
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday (tomorrow) at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 3 to 7 people.
Uber AI Plug and Play Language Model (PPLM)
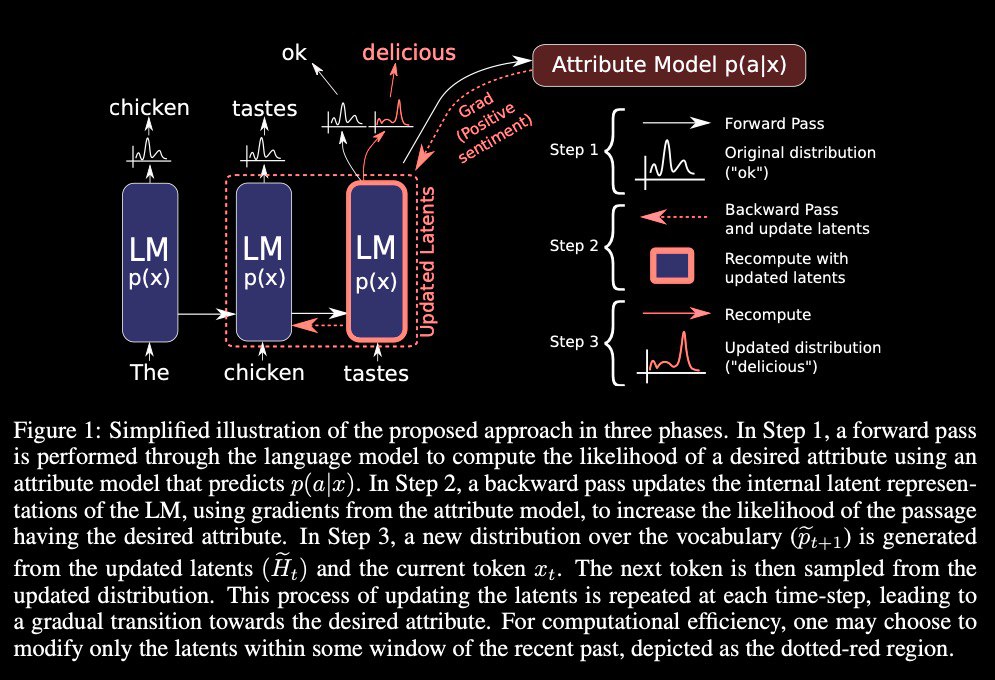
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
{kind=link}
10 ML & NLP Research Highlights of 2019
by Sebastian Ruder @ huggingface
The full list of highlights:
* Universal unsupervised pretraining
* Lottery tickets
* The Neural Tangent Kernel
* Unsupervised multilingual learning
* More robust benchmarks
* ML and NLP for science
* Fixing decoding errors in NLG
* Augmenting pretrained models
* Efficient and long-range Transformers
* More reliable analysis methods
blogpost: https://ruder.io/research-highlights-2019/
by Sebastian Ruder @ huggingface
The full list of highlights:
* Universal unsupervised pretraining
* Lottery tickets
* The Neural Tangent Kernel
* Unsupervised multilingual learning
* More robust benchmarks
* ML and NLP for science
* Fixing decoding errors in NLG
* Augmenting pretrained models
* Efficient and long-range Transformers
* More reliable analysis methods
blogpost: https://ruder.io/research-highlights-2019/
{kind=link}
📚Guest post on great example of book abandonment at GoodReads
An excellent new article from Gwern on analyzing abandoned (hard to finish, hard to read) books on Goodreads. This write up includes step by step instructions with source code, even the way he parsed the data from the website without an API.
It’s a shame analysis like this does not come from an online book subscription service like Bookmate or MyBook. They have vastly superior datasets and many able data scientists. I am quite sure amazon kindle team does prepare internal reports like that for some evil business purposes, but that’s a whole different story.
During my time at video game database company RAWG.io we’ve compiled ‘most abandoned’ and ‘most addictive’ reports for video games.
Do you make a popular service with valuable user behavior data? Funny data analysis reports are a good way to get some attention to your product. Take a lead from Pornhub, they are great at publicizing their data.
Link: https://www.gwern.net/GoodReads
Pornhub Insights: https://www.pornhub.com/insights/
—
This is a guest post by Samat Galimov, who writes about technology, programming and management in Russian on @ctodaily.
#DataAnalysis #GoodReads #statistics #greatstats #talkingnumbers
An excellent new article from Gwern on analyzing abandoned (hard to finish, hard to read) books on Goodreads. This write up includes step by step instructions with source code, even the way he parsed the data from the website without an API.
