
Please vote in our Mega Imprtant Audience Research!
So far we have collected 384 responses, which is really cool!
But we need more filled questinnaires to know YOU and YOUR PREFERENCES better.
Some to-date data about residency:
* 🇮🇹 There are 4.5% of people who reside in Italy
* 🇧🇷 Brazil — 3.2%
* 🇫🇷 France — 1.9%
* 🇳🇬 Nigeria — 1.1%
* 🇪🇸 Spain — 5.6%
Please, fill in the form https://forms.gle/GGNgukYNQbAZPtmk8 to help us provide better and more relevant content for you!
So far we have collected 384 responses, which is really cool!
But we need more filled questinnaires to know YOU and YOUR PREFERENCES better.
Some to-date data about residency:
* 🇮🇹 There are 4.5% of people who reside in Italy
* 🇧🇷 Brazil — 3.2%
* 🇫🇷 France — 1.9%
* 🇳🇬 Nigeria — 1.1%
* 🇪🇸 Spain — 5.6%
Please, fill in the form https://forms.gle/GGNgukYNQbAZPtmk8 to help us provide better and more relevant content for you!
Google Docs
@opendatascience audience research 2020
Hey, this is a form to study the audience of our channel to post more relevant and interesting content for you. Please fill in.
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
Please, vote: https://forms.gle/GGNgukYNQbAZPtmk8 (this is a scheduled message, we hopefuly have more than 400 responses by now)
CCMatrix: A billion-scale bitext data set for training translation models
The authors show that margin-based bitext mining in LASER's multilingual sentence space can be applied to monolingual corpora of billions of sentences.
They are using 10 snapshots of a curated common crawl corpus CCNet totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, they were able to mine 3.5 billion parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more than 30 million parallel sentences, 82 more than 10 million, and most more than one million, including direct alignments between many European or Asian languages.
They train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Also, they achieve a new SOTA for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French.
But, they will soon provide a script to extract the parallel data from this corpus
blog post: https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/
paper: https://arxiv.org/abs/1911.04944.pdf
github: https://github.com/facebookresearch/LASER/tree/master/tasks/CCMatrix
#nlp #multilingual #laser #data #monolingual
The authors show that margin-based bitext mining in LASER's multilingual sentence space can be applied to monolingual corpora of billions of sentences.
They are using 10 snapshots of a curated common crawl corpus CCNet totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, they were able to mine 3.5 billion parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more than 30 million parallel sentences, 82 more than 10 million, and most more than one million, including direct alignments between many European or Asian languages.
They train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Also, they achieve a new SOTA for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French.
But, they will soon provide a script to extract the parallel data from this corpus
blog post: https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/
paper: https://arxiv.org/abs/1911.04944.pdf
github: https://github.com/facebookresearch/LASER/tree/master/tasks/CCMatrix
#nlp #multilingual #laser #data #monolingual
{kind=link}
TyDi QA: A Multilingual Question Answering Benchmark
it's a q&a corpus covering 11 Typologically Diverse languages: russian, english, arabic, bengali, finnish, indonesian, japanese, kiswahili, korean, telugu, thai.
the authors collected questions from people who wanted an answer but did not know the answer yet.
they showed people an interesting passage from Wikipedia written in their native language and then had them ask a question, any question, as long as it was not answered by the passage and they actually wanted to know the answer.
blog post: https://ai.googleblog.com/2020/02/tydi-qa-multilingual-question-answering.html?m=1
paper: only pdf
#nlp #qa #multilingual #data
it's a q&a corpus covering 11 Typologically Diverse languages: russian, english, arabic, bengali, finnish, indonesian, japanese, kiswahili, korean, telugu, thai.
the authors collected questions from people who wanted an answer but did not know the answer yet.
they showed people an interesting passage from Wikipedia written in their native language and then had them ask a question, any question, as long as it was not answered by the passage and they actually wanted to know the answer.
