
Taskmaster-2 dataset by Google Research
The Taskmaster-2 dataset consists of 17 289 dialogs in seven domains:
– restaurants (3276)
– food ordering (1050)
– movies (3047)
– hotels (2355)
– flights (2481)
– music (1602)
– sports (3478)
All dialogs were collected using the same Wizard of Oz system used in Taskmaster-1 where crowdsourced workers playing the "user" interacted with human operators playing the "digital assistant" using a web-based interface
Github page: https://github.com/google-research-datasets/Taskmaster/tree/master/TM-2-2020
Web page: https://research.google/tools/datasets/taskmaster-2/
#nlp #datasets #dialogs
The Taskmaster-2 dataset consists of 17 289 dialogs in seven domains:
– restaurants (3276)
– food ordering (1050)
– movies (3047)
– hotels (2355)
– flights (2481)
– music (1602)
– sports (3478)
All dialogs were collected using the same Wizard of Oz system used in Taskmaster-1 where crowdsourced workers playing the "user" interacted with human operators playing the "digital assistant" using a web-based interface
Github page: https://github.com/google-research-datasets/Taskmaster/tree/master/TM-2-2020
Web page: https://research.google/tools/datasets/taskmaster-2/
#nlp #datasets #dialogs
GitHub
Taskmaster/TM-2-2020 at master · google-research-datasets/Taskmaster
Please see the readme file as well as our 2019 EMNLP paper linked here --> - google-research-datasets/Taskmaster
Natural Language Processing News
by Sebastian Ruder
This edition includes new results from NLP-Progress, a discussion about COVID-19, an update of the venerable Hutter Prize, which uses compression as a test for AGI, the latest resources around BERT and monolingual BERT models, an introduction to Green AI, and as usual lots of other resources, blog posts, and papers.
link to edition: http://newsletter.ruder.io/issues/covid-19-hutter-prize-compression-agi-bert-green-ai-229519
#nlp #news #progress #ruder
by Sebastian Ruder
This edition includes new results from NLP-Progress, a discussion about COVID-19, an update of the venerable Hutter Prize, which uses compression as a test for AGI, the latest resources around BERT and monolingual BERT models, an introduction to Green AI, and as usual lots of other resources, blog posts, and papers.
link to edition: http://newsletter.ruder.io/issues/covid-19-hutter-prize-compression-agi-bert-green-ai-229519
#nlp #news #progress #ruder
{kind=link}
Forwarded from Spark in me (Alexander)
Towards an ImageNet Moment for Speech-to-Text
First CV, and then (arguably) NLP, have had their ImageNet moment — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Following the release of our production models / metrics, this is our piece on this topic on thegradient.pub! So far this is the largest work ever we have done, and I hope that it will not go under the radar.
It is in our hands now to make sure that speech recognition brings value to people worldwide, and not only some fat cats.
So, without further ado:
- The piece itself https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/
- Some more links here https://spark-in.me/post/towards-an-imagenet-moment-for-speech-to-text
- If you are on Twitter, please repost this message - https://twitter.com/gradientpub/status/1243967773635571712
A lot of thanks to Thegradient team, especially Andrey and Jacob, for the sheer amount of work they put in to make this piece readable and understandable!
Please like, share, repost!
Also, there will be a second piece with criticism, so stay tuned!
#speech
#deep_learning
First CV, and then (arguably) NLP, have had their ImageNet moment — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Following the release of our production models / metrics, this is our piece on this topic on thegradient.pub! So far this is the largest work ever we have done, and I hope that it will not go under the radar.
It is in our hands now to make sure that speech recognition brings value to people worldwide, and not only some fat cats.
So, without further ado:
- The piece itself https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/
- Some more links here https://spark-in.me/post/towards-an-imagenet-moment-for-speech-to-text
- If you are on Twitter, please repost this message - https://twitter.com/gradientpub/status/1243967773635571712
A lot of thanks to Thegradient team, especially Andrey and Jacob, for the sheer amount of work they put in to make this piece readable and understandable!
Please like, share, repost!
Also, there will be a second piece with criticism, so stay tuned!
#speech
#deep_learning
The Gradient
Towards an ImageNet Moment for Speech-to-Text
First CV, and then NLP, have had their 'ImageNet moment' — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Listen to Transformer
It is an open source ML model from the Magenta research group at Google that can generate musical performances with some long-term structure. The authors find it interesting to see what these models can and can’t do, so they made this app to make it easier to explore and curate the model’s output.
The models were trained on an exciting data source: piano recordings on YouTube transcribed using Onsets and Frames. They trained each Transformer model on hundreds of thousands of piano recordings, with a total length of over 10k hours. As described in the Wave2Midi2Wave approach, using such transcriptions allows training symbolic music models on a representation that carries the expressive performance characteristics from the original recordings.