It’s a shame analysis like this does not come from an online book subscription service like Bookmate or MyBook. They have vastly superior datasets and many able data scientists. I am quite sure amazon kindle team does prepare internal reports like that for some evil business purposes, but that’s a whole different story.
During my time at video game database company RAWG.io we’ve compiled ‘most abandoned’ and ‘most addictive’ reports for video games.
Do you make a popular service with valuable user behavior data? Funny data analysis reports are a good way to get some attention to your product. Take a lead from Pornhub, they are great at publicizing their data.
Link: https://www.gwern.net/GoodReads
Pornhub Insights: https://www.pornhub.com/insights/
—
This is a guest post by Samat Galimov, who writes about technology, programming and management in Russian on @ctodaily.
#DataAnalysis #GoodReads #statistics #greatstats #talkingnumbers
gwern.net
The Most ‘Abandoned’ Books on GoodReads
<p>Which books on GoodReads are most difficult to finish? Estimating proportions in December 2019 gives an entirely different result than absolute counts.</p>
Robust breast cancer detection in mammography and digital breast tomosynthesis using annotation-efficient deep learning approach
ArXiV: https://arxiv.org/abs/1912.11027
#Cancer #BreastCancer #DL #CV #biolearning
ArXiV: https://arxiv.org/abs/1912.11027
#Cancer #BreastCancer #DL #CV #biolearning
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday (tomorrow) at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 7 to 11 people.
Cross-Lingual Ability of Multilingual BERT: An Empirical Study to #ICLR2020
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
{kind=link}
Deep Learning State of the Art (2020) | MIT Deep Learning Series by @lexfridman
https://youtu.be/0VH1Lim8gL8
slides: http://bit.ly/2QEfbAm
https://youtu.be/0VH1Lim8gL8
slides: http://bit.ly/2QEfbAm
YouTube
Deep Learning State of the Art (2020)
Lecture on most recent research and developments in deep learning, and hopes for 2020. This is not intended to be a list of SOTA benchmark results, but rather a set of highlights of machine learning and AI innovations and progress in academia, industry, and…
Data Science by ODS.ai 🦜
YouTokenToMe, new tool for text tokenisation from VK team Meet new enhanced tokenisation tool on steroids. Works 7-10 times faster alphabetic languages and 40 to 50 times faster on logographic languages, than alternatives. Under the hood (watch source)…
New rust tokenization library from #HuggingFace
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
Github: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
pip install tokenizersGithub: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
GitHub
tokenizers/tokenizers at main · huggingface/tokenizers
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production - huggingface/tokenizers
Online speech recognition with wav2letter@anywhere
Facebook have open-sourced wav2letter@anywhere, an inference framework for online speech recognition that delivers state-of-the-art performance.
Link: https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/
