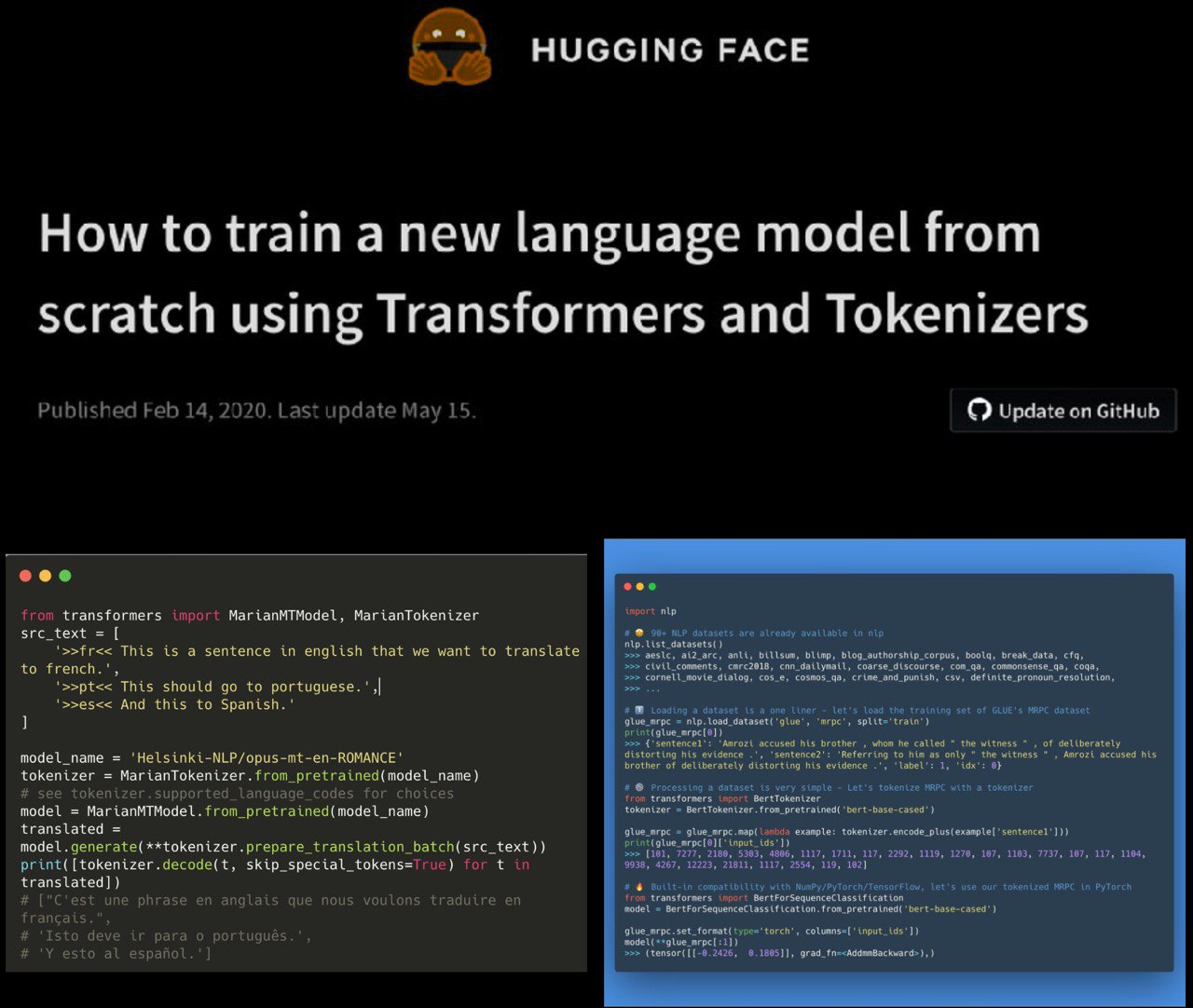
the latest news from :hugging_face_mask:
[0] Helsinki-NLP
With v2.9.1 released 1,008 machine translation models, covering of 140 different languages trained with marian-nmt
link to models: https://huggingface.co/models?search=Helsinki-NLP%2Fopus-mt
[1] updated colab notebook with the new Trainer
colab: https://t.co/nGQxwqwwZu?amp=1
[2] NLP – library to easily share & load data/metrics already providing access to 99+ datasets!