Also, the artwork for each song is algorithmically generated based on the notes in the song itself – while the notes are represented by random shapes, the opacity represents the velocity, and the size represents the duration of each note
paper: https://arxiv.org/abs/1809.04281
blog post: https://magenta.tensorflow.org/listen-to-transformer
github: https://github.com/magenta/listen-to-transformer
demos: https://magenta.github.io/listen-to-transformer/#a1_650.mid
#transformer #listen #music
It is an open source ML model from the Magenta research group at Google that can generate musical performances with some long-term structure. The authors find it interesting to see what these models can and can’t do, so they made this app to make it easier to explore and curate the model’s output.
The models were trained on an exciting data source: piano recordings on YouTube transcribed using Onsets and Frames. They trained each Transformer model on hundreds of thousands of piano recordings, with a total length of over 10k hours. As described in the Wave2Midi2Wave approach, using such transcriptions allows training symbolic music models on a representation that carries the expressive performance characteristics from the original recordings.
Also, the artwork for each song is algorithmically generated based on the notes in the song itself – while the notes are represented by random shapes, the opacity represents the velocity, and the size represents the duration of each note
paper: https://arxiv.org/abs/1809.04281
blog post: https://magenta.tensorflow.org/listen-to-transformer
github: https://github.com/magenta/listen-to-transformer
demos: https://magenta.github.io/listen-to-transformer/#a1_650.mid
#transformer #listen #music
{kind=link}
Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification
An enhanced augmentation strategy based on CutMix
Recently a large variety of regional dropout strategies have been proposed, such as Cutout, DropBlock, CutMix, etc. These methods help models to generalize better by partially occluding the discriminative parts of objects. However, they usually do it randomly, so a reasonable improvement would be to find some strategy of selecting the patches.
Attentive CutMix uses pretrained neural nets to find the most descriptive regions and replaces them. This further improves generalization because we make sure that patches are pasted not on the background, but on the areas of interest.
Authors train four variants each of ResNet, DenseNet and EfficientNet architectures on CIFAR-10, CIFAR-100, and ImageNet.
Attentive CutMix consistently provides an average increase of 1.5% over other methods which validates the effectiveness of our attention mechanism.
Paper: https://arxiv.org/abs/2003.13048
#deeplearning #augmentation
An enhanced augmentation strategy based on CutMix
Recently a large variety of regional dropout strategies have been proposed, such as Cutout, DropBlock, CutMix, etc. These methods help models to generalize better by partially occluding the discriminative parts of objects. However, they usually do it randomly, so a reasonable improvement would be to find some strategy of selecting the patches.
Attentive CutMix uses pretrained neural nets to find the most descriptive regions and replaces them. This further improves generalization because we make sure that patches are pasted not on the background, but on the areas of interest.
Authors train four variants each of ResNet, DenseNet and EfficientNet architectures on CIFAR-10, CIFAR-100, and ImageNet.
Attentive CutMix consistently provides an average increase of 1.5% over other methods which validates the effectiveness of our attention mechanism.
Paper: https://arxiv.org/abs/2003.13048
#deeplearning #augmentation
{kind=link}
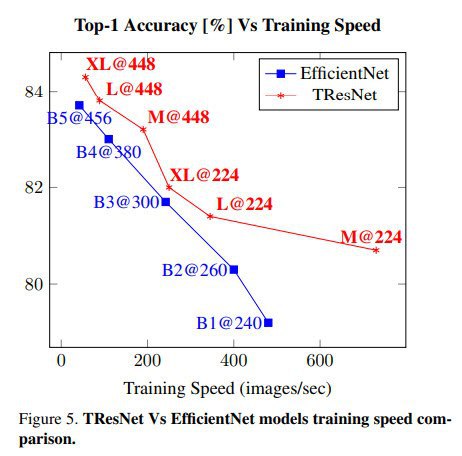
TResNet: High Performance GPU-Dedicated Architecture
An alternative design of ResNet Architecture to better utilize GPU structure and assets.
Modern neural net architectures provide high accuracy but often at the expense of FLOPS count.
The authors of this paper suggest various design and optimization improvements achieve both higher accuracy and efficiency.
There are three variants of architecture: TResNet-M, TResNet-L, and TResNet-XL. These three models vary only in-depth and the number of channels.
The refinements of the architecture:
– SpaceToDepth stem
– Anti-Alias downsampling
– In-Place Activated BatchNorm
– Blocks selection
– SE layers
They also use Jit Compilation for layers without learnable parameters and a custom implementation of Average pooling with up to 5 times speed increase.
Paper: https://arxiv.org/abs/2003.13630
Github: https://github.com/mrT23/TResNet
#deeplearning #architecture #optimization
An alternative design of ResNet Architecture to better utilize GPU structure and assets.