blog post: https://ai.googleblog.com/2020/02/tydi-qa-multilingual-question-answering.html?m=1
paper: only pdf
#nlp #qa #multilingual #data
{kind=link}
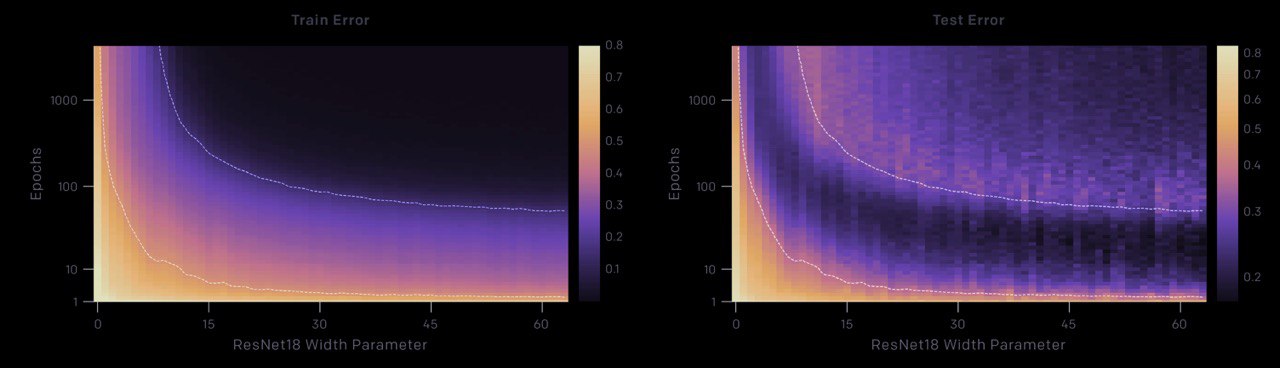
DEEP DOUBLE DESCENT
where bigger models and more data hurt
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
where bigger models and more data hurt
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
{kind=link}
Data Science by ODS.ai 🦜
🔝Great OpenDataScience Channel Audience Research The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we. Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to…
☺️526 responses collected thanks to you!
Now we are looking for a volunteer to perform an #exploratory analysis of responses an publish it as a an example on github in a form of #jupyter notebook. If you are familiar with git, jupyter, basics of #exploratory analysis and want to help, write to @opendatasciencebot bot (make sure you include your username, so we can reach you back).
In the mean time, please spend some free weekend time to fill in the questionnaire form if you haven’t filled it yet: https://forms.gle/GGNgukYNQbAZPtmk8 This will help us to make channel better for you.
2020 questionnaire link: https://forms.gle/GGNgukYNQbAZPtmk8
Now we are looking for a volunteer to perform an #exploratory analysis of responses an publish it as a an example on github in a form of #jupyter notebook. If you are familiar with git, jupyter, basics of #exploratory analysis and want to help, write to @opendatasciencebot bot (make sure you include your username, so we can reach you back).
In the mean time, please spend some free weekend time to fill in the questionnaire form if you haven’t filled it yet: https://forms.gle/GGNgukYNQbAZPtmk8 This will help us to make channel better for you.
2020 questionnaire link: https://forms.gle/GGNgukYNQbAZPtmk8
Google Docs
@opendatascience audience research 2020
Hey, this is a form to study the audience of our channel to post more relevant and interesting content for you. Please fill in.
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
{kind=link}
Few-shot Video-to-Video Synthesis
it's the pytorch implementation for few-shot photorealistic video-to-video (vid2vid) translation.
it can be used for generating human motions from poses, synthesizing people talking from edge maps, or turning semantic label maps into photo-realistic videos.
the core of vid2vid translation is image-to-image translation.
blog post: https://nvlabs.github.io/few-shot-vid2vid/
paper: https://arxiv.org/abs/1910.12713
youtube: https://youtu.be/8AZBuyEuDqc
github: https://github.com/NVlabs/few-shot-vid2vid
#cv #nips #neurIPS #pattern #recognition #vid2vid #synthesis
it's the pytorch implementation for few-shot photorealistic video-to-video (vid2vid) translation.
it can be used for generating human motions from poses, synthesizing people talking from edge maps, or turning semantic label maps into photo-realistic videos.
the core of vid2vid translation is image-to-image translation.