features
– get them all: built-in interoperability with pytorch, tensorflow, pandas, numpy
– simple transparent pythonic API
– strive on large datasets: nlp frees you from RAM memory limits
– smart cache: process once reuse forever
– add your dataset
colab: https://t.co/37pfogRWIZ?amp=1
github: https://github.com/huggingface/nlp
#nlp #huggingface #helsinki #marian #trainer # #data #metrics
[0] Helsinki-NLP
With v2.9.1 released 1,008 machine translation models, covering of 140 different languages trained with marian-nmt
link to models: https://huggingface.co/models?search=Helsinki-NLP%2Fopus-mt
[1] updated colab notebook with the new Trainer
colab: https://t.co/nGQxwqwwZu?amp=1
[2] NLP – library to easily share & load data/metrics already providing access to 99+ datasets!
features
– get them all: built-in interoperability with pytorch, tensorflow, pandas, numpy
– simple transparent pythonic API
– strive on large datasets: nlp frees you from RAM memory limits
– smart cache: process once reuse forever
– add your dataset
colab: https://t.co/37pfogRWIZ?amp=1
github: https://github.com/huggingface/nlp
#nlp #huggingface #helsinki #marian #trainer # #data #metrics
{kind=link}
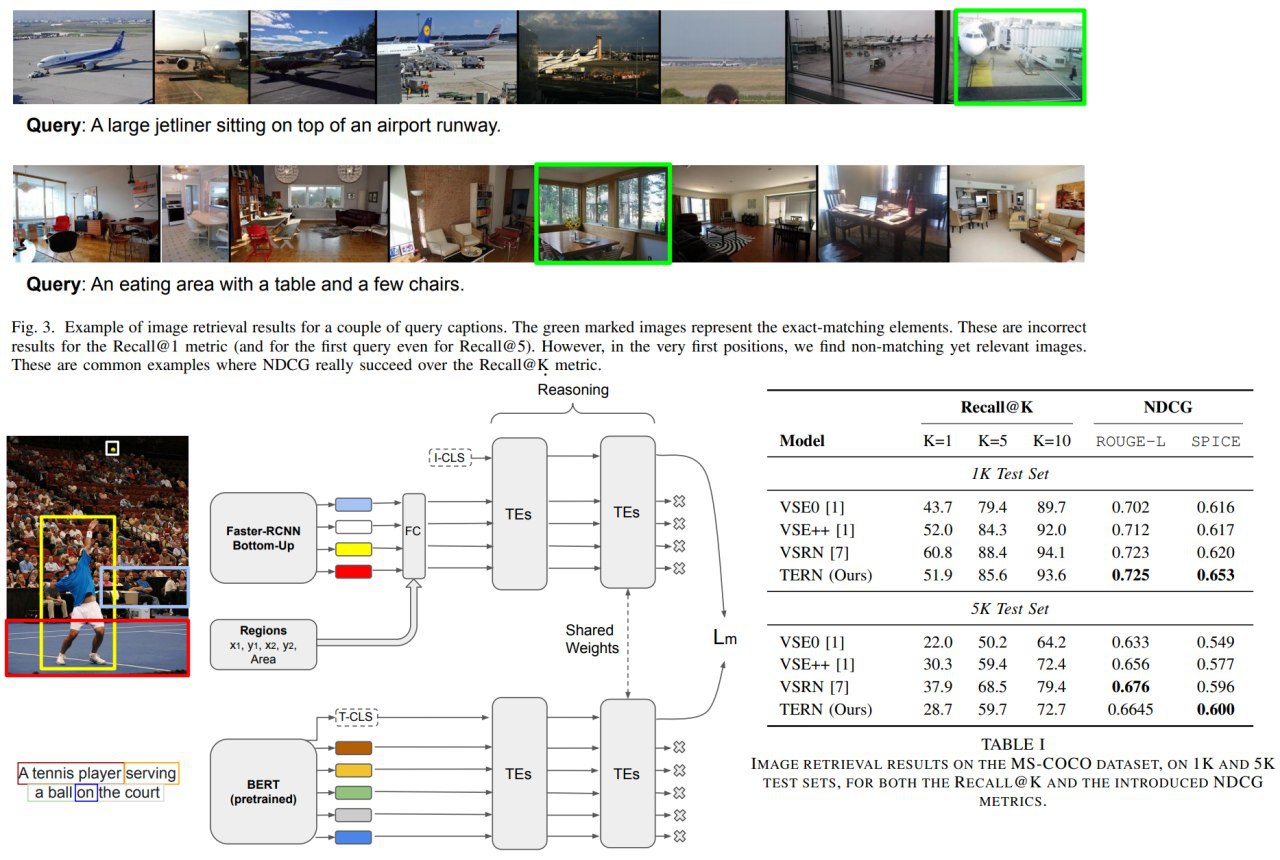
Transformer Reasoning Network for Image-Text Matching and Retrieval
A new approach for image-text matching using Faster-RCNN Bottom-Up and BERT.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Authors suggest an architecture, where images and texts are processed at first, and then their representations are combined.