Modern neural net architectures provide high accuracy but often at the expense of FLOPS count.
The authors of this paper suggest various design and optimization improvements achieve both higher accuracy and efficiency.
There are three variants of architecture: TResNet-M, TResNet-L, and TResNet-XL. These three models vary only in-depth and the number of channels.
The refinements of the architecture:
– SpaceToDepth stem
– Anti-Alias downsampling
– In-Place Activated BatchNorm
– Blocks selection
– SE layers
They also use Jit Compilation for layers without learnable parameters and a custom implementation of Average pooling with up to 5 times speed increase.
Paper: https://arxiv.org/abs/2003.13630
Github: https://github.com/mrT23/TResNet
#deeplearning #architecture #optimization
{kind=link}
Background Matting: The World is Your Green Screen
Thу authors propose a method for creating a matte – the per-pixel foreground color and alpha – of a person by taking photos or videos in an everyday setting with a handheld camera. Most existing matting methods require a green screen background or a manually created trimap to produce a good matte.
Automatic, trimap-free methods are appearing, but are not of comparable quality. In them trimap free approach, they ask the user to take an additional photo of the background without the subject at the time of capture. This step requires a small amount of foresight but is far less timeconsuming than creating a trimap.
They train a deep network with an adversarial loss to predict the matte. At first, they train a matting network with the supervised loss on ground truth data with synthetic composites. To bridge the domain gap to real imagery with no labeling, train another matting network guided by the first network and by a discriminator that judges the quality of composites.
paper: https://arxiv.org/abs/2004.00626
blog post: http://grail.cs.washington.edu/projects/background-matting/
github (training code coming soon): https://github.com/senguptaumd/Background-Matting
#CVPR2020 #background #matte
Thу authors propose a method for creating a matte – the per-pixel foreground color and alpha – of a person by taking photos or videos in an everyday setting with a handheld camera. Most existing matting methods require a green screen background or a manually created trimap to produce a good matte.
Automatic, trimap-free methods are appearing, but are not of comparable quality. In them trimap free approach, they ask the user to take an additional photo of the background without the subject at the time of capture. This step requires a small amount of foresight but is far less timeconsuming than creating a trimap.
They train a deep network with an adversarial loss to predict the matte. At first, they train a matting network with the supervised loss on ground truth data with synthetic composites. To bridge the domain gap to real imagery with no labeling, train another matting network guided by the first network and by a discriminator that judges the quality of composites.
paper: https://arxiv.org/abs/2004.00626
blog post: http://grail.cs.washington.edu/projects/background-matting/
github (training code coming soon): https://github.com/senguptaumd/Background-Matting
#CVPR2020 #background #matte
{kind=link}
ODS.ai in collaboration with Sberbank has launched a new competition to build an algorithm that most accurately predicts the dynamics of the number of reported cases of COVID-19 in each country over the next 7 days.
The objective of the competition is to draw attention to the forecasts of the coronavirus pandemic. Perhaps while solving this problem, you could find problems in the data sources or make a suitable forecast based on the most reliable data.
Remember, we are developing an open science in ODS.ai by creating new and testing the existing forecasting methods, so your input can help humanity to achieve bigger goals. Only solving the tasks based on the open and public benchmark we can test and compare different approaches, as well as come to the best practices, and make them accessible to the entire research community.
Link: https://ods.ai/competitions/sberbank-covid19-forecast
#ods #openscience #competition #sber
The objective of the competition is to draw attention to the forecasts of the coronavirus pandemic. Perhaps while solving this problem, you could find problems in the data sources or make a suitable forecast based on the most reliable data.
Remember, we are developing an open science in ODS.ai by creating new and testing the existing forecasting methods, so your input can help humanity to achieve bigger goals. Only solving the tasks based on the open and public benchmark we can test and compare different approaches, as well as come to the best practices, and make them accessible to the entire research community.
Link: https://ods.ai/competitions/sberbank-covid19-forecast
#ods #openscience #competition #sber
Open Data Science (ODS.ai)
Forecast the Global Spread of COVID-19
Use any data you can find to predict the future increase of the number of reported cases of COVID-19.