blog post: https://nvlabs.github.io/few-shot-vid2vid/
paper: https://arxiv.org/abs/1910.12713
youtube: https://youtu.be/8AZBuyEuDqc
github: https://github.com/NVlabs/few-shot-vid2vid
#cv #nips #neurIPS #pattern #recognition #vid2vid #synthesis
Data Science by ODS.ai 🦜
Three challenges of Deep Learning according to Yann LeCun
Yann LeCun's talk slides and video
Slides: https://drive.google.com/file/d/1r-mDL4IX_hzZLDBKp8_e8VZqD7fOzBkF/view
Video of the talks: https://vimeo.com/390347111
- 1:10 in for Geoff Hinton's keynote,
- 1:44 for Yann LeCunn's,
- 2:18 for Yoshua Bengio's,
- 2:51 for the panel discussion moderated by Leslie Pack Kaelbling
#talk #meta #master
Slides: https://drive.google.com/file/d/1r-mDL4IX_hzZLDBKp8_e8VZqD7fOzBkF/view
Video of the talks: https://vimeo.com/390347111
- 1:10 in for Geoff Hinton's keynote,
- 1:44 for Yann LeCunn's,
- 2:18 for Yoshua Bengio's,
- 2:51 for the panel discussion moderated by Leslie Pack Kaelbling
#talk #meta #master
Neighbourhood Components Analysis
a PyTorch implementation of Neighbourhood Components Analysis
NCA learns a linear transformation of the dataset such that the expected leave-one-out performance of kNN in the transformed space is maximized.
The authors propose a novel method for learning a Mahalanobis distance measure to be used in the KNN classification algorithm. The algorithm directly maximizes a stochastic variant of the leave-one-out KNN score on the training set.
It can also learn low-dimensional linear embedding of labeled data that can be used for data visualization and fast classification. Unlike other methods, this classification model is non-parametric, making no assumptions about the shape of the class distributions or the boundaries between them.
The performance of the method is demonstrated on several data sets, both for metric learning and linear dimensionality reduction.
paper (only pdf): https://www.cs.toronto.edu/~hinton/absps/nca.pdf
github: https://github.com/kevinzakka/nca
#kNN #pca #nca #PyTorch
a PyTorch implementation of Neighbourhood Components Analysis
NCA learns a linear transformation of the dataset such that the expected leave-one-out performance of kNN in the transformed space is maximized.
The authors propose a novel method for learning a Mahalanobis distance measure to be used in the KNN classification algorithm. The algorithm directly maximizes a stochastic variant of the leave-one-out KNN score on the training set.
It can also learn low-dimensional linear embedding of labeled data that can be used for data visualization and fast classification. Unlike other methods, this classification model is non-parametric, making no assumptions about the shape of the class distributions or the boundaries between them.
The performance of the method is demonstrated on several data sets, both for metric learning and linear dimensionality reduction.
paper (only pdf): https://www.cs.toronto.edu/~hinton/absps/nca.pdf
github: https://github.com/kevinzakka/nca
#kNN #pca #nca #PyTorch
{kind=link}
OpenCV ‘dnn’ with NVIDIA GPUs: 1.549% faster YOLO, SSD, and Mask R-CNN
- Object detection and segmentation
- Working Python implementations of each
- Includes pre-trained models
tutorial: https://t.co/Wt0IrJObcE?amp=1
#OpenCV #dl #nvidia
- Object detection and segmentation
- Working Python implementations of each
- Includes pre-trained models
tutorial: https://t.co/Wt0IrJObcE?amp=1
#OpenCV #dl #nvidia
Knowledge Graphs @ AAAI 2020
overview of several topics:
- KG-Augmented Language Models: in different flavours
- Entity Matching in Heterogeneous KGs: finally no manual mappings
- KG Completion and Link Prediction: neuro-symbolic and temporal KGs
- KG-based Conversational AI and Question Answering: going big
Link: https://medium.com/@mgalkin/knowledge-graphs-aaai-2020-c457ad5aafc0
#AAAI2020 #KnowledgeGraph #graph #kg
overview of several topics:
- KG-Augmented Language Models: in different flavours
- Entity Matching in Heterogeneous KGs: finally no manual mappings
- KG Completion and Link Prediction: neuro-symbolic and temporal KGs
- KG-based Conversational AI and Question Answering: going big
Link: https://medium.com/@mgalkin/knowledge-graphs-aaai-2020-c457ad5aafc0
#AAAI2020 #KnowledgeGraph #graph #kg
Medium
Knowledge Graphs @ AAAI 2020
The first major AI event of 2020 is already here! Hope you had a nice holiday break 🎄, or happy New Year if your scientific calendar…
Barak Obama’s deep fake video used as intro to MIT 6.S191 class
Brilliant idea to win attention of students and to demonstrate at the very beggining of the course one of the applications of the materials they have to stydy.