Main contributions of the paper:
- TERN Architecture
- NDCG metric in addition to Recall@K
- show SOTA result on the benchmark
Paper: https://arxiv.org/abs/2004.09144
Code: https://github.com/mesnico/TERN
#computervision #deeplearning #bert #imagetextmatching
A new approach for image-text matching using Faster-RCNN Bottom-Up and BERT.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Authors suggest an architecture, where images and texts are processed at first, and then their representations are combined.
Main contributions of the paper:
- TERN Architecture
- NDCG metric in addition to Recall@K
- show SOTA result on the benchmark
Paper: https://arxiv.org/abs/2004.09144
Code: https://github.com/mesnico/TERN
#computervision #deeplearning #bert #imagetextmatching
{kind=link}
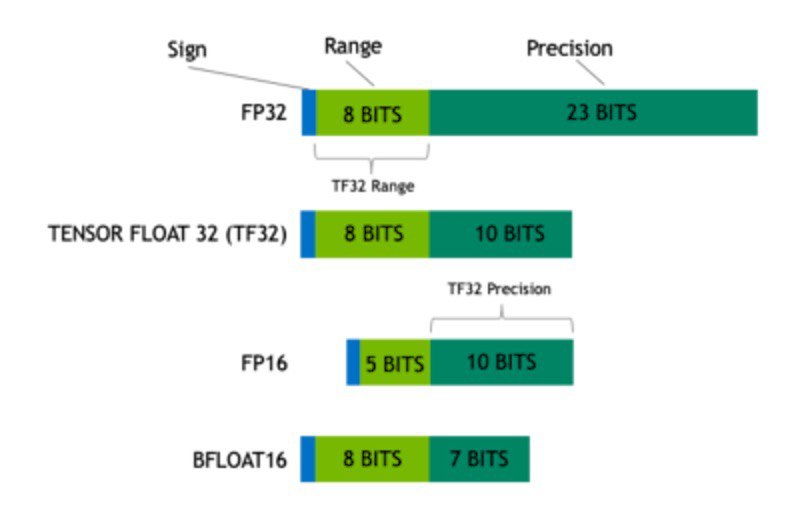
Brilliant article on different float types used in DL
FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO by Grigory Sapunov
Link: https://medium.com/@moocaholic/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407
#dl #engineering #cs #floatingpoint
FP64, FP32, FP16, BFLOAT16, TF32, and other members of the ZOO by Grigory Sapunov
Link: https://medium.com/@moocaholic/fp64-fp32-fp16-bfloat16-tf32-and-other-members-of-the-zoo-a1ca7897d407
#dl #engineering #cs #floatingpoint
{kind=link}
S2IGAN — Speech-to-Image Generation via Adversarial Learning
Authors present a framework that translates speech to images bypassing text information, thus allowing unwritten languages to potentially benefit from this technology.
ArXiV: https://arxiv.org/abs/2005.06968
Project: https://xinshengwang.github.io/project/s2igan/
#DL #audiolearning #speechrecognition
Authors present a framework that translates speech to images bypassing text information, thus allowing unwritten languages to potentially benefit from this technology.
ArXiV: https://arxiv.org/abs/2005.06968
Project: https://xinshengwang.github.io/project/s2igan/
#DL #audiolearning #speechrecognition
王新升
S2IGAN | 王新升
A framework that translates speech descriptions to photo-realistic images without using any text information.
Blackcellmagic extension for jupyter
There are people who like dark themes and are fond of them, but this extension helps to format the code.
Extension: https://github.com/csurfer/blackcellmagic
Black formatter: https://github.com/psf/black
#codestyle #python #jupyter
There are people who like dark themes and are fond of them, but this extension helps to format the code.
Extension: https://github.com/csurfer/blackcellmagic
Black formatter: https://github.com/psf/black
#codestyle #python #jupyter
Dear subscribers we remind you that our channel remains focused on DS-related news and updates, so you are welcome to read and submit any DS-related news to our separate repo: https://github.com/open-data-science/ultimate_posts/tree/master/COVID_2019
PRs are mostly welcome.