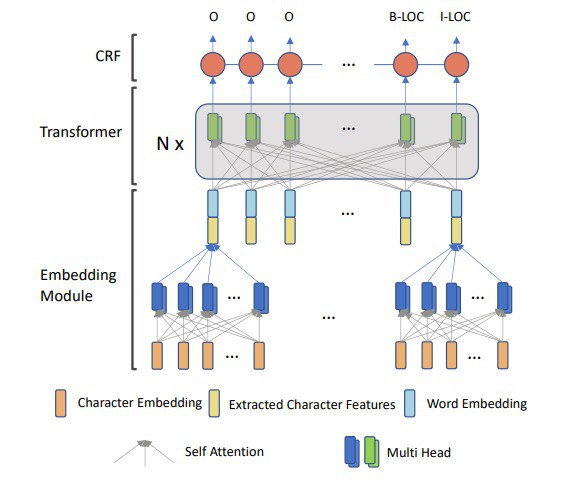
TENER: Adapting Transformer Encoder for Named Entity Recognition
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
{kind=link}
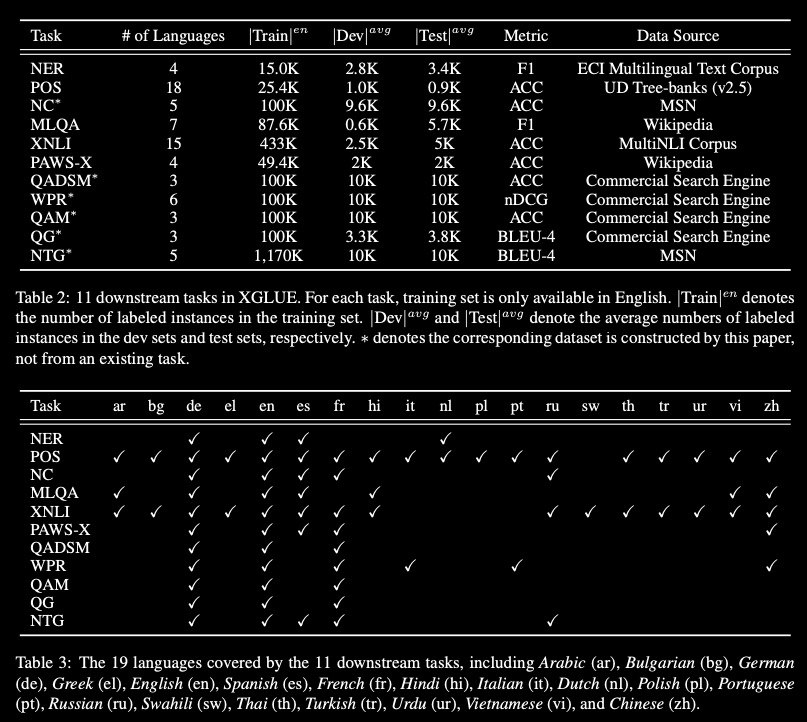
XGLUE: A New Benchmark Dataset
for Cross-lingual Pre-training, Understanding and Generation
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
for Cross-lingual Pre-training, Understanding and Generation
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
{kind=link}
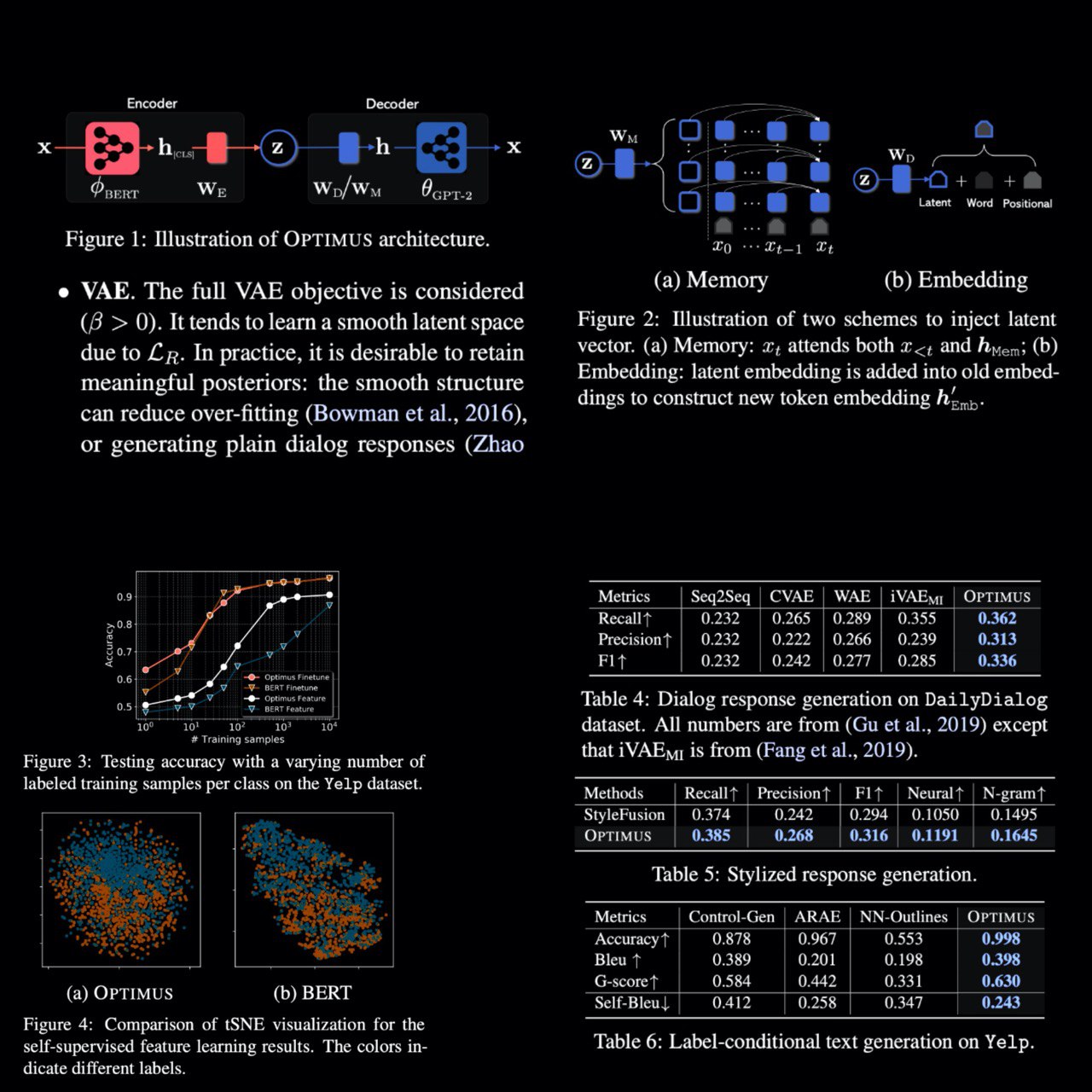
Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
{kind=link}
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization
The Cross-lingual TRansfer Evaluation of Multilingual Encoders (XTREME) benchmark is a benchmark for the evaluation of the cross-lingual generalization ability of pre-trained multilingual models. It covers 40 typologically diverse languages (spanning 12 language families) and includes nine tasks that collectively require reasoning about different levels of syntax and semantics. The languages in XTREME are selected to maximize language diversity, coverage in existing tasks, and availability of training data.
The tasks included in XTREME cover a range of standard paradigms in NLP, including sentence classification, structured prediction, sentence retrieval and question answering.
In order for models to be successful on the XTREME benchmark, they must learn representations that generalize across many tasks and languages. Each of the tasks covers a subset of the 40 languages included in XTREME. The languages were selected among the top 100 languages with the most Wikipedia articles to maximize language diversity, task coverage, and availability of training data.
More at blogpost
Paper: https://arxiv.org/abs/2003.11080.pdf
GitHub: https://github.com/google-research/xtreme/
#nlp #evaluation #benchmark
The Cross-lingual TRansfer Evaluation of Multilingual Encoders (XTREME) benchmark is a benchmark for the evaluation of the cross-lingual generalization ability of pre-trained multilingual models. It covers 40 typologically diverse languages (spanning 12 language families) and includes nine tasks that collectively require reasoning about different levels of syntax and semantics. The languages in XTREME are selected to maximize language diversity, coverage in existing tasks, and availability of training data.
The tasks included in XTREME cover a range of standard paradigms in NLP, including sentence classification, structured prediction, sentence retrieval and question answering.
In order for models to be successful on the XTREME benchmark, they must learn representations that generalize across many tasks and languages. Each of the tasks covers a subset of the 40 languages included in XTREME. The languages were selected among the top 100 languages with the most Wikipedia articles to maximize language diversity, task coverage, and availability of training data.