YouTube: https://www.youtube.com/watch?v=l82PxsKHxYc
#DL #DeepFake #MIT #video
Brilliant idea to win attention of students and to demonstrate at the very beggining of the course one of the applications of the materials they have to stydy.
YouTube: https://www.youtube.com/watch?v=l82PxsKHxYc
#DL #DeepFake #MIT #video
YouTube
Barack Obama: Intro to Deep Learning | MIT 6.S191
MIT Introduction to Deep Learning 6.S191 (2020)
DISCLAIMER: The following video is synthetic and was created using deep learning with simultaneous speech-to-speech translation as well as video dialogue replacement (CannyAI).
** NOTE**: The audio quality…
DISCLAIMER: The following video is synthetic and was created using deep learning with simultaneous speech-to-speech translation as well as video dialogue replacement (CannyAI).
** NOTE**: The audio quality…
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 6 to 17 people.
BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
tl;dr
with a huggingface – compatible weights
take original BERT, replace some of his layers with new (smaller) ones randomly during the distillation. the probability of replacing the module will increase over time, resulting in a small model at the end.
them approach leverages only one loss function and one hyper-parameter, liberating human effort from hyper-parameter tuning.
also, they outperform existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression
paper: https://arxiv.org/abs/2002.02925
github: https://github.com/JetRunner/BERT-of-Theseus
#nlp #compressing #knowledge #distillation #bert
tl;dr
[ONE loss] + [ONE hyperparameter] + [NO external data] = GREAT PERFORMANCEwith a huggingface – compatible weights
take original BERT, replace some of his layers with new (smaller) ones randomly during the distillation. the probability of replacing the module will increase over time, resulting in a small model at the end.
them approach leverages only one loss function and one hyper-parameter, liberating human effort from hyper-parameter tuning.
also, they outperform existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression
paper: https://arxiv.org/abs/2002.02925
github: https://github.com/JetRunner/BERT-of-Theseus
#nlp #compressing #knowledge #distillation #bert
{kind=link}
Catalyst – Accelerated DL & RL
tl;dr
– collect all the technical, dev-heavy, Deep Learning stuff in a framework
– make it easy to re-use boring day-to-day components
– focus on research and hypothesis testing in our projects
Most of the time in Deep Learning all you need to do is to specify the model dataflow, or how batches of data should be fed to the model. Why then, so much of our time is spent implementing those pipelines and debugging training loops rather than developing something new?
They think that it is possible to separate the engineering from the research so that we can invest our time once in the high-quality, reusable engineering backbone and use it across all the projects.
That is how Catalyst was born – an Open Source PyTorch framework, that allows you to write compact but full-features pipelines and let you focus on the core part of your project.
Link: https://github.com/catalyst-team/catalyst
Official TG channel: https://t.me/catalyst_team
tl;dr
– collect all the technical, dev-heavy, Deep Learning stuff in a framework
– make it easy to re-use boring day-to-day components
– focus on research and hypothesis testing in our projects
Most of the time in Deep Learning all you need to do is to specify the model dataflow, or how batches of data should be fed to the model. Why then, so much of our time is spent implementing those pipelines and debugging training loops rather than developing something new?
They think that it is possible to separate the engineering from the research so that we can invest our time once in the high-quality, reusable engineering backbone and use it across all the projects.
That is how Catalyst was born – an Open Source PyTorch framework, that allows you to write compact but full-features pipelines and let you focus on the core part of your project.
Link: https://github.com/catalyst-team/catalyst
Official TG channel: https://t.me/catalyst_team
{kind=link}
Photofeeler-D3
tl;dr: predict first impressions from a photo or video
some interesting items of note:
- notice how Smart is the dominant trait until he takes off his glasses
- when the glasses are taken off, his Attractive score rises
- there’s a quick dip in scores every time he blinks
- the overall top scores result from the genuine smile at the very end!