#wav2letter #audiolearning #soundlearning #sound #acoustic #audio #facebook
Facebook have open-sourced wav2letter@anywhere, an inference framework for online speech recognition that delivers state-of-the-art performance.
Link: https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/
#wav2letter #audiolearning #soundlearning #sound #acoustic #audio #facebook
GAN Lab
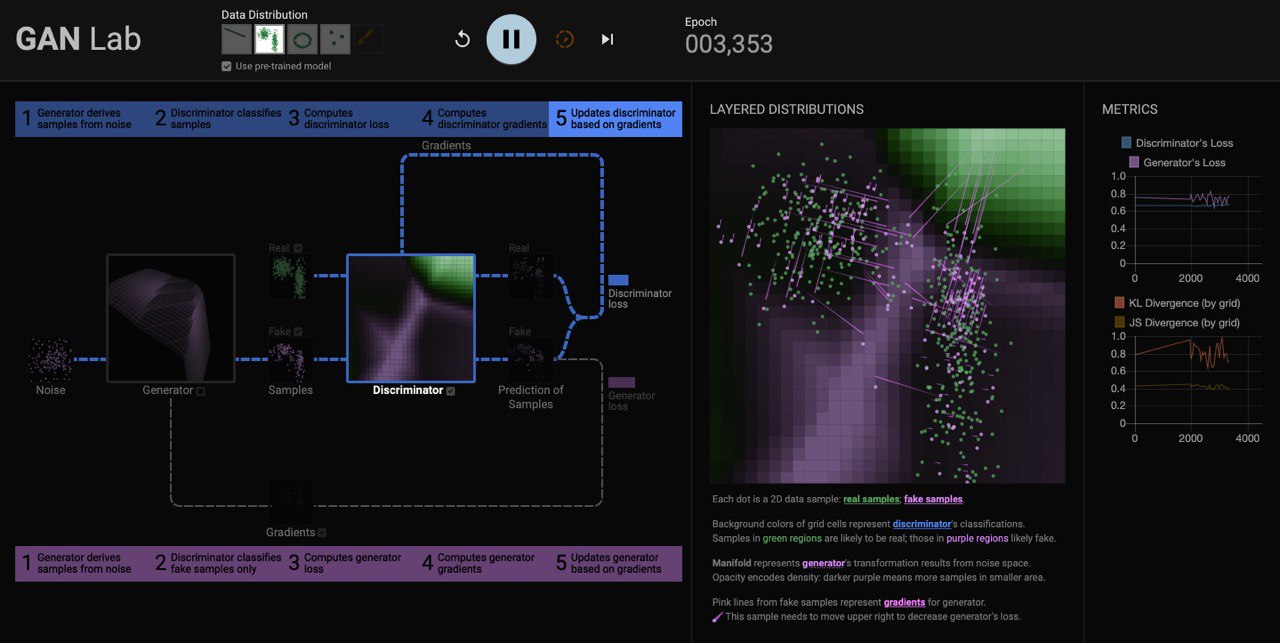
Understanding Complex Deep Generative Models using Interactive Visual Experimentation
#GAN Lab is a novel interactive visualization tool for anyone to learn & experiment with Generative Adversarial Networks (GANs), a popular class of complex #DL models. With GAN Lab, you can interactively train GAN models for #2D data #distributions and visualize their inner-workings, similar to #TensorFlow Playground.
web-page: https://poloclub.github.io/ganlab/
github: https://github.com/poloclub/ganlab
paper: https://minsuk.com/research/papers/kahng-ganlab-vast2018.pdf
Understanding Complex Deep Generative Models using Interactive Visual Experimentation
#GAN Lab is a novel interactive visualization tool for anyone to learn & experiment with Generative Adversarial Networks (GANs), a popular class of complex #DL models. With GAN Lab, you can interactively train GAN models for #2D data #distributions and visualize their inner-workings, similar to #TensorFlow Playground.
web-page: https://poloclub.github.io/ganlab/
github: https://github.com/poloclub/ganlab
paper: https://minsuk.com/research/papers/kahng-ganlab-vast2018.pdf
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts.
how to do open-source code/research
by Thomas Wolf @HuggingFace
tl;dr:
* consider sharing your code as a tool to build on more than a snapshot of your work
* put yourself in the shoes of a master student who has to start from scratch with your code
* give clear instructions on how to run the code
* use the least amount of dependencies
* spend 4 days to do it well or more :kekeke:
* consider merging with a larger repo
* you need to keep everything clear & visible
more at twitter thread: https://twitter.com/Thom_Wolf/status/1216990543533821952?s=20
by Thomas Wolf @HuggingFace
tl;dr:
* consider sharing your code as a tool to build on more than a snapshot of your work
* put yourself in the shoes of a master student who has to start from scratch with your code
* give clear instructions on how to run the code
* use the least amount of dependencies
* spend 4 days to do it well or more :kekeke:
* consider merging with a larger repo
* you need to keep everything clear & visible
more at twitter thread: https://twitter.com/Thom_Wolf/status/1216990543533821952?s=20
{kind=link}
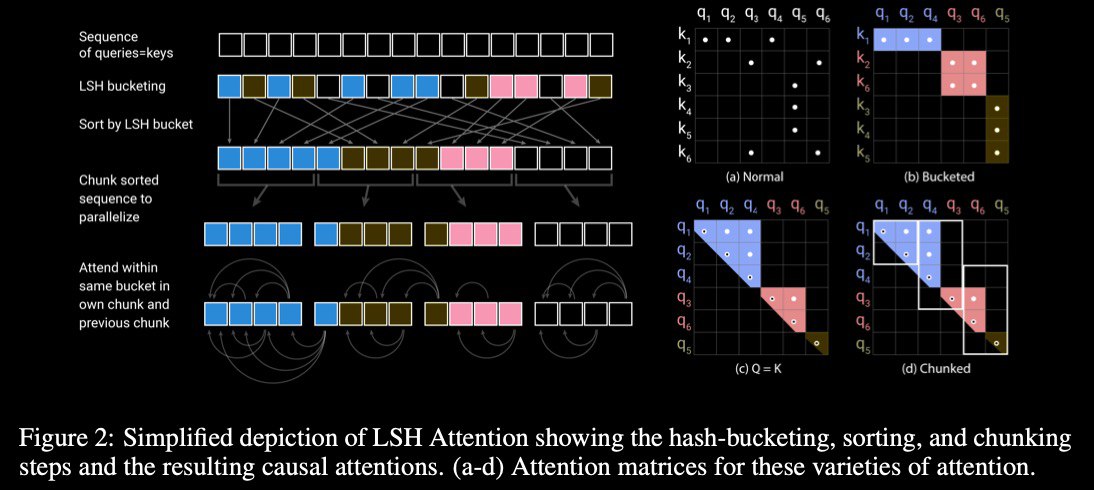
Reformer: The Efficient Transformer to #ICLR2020
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
{kind=link}
AI & Art
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
YouTube
How This Guy Uses A.I. to Create Art | Obsessed | WIRED
Artist Refik Anadol doesn't work with paintbrushes or clay. Instead, he uses large collections of data and machine learning algorithms to create mesmerizing and dynamic installations.