More at blogpost
Paper: https://arxiv.org/abs/2003.11080.pdf
GitHub: https://github.com/google-research/xtreme/
#nlp #evaluation #benchmark
{kind=link}
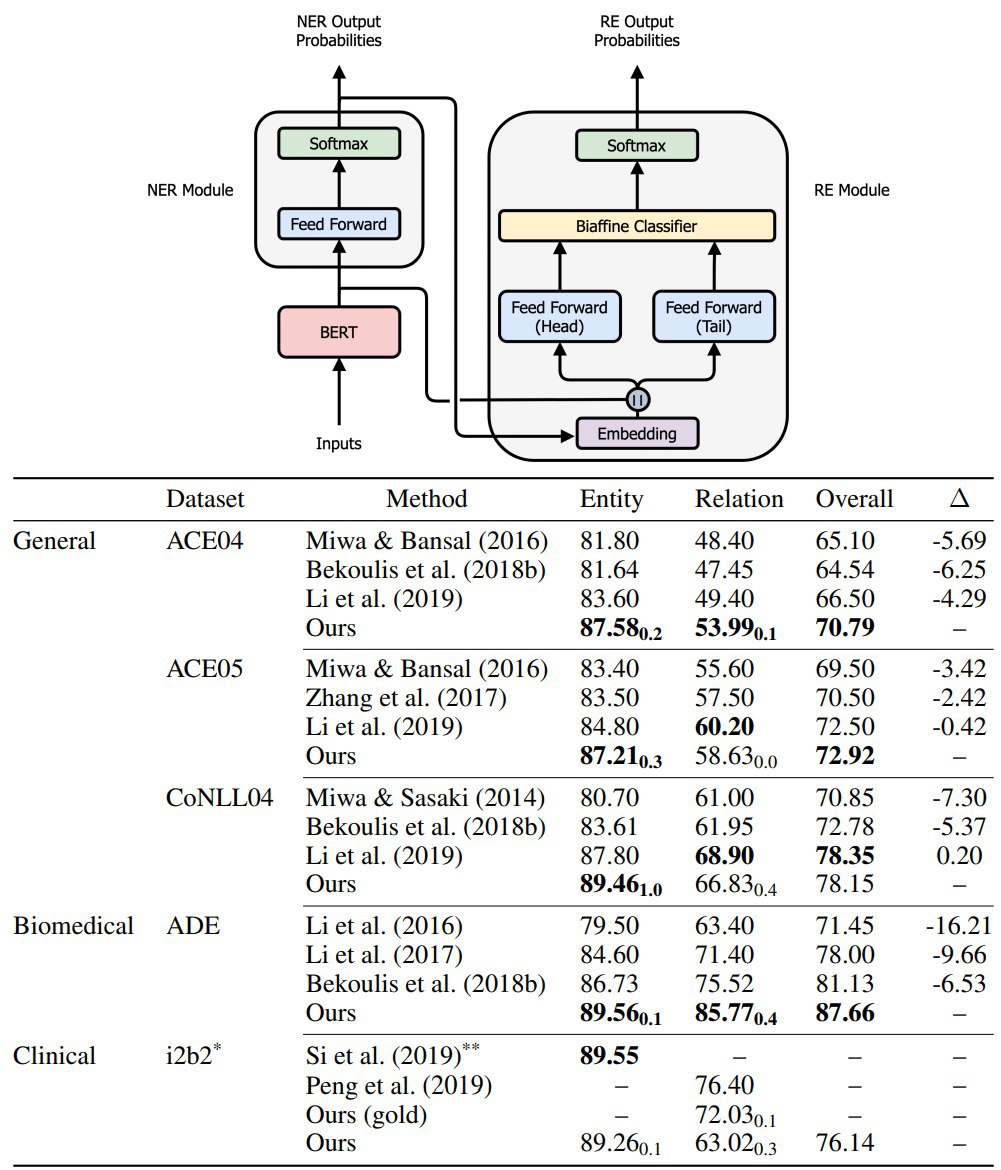
End-to-end Named Entity Recognition and Relation Extraction using Pre-trained Language Models
Authors propose an end-to-end model for jointly extracting entities and
their relations.
There were multiple approaches to solve this task, but they either showed a low predictive power or used some external tools. The authors suggest using BERT as a pre-trained model and a single architecture with modules for NER and ER.
This paper makes the following innovations:
– end-to-end approach, relying on no handcrafted features or external NLP tools
– fast training thanks to using pre-trained models
– match or exceed state-of-the-art results for joint NER and RE on 5 datasets across 3 domains
Paper: https://arxiv.org/abs/1912.13415
Code: https://github.com/bowang-lab/joint-ner-and-re
Unofficial code: https://github.com/BaderLab/saber/blob/development/saber/models/bert_for_ner_and_re.py
#deeplearning #nlp #transformer #NER #ER
Authors propose an end-to-end model for jointly extracting entities and
their relations.
There were multiple approaches to solve this task, but they either showed a low predictive power or used some external tools. The authors suggest using BERT as a pre-trained model and a single architecture with modules for NER and ER.
This paper makes the following innovations:
– end-to-end approach, relying on no handcrafted features or external NLP tools
– fast training thanks to using pre-trained models
– match or exceed state-of-the-art results for joint NER and RE on 5 datasets across 3 domains
Paper: https://arxiv.org/abs/1912.13415
Code: https://github.com/bowang-lab/joint-ner-and-re
Unofficial code: https://github.com/BaderLab/saber/blob/development/saber/models/bert_for_ner_and_re.py
#deeplearning #nlp #transformer #NER #ER
{kind=link}
Image Segmentation: tips and tricks from 39 Kaggle competitions
this article gave you some background into #image #segmentation tips and tricks
also, collect some tools and frameworks that you can use to start competing
the author overview:
* architectures
* training tricks
* losses
* pre-processing
* post processing
* ensembling
* tools and frameworks
link here
this article gave you some background into #image #segmentation tips and tricks
also, collect some tools and frameworks that you can use to start competing
the author overview:
* architectures
* training tricks
* losses
* pre-processing
* post processing
* ensembling
* tools and frameworks
link here
neptune.ai
Image Segmentation: Tips and Tricks from 39 Kaggle Competitions
Learn about image segmentation insights from 39 Kaggle comps: evaluation methods, ensembling techniques, and post-processing strategies.