Blog post: https://blog.photofeeler.com/photofeeler-d3/
ArXiV: https://arxiv.org/abs/1904.07435
Demo: available to the researchers on the request
#cv #dl #impression
tl;dr: predict first impressions from a photo or video
some interesting items of note:
- notice how Smart is the dominant trait until he takes off his glasses
- when the glasses are taken off, his Attractive score rises
- there’s a quick dip in scores every time he blinks
- the overall top scores result from the genuine smile at the very end!
Blog post: https://blog.photofeeler.com/photofeeler-d3/
ArXiV: https://arxiv.org/abs/1904.07435
Demo: available to the researchers on the request
#cv #dl #impression
ZeRO, DeepSpeed & Turing-NLG
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
1. Add Gradient Partitioning (
2. Add Parameter Partitioning (
They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
P_os_) – 4x memory reduction, same communication volume as data parallelism1. Add Gradient Partitioning (
P_os+g_) – 8x memory reduction, same communication volume as data parallelism2. Add Parameter Partitioning (
P_os+g+p_) – memory reduction is linear with data parallelism degree N_d_They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
{kind=link}
Single biological neuron can compute XOR
The active electrical properties of dendrites shape neuronal input and output and are fundamental to brain function. However, our knowledge of active dendrites has been almost entirely acquired from studies of rodents.
In this work, the authors investigated the dendrites of layer 2 & 3 (L2/3) pyramidal neurons of the human cerebral cortex ex vivo. In these neurons, they discovered a class of calcium-mediated dendritic action potentials (dCaAPs) whose waveform and effects on neuronal output have not been previously described.
In contrast to typical all-or-none action potentials, dCaAPs were graded; their amplitudes were maximal for threshold-level stimuli but dampened for stronger stimuli. These dCaAPs enabled the dendrites of individual human neocortical pyramidal neurons to classify linearly nonseparable inputs – a computation conventionally thought to require multilayered networks.
reddit: https://www.reddit.com/r/MachineLearning/comments/ejbwvb/r_single_biological_neuron_can_compute_xor
#neurons #human #brain
The active electrical properties of dendrites shape neuronal input and output and are fundamental to brain function. However, our knowledge of active dendrites has been almost entirely acquired from studies of rodents.
In this work, the authors investigated the dendrites of layer 2 & 3 (L2/3) pyramidal neurons of the human cerebral cortex ex vivo. In these neurons, they discovered a class of calcium-mediated dendritic action potentials (dCaAPs) whose waveform and effects on neuronal output have not been previously described.
In contrast to typical all-or-none action potentials, dCaAPs were graded; their amplitudes were maximal for threshold-level stimuli but dampened for stronger stimuli. These dCaAPs enabled the dendrites of individual human neocortical pyramidal neurons to classify linearly nonseparable inputs – a computation conventionally thought to require multilayered networks.
reddit: https://www.reddit.com/r/MachineLearning/comments/ejbwvb/r_single_biological_neuron_can_compute_xor
#neurons #human #brain
{kind=link}
AutoFlip: An Open Source Framework for Intelligent Video Reframing
Google released a tool for smart video cropping. Video cropping doesn't seem like a poblem until you release that object that should be in focus can be in different parts of picture. Now there is great attempt to provide one-click solution to cropping.
Interesting part: #AutoFlip is an application of #MediaPipe framework for building multimodal ML #pipelines.
Github: https://github.com/google/mediapipe/blob/master/mediapipe/docs/autoflip.md
MediaPipe: https://github.com/google/mediapipe/
#Google #GoogleAI #DL #CV
Google released a tool for smart video cropping. Video cropping doesn't seem like a poblem until you release that object that should be in focus can be in different parts of picture. Now there is great attempt to provide one-click solution to cropping.
Interesting part: #AutoFlip is an application of #MediaPipe framework for building multimodal ML #pipelines.
Github: https://github.com/google/mediapipe/blob/master/mediapipe/docs/autoflip.md
MediaPipe: https://github.com/google/mediapipe/
#Google #GoogleAI #DL #CV