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Revealing the Dark Secrets of BERT
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
{kind=link}
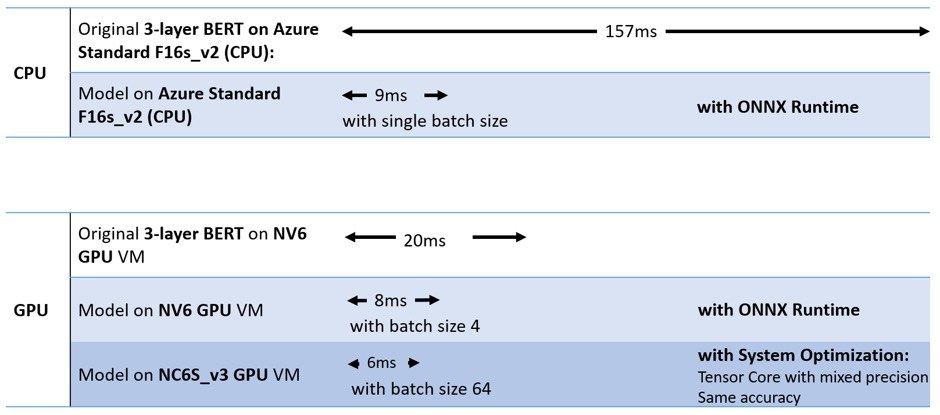
Microsoft open sources breakthrough optimizations for transformer inference on GPU and CPU
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
{kind=link}
AI Career Pathways: Put Yourself on the Right Track
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 5 to 14 people.
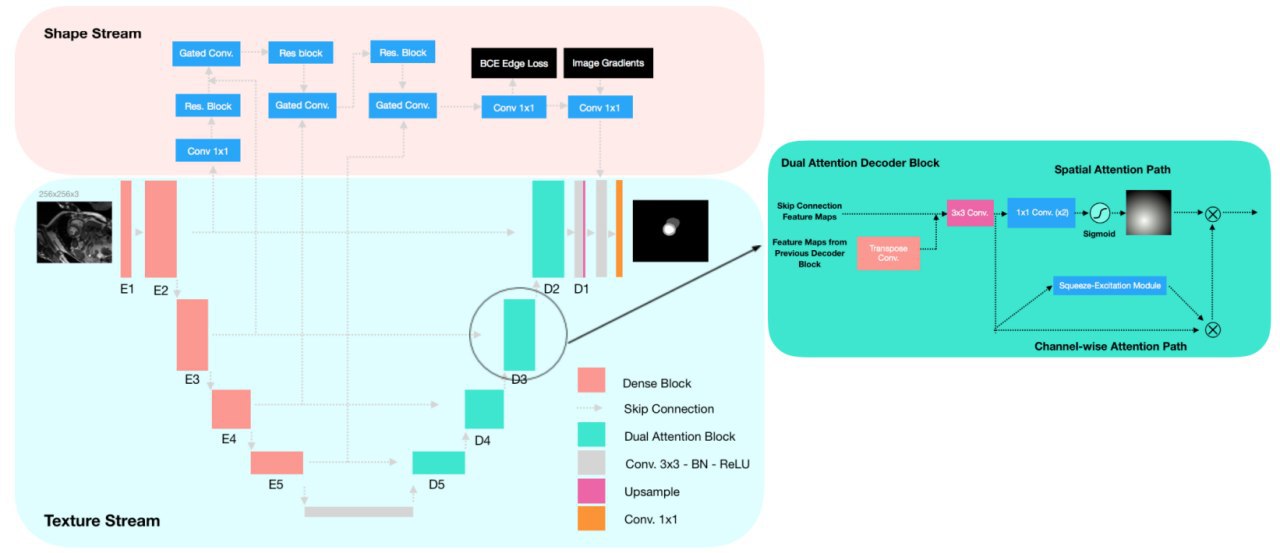
SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
{kind=link}