Interview about how DS startups are being scouted, grown and then sold
Most notable highlights:
Where to dig — what specific areas or technologies in the near future? What project / team would you invest in after this interview on the channel?
We currently are really interested in Voice Processing and are in the search of Voice experts.
Particularly we are discussing creating a technology that allows you to change your voice into the voice of a celebrity in real time. We also consider options related to creating non-copyright photos on a given topic, Media Compression, Calorie Calculator, using TikTok algorithms. If people are experts in these fields they can me on telegram paul_shab.
How to sell your companies and ideas to someone strategic? Suppose I don’t want a middle man who will receive a share of the company. How can I achieve it myself without grinding through endless investment funds?
You can always sell companies, Selling ideas is not possible. you need middlemen — they are good 🙂 they help you do work that you should not waste your time and frustration on. Usually if someone helps to connect and close the deal, it can cost 1–5% from the deal amount. This is acceptable — you want to reward a person who helped anyway.
Link: https://medium.com/@timooxaaaa/questions-to-the-investor-machine-learning-is-our-future-ebb8e4046ff2
#wheretodig #dsventure #botan
Most notable highlights:
Where to dig — what specific areas or technologies in the near future? What project / team would you invest in after this interview on the channel?
We currently are really interested in Voice Processing and are in the search of Voice experts.
Particularly we are discussing creating a technology that allows you to change your voice into the voice of a celebrity in real time. We also consider options related to creating non-copyright photos on a given topic, Media Compression, Calorie Calculator, using TikTok algorithms. If people are experts in these fields they can me on telegram paul_shab.
How to sell your companies and ideas to someone strategic? Suppose I don’t want a middle man who will receive a share of the company. How can I achieve it myself without grinding through endless investment funds?
You can always sell companies, Selling ideas is not possible. you need middlemen — they are good 🙂 they help you do work that you should not waste your time and frustration on. Usually if someone helps to connect and close the deal, it can cost 1–5% from the deal amount. This is acceptable — you want to reward a person who helped anyway.
Link: https://medium.com/@timooxaaaa/questions-to-the-investor-machine-learning-is-our-future-ebb8e4046ff2
#wheretodig #dsventure #botan
Medium
Questions to the investor. Machine learning is our future.
Botan Investments is an investment fund aimed at supporting and investing in the field of mobile technologies and artificial intelligence.
Forwarded from Находки в опенсорсе
In a chord diagram (or radial network), entities are arranged radially as segments with their relationships visualised by arcs that connect them. The size of the segments illustrates the numerical proportions, whilst the size of the arc illustrates the significance of the relationships1.
Chord diagrams are useful when trying to convey relationships between different entities, and they can be beautiful and eye-catching.
https://github.com/shahinrostami/chord
#python
Chord diagrams are useful when trying to convey relationships between different entities, and they can be beautiful and eye-catching.
https://github.com/shahinrostami/chord
#python
A tiny autograd engine
Andrej Karpathy recently released a library called micrograd which provides the ability to build & train a NN using a simple and intuitive interface.
In fact, he wrote the whole library in roughly 150 lines of code which he claims is the tiniest autograd engine there is. Ideally, such types of libraries can be used for educational purposes.
github: https://github.com/karpathy/micrograd
#karpathy #autograd
Andrej Karpathy recently released a library called micrograd which provides the ability to build & train a NN using a simple and intuitive interface.
In fact, he wrote the whole library in roughly 150 lines of code which he claims is the tiniest autograd engine there is. Ideally, such types of libraries can be used for educational purposes.