PRs are mostly welcome.
GitHub
ultimate_posts/COVID_2019 at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
This paper introduces a new method that significantly improves the sample efficiency of RL algorithms when learning from raw pixel data.
CURL architecture consists of three models: Query Encoder, Key Encoder, and RL agent. Query Encoder outputs embedding which used in RL agent as state representation. Contrastive loss computed from outputs of Query Encoder and Key Encoder. An important thing is that Query Encoder learns to minimize both RL and contrastive losses which allow all models to be trained jointly.
The method was tested on Atari and DeepMind Control tasks with limited interaction steps. It showed SOTA results for most of these tasks.
Paper: https://arxiv.org/abs/2004.04136.pdf
Code: https://github.com/MishaLaskin/curl
#rl #agent #reinforcement #learning
This paper introduces a new method that significantly improves the sample efficiency of RL algorithms when learning from raw pixel data.
CURL architecture consists of three models: Query Encoder, Key Encoder, and RL agent. Query Encoder outputs embedding which used in RL agent as state representation. Contrastive loss computed from outputs of Query Encoder and Key Encoder. An important thing is that Query Encoder learns to minimize both RL and contrastive losses which allow all models to be trained jointly.
The method was tested on Atari and DeepMind Control tasks with limited interaction steps. It showed SOTA results for most of these tasks.
Paper: https://arxiv.org/abs/2004.04136.pdf
Code: https://github.com/MishaLaskin/curl
#rl #agent #reinforcement #learning
{kind=link}
Forwarded from Находки в опенсорсе
Mypy stubs, i.e., type information, for numpy, pandas and matplotlib for your #ds #python projects.
Lots of functions are already typed, but a lot is still missing (numpy and pandas are huge libraries).
https://github.com/predictive-analytics-lab/data-science-types
Lots of functions are already typed, but a lot is still missing (numpy and pandas are huge libraries).
https://github.com/predictive-analytics-lab/data-science-types
{kind=link}
Remote online PyDoma meetup for russian-speaking community.
#PyData — worldwide events about anything related to storage, processing or visualization data with #python.
Link: https://pydata.timepad.ru/event/1318959/
P.S. We are happy to promote any national online activities, which are valuable and open to public.
#PyData — worldwide events about anything related to storage, processing or visualization data with #python.
Link: https://pydata.timepad.ru/event/1318959/
P.S. We are happy to promote any national online activities, which are valuable and open to public.
pydata.timepad.ru
PyDoma [PyData Moscow #12] / События на TimePad.ru
В этот раз PyData Moscow пройдет онлайн и под флагом самоизоляции — PyDoma.
А также просим вас принять участие в благотворительном марафоне и сделать любое пожертвование на акцию https://sluchaem.ru/event/5154 для помощи всем, кто пострадал от последствий…
А также просим вас принять участие в благотворительном марафоне и сделать любое пожертвование на акцию https://sluchaem.ru/event/5154 для помощи всем, кто пострадал от последствий…
Automatic product tagging on photoes on Facebook Pages
#FacebookAI released an improvement aiming at enhancing shopping platform.
Post: https://ai.facebook.com/blog/powered-by-ai-advancing-product-understanding-and-building-new-shopping-experiences
Paper: https://scontent-arn2-1.xx.fbcdn.net/v/t39.8562-6/99353320_565175057533429_3886205100842024960_n.pdf
#GrokNet #DL #segmentation #PyTorch
#FacebookAI released an improvement aiming at enhancing shopping platform.
Post: https://ai.facebook.com/blog/powered-by-ai-advancing-product-understanding-and-building-new-shopping-experiences
Paper: https://scontent-arn2-1.xx.fbcdn.net/v/t39.8562-6/99353320_565175057533429_3886205100842024960_n.pdf
#GrokNet #DL #segmentation #PyTorch
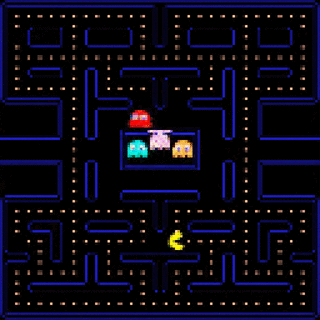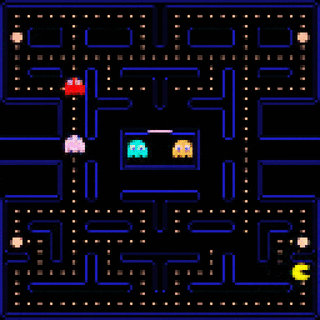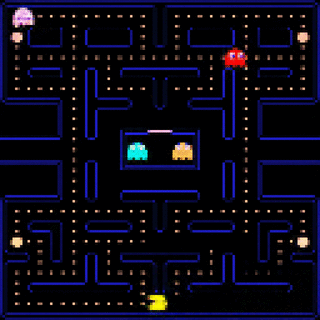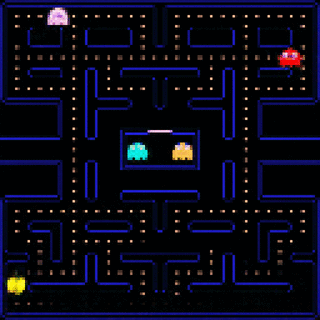
Learning to Simulate Dynamic Environments with GameGAN
#Nvidia designed a GAN that able to recreate games without any game engine. To train it, authors of the model use experience collected by reinforcement learning and other techniques.
GameGAN successfully reconstructed all mechanics of #Pacman game. Moreover, the trained model can generate new mazes that have never appeared in the original game. It can even replace background (static objects) and foreground (dynamic objects) with different images!
As the authors say, applying reinforcement learning algorithms to real world tasks requires accurate simulation of that task. Currently designing such simulations is expensive and time-consuming. Using neural networks instead of hand-written simulations may help to solve these problems.
Paper: https://cdn.arstechnica.net/wp-content/uploads/2020/05/Nvidia_GameGAN_Research.pdf
Blog: https://blogs.nvidia.com/blog/2020/05/22/gamegan-research-pacman-anniversary/
Github Page: https://nv-tlabs.github.io/gameGAN/
#GAN #RL
#Nvidia designed a GAN that able to recreate games without any game engine. To train it, authors of the model use experience collected by reinforcement learning and other techniques.
GameGAN successfully reconstructed all mechanics of #Pacman game. Moreover, the trained model can generate new mazes that have never appeared in the original game. It can even replace background (static objects) and foreground (dynamic objects) with different images!
As the authors say, applying reinforcement learning algorithms to real world tasks requires accurate simulation of that task. Currently designing such simulations is expensive and time-consuming. Using neural networks instead of hand-written simulations may help to solve these problems.
Paper: https://cdn.arstechnica.net/wp-content/uploads/2020/05/Nvidia_GameGAN_Research.pdf
Blog: https://blogs.nvidia.com/blog/2020/05/22/gamegan-research-pacman-anniversary/
Github Page: https://nv-tlabs.github.io/gameGAN/
#GAN #RL
{kind=link}
SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training
Authors introduce SpERT, an attention model for span-based joint entity and relation extraction.
This work investigates the use of Transformer networks for relation extraction: given a pre-defined set of target relations and a sentence such as “Leonardo DiCaprio starred in Christopher Nolan’s thriller Inception”, the goal is to extract triplets such as (“Leonardo DiCaprio”, Plays-In, “Inception”) or (“Inception”, Director, “Christopher Nolan”).
The main contributions of the paper are:
– a novel approach towards span-based joint entity and relation extraction
– ablation study showing that negative samples from the same sentence yield efficient training, a localized context representation is beneficial, finetuning a pre-trained model yields a strong performance increase over training from scratch.
This approach improves the SOTA score on CoNLL04 dataset by 2.6% (micro) F1.
Paper: https://arxiv.org/abs/1909.07755
Code: https://github.com/markus-eberts/spert
#nlp #deeplearning #transformer #bert #ner #relationextraction
Authors introduce SpERT, an attention model for span-based joint entity and relation extraction.
This work investigates the use of Transformer networks for relation extraction: given a pre-defined set of target relations and a sentence such as “Leonardo DiCaprio starred in Christopher Nolan’s thriller Inception”, the goal is to extract triplets such as (“Leonardo DiCaprio”, Plays-In, “Inception”) or (“Inception”, Director, “Christopher Nolan”).
The main contributions of the paper are:
– a novel approach towards span-based joint entity and relation extraction
– ablation study showing that negative samples from the same sentence yield efficient training, a localized context representation is beneficial, finetuning a pre-trained model yields a strong performance increase over training from scratch.
This approach improves the SOTA score on CoNLL04 dataset by 2.6% (micro) F1.
Paper: https://arxiv.org/abs/1909.07755
Code: https://github.com/markus-eberts/spert
#nlp #deeplearning #transformer #bert #ner #relationextraction
{kind=link}