github: https://github.com/karpathy/micrograd
#karpathy #autograd
{kind=link}
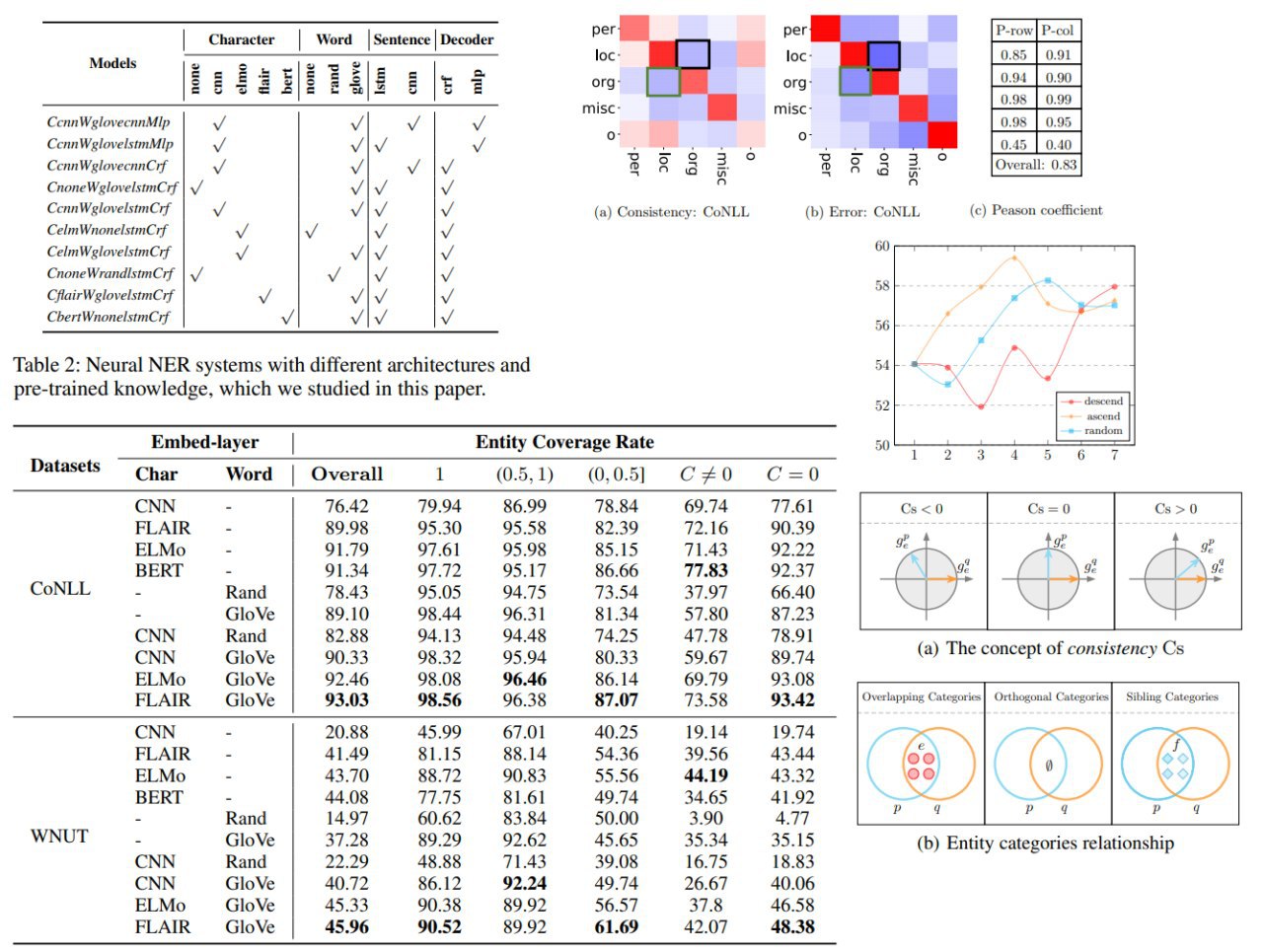
Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
{kind=link}
Tips for releasing research code in ML
with official NeurIPS 2020 recommendations
In repo you can find template that you can use for releasing ML research repositories. The sections in the template were derived by looking at existing repositories, seeing which had the best reception in the community, and then looking at common components that correlate with popularity.
The ML Code Completness Checklist consists of five items:
1 Specification of dependencies
2 Training code
3 Evaluation code
4 Pre-trained models
5 README file including table of results accompanied by precise commands to run/produce those results
Also, you can find additional awesome resources for releasing research code like: where to hosting pretrained models files, standardized model interfaces, results leaderboards, and etc.
github: https://github.com/paperswithcode/releasing-research-code
with official NeurIPS 2020 recommendations
In repo you can find template that you can use for releasing ML research repositories. The sections in the template were derived by looking at existing repositories, seeing which had the best reception in the community, and then looking at common components that correlate with popularity.
The ML Code Completness Checklist consists of five items:
1 Specification of dependencies
2 Training code
3 Evaluation code
4 Pre-trained models
5 README file including table of results accompanied by precise commands to run/produce those results
Also, you can find additional awesome resources for releasing research code like: where to hosting pretrained models files, standardized model interfaces, results leaderboards, and etc.
github: https://github.com/paperswithcode/releasing-research-code
GitHub
releasing-research-code/templates/README.md at master · paperswithcode/releasing-research-code
Tips for releasing research code in Machine Learning (with official NeurIPS 2020 recommendations) - paperswithcode/releasing-research-code
#StyleGan2 applied to maps
Ever imagined what happens in Inception on bigger scale?
#mapdreamer #GAN
Ever imagined what happens in Inception on bigger scale?
#mapdreamer #GAN